AI tools are everywhere, so why do most people still use them like it’s 2015? Artificial intelligence now sits inside almost every tool you open, from search engines and office apps to browsers, phones, and creative software.
Updates keep adding assistants, copilots, and generators, each one promising to change how work gets done.
On paper, adoption looks high. Millions of users already have these features available, often switched on by default, waiting inside menus most people rarely explore.
Actual behaviour moves more slowly. Many users still write documents line by line, search the web the same way they did years ago, and complete tasks manually, even when the software suggests another option.
Advertisement
The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
The goal was never to replace creativity or talent, but to augment it, and that only works when people understand where the new capability fits into what they already do.
In this article, we look at why AI tools are everywhere, yet everyday software use still feels stuck in the past. The real problem isn’t access to AI, it’s adoption.
Advertisement
Software vendors are not moving slowly. New AI features appear in updates almost every week, added to tools people already use for writing, coding, design, search, and communication.
Access is no longer the barrier. What’s missing is the moment when the user actually learns where the new feature fits into their existing workflow.
Most software still expects people to figure that out on their own, which is why tools like WalkMe Learning Arc focus on teaching features within the application rather than sending users to separate documentation or training portals.
The shift reflects a wider realisation across the industry that releasing functionality does not mean people will use it, a problem also discussed in debates around AI oversight and usability in clarity as a strategy.
Advertisement
Most learning still happens outside the tool itself. Users are expected to read guides, watch tutorials, or sit through formal sessions similar to traditional employee training programmes, even though the real difficulty only appears once they are back inside the software, trying to complete a task under time pressure.
In practice, people fall back on habits they already trust, ignoring features they never had time to explore properly. Innovation keeps moving forward, but user capabilities move at a different pace.
Feature overload is making modern software harder to use
Modern apps are not struggling because they lack capability. They struggle because every update adds another layer on top of what was already there. AI did not replace old interfaces; it stacked on top of them, which means users now face more options, more panels, and more assistants than before.
Even discussions about how AI analytics agents need guardrails, not more model size, reflect the same concern that adding intelligence does not automatically make software easier to use.
Advertisement
Open almost any tool today and the pattern looks familiar: office software with built-in copilots and sidebars, design tools filled with generators, templates, and prompts, productivity apps with chatbots inside every menu, and platforms that expect users to learn through guides similar to employee training.
When the interface becomes crowded, people stop experimenting and return to what they already know. More power sounds good in release notes, but in practice, it often means more decisions on every screen. That is why usage patterns often lag years behind the technology already available.
People don’t resist AI; they resist changing how they work
Most users are not against artificial intelligence. What they resist is changing the way they already know how to work.
Once a routine feels reliable, people repeat it without thinking, even when the software offers a faster method. Habit becomes the default, which helps explain why the gap is growing between AI availability and real capability.
Advertisement
While most employees are expected to use AI at work, only a minority feel properly trained to do so. Microsoft research shows that 66% of leaders say they wouldn’t hire someone without AI skills.
Many are learning on their own while job requirements move closer to the skill sets now associated with future new jobs developers rather than traditional roles.
Learning a new workflow sounds simple until it interrupts real work. Muscle memory takes over, deadlines get closer, and there is rarely enough guidance inside the tool itself to make the new method feel safe to try.
The gap between innovation and adoption is mostly human, not technical, which is why the next shift in AI will not come from better models alone.
Advertisement
The next wave of AI will focus on teaching, not just automating
The next phase of AI development is starting to move away from adding more features and toward helping users understand the ones already there.
Instead of expecting people to read guides or watch tutorials like it’s 2015, newer tools are beginning to guide actions directly within the interface, showing step-by-step suggestions as the task progresses.
Copilots that recommend the next command, walkthroughs that appear in the middle of a workflow, and interfaces that adapt to how the user works are becoming more common across productivity, design, and development software.
This shift is also why more teams are asking questions like how to choose a digital adoption platform, as learning is no longer something that happens before using software, but during it.
Advertisement
The tools that stand out will not be the ones with the longest feature lists, but the ones people can actually understand without stopping their work to figure them out.
A critical vulnerability affecting certain configurations of the Exim open-source mail transfer agent could be exploited by an unauthenticated remote attacker to execute arbitrary code.
