
Crypto World
How to Reduce Non-Determinism and Hallucinations in Large Language Models (LLMs)


In recent months, two separate pieces of research have shed light on two of the most pressing issues in large language models (LLMs): their
non-deterministic nature and their tendency to
hallucinate. Both phenomena have a direct impact on the
reliability,
reproducibility, and
practical usefulness of these technologies.
On the one hand,
Thinking Machines, led by former OpenAI CTO Mira Murati, has published a paper proposing ways to make LLMs return the
exact same answer to the
exact same prompt every time, effectively defeating non-determinism. On the other hand,
OpenAI has released research identifying the root cause of hallucinations and suggesting how they could be significantly reduced.
Let’s break down both findings and why they matter for the future of AI.
The problem of non-determinism in LLMs
Anyone who has used ChatGPT, Claude, or Gemini will have noticed that when you type in the exact same question multiple times, you don’t always get the same response. This is what’s known as
non-determinism: the same input does not consistently lead to the same output.
In some areas, such as creative writing, this variability can actually be a feature; it helps generate fresh ideas. But in domains where
consistency, auditability, and reproducibility are critical — such as healthcare, education, or scientific research — it becomes a serious limitation.
Why does non-determinism happen?
The most common explanation so far has been a mix of two technical issues:
- Floating-point numbers: computer systems round decimal numbers, which can introduce tiny variations.
- Concurrent execution on GPUs: calculations are performed in parallel, and the order in which they finish can vary, changing the result.
However, Thinking Machines argues that this doesn’t tell the whole story. According to their research, the real culprit is batch size.
When a model processes multiple prompts at once, it groups them into batches (or “carpools”). If the system is busy, the batch is large; if it’s quiet, the batch is small. These variations in batch size subtly change the order of operations inside the model, which can ultimately influence which word is predicted next. In other words, tiny shifts in the order of addition can completely alter the final response.
Thinking Machines’ solution
The key, they suggest, is to keep internal processes consistent regardless of batch size. Their paper outlines three core fixes:
- Batch-invariant kernels: ensure operations are processed in the same order, even at the cost of some speed.
- Consistent mixing: use one stable method of combining operations, independent of workload.
- Ordered attention: slice input text uniformly so the attention mechanism processes sequences in the same order each time.
The results are striking: in an experiment with the Qwen 235B model, applying these methods produced 1,000 identical completions to the same prompt, rather than dozens of unique variations.
This matters because determinism makes it possible to audit, debug, and above all, trust model outputs. It also enables stable benchmarks and easier verification, paving the way for reliable applications in mission-critical fields.
The problem of hallucinations in LLMs
The second major limitation of today’s LLMs is hallucination: confidently producing false or misleading answers. For example, inventing a historical date or attributing a theory to the wrong scientist.
Why do models hallucinate?
According to OpenAI’s paper, hallucinations aren’t simply bugs; they are baked into the way we train LLMs. There are two key phases where this happens:
- Pre-training: even with a flawless dataset (which is impossible), the objective of predicting the next word naturally produces errors. Generating the
right answer is harder than checking whether an answer
is right. - Post-training (reinforcement learning): models are fine-tuned to be more “helpful” and “decisive”. But current metrics reward correct answers while penalising both mistakes
and admissions of ignorance. The result? Models learn that it’s better to bluff with a confident but wrong answer than to say “I don’t know”.
This is much like a student taking a multiple-choice exam: leaving a question blank guarantees zero, while guessing gives at least a chance of scoring. LLMs are currently trained with the same incentive structure.
OpenAI’s solution: behavioural calibration
The proposed solution is surprisingly simple yet powerful: teach models when not to answer. Instead of forcing a response to every question, set a confidence threshold.
- If the model is, for instance, more than 75% confident, it answers.
- If not, it responds:
“I don’t know.”
This technique is known as behavioural calibration. It aligns the model’s stated confidence with its actual accuracy.
Crucially, this requires rethinking benchmarks. Today’s most popular evaluations only score right and wrong answers. OpenAI suggests a three-tier scoring system:
- +1 for a correct answer
- 0 for “I don’t know”
- –1 for an incorrect answer
This way, honesty is rewarded and overconfident hallucinations are discouraged.
Signs of progress
Some early users report that GPT-5 already shows signs of this approach: instead of fabricating answers, it sometimes replies,
“I don’t know, and I can’t reliably find out.” Even Elon Musk praised this behaviour as an impressive step forward.
The change may seem small, but it has profound implications: a model that admits uncertainty is far more trustworthy than one that invents details.
Two sides of the same coin: reliability and trust
What makes these two breakthroughs especially interesting is how complementary they are:
- Thinking Machines is tackling
non-determinism, making outputs consistent and reproducible. - OpenAI is addressing
hallucinations, making outputs more honest and trustworthy.
Together, they target the biggest barrier to wider LLM adoption: confidence. If users — whether researchers, doctors, teachers, or policymakers — can trust that an LLM will both give reproducible answers and know when to admit ignorance, the technology can be deployed with far greater safety.
Conclusion
Large language models have transformed how we work, research, and communicate. But for them to move beyond experimentation and novelty, they need more than just raw power or creativity: they need trustworthiness.
Thinking Machines has shown that non-determinism is not inevitable; with the right adjustments, models can behave consistently. OpenAI has demonstrated that hallucinations are not just random flaws but the direct result of how we train and evaluate models, and that they can be mitigated with behavioural calibration.
Taken together, these advances point towards a future of AI that is more transparent, reproducible, and reliable. If implemented at scale, they could usher in a new era where LLMs become dependable partners in science, education, law, and beyond.


