
AI is coming for the laptop class. While you clack away at your keyboard — writing code or drafting memos or making spreadsheets or scrolling X or perusing DoorDash or reading Vox or dreading death — machines are teaching themselves how to do your job.
Tech
Will AI replace your job? 4 reasons it might not.
Over the past four years, chatbots have gone from neat parlor tricks to hyperproductive polymaths. AI models can now generate new software out of a single English sentence, summarize case law in seconds, read CT scans with superhuman accuracy, and coordinate complex office workflows with scant human oversight.
Large language models (LLMs) — today’s premier form of artificial intelligence — still have their limitations. They can’t reliably fulfill most white-collar workers’ every function. But AI progress is compounding on itself. As LLMs automate the process of building better LLMs, they will kick off a feedback loop of exponential self-improvement.
- Despite AI’s rapid advances, it still hasn’t substantially increased unemployment.
- You don’t necessarily have to outperform AI at your job in order to keep it.
- The go-to evidence for exponential AI progress has serious methodological flaws.
Thus, by the end of next year — if not this one — AI will render much of America’s professional class obsolete and push unemployment to 20 percent. Within a decade, the technology could wipe out virtually all forms of knowledge work.
Or so many of AI’s champions and detractors believe.
In recent weeks, the drumbeat of catastrophic labor-market forecasts has grown louder, with tech CEOs, financial analysts, and journalists penning viral predictions of an impending unemployment crisis.
In my view, the threat of AI-induced unemployment is worth taking seriously. And I’ve sketched out the case for alarm in past essays.
If the AI doomers’ concerns are warranted, however, their certainty is misplaced. Artificial intelligence could trigger mass white-collar layoffs in the near future. But there are plausible arguments against that scenario.
To inject some balance into the AI discourse — and/or, reassure myself that my hard-won verbal skills aren’t about to be less economically valuable than my flimsy biceps — I’ve sought out reasons for optimism about the white-collar labor market. Here are the four that I found most compelling:
1) You can see the AI age everywhere except in the jobs data
The first reason to doubt the doomer scenario for AI and unemployment is that it keeps not happening.
Or, more precisely: Despite the astounding capacities of today’s LLMs, there still aren’t many signs of large-scale, AI-induced job loss.
It takes time for firms to adopt new technologies, of course. But generative AI has been remarkably powerful for a while now. As of late 2024, it could already automate many coding tasks, generate research reports, write ad copy, review legal documents, and make terrible music at a near-human level.
Yet America’s unemployment rate has barely budged over the past two years, hovering near 4 percent.
Even in the industries most suited to AI-driven automation, employment shifts have been modest. Job postings for software developers have actually increased over the past year. Employment in market research, meanwhile, went up after ChatGPT hit the market. Even customer service representatives — arguably, the workers most threatened by chatbots — have not suffered massive job losses: Although employment in the field fell 10 percent from 2023 to 2024, it has held steady since then and remains close to its pre-pandemic level.
What’s more, there are few indications that mass, white-collar layoffs are on the horizon. In a December survey by the accounting firm KPMG, 92 percent of CEOs said they were planning to grow their head counts, even as 69 percent were dedicating a large share of their budgets to AI deployment.
Similarly, a January survey from EY-Parthenon found that 69 percent of CEOs expected that AI would lead them to either maintain or expand their payrolls.
One could dismiss this as sunny bluster. But there is evidence that these executives’ ostensible intuition — that AI adoption and downsizing don’t necessarily go together — holds true in practice. In a study of 12,000 European businesses published in February, firms that adopted AI saw a 4 percent increase in labor productivity — yet did not reduce their staffing in response.
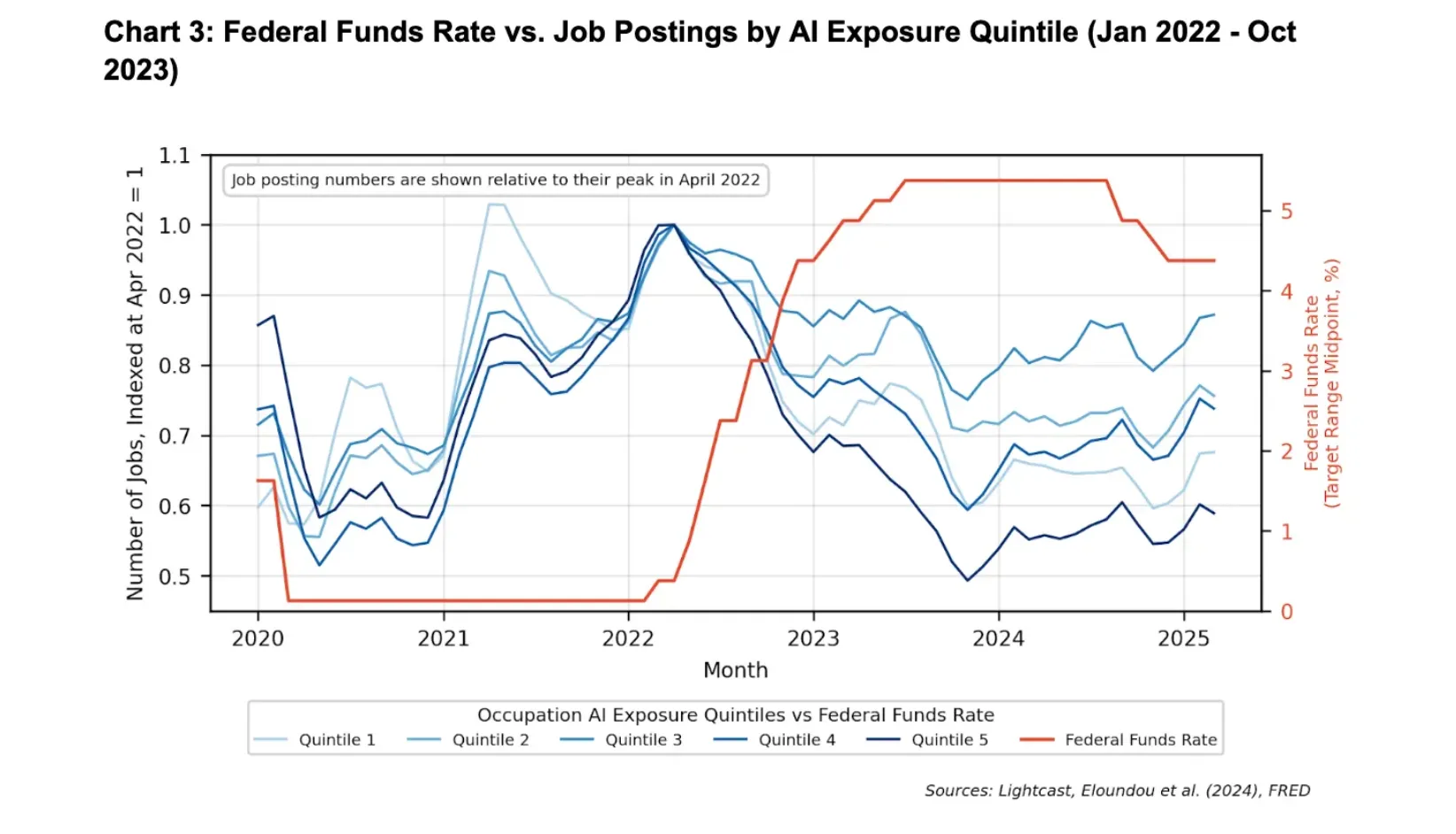
Granted, if you scour the jobs data for portents of an AI-driven unemployment crisis, you can come up with a few. For one, between November 2022 and January 2026, America’s core white-collar industries — finance, insurance, information, and professional and business services — cut their staffing by 1.9 percent. This is unusual; outside of recessions, these sectors have historically added jobs at a steady rate.
For another, a Stanford Digital Economy Lab study suggests that young workers in heavily AI-exposed fields have seen declining job prospects, relative to those in other sectors, since ChatGPT debuted.
Forecasts of an impending white-collar “bloodbath” tend to put a lot of weight on these data points. And yet, both developments likely have less to do with AI adoption than with monetary policy.
As two economists at Google recently observed, America’s most AI-exposed industries began to slash hiring six months before ChatGPT hit the market in November 2022. And white-collar job postings fell most precipitously in 2023, when corporate deployment of LLMs had barely begun; in the fourth quarter of that year, fewer than 10 percent of large businesses said they were even planning to use AI in the next six months.
This timeline is hard to square with the theory that AI drove the slowdown in white-collar hiring. By contrast, the timing neatly aligns with the Federal Reserve’s tightening cycle.
In March 2022, the central bank began hiking interest rates at a historically aggressive pace. A little over one month later, job postings began to fall in white-collar fields. When the Fed paused its hikes in 2024, that decline bottomed out; when the central bank began cutting rates in 2025, job openings started rebounding.

