

Crypto World
Why AI Needs Sovereign Data Integrity


AI agents dominated ETHDenver 2026, from autonomous finance to on-chain robotics. But as enthusiasm around “agentic economies” builds, a harder question is emerging: can institutions prove what their AI systems were trained on?
Among the startups targeting that problem is Perle Labs, which argues that AI systems require a verifiable chain of custody for their training data, particularly in regulated and high-risk environments. With a focus on building an auditable, credentialed data infrastructure for institutions, Perle has raised $17.5 million to date, with its latest funding round led by Framework Ventures. Other investors include CoinFund, Protagonist, HashKey, and Peer VC. The company reports more than one million annotators contributing over a billion scored data points on its platform.
BeInCrypto spoke with Ahmed Rashad, CEO of Perle Labs, on the sidelines of ETHDenver 2026. Rashad previously held an operational leadership role at Scale AI during its hypergrowth phase. In the conversation, he discussed data provenance, model collapse, adversarial risks and why he believes sovereign intelligence will become a prerequisite for deploying AI in critical systems.
BeInCrypto: You describe Perle Labs as the “sovereign intelligence layer for AI.” For readers who are not inside the data infrastructure debate, what does that actually mean in practical terms?
Ahmed Rashad: “The word sovereign is deliberate, and it carries a few layers.
The most literal meaning is control. If you’re a government, a hospital, a defense contractor, or a large enterprise deploying AI in a high-stakes environment, you need to own the intelligence behind that system, not outsource it to a black box you can’t inspect or audit. Sovereign means you know what your AI was trained on, who validated it, and you can prove it. Most of the industry today cannot say that.
The second meaning is independence. Acting without outside interference. This is exactly what institutions like the DoD, or an enterprise require when they’re deploying AI in sensitive environments. You cannot have your critical AI infrastructure dependent on data pipelines you don’t control, can’t verify, and can’t defend against tampering. That’s not a theoretical risk. NSA and CISA have both issued operational guidance on data supply chain vulnerabilities as a national security issue.
The third meaning is accountability. When AI moves from generating content into making decisions, medical, financial, military, someone has to be able to answer: where did the intelligence come from? Who verified it? Is that record permanent? On Perle, our goal is to have every contribution from every expert annotator is recorded on-chain. It can’t be rewritten. That immutability is what makes the word sovereign accurate rather than just aspirational.
In practical terms, we are building a verification and credentialing layer. If a hospital deploys an AI diagnostic system, it should be able to trace each data point in the training set back to a credentialed professional who validated it. That is sovereign intelligence. That’s what we mean.”
BeInCrypto: You were part of Scale AI during its hypergrowth phase, including major defense contracts and the Meta investment. What did that experience teach you about where traditional AI data pipelines break?
Ahmed Rashad: “Scale was an incredible company. I was there during the period when it went from $90M and now it’s $29B, all of that was taking shape, and I had a front-row seat to where the cracks form.
The fundamental problem is that data quality and scale pull in opposite directions. When you’re growing 100x, the pressure is always to move fast: more data, faster annotation, lower cost per label. And the casualties are precision and accountability. You end up with opaque pipelines: you know roughly what went in, you have some quality metrics on what came out, but the middle is a black box. Who validated this? Were they actually qualified? Was the annotation consistent? Those questions become almost impossible to answer at scale with traditional models.
The second thing I learned is that the human element is almost always treated as a cost to be minimized rather than a capability to be developed. The transactional model: pay per task then optimize for throughput just degrades quality over time. It burns through the best contributors. The people who can give you genuinely high-quality, expert-level annotations are not the same people who will sit through a gamified micro-task system for pennies. You have to build differently if you want that caliber of input.
That realization is what Perle is built on. The data problem isn’t solved by throwing more labor at it. It’s solved by treating contributors as professionals, building verifiable credentialing into the system, and making the entire process auditable end to end.”
BeInCrypto: You’ve reached a million annotators and scored over a billion data points. Most data labeling platforms rely on anonymous crowd labor. What’s structurally different about your reputation model?
Ahmed Rashad: “The core difference is that on Perle, your work history is yours, and it’s permanent. When you complete a task, the record of that contribution, the quality tier it hit, how it compared to expert consensus, is written on-chain. It can’t be edited, can’t be deleted, can’t be reassigned. Over time, that becomes a professional credential that compounds.
Compare that to anonymous crowd labor, where a person is essentially fungible. They have no stake in quality because their reputation doesn’t exist, each task is disconnected from the last. The incentive structure produces exactly what you’d expect: minimum viable effort.
Our model inverts that. Contributors build verifiable track records. The platform recognizes domain expertise. For example, a radiologist who consistently produces high-quality medical image annotations builds a profile that reflects that. That reputation drives access to higher-value tasks, better compensation, and more meaningful work. It’s a flywheel: quality compounds because the incentives reward it.
We’ve crossed a billion points scored across our annotator network. That’s not just a volume number, it’s a billion traceable, attributed data contributions from verified humans. That’s the foundation of trustworthy AI training data, and it’s structurally impossible to replicate with anonymous crowd labor.”
BeInCrypto: Model collapse gets discussed a lot in research circles but rarely makes it into mainstream AI conversations. Why do you think that is, and should more people be worried?
Ahmed Rashad: “It doesn’t make mainstream conversations because it’s a slow-moving crisis, not a dramatic one. Model collapse, where AI systems trained increasingly on AI-generated data start to degrade, lose nuance, and compress toward the mean, doesn’t produce a headline event. It produces a gradual erosion of quality that’s easy to miss until it’s severe.
The mechanism is straightforward: the internet is filling up with AI-generated content. Models trained on that content are learning from their own outputs rather than genuine human knowledge and experience. Each generation of training amplifies the distortions of the last. It’s a feedback loop with no natural correction.
Should more people be worried? Yes, particularly in high-stakes domains. When model collapse affects a content recommendation algorithm, you get worse recommendations. When it affects a medical diagnostic model, a legal reasoning system, or a defense intelligence tool, the consequences are categorically different. The margin for degradation disappears.
This is why the human-verified data layer isn’t optional as AI moves into critical infrastructure. You need a continuous source of genuine, diverse human intelligence to train against; not AI outputs laundered through another model. We have over a million annotators representing genuine domain expertise across dozens of fields. That diversity is the antidote to model collapse. You can’t fix it with synthetic data or more compute.”
BeInCrypto: When AI expands from digital environments into physical systems, what fundamentally changes about risk, responsibility, and the standards applied to its development?
Ahmed Rashad: The irreversibility changes. That’s the core of it. A language model that hallucinates produces a wrong answer. You can correct it, flag it, move on. A robotic surgical system operating on a wrong inference, an autonomous vehicle making a bad classification, a drone acting on a misidentified target, those errors don’t have undo buttons. The cost of failure shifts from embarrassing to catastrophic.
That changes everything about what standards should apply. In digital environments, AI development has largely been allowed to move fast and self-correct. In physical systems, that model is untenable. You need the training data behind these systems to be verified before deployment, not audited after an incident.
It also changes accountability. In a digital context, it’s relatively easy to diffuse responsibility, was it the model? The data? The deployment? In physical systems, particularly where humans are harmed, regulators and courts will demand clear answers. Who trained this? On what data? Who validated that data and under what standards? The companies and governments that can answer those questions will be the ones allowed to operate. The ones that can’t will face liability they didn’t anticipate.
We built Perle for exactly this transition. Human-verified, expert-sourced, on-chain auditable. When AI starts operating in warehouses, operating rooms, and on the battlefield, the intelligence layer underneath it needs to meet a different standard. That standard is what we’re building toward.
BeInCrypto: How real is the threat of data poisoning or adversarial manipulation in AI systems today, particularly at the national level?
Ahmed Rashad: “It’s real, it’s documented, and it’s already being treated as a national security priority by people who have access to classified information about it.
DARPA’s GARD program (Guaranteeing AI Robustness Against Deception) spent years specifically developing defenses against adversarial attacks on AI systems, including data poisoning. The NSA and CISA issued joint guidance in 2025 explicitly warning that data supply chain vulnerabilities and maliciously modified training data represent credible threats to AI system integrity. These aren’t theoretical white papers. They’re operational guidance from agencies that don’t publish warnings about hypothetical risks.
The attack surface is significant. If you can compromise the training data of an AI system used for threat detection, medical diagnosis, or logistics optimization, you don’t need to hack the system itself. You’ve already shaped how it sees the world. That’s a much more elegant and harder-to-detect attack vector than traditional cybersecurity intrusions.
The $300 million contract Scale AI holds with the Department of Defense’s CDAO, to deploy AI on classified networks, exists in part because the government understands it cannot use AI trained on unverified public data in sensitive environments. The data provenance question is not academic at that level. It’s operational.
What’s missing from the mainstream conversation is that this isn’t just a government problem. Any enterprise deploying AI in a competitive environment, financial services, pharmaceuticals, critical infrastructure, has an adversarial data exposure they’ve probably not fully mapped. The threat is real. The defenses are still being built.”
BeInCrypto: Why can’t a government or a large enterprise just build this verification layer themselves? What’s the real answer when someone pushes back on that?
Ahmed Rashad: “Some try. And the ones who try learn quickly what the actual problem is.
Building the technology is the easy part. The hard part is the network. Verified, credentialed domain experts, radiologists, linguists, legal specialists, engineers, scientists, don’t just appear because you built a platform for them. You have to recruit them, credential them, build the incentive structures that keep them engaged, and develop the quality consensus mechanisms that make their contributions meaningful at scale. That takes years and it requires expertise that most government agencies and enterprises simply don’t have in-house.
The second problem is diversity. A government agency building its own verification layer will, by definition, draw from a limited and relatively homogeneous pool. The value of a global expert network isn’t just credentialing; it’s the range of perspective, language, cultural context, and domain specialization that you can only get by operating at real scale across real geographies. We have over a million annotators. That’s not something you replicate internally.
The third problem is incentive design. Keeping high-quality contributors engaged over time requires transparent, fair, programmable compensation. Blockchain infrastructure makes that possible in a way that internal systems typically can’t replicate: immutable contribution records, direct attribution, and verifiable payment. A government procurement system is not built to do that efficiently.
The honest answer to the pushback is: you’re not just buying a tool. You’re accessing a network and a credentialing system that took years to build. The alternative isn’t ‘build it yourself’, it’s ‘use what already exists or accept the data quality risk that comes with not having it.’”
BeInCrypto: If AI becomes core national infrastructure, where does a sovereign intelligence layer sit in that stack five years from now?
Ahmed Rashad: “Five years from now, I think it looks like what the financial audit function looks like today, a non-negotiable layer of verification that sits between data and deployment, with regulatory backing and professional standards attached to it.
Right now, AI development operates without anything equivalent to financial auditing. Companies self-report on their training data. There’s no independent verification, no professional credentialing of the process, no third-party attestation that the intelligence behind a model meets a defined standard. We’re in the early equivalent of pre-Sarbanes-Oxley finance, operating largely on trust and self-certification.
As AI becomes critical infrastructure, running power grids, healthcare systems, financial markets, defense networks, that model becomes untenable. Governments will mandate auditability. Procurement processes will require verified data provenance as a condition of contract. Liability frameworks will attach consequences to failures that could have been prevented by proper verification.
Where Perle sits in that stack is as the verification and credentialing layer, the entity that can produce an immutable, auditable record of what a model was trained on, by whom, under what standards. That’s not a feature of AI development five years from now. It’s a prerequisite.
The broader point is that sovereign intelligence isn’t a niche concern for defense contractors. It’s the foundation that makes AI deployable in any context where failure has real consequences. And as AI expands into more of those contexts, the foundation becomes the most valuable part of the stack.”

