
Crypto World
Relief Rally Leads To Green Bitcoin, Altcoin Charts, But Will It Last?
Key points:
-
Bitcoin has started a relief rally, which is expected to face selling near $84,000.
-
Several major altcoins are at risk of breaking below their support levels if the bulls fail to clear the overhead resistance levels.
Bitcoin (BTC) turned up from the $74,508 level on Monday, and the buyers are attempting to maintain the price above $79,000. BTC analyst PlanC said in a post on X that the fall to the $75,000 to $80,000 zone might be “the deepest pullback opportunity this Bitcoin bull run.”
The Crypto Fear & Greed Index, which measures overall crypto market sentiment, plunged into the “Extreme Fear” zone with a score of 14, the lowest in 2026. Crypto analytics platform Santiment said in a report on Friday that the extreme negativity on social media was a silver lining as “historically, crypto markets move in the opposite direction of the crowd’s expectations.”

However, not everyone believes that a bottom is in. Several analysts are bearish on BTC and expect it to fall further. Traders on Polymarket also anticipate the downtrend to continue, with the odds of BTC falling below $65,000 rising to 72% on Monday.
Could BTC and the major altcoins start a strong relief rally in the near term? Let’s analyze the charts of the top 10 cryptocurrencies to find out.
S&P 500 Index price prediction
The S&P 500 Index (SPX) fell to the 50-day simple moving average (6,864) on Thursday, but the bulls successfully defended the level.

The bulls will have to thrust the price above the resistance line of the ascending channel pattern to indicate the resumption of the uptrend. The index may then rally to 7,290.
Contrary to this assumption, if the price turns down from the resistance line and breaks below the 20-day exponential moving average ($6,929), it suggests that the index may remain inside the channel for a while longer. The bears will gain the upper hand on a close below the support line. The index may then decline toward the 6,550 support.
US Dollar Index price prediction
The US Dollar Index (DXY) tumbled below the 96.21 support on Tuesday, but the bears could not sustain the lower levels.

The bulls pushed the price back above the 96.21 level on Wednesday, but the recovery is expected to face selling at the 20-day EMA ($97.78). If the price turns down sharply from the 20-day EMA, the bears will attempt to sink the index below the 96.21 level.
On the other hand, a break and close above the 20-day EMA suggests that the break below the 96.21 level may have been a bear trap. The index may then rally toward the stiff overhead resistance of 100.54.
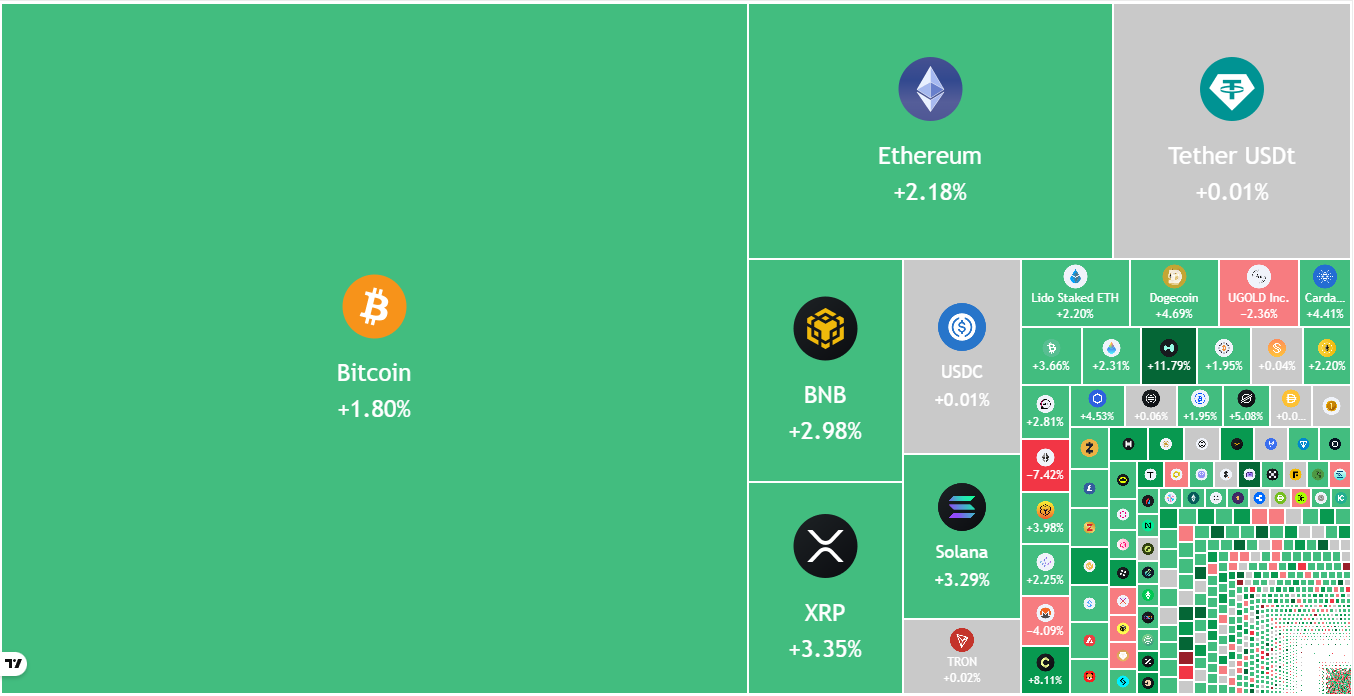
Bitcoin price prediction
BTC fell below the Nov. 21, 2025, low of $80,600 on Saturday and reached the critical support of $74,508 on Monday.

The relative strength index (RSI) plunged into the oversold territory, signaling a possible relief rally in the near term. The Bitcoin price is expected to face selling in the $80,600 to $84,000 zone. If the BTC/USDT pair turns down sharply from the overhead zone, the risk of a break below the $74,508 level increases. The next support on the downside is at $60,000.
The first sign of strength will be a break and close above the moving averages. That suggests the $74,508 level will continue to behave as a floor for some more time.
Ether price prediction
Ether (ETH) broke below the $2,623 level on Saturday and fell to the next major support of $2,111 on Monday.

The RSI has slipped into the oversold category, indicating that the selling may have been overdone in the near term. That increases the possibility of a relief rally, which is expected to face selling at the 20-day EMA ($2,833).
A shallow bounce off the current level or a sharp reversal from the 20-day EMA suggests that the advantage remains with the bears. If the $2,111 support cracks, the Ether price may descend to $1,750. The bulls will be back in the game after the ETH/USDT pair rises above the moving averages.
BNB price prediction
BNB (BNB) plummeted below the uptrend line and the $790 support on Saturday, indicating aggressive selling by the bears.

The bulls are attempting to protect the $730 support, but the relief rally is expected to face selling at the breakdown level of $790. If the BNB price turns down sharply from $790, it signals that the bears have flipped the level into resistance. That increases the prospects of a drop to $700.
Instead, if the price closes above $790, it suggests that the lower levels are attracting buyers. The BNB/USDT pair may then rally to the moving averages, where the bulls are expected to encounter solid selling by the bears.
XRP price prediction
XRP (XRP) is witnessing a tough battle between the buyers and sellers at the crucial $1.61 support.

