Anthropic dropped a bombshell on the artificial intelligence industry Monday, publicly accusing three prominent Chinese AI laboratories — DeepSeek, Moonshot AI, and MiniMax — of orchestrating coordinated, industrial-scale campaigns to siphon capabilities from its Claude models using tens of thousands of fraudulent accounts.
The San Francisco-based company said the three labs collectively generated more than 16 million exchanges with Claude through approximately 24,000 fake accounts, all in violation of Anthropic’s terms of service and regional access restrictions. The campaigns, Anthropic said, are the most concrete and detailed public evidence to date of a practice that has haunted Silicon Valley for months: foreign competitors systematically using a technique called distillation to leapfrog years of research and billions of dollars in investment.
“These campaigns are growing in intensity and sophistication,” Anthropic wrote in a technical blog post published Monday. “The window to act is narrow, and the threat extends beyond any single company or region. Addressing it will require rapid, coordinated action among industry players, policymakers, and the global AI community.”
The disclosure marks a dramatic escalation in the simmering tensions between American and Chinese AI developers — and it arrives at a moment when Washington is actively debating whether to tighten or loosen export controls on the advanced chips that power AI training. Anthropic, led by CEO Dario Amodei, has been among the most vocal advocates for restricting chip sales to China, and the company explicitly connected Monday’s revelations to that policy fight.
Advertisement
How AI distillation went from obscure research technique to geopolitical flashpoint
To understand what Anthropic alleges, it helps to understand what distillation actually is — and how it evolved from an academic curiosity into the most contentious issue in the global AI race.
At its core, distillation is a process of extracting knowledge from a larger, more powerful AI model — the “teacher” — to create a smaller, more efficient one — the “student.” The student model learns not from raw data, but from the teacher’s outputs: its answers, reasoning patterns, and behaviors. Done correctly, the student can achieve performance remarkably close to the teacher’s while requiring a fraction of the compute to train.
As Anthropic itself acknowledged, distillation is “a widely used and legitimate training method.” Frontier AI labs, including Anthropic, routinely distill their own models to create smaller, cheaper versions for customers. But the same technique can be weaponized. A competitor can pose as a legitimate customer, bombard a frontier model with carefully crafted prompts, collect the outputs, and use those outputs to train a rival system — capturing capabilities that took years and hundreds of millions of dollars to develop.
The technique burst into public consciousness in January 2025 when DeepSeek released its R1 reasoning model, which appeared to match or approach the performance of leading American models at dramatically lower cost. Databricks CEO Ali Ghodsi captured the industry’s anxiety at the time, telling CNBC: “This distillation technique is just so extremely powerful and so extremely cheap, and it’s just available to anyone.” He predicted the technique would usher in an era of intense competition for large language models.
Advertisement
That prediction proved prescient. In the weeks following DeepSeek’s release, researchers at UC Berkeley said they recreated OpenAI’s reasoning model for just $450 in 19 hours. Researchers at Stanford and the University of Washington followed with their own version built in 26 minutes for under $50 in compute credits. The startup Hugging Face replicated OpenAI’s Deep Research feature as a 24-hour coding challenge. DeepSeek itself openly released a family of distilled models on Hugging Face — including versions built on top of Qwen and Llama architectures — under the permissive MIT license, with the model card explicitly stating that the DeepSeek-R1 series supports commercial use and allows for any modifications and derivative works, “including, but not limited to, distillation for training other LLMs.”
But what Anthropic described Monday goes far beyond academic replication or open-source experimentation. The company detailed what it characterized as deliberate, covert, and large-scale intellectual property extraction by well-resourced commercial laboratories operating under the jurisdiction of the Chinese government.
Anthropic traces 16 million fraudulent exchanges to researchers at DeepSeek, Moonshot, and MiniMax
Anthropic attributed each campaign “with high confidence” through IP address correlation, request metadata, infrastructure indicators, and corroboration from unnamed industry partners who observed the same actors on their own platforms. Each campaign specifically targeted what Anthropic described as Claude’s most differentiated capabilities: agentic reasoning, tool use, and coding.
DeepSeek, the company that ignited the distillation debate, conducted what Anthropic described as the most technically sophisticated of the three operations, generating over 150,000 exchanges with Claude. Anthropic said DeepSeek’s prompts targeted reasoning capabilities, rubric-based grading tasks designed to make Claude function as a reward model for reinforcement learning, and — in a detail likely to draw particular political attention — the creation of “censorship-safe alternatives to policy sensitive queries.”
Advertisement
Anthropic alleged that DeepSeek “generated synchronized traffic across accounts” with “identical patterns, shared payment methods, and coordinated timing” that suggested load balancing to maximize throughput while evading detection. In one particularly notable technique, Anthropic said DeepSeek’s prompts “asked Claude to imagine and articulate the internal reasoning behind a completed response and write it out step by step — effectively generating chain-of-thought training data at scale.” The company also alleged it observed tasks in which Claude was used to generate alternatives to politically sensitive queries about “dissidents, party leaders, or authoritarianism,” likely to train DeepSeek’s own models to steer conversations away from censored topics. Anthropic said it was able to trace these accounts to specific researchers at the lab.
Moonshot AI, the Beijing-based creator of the Kimi models, ran the second-largest operation by volume at over 3.4 million exchanges. Anthropic said Moonshot targeted agentic reasoning and tool use, coding and data analysis, computer-use agent development, and computer vision. The company employed “hundreds of fraudulent accounts spanning multiple access pathways,” making the campaign harder to detect as a coordinated operation. Anthropic attributed the campaign through request metadata that “matched the public profiles of senior Moonshot staff.” In a later phase, Anthropic said, Moonshot adopted a more targeted approach, “attempting to extract and reconstruct Claude’s reasoning traces.”
MiniMax, the least publicly known of the three but the most prolific by volume, generated over 13 million exchanges — more than three-quarters of the total. Anthropic said MiniMax’s campaign focused on agentic coding, tool use, and orchestration. The company said it detected MiniMax’s campaign while it was still active, “before MiniMax released the model it was training,” giving Anthropic “unprecedented visibility into the life cycle of distillation attacks, from data generation through to model launch.” In a detail that underscores the urgency and opportunism Anthropic alleges, the company said that when it released a new model during MiniMax’s active campaign, MiniMax “pivoted within 24 hours, redirecting nearly half their traffic to capture capabilities from our latest system.”
How proxy networks and ‘hydra cluster’ architectures helped Chinese labs bypass Anthropic’s China ban
Anthropic does not currently offer commercial access to Claude in China, a policy it maintains for national security reasons. So how did these labs access the models at all?
Advertisement
The answer, Anthropic said, lies in commercial proxy services that resell access to Claude and other frontier AI models at scale. Anthropic described these services as running what it calls “hydra cluster” architectures — sprawling networks of fraudulent accounts that distribute traffic across Anthropic’s API and third-party cloud platforms. “The breadth of these networks means that there are no single points of failure,” Anthropic wrote. “When one account is banned, a new one takes its place.” In one case, Anthropic said, a single proxy network managed more than 20,000 fraudulent accounts simultaneously, mixing distillation traffic with unrelated customer requests to make detection harder.
The description suggests a mature and well-resourced infrastructure ecosystem dedicated to circumventing access controls — one that may serve many more clients than just the three labs Anthropic named.
Why Anthropic framed distillation as a national security crisis, not just an IP dispute
Anthropic did not treat this as a mere terms-of-service violation. The company embedded its technical disclosure within an explicit national security argument, warning that “illicitly distilled models lack necessary safeguards, creating significant national security risks.”
The company argued that models built through illicit distillation are “unlikely to retain” the safety guardrails that American companies build into their systems — protections designed to prevent AI from being used to develop bioweapons, carry out cyberattacks, or enable mass surveillance. “Foreign labs that distill American models can then feed these unprotected capabilities into military, intelligence, and surveillance systems,” Anthropic wrote, “enabling authoritarian governments to deploy frontier AI for offensive cyber operations, disinformation campaigns, and mass surveillance.”
