Knowing how your cloud application will behave in production usually requires significant development and testing in the environment in which it will be deployed, be that AWS, Azure, Google Cloud, or wherever. But this can be a resource-intensive endeavor, particularly with issues relating to latency (the time it takes to constantly send data) and the costs associated with this.
Swiss startup LocalStack has set out to address this by shifting the development process off the cloud and onto a developer’s local machine (i.e. their laptop), emulating the environment where it will go live. For now, its focus lies on AWS cloud apps, but the company is looking to ramp things up and go multi-cloud.
To back that strategy, the company on Tuesday said it has raised $25 million in a Series A round led by Notable Capital, one of the two entities that branched out of GGV Capital earlier this year.
For context, LocalStack started as an open source project while founder and co-CEO Waldemar Hummer (pictured above right, with co-founder Gerta Sheganaku, and Notable Capital managing partner Glenn Solomon) was at Atlassian in 2017. Initially, they were trying to help one of their Atlassian colleagues work while traveling into the office.
Advertisement
“We had a team member who was commuting on the train to work, and we wanted to get her productive even while being offline on the train,” Hummer told TechCrunch.
The idea germinated as a side project in the intervening years, with Hummer teaming up with Gerta Sheganaku, whom he’d known since his time at the University of Technology in Vienna in 2013, to drive early community adoption for the open source project. They launched as a full-time business in 2021, and after raising a small seed round, were later joined by a third co-founder, Thomas Rausch, who’s now head of engineering at the startup.
“What first got me excited about LocalStack was the increased adoption in the community, especially after LocalStack was publicly endorsed by Jeff Barr (AWS chief evangelist) — the GitHub Stars on the project saw a dramatic jump overnight and has been increasing ever since,” Sheganaku said. “By interacting with the community, we learned that some of the users were working in some of the largest companies of the world, trying to deploy LocalStack not only on their local machines, but also in their CI [continuous integration] pipelines.”
Today, the company counts some 900 paying users, including an impressive roster of self-serve customers including the likes of Apple, Comcast, IBM and Workday. LocalStack also works directly with some customers through an official procurement and onboarding process.
Advertisement
LocalStack. Image Credits:LocalStack
Going local
LocalStack’s offering consists of two core components: One is an emulator, which is basically a Docker image that the user downloads to their local machine with all the necessary AWS APIs. And the second part is a cloud platform, which serves access to additional features such as team collaboration, telemetry data, insights, and more.
The company has also retained some of its open source roots with a community version, making around one-third of its AWS services available through a public repository on GitHub. The additional two-thirds are held behind a private repository for paying customers. This community version serves as a useful tool for onboarding paying customers in the future, though that isn’t always the case.
“In many cases, community users sign up to LocalStack but do not become paying customers,” Sheganaku said. “We see many thousands of community users who have signed up for our web app, but not purchase any of the paid services.”
It’s worth noting that developers are already able to “mock out” certain parts of their infrastructure locally to run tests. There’s also popular frameworks like Testcontainers that can be used to simulate certain cloud services and infrastructure components on a local machine, though that usually has a different look, feel and “experience” to the actual cloud environment.
AWS itself also offers some tools to enable developers to emulate some of its services locally, such as AWS SAM, which supports the likes of AWS Lambda, DynamoDB and a few others. But LocalStack’s selling point is that it supports more than 100 core AWS services, including identity and access management (IAM) via Amazon Cognito, Amazon Kinesis data streams, and Amazon’s interactive query service Athena.
Advertisement
“LocalStack is almost like a drop-in replacement for AWS cloud,” Hummer said. “AWS SAM is really more specific to a certain set of services; LocalStack is much more comprehensive.”
The LocalStack team.Image Credits:LocalStack
LocalStack had hitherto raised an undisclosed $3 million in seed funding from CRV and Heavybit. Although it has operated largely under the radar, Hummer says it already has “substantial revenue numbers” and a global team of more than 50 operating mostly out of Europe. However, its customer base is substantively in the U.S., where it will now be looking to ramp things up in terms of product and go-to-market strategy — the fresh Series A round will help fund that effort.
For now, LocalStack’s core focus is AWS, though the company is also working on adding support for Snowflake, which is a different domain from that of AWS, but has similar challenges as it relates to cloud software development. Snowflake support remains in early-stage “preview” for now, but with the new $25 million in the bank, LocalStack is also gearing up to go multi-cloud, expanding support to Microsoft’s Azure, which Hummer said he hoped would be available some time in 2025.
“We’ve had a lot of requests for Azure,” Hummer said.
In addition to lead backer Notable Capital, LocalStack’s Series A round included participation from existing investors CRV and Heavybit.