A shallow bounce increases the likelihood of a drop to the support line of the descending channel pattern. Buyers are expected to defend the support line, as a break below it might sink the XRP/USDT pair to the Oct. 10, 2025, low of $1.25.
The moving averages are the critical resistance to watch out for on the upside. A close above the moving averages suggests that the XRP price may remain inside the channel for a few more days.
Solana price prediction
Solana (SOL) collapsed below the $117 level on Saturday and reached the critical support at $95.

The bulls have successfully defended the $95 level, but the failure to start a strong bounce suggests that the bears continue to exert pressure. If the $95 support gives way, the SOL/USDT pair may start the next leg of the downtrend to $79.
Contrarily, if the Solana price rises above $107, the recovery may reach the 20-day EMA ($121). Sellers will attempt to defend the 20-day EMA, but if the bulls prevail, the pair may march toward the $147 resistance.
Related: XRP price risks repeating 2022 crash as new buyers go underwater
Dogecoin price prediction
Dogecoin (DOGE) plunged below the Oct. 10, 2025, low of $0.10 on Saturday, indicating aggressive selling by the bears.

The bulls have started a relief rally, which is expected to face selling at the 20-day EMA ($0.12). If the Dogecoin price turns down sharply from the 20-day EMA, the risk of a break below the $0.10 level increases. The DOGE/USDT pair may then nosedive to $0.08.
Alternatively, if buyers pierce the 20-day EMA, it suggests that the market has rejected the break below the $0.10 level. The pair will then attempt a rally to the solid overhead resistance at $0.16.
Cardano price prediction
Cardano (ADA) fell below the Oct. 10, 2025, low of $0.27 on Saturday, signaling that the bears remain in charge.

The Cardano price has bounced off the support line but is expected to face selling at the 20-day EMA ($0.34). If the price turns down sharply from the 20-day EMA, the bears will again try to yank the ADA/USDT pair below the support line. If they succeed, the downtrend may extend to $0.20.
The bulls will have to catapult the price above the downtrend line to suggest that the downtrend may be ending. The pair may then ascend to the breakdown level of $0.50.
Bitcoin Cash price prediction
Bitcoin Cash (BCH) fell toward its pattern target of $456 on Saturday, where the buyers stepped in.

The bulls have started a relief rally, which is expected to face resistance in the zone between the 50% Fibonacci retracement level of $535 and the 61.8% retracement level of $551. If the Bitcoin Cash price turns down from the resistance zone, the bears will attempt to pull the BCH/USDT pair below $500.
On the contrary, if buyers propel the price above $551, the pair may reach the 20-day EMA ($571). A close above the 20-day EMA signals that the bulls are back in the game.
This article does not contain investment advice or recommendations. Every investment and trading move involves risk, and readers should conduct their own research when making a decision. While we strive to provide accurate and timely information, Cointelegraph does not guarantee the accuracy, completeness, or reliability of any information in this article. This article may contain forward-looking statements that are subject to risks and uncertainties. Cointelegraph will not be liable for any loss or damage arising from your reliance on this information.



