Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.




Market intelligence platform Klue suffered a OAuth breach that enabled the “Icarus” threat actors to steal Salesforce CRM data from multiple organizations in an ongoing extortion campaign.
Sources told BleepingComputer of the attack yesterday, telling us that numerous organizations had their Salesforce data stolen and were now being extorted by the relatively new extortion group.
Cybersecurity firms ReliaQuest and Huntress have both published reports confirming the security incident, with Huntress stating that their Salesforce data was stolen in the attack.

Salesforce has since disabled the Klue Battlecards integration on its platform while the breach is investigated.
“To protect our customers, Salesforce has disabled the connection between the Klue Battlecards app, installed by individual customers, and Salesforce as part of our response to a recent security incident,” Salesforce warned yesterday.
“As a result, organizations will not be able to connect to Salesforce via this app until further notice.”
If you have any information regarding this incident or other undisclosed attacks, you can contact us confidentially via Signal at 646-961-3731 or at tips@bleepingcomputer.com.
ReliaQuest stated that attackers gained access to Klue Battlecards integration service accounts and used OAuth tokens associated with customer Salesforce instances to carry out data theft.
The researchers observed the threat actors generating OAuth tokens and then using automated Python scripts to query Salesforce’s REST API for nearly 24 hours.
The activity began with reconnaissance of an organization’s Salesforce instances through the ‘/services/data/v59.0/sobjects’ endpoint before exfiltrating data using the ‘/services/data/v59.0/query’.
ReliaQuest said that for one of the organizations, the attackers slowly mapped out their Salesforce objects to identify valuable objects and then rapidly stole data once they knew what they wanted.
“The attacker then hit the same endpoint, sending almost a thousand queries in a 15-minute window in at least one environment,” explained ReliaQuest.
“Where the first stage was a slow, steady pull designed to blend in, this burst traded stealth for speed, suggesting either time pressure or a shift to targeted records. In another case, the exfiltration was observed over 6 hours.”
The researchers said the activity closely resembled previous Salesforce third-party integration data theft attacks by the ShinyHunters extortion group, but were unable to attribute the attacks to the threat actor.
However, BleepingComputer learned yesterday that ShinyHunters was not behind this attack, but rather a relatively new threat actor known as “Icarus” who had already begun emailing extortion demands to Klue customers impacted by the breach.
A ransom note shared with BleepingComputer showed that the emails were sent using the alias “mr bean” and included a Session Messenger ID to contact them.
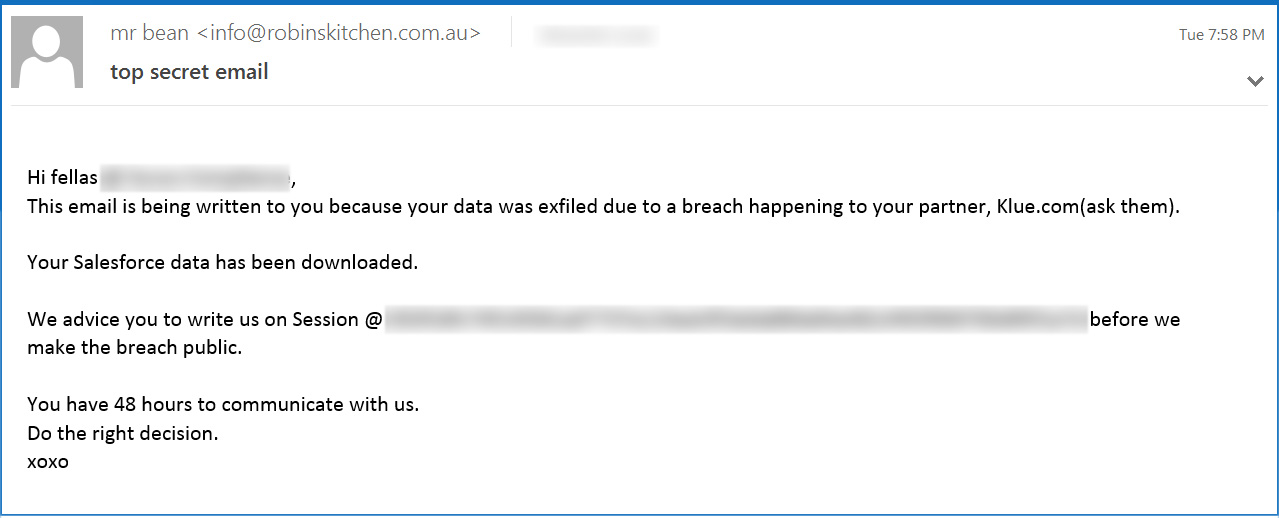
The threat actors’ data leak site also contains a message hinting at the extortion campaign in a simple post titled “Get Ready,” stating, “big corps getting listed. be ready.”
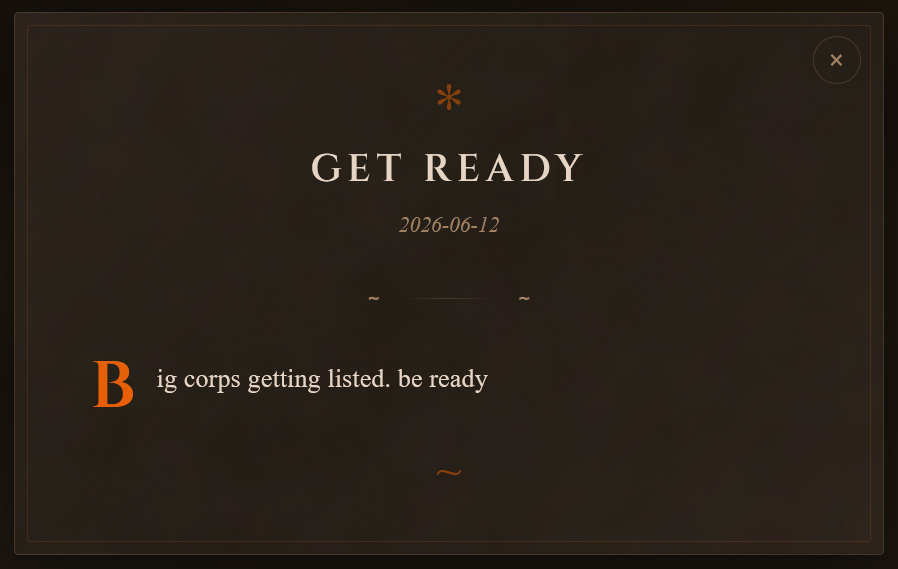
Icarus is believed to have launched in April 2026, and initially listed two victims on its leak site, with BleepingComputer learning that at least one of these victims is connected to the Klue campaign. That company has now been removed from the data leak site, which may indicate that negotiations are underway.
Today, Huntress disclosed that it was among the organizations impacted by the Klue breach, confirming that they had received a similar extortion email as seen by BleepingComputer. However, the Session ID used in later emails was different and was instead the one listed on the Icarus data leak site, providing additional evident that they were behind the attack.
“In the initial email, the adversary suggests, ‘we advice you to write to us on Session’ (sic),” reported Huntress.
“The Session Messenger ID that they provided matched the same values included on the dark web leak site of a new extortion group dubbed ‘Icarus.’”
According to Huntress, Klue told customers that attackers first compromised the company’s backend systems and then pushed a malicious code update that stole OAuth tokens customers use to integrate the Battlecards product with third-party platforms.
The attackers reportedly used a dormant but still active credential created by Klue for a prototype integration. After gaining access to Klue’s environment, they stole customer OAuth tokens and used them to query connected Salesforce environments directly.
Klue later disabled integrations with Salesforce, HubSpot, SharePoint, Zoom, Gong, Chorus, Clari, Google Drive, and Slack while responding to the incident.
Huntress said the stolen data includes CRM-related information, including business contacts, sales communications, price quotes, competitive intelligence reports, and account data.
The cybersecurity company said there was no evidence that threat intelligence, customer telemetry, passwords, payment card information, or engineering systems were compromised.
Both ReliaQuest and Huntress shared IP addresses linked to the attacks, which are listed below:
138.226.246.94
212.86.125.24
213.111.148.90
94.154.32.160
Organizations using Klue integrations are advised to review Salesforce and related SaaS logs for activity originating from these addresses, revoke and rotate OAuth tokens, terminate active sessions, and review Salesforce logs for unusual API activity.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


