Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


![]()
OpenAI appears to be testing a new subscription and experience for science use cases, but it’s unclear if it’ll be available to everyone regardless of their background.
As spotted on X, this new subscription/model is called “ChatGPT for Science,” and references to the feature were spotted on the web build.
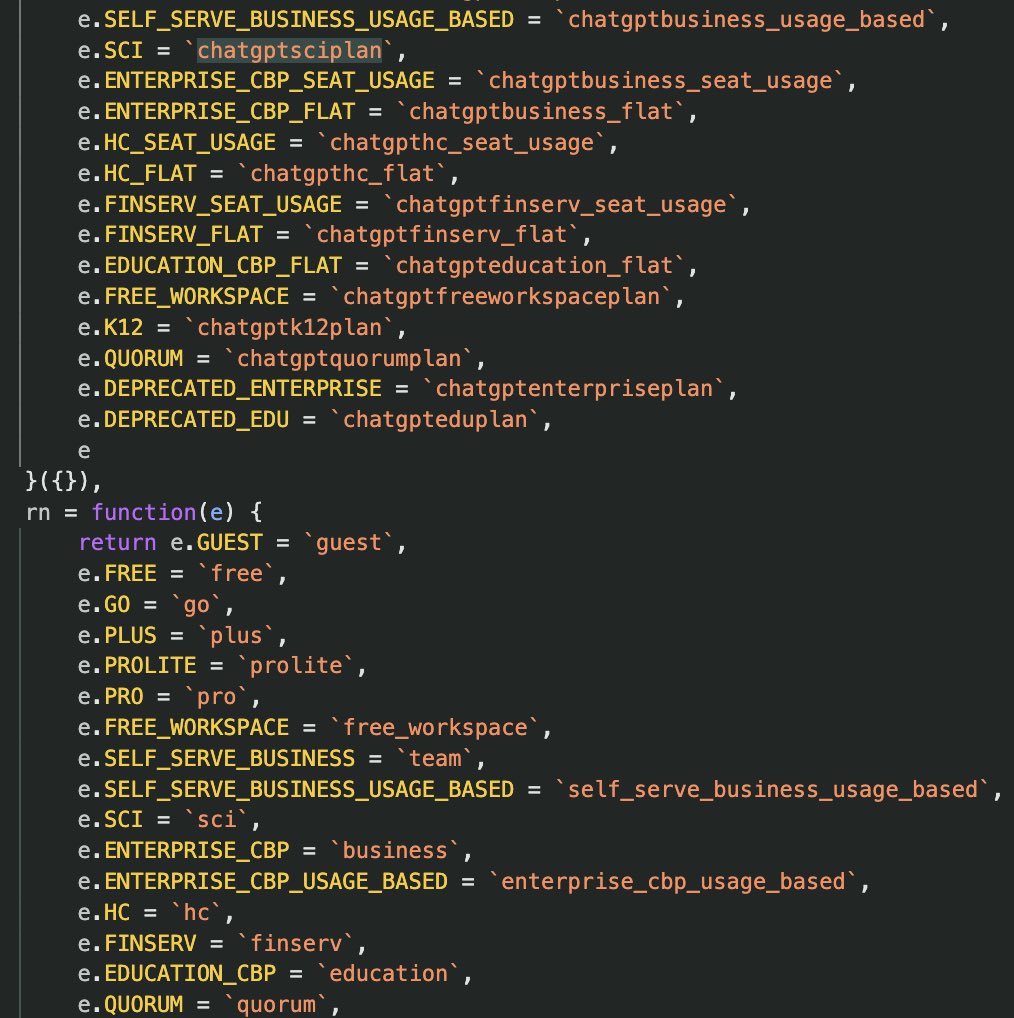
Right now, OpenAI offers ChatGPT for personal use, Teams, and business/enterprise.

While ChatGPT personal works for everybody, Teams requires you to have a company domain and at least three users. On the other hand, ChatGPT business is restricted to legal entities.
It’s likely that ChatGPT for Science will have similar restrictions, and only verified institutes or universities would be able to use it.
It’s not the first time we’ve seen OpenAI’s attempt to build models or subscriptions specifically for science use cases.
OpenAI recently announced GPT-Rosalind, which is built on the foundation of its advanced GPT-5.5 architecture, but it’s not just a reskinned ChatGPT with a science prompt.
Instead, it is a highly specialized, purpose-built model designed specifically for enterprise-scale life sciences research.
GPT-Rosalind is locked behind what OpenAI calls a “trusted-access deployment structure.”
This means the model is strictly available to eligible organizations, such as major pharmaceutical companies like Novo Nordisk or verified research institutions, that are conducting legitimate, public-benefit scientific research.
It requires enterprise-grade security and strong safety governance, mirroring and exceeding the strict requirements of ChatGPT Enterprise.
OpenAI may be planning to bring some of these capabilities to all institutions through ChatGPT for Science, rather than locking them to select partners.
In other words, ChatGPT for Science will have special grounding in discoveries and research around scientific topics compared to a regular subscription.
At the moment, we don’t know when ChatGPT for Science will go live, but it’s being actively tested on the web, and an announcement is likely weeks away.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


