
Crypto World
Lessons Learned After a Year of Building with Large Language Models (LLMs)


Over the past year, Large Language Models (LLMs) have reached impressive competence for real-world applications. Their performance continues to improve, and costs are decreasing, with a projected $200 billion investment in artificial intelligence by 2025. Accessibility through provider APIs has democratised access to these technologies, enabling ML engineers, scientists, and anyone to integrate intelligence into their products. However, despite the lowered entry barriers, creating effective products with LLMs remains a significant challenge. This is summary of the original paper of the same name by https://applied-llms.org/. Please refer to that documento for detailed information.
Fundamental Aspects of Working with LLMs
· Prompting Techniques
Prompting is one of the most critical techniques when working with LLMs, and it is essential for prototyping new applications. Although often underestimated, correct prompt engineering can be highly effective.
– Fundamental Techniques: Use methods like n-shot prompts, in-context learning, and chain-of-thought to enhance response quality. N-shot prompts should be representative and varied, and chain-of-thought should be clear to reduce hallucinations and improve user confidence.
Structuring Inputs and Outputs: Structured inputs and outputs facilitate integration with subsequent systems and enhance clarity. Serialisation formats and structured schemas help the model better understand the information.
– Simplicity in Prompts: Prompts should be clear and concise. Breaking down complex prompts into more straightforward steps can aid in iteration and evaluation.
– Token Context: It’s crucial to optimise the amount of context sent to the model, removing redundant information and improving structure for clearer understanding.
· Retrieval-Augmented Generation (RAG)
RAG is a technique that enhances LLM performance by providing additional context by retrieving relevant documents.
– Quality of Retrieved Documents: The relevance and detail of the retrieved documents impact output quality. Use metrics such as Mean Reciprocal Rank (MRR) and Normalised Discounted Cumulative Gain (NDCG) to assess quality.
– Use of Keyword Search: Although vector embeddings are useful, keyword search remains relevant for specific queries and is more interpretable.
– Advantages of RAG over Fine-Tuning: RAG is more cost-effective and easier to maintain than fine-tuning, offering more precise control over retrieved documents and avoiding information overload.
Optimising and Tuning Workflows
Optimising workflows with LLMs involves refining and adapting strategies to ensure efficiency and effectiveness. Here are some key strategies:
· Step-by-Step, Multi-Turn Flows
Decomposing complex tasks into manageable steps often yields better results, allowing for more controlled and iterative refinement.
– Best Practices: Ensure each step has a defined goal, use structured outputs to facilitate integration, incorporate a planning phase with predefined options, and validate plans. Experimenting with task architectures, such as linear chains or Directed Acyclic Graphs (DAGs), can optimise performance.
· Prioritising Deterministic Workflows
Ensuring predictable outcomes is crucial for reliability. Use deterministic plans to achieve more consistent results.
Benefits: It facilitates controlled and reproducible results, makes tracing and fixing specific failures easier, and DAGs adapt better to new situations than static prompts.
– Approach: Start with general objectives and develop a plan. Execute the plan in a structured manner and use the generated plans for few-shot learning or fine-tuning.
· Enhancing Output Diversity Beyond Temperature
Increasing temperature can introduce diversity but only sometimes guarantees a good distribution of outputs. Use additional strategies to improve variety.
– Strategies: Modify prompt elements such as item order, maintain a list of recent outputs to avoid repetitions, and use different phrasings to influence output diversity.
· The Underappreciated Value of Caching
Caching is a powerful technique for reducing costs and latency by storing and reusing responses.
– Approach: Use unique identifiers for cacheable items and employ caching techniques similar to search engines.
– Benefits: Reduces costs by avoiding recalculation of responses and serves vetted responses to reduce risks.
· When to Fine-Tune
Fine-tuning may be necessary when prompts alone do not achieve the desired performance. Evaluate the costs and benefits of this technique.
– Examples: Honeycomb improved performance in specific language queries through fine-tuning. Rechat achieved consistent formatting by fine-tuning the model for structured data.
– Considerations: Assess if the cost of fine-tuning justifies the improvement and use synthetic or open-source data to reduce annotation costs.
Evaluation and Monitoring
Effective evaluation and monitoring are crucial to ensuring LLM performance and reliability.
· Assertion-Based Unit Tests
Create unit tests with real input/output examples to verify the model’s accuracy according to specific criteria.
– Approach: Define assertions to validate outputs and verify that the generated code performs as expected.
· LLM-as-Judge
Use an LLM to evaluate the outputs of another LLM. Although imperfect, it can provide valuable insights, especially in pairwise comparisons.
– Best Practices: Compare two outputs to determine which is better, mitigate biases by alternating the order of options and allowing ties, and have the LLM explain its decision to improve evaluation reliability.
· The “Intern Test”
Evaluate whether an average university student could complete the task given the input and context provided to the LLM.
– Approach: If the LLM lacks the necessary knowledge, enrich the context or simplify the task. Decompose complex tasks into simpler components and investigate failure patterns to understand model shortcomings.
· Avoiding Overemphasis on Certain Evaluations
Do not focus excessively on specific evaluations that might distort overall performance metrics.
Example: A needle-in-a-haystack evaluation can help measure recall but does not fully capture real-world performance. Consider practical assessments that reflect real use cases.
Key Takeaways
The lessons learned from building with LLMs underscore the importance of proper prompting techniques, information retrieval strategies, workflow optimisation, and practical evaluation and monitoring methodologies. Applying these principles can significantly enhance your LLM-based applications’ effectiveness, reliability, and efficiency. Stay updated with advancements in LLM technology, continuously refine your approach, and foster a culture of ongoing learning to ensure successful integration and an optimised user experience.