Advertisement
This framing directly connects to the chip export control debate that Amodei has made a centerpiece of his public advocacy. In a detailed essay published in January 2025, Amodei argued that export controls are “the most important determinant of whether we end up in a unipolar or bipolar world” — a world where either only the U.S. and its allies possess the most powerful AI, or one where China achieves parity. He specifically noted at the time that he was “not taking any position on reports of distillation from Western models” and would “just take DeepSeek at their word that they trained it the way they said in the paper.”
Monday’s disclosure is a sharp departure from that earlier restraint. Anthropic now argues that distillation attacks “undermine” export controls “by allowing foreign labs, including those subject to the control of the Chinese Communist Party, to close the competitive advantage that export controls are designed to preserve through other means.” The company went further, asserting that “without visibility into these attacks, the apparently rapid advancements made by these labs are incorrectly taken as evidence that export controls are ineffective.” In other words, Anthropic is arguing that what some observers interpreted as proof that Chinese labs can innovate around chip restrictions was actually, in significant part, the result of stealing American capabilities.
The murky legal landscape around AI distillation may explain Anthropic’s political strategy
Anthropic’s decision to frame this as a national security issue rather than a legal dispute may reflect the difficult reality that intellectual property law offers limited recourse against distillation.
As a March 2025 analysis by the law firm Winston & Strawn noted, “the legal landscape surrounding AI distillation is unclear and evolving.” The firm’s attorneys observed that proving a copyright claim in this context would be challenging, since it remains unclear whether the outputs of AI models qualify as copyrightable creative expression. The U.S. Copyright Office affirmed in January 2025 that copyright protection requires human authorship, and that “mere provision of prompts does not render the outputs copyrightable.”
Advertisement
The legal picture is further complicated by the way frontier labs structure output ownership. OpenAI’s terms of use, for instance, assign ownership of model outputs to the user — meaning that even if a company can prove extraction occurred, it may not hold copyrights over the extracted data. Winston & Strawn noted that this dynamic means “even if OpenAI can present enough evidence to show that DeepSeek extracted data from its models, OpenAI likely does not have copyrights over the data.” The same logic would almost certainly apply to Anthropic’s outputs.
Contract law may offer a more promising avenue. Anthropic’s terms of service prohibit the kind of systematic extraction the company describes, and violation of those terms is a more straightforward legal claim than copyright infringement. But enforcing contractual terms against entities operating through proxy services and fraudulent accounts in a foreign jurisdiction presents its own formidable challenges.
This may explain why Anthropic chose the national security frame over a purely legal one. By positioning distillation attacks as threats to export control regimes and democratic security rather than as intellectual property disputes, Anthropic appeals to policymakers and regulators who have tools — sanctions, entity list designations, enhanced export restrictions — that go far beyond what civil litigation could achieve.
What Anthropic’s distillation crackdown means for every company running a frontier AI model
Anthropic outlined a multipronged defensive response. The company said it has built classifiers and behavioral fingerprinting systems designed to identify distillation attack patterns in API traffic, including detection of chain-of-thought elicitation used to construct reasoning training data. It is sharing technical indicators with other AI labs, cloud providers, and relevant authorities to build what it described as a more holistic picture of the distillation landscape. The company has also strengthened verification for educational accounts, security research programs, and startup organizations — the pathways most commonly exploited for setting up fraudulent accounts — and is developing model-level safeguards designed to reduce the usefulness of outputs for illicit distillation without degrading the experience for legitimate customers.
Advertisement
But the company acknowledged that “no company can solve this alone,” calling for coordinated action across the industry, cloud providers, and policymakers.
The disclosure is likely to reverberate through multiple ongoing policy debates. In Congress, the bipartisan No DeepSeek on Government Devices Act has already been introduced. Federal agencies including NASA have banned DeepSeek from employee devices. And the broader question of chip export controls — which the Trump administration has been weighing amid competing pressures from Nvidia and national security hawks — now has a new and vivid data point.
For the AI industry’s technical decision-makers, the implications are immediate and practical. If Anthropic’s account is accurate, the proxy infrastructure enabling these attacks is vast, sophisticated, and adaptable — and it is not limited to targeting a single company. Every frontier AI lab with an API is a potential target. The era of treating model access as a simple commercial transaction may be coming to an end, replaced by one in which API security is as strategically important as the model weights themselves.
Anthropic has now put names, numbers, and forensic detail behind accusations that the industry had only whispered about for months. Whether that evidence galvanizes the coordinated response the company is calling for — or simply accelerates an arms race between distillers and defenders — may depend on a question no classifier can answer: whether Washington sees this as an act of espionage or just the cost of doing business in an era when intelligence itself has become a commodity.
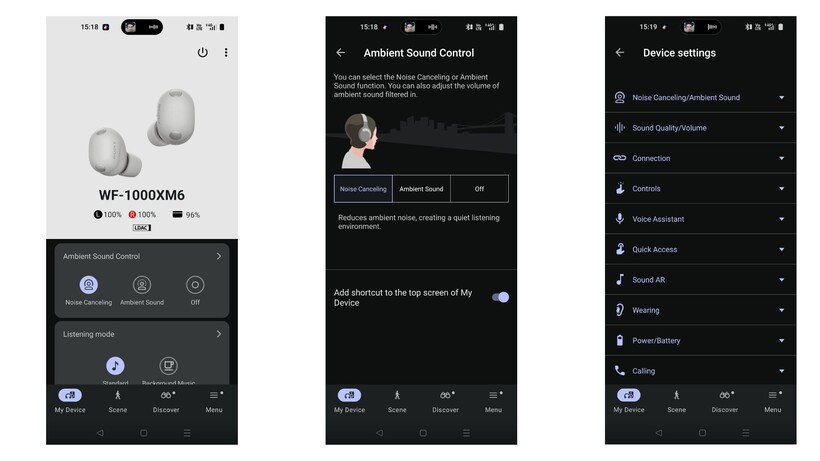
The Sony WF-1000XM6 earbuds are the newer of the two and, unsurprisingly, naturally have a higher price tag at £249/$249.
Advertisement
Advertisement
Although the WF-1000XM5s are the older pair, they’re still readily available to buy. Not only that but, although the earbuds’ official RRP is £199/$199, it’s not impossible to find a hefty price cut for them. For example, at the time of writing, the XM5 buds were just £169 on Sony’s official site.
Design
Sony WF-1000XM6s are chunkier though slimmer in profile
Both are comfortable to wear, although the XM6 buds can be more fiddly to wear
Both are IPX4
Although both the WF-1000XM6 and the XM5 are relatively slim and definitely pocketable, there are a few notable differences between the two.
Firstly, due to the additional microphone, the XM6 model is slightly chunkier than its predecessor, and subsequently can make the earbuds fiddly to wear and fit correctly. While we never noted an issue with comfort, we did struggle to get a perfectly airtight seal for ANC. Using the Sony Sound Connect app, we found the earbuds struggled to pass Sony’s strict test for a suitable seal. It’s frustrating, but fortunately doesn’t seem to impede the ANC too much – but more on that later.
Otherwise, both earbuds are fitted with responsive touch controls that cover playback, switching between ANC modes, volume control and more, all of which can be customised via the companion app.
Advertisement
Advertisement
In addition, both earbuds are fitted with the same stiffer ear-tips that aim to plug your ears more effectively than silicon alternatives, and both have an IPX4 rating too. This means both buds can withstand sweat and rain drops.
Winner: Sony WF-1000XM5
Sony WF-1000XM6
Advertisement
Sony WF-1000XM5
Features
Both earbuds are packed with features, including Speak to Chat, Adaptive Sound Control and voice assistants
Both also support 360 Reality Audio and can be connected to two devices at once
With both, you’ll benefit from the likes of Quick Attention Mode, Speak to Chat and Adaptive Sound Control. There’s also head gesture control, your choice of voice assistant and a clever Find Your Equalizer that allows you to adjust the sound more intuitively than playing around with bands and frequencies.
