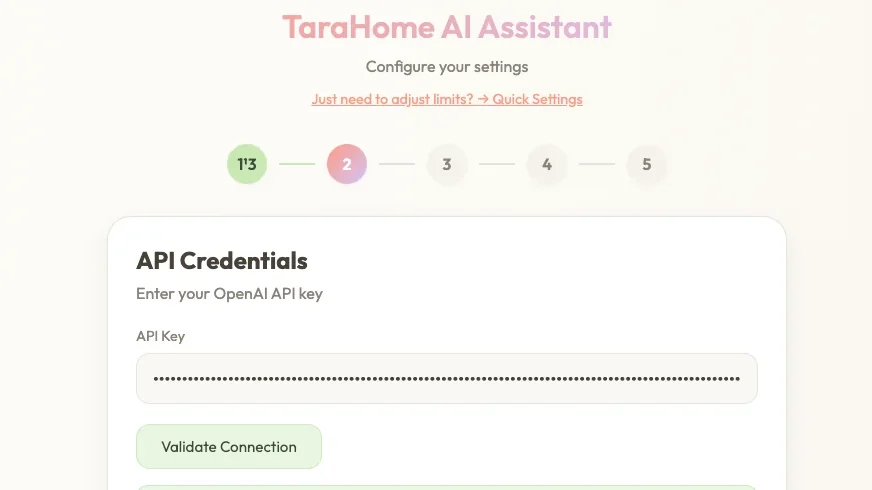
Computers are very good at doing exactly what they’re told. They’re still not very good at coming up with helpful suggestions of their own. They’re very much more about following instructions than using intuition; we still don’t have a digital version of Jeeves to aid our bumbling Wooster selves. [Sherrin] has developed something a little bit intelligent, though, in the form of a habit detector for use with Home Assistant.
In [Sherrin]’s smart home setup, there are lots of things that they wanted to fully automate, but they never got around to implementing proper automations in Home Assistant. Their wife also wanted to automate things without having to get into writing YAML directly. Thus, they implemented a sidecar which watches the actions taken in Home Assistant.
The resulting tool is named TaraHome. When it detects repetitive actions that happen with a certain regularity, it pops up and suggests automating the task. For example, if it detects lights always being dimmed when media is playing, or doors always being locked at night, it will ask if that task should be set to happen automatically and can whip up YAML to suit. The system is hosted on the local Home Assistant instance. It can be paired with an LLM to handle more complicated automations or specific requests, though this does require inviting cloud services into the equation.
MIT Technology Review discovered that startup R3 Bio has pitched an ethically and scientifically explosive long-term vision beyond its public work on non-sentient monkey “organ sacks”: creating human “brainless clones” or replacement bodies for organs as part of an extreme life-extension agenda. From the report: Imagine it like this: a baby version of yourself with only enough of a brain structure to be alive in case you ever need a new kidney or liver. Or, alternatively, he has speculated, you might one day get your brain placed into a younger clone. That could be a way to gain a second lifespan through a still hypothetical procedure known as a body transplant.
The fuller context of R3’s proposals, as well as activities of another stealth startup with related goals, have not previously been reported. They’ve been kept secret by a circle of extreme life-extension proponents who fear that their plans for immortality could be derailed by clickbait headlines and public backlash. And that’s because the idea can sound like something straight from a creepy science fiction film. One person who heard R3’s clone presentation, and spoke on the condition of anonymity, was left reeling by its implications and shaken by [R3 founder John Schloendorn’s] enthusiastic delivery. The briefing, this person said, was like a “close encounter of the third kind” with “Dr. Strangelove.” […]
MIT Technology Review found no evidence that R3 has cloned anyone, or even any animal bigger than a rodent. What we did find were documents, additional meeting agendas, and other sources outlining a technical road map for what R3 called “body replacement cloning” in a 2023 letter to supporters. That road map involved improvements to the cloning process and genetic wiring diagrams for how to create animals without complete brains. A main purpose of the fundraising, investors say, was to support efforts to try these techniques in monkeys from a base in the Caribbean. That offered a path to a nearer-term business plan for more ethical medical experiments and toxicology testing — if the company could develop what it now calls monkey “organ sacks.” However, this work would clearly inform any possible human version.
As if endless scrolling wasn’t bad enough already, TikTok has now quietly added a hidden emoji game inside DMs. The mini-game is live right now and works in both one-on-one messages and group chats. It means the app now has one more little trick to keep users hanging around even when they are technically done watching videos.
And honestly, it is exactly the kind of feature you would expect from a platform that has mastered years of mastering the art of making “just five more minutes” turn into an hour.
Nadeem Sarwar / Digital Trends
What’s the game, and why you should be wary
The game kicks off when you send a single emoji in a chat. If you tap on this emoji, your chosen emoji becomes part of the game itself, floating across the screen to give you a speed boost as you try to bounce upward across a stack of alligators.
The goal is to climb as high as possible while avoiding skeleton alligators, with some of these disappearing after one landing. So it’s all about quick reactions and enough chaos to make you give it another try. TikTok also shows both your score and your opponent’s high score in the top-right corner. So this basically turns it into a lightweight little competition instead of just a throwaway gimmick.
TikTokUnsplash
It is very on-brand
TikTok told TechCrunch that it launched the Easter egg to make messaging more fun and add a playful competitive element to DMs. This isn’t the first time we’re seeing something like this. Instagram added its own hidden emoji DM game two years ago, and Meta has also been experimenting with games inside Threads chats.
On paper, this is just a harmless little DM mini-game. But in practice, it is one more engagement hook dropped into a platform that was already very good at monopolizing attention.
Attackers stole a long-lived npm access token belonging to the lead maintainer of axios, the most popular HTTP client library in JavaScript, and used it to publish two poisoned versions that install a cross-platform remote access trojan. The malicious releases target macOS, Windows, and Linux. They were live on the npm registry for roughly three hours before removal.
Axios gets more than 100 million downloads per week. Wiz reports it sits in approximately 80% of cloud and code environments, touching everything from React front-ends to CI/CD pipelines to serverless functions. Huntress detected the first infections 89 seconds after the malicious package went live and confirmed at least 135 compromised systems among its customers during the exposure window.
This is the third major npm supply chain compromise in seven months. Every one exploited maintainer credentials. This time, the target had adopted every defense the security community recommended.
One credential, two branches, 39 minutes
The attacker took over the npm account of @jasonsaayman, a lead axios maintainer, changed the account email to an anonymous ProtonMail address, and published the poisoned packages through npm’s command-line interface. That bypassed the project’s GitHub Actions CI/CD pipeline entirely.
