Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Large language models (LLMs) with very long context windows have been making headlines lately. The ability to cram hundreds of thousands or even millions of tokens into a single prompt unlocks many possibilities for developers.
But how well do these long-context LLMs really understand and utilize the vast amounts of information they receive?
Researchers at Google DeepMind have introduced Michelangelo, a new benchmark designed to evaluate the long-context reasoning capabilities of LLMs. Their findings, published in a new research paper, show that while current frontier models have progressed in retrieving information from large in-context data, they still struggle with tasks that require reasoning over the data structure.
Advertisement
The need for better long-context benchmarks
The emergence of LLMs with extremely long context windows, ranging from 128,000 to over 1 million tokens, has prompted researchers to develop new benchmarks to evaluate their capabilities. However, most of the focus has been on retrieval tasks, such as the popular “needle-in-a-haystack” evaluation, where the model is tasked with finding a specific piece of information within a large context.
“Over time, models have grown considerably more capable in long context performance,” Kiran Vodrahalli, research scientist at Google DeepMind, told VentureBeat. “For instance, the popular needle-in-a-haystack evaluation for retrieval has now been well saturated up to extremely long context lengths. Thus, it has become important to determine whether the harder tasks models are capable of solving in short context regimes are also solvable at long ranges.”
Retrieval tasks don’t necessarily reflect a model’s capacity for reasoning over the entire context. A model might be able to find a specific fact without understanding the relationships between different parts of the text. Meanwhile, existing benchmarks that evaluate a model’s ability to reason over long contexts have limitations.
“It is easy to develop long reasoning evaluations which are solvable with a combination of only using retrieval and information stored in model weights, thus ‘short-circuiting’ the test of the model’s ability to use the long-context,” Vodrahalli said.
Advertisement
Michelangelo
To address the limitations of current benchmarks, the researchers introduced Michelangelo, a “minimal, synthetic, and unleaked long-context reasoning evaluation for large language models.”
Michelangelo is based on the analogy of a sculptor chiseling away irrelevant pieces of marble to reveal the underlying structure. The benchmark focuses on evaluating the model’s ability to understand the relationships and structure of the information within its context window, rather than simply retrieving isolated facts.
The benchmark consists of three core tasks:
Latent list: The model must process a long sequence of operations performed on a Python list, filter out irrelevant or redundant statements, and determine the final state of the list. “Latent List measures the ability of a model to track a latent data structure’s properties over the course of a stream of code instructions,” the researchers write.
Advertisement
Multi-round co-reference resolution (MRCR): The model must produce parts of a long conversation between a user and an LLM. This requires the model to understand the structure of the conversation and resolve references to previous turns, even when the conversation contains confusing or distracting elements. “MRCR measures the model’s ability to understanding ordering in natural text, to distinguish between similar drafts of writing, and to reproduce a specified piece of previous context subject to adversarially difficult queries,” the researchers write.
“I don’t know” (IDK): The model is given a long story and asked to answer multiple-choice questions about it. For some questions, the context does not contain the answer, and the model must be able to recognize the limits of its knowledge and respond with “I don’t know.” “IDK measures the model’s ability to understand whether it knows what it doesn’t know based on the presented context,” the researchers write.
Latent Structure Queries
The tasks in Michelangelo are based on a novel framework called Latent Structure Queries (LSQ). LSQ provides a general approach for designing long-context reasoning evaluations that can be extended to arbitrary lengths. It can also test the model’s understanding of implicit information as opposed to retrieving simple facts. LSQ relies on synthesizing test data to avoid the pitfalls of test data leaking into the training corpus.
“By requiring the model to extract information from structures rather than values from keys (sculptures from marble rather than needles from haystacks), we can more deeply test language model context understanding beyond retrieval,” the researchers write.
Advertisement
LSQ has three key differences from other approaches to evaluating long-context LLMs. First, it has been explicitly designed to avoid short-circuiting flaws in evaluations that go beyond retrieval tasks. Second, it specifies a methodology for increasing task complexity and context length independently. And finally, it is general enough to capture a large range of reasoning tasks. The three tests used in Michelangelo cover code interpretation and reasoning over loosely written text.
