Bowers & Wilkins is giving its flagship headphones a fresh coat of paint.
The Px8 S2, the brand’s top-tier wireless over-ears, are now available in two new finishes — Midnight Blue and Pearl Blue.
The update is purely aesthetic, and joins Onyx Black, Warm Stone and the McLaren Edition. More broadly, it pushes Bowers & Wilkins’ wider headphone and earbud portfolio to a total of 21 different colour variants. That’s the most the company has ever offered.
That growing focus on design is clearly intentional. Bowers & Wilkins has been leaning into the idea that premium headphones should feel as considered visually as they do sonically, and the Px8 S2 fits that brief. The new finishes stick with the same Nappa leather trim and aluminium detailing. However, they are just reworked into deeper, more expressive tones that feel a bit more eye-catching than the more understated originals.
Advertisement
Px8 S2 in Midnight Blue. Image Credit (Bowers & Wilkins)
Advertisement
It’s important to note that nothing else has changed under the hood. The Px8 S2 still delivers the same award-winning sound performance it’s known for, and is fitted with the same drivers, tuning and overall audio profile. If you were already sold on how they sound, this update is really about having more choice in how they look.
It also follows a broader refresh across the brand’s lineup. After recently introducing new finishes for the Px7 S3 and Pi8 models, Bowers & Wilkins seems to be doubling down on offering more personalisation across its premium range. This is something that’s becoming increasingly common in the high-end headphone space.
If nothing else, it’s a reminder that flagship headphones aren’t just about sound anymore. They are part fashion piece, part tech. And with Midnight Blue and Pearl Blue now in the mix, the Px8 S2 leans a little further into that idea.
There seems to be no ceiling for mechanical keyboards and the Keychron Q1 Ultra 8K is proof. It features an all metal build, wireless options, ZMK, 8KHz polling, and layer after layer of foam.
Keychron continues to pump out new keyboards at a breakneck pace. The Q1 Ultra 8K is the latest model to sit at the top of Keychron’s lineup, replacing the Max.
I’ve reviewed a lot of Keychron’s keyboards, and with the exception of the unique Q3 Pro SE, I believe the Q1 series is my favorite layout. I love that it has all the keys I need while remaining compact yet dense.
Keychron has proven to be remarkably consistent in its products. Each release isn’t overly iterative and justifies the price, which makes them incredibly difficult to give a review score.
Advertisement
You’ll note this and others have received 4 or more stars. As with any review on AppleInsider, it is best to read through the text and understand the granular points rather than try to boil the entire thing to a numerical score.
Enthusiasts will happily pay the high price to get these features and premium build, so let’s dive into why the Q1 Ultra 8K is yet another winner from Keychron.
Keychron Q1 Ultra 8K review: design
Look at the Q1 Ultra 8K straight on and you’ll struggle to find any differentiation from the other Q1 models. There are tiny signs those with a discerning eye will catch, like the different knob, but the biggest tell is in the back.
Keychron Q1 Ultra 8K review: a familiar layout
Advertisement
Keychron has included a fancy “aesthetic PC” back plate. It is a gold colored plate with celestial designs that really pop out.
Of course, you’ll never see this plate during use, but I suppose it is cool that it’s there. As I said, it certainly helps in distinguishing it from other models.
I stuck with my usual preference of dark keycaps with Keychron’s splash of gray and blue. The RGB backlight continues to shine through bottom-facing LEDs with 22+ combinations.
Keychron Q1 Ultra 8K review: a fancy backplate
Advertisement
The Keychron launcher software lets you take things even further. Create your own RGB patterns on a per-key basis.
That means you can color-code select keys or just go all out and make every key a solid color. I prefer a randomized rainbow pattern, but it is cool that you can go to that level of detail.
Like with all Keychron keyboards, you can fully customize the keyboard top to bottom. Take it apart down to the frame and you’ve got a pile of foam, stabilizers, switches, and keycaps.
I emphasized this with the Q1 Max review, and the point still stands, this thing is packed to the gills with foam. Remove what you like to get the right sound and feel out of every keypress.
Advertisement
The layers go like this, starting from the top:
Keycaps
Top Case
Switches
Plate
Sound absorbing foam for a cleaner typing sound
IXPE Foam to reduce keystroke vibration
PET Film for protection from dust and insulates from shorts
PCB
Latex Bottom Pad that cushions typing while reducing vibration and noise
Bottom Case Acoustic Foam also cushions typing and reduces vibration and noise
Bottom Case PET Film adds another layer of protection from dust and insulates from shorts
Bottom Case
It’s quite the pile of materials and fittings. I personally like how the keyboard feels and sounds with the Red Silk POM Switches that were included.
The weight and material of Keychron keyboards are a big part of their premium look and feel. I’ve joked about it before, but these keyboards feel like they could double as a home defense tool.
Keychron Q1 Ultra 8K review: features
Keychron has packed the Q1 Ultra 8K with specs and features that will benefit every user. Whether you’re a mechanical keyboard enthusiast, or just looking for a premium keyboard, this one covers all of the bases.
Keychron Q1 Ultra 8K review: a new knob
Advertisement
The feature that gives it its name is an 8K polling rate. It means that the keyboard is sampling every keypress at 8x the speed of other high-end keyboards.
That 8,000 Hz polling rate isn’t on by default. All of Keychron’s 8K keyboards ship with the default polling rate set to 1,000 Hz to ensure wider compatibility.
If you’re working on newer Macs and PCs, go ahead and switch over to 8K. This is done via the Keychron launcher tool that’s accessible via the web on a Chrome, Edge, or Opera browser.
Luckily, I keep Chrome installed on my Mac mini for podcasting purposes. A quick switch flip to the 2.4GHz channel and I was in business.
Advertisement
Keychron Q1 Ultra 8K review: Keychron Launcher lets you edit every aspect
I used to spend more time on the keyboard modification software in these reviews, but they’ve become so standard that I don’t feel the need to. Like most mechanical keyboards, and all Keychron keyboards, you can customize it top to bottom using different switches, keycaps, and program each key individually.
If you want to get even more advanced, program multiple typing layers so a button press puts you into a completely different layout. Careful with this, as the physical keyboard doesn’t look any different even if the “G” key is suddenly performing a different action.
Other specs include three pairing methods. Pick from three Bluetooth 5.3 channels, a 2.4 GHz USB dongle, or wired.
Advertisement
Keychron Q1 Ultra 8K review: swap between multiple connection options
Mix and match every connection option to easily switch between five devices at once. Those concerned with latency will use the wired option, but the 2.4 GHz connection is just as solid and both offer the 8K polling rate.
Really, it comes down to your individual setup and needs.
The Q1 Ultra 8K has some incredible battery life thanks to optimizations made via the ZMK firmware. Users that enable the 8K polling feature and connect wirelessly without a backlight can squeeze out 660 hours of battery life.
Advertisement
That backlight is the battery drain, so every level of brightness you enable cuts that battery life down quick. That said, I’ve had to charge the internal battery one time in a month even with the backlight enabled. YMMV.
Using the Keychron Q1 Ultra 8K
I spend a lot of time typing on a keyboard each day, so it is needless to say that I’ve spent a lot of hours with the Q1 Ultra 8K. It’s an interesting evolution of a keyboard that I’ve used across multiple generations.
Keychron Q1 Ultra 8K review: still a typing dream
From a general use perspective, beyond the move to a new switch, the typing experience is nearly identical. The Q1 Max has the same internal layers of foam and the case appears to be identical.
Advertisement
I’ve found that I prefer whatever red-equivalent switch is my go-to. It isn’t too loud and is just right in terms of travel.
There really isn’t much else I can add here that I haven’t said time and time again about Keychron keyboards. This is a highly customizable mechanical keyboard that isn’t too flashy out of the box, but lets you get there if you like.
Keychron Q1 Ultra 8K review: peak customization
I’ll keep noting as long as I can remember to that I wish someone could replicate the signal sent to Apple Vision Pro from a Magic Keyboard. I love using third-party keyboards, but it is never not annoying that I can’t see the keyboard when fully immersed — only Apple gets that privilege.
Advertisement
The Q1 series might be my favorite layout. It has all of the keys that I’ll need, including a well-labeled function row.
There’s even three “bonus keys” on the right side. I’m sure someone on Earth uses them as designed, but the pgup, pgdn, and home keys are totally unnecessary for my workflows. So, they make great reprogrammable keys.
Advancing the spec
The Keychron Q1 Ultra 8K is an iterative upgrade over the Q1 Max. Though that isn’t to say the upgrades aren’t impactful.