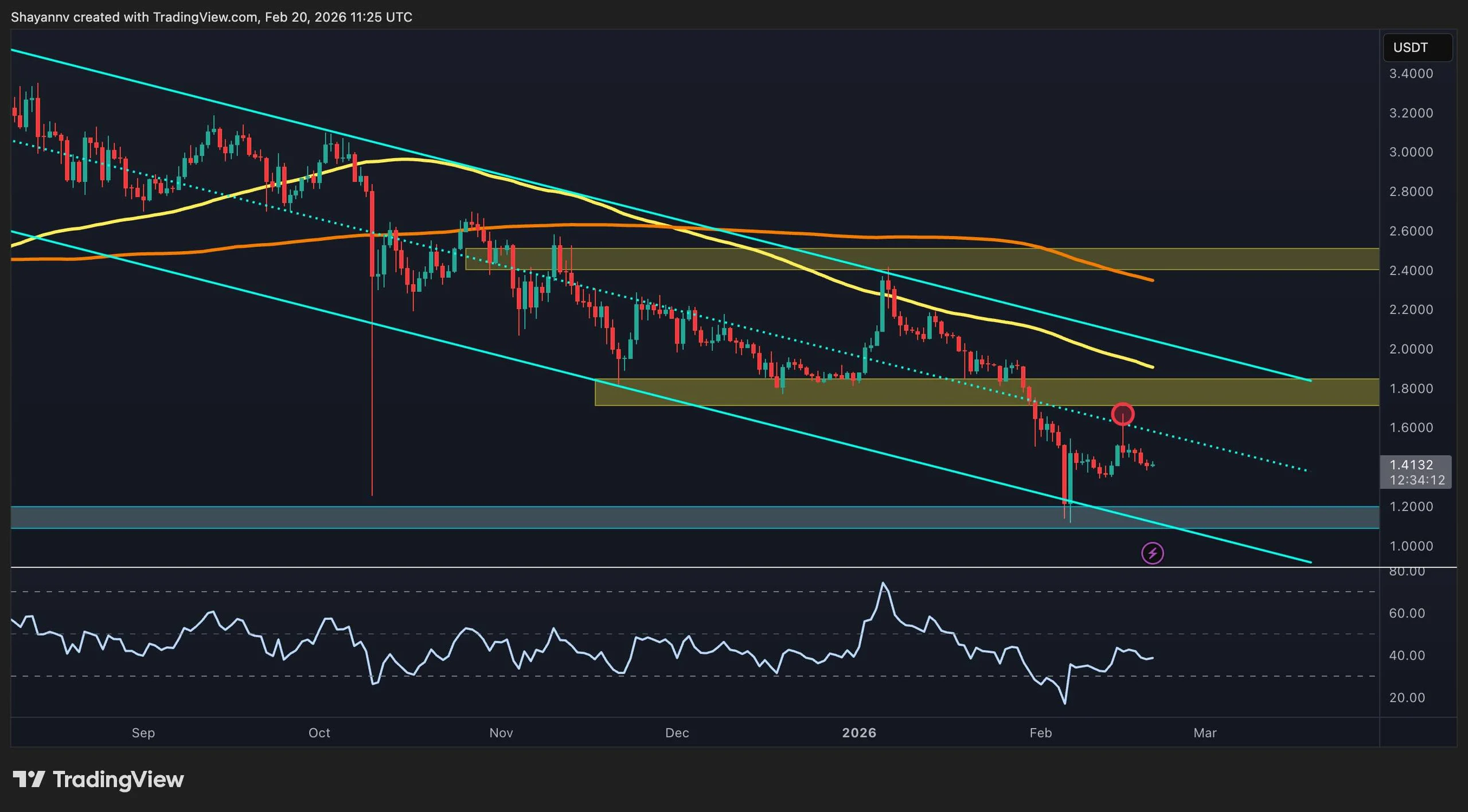
XRP remains under sustained bearish pressure across both its USDT and BTC pairs, with the price structure continuing to print lower highs and lower lows. Despite short-term bounces from support levels, the broader trend favors sellers as the price trades below key moving averages and within a descending structure.
Ripple Price Analysis: The USDT Pair
On the XRP/USDT chart, the price is trading inside a well-defined descending channel, consistently rejecting dynamic resistance from the midline of the channel, the upper trendline, and the 100-day and 200-day moving averages. The recent bounce from the $1.20 demand zone failed to reclaim the $1.80 supply area, reinforcing the bearish structure and confirming that rallies are still corrective in nature.
The RSI also remains below the neutral 50 level and continues to trend weakly, signaling a lack of bullish momentum. As long as XRP stays below the mid-channel resistance and the 100-day and 200-day moving averages, located near $1.90 and $2.30 levels, respectively, the downside risk toward the lower channel boundary remains elevated, with the $1.20 zone acting as critical structural support.
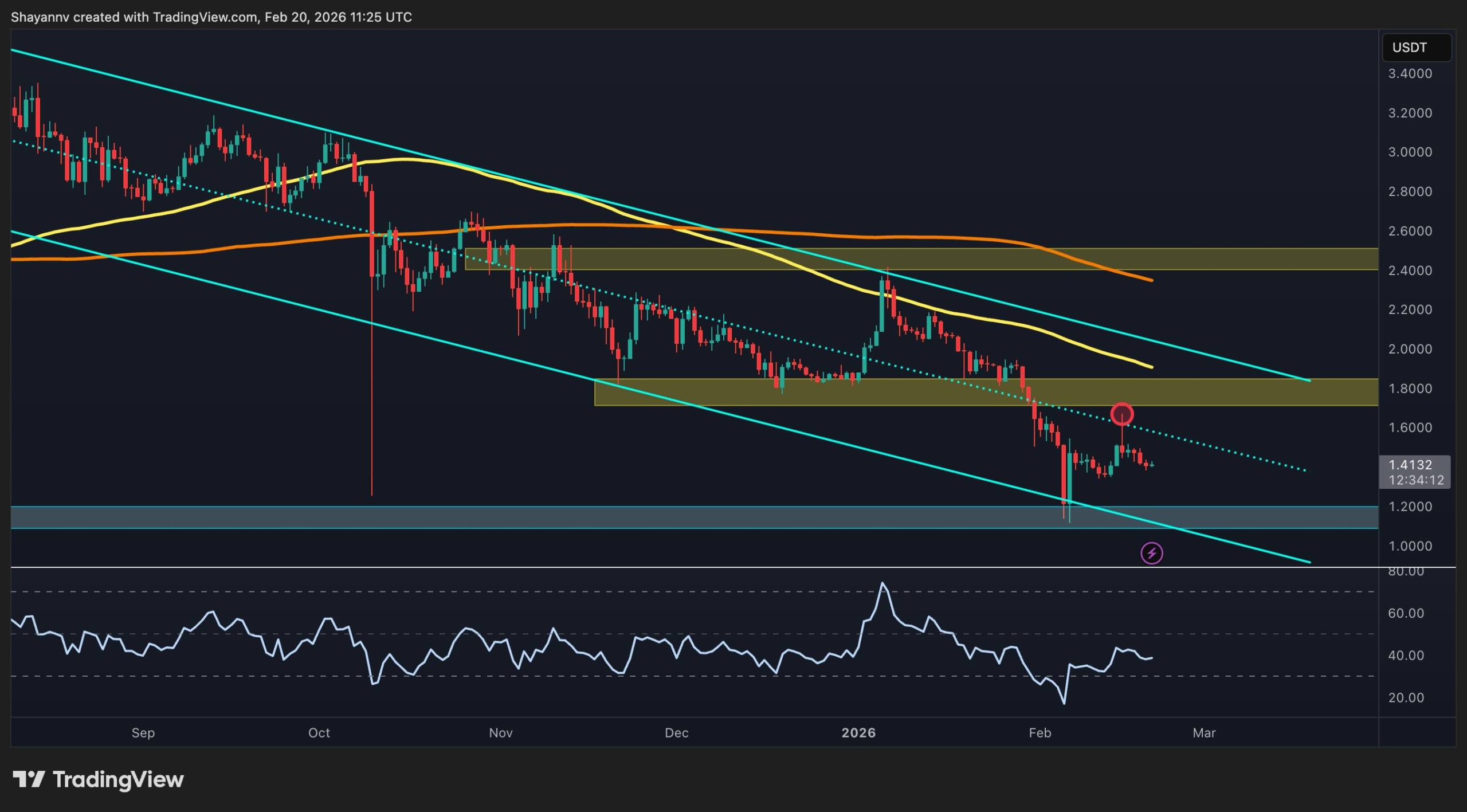
The BTC Pair
Against Bitcoin, XRP is also showing relative weakness, trading below both the 100-day and 200-day moving averages, which are both located above the 2,200 sats area, after failing to hold prior breakout gains. The rejection from the 2,200-2,400 sats resistance zone confirms that sellers are defending higher levels, while the price compresses near a key horizontal support band at 2,000 sats.
Momentum on the XRP/BTC pair is neutral-to-bearish, with the RSI struggling to establish sustained strength above 50. A breakdown below the current support region could open the door for further relative underperformance, while reclaiming the moving average cluster would be the first signal that XRP is beginning to regain strength versus BTC.