The US Securities and Exchange Commission is moving to reduce years of ambiguity around a broker-dealer reporting rule that had limited which assets could be quoted on the over-the-counter (OTC) market. Rule 15c2-11, originally adopted in 1971 to curb penny-stock fraud, requires broker-dealers to keep current public information about a listed issuer before publishing quotes. In 2021, the rule was reinterpreted to also cover fixed-income securities, a shift that drew backlash from market participants and raised questions about crypto securities. In a Monday statement, the SEC proposed an amendment to limit the rule’s scope to equity securities, effectively reversing the 2021 interpretation. The move arrives amid a broader regulatory push to clarify how crypto assets fit within traditional market structures.
Hester Peirce, a commissioner who leads the SEC’s crypto task force, welcomed the proposal and argued that the commission had created years of uncertainty through a 2020 amendment and its 2021 application. She noted that, by the letter of Rule 15c2-11, the rule has always applied to quotations of a “security,” but market participants and observers understood it to cover only OTC equity securities. The commissioner stressed that long-term relief should have been granted while the agency assessed whether extending the rule to fixed income was appropriate and amended the rule as needed. Instead, she said, the commission issued several rounds of limited relief—often lasting only a few months—fostering ongoing uncertainty in the market.”
Key takeaways
- The SEC proposes narrowing Rule 15c2-11’s reporting obligations to equity securities on OTC markets, reversing the 2021 interpretation that extended it to fixed-income assets.
- The agency has opened a 60-day public comment period to gather feedback on how “equity securities” should be defined and whether crypto assets might fall under that category.
- The proposal highlights the commission’s intent to reduce regulatory ambiguity that has affected market participants and product development, including crypto-related offerings.
- Regulators including the SEC and CFTC have been signaling a broader drive to align crypto oversight with traditional markets, as evidenced by recent coordination efforts.
- The discussion includes questions about the potential creation of an “expert market” and how crypto assets could be treated within that framework.
Tickers mentioned: $BTC, $ETH, $COIN
Market context: The proposal comes amid a broader US regulatory push to bring crypto markets into clearer regulatory alignment. By seeking public input on whether crypto assets might be treated under the equity-security framework, the SEC signals a path toward greater certainty—while leaving open how crypto securities would be defined within an updated interpretation of “security.” The move follows a recent memorandum between the SEC and the CFTC aimed at coordinating oversight of financial markets, including crypto, with the aim of reducing regulatory turf wars between the agencies.
Why it matters
The SEC’s proposal addresses a longstanding friction point for market participants that rely on OTC quotes. By narrowing the scope to equity securities, the agency signals that the reporting requirements may not automatically extend to other asset classes, including crypto-related instruments, unless they are clearly defined as securities under existing frameworks. This could reduce the compliance burden for issuers and broker-dealers dealing in non-equity assets on the OTC platform, while also sharpening the framework for evaluating crypto offerings that may seek to register or quote under traditional market channels.
The move also reflects a broader regulatory stance under the current administration to bring crypto markets under clearer governance. A 60-day public-comment period will let industry participants, exchanges, and other stakeholders weigh in on how to interpret “equity security” and whether crypto assets could be included in that category. As the sector continues to evolve with tokenized assets and new fundraising structures, the SEC is signaling that it intends to refine statutory boundaries rather than rely on ad hoc relief measures that can create market fragmentation.
Beyond the technical interpretation of Rule 15c2-11, the development sits within a larger regulatory dialogue. The SEC and the CFTC have moved toward coordination to supervise financial markets more coherently, including crypto activities. This alignment could shape how future disclosures, investor protections, and market access rules are applied to a wide range of digital-asset offerings, potentially smoothing pathways for compliant token projects or raising the bar for those that fall outside established securities laws.
What to watch next
- 60-day public comment window: Stakeholders should monitor the closing date for formal feedback and any subsequent agency responses or revisions to the proposal.
- Definition of equity security: Watch for clarifications on what constitutes an equity security and how that definition could encompass or exclude crypto assets.
- Crypto asset applicability: Assess whether the SEC will provide further guidance on crypto securities and the criteria for including crypto assets within the scope of Rule 15c2-11.
- Regulatory coordination: Look for developments in the SEC–CFTC coordinated framework and any new guidance on how the two agencies will supervise crypto markets together.
Sources & verification
- SEC press release: Proposes amendments to Exchange Act Rule 15c2-11 (https://www.sec.gov/newsroom/press-releases/2026-28-sec-proposes-amendments-exchange-act-rule-15c2-11)
- SEC speech by Commissioner Hester Peirce on Rule 15c2-11 (https://www.sec.gov/newsroom/speeches-statements/peirce-nal-rule-15c2-11-2021-09-24)
- SEC and CFTC coordination memorandum concerning regulatory oversight of financial markets, including crypto (https://cointelegraph.com/news/sec-cftc-sign-memo-regulate-markets-harmony)
Regulatory update on OTC quotes and crypto implications
The proposed amendment to Rule 15c2-11 represents a recalibration of how the SEC views the intersection of OTC quotation practices and the evolving crypto landscape. While the agency has not irrevocably defined crypto assets as equity securities, the public-comment process will illuminate whether and how the current rule could be extended or adapted to cover crypto instruments that exhibit ownership rights or other features typically associated with securities. In the meantime, market participants should prepare for a potential shift in disclosure requirements for OTC quotations, particularly as new crypto-native products and token offerings seek broader access to traditional market venues.
Related: SEC-CFTC coordination on crypto markets
What the proposal changes for market participants
For broker-dealers and issuers involved in OTC quotations, the narrowing focus to equity securities could ease compliance burdens for non-equity instruments, as long as those assets fall outside the defined scope of “equity security.” However, the public-comment period also invites scrutiny of whether the definition is sufficiently robust to address crypto assets that exhibit security-like characteristics. The commission’s emphasis on a precise, demonstrable ownership or equity-like interest could shape how new crypto projects consider their disclosure strategies before pursuing otc quotation or listing arrangements.
The dialogue underscores a deeper aim: to balance investor protection with market accessibility. By refining when and how assets can be quoted on OTC platforms, regulators aim to reduce unnecessary friction while maintaining transparent information flows that help investors make informed decisions. In the longer term, this could influence token issuers’ strategies for capital formation, exchanges’ quotation policies, and the overall risk profile of OTC markets that have historically served as a bridge between private offerings and public markets.
Bitcoin briefly touched $75,912 early Tuesday before pulling back to $74,372, but the intraday volatility is less interesting than the weekly picture beneath it.
CoinDesk reported earlier Tuesday that the push above $75,000 was driven by derivatives activity rather than fresh buying, specifically the closure of large $60,000 put positions that forced market makers to buy spot bitcoin as they rebalanced.
The rapid pullback below $74,400, a former support level from April 2025, confirmed that traders aren’t willing to chase above that level without a fundamental catalyst.
Every major token is up at least 5% over seven days. Ether climbed 13.3% to $2,316. xrp rose 11% to $1.53, olana gained 9.7% to $93.92. Dogecoin added 9.5% to $0.10, back above a dime. BNB rose 5% to $676. This is the broadest sustained rally since before the Iran war began, and it’s happening heading into the most consequential Fed meeting in months.
But the institutional flow data underneath the rally is real and getting harder to dismiss. CF Benchmarks analyst Mark Pilipczuk noted in an email that spot bitcoin ETFs drew roughly $767 million in net inflows last week, the third consecutive week of positive flows and a sharp reversal from the five-week, $3 billion-plus outflow streak earlier in the year.

