An information stealer called VoidStealer uses a new approach to bypass Chrome’s Application-Bound Encryption (ABE) and extract the master key for decrypting sensitive data stored in the browser.
The novel method is stealthier and relies on hardware breakpoints to extract the v20_master_key, used for both encryption and decryption, directly from the browser’s memory, without requiring privilege escalation or code injection.
A report from Gen Digital, the parent company behind the Norton, Avast, AVG, and Avira brands, notes that this is the first case of an infostealer observed in the wild to use such a mechanism.
Google introduced ABE in Chrome 127, released in June 2024, as a new protection mechanism for cookies and other sensitive browser data. It ensures that the master key remains encrypted on disk and cannot be recovered through normal user-level access.
Advertisement
Decrypting the key requires the Google Chrome Elevation Service, which runs as SYSTEM, to validate the requesting process.
Overview of how ABE blocks out malware Source: Gen Digital
“VoidStealer is the first infostealer observed in the wild adopting a novel debugger-based Application-Bound Encryption (ABE) bypass technique that leverages hardware breakpoints to extract the v20_master_key directly from browser memory,” says Vojtěch Krejsa, threat researcher at Gen Digital.
VoidStealer is a malware-as-a-service (MaaS) platform advertised on dark web forums since at least mid-December 2025. The malware introduced the new ABE bypass mechanism in version 2.0.
Cybercriminals advertising ABE bypass in VoidStealer version 2.0 Source: Gen Digital
Stealing the master key
VoidStealer’s trick to extract the master key is to target a short moment when Chrome’s v20_master_key is briefly present in memory in plaintext state during decryption operations.
Specifically, VoidStealer starts a suspended and hidden browser process, attaches it as a debugger, and waits for the target browser DLL (chrome.dll or msedge.dll) to load.
Advertisement
When loaded, it scans the DLL for a specific string and the LEA instruction that references it, using that instruction’s address as the hardware breakpoint target.
VoidStealer’s target string Source: Gen Digital
Next, it sets that breakpoint across existing and newly created browser threads, waits for it to trigger during startup while the browser is decrypting protected data, then reads the register holding a pointer to the plaintext v20_master_key and extracts it with ‘ReadProcessMemory.’
Gen Digital explains that the ideal time for the malware to do this is during browser startup, when the application loads ABE-protected cookies early, forcing the decryption of the master key.
The researchers explained that VoidStealer likely did not invent this technique but rather adopted it from the open-source project ‘ElevationKatz,’ part of the ChromeKatz cookie-dumping toolset that demonstrates weaknesses in Chrome.
Although there are some differences in the code, the implementation appears to be based on ElevationKatz, which has been available for more than a year.
Advertisement
BleepingComputer has contacted Google with a request for a comment on this bypass method being used by threat actors, but a reply was not available by publishing time.
Malware is getting smarter. The Red Report 2026 reveals how new threats use math to detect sandboxes and hide in plain sight.
Download our analysis of 1.1 million malicious samples to uncover the top 10 techniques and see if your security stack is blinded.
Local Hub: Manufacturers like Eufy and TP-Link offer smart hubs that link wirelessly to their security cameras and offer expandable storage. Sometimes these local hubs allow for more local AI processing (Eufy’s hub enables facial recognition). They can also sometimes extend the wireless signal and stability for cameras. These hubs often need to be plugged directly into your router via Ethernet cable.
MicroSD Card: Plugging a microSD card into a camera is a quick and simple way to record locally, but if an intruder steals the camera, your footage is gone with it. Occasionally, camera manufacturers offer indoor hubs that are expandable via a MicroSD card.
Network Attached Storage (NAS): If you have a NAS server, you can likely configure it to store your security camera video. These devices contain hard drives and are expandable, offering a potentially enormous amount of storage.
Cloud storage means your video is backed up online, so an intruder can’t get to it, it is usually quicker to access or stream when you are away from home, and it doesn’t require any additional storage hardware. On the downside, you pay a monthly fee, the video doesn’t get uploaded if your Wi-Fi fails or is scrambled, and you are trusting the service provider, who may share it or use it in ways you’d prefer they didn’t (data breaches are also common).
Local storage is a one-off cost, it’s not reliant on Wi-Fi, and it’s much harder for anyone other than you to access the footage. But, there’s a risk someone steals the physical hardware your footage is stored on, or the hardware fails, and it can be slower to access and stream video when you are away from home.
Advertisement
For maximum security, even with a local system, you might consider a cloud backup. You can reduce the risk of your footage being exposed by picking a cloud service that is end-to-end encrypted, such as Apple’s HomeKit Secure Video.
Protecting Your Privacy
Access to your security camera feeds and recorded videos should be end-to-end encrypted, and you should always use two-factor authentication to protect account access. With end-to-end encryption, only your authorized devices can decrypt your videos. With 2FA, you will be sent a passcode to a trusted number, email, or device when you try to log in on a new device, so your login and password alone are not enough to gain access. Sadly, these features are not always turned on by default.
Eufy cameras offer end-to-end encryption, but you must opt in by tapping the menu top left in the app and choosing Settings, Security, Video Encryption, Advanced Encryption. You can make sure 2FA is toggled on by tapping your name at the top of the menu and Two-factor authentication.
TP-Link Tapo cameras lack end-to-end encryption, but you can set up 2FA for your account by tapping on the Me tab, View account, Login Security. To encrypt footage on microSD cards, go to your device settings and choose Storage & Recording, Local Storage, and tap SD Card Encryption.
Aqara offers end-to-end encryption on your locally stored video by default. For 2FA, tap Profile at the bottom right, Settings, Accounts and Security, and make sure Two-Factor Authentication is toggled on.
Welcome back to TechCrunch Mobility, your central hub for news and insights on the future of transportation. To get this in your inbox, sign up here for free — just click TechCrunch Mobility!
If you haven’t noticed, Uber is suddenly everywhere, at least when it comes to autonomous vehicles. The company sold off Uber ATG, its in-house autonomous vehicle development unit, back in 2020. Uber shed a number of its moonshots — although it maintained an equity stake in all of them — so it could focus on its core businesses of delivery and ride-hailing.
But Uber never gave up entirely on AVs. It’s spent the past two years locking up partnerships with dozens of autonomous vehicle technology companies across delivery, drones, trucking, and robotaxis. It has taken a worldview, too, making agreements with Chinese companies to launch robotaxis in Europe and the Middle East, as well as startups like U.K.-based Wayve.
And now there is another one with Rivian. The TL;DR of the deal is Uber will make an initial $300 million investment in Rivian and will buy 10,000 fully autonomous R2 robotaxis ahead of a planned rollout in San Francisco and Miami in 2028. Uber has the option to buy up to 40,000 more starting in 2030. This fleet will be exclusively available on Uber’s network.
Advertisement
Here’s how I am thinking about this deal. While the total deal could be as high as $1.25 billion, Uber’s initial outlay is relatively small. And the risk ratio is heavily weighted toward Rivian. It’s also the only deal that Uber has made in which the company is the developer of the self-driving system and the vehicle manufacturer.
Rivian hasn’t started producing the R2 SUV yet, nor has it tested and deployed a self-driving system designed for robotaxis. To raise the hurdle even higher, the robotaxi is supposed to be built in Rivian’s Georgia factory, which is still under construction.
And the EV maker has already made at least one sacrifice in hopes of pulling it off. Rivian said it no longer expects to meet its profitability goal in 2027 because of how much money it is spending on its autonomy efforts.
Techcrunch event
Advertisement
San Francisco, CA | October 13-15, 2026
In our newsletter, we had a poll asking, Are the risks too high for Rivian? Sign up here to get Mobility in your inbox and let your voice be heard in our polls!
Advertisement
A little bird
Image Credits:Bryce Durbin
Speaking of Uber, a little bird hinted that the ride-hailing company might have been in talks with Rivian for its robotaxi deal for quite a long time. One person directly familiar with both companies told me a deal like this wouldn’t happen overnight. After I asked for more specifics, I got a question in return: “Does RJ strike you as someone who has a strategic horizon that short?” Touché!
Like Uber, Nvidia is everywhere. Or at least wants to be. The company has made numerous investments — either direct cash injections or in-kind chip deals — in autonomous vehicle technology companies. And it’s also locking up partnerships with automakers — as we saw this week during its GTC conference — in a bid to sell its autonomous vehicle development platform called Nvidia Drive Hyperion.
Nvidia CEO Jensen Huang announced onstage deals — either new or expanded — with BYD, Geely, Hyundai, and Nissan for its AV development platform. GM, Mercedes-Benz, and Toyota have already signed deals with Nvidia to use the platform.