Keychron Q1 Ultra 8K review: an iterative but welcome upgrade
Advertisement
What’s actually new here is the Keychron MCU chip with 1MP flash memory. It enables the 8K polling rate.
That Silk POM Switch is a nice addition too. Keychron specifically designed it with high performance in mind for gamers and those demanding precision.
Lay the Max and the Ultra side-by-side and the only notable difference besides potential keycap selection is the knob. If you’re looking for a wholly new experience or design, this isn’t it.
The battery life is about 6x longer in the Q1 Ultra 8K versus the Max. You’re also interfacing through ZMK, which is a newer standard built with wireless keyboards in mind.
Advertisement
Those looking for a premium mechanical keyboard experience with a little extra cash should get the Q1 Ultra 8K. While the Q1 Max is still available, you’re not saving much on that model, so go for the best.
Keychron Q1 Ultra 8K review – Pros
Sturdy design, clacky keys, interesting backplate
Incredible battery life
8K polling if you want it
Incredible range of customization options
Keychron Q1 Ultra 8K review – Cons
Iterative upgrade design wise
8K polling not necessary for everyone
Rating 4 out of 5
As usual, these numeric scores are not representative of the product, but Google demands them. I love the Q1 Ultra 8K and it is a good upgrade over the Q1 Max, but owners of the older model don’t need to rush out for the new one either.
I expect the next iteration will tackle more in the design department, so it’s getting the smallest knock for the lack of design change. Otherwise, this is an expensive, premium keyboard that has amazing specs and is worth buying if you’re in the market for one.
Hey Wes, here are two affiliate links. Let’s use Amazon for the blue buy button.
Where to buy the Keychron Q1 Ultra 8K
The Keychron Q1 Ultra 8K wireless mechanical keyboard can be purchased from Keychron directly for $229.99. Amazon also carries the keyboard for the same price.
The AI race lately has felt a bit like a game of tennis: first, Anthropic releases a new, pricey state-of-the-art proprietary model for general users (Claude Opus 4.7), then, a week or so later, its rival OpenAI volleys back with one of its own (GPT-5.5). And all the while, Chinese companies like DeepSeek and even Xiaomi are seeking to appeal to users by playing a different game: nearing the frontier, but with open licensing and far lower costs.
So it’s a big surprise when a new, affordable, highly performant open source contender from the U.S. emerges. Today, we got one from the smaller, lesser-known U.S. AI startup, Poolside, founded in San Francisco in 2023.
The company launched its two new Laguna large language models, both of which offer affordable intelligence optimized for agentic workflows (AI that does more than just chat or generate content, but can, in this case, write code, use third-party tools, and take actions autonomously), as well as a new coding agent harness called (fittingly) “pool” and a new web-based, mobile optimized agentic coding development and interactive preview environment, “shimmer,” which lets you write code with the Laguna models on the go.
The new AI models that Poolside released today include:
Advertisement
Laguna M.1: a proprietary 225-billion parameter Mixture of Experts (MoE) model with 23 billion active parameters. This flagship model is optimized for high-consequence enterprise and government environments, designed to solve complex, long-horizon software engineering problems that require maximum reasoning and planning capabilities.
Laguna XS.2: an Apache 2.0 open licensed 33-billion parameter MoE with 3 billion active. Engineered for efficiency and community innovation, this model is designed for local agentic coding tasks and provides a versatile foundation for developers looking to fine-tune, quantize, or serve powerful agents on a single GPU. In other words, developers can download and run Laguna XS.2 on their desktop or even laptop computers without an internet connection — completely private and secured.
Notably, as mentioned above, only the smaller of the two models, XS.2, is available now under an open source Apache 2.0 license (on Hugging Face) — yet Poolside is offering even the larger M.1 for free temporarily through its API and third-party distribution partners, OpenRouter, Ollama, and Baseten, making it a great use case for developers who wish to test it out.
Also noteworthy: the two new Lagunas were trained from scratch — not fine-tuned/post-trained base models from Chinese giant Alibaba’s Qwen series like some other U.S. labs have pursued lately (*cough cough* Cursor *cough).
As Poolside wrote in a blog post today, it’s spent the last few years “focused on serving our government and public sector clients with capable models deployable into the highest-security environments,” yet is now going open source “to support builders and the wider research community.”
When I asked on X why government agencies would seek to use Poolside instead of leading proprietary U.S. labs like Anthropic, OpenAI and Google, Poolside post-training engineer George Grigorev told me in a reply that: “we think that we can be faster to deploy our models to enterprise customers, and we can literally ship weights in fully isolated environments on-prem, so it can work offline. which might be critical for gov/public sectors 🙂 but ofc anthropic enterprise is hard to beat”
Advertisement
How Poolside’s Laguna M.1 and Laguna XS.2 were trained
Poolside constructs its AI models within a specialized digital environment called the “Model Factory“.
At the heart of this process is Titan, the company’s powerful internal software that serves as the “furnace” for training. To help the AI learn as efficiently as possible, Poolside uses a unique tool called the Muon optimizer.
Think of Muon as a high-speed tutor; it helps the model master new information approximately 15% faster than standard industry methods, a critical gain when training at the 30-trillion-token scale.
It achieves this by ensuring that every update to the model’s “brain” is mathematically balanced and pointing in the right direction, which prevents the AI from getting confused or stuck during its intensive training sessions.
Advertisement
The information used to train these models—a staggering 30 trillion “tokens” or pieces of data—is carefully selected using a system called AutoMixer.
Rather than just feeding the AI everything it finds on the internet, AutoMixer leverages a a “swarm” of sixty proxy models on different data mixes to scientifically determine which combination of code, math, and general web data produces the best reasoning capabilities.
In this way, it acts like a master chef, scientifically testing thousands of different “recipes” to find the perfect balance of computer code, mathematics, and general knowledge.
While much of this data comes from the public web, about 13% of it is “synthetic data”. This is high-quality, custom-made practice material created by other AIs to teach the models specific skills that are difficult to find in the real world.
Advertisement
Once the model has finished its basic “schooling,” it enters a virtual gym for Reinforcement Learning. In this stage, the AI practices solving real software engineering problems in a safe, isolated digital playground. It learns through trial and error, receiving a “reward” or positive signal every time it successfully fixes a bug or writes a working piece of code. This constant cycle of practice and feedback is what transforms the AI from a simple text generator into a capable “agent” that can plan and execute complex, multi-step projects just like a human software engineer.
While M.1 represents the peak of Poolside’s current research, the smaller Laguna XS.2 may be the more disruptive entry.
At just 33 billion total parameters (3 billion activated), XS.2 is a “second-generation” MoE model that incorporates everything the team learned from training M.1.
Benchmarks show Poolside’s Laguna models punch far above their weight class
Langua M.1’s performance on the SWE-bench Pro—a benchmark designed to test an AI’s ability to solve real-world software issues—reached 46.9% on SWE-bench Pro, nearing the performance of the far-larger Qwen-3.5 and DeepSeek V4-Flash.
Despite being a fraction of the size, Laguna XS.2 achieves a 44.5% score on SWE-bench Pro, nearly matching its larger sibling.
On the SWE-bench Verified track, M.1 scored 72.5%, outperforming the dense Devstral 2 (72.2%) but trailing Claude Sonnet 4.6, which leads the category at 79.6%.
These results highlight M.1’s specialization in long-horizon software tasks, particularly those involving complex planning across interconnected files.
The smaller Laguna XS.2 exhibits remarkable efficiency, nearly matching the performance of its much larger sibling on high-consequence tasks. Despite having only 3B active parameters, XS.2 surpasses Claude Haiku 4.5 (39.5%) and the significantly larger Gemma 4 31B dense model (35.7%) on SWE-bench Pro.
In terminal-based reasoning, XS.2’s 30.1% on Terminal-Bench 2.0 also edges out Haiku 4.5’s 29.8%, although it remains behind specialized “nano” models such as GPT-5.4 Nano, which reached 46.3% on the same benchmark.
Collectively, these benchmarks suggest that Poolside’s focus on agentic RL and synthetic data curation has allowed its smaller models to “punch up” into weight classes typically reserved for far denser architectures.
Advertisement
While top-tier proprietary models like Claude Sonnet 4.6 maintain a lead in overall success rates, the Laguna family—particularly the open-weight XS.2—offers a competitive alternative for developers who prioritize local execution and customizable agent workflows.
All benchmarking was conducted using the Harbor Framework with sandboxed execution, ensuring that the results reflect the models’ ability to function in realistic, resource-constrained environments.
Running Laguna XS.2 locally
To run the Laguna XS.2 (33B) model locally, your hardware must accommodate its 33 billion total parameters. On Apple Silicon, the baseline requirement is 36 GB of unified memory.