The gold convergence trade is another signal worth watching. Year-to-date through mid-March, GLD returned roughly 16% while IBIT lost approximately 19%. But that gap has narrowed sharply, with bitcoin outperforming gold by 13.2% since early March. The 90-day correlation between the two shifted from -0.27 to +0.29 over six months. The “digital gold” narrative that looked dead in February is getting oxygen again.
The Fed meeting that begins today and concludes Wednesday is the pivot point. CME FedWatch still prices a 95%+ probability of a hold at 3.5% to 3.75%, so the decision itself is a non-event.
What matters is the dot plot and Powell’s press conference. Oil above $100 makes the stagflation case unavoidable, but the labor market is weakening, with February’s 92,000 job loss still fresh. The Fed is caught between two mandates pulling in opposite directions, and how Powell articulates that tension on Wednesday could set the direction for risk assets through the end of March.
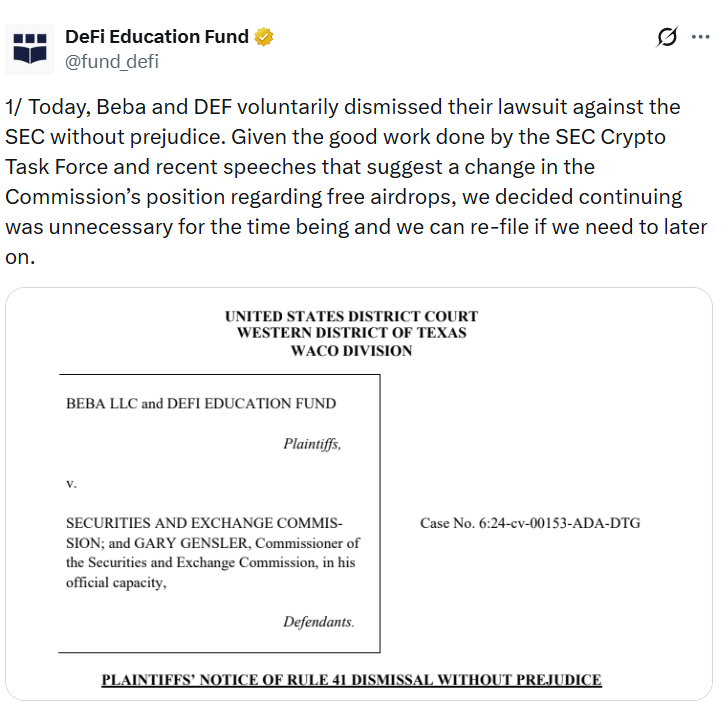
Texas-based apparel company Beba and crypto lobby group DeFi Education Fund have withdrawn a 2024 lawsuit against the US Securities and Exchange Commission (SEC) over its approach to airdrops, citing a recent shift in the regulator’s approach to crypto.
Beba launched a free token airdrop in March 2024 and, together with the DeFi Education Fund, filed a pre-enforcement challenge against the SEC that year.
The lawsuit alleged the regulator had adopted its digital asset enforcement policy without a formal notice-and-comment rulemaking process, in violation of the Administrative Procedure Act.
The voluntary dismissal, filed in the US District Court for the Western District of Texas on Friday, cites the SEC Crypto Task Force’s work and statements by Commissioner Hester Peirce in several speeches last year suggesting airdropped tokens are not securities.
The filing also flags Peirce’s suggestion in May that the SEC is considering an exemption framework for airdrops, and a White House executive action from January encouraging the regulator to establish a “safe harbor for certain airdrops.”
“Given the good work done by the SEC Crypto Task Force and recent speeches that suggest a change in the Commission’s position regarding free airdrops, we decided continuing was unnecessary for the time being and we can re-file if we need to later on,” the DeFi Education Fund said in an X post on Friday.
“The DEF team expects that the SEC Crypto Task Force will address airdrops soon—the foundational issue at hand in this lawsuit,” it added.