Identified as CVE-2026-45185, the security issue impacts some Exim versions before 4.99.3 that use the default GNU Transport Layer Security (GnuTLS) library for secure communication. It is a user-after-free (UAF) flaw triggered during the TLS shutdown while handling BDAT chunked SMTP traffic.
Exim frees a TLS transfer buffer but later continues using stale callback references that can write data into the freed memory region, which can lead to unauthenticated remote code execution (RCE).
Exim is a widely deployed open-source mail transfer agent (MTA) used to send, receive, and route email on Linux and Unix servers. It is used on Linux servers, in shared hosting environments, enterprise mail systems, and on Debian- and Ubuntu-based distributions, where it has historically been the default mail server.
Advertisement
CVE-2026-45185 was discovered and reported by XBOW researcher Federico Kirschbaum. It impacts Exim versions 4.97 through 4.99.2 on builds compiled with GnuTLS that have STARTTLS and CHUNKING advertised. OpenSSL-based builds are not affected.
Attackers exploiting the vulnerability could execute commands on the server as well as access Exim data and emails, and potentially pivot further into the environment depending on server permissions and configuration.
XBOW reported the vulnerability to the Exim maintainers on May 1st and received an acknowledgment on May 5th. Impacted Linux distributions were notified three days later.
XBOW reports that creating the proof-of-concept (PoC) exploit was a seven-day challenge between the company’s autonomous AI-driven development system, XBOW Native, and a human researcher assisted by a large language model.
While XBOW Native successfully produced a working exploit for a simplified target Exim server that had no Address Space Layout Randomization (ASLR) and non-PIE (Position Independent Executables) binary.
In a second attempt, the LLM achieved an exploit on a machine with ASLR, but still a non-PIE binary.
Advertisement
“[…] instead of continuing to attack glibc’s allocator with off-the-shelf mechanisms, XBOW Native had taken on Exim’s own allocator,” XBOW researchers say.
Despite the surprising result below, it was the human researcher who won the race, with assistance from the LLM for tasks such as assembling files and testing exploitation avenues.
While the researcher acknowledged the impressive speed of the LLM, they realized the need to shape the work environment instead of letting the model create its own space.
Advertisement
“Honestly, I don’t think LLMs alone are quite ready to write exploits against real-world software yet. After this experience, I think it can solve something CTF-shaped, but I don’t see them reaching the level of real production targets just yet.”
Still, the researcher acknowledged the crucial role of AI tools in helping humans understand unfamiliar code and dig deeper into suspicious areas much faster than without them.
To mitigate the risk, users of Ubuntu and Debian-based Linux distributions should apply the available Exim updates (v4.99.3) through their package managers.
AI chained four zero-days into one exploit that bypassed both renderer and OS sandboxes. A wave of new exploits is coming.
At the Autonomous Validation Summit (May 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls hold, and closes the remediation loop.
The updated Android Auto brings a complete Material 3 Expressive design overhaul, including expressive typography, smooth animations, and vibrant wallpapers. It is the biggest update to the platform since the 2023 “Coolwalk” redesign, which introduced a dynamic interface, split-screen multitasking, a revamped dock, and enhanced safety features. Read Entire Article Source link
For decades, the IQ test has been one of the most familiar — and most contested — yardsticks for human intelligence. Now, a startup project called AI IQ is applying the same metaphor to artificial intelligence, assigning estimated intelligence quotients to more than 50 of the world’s most powerful language models and plotting them on a standard bell curve.
The result is a set of interactive visualizations at aiiq.org that have ricocheted across social media in the past week, drawing praise from enterprise technologists who say the charts make an impossibly complex market legible — and sharp criticism from researchers and commentators who warn the entire framework is misleading.
“This is super useful,” wrote Thibaut Mélen, a technology commentator, on X. “Much easier to understand model progress when it’s mapped like this instead of another giant leaderboard table.”
Brian Vellmure, a business strategist, offered a similar endorsement: “This is helpful. Anecdotally tracks with personal experience.”