Courtesy of the Economic Innovation Group
Critically, interest rate hikes disproportionately impact AI-exposed industries. The sectors most susceptible to artificial intelligence — tech, finance, and professional services — are also among the most sensitive to tightening financial conditions. And when companies come under strain, they often pause entry-level hiring.
A pullback in employment caused by the Fed could therefore look a lot like one triggered by LLMs.
None of this is to deny that artificial intelligence has reduced employment in some occupations (for example, AI is almost certainly implicated in the recent decline of computer programming jobs). The point is just that the overall labor market impacts have been remarkably modest, given the scale of AI’s current capacities.
2) White-collar workers don’t need to outperform AI to remain economically valuable
The absence of a one-to-one correlation between increases in AI’s capabilities — and declines in white-collar employment — isn’t entirely surprising.
To remain economically valuable, a human worker does not need to outperform a machine at their job’s core tasks; they merely need to usefully complement that machine’s operations.
Consider translators. LLMs can convert text from one language to another at a speed and cost that no human could ever match. For many tasks, if corporations, authors, and publishers were forced to choose between having access to AI — or the world’s most gifted linguist — they would choose the bot.
And yet, a human translator working with an LLM still produces better text than the machine does by itself. While the latter blitzes through a first draft, the former can correct excessively literal translations of idiomatic expressions, tailor tone to the intended audience, and catch subtle errors that invite confusion or legal risk.
So long as human translators retain this utility, AI progress won’t necessarily reduce demand for their services. In fact, the technology could conceivably increase such demand.
That claim might seem unintuitive. After all, it surely takes fewer people to translate any given quantity of text in the age of generative AI than it did in years prior.
Yet humanity’s appetite for translated text is not fixed. If you drastically increase the efficiency of translation — and thus, reduce its cost — then people will purchase more of it.
And indeed, since the introduction of ChatGPT in 2022, demand for translation has surged. Perhaps for this reason, even as machines have come to match or exceed the skills of human translators across several dimensions, employment in the industry has grown in the European Union and stayed roughly level in the US.
And you can tell a similar story about myriad other fields.
AI can read medical images faster — and, for some types of cancer, more accurately — than any human. Still, a radiologist working with an AI yields better diagnoses than the machine working alone. And as LLMs have made radiology more efficient, demand for imaging has spiked — and with it, radiology employment.
3) People want some things done by people
In some domains, white-collar workers may retain an advantage over AI simply because they are human.
As the economist Adam Ozimek notes, many contemporary occupations could have been automated out of existence long ago, were technology the only concern. We’ve had player pianos and recorded music since the late 19th century. Yet many hotels and bars still pay human beings to tickle the keys for their customers.
“People are often willing to pay a premium for the ‘human touch.’”
For decades, it’s been easy to book your own travel online, relying on aggregators like Expedia and reviews on Yelp. Yet 67,500 Americans still make a living as travel agents. Workout videos make it possible for anyone to perform yoga at home, yet many hire personal instructors. Mechanical reproductions of famous paintings can be had at a low cost, yet people shell out millions for visibly indistinguishable versions that were produced by a specific human hand.
You could have asked ChatGPT to give you four reasons why AI won’t cause mass unemployment, and it would have instantly spit out a listicle. Instead, you’re reading an artisanally crafted explainer that Vox Media Inc. paid me to produce.
In other words, people are often willing to pay a premium for the “human touch.”
This won’t preempt an AI-induced employment crisis, all by itself. Consumers don’t typically care how their smartphone apps were coded or insurance claims were processed or tax returns were prepared. But a market for explicitly human-produced goods and services is likely to persist in many realms — including sales, medicine, legal services, and entertainment.
Heck, there might even be durable demand for journalism that’s conspicuously free of AI’s bizarre syntactical tics. That’s not just cope — it’s a serious possibility.
4) AI progress won’t necessarily be exponential
All these arguments may count for little, if AI’s capacities are truly growing at an exponential rate.
After all, exponential processes tend to creep up on you. When 32 cases of a supervirus become 64, almost no one notices. If that bug keeps doubling every couple days, however, the world will wake up a month later to 2.1 million infections. In that scenario, a glance at the pathogen’s impact on day three would have told you little about its consequences four weeks later.
In a world where AI progress is exponential, similar principles apply. Look around three years after ChatGPT’s debut and you might see little job loss. But if artificial intelligence is recursively self-improving — such that every advance accelerates the next — then today’s AI is only a pale imitation of 2030’s. The former may be to the latter as a hot-air balloon is to a space shuttle.
If so, then examining AI’s impact on jobs over the past four years wouldn’t shed much light on its effects over the next four. Likewise, the fact that white-collar workers can usefully complement AI today would scarcely guarantee their utility in the future.
But it’s not clear that AI has actually been improving at an exponential rate, much less that it will keep doing so, for years on end.
Without question, LLMs’ capabilities have been growing rapidly. But claims that this progress has been exponential tend to rest on a single, widely cited benchmark.
The AI research institute METR has long been the authority on the speed of AI progress. To gauge that pace, it tracks the duration of tasks that LLMs can complete with at least 50 percent accuracy. In this context, duration is measured by how long it would take a skilled human worker to complete the same assignment.
METR’s charts of how this has changed over time are ubiquitous in discussions of AI. And the trends are eye-popping.