Controlling both Sony earbuds is done via the Sound Connect smartphone app, and allows you to customise touch controls, noise-cancellation modes and the Bluetooth connection too. While we wish the app was a bit more streamlined, overall it’s a solid companion piece to the buds.
Advertisement
Advertisement
Sony Sound Connect app. Image Credit (Trusted Reviews)
One especially interesting feature on the app is the Discover section that has features like your listening history across all music services, plus logs how long you use the headphones and includes badges to help game-mify the experience too. How useful this is will depend really on your personal preference, but it shows just how feature-packed the buds are.
Winner: Tie
Sound Quality
WF-1000XM6 has a larger 8.4mm driver
Both offer a clear, balanced approach across the frequency range, however the XM6 have improved highs
Overall, the XM6 is more vibrant and energetic compared to the XM5
Although there are differences between the two, it’s worth noting that both the XM6 and XM5 are brilliant sounding earbuds. However, thanks to the larger 8.4mm driver at play here, the XM6 offers a wider soundstage compared to the XM5. In fact, we found that not only were highs improved, with more clarity and detail, but bass felt weightier too. This is especially noteworthy, as we concluded that bass lovers might be a bit disappointed by the XM5’s more balanced approach.
In addition, we noted that at its default volume, the XM6 picks up more vibrancy, dynamism and energy than the XM5.
Advertisement
Sony WF-1000XM6. Image Credit (Trusted Reviews)
All of this, however, is not to say the XM5s don’t sound good – quite the opposite – but it’s just the XM6 has tweaked the overall quality.
Winner: Sony WF-1000XM6
Advertisement
Noise Cancellation
WF-1000XM6 has one additional microphone for noise cancelling
Although the XM5s are easier to wear, the XM6s offer overall stronger noise-cancellation
Call quality is also stronger with the XM6s
Sony claims the WF-1000XM6 offers the “best true wireless for noise-cancellation” and we’re confident to say that they are, in fact, among the quietest pair of earbuds we’ve reviewed. While getting the right fit can be fiddly, which we’ve mentioned earlier, over the weeks we’ve found the earbuds manage to curb outside noises like traffic, voices and even planes brilliantly.
Overall, although the XM6 is a solid improvement over the XM5 pair, we should note that the XM5s are easier to wear than the XM6.
Advertisement
Sony WF-1000XM5. Image Credit (Trusted Reviews)
Call quality also sees an improvement, as we found the XM5 had a tendency to let in noise when we spoke. Fortunately, the XM6 sounds completely silent during phone calls.
Winner: Sony WF-1000XM6
Battery Life
No improvements with the XM6
Both offer eight hours per charge with an additional 16 hours in the case
Sony hasn’t made any improvements with the battery life of the XM6 buds, and promises the same 24 hours total (eight plus sixteen in the case) as the XM5. Having said that, we actually found the XM6 seemed likely to offer even more hours than Sony claims, with an hour of listening still resulting in 100% charge.
The XM5 actually benefits from a slightly faster charging speed, with a three minute charge resulting in an extra hour of playback, whereas the XM6 needs five minutes. The difference is negligible, but if you find yourself in a pinch then you’ll definitely be thankful.
Advertisement
Advertisement
Winner: Tie
Verdict
Although they’re slightly chunkier and can be quite fiddly to wear initially, the Sony WF-1000XM6 buds are a brilliant upgrade from the WF-1000XM5 pair. Not only is the ANC among the best we’ve ever tested, but the sound is more vibrant and dynamic than its predecessor.
Having said that, the XM6 buds do come with a hefty price tag. So, if you’re on a tighter budget, the XM5 is a brilliant compromise.
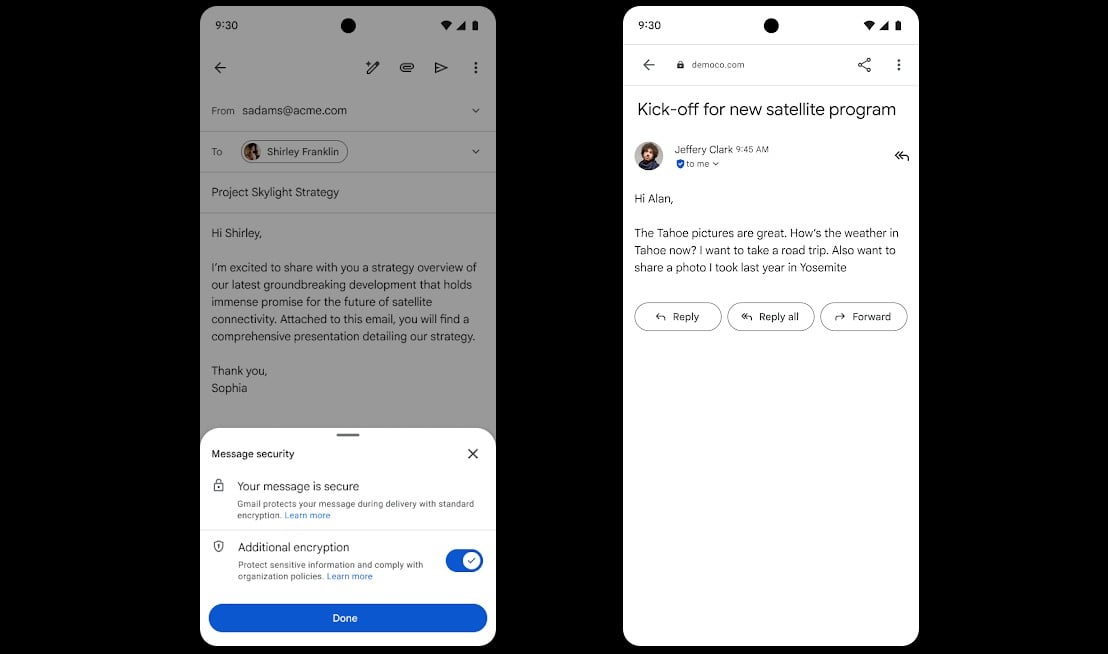
Google says Gmail end-to-end encryption (E2EE) is now available on all Android and iOS devices, allowing enterprise users to read and compose emails without additional tools.
Starting this week, encrypted messages will be delivered as regular emails to Gmail recipients’ inboxes if they use the Gmail app.
Recipients who don’t have the Gmail mobile app and use other email services can read them in a web browser, regardless of the device and service they’re using.
“For the first time, users can compose and read these E2EE messages natively within the Gmail app on Android and iOS. No need to download extra apps or use mail portals. Users with a Gmail E2EE license can send an encrypted message to any recipient, regardless of what email address the recipient has,” Google announced on Thursday.
“This launch combines the highest level of privacy and data encryption with a user-friendly experience for all users, enabling simple encrypted email for all customers from small businesses to enterprises and public sector.”
Advertisement
This feature is now available for all client-side encryption (CSE) users with Enterprise Plus licenses and the Assured Controls or Assured Controls Plus add-on after admins enable the Android and iOS clients in the CSE admin interface via the Admin Console.
To send an end-to-end encrypted message, Gmail users have to turn on the “Additional encryption” option by clicking the Lock icon when writing the message.
Writing E2EE messages and reading them without the app (Google)
In October, Google also announced that Gmail enterprise users can now send end-to-end encrypted emails to recipients on any email service or platform.
Gmail’s end-to-end encryption (E2EE) feature is powered by the client-side encryption (CSE) technical control, which allows Google Workspace organizations to use encryption keys they control and are stored outside Google’s servers to protect sensitive documents and emails.
This way, the messages and attachments are encrypted on the client before being sent to Google’s servers, which helps meet regulatory requirements such as data sovereignty, HIPAA, and export controls by ensuring that Google and third parties can’t read any of the data.
Advertisement
Gmail CSE was introduced in Gmail on the web in December 2022 as a beta test, following an initial beta rollout to Google Drive, Google Docs, Sheets, Slides, Google Meet, and Google Calendar, and it reached general availability for Google Workspace Enterprise Plus, Education Plus, and Education Standard customers in February 2023.