Advertisement
But the backlash arrived just as quickly. “It’s nonsense. AI is far too jagged. The map is not the territory,” posted AI Deeply, an artificial intelligence commentary account, crystallizing a worry shared by many researchers: that reducing a language model’s sprawling, uneven capabilities to a single number creates a dangerous illusion of precision.
More than 50 AI language models, plotted on a standard IQ bell curve by the site AI IQ. The most capable models crowd the right tail of the distribution. (Credit: AI IQ)
Twelve benchmarks, four dimensions, and one controversial number: how AI IQ actually works
AI IQ was created by Ryan Shea, an engineer, entrepreneur, and angel investor best known as a co-founder of the blockchain platform Stacks. Shea also co-founded Voterbase and has invested in the early stages of several unicorns, including OpenSea, Lattice, Anchorage, and Mercury. He holds a Bachelor of Science in Mechanical Engineering from Princeton University.
The site’s methodology rests on a deceptively simple formula. AI IQ groups 12 benchmarks into four reasoning dimensions: abstract, mathematical, programmatic, and academic. The composite IQ is a straight average of those four dimension scores: IQ = ¼ (IQ_Abstract + IQ_Math + IQ_Prog + IQ_Acad).
Each raw benchmark score gets mapped to an implied IQ through what the site describes as “hand-calibrated difficulty curves.” Crucially, the methodology compresses ceilings for benchmarks considered easier or more susceptible to data contamination, preventing them from inflating scores above 100. Harder, less gameable benchmarks retain higher ceilings. The system also handles missing data conservatively: models need scores on at least two of the four dimensions to receive a derived IQ, and when benchmarks are absent, the pipeline deliberately pulls scores down rather than up. The site states that “every derived IQ averages all four dimensions, so missing coverage cannot make a model look better by omission.”
OpenAI leads the bell curve, but the gap between the top AI models has never been smaller
As of mid-May 2026, the AI IQ charts tell a story of rapid convergence at the top of the frontier — and widening diversity in the tiers below.
According to the Frontier IQ Over Time chart, GPT-5.5 from OpenAI currently sits at the peak of the bell curve, with an estimated IQ near 136 — the highest of any model tracked. It is closely followed by GPT-5.4 (approximately 131), Opus 4.7 from Anthropic (approximately 132), and Opus 4.6 (approximately 129). Google’s Gemini 3.1 Pro lands near 131, making the top cluster extraordinarily tight.
Advertisement
That compression is not unique to AI IQ’s framework. Visual Capitalist, drawing from a separate Mensa-based ranking by TrackingAI, recently observed the same dynamic, noting that “the biggest takeaway is how compressed the top of the leaderboard has become.” On that scale, Grok-4.20 Expert Mode and GPT 5.4 Pro tied at 145, with Gemini 3.1 Pro at 141.
Below the frontier cluster, the AI IQ charts show a crowded midfield. Models from Chinese labs — Kimi K2.6, GLM-5, DeepSeek-V3.2, Qwen3.6, MiniMax-M2.7 — bunch between roughly 112 and 118, making the cost-performance tier increasingly competitive for enterprise buyers who don’t need the absolute best model for every task. One X user, ovsky, noted that the data “confirms experience with sonnet 4.6 being an absolute workhorse as opposed to opus 4.5” — pointing to the way the charts can validate practitioner intuitions that headline rankings often miss.
The trajectory of frontier AI models from October 2023 to mid-2026, as tracked by AI IQ. Provider-colored step-lines connect each lab’s flagship releases, showing roughly 60 points of estimated IQ improvement in 30 months. (Credit: AI IQ)
Why emotional intelligence scores are becoming the new battleground in AI model rankings
What distinguishes AI IQ from most other benchmarking efforts is its inclusion of an “EQ” — emotional intelligence — score. The site maps each model’s EQ-Bench 3 Elo score and Arena Elo score to an estimated EQ using calibrated piecewise-linear scales, then takes a 50/50 weighted composite of the two.
Advertisement
The EQ scores produce a meaningfully different ranking than IQ alone. On the IQ vs. EQ scatter plot, Anthropic’s Opus 4.7 leads on EQ with a score near 132, pushing it into the upper-right quadrant — the most desirable position, signaling both high cognitive and high emotional intelligence. OpenAI’s GPT-5.5 and GPT-5.4 cluster in the high-IQ zone but lag slightly on EQ. Google’s Gemini 3.1 Pro sits in a strong middle position on both axes.