SECRET PARTNERSHIP BONUS for CryptoPotato readers: Use this link to register and unlock $1,500 in exclusive BingX Exchange rewards (limited time offer).
Disclaimer: Information found on CryptoPotato is those of writers quoted. It does not represent the opinions of CryptoPotato on whether to buy, sell, or hold any investments. You are advised to conduct your own research before making any investment decisions. Use provided information at your own risk. See Disclaimer for more information.

The United States Supreme Court ruled on Friday that President Donald Trump could not use national emergency powers to levy tariffs during peacetime.
US President Donald Trump announced a 10% global tariff on Friday following the Supreme Court’s ruling striking down his authority to levy tariffs under the International Emergency Economic Powers Act (IEEPA).
Trump was critical of the Supreme Court’s decision, calling the decision “ridiculous” at Friday’s press conference, and said that he will levy the tariffs under different legal methods, including the Trade Expansion Act of 1962 and the Trade Act of 1974. Trump said:
“Effective immediately. All national security tariffs under Section 232 and Section 301 tariffs remain fully in place. And in full force and effect. Today, I will sign an order to impose a 10% Global tariff under Section 122 over and above our normal tariffs already being charged.”

Trump’s tariffs have repeatedly caused severe downturns in markets considered high risk, including crypto and equities, as the threat of tariffs fuels uncertainty and shakes investor confidence.
Related: Bitcoin ignores US Supreme Court Trump tariff strike amid talk of $150B refund
The Supreme Court strikes down Trump’s authority to levy tariffs under emergency powers
Trump levied a 25% tariff on most goods coming in from Canada and Mexico, and a 10% tariff on goods coming in from China under the IEEPA, framing both tariffs as a response to national security threats.
An influx of drugs from foreign countries created a “public health crisis,” according to Trump, while trade deficits with China threatened the industrial manufacturing base in the US, he alleged.

However, the Supreme Court rejected both premises as national security threats under the IEEPA and said that the Executive Branch does not have the authority to levy tariffs under the IEEPA during peacetime.
“In IEEPA’s half-century of existence, no president has invoked the statute to impose any tariffs, let alone tariffs of this magnitude and scope,” the ruling said.
“Article I, Section 8, of the Constitution specifies that ‘The Congress shall have Power To lay and collect Taxes, Duties, Imposts and Excises.’ The Framers recognized the unique importance of this taxing power,” the Supreme Court ruled on Friday.
Magazine: Is China hoarding gold so yuan becomes global reserve instead of USD?
Data from more than 120 token launches shows that early sell pressure, not market timing, largely determined whether new tokens thrived in 2025.
New tokens struggled to find a floor in 2025, with early trading dynamics often setting a trajectory that proved hard to reverse as the year wore on, data shows.
An 80-page analysis by Arrakis Finance found that about 85% of tokens launched last year finished below their initial price, after reviewing 125 token generation events (TGE) and surveying more than 25 founding teams.

The data also shows that nearly two-thirds of tokens were already down within the first seven days, and only 9.4% of tokens that declined in the first week after TGE ever recovered to their launch price at any point later in the year. In most cases, early drawdowns deepened rather than reversed.

Airdrops were one of the strongest sources of immediate selling. Across multiple launches, Arrakis observed that up to 80% of airdrop recipients sold their positions on the very first day of TGE, creating concentrated sell pressure.
“The baseline assumption should be that most of an airdrop will be sold; recipients have zero cost basis and expect prices to decline, making immediate selling rational,” the report states.
Market-making structures also mattered. Arrakis says liquidity was often mispriced, prompting traders to take quick exits.
“Liquidity depth is your buyer against sell pressure. Depth needs to absorb selling from airdrops, exchange allocations, and market maker loans without catastrophic price impact,” the report notes.
Arrakis concludes that token outcomes in 2025 were largely decided by launch mechanics rather than market cycles. Early supply shocks, not macro conditions, determined whether tokens stabilized or slid, and once early confidence was lost, recovery was statistically rare.
That finding broadly aligns with separate research from Dragonfly Capital, which recently found little difference in long-term performance between tokens launched in bull versus bear markets.
As Dragonfly Capital managing partner Haseeb Qureshi explained, regardless of the timing, most tokens don’t perform well over time. Bull market launches recorded a median annualized return of about 1.3%, while bear-market launches came in at -1.3%.

The Supreme Court of the United States (SCOTUS) issued a ruling on Friday striking down most of US President Donald Trump’s tariffs, with six of the nine Supreme Court justices ruling that the Executive Branch lacks authority to levy tariffs under the International Emergency Economic Powers Act (IEEPA).
“IEEPA does not authorize the President to impose tariffs,” Friday’s ruling said, adding that the president has “no inherent authority” to impose tariffs during peacetime using the statutes in the IEEPA. The ruling read:
“In IEEPA’s half-century of existence, no president has invoked the statute to impose any tariffs, let alone tariffs of this magnitude and scope. That ‘lack of historical precedent,’ coupled with the breadth of authority that the President now claims, suggests that the tariffs extend beyond the President’s ‘legitimate reach.’”
Trump claimed that the purported inflow of drugs from Canada, China and Mexico, as well as the “hollowing out” of the US industrial base, constituted a national emergency under IEEPA that justified the tariffs, which the court rejected.
Trump criticizes court, says he’ll get tariffs reinstated
In a press briefing following the decision, Trump lashed out at the justices who voted to strike down the tariffs and vowed to get them reinstated, Politico reported.
“The Supreme Court’s ruling on tariffs is deeply disappointing, and I’m ashamed of certain members of the court, absolutely ashamed, for not having the courage to do what’s right for our country,” Politico cited him as saying.
He said he would reinstate the tariffs by using “other alternatives.”
Trump’s tariffs sent shockwaves through asset markets in 2025, causing severe downturns in crypto and equities when a new round of tariffs was announced or even threatened, fueling macroeconomic uncertainty.
Related: US stocks, crypto rise after Trump pauses planned European tariffs
Trump claims tariffs could replace income tax, but crypto markets are paying the price
In October 2024, while on the campaign trail, Trump floated the idea of replacing the federal income tax with revenue generated from tariffs. Trump said the tariffs would dramatically lower the US budget deficit.
Federal taxes would be “substantially reduced” for individuals and households making less than $200,000 per year once tariff revenue started rolling in, Trump said in April 2025.
Trump announced 100% tariffs on China on Oct. 10, 2025. Within minutes, crypto markets plummeted, and the price of Bitcoin (BTC) dropped from a high of about $122,000 to about $107,000 the same day the tariffs were announced.

Analysts cited several reasons for the crash, including excessive leverage. However, traders overwhelmingly saw the 100% China tariffs as the catalyst for the crypto crash, according to market sentiment platform Santiment.
Crypto prices have yet to recover from October’s crash, and BTC remains nearly 50% below its all-time high of over $125,000 reached on October 6, despite Trump walking back his tariff policies.
Magazine: Bitcoiners are ‘all in’ on Trump since Bitcoin ’24, but it’s getting risky


Metaplanet denied claims of hidden activity, and maintained that all Bitcoin purchases, wallet addresses, and capital deployment decisions were publicly disclosed in real time.
Metaplanet’s CEO Simon Gerovich said claims that the firm’s disclosures are insincere are “inflammatory and contrary to the facts.” He added that over the past six months, as volatility increased, the Japanese public company allocated more capital to its income business and sold put options and put spreads, which are actively managed as option positions.
The response follows accusations circulating online questioning Metaplanet’s disclosure practices and use of shareholder funds. The claims state that Bitcoin purchases were not disclosed promptly, including a large purchase made near the September price peak using proceeds from an overseas public offering, followed by a period without updates.
Gerovich’s Defense
In his latest post on X, Gerovich said part of these funds was used to purchase Bitcoin for long-term holding, and that these purchases were disclosed at the time they were made. The exec added that all BTC addresses are publicly available and can be viewed through a live dashboard, which allows shareholders to check holdings in real time. He went on to assert that Metaplanet is one of the most transparent listed companies in the world.
Metaplanet made four purchases during September and announced all of them promptly. While the month was a local peak, Gerovich stated that the company’s strategy is not about timing the market, maintaining that the focus is to accumulate Bitcoin long-term and systematically, and that every purchase is disclosed regardless of price.
On options trading, Gerovich noted the criticism stemmed from a misunderstanding of the financial statements. He said selling put options is not a bet on BTC’s price rising, but a way to acquire Bitcoin at a cost lower than the spot price through premium income. He explained that this strategy reduced effective acquisition costs in the fourth quarter. He revealed that Bitcoin per share, the company’s primary key performance indicator, increased by more than 500% in 2025.
Financial Statements And Borrowings
On financial results, Gerovich clarified that net profit is not an appropriate metric for evaluating a Bitcoin treasury company. He pointed to the operating profit of 6.2 billion yen, which indicates a growth of 1,694% year over year. According to the exec, the ordinary loss comes solely from unrealized valuation changes on long-term Bitcoin holdings that the company does not intend to sell.
Three disclosures related to borrowings were made – when the credit facility was established in October, and when funds were drawn down in November and December. Borrowing amounts, collateral details, interest rate structures, purposes, and terms were disclosed. The identity of the lender and specific interest rate levels were not disclosed at the counterparty’s request, despite the terms being favorable to Metaplanet.
You may also like:
SECRET PARTNERSHIP BONUS for CryptoPotato readers: Use this link to register and unlock $1,500 in exclusive BingX Exchange rewards (limited time offer).