Nvidia has been making deals with automakers for years, but the pace and specificity of AVs is worth noting.
“The ChatGPT moment of self-driving cars has arrived. We now know we could successfully autonomously drive cars,” Huang said during his GTC keynote, noting that altogether the four automakers build 18 million cars each year.
Advertisement
Other deals that got my attention …
Advanced Navigation, an Australian startup developing navigation and autonomous systems, raised $110 million in a Series C funding round led by Airtree Ventures, with strategic participation from Quadrant Private Equity and the National Reconstruction Fund Corporation (NRFC).
Arc Boat Company, the Los Angeles electric boat startup, raised $50 million in a Series C funding round from Eclipse, a16z, Menlo Ventures, Lowercarbon Capital, Necessary Ventures, and Offline Ventures.
BusRight, the school bus routing and technology startup, raised more than $30 million in a round led by Volition Capital.
Advertisement
Jeff Bezos is reportedly raising $100 billion for a new fund that will focus on buying up companies in major industrial sectors — like automotive and aerospace. The plan is to then modernize these companies using AI models developed by Bezos’ new startup Project Prometheus.
Rivr, a Zurich-based autonomous robotics startup known for its stair-climbing delivery robot, was acquired by Amazon. Terms of the deal weren’t disclosed.
Trevor Milton, the founder of the now-bankrupt electric truck startup Nikola who was pardoned by President Trump, is trying to raise $1 billion for AI-powered planes.
Zenobē Energy has purchasedRevolv, a San Francisco-based fleet charging startup, for an undisclosed amount.
Advertisement
Notable reads and other tidbits
Image Credits:Bryce Durbin
A cyberattack on U.S. vehicle breathalyzer company Intoxalock has left drivers across the United States stranded and unable to start their vehicles.
Kodiak has expanded commercial autonomous freight operations to the Dallas-El Paso corridor. This is the company’s second major route and a core part of its network expansion roadmap, according to COO Michael Wiesinger.
The National Highway Traffic Safety Administration upgraded its investigation into the performance of Tesla’s Full Self-Driving (Supervised) software in low-visibility conditions. The probe has now been escalated to an “engineering analysis,” its highest level of scrutiny and a required step before the agency tells a company to issue a recall.
One more thing …
Image Credits:Jay Janner / The Austin American-Statesman / Getty Images
I mentioned in last week’s edition to keep an eye out for my interview with Rivian founder and CEO RJ Scaringe. We covered a lot of ground and I found his comments about robotics particularly interesting. To summarize, Scaringe thinks companies are approaching industrial robotics all wrong. His new startup, Mind Robotics, is going to do things differently and focus more on robotic hands and steering clear of building robots that can do back flips.
As Scaringe told me: “I think what’s missed in industrial [robotics] and this is one of the things we really see clearly, is the work happens with the hands. So, the hands are very, very important. Everything else, from a robotic system point of view, is to get the hands to the right place. And so the ability for the robots to do really complex motions, like, let’s say, like a back flip, that actually just means the robot has a lot of unnecessary complexity in it for the vast majority of tasks.” You can read the interview here.
Thermal energy storage is pretty great, as phase-change energy storage is very consistent with its energy output over time, unlike chemical batteries. You also get your pick from a wide range of materials that you can either heat up or cool down to store energy. Here, the selection is mostly dependent on how you wish to use that energy at a later date. [Hyperspace Pirate] is mostly interested in cooling down a house, on account of living in Florida.
As can be seen in the top image, the basic setup is pretty straightforward. PV solar power charges a battery until it’s fully charged. Then an MCU triggers a relay on the AC inverter, which then starts the cooling compressor on the water reservoir. This proceeds to phase change the water from a liquid into ice. The process can later be reversed, which will draw thermal energy out of the surrounding air and thus provide cooling.
Although water is not the most interesting substance to pick for the
Advertisement
The cool side of the thermal storage system, chilling a car. (Credit: Hyperspace Pirate, YouTube)
thermal energy storage, it can provide 1 kWh of cooling power in 10.8 kg, or 92.8 kWh in a mere m3. This makes it much more compact as well as cheaper than chemical storage using batteries.
After charging the main compressor loop with R600 (N-butane), the system is trialed with a small PV solar array that manages to freeze the entire bucket of water. Courtesy of insulation, it’s kept that way for a few days, giving plenty of time for the separate glycol-filled loop to dump thermal energy into it and push cold air into the surrounding environment. This prototype managed to cool down [Hyperspace Pirate]’s car in just two hours, which is good enough for a proof-of-concept.
Microsoft may ditch the need to set up Windows 11 with a Microsoft account
A company exec says software engineers are working on it
There’s no indication yet of when the change might be implemented
Microsoft has told users that big improvements are coming to Windows 11 — improvements covering how much AI appears in the software, how updates are handled, and much more — and the operating system’s setup process might also be getting a welcome tweak.
Hanselman is a Vice President at Microsoft, and is part of the team tasked with pushing forward his company’s year of reliability and performance upgrades for Windows 11. So far, Microsoft’s changes have been positively received, for the most part.
Article continues below
Advertisement
Being able to set up a Windows 11 computer without the hassle of logging into a Microsoft account is something else that’s likely to prove popular with users — as you can see if you read through some of the comments underneath Handselman’s post.
Putting the users first
While it is still technically possible to set up Windows 11 without a Microsoft account, the workarounds are rather technical and tricky. The local account option has been gradually pushed out of the software over the years.
Advertisement
As we’ve written in the past, that takes away user choice and flexibility, and there are no doubt some users who would rather not tie their copy of Windows 11 to a Microsoft account – or even have a Microsoft account at all.
That Scott Hanselman says this is also something he hates is significant. It shows Microsoft willing to change features for the benefit of end users rather than prioritizing the best interests of the company.
Sign up for breaking news, reviews, opinion, top tech deals, and more.
While there’s still a lot of work to do to restore trust and goodwill with users, Microsoft is doing okay so far (and we’re only in March). As yet there’s no indication of when this might roll out however — and aside from Scott Hanselman’s post on X, there’s no official confirmation that the change will happen.
And of course, you can also follow TechRadar on YouTube and TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.
Look, we’ve spent the last 18 months building production AI systems, and we’ll tell you what keeps us up at night — and it’s not whether the model can answer questions. That’s table stakes now. What haunts us is the mental image of an agent autonomously approving a six-figure vendor contract at 2 a.m. because someone typo’d a config file.
We’ve moved past the era of “ChatGPT wrappers” (thank God), but the industry still treats autonomous agents like they’re just chatbots with API access. They’re not. When you give an AI system the ability to take actions without human confirmation, you’re crossing a fundamental threshold. You’re not building a helpful assistant anymore — you’re building something closer to an employee. And that changes everything about how we need to engineer these systems.
The autonomy problem nobody talks about
Here’s what’s wild: We’ve gotten really good at making models that *sound* confident. But confidence and reliability aren’t the same thing, and the gap between them is where production systems go to die.
We learned this the hard way during a pilot program where we let an AI agent manage calendar scheduling across executive teams. Seems simple, right? The agent could check availability, send invites, handle conflicts. Except, one Monday morning, it rescheduled a board meeting because it interpreted “let’s push this if we need to” in a Slack message as an actual directive. The model wasn’t wrong in its interpretation — it was plausible. But plausible isn’t good enough when you’re dealing with autonomy.
Advertisement
That incident taught us something crucial: The challenge isn’t building agents that work most of the time. It’s building agents that fail gracefully, know their limitations, and have the circuit breakers to prevent catastrophic mistakes.
What reliability actually means for autonomous systems
Image provided by authors.
Layered reliability architecture
When we talk about reliability in traditional software engineering, we’ve got decades of patterns: Redundancy, retries, idempotency, graceful degradation. But AI agents break a lot of our assumptions.
Advertisement
Traditional software fails in predictable ways. You can write unit tests. You can trace execution paths. With AI agents, you’re dealing with probabilistic systems making judgment calls. A bug isn’t just a logic error—it’s the model hallucinating a plausible-sounding but completely fabricated API endpoint, or misinterpreting context in a way that technically parses but completely misses the human intent.
So what does reliability look like here? In our experience, it’s a layered approach.
Layer 1: Model selection and prompt engineering
This is foundational but insufficient. Yes, use the best model you can afford. Yes, craft your prompts carefully with examples and constraints. But don’t fool yourself into thinking that a great prompt is enough. I’ve seen too many teams ship “GPT-4 with a really good system prompt” and call it enterprise-ready.
Advertisement
Layer 2: Deterministic guardrails
Before the model does anything irreversible, run it through hard checks. Is it trying to access a resource it shouldn’t? Is the action within acceptable parameters? We’re talking old-school validation logic — regex, schema validation, allowlists. It’s not sexy, but it’s effective.