Adobe has announced a major expansion of its “creative agent” across its flagship Creative Cloud suite and upgraded Firefly AI studio.
Available in public beta starting today across Premiere Pro, Photoshop, Illustrator, InDesign, and Frame.io, the agent is designed to serve everyone from individual creators to enterprise marketing teams.
Unlike first-generation generative AI tools that simply output flat media from a chat interface, Adobe’s embedded assistant acts as an orchestration layer.
It interprets natural language prompts and directly accesses the underlying software’s APIs to execute complex, multi-step production workflows—from batch-renaming video sequences to dynamically updating brand assets across print layouts—while leaving the final aesthetic decisions entirely in the hands of the human designer.
At the core of this release is a significant technical upgrade to how Adobe’s AI handles persistent memory and context window management. In its upgraded Firefly creative AI studio—currently in private beta—Adobe has introduced two foundational architectural components: “Elements” and “Projects”.
Elements functions as a visual variables library, allowing users to save and reuse specific characters, locations, and objects across multiple generations to ensure strict visual consistency as campaigns scale.
Projects acts as the contextual memory layer, storing assets, generations, and session history in a unified space so users can pick up where they left off without rebuilding their prompt context.
Beyond pixel generation, the system’s most critical technological leap is its ability to operate seamlessly within the complex document structures of desktop applications. “Our Adobe Creative Agent can leverage the decades of powerful features, workflows, APIs that we’ve brought into our application and exposed through tooling that can now be invoked through a creative agent,” an Adobe representative explained.
The practical application of this technology fundamentally alters standard production workflows. Adobe is positioning the human user as a “creative director” capable of delegating repetitive, labor-intensive tasks to the AI. The rollout introduces highly specific specialist agents tailored to the logic of each application:
Premiere Pro: The agent handles tedious project setup, analyzing and sorting source media into bins, batch renaming clips, identifying interview questions, and assembling a rough working starting point.
Illustrator: The assistant automates mathematical and multi-step design tasks, such as generating 50 versioned files from a spreadsheet or running pre-flight checks to flag color mode errors before printing. It can even programmatically duplicate a vector shape 100 times, randomize its position, and change its size based on its z-depth and transparency.
Photoshop & InDesign: The agent executes batch background removals, dynamic layer organization, and applies brand updates across multi-page layouts.
Furthermore, Adobe is actively integrating its creative agent into major third-party enterprise platforms, including OpenAI’s ChatGPT, Anthropic’s Claude, Microsoft 365 Copilot, and soon, Google Gemini and Slack.
Unlike open-source orchestration frameworks or models released under MIT or Apache licenses, Adobe’s creative agent operates strictly within a proprietary, commercial SaaS ecosystem. For enterprise decision-makers, this carries specific implications. Because the agent relies on Adobe’s proprietary APIs to manipulate project files, it requires an active Creative Cloud commercial license. Additionally, by bringing the “Adobe for creativity connector” to platforms like Slack and Microsoft Copilot , enterprise IT and systems architects must consider how internal chat tools will interface with Adobe’s cloud processing environments to support enterprise creative and marketing teams securely.
While Adobe’s announcements highlight a powerful user interface and deep integration within its own flagship applications, several critical questions remain for enterprise technical decision-makers tasked with building bespoke AI systems. VentureBeat has reached out to Adobe for clarification on these infrastructure-level details and will update this coverage as we learn more.
For AI system architects, the value of a creative agent lies not just in a native application UI, but in its extensibility. It remains unclear if Adobe plans to expose these new agentic capabilities via API, or if the company will support the Model Context Protocol (MCP). Without MCP support or direct API access, enterprise teams will face friction integrating Adobe’s tools into their own custom task-routing frameworks and internal LLM pipelines.
Adobe’s new “Elements” feature promises to solve the generative AI consistency problem by anchoring characters and objects across generations.
However, the backend architecture driving this persistent memory is not yet detailed. Whether Adobe is leveraging on-the-fly Low-Rank Adaptation (LoRA) based on user uploads or utilizing a form of visual Retrieval-Augmented Generation (RAG) is a critical distinction for technology leaders managing compute costs, model evaluations, and enterprise-grade inference pipelines.
As organizations build out “Projects” and define brand-specific “Elements”, security and data decision-makers require strict guarantees regarding data provenance and storage. It is currently unknown exactly where this contextual workflow and vector data lives—specifically, whether it remains strictly sandboxed within the customer’s enterprise Creative Cloud instance on Adobe servers, and how role-based permissions apply to these new agentic workflows.
Finally, as lightning-fast, developer-first, multi-model AI creative platforms like fal.ai gain significant traction among enterprises and developers, Adobe’s position in the broader developer ecosystem remains a point of interest.
Whether Adobe views these infrastructure-level API providers as direct competitors to its Firefly AI studio or as potential integration points for bespoke enterprise environments has yet to be seen.
The integration of agentic AI touches on the tension between eliminating drudgery and surrendering creative control. According to Adobe’s recent Creators’ Toolkit Report, which surveyed over 16,000 creators globally, the market is highly receptive to AI as an operational assistant rather than an autonomous creator.
75 percent of surveyed creators describe creative AI as integrated or essential to their current workflows.
85 percent emphasized that the final creative decision must always remain in human hands.
This sentiment is central to Adobe’s messaging. By focusing the agent’s capabilities on file organization, layer management, and brand compliance, Adobe aims to automate what a spokesperson called the “tedious parts of their workflow”. The goal, according to Adobe executive David Wadhwani, is to let creatives focus on the craft so they can “apply their taste and make the calls that only they can”.
Businesses are still investing heavily in AI while they figure out where it can be used best, but Confluent believes the volume of investment isn’t a blocker anymore. Instead, it’s the quality of the data AI systems rely on that’s letting them down.
Three in four (72%) IT leaders say poor real-time data infrastructure is preventing them from being able to scale properly.
Real-time data processing (72%), data lineage uncertainty (66%) and fragmented data ownership (65%) are among the biggest challenges that companies face when trying to implement AI.
These challenges have ultimately led to lower-than-expected AI deployments and poor ROI – only 32% say they have agentic AI in production, and the majority instead experience delays.
To fix it, 80% say they’re now prioritizing using enterprise data to drive AI-based systems, with data streaming platforms cited as one of the biggest supports by 88% of IT leaders. In fact, it’s more of a priority than AI and ML (82%), indicating that leaders are increasingly aware of how they could fix the problem.
“Models need to be connected to the systems, events and signals that reflect what is happening across the business,” Chief Product Officer Shaun Clowes wrote, referencing the currently fragmented data systems. But Clowes acknowledged that it’s not necessarily organizations’ faults that AI systems are failing.
Clowes explained that current infrastructures weren’t designed for continuous intelligence, which is why all companies regardless of sector or size are facing the same issues.
“The companies making the most progress are investing not only in AI itself, but in the data foundations needed to support it,” he concluded.

Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds.
For a long time organizations like the Southern Environmental Law Center (SELC) have noted how Elon Musk’s xAI data center in Memphis disproportionately pollutes the air in minority neighborhoods. A joint lawsuit by SELC, Earthjustice, and the NAACP filed last April argued that Musk and friends didn’t even bother to get the necessary permits to run the turbines at its xAI’s Colossus 2 data center.
The lawsuit also notes how these 27 turbines (which has ballooned to 57 turbines since the lawsuit was filed) belch all manner of contaminants, including formaldehyde, into minority neighborhoods already seeing some of the highest asthma rates in the country, violating the Clean Air Act.
But this being Elon Musk, he apparently has been able to leverage the presidency he helped purchase to get those pesky Memphis minorities off of his back. In a filing this week obtained by Wired, the DOJ is trying to claim the lawsuit can’t proceed because xAI and Grok are highly tethered to the country’s national security efforts:
“In a filing, the agency sided with Elon Musk’s company, saying attempts to stop xAI from running the natural gas turbines “threatens American national, economic, and energy security by seeking to shut off the power supply for artificial-intelligence innovation that supports the Department of War’s military operations.”
Musk and his friends at the DOJ are asking the courts to dismiss the lawsuit. In May, the NAACP filed a request for a preliminary injunction, stating that the climbing rates of environmental pollution “increases risks of asthma attacks and heart disease” in communities that already face significant pollution thanks to regulatory capture and systemic racism.
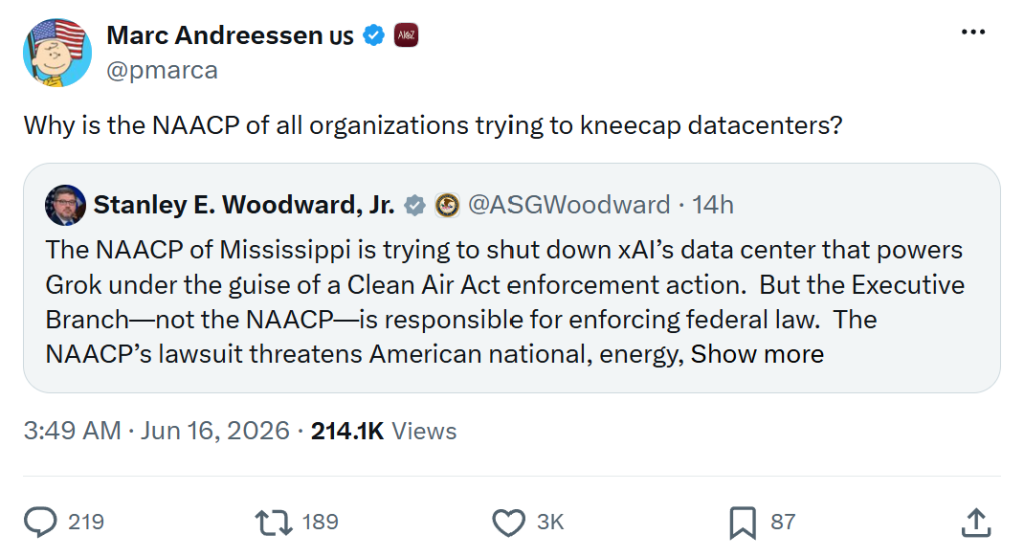
Over on Elon Musk’s right wing propaganda website, Marc Andreessen pretended to not understand why a civil rights group might be upset that unregulated data centers are pumping pollution into minority Memphis neighborhoods:

