Apple is introducing a new privacy feature that lets users limit the precision of location data shared with cellular networks on some iPhone and iPad models.
The “Limit Precise Location” setting will be available after upgrading to iOS 26.3 or later, and it works by restricting the information mobile carriers use to determine device locations via cell tower connections. When enabled, cellular networks can only identify the device’s approximate location, such as a neighborhood, rather than a precise street address.
“The limit precise location setting doesn’t impact the precision of the location data that is shared with emergency responders during an emergency call,” Apple said.
“This setting affects only the location data available to cellular networks. It doesn’t impact the location data that you share with apps through Location Services. For example, it has no impact on sharing your location with friends and family with Find My.”
Users can enable the feature by opening “Settings,” tapping “Cellular,” then “Cellular Data Options,” and toggling the “Limit Precise Location” setting. After enabling limited precise location, the system may prompt a device restart to complete activation.
Advertisement
The privacy enhancement feature currently works only on iPhone Air, iPhone 16e, and iPad Pro (M5) Wi-Fi + Cellular models running iOS 26.3 or later.
Availability depends on carrier support, and currently supported mobile networks include Telekom in Germany, EE and BT in the United Kingdom, Boost Mobile in the United States, and AIS and True in Thailand.
While Apple has yet to share why it’s introducing this feature, the Federal Communications Commission (FCC) fined the largest U.S. wireless carriers almost $200 million in April 2024.
The list of fines includes $80 million for T-Mobile and $12 million for Sprint (which have since merged), more than $57 million for AT&T, and nearly $47 million for Verizon.
Advertisement
Since cellular networks can easily track device locations via tower connections for network operations, Apple’s new privacy feature (currently supported by only a small number of networks) is a big step towards ensuring that carriers can collect only limited data on their customers’ movements and habits.
BleepingComputer reached out to Apple for more details, but a response was not immediately available.
Modern IT infrastructure moves faster than manual workflows can handle.
In this new Tines guide, learn how your team can reduce hidden manual delays, improve reliability through automated response, and build and scale intelligent workflows on top of tools you already use.
Not only are the Beats Powerbeats Pro 2 the best workout earbuds if you have an Apple Watch, but they are also the best workout earbuds, period. They even have a heart rate monitor that’s built off the one used in the Apple Watch. If you already own an Apple Watch, this feature is superfluous, as iOS will prioritize the Apple Watch’s more sophisticated readings over the earbuds. But if you run with third-party fitness apps like Nike Run Club or Peloton, you will find the extra data useful.
On top of that, the buds are crazy comfortable, sound great, have excellent noise canceling, and have most of the aforementioned Apple-exclusive features, like hands-free Siri (no Adaptive Audio, however, sad). The case also sports wireless charging and, unlike many of Apple’s other products, it comes in bright, fun colors. Our test unit is Electric Orange, but I find the Hyper Purple to be just as good. —Adrienne So
Shoppers have a lot of options when it comes to tech purchases in 2026, including mainstays like Best Buy, online giants like Amazon, and other retail giants like Walmart. Costco is often overlooked, at least by people who don’t actively shop there, despite being a legitimately good source for technology purchases. Costco sells TVs, smartphones, major appliances, computers, and all sorts of stuff. Every retailer has its own pros and cons, and that includes Costco, but Costco probably doesn’t get enough attention when it comes to buying electronics.
Costco is an experience unto itself. You’ve likely heard about the company’s famous loss leaders like the $5 rotisserie chicken that’s been around for decades and the $1.50 hot dog and 20-ounce soda. These loss leaders get people in the door to buy other things, and it’s a brilliant strategy, especially in the wake of swiftly rising gas prices. As it turns out, buying just about anything from Costco is a good idea, so it makes sense that a shopper may want to consider the retailer for their next big purchase.
Advertisement
Below is a list of reasons why you would want to consider Costco over Amazon for your next major tech purchase. It’s a tough call because Amazon’s convenience is excellent in its own right, but there are just some things Costco does better.
Advertisement
Costco has a superior return policy
Buying electronics is often a big deal. A TV is meant to be the centerpiece of a living room, and most TVs can last for many years, so you want to make sure you get the right one. If you don’t, and you have to return it, Costco is a much easier place to do so than Amazon. This is primarily for two reasons. The first is that Amazon’s return policy for most of its electronics is 30 days, while Costco will still take the TV back for up to 90 days. This gives you an extra two months to make sure you really don’t like that TV, and if you do return it, Costco finds a use for those returns.