Amazon Leo has asked the Federal Communications Commission to approve its plan to launch up to 5,105 satellites capable of providing space-based connectivity for mobile devices.
“Our plan is to start deploying in 2028, and we’re excited to work with partners to make it happen,” Chris Weber, vice president of business and product for Amazon Leo, said on X.
The direct-to-device network, Amazon Leo D2D, would complement Amazon’s satellite network for high-speed internet service via fixed antennas. It would also leverage the existing direct-to-device network operated by Globalstar, which is in the midst of a merger with Amazon.
So far, more than 390 Amazon Leo satellites have been launched into low Earth orbit, and Amazon says it plans to start rolling out commercial service later this year. The company plans to have 3,232 first-generation satellites in orbit by mid-2029, and the FCC has already given the go-ahead for more than 4,500 second-generation satellites that would give an extra boost to network coverage.
This latest move, which was expected ever since the plans for acquiring Globalstar were announced in April, aims to capitalize on the growing interest in direct-to-device connectivity.
“In the large parts of the world where mobile phones serve as the primary means of internet connection, the Leo D2D System will give customers greater speed and throughput to expand what they can accomplish today,” Amazon said in a news release. “The system is designed to reach any compatible mobile device — including any of the growing number of smartphones from major manufacturers that have satellite-capable chipsets built in.”
In addition to services for individual users, direct-to-device service can provide uninterrupted communications for disaster response, global fleet management, remote operations across worksites and supply chains, and connectivity for remote sensors, Amazon said.
Globalstar’s network already supports emergency SOS, dead-zone texting and roadside assistance for compatible iPhones and Apple Watch models, and Amazon said it would collaborate with Apple on future satellite services using the expanded network.
The FCC application calls for deploying satellites in five orbital shells, ranging in altitude from 510 to 580 kilometers (317 to 360 miles). The satellites would communicate with each other via optical laser links, with mobile devices using L-band and S-band radio frequencies, and with Amazon ground stations via Ka-band and V-band frequencies.
Amazon Leo has already announced partnerships with telecom operators including Vodafone, DirecTV, Herotel and Australia’s National Broadband Network. Amazon said its D2D service would help those partners fill in their coverage gaps.
Direct-to-device is an emerging frontier in connectivity, but that frontier is already starting to get crowded. SpaceX’s Starlink Mobile network is currently leading the pack, in partnership with T-Mobile and other telecom operators around the world. Other players include AST SpaceMobile, Orbcomm, Viasat, Lynk Global and Iridium.
In its application, Amazon pledged that its network would be structured to minimize interference with other networks.
Why you can trust TechRadar
We spend hours testing every product or service we review, so you can be sure you’re buying the best. Find out more about how we test.
When I first caught a glimpse of The Adventures of Elliot: The Millennium Tales, it sparked a great sense of anticipation within me. After all, Square Enix and Claytechworks were collaborating to bring a brand new HD-2D RPG to the table, which appeared to combine sprinklings of classic Zelda titles with the visual, sonic, and environmental grandeur from series such as Mana and Dragon Quest.
Review info
Platform reviewed: PS5
Available on: PS5, Nintendo Switch 2, Xbox Series X and Series S, PC
Release date: June 18, 2026
I’m a huge fan of the HD-2D graphical style, and massively enjoyed recent releases such as Final Fantasy: The Ivalice Chronicles and Dragon Quest 1 & 2 HD-2D Remake, but I still wasn’t quite sure if I’d love The Adventures of Elliot. Was the action combat going to be polished and engaging enough? Was the world going to deliver the spectacle and appeal conjured up with other series? Would the narrative have me hooked?
Well, after playing the game for more than 25 hours now, I have an answer to all of those questions. Here’s what I made of The Adventures of Elliot: The Millennium Tales.
Latest Videos FromTechRadar