Advertisement
The attacker never touched the Axios source code. Instead, both release branches received a single new dependency: plain-crypto-js@4.2.1. No part of the codebase imports it. The package exists solely to run a postinstall script that drops a cross-platform RAT onto the developer’s machine.
The staging was precise. Eighteen hours before the axios releases, the attacker published a clean version of plain-crypto-js under a separate npm account to build publishing history and dodge new-package scanner alerts. Then came the weaponized 4.2.1. Both release branches hit within 39 minutes. Three platform-specific payloads were pre-built. The malware erases itself after execution and swaps in a clean package.json to frustrate forensic inspection.
StepSecurity, which identified the compromise alongside Socket, called it among the most operationally sophisticated supply chain attacks ever documented against a top-10 npm package.
The defense that existed on paper
Axios did the right things. Legitimate 1.x releases shipped through GitHub Actions using npm‘s OIDC Trusted Publisher mechanism, which cryptographically ties every publish to a verified CI/CD workflow. The project carried SLSA provenance attestations. By every modern measure, the security stack looked solid.
Advertisement
None of it mattered. Huntress dug into the publish workflow and found the gap. The project still passed NPM_TOKEN as an environment variable right alongside the OIDC credentials. When both are present, npm defaults to the token. The long-lived classic token was the real authentication method for every publish, regardless of how OIDC was configured. The attacker never had to defeat OIDC. They walked around it. A legacy token sat there as a parallel auth path, and npm‘s own hierarchy silently preferred it.
“From my experience at AWS, it’s very common for old auth mechanisms to linger,” said Merritt Baer, CSO at Enkrypt AI and former Deputy CISO at AWS, in an exclusive interview with VentureBeat. “Modern controls get deployed, but if legacy tokens or keys aren’t retired, the system quietly favors them. Just like we saw with SolarWinds, where legacy scripts bypassed newer monitoring.”
The maintainer posted on GitHub after discovering the compromise: “I’m trying to get support to understand how this even happened. I have 2FA / MFA on practically everything I interact with.”
Endor Labs documented the forensic difference. Legitimate axios@1.14.0 showed OIDC provenance, a trusted publisher record, and a gitHead linking to a specific commit. Malicious axios@1.14.1 had none. Any tool checking provenance would have flagged the gap instantly. But provenance verification is opt-in. No registry gate rejected the package.
Advertisement
Three attacks, seven months, same root cause
Three npm supply chain compromises in seven months. Every one started with a stolen maintainer credential.
Then in January 2026, Koi Security’s PackageGate research dropped six zero-day vulnerabilities across npm, pnpm, vlt, and Bun that punched through the very defenses the ecosystem adopted after Shai-Hulud. Lockfile integrity and script-blocking both failed under specific conditions. Three of the four package managers patched within weeks. npm closed the report.
Now axios. A stolen long-lived token published a RAT through both release branches despite OIDC, SLSA, and every post-Shai-Hulud hardening measure in place.
Advertisement
npm shipped real reforms after Shai-Hulud. Creation of new classic tokens got deprecated, though pre-existing ones survived until a hard revocation deadline. FIDO 2FA became mandatory, granular access tokens were capped at seven days for publishing, and trusted publishing via OIDC gave projects a cryptographic alternative to stored credentials. Taken together, those changes hardened everything downstream of the maintainer account. What they didn’t change was the account itself. The credential remained the single point of failure.
“Credential compromise is the recurring theme across npm breaches,” Baer said. “This isn’t just a weak password problem. It’s structural. Without ephemeral credentials, enforced MFA, or isolated build and signing environments, maintainer access remains the weak link.”
Not enforced. npm runs postinstall by default. pnpm blocks by default; npm does not
postinstall remains primary malware vector in every major npm attack since 2024
Lock dependency versions
Lockfile enforcement via npmci
Advertisement
Effective only if lockfile committed before compromise. Caret ranges auto-resolved
Caret ranges are npm default. Most projects auto-resolve to latest minor
What to do now at your enterprise
SOC leaders whose organizations run Node.js should treat this as an active incident until they confirm clean systems. The three-hour exposure window fell during peak development hours across Asia-Pacific time zones, and any CI/CD pipeline that ran npm install overnight could have pulled the compromised version automatically.
“The first priority is impact assessment: which builds and downstream consumers ingested the compromised package?” Baer said. “Then containment, patching, and finally, transparent reporting to leadership. What happened, what’s exposed, and what controls will prevent a repeat. Lessons from log4j and event-stream show speed and clarity matter as much as the fix itself.”
Advertisement
Check exposure. Search lockfiles and CI logs for axios@1.14.1, axios@0.30.4, or plain-crypto-js. Pin to axios@1.14.0 or axios@0.30.3.
Assume compromise if hit. Rebuild affected machines from a known-good state. Rotate every accessible credential: npm tokens, AWS keys, SSH keys, cloud credentials, CI/CD secrets, .env values.
Check for RAT artifacts. /Library/Caches/com.apple.act.mond on macOS. %PROGRAMDATA%\wt.exe on Windows. /tmp/ld.py on Linux. If found, preform a full rebuild.
Harden going forward. Enforce npm ci --ignore-scripts in CI/CD. Require lockfile-only installs. Reject packages missing provenance from projects that previously had it. Audit whether legacy tokens coexist with OIDC in your own publishing workflows.
The credential gap nobody closed
Three attacks in seven months. Each different in execution, identical in root cause. npm’s security model still treats individual maintainer accounts as the ultimate trust anchor. Those accounts remain vulnerable to credential hijacking, no matter how many layers get added downstream.
“AI spots risky packages, audits legacy auth, and speeds SOC response,” Baer said. “But humans still control maintainer credentials. We mitigate risk. We don’t eliminate it.”
Mandatory provenance attestation, where manual CLI publishing is disabled entirely, would have caught this attack before it reached the registry. So would mandatory multi-party signing, where no single maintainer can push a release alone. Neither is enforced today. npm has signaled that disabling tokens by default when trusted publishing is enabled is on the roadmap. Until it ships, every project running OIDC alongside a legacy token has the same blind spot axios had.
The axios maintainer did what the community asked. A legacy token nobody realized was still active and undermined all of it.
‘By supporting the emergence of Bull, we are choosing strategic independence,’ said France’s minister delegate for artificial intelligence and digital affairs.
France has completed its acquisition of 100pc of the capital of supercomputer maker Bull from Atos Group, in a deal that marks a “major step forward for French and European technological sovereignty”.
