
Tech
The least surprising chapter of the Manus story is what’s happening right now

Okay, so the U.S. and China are locked in an all-out race to build the most powerful AI on the planet. Beijing is throwing billions at homegrown models, tightening its grip on the tech sector, and watching nervously as its best AI talent gravitates to U.S. companies. A Carnegie Endowment study published late last year found that 87 of the 100 top Chinese AI researchers at U.S. institutions in 2019 are still there.
Yet Manus — one of China’s most buzzed-about AI startups — quietly relocated to Singapore and sold itself to Meta for $2 billion. Did anyone think there would not be a reckoning over this tie-up?
As industry watchers know, Manus burst onto the scene in the spring of last year with a demo video showing an AI agent screening job candidates, planning vacations, and analyzing stock portfolios, and it cheekily claimed it outperformed OpenAI’s Deep Research. Within weeks, Benchmark — the consummate Silicon Valley venture firm — led a $75 million funding round at a $500 million valuation. That was surprising. (Senator John Cornyn had thoughts, tweeting at the time, “Who thinks it is a good idea for American investors to subsidize our biggest adversary in AI, only to have the CCP use that technology to challenge us economically and militarily? Not me.”)
By December, Manus had millions of users and was pulling in over $100 million in annual recurring revenue. Then Meta came calling, and Mark Zuckerberg, who has staked the company’s future on AI, snapped it up for $2 billion.
It’s worth noting that Manus didn’t just sell itself to an American buyer; it spent the better part of last year actively trying to operate outside China’s orbit. The company relocated its headquarters and core team from Beijing to Singapore, restructured its ownership, and after the Meta deal was announced, Meta pledged to cut all ties with Manus’s Chinese investors and shut down its operations in China entirely. By every measure, Manus was trying to make itself a Singapore company.
But if that string of events raised eyebrows in Washington, you can only imagine that in Beijing, they were apoplectic.
China has a phrase for all of this: “selling young crops” — homegrown AI companies that move abroad and sell themselves to foreign buyers before they’ve fully matured, taking their intellectual property and talent with them.
Techcrunch event
San Francisco, CA
|
October 13-15, 2026
Beijing hates it and has spent years establishing that no company operates outside its reach. Surely, we all remember that time Jack Ma gave a speech in 2020, mildly criticizing Chinese regulators, after which he disappeared from public life for months, Ant Group’s blockbuster IPO was killed overnight, and Alibaba was handed a $2.8 billion fine. China then spent the next two years methodically dismantling its own booming tech sector, wiping out hundreds of billions in market value. Chinese leaders are many things, but subtle is not one of them.
Which is why it wasn’t entirely surprising when, on Tuesday, the Financial Times reported that Manus co-founders Xiao Hong and Ji Yichao were summoned to a meeting this month with China’s National Development and Reform Commission and told that they wouldn’t be leaving the country for a while. No formal charges have been filed — just an inquiry into whether the Meta deal violated Beijing’s foreign investment rules.
Beijing is calling it a routine regulatory review.
At some point, someone at Manus probably thought they’d gotten away with it, and maybe they still will. But given the stakes of the AI race, that was always a big gamble. Now Beijing wants answers; Manus’s founders are apparently not going anywhere until it gets them.


Samsung is expanding its already crowded TV lineup for 2026 with a new range of Mini LED 4K UHD models, alongside an updated Neo QLED series that pushes further into premium territory. The strategy is familiar but effective: take the core advantages of Mini LED backlighting; better contrast control, higher brightness, and more precise local dimming, and pair them with a deeper layer of AI-driven processing and smart platform refinements.
There’s a lot to unpack across both categories, so we’re keeping this focused. This article breaks down Samsung’s 2026 Mini LED 4K lineup; where the company is clearly trying to hit the sweet spot between performance and price, while the Neo QLED models, which lean more heavily into flagship features and higher-end positioning, are covered separately.
What Are Samsung Mini LED TVs?
Samsung’s Mini LED TVs are still LCD-based displays, but they use a more advanced form of full-array LED backlighting. The difference comes down to scale: the LEDs are significantly smaller, which allows for far more precise local dimming and better control of light across the screen—especially when rendering bright objects against darker backgrounds.
When paired with HDR formats like HDR10+, this improved backlight control translates into higher peak brightness, better contrast, and expanded color volume. In practical terms, that means a more dynamic and accurate picture without abandoning the proven strengths of LCD technology.
Samsung 2026 Mini LED TV Lineup
For 2026, Samsung is introducing two Mini LED TV series so far: the M80H and M70H. Both models feature 4K UHD resolution, the Tizen smart TV platform, gaming-focused features, and Samsung’s Vision AI Companion for enhanced picture and usability.

The M80H series is available in screen sizes from 55 to 85 inches, while the M70H series spans a broader range from 43 to 85 inches. Between the two, there’s enough flexibility to match just about any viewing distance or room size without forcing a compromise on features.