Let’s start by addressing my curiosity surrounding combat in The Adventures of Elliot — just how good is it? Well, I’m pleased to report that I had a lot of fun with the action in this game. It clearly pulls on 2D Zelda, with real-time combat that challenges you to use a variety of weapons to overcome your foes.
You can equip two weapons at once, and while I typically used my sword for close range attacks and bow for projectiles, I found genuine utility in a lot of equipment, be that bombs, a hammer, spear, and more. Combat feels fluid, responsive, and well balanced. You can also defend or parry with a shield, and using this to avoid big damage can be crucial.
There’s a pretty fast, high-octane feel to battles, big or small, and by defeating multiple foes in a row, you can build up a streak to obtain better drops. This adds a layer of fun to combat, and gives you a genuine reason to seek out and destroy random creatures in your vicinity — I had a lot of fun pushing myself to get that streak as high as possible.
Combat is absolutely at its best during boss fights, though. These can offer genuine challenges, and often require you to switch up attacks, defend with care, and employ a variety of weapons to get the win. The satisfaction I got when evading a robotic titan’s assault and slashing it to smithereens with my blade was nothing short of exhilarating.
Best bit

The highlight of this game is without question its majestic boss battles. Whether I was taking on Minister Kaifried or a bunch of deadly robotic guardians, I enjoyed making use of my full arsenal of weapons in order to emerge victorious.
What’s more, you can customize weapons with something called Magicite, which imparts specific abilities to help you wipe out the opposition with greater ease. This is executed very well, and helps you to raise attack power, unlock elemental attacks, and extend the reach of your attacks, for instance.
By spending more Tul (the in-universe currency), you can use more Magicite, and this helps you scale in terms of power as the game unfolds, making progression feel natural and well-paced.
Other gameplay elements are solid too. Platforming isn’t a massive part of the game, but feels precise and smooth. Your companion for most of the journey, Faie, also has abilities such as dashing and warping, which make traversing environments and taking down enemies even more varied and seamless, and you can unlock more of — and improve on — said abilities as the game progresses.

So, the gameplay in The Adventures of Elliot is a hit, in my book. The brilliant bosses and close contests against frogs, robots, slugs, and more kept me coming back for more. But unfortunately, some things made me feel reluctant to indulge in long, uninterrupted play sessions — namely, the game’s narrative and dialogue.
Simply put, the story in The Adventures of Elliot lacks the spark that I was looking for. It often feels flat, lacking moments of surprise and suspense, and its largely predictable plot points paired with sluggish and dull dialogue meant that I was tempted, at times, to skip through a few scenes — something I never do with story-driven RPGs.
On top of this, the cast of characters is surprisingly weak for a Square Enix game. The protagonist, Elliot, feels somewhat hollow, and spends much of the game telling people to follow their heart, chase their dreams, and to believe in themselves. To be blunt, it feels a bit sappy, and despite his striking appearance, he’s actually quite an uninteresting lead.

A lot of the other characters are written in a slightly wooden way, too. Elliot will meet them, they’ll reveal something that troubles them — be that isolation, missing a loved one, or seeking connection with others — the hero will do something to assist them, and then you move on. As a result, characters often lack nuance or depth, and it feels hard to care about the various individuals involved.
Like a lot of other players have pointed out online, your companion, Faie, is also rather irritating. She speaks up…a lot…and her hand-holdy, pointless interjections can feel grating. You can mute your companion, thankfully, which is a good thing given that the fairy’s high-pitched tone is still haunting me.
Much of the game is centered around time travel, another element that could’ve been handled more effectively in my view. A lot of the environments look identical across different eras, and enemy variety can be pretty limited across time as well.
I did like the discoveries you could make across different ages, though, and hunting for new weapons in the various dungeons, and general exploration, was pretty enjoyable. My critique here, however, is that the puzzles within various areas are very easy, and require little effort to overcome. Therefore, anyone seeking out the ingenious design of classic Zelda dungeons may be left wanting more.

The Adventures of Elliot still nails a lot of the fundamentals, with a beautiful soundtrack, gorgeous HD-2D visuals, and a neat UI. But when I look at the full package, I’m left feeling conflicted.
While the combat is slick and enticing, the underwhelming story and lack of variation in environments and enemies slightly disappointed me.
Although I still had a decent time with The Adventures of Elliot, and I enjoyed its delicious HD-2D graphics and high-octane battles, it’s clear that the new IP has gone through a few growing pains. And unfortunately, its forgettable characters and lacking dialogue bring the overall experience down a touch, meaning it doesn’t quite hit the highest of heights.