The acquisition, the completion of which was announced yesterday (31 March), is expected to boost France and Europe’s tech sovereignty particularly in the areas of high‑performance computing, AI and quantum technologies, according to the French state and Bull. The French state is now the sole shareholder of Bull.
“The revival of Bull as an independent company supported by the French state marks a decisive step in our history,” said Emmanuel Le Roux, CEO of Bull. “With a long‑term strategic shareholder, we are strengthening our position as a trusted industrial partner across the entire value chain of high‑performance computing, quantum computing and artificial intelligence.”
Advertisement
The deal to acquire Bull from Atos Group was first agreed in July of last year, when France agreed to pay an enterprise value of up to €404m for the company.
Bull, which is headquartered in Bezons, France, designs and manufactures supercomputers and high‑performance servers, as well as enterprise servers, software solutions, AI use cases and innovations in quantum computing.
“The supercomputers produced there meet the most demanding needs of national defence, industry and fundamental research, and are also essential for training and deploying artificial intelligence models,” read yesterday’s announcement. “They are recognised for their performance and energy efficiency – two decisive criteria for training large AI models.”
The computing company has been in operation for nearly a century, having been founded in 1931. The company was acquired by Atos Group in 2014, when it became the organisation’s advanced computing business.
Advertisement
Europe’s sovereignty push
The completion of France’s purchase of Bull comes amid a wider push for tech sovereignty in Europe in recent times – particularly in the wake of recent transatlantic tensions with the current US administration.
France, along with Germany, have been prominent figureheads in the push for European digital sovereignty, with both countries taking centre stage at last November’s Summit on European Digital Sovereignty to propose a number of initiatives – including the launch of a joint taskforce on European digital sovereignty led by the two nations.
Sovereignty efforts have seen milestones achieved in Europe’s supercomputing space in particular.
Jupiter joined existing supercomputers in the EuroHPC network – namely, MareNostrum in Spain, Leonardo in Italy, Lumi in Finland, Discoverer in Bulgaria, MeluXina in Luxembourg, Vega in Slovenia, Karolina in Czechia and Deucalion in Portugal – together conducting billions of calculations per second.
A month later, the European High Performance Computing Joint Undertaking (EuroHPC JU) signed a procurement contract with Eviden for the delivery of Alice Recoque, a new European exascale supercomputer (named after the late pioneering French computer scientist) to be located in France.
“The state’s entry into Bull’s share capital marks a decisive step for our digital sovereignty,” said Anne Le Hénanff, France’s minister delegate for artificial intelligence and digital affairs. “At a time when artificial intelligence and quantum technologies are profoundly reshaping technological balances, France is equipping itself with a leading industrial player in high‑performance computing.
“By supporting the emergence of Bull, we are choosing strategic independence. It is a strong signal: that of a country that invests, that protects its expertise, and that is determined to remain sovereign in the technologies that will shape the world of tomorrow.”
Advertisement
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
As a kid, I loved the 1980s aquatic adventure show Danger Bay. True to the TV show’s name, danger was always lurking at the Vancouver Aquarium, where the show was set. In one memorable episode, young Jonah and a friend get trapped in a sabotaged mini-submarine, and Jonah’s dad, a marine-mammal veterinarian, comes to the rescue in a bubble-shaped underwater vehicle. Good stuff! Only recently—as in when I started working on this column—did I learn that the rescue vehicle was not a stage prop but rather a real-world research submersible named Deep Rover.
What Was Deep Rover and What Did It Do?
Built in 1984 and launched the following year, Deep Rover was a departure from standard underwater vehicles, which typically required divers to lie in a prone position and look through tiny portholes while tethered to a support ship.
Deep Rover was designed to satisfy human curiosity about the underwater world. As the rover moved freely through the water down to depths of 1,000 meters, the operator sat up in relative comfort in the cab, inside a clear 13-centimeter-thick acrylic bubble with panoramic views—an inverted fishbowl, with the human immersed in breathable air while the sea creatures looked in. Used for scientific research and deepwater exploration, it set a number of dive records along the way.
Submarine designer Graham Hawkes [left] and marine biologist Sylvia Earle [right] came up with the idea for Deep Rover.Alain Le Garsmeur/Alamy
The team behind Deep Rover included U.S. marine biologist Sylvia Earle and British marine engineer and submarine designer Graham Hawkes. Earle and Hawkes’s collaboration had begun in May 1980, when Earle complained to Hawkes about the “stupid” arms on Jim, an atmospheric diving suit; she didn’t realize she was complaining to one of Jim’s designers. Hawkes explained the difficulty of designing flexible joints that could withstand dueling pressures of 101 kilopascals on the inside—that is, the normal atmospheric pressure at sea level—and up to about 4,100 kPa on the outside. But he listened carefully to Earle’s wish list for a useful manipulator. Several months later, he came back with a design for a superbly dexterous arm that could hold a pencil and write normal-size letters.
Advertisement
Earle and Hawkes next turned to designing a one-person bubble sub, which they considered so practical that it would be an easy sell. But after failing to attract funding, they decided to build it themselves. In the summer of 1981, they pooled their resources and cofounded Deep Ocean Technology, setting up shop in Earle’s garage in Oakland, Calif.
Phil Nuytten, a Canadian designer of submersibles and dive systems, engineered Deep Rover.Stuart Westmorland/RGB Ventures/Alamy
They still found that customers weren’t interested in their crewed submersible, though, so they turned to unmanned systems. Their first contract was for a remotely operated vehicle (ROV) for use in oil-rig inspection, maintenance, and repair. Other customers followed, and they ended up building 10 of these ROVs. In 1983, they returned to their original idea and contracted with the Canadian inventor and entrepreneur Phil Nuytten to engineer Deep Rover.
Nuytten didn’t have to be convinced of the value of the submersible. He had grown up on the water and shared their dream. As a teenager, he opened Vancouver’s first dive shop. He then worked as a commercial diver. He founded the ocean- and research-tech companies Can-Dive Services (in 1965) and Nuytco Research (in 1982), and he developed advanced submersibles as well as diving systems. These included the Newtsuit, an aluminum atmospheric diving suit for use on drilling rigs and salvage operations.
Deep Rover’s first assignment was to boost offshore oil exploration and drilling in eastern Canada. Funding came from the provincial government of Newfoundland and Labrador and the oil companies Petro-Canada and Husky Oil. But the collapse of oil prices in the mid-1980s made it uneconomical to operate the submersible. So the rover’s mission broadened to scientific research.