Crypto World
Bitcoin Dips Below $70,000 as Extreme Fear Index Hits 10: What Traders Are Watching Next

TLDR:
- Bitcoin fell over 3% in 24 hours, sliding from above $74,000 to around $68,700 on Sunday amid macro fears.
- The Crypto Fear and Greed Index dropped to an extreme fear reading of 10, reflecting sharp decline in market confidence.
- Trader Lennaert Snyder targets a Bitcoin drop to $65,580, planning to add shorts after a confirmed bearish structure break.
- Institutional buyers continue accumulating BTC as exchange supply hits multi-year lows, contrasting with heavy retail panic selling.
Bitcoin fell sharply on Sunday, dropping from above $74,000 to around $68,700 in a matter of hours. The move pushed the Crypto Fear & Greed Index to an extreme fear reading of just 10.
Rising oil prices, a pause in Federal Reserve rate cuts, and ongoing geopolitical tensions drove the sell-off. Bitcoin recorded a 3.11% decline over 24 hours, with trading volume reaching approximately $29.1 billion.
Short Positions Build as Bears Set Their Sights on $65,000
The latest price drop has given bearish traders confidence to hold and grow their short positions. Selling pressure remained active throughout the week, contributing to a total seven-day decline of 4.02%.
This combination of macro pressure and bearish momentum pushed market fear to its most extreme reading in recent weeks.
Crypto trader Lennaert Snyder shared his bearish stance openly on social media during Sunday’s session. “My target is still the ~$65,580 low, and possibly even lower for Bitcoin,” Snyder wrote. He also planned to add margin to his shorts using the upper wick of the next weekly candle.
Snyder noted caution around a key level at $72,700, identifying it as a Fair Value Gap zone. He stated he would only enter a trade after seeing a liquidity push and a bearish market structure break.
His approach pointed to a disciplined strategy, waiting for price confirmation before committing to new short trades.
A notable counterrisk, however, remains for those currently holding short positions. Whale Insider reported that $5 billion in crypto shorts would face forced liquidation if Bitcoin climbs back to $75,000. That level therefore becomes both a target for bulls and a danger zone for active short sellers in the market.
Institutional Buyers Accumulate as Exchange Supply Drops to Multi-Year Lows
Even as retail sentiment fell to extreme fear, institutional buyers continued accumulating Bitcoin through the downturn.
This divergence between retail and large-scale buyers has been a repeated pattern during past crypto market corrections. Institutions appear to view the current dip as an entry point rather than a reason to sell.
Exchange supply has also dropped to multi-year lows, further shaping the current market picture. Lower exchange balances typically point to Bitcoin being moved into cold storage for long-term holding.
This movement often tightens available sell-side supply on exchanges, setting the stage for potential price rebounds.
Market watchers are now turning their attention to Monday’s session, closely eyeing the $72,000 price level. A recovery above that zone could signal a momentum shift and place short positions at increased risk. Bulls will need consistent buying volume to challenge the bearish tone that dominated the weekend.
Bitcoin’s near-term path will largely depend on how macro factors unfold over the coming days. Bears are holding firm to the $65,580 target, while bulls look for a sustained break above $72,000.
The market remains at a crossroads, with either outcome carrying major consequences for active traders on both sides.