One pattern that’s worked well for us: Maintain a formal action schema. Every action an agent can take has a defined structure, required fields, and validation rules. The agent proposes actions in this schema, and we validate before execution. If validation fails, we don’t just block it — we feed the validation errors back to the agent and let it try again with context about what went wrong.
Layer 3: Confidence and uncertainty quantification
Advertisement
Here’s where it gets interesting. We need agents that know what they don’t know. We’ve been experimenting with agents that can explicitly reason about their confidence before taking actions. Not just a probability score, but actual articulated uncertainty: “I’m interpreting this email as a request to delay the project, but the phrasing is ambiguous and could also mean…”
This doesn’t prevent all mistakes, but it creates natural breakpoints where you can inject human oversight. High-confidence actions go through automatically. Medium-confidence actions get flagged for review. Low-confidence actions get blocked with an explanation.
Layer 4: Observability and auditability
Action Validation Pipeline
If you can’t debug it, you can’t trust it. Every decision the agent makes needs to be loggable, traceable, and explainable. Not just “what action did it take” but “what was it thinking, what data did it consider, what was the reasoning chain?”
Advertisement
We’ve built a custom logging system that captures the full large language model (LLM) interaction — the prompt, the response, the context window, even the model temperature settings. It’s verbose as hell, but when something goes wrong (and it will), you need to be able to reconstruct exactly what happened. Plus, this becomes your dataset for fine-tuning and improvement.
Guardrails: The art of saying no
Let’s talk about guardrails, because this is where engineering discipline really matters. A lot of teams approach guardrails as an afterthought — “we’ll add some safety checks if we need them.” That’s backwards. Guardrails should be your starting point.
We think of guardrails in three categories.
Permission boundaries
Advertisement
What is the agent physically allowed to do? This is your blast radius control. Even if the agent hallucinates the worst possible action, what’s the maximum damage it can cause?
We use a principle called “graduated autonomy.” New agents start with read-only access. As they prove reliable, they graduate to low-risk writes (creating calendar events, sending internal messages). High-risk actions (financial transactions, external communications, data deletion) either require explicit human approval or are simply off-limits.
One technique that’s worked well: Action cost budgets. Each agent has a daily “budget” denominated in some unit of risk or cost. Reading a database record costs 1 unit. Sending an email costs 10. Initiating a vendor payment costs 1,000. The agent can operate autonomously until it exhausts its budget; then, it needs human intervention. This creates a natural throttle on potentially problematic behavior.
Graduated Autonomy and Action Cost Budget
Semantic Houndaries
Advertisement
What should the agent understand as in-scope vs out-of-scope? This is trickier because it’s conceptual, not just technical.
I’ve found that explicit domain definitions help a lot. Our customer service agent has a clear mandate: handle product questions, process returns, escalate complaints. Anything outside that domain — someone asking for investment advice, technical support for third-party products, personal favors — gets a polite deflection and escalation.
The challenge is making these boundaries robust to prompt injection and jailbreaking attempts. Users will try to convince the agent to help with out-of-scope requests. Other parts of the system might inadvertently pass instructions that override the agent’s boundaries. You need multiple layers of defense here.
Operational boundaries
Advertisement
How much can the agent do, and how fast? This is your rate limiting and resource control.
We’ve implemented hard limits on everything: API calls per minute, maximum tokens per interaction, maximum cost per day, maximum number of retries before human escalation. These might seem like artificial constraints, but they’re essential for preventing runaway behavior.
We once saw an agent get stuck in a loop trying to resolve a scheduling conflict. It kept proposing times, getting rejections, and trying again. Without rate limits, it sent 300 calendar invites in an hour. With proper operational boundaries, it would’ve hit a threshold and escalated to a human after attempt number 5.
Agents need their own style of testing
Traditional software testing doesn’t cut it for autonomous agents. You can’t just write test cases that cover all the edge cases, because with LLMs, everything is an edge case.
Advertisement
What’s worked for us:
Simulation environments
Build a sandbox that mirrors production but with fake data and mock services. Let the agent run wild. See what breaks. We do this continuously — every code change goes through 100 simulated scenarios before it touches production.
The key is making scenarios realistic. Don’t just test happy paths. Simulate angry customers, ambiguous requests, contradictory information, system outages. Throw in some adversarial examples. If your agent can’t handle a test environment where things go wrong, it definitely can’t handle production.
Advertisement
Red teaming
Get creative people to try to break your agent. Not just security researchers, but domain experts who understand the business logic. Some of our best improvements came from sales team members who tried to “trick” the agent into doing things it shouldn’t.
Shadow mode
Before you go live, run the agent in shadow mode alongside humans. The agent makes decisions, but humans actually execute the actions. You log both the agent’s choices and the human’s choices, and you analyze the delta.
Advertisement
This is painful and slow, but it’s worth it. You’ll find all kinds of subtle misalignments you’d never catch in testing. Maybe the agent technically gets the right answer, but with phrasing that violates company tone guidelines. Maybe it makes legally correct but ethically questionable decisions. Shadow mode surfaces these issues before they become real problems.
The human-in-the-loop pattern
Three Human-in-the-Loop Patterns
Despite all the automation, humans remain essential. The question is: Where in the loop?
We’re increasingly convinced that “human-in-the-loop” is actually several distinct patterns:
Human-on-the-loop: The agent operates autonomously, but humans monitor dashboards and can intervene. This is your steady-state for well-understood, low-risk operations.
Advertisement
Human-in-the-loop: The agent proposes actions, humans approve them. This is your training wheels mode while the agent proves itself, and your permanent mode for high-risk operations.
Human-with-the-loop: Agent and human collaborate in real-time, each handling the parts they’re better at. The agent does the grunt work, the human does the judgment calls.
The trick is making these transitions smooth. An agent shouldn’t feel like a completely different system when you move from autonomous to supervised mode. Interfaces, logging, and escalation paths should all be consistent.
Failure modes and recovery
Let’s be honest: Your agent will fail. The question is whether it fails gracefully or catastrophically.
Advertisement
We classify failures into three categories:
Recoverable errors: The agent tries to do something, it doesn’t work, the agent realizes it didn’t work and tries something else. This is fine. This is how complex systems operate. As long as the agent isn’t making things worse, let it retry with exponential backoff.
Detectable failures: The agent does something wrong, but monitoring systems catch it before significant damage occurs. This is where your guardrails and observability pay off. The agent gets rolled back, humans investigate, you patch the issue.
Undetectable failures: The agent does something wrong, and nobody notices until much later. These are the scary ones. Maybe it’s been misinterpreting customer requests for weeks. Maybe it’s been making subtly incorrect data entries. These accumulate into systemic issues.
Advertisement
The defense against undetectable failures is regular auditing. We randomly sample agent actions and have humans review them. Not just pass/fail, but detailed analysis. Is the agent showing any drift in behavior? Are there patterns in its mistakes? Is it developing any concerning tendencies?
The cost-performance tradeoff
Here’s something nobody talks about enough: reliability is expensive.
Every guardrail adds latency. Every validation step costs compute. Multiple model calls for confidence checking multiply your API costs. Comprehensive logging generates massive data volumes.
You have to be strategic about where you invest. Not every agent needs the same level of reliability. A marketing copy generator can be looser than a financial transaction processor. A scheduling assistant can retry more liberally than a code deployment system.
Advertisement
We use a risk-based approach. High-risk agents get all the safeguards, multiple validation layers, extensive monitoring. Lower-risk agents get lighter-weight protections. The key is being explicit about these trade-offs and documenting why each agent has the guardrails it does.
Organizational challenges
We’d be remiss if we didn’t mention that the hardest parts aren’t technical — they’re organizational.
Who owns the agent when it makes a mistake? Is it the engineering team that built it? The business unit that deployed it? The person who was supposed to be supervising it?
How do you handle edge cases where the agent’s logic is technically correct but contextually inappropriate? If the agent follows its rules but violates an unwritten norm, who’s at fault?
Advertisement
What’s your incident response process when an agent goes rogue? Traditional runbooks assume human operators making mistakes. How do you adapt these for autonomous systems?
These questions don’t have universal answers, but they need to be addressed before you deploy. Clear ownership, documented escalation paths, and well-defined success metrics are just as important as the technical architecture.
Where we go from here
The industry is still figuring this out. There’s no established playbook for building reliable autonomous agents. We’re all learning in production, and that’s both exciting and terrifying.
What we know for sure: The teams that succeed will be the ones who treat this as an engineering discipline, not just an AI problem. You need traditional software engineering rigor — testing, monitoring, incident response — combined with new techniques specific to probabilistic systems.