OpenAI is preparing to release an autonomous AI agent that can control computers and perform tasks independently, code-named “Operator.” The company plans to debut it as a research preview and developer tool in January, according to Bloomberg.
This move intensifies the competition among tech giants developing AI agents: Anthropic recently introduced its “computer use” capability, while Google is reportedly preparing its own version for a December release. The timing of Operator’s eventual consumer release remains under wraps, but its development signals a pivotal shift toward AI systems that can actively engage with computer interfaces rather than just process text and images.
All the leading AI companies have promised autonomous AI agents, and OpenAI has hyped up the possibility recently. In a Reddit “Ask Me Anything” forum a few weeks ago, OpenAI CEO Sam Altman said “we will have better and better models,” but “I think the thing that will feel like the next giant breakthrough will be agents.” At an OpenAI press event ahead of the company’s annual Dev Day last month, chief product officer Kevin Weil said: “I think 2025 is going to be the year that agentic systems finally hit the mainstream.”
AI labs face mounting pressure to monetize their costly models, especially as incremental improvements may not justify higher prices for users. The hope is that autonomous agents are the next breakthrough product — a ChatGPT-scale innovation that validates the massive investment in AI development.
Watching old episodes of ER won’t make you a doctor, but watching videos may be all the training a robotic surgeon’s AI brain needs to sew you up after a procedure. Researchers at Johns Hopkins University and Stanford University have published a new paper showing off a surgical robot as capable as a human in carrying out some procedures after simply watching humans do so.
The research team tested their idea with the popular da Vinci Surgical System, which is often used for non-invasive surgery. Programming robots usually requires manually inputting every movement that you want them to make. The researchers bypassed this using imitation learning, a technique that implanted human-level surgical skills in the robots by letting them observe how humans do it.
The researchers put together hundreds of videos recorded from wrist-mounted cameras demonstrating how human doctors do three particular tasks: needle manipulation, tissue lifting, and suturing. The researchers essentially used the kind of training ChatGPT and other AI models use, but instead of text, the model absorbed information about the way human hands and the tools they are holding move. This kinematic data essentially turns movement into math the model can apply to carry out the procedures upon request. After watching the videos, the AI model could use the da Vinci platform to mimic the same techniques. It’s not too dissimilar from how Google is experimenting with teaching AI-powered robots to navigate spaces and complete tasks by showing them videos.
“It’s really magical to have this model and all we do is feed it camera input and it can predict the robotic movements needed for surgery. We believe this marks a significant step forward toward a new frontier in medical robotics,” senior author and JHU assistant professor Axel Krieger said in a release. “The model is so good learning things we haven’t taught it. Like if it drops the needle, it will automatically pick it up and continue. This isn’t something I taught it do.”
The idea of an AI-controlled robot holding blades and needles around your body might sound scary, but the precision of machines can make them better in some cases than human doctors. Robotic surgery is increasingly common in some instances. A robot performing complex procedures independently might actually be safer, with fewer medical errors. Human doctors could have more time and energy to focus on unexpected complications and the more difficult parts of a surgery that machines aren’t up to handling yet.
Advertisement
The researchers have plans to test using the same techniques to teach an AI how to do a complete surgery. They’re not alone in pursuing the idea of AI-assisted robotic healthcare. Earlier this year, AI dental technology developer Perceptive showcased the success of an AI-guided robot performing a dental procedure on a human without supervision.
You might also like
Sign up to be the first to know about unmissable Black Friday deals on top tech, plus get all your favorite TechRadar content.
Strava, a popular app for tracking fitness activities, is expanding its Hatmaps feature to help improve the safety of its users. The update should be especially useful now for users in the Northern Hemisphere, which is heading into winter with reduced daylight.