The XRP price CLARITY Act connection has never been tighter: with the Senate Banking Committee targeting a late April markup and Senator Bernie Moreno warning that failure to pass by May effectively kills the bill for 2026, the next three weeks in Washington are the most consequential period XRP has faced this year.
Summary
- The Senate returns from Easter recess on April 13 with a CLARITY Act Banking Committee markup targeted for the second half of the month; if the bill does not reach the Senate floor by May, Senator Moreno warns it will not move again before the 2026 midterms
- If the CLARITY Act advances through committee, analysts project $4 to $8 billion in additional XRP ETF inflows, which could push XRP above $1.60 and toward its prior highs; if the bill stalls, XRP risks falling below $1.20 and potentially toward $0.82 if Bitcoin simultaneously breaks $60,000
- XRP posted its worst quarter in eight years in Q1 2026, falling 27% despite a string of regulatory wins including SEC/CFTC commodity classification and $1.44 billion in ETF inflows since last year’s launches
The XRP (XRP) price CLARITY Act deadline is now a matter of weeks, not months. XRP is trading around $1.34 on April 6, up 2.2% on ceasefire-related risk-on sentiment, but still down more than 63% from its July 2025 peak of $3.65. According to 24/7 Wall St., Q1 2026 was XRP’s worst quarter in eight years, with its market cap shrinking by nearly $29 billion despite the SEC and CFTC jointly classifying XRP as a digital commodity on March 17.
The problem, analysts argue, is that regulatory clarity alone is not enough. Banks and large asset managers need the CLARITY Act to become federal law before they will commit capital at scale, because the current commodity classification is an interpretive release rather than legislation, and a future administration could reverse it.
The Senate returns from Easter recess on April 13. The Banking Committee markup is targeted for the second half of April. That is the window. As crypto.news reported, the long-running stablecoin yield dispute between banks and crypto firms appears to be entering its endgame, with Senators Tillis and Alsobrooks having reached a compromise in principle on March 20 that bans passive yield on stablecoin balances but permits activity-based rewards tied to payments and platform use.
Polymarket currently gives the CLARITY Act roughly a 63 to 66% probability of being signed into law in 2026. But Senator Moreno has stated publicly that if the bill does not reach the full Senate floor by May, midterm election dynamics will push it off the calendar for the rest of the year. Ripple CEO Brad Garlinghouse has already pushed his own expected passage timeline from end of April to end of May.
The Bullish Scenario: $1.60 and Beyond
If the Senate Banking Committee advances the bill in late April, analysts project the development would unlock $4 to $8 billion in additional XRP ETF inflows, according to Standard Chartered’s Geoffrey Kendrick. Seven US spot XRP ETFs already pulled in $1.44 billion since launching between September and December 2025 without the CLARITY Act as law. With it, the institutional capital currently on the sidelines would have permanent legal cover. That scale of inflows would lock hundreds of millions of XRP tokens in custody, tightening circulating supply and, according to the 24/7 Wall St. analysis, providing the momentum needed to push XRP above $1.60 and potentially toward its prior cycle high.
The Bearish Scenario: Below $1.20
As crypto.news noted, the CLARITY Act enters the Senate Banking Committee with broad support but a narrowing clock and almost no room for further substantive revision. If the bill stalls past May, Standard Chartered’s 2026 XRP price target falls to $2.80 at best, the forecast already cut from $8 when delays first materialized. Without the bill, XRP would likely follow Bitcoin’s direction in a market where BTC is currently range-bound between $65,000 and $73,000 with the Fed holding rates through at least December. A stall combined with Bitcoin breaking below $60,000 could see XRP drop toward $0.82, according to the 24/7 Wall St. analysis.
“April is the narrowest window XRP has had for that to change,” 24/7 Wall St. wrote. “If the CLARITY Act advances through the Banking Committee before May, Q2 starts with something Q1 never had.”
Crypto World
Cardano News: Can a New Crypto Beat What ADA’s Rally Signal Will Take Months to Deliver
The cardano news today starts with a breakout. ADA just pushed above $0.25 on April 6 for the first time in weeks, and the first exchange inflow week since November 2025 just flashed, a signal that has come before every major Cardano rally in the past year according to CryptoNews.
ADA still sits 92% below its all-time high despite real progress on Protocol 11 and the Midnight sidechain. That gap between what Cardano builds and what holders actually see in their wallets is pushing money toward entries that combine real tools with a single listing that turns months of waiting into one day.
ADA crossed $0.25 on April 6 with RSI at 69.64 on the 2-hour chart, the highest momentum reading in weeks according to CryptoNews.
The first exchange inflow week since November 2025 appeared at the same time, a pattern that showed up before every major ADA bounce in the past year.
The Van Rossem hard fork to Protocol Version 11 is close, bringing new Plutus smart contract tools and on-chain governance that lets token holders cast votes on treasury spending according to CoinMarketCap. The Midnight privacy sidechain went live March 29 with Google Cloud and Worldpay as early validators.
The cardano news confirms the upgrades are real, but the spread between 680 commits a week from developers and a 92% drop from the peak keeps getting wider.
Top Plays While ADA’s Governance Upgrades Land
Pepeto: Can This Presale Give You Better Returns Than Cardano This Year?
The biggest story this week is the rally signal, but for wallets looking for the fastest path to gains, Pepeto is where capital flows when the cycle turns. PepetoSwap handles every swap at zero fees. The built-in scanner reads contracts and spots wallets holding too much supply before your money goes in. The bridge sends your portfolio across chains at no cost. The platform solves a real issue that gets worse every time new tokens fight for the same buyers.
Over $8.78M raised during Fear and Greed at 13 at $0.0000001862. Each round fills quicker as the confirmed Binance listing draws near. SolidProof audited every contract running on the platform. An ex-Binance dev lead who handled token launches built the listing roadmap. Staking at 187% APY adds to your position while the exchange grows.
Meme hype and real exchange tools landing together shows up once per cycle. The Binance listing is the one event that produces the return. The wallets already inside can see what listing day brings, and the entry is still live for anyone who sees how strong this window is.
Cardano News: ADA Price Tests $0.25 as Protocol 11 and Rally Signal Target Recovery
ADA trades at $0.2519 according to CoinMarketCap, with Protocol 11 approaching and the first exchange inflow signal since November pointing toward a move. CoinCodex projects $0.38 by mid-2026 while Changelly sees $0.307 to $0.412 for April.
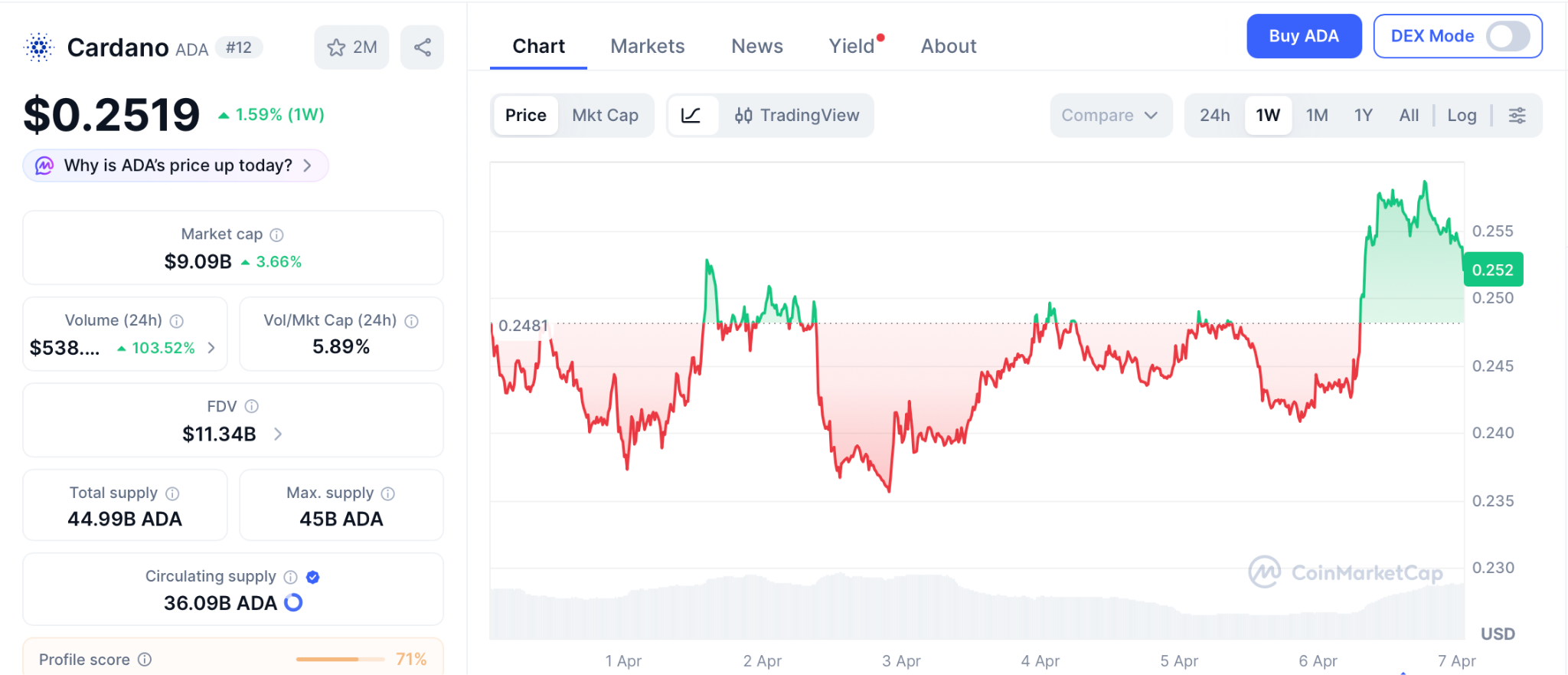
Support holds at $0.236 with $0.26 as the first wall and $0.28 above that. The SEC gave ADA a digital commodity tag, clearing the legal path. The cardano news shows strong technical progress, but the token has to push from $0.25 all the way to $0.34 just to reach first real resistance, and that takes time while a presale listing squeezes the same kind of move into a single day.
Conclusion
The cardano news is turning positive with ADA breaking $0.25 and the first rally signal since November flashing at the same time. But ADA still needs months to reach targets that matter from a $9.09 billion cap.
Pepeto through the Pepeto official website is where meme hype, working exchange tools, and a confirmed Binance listing all land in one token, a setup crypto has not built before. The cycle is turning, and in past runs both meme coins and early exchange tokens handed out the kind of gains every trader talks about for years. Having both inside one project makes Pepeto the entry you do not want to skip, and the cardano news rally signal says the window is shrinking. The project launches soon, and once it does, this early price is gone.
Click To Visit Pepeto Website To Enter The Presale

FAQs
What does the cardano news rally signal mean for ADA holders?
ADA broke above $0.25 with the first exchange inflow week since November, a pattern that came before every major ADA rally in the past year. The outlook is bullish, but Pepeto’s listing compresses what ADA takes months to deliver into one event.
How does the cardano news compare to what Pepeto offers right now?
The cardano news shows ADA needs to reach $0.34 just to hit first resistance from $0.25. Pepeto at $0.0000001862 with 187% APY staking and a Binance listing ahead reaches its return from one listing day through the Pepeto official website.
Disclaimer: This is a Press Release provided by a third party who is responsible for the content. Please conduct your own research before taking any action based on the content.