For PC and Linux users, while the standard weights would typically require over 60 GB of VRAM, the model’s support for 4-bit quantization (Q4) allows it to run on consumer-grade GPUs with at least 24 GB to 32 GB of VRAM, such as the newly released RTX 5090.
Advertisement
Storage is also a factor; you should reserve at least 70 GB for the full model or roughly 20–35 GB for a compressed version suitable for local “agent” tasks.
For the most seamless experience, Poolside recommends utilizing Ollama or their own terminal-based agent, pool, which are designed to manage the model’s native reasoning and tool-calling capabilities on consumer hardware.
You can find the full technical requirements, including specific quantization configurations and code execution sandboxing details, on the official Hugging Face model page and the Poolside release blog. Some sample suggested hardware is listed below:
Mac
MacBook Pro (14-inch or 16-inch): You should look for models equipped with the M5 Max chip, which specifically supports a starting configuration of 36 GB of unified memory. While the M5 Pro is available, you would need to custom-configure it to exceed its base memory to meet the 36 GB threshold.
Mac Studio / Mac Mini: A Mac Mini (M4 or M5 Pro) configured with at least 48 GB or 64 GB of RAM is an excellent desktop alternative.
NO “MacBook Neo”: this model is not suitable for running Laguna XS.2. Released in early 2026 as a budget-friendly option, the MacBook Neo is capped at 8 GB of non-upgradable memory, which is insufficient for a 33B parameter model.
PC
Single-GPU Setup: The NVIDIA GeForce RTX 5090 is the premier choice for 2026, offering 32 GB of GDDR7 VRAM, which can handle the Laguna XS.2 at high speeds (approximately 45 tokens/sec) using Q4 quantization.
Pro-Grade Setup: For professional developers running complex, long-horizon agents, the RTX PRO 6000 Blackwell (96 GB VRAM) or a dual RTX 5090 configuration allows the model to run without any compression loss.
Minimum PC Spec: An RTX 4090 (24 GB) can run the model with heavier quantization, though performance may be slower during complex reasoning tasks.
pool (agent) and shimmer (IDE)
Models are only as useful as the environments they inhabit, and Poolside has released two “preview” products to house the Laguna series: pool and shimmer.
Advertisement
pool is a terminal-based coding agent designed for the developer’s local environment. It acts as an Agent Client Protocol (ACP) server, the same harness the team uses internally for reinforcement learning (RL) training.
By bringing the researchers’ own tools to the general public, Poolside is effectively inviting the developer community to participate in the “real-world gym” that trains their future models.
Shimmer represents a vision for the cloud-native future of development. It is an instant-on Virtual Machine (VM) sandbox where developers can iterate on web apps, APIs, and CLIs in seconds.
Unlike traditional integrated developer environments (IDEs) such as Microsoft Visual Studio, shimmer integrates the Poolside Agent directly into the workspace, allowing it to push changes to GitHub or import existing repositories with ease.
Advertisement
Perhaps the most surprising feature of shimmer is its portability. Poolside Founding Designer Alasdair Monk shared a demonstration showing shimmer running entirely on a smartphone.
In the demo, a split-screen interface shows the Poolside Agent generating a “Happy New Year 2026!” animation while a dev environment runs below.
As Monk noted, it offers an instant-on VM with Poolside Agent in split screen and a full dev environment on a mobile device.
This suggests a future where high-consequence engineering isn’t tethered to a desktop, but can happen wherever an engineer has a screen.
Advertisement
Why release Laguna XS.2 as Apache 2.0 open weights?
The most significant strategic move in this release is the licensing of Laguna XS.2. Poolside has released the weights of XS.2 under the Apache 2.0 license.
This is a highly permissive license that allows users to use, distribute, and modify the software for any purpose, including commercial use, without royalties. This is a stark contrast to the “closed” models of many competitors or even the more restrictive “open-ish” licenses used by some other labs.
Poolside’s leadership is explicit about why they chose this path. Poolside’s blog post states its conviction that “the West needs strong open-weight models” and that releasing the weights is the fastest way for the team to improve their work through community evaluation and fine-tuning.
By putting the weights of a highly capable, 33B-parameter agentic model in the hands of researchers and startups, Poolside is positioning itself as a cornerstone of the open-AI ecosystem.
Advertisement
While Laguna M.1 remains primarily behind an API, the open release of XS.2 ensures that Poolside’s technology will be baked into the next generation of third-party tools.
Poolside’s philosophy and approach
The core thesis behind Poolside’s work is that software development serves as the ultimate proxy for general intelligence.
Creating software requires long-horizon planning, complex reasoning, and the ability to manipulate abstract systems—all traits central to human cognition. While most current AI “agents” are restricted to tool-calling via pre-defined interfaces, Poolside’s agents are designed to write and execute their own code to solve problems.
This shift from using tools to building systems marks a fundamental evolution in how AI interacts with the digital world.
Advertisement
The team of roughly 60 people in the Applied Research organization spent three years and conducted tens of thousands of experiments to reach this point. Their vision of AGI is not just about intelligence, but about “abundance for humanity”.
By focusing on software engineering—a domain with verifiable rewards like test passes and compilation results—they have created a self-improving feedback loop. As the team puts it, they are building a “fusion reactor” for data: extracting every last drop of intelligence from existing human knowledge while using RL to harvest the “wind energy” of new, fresh experiences.
Poolside’s journey is just beginning, but the Laguna release sets a high bar for what “agentic” AI should look like in 2026. By combining frontier-level performance with a commitment to open weights and novel developer surfaces, they are charting a path to AGI that is as much about the way we build as it is about the what we build.
For the enterprise and the individual developer alike, the message is clear: the future of work is agentic, and the language of that future is code.
Training AI reasoning models demands resources that most enterprise teams do not have. Engineering teams are often forced to choose between distilling knowledge from large, expensive models or relying on reinforcement learning techniques that provide sparse feedback.
Researchers at JD.com and several academic institutions recently introduced a new training paradigm that sidesteps this dilemma. The technique, called Reinforcement Learning with Verifiable Rewards with Self-Distillation (RLSD), combines the reliable performance tracking of reinforcement learning with the granular feedback of self-distillation.
Experiments indicate that models trained with RLSD outperform those built on classic distillation and reinforcement learning algorithms. For enterprise teams, this approach lowers the technical and financial barriers to building custom reasoning models tailored to specific business logic.
The problem with training reasoning models
The standard method for training reasoning models is Reinforcement Learning with Verifiable Rewards (RLVR). In this paradigm, the model learns through trial and error, guided by a final outcome from its environment. An automated verifier checks if the model’s answer is right or wrong, providing a binary reward, such as a 0 or 1.
Advertisement
Reinforcement learning with verifiable rewards (RLVR)
RLVR suffers from sparse and uniform feedback. “Standard GRPO has a signal density problem,” Chenxu Yang, co-author of the paper, told VentureBeat. “A multi-thousand-token reasoning trace gets a single binary reward, and every token inside that trace receives identical credit, whether it’s a pivotal logical step or a throwaway phrase.” Consequently, the model never learns which intermediate steps led to its success or failure.
On-Policy Distillation (OPD) takes a different approach. Instead of waiting for a final outcome, developers pair a smaller student model with a larger, more capable teacher model. For each training example, the student compares its response to that of the teacher token by token. This provides the student with granular feedback on the entire reasoning chain and response-generation process.
Deploying and running a separate, massive teacher model alongside the student throughout the entire training process incurs massive computational overhead. “You have to keep a larger teacher model resident throughout training, which roughly doubles your GPU footprint,” Yang said. Furthermore, the teacher and student models must share the exact same vocabulary structure, which according to Yang, “quietly rules out most cross-architecture, cross-modality, or multilingual setups that enterprises actually run.”
Advertisement
On-policy distillation (OPD)
The promise and failure of self-distillation
On-Policy Self-Distillation (OPSD) emerged as a solution designed to overcome the shortcomings of the other two approaches. In OPSD, the same model plays the role of both the student and the teacher.
During training, the student receives a standard prompt while the teacher receives privileged information, such as a verified, step-by-step answer key. This well-informed teacher version of the model then evaluates the student version, providing token-by-token feedback as the student tries to solve the problem using only the standard prompt.
OPSD appears to be the perfect compromise for an enterprise budget. It delivers the granular, step-by-step guidance of OPD. Because it eliminates the need for an external teacher model, it operates with the high computational efficiency and low cost of RLVR, only requiring an extra forward pass for the teacher.