Faced with these vertiginous slopes, many jump straight to wondering whether they will enjoy life as a “machine God’s” pet — forgetting to first ask themselves, “Wait, how does METR know that?”
Which is unfortunate, since the short answer is it doesn’t.
METR isn’t spying on every white-collar laborer in America, implanting bugs and honeypots in their break rooms, so as to determine how long it takes each worker to perform their jobs’ tasks.
Rather, to generate its estimates, the institute presents human software engineers with a bucket of coding assignments, measures how long they take to complete their tasks, and then sees whether AI models can perform the same feats. Through this process, METR estimates that the latest version of Claude can autonomously perform tasks that would take a skilled worker up to 14.5 hours to execute.
And yet, as NYU’s Nathan Witkin argues, there are massive problems with METR’s methodology, defects that severely limit what its findings can actually tell us about AI’s capabilities. To name just a few:
METR’s tasks are unrealistically basic. In METR’s own analysis, the bulk of their sample tasks differ from real-world engineering problems in systematic ways. Specifically, the former occur in static environments, require no coordination with other people (or agents), and include few resource constraints. METR also largely excluded tasks in which a single mistake could derail the entire project, so as to “reduce the expected cost of collecting human baselines.”
When the institute charted AI’s progress on its “messiest” tasks — which is to say, its most realistic ones — this was the result:

Viewed like this, AI progress does not look terribly exponential.
METR’s human baselines are unreliable. The sample of engineers who established METR’s baseline for human performance was neither large nor representative. Rather, as of 2025, its testing included only 140 people, recruited primarily from METR staffers’ professional networks.
More critically, on the more complex tasks, these recruits were often operating outside of their areas of expertise. In real life, these assignments would typically be handled by specialists, who would surely complete them more rapidly than random engineers with little domain knowledge.
Making matters worse, METR paid its baseliners on a per-hour basis, giving them an incentive to drag out their tasks.
AI could have simply memorized the answers to many of its assigned tasks. About one-third of the tested tasks had publicly available solutions. For these assignments, the models may have just been recalling answers they had encountered on the internet, in which case their success wouldn’t necessarily reflect growth in their general capabilities. (If a high-school student gains access to a calculus test in advance, and memorizes the answer, their performance on that problem wouldn’t tell us much about their general math skills.)
None of this is meant to disparage METR’s intentions, or to suggest that its data has zero utility. The pace of AI progress is not an easy thing to measure. And the organization is making an admirable effort.
Still, the fact that its charts are AI boosters’ (and doomers’) go-to evidence for exponential progress — despite the extreme limitations of its figures — calls the existence of that progress into question.
Moreover, even if we knew that AI has been improving exponentially over the past three years, we still couldn’t take a continuation of that trend for granted. Technologies routinely improve at an exponential rate for a period, only to stall out at a certain level of capability.
Machines might still replace us
These arguments don’t prove that the laptop class is going to be fine. They merely offer a basis for believing that it might be.
Indeed, everything I just wrote could be true — and AI could still drastically erode knowledge workers’ economic prospects.
Even if most white-collar laborers still usefully complement AI, a large minority may not. Meanwhile, those who remain employable might command drastically lower wages than they once did: When building software merely requires the ability to write instructions in plain English — rather than mastering complicated coding languages — programmers’ bargaining power may plummet.
And while AI-driven productivity gains might increase demand for certain goods and services, Americans’ latent appetite for tax advice, HR compliance audits, and contract review is not infinite. In these areas, AI’s boosts to efficiency are liable to yield job losses.
Finally, AI might not be improving at an exponential rate. But over time, linear gains may be sufficient to drastically reduce knowledge workers’ economic utility.
All this said, as the world’s most influential business leaders and intellectuals discuss the impending elimination of white-collar work as though it were no more hypothetical than tomorrow’s sunrise, it’s worth keeping their narrative’s liabilities in mind: This doomsday scenario has scant support in existing employment trends, sits in tension with multiple economic principles, and relies on dubious assumptions about the pace of AI progress.
In other words, while it’s past time for policymakers to prepare for AI-induced unemployment spikes, knowledge workers don’t yet need to toss our keyboards and learn to plumb.