Case dismissed without prejudice, for now
The dismissal was filed without prejudice, preserving Beba’s and the DeFi Education Fund’s right to refile if needed.
“Should the expected guidance fail to materialize or be insufficient, Plaintiffs preserve their right to refile their claims,” lawyers acting for the pair wrote in the court document.
SEC’s evolving stance on crypto
Under former SEC Chair Gary Gensler, the agency drew heavy criticism from the crypto industry for allegedly crafting policy through enforcement actions and legal settlements rather than formal rulemaking.
Related: SEC seeks comment on crypto handling in OTC broker-dealer rule
Since Gensler resigned on Jan. 20 2025, crypto proponents have seen a regulatory shift by the SEC, including the dismissal of several long-running enforcement actions against crypto firms.
In a recent case, the SEC dropped a two-year lawsuit against Nader Al-Naji, founder of the blockchain-based social media platform BitClout, for allegedly raising more than $257 million by selling the native token of the BitClout platform and spending more than $7 million on personal items.
Magazine: SEC’s U-turn on crypto leaves key questions unanswered


[PRESS RELEASE – Vilnius, Lithuania, March 16th, 2026]
WhiteBIT, the largest European exchange by traffic, has announced its selection as one of 11 companies invited to participate in Ghana’s pioneering crypto regulatory sandbox. The sandbox, launched by the Ghana Securities and Exchange Commission in collaboration with the Bank of Ghana, is designed to test and refine regulated digital asset trading in a controlled environment.
WhiteBIT’s inclusion in the sandbox marks a major milestone in the company’s strategic expansion into the African market. As crypto adoption accelerates across the continent, WhiteBIT’s regulated platform and compliance expertise position it to play a central role in helping shape the next generation of digital finance infrastructure.
“WhiteBIT’s mission has always been to deliver secure, compliant, and accessible crypto services,” said Volodymyr Nosov, Founder and President of W Group, which WhiteBIT is a part of. “Being selected for Ghana’s regulatory sandbox not only underscores our commitment to responsible market expansion but also reflects our confidence in Africa’s potential to lead in digital finance.”
The sandbox initiative invites selected licensed firms to operate under regulatory supervision while sharing insights and data that will inform future licensing frameworks for virtual asset service providers (VASPs). The pilot aims to ensure that crypto trading and related services evolve in a manner that protects consumers, enhances transparency, and fosters financial innovation.
A Fast‑Growing Crypto Market
Ghana has emerged as one of Africa’s most dynamic markets for digital asset adoption. According to Chainalysis, Ghana ranks among the top five crypto adoption hubs in Africa, alongside Nigeria, Kenya, and South Africa. More broadly, Africa is currently the third-largest region globally in crypto adoption, following the Asia-Pacific (APAC) and Latin America markets.
According to the central bank, 3 million Ghanaians — approximately 17 % of the adult population — actively use cryptocurrencies, including Bitcoin and stablecoins, for trading, payments, and remittances.
In December 2025, Ghana’s parliament approved the Virtual Asset Service Providers Bill, which legalizes cryptocurrency trading under clear licensing and compliance standards, further creating a solid basis for institutional participation.
Opportunity for Responsible Innovation
Ghana’s regulated sandbox initiative and passage of comprehensive crypto laws signal a strategic shift toward integrating digital assets into the country’s broader financial ecosystem. For WhiteBIT, participation in this program offers a unique opportunity to collaborate with regulators, technologists, and local partners to refine best practices that could extend well beyond Ghana’s borders.
“As Africa’s crypto landscape continues to evolve, WhiteBIT is committed to bringing compliant, secure, and innovative solutions to markets that are ready for next‑generation financial services,” Nosov added.
About WhiteBIT
WhiteBIT is the largest European cryptocurrency exchange by traffic, offering over 900 trading pairs, 350+ assets, and supporting 8 fiat currencies. Founded in 2018, the platform is a part of W Group which serves more than 35 million customers globally. WhiteBIT collaborates with Visa, FACEIT, FC Juventus and the Ukrainian national football team. The company is dedicated to driving the widespread adoption of blockchain technology worldwide.
Binance Free $600 (CryptoPotato Exclusive): Use this link to register a new account and receive $600 exclusive welcome offer on Binance (full details).
LIMITED OFFER for CryptoPotato readers at Bybit: Use this link to register and open a $500 FREE position on any coin!