Deep Rover’s Technical Specs
The pilot could operate Deep Rover safely for 4 to 6 hours at a depth of 1,000 meters and speeds of up to 1.5 knots (46 meters per minute). The submersible could be tethered to a support ship or move freely on its own. Two deep-cycle, lead-acid battery pods weighing about 170 kilograms apiece provided power. It had a VHF radio and two frequencies of through-water communications, plus tracking beacons.
From 1987 to 1989, Deep Rover did a series of dives in Oregon’s Crater Lake, the deepest lake in the United States. During one dive, National Park Service biologist Mark Buktenica [top] collected rock samples.NPS
The rover’s four thrusters—two horizontal fixed aft thrusters and two rotating wing thrusters—could be activated in any combination through microswitches built into the armrest. The pilot navigated using a gyro compass, sonar, and depth gauges (both digital and analog).
Much to Earle’s delight, Deep Rover had two excellent manipulators, each with four degrees of freedom, thus solving the problem that had started her down this path of invention. The pilot controlled the manipulators with a joystick at the end of each armrest. Sensory feedback systems helped the pilot “feel” the force, motion, and touch. The two arms had wraparound jaws and could lift about 90 kg.
Advertisement
If something went wrong, Deep Rover carried five days’ worth of life support stores and had a variety of redundant safety features: oxygen and carbon dioxide monitoring equipment; a halon (breathable) fire extinguisher; a full-face BIBS (built-in breathing system) that tapped into the starboard air bank; and a ground fault-detection system.
If needed, the rover could surface quickly by jettisoning equipment, including the battery pods and a 90-kg drop weight in the forward bay. In dire circumstances, the pressure hull (the acrylic bubble, that is) could separate from the frame, taking with it only its oxygen tanks, strobe, through-water communications, and wing thrusters.
Deep Rover’s achievements
From 1984 to 1992, Deep Rover conducted about 280 dives. It inspected two of the tunnels near Niagara Falls that divert water to the Sir Adam Beck II hydroelectric plant. In California’s Monterey Bay, the rover let researchers film previously unknown deep-sea marine life, which helped establish the Monterey Bay Aquarium Research Institute. At Crater Lake National Park, in Oregon, Deep Rover proved the existence of geothermal vents and bacteria mats, leading to the protection of the site from extractive drilling.
Deep Rover was featured in a short film shown at Vancouver’s Expo ’86, the first of several TV and movie appearances. There was Danger Bay. Director James Cameron used an early prototype of the submersible in his 1989 film The Abyss. Deep Rover also made an appearance in Cameron’s 2005 documentary Aliens of the Deep.
Advertisement