Continue Reading

Apple reportedly has full access to customize Google’s Gemini model, allowing it to distill smaller on-device AI models for Siri and other features that can run locally without an internet connection. MacRumors reports: The Information explains that Apple can ask the main Gemini model to perform a series of tasks that provide high-quality results, with a rundown of the reasoning process. Apple can feed the answers and reasoning information that it gets from Gemini to train smaller, cheaper models. With this process, the smaller models are able to learn the internal computations used by Gemini, producing efficient models that have Gemini-like performance but require less computing power.
Apple is also able to edit Gemini as needed to make sure that it responds to queries in a way that Apple wants, but Apple has been running into some issues because Gemini has been tuned for chatbot and coding applications, which doesn’t always meet Apple’s needs.

Meta and Google have been found liable for building intentionally addictive social media services, in a trial that sets a strong precedent for hundreds of other lawsuits that are still pending.

Meta CEO Mark Zuckerberg
On Wednesday, a jury in Los Angeles Superior Court finished its deliberations over a lawsuit between Meta and Google, and a young woman. The jury found that the tech giants were liable for enabling a woman identified as Kaley to become addicted to social media as a child.
The lawsuit commenced in January, while the jury deliberations started on March 13.
Continue Reading on AppleInsider | Discuss on our Forums

Spotify is working on a new feature to help users discover music. The immensely popular streaming service recently introduced SongDNA, an “immersive” experience that provides extended credits to the people who contributed to one or more music productions.
Read Entire Article
Source link


Meanwhile, a Los Angeles jury is deliberating a social media addiction lawsuit against Meta and Google.
A New Mexico jury has found that Meta endangered children by misleading users about the safety of its platforms. The decision comes after a nearly seven-week trial, resulting in Meta being told to pay $375m in damages.
“The jury’s verdict is a historic victory for every child and family who has paid the price for Meta’s choice to put profits over kids’ safety,” said New Mexico attorney general Raúl Torrez, who filed the lawsuit against Meta in 2023.
In the suit, he claimed Meta knowingly exposes children to sexual exploitation and mental harm for profit. Meta owns Instagram, Facebook and WhatsApp.
According to the New Mexico Department of Justice, evidence presented at the trial established that Meta’s design features enable bad actors to engage in child sexual exploitation. Evidence also showed platforms are also designed to addict young people, according to the department.
“Meta executives knew their products harmed children, disregarded warnings from their own employees, and lied to the public about what they knew. Today the jury joined families, educators, and child safety experts in saying enough is enough,” Torrez added. The company has been found to have violated parts of the state’s Unfair Practices Act.
Meta plans to appeal the decision. “We respectfully disagree with the verdict and will appeal,” Meta said in statement yesterday (24 March).
“We work hard to keep people safe on our platforms and are clear about the challenges of identifying and removing bad actors or harmful content. We will continue to defend ourselves vigorously, and we remain confident in our record of protecting teens online.”
Meanwhile Torrez will be asking the presiding judge to place additional penalties on Meta during a bench trial scheduled in early May. Torrez will also be asking the court to force Meta to make its apps safer for children.
The New Mexico verdict is a major loss for Meta, which is gearing up for a number of trials set for this year. A jury in Los Angeles is currently deliberating a social media addiction suit against Meta and Google. TikTok and Snapchat were involved in the original suit, but have since settled out of court.
Thousands have filed lawsuits against social media companies over the alleged harm they pose to their users, including more than 40 US state attorney generals.
A coalition suit filed in 2023 accused Meta of designing and deploying “harmful features” on Instagram and Facebook, which get younger people addicted to these platforms.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.

Big Tech is not alone in the AI innovation race. Four startup founders took the stage at GeekWire’s Agents of Transformation event Tuesday in Seattle for a rapid-fire pitch competition.
Ideas from Pay-i, Cascade, Autessa and GemaTEG were pitched to the crowd and a panel of judges, with Pay-i founder David Tepper emerging as winner and most impressive under pressure.
Judges Bryan Hale of Anthos Capital, Yifan Zhang of AI House, and T.A. McCann of Pioneer Square Labs said they were looking for someone who was “both great at presenting but also fantastic at answering the questions.”
Read more about each pitch:
Pay-i (pitch by David Tepper, founder/CEO)

An AI spend management platform that tracks ROI across an organization’s entire AI footprint — not just tokens, but the full cost stack including models, tools, and GPU resources.
David Tepper argued that tokens account for only 72% of the total expense associated with AI, and that the complexity multiplies fast when agents are drawing on multiple models, enterprise discounts, and rented GPU banks simultaneously.
Born from his days tracking Microsoft’s internal Gen AI spend on Excel spreadsheets — a period when he says he once saved his division $300,000 a week by simply asking the right questions — the company targets enterprises spending at least $500,000 on AI annually.
“After all the hype and FOMO wears off, there’s three letters that are going to survive the AI revolution, and that’s ROI,” he said.
Cascade AI (pitch by Ana-Maria Constantin, co-founder/CEO)

An agentic HR and IT support platform that deploys AI agents to handle sensitive employee situations — benefits navigation, mental health resources, leave management — confidentially and around the clock, freeing HR teams for higher-stakes human judgment.
Ana-Maria Constantin opened her pitch with a show of hands, asking the audience whether they’d ever hesitated to go to HR because they weren’t sure whose side HR would be on.
“Imagine if that’s the case for the people in this room, senior leaders working for some of the most successful companies in the world,” she said. “Imagine how regular employees are feeling. That’s the problem we’re working on at Cascade AI.”
Autessa (pitch by Roshnee Sharma, CEO)