There are a number of ways to customize the experience in The Adventures of Elliot: The Millennium Tales. There are a handful of text languages, and you can swap between English or Japanese voices. You can alter text display speed, and set dialogue to auto if you want to watch scenes unfurl naturally.
There are a range of difficulty modes too, and you can remap controls to your liking for a more custom experience. Unfortunately, there’s no colorblind mode, or similar.


I spent more than 25 hours playing through the main story and side quests in The Adventures of Elliot: The Millennium Tales. I played on Normal difficulty in this instance.
For the most part, I played the game on my PS5, which is connected up to my Sky Glass Gen 2 TV and Marshall Heston 120 soundbar. However, I occasionally dipped into the title on my PS Portal, and used the Sennheiser CX 80U to enjoy in-game audio while on the go.
More generally, I’ve reviewed a wide range of games here at TechRadar, though my main focus has been on RPGs, including Square Enix titles like Final Fantasy: The Ivalice Chronicles and Dragon Quest 1 & 2 HD-2D Remake.
First reviewed: July 2026

wiredmikey shares a report from SecurityWeek: Nvidia and a large group of technology, cybersecurity, and enterprise software companies have launched new initiative aimed at developing and sharing open source tools, models, and techniques for securing AI systems and agents. The new Open Secure AI Alliance aims to give defenders more open tools for testing, auditing and protecting AI models and agents. Nvidia points to the recent security incident involving OpenAI and Hugging Face, noting that when closed AI tools could not differentiate between attackers and defenders and blocked forensic work, Hugging Face used the open-weight GLM 5.2 model on its own systems to review over 17,000 actions and contain the breach. “The right response is not to deny defenders access to capable open systems. It is to pair openness with strong safeguards, clear rules against malicious misuse, rigorous evaluation and rapid remediation. In cybersecurity, the safer path is the one that gives more defenders the ability to test, verify and strengthen the systems on which society relies,” Nvidia said.
Thanks to longtime Slashdot reader SphericalCrusher for also sharing the news.

Arizona State University has launched a 120-credit bachelor’s degree in content creation that teaches video, podcasting, branding, analytics, media law, and social strategy. For their capstone, students are “expected to build a real social media account and demonstrate audience growth during the program,” reports Dexerto. From the report: The Content Creation BA is housed within ASU’s Walter Cronkite School of Journalism and Mass Communication and appears in the university’s 2026-2027 course catalog. The 120-credit-hour degree prepares students to become “an influencer and strategic storyteller” by teaching video production, podcasting, personal branding, audience analytics and social media strategy. The program was approved by the ASU University Senate in March 2026. Its proposal said graduates would be prepared to work independently as influencers and content creators across livestreaming, videography, writing, podcasting, graphics and emerging media.
[…] For the program’s final project, students will choose a social media platform, such as TikTok, create a content and growth strategy, and attempt to gain real followers throughout the semester. “They will have demonstrable audience growth,” [explained Jessica Pucci, senior associate dean at the Cronkite School]. “They will have a platform of their choice with real content and real followers and a real audience behind them.” The curriculum includes courses titled How to Become an Influencer, On-Camera Presence, Introduction to Editing, Videography, Podcasting and Audio Storytelling, Social Media Foundations and The Digital Audience.


You’ll almost never see a negative comment about the Mazda MX-5 Miata thanks to its go-kart-like handling, affordable price point, and adorable design. But there’s one problem, which was even highlighted in our own review of the latest Miata: the cabin and cargo room is lacking. Hey, nobody said the Miata was practical. However, a lot of people still wonder if they can fit golf clubs inside the Miata. I mean, cruising to the course with the top down sounds like a dream. But is it possible?
Whether you get the Sport, Club, or Grand Touring variant of the Miata, you’re getting the same cramped interior space. The headroom is 37.4 inches, the shoulder room is 52.2 inches, the hip room is 52 inches, the legroom is 43.1 inches, and the cargo volume is 4.59 cubic feet. And there are many small cars with larger trunks than the Miata.
Golf bags range in size from 34 to 38 inches for stand bags and 38 to 42 inches for cart and tour bags. Generally, a golf bag cannot lay flat inside of a Miata’s trunk since they are longer than the length of the trunk and it’s not deep enough to lay it diagonally. Even some individual clubs are too long. Alternatively, you can put the golf bag in the passenger seat if nobody is sitting there.
For many car enthusiasts, the small cargo space of the Miata is a deal breaker despite all of its other positive features. The Miata makes for a comfortable and fun commuter, but not having room for hobby supplies and having no room for luggage does make the Miata fall short for some families. SlashGear’s Chris Davies noted in his review that “there are EVs with bigger frunks than the Mazda’s trunk” (although Ford will charge you for that now). He then added that there are is no traditional glovebox in the cabin either.
Sports cars, to be fair, are not known for their trunk space. However, there are a handful of options that can fit a golf bag if you want a weekend cruiser that gets you to the green. For example, the Honda Civic Type R has 24.8 cubic feet of cargo volume while the Volkswagen Golf GTI has 19.9 cubic feet — and both of these cars are cheaper than the Miata. If you want to splurge a bit, the BMW M3 has 16.9 cubic feet of cargo space.