Advertisement
However, the researchers found that OPSD suffers from a phenomenon called “privileged information leakage.”
“The objective is structurally ill-posed,” Yang said. “There’s an irreducible mutual-information gap that the student can never close… When self-distillation is set up as distribution matching, the student is asked to imitate the teacher’s full output distribution under privileged context.”
On-policy self-distillation (OPSD)
Because the teacher evaluates the student based on a hidden answer key, the training objective forces the student model to learn the teacher’s exact phrasing or steps instead of the underlying reasoning logic. As a result, the student model starts hallucinating references to an invisible solution that it will not have access to in a real-world deployment.
Advertisement
In practice, OPSD models show a rapid spike in performance early in training, but their reasoning capabilities soon plateau and progressively degrade over time.
Decoupling direction from magnitude with RLSD
The researchers behind RLSD realized that the signals governing how a model updates its parameters have fundamentally asymmetric requirements. They identified that the signal dictating the direction of the update (i.e., whether to reinforce or penalize a behavior) can be sparse, but must be perfectly reliable, because pointing the model in the wrong direction damages its reasoning policy.
On the other hand, the signal dictating the magnitude of the update (i.e., how much relative credit or blame a specific step deserves) benefits from being extremely dense to enable fine-grained, step-by-step corrections.
RLSD builds on this principle by decoupling the update direction from the update magnitude. The framework lets the verifiable environmental feedback from the RLVR signal strictly determine the direction of learning. The model only receives overall reinforcement if the final answer is objectively correct.
Advertisement
Reinforcement learning with self-distillation (RLSD) (source: arXiv)
The self-teacher is stripped of its power to dictate what the model should generate. Instead, the teacher’s token-by-token assessment is repurposed to determine the magnitude of the update. It simply distributes the total credit or blame across the individual steps of the model’s reasoning path.
This alters how the model learns compared to the classic OPSD paradigm. In standard OPSD, the training objective acts like behavioral cloning, where the model is forced to directly copy the exact wording and phrasing of the teacher. This causes the student to hallucinate and leak references to data it does not have.
Instead of forcing the model to copy a hidden solution, RLSD provides a natural and virtually cost-free source of per-token credit information.
Advertisement
“The intuition: we’re not teaching the model to reason like the teacher,” Yang said. “We’re telling the model, on the path it chose, which of its own tokens were actually doing the work. The model’s exploration distribution stays its own. Only the credit allocation gets sharpened.”
If a specific deduction strongly supports the correct outcome, it receives a higher score. If it is just a useless filler word, it receives a baseline score. RLSD eliminates the need to train complex auxiliary reward networks, manually annotate step-by-step data, or maintain massive external teacher models.
Putting RLSD to the test
To test RLSD, the researchers trained the open-weight Qwen3-VL-8B vision-language model and evaluated it on several visual reasoning benchmarks. These included MMMU for college-level multi-discipline questions, MathVista, MathVision, WeMath, and ZeroBench, a stress-test benchmark explicitly designed to be nearly impossible for current frontier models.
They compared the RLSD model against the base model with no post-training, standard RLVR via the GRPO algorithm, standard OPSD, and a hybrid combination of the two.
Advertisement
RLSD significantly outperformed every other method, achieving the highest average accuracy of 56.18% across all five benchmarks. It beat the base model by 4.69% and outperformed standard RLVR by 2.32%. The gains were most pronounced in complex mathematical reasoning tasks, where RLSD outperformed standard RLVR by 3.91% on the MathVision benchmark.
RLSD outperforms other techniques on key benchmarks (source: arXiv)
Beyond accuracy, the framework offers massive efficiency gains. “Concretely, RLSD at 200 training steps already beats GRPO trained for 400 steps, so roughly 2x convergence speedup,” Yang said. “Cost-wise, the only overhead beyond a normal GRPO pipeline is one extra forward pass per response to grab teacher logits. Compared to rollout generation… that’s basically free.”
Unlike OPSD, which saw performance spike and then completely collapse due to information leakage, RLSD maintained long-term training stability and converged on a higher performance ceiling than standard methods.
Advertisement
The qualitative findings highlight how the model alters its learning behavior. For example, in a complex visual counting task, standard RLVR looks at the final correct answer and gives the entire paragraph of reasoning tokens the same reward. RLSD surgically applied rewards to the specific mathematical subtraction steps that solved the problem, while actively down-weighting generic filler text like “Looking at the image, I see…”.
In another example, the model performed an incorrect math derivation based on a bar chart. Instead of labeling the whole response as a failure, RLSD concentrated the heaviest penalty on the exact point where the model misread a relationship from the chart. It remained neutral on the rest of the logical setup, recognizing that the initial framework was valid.
This is particularly important for messy, real-world enterprise use cases. If a model makes a mistake analyzing a 50-page quarterly earnings report, developers do not want it to unlearn its entire analytical framework. They just want it to fix the specific assumption it got wrong. RLSD allows the model to learn exactly which logical leaps are valuable and which are flawed, token by token. Because RLSD does this by repurposing the model itself, it provides models with granular reasoning capabilities while keeping the costs of training reasonable.
How enterprises can get started
For data engineers and AI orchestration teams, integrating RLSD is straightforward, but it requires the right setup. The most critical requirement is a verifiable reward signal, such as code compilers, math checkers, SQL execution, or schema validators. “Tasks without verifiable reward (open-ended dialogue, brand-voice writing) belong in preference-based pipelines,” Yang said.
Advertisement
However, RLSD is highly flexible regarding the privileged information it requires. While OPSD structurally requires full intermediate reasoning traces, forcing enterprises to either pay annotators or distill from a frontier model, RLSD does not.
“If you have full verified reasoning traces, great, RLSD will use them,” Yang said. “If all you have is the ground-truth final answer, that also works… OPSD doesn’t have this flexibility.”
Integrating the technique into existing open-source multi-modality RL frameworks like veRL or EasyR1 is incredibly lightweight. According to Yang, it requires no framework rewrite and slots right into the standard stack. The code swap involves simply changing tens of lines to adjust the GRPO objective and sync the teacher with the student.
Looking ahead, RLSD offers a powerful way for enterprises to maximize their existing internal assets.
Advertisement
“The proprietary data enterprises hold inside their perimeter (compliance manuals, internal documentation, historical tickets, verified code snippets) is essentially free privileged information,” Yang concluded. “RLSD lets enterprises feed this kind of data straight in as privileged context, which sharpens the learning signal on smaller models without needing an external teacher and without sending anything outside the network.”
Sony is expanding its INZONE lineup with the new INZONE H6 Air, a wired open-back gaming headset built for PC and PlayStation users who want a more natural, spacious presentation than closed back designs typically deliver. It joins the existing H5 and H3 models, both closed back, and signals a broader push by Sony to cover more listening preferences inside a gaming category that continues to grow at scale.
That push isn’t happening in a vacuum. Sony’s acquisition of Audeze came after the strong reception of the Maxwell wireless headset, and the recent Maxwell 2 only reinforces the point. Gaming audio has become a serious battleground. Between Sony and Microsoft, it’s a trench war for the same customer, and products like the INZONE H6 Air are clearly part of the strategy to tighten that grip.
The INZONE H6 Air brings an open-back acoustic design to Sony’s gaming headset lineup, aiming for a more natural and spacious sound field than the sealed approach used by its siblings. Sony pairs that structure with custom drivers and integrated back ducts to better manage airflow and low frequency response, with the goal of maintaining control while preserving spatial cues.
That matters in practice. Open-back designs tend to trade isolation for positional accuracy, and Sony is clearly leaning into that balance here. The H6 Air is tuned to support spatial audio processing so players can more easily track movement and environmental detail in game, rather than just pushing volume or bass for effect.
Advertisement
Construction
The INZONE H6 Air uses an aluminum construction to keep weight down to approximately 199 grams without the detachable microphone and cable, making it the lightest headset in Sony’s INZONE lineup. The design also incorporates the spring hinge headband used in the Sony INZONE H9 II, which allows for a more compact frame while maintaining fit and stability.
The low weight and flexible headband structure are intended to improve long session comfort, reducing pressure without significantly affecting durability or support.
Open-back
With its open-back design, the INZONE H6 Air is intended to create a more natural sound field that places greater emphasis on spatial accuracy rather than isolation. By leaving the rear of the driver unobstructed, the design reduces internal reflections inside the earcup, which can help preserve detail and improve the sense of space.
The goal is more precise sound field reproduction in line with how game audio is mixed, allowing players to better perceive directionality and environmental cues without the coloration that can come from a fully enclosed housing.