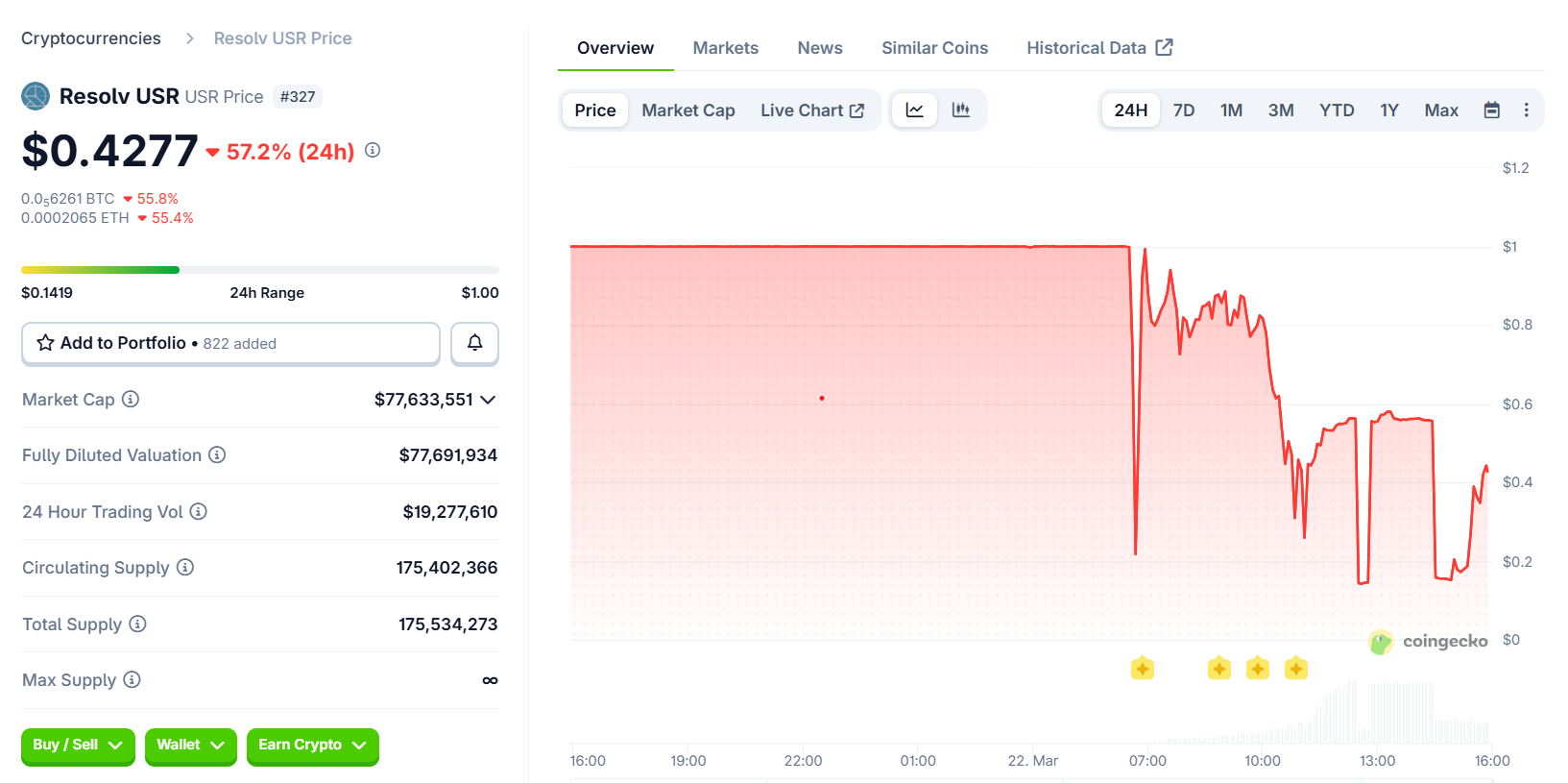
Resolv Labs recently experienced a major exploit in its USR stablecoin system, leading to the minting of 80 million unbacked tokens.
Summary
- USR stablecoin crashes to $0.14 after exploit, rebounding to $0.42.
- DeFi protocols quickly respond to exploit, with some pausing markets to limit risk.
- Resolv Labs reassures users, stating collateral pool remains intact despite exploit.
Meanwhile, this triggered a sharp drop in the token’s value, causing it to fall as low as $0.14 before rebounding to $0.42. The incident has raised concerns among decentralized finance (DeFi) protocols and users exposed to the exploit, prompting a rapid response to contain the fallout.
As Crypto News reported earlier on Sunday, Resolv Labs confirmed that an attacker had exploited the minting mechanics of its USR stablecoin. The attacker was able to create tens of millions of unbacked USR tokens and sell them through DeFi pools. This led to a dramatic depeg of the token, which dropped as low as $0.14, 86% below its intended $1 value.
The price of USR quickly rebounded to $0.42, but the attack had already caused significant damage. Resolv Labs reassured users by stating that the collateral pool “remains fully intact” and that the issue was isolated to the USR issuance mechanics. The team has paused the protocol to assess the situation and prevent further exploitation.
Following the exploit, DeFi protocols that had exposure to USR moved quickly to contain any potential damage. Lido, Morpho, and Aave all issued statements confirming that their systems were unaffected, although some vaults did have exposure to the exploit.
According to Michael Pearl of Cyvers, the risk from the exploit seemed concentrated in lending and leverage markets, particularly those using USR or RLP as collateral. Some platforms like Euler, Venus, and Fluid paused markets or isolated vaults to prevent further risks. Pearl noted that the impact appeared to be localized, with no signs of a broader contagion affecting the entire DeFi ecosystem.
Moreover, despite Resolv Labs’ smart contracts undergoing multiple audits, the exploit has raised questions about the limitations of these audits. Security firm Pashov, which had audited Resolv’s staking module in July 2025, pointed out that the attack likely stemmed from an operational security flaw rather than a design issue. The firm highlighted the potential compromise of a private key as the root cause of the exploit.
Experts like Pearl argued that real-time monitoring powered by artificial intelligence is essential to detect anomalies in protocol activity. Monitoring mint and burn flows and validating supply against reserves would help detect issues before they escalate.
Containment and recovery efforts
Resolv Labs has reassured its users that it is actively investigating the exploit and working on recovery. While the exploit did not result in any loss of assets from the collateral pool, the attack has emphasized the need for continuous monitoring and stronger operational security. The DeFi community is closely watching how Resolv Labs handles the situation, especially as the price of USR stabilizes and more data on the full impact of the exploit becomes available.
Crypto World
TSMC Helium Crisis: How the Persian Gulf War Put the World’s Chip Supply on an 11-Day Clock
TLDR:
- TMSC holds only 11 days of LNG reserve, the least of any major semiconductor economy on Earth.
- Helium from Qatar powers EUV machines that print every advanced AI chip at 3-nanometre scale globally.
- Helium spot prices have surged up to 100% since Iranian strikes shut down Qatar’s Ras Laffan complex.
- Two US carrier strike groups have shifted to the Gulf, thinning Pacific presence and raising Taiwan risk.
TSMC produces 90 percent of the world’s most advanced logic chips. Taiwan, where TSMC operates, imports 97 percent of its energy and holds only 11 days of gas in reserve.
A war in the Persian Gulf has now disrupted Taiwan’s helium supply. Helium is critical for printing transistors at 3 nanometres, with no substitute available. The crisis has put global semiconductor supply chains under immediate pressure.
Helium Shortage Pushes Advanced Chip Manufacturing Toward a Critical Threshold
Qatar’s Ras Laffan complex once processed roughly one-third of the world’s helium. Iranian strikes shut it down, and repairs will take three to five years.
Taiwan relies on Qatar for the bulk of its helium supply. SK Hynix also sourced 64.7 percent of its helium from Qatar. Helium spot prices have since surged between 40 and 100 percent.
Helium cools the EUV lithography systems that print chips at 3 nanometres. It purges etching chambers of contamination and tests wafer seals.
No substitute for helium exists in these manufacturing processes. Without it, EUV machines stop entirely not slowly, but completely.
Analyst Shanaka Perera wrote on X that helium is “the molecule the market is not pricing.” He added that without it, EUV machines stop “not slow down. Stop.” Bloomberg reported TSMC may prioritise AI chip production over consumer products during shortages.
Fitch Ratings flagged Taiwan and South Korea as the most exposed semiconductor economies. TSMC’s shares have fallen 7 percent since the war began.
Taiwan holds the smallest energy reserve among major semiconductor economies. South Korea holds 52 days of reserve; Japan holds three weeks.
Geopolitical Pressure Compounds Taiwan’s Strategic Energy Exposure
Taiwan’s Ministry of Economic Affairs says helium supplies are secured through mid-May. Negotiations for June are ongoing, and officials called the situation a controllable risk. The government also announced plans to raise the mandatory LNG reserve from 11 to 14 days next year.
The Persian Gulf war has redirected two US carrier strike groups away from the Pacific. This has thinned the naval presence that historically deters pressure on Taiwan. Regional tensions around Taiwan have been building since 2023.
Beijing does not need an invasion to apply pressure on Taiwan. A military exercise near the island during a supply crisis achieves disruption through perception. That signal alone can alter market behaviour and shipping logistics.
Perera noted that seven reinsurance letters closed the Strait of Hormuz commercially in five days. The same mechanism could apply to the Taiwan Strait, which is 110 miles wide at its broadest point. If risk models shift, insurance letters follow, and shipping stops without any military action.
Taiwan imports 97 percent of its energy, with one-third from the Middle East. Qatar remains the dominant LNG supplier.
The chain connecting helium, LNG, and the world’s advanced chips now runs through an active war zone. TSMC remains the most critical manufacturer of advanced semiconductors on Earth.
Resolv Labs moved Sunday to reassure users after an exploit hit the issuance mechanics of its USR stablecoin, knocking the token off its dollar peg and prompting decentralized finance (DeFi) protocols with exposure to move quickly to contain any fallout.
Cointelegraph reported earlier Sunday that an attacker exploited USR’s minting mechanics, creating tens of millions of unbacked tokens and dumping them through DeFi pools, which broke the stablecoin’s peg and prompted Resolv to pause protocol functions as it assessed the damage.
The token dropped as low as $0.14 (86% below its intended $1 price) after the exploit before rebounding to $0.42 at the time of writing, according to data from CoinGecko.
In a recent statement on X, the Resolv team said that the collateral pool “remains fully intact,” and that the problem appears “isolated to USR issuance mechanics.” Containment and impact assessment remain ongoing.
Onchain data from Arkham, corroborated by Web3 security firm Cyvers, showed that the attacker had converted most of the minted USR into Ether (ETH), selling part of the haul for about 11,400 ETH (around $24 million). Independent analysts also noted that the remaining 36.74 million USR was “still being continuously dumped.”