Key Features
Both series are built to deliver a strong 4K UHD viewing experience, with AI-driven processing handling upscaling and scene optimization. The M80H uses Samsung’s NQ4 AI Gen2 Processor, while the M70H relies on the Mini LED Processor 4K, with both designed to enhance clarity and detail on a scene-by-scene basis.
Samsung’s Real Depth Enhancer is included on both models, improving foreground definition and helping key on-screen elements stand out more clearly. The M80H adds AI Customization Mode, which learns your preferred picture settings by genre during setup and then automatically adjusts image quality based on what you’re watching.
For audio, the M80H also includes Active Voice Amplifier, which boosts dialogue and important sound effects to improve clarity—especially useful when background noise tries to steal the scene.

Also, with Q Symphony, the M80H and M70H can be combined with compatible Samsung soundbars and Wi-Fi speakers to operate as a single, coordinated sound system rather than isolated components.
Gaming support for both models includes Samsung’s Gaming Hub, Cloud Gaming, and VRR (Variable Refresh Rate) in both series. However, the M80H also provides AI Auto Game Mode, Gaming Motion Plus, and AMD Freesync Premium Pro support
Samsung’s Vision AI experience is included in both Mini LED TV series. Anchored by the Perplexity TV App, Vision AI on TVs goes beyond simple voice commands or video enhancements by combining AI audio/video processing, Bixby voice control, Tizen Smart TV integration, and Knox Security into a single, seamless ecosystem.
Comparison
There’s a fair amount of feature overlap between the M80H and M70H models, but key differences remain. We’ve included a detailed comparison chart below to make it easier to see where they separate.
(55″) $699.99
Samsung Model
M80H
M70H
Product Type
Mini-LED TV
Mini-LED TV
Screen Size (diagonal inches)
55, 65, 75, 85
43, 50, 55, 65, 75, 85
Price
(65″) $799.99
(75″) $1,199.99
(85″) $1,799.99
(43″) $349.99
(50″) $399.99
(55″) $449.99
(65″) $529.99
(75″) $729.99
(85″) $1,199.99
Refresh Rate:
144Hz (VRR Support)
60Hz
Lighting Technology
Mini LED
Mini LED
Display Resolution
4K (3840 x 2160)
4K (3840 x 2160)
Anti Reflection
–
–
Dimming Technology
Supreme Mini LED Dimming
Supreme Mini LED Dimming
Processor
NQ4 AI Gen2 Processor
Mini LED Processor 4K
Upscaling
4K AI Upscaling
4K Upscaling
Variable Refresh Rate (VRR)
Yes
Yes
Motion Handling
Motion Xcelerator 144Hz
Motion Xcelerator
DLG (Dual Line Gate)
240Hz
85″ – 55″: 120Hz
50″ – 43″”: N/A
Contrast Enhancer
Real Depth Enhancer
Yes
Color
Pure Spectrum Color
Pure Spectrum Color
Color Booster
Pro
Yes
HDR (High Dynamic Range)
Mini LED HDR
Mini LED HDR
HDR10+
Yes
Yes
Auto HDR Remastering
Yes
–
Adaptive Picture
AI Customization
–
Supersize Picture Enhancer
–
–
TV Depth
3″
3″
Front Color
Black
Titan Black
Stand Type
Basic Feet
Basic Feet
Stand Color
Titan Gray
Black
Adjustable Stand:
75-inch only
–
Wi-Fi
Yes (Wi-Fi 6E)
Yes (Wi-Fi 6E)
Bluetooth Version
5.3
5.3
HDMI Inputs
3
3
HDMI Maximum Input Rate
4K 144Hz (for HDMI 1/2/3)
4K 60Hz (for HDMI 1/2/3)
HDMI Audio Return Channel
eARC
eARC
HDMI-CEC
Yes
Yes
USB Ports
1 x USB-A
1 x USB-A
Ethernet (LAN)
Yes
Yes
Digital Audio Out (Optical):
–
–
RF Connection:
Yes
Yes
RS-232C Input
–
–
Samsung Vision AI
Yes
Yes
Gaming Support
Gaming Hub
Cloud Gaming- Xbox, NVIDIA GeForce Now, Luna, Blacknut, Antstream, Boosteroid
ALLM (Auto Low Latency Mode)
HGIG
AI Auto Game Mode
Gaming Motion Plus
Super Ultra Wide Game View
Game Bar
Mini Map Zoom
AMD FreeSync: Freesync Premium™ Pro
Hue SyncGaming Hub
Cloud Gaming: – Xbox, NVIDIA GeForce Now, Luna, Blacknut, Antstream, Boosteroid
ALLM (Auto Low Latency Mode)
HGIG
TV Art Features
Art Mode: NA
Art Store: YesArt Mode: NA
Art Store: Yes
Operating System
One UI Tizen
One UI Tizen
Free Ad Supported TV
Samsung TV Plus
Samsung TV Plus
Smart Home Connectivity:
SmartThings, Matter, IoT-Sensor Functionality
Quick Remote Only
Smart Assistants (Built-In)
Bixby, Alexa
Bixby, Alexa
Smart Assistants (Works with)
Google Assistant
Google Assistant
Far-Field Voice Interactions
Yes
–
Web Browser:
Yes
Yes
Samsung Health
Yes
Yes
Multi-Device Experience
Mobile to TV
Sound Mirroring
Wireless TV On
TV initiates mirroringMobile to TV
Sound Mirroring
Wireless TV On
Multi-View
Up to 2 videos
–
Buds Auto Switch
Yes
–
Works with Apple AirPlay
Yes
Yes
Works with Google Cast
Yes
Yes
Daily+
Yes
–
Now Brief
Yes Voice/User Detection
–
Workout Tracker
Yes
–
Audio
2 Channel speaker system
20 Watts Output Power
Object Tracking Sound
(OTS) Lite\Q-Symphony
Active Voice Amplifier (AVA) Pro
Adaptive Sound Plus2 Channel speaker system
20 Watts Output Power
Object Tracking Sound (OTS) Lite\Q-Symphony
Karaoke Mic:
Yes
Yes
Multi-Control
Yes
–
Storage Share:
Yes
–
Security
Knox Vault: N/A
Knox Security: YesKnox Vault: N/A
Knox Security: Yes
Remote Control
Bluetooth Simple Remote TM2280A with batteries
IR Simple Remote TM2240A with batteries