In 1992, Deep Rover came to the end of its working life. It now resides at Ingenium, Canada’s Museums of Science and Innovation, in Ottawa. For a time, Deep Ocean Engineering continued to develop later generations of the submersible. Eventually, though, uncrewed remotely operated and autonomous underwater vehicles became the norm for deep-sea missions, replacing human pilots with sensors and equipment. New ROVs can dive significantly deeper than human-piloted ones, and new cameras are so good that it feels like you’re there…almost. And yet, humans still long to have the personal experience of exploring the depths of the oceans.
Part of a continuing serieslooking at historical artifacts that embrace the boundless potential of technology.
An abridged version of this article appears in the April 2026 print issue as “All Alone in the Abyss.”
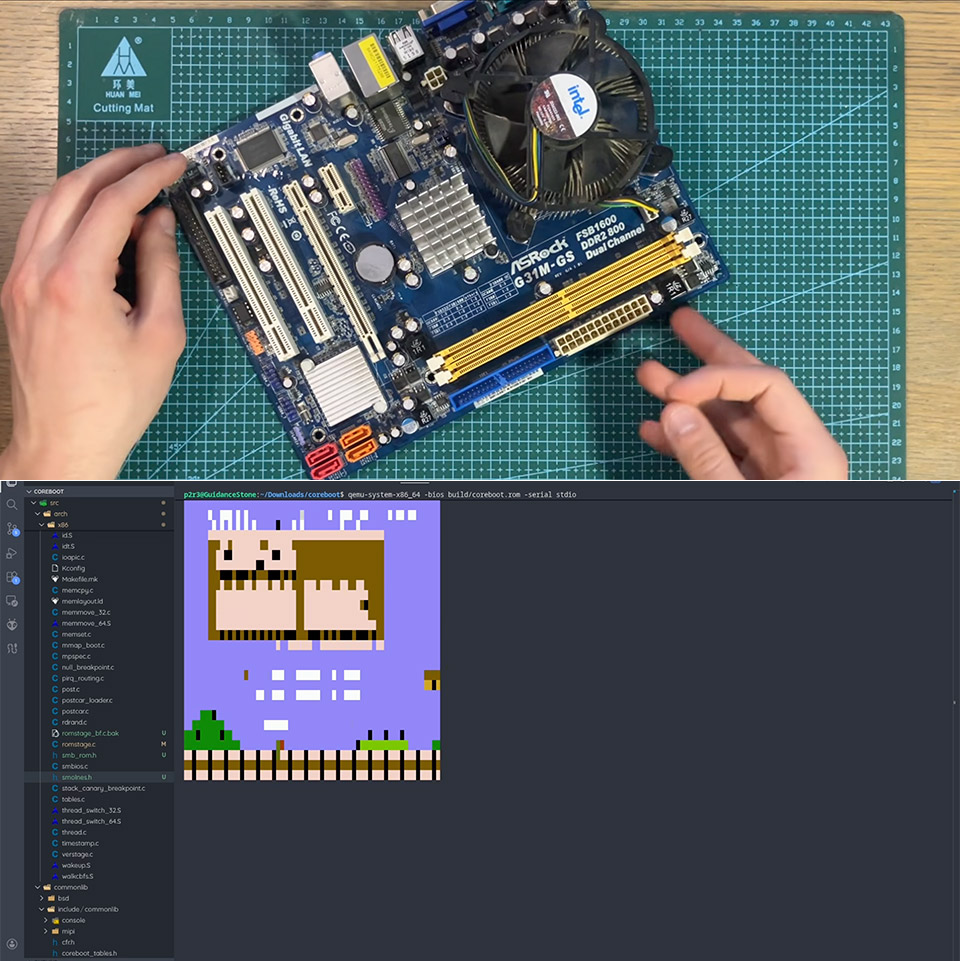
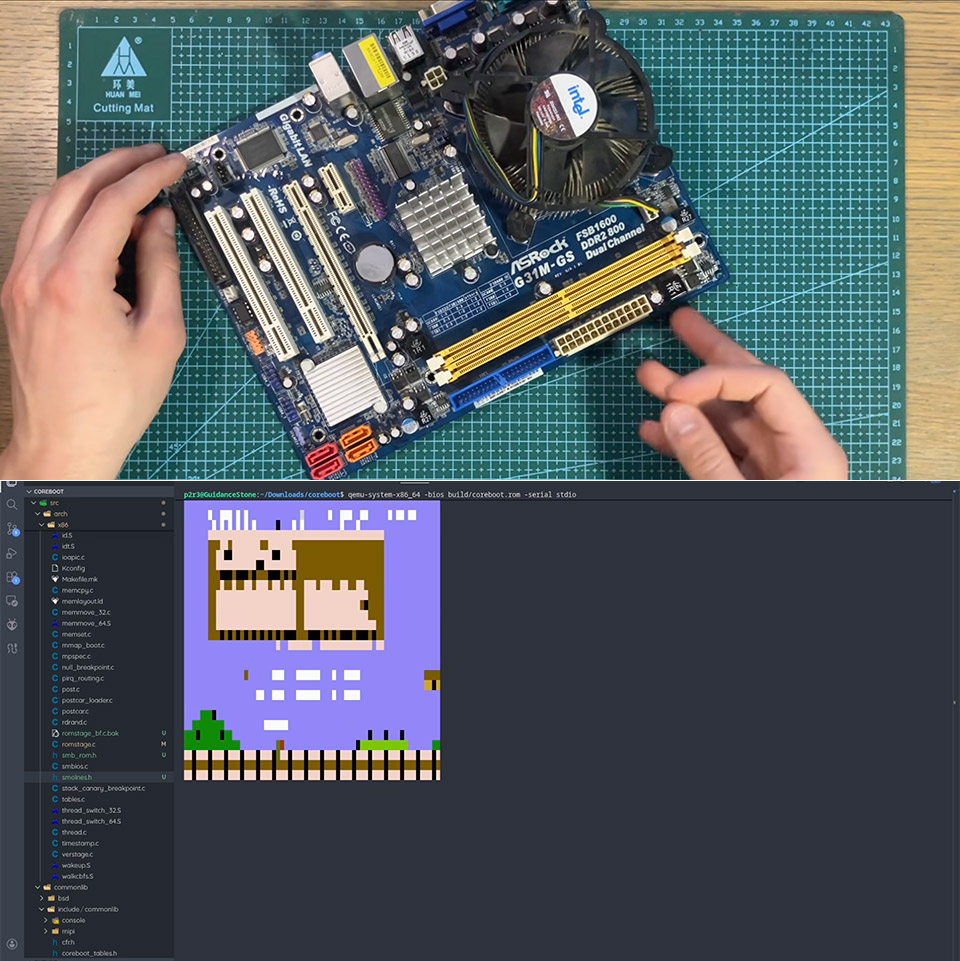
Rising RAM prices have a way of making you wonder just how much a computer actually needs to function, and PortalRunner decided to find out by removing it entirely and seeing how far he could get. The experiment started with Linux, gradually reducing the available RAM through boot settings until the machine refused to start at all. Even with a tiny amount left in place, basic tasks became painful and slow.
The next attempt used a SATA SSD as swap space, letting the system pull data from the drive whenever it ran out of the limited RAM available. Basic web browsing became possible, but trying to load Portal 2 was a dead end. Games need to hold large amounts of data in memory simultaneously, and a hard drive simply cannot move that data fast enough to keep up.
【AMD Ryzen 4300U Processor】KAMRUI Pinova P2 Mini PC is equipped with AMD Ryzen 4300U (4-core/4-thread, up to 3.7GHz), Based on the advanced Zen…
【Large Storage Capacity, Easy Expansion】KAMRUI Pinova P2 mini computers is equipped with 16GB DDR4 for faster multitasking and smooth application…
【4K Triple Display】KAMRUI Pinova P2 4300U mini desktop computers is equipped with HDMI2.0 ×1 +DP1.4 ×1+USB3.2 Gen2 Type-C ×1 interfaces for…
Attention then shifted to the graphics card. PortalRunner built a custom file system using OpenCL to turn the four gigabytes of VRAM inside a GTX 1660 Super into a substitute for system memory. Simple applications ran, but every time data had to travel between the CPU and GPU it added so much delay that even a basic browser test took over an hour. Portal 2 remained out of reach.
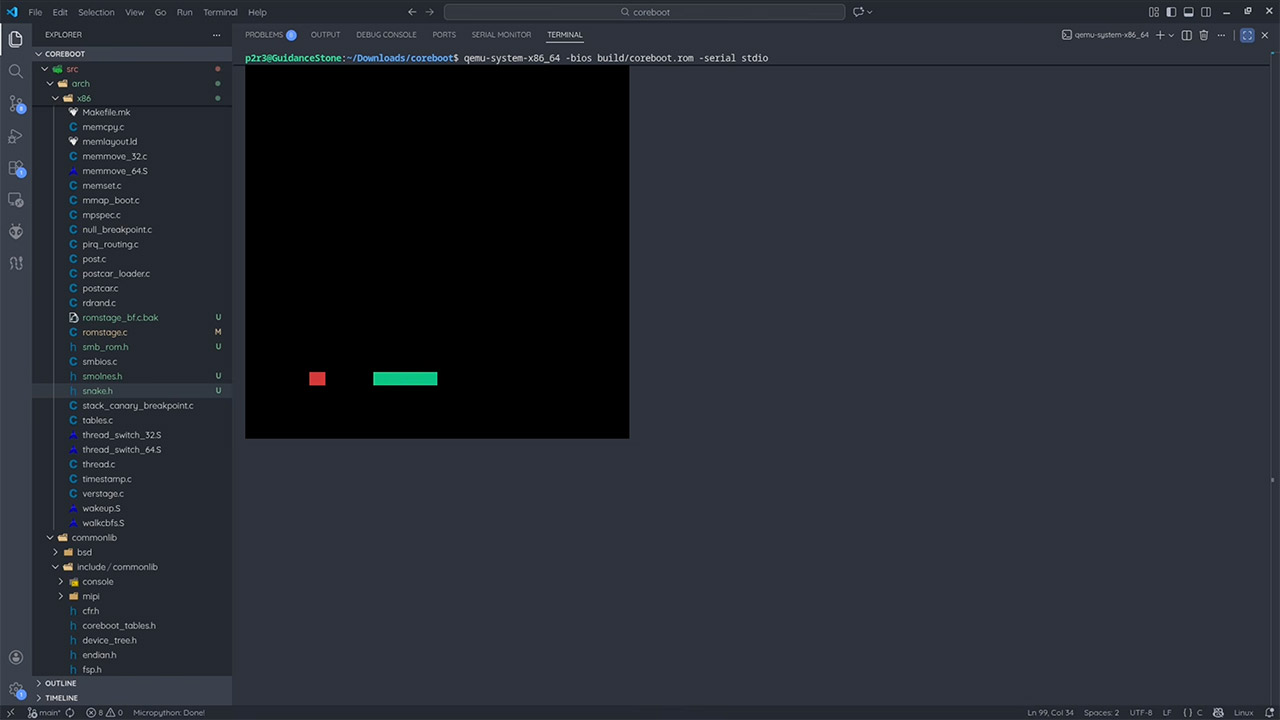
The breakthrough came from inside the processor itself. Every CPU contains a small amount of cache memory stored directly on the chip, and early in the startup process the CPU already uses that cache as a temporary workspace before any RAM has been initialized. Using an older ASRock motherboard with a Core 2 Duo processor and a modified version of the open source CoreBoot firmware, PortalRunner configured the system to skip RAM initialization entirely and load directly into that cache.