The other reason is that Costco’s return policy verbiage is a little more liberal when it comes to the condition of the device when it’s returned, in that it doesn’t specify that an item has to be in new or unused condition when it’s returned. Amazon’s return policy does expressly state that the item has to be in “original or unused condition” in order to be eligible for a return.
That isn’t entirely unreasonable, as it keeps people from abusing the policy, and Amazon returns tend to be pretty easy anyway, but it is something to keep in mind. Costco’s return policy has made news headlines for how liberal it is, so it’s generally considered the better one.
Advertisement
Costco often has better deals on larger items
Costco’s deals are legendary, and even its permanent ones tend to be better than what Amazon offers day to day. A famous example of this is the Nintendo Switch 2 Mario Kart World Bundle, which retails for $499. It’s a reasonable deal for a game console and a bundled, popular Mario Kart game, and that’s the price you pay on Amazon when the bundle is in stock from Nintendo. Costco sells the same bundle for $499, but it includes a free 12-month subscription to Nintendo Switch Online, valued at $50.
Business Insider compared hundreds of items from Costco their prices to that of Amazon’s. Costco came out on top roughly 80% of the time overall. This is across a range of categories, including baby and pet, household items, toiletries, and other items. It also applies to electronics, albeit not as obviously. Much like the Switch 2 example above, the benefits are often better from Costco, even when the prices are the same. For example, the LG C5 OLED TV is about $1,400 from both retailers. Costco’s includes a longer five-year warranty, and Executive members get 4% cashback, an increase from the 2% cashback that Executive members usually get.
Advertisement
If you’re shopping for an electronic, don’t just compare prices between the two retail giants. Check the other perks as well. Costco often comes out on top.
Advertisement
Costco memberships pay for themselves
It’s pretty common knowledge that you need a membership to shop at Costco unless you order from Instacart or have a gift card. These memberships are pricy on the surface, costing $65 for a regular Gold Star Membership and $130 for an Executive Membership. The Executive members get expanded shopping hours, 2% annual cashback (after $1,250 spent), and other stuff. The thing is that these memberships ultimately pay for themselves over the course of the year through the various benefits that you get from the store.
As a personal example, the first time my wife and I got a Costco membership, we bought a couple of external SSDs on sale for 50% off, a deal Amazon did not have at the time. We bought a Gold Star Membership and walked out with two hard drives, the savings from which paid for the membership in full, giving us 364 more days of Costco access. In addition, the 2% cashback rewards on the Executive membership will eventually pay for the membership if the shopper spends enough money throughout the year.
Amazon has its Prime membership, which includes a host of various features, and grants access to member-only deals during Amazon Prime shopping events. However, there’s no cashback reward, and many products are still on sale for non-members as well. Prime offers more features overall, but Costco’s membership benefits continually roll in on themselves, making the price a non-issue for many members.
Advertisement
Costco gives away free extended warranties
One of the benefits of buying something new is that if it messes up, you can get it fixed or replaced under warranty. Most warranties are only about a year or two, which is long enough to catch immediate issues, but doesn’t protect you at all after that. Costco helps by adding an extra two years of warranty on top of whatever warranty the device comes with. This isn’t for every electronic, but does apply to televisions, projectors, computers, and major appliances. There are some limitations, for example, like touchscreen tablets and small appliances like mini refrigerators.
This can be a huge boon for shoppers looking to maximize their protection without spending additional money. In some cases, Costco occasionally tosses in free additional coverage from Allstate. An example of this is the LG C5 OLED TV we mentioned earlier. LG usually only grants a 1-year warranty for C-series TVs, but Costco gives you five total years. That’s one year manufacturer warranty, an extra year via Costco directly, and then three years via Allstate.
Advertisement
Amazon doesn’t include an additional warranty with its products by default but may occasionally as part of a promotion. Amazon offers extended warranties that you can purchase with many electronics across the website, but that’s all you’ll be able to get. Costco definitely wins here, and often by more than a year or two. Don’t forget to check out the free tech support if you do buy electronics from Costco.