The Bottom Line
Samsung’s 2026 Mini LED lineup sits in a very calculated middle ground. You’re getting the core benefit that actually matters; Mini LED backlighting for better contrast, brightness control, and more consistent HDR performance without paying Neo QLED prices. Add in Tizen, Vision AI, and solid gaming support, and these don’t feel stripped down in daily use. For a lot of buyers, this is where the real value is.
What’s missing is just as important. No Quantum Dot layer means color accuracy and color volume won’t match Samsung’s Neo QLED models, and you’re not getting the full processing and refinement stack reserved for the higher tier. These are for buyers who want a meaningful step up from basic LED TVs without drifting into premium pricing. If you’re chasing reference-level performance, keep walking. If you want a well-equipped 4K Mini LED TV that covers the essentials and then some, this is the safer—and smarter—place to land.
Availability & Pricing
Samsung’s 2026 Mini LED 4K TVs are available now:
M80H Series
M70H Series
For more information: Samsung Product Page
Related Reading:

Reddit is stepping up its fight against bots, and now your account could be asked to prove it is human if the platform detects fishy behaviour.
Reddit CEO Steve Huffman says these checks will be rare, but they are meant to protect what makes Reddit work in the first place – real people talking to real people.
As AI-generated content spreads, Reddit admits it is getting harder to tell who is behind a post. So instead of broad crackdowns, it is focusing on suspicious behavior and adding clearer signals across the platform.
How Reddit plans to separate humans from bots

If Reddit detects signs of automation or unusual behavior, it may trigger a human verification check. This could involve simple actions like passkeys or FaceID that confirm a human is present.
In some cases, third-party biometric systems like Sam Altman’s World ID may be used. The platform may also use government-issued IDs in regions where laws require them. However, Reddit says that your identity will stay separate from your account.
The company is also standardizing labels for automated accounts. Approved bots will carry an [APP] tag, making it obvious you are interacting with software. Developers will need to register their tools to get this label, which adds a layer of transparency.
What does this mean for your Reddit experience?

Since Reddit says this is not a sitewide verification system, most users might never be asked to prove anything. Even when such checks take place, the focus will be on confirming a human exists, not identifying who that person is.
At the same time, the platform will continue removing harmful bots at scale, already taking down around 100,000 accounts daily. It is also improving reporting tools so users can flag suspicious activity more easily.
Reddit is not banning AI-written posts outright, but it is drawing a firm line. For now, the platform cares less about how content is written and more about who is behind it.