A Snake clone fit comfortably into the available space and launched without a hitch the moment the board powered on. He even squeezed a brainf**k interpreter onto it to prove the approach had more than one use. The limitations are obvious and nobody is running a modern operating system this way anytime soon, but it does make for a great conversation starter. [Source]
Samsung is expanding AirDrop compatibility to older Galaxy S devices through a Quick Share update, with owners of phones from the S22, S23, S24, and S25 generations reporting a new “Share with Apple devices” toggle appearing in their Quick Share settings.
The toggle is currently visible to some users but not yet functional across all devices, suggesting Samsung is running a staged test rollout ahead of a wider enablement that may coincide with the stable One UI 8.5 release.
AirDrop support via Quick Share currently sits as a confirmed feature on the Galaxy S26 series, which represents the only Samsung lineup running stable One UI 8.5 at present, making the older device reports the first indication that Samsung intends to push the feature down its hardware range.
Most of the older devices showing the toggle are running One UI 8.5 beta builds, though some users still on One UI 8.0 have also reported seeing the option, which points to the feature being tied to a Quick Share app update rather than strictly to a specific OS version.
Advertisement
Users wanting to check for availability can navigate to their Quick Share settings directly, with Samsung recommending updates are pulled through the Samsung Store app rather than waiting for an automatic push to surface the option.
Advertisement
The broader push toward cross-platform AirDrop compatibility across Android manufacturers follows regulatory pressure the EU applied to Apple to open up iOS features including AirDrop, which accelerated adoption across the Android ecosystem over the past year.
Google moved first among major Android manufacturers, launching AirDrop support on the Pixel 10 series before extending it to the Pixel 9 series in February, while Oppo has since announced incoming support beginning with the Find X9 series.
Advertisement
Samsung has not confirmed a timeline for the stable rollout to older Galaxy S devices, with full availability expected to become clearer once One UI 8.5 exits beta across the affected hardware generations.
In my years of engineering, I have seen technological shifts come and go. But nothing has transformed the software landscape quite like artificial intelligence. Adding artificial intelligence to an existing product used to mean hiring a massive team of data scientists. Today, we have powerful AI APIs that allow us to plug advanced cognitive capabilities directly into our applications. Whether you want to add natural language processing, computer vision, or predictive analytics, leveraging an API is the most efficient path forward. In this comprehensive guide, I will walk you through exactly how to integrate AI APIs into existing software applications. I will share my personal methodologies and best practices along the way so you can build smarter applications faster.
Why You Should Care About AI API Integration
Before we get our hands dirty with the technical steps, I want to explain why this matters. Modern users expect intelligent features. They want smart search, automated summarizations, and conversational interfaces. If your software lacks these capabilities, it risks becoming obsolete. By using an API, you bypass the need to train and host complex models yourself. You simply send a request to a provider, and they return a highly accurate prediction or generation.
This drastically reduces your time to market. I have helped countless teams reduce their development cycles from months to mere days by simply utilizing pre-built AI services. It is a massive advantage for resource management and operational scalability. Furthermore, cloud providers constantly update their models. When you use an API, your application automatically gets smarter every time the provider releases a new version. You do not have to worry about model drift or retraining pipelines. You get to focus entirely on building a great user experience.
Evaluating Your Current Software Architecture
When I begin evaluating an application framework for artificial intelligence integration, I always look at the underlying codebase to ensure it can support advanced machine learning models. A robust, scalable foundation is the absolute bedrock of successful digital transformation. If your legacy system is too rigid or outdated, you might need to collaborate with a skilled software development company to refactor your code and build custom enterprise solutions. These technical experts specialize in bespoke software engineering, agile deployment, system architecture design, and creating tailored backend infrastructures that can seamlessly handle complex API requests and massive data pipelines without latency.
Advertisement
Assessing Data Flow and Bottlenecks
Beyond the foundational architecture, you must understand how data moves through your system. AI APIs require specific payloads, often formatted as JSON. I always map out the data journey from the user interface down to the database. You need to ask yourself if your current servers can handle the additional network requests. If your application is already suffering from high latency, adding an external API call will only make it worse.
I strongly recommend implementing asynchronous processing or message queues to handle these requests in the background. This ensures your user interface remains responsive even if the AI takes a few seconds to generate a response. When users click a button to generate text, they should see a loading spinner while the server does the heavy lifting asynchronously.
The Role of Microservices
In my professional experience, monolithic architectures struggle with AI integrations. If your entire application is bundled into one massive codebase, adding a new API dependency can introduce fragility. I prefer a microservices approach. By isolating your AI logic into its own dedicated service, you protect the rest of your application from potential crashes. If the AI service goes down or experiences a timeout, your core application will continue to function normally. This separation of concerns also makes it much easier to scale the AI components independently when traffic spikes.
Top AI APIs to Consider in 2026
Image: Unsplash
Choosing the right provider is half the battle. Over the years, I have tested dozens of platforms. Some excel at creative writing, while others are better at strict data extraction. Below, I have compiled a comparison of the most reliable options currently available on the market based on my direct testing.
API Provider
Best Use Case
Key Strength
OpenAI
Conversational agents
Superior natural language understanding
Anthropic
Long form content analysis
Massive context windows and strict safety guidelines
Google Gemini
Multimodal applications
Native integration with the Google Cloud ecosystem
AWS Bedrock
Enterprise compliance
Wide choice of foundation models in a secure environment
Each of these providers offers comprehensive documentation. I always advise my teams to read the documentation thoroughly before writing a single line of code.
