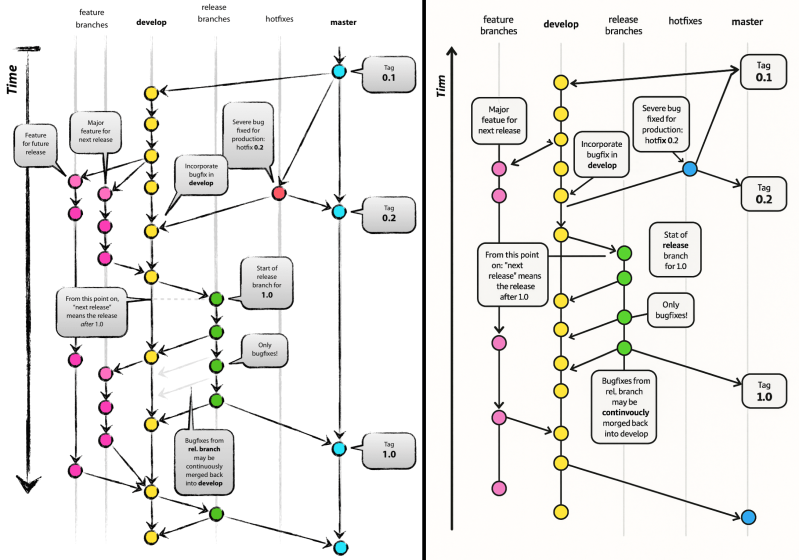
It’s becoming somewhat of a theme that machine-generated content – whether it’s code, text or graphics – keeps pushing people to their limits, mostly by how such ‘AI slop’ is generally of outrageously poor quality, but as in the case of [Vincent Driessen] there’s also a clear copyright infringement angle involved. Recently he found that Microsoft had bastardized a Git explainer graphic which he had in 2010 painstakingly made by hand, with someone at Microsoft slapping it on a Microsoft Learn explainer article pertaining to GitHub.
As noted in a PC Gamer article on this clear faux pas, Microsoft has since quietly removed the graphic and replaced it with something possibly less AI slop, but with zero comment, and so far no response to a request for comment by PC Gamer. Of course, The Internet Archive always remembers.
What’s probably most vexing is that the ripped-off diagram isn’t even particularly good, as it has all the hallmarks of AI slop graphics: from the nonsensical arrows that got added or modified, to heavily mutilated text including changing ‘Time’ to ‘Tim’ and ‘continuously merged’ into ‘continvuocly morged’. This makes it obvious that whoever put the graphic on the Microsoft Learn page either didn’t bother to check, or that no human was involved in generating said page.
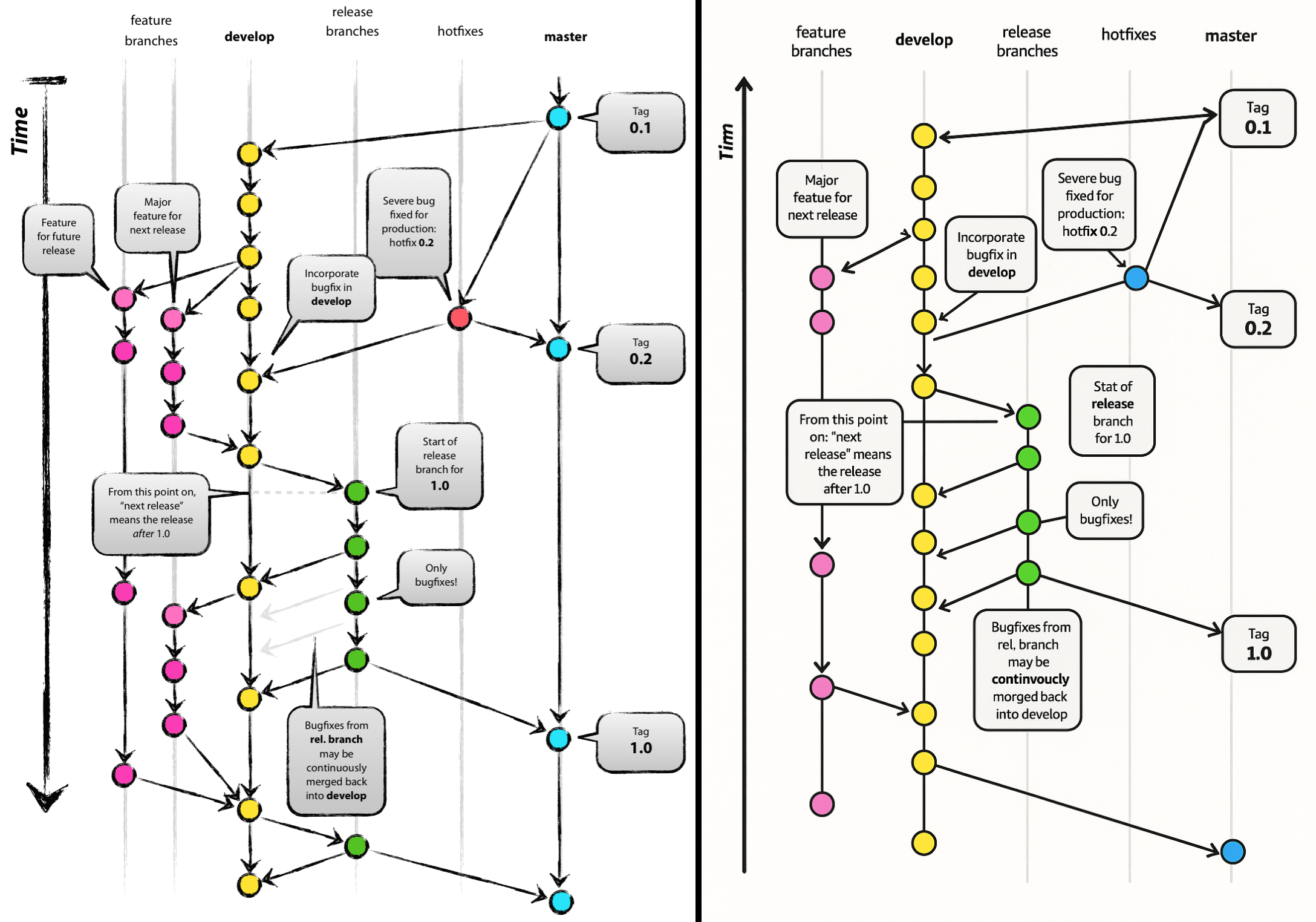
It definitely gives a dystopian ‘Dead Internet’ vibe where the fruits of past labor are being cynically regurgitated and spat out in the form of AI slop that bears little resemblance to the original, and should send real humans either running off in abject terror or fall over in uncontrollable laughter.