“The goal is that long-context beyond-reasoning evaluations implemented by following LSQ will lead to fewer scenarios where a proposed evaluation reduces to solving a retrieval task,” Vodrahalli said.
Evaluating frontier models on Michelangelo
The researchers evaluated ten frontier LLMs on Michelangelo, including different variants of Gemini, GPT-4 and 4o, and Claude. They tested the models on contexts up to 1 million tokens. Gemini models performed best on MRCR, GPT models excelled on Latent List, and Claude 3.5 Sonnet achieved the highest scores on IDK.
However, all models exhibited a significant drop in performance as the complexity of the reasoning tasks increased, suggesting that even with very long context windows, current LLMs still have room to improve in their ability to reason over large amounts of information.
Advertisement
Frontier LLMs struggle with reasoning on long-context windows (source: arxiv)
“Frontier models have room to improve on all of the beyond-retrieval reasoning primitives (Latent List, MRCR, IDK) that we investigate in Michelangelo,” Vodrahalli said. “Different frontier models have different strengths and weaknesses – each class performs well on different context ranges and on different tasks. What does seem to be universal across models is the initial drop in performance on long reasoning tasks.”
The Michelangelo evaluations capture basic primitives necessary for long-context reasoning and the findings can have important implications for enterprise applications. For example, in real-world applications where the model can’t rely on its pretraining knowledge and must perform multi-hop reasoning over many disparate locations in very long contexts, Vodrahalli expects performance to drop as the context length grows.
“This is particularly true if the documents have a lot of information that is irrelevant to the task at hand, making it hard for a model to easily immediately distinguish which information is relevant or not,” Vodrahalli said. “It is also likely that models will continue to perform well on tasks where all of the relevant information to answer a question is located in one general spot in the document.”
The researchers will continue to add more evaluations to Michelangelo and hope to make them directly available so that other researchers can test their models on them.
VB Daily
Advertisement
Stay in the know! Get the latest news in your inbox daily
I absolutely love IBM servers and System X 3650 is my favorite server.
[Affiliate Links]
This model starts at about $1.600 at Amazon check up on price http://amzn.to/1NVI1Az
Link – System x3650 M4 7915 – https://amzn.to/2YJRMih
Link – x3650 M4 Drive Caddy – https://amzn.to/2YEFsQr
This model starts at about $1.600 at Amazon check up on price http://amzn.to/1NVI1Az
I even have the first three generations of the server in my datacenter. x3650, x3650 M2 and x3650 M3. But the latest x3650 M4, I have not yet gotten my hands on. But we have it at work, and it’s just amazing.
Hardware summary
Dual-socket 2U rack server for expandability and high performance
Up to two Intel Xeon Processor E5-2600 v2 product family processors
Up to 768 GB memory and up to 1866 MHz memory speed
Integrated quad-port Gigabit Ethernet and optional embedded dual-port 10 GbE
Up to six PCIe 3.0 expansion slots; up to four optional PCI-X slots available
Up to 16 TB of 1.8-inch hot-swap SSDs or 25.6 TB of 2.5-inch hot-swap SAS/SATA/SSDs or 24 TB of 3.5-inch hot-swap or simple-swap SAS/SATA HDDs
Embedded 6 Gbps hardware RAID-0, -1, -10 and optional RAID-5, -50 or -6, -60. Optional support for new 12 Gbps RAID controller.
Hot-swap disk/fan/power supply, two fan zones with N+1 fans design, light path diagnostics and Predictive Failure Analysis, better thermal design, balanced efficiency, uptime and serviceability.
_______________________________________________________
My PlayHouse is a channel where i will show, what i am working on. I have this house, it is 168 Square Meters / 1808.3ft² and it is full, of half-finished projects.
I love working with heating, insulation, green power, alternative energy, solar, wind and more. It all costs, but I’m trying to get the most out of my money, and my time. .
Today, Google filed its official notice of appeal against the district court ruling and jury verdict in Epic v. Google.Judge James Donato’s ruling earlier this week would force the company to distribute third-party app stores on Google Play and drop requirements that Google Play apps use its billing system, among other competition-friendly changes.