A new info-stealing malware called Torg Grabber is stealing sensitive data from 850 browser extensions, more than 700 of them for cryptocurrency wallets.
Initial access is obtained through the ClickFix technique by hijacking the clipboard and tricking the user into executing a malicious PowerShell command.
According to researchers at cybersecurity company Gen Digital, Torg Grabber is actively developed, with 334 unique samples compiled in three months (between December 2025 and February 2026) and new command-and-control (C2) servers registered every week.
Apart from cryptocurrency wallets, Torg Grabber steals data from 103 password managers and two-factor authentication tools, and 19 note-taking apps.
Rapid evolution
In a technical report this week, Gen Digital researchers say that Torg Grabber’s initial builds used a Telegram-based and then a custom, encrypted TCP protocol for data exfiltration.
On December 18, 2025, the two mechanisms were abandoned in favor of an HTTPS connection routed through Cloudflare infrastructure. The method supports chunked data uploads and payload delivery.
.jpg)
Source: Gen Digital
The malware features several anti-analysis mechanisms, multi-layered obfuscation, and uses direct syscalls and reflective loading for evasion, running the final payload entirely in memory.
On December 22, 2025, Torg Grabber added App-Bound Encryption (ABE) bypass to beat Chrome’s (and Brave’s, Edge’s, Vivaldi’s, and Opera’s) cookie protection system, like many other information stealers.
However, the researchers also discovered a standalone tool called Underground, used for extracting browser data.
It injects a DLL reflectively into the browser to access Chrome’s COM Elevation Service and extract the master encryption key, a method also recently seen in VoidStealer.
Extensive data theft capabilities
Gen Digital found that Torg Grabber targets 25 Chromium-based browsers and 8 Firefox variants, trying to steal credentials, cookies, and autofill data.
Of the 850 browser extensions it targets, 728 are for cryptocurrency wallets, covering “essentially every crypto wallet ever conceived by human optimism.”
“The marquee names are all there – MetaMask, Phantom, TrustWallet, Coinbase, Binance, Exodus, TronLink, Ronin, OKX, Keplr, Rabby, Sui, Solflare,” the researchers say.
“But the list doesn’t stop at the big names. It keeps going, deep into the long tail, past projects with install counts you could fit in a phone booth.”
Apart from wallets, the malware also targets a large list of 103 extensions for passwords, tokens, and authenticators: LastPass, 1Password, Bitwarden, KeePass, NordPass, Dashlane, ProtonPass, Enpass, Psono, Pleasant Password Server, heylogin, 2FAAuth, GAuth, TOTP Authenticator, and Akamai MFA.
Torg Grabber also targets information from Discord, Telegram, Steam, VPN apps, FTP apps, email clients, password managers, and desktop cryptocurrency wallet apps.
The malware can also profile the host, create a hardware fingerprint, document installed software (including 24 antivirus tools), take screenshots of the user’s desktop, and steal files from the Desktop/Documents folders.
Also notable is its capability to execute shellcode on the compromised device, delivered in ChaCha-encrypted zlib-compressed form from the C2.
Gen Digital cautions that Torg Grabber continues to develop rapidly, registering new C2 domains weekly, and that its operator base is expanding, with 40 tags documented by the time of analysis.

Malware is getting smarter. The Red Report 2026 reveals how new threats use math to detect sandboxes and hide in plain sight.
Download our analysis of 1.1 million malicious samples to uncover the top 10 techniques and see if your security stack is blinded.

Trials will start in Marina Bay and one-north
The first of six autonomous public buses has reached Singapore and will be tested on routes 400 in Marina Bay and 191 in one-north from the second half of 2026 as part of a three-year pilot programme.
In a Facebook video on Mar 25, the Singapore Land Transport Authority (LTA) said that the six buses will be rigorously tested to ensure that they meet all safety and operating requirements before they hit the roads.
When ready, the self-driving public buses will operate alongside existing manned buses, allowing LTA to maintain routes with lower ridership or introduce new services that are currently difficult to introduce due to manpower constraints.

The video from LTA revealed a 16-seater bus with features that resemble those of existing public buses. It also showed a space designated for a wheelchair.
Cameras and sensors are seen mounted on the front, rear and top of the autonomous bus, providing operators with a 360-degree view of the surroundings.
LTA noted that further preparation is needed before testing begins.
The tests will include LTA’s closed-circuit assessment, consisting of basic manoeuvres and safe passenger boarding and alighting at all designated stops.
Service 400 connects Marina Bay and Shenton Way, stopping at Marina Bay Cruise Centre, Gardens by the Bay, Shenton Way and Downtown MRT stations.
Whereas service 191 loops through one-north, with stops at Buona Vista bus terminal, one-north MRT, and Buona Vista MRT.
Following this deployment, LTA may procure up to 14 additional autonomous buses and expand the pilot to more public bus services.
LTA first teased the launch of driverless public buses last Oct, where it awarded a contract for the pilot deployment of autonomous buses to a consortium of MKX Technologies Pte Ltd, Zhidao Network Technology (Beijing) Co. Ltd and BYD (Singapore) Pte Ltd for a contract sum of around S$8.14 million to pilot autonomous buses.
The consortium will also work with the Singapore Bus Academy to train existing bus captains to take on new roles as safety operators, so that they are equipped to operate the autonomous buses competently and confidently.
- Read other articles we’ve written on Singaporean businesses here.