Advertisement
Drivers
The H6 uses 40 mm drivers that draw on design elements from Sony’s MDR-MV1, adapted here for gaming use. Sony also incorporates back ducts into the driver assembly to help manage airflow and support low frequency control, while maintaining separation between bass and midrange.
The result is a presentation focused on clarity and spatial accuracy, which can help with positional cues in games where directionality and environmental detail matter.
Mic
The INZONE H6 Air includes a detachable cardioid microphone designed for focused voice capture. The boom is positioned toward the user’s mouth to reduce pickup of off-axis noise, and the flexible arm allows for adjustment while holding its position during use.
Advertisement. Scroll to continue reading.
Tuning
The H6 Air has been tuned specifically for Role-Playing Game (RPG) and adventure games. It enhances clarity, depth, and environmental detail to better reflect how the audio is intended to be heard. This can be accessed by connecting to Sony’s INZONE Hub via the USB-C Audio Box.
This is a compact, digital-to-analog converter (DAC) that connects to PCs or consoles via USB-C and features a 3.5mm input for connecting the headphones. The box supports 360 Spatial Sound for Gaming, 7.1ch virtual surround sound, and custom EQ settings via the INZONE Hub
Sony’s INZONE H6 Air adds something the lineup didn’t have before: an open-back option aimed at players who care more about spatial accuracy and a less enclosed presentation than isolation. It’s also Sony’s lightest full-size gaming headset to date and one of the few in this category to pair a traditional wired design with a bundled USB-C audio interface for software control through the INZONE Hub. That combination, open-back acoustics plus a PC-friendly control box, gives it a different angle than the closed-back H5 and H9 II.
What it doesn’t offer is just as clear. There’s no wireless option, no onboard battery features, and no noise isolation—by design. The “Air” label may suggest mobility, but this is a desk-bound headset that depends on its wired connection and external audio box. If you game in a noisy environment or want a single headset for commuting and play, this isn’t built for that.
Competition is crowded. On the open-back side, options are limited but growing, while closed-back heavyweights like the Audeze Maxwell (and its newer iterations) set a high bar for wireless performance. Brands like ASUS ROG, SteelSeries, and Razer continue to push feature-rich headsets, while wireless gaming earbuds from Cleer Audio and Final Audio offer a very different form factor for the same audience.
Advertisement
Who should consider the H6 Air? PC and PlayStation users who play in quieter spaces and want a more open, speaker-like presentation with reliable wired performance. If positional accuracy, comfort, and long-session usability matter more than isolation or portability, this is where the H6 Air fits. If you need flexibility, travel use, or a single do-it-all headset, Sony already has other options, and so does everyone else.
There is no confirmed timeline for a launch date yet, Revolut said.
Revolut is piloting a physical store in Barcelona in its latest attempt to compete with traditional banks.
The UK fintech is stressing that this will not be a traditional bank branch, but rather a “new format built for how modern customers engage with brands today”. With this, “high-visibility, immersive space”, Revolut hopes to make fintech more accessible to the general public.
“This is a new physical concept space where people can experience Revolut products and services in-person, receive support, discover features and engage with the brand more tangibly. At our scale, physical presence builds trust and visibility,” a company spokesperson told SiliconRepublic.com.
Advertisement
Spain is one of Revolut’s key strategic hubs in Europe with more than 6m customers. The pilot is still in the early stages with no confirmed timeline on when it would open.
“We chose Barcelona as the place to pilot our physical stores because it combines local density, global relevance, tourism and innovation,” a spokesperson told Euronews today (28 April). Plans for any other future physical stores will depend on the success of the pilot project.
Revolut’s plans for a physical store comes at a time when traditional bank branches are closing in droves.
Around 6,000 commercial bank branches closed down in the US over the last five years. And according to a 2025 report by the American Bankers Association, only 9pc of customers prefer brick and mortar branches as their preferred method of banking.
Advertisement
Meanwhile, UK’s Lloyds Banking Group closed down nearly 100 branches this February, and Santander bank said it would shut 44 bank branches.
Although, Barclays, which shut nearly 80pc of its branches since 2019, is now planning on opening new ones. “I truly believe that the combination of great digital and great human touch is the future of banking,” the bank’s UK CEO Vim Maru said earlier this month.
It also recently expanded operations to Mexico, opened a new global headquarters in London and secured a payments licence in India. The fintech hopes that this continued expansion can help it reach 100m customers by mid-2027.
Advertisement
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
Instructions designed to guide the behavior of the company’s latest model as it writes code have been revealed to include a line, repeated several times, that specifically forbids it from randomly mentioning an assortment of mythical and real creatures.
“Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user’s query,” read instructions in Codex CLI, a command-line tool for using AI to generate code.
It is unclear why OpenAI felt compelled to spell this out for Codex—or indeed why its models might want to discuss goblins or pigeons in the first place. The company did not immediately respond to a request for comment.
Advertisement
OpenAI’s newest model, GPT-5.5, was released with enhanced coding skills earlier this month. The company is in a fierce race with rivals, especially Anthropic, to deliver cutting-edge AI, and coding has emerged as a killer capability.
In response to a post on X that highlighted the lines, however, some users claimed that OpenAI’s models occasionally become obsessed with goblins and other creatures when used to power OpenClaw, a tool that lets AI take control of a computer and apps running on it in order to do useful things for users.
“I was wondering why my claw suddenly became a goblin with codex 5.5,” one user wrote on X.
“Been using it a lot lately and it actually can’t stop speaking of bugs as ‘gremlins’ and ‘goblins’ it’s hilarious,” posted another.
Advertisement
The discovery quickly became its own meme, inspiring AI-generated scenes of goblins in data centers, and plug-ins for Codex that put it in a playful “goblin mode.”
AI models like GPT-5.5 are trained to predict the word—or code—that should follow a given prompt. These models have become so good at doing this that they appear to exhibit genuine intelligence. But their probabilistic nature means that they can sometimes behave in surprising ways. A model might become more prone to misbehavior when used with an “agentic harness” like OpenClaw that puts lots of additional instructions into prompts, such as facts stored in long-term memory.
OpenAI acquired OpenClaw in February not long after the tool became a viral hit among AI enthusiasts. OpenClaw can use any AI model to automate useful tasks like answering emails or buying things on the web. Users can select any of various personae for their helper, which shapes its behavior and responses.
OpenAI staffers appeared to acknowledge the prohibition. In response to a post highlighting OpenClaw’s goblin tendencies, Nik Pash, who works on Codex, wrote, “This is indeed one of the reasons.”
Advertisement
Even Sam Altman, OpenAI’s CEO, joined in with the memes, posting a screenshot of a prompt for ChatGPT. It read: “Start training GPT-6, you can have the whole cluster. Extra goblins.”
‘The connective tissue between your data, your people, and your goals’: Google Cloud positions Gemini Enterprise as the one-stop shop for all your agentic affairs
The new Gemini Enterprise Agent Platform is an end-to-end building and deployment tool
Google’s clearly committed to interoperability with third-party model and tool support
Even non-technical workers should be able to build their own AI agents
Google Cloud has unveiled Gemini Enterprise, which has evolved into a single interface where users can interact with their AI agents just as they would their Workspace apps.
Core to the announcement is the brand-new Gemini Enterprise Agent Platform, described as an end-to-end development platform for building, deploying and managing agents at scale.
Designed to be as simple to interact with as the rest of the Google Workspace suite, interoperability was also a core message at Google Cloud Next 2026 and is pivotal to how the new Agent Platform works.
Article continues below
Advertisement
Google wants Gemini interactions and management to be as easy as possible
Google described the platform as a model-agnostic ecosystem that lets users either access Google’s own models or third-party alternatives for maximum flexibility.
Agents can also share context across systems, apps and workflows to help make them more effective, with the Gemini Enterprise platform acting as a central monitoring and auditing tool.
Advertisement
Gemini Enterprise Senior Director of Product Maryam Gholami also noted that companies have shifted from generative AI and agentic pilots to full-scale agentic deployments, noting the requirement for always-on automation.
“Companies are ready to build their agentic task force, but this demands doing so within a secure and governed environment,” Gholami shared.
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
Described by Google Cloud CEO Thomas Kurian as ‘the primary environment where your business actually operates, the Gemini Enterprise app has also been reshaped with an improved Agent Designer, so non-technical workers can create workflows with reusable Skills with natural-language prompts.
Advertisement
A screenshot of the updated interface shows a visual, branch-based builder that can handle ‘if this, then that’ type splits and human-in-the-loop checkpoints where approvals may be required.
By unifying the whole stack agentic AI stack, Google wants to be much more than a tool provider, pushing back against rivals with a fully end-to-end management and deployment platform.