It’s worth noting that when Musk built the Colossus 2 data center near Memphis, he promised that the facility would largely re-use water via a next-generation water-recycling plant as to not strain the area water supply. But curiously, construction of that part of the project has stalled out completely. Musk says the company needs to focus on finishing their other data center in the region, then will finish construction. But, well, it’s Musk. The guy always saying we’re *this close* to settling Mars.
Meanwhile, you’ve got a lot of rich assholes (and the politicians who love them) increasingly trying to falsely claim that all of the bubbling over animosity at AI is an inauthentic Chinese “psy-op.” And you’ve got CEOs getting booed at their commencement speeches wondering why AI animosity is so white hot.
The youth movement has tethered AI to the country’s growing fascist, racist corruption and income inequality (and the tech sector that openly embraced it at almost every turn), and it’s going to take a lot more than sloppy CBS propaganda and new software updates to shift the perception. I’m not sure the tech sector truly groks what their enthusiastic support of Trumpism will ultimately reap them.
This is the future we’ve built in a country too corrupt to have functional regulatory oversight of obscenely rich men and corporate power. Without a meaningful ethical renaissance and profound political sea change, it only gets uglier and more violent from here.
Filed Under: ai, clean air act, data center, elon musk, environmental law, lawsuit, memphis, pollution
Companies: naacp, spacex, xai