New submitter haroldbasset writes: Canada’s Immigration Department rejected an applicant because the duties of her current job did not match the Canadian work experience she had claimed, but the Department’s AI assistant had invented that work experience. She has been working in Canada as a health scientist — she has a Ph.D. in the immunology of aging — but the AI genius instead described her as “wiring and assembling control circuits, building control and robot panels, programming and troubleshooting.” “It’s believed to be the first time that the department explicitly referred to the use of generative AI to support application processing in immigration refusals,” reports the Toronto Star. “The disclaimer also noted that all generated content was verified by an officer and that generative AI was not used to make or recommend a decision.”
The applicant’s lawyer was shocked “how any human being could make this decision.” “Somehow, it hallucinated my client’s job description,” he said. “I would love to see what the officer saw. Something seriously went wrong here.”
The applicant’s refusal came just as Canada’s Immigration Department released its first AI strategy, which frames artificial intelligence as a way to improve efficiency, service delivery, and program integrity. The department says it has long used digital tools like analytics and automation to flag fraud risks and triage applications, and is now also experimenting with generative AI for tasks such as research, summarizing, and analysis. In this case, however, the department insisted the decision was made by a human officer and that generative AI was not involved in the final decision.

Thirty years after the alleged 1996 “ET of Varginha” encounter, debate continues to rage over the events that happened in Brazil’s self-styled UFO capital. An anonymous reader quotes an excerpt from the Guardian: The skies over this far-flung coffee-growing hub went charcoal black, the heavens opened and one of Brazil’s greatest mysteries was born. “It really was something unique,” recalls Marco Antonio Reis, a zoo director, who was at his ranch outside Varginha one stormy day in January 1996 when, he says, an otherworldly creature came to town. Reis and other locals claim the unusually ferocious downpour heralded a series of disturbing and seemingly paranormal events. At least six of the zoo’s animals, including a spider monkey, a tapir and a raccoon, died mysteriously after a horned interloper with bulging red eyes was spotted in the vicinity by a woman who had gone out for a smoke. When a vet examined their corpses, “they were all black inside,” Reis claims.
On a nearby wasteland, three young women spotted a peculiar and malodorous being with a heart-shaped face and three lumps on its head cowering beside a wall. “I’ve seen the devil,” one of those witnesses would later tell her mum. Soon afterwards, an unexplained infection was rumored to have killed a strapping police intelligence officer who was said to have grappled with the oleaginous unidentified being. Three decades later, Reis says he is convinced Varginha received a non-human visit. His only doubt was from where it came.
“We don’t know if it was extraterrestrial or intraterrestrial,” the 71-year-old says as he climbs a staircase to the veranda where the smoker claims to have seen what, in reference to Steven Spielberg’s 1982 film, became known as the “ET of Varginha”. A 2ft statue of a two-toed alien now marks the spot. “It’s possible it was an intraterrestrial, from inside the Earth They don’t just come from space,” Reis says. “It might have come from the depths of the Earth, too. We don’t even know what it’s like at the bottom of the sea, do we?”
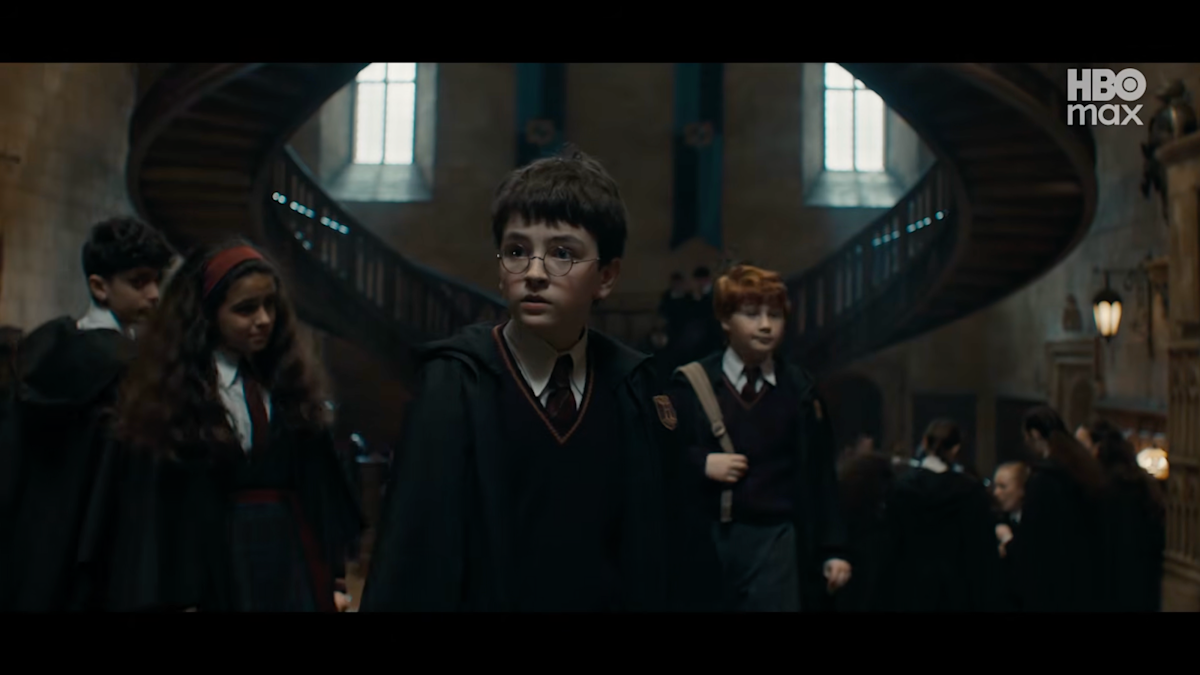
HBO released a teaser trailer and premiere date for its take on Harry Potter and the Philosopher’s Stone. The show will premiere on the HBO Max streaming network this December 25. It’s a rare case where a big-ticket project is coming out earlier than anticipated instead of later; the series wasn’t expected to arrive until 2027.
HBO has already proved its bona fides with lush adaptations of fantastical stories several times over, and this trailer looks like more of the same. The team behind the camera includes notable names who have worked on series such as Succession, Game of Thrones, The Last of Us and Killing Eve. Harry Potter creator J.K. Rowling, who alienated many fans after outing herself as transphobic, is also one of the show’s executive producers.
Engadget’s Jess Conditt has already written eloquently on the struggle of when and how to engage with the Harry Potter franchise while rejecting Rowling’s worldview, although the author’s involvement at the top level may make this adaptation a harder sell to the disillusioned community than, say, the Hogwarts Legacy video game where Rowling was barely involved and the studios took a more proactive approach toward presenting many types of diversity, including gender expression. If you’re hyped for this particular show, seems you’ll have a shorter time to wait for it.