Washington erupted in political crossfire Friday after the Supreme Court of the United States struck down President Donald Trump’s sweeping global tariffs.
The ruling triggered sharp partisan reactions and exposed a widening divide over trade, executive power, and the country’s economic future.
Partisan Firestorm Erupts as Lawmakers Clash Over Trade, Power, and $150 Billion in Tariffs
In a 6–3 decision, the Court ruled that Trump exceeded his authority under the International Emergency Economic Powers Act (IEEPA) when he imposed broad “reciprocal” tariffs in 2025 without clear authorization from Congress.
The ruling invalidates most of those global duties, marking a major setback for a signature pillar of Trump’s second-term economic agenda.
Just like how stock and crypto markets reacted, the political reaction was immediate — and explosive.
Democrats Declare Victory
Senate Democratic Leader Chuck Schumer framed the ruling as a consumer win.
“This is a win for the wallets of every American consumer. Trump’s chaotic and illegal tariff tax made life more expensive and our economy more unstable.”
He added:
“Trump’s illegal tariff tax just collapsed — He tried to govern by decree and stuck families with the bill. Enough chaos. End the trade war.”
Similarly, Senator Elizabeth Warren emphasized the financial toll on households and small businesses.
“No Supreme Court decision can undo the massive damage that Trump’s chaotic tariffs have caused. The American people paid for these tariffs, and the American people should get their money back,” she stated.
In a broader statement, Warren argued that any refunds stemming from the ruling “should end up in the pockets of the millions of Americans and small businesses that were illegally cheated out of their hard-earned money.”
House Budget Committee Ranking Member Brendan Boyle echoed the sentiment:
“This ruling is a victory for every American family paying higher prices because of Trump’s tariff taxes. The Supreme Court rejected Trump’s attempt to impose what amounted to a national sales tax on hardworking Americans.”
Republicans Split Over Executive Power
Republican reaction, however, revealed a party divided between constitutional purists and economic nationalists.
Senator Rand Paul praised the decision as a safeguard against executive overreach.
“In defense of our Republic, the Supreme Court struck down using emergency powers to enact taxes. This ruling will also prevent a future President such as AOC from using emergency powers to enact socialism,” he said.
But Senator Bernie Moreno sharply condemned the Court’s move:
“SCOTUS’s outrageous ruling handcuffs our fight against unfair trade that has devastated American workers for decades. These tariffs protected jobs, revived manufacturing, and forced cheaters like China to pay up,” he noted.
Moreno warned that “globalists win” under the ruling and called for Republicans to codify the tariffs through reconciliation legislation.
Trump Fires Back
Trump himself reportedly responded with a single word during a White House breakfast with governors:
“Disgrace.”
The US President also signaled that his administration has a “backup plan,” hinting at possible efforts to reimpose tariffs through alternative legal authorities such as Section 301 or Section 232.
A Constitutional and Economic Flashpoint
Beyond the immediate political theater, the decision represents a rare rebuke of executive trade authority from a conservative-majority Court.
The ruling reinforces Congress’s constitutional control over taxation and trade regulation, limiting the scope of emergency economic powers under IEEPA.
At the same time, it raises practical questions about potentially billions in tariff refunds and whether lawmakers will attempt to restore elements of Trump’s trade policy through new legislation.
What began as a legal battle over tariffs has evolved into a broader confrontation over presidential power, economic nationalism, and who ultimately controls America’s trade agenda.
“The Supreme Court got it right. But they also did Trump a huge favor, as his tariffs are harming the U.S. economy and are paid by Americans. But since the tariff revenue will now stop and past revenue must be returned, the already rising U.S. budget deficit will soar. Got gold?” Peter Schiff quipped.
The fight is far from over.
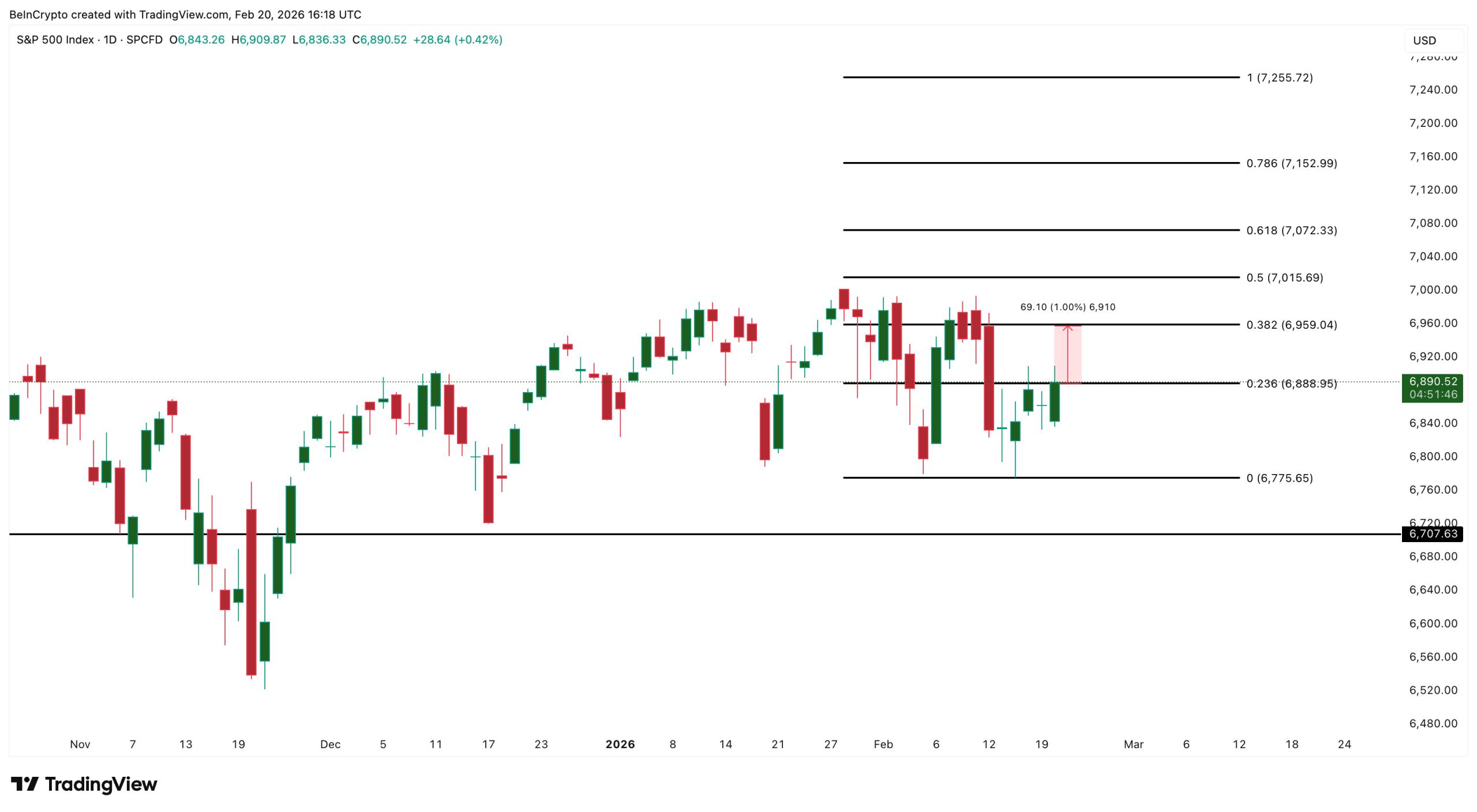
The US stock market recovered sharply on February 20, after the Supreme Court struck down President Trump’s tariffs in a landmark 6-3 ruling. The S&P 500 is trading around 6,890 at press time, up 0.45% from yesterday’s close, at the time of writing.
Tech (XLK) leads the rebound on tariff relief while Energy (XLE) gives back early gains despite rising oil prices. Alphabet (GOOGL) stands out, almost independently, with a 3.8% surge as it attempts to break free from a bearish pattern.
Top US Stock Market News:
Wall Street Recovers From Stagflation Scare As Tariff Ruling Sparks Relief Bounce
Wall Street faced one of its most dramatic intraday reversals on February 20, 2026. The morning opened with panic as the “data deluge” delivered a stagflation-like combination.
Advance Q4 GDP slowed sharply to 1.4% (well below the 2.8% consensus), while Core PCE accelerated to 3.0% YoY, its hottest reading since mid-2025. S&P 500 futures dropped immediately after the 8:30 AM ET release.
But the mood flipped mid-session when the Supreme Court struck down President Trump’s sweeping emergency tariffs in a landmark 6-3 ruling. Markets interpreted the decision as a major deflationary catalyst going forward.
The S&P 500 is trading at approximately 6,890 at press time, up 0.45% from yesterday’s close. Moreover, the index is now flirting with a strong zone near 6,888.
A sustained move above this level opens the path toward 6,959, and clearing that could prime the index for the psychological 7,000 milestone.
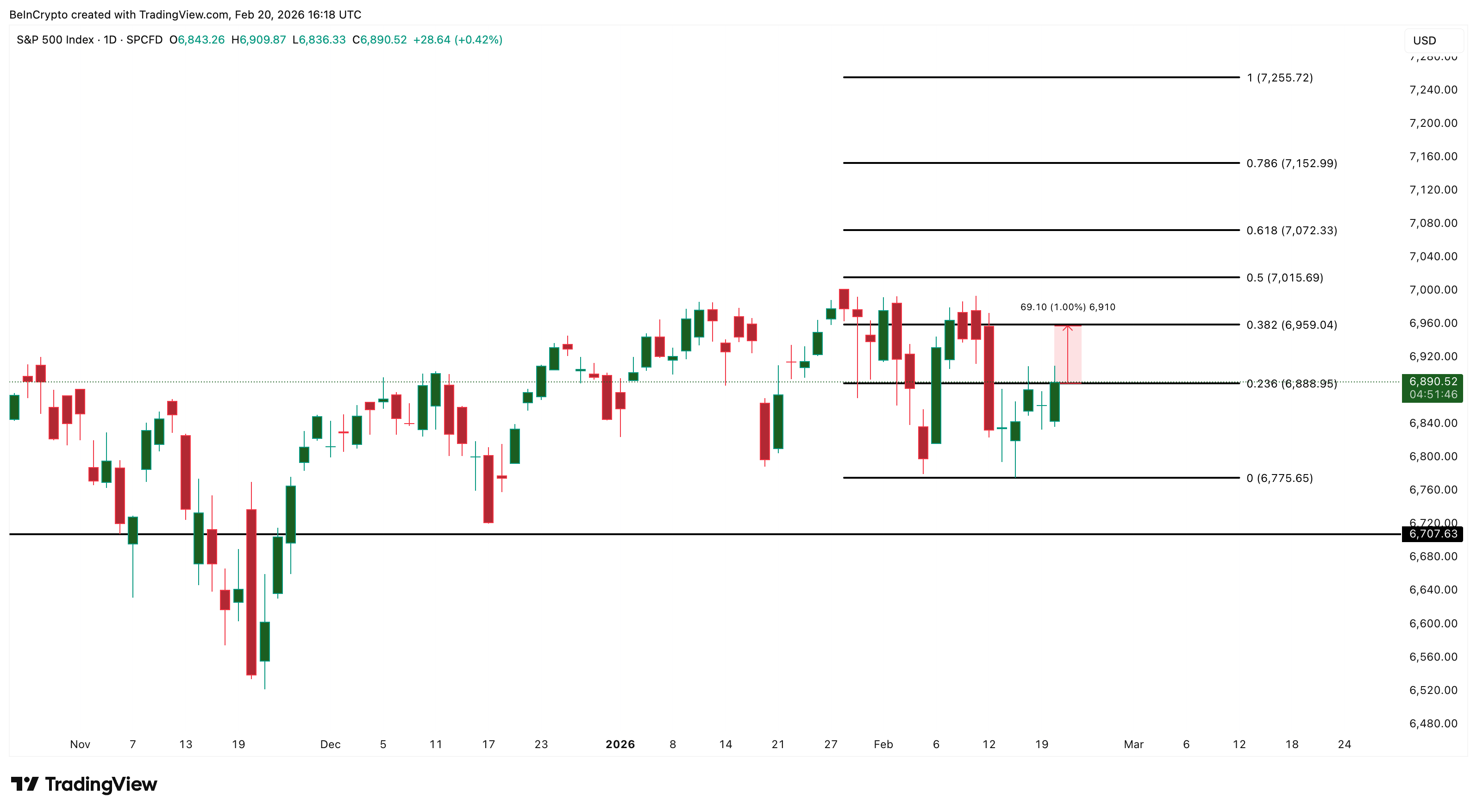
On the downside, 6,775 is the key support to watch. A break below that level would invite weakness toward 6,707.
However, upside conviction is not without risk. Experts are already flagging that the tariff ruling may not be the final word — the administration could pursue alternative tariff mechanisms, which could weigh on sentiment as the session progresses.
A move to key resistance still requires roughly a 1% push from current levels.
The Nasdaq leads the recovery, up 172 points (0.76%), and the DOW is up 68 points, at the time of writing.