In the early 2000s, classrooms were simple.
One desktop computer sat in the back of the room, usually reserved for Accelerated Reader quizzes, and a computer lab down the hall hosted weekly keyboarding lessons. When laptop carts arrived, it felt like the future had rolled in on wheels.
My principal believed in slow, intentional adoption. The first month, she handed each teacher a laptop and said, “Keep it on your desk. Turn it on. That is all you have to do.” No pressure. No mandates. Just familiarity.
For most teachers across the country, the shift looked nothing like this. Schools scrambled to adopt technology, sometimes for learning, sometimes simply to keep up.
Debates emerged: Should we still teach cursive if students will be typing anyway? Should computer labs disappear? Should every student have a device?
As the years progressed, students arrived more digitally fluent than ever and quickly outpaced teachers despite ongoing professional development.
Districts kept adding more software, more platforms, more bells and whistles. Learning management systems became central to instruction. Individually, each tool was an advancement. Collectively, they created noise.
COVID accelerated everything, but it was not the sole cause of technology fatigue. By 2021, 90% of schools had adopted at least one new digital platform, but fewer than half provided sustained professional development to support its use. Teachers were overwhelmed. Parents were unprepared. Students were distracted.
So where did we go wrong, and how do we get back on track?
1. We Adopted Technology Without Guardrails or Purpose
Before adopting any tool, districts must answer a simple question: Is this for learning, productivity, accessibility, or innovation? The distinction matters. Digitizing worksheets is not innovation.
Tools should help students create, collaborate, and solve problems—the very skills the future workforce will require. Guardrails also mean limiting screen time to when it is instructionally essential. Unstructured screen time can reduce attention and retention. Technology should amplify learning, not replace thinking. So how do we make sure we are using tech with purpose? Classroom teachers should decide when, how, and why to use a tech tool.
For example:
If your students are in a 1: 1 environment, establish clear norms for when devices should be open or closed, and teach these routines from day one.
A simple visual cue—like a device GO or CLOSED sign—helps students internalize expectations without constant reminders.
Before anyone opens a laptop or iPad, model the steps students will take. This 30-second preview prevents the
“Tech scramble” that derails lessons and keeps the focus on learning instead of troubleshooting.
Start every class with a short, analog bell-ringer in a composition notebook to signal from the very beginning that attention and thinking come first.
When students learn this routine on day one, it becomes clear that devices stay closed until the learning calls for them.
In elementary classrooms, station rotation can quickly become device-heavy if every center includes a screen.
Build in intentional no-tech stations for word work, manipulatives, partner games, writing, or read-to-self so students practice foundational skills without device distraction. This helps young learners build stamina, independence, and social interaction while keeping technology in its proper place as just one part of the rotation, not the default.
2. We Overspent on Redundant Tools Instead of Building Coherent Ecosystems
Schools often pay for multiple tools that serve the same purpose.
Gimkit and Kahoot? Pick one.
Nearpod and Pear Deck? Pick one.
Three reading platforms that all claim to personalize learning? Pick one.
Districts use an average of 2,739 edtech tools per year. A lean ecosystem increases fidelity, clarity, and impact.
This year, model the same intentional learning you want for your students. Choose one tool you truly want to master and commit to it. Consistent use builds coherence, reduces cognitive load, and strengthens instructional impact.
Attend professional development, watch videos, learn from colleagues and even your students, and look for ways to integrate the tool across units. Becoming deeply skilled with one platform is far more powerful than dabbling in many.
Admin and district tech leaders, work with your curriculum departments to evaluate actual usage data and efficacy of redundant tools. Consider budgets and which tools have the most impact for their cost.
3. We Removed Agency from Teachers and Students
Forced technology use backfires. When a tool does not meet the needs of the teacher or learner, it becomes a barrier rather than a bridge. Teacher autonomy is directly linked to higher instructional quality and student engagement. Agency builds ownership, and ownership builds authentic use.
Teachers, when it’s instructionally appropriate, give students the choice to work digitally or on paper. Choice builds ownership and reduces frustration. For example, some students prefer reading a novel on a device because they rely on accessibility tools, while others focus better with a print copy. Offering both options, when feasible, helps students select the format that supports their learning needs.
Administrators and coaches should classrooms with the intention of learning and gathering information. Pay attention to how long navigation takes, where students get stuck, and when technology supports or interrupts the learning goal.
Use these observations as data to shape coaching and professional development, and give teachers choice within required platforms so they can align tools with their instructional purpose.
4. We Went All-In on Technology Instead of Balancing It with Authentic Methods
In the rush to modernize, we saturated the system with software, tools, and devices. Teachers became device managers. Students became tab switchers. Parents became technology police.
Blended instruction, not technology-heavy instruction, produces the strongest learning gains. Students need both the tactile and the digital, the concrete and the abstract, the human and the automated.
To find it:
Seek clarity on expectations. Professional development on tech does not automatically mean mandatory use.
If a tool feels unrealistic for your students, ask your administrator to clarify how and when it should be used. Alignment with student needs matters more than checking a box.
Set a time limit for digital tasks and compare it to the analog alternative. Choose the method that protects instructional time.
Model the workflow before students touch devices so the focus stays on thinking, not troubleshooting.
Build in device-free moments during the lesson such as discussion, think-pair-share, and modeling to keep the cognitive load on the learning, not the screen.
5. We Failed to Adapt Quickly Enough, Especially to AI
It took years to reach basic technology integration, and now AI has changed everything overnight. AI literacy is now considered a foundational skill. Districts must embrace AI as a learning partner, train teachers to use it for planning and feedback, teach students to use it ethically, and encourage experimentation. Adaptation is the new literacy, and we need to strike while the iron is hot.
Don’t wait for a district policy to start building your own AI fluency. Experiment with low-stakes, everyday tasks such as planning a trip, organizing a grocery list, or drafting a message so you can explore features without pressure. Take advantage of free professional learning from Microsoft Elevate for Educators, Grow with Google, Code.org’s AI 101 for Teachers, and many others.
And the most important thing you can do right now: be open-minded.
The Train Has Not Left the Station
Edtech did not fail us. We failed edtech by implementing it without vision, guardrails, balance, or humanity.
But we can get back on track. We can return to what my early principal modeled: slow, intentional, joyful integration that starts with people rather than devices. We can build systems where technology supports learning rather than drives it.
The future of education is not defined by more devices or apps. It is defined by smarter systems, thoughtful integration, streamlined tools, and curriculum guiding the choices we make.
On April 19, 2026, the Honor Lightning humanoid robot ran a half-marathon in 50 minutes and 26 seconds, beating the human world record by 7 minutes and the best robot time from 2025 by almost two hours.
How did they do it? Is there some magical technology or technique that unlocked this performance? How did they beat the significantly better-known Unitree (who reportedly had to supply an ice backpack to try and complete the race without overheating)? My doctoral thesis involved building and controlling hopping and running robots, and since then I’ve tried to design and build efficient commercial legged robots, giving me a decent idea of the constraints involved. In this article, we take a look at the fundamental underlying constraints to try and answer these questions.
Running consists of alternating phases of a leg pushing against the ground (“stance phase”) and the body flying through the air (“aerial phase”). In the aerial phase, the body falls due to gravity, losing vertical momentum. The leg in stance phase pushes against the ground to redirect the vertical momentum upward, while the other leg swings forward to reposition for the next foothold.
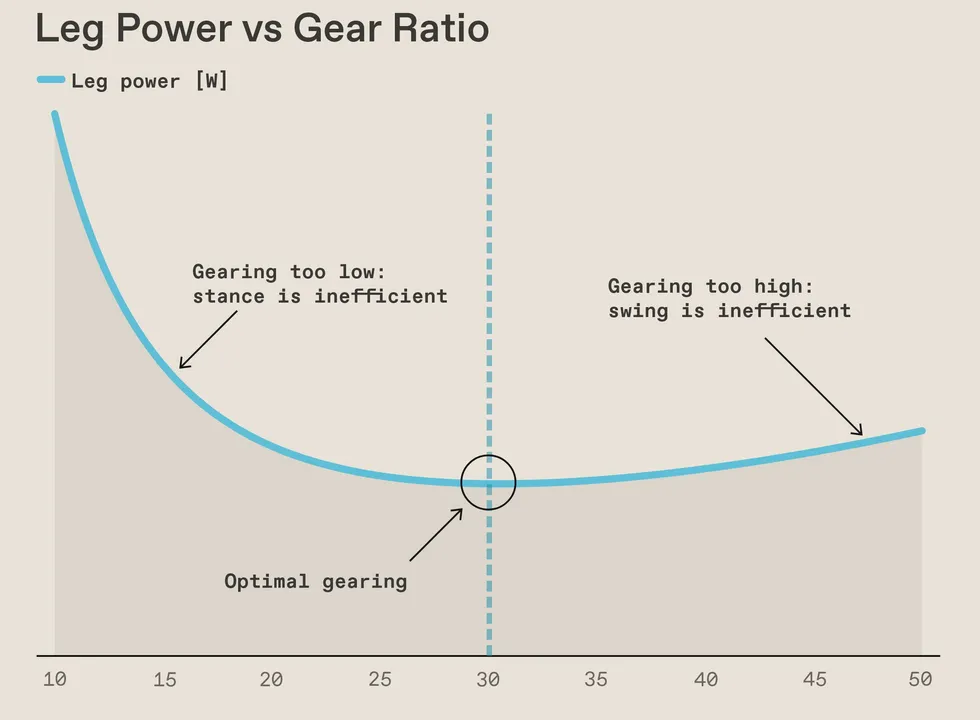
Electric motors use energy to produce torque- the higher the torque, the more energy lost as heat. Adding a geartrain after the motor amplifies its torque and reduces its speed. A large reduction helps with torque production, but since the rotor of the motor itself has to spin faster, it becomes very sluggish at accelerating its output. This is obviously bad for the swing phase described above. These competing effects mean that for a particular motor, there is usually a sweet spot for the gear ratio:
 The power consumed by a robot leg is minimized at an optimal gear ratio (30:1 in this example).Avik De/Datawrapper
The power consumed by a robot leg is minimized at an optimal gear ratio (30:1 in this example).Avik De/Datawrapper
While the Lightning’s motor specifications are not published, the hip and knee motors roughly have a 110-150mm outer diameter. For an approximate set of motor parameters, I looked to the ILM115x25 motor due to its relevant size and detailed specifications.
We can use a simple physics model to estimate the power consumption for running at 7 m/s (the Lightning’s average half marathon speed) as gear ratio varies:
 The light blue curve shows how to pick the optimal gearing (45:1). The dark blue curve shows how much heat will be produced in the knee motor, ~150W for the optimal gearing.Avik De/Datawrapper
The light blue curve shows how to pick the optimal gearing (45:1). The dark blue curve shows how much heat will be produced in the knee motor, ~150W for the optimal gearing.Avik De/Datawrapper
We see that the drivetrain is not magical: with a gear ratio chosen for this task (we’ll return to this below), the approximate robot power consumption would be a very reasonable 400W.
However, the dissipated knee power ( typically the main thermal limiting factor) is ~150W. This is almost an unavoidable consequence — running at human speeds with a humanoid-sized robot will inevitably generate this amount of heat! Over a prolonged period, keeping the motor from overheating would be a challenge, but the Lightning has a trick up its sleeve:
According to Honor, the liquid – cooling pipes penetrate deep into the motors like capillaries. The high – power liquid pump has a heat – exchange flow rate of more than 4 liters per minute. Each of the four drive motors in the lower limbs is equipped with an independent liquid – cooling circuit.
Liquid cooling is not new, but it’s definitely not a commodity. It has shown up in research periodically, and on the commercial side Apptronik tried it for a few of their prototypes but (to my knowledge) does not use it on their main Apollo platform. Basic air convection-based cooling would not continuously be able to extract 150W out of the knee motor, and so the cooling technology is a key enabler of this type of performance.
Why did Honor’s competitors, including more established and widely-shipped humanoids such as from Unitree or Agibot, not compete as well?
We can use the same model to generate an equivalent energetics plot for walking at 1.5 m/s, a much more modest but potentially more common activity for a commercial humanoid robot:
 The solid and dashed light blue lines show a running-optimized design, while green lines show a walking-optimized design. The optimal ratio for walking is much lower (30:1 vs 45:1). However, the power dissipated in the knee motor while running (dark blue) is much higher at 30:1 vs 45:1—the price to pay for running with a walking-optimized design.Avik De/Datawrapper
The solid and dashed light blue lines show a running-optimized design, while green lines show a walking-optimized design. The optimal ratio for walking is much lower (30:1 vs 45:1). However, the power dissipated in the knee motor while running (dark blue) is much higher at 30:1 vs 45:1—the price to pay for running with a walking-optimized design.Avik De/Datawrapper
The plot adds a new green curve for the walking power, and the optimal gearing is significantly different!
Let’s say you design your robot to excel at the normal walking task and choose the green design with 30:1 gearing. The knee motor power to run a half marathon is over 300W (red arrow), more than 2x what we had with the running-optimized design. It wouldn’t be so surprising to need ice packs!
Conversely, visually following the green curve shows that the running-optimized robot wastes more power for walking. Using larger motors sized for running increases the weight of the robot and wastes power when it is standing or walking. The larger motors also pose practical issues like bumping into objects while operating in homes or factories.
Honor’s half marathon performance was an impressive engineering effort and result. It didn’t need any magical leaps in technology, but the deployment of the capillary motor cooling solution is a notable advance without which this running pace would have been unsustainable. The cooling, weight optimization, and robustness advances may well be useful for more practical purposes like carrying heavy payloads down the line.
 The Honor Lighting robot [right] has much larger motors driving its legs than the Unitree H1 robot [left], making it a more efficient runner but a less efficient walker.Left: Wei Zhiyang/Zhejiang Daily Press Group/VCG/Getty Images; Right: VCG/Getty Images
The Honor Lighting robot [right] has much larger motors driving its legs than the Unitree H1 robot [left], making it a more efficient runner but a less efficient walker.Left: Wei Zhiyang/Zhejiang Daily Press Group/VCG/Getty Images; Right: VCG/Getty Images
However, the Lightning is not as well-suited to other tasks as a robot designed for greater versatility. Engineering is always characterized by tradeoffs, and making the correct ones separates good products from great ones. With consistently improving AI language models, this very human skill is becoming the most valuable one an engineer can have.
The news coverage seemed to overly focus on the fact that the human half-marathon record had been broken by a robot. Machines and humans have very different capabilities and constraints, so why should we ever have expected the half marathon time for a robot and human to be related? As in Deep Blue’s 1997 defeat of Garry Kasparov in chess, where it couldn’t physically move the pieces, the Honor robot’s capabilities are much narrower than a human running elbow-to-elbow with other runners while visually navigating the course without GPS. Comparing the robot runner to a human runner is just an apples-to-oranges comparison, and only risks diminishing Honor’s engineering achievement on one hand, and human athletic achievement on the other.
From Your Site Articles
Related Articles Around the Web