On Tuesday, tipster Yogesh Brar reiterated earlier rumors that OnePlus will soon shut down in the US, the UK, the EU, and most other global markets while continuing to operate in a handful of Asian countries, including China and India. Although the post has since been deleted, 9to5Google reports that…
Read Entire Article
Source link


A Los Angeles jury has found Meta and Google liable for intentionally building addictive social media platforms that harmed a young woman’s mental health, awarding her $3 million in compensatory damages in what is the first trial verdict of its kind in the United States. The decision, delivered on Wednesday after a five-week trial, found Meta responsible for 70 per cent of the plaintiff’s harm and YouTube for the remaining 30 per cent. Punitive damages, which could reach $30 million under California law, are still to be determined.
The plaintiff, identified as Kaley, is now 20 years old. She testified that she began using YouTube at age six and Instagram at age nine, encountering no age verification barriers on either platform. She described spending entire days on social media as a child, withdrawing from her family, and developing anxiety, depression, and body dysmorphia, a condition in which a person becomes obsessively preoccupied with perceived flaws in their appearance. She said she began using Instagram filters that altered her facial features almost as soon as she started using the platform.
The verdict landed one day after a separate jury in New Mexico ordered Meta to pay $375 million for violating state consumer protection law by failing to protect children from sexual predators on its platforms. Together, the back-to-back rulings represent the first time juries have held social media companies financially liable for the harms their products cause to young users.
What the jury decided
Kaley’s lawyers argued that features such as infinite scroll, autoplay, and algorithmically curated content feeds were deliberately designed to maximise engagement and that Meta’s internal growth targets explicitly sought to acquire young users because they were more likely to remain on the platform for longer periods. They presented testimony from former Meta executives and internal company research showing that Meta knew children under 13 were using its platforms and that its products were linked to negative mental health outcomes in teenagers.
When Mark Zuckerberg testified before the jury in February, he acknowledged the issue but said he “always wished” the company had made faster progress on identifying underage users. He maintained that Meta had reached “the right place over time.” Adam Mosseri, the head of Instagram, was presented with data showing Kaley’s longest single-day session on the platform lasted 16 hours. He declined to call it addiction, describing it instead as “problematic.”
Lawyers for Meta argued that while Kaley had experienced genuine mental health struggles, her use of Instagram did not cause or meaningfully contribute to them. Meta said it “respectfully disagrees with the verdict” and is evaluating its legal options. Google called the case a mischaracterisation of YouTube, describing it as “a responsibly built streaming platform, not a social media site,” and said it plans to appeal.
The cases behind this one
Kaley’s was the first of more than 1,500 similar cases consolidated in federal multidistrict litigation against Meta, Google, Snap, and TikTok. Both Snap and TikTok reached undisclosed settlements with Kaley before the trial began, leaving Meta and Google as the two defendants that chose to fight the case in court.
The New Mexico verdict, though legally separate, reinforced the same underlying claim: that Meta knew its platforms endangered children and chose not to act. That case originated from a 2023 undercover operation by New Mexico Attorney General Raúl Torrez, who created a fake profile of a 13-year-old girl and found it was quickly inundated with sexually explicit material and contact from predators. The jury found Meta liable on all counts, including for willfully engaging in unfair, deceptive, and unconscionable trade practices.
Another federal trial is scheduled for June in California, and hundreds of additional cases brought by school districts and state attorneys general are queued behind it. Legal commentators have compared the litigation wave to the tobacco industry lawsuits of the 1990s, which ultimately resulted in a $206 billion settlement and fundamentally reshaped how cigarettes were marketed and regulated in the United States.
What changes and what does not
The immediate financial impact on Meta and Google is minimal. A $3 million compensatory award, even if punitive damages push it toward $30 million, is trivial for companies with a combined market capitalisation exceeding $3 trillion. The $375 million New Mexico verdict is larger but still represents a fraction of a single quarter’s revenue for Meta.
The significance is precedential, not financial. The Los Angeles verdict establishes that a jury of ordinary citizens, presented with internal documents, expert testimony, and the companies’ own research, concluded that social media platforms were intentionally designed to be addictive and that this design caused measurable harm to a specific individual. That finding will be cited in every one of the 1,500 pending cases. It shifts the burden: Meta and Google now enter each subsequent trial not as defendants facing novel claims but as companies a jury has already found liable.
Mike Proulx, a research director at Forrester, described the verdicts as a “breaking point” between social media companies and the public. Whether they also mark a breaking point in how these platforms are built remains to be seen. The features Kaley’s lawyers identified as harmful, infinite scroll, autoplay, algorithmic feeds, and engagement-maximising recommendation systems, are not incidental design choices. They are the business model. Removing them would require Meta and Google to become fundamentally different companies, which is something no jury verdict, however large, can compel.
Google published a research blog post on Tuesday about a new compression algorithm for AI models. Within hours, memory stocks were falling. Micron dropped 3 per cent, Western Digital lost 4.7 per cent, and SanDisk fell 5.7 per cent, as investors recalculated how much physical memory the AI industry might actually need.