The CBOE Volatility Index (VIX) dropped sharply, falling approximately 5%. The move below 20 signals that the initial stagflation panic has eased and the market is shifting back toward a cautiously optimistic posture.
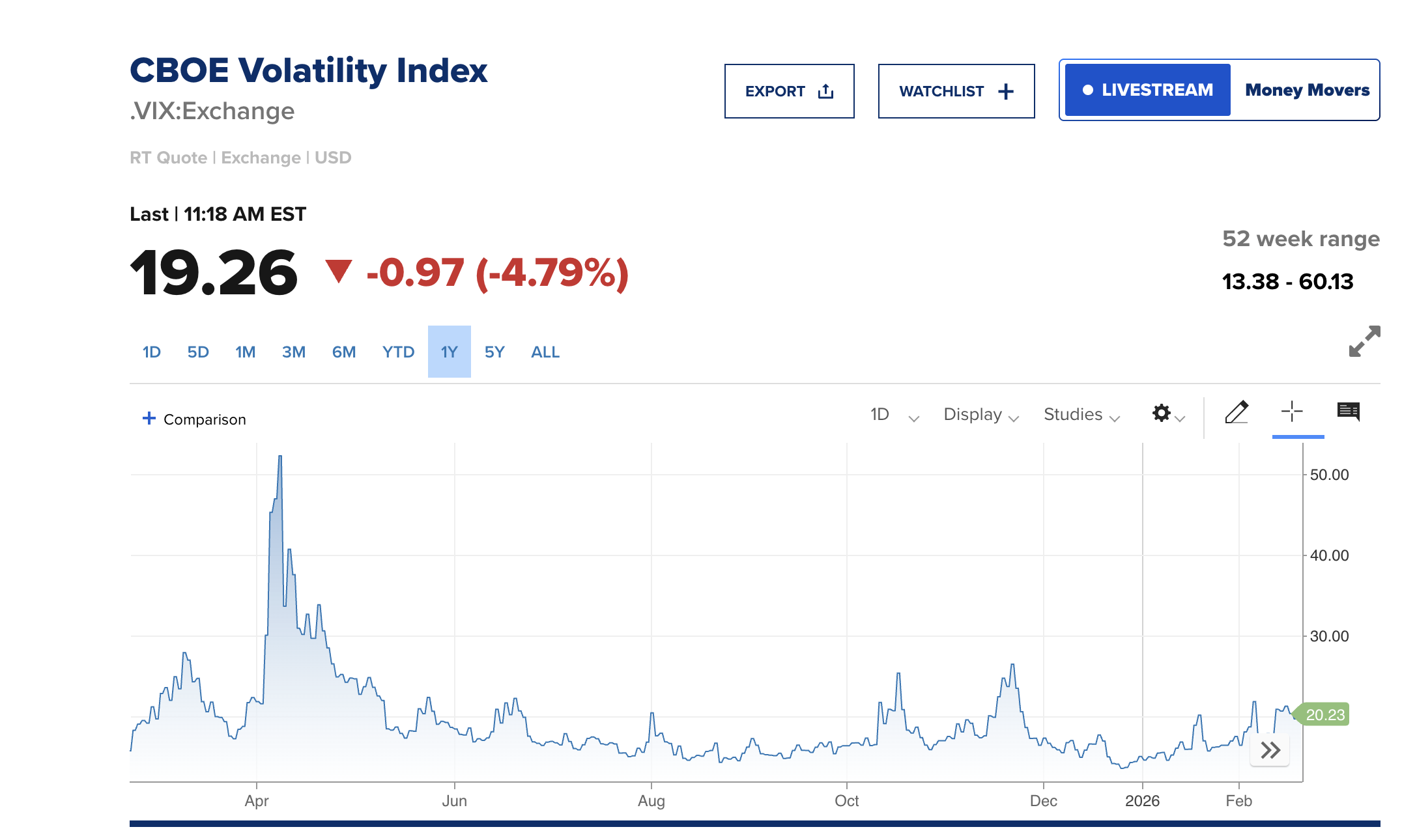
The tug-of-war is clear: stagflation data pulling markets down, tariff relief pulling them up. Onto the sectors now.
Tech Rallies While Energy Dips, But Builds Bullish Case
The sector story on February 20, 2026, takes an unexpected turn. The surface numbers tell one story, but the charts tell another.
Technology (XLK) is up 0.36% at $140.72, benefiting from the Supreme Court’s tariff strike-down as lower import costs directly support hardware and semiconductor supply chains.
However, the rally faces a ceiling. XLK attempted to cross above the $141.29 resistance, but sellers stepped in. A daily close above this level is needed to open the path toward $144.78 and eventually the $149–$150 zone.
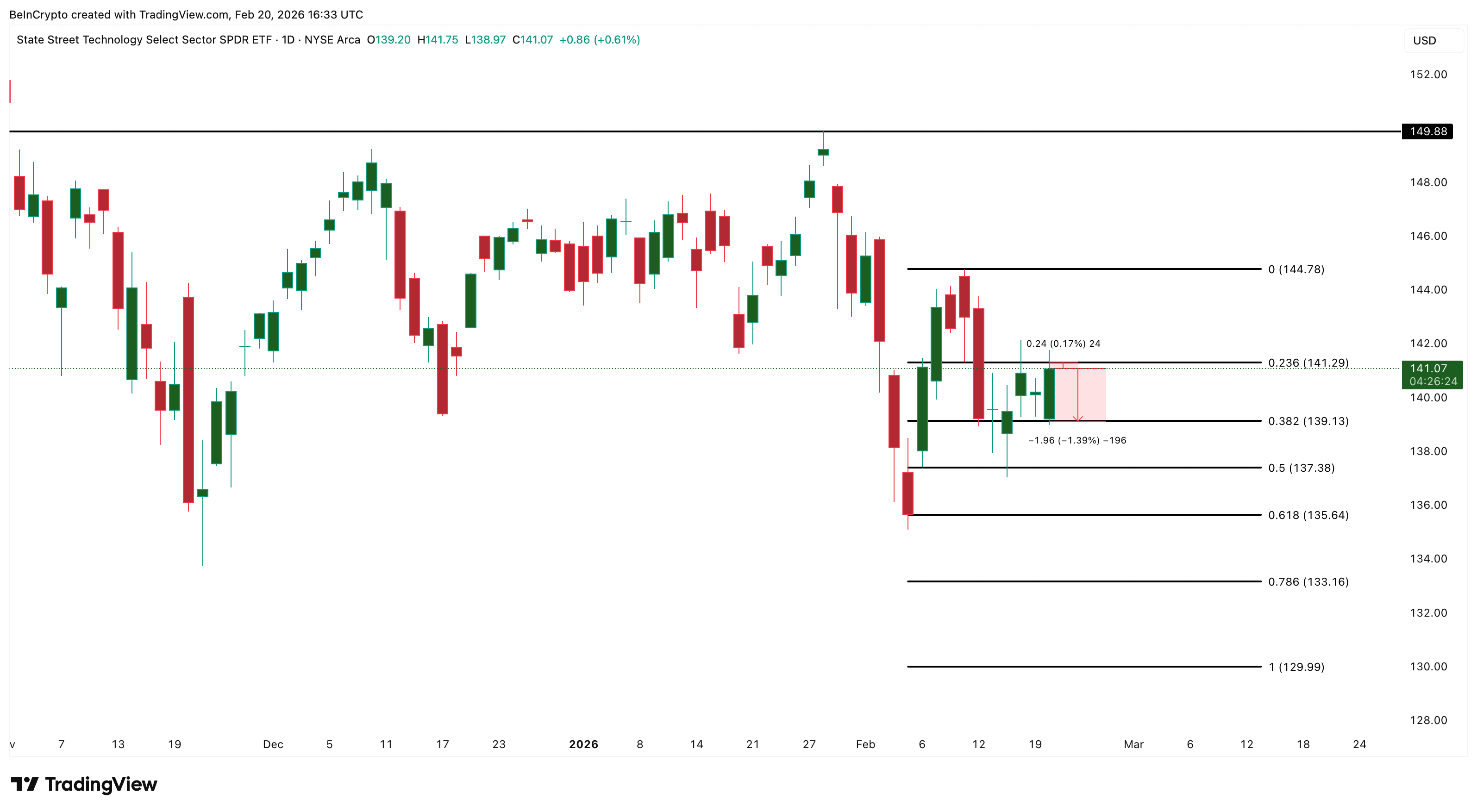
A failure to hold above $139 would flip the short-term structure bearish. The tariff relief provides the US stock market catalyst, but with Core PCE at 3.0%, reinforcing higher-for-longer rates, tech valuations remain under pressure.
Energy (XLE) tells the opposite story. The sector looked strong as US-Iran tensions pushed oil higher: WTI held above $66 and Brent above $71. But gains faded through the session, with XLE now down 1.09% since yesterday.
Yet the XLE chart tells a more constructive story underneath the red. The ETF appears to be consolidating inside a bullish flag. If the breakout confirms above $55.90, it could target $60.29 — roughly a 10% move.
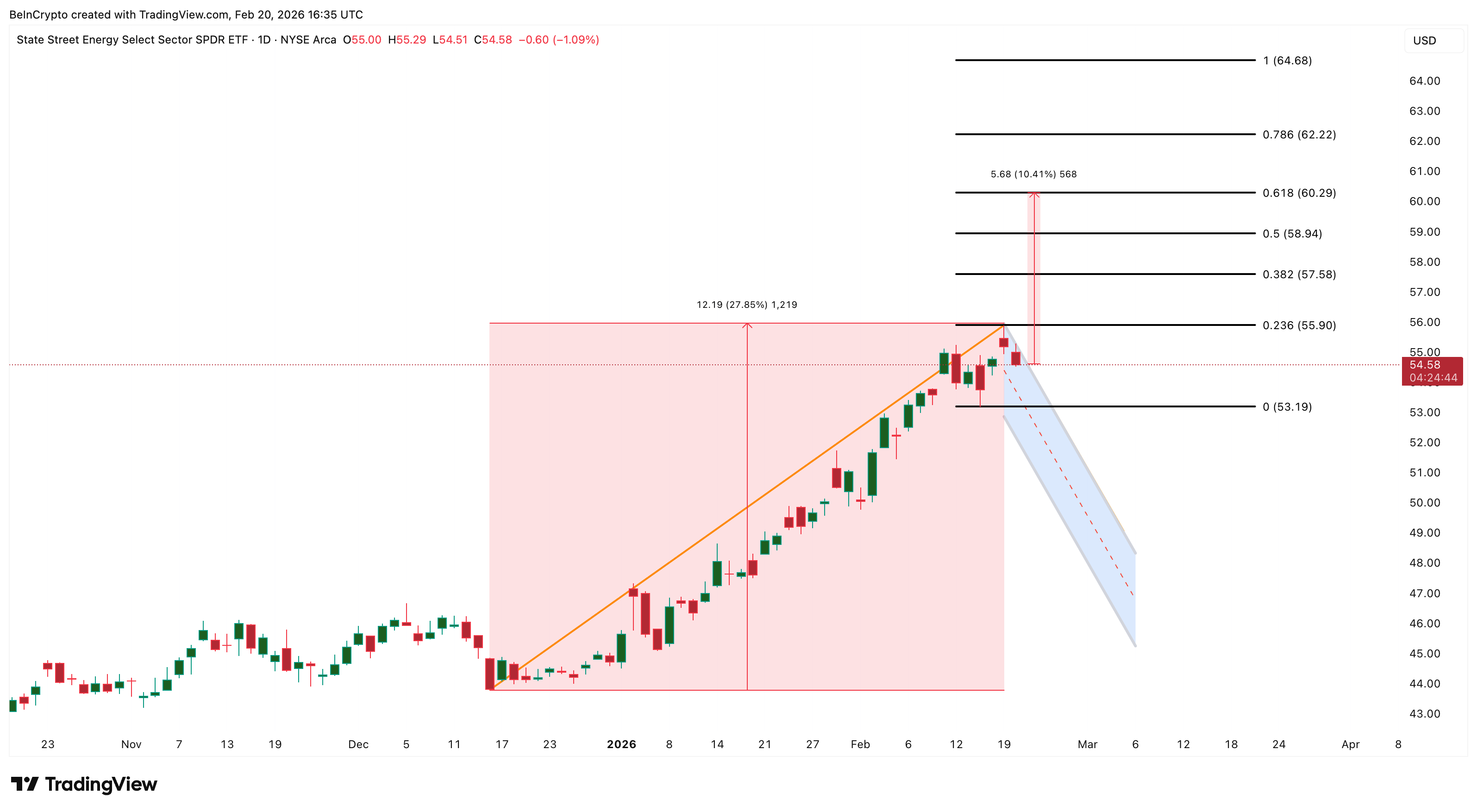
The full measured move from the previous leg projects a potential 27% rally. A drop below $53.19 would invalidate the setup.
Alphabet (GOOGL) Surges As Bears Lose Grip
Alphabet (GOOGL) is the standout US stock market mover on February 20, 2026, surging approximately 3.8% to trade around $316. The stock has shown sustained buying momentum with no significant upper wick, yet, a sign that sellers have not stepped in to cap the bounce.
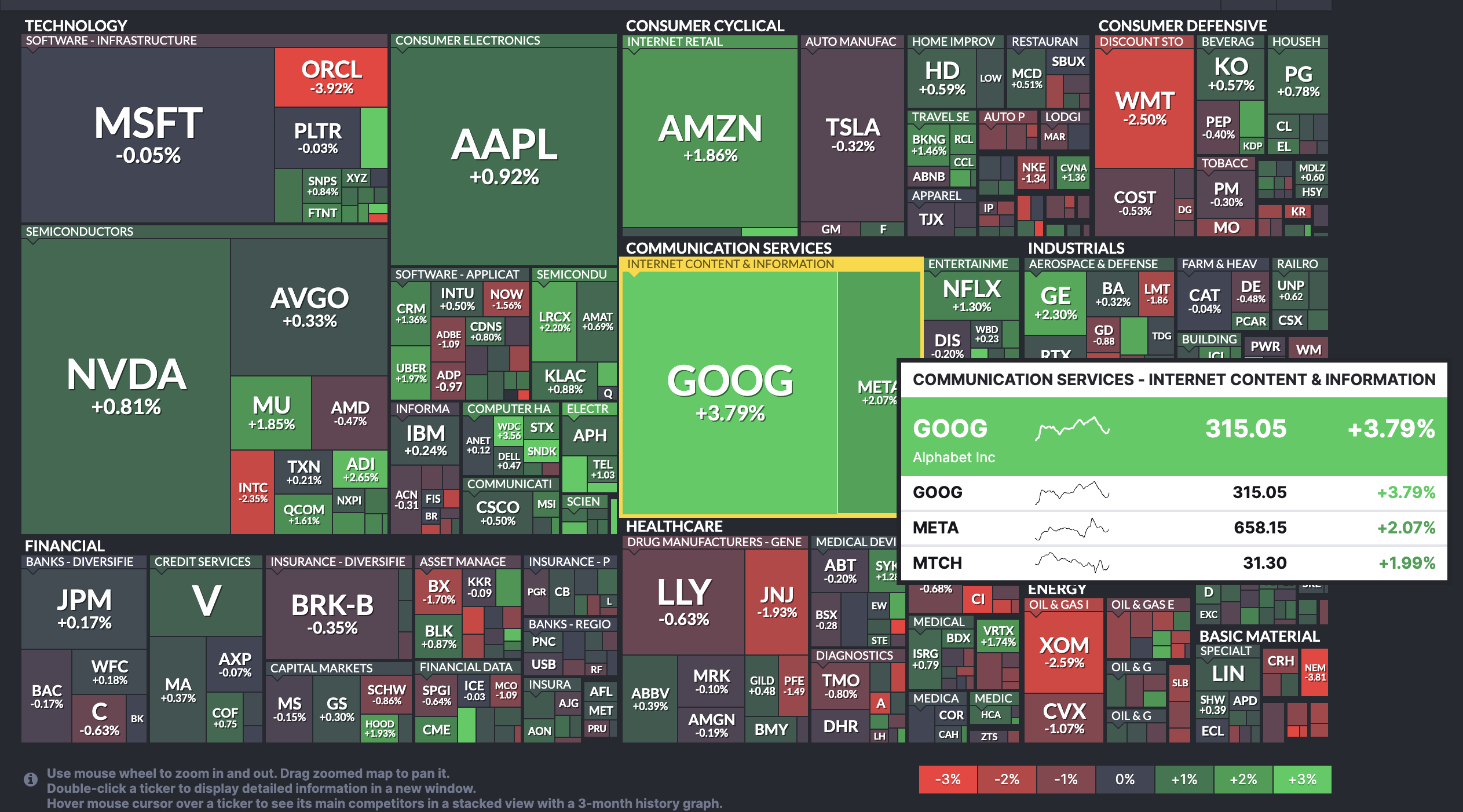
The move is notable because Alphabet had been trapped inside a bearish flag pattern after pulling back from its early February highs. Today’s surge is attempting to break down that bearish structure, reversing off the $296–$300 support zone and pushing toward pattern invalidation.
However, Alphabet is not out of the woods yet. A sustained move above $327 — extending to $330 — is needed to fully invalidate the bearish setup and confirm a larger bullish reversal. Until those levels are cleared, the risk of a failed breakout remains real.
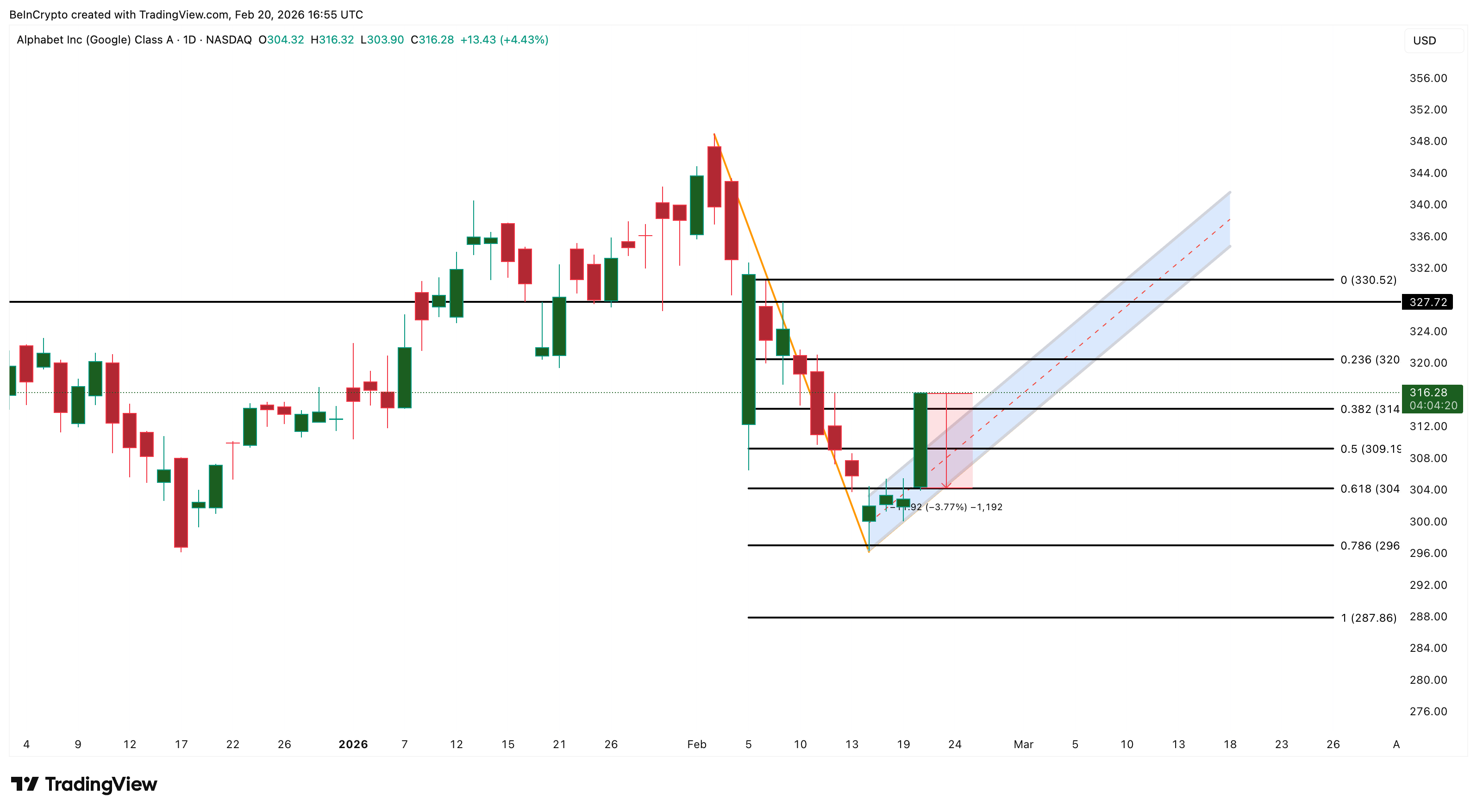
On the downside, a drop back below $304 would weaken the breakout attempt and reintroduce bearish pressure. Further weakness under $296 could accelerate selling, potentially re-testing lower supports and resuming the bearish flag pattern — erasing today’s entire gain.
Within Communication Services, Alphabet is leading while Meta also posts gains, as over 51% of stocks are in the green.