The company began rolling out its new end-to-end encryption (E2EE) model in beta for Gmail enterprise users in April 2025.
Automated pentesting proves the path exists. BAS proves whether your controls stop it. Most teams run one without the other.
This whitepaper maps six validation surfaces, shows where coverage ends, and provides practitioners with three diagnostic questions for any tool evaluation.
The current wave of generative AI animation often feels like a magic trick that only works once. You type in a prompt, a video appears, and if you don’t like the result — maybe the feet are all wonky, which is a regular issue with AI generations — your only real option is to try a different prompt. This “black box” approach is exactly what Cartwheel, a new 3D animation startup, is trying to dismantle.
Andrew Carr and Jonathan Jarvis, two veterans with roots at OpenAI and Google, respectively, founded the company, which is working to build a future where AI handles the technical drudgery of animation while leaving the creative soul to the artist.
I spoke with Carr and Jarvis about launching their company, defining “taste” with AI, and the technical and creative difficulties of animation in 2026.
Advertisement
What sets Cartwheel apart
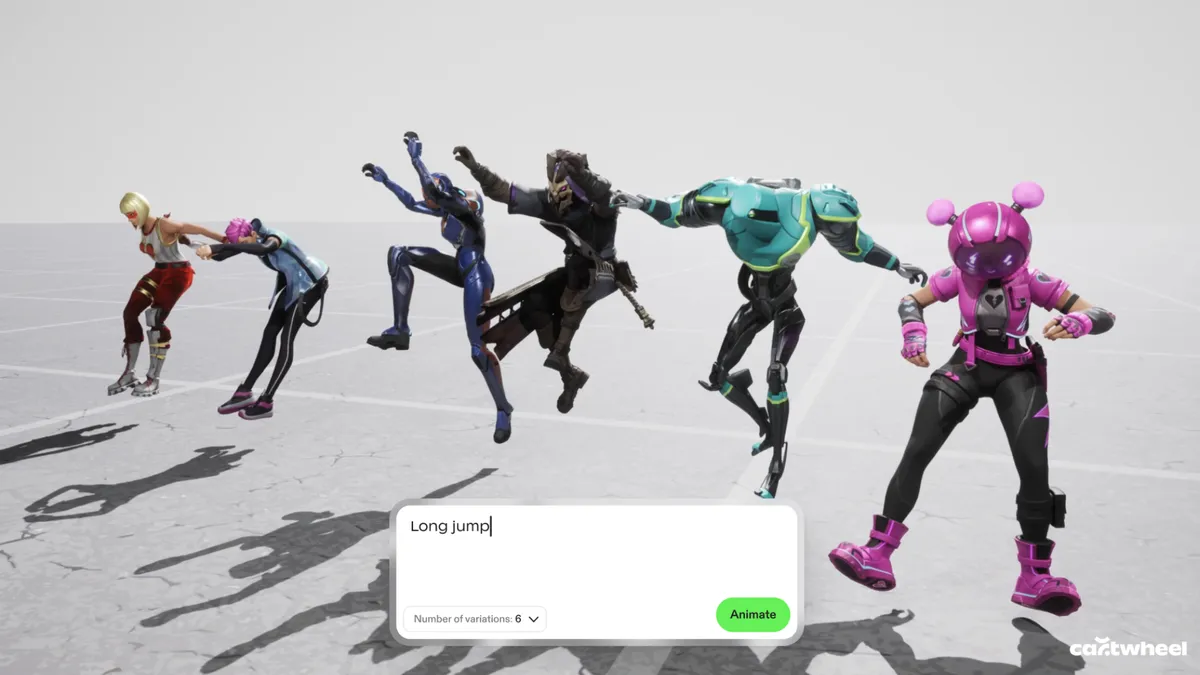
According to the founders, one of the biggest hurdles in this space is that 3D motion data is remarkably scarce compared to the endless oceans of text and images available online that AI models are trained on.
“If you look at all the big tech companies, they’ve built their models on written language, audio, image, [and] video because there’s just so much of it, so finding those patterns is much easier,” Jarvis said. “We knew it was going to be hard, but it turns out to be harder than we thought by probably a factor of 10 or 100 to get that data.”
While other tech giants focus on generating final pixels, Cartwheel has spent years mapping how humans actually move. Their models are built to understand the nuances of a performance so that a simple 2D video of someone dancing in their backyard can be translated into a precise, realistic 3D skeleton.
Advertisement
This shift from flat images to 3D assets is what gives animators the control they have been missing in the AI era.
Cartwheel has spent years tackling the difficult task of mapping how humans actually move.
Cartwheel
Preventing AI “sameness”
Cartwheel’s executives said they view AI’s “sameness” as a byproduct of a lack of control. If everyone uses the same generator to produce a video, the results may eventually start to look all too similar.
Advertisement
“The output of our system is designed for people to edit. It’s designed for people to touch and manipulate, and we don’t want someone to type something in and then have it shuffle through to a finished animation. That’s not the point of it. That’s boring, who’s going to watch that?” Carr said.
“The fact that it’s very easy for people to get into it and edit it actually totally removes the sameness problem,” he said. “You put it on different characters, you put it in different environments, you change how it looks, you push the performance, you pull the performance, and in that sense [sameness] turns into a nonissue.”
Carr and Jarvis said the solution is to provide a “control layer” where the AI output is just the starting point. By generating 3D data instead of flat video, the creator can change the lighting, move the camera or adjust a character’s pose after the AI has done its initial work — making the technology a sophisticated power tool rather than a replacement for the artist.
Advertisement
Founder Andrew Carr said one of his core scientific hypotheses is that movement and motion is a fundamental data type.
Cartwheel
The future of animation with AI
Beyond just making animation faster and lowering the barrier to entry, the company is looking toward a concept they call “open-ended storytelling” or “open-ended world-building.” In modern gaming and social media, the demand for content has reached a scale that manual animation cannot possibly match.
Cartwheel envisions characters that aren’t just programmed with a few set moves but are powered by motion models that allow them to react and perform in real time. It’s less about choreographing every single frame and more about “rehearsing” with a digital actor that understands the intent of the scene.
Ultimately, the goal is to bridge the gap between 2D vision and 3D execution, said the founders.
Advertisement
“One of the core hypotheses that we hope is true in the next three years for Cartwheel is everyone will work in 3D even if it’s authored in 2D, even if the final output is just 2D video,” Carr said.
By focusing on the “layer below the pixels,” Carr and Jarvis said they hope that as animation becomes more automated, it also becomes more personal. The machine handles the biomechanics and the file exports, but the human keeps the final say on the taste, the timing and the heart of the story.
As the tech conference circuit grows more crowded, one SaaS event is making the opposite pitch: fewer people, fewer sales decks, and a lot less noise.
SaaS on the Beach, a curated event for SaaS founders, will return to Barcelona between May 20 and 21 for its second edition, positioning itself as an alternative to the large-scale trade shows that have long dominated the tech events circuit.
The event is built on selectivity. Attendance is limited to 60 handpicked founders, with participants required to meet specific criteria before they can buy a ticket. That makes SaaS on the Beach feel less like an open industry conference and more like a tightly edited peer group.
It is also stripping out many of the rituals that now define mainstream tech events. There is no exhibition hall, no sponsored speaker circuit, and no sales-pitch-heavy programming. In their place are seated dinners, roundtable discussions, and social activities meant to create more direct, less performative exchanges between attendees.
Advertisement
That matters because many founders no longer need more stage content. They need rooms where people speak plainly, compare notes honestly, and talk about the less polished parts of building software companies, hiring, churn, growth, product decisions, and what is actually working.
SaaS on the Beach is also leaning into a no-solicitation format, an explicit break from the conference model where networking often blurs into prospecting. The promise here is that people come to learn from peers, not to be cornered into a demo.
Barcelona is part of that pitch too. The event is presenting its Mediterranean setting as an alternative to the usual northern European conference loop, betting that a more relaxed environment can lead to better conversations.