Michael Pearl, vice president GTM and strategy at Cyvers, told Cointelegraph that since the supply had inflated faster than the market could absorb and the token had immediately depegged, the value of the remaining tokens was significantly impaired.
Related: Google Threat Intel flags ‘Ghostblade’ crypto-stealing malware
DeFi protocols move to contain fallout
Decentralized finance (DeFi) protocols with exposure to Resolv raced to clarify their positions. Liquid staking provider Lido said that Lido Earn user funds were safe. Morpho cofounder Merlin Egalite emphasized that the lending protocol’s own contracts were unaffected and that only certain vaults had exposure, and Aave’s founder, Stani Kulechov, said that the platform had no direct USR exposure and that Resolv was repaying its outstanding debt.
The X account “yieldsandmore” pointed to potential losses in Resolv’s junior RLP tranche, highlighting possible knock-on effects for yield platforms such as Stream and yoUSD that used RLP as collateral.
Pearl told Cointelegraph that, based on available data, the exposure appeared to be “relatively concentrated” in lending markets and leverage loops “rather than system-wide,” and primarily in protocols that integrated USR, wstUSR, or RLP into lending, leverage or yield strategies.
Related: Hacked crypto tokens drop 61% on average and rarely recover, Immunefi report says
He said that several protocols, such as Euler, Venus, Lista and Fluid, had taken precautionary actions such as pausing markets or isolating vaults, while others had declared no exposure at all. “It is more accurate to describe the risk as concentrated with localized spillover, rather than widespread contagion,” he said.
Ledger chief technical officer Charles Guillemet also assessed the fallout on X, stating that, due to the relatively small size of USR, “this is not a Terra Luna-type event.”
Questions around limitations of security audits
Resolv’s smart contracts have undergone multiple audits since 2024, but Pearl said that, while audits were “necessary,” they were also “inherently static and scoped.” Real-time, artificial intelligence-powered monitoring to “continuously analyze protocol activity” was needed, he argued, to detect anomalies as they emerge.
For stablecoin systems specifically, he said that meant monitoring mint and burn flows against expected behavior in real time, continuously validating supply against reserves and backing assets, and detecting anomalies in oracle inputs, pricing and liquidity conditions.
Security firm Pashov, which audited Resolv’s staking module in July 2025, told Cointelegraph that Resolv’s design was “good,” and that the root cause was “not the design so much as the private key compromise,” which was likely an operational security flaw. “We have to understand how that happens,” he said.
Cointelegraph reached out to Resolv Labs for comment but had not received a response by publication.
AI Eye: IronClaw rivals OpenClaw, Olas launches bots for Polymarket
Bitcoin’s (BTC) price has recently slipped back toward $68,000, erasing some of its gains from the previous weeks.
Summary
- Bitcoin struggles at $68K due to macro factors, including the Fed’s stance and geopolitical tensions.
- Bitcoin ETFs saw a reversal, with $300M pulled out, contributing to the recent price decline.
- Geopolitical tensions and Fed’s comments on inflation pressure Bitcoin’s price, adding volatility.
Bitcoin’s price had previously surged to a six-week high of $76,000, recovering $13,000 since the escalation of the Middle East conflict. However, after reaching this peak, Bitcoin faced a sharp rejection and has since fallen by $8,000.
The price volatility is compounded by broader market trends, as Bitcoin now struggles to maintain its position above the $68,000 support level. The current trading range is marked by price fluctuations, with Bitcoin caught between support at $68,000 and resistance at $76,000.
Analysts, including Michaël van de Poppe, have noted that Bitcoin is stuck within a range, awaiting a breakout. Van de Poppe stated, “Nothing special so far for $BTC,” suggesting that Bitcoin’s movement remains largely dependent on reaching either the lower or upper bounds of the range, where traders may act on the volatility.
Macro factors and federal reserve’s influence
A major reason behind Bitcoin’s recent price decline can be traced to the Federal Reserve’s stance on interest rates. Despite expectations that no changes would be made during its latest meeting, Fed Chair Jerome Powell’s hawkish remarks about inflation concerns have added pressure on risk assets like Bitcoin. Powell indicated that rate cuts may not occur for over a year, leading to uncertainty in markets, including cryptocurrencies.
This outlook has contributed to a more cautious approach from investors, as market volatility tends to increase under such conditions. As predictions suggest that rate cuts could be delayed, Bitcoin’s price faces downward pressure, mirroring the broader downturn in risk assets.
In addition, geopolitical developments, particularly the escalating tensions in the Middle East, also played a role in Bitcoin’s price decline. A dramatic dip was observed after U.S. President Trump made threats regarding Iran, which caused a brief but sharp drop in Bitcoin’s price. These events highlight the sensitive nature of Bitcoin as a risk-on asset, reacting swiftly to global political unrest.
Bitcoin’s volatility is often exacerbated by such geopolitical tensions, as investors move funds into or out of assets like Bitcoin based on the prevailing market sentiment.
ETF reversal and capital outflows
Another factor contributing to Bitcoin’s price decline is the reversal in ETF inflows. Bitcoin ETFs had seen a strong seven-day streak of positive inflows, reaching $200 million on March 17.
However, in the days that followed, investors began pulling funds out, with more than $300 million in withdrawals over the course of three days. This sudden shift in ETF flows coincided with Bitcoin’s price correction, indicating that institutional sentiment may be cooling, adding to the overall market pressure.
Disclosure: This article does not represent investment advice. The content and materials featured on this page are for educational purposes only.
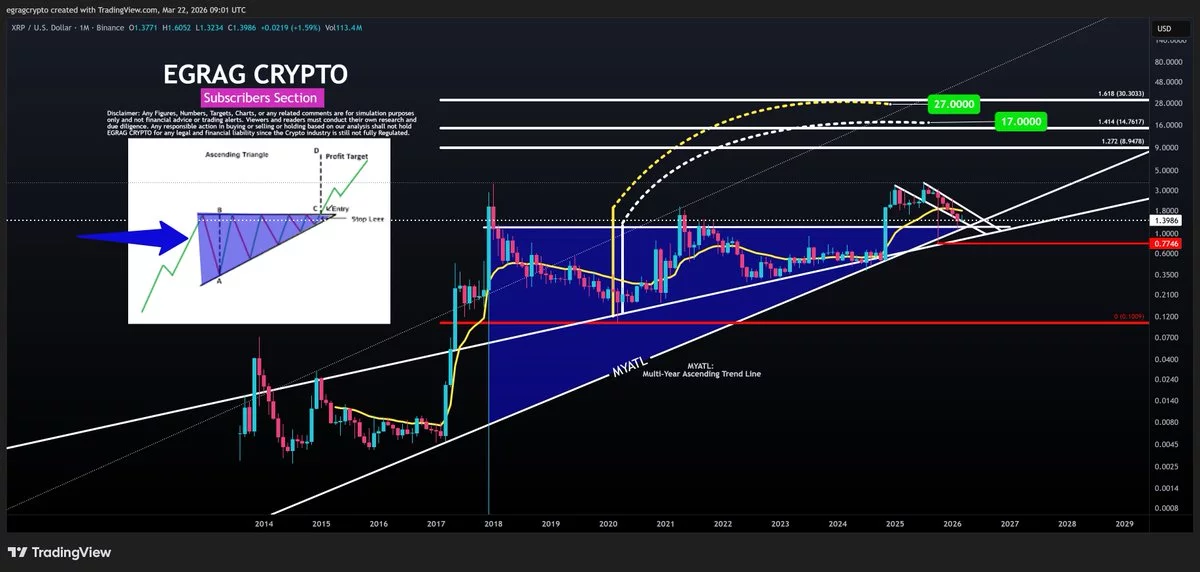
Ripple’s (XRP) price has recently slipped after a failed recovery attempt, with high-volume selling pushing the token back toward a key support level of $1.40. The token has struggled with a broader corrective phase since its peak in mid-2025, with rallies consistently failing to build momentum.
Summary
- XRP’s price drops to $1.40, facing a broader corrective phase since mid-2025.
- Retail investors continue to support XRP, while institutional interest remains cautious.
- XRP’s price action depends on upcoming regulatory developments and macroeconomic conditions.
XRP’s price is currently $1.40, experiencing a 3% decline over the past 24 hours. The cryptocurrency’s market cap stands at approximately $86 billion.
Despite some short-term attempts at recovery, XRP remains trapped in a larger corrective phase. The latest pullback comes after a brief rebound in mid-March, which failed to surpass the $1.60 mark.
XRP’s price struggles are compounded by macroeconomic factors, with the Federal Reserve’s recent policy stance influencing broader market sentiment. This has led to a cautious trading environment for many cryptocurrencies, including XRP. While the asset’s technical structure shows some resilience, traders are closely monitoring whether XRP can stabilize or continue to fall within its established range.
Retail adoption and institutional caution
While institutional interest in XRP remains cautious, the cryptocurrency continues to see strong support from retail investors. According to crypto analyst Egrag Crypto, XRP is currently in the retest phase of a macro ascending triangle, and the pullback in price is seen as confirmation rather than weakness. Egrag highlights a bullish long-term view, with potential price targets for XRP reaching $8, $17, and $27, provided the trendline holds.
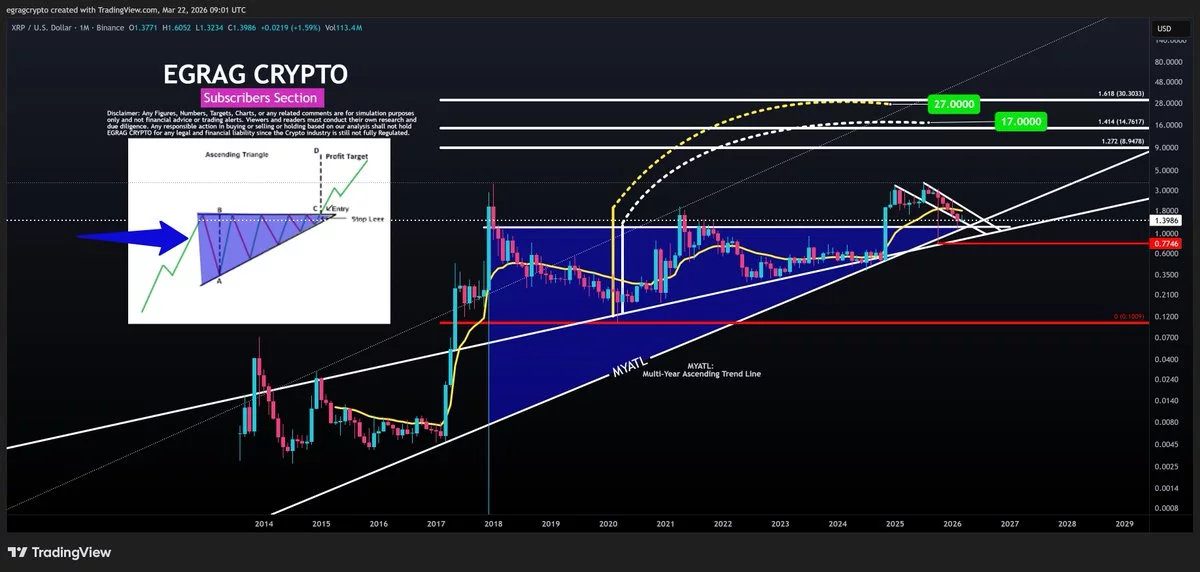
Retail demand is becoming a key driver of XRP’s growth, with blockchain data showing a strong retail presence. Analysts are optimistic about the asset’s future potential, especially as macroeconomic factors and regulatory clarity evolve. However, skepticism remains within institutional circles, reflecting the more conservative approach from major investors.
XRP’s exchange activity signals resilience
Despite recent price declines, XRP continues to show resilience, with activity on top crypto exchanges, particularly Binance, signaling sustained demand. Data from CryptoQuant shows a modest shortage of XRP reserves on Binance, dropping to $2.79 billion as of March 22.
This suggests that traders are either holding onto their XRP or buying more, rather than selling off their holdings. XRP’s performance on exchanges indicates that the asset has not lost its appeal to investors, even amid the broader market downturn.
Moreover, XRP’s price action will likely depend on upcoming regulatory developments and broader market conditions. Analyst X Finance Bull points out that various catalysts, including the potential passage of the CLARITY Act and growing institutional interest, could provide upward momentum for XRP. However, the asset’s performance will continue to be shaped by both retail sentiment and institutional caution, creating a complex market dynamic moving forward.
Disclosure: This article does not represent investment advice. The content and materials featured on this page are for educational purposes only.