Prediction markets like Polymarket and Kalshi now clear nearly $24b a month as AI bots, Wall Street capital and new CFTC rules drag the sector into mainstream finance.
Summary
- Prediction markets led by Polymarket and Kalshi have exploded from a niche crypto product into one of finance’s hottest sectors in under a year.
- Platforms now span DeFi-native venues, fully regulated exchanges, AI-powered tools and sports-focused apps, with cumulative monthly volumes in the tens of billions of dollars.
- Regulators and Wall Street players are circling the space, with the White House reviewing new CFTC rules as investors treat prediction odds as a new kind of market data.
Prediction markets are moving from the fringes of crypto into the core of global finance, with X account Top 7 Crypto | Analytics & Alpha arguing they have become “one of the hottest sectors in finance in under 12 months” thanks to platforms such as Polymarket and Kalshi. In a post that has drawn nearly 50,000 views, the account describes an expanding “Prediction Markets Landscape” that now includes “DeFi natives, regulated exchanges, AI-powered and sports-focused platforms,” and urges followers to “Save the list before your feed buries it,” underscoring how fast new venues are appearing.
That momentum reflects a sector-wide surge: industry research cited by Hashgraph Ventures notes that prediction market volumes nearly quintupled from early 2025, while a16z has flagged the space as a breakout category after the 2024 U.S. election cycle.
A detailed report from TRM Labs found that prediction market transactions hit 191 million in March, with trading volume reaching about $23.9 billion, a 2,800% jump from the prior year as geopolitical and macroeconomic bets dominated flows. Crypto.news has separately reported that, for the week ending March 9, nominal volume on Polymarket hit $2.49 billion, while CFTC-regulated Kalshi posted $2.85 billion, pushing total sector volume to $14.5 billion and lifting unique users to 2.8 million. Phemex analysis suggests that for full-year 2025, combined volumes on Polymarket and Kalshi approached $40 billion, helping turn both into multibillion‑dollar companies. On both platforms, ultra‑short‑term contracts now drive activity: according to a recent crypto.news story, five‑ to 15‑minute “up‑down” contracts on BTC, ETH and other coins already account for more than half of their crypto trading, with combined daily volume around $70 million.
Top 7 Crypto’s thread, based on a landscape graphic from analytics firm @surgence_io, highlights how broad the category has become, drawing in replies from projects spanning on-chain metrics, AI assistants and sports betting. Hedgehog, a data platform that focuses on gas fees and funding rates, wrote that “the prediction market landscape is expanding fast” and said it is “focused on the layer underneath everything else: on-chain metrics… The costs that power every transaction on every chain.” Other builders chimed in to stress the AI and tooling angle: “We are also AI powered tools for prediction market,” wrote @Bobbxu, pointing to @questflow as a way to automate analysis and execution around event contracts. Sports-focused accounts including Trajan Capital and Overtime.io protested being left off the initial list, with Trajan saying that excluding @BetOpenly, @4CxSweeps and @PlayProphetX was “like listing car makes and skipping BMW, Mercedes and Porsche.”
Behind that noisy expansion sits a clearer split between permissionless and regulated rails. Polymarket, built on crypto infrastructure, has leaned into global access while facing mounting pressure from regulators, including a recent crypto.news story on its ban in Argentina after a gambling probe and an earlier lawsuit against Massachusetts over state-level restrictions. Kalshi, by contrast, stresses its status as a CFTC‑regulated Designated Contract Market, explaining in its Market Integrity Hub that all of its event contracts are subject to the Commodity Exchange Act and “23 Core Principles” that govern futures exchanges. That regulatory positioning has attracted both enforcement attention and institutional interest: a crypto.news report noted that ARK Invest is now using Kalshi data “to track market expectations” and integrate market‑implied probabilities into research and risk management.
The capital entering the space looks increasingly like traditional finance. According to Bloomberg, Intercontinental Exchange, owner of the New York Stock Exchange, plans to invest up to $2 billion in Polymarket, valuing the platform at roughly $8 billion and signalling that big exchanges see event contracts as a strategic product line. A separate Bloomberg report on a 2025 fintech funding rebound noted that Polymarket and Kalshi together raised about $3.71 billion in fresh capital that year, helping push global fintech funding to $55.94 billion, up 25% from 2024. A follow‑up piece cited by crypto outlets added that Polymarket is negotiating new funding at a valuation between $12 billion and $15 billion, while Kalshi’s valuation has climbed above $10 billion, underlining how quickly markets now value their flows.
Policymakers are responding. The U.S. Commodity Futures Trading Commission recently issued new guidance and enforcement advisories on prediction markets, reminding platforms that it retains “full authority to police illegal trading practices” on Designated Contract Markets. The White House is currently reviewing a fresh set of CFTC measures that would clarify the status of event-linked derivatives, a step crypto.news says could shape how platforms structure contracts on elections, macro data and geopolitics far beyond the crypto niche. In parallel, a Financial Times feature titled “Prediction markets: the hunt for the new ‘dumb money’” chronicles how retail traders are flocking into markets where odds on politicians, central banks and even pop culture become tradable data points, and notes one user who migrated from regulated Kalshi to offshore Polymarket to chase higher leverage.