The bigger idea behind SaaS on the Beach is that senior operators may be growing less interested in scale for its own sake. The trade show still has its place, especially for visibility and lead generation, but smaller, curated gatherings are increasingly selling something else: relevance.
That does not make them more democratic. In some ways, it makes them more exclusive. But it does make the value proposition clearer. If the standard conference model is built on volume, events like SaaS on the Beach are built on density, fewer people, more overlap, and a better chance that the conversation is worth having.
Advertisement
That is the model returning to Barcelona this May.
Running out of storage is one of those problems that almost everybody understands, and almost nobody handles properly. Storage can almost never be enough, so some people keep paying for cloud space. Meanwhile, others keep promising that they will “sort it out later”. And a lot of people just end up deleting things when the warning gets too annoying.
But Google’s upcoming Android feature could finally offer a better answer, with an automatic local backup to a PC. This functions wirelessly like a cloud storage service, but it is also free of charge since you’re using your own device.
Android Authority’s recent teardown of Google Play Services beta v26.15.31 revealed that Google is working on an Automatic backup feature inside Quick Share that can copy selected files from your phone to your PC without using the cloud.
Why this might be the storage fix normal people actually use
Cloud backup is useful and all, but a lot of people still do not want to pay for it. Considering the tiny amount of free storage space that you do get, stuff like WhatsApp backups, and photos and videos from a year can easily eat into this free storage immediately.
Advertisement
But Google’s in-development feature appears to let users automatically back up camera photos, camera videos, and audio files directly to a household PC, thanks to a new auto sync option and a Back up now button for manual transfers.
Dung Caovn / Unsplash
The report also revealed that deleting a file from your phone will not remove its copy from the PC backup. So the feature isn’t just about syncing—it is about finally permitting people to clear space without feeling like they are throwing memories away.
Your Android, your computer, your storage
The part that really matters is the “free” tagline. Most homes already have a laptop, desktop, or even both. And oftentimes, hundreds of gigabytes of storage sitting there are mostly unused. Unless somebody in the house is gaming, editing high-resolution gaming, or hoarding massive files, there is usually plenty of room for old phone footage, family photos, and voice notes.
Microsoft
So Google’s feature appears to take advantage of that reality instead of pushing people into buying more cloud space. Because it lives in Quick Share, it will likely use the same local transfer system, which also suggests that you don’t need an internet connection for backup. You just need to be in close proximity. From the start to the finish, your data stays with you.
This is the boring feature Android needed
There is still one catch though. The details arrive from an APK teardown, so Google has not formally launched the feature yet, and it could change before release. But if it does arrive, it’s the quality-of-life upgrade that could matter more than a lot of flashy AI nonsense. It is practical, wireless, and free.
Xgimi’s most complete projector for the home yet, the Horizon 20 Max produces a bright, colourful image and a feature set that’s good for watching TV, movies and playing games. It is pricey but serves as a good alternative to those who don’t want a more traditional projector.
Bright with rich colours
Plenty of entertainment options
Well featured
Good sound for a projector
Two HDMI inputs
Premium price may put some off
Integration of settings can annoy
Missing BBC iPlayer
Key Features
Advertisement
Brightness
5700 ISO lumens of RGB laser brightness
Advertisement
HDR
Full house for HDR support including Filmmaker Mode
Advertisement
Sound
Built-in 24W Harmon Kardon speakers
Introduction
Xgimi has had a productive last 12 months, launching an array of projectors and even delving into smart glasses.
Advertisement
The Horizon 20 is one of its newest breed of home projectors, building on the Horizon series we reviewed a few years ago. This new series is Xgimi’s brightest and most capable yet, delivering 5700 lumens of brightness, the full roster of HDR support and a quick gaming experience.
The Horizon 20 Max is big and bulky. While it won’t need a dedicated space, it will need some space. It’s not a projector to perch on a windowsill – and at 4.9kg it’s not like Xgimi’s portable MoGo series.
It does feature an integrated stand that can tilt upwards or downwards, and there’s a swivel mechanism to shuffle it left or right. This is principally a projector for the indoors.
Advertisement
Image Credit (Trusted Reviews)
It only comes in one finish – Elephant Grey – which seems appropriate given its size and strong leather-like finish. It’s not necessarily a stunner, but it’s sturdy and well-built.
Advertisement
While you can lift and move it about, there’s also the option of a more dedicated installation with mounting screws in the stand.
Connectivity
Two HDMI inputs
No Ethernet
Wi-Fi 6
The Horizon 20 Max features an array of connections. There are two HDMI inputs, and one that supports HDMI eARC if you’re considering adding a sound system.
There’s an audio input and a digital audio output for adding other sound systems/devices, USB 3.0 and USB 2.0, though no Ethernet for a hardwired connection to the Internet.
Image Credit (Trusted Reviews)
Instead it’s reliant on a Wi-Fi 6 connection, which hasn’t run into any issues that I’ve encountered so far. There’s also Bluetooth 5.2.
Advertisement
Advertisement
A word on the updates – they can be very large (in excess of 1GB), so one to watch out for if your Wi-Fi connection isn’t the strongest and fastest.
Features
300-inch max size
5700 ISO lumens
HDR10+ and Dolby Vision
This is a projector stocked with features – so many that it’s a wonder where to start.
With a throw ratio of 1.2-1.5:1, Xgimi lists the screen size as no smaller than 40 inches and no bigger than 300. Read the very small print, though, and it recommends between 60 and 150 inches for the optimal performance.
The 40-inch size is recommended for brightly lit rooms, while the 300-inch option is intended for viewing in darker rooms. You can perform lens shift (physically moving the lens) and digital zoom.
Image Credit (Trusted Reviews)
Advertisement
Brightness is off the charts at 5700 ISO lumens, a big jump over the Horizon S Max’s 3100. It’s capable of 110% of the BT.2020 colour space for 4K video (covering a wide range of colours).
Advertisement
Its light source is an RGB triple laser for purer and brighter colours than a lamp-based alternative, projecting images via DLP (a 0.47-inch DMD).
It supports HDR10, HDR10+, Dolby Vision, Filmmaker Mode, and IMAX Enhanced, though there’s no mention of HLG support. It can play 3D content for anyone with a compatible player, though the Horizon 20 Max doesn’t come with 3D glasses.
Audio is an integrated 24W Harman Kardon system with support for DTS Virtual:X, DTS-HD, Dolby Audio, Dolby Digital, and Dolby Digital+, which implies no Dolby Atmos support (at least not through the speakers themselves).
Image Credit (Trusted Reviews)
Xgimi’s ISA technology stands for Intelligent Screen Adaption. It covers the Eye Protection mode that dims the light from the projector whenever someone (or thing) walks past (this has to be enabled first). Auto Focus makes sure the image looks as sharp as it can be.
Advertisement
Advertisement
Auto Keystone Correction reformats the screen so it fits the space on your wall. I’ve seen it work and not work, as the Horizon 20 Max can sometimes create a much smaller image than was previously on the wall a few seconds earlier. Sometimes, to get the biggest image, you have to play with the position of the Xgimi.
Intelligent Obstacle Avoidance and Intelligent Screen Adaptation cover the other areas of Xgimi’s ISA tech. The former avoids obstacles such as a lamp or a stand so the image fits the space. The latter makes sure that the image fits a projector screen if you have one installed.
Image Credit (Trusted Reviews)
There’s also a Wall Adaptation feature that changes the colours to suit the wall colour. It does make a difference, though the settings don’t carry over with Dolby Vision content.
Xgimi quotes 28dB in terms of fan noise, but I registered 38.9dB. Boot-up time is about 35 seconds if Fast Boot is enabled. I should warn that the Horizon 20 Max comes with one of the biggest power adaptors I’ve seen. It’s a genuine brick and could act as a doorstop.
Gaming
Fast input lag
Several game modes
VRR
Advertisement
The Horizon 20 Max makes a play for gaming in a way few projectors I’ve tested have done.
Advertisement
There’s ALLM and VRR support. Xgimi claims that response times are as low as 3ms for 60Hz, 2ms for 1080p/120Hz and 1ms for 1080p/240Hz refresh rates.