A platform that replaces off-the-shelf SaaS with custom-built software staffed by “AI employees” — agents that handle workflows like lead qualification and order processing.
Roshnee Sharma’s pitch opened with a crowd-participation moment: what does SaaS really stand for? “Software as a spend,” she declared.
The company targets mid-market businesses with $20 million to $500 million in revenue, and prices its AI employees at roughly $7 to $10 each.
Judges pushed back on whether results were truly cost-saving or merely cost-neutral; Sharma argued the savings are real because clients avoid having to hire additional headcount: “We didn’t fire people. We got people able to do more of the work that they wanted to do.”
GemaTEG (pitch by Manfred Markevitch, co-founder/CEO)

The outlier of the group: a hardware thermal management company targeting AI data centers, using solid-state cooling technology that requires no water and uses 40% less power than conventional systems.
“AI runs on hardware. It’s not only software,” co-founder and CEO Manfred Markevitch told the crowd, noting that a conventional hybrid-scale data center can consume a million gallons of water per day.
GemaTEG’s granular approach cools at the individual chip level rather than the whole building, and the company claims its systems perform twice as well as conventional ones on a per-watt basis. The company already has installations with the U.S. Department of Energy, and partners in Italy and Switzerland.
Hyperscaler deployment is one to two years out, with chip manufacturer design-in conversations already underway. Judges pressed hard on customer lock-in risk; Markevitch compared the stickiness of their solution to Intel Inside — once designed in, it spans multiple chip generations.
Related coverage:
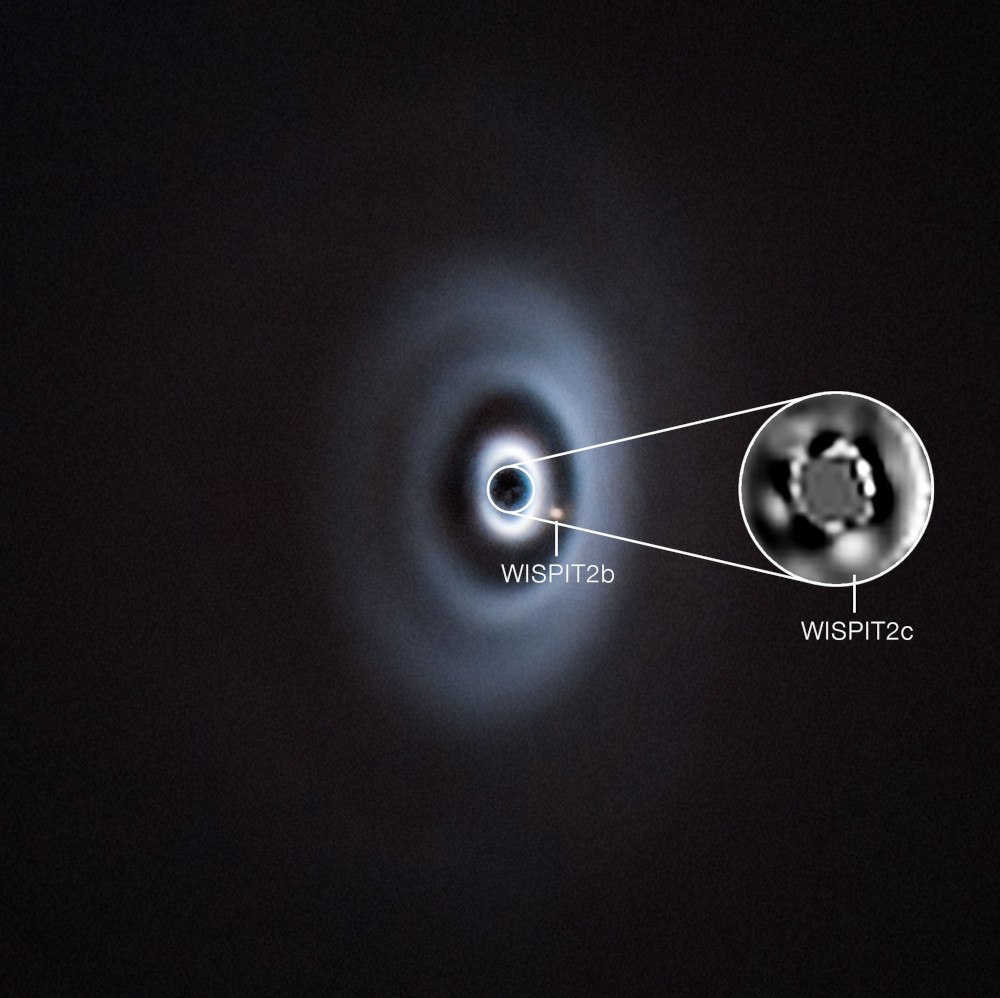
‘Wispit 2C’ is estimated to be about 5m years old and most likely 10 times the mass of Jupiter.
Galway native Chloe Lawlor has discovered a new planet – the second one to be found forming near an infant star called ‘Wispit 2’, some 437 light years away.
As a child, Lawlor wanted to be an artist, she tells SiliconRepublic.com. However, she changed her mind once she joined university. “I moved into physics because I did like physics in school, so I thought, ‘Oh, maybe I’ll just try this out.’”
The 25-year-old says discoveries such as these feed the innate curiosity humans have in wanting to know how we came to be, how we evolved and why we are here. Lawlor is a PhD student at the University of Galway’s Centre for Astronomy at the School of Natural Sciences and the Ryan Institute.
She is working in collaboration with project lead Richelle van Capelleveen, a PhD student from Leiden Observatory in the Netherlands, and postdoctoral researcher Guillaume Bourdarot from the Max Planck Institute for Extraterrestrial Physics in Germany, to learn more about young planets and how they’re forming.
“Most of the planets that we’ve observed have been much older,” Lawlor says. “We don’t know how they get to those sort of final stages like something like our solar system. This is really key for these formation theories and it’s hopefully going to tell us a lot about these young systems, how they’re forming, and then how they evolve.”
Lawlor’s new discovery, an exoplanet named ‘Wispit 2C’, is thought to be about 5m years old. ‘Wispit 2B’, a nearby planet, was discovered last year by van Capelleveen and Dr Laird Close from the University of Arizona.
Both these exoplanets are at early stages of formation in the disc around Wispit 2, which is located in the Constellation of the Eagle, a prominent equatorial constellation visible in the northern hemisphere summer along the Milky Way.
Lawlor’s discovery makes Wispit 2 the second known young and still forming multi-planet system. The only other system yet discovered with more than one planet developing is PDS 70, some 400 light years away from Earth.
Wispit 2C is a gas giant, likely around 10 times the mass of Jupiter. It is twice as massive as Wispit 2B and orbits four-times closer to its host star, which makes it incredibly difficult to detect with ground-based telescopes.