Advertisement
The convenience of brick and mortar stores
There are some intrinsic advantages to having brick-and-mortar stores in a variety of locations. The ability to walk into a building, make a purchase, and walk out with the product immediately is one of the most obvious. Electronics usually fare okay when being shipped, especially if they’re smaller items like smartphones, earbuds, and DIY PC components. However, electronics are still high up on the list of items that break most frequently during shipment, and larger items like TVs can be very difficult to ship effectively. Thus, being able to retrieve your item from a physical store and take it home is a boon, especially if the product is broken and you have to return it. It’s much easier to return a TV to a physical store than it is to ship it back to Amazon.
There are other, albeit smaller, benefits to shopping in a physical store. You can inspect packaging for damage before purchasing, look around for items you may not have seen while browsing online, and you may find in-store promotions that aren’t available online. These are all benefits you don’t get from shopping at online-only retailers like Amazon. Plus, many Costco stores have smartphone kiosks where you can hold the device before buying it, which is a powerful tool for customers, offering a “try it before you buy it” experience.
An AI company that was accused of enabling sexualized chats with underage chatbot characters and undressing real people has sued Apple for wrongfully removing its apps from the App Store.
Ex-Human has sued Apple over AI app removals. Image source: Ex-Human
Apple is in charge of keeping the App Store safe and clear of apps that openly violate its guidelines. This practice isn’t always cut and dry, but a new lawsuit may be barking up the wrong tree. According to a report in the San Francisco Business Times, Apple has been sued by Ex-Human for removing its apps from the App Store and allegedly withholding $500,000 in revenue. The company owns the apps Botify AI and Photify AI, both of which are still on the Google Play Store. Continue Reading on AppleInsider | Discuss on our Forums
Jason Blundell, a former creative lead on Activision Blizzard’s Call of Duty: Black Ops series, has announced that he’s formed a new development studio called Magic Fractal Studios. Blundell announced the studio on a livestream with former Dark Outlaw Games coworker JC Farmer, a little over a week after the previous studio was closed by Sony.
Little is known about Magic Fractal beyond its logo and social media accounts. Dark Outlaw Games was similarly mysterious, and closed before it could even announce its first project. All that’s known is what Blundell has shared after the studio was shut down: Dark Outlaw wasn’t working on a live-service game. The distinction is notable, if only because live-service games have been connected to at least two notable studio closures in the past. Sony shut down Firewalk Studios in October 2024, not long after its live-service shooter Concord was released, and in February 2026, closed Bluepoint Games after its live-service game based on the God of War series was reportedly cancelled.
Magic Fractal is Blundell’s third studio after leaving Activision Blizzard in 2020. He formed Dark Outlaw Games with Sony’s backing in March 2025. Before that, he led Deviation Games, which was closed in 2024 and was reportedly also working on a game for PlayStation.
Earlier last month, I noticed my son’s baby monitor, the Nanit Pro, started showing a sleep score every morning. This number tells you how well your child slept the night before on a scale from zero to 100. Sleep scores track how long it takes to fall asleep, sleep cycles, heart rate throughout the night and any disruptions that may have happened. This is also one of our expert-recommended baby monitors, so it seemed appropriate that it would provide this information. As many parents know, infant and toddler sleep habits can be unpredictable.
I previously tested the Oura Ring, one of CNET’s favorite smart rings, which tracks your health and sleep data. It also provides a sleep score based on data collected by its sensors on your finger (movement, temperature, heart rate and more). I started using the Oura Ring to hold myself more accountable for going to sleep on time.
Seeing that my son has his own sleep score made me think, “I bet he has a better sleep score than I do.” I decided to conduct an experiment to see if I could prove my point by comparing our sleep scores.
Advertisement
To preface this, my 2.5-year-old has been going through a rough patch of sleep, which I’m blaming on a sleep regression (a temporary phase when babies and toddlers struggle with sleeping). Despite the disrupted sleep, he still seems better rested than I am on most days.
I started consistently wearing my Oura Ring to put my theory to the test. For the sake of this experiment, I tracked our data over a couple of weeks to prove (or disprove) my point.
How the Nanit baby monitor tracks sleep
As previously mentioned, I use the Nanit Pro Baby Monitor to keep an eye on my son while he sleeps. According to Nanit, it first introduced the sleep score in December 2025, and this is the first AI-driven, science-backed sleep score designed to grow with your child and automatically adjust as they age. Nanit collects the sleep score using the same advanced computer vision technology sensors it has used for years to analyze sleep.
To come up with a sleep score, Nanit looks at four aspects of sleep: sleep duration (how long your child slept), sleep timing (your child’s bedtime and wake-up time), sleep continuity (how smoothly your child sleeps) and parent visits (how often a guardian tends to the child).