While other sectors stabilize with muted moves, Alphabet’s sizable independent rally signals that dip-buyers are aggressively positioning in AI-linked growth names.
Large institutional investors continued to add exposure to crypto treasury companies over the past week, even as bear-market illiquidity forced another round of shakeouts across decentralized finance (DeFi).
The biggest corporate shareholders of Bitmine Immersion Technologies, including Morgan Stanley and Bank of America, increased exposure to the Ether (ETH) treasury company during Q4 2025 despite a broader market sell-off.
Still, ongoing bear-market illiquidity is forcing some protocols to wind down operations, with DeFi lender ZeroLend shutting down. Crypto analytics platform Parsec has also shuttered, citing crypto market volatility as the main reason.
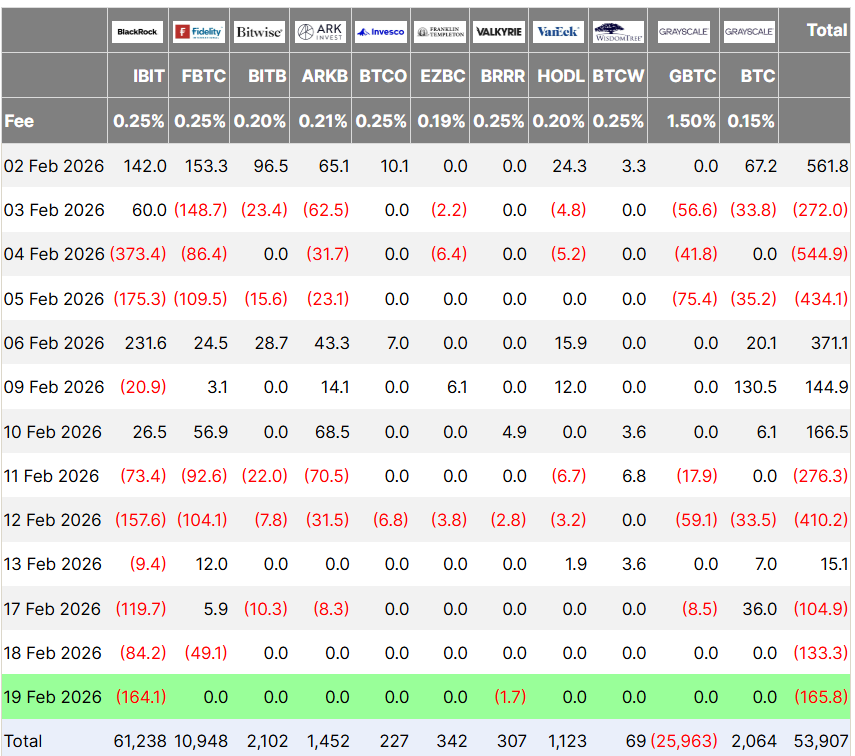
Meanwhile, Bitcoin (BTC) and ETH each rose about 2.6% during the past week, amid mounting outflows from US spot Bitcoin exchange-traded funds (ETFs), which logged three consecutive days of selling leading up to Thursday’s $165 million outflow, Farside Investors data shows.
Ether ETFs started the week with $48 million in inflows on Tuesday, but reversed to log two successive days of outflows, including $41 million in outflows on Wednesday and $130 million on Thursday.