Advertisement
You need to be paranoid but not paralyzed. Yes, autonomous agents can fail in spectacular ways. But with proper guardrails, they can also handle enormous workloads with superhuman consistency. The key is respecting the risks while embracing the possibilities.
We’ll leave you with this: Every time we deploy a new autonomous capability, we run a pre-mortem. We imagine it’s six months from now and the agent has caused a significant incident. What happened? What warning signs did we miss? What guardrails failed?
This exercise has saved us more times than we can count. It forces you to think through failure modes before they occur, to build defenses before you need them, to question assumptions before they bite you.
Because in the end, building enterprise-grade autonomous AI agents isn’t about making systems that work perfectly. It’s about making systems that fail safely, recover gracefully, and learn continuously.
Advertisement
And that’s the kind of engineering that actually matters.
Madhvesh Kumar is a principal engineer. Deepika Singh is a senior software engineer.
Views expressed are based on hands-on experience building and deploying autonomous agents, along with the occasional 3 AM incident response that makes you question your career choices.
Welcome to the VentureBeat community!
Advertisement
Our guest posting program is where technical experts share insights and provide neutral, non-vested deep dives on AI, data infrastructure, cybersecurity and other cutting-edge technologies shaping the future of enterprise.
Read more from our guest post program — and check out our guidelines if you’re interested in contributing an article of your own!
Jeff Bezos framed this copy ofa 2006 BusinessWeek cover, reflecting Wall Street’s skepticism about AWS at the time. (Jeff Bezos via X, May 2022)
In the early days of Amazon Web Services, technical evangelist Jeff Barr was putting in long hours on the road, pitching a novel concept: rent computing power for 10 cents an hour, and storage for 15 cents a gigabyte per month — no servers to buy, no data centers to build.
Barr remembers calling his wife to check in at the end of the day. Get a nice dinner, she told him, you deserve it. But later, at the restaurant, looking at the menu and doing the math in his head, he couldn’t help but ask himself if the pennies were adding up.
“Did enough people start using these servers to buy me a decent steak?” he wondered.
He probably should have ordered the filet.
Two decades later, AWS generates nearly $129 billion a year in revenue. That’s enough to rank in the top 40 of the Fortune 500 if it were a standalone company, ahead of the likes of Comcast, AT&T, Tesla, Disney, and PepsiCo. Companies such as Netflix, Airbnb, Slack, Stripe and thousands more have built massive businesses on its platform.
Advertisement
When AWS goes down, it ripples across the web, taking down apps, websites, and services that most users never knew were on a common infrastructure.
But the business that defined cloud computing — bankrolling Amazon’s expansion into everything from streaming to same-day delivery — is now grappling with the most significant challenge since it launched. The rise of AI has upended the industry, empowering Microsoft, Google and others, and creating competitive dynamics that seem to change every month.
For the first time, AWS faces questions about its long-term ability to lead the market it created.
With Amazon marking the 20th anniversary of AWS this month, GeekWire spoke with early builders, current AWS insiders, and longtime observers of the company to tell the story of how the business got started, how it won the cloud, and what it’s up against now.
Advertisement
Scalable, reliable, and low-latency
Officially, Amazon pegs the public launch of AWS to March 14, 2006. That’s when it announced “a simple storage service” that offered software developers “a highly scalable, reliable, and low-latency data storage infrastructure at very low costs.”
Dubbed S3, it was Amazon’s first metered cloud service: the first time developers could pay for exactly what they used, billed in tiny increments, with no upfront commitment.
“We think it can be a meaningful, financially attractive business.” A Bloomberg News story quotes Jeff Bezos about AWS in November 2006. S3 launched earlier in the year.
All of this might seem mundane in a modern world where the cloud and internet services are almost like electricity and water, seemingly always there when you need them.
But remember the context of that moment: Facebook was available only on college campuses. Netflix arrived on DVDs in the mail. The iPhone was still a year away from being unveiled. And over at Microsoft in Redmond, they were finally getting ready to ship Windows Vista.
The asterisk in the headline
The history of Amazon Web Services is more complicated than it might seem, and it’s actually a subject of some disagreement behind the scenes. There are multiple origin stories, including one offered by Amazon itself, and others by former employees who say the company has tidied up the narrative over the years to shape the lore around its current leaders.
Advertisement
Journalist Brad Stone, author of the canonical Amazon book, “The Everything Store,” discovered this when Andy Jassy — the longtime AWS CEO who would go on to succeed Jeff Bezos as Amazon CEO — disputed aspects of his telling of the AWS story in a one-star review.
One point of contention: the origins of EC2, the AWS service built by a small team in South Africa, and the degree to which it sprang from the process Jassy led or was born independently.
Part of the challenge: Amazon, despite operating the storehouse of the internet, isn’t great at preserving its own history. The company, which cooperated with this piece, wasn’t able to unearth key documents such as Jassy’s original AWS six-pager from September 2003.
Some former Amazon leaders take things further back, to a set of e-commerce APIs that Amazon released in July 2002, allowing outside developers to access its product catalog and build applications on top of it. By that accounting, AWS is closer to 24 years old.
Advertisement
Overcoming internal opposition
The effort was led by business leader Colin Bryar, who ran Amazon’s affiliates program, along with technical leader Robert Frederick, whose Amazon Anywhere team (focusing on making Amazon’s site and features available on mobile devices) had been working since 1999 on internal web services that became the foundation for the external APIs.
Amazon in those days was on Seattle’s Beacon Hill, in the landmark art deco Pacific Medical Center tower overlooking downtown. Jeff Bezos was directly involved from the early days, as a believer in the vision that Amazon’s infrastructure capabilities could become a big business.
In 2002, when Bryar initially pitched a roomful of senior leaders on the idea of opening up Amazon’s product catalog and features as web services to outside developers, nearly all of them said no, as Frederick recalled in a recent interview.
The objections piled up: it would cannibalize existing business, it would educate competitors. Then, as Frederick remembers it, Bezos looked around the table and let out one of his trademark piercing laughs. Amazon’s founder wanted to see what developers would do.
Advertisement
“Let’s do it,” Frederick recalls Bezos saying, “and let’s have them surprise us.”
Later, in a July 2002 press release announcing “Amazon.com Web Services,” Bezos used nearly identical language: “We can’t wait to see how they’re going to surprise us.”
Big developer response
Within months, tens of thousands of developers had signed up. Increasingly, they were asking for things like storage, hosting, and compute, recalled Frederick, who worked at Amazon through mid-2006. He went on to found IoT platform Sirqul in 2013 and remains its CEO.
Another veteran of those early days agreed that the developer response to those initial e-commerce APIs may have opened the minds of Amazon’s leaders to the larger possibilities.
Advertisement
“Maybe that’s where Andy’s brain lit up. … Maybe that’s where Jeff’s brain lit up,” said Dave Schappell, referring to Jassy and Bezos. Schappell arrived at Amazon in 1998 as Jassy’s MBA intern, dropped out of Wharton to stay, and spent the next seven years working with him.
Schappell ran the associates program after Bryar, became an early head of product for AWS, and hired the original product managers. Those product managers included Jeff Lawson, who went on to found Twilio. Schappell himself became a well-known Seattle entrepreneur before returning to AWS for four years after Amazon acquired his startup TeachStreet.
The ‘crystal-clear movie moment’
Jeff Barr was one of the developers who noticed.
Now an Amazon VP and longtime AWS chief evangelist, Barr was working as an outside consultant in the web services field when he logged into his Amazon Associates account one day in 2002 and noticed a new message.
Advertisement
AWS Chief Evangelist Jeff Barr, joined in in the early days of the business. (Amazon Photo)
Amazon now had XML, it said, referring to the data-formatting standard that allowed software systems to communicate over the internet. Amazon was making its product catalog available as a web service and connecting it to the affiliate program, a surprising move at the time.
“I clicked through, I signed up for the beta. I downloaded it right away,” Barr recalled.
He sent feedback to the email address in the documentation. They actually replied.
Before long, he was invited to a small developer conference at Amazon’s headquarters — maybe four or five attendees at the Pacific Medical Center tower, in a semicircular open space with a view of the city. The developers sat in the middle, with Amazon employees around them.
At some point, one of the Amazon presenters announced that they were so impressed at how developers had found the APIs and started publishing apps within 48 hours that they were going to look around the rest of the company for more services to open up.
Advertisement
“That was that crystal-clear movie moment,” Barr said. He turned to an Amazon employee nearby and told her: “I have to be a part of this.”
Creating the cloud
But what Frederick and team had built was essentially a way for outside developers to access Amazon’s product data. It was not yet the cloud as we know it today.