Bitcoin faced a retreat after a brief surge tied to geopolitical jitters, slipping back in line with the broader risk-off tone that has weighed on US equities in recent sessions. The move underscores a renewed relationship between BTC and traditional markets as macro headwinds persist.
As of Sunday, BTC/USD traded around $68,700, down about 5.7% for the week, while the S&P 500 finished the period down roughly 1.9%. The renewed correlation with equities adds a layer of caution for traders who had hoped for a decoupling amid persistent inflation, elevated oil prices, and a less favorable outlook for aggressive monetary easing.
Key takeaways
- Bitcoin’s recent uptick in correlation with the S&P 500 has historically preceded deeper price declines, with average drawdowns near 50% since 2018.
- The BTC-SPX relationship has tightened again, with the 20-week rolling correlation easing to about 0.13 after previously flirting with negative territory.
- Absent fresh buying by major strategic holders, Bitcoin remains vulnerable to a broader risk-off sell-off that could pull BTC lower along with equities.
- Analysts have pointed to downside targets around $34,350 if the historical pattern repeats; some projections still contemplate a Bitcoin bottom in the $30k–$40k range in the longer run, depending on macro developments.
Correlation with equities reemerges as a market signal
The renewed BTC-Stock connection is being watched closely by traders and analysts. A rising 20-week correlation between BTC and the S&P 500 suggests that Bitcoin may be increasingly swept up in risk-off dynamics that pressure equities, rather than acting as a separate flight-to-safety vehicle. The latest reading sits near 0.13, a rebound from a period when the metric briefly hovered around negative territory, underscoring how quickly Bitcoin can move in step with the stock complex during macro stress.
Historically, patterns where BTC begins to track the stock market more closely have tended to precede larger corrections in Bitcoin’s price. Tony Severino, a market analyst, described the dynamic as a warning sign that a broader stock-market pullback could pull BTC lower as well. While past performance is not a guarantee of future moves, the implication for traders is clear: macro headwinds can reassert themselves and pull the crypto cycle back toward the risk-off regime seen in prior cycles.
From a price perspective, the research across periods since 2018 points to severe downside when the BTC-SPX correlation strengthens after a long stretch of independence. If the current pattern holds, a hypothetical 50% decline from the present level would place Bitcoin near $34,350—a level some analysts have flagged as a plausible target if weaker macro conditions persist and risk assets continue to slide.
Macro backdrop and the path to a potential bottom
The renewed risk-off tone is reinforced by macro indicators that weigh on Bitcoin’s near-term trajectory. Elevated oil prices, ongoing inflation pressures, and a less-than-dovish stance on rate expectations all contribute to a bearish tilt for both stocks and risk assets, including BTC. In this environment, the likelihood of a policy shift that would spur a quick re-acceleration in risk appetites appears constrained in the near term, adding another layer of complexity for traders trying to gauge the timing of any meaningful crypto upcycle.
Market observers have revisited historical analogs where Bitcoin’s price action lagged turns in the equity market. In 2020 and 2022, for instance, Bitcoin’s declines often followed shifts in equity correlations after bullish false starts that briefly lifted BTC before selling pressure resumed. The current backdrop—tighter correlations paired with macro headwinds—suggests investors should brace for a broader test of BTC’s resilience if risk appetite remains elusive.
Strategic holdings pause compounds caution
The intraweek dynamic around strategic Bitcoin buyers adds another dimension to the risk calculus. Strategy (the firm behind the STRC vehicle) has not executed fresh BTC purchases through its STRC listing this week, per data tracked by STRC.LIVE. This follows a March 16 action in which the firm declared a buy that added 22,337 BTC worth about $1.57 billion, lifting its total holdings to roughly 761,068 BTC. That purchase had coincided with a period when Bitcoin outperformed US stocks, contributing to a temporary resilience in the crypto market.
With no new buys this week, Bitcoin’s near-term outlook hinges more on external risk appetite than on the stabilizing force of large, long-duration demand from major corporate buyers. In a risk-off regime, the absence of fresh strategic accumulation could leave BTC more exposed to downdrafts in the broader market, rather than benefiting from any immediate, independent crypto-driven catalysts.
As the market weighs macro signals and evolving correlations, investors are paying closer attention to how BTC behaves as equities navigate volatility. The question remains whether Bitcoin can reassert its own narrative—an inflation hedge narrative or a technology-led growth story—or if it continues to ride the coattails of stock-market dynamics until macro headwinds ease.
This article does not constitute investment advice. Readers should conduct their own research and consider their risk tolerance before making trading decisions.