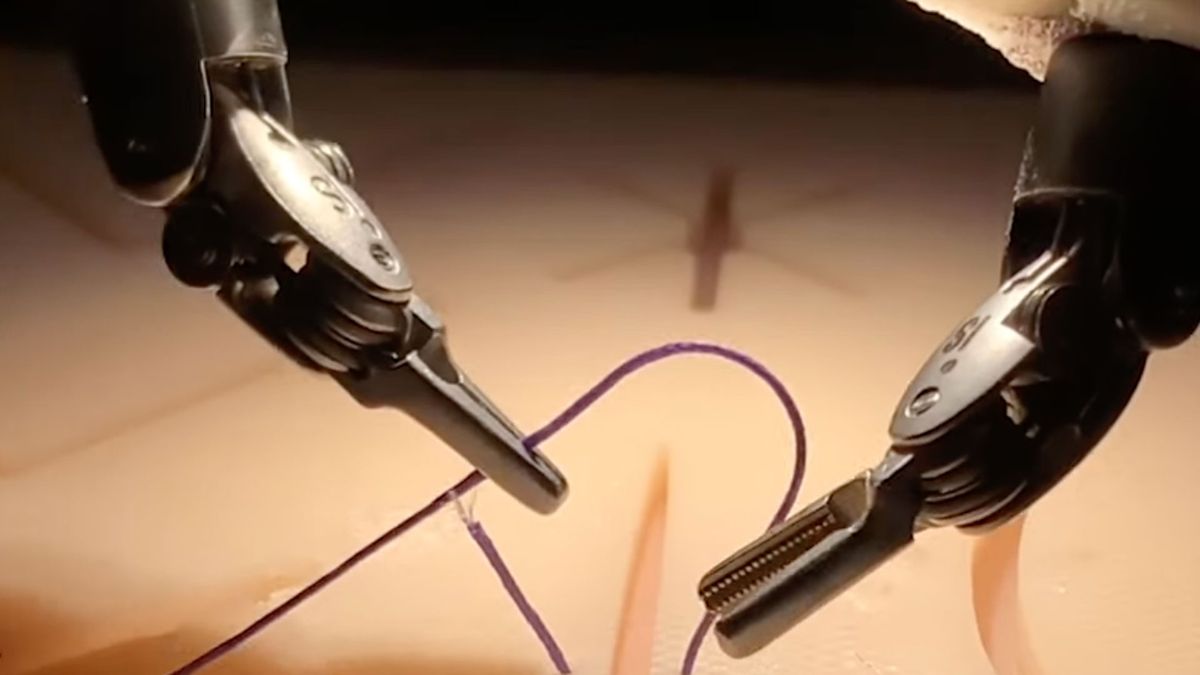
The new Night and Weekly Heatmaps were announced by the San Francisco-based company on Wednesday and are available to all Strava subscribers. As the name of the feature suggests, the Heatmaps show where Strava users are choosing to exercise, with dark thick lines showing well-used routes, and light thin lines showing less popular ones.
First up, the new Night Heatmaps feature is ideal for those who are doing their activities in the late evening or early morning hours, when there’s less light. They show the most popular areas for outdoor activities from sunset to sunrise, helping athletes to better plan their outdoor activities during this time frame. If it’s a new area for you, you may also want to cross-check the Night Heatmap data with Google Street View images to get a better understanding of the place.
Weekly Heatmaps, on the other hand, show data for recent heat from the last seven days so that users can see which trails and roads are currently active, particularly during seasonal transitions when conditions may be impacted by weather.
Advertisement
“Our global community powers ourHeatmaps and now we’ve made it easier for our community members to build routes with confidence, regardless of the season or time of day,” Matt Salazar, Strava’s chief product officer, said in Wednesday’s announcement about the new features. “We are continually improving our mapping technology to make human-powered movement easier for all skill levels.”
Strava has also shared a useful at-a-glance guide to all four of its Heatmaps, Night, Weekly, Global, and Personal:
Night (new): Discover the most frequented areas between sunset and sunrise; ideal for evening or early morning users.
Weekly (new): Stay updated with the latest data from the past seven days; perfect for adjusting plans around seasonal changes or unexpected closures.
Advertisement
Global (existing): Viewable by anyone regardless of whether you have a Strava account, the Global Heatmap allows you to see what areas are most popular around the world based on community activity uploads.
Personal (existing): A one-of-a-kind illustration showing the record of everywhere you’ve logged a GPS activity. This heatmap is private and only available to you.
Google’s Gemini is useful as an educational tool to help you study for that exam. However, Gemini is sort of the “Everything chatbot” that’s useful for just about everything. Well, Google has a new model for people looking for more of a robust educational tool. Google calls it Learn About, and it could give other tools a run for their money.
Say what you want about Google’s AI, the company has been hard at work making AI tools centered around teaching rather than cheating. For example, it has tools in Android studio that guides programmers and help them learn coding. Also, we can’t forget about NotebookLM. This is the tool that takes your uploaded educational content and helps you digest it. We can’t forget abou the Audio Overviews feature that turns your uploaded media into a live podcast-style educational discussion.
So, Google has a strong focus on education with its AI tools. Let’s just hope that other companies will follow suit.
Google’s new AI tool is called Learn About
This tool is pretty self-explanatory, as it focus on giving you more text-book style explanations for your questions. Rather than simply giving you answers, this tool will go the extra mile to be more descriptive with its explanation. Along with that, Learn About will also provide extra context on the subject and give you other educational material on it.
Advertisement
Google achieved this by using a totally different model to power this tool. Rather than using the Gemini model, Ask About uses a model called LearnLM. At this point, we don’t really know much about this model, but we know that Google steered it more towards providing academic answers.