Wispit 2B and Wispit 2C forming around Wispit 2. Image: ESO/C Lawlor, R F van Capelleveen et al.
The exoplanet was detected using the European Southern Observatory’s Very Large Telescope in Chile’s Atacama desert. By linking several telescopes together to act as one giant instrument, the research team was able to observe regions very close to the star. In their analysis, the team was able to detect carbon monoxide gas, a chemical commonly found in the atmospheres of young giant planets.
Lawlor said earlier this week: “At first, we weren’t sure if it was a planet or a very large dust clump. We very quickly made follow-up observations using the Very Large Telescope Interferometer, an incredible setup where multiple telescopes can be connected to form a large virtual telescope.
“This allowed us to take what we call a spectrum, which is essentially a chemical fingerprint revealing the elements and molecules in an object’s atmosphere.”
Lawlor led the study, which has been published in The Astrophysical Journal Letters.
Prof Frances Fahy, director of the Ryan Institute, said: “The discovery of the planet Wispit 2C is a remarkable achievement and highlights the world-class astrophysics research taking place at University of Galway.”
The team will continue on with their efforts to hopefully find more planets in the system.
Last year, a study from Scotland’s University of St Andrews showed how giant free-floating planets could make their own miniature planetary systems without needing a star to orbit around. In a different study from 2025, scientists – for the first time – observed the very early stages of the creation of a new solar system around a baby star.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.

Go ahead and get ready to cue your inevitable comparisons: the new trailer for HBO’s Harry Potter series dropped on Wednesday, giving audiences a first look at muggles, magical Hogwarts students and The Boy Who Lived. Due to hit HBO and HBO Max for Christmas 2026, the TV show will be a direct adaptation of the wizarding books, starting off with The Philosopher’s Stone.
To fans familiar with the movie franchise, this may feel like a rediscovery — or reintroduction — to the live-action version of the world of Harry Potter. The trailer shows a young Harry and his signature scar, his tyrant of an aunt and the moment he received his invitation from Hogwarts. Take a look at the first meet with Hagrid, tender moments with Ron and Hermione, and a look at Lucius Malfoy and Snape.
The series features Dominic McLaughlin as Harry Potter, Arabella Stanton as Hermione Granger and Alastair Stout
as Ron Weasley, and the expansive cast also includes Nick Frost as Hagrid, John Lithgow as Hogwarts headmaster Dumbledore and Paapa Essiedu as Professor Snape.

Nintendo might finally be doing something gamers have been asking for… forever. The company has officially confirmed that Switch 2 games will have different pricing for digital and physical versions, with digital copies expected to be cheaper.

The change begins in May 2026, starting with titles like Yoshi and the Mysterious Book. For example, early listings on the eShop show the game priced at $59.99 digitally vs $69.99 physically, marking a clear shift in how Nintendo handles game pricing.
Why is Nintendo doing this?
Let’s be real, physical games are comparatively expensive to make. Nintendo says the change reflects the higher costs of manufacturing and distributing cartridges, compared to digital downloads. This aligns with what the industry has been doing for years, except Nintendo has been one of the few holdouts where digital and physical games often cost the same.

There’s also a bigger strategy at play here. By making digital games cheaper, Nintendo could nudge more players toward digital purchases. That essentially translates to higher margins, fewer logistics headaches, and a tighter grip on its ecosystem. In other words, this isn’t just about fairness in pricing… It’s also about where Nintendo wants its future sales to go.
What does this mean for players?
So, does this mean all games going forward will have different prices? Well, not exactly, and this is where things get a little messy. While Nintendo is setting a lower MSRP for digital games, actual pricing can still vary depending on the title and retailer. Plus, not every game will follow the same pattern, so bigger releases could still carry higher price tags, making the gap between digital and physical a bit inconsistent.

For players, though, this is still a win. Digital games are finally getting a clear pricing advantage after years of being oddly equal (or sometimes pricier) than physical copies. That said, the trade-off remains. Physical games can be resold or shared, while digital ones stay locked to your account.