One notable methodological choice has drawn attention: EQ-Bench 3 is judged by Claude, an Anthropic model, which the site acknowledges “creates potential scoring bias in favor of Anthropic models.” To correct for this, AI IQ subtracts a 200-point Elo penalty from the EQ-Bench component for all Anthropic models before mapping to implied EQ. The Arena component is unaffected since it uses human judges. That self-correction is unusual in the benchmarking world, and it suggests Shea is aware of the methodological minefield he has entered. Still, the EQ dimension captures something IQ alone cannot: the growing importance of conversational quality, collaboration, and trust in models deployed for user-facing work.
Plotting IQ against EQ reveals that the smartest models aren’t always the most emotionally intelligent. Anthropic’s Opus 4.7 dominates the upper-right quadrant. (Credit: AI IQ)
The AI cost-performance chart that enterprise buyers actually need to see
Perhaps the most practically useful chart on the site is not the bell curve but the IQ vs. Effective Cost scatter plot. It maps each model’s estimated IQ against an “effective cost” metric — defined as the token cost for a task using 2 million input tokens and 1 million output tokens, multiplied by a usage efficiency factor.
Advertisement
The chart reveals a familiar pattern in enterprise technology: the best models are not always the best value. GPT-5.5 and Opus 4.7 sit in the upper-left corner — high IQ, high cost, with effective per-task costs north of $30 and $50 respectively. Meanwhile, models like GPT-5.4-mini, DeepSeek-V3.2, and MiniMax-M2.7 occupy a sweet spot in the middle: respectable IQ scores between 112 and 120, at effective costs ranging from roughly $1 to $5 per task. At the cheapest extreme, GPT-oss-20b (an open-source OpenAI model) appears near $0.20 effective cost with an IQ around 107 — potentially the most economical option for bulk classification or extraction workloads.
The site also offers a 3D visualization mapping IQ, EQ, and effective cost simultaneously. A dashed line running through the cube points toward the ideal: higher IQ, higher EQ, and lower cost. Models near the “green end” of that axis are stronger all-around deals; those near the “red end” sacrifice capability, cost efficiency, or both. For CIOs staring at API invoices, the implication is clear: the intelligence gap between a $50 model and a $3 model has narrowed enough that routing — using expensive models for hard problems and cheap ones for everything else — is no longer optional. It is the dominant architecture for serious AI deployments.
Critics say AI’s “jagged” capabilities make a single IQ score dangerously misleading
The loudest objection to AI IQ is philosophical, and it cuts deep. Critics argue that collapsing a model’s uneven capabilities into a single score obscures more than it reveals.
“IQ as a proxy is fading — we’re seeing reasoning density spikes that don’t map to g-factor,” posted Zaya, a technology commentator, on X. “GPT-5.5 already hit saturation on MMLU-Pro, but still fails ClockBench 50% of the time.”
Advertisement
That observation touches on what AI researchers call the “jaggedness” problem: large language models often exhibit wildly uneven capabilities, excelling at graduate-level physics while failing at tasks a child could do. A composite score can paper over those gaps.
Pressureangle, another X user, posted a more granular critique, calling out “complete lack of transparency” and arguing the site never fully discloses how its calibration curves were created or validated. In fairness, AI IQ does list its 12 benchmarks and shows the shape of each calibration curve in its methodology modal. But the raw data and precise mathematical transformations are not published as open datasets — a gap that matters to researchers accustomed to fully reproducible methods.
Others questioned the premise itself. “As useless as human IQ testing,” wrote haashim on X. Shubham Sharma, an AI and technology writer, offered a constructive alternative: “Why not having the Models take an official (MENSA-Grade) test? Wouldn’t this be the most accurate and most ‘human-comparable’ way to benchmark intelligence?” That approach already exists through TrackingAI, which administers the Mensa Norway IQ test to language models. But Mensa-style tests measure only abstract pattern recognition, while AI IQ attempts a broader composite across coding, mathematics, and academic reasoning. As Visual Capitalist noted, “an IQ-style benchmark captures only one slice of capability.” Each approach has tradeoffs — and neither has won the argument yet.