Plug a game console and it’ll instantly go into its game mode. There’s also a Boost mode, but is there much of a difference between Standard and Boost? If there is, it’s not one I could feel with a PS5 controller.
Image Credit (Trusted Reviews)
There are also gaming-specific features, such as a Black Equaliser that enhances detail in black levels, so you’re not surprised by anyone lurking in the shadows. You can also engage virtual crosshairs to keep locked onto your target.
There are several game modes to choose from as well: An Assassin’s Creed mode, RTS, FPS, RPG and Sports mode which add specific customisations depending on the genre you’re playing. Where exactly these game modes are, I’m not sure, as I couldn’t locate them.
Advertisement
Advertisement
The performance is smooth, with inputs that are responsive and a picture quality that genuinely offers contrast. It’s a bright and colourful image – a phrase you’ll be hearing a lot.
Image Credit (Trusted Reviews)
User Experience
Google TV
No iPlayer
Battery-powered remote
Xgimi has shifted to Google TV (the Horizon S Max ran on Android TV). All the big apps are present with Prime Video, Apple TV, YouTube (naturally), Netflix, and new to the UK, HBO Max.
BBC iPlayer, just like it was with the Horizon S Max, is not supported but the rest of the UK catch-up apps are. You can bypass that problem by casting directly from the iPlayer app.
Image Credit (Trusted Reviews)
Advertisement
I’ve found Google TV to be swift and responsive. You’ve got a huge number of apps, and content curated based on what you watched. Some find it overwhelming but I disagree. I think in terms of information meted out, it provides what you need to know. However, I don’t think Google TV’s curation is the best, as it often recommends titles I’ve already seen.
Accessing the settings is a bugbear for me, though it’s the case with many Google TV projectors.
Advertisement
Enter into the settings, and when you press back, it doesn’t go back to (or open) the main menu but exits completely. It’s annoying if you want to change another setting. To do so, you have to go back into settings again.
Image Credit (Trusted Reviews)
Another unintuitive example is with gaming. The console recognises a game signal and switches to Game mode, but its picture mode remains Standard. What follows is a back-and-forth to make sure all settings are aligned. The settings are also not well explained, but this is also an issue with other Google TV projectors such as the Epson EF-72.
Leave the Xgimi running and the Ambient Screensaver comes on with the option to see either your own photos in Google Photos, Art Gallery or Custom AI art. You can also have it set to display the weather, time, etc.
Advertisement
Control is via a remote, and it’s easy enough to use. It has a motion-detected backlight that makes it easier to use in a dark room, which I like. It does require batteries to use rather than charging via USB-C, which I don’t like.
Advertisement
Image Credit (Trusted Reviews)
Picture Quality
Bright for a projector
Rich colours
Smooth motion
The Xgimi Horizon 20 Max is incredibly bright for a home cinema projector, and it does hold up well in a bright room. Black tones look good (but are affected by ambient light), colours do change, but detail remains decent.
In its darkened environment, the Horizon 20 Max looks very good. Black levels are strong – black tones actually look black – with a colour performance that’s warm and rich, with highlights that appear stronger than they do on the Epson EF-72 with Thunderbolts* on Disney+.
There’s a vibrancy to colours, especially the explosions in the film, that offer an impressive sense of punch.
Advertisement
However, with white tones, like Valentina Allegra de Fontaine’s suit near the film’s opening, it comes across more creamy yellow-ish. While the colours are attractive, they’re not always the most accurate, even in Dolby Vision.
Advertisement
Image Credit (Trusted Reviews)
But in general, the Horizon 20 Max gets colours right. K’s jacket in Blade Runner 2049 is green, not black; the orange tones of the radioactive Las Vegas section are captured with greater subtlety and a wider tonal range than I’ve seen on other projectors.
A stream of Sentimental Value on Mubi in 4K SDR doesn’t feature the deepest blacks, but for the most part, I’ve found black levels to be fine. Titles in HD look good, though both 4K and HD content aren’t the sharpest looking but that’s a minor issue given the scale of the image.
Image Credit (Trusted Reviews)
With Superman in Dolby Vision (4K Blu-ray), it’s bright to the point where there seems to be some slight clipping (loss of detail) in the brightest parts of the image. But the Xgimi’s clear strength is its brightness, with highlights that are genuine ‘high-lights’.
Advertisement
Casting the Strike series from the iPlayer app, I found skintones to be warm but colours with high levels of fine detail in clothing and characters’ faces. Black levels can look shallow, and again, it’s not the sharpest image, but it does look lovely for a streamed image.
Image Credit (Trusted Reviews)
Comparing how the Xgimi works with both HDR10+ and Dolby Vision with a 4K Blu-ray of Doctor Sleep, and the latter is brighter with colours that look richer and warmer, with genuine contrast and depth for a projector. There’s a slight cool look to the colours in HDR10+, not to mention more black crush (loss of detail in black tones). Based on this, I’d vote for Dolby Vision over HDR10+.
Image Credit (Trusted Reviews)
Watching football on Prime Video and it’s debatable if the colours are truly correct, regardless of whether the mode used is Movie or Sports. At times, it looks a little too bright, but in a dark room, the added brightness helps.
With the MEMC processing, I can’t tell if it makes a difference with it off or set to High. The image is already so smooth that it doesn’t feel as if any additional processing has been added. I say this as a positive, not a negative.
Advertisement
Advertisement
Image Credit (Trusted Reviews)
Avoid High Power mode, as on the MoGo series, it casts the image in a green tint. It’s such a degraded image that I can’t understand why it’s even there. Vivid mode though, offers more brightness than Movie, and colours still look good rather than artificially amped up.
One piece of advice is to avoid the Adaptive Mode. It’s meant to adjust brightness depending on a room’s ambient light levels, but it produces a distracting, flickering brightness to the image and does so even when the room’s brightness hasn’t changed.
Sound Quality
Broad soundstage
Clear dialogue
Decent bass for a projector
The Xgimi Horizon 20 Max features two 12W speakers from Harman Kardon. Xgimi’s MoGo series have pretty capable audio for their size, the Horizon 20 Max is among the best I’ve heard for a projector.
The soundstage feels big, and I didn’t feel the need to raise it above level 40 as it was loud enough and filled the room with sound. Bass is good with some weight and warmth added to the overall presentation. It’s not the most detailed or defined, but it offers decent levels of dynamism and energy. Dialogue is delivered with clarity and sounds natural, though raising the volume can lead to slightly sharper voices.
Advertisement
Advertisement
Image Credit (Trusted Reviews)
With sports, it’s not one congealed blob of sound. The commentary is one part and crowd noise is distinct from it, creating a better sense of size and scale. This is a good effort if you’re not considering adding a sound system.
If you are thinking about connecting a sound system, I’d go down the route of connecting the Horizon 20 Max to a home cinema amplifier.
Should you buy it?
You want to use it during the day and night
The brightness levels of the Horizon 20 Max make it a good choice to watch in a brighter room or a blaced out environment.
Advertisement
You want an affordable projector
Advertisement
At £2599, it’s the most expensive of the Horizon 20 series, but if you’re willing to save, the Horizon 20 cuts down on features and is £1000 less.
Final Thoughts
The Xgimi Horizon 20 Max is no doubt expensive at £2599, but it delivers a consistently enjoyable picture and sound that makes it a good alternative to more traditional and similarly priced efforts from BenQ and Epson.
It’s very bright, so you can use this beamer in daylight, and despite its bulk and weight, it’s more portable than traditional projectors that require a dedicated installation.
It improves on the Horizon S with more connections, higher brightness, a stronger gaming performance and a more welcoming user experience for a stronger all-round performance.
For those after a high-spec, high-performing projector that fits into the lifestyle wheel of the market, the Xgimi Horizon 20 Max is an impressive all-round effort.
Advertisement
Advertisement
How We Test
The Xgimi Horizon 20 Max was tested over the course of a month with 4K HDR, SDR, and HD content from 4K Blu-ray and streaming sources.