Market intelligence platform Klue suffered a OAuth breach that enabled the “Icarus” threat actors to steal Salesforce CRM data from multiple organizations in an ongoing extortion campaign.
Sources told BleepingComputer of the attack yesterday, telling us that numerous organizations had their Salesforce data stolen and were now being extorted by the relatively new extortion group.
Cybersecurity firms ReliaQuest and Huntress have both published reports confirming the security incident, with Huntress stating that their Salesforce data was stolen in the attack.

Salesforce has since disabled the Klue Battlecards integration on its platform while the breach is investigated.
“To protect our customers, Salesforce has disabled the connection between the Klue Battlecards app, installed by individual customers, and Salesforce as part of our response to a recent security incident,” Salesforce warned yesterday.
“As a result, organizations will not be able to connect to Salesforce via this app until further notice.”
If you have any information regarding this incident or other undisclosed attacks, you can contact us confidentially via Signal at 646-961-3731 or at tips@bleepingcomputer.com.
ReliaQuest stated that attackers gained access to Klue Battlecards integration service accounts and used OAuth tokens associated with customer Salesforce instances to carry out data theft.
The researchers observed the threat actors generating OAuth tokens and then using automated Python scripts to query Salesforce’s REST API for nearly 24 hours.
The activity began with reconnaissance of an organization’s Salesforce instances through the ‘/services/data/v59.0/sobjects’ endpoint before exfiltrating data using the ‘/services/data/v59.0/query’.
ReliaQuest said that for one of the organizations, the attackers slowly mapped out their Salesforce objects to identify valuable objects and then rapidly stole data once they knew what they wanted.
“The attacker then hit the same endpoint, sending almost a thousand queries in a 15-minute window in at least one environment,” explained ReliaQuest.
“Where the first stage was a slow, steady pull designed to blend in, this burst traded stealth for speed, suggesting either time pressure or a shift to targeted records. In another case, the exfiltration was observed over 6 hours.”
The researchers said the activity closely resembled previous Salesforce third-party integration data theft attacks by the ShinyHunters extortion group, but were unable to attribute the attacks to the threat actor.
However, BleepingComputer learned yesterday that ShinyHunters was not behind this attack, but rather a relatively new threat actor known as “Icarus” who had already begun emailing extortion demands to Klue customers impacted by the breach.
A ransom note shared with BleepingComputer showed that the emails were sent using the alias “mr bean” and included a Session Messenger ID to contact them.
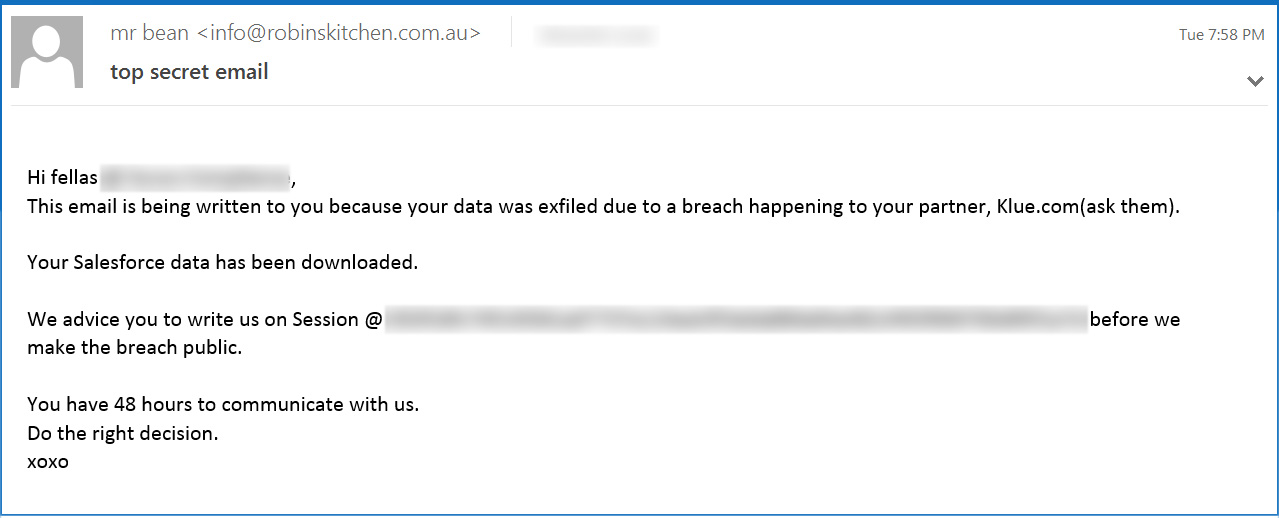
The threat actors’ data leak site also contains a message hinting at the extortion campaign in a simple post titled “Get Ready,” stating, “big corps getting listed. be ready.”
Icarus is believed to have launched in April 2026, and initially listed two victims on its leak site, with BleepingComputer learning that at least one of these victims is connected to the Klue campaign. That company has now been removed from the data leak site, which may indicate that negotiations are underway.
Today, Huntress disclosed that it was among the organizations impacted by the Klue breach, confirming that they had received a similar extortion email as seen by BleepingComputer. However, the Session ID used in later emails was different and was instead the one listed on the Icarus data leak site, providing additional evident that they were behind the attack.
“In the initial email, the adversary suggests, ‘we advice you to write to us on Session’ (sic),” reported Huntress.
“The Session Messenger ID that they provided matched the same values included on the dark web leak site of a new extortion group dubbed ‘Icarus.’”
According to Huntress, Klue told customers that attackers first compromised the company’s backend systems and then pushed a malicious code update that stole OAuth tokens customers use to integrate the Battlecards product with third-party platforms.
The attackers reportedly used a dormant but still active credential created by Klue for a prototype integration. After gaining access to Klue’s environment, they stole customer OAuth tokens and used them to query connected Salesforce environments directly.
Klue later disabled integrations with Salesforce, HubSpot, SharePoint, Zoom, Gong, Chorus, Clari, Google Drive, and Slack while responding to the incident.
Huntress said the stolen data includes CRM-related information, including business contacts, sales communications, price quotes, competitive intelligence reports, and account data.
The cybersecurity company said there was no evidence that threat intelligence, customer telemetry, passwords, payment card information, or engineering systems were compromised.
Both ReliaQuest and Huntress shared IP addresses linked to the attacks, which are listed below:
138.226.246.94
212.86.125.24
213.111.148.90
94.154.32.160
Organizations using Klue integrations are advised to review Salesforce and related SaaS logs for activity originating from these addresses, revoke and rotate OAuth tokens, terminate active sessions, and review Salesforce logs for unusual API activity.
Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