Gemini’s answer vs. Learn About’s answers
We tested it out by asking what pulsars are, and we compared the answer to what Gemini gave us for the same question. Gemini delivered a pretty fleshed-out explanation in the form of a few paragraphs. It also snagged a few pictures from the internet and pasted the link to a page at the bottom. This is good for a person who’s casually looking up a definition. Maybe that person isn’t looking to learn the ins and outs of what a pulsar is.
There was one issue with Gemini’s answer; one of the images that it pasted was an image of a motorcycle. It pasted an image of the Bajaj Pulsar 150. So, while it technically IS a pulsar, a motorcycle shares very few similarities with massive rapidly spinning balls of superheated plasma billions of miles away from Earth.
What about Learn About?
Learn About also gave an explanation in the form of a few paragraphs; however, Learn About’s explanation was shorter. It makes up for it by producing more extraneous material. Along with images, it provided three links (one of which was a YouTube video) and chips with commands like Simplify, Go deeper, and Get images (more on the chips below).
Advertisement
Under the chips, you’ll see suggestions of other queries that you can put in for additional context. Lastly, in textbook style, you’ll see colored blocks with additional content. For example, there’s a Why it matters block and a Stop & think block.
Chips
Going back to the aforementioned chips, selecting Simplify and Get images are axiomatic enough. Tapping/clicking on the Go Deeper chip is a bit more interesting. It brought up an Interactive List consisting of a selection of additional queries that will provide extra information about pulsars. Each query you select will bring up even more information.
Textbook blocks
Think about the textbooks you used in school, and you’ll be familiar with these blocks. These blocks come in different colors. The Why it matters block tells you why this information is important. Next, the Stop & think block seems to give you a little bit of tangential information. It asks a question and has a button to reveal the answer. It’s a way to get you to think outside of the box a bit.
There’s a Build your vocab box that introduces you to a relevant term and shows you a dictionary-style definition of it. This is a term that the reader is most likely not familiar with.
Advertisement
The next block we encountered was the Test your knowledge block. This one has a quiz-style question and it gives you two options. Other subject matters might have more choices, but this is what we got in our usage.
We also saw a Common misconception block. This one pretty much explains itself.
Bottom bar
At the very bottom of the screen, you’ll see a bar with some additional chips. One chip should show the title of the current subject, and Tapping/clicking on it will bring up a floating window with additional topic suggestions. In our case, we also saw the interactive list that we saw previously. This one will show the list in a floating window.
One issue
So, do you remember when Gemini gave us the image of the motorcycles? Well, while the majority of Learn About’s images were relevant to the subject, it still retrieved two images of the motorcycles. As comical as it is, it shows that Google’s AI still has a ways to go before it’s perfect. However, barring that little mishap, Learn About runs as smoothly as the motorcycle it’s surfacing pictures of.
Advertisement
Use it today!
You can use Learn About today if you want to try it out. Just go to the Learn About website Learn About website, and you’ll be able to try it out. Just know that, as with most Google services, the availability will depend on your region. We were able to access it in the U.S. in English. Just know that you may not have it in regions that Google typically overlooks.
You can use it regardless of if you’re a free or paid user. Please note that Learn About is technically an experiment. This means that Google only put this on the market for testing. Google could potentially lock this behind a paywall after the beta testing phase. Just know that this feature could disappear down the line. So, you’ll want to get in and use it while you can.
GOG is launching an effort to help make older video games playable on modern hardware. The will label the classic titles that the platform has taken steps to adapt in order to make them compatible with contemporary computer systems, controllers and screen resolutions, all while adhering to its DRM-free policy. The move could bring new life to games of decades past, just as GOG did two years ago with a refresh of . So far, 92 games have received the preservation treatment.
“Our guarantee is that they work and they will keep working,” the company says in the video announcing the initiative.
Preservation has been a hot topic as more games go digital only. Not only are some platforms disk drives by default, but ownership over your library is more ephemeral than it seems. After all, most game purchases are , and licenses can be revoked (as The Crew players know ).
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
One-bit large language models (LLMs) have emerged as a promising approach to making generative AI more accessible and affordable. By representing model weights with a very limited number of bits, 1-bit LLMs dramatically reduce the memory and computational resources required to run them.
Microsoft Research has been pushing the boundaries of 1-bit LLMs with its BitNet architecture. In a new paper, the researchers introduce BitNet a4.8, a new technique that further improves the efficiency of 1-bit LLMs without sacrificing their performance.
The rise of 1-bit LLMs
Traditional LLMs use 16-bit floating-point numbers (FP16) to represent their parameters. This requires a lot of memory and compute resources, which limits the accessibility and deployment options for LLMs. One-bit LLMs address this challenge by drastically reducing the precision of model weights while matching the performance of full-precision models.