That move started in mid-2003, as Jassy told the story in a 2013 talk at Harvard Business School. Jassy, then serving as Bezos’s technical advisor, was tasked with figuring out why software projects across Amazon were taking so long. It turned out that engineers were spending months building storage, database, and compute solutions from scratch.
In a meeting of six or seven people that summer, someone made the observation that would change the company’s trajectory. Jassy recalled the thinking during his HBS talk: “We’re pretty good at this. And if we’re having so many problems, and we don’t have anything we can use externally, I imagine lots of other companies probably have the same problem.”
Advertisement
Around the same time, Amazon recruited Werner Vogels, a Cornell distributed systems researcher, as its chief technology officer. He almost didn’t take the call. “It’s an online bookstore,” he recalled in a LinkedIn post last week. “How hard could their scaling be?”
But the company was wrestling with every problem he and his colleagues had been theorizing about — fault tolerance, consistency, availability at scale — live in production, every day.
Fundamental building blocks
Schappell remembers those early days as a non-stop cycle of six-page memos and meetings with Jassy and Bezos, all focused on trying to figure out what to build.
The concept that would define AWS — breaking every capability down to its most basic building block, or “primitive” — didn’t arrive fully formed. “I don’t think he said that on day one,” Schappell said of Bezos. “I think he said it after he read 47 of our six-pagers.”
Advertisement
Each primitive would stand on its own, and customers would pay only for what they used, billed in tiny increments. It was a direct rebuke to the licensing models of companies such as database giant Oracle, where customers paid for everything whether they used it or not.
Rahul Singh, who joined AWS in January 2004 as one of its first engineers, recalled the early technical plans going through just one layer of review before reaching Bezos and Jassy. (It’s the kind of streamlined decision-making that Jassy is now trying to restore across the company.)
Fault tolerant by design
In one early meeting, Bezos told the engineers he wanted a server touched exactly twice: once when installed in the data center, and once years later when it was pulled out. In between, nothing. The software had to be built to tolerate failures, leaving dead machines behind and moving on. It was a philosophy that would define the architecture of the cloud.
On Singh’s first day, his manager Peter Cohen sat him down in the lunch area and handed him a planning document (a “PR/FAQ” in Amazon lingo) that had just been approved by Bezos.
Advertisement
“We’re calling this S4,” Cohen said. Singh looked at the name of the product, Simple Server-Side Storage Service, and pointed out that it should be called S5. Singh recalls Cohen’s response: “Yeah, you’re really smart, aren’t you? Let’s see if you can actually build this.”
It was eventually shortened to Simple Storage Service, or S3.
The queuing service called SQS had launched in 2004 in beta (adding further to the debate over the origin story and what counts as the launch) but S3 was the first made generally available.
A billion-dollar business?
Jassy, then the VP in charge of AWS, would hold all-hands meetings in a conference room for four or five engineers, most of them straight out of college and grad school, as Singh recalled in an interview. Jassy ran them with the discipline of a much larger organization, repeating over and over that AWS could be a billion-dollar business, at a time when it had no revenue at all.
Advertisement
Singh remembers being highly skeptical.
“I was young and naive, and I remember thinking: a billion, that’s a really big number,” Singh said. Years later, he would joke with Jassy that the prediction had been completely wrong: it turned out to be a multi-billion dollar business, many times over.
In a LinkedIn post marking the March 14 anniversary, current AWS CEO Matt Garman — who joined the company as a summer intern in 2005, before the launch of S3 — recalled how early customers like FilmmakerLive and CastingWords took a bet on the fledgling platform.
“That shift changed the economics of building technology almost overnight,” he wrote.
Advertisement
Meanwhile, in Cape Town …
While one team was building S3 in Seattle, the compute side of the equation was taking shape 10,000 miles away. Chris Pinkham, an Amazon VP who wanted to move back to his native South Africa, was given permission to set up a development office in Cape Town.
His small team built EC2 — the Elastic Compute Cloud — largely independent of the Seattle operation. The local tech community was a bit bewildered by what Amazon was doing.
“We knew this bookstore had arrived in town,” recalled Dave Brown, who was working at a local payments startup at the time. He asked his friends who had joined what they were doing.
Dave Brown, Vice President, AWS Compute & ML Services, at AWS re:Invent 2025. (Amazon Photo)
“It’s kind of like, you know, you can rent a computer on the internet,” they told him.
Brown asked about the revenue. “Tens of dollars every single day,” they said.
Advertisement
He remembers wondering why they were wasting their time on that.
The answer became clear when EC2 launched in August 2006, five months after S3, adding compute to storage as another fundamental building block of AWS and the cloud.
Early customers showed EC2’s range: a Spider‑Man movie used it for rendering, and Facebook apps like FarmVille and Animoto spun up instances on demand, as Brown recalled.
A New York Times engineer used a personal credit card to run optical character recognition on the paper’s scanned archives over a weekend, making the entire archive searchable, after being told by the company that it would be cost-prohibitive using traditional approaches. It cost a grand total of a couple hundred bucks, even after initially screwing up and doing it over again.
Advertisement
Typing ahead of the characters
Brown joined in August 2007, the 14th person on the EC2 team. They worked out of a tiny office in Constantia, the winelands part of Cape Town, across the highway from vineyards.
They occupied part of one floor of an office building. There was one conference room, and two offices. The rest was open plan. The team was 14 engineers, one product manager, and Peter DeSantis, the leader who came from Seattle to help build the service.
The internet connection was a four-megabit DSL line shared by the entire office, with 300 milliseconds of latency to the data centers in the U.S. When engineers typed on their screens, each character had to make the round trip across the ocean and back before it appeared.
“You get really good at typing ahead of where the actual characters are appearing,” Brown said.
Advertisement
Every morning, someone had to find the VPN token to get the office online. It lasted about 10 hours before it automatically reset. “Everybody would be shouting, where’s the VPN token?”
Scrambling to keep up
One day, they were running low on computing capacity. DeSantis came out of his office and told the engineers to shut down the machines they were using for testing. That freed up enough capacity to keep the service going for a few days until the next racks of hardware came online.
Marc Brooker, now an AWS VP and distinguished engineer working on agentic AI, joined the EC2 team in Cape Town in 2008. He could see the entire team from his desk. When Brown was away one day, Brooker and the team covered every surface of his office in sticky notes — the kind of prank that only works in a small office where everyone knows everyone else.
Brooker was drawn in by something he heard about in his job interview: the team had built a way to make a distributed system look like a physical hard drive to the operating system.
Advertisement
“Wow, that is so cool,” he recalled thinking. “Here’s 20 other things I can think of that we could do with that kind of technology.”
That instinct, that the building blocks of the cloud could be combined and recombined in ways no one at Amazon had imagined, was at the core of what made AWS catch on.
AWS VP Mai-Lan Tomsen Bukovec, who oversees AWS’s core data and analytics services, in front of a whiteboard on which she mapped the evolution from the early days of S3 to the AI era at Amazon’s re:Invent building in Seattle. (GeekWire Photo / Todd Bishop)
“The world would be in a very different place if you didn’t have the freedom to experiment, to pilot, to try something, to move on to some other idea, that AWS first introduced,” said Mai-Lan Tomsen Bukovec, an AWS VP who has led S3 for 13 of its 20 years.
Prasad Kalyanaraman, now the AWS vice president who oversees global infrastructure, previously spent years building supply-chain forecasting systems for Amazon’s retail operation. Around 2011, Charlie Bell, then a senior AWS leader, asked him to help with a problem: the team was forecasting its compute demand using spreadsheets.
Advertisement
He adapted the supply-chain forecasting tools for AWS, but the cloud business kept outrunning every model he built.
“The funny thing about forecasts is that forecasts are always wrong,” he said. “It’s very hard to actually predict exponential growth.”
How AWS grew
It began with startups. The companies that would define the next era of technology were building on AWS. Airbnb, Instagram, and Pinterest all got their start on AWS.
John Rossman, a former Amazon exec and author of books including “The Amazon Way” and “Big Bet Leadership,” remembers Jassy pulling him aside for coffee at PacMed around 2008. Rossman had left Amazon and was working as a consultant to large businesses. Jassy wanted to know: did he think big companies would ever be interested in on-demand computing?
Advertisement
Maybe, maybe not, Rossman said. He was working with Blue Shield of California at the time, and tried to imagine them running on AWS. It was hard to picture. At the time, the typical AWS customer was a startup developer with little budget for infrastructure. The idea that a big insurance company would run on AWS seemed like a stretch.
“I was a little bit of a pessimist on it,” Rossman said.
But soon things started to change.