Anthropic founder and CEO Dario Amodei responded on Monday afternoon to murmuring in the industry that his company somehow supports efforts by the U.S. government to ban open-weight Chinese models, or possibly open-weight models generally.
“Anyone who has read my past writing should know that I don’t regard such bans as a useful measure, but let me state it clearly so that there is no doubt: Anthropic has never advocated for a ban on open-weights models,” he wrote, emphasis his own.
His response came after Nvidia founder and CEO Jensen Huang took to X (his first post on the platform) to share an open letter on Friday in which Nvidia and a long list of other AI companies including Hugging Face, Meta, Microsoft, Mistral, and Nvidia urged policymakers not to impose broad “premature restrictions” on open-weight AI models.
While that letter did not mention China specifically, the debate in the industry has centered on allegations that Chinese AI labs are growing in capability often by stealing intellectual property from their American counterparts. One method is distillation, where an AI bombards another model with prompts to learn how it works.
Amodei said in the blog post published Monday that he views open-weight models as falling into a different bucket than the threat China poses. “Open-weights models that don’t have dangerous capabilities are a public good: they don’t cost anything besides the compute needed to run them, and they provide value to businesses, developers, and researchers.”
Amodei said in his post that he has longstanding fears about AI, but businesses using open-weight models, even ones from China, are not among them.
His fear is that “authoritarian governments” will build models that are more powerful than those in the U.S. to achieve “permanent military superiority” and/or use AI to repress their own people. He said the Chinese Communist Party (CCP) isn’t the only authoritarian government he’s concerned about, but it is the “most capable.”
Amodei also said he fears AI will enable “biological attacks” not just cybersecurity ones. And, in his view, open-weight models are more dangerous in those scenarios because it’s difficult to apply guardrails to them or monitor their usage. He also noted, citing a UK AI Security Institute report, that once open-weights are released they cannot be withdrawn
This runs counter to what open source advocates argue: that access to powerful open models not controlled by a single entity helps defenders protect themselves.
Amodei listed actions he believes would thwart China, including restricting its access to powerful chips (which has been a longstanding U.S. policy) and calling for a formal crackdown on distillation. The U.S. has threatened sanctions against China if it determined there was IP theft involving U.S. models.
Interestingly, Amodei also said he supports growing efforts, some led by the U.S., to create a model safety testing organization, especially if the entire world, including China, agreed to submit to it.
“I think this idea is actually close to a consensus: I have been heartened both that the Trump administration has moved in this direction in recent months, and by recent industry proposals that would apply such testing to the most capable models regardless of their country of origin or whether they are open or closed (while exempting less capable models, such as those from startups and academia, entirely),” Amodei wrote.
“Note that to be effective,” he added, “testing would need to be global, which means even the CCP would need to be on board. I think this may actually be possible … limited cooperation around preventing AI biological weapons may be possible because it is in China’s interest too.”
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.