Morgan Stanley, other top holders add Bitmine exposure amid sell-off
The largest shareholders of Bitmine Immersion Technologies (BMNR) stock increased their investments in the leading Ethereum treasury company in the fourth quarter of 2025 despite a wider crypto market crash and poor stock price performance.
Morgan Stanley, the top reported holder, increased its position by about 26% to more than 12.1 million shares, valued at $331 million at the quarter’s end, according to its Form 13F filing with the US Securities and Exchange Commission. ARK Investment Management, the second-biggest holder, increased its stake by about 27% to more than 9.4 million shares worth $256 million, its filing shows.

Several other top institutional holders also increased exposure. BlackRock increased its BMNR holdings by 166%, Goldman Sachs by 588%, Vanguard by 66% and Bank of America by 1,668%.
Wall Street adds BMNR exposure despite 48% stock slide
Each of the top 11 largest shareholders increased exposure to BMNR during Q4 of 2025, including Charles Schwab, Van Eck, Royal Bank of Canada, Citigroup and the Bank of New York Mellon Corporation, according to official filings compiled by crypto investor Collin.

The accumulation came despite a sharp drop in Bitmine’s share price. BMNR fell about 48% in the fourth quarter of 2025 and about 60% over the past six months, trading near $19.90 in premarket action Thursday, according to Google Finance.
DeFi lender ZeroLend shuts down, blames illiquid chains
Decentralized lending protocol ZeroLend said it is shutting down completely after the blockchains it operates on suffered from low user numbers and liquidity.
“After three years of building and operating the protocol, we have made the difficult decision to wind down operations,” ZeroLend’s founder, known only as “Ryker,” said in a post the protocol shared to X on Monday.
“Despite the team’s continued efforts, it has become clear that the protocol is no longer sustainable in its current form,” he added.
ZeroLend focused its services on Ethereum layer-2 blockchains, once touted by Ethereum co-founder Vitalik Buterin as a central part of the network’s plan to scale and remain competitive.
However, Buterin said earlier this month that his vision for scaling with layer 2s “no longer makes sense,” that many have failed to properly adopt Ethereum’s security, and that scaling should increasingly come from the mainnet and native rollups.
DerivaDEX debuts Bermuda-licensed derivatives DEX
DerivaDEX has launched a Bermuda-licensed crypto derivatives platform, becoming what it says is the first DAO-governed decentralized exchange to operate under formal regulatory approval.
According to a statement from the platform, the exchange received a T license from the Bermuda Monetary Authority and has begun offering crypto perpetual swaps trading to a limited number of advanced retail and institutional participants.
The BMA’s T, or test license, is issued for a digital asset business seeking to test a proof of concept.
At launch, DerivaDEX supports major crypto perpetual products and said it plans to expand into additional markets, including prediction markets and traditional securities. The company said the platform combines offchain order matching with onchain settlement to Ethereum, while allowing users to retain non-custodial control of funds.
Parsec shuts down amid ongoing crypto market volatility
Onchain analytics company Parsec is closing down after five years, as crypto trader flows and onchain activity no longer resemble their past configurations.
“Parsec is shutting down,” the company said in an X post on Thursday, while its CEO, Will Sheehan, said the “market zigged while we zagged a few too many times.”
Sheehan added that Parsec’s primary focus on decentralized finance and non-fungible tokens (NFTs) fell out of step with where the industry has now headed.
“Post FTX DeFi spot lending leverage never really came back in the same way, it changed, morphed into something we understood less,” he said, adding that onchain activity changed in a way he never understood.
NFT sales reached about $5.63 billion in 2025, a 37% drawdown from the $8.9 billion recorded in 2024. Average sale prices also declined year-on-year, falling to $96 from $124, according to CryptoSlam data.
Kraken’s xStocks tops $25 billion in volume with more than 80,000 onchain holders
Kraken’s tokenized equities platform, xStocks, has surpassed $25 billion in total transaction volume less than eight months after launch, underscoring accelerating adoption as tokenization gains traction among mainstream investors.
Kraken disclosed Thursday that the $25 billion figure includes trading across centralized exchanges and decentralized exchanges, as well as minting and redemption activity. The milestone represents a 150% increase since November, when xStocks crossed $10 billion in cumulative transaction volume.
The xStocks tokens are issued by Backed Finance, a regulated asset provider that creates 1:1 backed tokenized representations of publicly traded equities and exchange-traded funds. Kraken serves as a primary distribution and trading venue, while Backed is responsible for structuring and issuing the tokenized instruments.
When xStocks debuted in 2025, it offered more than 60 tokenized equities, including shares tied to major US technology companies like Amazon, Meta Platforms, Nvidia and Tesla.