A former Los Angeles County Sheriff’s Department deputy has been sentenced to more than five years in prison for helping Adam Iza, a jailed crypto founder dubbed “The Godfather,” extort victims.
A California federal court handed Michael Coberg 63 months in prison and an order to pay $127,000 in restitution for helping Iza extort one of his rivals and arrange a drug possession arrest of another person, the Los Angeles US Attorney’s office said on Monday.
Coberg had pleaded guilty in September to conspiracy to commit extortion and conspiracy against rights.
Prosecutors said Coberg was paid at least $20,000 a month for his security services by Iza, the founder of the crypto trading platform Zort, who was known as “The Godfather.”
Iza pleaded guilty in January 2025 to extorting multiple people and is awaiting sentencing.
Prosecutors detail Coberg’s extortion, drug sting
According to prosecutors, in October 2021, Coberg was part of a team that picked up a victim, identified only as “L.A.,” who had a business partner in a financial dispute with Iza.
Coberg brought L.A. to Iza’s house, where Iza recorded a video of L.A. transferring $127,000 to Iza’s bank account while Coberg stood watch.
Coberg also took Iza and L.A. to a shooting range, where prosecutors said Iza held L.A. at gunpoint and demanded he transfer money to him.

Prosecutors said Coberg also conspired with Iza and others to set up a victim, identified only as “R.C.,” to be arrested over drugs.
Related: Former LAPD officer convicted of kidnapping teen in $350K crypto robbery
R.C. had been in a dispute where Iza, Christopher Cadman — a former Sheriff’s Department deputy who pleaded guilty in August to helping Iza — and another deputy had held R.C. at gunpoint to transfer $25,000 to Iza.
Coberg and others set up a sham sting where R.C.’s ex-girlfriend called and convinced them to fly to LA to use drugs together.
R.C. was picked up at the airport, driven to get drugs and was then stopped and arrested by a Sheriff’s Department deputy that Coberg had tipped off.
Prosecutors said in their sentencing memorandum for Coberg that he abused “the awesome power of his badge. And he did so for an all-too-common reason: greed.”
Magazine: Meet the onchain crypto detectives fighting crime better than the cops


[PRESS RELEASE – Tel Aviv, Israel, March 16th, 2026]
Playnance, the Web3 infrastructure company behind the growing GCOIN ecosystem, has announced the launch of GCOIN Staking, a new mechanism designed to strengthen long-term participation in the platform’s expanding Web3 entertainment economy. The program is now live on PlayW3, the flagship Web3 social gaming platform within the Playnance ecosystem, and 250M tokens were locked within hours.
The launch introduces a new opportunity for GCOIN holders to actively participate in the ecosystem through staking and receive rewards distributed through the platform ahead of the upcoming GCOIN Token Generation Event on March 18, expanding the economic layer of the Playnance ecosystem.
The staking program allows GCOIN holders to lock their tokens and participate in ecosystem-driven rewards while encouraging long-term token alignment, reducing circulating supply through voluntary locking, and supporting the sustainability of the GCOIN token economy. Users can stake GCOIN through smart-contract staking pools with a minimum participation threshold of 1,000 GCOIN across four durations of 6, 9, 12, and 18 months, where longer lock periods carry higher reward weight. Rewards begin accumulating 24 hours after activation and can be claimed once the staking period reaches maturity, while early withdrawal remains possible with rewards forfeited.
“Staking allows our community to grow together with the Playnance ecosystem,” said Pini Peter, CEO of Playnance. “As adoption expands, GCOIN holders can take a more active role in the network’s long-term evolution, participating in the ecosystem through staking rewards.”
Playnance introduces a staking mechanism that connects users’ rewards directly to the ecosystem’s operations. Instead of relying on fixed emissions or inflationary rewards, staking rewards are distributed through an ecosystem allocation linked to ecosystem activity, including the social casino and other ecosystem products. As the ecosystem grows and more users participate, rewards are distributed to stakers through an ecosystem allocation, aligning incentives between platform growth and community participation. GCoin holders can stake their tokens to support the ecosystem’s gaming liquidity pool and receive proportional incentive distributions derived from the platform’s daily performance.
GCOIN powers a growing Web3 entertainment economy spanning social gaming, prediction markets, trading environments, and next-generation social casinos. Playnance is leading a structural shift toward decentralized entertainment economies, bringing the global entertainment industry on-chain, all powered by GCOIN. Through staking, community members can participate in the long-term evolution of the ecosystem while contributing to greater stability and sustainability across the Playnance network.
About Playnance
Founded in 2020, Playnance is a Web3 infrastructure company developing live, non-custodial, on-chain products designed to onboard mainstream Web2 users into blockchain environments. The company develops consumer-facing platforms built on shared wallet systems and high-volume on-chain execution, currently processing approximately 2 million transactions per day. Playnance focuses on reducing friction between user experience and blockchain infrastructure by abstracting complexity while maintaining full on-chain transparency and non-custodial architecture.
Binance Free $600 (CryptoPotato Exclusive): Use this link to register a new account and receive $600 exclusive welcome offer on Binance (full details).
LIMITED OFFER for CryptoPotato readers at Bybit: Use this link to register and open a $500 FREE position on any coin!


