





























































































































































































































































































































































If you were anywhere near a computer in the mid-to-late 1990s, you almost certainly encountered a Zip drive. That distinctive purple peripheral, with its satisfying clunk as you slotted in a cartridge, was as much a fixture of the era as beige tower cases and CRT monitors. Iomega, the company behind it, went from an obscure Utah outfit to a multi-billion-dollar darling of Wall Street in the span of about two years. And then, almost as quickly, it all fell apart.
The story of Iomega is one of genuine engineering innovation and the fickle nature of consumer technology. As with so many other juggernauts of its era, Iomega was eventually brought down by a new technology that simply wasn’t practical to counter.
The House That Bernoulli Built
Iomega was founded in Utah, in 1980, by Jerome Paul Johnson, David Bailey, and David Norton. The company soon developed a novel approach to removable magnetic storage based on the Bernoulli effect. The Bernoulli Box arrived in 1982, which was a drive relying on PET film disks spun at 1500 RPM inside a rigid, removable cartridge. The airflow generated by the spinning disk pulled the media down toward the read/write head thanks to the eponymous Bernoulli effect. While spinning, the disk would float a mere micron above the head surface on a cushion of air. If the power cut out or the drive otherwise failed, the disk simply floated away from the head rather than crashing into it—a boon over contemporary hard drives for which head crashes were a real risk. The Bernoulli Box made them essentially impossible.
Early Bernoulli Box drives offered 10 MB and 20 MB of removable storage at a time when a fixed hard drive might hold 30 MB. Bernoulli Boxes were never really aimed at the home market, but found a devoted following among power users—publishers, CAD users, and anyone who needed to move serious amounts of data between machines. Sales were strong, and by 1983, Iomega hit the stock market running with an initial public offering raising $21.7 million.
As hard drive prices continued to dive over time due to economies of scale, though, the expensive Bernoulli Box became a less attractive proposition even despite its portability and greater storage. By 1986, Iomega had sold over 70,000 units and more than a million cartridges, but sales had peaked. The company had racked up serious debt and slow sales left the company saddled with undesirable inventory that wouldn’t move. Upgrades came thick and fast as Iomega pushed to keep up with the rapidly-changing storage market, which was enough to keep Iomega relevant if not flourishing. By 1993, the largest Bernoulli carts could hold 230 MB if you had a suitable model drive to read them, though the expensive drives mostly remained the domain of large corporate and government users.
Zipping To The Top

The next phase for Iomega saw the company reach its greatest peak. The Zip drive launched in March 1995, and aimed to be a more affordable solution to high-capacity removable storage. It hit the market with 100 MB cartridges priced at $19.95 each, in an era when the standard 3.5” floppy could only hold 1.44 MB. For anyone regularly shuffling large files between home and office, or backing up a hard drive that might only hold a few hundred megabytes, it was a great leap forward. The iconic external model became popular in businesses, universities, and homes, and before long, OEMs like Apple, Dell, and Gateway started offering internal Zip drives as factory options. It became as close to a defacto standard for removable storage as a proprietary storage solution could ever be.

When the Zip drive hit, the sales numbers were staggering. Iomega’s revenue leapt from $362 million in 1995 to $1.2 billion in 1996. At its peak, Iomega was valued at nearly $7 billion. The company’s stock became a darling of investors addicted to massive gains. For a time, they appeared to be an unstoppable tech juggernaut, hanging on to a sizable chunk of the removable storage market without any obvious competitors on the horizon.