Bitcoin and most altcoins experienced a decline in value following recent geopolitical developments, with Bitcoin facing rejection at $71,000.
Summary
- Bitcoin and altcoins see sharp declines, while SIREN surges 90% in 24 hours.
- Ethereum, XRP, and Solana follow Bitcoin’s downward trend, losing significant value.
- The crypto market cap drops $200B as macroeconomic factors weigh heavily on prices.
The broader cryptocurrency market, including Ethereum, XRP, and other major tokens, followed Bitcoin’s downward trend. Meanwhile, one altcoin, SIREN, managed to defy the market slump with a significant surge.
Bitcoin’s price faced significant volatility this week, with a high of $76,000 on Monday after it broke above $74,000. However, its upward momentum was short-lived, and the price quickly returned to $74,000 by Wednesday.
Volatility spiked ahead of and after the Federal Open Market Committee (FOMC) meeting, with Bitcoin falling by $3,000 before the event. After the Federal Reserve decided to leave interest rates unchanged, Bitcoin briefly bounced back to $72,000.
However, hawkish comments from Fed Chairman Jerome Powell regarding no rate reductions in 2026 led to another drop, with Bitcoin reaching a three-week low of around $68,000. Despite efforts to recover, the cryptocurrency is still struggling to regain stability.
Altcoins follow Bitcoin’s decline
Ethereum has experienced a decline of over $300 since its peak of $2,400, dropping below $2,100. XRP also saw a sharp drop, rejected at $1.60, and now struggles below $1.40. Other prominent altcoins like Solana (SOL), Cardano (ADA), Dogecoin (DOGE), Binance Coin (BNB), and Chainlink (LINK) are all down by 2-4% in the past 24 hours.
One of the worst performers in this market downturn has been HYPE, which lost almost 5% of its value and now trades around $38. ZEC (Zcash) also experienced a significant drop, shedding 7% of its value. Other altcoins such as AAVE, DOT, and SUI are down by 3-4%.