Crypto-native firms are now treating this data as a new market primitive. A recent crypto.news story on Coinbase’s “everything exchange” strategy described how the company wants regulated prediction markets to sit alongside spot crypto and tokenized assets, with executives arguing that odds from venues such as Polymarket and Kalshi can compete with polling, sell‑side research and even traditional media feeds. Another crypto.news story on “Prediction market activity jumps 2800%” tied the recent spike to geopolitical contracts, pointing out that broadcasters including CNBC and Dow Jones have begun integrating live odds into their coverage. With Top 7 Crypto promising an updated “Prediction Markets Landscape” to reflect the dozens of teams now vying for attention, the sector’s next phase will likely hinge on whether this flow of dollars, regulatory clarity and media exposure can turn what was once a degen side hobby into a durable piece of financial infrastructure.
Crypto World
XRP Price Prediction: XRP Price After Ripple Signs Mastercard While Whales Invest Heavy In Pepeto Now
Ripple just locked in a deal with Mastercard, and XRP barely moved. The token sits at $1.35, down 64% from its $3.65 high, while the xrp price prediction crowd waits for a bounce that keeps stalling at the same ceiling.
That gap between what Ripple does behind the scenes and what XRP holders actually see in their wallets is the question that makes you rethink where the real returns come from.
There is another project that is currently attracting huge whale capital, Pepeto pulled in $8.84M faster than any meme token this year, and the xrp price prediction numbers show exactly why money keeps moving into this presale instead.
Ripple signed a deal with Mastercard to bring cross-border payment tools to the card giant’s network, as Motley Fool reported on April 3. XRP jumped to $1.37 on the news and gave it all back within days.
24/7 Wall Street reports XRP ETFs lost $31 million in March while total assets dropped from $1.24 billion to $947 million. XRP trades at $1.35 on April 6 according to CoinMarketCap, down 64% from $3.65 with Fear and Greed at 13. The big names signed the deals. The xrp price prediction still has not followed.
Where the XRP Outlook and the Pepeto Presale Tell Two Different Stories
Pepeto: The Play That XRP’s Market Cap Cannot Give You
The xrp price prediction talk keeps holders glued to whether $1.30 holds or cracks, but Pepeto is where the whale wallets hunting for big multiples are sending money right now, and the tools behind the presale make the reason obvious.
What would XRP look like if zero-fee trading was baked into the token instead of relying on outside partners? Pepeto closes that gap. PepetoSwap runs every swap at zero cost so your buy price stays clean, and the token scanner reads each contract before you commit so the danger hits your screen before it hits your bag.
Think about holding XRP before the SEC case ended in August 2025, when it traded under $0.50 and nobody thought it would clear. The wallets that stacked during that panic turned small buys into a 7x within months. Every holder who caught that move says the same thing: they nearly walked away and they wish they had bought more.
Pepeto sits in that exact kind of moment today. Over $8.84M pulled in at $0.0000001862 during Fear and Greed at 13, built by the Pepe cofounder with an ex-Binance dev lead who put the exchange together, and every contract cleared by SolidProof before the first dollar went in. Staking at 187% APY grows your bag while the listing gets closer. The big wallets loading this presale watched XRP levels before the ruling dropped, and they can see what the Binance listing does to this kind of entry.
XRP Price Prediction: Where Does XRP Go From $1.35?
XRP trades at $1.35 on April 6, sitting 64% under its $3.65 peak even after the SEC commodity tag and a new Mastercard partnership according to CoinMarketCap.
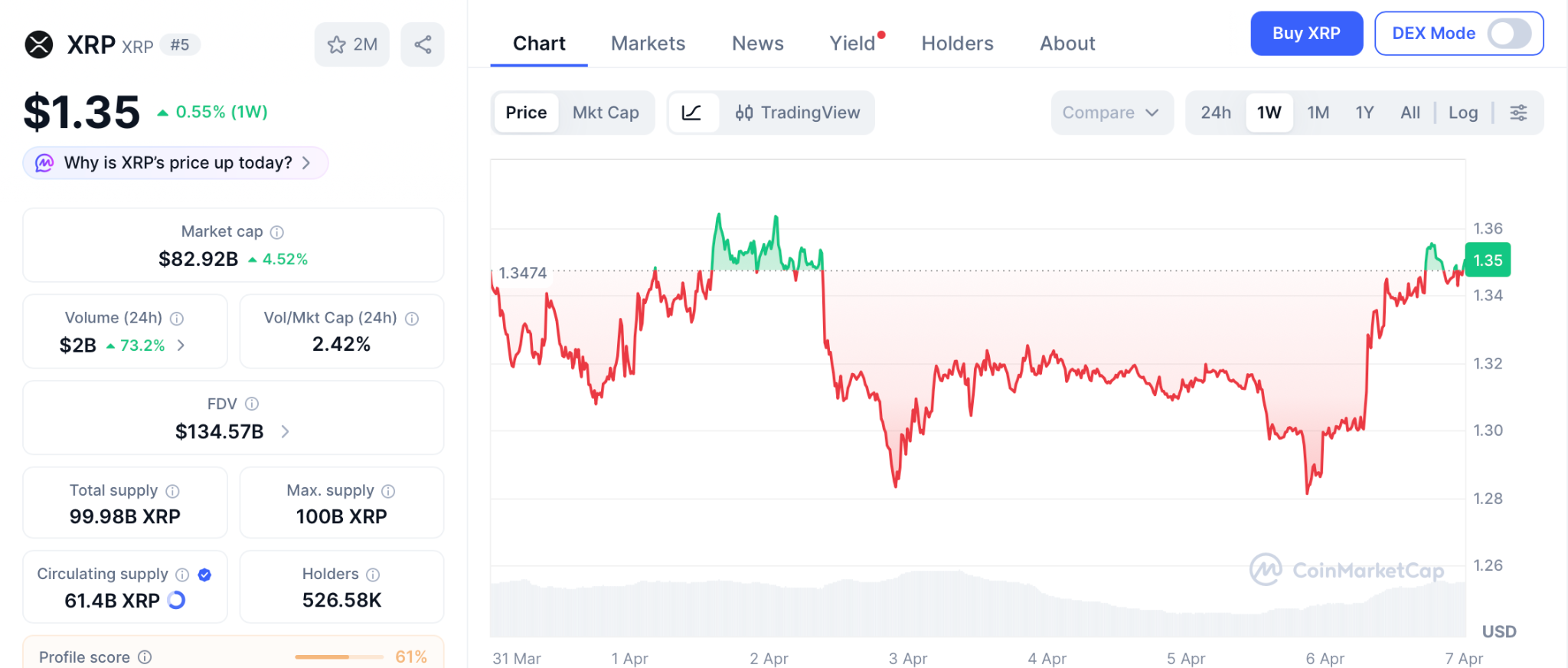
Standard Chartered dropped its target from $8 down to $2.80. The $1.28 floor has held every dip, with 24/7 Wall Street reporting heavy buying at that zone. The 50-day moving average at $1.38 acts as the first cap. Clearing it opens $1.60 and then a shot at $2.80. Losing $1.28 drops the path toward $1.11.
The xrp price prediction reality from an $82 billion market cap means even a 3x takes the kind of new money that arrives over quarters, and that limit is why wallets keep turning to presale plays where a single listing hands you what XRP takes years to produce.
Conclusion
The xrp price prediction and Ripple’s Mastercard deal both tell you the same thing: a token with an $82 billion cap where every rally hits a wall of sellers cannot hand you the kind of gains that reshape your future, and Pepeto is where the numbers still add up.
The XRP holders who stacked under $0.50 before the SEC ruling all repeat the same line: they nearly passed and they wish they had gone heavier. That pattern is now playing out with Pepeto at $8.84M raised during Fear 13 and a Binance listing ahead.
The Pepeto official website still has presale pricing live, and buying while fear keeps the crowd away is exactly what those early XRP wallets did to build what they have now. Passing on this presale could be the one choice you think about for the rest of the cycle.
Click To Visit Pepeto Website To Enter The Presale