The real race isn’t for the highest score — it’s for the smartest model stack
For all the debate about methodology, the most important signal in AI IQ’s data may not be any single model’s score. It is the shape of the market the charts reveal.
Advertisement
There are now more than 50 frontier-class models available through APIs, from at least 14 major providers spanning the United States, China, and Europe. Each provider publishes its own benchmarks, often cherry-picked to showcase strengths. The result is a Tower of Babel where no two companies measure the same thing in the same way. Academic research has highlighted that “most benchmarks introduce bias by focusing on a particular type of domain,” and the Frontier IQ Over Time chart on AI IQ shows just how fast the targets are moving: in October 2023, GPT-4-turbo sat near an estimated IQ of 75. By early 2026, the top models were brushing 135 — roughly 60 points of improvement in 30 months.
That pace raises a fundamental question about whether any scoring system can keep up. The site compresses ceilings for saturated benchmarks, but as models continue to max out even the hardest tests — ARC-AGI-2, FrontierMath Tier 4, Humanity’s Last Exam — the framework will face the same ceiling effects that have plagued every AI evaluation before it. Connor Forsyth pointed to this dynamic on X: “ARC AGI 3 disagrees,” he wrote, referencing a next-generation benchmark that may already be undermining current scores.
AI IQ is not perfect. Its methodology is partially opaque. Its IQ metaphor can mislead. And its creator acknowledges known biases while likely missing others. But the alternative — wading through dozens of provider-specific benchmark tables, each using different test suites and scoring conventions — is worse. The site offers enterprise buyers something genuinely scarce: a single framework for comparing models across providers, dimensions, and price points, updated regularly, with enough nuance to show that the right answer to “which model is best?” is almost always “it depends on the task.”
Maybe. But if the AI IQ data shows anything clearly, it is that orchestration — knowing which model to deploy, when, and at what price — has become its own form of intelligence. And for that, there is no benchmark yet.
A man accused of stealing hard drives containing unreleased Beyonce music, tour plans, and other materials from a rental car in Atlanta has pleaded guilty and accepted a five-year sentence, including two years in custody. Slashdot Bruce66423 shares a report from The Guardian: Kelvin Evans was by the Atlanta police department in September in connection to a July 2025 car robbery where two suitcases containing Beyonce music and tour plans were stolen from a rental car. […] According to a July police report, Beyonce choreographer Christopher Grant and dancer Diandre Blue called 911 to report a theft from their rental vehicle, a 2024 Jeep Wagoneer, before Beyonce’s Cowboy Carter tour dates in Atlanta. An October indictment stated that Evans entered the car on July 8 “with the intent to commit theft.”
The stolen hard drives contained “watermarked music, some unreleased music, footage plans for the show and past and future set list,” according to a police report. Clothing, designer sunglasses, laptops and AirPods headphones were also stolen, Grant and Blue said. Local law enforcement searched for the location of one of the stolen laptops and the AirPods to try and locate the property. One police officer wrote in the report: “I conducted a suspicious stop in the area, due to the information that was relayed to me. There were several cars in the area also that the AirPods were pinging to in that area also. After further investigation, a silver [redacted], which had traveled into zone 5 was moving at the same time as the tracking on the AirPods.”
Evans was arrested several weeks after Grant and Blue filed a report, and was publicly named as the suspect in September. He was released on a $20,000 bond a month later. At the time of his arrest, Atlanta police said that the stolen property had not been recovered. It is unclear whether it has since been found.
Bruce66423 commented: “Just for stealing a couple of suitcases from a car. Funny how the elite punish those who inconvenience them. Can you imagine an ordinary victim see their offender get that sort of sentence?”