SIREN defies the market slump
While the majority of the crypto market faced losses, SIREN, an AI-focused cryptocurrency operating on the BNB chain, saw a remarkable surge. The token skyrocketed by 90% in the past 24 hours, reaching a new all-time high of over $1.70.
SIREN’s performance stands in contrast to the broader market slump, making it one of the standout performers during this period of market uncertainty.
Moreover, the total cryptocurrency market cap has taken a hit, shedding nearly $200 billion since Wednesday morning. As of the latest data, the total market cap stands at $2.43 trillion. This decline is a direct result of the drop in Bitcoin and altcoin prices, which have been influenced by both macroeconomic factors and market sentiment following the FOMC meeting.
Disclosure: This article does not represent investment advice. The content and materials featured on this page are for educational purposes only.


A new report from 10x Research reveals that the cryptocurrency market is currently seeing a divide in capital flows between retail and institutional investors. While institutional capital continues to support assets like Solana (SOL) and Ethereum (ETH), the XRP ecosystem is experiencing strong growth driven by retail adoption.
Summary
- XRP’s growth is largely driven by strong retail demand, with limited institutional involvement.
- Institutional capital favors Solana and Ethereum, with XRP receiving cautious interest.
- XRP Ledger sees growing retail participation, with 5.66M wallets holding under 100 XRP.
According to the 10x Research report, XRP’s price action is mainly supported by “strong retail demand and expanding utility.” The XRP ecosystem is seeing increasing adoption, with retail investors leading the charge in its growth.
While institutional interest in XRP remains cautious, retail investors continue to push the asset forward. The XRP Ledger (XRPL) is developing real-world use cases, but the absence of significant institutional flows reflects a more conservative stance from Wall Street.
Institutional capital continues to be a driving force for other major cryptocurrencies, particularly Solana and Ethereum. According to the report, institutional interest in Solana remains strong, as shown by its $20 million in ETF net flows for the week, while Ethereum has seen institutional outflows of $60 million.
In contrast, XRP ETFs only saw a modest $0.6 million in positive flows, reinforcing the notion that institutional investors are still cautious about XRP despite its growing retail base.
In addition, XRP’s strength is being supported by growing on-chain retail adoption. Blockchain analytics firm Santiment reported that the XRP Ledger recently reached a new milestone, with 5.66 million wallets holding under 100 XRP. This surge in retail participation signals that the XRP ecosystem is attracting more users despite the lack of significant institutional investment.