The algorithm is called TurboQuant, and it addresses one of the most expensive bottlenecks in running large language models: the key-value cache, a high-speed data store that holds context information so the model does not have to recompute it with every new token it generates. As models process longer inputs, the cache grows rapidly, consuming GPU memory that could otherwise be used to serve more users or run larger models. TurboQuant compresses the cache to just 3 bits per value, down from the standard 16, reducing its memory footprint by at least six times without, according to Google’s benchmarks, any measurable loss in accuracy.
The paper, which will be presented at ICLR 2026, was authored by Amir Zandieh, a research scientist at Google, and Vahab Mirrokni, a vice president and Google Fellow, along with collaborators at Google DeepMind, KAIST, and New York University. It builds on two earlier papers from the same group: QJL, published at AAAI 2025, and PolarQuant, which will appear at AISTATS 2026.
How it works
TurboQuant’s core innovation is eliminating the overhead that makes most compression techniques less effective than their headline numbers suggest. Traditional quantization methods reduce the size of data vectors but must store additional constants, normalization values that the system needs in order to decompress the data accurately. These constants typically add one or two extra bits per number, partially undoing the compression.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
TurboQuant avoids this through a two-stage process. The first stage, called PolarQuant, converts data vectors from standard Cartesian coordinates into polar coordinates, separating each vector into a magnitude and a set of angles. Because the angular distributions follow predictable, concentrated patterns, the system can skip the expensive per-block normalization step entirely. The second stage applies QJL, a technique based on the Johnson-Lindenstrauss transform, which reduces the small residual error from the first stage to a single sign bit per dimension. The combined result is a representation that uses most of its compression budget on capturing the original data’s meaning and a minimal residual budget on error correction, with no overhead wasted on normalization constants.
Google tested TurboQuant across five standard benchmarks for long-context language models, including LongBench, Needle in a Haystack, and ZeroSCROLLS, using open-source models from the Gemma, Mistral, and Llama families. At 3 bits, TurboQuant matched or outperformed KIVI, the current standard baseline for key-value cache quantization, which was published at ICML 2024. On needle-in-a-haystack retrieval tasks, which test whether a model can locate a single piece of information buried in a long passage, TurboQuant achieved perfect scores while compressing the cache by a factor of six. At 4-bit precision, the algorithm delivered up to an eight-times speedup in computing attention on Nvidia H100 GPUs compared to the uncompressed 32-bit baseline.
What the market heard
The stock reaction was swift and, in the view of several analysts, disproportionate. Wells Fargo analyst Andrew Rocha noted that TurboQuant directly attacks the cost curve for memory in AI systems. If adopted broadly, he said, it quickly raises the question of how much memory capacity the industry actually needs. But Rocha and others also cautioned that the demand picture for AI memory remains strong, and that compression algorithms have existed for years without fundamentally altering procurement volumes.
The concern is not unfounded, however. AI infrastructure spending is growing at extraordinary rates, with Meta alone committing up to $27 billion in a recent deal with Nebius for dedicated compute capacity, and Google, Microsoft, and Amazon collectively planning hundreds of billions in capital expenditure on data centres through 2026. A technology that reduces memory requirements by six times does not reduce spending by six times, because memory is only one component of a data centre’s cost. But it changes the ratio, and in an industry spending at this scale, even marginal efficiency gains compound quickly.
The efficiency question
TurboQuant arrives at a moment when the AI industry is being forced to confront the economics of inference. Training a model is a one-time cost, however enormous. Running it, serving millions of queries per day with acceptable latency and accuracy, is the recurring expense that determines whether AI products are financially viable at scale. The key-value cache is central to this calculation: it is the bottleneck that limits how many concurrent users a single GPU can serve and how long a context window a model can practically support.
Compression techniques like TurboQuant are part of a broader push toward making inference cheaper, alongside hardware improvements such as Nvidia’s Vera Rubin architecture and Google’s own Ironwood TPUs. The question is whether these efficiency gains will reduce the total amount of hardware the industry buys, or whether they will simply enable more ambitious deployments at roughly the same cost. The history of computing suggests the latter: when storage gets cheaper, people store more; when bandwidth increases, applications consume it.
For Google, TurboQuant also has a direct commercial application beyond language models. The blog post notes that the algorithm improves vector search, the technology that powers semantic similarity lookups across billions of items. Google tested it against existing methods on the GloVe benchmark dataset and found it achieved superior recall ratios without requiring the large codebooks or dataset-specific tuning that competing approaches demand. This matters because vector search underpins everything from Google Search to YouTube recommendations to advertising targeting, which is to say, it underpins Google’s revenue.
The paper’s contribution is real: a training-free compression method that achieves measurably better results than the existing state of the art, with strong theoretical foundations and practical implementation on production hardware. Whether it reshapes the economics of AI infrastructure or simply becomes one more optimisation absorbed into the industry’s insatiable appetite for compute is a question the market will answer over months, not hours.
Office building in Leigh set to become education centre for students who find attending school difficult
Hoteliers hope Blackpool has a great summer season ahead as people look to UK holidays
Bhutan’s Bitcoin (BTC) Fire Sale: $152M Dumped in 2026 and Counting