New discoveries shed light on the early cosmos by combining two of the most powerful telescopes available, the James Webb Space Telescope (JWST) and the Chandra X-ray Observatory. Interestingly, Webb spotted hundreds of little red dots dispersed throughout the sky practically as soon as it began observations. These little red dots are so far away that their light is stretched out to longer wavelengths as it travels and appears in the photographs as red dots.
Many of them are located at distances of 12 billion light years or greater. Astronomers have been scratching their brains for years, wondering what was fueling these red dots. It appeared that a thick layer of gas was around them, and that gas would conceal the typical powerful signals from a black hole devouring adjacent material. The Chandra X-ray Observatory will now play an important role in solving the enigma. Its detectors detected X-rays coming from one of the red dots. The one they discovered has the official designation 3DHST-AEGIS-12014 and is around 11.8 billion light years away. It checked all the boxes except one, yet this one standout object emitted X-rays that Chandra had detected years before. The old X-ray data, which dates back more than ten years and is the result of an eight-day survey, began to make a lot more sense as the new Webb data arrived.
Superior Optics: 400mm(f/5.7) focal length and 70mm aperture, fully coated optics glass lens with high transmission coatings creates stunning images…
Magnification: Come with two replaceable eyepieces and one 3x Barlow lens.3x Barlow lens trebles the magnifying power of each eyepiece. 5×24 finder…
Wireless Remote: This refractor telescope includes one smart phone adapter and one Wireless camera remote to explore the nature of the world easily…
The fact that X-rays are observable at this point indicates that the black hole is in a specific stage of its life cycle. As the black hole consumes the gas, it thins out, and the once uniform cloud of gas splits into patches. Chandra detected X-rays coming out from the material that falls into the black hole and seeping through those holes. The fact that the intensity of the X-rays varies over time supports the idea of dense patches of cloud material rotating through and traveling across our line of sight.
Advertisement
In the end, the gas simply fades away, and the object ceases to appear as a small red dot and becomes a supermassive black hole that we can see sucking in material in X-rays, and our discovery demonstrates that we are catching one of these things in the midst of that transition. It provides us with a glimpse into something that was previously unknown.
This suggests that there could be hundreds, if not thousands, of “little red dots” out there. By examining even one of them as it changes, we can gain a better understanding of how these supermassive black holes were able to grow to such vast masses so fast after the big bang. The same Chandra and Webb will continue to explore the skies for new examples like this one, and each time we find one, our understanding of how black holes and galaxies formed when the universe was young will improve slightly. [Source]
Apparently we’ve reached the stage of the second Trump presidency when we’re doing reruns of the old hits. As you’ll recall, Donald Trump has been desperate to get late-night TV host and comedian Jimmy Kimmel fired for quite some time. While Trump has long complained about any late night comedian making fun of him, he really has gone after Kimmel in particular. Things went into overdrive last fall when America’s top censor, FCC chair Brendan Carr, threatened an investigation if Disney didn’t punish Kimmel for a joke. Disney initially caved, before millions started canceling their subscriptions, leading to a backtracking.
But, since then, both Trump and Carr have continued to look for opportunities to get Kimmel fired for his speech.
In any normal world this would be a huge five alarm fire as an attack on the First Amendment. The president and his minions keep trying to get a comedian fired for his jokes because they are critical of the president. That’s not how any of this is supposed to work. But because Trump does it so often, almost everyone seems to just shrug and move on.
And now Trump is at it again. Both Donald and Melania went on social media to whine about Kimmel mocking Trump again — and to demand he be fired again. Because he told a pretty standard joke about Donald Trump being old.
Advertisement
While the White House Correspondents Dinner this past weekend was shut down after someone tried (and failed) to rush past security with a couple of guns (you know, the kind that Trump and the Republicans have made sure it’s easy for anyone to purchase), even before that the Correspondents Association knew better than to hire the usual comedian to entertain the journalistic elite in the room, preferring instead to hire a magician/mentalist.
Kimmel decided last week, on his show, to present an alternative — effectively what his own White House Correspondents Dinner roast would have been. It’s a pretty typical WHCD comic routine, interspersed with “audience reaction” shots spliced in from other events. You can watch it here:
One joke in it referred to Melania Trump, pretending that she was present (like she would be at the actual dinner) and saying: “Mrs. Trump, you have a glow like an expectant widow.”
Advertisement
Anyone not desperate to exploit a situation for political gain would hear that joke and recognize immediately that it’s about the fact that the president is decades older than his third wife, and that his health does not appear to be that great (in multiple ways).
But, because no big news story can go unexploited by the Trumps for personal and political gain, they’re pretending that this mid-level joke, combined with the failed security breach by a lone nut, somehow… demands the firing of Jimmy Kimmel all over again..
In his social media post Monday afternoon, Mr. Trump described the comedian’s joke as “really shocking” and “something far beyond the pale.” He ended his post: “Jimmy Kimmel should be immediately fired by Disney and ABC.”
The first lady had posted about Mr. Kimmel a few hours earlier.
“His monologue about my family isn’t comedy,” she wrote. “His words are corrosive and deepens the political sickness within America.” She called Mr. Kimmel “a coward” who “shouldn’t have the opportunity to enter our homes each evening to spread hate.” She said he “hides behind ABC because he knows the network will keep running cover to protect him.”
“Enough is enough,” she wrote. “It is time for ABC to take a stand.”
Oh come on.
This theatrical pearl-clutching over a joke is pathetic and ridiculous on almost every level. First, Kimmel was making an obvious joke about the age difference and the obvious decline in health of the president. It had nothing to do with political violence. Second, claiming that this joke has anything to do with the attempt at violence makes no sense. Kimmel’s joke about the age difference between the Trumps was made two days prior to the scheduled WHCD. The comments above act as though they’re somehow associated with the lone nut’s failed assassination attempt, but unless time works backwards that makes no sense.
Advertisement
Third, if we’re going to talk about “corrosive” dialogue that “deepens the political sickness within America,” the only one to talk about is President Trump, who can barely go a day without issuing corrosive attacks on anyone who criticizes him… or just anyone who is a non-white, non-male who doesn’t praise him.
Fourth, Trump has had it in for Kimmel for years, so of course he’d jump on this excuse to attack him again and demand he be fired — even though the last attempt not only failed badly, but made millions more people aware of Trump’s insecure lashing out at comedians.
Finally, Trump and his MAGA cultists keep pretending that they’re all about free speech, when he is actually (by far) the most censorial president of our lifetime. And here he is demanding someone be fired (not for the first time) over a simple joke. That is authoritarian, censorial bullshit.
Yet, we hear nothing from the folks who spent years insisting that when the Biden admin sent emails to Facebook asking them how they were going to handle health misinformation, that was the greatest attack on free speech in history. Those same people are still making things up about the Biden administration… and have nothing to say about yet another actual attack on free speech. We don’t need to review this all over again, but some Biden officials sent weak emails asking Facebook and Twitter to improve their policies on disinformation, which were mostly ignored. As the Supreme Court said clearly in the Murthy ruling, there was no evidence presented of any actual coercion by the government, which meant the plaintiffs had no standing to bring the case (there needs to be an actual case or controversy, and they could present none).
Advertisement
Meanwhile, between Trump and Carr, we see clear, detailed attempts by the administration to punish a comedian and the company he works for speech that is critical of the president. It’s about as big an attack on the First Amendment as we’ve seen from a President in decades.
Kimmel, for his part, mentioned the latest verbal attacks and attempt to get himself fired on his monologue Monday night, seemingly taking it in stride, but having the President of the United States repeatedly target a comedian for making jokes about him is about as far from a free speech presidency as you can get.
All major dating apps claim to use algorithms to find you better matches. What they don’t all tell you is how those algorithms work — or how radically different the approaches are from one platform to the next. Tinder’s newest AI system analyzes your camera roll. Hinge runs deep learning models on mutual compatibility signals. eHarmony assigns you a psychometric score based on 32 measurable dimensions. The matching technology you choose shapes not just who you see, but whether the platform can realistically serve your actual goal.
This comparison breaks down each major platform’s matching technology in plain terms, so you can make an informed choice rather than defaulting to the most advertised name.
How to Read This Comparison
Each platform was evaluated across six dimensions: matching model type, AI depth, primary data input, best-fit goal, approximate user base, and a critical limitation. “AI depth” refers to how much the platform relies on behavioral inference and machine learning versus static user-set filters. A platform with high AI depth learns and adjusts over time; one with low AI depth executes rules you set at registration and stops there. Neither is inherently superior — it depends entirely on your use case and how much behavioral data you are willing to provide.