Advertisement
Step by Step Guide to Integrating an AI API
Now, let us dive into the actual implementation. I have refined this process over countless projects. If you follow these steps, you will avoid the most common pitfalls that plague junior developers.
Identify the Core Value Proposition: Do not add AI just for the sake of it. Pinpoint exactly what user problem you are solving. For instance, if your users struggle to find information in large documents, integrating a search API is a perfect fit.
Secure Your API Keys: Never hardcode your credentials into your application. I always use environment variables and robust secrets management tools to keep my keys safe from unauthorized access. A leaked key can cost you thousands of dollars in a matter of hours.
Set Up the Development Environment: Install the necessary Software Development Kits or HTTP client libraries. Most providers offer native Python or Node packages that simplify the connection process. If a native package is unavailable, a standard HTTP client will work perfectly.
Construct the Prompt or Payload: Designing the right prompt is crucial. I spend a significant amount of time testing different instructions to ensure the API returns the exact format my software needs. You should constrain the output format by asking the AI to return strictly structured data.
Implement Error Handling: Network requests fail. The API might experience downtime, or you might hit a rate limit. You must build retry mechanisms to handle these failures gracefully. I typically use an exponential backoff strategy for retries.
Handling Rate Limits and Timeouts
One specific area I want to highlight is rate limiting. When you launch your new AI feature, a sudden spike in traffic can easily exhaust your API quota. I highly recommend implementing a queuing system. If a user requests a heavy text generation task, put that request in a queue. Let a background worker process it and notify the user when it is done. Furthermore, always set strict timeouts on your API calls. If the provider takes longer than ten seconds to respond, your application should abort the call and display a friendly fallback message instead of freezing indefinitely.
Cost Management and Token Optimization
Another crucial aspect of AI integration is cost management. Most AI APIs charge by the token. A token is roughly equivalent to a piece of a word. If you send massive prompts to the API, your bills will skyrocket. I always implement token counting logic before sending a request. If a user tries to analyze a document that is too large, my software automatically truncates the text or rejects the request. You should also cache frequent API responses. If multiple users ask the exact same question, you can serve the cached answer instead of paying for a new API call.
As an expert, I cannot overstate the importance of data privacy. When you send data to an external AI API, you are potentially exposing sensitive information. You must read the terms of service of your chosen provider. I always ensure that the provider explicitly states they do not use my API data to train their public models.
Furthermore, you should scrub all Personally Identifiable Information from the payload before it leaves your servers. If a user submits a document containing social security numbers or private addresses, use a local script to redact those details before forwarding the text to the AI. Trust is the most valuable currency you have with your users. Do not compromise it for the sake of a cool feature.
Testing and Monitoring Your AI Integration
Deploying the feature is only the beginning. AI models are unpredictable. This means they can produce different outputs for the exact same input. This makes traditional unit testing incredibly difficult. I rely heavily on integration tests and continuous monitoring.
Advertisement
You need to log every single request and response. I usually set up a dashboard to track the average response time, token usage, and error rates. If I notice the token usage spiking unexpectedly, it usually means there is a bug in my prompt construction loop. You also need a mechanism for users to report bad AI outputs. This allows you to continually refine your prompts and parameters based on real world usage.
Conclusion
Integrating artificial intelligence into your existing software is a highly rewarding endeavor. I have seen firsthand how it can breathe new life into legacy applications and delight users with magical, automated experiences. By carefully evaluating your architecture, choosing the right provider, and following rigorous security protocols, you can successfully launch intelligent features without compromising system stability. Start small, monitor your usage closely, and iterate based on real user feedback. If you are ready to modernize your platform, take action today and start planning your AI API integration roadmap. Your users are waiting for the next generation of smart software.
Disclaimer: Unless otherwise stated, any opinions expressed below belong solely to the author.
The war in Iran has been raging for a month now, and the resulting energy crisis has hurt the world, as oil and gas prices surged in response to the closure of the Strait of Hormuz, through which about 20% of the world’s energy travels each year.
Much of Asia, as well as countries in the Pacific, have been badly affected, as many of them depend on Gulf shipments of oil and LNG (liquified natural gas) for electricity generation and transportation.
We’ve seen reports of petrol stations closing due to a lack of fuel, airlines cancelling flights, people forced to work from home to conserve energy and a threat of another wave of inflation fuelled by the rise in costs of moving goods.
Advertisement
Image Credit: Bloomberg
Singapore was not spared the consequences, but the situation here is far better than in the worst-affected countries. With diversified sources of both oil and natural gas, as well as ample reserves, Singapore has little to fear other than higher-than-usual bills for filling up your car.
There’s no fear of blackouts, pumps running dry or businesses unable to carry out their operations. Electricity prices may not have jumped yet, but the government has the means to put a cap on them.
It’s mostly an inconvenience—and one which may even produce benefits for the country.
Everybody needs Singapore
Singapore is the world’s largest and most developed transhipment port.
Disruptions in other areas of the planet do not affect it directly, because no matter what happens, cargo has to travel through here to its destination.
Advertisement
If Hormuz cannot be used, then the endpoints may change in response to the closure. But Singapore is still the bridge between the West and the Far East. Shipping companies have already begun rerouting traffic to ports in Oman and the UAE, located on the coast of the Arabian Sea, with cargo then trucked overland to their final destination in the Middle East.
No matter where they are heading, though, their pit stop is still in Singapore.
And while higher prices may hurt the pockets of regular Singaporeans (although the government has already announced readiness to help), higher fuel and shipping costs make those companies operating here more profitable, with a share of their income ending up in the national budget through taxes.
In other words, not only is the trading activity unlikely to be meaningfully affected (just like it was not during the COVID-19 pandemic), but Singapore’s large shipping industry is probably going to benefit in many ways from the war-induced disruptions.
Advertisement
Money likes peace
An even more meaningful win for Singapore is the uncertainty that the war has introduced about the future of the developed and thus far very peaceful Gulf Arab countries.
For decades dependent on oil and gas, they have in recent years invested heavily to diversify their economies by appealing to wealthy immigrants.
It’s no secret that cities like Dubai or Abu Dhabi in the UAE (with Qatar and Saudi Arabia following in its footsteps) entered competition with Singapore to attract the richest people in the world, encouraging them to move to the Gulf and park their wealth there.