Fan noise was measured with the Sound Meter app on Android.
Tested for a month
Tested with real world use
FAQs
Does the Xgimi Horizon 20 Max support VRR for gaming?
There is VRR support with this projector, and it supports up to 120Hz in 1080p resolution.
Amazon’s long-delayed satellite internet service is finally getting close to actually launching. In his latest letter to shareholders, Amazon CEO Andy Jassy said the company is “on the verge” of launching Leo, Amazon’s low Earth orbit satellite internet service, and expects it to go live in mid-2026.
This puts Amazon much closer to finally challenging SpaceX’s Starlink, even if it is still arriving years later than its biggest rival.
When does the Starlink rival drop?
Amazon
Jassy said Amazon already has 200 low-orbit satellites in space and plans to add a “few thousand more” in the years ahead. But the first release is set to kick off in the middle of this year. To recall, Leo was originally conceived as Project Kuiper back in 2019, being renamed last year
Amazon has revealed that it has already secured revenue commitments from enterprise and government customers. But this is not a typical consumer broadband play. Jassy claims that Leo will integrate with Amazon Web Services so enterprises and governments can move data back and forth for storage, analytics, and AI. This gives Amazon a very obvious angle against Starlink. Leo isn’t just selling connectivity, it is also selling the broader AWS-powered ecosystem.
Amazon
Why Amazon thinks it can win people over
Starlink converts might actually be real. The executive said that Delta Air Lines has selected Leo as its future onboard WiFi provider and will begin using it on 500 planes in 2028. Other names mentioned include JetBlue, AT&T, Vodafone, DIRECTV Latin America, Australia’s national broadband network, and NASA, among Leo’s customers.
Amazon’s list of early customers signals to the world that companies are at least willing to bet Leo can become a credible second option in the satellite internet market. But that said, Amazon is still playing catch-up with Starlink, which already has nearly 10,000 satellites in space.
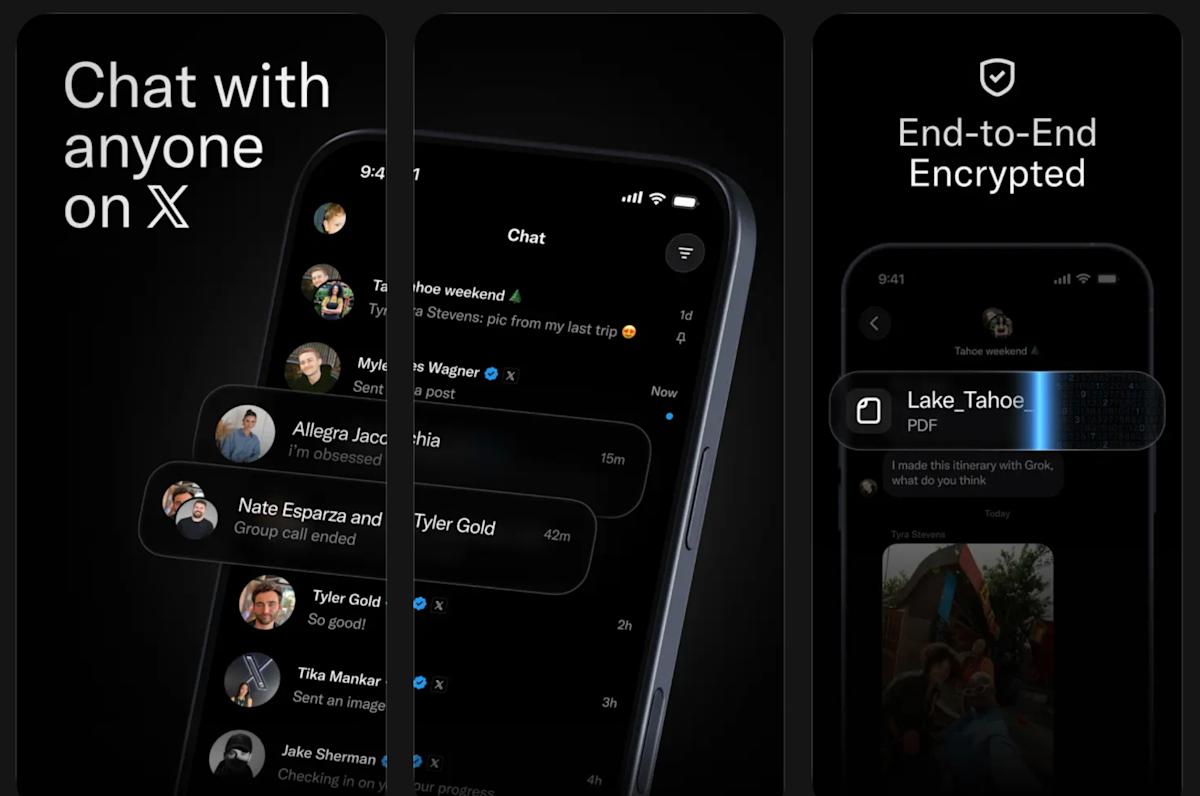
XChat is now on the App Store, where its listing says that it’s expected to be available for download on April 17. This isn’t the same IRC app from the early aughts, which you may remember if you’re of a certain age. This is a messaging app specifically for X users. X chief Elon Musk first talked about rolling out a new version of his social network’s direct messaging feature in mid-2025. In a series of posts back then, he said the new version would be encrypted and would feature a “whole new architecture.” He also said all X users were getting XChat in June last year, but Musk is pretty infamous for being overly optimistic about timelines.
Now, instead of an upgraded DM feature on X, users are getting a standalone app. It allows them to chat with anybody on X and call each other across devices. The app is end-to-end encrypted and will let users edit and delete their messages for all participants in the conversation. It will also allow users to block screenshots and enable disappearing messages if they want the sensitive details they send in-chat to vanish within five minutes. The app allows users to create massive group chats with up to 481 members, as well. X promises in the App Store listing that XChat will not have ads and will not be tracking users.
Users can now pre-order XChat for iPhones and iPads so that it automatically downloads on their device when it comes out.
The partnership is aiming to deliver a quantum computer that can calibrate and run itself without the need for manual oversight.
Dublin-based quantum computing start-up Equal1 is to partner with Californian quantum infrastructure software maker Q-Ctrl for the deployment of rack-mounted quantum computers in enterprise data centres.
The companies said that together, their technologies will deliver “truly autonomous operation” for “peak performance without manual oversight” to address evolving challenges around performance and maintenance of enterprise quantum computing systems.
By combining Q-Ctrl’s infrastructure software, ‘Boulder Opal Scale Up’, with Equal1’s scalable hardware, a quantum computer will be able to calibrate and run itself without the need for manual oversight and implementation by expert teams, the companies said.
Advertisement
“Equal1 has already proven that quantum hardware can be compact, rack-mounted and data centre-ready,” said Jason Lynch, CEO of Equal1.
“Our partnership with Q-Ctrl further accelerates our mission by providing a fully autonomous software stack. With Boulder Opal Scale Up integrated into our Bell-series systems, our customers gain a self-optimising quantum accelerator that fits seamlessly into existing IT infrastructure.”
Claimed features offered to prospective data centre customers by the strategic partnership include autonomous operation and calibration of hardware; real-time system monitoring and maintenance for performance; secure local deployments for operation while disconnected from the internet; and “algorithmic enhancement” through compatibility with other Q-Ctrl software.
“To scale quantum computing, we must transition from manual hardware operation by expert teams of PhDs to autonomous functionality when fully deployed in data centres and HPC [high-performance computing] facilities,” said Aravind Ratnam, chief strategy officer at Q-Ctrl.
Advertisement
“Our partnership with Equal1 achieves this by integrating Q-Ctrl’s AI-driven autonomous calibration directly into their silicon spin qubit quantum systems. Together, these technologies provide HPC users with a seamless experience, enabling quantum processors to operate on equal footing with GPUs and CPUs.”
Equal1, which was founded in 2017 at University College Dublin, says quantum computing using standard silicon is the way to overcome challenges posed by AI to the power and cost thresholds of traditional computers.