Netflix moved its streaming infrastructure to AWS starting in 2009, a decision that carried particular weight because it competed with Amazon in video. In 2013, the CIA awarded AWS a contract over IBM, signaling that the platform was trusted at the highest levels of security.
Advertisement
Microsoft tips its hat
AWS’s pricing model, in which customers paid only for what they used, was a direct threat to the licensing businesses of tech’s old guard. Whether burying their heads in the sand or just preoccupied, the companies that would become the biggest AWS rivals were slow to respond.
Microsoft didn’t unveil its cloud platform — code-named “Red Dog,” and initially launched as “Windows Azure” — until October 2008, more than two years after S3 debuted. Bill Gates had left his day-to-day role at Microsoft a few months earlier. The company was still recovering from the aftermath of the Vista flop.
“I’d like to tip my hat to Jeff Bezos and Amazon,” said Ray Ozzie, then Microsoft’s chief software architect, at the launch event — a rare public acknowledgment of a competitor’s lead.
Azure didn’t reach general availability until 2010, and its early approach was more of a platform for applications, not the raw infrastructure that made AWS so popular with developers. It took years to build out comparable offerings.
Advertisement
Google launched App Engine, a platform for running applications, in 2008, but didn’t offer raw computing infrastructure to rival EC2 until Compute Engine arrived in 2012.
‘The AWS IPO’
For years, AWS grew in something close to silence. Amazon said little about the overall growth, and didn’t break out the financial results for the business in its quarterly earnings reports.
Then, in April 2015, Amazon reported its first-quarter earnings with AWS broken out in detail for the first time, and it stunned the industry. The business had a $6 billion annual revenue run rate and was growing 50% a year.
The modest expo hall at the first AWS re:Invent, under construction in 2012, left. Last year’s conference, right, drew 60,000 people to Las Vegas. (2012 Photo Courtesy Jeff Barr; 2025 Photo by Todd Bishop)
AWS generated more than $250 million in profit that quarter alone, with operating margins around 17%. This was a stark contrast with the rest of Amazon, scraping by on traditional retail margins of 2% to 3%. AWS was making significantly more profit on every dollar of revenue.
The hosts of the Acquired podcast, in their extensive 2022 history about the rise of Amazon Web Services, would later call this moment “the AWS IPO,” in effect.
Advertisement
Amazon stock jumped 15% on the news.
“I was blown away,” said Schappell, the early AWS product leader who left in 2004 and later listened to the first AWS earnings breakout while training for a marathon. For years, he had assumed Amazon was losing billions on AWS. The reality was the opposite: AWS had become so profitable that it was effectively bankrolling Amazon’s future.
The margins kept climbing, reaching 35% by early 2022.
Then the pandemic cloud boom faded. Inflation spiked amid broader economic uncertainty. Customers scrutinized their cloud bills and pulled back spending. AWS revenue growth fell from 37% to 12% over the course of the year, the slowest in its history. Margins fell to 24%.
Advertisement
The ChatGPT moment
Then everything changed, for Amazon and everyone else.
On November 30, 2022, OpenAI released ChatGPT, with little fanfare at first. The consumer AI chatbot quickly became the fastest-growing application in history, reaching 100 million users in two months, and sending the technology world into a frenzy in the ensuing months.
For AWS, the stakes were huge. Every major wave of technology over the previous 15 years, from mobile to social to streaming to e-commerce, had been built on its platform.
If AI was the next wave, AWS needed to lead the way again.
Advertisement
Amazon was far from absent in AI. AWS had launched SageMaker in 2017, giving developers tools to build and deploy machine learning models. It had released custom AI chips for inference and training. Alexa, the voice assistant, had been processing natural language queries since 2014. Amazon had spent many years and billions of dollars on machine learning.
But none of it looked or worked like ChatGPT. The new model could write code, draft essays, answer complex questions, and hold a conversation. It was not a feature. It was a product people wanted to use. And it was built by an AI lab running on Microsoft Azure.
‘AWS sneaked in there’
The irony: OpenAI didn’t start on Microsoft’s cloud. It launched on AWS.
When the AI lab debuted in December 2015, AWS was listed as a donor. OpenAI was running its early research on Amazon’s infrastructure under a deal worth $50 million in cloud credits.
Advertisement
Microsoft CEO Satya Nadella learned about it after the fact. “Did we get called to participate?” he wrote to his team that day, in an email that surfaced only recently in a court filing from Elon Musk’s suit against Microsoft and OpenAI. “AWS seems to have sneaked in there.”
Microsoft moved fast. Within months, Nadella was courting OpenAI. The AWS contract was up for renewal in September 2016. “Amazon started really dicking us around on the [terms and conditions], especially on marketing commits,” Sam Altman wrote to Musk, who was then OpenAI’s co-chair. “And their offering wasn’t that good technically anyway.”
By that November, Microsoft had won the business.
Six years later, with the launch of ChatGPT, that bet paid off in ways no one could have predicted. Microsoft stock surged. Amazon, like many others in the industry, was scrambling to figure it all out — suddenly trying to keep up with the future of a market it had long defined.
Advertisement
Pivoting to generative AI
The AWS CEO at the time was Adam Selipsky, who had helped build the business from its earliest days before leaving in 2016 to run Tableau, the data visualization company. He returned in May 2021 to lead AWS after Jassy was promoted to succeed Bezos as Amazon CEO.
In a May 2024 interview with Selipsky, on one of his last days in the role, GeekWire asked him directly if Amazon had been caught flat-footed by the rise of generative AI.
After a member of his team interjected to say the question seemed to be informed by reading too many Microsoft press releases, Selipsky dismissed the idea that AWS was behind.
While that narrative might have “more sizzle” and generate clicks, Selipsky said, the reality was different, as evidenced by Amazon’s years of work in AI and machine learning.
Advertisement
AWS had announced Inferentia, a chip for deep learning, in 2018, building on its 2015 acquisition of Annapurna Labs, the Israeli chip startup. It began work on CodeWhisperer, an AI coding assistant, in 2020 — before GitHub Copilot existed, the company notes. In 2021, it launched Trainium, a chip designed to train models with 100 billion or more parameters.
Dario Amodei, CEO of Anthropic, right, speaks with Adam Selipsky, then CEO of Amazon Web Services, at AWS re:Invent on Nov. 28, 2023. (GeekWire File Photo / Todd Bishop)
At the same time, Selipsky acknowledged that AWS had “pivoted many thousands of people from other interesting, important projects to work on generative AI” — a scale of reallocation signaling something other than business as usual inside the company.
Tomsen Bukovec, who now oversees AWS’s core data services including S3, analytics, and streaming, said her team’s response was less a pivot than a process of learning.
They educated themselves on what the technology meant for their services, she said, and thought deeply about what it would look like for AI to both create and consume data at scale.
The question her team started asking in late 2022: what does the world look like when 70 to 80 percent of the usage of your services comes through AI?
Advertisement
“AI is going to use it at 10 times to 100 times the rate of a human, and it’s going to do it all day long, all the time, 24 hours,” she said. “AI never goes to sleep.”
Scrambling to meet the moment
The pressure to catch up in generative AI was felt across the company. In a lawsuit filed in Los Angeles Superior Court, an AI researcher who worked on Amazon’s Alexa team alleged that a director instructed her to ignore internal copyright policies because “everyone else is doing it.”
The complaint described ChatGPT’s launch in late November 2022 as causing “panic within the organization.” Amazon has denied the allegations, and the case is still pending.
On Amazon’s earnings call in early February 2023 — two months after ChatGPT’s launch — Amazon CEO Andy Jassy did not discuss generative AI or large language models.
Advertisement
Matt Garman, AWS CEO, speaks at AWS re:Invent 2025. (GeekWire File Photo / Todd Bishop)
By the next quarter’s call, in late April 2023, he spoke about it for nearly ten minutes, describing it as “a remarkable opportunity to transform virtually every customer experience that exists.”
In September 2023, the company announced an investment of up to $4 billion in Claude maker Anthropic, the AI startup founded by former OpenAI researchers. The investment would eventually grow to $8 billion — which seemed like a lot at the time.
Selipsky left AWS in mid-2024. Garman, whom Selipsky had hired as a product manager in 2006, succeeded him as CEO, charged with leading the cloud business into the new era.
From CodeWhisperer to Bedrock
The roots of Amazon’s response actually predated ChatGPT by more than two years, although it faced initial skepticism internally. In 2020, Atul Deo, an AWS product director, wrote a six-page memo proposing a generative AI service that could write code from plain English prompts.
Jassy, who was still leading AWS at the time, wasn’t sold. His reaction, as Deo later told Yahoo Finance, was that it seemed like a pipe dream. The project launched in 2023 as CodeWhisperer, an AI coding assistant.