Musicians are accustomed to getting paid each time their creative work is used. Across vinyl/CD sales, streams, radio, cover versions, and those numerous niches like karaoke, there are agreements in place about what “use” means. Underlying this is a simple economic principle: The more something is used, the more money it makes.
Generative AI has complicated the definition of use. On the one hand, you could argue that the use of a piece of musical training data happens just once, at the point of training. On the other hand, creators would be right to complain that the creative essence of their work lives on in the structure of the model, used every time the model produces an output.
Now, companies like Sureel and SoundVerse are working to re-create the essential economic principle that motivates creativity in an era of AI. Such initiatives aim to turn the generative AI industry from one guilty of “the biggest act of copyright theft in history” into one that coexists harmoniously with hardworking artists.
Sureel, a startup Warner Music Group just acquired, has partnered with the Swedish copyright agency STIM to explore the potential for music creators to get paid when their music is used to train generative AI tools. Sureel’s software labels online media, such as a music file, with instructions determined by the owner. The instructions specify whether an AI company may use the media freely in training, limit its influence in any given training set, or avoid it altogether. The software then tracks how the AI company uses the media in training and sets licensing fees accordingly.
Meanwhile, the founders of the AI music company SoundVerse “[reject] one-time royalty buyouts as insufficient and [advocate] for ongoing participation of artists in the AI lifecycle,” they wrote in a 2025 white paper. They argue that each time a generative AI system produces an output, certain pieces of training data play a greater role than others. If the system outputs music resembling jazz, the jazz in the training set has arguably contributed more than, say, the folk music. You can therefore differentially reward each piece of training data for each output.
Sureel’s Co-President Benji Rogers told me, “Attribution isn’t about re-creating the old economics. It’s about measuring, for the first time, the thing the old economics only approximated.”
Such influence attribution needs to do more than superficially measure how similar a training data point is to the AI output. The challenge is to attribute causality, or a relationship between the training data and the trained AI, Sureel CEO Tamay Aykut says.
Even if the AI industry achieved that, however, it might encourage people to create music designed to maximize training-data royalties. While all creative markets lead to new incentives (music streaming, for example, has driven songs to have shorter intros), the industry could do without another economic structure that is easily gamed, in which someone’s reverse-engineered pastiche diverts royalties away from original works of creative expression.
Inferring the influence of a particular piece of music on a generated piece of music, if a well-defined problem at all, may involve more advanced information theoretic principles, or modelling the actual historical role and impact of individual works. Aykut proposes that in carefully designed attribution systems, more unusual and unpolished musical works could even have more inherent value than radio standards.
Simon Gozzi, Head of Business Development at STIM, says the company is in the process of seeing how Sureel’s attribution reports could underlie licensing agreements between musicians and AI companies. Could generative AI attribution strategies not only sustain the economic logic that “popularity pays,” but also motivate musical experimentation and diversity? It’s a compelling concept when public sentiment rightly fears generative AI’s threat to cultural vibrancy, pushing power towards tech companies, deskilling creative workers, shrinking revenue in the creative sector, and filling the internet with slop. “Attribution is one of the few credible tools we have,” Rogers says.
There’s a window of opportunity to debate and establish approaches to paying for AI training data that serve a vibrant and sustainable creative sector.
The technical problem of training data attribution is both complex and ill-defined. Just as a simplistic attribution strategy based on measuring similarity might motivate people to reverse-engineer the canonical works of a genre to capture royalties, a more complex attribution strategy based on some information theory of originality might be easily gamed or fail to reward human cultural production.
For creative workers, there’s good reason to fear that even with the best intentions, AI attribution will only compound the baroque and opaque arms races that they are already weary of navigating. Some voices within the music AI sector are also skeptical. Drew Silverstein, president of SourceAudio, says, “Attribution would seem to be the obvious answer, but it’s flawed in AI, so we have to look at other models.” He advocates simple negotiated agreements with an agreed or annually recurring price at the point of training.
Meanwhile, the copyright lawsuits that have dominated the generative AI revolution are beginning to give way to an increasing number of privately negotiated agreements, such as those between Universal, Warner, and major AI companies to work together on training models with copyright consent. Although little is certain, these agreements may have considerable influence over the industry norms that arise.
Right now, there’s a window of opportunity to debate and establish approaches that pay for AI training data while also sustaining a vibrant creative sector. Sophisticated engineering solutions will have a role to play, but they need to take into account the cultural complexity of the challenge, and enable fairness and transparency through good design.
It remains to be seen whether monolithic generative models such as Suno actually have as much credibility as first touted. In many creative applications of AI, there’s a renewed focus on smaller customized models that are tailored for specific human creative expressive needs such as IRCAM’s RAVE model or Jen’s Style Filters. Meanwhile, more mainstream “end user” creative applications may be shifting towards a focus on fan engagement. OpenAI’s sudden dropping of Sora, despite being in negotiations with Disney and Suno’s recent emphasis on building fan engagement experiences that draw directly on the work of artists, following its deal with Universal, both point to teething troubles in the creative AI sector.
A move to smaller, more targeted models and applications would give more room for creator alliances. For example, collectives of musicians might band together to provide the training data for a smaller custom model, for which revenue splits might be egalitarian or based on other principles of fairness.
The same may possibly be true of hybrid model architectures and structured training regimes where different data sources are used at different points in the training process, as well as retrieval augmented generation, which mixes context-specific information with training data to improve results. An approach that produces worse results but enables fairer or more transparent paths of attribution may be more successful if it brings creators on board with more lucrative royalty flows and even clear credits.
Also, no matter how sophisticated an attribution algorithm is, it will always be grounded in human decisions, ranging from the wise and the fair to the arbitrary and corrupt. Ask a music industry insider to explain how the percentage split between recording and songwriting royalties is determined, and you’re in for a long answer. At best, the machinery of training data attribution will enable open and informed discussion about what makes our creative and cultural sectors fair and vibrant. At worst, it will conceal already opaque private agreements in complex black boxes.
This is where national policies are vital. Attribution must be “multi-layered and auditable, open to expert and regulatory scrutiny,” Rogers says. Crafting such policies will take expertise from computer science, musicology, law, and economics. AI-competitive governments will be able to boost their cultural and creative sectors by supporting institutions that fulfil this purpose.
Even the most neoliberal economies look beyond markets to sustain cultural expression, whether through public arts funding or measures like local music quotas for radio. As the economic impact of generative AI in the creative sector takes form, taxation, redistribution, and active support of cultural infrastructures may still be the most effective way to support positive social outcomes. Taxing big AI and redistributing that revenue back to the creative workers that contributed to the industry’s wealth is, after all, another “AI attribution strategy.”
From Your Site Articles
Related Articles Around the Web