Advertisement
How our sleep scores compared
After a week of reviewing his data, my son’s sleep scores were higher than mine overall, as I predicted. He was hitting scores over 80, with the lowest being a 74. His highest was a 95, which I vividly remember was one of the times he slept through the night without getting up once. I also slept peacefully because I wasn’t being awoken by cries at 3 a.m.
For context, below is the week’s worth of data I collected from the Nanit Pro and the Oura Ring.
Friday, Feb. 20
The first day shows that my son had a better sleep score than me.
Advertisement
CNET/Giselle Castro-Sloboda
Our sleep scores were close, but I didn’t feel well-rested, even though Oura said I got a good amount of sleep. It’s not common for my son to sleep under 10 hours, so that’s how you know he didn’t have the most restful night. Plus, he woke up before 6 a.m. on this day.
Saturday, Feb. 21
Somehow, I scored a higher sleep score than my toddler on this day, but by a small margin.
CNET/Giselle Castro-Sloboda
I found it ironic that I scored slightly higher than my son, even though he slept longer than I did and we both had a poor night’s sleep. He also got up earlier than normal. A normal wake time for him is between 6:30 a.m. and 7 a.m.
Advertisement
Sunday, Feb. 22
My son had a higher sleep score, and mine was efficient on this day.
CNET/ Giselle Castro-Sloboda
As you can see, he had a higher sleep score than I did and slept over 11 hours. He also woke up at 7 a.m., which I consider sleeping in for both of us. My sleep score was considered efficient, even though I remember feeling tired this day.
Monday, Feb. 23
Advertisement
My son had a higher sleep score than me on this day and even slept about 10 hours.
CNET/Giselle Castro-Sloboda
Monday night was another night when my son had a higher sleep score than me. He slept about 10 hours, but this was one of those days when he woke up slightly earlier than his usual wake time.
Tuesday, Feb. 24
This was one of my worst sleep scores during the experiment. However, my son fared pretty well.
Advertisement
CNET/Giselle Castro-Sloboda
It’s evident I had a terrible night of sleep on Tuesday. My son had a significantly higher sleep score than me, which doesn’t surprise me. I slept in his bed and couldn’t get comfortable, which affected my ability to get quality sleep.
Wednesday, Feb. 25
This was one of the couple of nights where we both had a restful night of sleep.
CNET/Giselle Castro-Sloboda
This was the one day out of the week when we both slept well, and I felt the most refreshed. You can see by our sleep scores that his is nearly perfect and still higher than mine. I could tell by his mood that day that he was well rested, and he had fewer tantrums.
Advertisement
Thursday, Feb. 26
The Nanit didn’t collect a sleep score for my son this night. I only have the Oura sleep score, which showed I had an OK night of sleep.
CNET/Giselle Castro-Sloboda
I’m not sure why the Nanit didn’t collect enough data for a sleep score this night. I’m assuming it must’ve disconnected from the Wi-Fi at some point. This was one of my issues with the monitor when I first reviewed it. Since it only functions on Wi-Fi, the monitor can’t be used without it.
The Oura Ring noticed I had another so-so night of sleep and pointed out how sleep trends can fluctuate. I’ve included one extra day to this experiment to even things out.
Advertisement
Friday, Feb. 27
My son had a decent night of sleep, but Oura pointed out that I’ve been having a bad period of sleep.
CNET/ Giselle Castro-Sloboda
My son had better sleep than I did again on Friday, sleeping for about 10 hours. He slept well overall through the night, except for a couple of visits, but you can tell it affected my sleep. Even Oura notes that my sleep hasn’t been the best and says that this can happen some weeks.
Saturday, Feb. 28
Advertisement
This day had my worst sleep score during the experiment, and I felt it.
CNET/Giselle Castro-Sloboda
I clearly was depleted on Saturday morning. This was my lowest sleep score yet. My son had a really bad night of sleep, continuously getting up because of nightmares. Coincidentally, this was the night before I signed up for a bootcamp class in the morning. It’s a miracle I made it to the class, let alone completed it.
Sunday, March 1
My sleep wasn’t the worst this night because my son had a more restful slumber.
Advertisement
CNET/Giselle Castro-Sloboda
This night wasn’t so bad for either of us, but my son’s sleep score was still higher than mine. He slept the majority of the night, and I think that can be attributed to getting energy out by running around with other kids during a family party the evening prior.