FAQs
What xrp price prediction levels matter after the Mastercard deal?
Support holds at $1.28 with the 50-day moving average at $1.38 as the nearest cap and $1.60 above that. Pepeto at $0.0000001862 offers presale pricing with a Binance listing closing in through the Pepeto official website.
Can the xrp price prediction match the returns Pepeto presale holders expect?
XRP needs years for a 3x from its $82 billion cap. Pepeto reaches those multiples in one listing event from current presale pricing at $0.0000001862 with 187% APY staking adding to positions daily.
Disclaimer: This is a Press Release provided by a third party who is responsible for the content. Please conduct your own research before taking any action based on the content.


A new investigation published argues that the federal government is rushing into artificial intelligence the same way it rushed into cloud computing a decade ago, and with the same structural vulnerabilities still in place.
Summary
- ProPublica reporter Renee Dudley draws on years of federal cybersecurity reporting to outline three cautionary lessons as the Trump administration pushes agencies to rapidly adopt AI tools from OpenAI, Google, and xAI at cut-rate government pricing
- The first lesson: so-called free or cheap tech deals eventually lock agencies in; the second: oversight programs like FedRAMP have been gutted and lack resources to vet what they approve; the third: the third-party auditors rating AI providers are paid by those same providers
- The White House is framing AI adoption as urgent and competitive, mirroring language the Obama administration used to push cloud computing, a transition ProPublica’s reporting found was riddled with cybersecurity failures
ProPublica’s Renee Dudley published an investigation on April 6 arguing that as the Trump administration encourages federal agencies to rapidly adopt AI from major tech companies, it is repeating the patterns that plagued Washington’s transition to cloud computing, where speed trumped security, oversight was defunded, and the government eventually became deeply dependent on contractors it had little leverage over.
The White House has positioned AI as a national competitiveness imperative. Agencies can now access OpenAI’s ChatGPT for $1, Google’s Gemini for 47 cents per user, and xAI’s Grok for 42 cents. The framing, Dudley writes, closely mirrors the language used when the Obama administration declared cloud computing a transformational priority in the early 2010s.
Lesson one: There is no such thing as a free lunch. ProPublica’s investigation found that Microsoft’s pledge in 2021 to give the federal government $150 million in security services was, in practice, a lock-in mechanism. After agencies adopted the free upgrades, switching to a competitor would have been costly and disruptive. “It was successful beyond what any of us could have imagined,” one former Microsoft salesperson told ProPublica. As crypto.news has reported, Microsoft and OpenAI have since clashed over the terms of their own AI partnership, a signal of how fraught big-tech AI contracts can be even among the parties involved.
Lesson two: Oversight programs require actual resources. The Federal Risk and Authorization Management Program, known as FedRAMP, was created in 2011 to vet cloud computing services before federal agencies were allowed to use them. ProPublica found that the agency wore down FedRAMP over five years to get approval for a major cloud product despite serious cybersecurity reservations. That was before DOGE. FedRAMP now says it operates “with an absolute minimum of support staff” and “limited customer service.” A GSA spokesperson defended the program, saying it “operates with strengthened oversight and accountability mechanisms,” but former employees told ProPublica it functions as a rubber stamp.
Lesson three: Independent reviews are only so independent. As FedRAMP’s in-house capacity has shrunk, third-party auditing firms have assumed more of the vetting function. Those firms are paid by the same cloud companies they are rating. Agencies, often understaffed, lack the capacity to conduct their own thorough reviews and largely rely on those ratings. As crypto.news noted, the broader concern across observers is that governments are consistently slower to govern transformative technology than the companies deploying it.
A Pattern the White House Has Not Addressed
The GSA has acknowledged that AI “usage costs can grow quickly without proper monitoring and management controls” and has advised agencies to set usage limits and review consumption reports. But the underlying structural issues remain: underfunded oversight bodies, vendor-dependent reviews, and agencies with little leverage once adoption becomes entrenched.
Dudley’s conclusion is pointed: “The implications of this downsizing for federal cybersecurity are far-reaching” as agencies take on AI tools that process sensitive government data under the same weakened oversight framework that struggled to manage the cloud.


Chinese AI tracking companies with ties to the People’s Liberation Army are marketing detailed intelligence on US military movements during the Iran war, built entirely from publicly available satellite imagery, flight data, and shipping records, according to a Washington Post investigation.
Summary
- Washington Post reporters Cade Cadell and Lyric Li identified at least two Hangzhou-based firms, MizarVision and Jinghan Technology, selling AI-generated military intelligence on US carrier movements, aircraft deployments, and base activity in the Middle East
- The firms use open-source data including commercial satellite imagery, ADS-B aircraft tracking, and AIS vessel tracking, all processed through AI tools, to produce near real-time intelligence products
- The House Select Committee on China warned that “companies tied to the CCP are turning AI into a battlefield surveillance tool against America,” and Planet Labs has since suspended satellite imagery services for the region at the US government’s request
Chinese AI tracking firms are turning public data into battlefield intelligence, and the US military is on the receiving end. The Washington Post reported that private Chinese technology companies, some holding official People’s Liberation Army supplier certifications, have been marketing detailed analyses of US force movements since the Iran war began five weeks ago. The information was not obtained through leaks or espionage. It was assembled from satellite imagery, flight tracking systems, and maritime data, all commercially available, and processed using AI to produce military-grade intelligence products.
MizarVision, based in Hangzhou and certified as a PLA military supplier, tracked the movements of the USS Gerald R. Ford and USS Abraham Lincoln carrier strike groups during the buildup to Operation Epic Fury. The firm published detailed breakdowns of aircraft types and quantities at US bases in Saudi Arabia, Qatar, and Israel, including the Prince Sultan Air Base, which later sustained damage from Iranian airstrikes. It claimed on its website to have “cross-validated massive amounts of ship and flight data” covering more than 100 US warships.
Jinghan Technology, also Hangzhou-based and described by analysts as “China’s Palantir,” counts China’s Central Military Commission among its clients. The firm posted audio it claimed contained communications from US Air Force B-2A stealth bombers in the early stages of the war, then deleted the post. It also claimed to have predicted the war approximately 50 days in advance by detecting unusual US force concentrations.
Data Sources and US Response
The companies draw from the Jilin commercial satellite constellation, Western flight and vessel tracking databases, and social media open-source intelligence, all filtered through AI. As crypto.news has covered, Washington has grown increasingly concerned about Chinese firms using commercial technology as a national security vector, a pattern that previously surfaced around Chinese-made crypto mining hardware operating near US military installations.
Planet Labs notified customers Sunday it would indefinitely suspend satellite imagery services for Iran and conflict-adjacent zones, a move widely interpreted as a US government-driven effort to cut off one data stream flowing to firms like MizarVision.
Washington Raises the Alarm
“The proliferation of more and more capable private sector geospatial analysis companies in China will augment China’s defence capabilities and ability to contest US forces in a crisis,” Ryan Fedasiuk of the American Enterprise Institute told the Washington Post. The House Select Committee on China went further, warning that companies tied to the Chinese Communist Party are converting AI into a battlefield surveillance tool against the United States.
As crypto.news noted in reporting on Chinese tech and national security, the US has increasingly struggled to draw a clear line between China’s civilian commercial sector and its military-linked entities, a challenge that the Iran war has made significantly harder to ignore.