It’s not as if John Ternus was likely to shut down Apple TV, but he has now affirmed that it will continue to develop when he becomes Apple CEO.
If you subscribe to the argument that Apple should be making hardware devices instead of TV shows, you could have expected engineer John Ternus to agree. Or at least that his focus as CEO would be on devices instead of movies.
Speaking at the launch of the new fourth season of “Ted Lasso,” Ternus said all the right things to reassure Apple TV viewers and staff. According to Reuters, he described Apple TV as amazing.
“I think we have such tremendous momentum right now on Apple TV,” he said. “There’s so many amazing shows, so many amazing characters and stories, and so we’re just gonna keep building on that momentum.”
Tim Cook was also at the “Ted Lasso” launch and talked about the aims he has had since the start of the streaming service in 2019. “Our role is to be the best, that’s our lane,” he said.
“We’re not about the most, there are… other companies that do that,” he continued, “but we’re about the best, and I feel like we really hit our stride in providing that.”
Cook also said that the intention with Apple TV is to produce shows where the company thinks it can be unique. “Where we can innovate in a way that others might not be able to,” he said.
Season four of “Ted Lasso” was launched on July 27, 2026, at the Academy Museum in Los Angeles. It’s debut on Apple TV is on August 5, 2026.
This story was originally published by ProPublica. Republished under a CC BY-NC-ND 3.0 license.
For decades, the U.S. Department of State gave money to groups protecting free speech, human rights and persecuted minorities in poor and authoritarian countries.
To decide what to fund, staffers with deep expertise typically pored over reams of information on abuses under the most repressive regimes and held an open competition to fund groups to work in those countries.
This year, Trump administration officials presented State Department workers with their own list of organizations that should be funded. To the shock of many staffers and lawmakers, they proposed at least a dozen grants that would bypass the normal open bidding process. They also sought to give taxpayer dollars to groups aligned with conservative and anti-immigration movements in Europe as well as advocates for white South Africans, according to interviews and documents reviewed by ProPublica.
Among the organizations appointees have considered funding in recent months are a British free-speech organization that has fought against bans on “gay conversion therapy” and an Afrikaner group run by a controversial figure who has called for self-governance of the white ethnic minority within South Africa.
This type of giving would mark a stark departure from the traditional aid that helped torture victims and documented rapes, political violence and other abuses in some of the most oppressive countries in the world, according to more than a dozen former State Department employees. One new program with $4.9 million of competitive funding available to groups to develop “civilizational self-confidence in Europe” is slated for “research, conferences, cultural engagements, and support for civil society” in wealthy democracies. The call for proposals says recipients should “not attempt to reform the legislative processes,” but experts and lawmakers have expressed concern that the U.S. is seeking to influence politics in allied countries.
That emphasis on Western nations was evident in a grant the State Department has been working on for months to a fledgling British American think tank dedicated to “renewing our Judeo-Christian culture and civilisational mission.” After pushback from Congress, the State Department abandoned those plans in recent days.
“I’ve never before seen U.S. government funding for such groups,” said William Allchorn, a senior research fellow at Anglia Ruskin University and an expert on radical-right extremism in the United Kingdom. “It’s crossing the Rubicon, isn’t it?”
A review of proposed grants shows several are being directed to more traditional human rights purposes, but even some of those have raised concerns in and outside the State Department.
Strict agency rules have long required an open bidding process whenever possible to guard against waste, fraud and abuse. Generally, the State Department is allowed to offer awards directly to a single entity or to a small group of potential grantees in rare instances, such as when only one organization is capable of the work or an emergency necessitates providing money so quickly that open competition is impossible. It has also used such “sole-source” and “limited-source” awards, which are not publicly announced, in highly sensitive countries where openly working on human rights can be dangerous.
None of those justifications appear to apply here, according to contracting experts and former staffers consulted by ProPublica. The situation is all the more concerning, they said, because Trump officials handpicked the potential recipients, decisions previously made by a panel of government experts who evaluated applicants based on the organizations’ experience and qualifications.
“It’s not good governance to have political appointees give grants to individuals for unknown reasons,” one former bureau staffer said.
Directing awards to organizations in high-income countries further complicates the funding. The practice is so unusual that an internal waiver justifying the choice is typically required.
The State Department did not answer when asked whether it had sought waivers for the grants to high-income countries.
During private briefings this month, members of Congress expressed concern over both the list of potential recipients and the plan to award no-bid or limited-bid grants, according to officials familiar with the closed-door meetings who weren’t authorized to publicly discuss them.
In response to a detailed list of questions about this story, the State Department sent a short written response, noting that “programs are still in active deliberation and receipt of a grant is not guaranteed to any organization that does not meet all requirement and standards for federal grants.” A State Department official who declined to be named stressed that the process for awarding grants was ongoing and that multiple offices provide input. They also said the administration has serious concerns about the human rights situation in South Africa that need to be addressed.
Asked about the potential grants, Sen. Jeanne Shaheen, a Democrat from New Hampshire and the ranking member of the Senate Committee on Foreign Relations, said Congress expects the State Department “to invest resources to advance human rights, democratic institutions, civil society, freedom of expression and worker rights” and that the proposals are “an appalling departure from that practice and an affront to our democratic allies.”
“These awards suggest that the Department intends to select awardees for federal funding based on their political ideology,” Shaheen said, “not in the interest of American taxpayers or national security.”
Internal records and interviews show one of the key figures involved in the grants is Samuel Samson, a 27-year-old deputy assistant secretary of state who previously worked as a fundraiser for a group that aims to bring people with an “America first” worldview into government.
On the day of President Donald Trump’s second inauguration, Samson started work as a senior adviser to the Bureau of Democracy, Human Rights and Labor, also known as DRL, the State Department unit that selects and distributes the human rights grants.
Over the past 18 months, he has courted far-right leaders in Europe, an area with which he believes the U.S. shares a “common civilizational struggle.” In recent weeks, Samson has defended the agency’s grantmaking plans during private meetings with lawmakers.
One group expected to receive a no-bid grant is the Free Speech Union, a British organization founded in 2020 to counter “cancel culture.” The group often steps in to defend people accused of being transphobic and has created a petition opposing the U.K.’s proposed ban on discredited therapy practices that attempt to convert gay people to heterosexuality. It’s unclear if the grant would go to the British-based organization or its international offshoot. The $5 million grant is to be used to combat “digital overregulation,” provide support for individuals facing “deplatforming” and advocate against “restrictive online safety and hate speech laws,” according to a document reviewed by ProPublica. Trump officials met with the group during a European tour late last year, according to Politico.
Scholars said the U.S. government’s support for these groups could give them a layer of legitimacy they wouldn’t otherwise have.
“We see them as intellectualizing or sanitizing radical-right ideas that are then taken up by the parties in power,” said Allchorn, the U.K. extremism expert.
The Free Speech Union’s website says it is nonpartisan and does not take government funds. In response to questions from ProPublica about the potential grant, the organization’s founder, Toby Young, said, “We have neither applied for nor been awarded a grant from the US State Department or any other branch of the US Government.” He did not respond to criticisms about the award or his organization.
The largest award the bureau has put forward this year, $40 million, is for the Victims of Communism Memorial Foundation, which was created by Congress and signed into law by President Bill Clinton. The foundation’s goal is to memorialize those killed by communist regimes and pursue freedom for people still living under totalitarian rule.
The proposed sum is staggering to people familiar with the State Department’s allocation practices and would dwarf the organization’s budget. Victims of Communism has received a handful of government grants in the past, but for much smaller sums. Its most recent publicly available tax forms, from 2024, show its total assets come to about $12 million. Four sources familiar with the foundation’s previous U.S.-funded work questioned its ability to manage such a large award.
Samson has a personal connection to the organization. The foundation’s board chair, Elizabeth Spalding, is a visiting fellow at a graduate school branch of Hillsdale College in Washington, D.C.; Samson was enrolled in the same small graduate program of the Christian conservative college as recently as this year, according to his LinkedIn profile (which is no longer publicly available). Spalding’s husband, Matthew, is that graduate school’s dean, and Samson has taken classes with one or both of them, according to a State Department official.
The State Department official who declined to be named said Samson’s relationship with the Spaldings had nothing to do with the grant.
The foundation’s proposed award is to “amplify the voices of dissidents and political prisoners while educating global audiences about the dangers of communist and authoritarian regimes,” according to a document reviewed by ProPublica.
In response to questions from ProPublica about the award and concerns about its ability to manage it, the foundation said it was not aware of the proposed funding, but “if true, the 100 million victims murdered by communism in the past, and another 1.5 billion men, women, and children still enduring communism today will rejoice.”
The State Department declined to comment on awards in process but noted that Victims of Communism has long worked with the State Department. “As President Trump has said, communism is a mortal threat to American liberty — and as Secretary Rubio has repeatedly emphasized, America will not allow radical extremists to undermine our sovereignty and national security,” the agency said in a statement. “Our foreign assistance programming is aligned to support our strategic priorities.”
Trump officials are also planning to finance at least one organization to research crime and atrocities against minority populations in South Africa. This spring, DRL staff were initially told to begin the process of awarding funds to Lex Libertas, a South African organization founded by a prominent member of the nation’s white Afrikaner movement. The group, which claims that white South African farmers are victims of racial discrimination and violence, is fundraising to place 3,000 white crosses on the National Mall in remembrance of attacks on South African farmers.
The proposed award to fund the South African crime research was later widened to allow other invited groups to apply for a $1 million grant, according to people with knowledge of the process. The State Department declined to say whether Lex Libertas will be among those invited to compete, saying the grant is still under deliberation.
Extensive research shows white South African farmers are not victims of crime at higher rates than other groups. But Trump has argued there is a genocide of white South Africans and is using claims that white people are subjected to disproportionate violence to justify cutting off South Africa’s funding for HIV treatment and research.
Former diplomats told ProPublica that it makes little sense to focus on the victimization of white South Africans given the enormous suffering elsewhere in the region. “It’s laughable to suggest that on the African continent, the prime issue of human rights concern is whites in South Africa,” one former agency official told ProPublica.
Lex Libertas did not respond to questions.
One of the most controversial grants that officials singled out for funds was recently dropped, the State Department official told ProPublica. The decision came after Democratic lawmakers raised objections during briefings last week about the months-old organization and its agenda. That grant was to 878, a British American think tank created this year focused on “existential threats to Britain, to America, and to our shared Judeo-Christian civilisation,” according to its website. The sole-source $7 million grant aimed to advance “Anglo-American values” in the U.K., Europe and “allied partner countries,” according to a document ProPublica reviewed.
878 did not respond to questions.
Since creating a bureau to focus on human rights in 1977, the State Department has championed human rights and democracy in more than 100 countries. Its awards have sought to support documenting and investigating rapes committed during political violence in Burma; preventing torture in Tunisia and rehabilitating torture survivors in Syria; and combating pervasive sexual violence in Mauritania.
Since at least 2011, as anti-LGBTQ+ laws and violence spread globally, the bureau added a specific focus on people persecuted for their sexual orientation or gender identity.
Throughout most of its existence, DRL has enjoyed bipartisan support. Democrats applauded its championing of international labor standards and marginalized communities, while Republicans favored its defense of democratic freedoms in China, North Korea, Cuba and other communist countries. As a senator, Marco Rubio was a strong supporter of the bureau and human rights broadly, once arguing from the Senate floor that safeguarding the freedoms of gay men who were persecuted in Chechnya — and all people — was in the national interest. In 2018, he urged the president to appoint an assistant secretary to oversee DRL, a post Trump had left vacant for over a year.
But after Rubio became secretary of state in January 2025, the fate of DRL dramatically changed. Trump suspended all foreign aid in his first week in office. Within months, cuts by Trump’s newly installed Department of Government Efficiency decimated the bureau, and Rubio closed most of its offices. In April 2025, Rubio published a Substack post smearing the bureau he once championed as “a platform for left-wing activists to wage vendettas against ‘anti-woke’ leaders.”
Samson also sent shock waves through the bureau. In March, he traveled to the U.K., meeting an anti-abortion protester and the anti-immigration politician Nigel Farage. In his own essay on the State Department’s Substack, Samson lashed out at the U.K. for arresting anti-abortion protesters and at Germany for labeling its hard-right Alternative for Germany party “extremist,” likening the countries’ actions to the “censorship, demonization, and bureaucratic weaponization” used against Trump.
Meanwhile, DRL’s remaining skeleton crew was tasked with removing trigger words from documents. “We would try to talk about human rights defenders in talking points, only to have them struck,” said one former bureau employee, requesting anonymity for fear of retribution.
“We went from having a real, dynamic appreciation for individuals and their human rights and fundamental freedoms to erasing that, especially if individuals were part of an underrepresented group or marginalized community,” the former employee said.
The bureau is working with a severely reduced budget — about $190 million compared with over $500 million in 2024. Now the administration is preparing to put money behind its new priorities.
“We’re just implementing the agenda of the president as we’ve been directed through the national security strategy and the White House,” the State Department official told ProPublica.
Filed Under: bigotry, donald trump, europe, racism, samuel samson, south africa, state department, uk
Companies: free speech union, lex libertas