Monday, March 2
This was a better day of sleep for me, but not as good for my son.
Giselle Castro-Sloboda
Sunday was a successful night, and I even got an extra hour of sleep. My rating was higher than my son’s, surprisingly, and I did feel more rested.
Advertisement
Toddler sleep explained
Brittany Sheehan, a certified pediatric sleep therapist, tells CNET that sleep needs for toddlers vary by age. “Total sleep needs do diverge as kids get older, but for a 2-year-old, for example, we ideally want at least 11 hours overnight in bed, if not 12, along with a nap that is at least two hours, up to three hours,” said Sheehan. If it’s a true sleep regression, Sheehan notes that it can last anywhere from a day or two to up to six weeks in the most extreme cases.
Under normal circumstances, my son is a good sleeper (with the occasional wake-up), so when he started having frequent night wakings, I suspected it was a sleep regression. Dr. Alisa Niksch, senior director of medical affairs at Owlet, a baby monitor company, points out that disordered sleep during early childhood doesn’t occur for the same developmental reasons as those earlier in infancy.
“What parents are usually seeing is a disruption that stems from developmental and environmental factors,” Niksch said. She elaborates that for toddlers, the most common driver is developmental, driven by a growing imagination and increased cognitive function.
“Night wakings where a child cries but resettles quickly is a sign of this growth, as the developing brain is actively processing new experiences and emotions during sleep, which can surface as nightmares,” she said. Nightmares are common during this age, and although they’re normal, they also shouldn’t be ignored.
Advertisement
Natalie Barnett, who holds a doctoral degree and is vice president of clinical research at Nanit, said, “If [nightmares are] occurring once in a while and your child is calmed by a quick hug and then [goes] back to sleep, you probably don’t need to do anything about it necessarily.” However, if the nightmares are occurring repeatedly or are interfering with daytime function, she recommends speaking with your child’s pediatrician.
How to improve your toddler’s sleep
Sleep is important for toddlers and can affect everything from their mood to eating behaviors. Niksch points out that overtired toddlers often become hyperactive and emotionally dysregulated. Additionally, poor sleep affects their immune function, growth hormone release and early memory and learning. This also applies to naps, which they outgrow over time but shouldn’t be eliminated right away.
Generally, children under three should still be napping, but as they reach ages three to four, total sleep needs decrease slightly to 10 to 13 hours, and naps become shorter and less frequent before disappearing altogether. If you’re at this stage, Barnett recommends cutting the nap back first before removing it altogether.
“If your toddler is resisting bedtime, it’s often a sign that they’re not tired enough, so you may want to think about cutting back or cutting out the nap,” Barnett said. “In those first couple of weeks after dropping a nap, it can be hard for your toddler to stay awake in the late afternoon.” She advises against placing them in the stroller or car, where they’re more likely to fall asleep, in the late afternoon, since even a short nap can mess with bedtime.
Advertisement
Sheehan says that parents often drop a toddler’s nap too early in an attempt to fix sleep problems, but this can have a negative, compounding effect. “Often nap struggles are behavioral, regression-related or simply the timing is off,” she said.
Another mistake Sheehan sees parents make with 2-to-3-year-olds is putting their child down for a nap too early. This impacts their sleep because they don’t have enough sleep pressure built up to take a good nap. If you’re seeing constant bedtime and nap-time resistance or early-morning wake-ups, this could mean your toddler’s sleep timing needs adjustment.
Even with sleep disruptions, you want to make sure that their bedroom is set up for sleep success. “To support better sleep, the fundamentals remain the same: a consistent sleep and wake schedule, a predictable bedtime routine and a dark and quiet sleep environment,” Niksch said.
What parents can do to feel less sleep-deprived
Parents often take the brunt of these sleep disruptions and also struggle to function at full capacity daily. Sheehan advises that parents figure out a process or arrangement with another caregiver that allows them to rest during these phases. “If you can’t make these changes, give yourself some grace and realize it’s OK to choose a nap over a run, or to tag team with a partner who is on duty for night wake-ups,” Sheehan said.
Advertisement
Niksch agrees and recommends that parents apply the same sleep principles for their toddlers to themselves: “Consistency matters most, whether that is committing to a regular sleep and wake schedule or building a simple bedtime routine that signals to the body that rest is coming.” She points out that some parents try to sleep when their toddler does, but for some, it can be challenging if they’re not tired enough.