Key Highlights
- Share repurchase authorization elevated to $1.5 billion, demonstrating management conviction
- CRWD stock stabilizes around $400 mark with minimal 0.26% session decline
- Recent buyback activity totaled $150.6M following impressive fourth-quarter performance
- Artificial intelligence integration fueling cybersecurity platform expansion and revenue targets
- Enhanced repurchase program underscores management’s belief in current valuation opportunity
CrowdStrike Holdings (CRWD) experienced minimal downward pressure during trading while simultaneously reinforcing its shareholder value initiatives. The cybersecurity platform provider saw shares settle at $398.08, representing a slight 0.26% decrease, as the company unveiled an enhanced share repurchase framework reflecting strong institutional confidence in its artificial intelligence-powered growth trajectory.
CrowdStrike Holdings, Inc., CRWD
Enhanced Repurchase Authorization Demonstrates Financial Strength
CrowdStrike elevated its authorized share repurchase capacity to $1.5 billion, marking a significant increase from its prior authorization level. This strategic move followed the company’s recent acquisition of $150.6 million worth of shares at an average cost of $364.57 per share. Leadership emphasized maintaining operational flexibility for future repurchase execution.
The cybersecurity firm successfully completed the acquisition of more than 413,000 Class A common shares through its active repurchase initiative. These strategic transactions demonstrate a disciplined framework for returning value to shareholders while preserving financial flexibility. The program aligns seamlessly with the organization’s overarching financial strategy and competitive market position.
The repurchase framework operates without predetermined termination dates or mandatory purchase volumes. CrowdStrike maintains discretionary authority to execute transactions according to prevailing market dynamics and strategic priorities. This structure provides management with maximum flexibility regarding transaction timing, pricing strategies, and execution methodologies.
Artificial Intelligence Drives Platform Innovation and Revenue Expansion
CrowdStrike consistently advances its cybersecurity ecosystem through cutting-edge artificial intelligence integration. The organization correlates its expansion roadmap with accelerating enterprise appetite for AI-enhanced security solutions. Management has established an ambitious target of achieving $20 billion in annual recurring revenue before the conclusion of fiscal year 2036.
Leadership identified a valuation discrepancy between the company’s operational performance and current market pricing. This perceived undervaluation served as a catalyst for amplifying the repurchase authorization while simultaneously maintaining aggressive growth investment levels. The company continues scaling its comprehensive platform architecture to capture expanding enterprise market opportunities.
The cybersecurity industry has experienced substantial momentum in adopting artificial intelligence-powered threat intelligence and automated response technologies. CrowdStrike embeds these advanced capabilities throughout its flagship Falcon platform to maximize operational effectiveness and efficiency. The organization balances continuous innovation initiatives with prudent capital management strategies.
Share Price Action Demonstrates Technical Stability
CrowdStrike equity experienced marginal downward pressure throughout the trading session despite periodic recovery momentum. The stock maintained positioning immediately beneath the psychological $400 threshold, suggesting a period of technical consolidation. Price behavior indicates underlying stability rather than fundamental deterioration.
Intraday fluctuations represented equilibrium between profit realization activities and persistent institutional accumulation. Strategic buyers provided support following midday softness, effectively preventing more pronounced declines. Near-term resistance around the $400 level continues limiting immediate upside advancement.
CrowdStrike preserves a constructive technical structure underpinned by its comprehensive growth strategy and capital allocation framework. The expanded repurchase authorization signals strong management conviction regarding future operational performance and valuation normalization. The company successfully navigates the balance between technological innovation, revenue growth acceleration, and consistent shareholder value creation.


Charles Schwab will launch Schwab Bitcoin Ethereum trading in Q2 2026, giving its 38.9 million active brokerage clients direct spot access to crypto for the first time through a new service called Schwab Crypto.
Summary
- Schwab confirmed a phased rollout of direct spot Bitcoin and Ethereum trading in Q2 2026, operated through its banking subsidiary Charles Schwab Premier Bank and branded as Schwab Crypto
- CEO Rick Wurster first signaled the move in mid-2025, confirmed the Q2 timeline in a March 2026 interview with Barron’s, and said the company is “ready to compete in spot Bitcoin and Ethereum trading”
- Schwab manages $12.22 trillion in client assets, saw a 400% spike in crypto site traffic in 2025, and plans to follow the spot launch with a stablecoin product once the GENIUS Act is in effect
Charles Schwab Schwab Bitcoin Ethereum trading is now confirmed and imminent. As crypto.news reported, the firm confirmed it “remains on track to launch our spot crypto offer in the first half of 2026, starting with bitcoin and ether,” with a rollout beginning in Q2. The service will be operated through Charles Schwab Premier Bank, SSB, a regulated banking subsidiary, and is branded as Schwab Crypto. A waitlist for early access is already open.
CEO Rick Wurster confirmed the timeline in a March 2026 interview with Barron’s. He said the company is “ready to compete in spot Bitcoin and Ethereum trading,” framing the launch as the natural next step in a deliberate, multi-year build-out.
The service represents a structural departure from Schwab’s prior crypto model. Until now, clients could access Bitcoin and Ethereum only through ETFs, futures contracts, and Schwab’s Crypto Thematic Index ETF. Schwab Crypto will allow clients to hold actual cryptocurrency through Schwab’s banking infrastructure, eliminating the need to open a separate account at a crypto-native exchange.
The rollout will be phased: internal employee testing comes first, followed by a limited client launch, then a broader rollout to the wider brokerage base. The service will not initially be available in New York or Louisiana. Not all applicants will qualify.
The Scale of What This Represents
Schwab manages $12.22 trillion in client assets across 38.9 million active brokerage accounts. As crypto.news noted, the firm reported a 400% increase in traffic to its crypto site in 2025, with 70% of that traffic coming from non-clients, a signal of how large the untapped demand pool is among mainstream investors who prefer a familiar brokerage environment over crypto-native platforms.
Schwab’s March 2026 internal research characterized Bitcoin as a “matured mainstream asset,” a shift in institutional framing that helped clear the path for the launch. The Trump administration’s rollback of SEC accounting restrictions on crypto and the Federal Reserve’s loosening of bank crypto guidelines provided the regulatory runway Schwab had been waiting for since Wurster first flagged the plan.
Competitive Implications
The competitive threat to existing crypto exchanges is significant. Schwab’s scale could allow it to undercut existing platforms on fees, and the firm’s existing brokerage relationship with tens of millions of retail investors gives it a distribution advantage that no crypto-native exchange can replicate. Morgan Stanley is also preparing a comparable launch through its E*TRADE platform.
Schwab has additionally indicated plans to introduce a stablecoin product once the GENIUS Act clears, a sign that the firm is treating spot trading as the start of a more comprehensive crypto build-out rather than a one-time product launch.

TLDR:
- Circle plans phased quantum resistance across Arc, starting with opt-in post-quantum signatures at mainnet launch
- Arc design allows users and developers to adopt quantum-safe features gradually without disrupting existing systems
- Roadmap addresses risks of future decryption threats by enabling early protection against quantum computing advances
- Infrastructure layers, including validators, will integrate quantum resistance over time for full network security
Circle has outlined a phased roadmap for its Arc blockchain, focusing on long-term security against quantum computing risks.
The plan introduces post-quantum cryptography at launch, while maintaining flexibility through opt-in adoption across wallets, validators, and core infrastructure layers.
Phased rollout targets quantum-resistant infrastructure
A recent update shared by Wu Blockchain on X detailed Circle’s approach to building Arc with quantum resilience in mind.
The roadmap shows a structured path toward securing every layer of the network, starting from wallets to deeper infrastructural components.
The mainnet launch will introduce post-quantum signature support as an optional feature. This allows users to create wallets secured against future quantum threats without forcing immediate system-wide changes. At the same time, existing cryptographic standards remain usable during the transition period.
This phased design reduces disruption across the ecosystem. Developers can continue building without rewriting applications, while users retain control over when to upgrade their security settings. As a result, the network maintains stability during gradual adoption.
Circle’s roadmap also addresses concerns tied to “harvest now, decrypt later” scenarios. In such cases, encrypted data collected today could become vulnerable once quantum computing advances. By enabling early adoption of quantum-resistant tools, Arc aims to reduce that exposure over time.
The update further notes that quantum computing could challenge public-key cryptography by 2030 or earlier. This timeline has shaped the decision to embed quantum resistance directly into the network’s foundation rather than relying on future upgrades.
Mainnet launch introduces opt-in post-quantum signatures
The roadmap places strong focus on the mainnet phase, where post-quantum signatures will be introduced. This step marks the first practical implementation of Arc’s long-term security strategy within a live environment.
Users will have the option to create wallets secured by post-quantum cryptographic schemes at launch. This approach avoids forcing migrations while still offering advanced protection for those who choose it early. Over time, adoption can expand based on user preference and ecosystem readiness.
The design also ensures forward compatibility. As new cryptographic standards evolve, the network can integrate updates without requiring disruptive resets. This supports continuity for both developers and institutions operating on the platform.
Validators and infrastructure layers are also included in later phases of the roadmap. These components will gradually adopt quantum-resistant mechanisms, aligning the entire system under a unified security framework.
Circle’s approach reflects a shift toward building infrastructure prepared for future risks. Instead of reacting to emerging threats, Arc’s roadmap introduces security measures during early development stages. This method reduces the need for urgent fixes later.
The structured rollout ensures that each layer of the network evolves without breaking existing functionality. At the same time, it allows stakeholders to adapt at their own pace while maintaining network integrity.