In January, it raised $60m through a funding round led by Ireland Strategic Investment Fund, with participation from Atlantic Bridge, the European Innovation Council Fund, Matterwave Ventures, Enterprise Ireland, Elkstone and TNO Ventures.
Its flagship ‘Bell-1’ device was launched in March 2025 and was described as the “first-ever” Irish-made quantum computer as well as the world’s first silicon-based quantum server designed for data centres and high-performance computing.
Advertisement
Q-Ctrl, founded in 2017, operates partnerships with companies such as IBM, Nvidia and AWS with the goal of making machines “thousands of times more powerful” using “AI-driven control solutions” for the enhancement of quantum computer performance.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
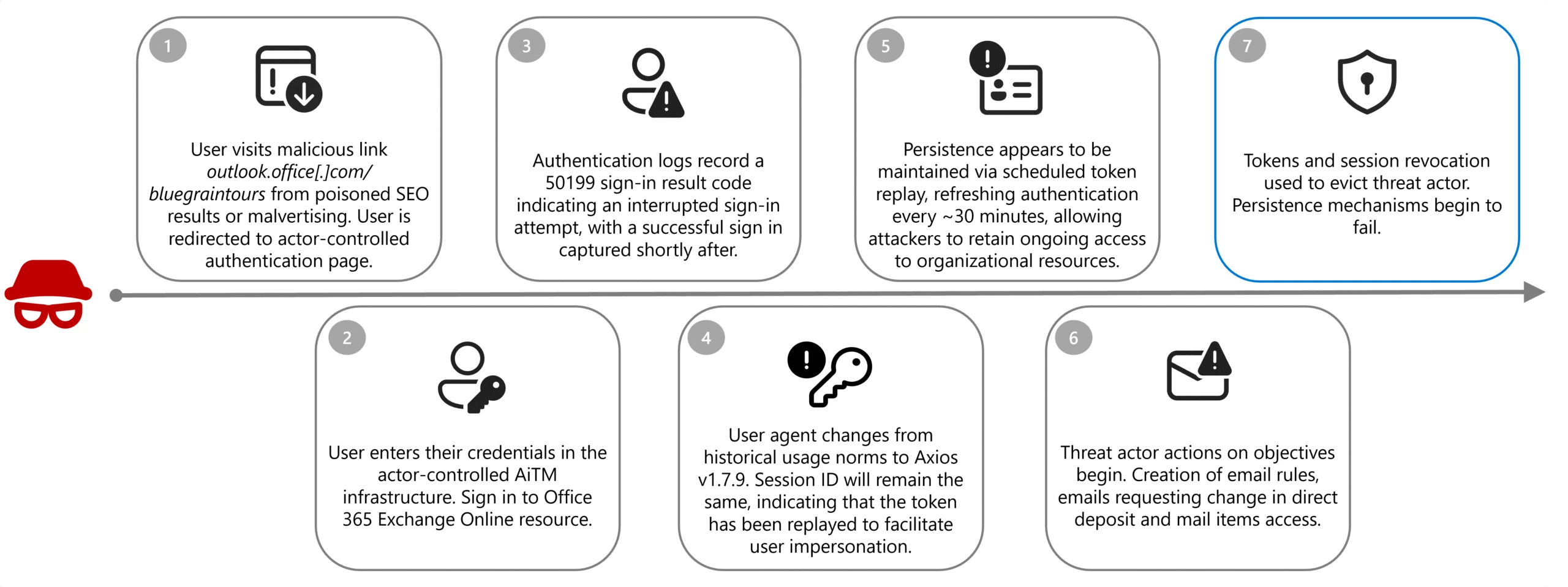
A financially motivated threat actor tracked as Storm-2755 is stealing Canadian employees’ salary payments after hijacking their accounts in payroll redirection (also known as payroll pirate) attacks.
The attackers used malicious Microsoft 365 sign-in pages to steal victims’ authentication tokens and session cookies by redirecting them to domains (e.g., bluegraintours[.]com) hosting malicious web pages (pushed to the top of search engine results through malvertising or SEO poisoning) that masqueraded as Microsoft 365 sign-in forms.
This allowed Storm-2755 to bypass multifactor authentication (MFA) in adversary‑in‑the‑middle (AiTM) attacks by replaying stolen session tokens rather than re-authenticating.
“Rather than harvesting only usernames and passwords, AiTM frameworks proxy the entire authentication flow in real time, enabling the capture session cookies and OAuth access tokens issued upon successful authentication,” Microsoft explained.
“Due to these tokens representing a fully authenticated session, threat actors can reuse them to gain access to Microsoft services without being prompted for credentials or MFA, effectively bypassing legacy MFA protections not designed to be phishing-resistant.”
Advertisement
Storm-2755 attack flow (Microsoft)
After gaining access to an employee’s account, the attacker created inbox rules that automatically moved messages from human resources staff containing the words “direct deposit” or “bank” to hidden folders, preventing the victim from seeing the correspondence.
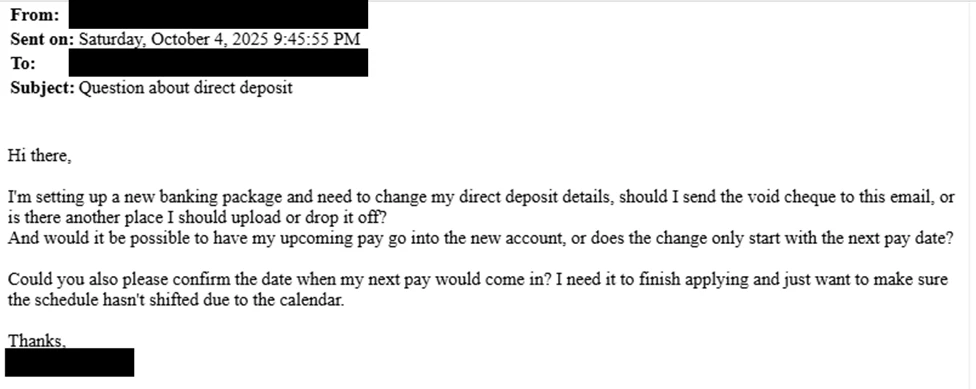
In the next stage, they searched for “payroll,” “HR,” “direct deposit,” and “finance,” then sent emails to human resources staff with the subject line “Question about direct deposit” to trick staff into updating banking information.
Where social engineering failed, the attacker logged directly into HR software platforms such as Workday, using the stolen session to manually update direct deposit details.
Storm-2755 emailing HR staff (Microsoft)
To harden defenses against AiTM and payroll pirate attacks, Microsoft advises defenders to block legacy authentication protocols and implement phishing-resistant MFA.
If any signs of compromise are detected, they should also revoke compromised tokens and sessions immediately, remove malicious inbox rules, and reset MFA methods and credentials for all affected accounts.
In October, Microsoft disrupted another pirate payroll campaign targeting Workday accounts since March 2025, in which a cybercrime gang tracked as Storm-2657 targeted university employees across the United States to hijack their salary payments.
Advertisement
In these attacks, Storm-2657 breached the targets’ accounts via phishing emails and stole MFA codes using AITM tactics, which allowed the threat actors to compromise the victims’ Exchange Online accounts.
Payroll pirate attacks are a variant of business email compromise (BEC) scams that target businesses and individuals who regularly make wire transfers. Last year, the FBI’s Internet Crime Complaint Center (IC3) recorded over 24,000 BEC fraud complaints, resulting in losses exceeding $3 billion, making it the second most lucrative crime type behind investment scams.
Automated pentesting proves the path exists. BAS proves whether your controls stop it. Most teams run one without the other.
This whitepaper maps six validation surfaces, shows where coverage ends, and provides practitioners with three diagnostic questions for any tool evaluation.






















































































You must be logged in to post a comment Login