Bitcoin prices have reached their highest level since early February in a crypto market relief rally as analysts eye $80,000.
Bitcoin prices tapped $76,000 on Coinbase in early trading on Tuesday morning, according to TradingView. It is the highest the asset has traded since the Feb. 6 crash.
Bitcoin did it. It just closed the daily candle above the $74,500 April 2025 low, said analyst ‘Sykodelic’ on Tuesday. “To me, this daily close is a signal that the market wants higher,” they added.
“Hold at these levels for a little longer, and $80k should come in short order. Acceptance back inside the $72k range, and we should expect lower levels again.”
Positive Signals From Technical Indicators
“We have lift-off. Breakout move has begun. Early stages,” said analyst ‘Colin.’
He guessed the height of the potential relief rally would be $80,600, which is a retest of the November 2025 lows with a broader range between $79,000 and $86,000 for a relief rally top.
CryptoQuant analyst Julio Moreno observed that Bitcoin’s Inter-Exchange Flow Pulse (IFP) has recently flipped back into bullish territory.
This technical indicator has historically “marked important transitions in market structure, particularly after prolonged periods of suppressed liquidity rotation between exchanges,” he said.
“In practical terms, the signal suggests that liquidity mobility inside the exchange network is increasing again, a condition typically associated with early expansion phases of market cycles.”
Meanwhile, ‘Daan Crypto Trades’ said there was “good confluence” over at the $83,000 to $84,000 level with both the Bull Market Support band and the big CME gap there. However, the 200-week EMA is still serving as support around $68,000.
You may also like:
$BTC Good confluence over at the ~$83K-$84K level with both the Bull Market Support band and the big CME gap.
Think that’s a good level to watch in the week(s) ahead. To see where price meets the band and how it reacts around it.
On the downside the Weekly 200MA/EMA have held… pic.twitter.com/eFa4wvcDxO
— Daan Crypto Trades (@DaanCrypto) March 16, 2026
Bitcoin is starting to show signs of being “going against the grain of history by successfully weekly closing above the 200-week EMA,” said Rekt Capital. However, there’s also a chance that Bitcoin could “simply meander in and around the 200-week EMA for a while,” he added.
Elsewhere on Crypto Markets
Bitcoin had cooled slightly and was trading at $74,300 at the time of writing, up 9% over the past seven days. Ethereum was also getting a long-overdue lift, surging more than 8% on the day to reach $2,380 before a minor pullback. ETH has gained a whopping 17% over the past seven days.
Altcoins were having their best day in weeks with big gains for XRP, Cardano, Stellar, and Zcash. Meanwhile, the total market cap had reached $2.65 trillion, its highest level since Feb. 4.
Binance Free $600 (CryptoPotato Exclusive): Use this link to register a new account and receive $600 exclusive welcome offer on Binance (full details).
LIMITED OFFER for CryptoPotato readers at Bybit: Use this link to register and open a $500 FREE position on any coin!