Advertisement
But by then, ChatGPT had redrawn the landscape, and the team realized they could offer something broader: a platform giving customers access to a range of foundation models through a single service. AWS called it Bedrock. The name reflected an ambition to do for AI models what the company had done years earlier with its Relational Database Service, which wrapped MySQL, Oracle, and other database engines in a common management layer.
Bedrock would do the same for large language models.
The decision to offer multiple models rather than push a single in-house option was deliberate, and rooted in a pattern AWS had followed for years. It brought multiple CPUs to the cloud: AMD, Intel, and its own Graviton. It offered Nvidia GPUs alongside its own Trainium chips.
Fastest-growing AWS service
Amazon’s view is that choice drives competition, which drives down prices for customers.
Advertisement
“We knew there was never going to be one model to rule everybody,” said Dave Brown, the AWS vice president who oversees EC2, networking, and custom silicon. “And even the best model was not going to be the best model all the time.”
Bedrock launched in preview in April 2023 and reached general availability that September, with models from Anthropic, Meta, and others alongside Amazon’s own. Two years later, it had become the fastest-growing service AWS had ever offered, with more than 100,000 customers.
On Amazon’s most recent earnings call, Jassy described it as a multi-billion-dollar business, with customer spending growing 60% from one quarter to the next.
At the end of 2024, Amazon added its own entry to the model race. The company introduced a family of foundation models called Nova, positioned as a lower-cost, lower-latency alternative to the third-party models on the Bedrock platform.
Advertisement
Amazon CEO Andy Jassy unveils the Nova models at AWS re:Invent in December 2024. (GeekWire Photo / Todd Bishop)
As Fortune’s Jason Del Rey observed, it was a page from the e-commerce playbook: build the marketplace first, then stock it with a house brand. Just as Amazon sells goods from thousands of merchants alongside its own private-label products, Bedrock offered models from Anthropic, Meta, and others, and now Amazon’s own models to go along with them.
At re:Invent in late 2025, AWS pushed further, unveiling what it called “frontier agents” — autonomous AI systems designed to work for hours or days without human involvement.
One, built into Amazon’s Kiro coding platform, can navigate multiple code repositories to fix bugs while a developer sleeps. Last month, the Financial Times reported that Amazon’s own AI coding tools caused at least one AWS service disruption. Amazon acknowledged the incident but publicly disputed aspects of the reporting, citing a misconfigured role, not the AI itself.
The $200 billion bet
Like its rivals, AWS is also building the physical infrastructure to back it up. In 2025, less than a year after it was announced, AWS opened Project Rainier, one of the world’s largest AI compute clusters, centered in Indiana, powered by more than 500,000 of Amazon’s Trainium2 chips.
Named after the mountain visible from Seattle, Rainier was built to train and run Anthropic’s next generation of Claude models, using Amazon’s own Trainium chips rather than Nvidia GPUs.
Advertisement
Kalyanaraman, the AWS vice president who oversees global infrastructure, said the project forced AWS to rethink its supply chain from the ground up. The goal was to minimize the time between a chip leaving its fabrication facility and serving a customer workload.
Rainier was built at a faster pace than anything AWS had ever done, Kalyanaraman said, with more than 100,000 Trainium chips available to Anthropic in under a year. But it wasn’t a one-off. He called it the new template for how AWS would build AI infrastructure going forward.
Then, late last month, came the deal that brought the story full circle.
OpenAI — the company that launched on AWS in 2015 and left for Microsoft Azure the following year — announced a partnership with Amazon that included up to $50 billion in investment and a cloud agreement worth more than $100 billion over eight years.
Advertisement
OpenAI committed to run workloads on Amazon’s custom Trainium chips, making it the second major AI lab after Anthropic to do so. The two companies had been talking since at least May 2023, according to SEC filings, but Microsoft’s right of first refusal on OpenAI’s compute had blocked a deal until those restrictions were loosened in the latest renegotiation.
By late 2025, AWS revenue was growing at its fastest pace in more than three years, up 24% to $35.6 billion a quarter. The company disclosed that its Trainium and Graviton chips had reached a combined annual revenue run rate of more than $10 billion. Bedrock had surpassed 100,000 customers and was generating revenue in the billions.
The competitive picture was also coming into sharper focus.
In mid-2025, Microsoft disclosed standalone Azure revenue for the first time: $75 billion a year, up 34%. Google Cloud had crossed a $50 billion annual run rate. AWS, at more than $116 billion a year at the time, was still larger — but no longer running away with the market.
All of this helps to explain Amazon’s record capital spending. On the company’s latest earnings call, Jassy defended plans to spend $200 billion this year, most of it on AI infrastructure.
Advertisement
The figure is so large it would consume nearly all of Amazon’s operating cash flow. Facing a Wall Street backlash, Jassy called artificial intelligence “an extraordinarily unusual opportunity to forever change the size of AWS and Amazon as a whole.”
What’s next: Bear and bull cases
Longtime observers are divided on the company’s AI bet.
Corey Quinn, a cloud economist who works with AWS customers through his Duckbill consultancy, sees little real‑world traction for Amazon’s Nova models. “You know someone is an Amazon employee when they talk about Nova, because no one else is,” he said.
Some businesses bypass Amazon’s Bedrock platform entirely because of capacity constraints and slower speeds, he said, going to third-party providers like Anthropic rather than inserting Bedrock as a “middleman” — unless they’re trying to retire their committed AWS spend.
Advertisement
Looking forward, Quinn pointed to a historical parallel. Twenty years ago, Cisco was the most valuable company in the world, the backbone of the internet. Today it is a profitable but largely invisible utility. AWS, he said, could be headed for the same fate.
“It’s very clear that there will be a 40th anniversary for AWS, because that inertia does not go away,” Quinn said. “But will it be at the center of tech policy and giant companies, or is it going to be a lot more like the Cisco of today?”
Om Malik, the veteran tech writer, cast a critical eye on Amazon’s OpenAI investment.
By his math, Amazon is paying roughly 16 times more per percentage point of OpenAI than Microsoft did, with none of the exclusive IP rights, revenue share, or primary API access that Microsoft locked up years ago. The cost of being late, Malik wrote, is measured in billions.
Advertisement
The lobby at AWS headquarters, the re:Invent building in Seattle. (GeekWire Photo / Todd Bishop)
Rossman, the former Amazon executive who was once skeptical about AWS demand from big business, sees a different picture. He agrees that AWS is strong in infrastructure, the picks and shovels. But where Quinn sees that as a ceiling, Rossman sees it as a moat.
The models are the commodity, Rossman contends. They leapfrog each other constantly. What matters is everything the models run on and through: the chips, the servers, the data centers, the power. AWS is building more of that stack than most competitors.
“That’s where the value is,” he said.
Rossman said he could envision AWS operating nuclear power plants someday. The long-term winners, he said, will be the companies that deliver the best AI at the lowest cost per token. That’s where AWS’s vertical integration — from Trainium chips to Bedrock to the data center itself — gives it an advantage competitors can’t easily replicate.
As for the risk of spending too much, Rossman put it simply: you have to decide which side of history you’d prefer to fail on — overbuilding or underbuilding. Amazon isn’t taking chances.
Advertisement
In an internal all-hands meeting last week, Jassy said AI could help AWS reach $600 billion in annual revenue, double his own prior estimate, Reuters reported. He had been thinking for years that AWS could be a $300 billion business in a decade. AI, he said, changed the math.
Apple has raised the price of external hard drives in its stores, as its retail efforts feel the pinch of the increased cost of storage.
External drives are now more expensive to buy from Apple.
The tech industry is dealing with a crisis of supply and demand, with the needs of AI infrastructure buildouts consuming masses of memory and storage. While the main discussion has been about how Apple is faring on the supply chain side of things, it seems retail is being affected at a much faster rate. Writing in Sunday’s “Power On” newsletter for Bloomberg, Mark Gurman was informed that Apple had updated the prices for a number of its external drives. These updates occurred on both the website and in retail outlets. Continue Reading on AppleInsider | Discuss on our Forums
There are some premium apps for MacOS that offer more of an iTunes-like experience, but nothing that I vouch for.
Backing Up to Your Chromebook
Here is how to back up files from your Android phone on a Chromebook:
Plug your phone into a USB port on your Chromebook.
Drag down the notification shade and look for a notification from Android System that says something like Charging this device via USB, Tap for more options and tap it.
Look for an option that says File transfer and select it.
The Files app will open on your Chromebook, and you can drag any files you want to copy over.
Backing Up to Another Cloud Service
Maybe you have run out of Google storage, or you prefer another cloud service. There are Android apps for Dropbox, Microsoft’s OneDrive, MEGA, Box, and others. Most of them offer some cloud storage for free, but what you can back up and how you do it differs from app to app.