Washing machines can save us a lot of time and effort when it comes to keeping our clothes clean and fresh. But like many appliances in our home, they also require cleaning themselves to be able to operate properly. While Whirlpool washers are known to usually last around a decade, this number isn’t set in stone. In reality, how long your machine will last really depends on how well you’ve taken care of it.
While some signs that a washing machine is about to break can be quite obvious, others can take more time to spot. However, if you notice that your machine also isn’t draining properly before, during, or after a wash (or you’re getting drainage-specific error codes), there’s a big chance that you need to look at your drain filter. In that case, you’ll need to find it on the bottom of your washing machine — possibly from behind its storage drawer, depending on the model you have.
When washing our clothes, it’s normal for lint and debris to clump together. In some cases, things like coins, buttons, and other small items also end up where they shouldn’t be. Because of this, manufacturers included a drain filter to prevent foreign objects from damaging your washing machine. Once it gets packed, we need to clean the drain filter so it continues to do its job. First, it’s always a good idea to turn off and unplug it first to avoid electric shocks. Finding the filter from there is a simple matter, but accessing and cleaning it could be another story.
On Whirlpool washing machines with storage drawers, the drain pump filter is located behind the dispenser drawer that is found at the bottom part of the machine. To remove the drawer, you’ll want to press the tabs located on both sides. On the right side, you’ll need to release the tab by pushing it down. On the left side, you’ll want to pull the tab upwards. But if you have a Whirlpool washing machine without a storage drawer, you won’t have to go through all of this since you can easily access it from the panel door.
Once you’ve found your drain pump filter, the process for cleaning is the same. First, you’ll want to manage the possible spills by having either a shallow tray or broad flat container on-hand to catch both the water and the debris. Grab the black hose, remove its plug, and drain the water into a container. After you’ve drained it completely, put back the plug and return the black hose to its clip. Next, rotate the drain filter counterclockwise to remove it. You’ll be able to remove the clumps of hair, lint, and other debris with your hands. Once all the big clumps are gone, you can rinse the filter with water before putting it back. Then, either close their access panel door or re-insert the storage drawer until you hear the rails lock into place. Lastly, grab a towel to wipe down any accidental spills.
Two of the most obvious ways that the drain filter needs cleaning is when the water doesn’t drain properly or you see a drain-related error code (such as F9 E1) on your washing machine. However, other signs that you should also look out for include weird sounds, clothes smelling bad, or the drum not spinning. If you don’t want to wait until your washing machine starts having problems, just know that Whirlpool doesn’t list an official recommended cleaning frequency. But professional cleaning service Home Alliance mentions that it should be done every two to four months. And, of course, you’ll want to consider doing it more often if you’ve been washing heavily soiled items or pet beds after a particularly bad shedding season.
Most people don’t really clean their washing machines often enough, so if you’re already working on your drain pump, you might as well do everything else too. To cover all your bases, you can check your specific washing machine’s care guide, since there are slightly different steps for front and top load models. But if you don’t have access to these anymore, Whirlpool has a great guide that you can follow which includes using affresh tablets inside the tub, machine cleaning wipes for the dispensers, around the doors, and the outside of the unit. You can also manage mold by leaving the door open every now and then run cleaning cycles.