Even if this output was the result of [Vincent]’s original graphic getting scraped and shoved struggling and screaming into a diffusion model’s training dataset, there are so many dead giveaways that it was based on this original: from the text blurbs, to the use of the label ‘feature branches’ that’s retained in the reproduction even though the second feature branch has been trimmed.
All of this raises many uncomfortable questions about copyright in the context of both large language models and diffusion models, with cases like these making it clear that sometimes substantial elements of copyrighted works are being reproduced nearly verbatim. Depending on the associated copyright license, this can result in very expensive copyright infringement lawsuits, with some of these already working, or having worked their way through various courts pertaining to primarily stock images and books.
And to think that all that Microsoft would have had to do here was to check with [Vincent] for the license on the graphic if they had wanted to use it. As [Vincent] indicates, he would have been more than happy to do so if a backlink and credit was provided. This obviously is the human way to do things, where a human contacts a fellow human being to inquire about their thoughts on a topic, or peruses the works by fellow humans to find something to their liking prior to contacting said human with a usage question.
In this era of ‘just ask the machine’ by mashing in a query on a prompt, it would seem that this particular case will be far from the last one. The cynical take here is that the value of human output has been reduced to mere training data for the content machines, but maybe Microsoft will surprise us here with a tearful apology and real actions to prevent such events from ever happening again.