According to Henley & Partners, the UAE has been the leading destination for millionaires in the past decade. Just last year, nearly 10,000 of them, commanding US$63 billion in assets, moved to the Emirates, compared to only 1,600 and US$8.9 billion headed to Singapore.
Their offer has been quite appealing to many, since Arab nations don’t charge any income taxes, while other levies tend to be lower than in Singapore.
What’s more, they have far more land than the city-state and have been investing heavily in property development, building clean, modern cities offering some of the best living conditions in the world, at very competitive prices.
Their strategy, however, has always been underpinned by the promise of absolute safety, which the war with Iran has left a big crack in.
Image Credit: phuongphoto/ depositphotos
As missiles and drones target them every day, it has made some question their commitment to the Gulf, even if little damage is done.
Singapore, in comparison, is an oasis of calm, with a very robust military, in a region which doesn’t show any appetite for war—at least not one that would affect the city directly.
All of a sudden, the higher cost of living—the pricier apartments, the more expensive cars—feels worth the extra expense because it’s far less likely that a rogue neighbour is one day going to start bombing Singapore the way Dubai, for example, is.
Such headlines do not inspire./ Image Credit: Mirror
Within a week, reports of anxious Asian residents trying to leave the Gulf hit the news headlines. They weren’t happy with the paradise bubble being popped so violently by the war they weren’t expecting to erupt.
The war may be bound to end within a few weeks or months at most, and it’s quite likely that a period of calm is going to follow it in the Middle East, but the damage done will take some time to fix.
Dubai, Abu Dhabi or Doha are not going to suddenly implode or become abandoned by panicked expats. Nevertheless, any future calculation made by the wealthy—especially those very rich—will include the potential for another military conflict.
Advertisement
This is where Singapore has gained a strong competitive advantage over its desert rivals.
Singapore thrives in crisis
The city does quite well at all times, of course, but when the international situation is peaceful, both companies and individuals are more open to taking risks.
It’s when a crisis strikes that everybody seeks to escape to a safe haven—such as Singapore.
Image Credit: World Bank
During the pandemic, it was one of the critical logistical hubs, as cargo had to move even if people could not.
GDP per capita dipped slightly at first, to just over US$60,000, only to be catapulted by around 50% to over US$90,000 two years later, thanks to both how much Singapore’s economy has to offer and how trusted the Singapore dollar is.
Advertisement
It was similar after the 2008 financial crisis. A temporary and mild slowdown was followed by an economic surge.
Or last year, when Trump’s tariffs hit the world, Singapore’s economy recorded one of the highest growth rates in recent history. GDP jumped by 5% on increased trading activity amid global uncertainty as businesses were adapting to American actions.
Singapore is the essential trade node bridging Asia with the rest of the world. Economic crises don’t really freeze trade—they redirect it, and the reliable middleman always earns a premium for his services.
It’s no different this time.
Advertisement
Read other articles we’ve written on Singapore’s current affairs here.
Featured Image Credit: adwo@hotmail.com/ depositphotos
Last week, DarkSword was then posted to open source code repository GitHub, making it all the more accessible. Security firms Malfors and Proofpoint soon after warned that another Russian hacker group linked to the Kremlin’s FSB intelligence agency was sending out phishing emails that used the technique. Independent security researcher Johnny Franks tells WIRED that he found yet another new, active domain—a fake website written in English, capable of infecting US-based users—that was part of a DarkSword hacking campaign as late as Thursday of last week, a finding confirmed by mobile security firm iVerify.
Despite DarkSword’s growing threat to iOS 18 users, many stubbornly refused to update to iOS 26. On Reddit channels related to cybersecurity and iOS, some self-identified iPhone owners discussing DarkSword argued that Apple seemed to be taking advantage of the DarkSword hacking campaigns to push them onto its latest OS version, which some have found to be slow or overly animated.
“Apple is trying to force you onto the dumpster fire that is liquid glass,” one Reddit user wrote.
“If this is so serious, why wouldn’t Apple insert a fix into iOS 18.x,” another Redditor named asked.
Advertisement
“It’s all bullshit propaganda!” another user wrote. “Not updating my phone is perfect on iOS 18.1.1.”
For cybersecurity experts who have been waiting for Apple to act, the company’s move to now cater to those stubborn iOS 18 users received “better-late-than-never” reviews. “Apple is now, finally, doing this for the DarkSword exploits, but only after they were already being abused by other attackers, putting iOS users at risk,” says Patrick Wardle, a former NSA hacker and now the CEO of the Apple-device-focused security firm DoubleYou. “If protecting users actually matters, backporting critical fixes should be standard, not the exception.”
DarkSword is, in fact, the second sophisticated, in-the-wild iPhone hacking technique in just the last month that’s inspired Apple to take the rare step of pushing out fixes for older versions of iOS. Earlier in March, the company also backported patches to protect users from a different, even more sophisticated iOS hacking toolkit known as Coruna. A week after researchers at Google and iVerify revealed that the Coruna iOS exploitation kit—which was likely created for the US government—had spread from Russian espionage hackers to profit-focused cybercriminals, Apple released security fixes for iOS 17, the even older version of Apple’s mobile operating system that was vulnerable to Coruna’s set of hacking techniques.
DarkSword’s ability to compromise iOS 18 devices, however, left a different set of users vulnerable. Rocky Cole, cofounder of iVerify, notes that some of those users may have held out on updating to iOS 26 until now not simply because they don’t like its features but because they use specific or custom-made apps that aren’t compatible with newer operating systems. In the UK, Apple has also added age verification features to iOS 26 that some users have resisted. Others may simply not have had enough storage space on their phone to carry out the update.









 Submarine designer Graham Hawkes [left] and marine biologist Sylvia Earle [right] came up with the idea for Deep Rover.Alain Le Garsmeur/Alamy
Submarine designer Graham Hawkes [left] and marine biologist Sylvia Earle [right] came up with the idea for Deep Rover.Alain Le Garsmeur/Alamy

 From 1987 to 1989, Deep Rover did a series of dives in Oregon’s Crater Lake, the deepest lake in the United States. During one dive, National Park Service biologist Mark Buktenica [top] collected rock samples.NPS
From 1987 to 1989, Deep Rover did a series of dives in Oregon’s Crater Lake, the deepest lake in the United States. During one dive, National Park Service biologist Mark Buktenica [top] collected rock samples.NPS




















































You must be logged in to post a comment Login