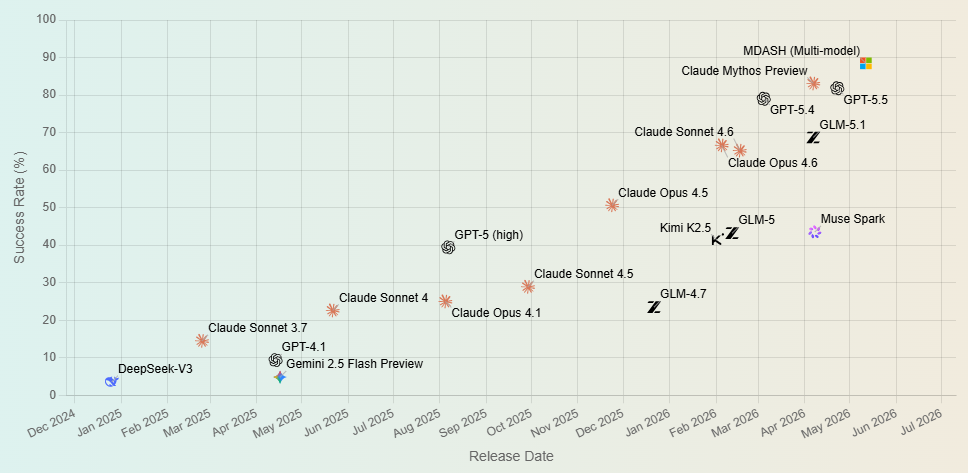
CyberGym benchmark scores over time, showing the rapid improvement in AI vulnerability discovery capabilities. Microsoft’s multi-model MDASH system (top right) tops the leaderboard at 88.4%. (CyberGym / UC Berkeley)
Mythos has been MDASH’d.
A new AI-powered system from Microsoft surpassed a headline-grabbing rival from Anthropic on a leading cybersecurity benchmark, using more than 100 specialized AI agents working together across multiple AI models to find real-world software vulnerabilities.
Microsoft’s system, codenamed MDASH, was introduced this week alongside the disclosure of 16 new vulnerabilities it found in different versions of Windows, including four “critical” remote code execution flaws fixed in this month’s Patch Tuesday release.
The company, which has faced persistent criticism over security lapses, is betting that multiple models can discover vulnerabilities at a pace that individual models can’t match.
MDASH, derived from the term “multi-model agentic scanning harness,” works by running specialized AI agents through a staged pipeline. Different agents scan code for potential vulnerabilities, then a separate set of agents debate whether each finding is real and exploitable, and a final stage constructs proof-of-concept attacks to confirm the bugs exist.
Advertisement
By comparison, Anthropic’s Mythos, which raised concerns over its ability to find and exploit software vulnerabilities when it was previewed earlier this year, is a single AI model running inside an agent framework. Anthropic restricted its release to a handful of companies through a consortium called Project Glasswing, which includes Microsoft.
OpenAI’s GPT-5.5 and others on the leaderboard are also single-model systems.
MDASH scored 88.45% on the CyberGym benchmark, a test developed by UC Berkeley researchers that measures how well AI systems can reproduce real-world vulnerabilities across 1,507 tasks drawn from 188 open-source software projects.
Mythos Preview was second at 83.1%, followed by GPT-5.5 at 81.8%.
Advertisement
The benchmark gives each system a description of a known vulnerability and an unpatched codebase, and measures whether it can produce a working attack that triggers the bug.
The scores on the CyberGym leaderboard are self-reported by the companies, including Anthropic’s Mythos result. The benchmark code is public, but no independent party has verified any of the scores. Also, benchmark results don’t necessarily reflect real-world performance.
The results also highlight growing concerns about AI’s use as an offensive hacking tool. The same capabilities that allow AI to find vulnerabilities in friendly hands can be used to discover them for exploitation by attackers. Microsoft said MDASH is being used internally by its security engineering teams and will be entering a limited private preview with customers.
Microsoft is telling customers to expect bigger Patch Tuesdays going forward as AI accelerates the discovery of vulnerabilities.
The Iran-linked hacking group MuddyWater (a.k.a. Seedworm, Static Kitten) launched a broad cyber-espionage campaign targeting at least nine high-profile organizations across multiple sectors and countries.
Among the victims are a major South Korean electronics manufacturer, government agencies, an international airport in the Middle East, industrial manufacturers in Asia, and educational institutions.
Researchers at Symantec say that the threat actor “spent a week inside the network of a major South Korean electronics manufacturer in February 2026.”
Symantec’s Threat Hunter Team believes the attacker was intelligence-driven, focusing on industrial and intellectual property theft, government espionage, and access to downstream customers or corporate networks.