Ripple’s CTO emeritus David Schwartz recently engaged in an interesting exchange on X, responding to a post about XRP with a meme and supporting comments.
Summary
- David Schwartz responded to Solana with a meme, fueling the ongoing XRP-Solana rivalry.
- XRP’s integration on Solana through wrapped tokens highlights growing blockchain collaboration.
- XRP Ledger sees increased activity, but AI tools may cause failed transactions and higher fees.
Meanwhile, the interaction occurred after a statement from Solana Foundation President Lily Liu, which sparked reactions from the crypto community, particularly surrounding the future of blockchain gaming.
The conversation began when Solana’s official X account responded to a tweet from the Solana Foundation President, Lily Liu, who had stated that blockchain gaming was “not coming back.” In response, an X user jokingly announced they were switching chains and asked for a recommendation. Solana’s official account replied, saying,
“we hear XRP is nice this time of year.”
This prompted Ripple CTO emeritus David Schwartz to engage with the tweet from XRP-friendly exchange Bitrue. Bitrue had shared Solana’s tweet, and Schwartz responded with a GIF meme saying, “You’re goddamn right,” further fueling the ongoing discussion about XRP and Solana’s relationship. This playful back-and-forth highlighted the ongoing rivalry and camaraderie between the two blockchain ecosystems.
In December 2025, XRP made its way onto the Solana blockchain via Hex Trust’s wrapped XRP (wXRP) token. This move allowed XRP to be traded alongside the Ripple USD stablecoin (RLUSD) on the Solana network, marking a significant step in the collaboration between the two blockchains. The integration also raised curiosity about how these ecosystems could coexist and complement each other.
Schwartz’s response reflects the growing relationship between the two projects. Despite the ongoing competition in the blockchain space, it appears that XRP and Solana are finding ways to collaborate and engage with each other’s communities.
XRP Ledger activity and AI coding
Meanwhile, XRP Ledger (XRPL) has seen a spike in activity recently, with XRPL validator Vet suggesting that increased use of AI tools and scripts might be contributing to the rise in transactions. While this increase in activity is positive, Vet pointed out that it often results in complex queries or failed transactions, which can overload public infrastructure.
One user experienced a costly mishap, spending over $2,000 in transaction fees due to failed XRP Ledger transactions. Vet cautioned that while AI tools may improve efficiency, users should remain cautious and oversee their transactions to prevent potential issues.

Cuba starts restoring power after nationwide grid collapse

Allegations against ICC war crimes prosecutor still under review despite report he was cleared
Bitcoin Dips Below $70,000 as Extreme Fear Index Hits 10: What Traders Are Watching Next






-

 Tech7 days ago
Tech7 days agoYour Legally Registered ‘Motorcycle’ Might Not Count Under Proposed US Law
-

 Fashion2 days ago
Fashion2 days agoWeekend Open Thread: Adidas – Corporette.com
-

 Politics2 days ago
Politics2 days agoJenni Murray, Long-Serving Woman’s Hour Presenter, Dies Aged 75
-
 Tech5 days ago
Tech5 days agoAre Split Spacebars the Next Big Gaming Keyboard Trend?
-

 Crypto World16 hours ago
Crypto World16 hours agoBest Crypto to Buy Now: Strategy Just Spent $1.57 Billion on Bitcoin During Fear While Early Investors Quietly Enter Pepeto for 150x Potential
-

 News Videos4 days ago
News Videos4 days agoRBA board divided on rate cut, unusually buoyant share market | Finance Report | ABC NEWS
-

 Crypto World17 hours ago
Crypto World17 hours agoBitcoin Price News: Bhutan Sells $72 Million in BTC Under Fiscal Pressure, but the Smart Money Entering Pepeto Sees What the Market Does Not
-

 Business7 days ago
Business7 days agoSearch for Savannah Guthrie’s Mother Enters Seventh Week with No Arrests
-
 Crypto World2 days ago
Crypto World2 days agoNIO (NIO) Stock Plunges 6.5% as Shelf Registration Sparks Dilution Worries
-

 Business6 days ago
Business6 days agoAustralian shares drop as Iran war enters third week
-

 Crypto World6 days ago
Crypto World6 days agoCrypto Lender BlockFills Enters Chapter 11 with Up to $500M in Liabilities
-

 Politics4 days ago
Politics4 days agoThe House | The new register to protect children from their abusers shows Parliament at its best
-

 Fashion6 days ago
Fashion6 days ago25 Celebrities with Curly Hair That Are Naturally Beautiful
-

 Tech2 days ago
Tech2 days agoinKONBINI Lets You Spend Summer Days Behind the Register
-

 Crypto World4 days ago
Crypto World4 days agoCanada’s FINTRAC revokes registrations of 23 crypto MSBs in AML crackdown
-
 Politics5 days ago
Politics5 days agoReal-time pollution monitoring calls after boy nearly dies
-
 NewsBeat4 days ago
NewsBeat4 days agoResidents in North Lanarkshire reminded to register to vote in Scottish Parliament Election
-

 Business6 days ago
Business6 days agoMeta planning major layoffs as AI spending and automation reshape workforce
-

 News Videos4 days ago
News Videos4 days agoPARLIAMENT OF MALAWI – PAC MEETING WITH REGISTRAR OF FINANCIAL ON AMARYLLIS HOTEL – INQUIRY LIVE
-
Crypto World7 days ago
U.S. Oil Companies Post Record Profits as Oil Prices Break $100
You must be logged in to post a comment Login