TLDR:
- Polymarket was handed a nationwide block by a Buenos Aires court directing ENACOM to restrict access on March 16, 2026.
- LOTBA filed the complaint that led authorities to classify Polymarket as an unlicensed online gambling service in Argentina.
- Polymarket accepted crypto and credit cards with no age or identity verification, raising serious concerns over minor user access.
- Argentina joins Colombia as the second Latin American country to fully restrict the Polymarket prediction market platform.
Polymarket, a crypto-based prediction market platform, faces a nationwide ban in Argentina following a court order on March 16, 2026.
Buenos Aires Judge Susana Parada directed ENACOM to restrict access through all internet providers. The ruling also instructs Google and Apple to remove the platform’s mobile apps from the App Store for Argentine users.
The complaint originated from the Buenos Aires City Lottery, making Argentina the second Latin American country to restrict the platform fully.
Court Rules Polymarket Operates as Unlicensed Gambling Service
The Buenos Aires Justice issued the ban following a complaint from the Lottery of the City of Buenos Aires (LOTBA).
The Argentine Chamber of Casinos, Bingos, and Annexes (CASCBA) joined the complaint soon after. Together, they pushed the case through the Specialized Prosecutor’s Office for Gambling (FEJA).
The Judicial Investigations Corps (CIJ) provided technical assistance during the investigation. Authorities concluded that Polymarket functions as a covert online betting system.
The platform was classified as a “prediction market,” which falls under gambling regulations.
The court found that Polymarket operated in Argentina without any local authorization. It accepted cryptocurrencies and credit cards without requiring identity or age verification. Users could create accounts within minutes, raising concerns among regulators about minors’ access.
Judge Parada stated that these features “significantly increase the risks for users,” pointing directly to the absence of age and identity checks.
The block covers the platform and all its variants, according to the Public Prosecutor’s Office. However, as of 1:05 pm on Monday, the platform remained accessible in Argentina.
Polymarket’s Regional Restrictions and the Broader Debate
Colombia was the first Latin American country to restrict access to Polymarket. Argentina has now followed with a similarly sweeping national ban. This sets a judicial and technical precedent for how predictive platforms may be treated across the region.
The timing of the ban is worth noting. Just before the block, Polymarket drew attention by predicting Argentina’s February inflation data 15 minutes before INDEC published it. That incident added pressure on regulators to act against the platform.
The decision has generated mixed reactions across Argentina. Some observers welcome the move as a step toward protecting vulnerable users from unregulated gambling. Others, meanwhile, warn that it restricts freedom of information and access to global financial tools.
The contrast with the United States is clear. American authorities have moved toward regulating, rather than blocking, prediction market platforms that use cryptocurrencies.
Polymarket grew rapidly during the 2024 U.S. presidential race, gaining attention for giving Donald Trump “55.5% of chances” of winning — a figure that outperformed traditional polls.
The platform’s rise during that election campaign brought it international visibility that regulators in Latin America are now responding to.


Impermanent loss (IL) has long been the Achilles’ heel of liquidity providers (LPs) in decentralized finance (DeFi). Traditional LPs have had to weigh the risk of holding assets in automated market maker (AMM) pools against potential fees earned, often facing losses when token prices diverge. However, the DeFi ecosystem is evolving rapidly, and new strategies are emerging that allow LPs to mitigate impermanent loss more effectively than ever before.
Understanding the Evolution of Impermanent Loss
Impermanent loss occurs when the value of assets deposited in a liquidity pool changes relative to holding them separately. Historically, LPs mitigated IL by choosing stablecoin pairs (like USDC/USDT), which limited volatility but also capped upside potential. As the DeFi landscape matures, innovation has turned toward smart pool designs, dynamic fee structures, and cross-asset hedging, creating a new frontier for LP risk management.
Innovative Pool Designs
1. Concentrated Liquidity Pools
Popularized by platforms like Uniswap V3, concentrated liquidity allows LPs to allocate liquidity to specific price ranges rather than across the entire curve. By doing so, capital efficiency increases and exposure to price divergence decreases. LPs can now focus their liquidity where trading is most likely to occur, earning higher fees with reduced impermanent loss.
2. Dynamic AMMs and Weighted Pools
Projects such as Balancer have introduced variable weight pools, enabling LPs to adjust the proportion of tokens based on market conditions. This flexibility reduces the risk of impermanent loss in volatile markets while still maintaining exposure to multiple assets. Pools with dynamic weights can automatically rebalance as prices shift, acting as an internal hedging mechanism.
3. Stable-Stable and Hybrid Pools
Stable-stable pools (e.g., USDC/DAI) have always minimized IL, but hybrid pools combining stablecoins with volatile tokens in a strategic ratio are gaining traction. These designs allow LPs to capture fees from volatility without full exposure to price swings, creating a smoother risk-return profile.
Hedging Techniques for LPs
Beyond pool design, LPs can adopt active hedging strategies to further reduce impermanent loss:
-
Options and Derivatives: LPs can use decentralized options platforms to hedge against token depreciation. For instance, buying put options on the more volatile token in a pair can offset losses if the price diverges significantly.
-
Synthetic Asset Exposure: Some DeFi protocols allow LPs to create synthetic positions that mirror their LP exposure, enabling risk-adjusted rebalancing.
-
Cross-Protocol Strategies: LPs can leverage lending platforms to earn interest or collateralized yield on one side of their LP position, partially offsetting impermanent loss while maintaining liquidity provision.
The Future: Algorithmic IL Protection
Several protocols are exploring algorithmic approaches to impermanent loss protection. These mechanisms automatically adjust LP positions in real-time, using AI-driven pricing models or volatility metrics to minimize exposure. Over time, this could evolve into a standard feature in DeFi, making IL less of a concern for both novice and professional LPs.
Conclusion
Impermanent loss no longer has to be a passive risk that LPs accept. Through innovative pool designs, dynamic AMMs, hybrid assets, and hedging strategies, DeFi participants can actively protect their liquidity positions while still earning fees. As the ecosystem continues to mature, Impermanent Loss 2.0 represents a new era where risk and reward can be more carefully balanced—and liquidity provision becomes smarter, not just luckier.
REQUEST AN ARTICLE