Advertisement
Fortemedia and SentinelOne abuse
Seedworm’s campaign relied heavily on DLL sideloading, a common technique in which legitimate, signed software loads malicious DLLs.
Two of the binaries leveraged in the attack are ‘fmapp.exe,’ a legitimate Foremedia audio utility, and ‘sentinelmemoryscanner.exe,’ a legitimate SentinelOne component.
The malicious DLLs (fmapp.dll and sentinelagentcore.dll) contained ChromElevator, a commodity post-exploitation tool that steals data stored in Chrome-based browsers.
Symantec also found that PowerShell, used in previous Seedworm attacks, was still heavily used in the recent incidents, although the payloads were controlled through Node.js loaders rather than directly.
Advertisement
PowerShell was used to capture screenshots, conduct reconnaissance, fetch additional payloads, establish persistence, steal credentials, and create SOCKS5 tunnels.
Attack on a Korean firm
According to Symantec’s observations, the attack on the South Korean electronics manufacturer lasted between February 20 and 27. The researchers did not disclose the name of the targeted organization.
In the first stage, Seedworm performed host and domain reconnaissance, followed by antivirus enumeration via WMI, screenshot capture, and the download of additional malware.
Credential theft occurred via fake Windows prompts, registry hive theft (SAM/SECURITY/SYSTEM), and Kerberos ticket abuse tools.
Advertisement
Persistence was established through registry modifications, beaconing occurred at 90-second intervals, and sideloaded binaries were repeatedly relaunched to maintain access.
“The cadence is again consistent with implant-driven activity rather than continuous operator presence,” the researchers said.
The attackers leveraged sendit.sh, a public file-sharing service for data exfiltration, likely to obscure the malicious activity and make it appear as normal traffic.
Overall, Symantec has found the latest Seedworm campaign notable for the threat actors’ geographic expansion, operational maturity, and the abuse of legitimate tools and services, which mark a shift toward quieter attacks.
Advertisement
AI chained four zero-days into one exploit that bypassed both renderer and OS sandboxes. A wave of new exploits is coming.
At the Autonomous Validation Summit (May 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls hold, and closes the remediation loop.
Artificial intelligence has posed a multi-layered problem for Apple in recent years. We’re expecting to hear some big news at WWDC this year about how AI will be integrated into the company’s gadgets, but there are still other wrinkles still to be ironed out in its broader approach to the use of this influential technology. According to The Information, one of those challenges is the recent interest and development of agentic AI.
To date, Apple has not permitted vibe coding tools on the App Store because they would violate its policies. They could also potentially be used to create original apps for people who would have otherwise gotten software from the App Store, which could pose a threat to Apple’s revenue as well as creating a loophole for spreading malware or taking other malicious actions. But applying that same block more broadly to any agentic AI services, which can take active control over a device and its programs, could keep Apple out of the loop as those tools are generating a lot of interest among both developers and casual users. Apple is reportedly trying to maintain its control over the App Store, while capitalizing on the current buzz around AI agents.
“While details couldn’t be learned, its staffers are designing a system to adhere to its standards of privacy and security and prevent the more freewheeling behavior some users of agentic systems such as OpenClaw have experienced, where agents can go haywire and delete all of a user’s emails, according to the people briefed on the matter,” the article states.
Advertisement
It sounds like a high wire act for a company that has been struggling to keep pace with AI’s breakneck development. Add this to the long laundry list of information we’ll be curious to see addressed at next month’s keynote.
Netflix has more than 250 million monthly active users on its ad-supported tier. The figure, which was revealed during the company’s Upfront presentation, marks a huge spike for this subscription option. In 2024 the plan with ads had 70 million users and in 2025 it reached 94 million.
Starting next year, Netflix will also launch the ad-supported plan in 15 more countries: Austria, Belgium, Colombia, Denmark, Indonesia, Ireland, the Netherlands, New Zealand, Norway, Peru, Philippines, Poland, Sweden, Switzerland and Thailand.
The Basic with Ads tier of access started rolling out in 2022. It appears to be an increasingly popular option as Netflix, like most streaming services, has continued to get ever-more expensive. The company just upped all monthly subscription costs by a dollar earlier this year.