realme has announced new milestones for its P Series in India. The company said the lineup continues to see strong demand on Flipkart. According to realme, the P Series became Flipkart’s best-selling smartphone series by sales volume from July 1, 2026. The achievement adds to the lineup’s strong performance during the first half of the year. It also comes at a time when India’s smartphone market is facing slower growth.
In the first half of 2026, Realme managed to occupy the second position in terms of its market share on the platform. However, the good performance was noted across various price ranges. Realme managed to lead in the ₹10,000 to ₹15,000 price range while securing top-three positions in the ₹15,000 to ₹20,000 and ₹20,000 to ₹25,000 price ranges. These achievements, according to the company, highlight the increasing popularity of the P Series.

As reported by Counterpoint Research, the Indian market for smartphones experienced a 10% drop in the second quarter of 2026. However, despite the slowdown in the market, Realme still succeeded in becoming a stronger player. The company’s market share grew from 9.6% in Q2 2025 to 10% in Q2 2026.
The company is also preparing for the second half of 2026 by investing more than ₹10 crore in co-created marketing campaigns. Through these efforts, realme hopes to connect with more consumers, strengthen its position before Diwali, and continue growing its share in the Indian smartphone market.




Weekend Open Thread: Brooks Brothers


How a former Blue Peter presenter stunned America’s Got Talent judges


Intel is reversing course and bringing hyper-threading back to its server chips

New Jersey voter registration controversy explained: How 6,600 noncitizens got on the rolls, and what happens next

Johnny Depp’s R-Rated Gothic Cult Classic Gets New Release Ahead of Sydney Sweeney Remake


Ethics, other provisions in crypto Clarity Act to be further discussed


Luke Littler dismantles Gerwyn Price to retain title in Blackpool

Commonwealth Games boxing: Jadumani Singh seals dominant 5-0 win over Pakistan’s Sumama Rehman to enter quarter-finals | Commonwealth Games News


2026 3M Open leaderboard: Scottie Scheffler finds putter in Round 1, sits three back


16 Dresses for the High Summer Event


The Peugeot Family: How 200 Years of an “Old Money” Dynasty Died in A Boardroom


The Part of the Electric Transition Nobody Wants to Discuss


Spain sweeps the board at 2026 World Cup with individual awards

BITCOIN JUST ENTERED THIS CRITICAL ZONE…

A New Post-Apocalyptic Gundam Anime Series Blasts Into SDCC


XRP Ledger adds $2.6B as RWA inflows rank second


Ripple bought a bank in pieces. The $4 billion audit


Anthropic launches Claude Opus 5, a cheaper AI model for coding, agents and enterprise workflows


Uniswap (UNI) pushes deeper into tokenized RWAs with permissioned trading pools
Sara Gilson Killed By Husband After Viral “Pedophile” TikTok Video







You must be logged in to post a comment Login