A jury found Meta and YouTube negligent in a landmark social media addiction case, ruling that addictive design features such as infinite scroll and algorithmic recommendations harmed a young user and contributed to her mental health distress. The verdict awards $3 million in compensatory damages so far and could pave the way for more lawsuits seeking financial penalties and product changes across the social media industry. “Meta is responsible for 70 percent of that cost and YouTube for the remainder,” notes The New York Times. “TikTok and Snap both settled with the plaintiff for undisclosed terms before the trial started.” From the report: The bellwether case, which was brought by a now 20-year-old woman identified as K.G.M., had accused social media companies of creating products as addictive as cigarettes or digital casinos. K.G.M. sued Meta, which owns Instagram and Facebook, and Google’s YouTube over features like infinite scroll and algorithmic recommendations that she claimed led to anxiety and depression.
The jury of seven women and five men will deliberate further to decide what further punitive damages the companies should pay for malice or fraud. The verdict in K.G.M.’s case — one of thousands of lawsuits filed by teenagers, school districts and state attorneys general against Meta, YouTube, TikTok and Snap, which owns Snapchat — was a major win for the plaintiffs. The finding validates a novel legal theory that social media sites or apps can cause personal injury. It is likely to factor into similar cases expected to go to trial this year, which could expose the internet giants to further financial damages and force changes to their products. The verdict also comes on the heels of a New Mexico jury ruling that found Meta liable for violating state law by failing to protect users of its apps from child predators.
Standard RAG pipelines break when enterprises try to use them for long-term, multi-session LLM agent deployments. This is a critical limitation as demand for persistent AI assistants grows.
xMemory, a new technique developed by researchers at King’s College London and The Alan Turing Institute, solves this by organizing conversations into a searchable hierarchy of semantic themes.
Experiments show that xMemory improves answer quality and long-range reasoning across various LLMs while cutting inference costs. According to the researchers, it drops token usage from over 9,000 to roughly 4,700 tokens per query compared to existing systems on some tasks.
For real-world enterprise applications like personalized AI assistants and multi-session decision support tools, this means organizations can deploy more reliable, context-aware agents capable of maintaining coherent long-term memory without blowing up computational expenses.
RAG wasn’t built for this
In many enterprise LLM applications, a critical expectation is that these systems will maintain coherence and personalization across long, multi-session interactions. To support this long-term reasoning, one common approach is to use standard RAG: store past dialogues and events, retrieve a fixed number of top matches based on embedding similarity, and concatenate them into a context window to generate answers.
However, traditional RAG is built for large databases where the retrieved documents are highly diverse. The main challenge is filtering out entirely irrelevant information. An AI agent’s memory, by contrast, is a bounded and continuous stream of conversation, meaning the stored data chunks are highly correlated and frequently contain near-duplicates.
To understand why simply increasing the context window doesn’t work, consider how standard RAG handles a concept like citrus fruit.
Imagine a user has had many conversations saying things like “I love oranges,” “I like mandarins,” and separately, other conversations about what counts as a citrus fruit. Traditional RAG may treat all of these as semantically close and keep retrieving similar “citrus-like” snippets.
“If retrieval collapses onto whichever cluster is densest in embedding space, the agent may get many highly similar passages about preference, while missing the category facts needed to answer the actual query,” Lin Gui, co-author of the paper, told VentureBeat.
A common fix for engineering teams is to apply post-retrieval pruning or compression to filter out the noise. These methods assume that the retrieved passages are highly diverse and that irrelevant noise patterns can be cleanly separated from useful facts.
This approach falls short in conversational agent memory because human dialogue is “temporally entangled,” the researchers write. Conversational memory relies heavily on co-references, ellipsis, and strict timeline dependencies. Because of this interconnectedness, traditional pruning tools often accidentally delete important bits of a conversation, leaving the AI without vital context needed to reason accurately.

Why the fix most teams reach for makes things worse
To overcome these limitations, the researchers propose a shift in how agent memory is built and searched, which they describe as “decoupling to aggregation.”
Instead of matching user queries directly against raw, overlapping chat logs, the system organizes the conversation into a hierarchical structure. First it decouples the conversation stream into distinct, standalone semantic components. These individual facts are then aggregated into a higher-level structural hierarchy of themes.
When the AI needs to recall information, it searches top-down through the hierarchy, going from themes to semantics and finally to raw snippets. This approach avoids redundancy. If two dialogue snippets have similar embeddings, the system is unlikely to retrieve them together if they have been assigned to different semantic components.
For this architecture to succeed, it must balance two vital structural properties. The semantic components must be sufficiently differentiated to prevent the AI from retrieving redundant data. At the same time, the higher-level aggregations must remain semantically faithful to the original context to ensure the model can craft accurate answers.
A four-level hierarchy that shrinks the context window
The researchers developed xMemory, a framework that combines structured memory management with an adaptive, top-down search strategy.
xMemory continuously organizes the raw stream of conversation into a structured, four-level hierarchy. At the base are the raw messages, which are first summarized into contiguous blocks called “episodes.” From these episodes, the system distills reusable facts as semantics that disentangle the core, long-term knowledge from repetitive chat logs. Finally, related semantics are grouped together into high-level themes to make them easily searchable.

xMemory uses a special objective function to constantly optimize how it groups these items. This prevents categories from becoming too bloated, which slows down search, or too fragmented, which weakens the model’s ability to aggregate evidence and answer questions.
When it receives a prompt, xMemory performs a top-down retrieval across this hierarchy. It starts at the theme and semantic levels, selecting a diverse, compact set of relevant facts. This is crucial for real-world applications where user queries often require gathering descriptions across multiple topics or chaining connected facts together for complex, multi-hop reasoning.
Once it has this high-level skeleton of facts, the system controls redundancy through what the researchers call “Uncertainty Gating.” It only drills down to pull the finer, raw evidence at the episode or message level if that specific detail measurably decreases the model’s uncertainty.
“Semantic similarity is a candidate-generation signal; uncertainty is a decision signal,” Gui said. “Similarity tells you what is nearby. Uncertainty tells you what is actually worth paying for in the prompt budget.” It stops expanding when it detects that adding more detail no longer helps answer the question.
What are the alternatives?
Existing agent memory systems generally fall into two structural categories: flat designs and structured designs. Both suffer from fundamental limitations.
Flat approaches such as MemGPT log raw dialogue or minimally processed traces. This captures the conversation but accumulates massive redundancy and increases retrieval costs as the history grows longer.
Structured systems such as A-MEM and MemoryOS try to solve this by organizing memories into hierarchies or graphs. However, they still rely on raw or minimally processed text as their primary retrieval unit, often pulling in extensive, bloated contexts. These systems also depend heavily on LLM-generated memory records that have strict schema constraints. If the AI deviates slightly in its formatting, it can cause memory failure.
xMemory addresses these limitations through its optimized memory construction scheme, hierarchical retrieval, and dynamic restructuring of its memory as it grows larger.
When to use xMemory
For enterprise architects, knowing when to adopt this architecture over standard RAG is critical. According to Gui, “xMemory is most compelling where the system needs to stay coherent across weeks or months of interaction.”
Customer support agents, for instance, benefit greatly from this approach because they must remember stable user preferences, past incidents, and account-specific context without repeatedly pulling up near-duplicate support tickets. Personalized coaching is another ideal use case, requiring the AI to separate enduring user traits from episodic, day-to-day details.
Conversely, if an enterprise is building an AI to chat with a repository of files, such as policy manuals or technical documentation, “a simpler RAG stack is still the better engineering choice,” Gui said. In those static, document-centric scenarios, the corpus is diverse enough that standard nearest-neighbor retrieval works perfectly well without the operational overhead of hierarchical memory.
The write tax is worth it
xMemory cuts the latency bottleneck associated with the LLM’s final answer generation. In standard RAG systems, the LLM is forced to read and process a bloated context window full of redundant dialogue. Because xMemory’s precise, top-down retrieval builds a much smaller, highly targeted context window, the reader LLM spends far less compute time analyzing the prompt and generating the final output.
In their experiments on long-context tasks, both open and closed models equipped with xMemory outperformed other baselines, using considerably fewer tokens while increasing task accuracy.