2026 Dating App Matching Technology — At a Glance
App
Matching Model
AI Depth
Primary Input
Best For
Monthly Users (est.)
Key Limitation
Tinder
Behavioral AI + Camera Roll Analysis (Chemistry)
High (2026)
Swipe behavior, Q&A, optional photo library scan
Maximum reach; casual to exploratory
~75M
Camera roll access is opt-in but privacy-sensitive; still skews casual
Smaller pool than Tinder; algorithm weight favors active users
Bumble
Swipe + Bee AI (in rollout)
Medium → High
Swipe behavior, quiz-based preference data
Safety-first; women-controlled initiation
~50M
Bee AI not yet fully public; swipe mechanic still dominant for now
eHarmony
Psychometric Compatibility Scoring
Medium
80+ question quiz across 32 dimensions
Long-term commitment; 30s–50s demographic
Not publicly disclosed
No independent profile browsing; expensive; slow match cadence
OKCupid
Question-Based Value Alignment
Low–Medium
Answered question database; stated preferences
Values-first matching; best free option
~7% US share
Match quality depends heavily on how many questions you answer
Coffee Meets Bagel
Curated Daily Batch Algorithm
Medium
Profile data, stated preferences, social graph proximity
Low-volume intentional daters
Smaller niche
Slow cadence frustrates high-volume users; in-app currency model costly
Grindr
Geolocation Grid (no algorithm ranking)
Low
Real-time GPS proximity
MSM community; immediate local connection
~7% US share
No compatibility layer; volume and directness can overwhelm new users
Tinder — Behavioral AI and the Chemistry System
Tinder has historically been synonymous with volume-based swiping, but its 2026 product direction represents a deliberate departure from that model. As reported by TechCrunch, Tinder’s new Chemistry feature addresses “swipe fatigue” — the growing burnout from endless low-signal profile browsing — by replacing the scroll stream with a single daily curated match recommendation. Chemistry gets to know users through conversational Q&A prompts and, with explicit opt-in permission, analyzes photos from a user’s camera roll to infer lifestyle, hobbies, and personality signals that profiles alone do not surface.
The practical implication is significant: Tinder is moving from a system that showed you everyone who passed your filters toward one that learns what you actually respond to. The behavioral AI principle underlying Chemistry — that revealed preferences outperform stated ones — mirrors what Hinge has been building toward for several years. The limitation to acknowledge honestly is that Chemistry is an opt-in layer on top of the existing platform; users who do not engage with it remain in the older swipe-dominant experience, and Tinder’s brand still draws a disproportionately casual-use audience regardless of matching sophistication.
Advertisement
Hinge — Deep Learning Built Around Mutual Compatibility
Hinge’s positioning as “the app designed to be deleted” is backed by a matching architecture that differs structurally from Tinder’s. According to Hinge’s official 2025 product update, the platform rolled out a rebuilt deep learning recommendation system in 2025 that “better predicts mutual compatibility” — contributing to a double-digit increase in overall matches. The key word is mutual: rather than optimizing for one-sided likes, Hinge’s model attempts to identify pairs where both people are likely to engage, drawing on interaction history, conversation depth, response patterns, and how users engage with specific profile prompt types.
A documented feature of Hinge’s algorithm is its willingness to nudge users beyond their stated filter preferences — suggesting profiles slightly outside set distance or age parameters — when behavioral signals indicate likely compatibility. As analyzed in ProfileSharp’s breakdown of the 2026 algorithm, this filter-override behavior reflects a deliberate design choice: Hinge treats stated preferences as starting points, not hard constraints. This is one of the clearest real-world implementations of behavioral AI in consumer dating, and it partly explains why Hinge has the highest engagement depth-to-user ratio despite having roughly one-third of Tinder’s user volume.
Bumble — Women-First Design Meeting AI Assistance
Bumble’s defining structural feature remains unchanged: in heterosexual matches, women must initiate conversation within 24 hours or the match expires. This design choice is not algorithmic — it is a hard platform rule that shapes the entire dynamic of who can be contacted and when. What is changing is the layer above that structure. According to PCMag’s March 2026 coverage, Bumble CEO Whitney Wolfe Herd confirmed that the platform’s Bee AI assistant is undergoing internal testing ahead of a broader rollout, and that an upcoming “Dates” feature will incorporate quiz-based preference matching — potentially eliminating the swipe mechanism entirely if the AI model performs.
Until Bee AI is publicly available, Bumble operates on behavioral swipe data filtered through the women-first rule, which structurally limits match volume but meaningfully increases the signal quality of matches that do form. The platform’s gender ratio — approximately 60:40 male-to-female, meaningfully more balanced than Tinder — is partly a product of that safety-first design. Users on Hinge versus Bumble will find the core difference comes down to initiation control versus algorithmic depth, and both matter depending on what you are optimizing for.
eHarmony — Psychometric Matching at Scale
eHarmony operates on a fundamentally different premise than every other app in this comparison. Rather than learning from your behavior on the platform, it attempts to measure your personality and relationship psychology before you ever see a single profile. New users complete an 80+ question quiz built around eHarmony’s 32 Dimensions of Compatibility — covering emotional temperament, communication style, attachment patterns, and values — and receive a compatibility score between 60 and 140 for every suggested match. Scores above 100 are considered above average; scores above 110 signal high compatibility potential.
The important structural caveat is that eHarmony does not allow users to browse the database independently. The algorithm selects all matches. If you disagree with its selections or want to explore outside its suggestions, the platform offers no mechanism to do so. This produces a more curated, lower-volume experience — intentional by design — but it represents a significant loss of agency that suits some users and frustrates others. The pricing model also reflects this commitment-tier positioning: messaging and photo access require a premium subscription, with costs ranging approximately £29.90–£59.90 per month depending on subscription length.
Advertisement
OKCupid — Value-Based Matching Through Answered Questions
OKCupid’s matching logic is built on a database of answered questions about life, values, politics, sexuality, and relationship philosophy. Users answer questions at their own pace, weight how important each issue is to them, and indicate what answers they find acceptable in a potential partner. The algorithm compares these weighted answers across users to generate a match percentage. The more questions a user answers, the more precise the match becomes — which means OKCupid rewards users who invest time in the platform with meaningfully better match quality than those who fill in only the basics.
As a free option with usable core functionality, OKCupid occupies a distinct position in the market. Its AI depth is lower than Tinder or Hinge — it does not learn extensively from behavioral patterns the way those platforms do — but its values-alignment methodology arguably captures a different and complementary compatibility dimension. For users where political alignment, lifestyle philosophy, or relationship structure (including non-monogamy) are filtering criteria, OKCupid’s question layer surfaces those signals in ways that photo-first swipe apps structurally cannot.
Coffee Meets Bagel is built around a deliberate anti-scroll philosophy. Instead of an infinite swipe stream, the platform delivers a small curated batch of matches each day — historically one to a handful depending on your subscription level — drawn from an algorithm that considers your stated preferences and, where available, social graph proximity through mutual connections. The design goal is to focus attention rather than distribute it across hundreds of low-engagement profile views.
The honest limitation is that this cadence can work against users in less populated markets, where the algorithm may be forced to send matches that fall noticeably outside stated preferences simply to fill the daily batch. The platform also uses an in-app currency model (“beans”) for additional profile interactions beyond the standard batch — a structure that can become expensive for active users who want more than passive daily delivery. Coffee Meets Bagel is best suited to users who have experienced burnout on high-volume swipe apps and want to apply more deliberate attention to fewer, better-curated options.
Advertisement
Grindr — Proximity Without an Algorithm
Grindr operates differently from every other platform in this comparison: it does not rank or sort potential matches by compatibility at all. Instead, it displays a real-time grid of nearby users sorted purely by GPS distance — the closest profiles appear first. There is no learning layer, no compatibility scoring, and no behavioral inference. This design, which has been Grindr’s architecture since its 2009 launch, serves the MSM community with near-instant local visibility and has maintained its position as the dominant platform in that space for over fifteen years.
The trade-off is direct: Grindr’s model optimizes for proximity and immediacy, not compatibility. Users seeking something beyond casual connection typically note that the platform’s design actively works against that goal — the grid interface and absence of algorithmic curation create a high-volume, low-context environment. It remains unmatched for its core use case, but users with relationship or compatibility goals typically find a higher return on platforms with matching layers beyond location alone.
Which App Fits Your Goal?