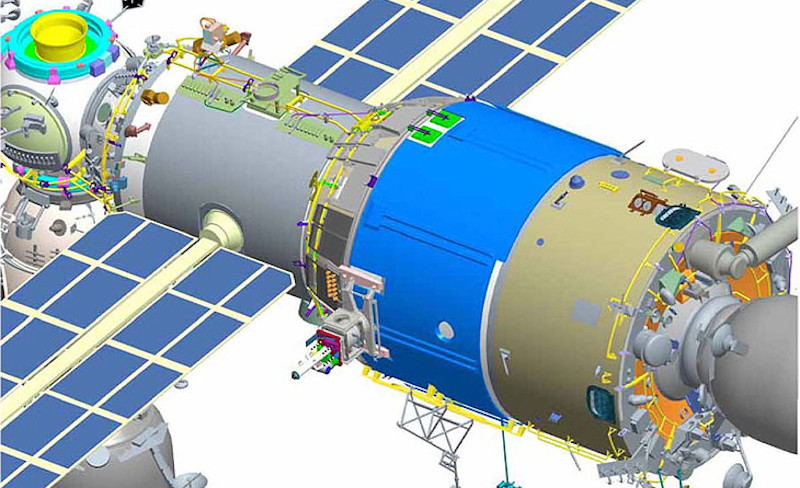
There was a particularly tense moment aboard the International Space Station earlier this month, with NASA directing their astronauts to secure themselves in the Dragon capsule and prepare for a potential return to Earth while their Russian counterparts engaged in what we now know to have been some impromptu demolition work on their side of the orbiting complex.
Despite objections from their American partners, Roscosmos had given their cosmonauts the go-ahead to drill and cut into the walls of the Zvezda module — one of the core components of the ISS which has been in orbit since 2000 — to try and identify and ultimately repair persistent leaks that have been venting the Station’s atmosphere out into space for several years. We may never know the exact nature of the behind-the-scenes communication that went on between the two space agencies, but in the end the Russians abandoned their plan and NASA’s personnel were told to resume their normal duties.
But where do things go from here? Although it’s true the International Space Station is entering its final years, the mission isn’t over yet, and that means the two countries need to continue to work together if they hope to get any science done in the time they have left.
At this point there hasn’t been any official word from either agency, but sources that wish to remain anonymous have been dropping hints, and that’s got the rumors swirling. With the understanding that anything is still possible, at this point it looks like Russia is going to abandon any further attempts to repair the leak and instead seal off the crippled compartment of the Zvevzda module. This won’t solve all the problems, and in fact will create some new ones. But if that’s what it will take to keep the peace with NASA until Station operations wind down, it’s apparently a bargain they’re willing to make.
It probably goes without saying that the best kind of leak on a space station is no leak. Having breathable air is rather important when you’re trying to live and work in space, and while the life support systems on the International Space Station are robust enough to compensate for the steady loss of atmosphere they’ve been experiencing up to this point, there’s always a possibility that the rate of loss could increase and put that balance in jeopardy.
There’s also a chance that the leak is a harbinger for something far more serious — a structural failure of the pressure vessel itself. Even with advanced warning, it would be an existential threat to the entire program if one of the ISS modules literally cracked open. We don’t need to go into details about the potential for tragedy should it occur without warning.
All that is to say, if your orbiting laboratory does have to spring a leak, you couldn’t ask for it to be in a better place than where it is on the ISS. After the Station started losing air back in 2019, the crew was able to narrow it down to the Transfer Chamber at the aft end of the Zvevzda module.
Known as the PrK by the Russians, this small space is a sort of vestibule that connects the inside of the module to the rear docking port, which in turn allows access to visiting spacecraft. The PrK is unique in that it traverses an unpressurized equipment bay; think of it like a tube within a tube. Cracks in the walls of the PrK have been allowing the atmosphere inside the Station to leak out into this unpressurized space even though the external hull of the module hasn’t actually been breached so far as anyone is aware.
The good news is, the easiest and most immediate way to stem the loss of air is to simply close the hatch leading into the PrK. Of course, that means abandoning the docking port on the other side of it.
The Russian section of the Station has multiple docking ports which can be used to transfer crew and cargo, so while having to abandon one of them is hardly ideal, it’s a survivable scenario. It’s fair to say that this would have been a far less palatable solution a decade ago, but now it’s the sort of compromise that you’d expect when working with hardware that’s been in space for more than 20 years.
Shuffling spacecraft between the various docking ports on the ISS has become increasingly common as the fleet of vehicles that can visit the orbiting complex has grown over the years. With more cargo-carrying craft set to come online before the end of the decade, things will only get busier. Losing a docking port would add to the logistical challenge, but there’s no question it will be manageable.
Plus, it’s not as if they would have to stop using the port entirely. While sealing off the PrK passage means crew and cargo will no longer be able to pass between a visiting spacecraft and the Zvevzda module, the same isn’t true for deliveries of gasses and liquids. The plumbing that moves water, oxygen, and the propellants for the Station’s thrusters over from the Progress resupply spacecraft is all run on the outside of the structure and is linked up automatically through connectors in the docking port.
Since crew members don’t need to access the inside of the Progress vehicle to transfer these liquids over, the port can still be used for at least some resupply activities.
While crew and cargo transfers can be performed on an alternate docking port, and Zvevzda’s rear port can still support transferring water and other fluids with the PrK hatch closed, there’s still the question of reboost maneuvers.
Normally, a Progress spacecraft docked to the rear of Zvevzda would use its own thrusters to change the velocity of the entire complex. This is most commonly used to counteract atmospheric drag and keep the Station in the intended orbit, as it would otherwise slowly fall back down into the atmosphere and eventually burn up. This maneuver must be done from the rear docking port of Zvevzda as that allows the visiting spacecraft to push along the center line of the Station.
While these reboosts could still be performed without opening the PrK hatch, there’s a question about whether or not it’s safe to continue putting so much stress on the surrounding structure. In fact, though there has been no official determination made, some believe that the repeated stress of performing the reboost maneuvers from that specific docking port could be one of the factors that lead to the cracks forming in the PrK to begin with.
If NASA and Roscosmos determine that continuing to push the entire mass of the ISS through this structure is no longer safe, their only alternative is to do it from the US side. The Space Shuttle was used to reboost the Station this way before its retirement in 2011, and more recently, a Cargo Dragon specially modified to carry additional propellant demonstrated it could fill this particular role if need be.
If you’ve been following space news for a bit now, this might all sound a bit familiar to you — that’s because this isn’t the first time Russia decided that the best course of action was to simply close the door on the PrK. Going back to at least 2024, the official procedure was for the crew to keep the hatch closed unless they were actively loading or unloading a docked vehicle.
That greatly reduced how much air was leaking out, but as long as crews were occasionally opening up the PrK and moving through it, there was a risk of something going catastrophically wrong. Should the rumors prove true, the difference this time is that the door would stay shut and the PrK would remain undisturbed for as long as the ISS remained in orbit. It’s not exactly a fix, but it’s good enough for an aging space station that’s only got a few more years on the clock.