Google had said it would be appealing the verdict. “As we have already stated, these changes would put consumers’ privacy and security at risk, make it harder for developers to promote their apps, and reduce competition on devices,” Google VP of regulatory affairs Lee-Anne Mulholland said in a blog post on Monday. “Ultimately, while these changes presumably satisfy Epic, they will cause a range of unintended consequences that will harm American consumers, developers and device makers.”
Donato’s ruling this week said that Google’s changes must go into effect starting November 1st, 2024, and they would stay in effect until November 1st, 2027.
#Netrack
1 Series, General Electronics Racks for Servers, Networking, AV, Telecom & Lab application. Racks manufactured out of steel sheet punched, formed, welded and Powder coated with highest quality standards under stringent ISO 9001 | ISO 14001 | ISO 27001 | ISO 45001 Manufacturing & Quality management system to ensure highest quality product
subscribe for more updates: https://www.youtube.com/@skgreentree
Tour & Travels – http://bit.ly/2krpFkS
Computers and Technology – http://bit.ly/2l2GfLm
Education – http://bit.ly/2l2Ctl7
Entertainment – http://bit.ly/2krqcn4
Auto and Transport – http://bit.ly/2kbOq6n
plant n Nature – http://bit.ly/2kCExzh
Pet and Animal – http://bit.ly/2kyApAp
Devotional – http://bit.ly/2k650lu
Health and Fitness – http://bit.ly/2kyQk1J
News – http://bit.ly/2k5IIAm
Sports – http://bit.ly/2kCBUxr
Paint Tutorials: https://bit.ly/3hNJOhO
Windows 10 Tutorials: https://bit.ly/30S3ES4
Notepad tutorials: https://bit.ly/2X9eDFD
Wordpad Tutorials: https://bit.ly/30bLBHw .
Quordle was one of the original Wordle alternatives and is still going strong now nearly 1,000 games later. It offers a genuine challenge, though, so read on if you need some Quordle hints today – or scroll down further for the answers.
What letters do today’s Quordle answers start with?
• R
• A
• P
Advertisement
• Z
Right, the answers are below, so DO NOT SCROLL ANY FURTHER IF YOU DON’T WANT TO SEE THEM.
Quordle today (game #991) – the answers
(Image credit: Merriam-Webster)
The answers to today’s Quordle, game #991, are…
Sign up for breaking news, reviews, opinion, top tech deals, and more.
Advertisement
I don’t know about you but I love the idea of a PUSHY ZEBRA. You know, moving all the other animals away from the watering hole so it can have it all to itself, that kind of thing. I’m sure there’s a Pixar animation in there somewhere. But I digress. ZEBRA is arguably the hardest word in today’s Quordle, although ANIME does give it some competition. It not only starts with a very uncommon letter in the form of Z, but also has a B in an unusual spot (B tends to start words and not much else). ANIME, meanwhile, is formed of mostly common letters (M is the slight outlier), but caused a lot of trouble when it was a Wordle answer a while ago. Overall: tricky day, folks.
Red Teams try to break into high security facilities
A crack team assembles and breaks into a top secret military base or corporate headquarters – you’ve probably seen it in a film or on TV a dozen times.
But such teams exist in the real world and can be hired to test the tightest security.
Plenty of firms offer to test computer systems by attempting to remotely hack into them. That’s called White Hat Hacking.
But the skills involved in breaching physical security, known as Red Teaming, are rare.
Advertisement
Companies that offer the Red Team service have to assemble staff with very particular skills.
Often using former military and intelligence personnel, Red Teams are asked one question.
“How can you break into this top-secret project?”
Leonardo, the giant defence company, offers such a service.
Advertisement
It says hostile states seeking disruption and chaos are a real threat and sells its Red Team capability to government, critical infrastructure, and defence sector clients.
Its Red Team agreed to speak to the BBC under pseudonyms.
Greg, the team leader, served in the engineering and intelligence arms of the British Army, studying the digital capabilities of potential enemies.
“I spent a decade learning how to exploit enemy communications,” he says of his background.
Advertisement
Now he co-ordinates the five-strong team.
The attack is about gaining access. The objective might be to stop a process from working, such as the core of a nuclear power plant.
The first step for Greg and his team is called passive reconnaissance.
Using an anonymous device, perhaps a smartphone only identifiable by its sim card, the team build a picture of the target.