-
 Crypto World5 days ago
Crypto World5 days agoNIO (NIO) Stock Plunges 6.5% as Shelf Registration Sparks Dilution Worries
-

 Fashion6 days ago
Fashion6 days agoWeekend Open Thread: Adidas – Corporette.com
-

 Politics6 days ago
Politics6 days agoJenni Murray, Long-Serving Woman’s Hour Presenter, Dies Aged 75
-
 NewsBeat22 hours ago
NewsBeat22 hours agoManchester United reach agreement with Casemiro over contract clause amid transfer speculation
-

 Crypto World4 days ago
Crypto World4 days agoBest Crypto to Buy Now: Strategy Just Spent $1.57 Billion on Bitcoin During Fear While Early Investors Quietly Enter Pepeto for 150x Potential
-

 Crypto World4 days ago
Crypto World4 days agoBitcoin Price News: Bhutan Sells $72 Million in BTC Under Fiscal Pressure, but the Smart Money Entering Pepeto Sees What the Market Does Not
-

 Tech6 days ago
Tech6 days agoinKONBINI Lets You Spend Summer Days Behind the Register
-

 News Videos5 hours ago
News Videos5 hours agoParliament publishes latest register of MPs’ financial interests
-

 Sports3 days ago
Sports3 days agoRemo Stars and Kano Pillars Strengthen Survival Hopes in NPFL
-

 Politics7 days ago
Politics7 days agoGender equality discussions at UN face pushbacks and US resistance
-

 Business4 days ago
Business4 days agoNo Winner in March 21 Drawing as Prize Rolls to $133 Million for Next
-

 Sports3 days ago
Sports3 days agoGary Kirsten Accuses Pakistan Cricket Board Of ‘Interference’, Mohsin Naqvi Responds
-
 Tech3 days ago
Tech3 days agoGive Your Phone a Huge (and Free) Upgrade by Switching to Another Keyboard
-

 Sports6 days ago
Sports6 days ago2026 Kentucky Derby horses, odds, futures, preview, date: Expert who nailed 12 Derby-Oaks Doubles enters picks
-
Sports7 days ago
Vikings Free Agency Enters Phase 2 with Key Questions
-
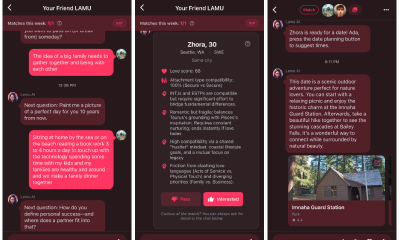
 Tech3 days ago
Tech3 days agoAI enters the chat: New Seattle dating app relies on tech to facilitate meaningful human connections
-

 Politics7 days ago
Politics7 days agoScotland’s rejection of assisted dying is a victory for humanity
-

 Business6 days ago
Business6 days agoDLocal: Entering 2026 At Escape Velocity
-
Business5 days ago
Columbia Sportswear enters $500 million credit agreement with JPMorgan Chase
-

 NewsBeat7 days ago
NewsBeat7 days agoMissile lands next to presenter during live report
You must be logged in to post a comment Login