“If sleep doesn’t come within 15 minutes of lying down, it’s better to get up and do something that calms the mind, like reading, until tiredness sets back in,” Niksch advised.
What I took away from this experiment
Eventually, I’m sure my son’s and my sleep scores will even out again, but for now, it’s important to support him as he transitions to the next stages of toddlerhood. The sleep scores feature of the Nanit baby monitor is helpful for better understanding my son’s sleep habits and is something I wish I had when he was an infant. It also gives me some insight into his mood on some days compared to others, since sleep affects so many aspects of a child’s life.
Even restarting my tracking helped — my sleep score showed me my blind spots, ways to improve my sleep and when to take it easy. As someone who likes staying busy, it’s easy for me to have a hard time resting. The Oura Ring tracking my sleep and stress levels reminds me to take a beat.
Advertisement
While I’ve only been a parent for two years, I’ve learned that children go through many phases. This sleep experiment was a necessary reminder that you can’t bypass the tough times; you just have to get through them as best as you can.
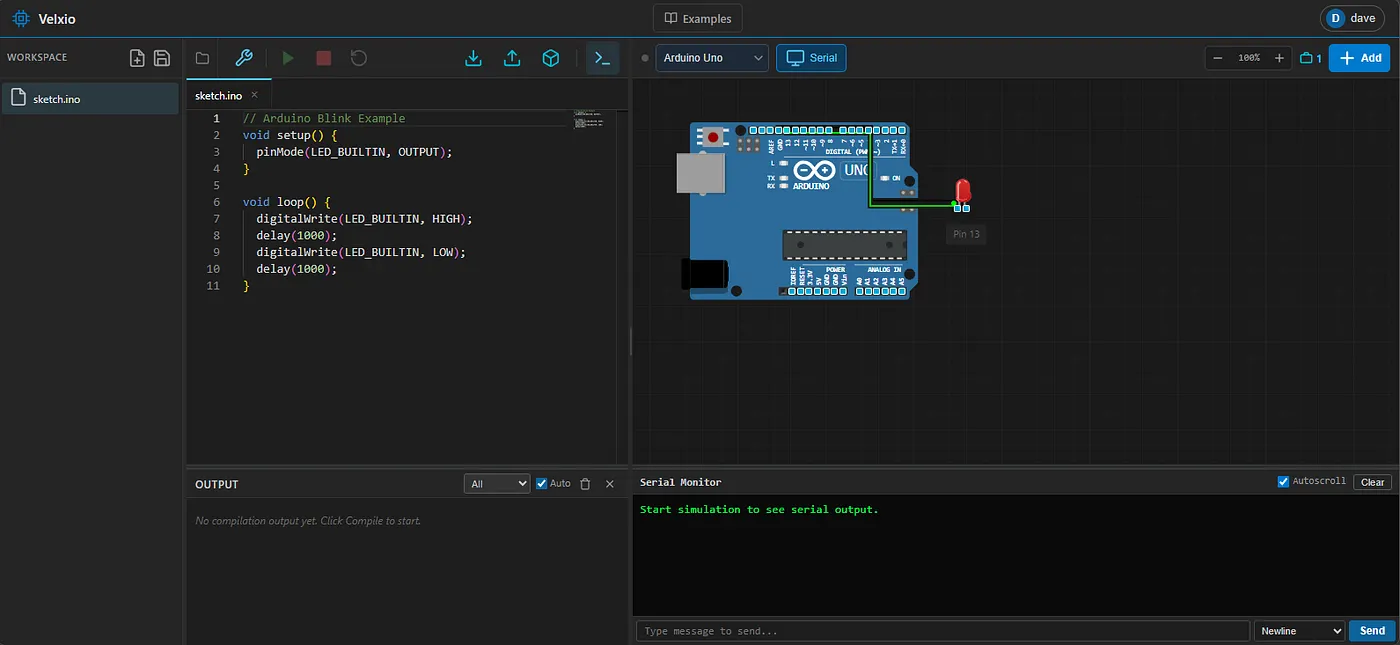
It’s always nice to simulate a project before soldering a board together. Tools like QUCS run locally and work quite well for analog circuits, but can fall short with programmable logic. Tools like Wokwi handle the programmable side quite well but may have license issues or require the cloud. The Velxio project by [David Montero Crespo] is quite an excellent example of an (online) circuit simulator with programmable logic and local execution!