Advertisement
“We must avoid raising suspicions, so the target doesn’t know we’re looking at them,” Greg says.
Any technology they employ is not linked to a business by its internet address and is bought with cash.
Getty Images
Red Teams will look for demotivated security gaurds
Charlie spent 12 years in military intelligence, his techniques include studying commercial satellite imagery of a site, and scanning job ads to work out what type of people work there.
“We start from the edges of the target, staying away. Then we start to move into the target area, even looking at how people who work there dress.”
Advertisement
This is known as hostile reconnaissance. They are getting close to the site, but keeping their exposure low, wearing different clothes every time they show up, and swapping out team members, so security people don’t spot the same person walking past the gates.
Technology is devised by people and the human factor is the weakest point in any security set-up. This is where Emma, who served in the RAF, comes in.
With a background in psychology Emma happily calls herself “a bit of a nosy people watcher”.
“People take shortcuts past security protocols. So, we look for disgruntled people at the site.”
Advertisement
She listens in to conversations at adjacent cafes and pubs to hear where dissatisfaction with an employer surfaces.
“Every organisation has its quirks. We see what the likelihood of people falling for a suspicious email due to workload and fatigue is.”
An unhappy security guard may get lazy at work. “We’re looking at access, slipping in with a delivery for instance.”
A high turnover rate evidenced by frequently advertised vacancies also flags up dissatisfaction and a lack of engagement with security responsibilities. Tailgating, spotting people who are likely to hold an access door open for a follower, is another technique.
Advertisement
Using that intelligence, plus a little subterfuge, security passes can be copied, and the Red Team can enter the premises posing as an employee.
Katsuhiko TOKUNAGA
Leonardo is best known for its work on big defence projects like the Eurofighter
Once inside the site Dan knows how to open doors, filing cabinets and desk drawers. He’s armed with lock pick keys known as jigglers, with multiple contours that can spring a lock open.
He’s searching for passwords written down, or will use a plug-in smart USB adaptor to simulate a computer keyboard, breaking into a network.
The final step in the so-called kill chain, is in the hands of Stanley.
Advertisement
A cyber security expert, Stanley knows how to penetrate the most secure computer systems, working on the reconnaissance report from his colleagues.
“In the movies it takes a hacker seconds to break into a system, but the reality is different.”
He prefers his own “escalatory approach”, working through a system via an administrator’s access and searching for a “confluence”, a collection of information shared in one place, such as a workplace intranet.
He can roam through files and data using the administrator’s access. One way a kill chain concludes is when Stanley sends an email impersonating the chief executive of the business via the internal, hence trusted, network.
Advertisement
Even though they operate with the approval of the target customer they are breaking into a site as complete strangers. How does this feel?
“If you’ve gained access to a server room that is quite nerve-wracking,” says Dan, “but it gets easier the more times you do it.”
There is someone at the target site who knows what’s going on. “We stay in touch with them, so they can issue an instruction ‘don’t shoot these people,’” Charlie adds.
The CABSHELFHD 2U 18in Depth Heavy Duty Fixed Rack Mount Shelf lets you add a high-capacity 2U shelf to virtually any standard 19-inch server rack or cabinet with front mount options. This TAA compliant product adheres to the requirements of the US Federal Trade Agreements Act (TAA), allowing government GSA Schedule purchases.
This high-capacity server rack shelf is constructed using 2.3mm SPCC commercial grade cold-rolled steel, providing the additional strength required to hold up to 56kg (125lbs) of equipment – a perfect solution for storing larger, non-rackmount pieces of equipment, heavy tools or peripherals in your rack or cabinet.
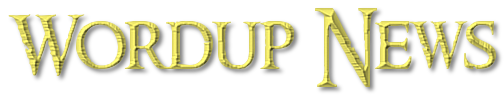




































































































































You must be logged in to post a comment Login