However, this efficient retrieval comes with an upfront cost. For an enterprise deployment, the catch with xMemory is that it trades a massive read tax for an upfront write tax. While it ultimately makes answering user queries faster and cheaper, maintaining its sophisticated architecture requires substantial background processing.
Unlike standard RAG pipelines, which cheaply dump raw text embeddings into a database, xMemory must execute multiple auxiliary LLM calls to detect conversation boundaries, summarize episodes, extract long-term semantic facts, and synthesize overarching themes.
Furthermore, xMemory’s restructuring process adds additional computational requirements as the AI must curate, link, and update its own internal filing system. To manage this operational complexity in production, teams can execute this heavy restructuring asynchronously or in micro-batches rather than synchronously blocking the user’s query.
For developers eager to prototype, the xMemory code is publicly available on GitHub under an MIT license, making it viable for commercial uses. If you are trying to implement this in existing orchestration tools like LangChain, Gui advises focusing on the core innovation first: “The most important thing to build first is not a fancier retriever prompt. It is the memory decomposition layer. If you get only one thing right first, make it the indexing and decomposition logic.”
Retrieval isn’t the last bottleneck
While xMemory offers a powerful solution to today’s context-window limitations, it clears the path for the next generation of challenges in agentic workflows. As AI agents collaborate over longer horizons, simply finding the right information won’t be enough.
“Retrieval is a bottleneck, but once retrieval improves, these systems quickly run into lifecycle management and memory governance as the next bottlenecks,” Gui said. Navigating how data should decay, handling user privacy, and maintaining shared memory across multiple agents is exactly “where I expect a lot of the next wave of work to happen,” he said.

Crypto World16 seconds ago
BTC USD Price Outlook: Bitcoin Resurgence and Gold Losing Streak

Politics1 minute ago
UEFA rejects English clubs plea for more players

Entertainment2 minutes ago
Young and the Restless Early Spoilers Mar 30-Apr 3: Cane Discovers Disturbing Truth & Audra Falls Hard for Someone New!






-
 Crypto World5 days ago
Crypto World5 days agoNIO (NIO) Stock Plunges 6.5% as Shelf Registration Sparks Dilution Worries
-

 Fashion5 days ago
Fashion5 days agoWeekend Open Thread: Adidas – Corporette.com
-

 Politics5 days ago
Politics5 days agoJenni Murray, Long-Serving Woman’s Hour Presenter, Dies Aged 75
-
 NewsBeat12 hours ago
NewsBeat12 hours agoManchester United reach agreement with Casemiro over contract clause amid transfer speculation
-

 Crypto World4 days ago
Crypto World4 days agoBest Crypto to Buy Now: Strategy Just Spent $1.57 Billion on Bitcoin During Fear While Early Investors Quietly Enter Pepeto for 150x Potential
-

 Crypto World4 days ago
Crypto World4 days agoBitcoin Price News: Bhutan Sells $72 Million in BTC Under Fiscal Pressure, but the Smart Money Entering Pepeto Sees What the Market Does Not
-

 Tech6 days ago
Tech6 days agoinKONBINI Lets You Spend Summer Days Behind the Register
-

 Sports2 days ago
Sports2 days agoRemo Stars and Kano Pillars Strengthen Survival Hopes in NPFL
-

 Politics6 days ago
Politics6 days agoGender equality discussions at UN face pushbacks and US resistance
-

 Business3 days ago
Business3 days agoNo Winner in March 21 Drawing as Prize Rolls to $133 Million for Next
-

 Sports2 days ago
Sports2 days agoGary Kirsten Accuses Pakistan Cricket Board Of ‘Interference’, Mohsin Naqvi Responds
-
 Tech3 days ago
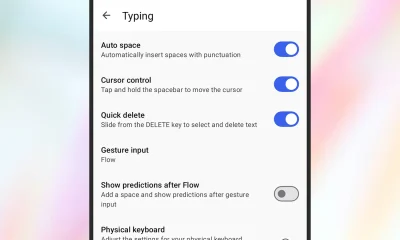
Tech3 days agoGive Your Phone a Huge (and Free) Upgrade by Switching to Another Keyboard
-

 Sports5 days ago
Sports5 days ago2026 Kentucky Derby horses, odds, futures, preview, date: Expert who nailed 12 Derby-Oaks Doubles enters picks
-
Sports7 days ago
Vikings Free Agency Enters Phase 2 with Key Questions
-
 Tech3 days ago
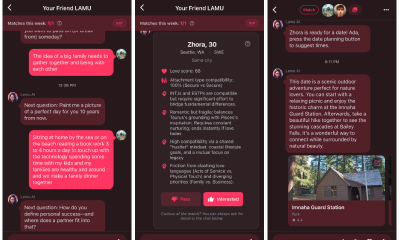
Tech3 days agoAI enters the chat: New Seattle dating app relies on tech to facilitate meaningful human connections
-

 News Videos7 days ago
News Videos7 days agoAmazing Cardboard Gadget That Turns Paper Into Money #techgadgets #ytshorts
-

 Politics6 days ago
Politics6 days agoScotland’s rejection of assisted dying is a victory for humanity
-

 Tech7 days ago
Tech7 days agoCorsair K100 Air Wireless Mechanical RGB Keyboard Packs Full Power Into a Slim Frame
-

 Business6 days ago
Business6 days agoDLocal: Entering 2026 At Escape Velocity
-
Business5 days ago
Columbia Sportswear enters $500 million credit agreement with JPMorgan Chase
You must be logged in to post a comment Login