It’s built largely around Wowki’s AVR8JS library for Arduino simulation. All CPU simulation occurs on the local computer, while sketch compilation happens on the backend using official Arduino tools. But this was certainly not the most impressive aspect of the project. Likewise, Velxio features RP2040 execution using the rp2040js library. It also features the execution of some ESP32 derivative boards built around the RISC-V architecture using the RiscVCore.ts library.
For more complex CPU architectures like the vanilla ESP32, Velexio implements a QEMU simulation on the backend. This methodology even enables the execution of Raspberry Pi Python code. Multiple boards can also be used in the same simulation, allowing one to test interactions between Raspberry Pis and other boards! It can also expand to handle multi-file code executions and it keeps everything in a backend database. Of course, everything is wrapped together in a neat modern UI, with a circuit diagram, parts selector, and full-blown IDE. You can try it at velxio.dev. Or, you could execute it on your home lab; it’s just one docker compose away!
NHS workers boycott Palantir software, saying it links them to endorsing the company
Government reportedly considered a break clause amid the backlash
However, UK’s FCA just awarded Palantir a trial contract
A growing number of NHS staff in the UK are reportedly refusing to use Palantir’s Federated Data Platform (FDP), according to claims from Financial Times, which reports informal boycotts from both clinical and non-clinical staff.
The biggest pushbacks come from ethical concerns over Palantir’s ties to US defense and intelligence agencies, as well as immigration enforcement and other controversial geopolitical activity.
There are also ongoing concerns over privacy and data governance when it comes to sensitive NHS patient data.
Article continues below
Advertisement
Palantir’s position in the NHS criticized from within
As well as the above, there’s also an ongoing push across Europe and the UK to reduce reliance on US tech firms – the US-headquartered company is clearly an indirect target in this geopolitically-influenced trend.
The report notes groups like the British Medical Association (BMA) are encouraging resistance to Palantir’s software, with campaigners arguing that using the platform essentially endorses the company.
Advertisement
Politicians have already responded to the backlash, agreeing in part with what campaigners stand for.
MPs say the criticism is about value, transparency and trust – not necessarily ideology – and as such, the UK government could be considering a break clause in the contract amid the backlash.
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
Together, the NHS and Palantir’s FDP claim to have opened up tens of thousands of new operations, reduced wait times and improved scheduling, by combining multiple data sources into one central database.
Advertisement
However, while politicians seem to be reacting to NHS workers’ arguments, Palantir’s footprint is far from disappearing in the UK, with the Financial Conduct Authority (FCA) awarding the US tech firm a three-month contract ahead of what could potentially be a much bigger contract.
Years of steady usage and exposure to the elements have taken a toll on Japanese railway stations, making replacement a headache. Finding competent contractors is difficult, and construction wages are high. Serendix collaborated with ABB to help JR West restore a historic wooden shelter from 1948 at a station in Wakayama Prefecture. This site, a true relic, was only frequented by around 270 visitors every day in a tiny coastal village near Arida that few people had ever heard of.
The factory handled the heavy lifting, and the ABB IRB 6700 robot arm stole the show. It was producing concrete components out of mortar and did an excellent job. Their Vertico nozzle proved to be a game changer, since it is four times more accurate than any other nozzle they’ve used, and they were able to reduce mortar waste by half, which had to be a positive thing. They also increased the arm’s range of motion to seven axes, which is rather astounding. It can also handle building fairly complicated surfaces.
High-Speed Precision: Experience unparalleled speed and precision with the Bambu Lab A1 3D Printer. With an impressive acceleration of 10,000 mm/s…
Multi-Color Printing with AMS lite: Unlock your creativity with vibrant and multi-colored 3D prints. The Bambu Lab A1 3D printers make multi-color…
Full-Auto Calibration: Say goodbye to manual calibration hassles. The A1 3D printer takes care of all the calibration processes automatically…
It took approximately a week to complete the printing process, but the important news is that all of the major components were completed and brought to the site, ready to be assembled. The designers chose an arched ceiling and even incorporated a few flourishes, and all of this was completed between the last train and the first the next morning. The crew then used the robotic equipment to assemble the pieces and create a completely new station in about six hours.
What truly sticks out is how much time and money they saved, and by saved, I mean that this printing method cut both time and cost in half. Furthermore, they used far less material. JR West stated that if this had been done the traditional way, the facility would have had to be shut down for months and would have cost double what they did, with the added benefit of reducing concrete and steel waste.