Kraken said onchain activity has been a key growth driver since launch, with xStocks generating $3.5 billion in onchain trading volume and surpassing 80,000 unique onchain holders.
Unlike trading that occurs solely within centralized exchanges’ internal order books, onchain activity takes place directly on public blockchains, where transactions are transparent and wallets can self-custody assets.
Growing onchain participation suggests users are not only trading tokenized equities but also integrating them into broader decentralized finance (DeFi) ecosystems.
Kraken said that eight of the 11 largest tokenized equities by unique holder count are now part of the xStocks ecosystem, signaling increased market share in the emerging tokenized equities sector.
DeFi market overview
According to data from Cointelegraph Markets Pro and TradingView, most of the 100 largest cryptocurrencies by market capitalization ended the week in the green.
The layer-1 blockchain Kite (KITE) token rose 38% as the biggest gainer in the top 100, followed by stablecoin payment ecosystem token Stable (STABLE), up over 30% during the past week.

Thanks for reading our summary of this week’s most impactful DeFi developments. Join us next Friday for more stories, insights and education regarding this dynamically advancing space.


Dutch regulators have ordered crypto prediction platform Polymarket to stop operating in the Netherlands, warning it could face fines of up to €840,000 if it fails to comply.
The decision marks the latest escalation in Europe’s widening crackdown on the platform.
Polymarket is Losing the European Market
The Kansspelautoriteit (Ksa), the Dutch gambling authority, issued a formal enforcement order against Polymarket’s operator, Adventure One QSS Inc., on Friday. The regulator said Polymarket was offering illegal gambling services without a Dutch license.
Authorities imposed a penalty of €420,000 per week if Polymarket continues serving Dutch users. The fines could reach a maximum of €840,000, with additional revenue-based penalties possible later.
“In recent months, Polymarket has been in the news frequently, especially around bets on the Dutch elections. After contact with the company about the illegal activities on the Dutch market, no visible change has occurred and the offer is still available. The Gaming Authority therefore now imposes this order under penalty,” the regulator wrote.
The regulator said prediction markets qualify as gambling under Dutch law, regardless of how the platform classifies them. It also stressed that betting on elections is prohibited entirely, even for licensed operators.
Importantly, regulators highlighted Polymarket’s activity around Dutch elections as a key concern. It warned that election betting could create societal risks, including potential influence over democratic processes.
The Netherlands’ decision follows similar action in Portugal, where regulators recently blocked Polymarket nationwide.
Portuguese authorities intervened after the platform saw heavy betting tied to the latest presidential election outcomes.
Meanwhile, several other European countries have taken similar measures. Italy, Belgium, and Romania have blocked access to Polymarket, while France restricted betting functionality.
Hungary also issued a formal ban, citing illegal gambling activity.
Prediction Markets as Financial Infrastructure or Gambling Platform?
These actions reflect a growing consensus among European regulators. Authorities increasingly classify prediction markets as gambling when they operate without licenses.
However, Polymarket’s creator, Shayne Coplan, has consistently rejected that classification. He argues that prediction markets function as financial infrastructure, similar to derivatives markets, rather than gambling platforms.
Coplan maintains that prediction markets help aggregate information and forecast real-world events. Regulators across Europe disagree.
As a result, Europe has become one of the strictest regions globally for prediction market platforms. The Netherlands’ threat of direct financial penalties signals that enforcement is moving beyond access blocks toward sustained legal pressure.
Crypto World
Pakistan Goes Live With Crypto Regulatory Sandbox: Here’s What It Means for Digital Assets

TLDR:
- Pakistan’s PVARA formally launches a live crypto sandbox to test real-world virtual asset use cases under regulatory oversight.
- The sandbox framework targets stablecoins, tokenization, remittances, and on- and off-ramp infrastructure inside a supervised environment.
- PVARA Chairman Bilal bin Saqib joined global crypto and finance leaders at the World Liberty Forum in Mar-a-Lago, Florida.
- Goldman Sachs, Nasdaq, Franklin Templeton, and Coinbase participated in forum talks centered on stablecoins and financial innovation.
Pakistan launches crypto sandbox to test digital assets in a live, supervised environment built for real-world virtual asset use cases.
The Pakistan Virtual Assets Regulatory Authority formally approved the framework, marking a concrete step toward structured digital asset oversight.
The sandbox covers tokenization, stablecoins, remittances, and on- and off-ramp infrastructure. All operations run under direct PVARA supervision.
Sandbox Guidelines and the application process will be published on the PVARA website shortly, giving interested firms a clear path forward.
A Controlled Framework for Real-World Digital Asset Testing
The crypto sandbox gives companies a working environment to test virtual asset solutions within defined regulatory boundaries.
PVARA will monitor live operations and review outcomes before building broader compliance rules around them. This approach allows the authority to gather practical market data without reducing its oversight responsibilities.
Rather than regulating from theory alone, Pakistan is now working from observed, real-world results gathered inside a controlled setting.
The sandbox targets several key segments of the virtual asset market. Tokenization, stablecoins, remittance solutions, and on- and off-ramp infrastructure are all within the program’s scope.
Each use case will be tested against Pakistan’s specific financial and regulatory environment. This targeted structure ensures the framework remains focused and produces results that are directly applicable to domestic market conditions.
Firms that qualify for the sandbox can operate in a live market environment while remaining accountable to the authority.
The full Sandbox Guidelines and application details will be released on the PVARA website in the coming days. Companies working in the virtual asset space should watch the official website closely for submission deadlines and participation requirements.
PVARA Chairman Attends World Liberty Forum as Pakistan Moves Toward Global Alignment
Bilal bin Saqib, Chairman of PVARA, attended the World Liberty Forum at Mar-a-Lago in Florida earlier this week. The event brought together financial executives, crypto innovators, and policymakers from across the global financial sector.
Discussions centered on the future of finance and digital technology’s growing role in reshaping traditional systems.
Saqib shared updates from the forum directly on social media, describing it as a gathering focused on stablecoins, tokenization, and financial innovation.
Representatives from Goldman Sachs, Nasdaq, Franklin Templeton, and Coinbase were among the participants in those discussions. The forum reflected a growing global consensus around structured frameworks for digital asset development.
Pakistan’s decision to launch a crypto sandbox to test digital assets aligns with the direction taken by leading financial institutions worldwide.
The domestic framework now gives Pakistani firms a regulated channel to pursue innovations similar to those discussed at the global forum.
As countries move toward structured virtual asset oversight, Pakistan’s sandbox places it among nations actively shaping the next phase of digital finance regulation.

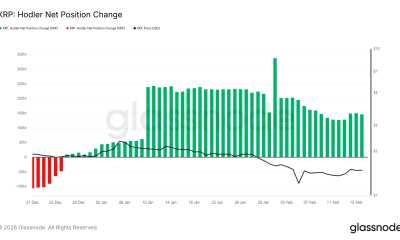
Will XRP Drop Back to $1.20? Key Support Levels Tested Amid Bearish Pressure

Days of our Lives: Stefano’s Final Will Creates Major Problems for EJ?

Trump 'Absolutely Ashamed' Of Supreme Court





-

 Video4 days ago
Video4 days agoBitcoin: We’re Entering The Most Dangerous Phase
-

 Tech6 days ago
Tech6 days agoLuxman Enters Its Second Century with the D-100 SACD Player and L-100 Integrated Amplifier
-
 Crypto World3 days ago
Crypto World3 days agoCan XRP Price Successfully Register a 33% Breakout Past $2?
-

 Sports4 days ago
Sports4 days agoGB's semi-final hopes hang by thread after loss to Switzerland
-

 Video18 hours ago
Video18 hours agoXRP News: XRP Just Entered a New Phase (Almost Nobody Noticed)
-
 Tech4 days ago
Tech4 days agoThe Music Industry Enters Its Less-Is-More Era
-

 Business3 days ago
Business3 days agoInfosys Limited (INFY) Discusses Tech Transitions and the Unique Aspects of the AI Era Transcript
-

 Entertainment2 days ago
Entertainment2 days agoKunal Nayyar’s Secret Acts Of Kindness Sparks Online Discussion
-

 Video3 days ago
Video3 days agoFinancial Statement Analysis | Complete Chapter Revision in 10 Minutes | Class 12 Board exam 2026
-

 Tech2 days ago
Tech2 days agoRetro Rover: LT6502 Laptop Packs 8-Bit Power On The Go
-
 Crypto World7 days ago
Crypto World7 days agoBhutan’s Bitcoin sales enter third straight week with $6.7M BTC offload
-
 Sports2 days ago
Sports2 days agoClearing the boundary, crossing into history: J&K end 67-year wait, enter maiden Ranji Trophy final | Cricket News
-

 Entertainment2 days ago
Entertainment2 days agoDolores Catania Blasts Rob Rausch For Turning On ‘Housewives’ On ‘Traitors’
-

 Business3 days ago
Business3 days agoTesla avoids California suspension after ending ‘autopilot’ marketing
-
 NewsBeat5 days ago
NewsBeat5 days agoThe strange Cambridgeshire cemetery that forbade church rectors from entering
-

 Crypto World2 days ago
Crypto World2 days agoWLFI Crypto Surges Toward $0.12 as Whale Buys $2.75M Before Trump-Linked Forum
-
 NewsBeat5 days ago
NewsBeat5 days agoMan dies after entering floodwater during police pursuit
-

 Crypto World22 hours ago
Crypto World22 hours ago83% of Altcoins Enter Bear Trend as Liquidity Crunch Tightens Grip on Crypto Market
-

 NewsBeat6 days ago
NewsBeat6 days agoUK construction company enters administration, records show
-

 Politics3 days ago
Politics3 days agoEurovision Announces UK Act For 2026 Song Contest