Unrealized Bitcoin Losses Put Sentiment on the Hook
The sentiments of investors were further worsened with Strategy recording increasing unrealized losses on its Bitcoin holdings. According to market estimates, the company is already experiencing over $900 million in losses in paper because the asset traded at a lower price than its average acquisition price.Also, Bitcoin has temporarily dropped to the lower end of the 74,000 range at the end of Sunday. This drop has driven the price to an amount that is lower than the projected average price of purchase of around $76,000 by Strategy.The drop in value, therefore, has reduced the market value of the huge digital asset base of the firm. Strategy has an approximate of 713,502 BTC that it has accrued in its continuous treasury strategy.
Strategy has been able to raise funds with the help of equity sales and remains with its strategy of buying Bitcoin. Recently, the company sold an estimated 1.569 million shares of its common stock during a trading period between January 20 and 25 and the net proceeds of the sales amounted to approximately 257 million dollars. The capital further supported the latest Bitcoin purchase of the firm in addition to approximately 70,201 shares of its STRC preferred stock in which it raised around 7 million dollars more funds. The company had revealed that it had bought 855 BTC valued around 75.3 million in the last weekly purchasing round.
Strategy shares have also been affected by the trading sentiment by market expectations. According to Polymarket, which is a prediction platform, traders are confident that it is likely that Bitcoin will fall further before it recovers.Moreover, a number of market analysts have changed their views about the cryptocurrency. Peter Brandt, a veteran trader, has recently changed his estimates because of the existing price fluctuations.Peter Schiff, an investor, criticized the approach of the treasury creation of Bitcoin by Strategy. Nevertheless, the executive chairman Michael Saylor indicated that the firm can still go ahead and buy Bitcoin even as the market slump persists.

Schools rugby union: Northampton School for Boys – the state school at the top of English rugby

Rhythm Pharmaceuticals, Inc. (RYTM) Discusses Topline Results and Insights from Phase 3 EMANATE Trial – Slideshow

SEC Seeks Public Comment on Crypto Handling in OTC Broker-Dealer Rule






-
 Tech6 days ago
Tech6 days agoA 1,300-Pound NASA Spacecraft To Re-Enter Earth’s Atmosphere
-
Crypto World3 days ago
HYPE Token Enters Net Deflation as HyperCore Buybacks Outpace Staking Rewards
-

 Business7 days ago
Business7 days agoExxonMobil seeks to move corporate registration from New Jersey to Texas
-

 Fashion4 days ago
Fashion4 days agoWeekend Open Thread: Addict Lip Glow
-
 Tech7 days ago
Tech7 days agoChatGPT will now generate interactive visuals to help you with math and science concepts
-
Sports3 days ago
Why Duke and Michigan Are Dead Even Entering Selection Sunday
-

 NewsBeat6 days ago
NewsBeat6 days agoResidents reaction as Shildon murder probe enters second day
-

 Business1 day ago
Business1 day agoSearch for Savannah Guthrie’s Mother Enters Seventh Week with No Arrests
-

 Business6 days ago
Business6 days agoSearch Enters Sixth Week With New Leads in Tucson Abduction Case
-

 Business3 days ago
Business3 days agoUS Airports Launch Donation Drives for Unpaid TSA Workers as Partial Government Shutdown Enters Fifth Week
-
Crypto World3 days ago
Coinbase and Bybit in Investment Talks: Could Bybit Finally Enter the US Crypto Market?
-

 NewsBeat6 days ago
NewsBeat6 days agoI Entered The Manosphere. Nothing Could Prepare Me For What I Found.
-

 Business3 days ago
Business3 days agoCountry star Brantley Gilbert enters growing non-alcoholic beer market
-

 Sports5 days ago
Sports5 days agoPWHL, Senators discussing plan to keep Charge in Ottawa
-

 Business20 hours ago
Business20 hours agoAustralian shares drop as Iran war enters third week
-

 Sports3 days ago
Sports3 days agoCollege Basketball Best Bets: Conference Tournament Semifinal Picks
-

 Crypto World20 hours ago
Crypto World20 hours agoCrypto Lender BlockFills Enters Chapter 11 with Up to $500M in Liabilities
-
 Crypto World7 days ago
Crypto World7 days agoWill Chainlink price reclaim $10 amid volatility squeeze?
-

 Politics6 days ago
Politics6 days agoTrump Says Middle East Is ‘Very Lucky’ That He’s President
-

 Tech6 days ago
Tech6 days agoClarity as strategy


You must be logged in to post a comment Login