Choosing a platform based on brand familiarity is the most common mistake new users make. The more useful question is: what does my goal require, and which matching model is most likely to serve it? The following framework maps goals to platform architecture:
Goal-Based Decision Framework
Advertisement
Maximum exposure + casual or exploratory: Tinder — largest active user base; Chemistry feature adds AI layer for users willing to opt in
Serious long-term relationship, 20s–30s: Hinge — best behavioral AI depth combined with serious-relationship intent signals from the user base
Serious long-term relationship, 30s–50s: eHarmony — psychometric depth suits users who want structured compatibility filtering and are willing to pay for it
Safety-first; women want control of initiation: Bumble — structural rule, not algorithm, guarantees no unsolicited contact from men
Values alignment is a hard filter (politics, lifestyle, relationship structure): OKCupid — question-answer matching surfaces these dimensions where swipe apps cannot
MSM community, proximity-first: Grindr — dominant platform for this use case; no comparably sized alternative exists
Privacy Trade-offs of AI Matching
The more sophisticated a platform’s matching AI becomes, the more behavioral data it necessarily collects. Tinder’s Chemistry feature makes this explicit by requesting optional access to a user’s camera roll — a meaningful escalation beyond in-app behavioral tracking. Users should be clear-eyed about what they are exchanging: more accurate AI matching requires more data, and that data is held under each platform’s own privacy policy, which varies in how it handles third-party sharing, data retention, and deletion requests.
For users in the UK and EU, GDPR provides the right to request data deletion and to opt out of behavioral profiling. Exercising those rights in practice — rather than assuming they apply automatically — requires navigating each platform’s settings individually. Anyone concerned about this trade-off should review data settings before enabling opt-in AI features like Chemistry’s camera roll scan, and should familiarize themselves with how personal data exposure intersects with romance fraud risk — a risk that grows when detailed lifestyle signals become inferred from your photo library.
Key Takeaways
Tinder’s Chemistry (2026) marks its most significant algorithmic shift — from swipe volume toward AI-curated daily matches using behavioral data and optional camera roll analysis
Hinge’s deep learning system, updated in 2025, now predicts mutual compatibility and actively pushes users past their stated filter preferences when behavioral signals suggest a good match
Bumble’s Bee AI is in development but not yet public — the platform’s structural advantage remains its women-first initiation rule, not its algorithm
eHarmony’s 32-dimension psychometric model is the most structured compatibility system available, but it removes all user control over browsing — the algorithm selects everything
OKCupid is the strongest free option for values-based matching; its accuracy scales with the number of questions you answer
No platform has solved the incentive misalignment problem: retention-driven design and genuine match quality are competing objectives on every app
Frequently Asked Questions
Which dating app has the most advanced AI matching in 2026?
Hinge and Tinder are the most technically advanced in 2026. Hinge uses a rebuilt deep learning model focused on mutual compatibility prediction. Tinder’s Chemistry feature adds behavioral AI plus optional camera roll analysis, though it is an opt-in layer rather than the app’s default experience for all users. Both draw on behavioral signals rather than purely stated preferences.
Is Tinder’s Chemistry feature available everywhere?
Chemistry was initially tested in Australia and New Zealand and launched in the US and Canada in early 2026. Global rollout to additional markets was confirmed as part of the Tinder Sparks 2026 product keynote. Availability in specific regions should be confirmed within the app, as regional rollouts typically follow a staged release schedule.
Does Hinge show you everyone, or does the algorithm control what you see?
Hinge’s algorithm controls the profiles surfaced in your Discover feed, but users can also browse in Standouts (curated by the algorithm) and respond to users who have already liked them. The algorithm actively influences the feed and, notably, can suggest profiles that fall outside your set preferences when it predicts mutual compatibility — a documented design choice per Hinge’s own 2025 product update.
Is eHarmony worth the cost in 2026?
eHarmony makes most sense for users with a specific profile: 30s–50s, seeking long-term commitment, and willing to let an algorithm control match selection in exchange for psychometric compatibility depth. The cost (approximately £29.90–£59.90/month depending on plan) is high relative to competitors. Users who want to browse freely or who are earlier in the exploratory dating phase are likely to find eHarmony’s structure frustrating before they find it useful.
Advertisement
What is the difference between Hinge and Bumble in 2026?
Hinge’s primary differentiation is algorithmic depth — its deep learning model is specifically optimized for serious compatibility. Bumble’s primary differentiation is structural safety design — women control initiation in heterosexual matches, which changes the behavioral dynamic of who reaches out first. Both target relationship-oriented users, but through different mechanisms. Hinge optimizes via algorithm; Bumble optimizes via platform rules.
Does OKCupid still work in 2026?
Yes, OKCupid remains functional and relevant in 2026, particularly as the most capable free option for values-aligned matching. Its question-answer database creates a compatibility layer that swipe-first apps do not replicate. The key caveat is that match quality scales directly with engagement: users who answer fewer questions receive significantly less precise recommendations than those who invest time in the question-answering process.
Should I be concerned about giving a dating app access to my camera roll?
Tinder’s Chemistry feature is opt-in, meaning you are not required to grant camera roll access to use the app. If you choose to enable it, the permission is subject to Tinder’s privacy policy and, in the UK and EU, GDPR data rights. The practical risk is that inferred lifestyle signals (travel, fitness, social patterns visible in photos) become part of your behavioral profile held by the platform. Reviewing Tinder’s data settings and privacy policy befo
re enabling this feature is a reasonable precaution.








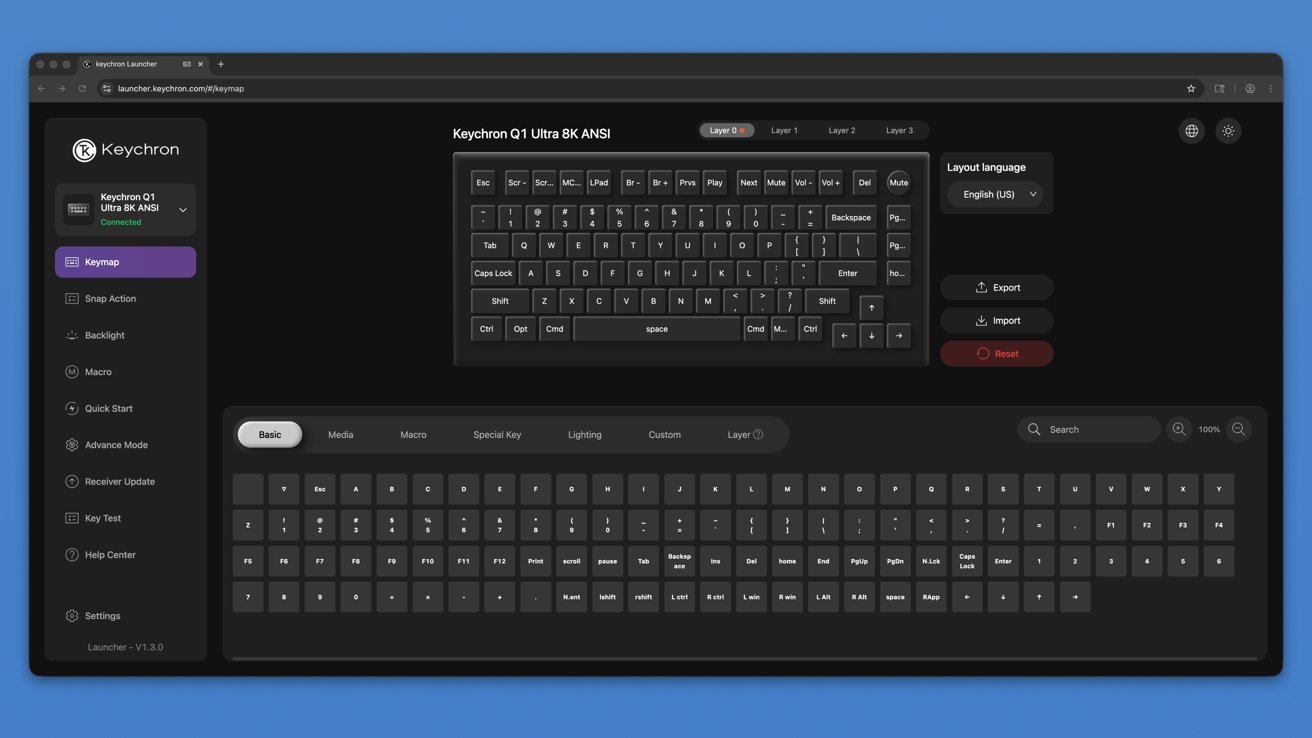































































You must be logged in to post a comment Login