Iomega chased the success of the Zip drive with the even higher-capacity Jaz drive, which could store 1 GB in early models on hefty cartridges that contained rigid drive platters not dissimilar from those in contemporary hard disks. They were a great solution for power users moving what was then considered a lot of data, but their higher price meant they were never a consumer-grade darling like the cheaper Zip drive itself. The later “Clik” or “PocketZip” drive came along later in 1999, with a diminutive form factor and 40 MB disks. It too failed to gain the foothold of Zip, however, with a low install base limiting the usefulness of the removable format.
It wasn’t all smooth sailing, of course. A serious blow to Iomega’s reputation came from its own engineering. Some Zip drives developed a fault that came to be known as the “Click of Death.” The term referred to a clicking sound of the drive heads bouncing off their end stops when they became misaligned. In extreme cases, misaligned heads in a bad drive could damage disks, which would then damage the next drive they were used in. It was a mark against the technology that was supposed to be robust enough to be used as mobile storage. A class action lawsuit was filed in September 1998 and eventually settled in 2001, but the reputational damage remained.
Downfall
It wasn’t the Click of Death debacle that doomed Iomega, though. It was merely the march of competing technologies that made its storage solutions less attractive over time. CD-R drives, which had been expensive curiosities in the mid-1990s, became dirt cheap just a few years later. By 2000, blank CD-Rs were retailing for as little as fifty cents each, and they held 650 MB a pop— more than six times the capacity of a Zip disk, on media that cost a fraction of the price and didn’t require proprietary hardware. They were so cheap, the write-once nature almost failed to matter. It was far more attractive to many customers to just burn another cheap CD that anyone could read than to go out and buy a Zip drive, an expensive 100 MB disk, and hope that whoever you were sending the disk to also had a drive that could read it. The CD-RW followed soon enough after, and writable DVDs would then take storage capacities well into the multi-gigabyte range. Zip drives jumped to 250 MB and then 750 MB, while the Jaz line was upgraded to 2 GB, but by and large, consumers were choosing writable optical discs over Iomega’s proprietary solutions.
USB flash drives would then prove to be the final nail in the coffin. They were compact and cheap, and required no special hardware whatsoever. You could just plug them into any USB port on any computer and your files were right there. They too would become cheap enough to be disposable, in a way that Iomega’s bespoke drives and mechanically-complicated cartridges would never be.
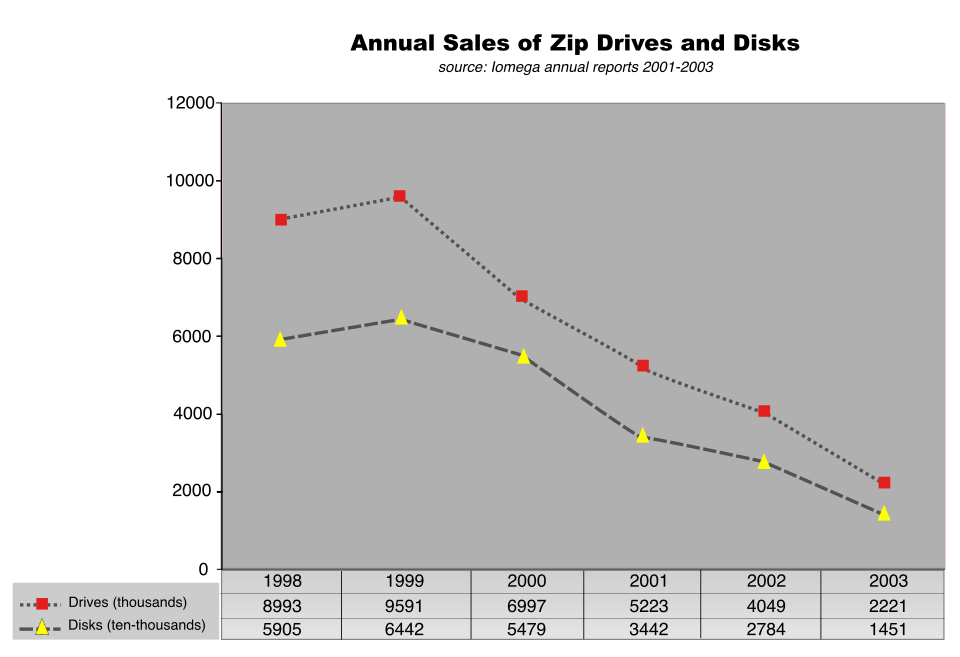
By 2002, the Jaz drive was dead, and the Zip drive followed soon after in 2003. It was CD burners that did the most damage, with the leap to DVD and the rising prominence of the USB drive that promised there would be no way back for removable magnetic cartridge media. These solutions were far less mechanically complex and a lot cheaper in terms of cost per megabyte.
Iomega was, at this point, a lumbering corporation with hundreds of employees, a dying product line, and a bleak future ahead. The company pivoted to other storage solutions, like selling rebranded optical disc drives, external hard drives, and network-attached storage devices. However, none of these products were particularly unique or competitive, as Iomega went from dominating a specific niche to fighting in a market segment where it had no particular competitive advantage. They became a small, sickly fish in a big pond, competing against dozens of other established storage brands that were far more renowned in their fields.

The end came in April 2008, when EMC Corporation announced plans to acquire Iomega for $213 million — a tiny fraction of the company’s peak valuation. EMC saw lingering value in Iomega’s small office and home office customer base, and kept the brand alive for a few years, slapping the Iomega name on NAS boxes and media adapters. These weren’t iconic products unique to the brand, so much as middle-of-the-road options that had no technical edge or promise to speak of. In 2013, EMC formed a joint venture with Lenovo called LenovoEMC. Iomega’s remaining products were rebadged accordingly, and the brand effectively ceased to exist. There was no reason to continue Iomega, because what it was built to do was simply no longer relevant in the modern marketplace.
The Iomega story is, in many ways, the archetypal cautionary tale of the consumer technology industry. In the 1990s, the company identified a genuine need—affordable, portable, high-capacity removable storage. It nailed this brief with the Zip drive, which propelled the company’s fortunes into the stratosphere. However, the entire business hinged on a product category that had a shelf life measured in years. Iomega simply couldn’t hold on to its edge in removable storage against so many competitors that were both cheaper and more practical. It’s the same death that Blockbuster died—fail to see the future, and you will inevitably succumb to it.




















































You must be logged in to post a comment Login