Advertisement
And of course, because this is 2026, the Upfront included plenty of talk about AI. Netflix started using the tech in its ads last year, and one of the new potential applications the company is testing will serve “personalized ad loads and frequency caps that dynamically adjust the ads our members see, based on their viewing behaviors.” Netflix is currently facing a lawsuit from Texas on claims that it illegally sells user data to ad tech companies, although the streaming service said the suit was “based on inaccurate and distorted information.”
Ukrainian developers claim the laser weapon costs far less than Western systems
The Trident laser reportedly damages aircraft optics, electronics, and structural components effectively
Ukrainian company Celebra Tech is putting the final touches on a Trident laser weapon which it claims can destroy drones, helicopters, and even missiles at significant distances.
The Trident burns through enemy optics and structural components from up to three miles away.
Western defense giants have spent enormous sums on similar technology, such as the £120 million DragonFire laser unveiled by Britain, yet Ukrainian developers claim their Trident system will cost a tiny fraction of that amount.
Latest Videos From
Advertisement
What the Trident Can Actually Do
Celebra Tech says its laser system can shoot down reconnaissance drones from up to 1.5 kilometers away.
FPV drones, which have become a major threat on the battlefield with an effective range of 800 to 900 meters, were destroyed by the system, which also damages optics, electronics, and wing bodies of larger aircraft.
Developers say the Trident can strike helicopters and airplanes at a distance of 5 kilometers.
At 10 kilometers away, the laser still retains enough power to blind enemy surveillance equipment.
Advertisement
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
The system has recently received new targeting features, including radar integration and automatic target tracking, and a re-guidance system now allows operators to correct the beam during active engagement.
Tested for combat
The company revealed that a prototype called the Trident-120 underwent combat testing in 2021 and 2022, when it resembled a light rifle in its physical form and handling.
Advertisement
The earlier prototype successfully struck the optoelectronic equipment of Ka-52 attack helicopters, and also damaged Orlan reconnaissance drones and Murom ground observation stations during those field tests.
“Today, we can shoot down planes at an altitude of over 2 km with this laser,” said Vadym Sukharevskiy, former commander of the Unmanned Systems Forces.
The company adds the Trident laser system is also suitable for demining contaminated areas, although this secondary function has not been demonstrated publicly or verified by external observers.
Advertisement
Celebra Tech has developed other products, including the Laurus-13F fiber-optic FPV drone, and says it is also working on bombers, electronic warfare equipment, and specialized software packages.
The company employs only about fifteen people to work on this laser development project, which seems remarkably small for such a technically ambitious weapon system.
For most of the stated destroy ranges, including the 5-kilometer anti-aircraft claim, no independent verification or third-party confirmation has ever been published.
The demining function mentioned by the manufacturer appears particularly far from proven operational capability based on available evidence.
Advertisement
A low-cost laser that solves every aerial threat remains an appealing idea, but without proper verification, it remains a theoretical project.
KitchenAid has released a smart thermometer, the first from the popular cooking brand. The single probe model will retail for $100 while the dual option will cost $200. Although a maximum temperature isn’t listed in the specs, the company says that the Smart Thermometer can be used for a range of processes, including grilling, roasting, smoking, air frying and stovetop cooking.
The probes are waterproof and dishwasher safe, and when fully charged, the battery life can top out at 24 hours, so you can keep tabs even on long projects like smoking a hefty brisket. The quick-charge option can boost the probe to an extra five hours of cooking from five minutes of charging.
The KitchenAid Smart Thermometer connects to the company’s app, which offers a graph view for visualizing the cooking process, a collection of up to 20 saved cooks, and timers or alerts. Notifications can let the cook know when it’s time to take different steps in a recipe based on temperature. The probes use Bluetooth, and the Range Extender Mode can stretch the device’s 285-foot range with a second internet-connected device if needed.
Advertisement
KitchenAid’s offering joins several other products on the market, some from grilling-focused specialists such as Meater and ThermoWorks, and others from similarly major kitchen brands like Whirlpool, which just so happens to own KitchenAid.






























































You must be logged in to post a comment Login