Advertisement
Previous BitNet models used 1.58-bit values (-1, 0, 1) to represent model weights and 8-bit values for activations. This approach significantly reduced memory and I/O costs, but the computational cost of matrix multiplications remained a bottleneck, and optimizing neural networks with extremely low-bit parameters is challenging.
Two techniques help to address this problem. Sparsification reduces the number of computations by pruning activations with smaller magnitudes. This is particularly useful in LLMs because activation values tend to have a long-tailed distribution, with a few very large values and many small ones.
Quantization, on the other hand, uses a smaller number of bits to represent activations, reducing the computational and memory cost of processing them. However, simply lowering the precision of activations can lead to significant quantization errors and performance degradation.
Furthermore, combining sparsification and quantization is challenging, and presents special problems when training 1-bit LLMs.
Advertisement
“Both quantization and sparsification introduce non-differentiable operations, making gradient computation during training particularly challenging,” Furu Wei, Partner Research Manager at Microsoft Research, told VentureBeat.
Gradient computation is essential for calculating errors and updating parameters when training neural networks. The researchers also had to ensure that their techniques could be implemented efficiently on existing hardware while maintaining the benefits of both sparsification and quantization.
BitNet a4.8
BitNet a4.8 addresses the challenges of optimizing 1-bit LLMs through what the researchers describe as “hybrid quantization and sparsification.” They achieved this by designing an architecture that selectively applies quantization or sparsification to different components of the model based on the specific distribution pattern of activations. The architecture uses 4-bit activations for inputs to attention and feed-forward network (FFN) layers. It uses sparsification with 8 bits for intermediate states, keeping only the top 55% of the parameters. The architecture is also optimized to take advantage of existing hardware.
“With BitNet b1.58, the inference bottleneck of 1-bit LLMs switches from memory/IO to computation, which is constrained by the activation bits (i.e., 8-bit in BitNet b1.58),” Wei said. “In BitNet a4.8, we push the activation bits to 4-bit so that we can leverage 4-bit kernels (e.g., INT4/FP4) to bring 2x speed up for LLM inference on the GPU devices. The combination of 1-bit model weights from BitNet b1.58 and 4-bit activations from BitNet a4.8 effectively addresses both memory/IO and computational constraints in LLM inference.”
Advertisement
BitNet a4.8 also uses 3-bit values to represent the key (K) and value (V) states in the attention mechanism. The KV cache is a crucial component of transformer models. It stores the representations of previous tokens in the sequence. By lowering the precision of KV cache values, BitNet a4.8 further reduces memory requirements, especially when dealing with long sequences.
The promise of BitNet a4.8
Experimental results show that BitNet a4.8 delivers performance comparable to its predecessor BitNet b1.58 while using less compute and memory.
Compared to full-precision Llama models, BitNet a4.8 reduces memory usage by a factor of 10 and achieves 4x speedup. Compared to BitNet b1.58, it achieves a 2x speedup through 4-bit activation kernels. But the design can deliver much more.
“The estimated computation improvement is based on the existing hardware (GPU),” Wei said. “With hardware specifically optimized for 1-bit LLMs, the computation improvements can be significantly enhanced. BitNet introduces a new computation paradigm that minimizes the need for matrix multiplication, a primary focus in current hardware design optimization.”
Advertisement
The efficiency of BitNet a4.8 makes it particularly suited for deploying LLMs at the edge and on resource-constrained devices. This can have important implications for privacy and security. By enabling on-device LLMs, users can benefit from the power of these models without needing to send their data to the cloud.
Wei and his team are continuing their work on 1-bit LLMs.
“We continue to advance our research and vision for the era of 1-bit LLMs,” Wei said. “While our current focus is on model architecture and software support (i.e., bitnet.cpp), we aim to explore the co-design and co-evolution of model architecture and hardware to fully unlock the potential of 1-bit LLMs.”
VB Daily
Advertisement
Stay in the know! Get the latest news in your inbox daily
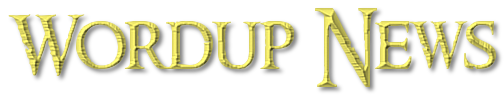




































































































































































You must be logged in to post a comment Login