Building a context layer between enterprise data stores and AI agents is bespoke work, with no standard service to automate or maintain the graphs over time. Amazon is making a direct play to change that.
Amazon on Wednesday entered the space, announcing a series of three products it’s positioning as a context intelligence stack for AI agents. The centerpiece is AWS Context, a new knowledge graph service that gets smarter through agent usage over time. AWS also announced the general availability of Amazon S3 Annotations and a preview of skill assets in AWS Glue Data Catalog.
The context layer is now a contested architectural category with no shortage of options from different vendors. AWS is entering that market with a different architectural premise: that the graph should learn from how agents use it automatically, without human re-curation.
“Your agents now get smarter without you having to rebuild anything from scratch,” said Swami Sivasubramanian, vice president of Agentic AI at AWS, during his AWS Summit NYC keynote.
“This service automatically builds a knowledge graph from all your existing data,” he said. “This service infers relationships across your data sets, business rules, and domain knowledge, and makes all of it available to your agents and your organization at runtime.”
It’s a problem AWS says it has seen repeatedly in customer deployments.
AWS Context maps relationships across existing data automatically: what tables exist, what columns mean, how sources relate and which sources are authoritative. It combines semantic search with graph-level reasoning and infers relationships across datasets, business rules and domain knowledge, making all of it available to agents at runtime.
“The knowledge graph improves itself over time as it learns which sources produce correct results and which parts get used,” Sivasubramanian said.
Data stewards manage the graph through the AWS Management Console, reviewing inferred relationships, promoting them to production and attaching business definitions and usage rules. Every query inherits the calling user’s IAM and Lake Formation permissions, making agent data access auditable by identity through controls enterprises already rely on.
All metadata is published in Apache Iceberg format to Amazon S3 Tables, queryable via Athena, Redshift, Spark or any Iceberg-compatible engine, with no proprietary APIs. Third-party catalog connections are supported, so context from systems outside AWS can be pulled into the same graph. Agents query through agentic search APIs and MCP tools across Bedrock AgentCore, EKS or any MCP-compatible framework.
Context is a complicated space and AWS is layering multiple services to help enterprises build context across the data stack.
Amazon S3 Annotations. This service enables users to attach rich business context at the storage layer, directly to individual S3 objects.
AWS Glue Data Catalog skill assets. Glue skill assets attach domain knowledge at the catalog layer, linking runbooks, query patterns and usage rules to data assets across the estate.
AWS Context then synthesizes both into the knowledge graph that agents query at runtime, combining semantic search with graph-level reasoning across structured and unstructured sources. Each layer feeds the next.
Snowflake announced its context approach earlier this month with its Horizon Context and Cortex Sense services. Microsoft is providing context via its Fabric IQ platform that provides a semantic ontology for data. Redis has developed a context platform that optimizes data for retrieval. Vector database vendor Pinecone has its Nexus context offering that compiles enterprise data into task-specific artifacts before agents ever query them.
AWS’s structural argument is straightforward: for enterprises already running S3, Glue and Lake Formation, AWS Context extends an existing identity model with no data movement required. The pitch is zero-integration friction — not just cost consolidation.
“Context makes agents more powerful and as the whole world is building agents, every agentic platform vendor needs a context capability,” Holger Mueller, VP and Principal analyst at Constellation Research, told VentureBeat.
Mueller noted that AWS is no exception. “The concern — as with all context offerings — is going to be performance, especially for transactional data, we will see,” he said.
In the modern workplace, the line between personal convenience and professional obligation hasn’t just blurred, it has effectively vanished.
At the center of this shift is WhatsApp.
What began as a tool for social connection has evolved into the primary catalyst for a shadow communication era, where enterprise messaging is often conducted in the palm of a hand, often entirely out of sight of the organization.
Head of North America, Movius.
Once viewed primarily as a consumer messaging platform dominant outside the United States, WhatsApp has increasingly become embedded in global business workflows as the go to enterprise messaging platform.
Cross-border client relationships, hybrid work environments, and international collaboration have accelerated adoption among U.S.-based professionals, particularly in industries such as legal services, finance, healthcare, and consulting. For example, monthly active WhatsApp users on iOS in the U.S. have increased 39% since 2020.
Unfortunately, the platform’s ease of use and worldwide adoption have led it to become a ticking time bomb for organizations across all sectors. We are no longer dealing with a minor IT headache, we are facing a multi-billion-dollar legal and operational liability.
In the last two years, global regulators have signaled a permanent shift in how they view corporate communication. The era of firms looking the other way while employees use consumer apps for speed, is over.
Regulators are no longer treating off-channel messaging as isolated employee misconduct. Increasingly, enforcement actions point to systemic governance failures where organizations lacked the controls, oversight, and technology needed to manage modern communication behavior.
The very features that make WhatsApp a boon for personal privacy make it a blind spot for corporate oversight. This creates a fundamental breakdown in three key areas:
Record-Keeping Failures: The “Delete for Everyone” feature is loathed when it comes to regulatory requirements. If a message can be scrubbed from existence at the whim of a user, the firm has failed its duty to maintain an immutable audit trail.
The Encryption Trap: End-to-end encryption is essential for protecting communications from external threats. However, when organizations rely on consumer-grade encrypted apps without enterprise oversight, they may lose the ability to retain records, supervise business communications, or respond effectively to audits and litigation.
The Global Compliance Gap: Utilizing consumer apps often leads to a jurisdictional nightmare. Data flows across borders without the safeguards required by GDPR, while U.S. organizations face growing exposure under HIPAA, SEC and FINRA recordkeeping obligations, and state privacy frameworks such as CCPA and CPRA. The challenge is no longer isolated to financial services or healthcare—it now spans any organization where sensitive customer, legal, or operational conversations occur on unmanaged channels.
We’ve already seen what happens when encrypted messaging apps claim to be secure and then fall victim to breaches, resulting in private and sensitive communications being exposed online. This not only exposes a company financially but puts their brand and reputation at stake.
Law firms are facing a particularly difficult balancing act. The legal sector’s growing embrace of mobile-first communication is reshaping client expectations. Recent industry analysis found that 89% of Am Law 200 firms now deploy mobile applications for client communication or matter management, increasing pressure on firms to balance convenience with governance and discovery obligations.
Clients increasingly expect the speed and convenience of mobile messaging, while firms remain responsible for preserving communications, protecting privileged information, and meeting discovery obligations. This tension is pushing many firms to reevaluate whether consumer messaging apps can coexist with enterprise-grade governance requirements.
Ignoring the WhatsApp phenomenon is no longer a viable strategy. Organizations must proactively transition from shadow messaging to secure, governed ecosystems. To avoid regulatory or security exposure, leadership should consider the following steps:
1. Conduct a Reality Audit: Acknowledge that your employees are likely already using these tools. Survey your teams to understand why—is it the interface, the speed, or the client’s preference?
2. Define the “Off-Channel” Policy: It is no longer enough to have a broad policy. Firms must explicitly define what constitutes business communication and mandate that these conversations occur only on approved, captured platforms.
3. Research Enterprise-Grade Alternatives: The goal isn’t to take away the convenience of mobile messaging, but to provide a compliant version of it. This means implementing solutions that offer WhatsApp messaging experiences for the user while ensuring data is captured, archived, and owned by the enterprise.
4. Analyze Security and Compliance: Before fully adopting a solution, ensure it meets your business needs. Is it compliant with the necessary regulatory bodies? Is archived communication securely transferred and retained? Checking these boxes could make or break your organization’s success.
5. Prioritize Data Sovereignty: Ensure that your communication ecosystem allows you to separate personal and professional data on a single device, protecting employee privacy while maintaining corporate control over business records.
6. Vet Communications Partners Carefully: Organizations should evaluate whether a communications provider can support multiple channels and devices, integrate with existing compliance and archiving systems, provide immutable audit trails, and support regional data residency requirements. Flexibility and interoperability are becoming increasingly critical in globally distributed workplaces.
The WhatsApp time bomb detonates when an organization waits for a regulator to knock before addressing its communication gaps. In an era where a single deleted message can lead to an eight-figure fine, the transition to secure, compliant communication is no longer an IT project, it is a core pillar of corporate survival.
Organizations that thrive in this new landscape will be those that embrace transparency and governance, turning their communication ecosystems from a liability into a strategic asset.
We feature the best privacy tools and anonymous browsers.
This article was produced as part of TechRadar Pro Perspectives, our channel to feature the best and brightest minds in the technology industry today.
The views expressed here are those of the author and are not necessarily those of TechRadarPro or Future plc. If you are interested in contributing find out more here: https://www.techradar.com/pro/perspectives-how-to-submit









No Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw


Weekend Open Thread: Tuckernuck – Corporette.com

Markets Rally as SpaceX IPO Looms Amid Iran Tensions and Inflation Surge

Zimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations


Bitget enters Argentina’s regulated crypto market through PSAV registration


NanoClaw integrates JFrog registries to secure AI agent downloads


This Week In Security: Microsoft On Microsoft, Register Your Domains, Linux On ARM, And FreeBSD Joins The File Cache Club


El Nino has formed in the Pacific and could set records, forecasters say

Donnie Wahlberg & More Heat Up Las Vegas at Circa’s Barry’s Downtown Prime

Opendoor Ends India Operations, Fueling a Bigger Conversation About AI and Outsourcing


FBI searches office of Ohio voter registration group

Anthropic is spending $150M to embed 1,000 AI fellows inside nonprofits. No degree required.

‘The Pitt’s Fan-Favorite Doctor Confirms Noah Wyle Gave His Blessing to Return [Exclusive]


Klipsch Heritage First Listen at High End Vienna 2026: Rebellion, OJAS and Klipschorn Bring the Horns

Ripple and Bitso Bring MXNB Stablecoin to XRP Ledger


Coffee Break: Scarf Waist Belt


Former AWS CEO Adam Selipsky to lead new $10B AI data center venture

Matt Damon’s Viral Sci-Fi Thriller Has Taken Over HBO Max


Anthropic staff to meet White House officials next week, Axios reports


As AI companies race to go public, who else is along for the ride?


You must be logged in to post a comment Login