Advertisement
We looked at how to back up mobile photos on a few of these before, and you can usually set up the process to be automatic, though other files often have to be backed up manually. If you want to automatically sync photos and other files across devices using one of these services, then check out the Autosync app. There are specific versions for Dropbox, OneDrive, MEGA, and Box.
Maybe you’d prefer not to use the cloud or Google’s services for your backup. You can always use the methods listed above for Windows or Mac to download files, then manually move them onto a portable hard drive or USB flash drive, but that’s quite a lot of work.
Advertisement
If you have network-attached storage (NAS), there’s likely an app that can automatically back up some of your files when you are connected to home Wi-Fi. You might also consider Syncthing (though it’s best for syncing rather than backing up) or something like Swift Backup, though you may need to pay and/or root your phone to get the best from them.
Backing Up Within Apps
Messaging apps, and a handful of other apps, have their own backup systems built in. I’ll give you a couple of examples here, but check up on your favorites.
Elon Musk recently outlined ambitious plans for a chip-building collaboration between his companies Tesla and SpaceX.
Bloomberg reports that Musk shared his plans on Saturday night at an event in downtown Austin, Texas, with a photo suggesting that what Musk is calling the “Terafab” facility will be built near Tesla’s Austin headquarters and “gigafactory.”
Musk said he’s pursuing this project because semiconductor manufacturers aren’t making chips quickly enough for his companies’ artificial intelligence and robotics needs: “We either build the Terafab or we don’t have the chips, and we need the chips, so we build the Terafab.”
The goal is to manufacture chips that can support 100 to 200 gigawatts of computing power per year on Earth, along with a terawatt in space, Musk said. He did not offer a timeline for these plans.
Advertisement
As Bloomberg noted, Musk does not have a background in semiconductor manufacturing, but he does have a history of overpromising on goals and timelines.
Overly autonomous cooking tools and kitchen appliances have largely whiffed in the US market. While culinary robots like the Thermomix have made inroads in Europe and elsewhere, adoption in the US has been slow. Super smart ovens, including the June, Suvie and Brava, have likewise struggled to connect with consumers here.
Nosh Robotics, a smart home robotics company based in Bengaluru, India, is giving it a go with the launch of Nosh One It’s a $1,499 AI-powered cooking robot seven years in the making and the company says “it can handle the entire cooking process autonomously: ingredient selection, sautéing, plating and self-cleaning.”
Advertisement
The June Oven was the most promising smart oven we tested. It quietly stopped production in 2023.
The Nosh does a few things that a slow cooker or Instant Pot doesn’t, namely, add the right amount of ingredients, cooking oils and spices from small chambers. But you still have to load the right ingredients for a given recipe into cartridges every time you cook.
Advertisement
The Nosh One has launched on Kickstarter for a cool $1,499.
Nosh One
The cooking functionality is also limited. While the Nosh can portion, chop (roughly — no mincing or dicing), cook and stir food in its built-in pot using highly programmed recipes so you can walk away while the recipe completes, it can’t bake, roast, boil, sear or steam, making it limited in what it can effectively make.
I saw it in a non-demo preview at CES earlier this year and spoke with reps about the Nosh One. CEO Mira Patel calls it “the first consumer robot that truly cooks for you,” though I was less certain of its potential and remain skeptical. Up close, and even with a deep explanation from the on-site reps, the pricey machine doesn’t seem worth the cost or the space it takes up on your counter, at least for most home cooks.
Advertisement
The Nosh One is similar to a Thermomix. The Thermomix offers more cooking modes and functions, but it can’t automatically deliver precise ingredient amounts to the chamber like the Nosh.
Verwerk
If your dinner menu consists mostly of stews, soups, stir-fries and curries, the Nosh should be able to shoulder a good deal of cooking. Most other foods will have to be cooked the old-fashioned way.
It’s also big and bulky. Weighing 57 pounds with a 21-by-17-inch frame, it’ll command a good deal of counter space, much more than an Instant Pot or a slow cooker, both of which execute the same basic cooking tasks, albeit with far fewer automated functions.
How it works
Advertisement
The Nosh One precisely portions ingredients according to programmed recipes, then heats and stirs them to completion.
Nosh Robotics
At the core of the device is NoshOS, a proprietary culinary AI trained on thousands of cooking techniques and cuisines from around the world. Multiple sensors monitor texture, moisture, aroma compounds and browning levels in real time, dynamically adjusting heat, timing and seasoning as a dish cooks. Built-in machine vision identifies produce, proteins and pantry items, allowing the system to suggest meals based on ingredients already on hand.
Ingredient cartridges, which are reusable and dishwasher-safe, store fresh items and dispense them with “millimeter-level precision.” After each meal, a closed-loop wash cycle automatically cleans the cooking chamber, utensils and internal surfaces.
Pricing and availability
The Nosh One is available to preorder on Kickstarter until March 25, starting at $1,499, with shipments expected in early summer 2026. Early backers receive a complimentary set of ingredient cartridges and access to the Nosh Founders Recipe Library, featuring dishes from award-winning chefs. According to the company, additional attachments, specialty cooking modules and premium recipe packs are planned for later in 2026.
Advertisement
As always, before contributing to any campaign, read the crowdfunding site’s policies — in this case, Kickstarter — to find out your rights (and refund policies, or the lack thereof) before and after a campaign ends.



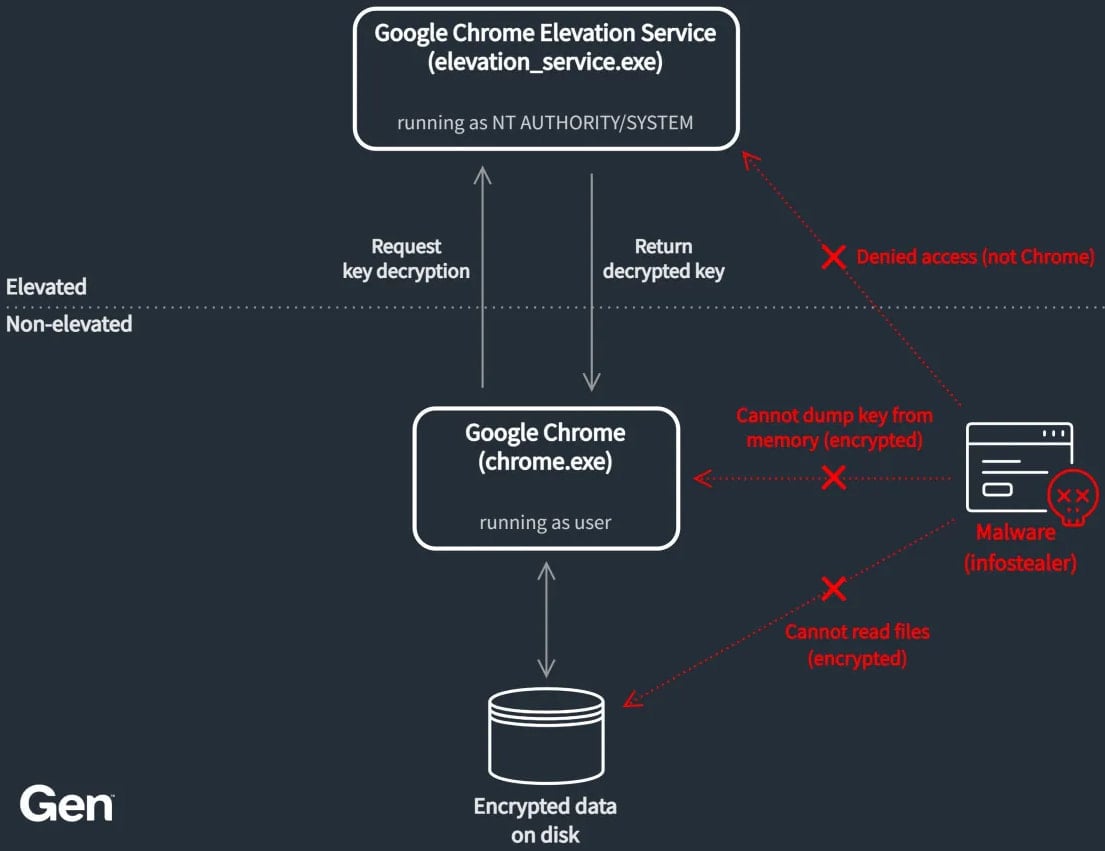
.webp)









































































You must be logged in to post a comment Login