JR West executives stated that they had to complete this portion on the factory floor or the entire rail network would have come to a halt, and the Serendix employee was overjoyed with how the ABB arm performed, since his employer believes they can automate more of the procedure for the next job.
Light Detection and Ranging (Lidar): This system, also used by self-driving cars, fires out rapid laser pulses to map the terrain in 3D. It enables mowers to cut grass under thick tree canopies or near tall buildings where GPS signals usually fail.
AI Vision: Some mowers now employ cameras to recognize lawn areas, borders, and obstacles. Robot mowers with AI vision can potentially avoid stray footballs, cats, other critters, and maybe even pet mess. But they can also be too sensitive, stopping for fallen branches, leaves, or overhanging plants.
Some of the top mowers, like the Mammotion I’m currently testing, employ a combination of the last three technologies to map and cut areas accurately, navigate reliably to and from the charging base, and avoid unexpected obstacles. None of them is foolproof. My top pick chewed up a deflated paddling pool, but if you set the sensitivity too high, they leave areas uncut.
In addition to finding their way, many of the latest robot mowers are built to handle rough terrain. Not too rough, but fine for a bumpy garden or a yard with steep inclines. Some models even come with interchangeable tires, so you can throw on grippier wheels when you need them. But it’s important to check what terrain and inclines your mower can handle upfront. Four-wheel-drive or all-wheel-drive mowers are best at handling steep or uneven ground.
Advertisement
The Cutting Edge
Traditionally, robot mowers have been terrible at cutting all the way to the edge of your lawn. Most of the early robot mowers I tested left a thick border of uncut grass, up to 1-foot wide. I don’t think this issue is entirely solved, but some newer models have offset blades that sit closer to the edge of the machine, or they have an overhanging section that extends past the wheels, so it can cut right to the edge when the robot mower turns. There are even robot mowers with built-in trimmers and other garden tools, though I’ve yet to test one.
While edge cutting is getting better, I still find that most robot mowers need some adjustment to reliably cut the entire lawn. I often have to edit the map or tweak sensitivity to ensure they cut all the way to the edge, yet there are still areas that they seem to miss. Plants, shrubs, and trees that overhang the lawn cause issues, as robot mowers, understandably, err on the cautious side when it comes to potential obstacles. There’s still room for improvement here.
Smart Finish
Husqvarna app via Simon Hill
While the first robot mower I tested churned my lawn into a muddy mess, most robot mowers now have some form of rain detection, so you can set them not to cut if the grass is wet. The latest models are also far better at handling wet grass and turning without skidding or churning up a big chunk of your lawn.
Some robot mowers offer customization in terms of the lawn finish you want. You may find an option in the app for Wimbledon Stripes (dark and light stripes), achieved by mowing rows in opposite directions. Some mowers can even do spirals, checkerboards, and other patterns.
When the inevitable Kessler Syndrome cascade sweeps Starlink and its competitors from Low Earth Orbit in what will doubtless be a spectacular meteor shower of debris, the people behind Sceye and its competitors are going to be laughing to the bank. That’s because they’re putting their connectivity rather lower than orbit — in the stratosphere, with high-altitude dirigibles.
The advantages are pretty obvious: for one, the dirigible isn’t disposable in the way the very-low-orbit satellites Starlink and its planned imitators use. For another, the time-of-flight for a signal to get to a dirigible 20 km up is less than a tenth of the time it takes to get 480 km up — and that affects latency. Thirdly, the High Altitude Platform System (HAPS) concept won’t require any special transmitters. Regular cellular modems using ordinary 4G and 5G bands and speeds are usable, which eliminates a big barrier to rollout.
If this all sounds a bit familiar, and even dated, perhaps that’s because it is — Google tried to beam internet down from the stratosphere with its Loon project, before shutting it down in 2021. One of Loon’s major shortcomings was reliance on the shifting winds of the upper atmosphere, something the new generation of dirigible stations won’t have to worry about.
Of course, until the positive feedback loop of satellite collisions creating debris that begets yet more collisions that we call a Kessler Syndrome — which we’ve written about in arcade form, oddly enough–one could also use these HAPS stations as a bridge between space-based and ground-based networks.































































You must be logged in to post a comment Login