Georgia’s legislature adjourns today, April 6, having sent three AI-related bills to Governor Brian Kemp’s desk, the most notable being a Georgia AI chatbot bill that mandates disclosure, child protections, and crisis response protocols for self-harm.
Summary
- Georgia’s SB 540, a chatbot disclosure and child safety bill, requires operators to notify users they are interacting with AI, limit certain actions by minors, offer privacy tools, and follow protocols when users express suicidal ideation or intent to self-harm
- Two additional bills also await the governor: SB 444, which bans AI-only health insurance coverage decisions, and SR 789, a resolution creating a study committee on AI’s broader societal impact
- Georgia’s SB 540 stands out nationally because it contains no carve-out for chatbots embedded within larger platforms, meaning major tech companies including Meta and Google would need to comply
Georgia’s 2026 legislative session is closing today with three AI bills awaiting Governor Brian Kemp’s signature, including a Georgia AI chatbot bill that is drawing national attention for its breadth and lack of industry exemptions, according to the Transparency Coalition AI’s legislative tracker. The package arrives as more than 27 states advance chatbot safety legislation in 2026, creating a fast-moving patchwork of AI regulations that the White House has publicly warned against.
Georgia’s SB 540 passed the Senate on March 6, cleared the House on March 25, and received Senate agreement on the reconciliation version on March 27. The bill requires chatbot operators to notify users that they are interacting with AI, implement steps that limit certain interactions with minors, provide privacy tools, and establish response protocols when users express suicidal ideation or self-harm intent.
What makes the bill unusual nationally is that it does not include a carve-out for chatbots embedded within a broader service, an exemption that most similar bills include and that would otherwise shield platforms like Meta and Google from having to comply. As crypto.news reported, the global push for chatbot child safety regulation gained momentum earlier this year when UK Prime Minister Keir Starmer signalled plans to bring AI chatbots under stricter online safety rules, citing identical concerns around emotional dependency and unregulated AI-generated advice to minors.
The Other Two Bills on Kemp’s Desk
SB 444 prohibits health insurance coverage decisions from being based solely on AI systems or software tools, requiring human involvement in coverage determinations. It addresses a growing concern that automated denial systems are replacing clinical judgment without appropriate oversight.
SR 789 is a Senate resolution creating a Senate Study Committee on the Impact of Artificial Intelligence, a recognition that Georgia’s legislature intends to keep engaging on the issue after adjournment.
A State-Level Wave the White House Is Watching
As crypto.news has noted, the acceleration of AI safety regulation without clear standards risks creating a compliance landscape where enforcement is inconsistent and under-resourced. The Trump administration has explicitly warned states against “onerous” AI laws and is pushing for a national standard to preempt state-level patchworks. A 10-year moratorium on state AI laws was proposed in the One Big Beautiful Bill Act last summer but was removed from the final legislation in a 99-to-1 Senate vote.
Tennessee’s Governor Bill Lee recently signed an AI therapy bot ban into law. Idaho approved four AI bills before session end. With Georgia now adjourning, the 2026 state AI legislative wave has not peaked.
“SB 540 is a chatbot disclosure and child safety bill, requiring notification of AI nature, steps to limit certain actions by minors, provide privacy tools, and protocols for response to suicidal ideation or self-harm,” the Transparency Coalition AI wrote in its April 3 legislative update. Whether Governor Kemp signs or vetoes the bills will be one of the first signals of how Republican-led states will navigate Washington’s pressure to stand down on AI regulation.
Harry Potter Star’s Forgotten Historical Mystery Is Suddenly a Streaming Hit Again
I’m A Celebrity South Africa fans brand Beverley Callard their ‘winner’ as potential feud emerges

COPJ: Outperforming COPX, With A Compelling Investment Case Ahead (NASDAQ:COPJ)






-

 NewsBeat4 days ago
NewsBeat4 days agoSteven Gerrard disagrees with Gary Neville over ‘shock’ Chelsea and Arsenal claim | Football
-

 Business4 days ago
Business4 days agoNo Jackpot Winner and $194 Million Prize Rolls Over
-

 Fashion3 days ago
Fashion3 days agoWeekend Open Thread: Spanx – Corporette.com
-
 Crypto World5 days ago
Crypto World5 days agoGold Price Prediction: Worst Month in 17 Years fo Save Haven Rock
-

 Business24 hours ago
Business24 hours agoThree Gulf funds agree to back Paramount’s $81 billion takeover of Warner, WSJ reports
-
Crypto World6 days ago
Dems press CFTC, ethics board on prediction-market insider trades
-

 Sports2 days ago
Sports2 days agoIndia men’s 4x400m and mixed 4x100m relay teams register big progress | Other Sports News
-

 Business5 days ago
Business5 days agoLogin and Checkout Issues Spark Merchant Frustration
-

 Tech7 days ago
Tech7 days agoEE TV is using AI to help you find something to watch
-

 Sports6 days ago
Sports6 days agoTallest college basketball player ever, standing at 7-foot-9, entering transfer portal
-
Tech7 days ago
Daily Deal: StackSkills Premium Annual Pass
-
 Tech7 days ago
Tech7 days agoFlipsnack and the shift toward motion-first business content with living visuals
-

 Tech7 days ago
Tech7 days agoHow to back up your iPhone & iPad to your Mac before something goes wrong
-
Crypto World7 days ago
Valinor raises $25m to put private credit on-chain
-

 Tech7 days ago
Tech7 days agoWhat Are The Biggest Limitations Of Supercomputers?
-

 Crypto World6 days ago
Crypto World6 days agoBitcoin enters the public bond market as Moody’s gives a first-of-its-kind crypto deal a rating
-

 Politics7 days ago
Politics7 days ago‘Out of touch, smug and overpaid’
-

 Politics7 days ago
Politics7 days agoTransform Your Space with Stunning Small Works
-

 Politics6 days ago
Politics6 days agoStarmer’s centre has collapsed, and the left was right all along
-
Crypto World6 days ago
Bitcoin stalls below key resistance as technical signals skew bearish
You must be logged in to post a comment Login