



By SuperWest Sports Staff
Sports
St. Louis City acquire M Dante Polvara from Aberdeen

 Dec 13, 2019; Cary, NC, USA; Georgetown Hoyas midfielder Dante Polvara (17) with the ball in the first half at WakeMed Soccer Park. Mandatory Credit: Bob Donnan-Imagn Images
Dec 13, 2019; Cary, NC, USA; Georgetown Hoyas midfielder Dante Polvara (17) with the ball in the first half at WakeMed Soccer Park. Mandatory Credit: Bob Donnan-Imagn Images St. Louis City acquired American midfielder Dante Polvara from Scotland’s Aberdeen FC on Friday.
The 25-year-old former Georgetown star is signed through the 2027-28 MLS season with an option for 2028-29.
“We’re excited to bring Dante to St. Louis and believe he will add quality and competition to our group,” sporting director Corey Wray said. “He is a versatile player who can impact games in both defense and in midfield, and at 6-foot-4, he brings an imposing physical presence while still being technically clean on the ball.
“He’s still young but has gained valuable experience from Scotland and European competition, which will help him contribute right away.” Polvara tallied six goals and seven assists in 93 appearances since making his pro debut with Aberdeen in 2022. He helped the club win the Scottish Cup last season.
St. Louis sent up to $150,000 in general allocation money to New York City FC to acquire his right of first refusal. NYCFC also retained a percentage of any potential future transfer or trade.
–Field Level Media
Continue Reading

One of the biggest challenges in perfecting your golf swing is that improvement often requires you to move your body in ways that feel unnatural or awkward. That’s why many instructors rely on real-life comparisons — connecting swing positions and movements to actions you already know — so you’re able to learn them more easily.
A great example of this is a simple slice-fix tip that Cameron McCormick, a GOLF Top 100 Teacher, recently shared on Instagram. In the clip below, he explains how a mundane task that many of us do every day can help transform your slice into a draw. Let’s break it down.
golfbffs’s profile picture
cmccormickgolf
Original audio
cmccormickgolf’s profile picture
cmccormickgolf
cmccormickgolf
Original audio
cmccormickgolf’s profile picture
cmccormickgolf
1w
Here’s a simple feel to fix the slice.
martin.daryl’s profile picture
martin.daryl
1w
Absolutely awesome drill to use.
mcgoose70’s profile picture
mcgoose70
1w
This is great
aaaddd2602’s profile picture
aaaddd2602
1w
拮抗する力なら反対に捻ってもいい?
golfpromo.ig’s profile picture
golfpromo.ig
1w
Send this video ✅
bestgolfstars’s profile picture
bestgolfstars
1w
Send reel ✅
539
5
March 13
Add a comment…
More posts from
Meta
About
Blog
Jobs
Help
API
Privacy
Consumer Health Privacy
Terms
Locations
Instagram Lite
Meta AI
Threads
Contact Uploading & Non-Users
Meta Verified
English
English
© 2026 Instagram from Meta
Include caption
By using this embed, you agree to Instagram’s API Terms of Use.
Wring the towel to close the face
As McCormick demonstrates in the clip, the simple act of wringing out a wet towel is an effective drill for learning to close your clubface through transition — which is key for golfers struggling who struggle with a slice.
The feel works because it encourages your lead hand to rotate naturally. Your knuckles and palm move in a way that mirrors the hand action needed to square the clubface at impact.
“Wringing the water out of this wet towel in transition, turning your knuckles away and turning your palm away is going to help you close that clubface in transition and turn that slice into straight balls or draws,” McCormick says.
Instead of leaving the face open — which sends the ball to the right — with a bit of practice, you can learn to square your clubface.
Once you’ve dialed in the motion with the towel, McCormick says to try adding in your club. As you take the club back, stop at the top of your swing. Before you transition into the downswing, make that same wringing motion. You should feel the clubface rotate slightly, and with a little repetition, your shots should start to straighten out.

Sign up for GOLF Schools Today
Improve your game with GOLF Top 100 Teachers.
Sports
“Super Eagles Players Did Not Contribute Money for Godswill Akpabio International Stadium Maintenance” – Official Statement Debunks False Reports

The Akwa Ibom State Government has dismissed as false, misleading, and baseless reports in social media platforms suggesting that Super Eagles players contributed funds for the renovation of the Godswill Akpabio International Stadium and are dissatisfied with alleged delays in renovation works.
Fielding questions from newsmen, the State Commissioner for Information, Hon. Aniekan Umanah, alongside his Sports counterpart, Elder Paul Bassey, clarified that the stadium is 100 percent maintained by the Akwa Ibom State Government, and at no time did any Super Eagles player, or any individual, donate money for its upgrade or upkeep. They emphasized that the facility remains in excellent condition.
“The Godswill Akpabio International Stadium is one of the best football facilities in the world and currently the only stadium in Nigeria approved by both CAF and FIFA for international matches,” the Commissioners said, highlighting its compliance with global standards.
They made it clear that the stadium is maintained under a running contract with Julius Berger Plc which ensures an impeccable playing pitch, modern dressing rooms, FIFA-approved floodlights, and a fully functional electronic scoreboard, all of which were used during the last Super Eagles match in Uyo.
The Commissioners also pointed to recent recognition of the State by Sportsville, which named Akwa Ibom State Best in Sports Infrastructure, describing the accolade as independent validation of the government’s substantial investment in sports development.
Commissioner Paul Bassey further reiterated that the stadium has served as the home of the Super Eagles for over a decade without complaints from players, officials, or football authorities, and that the state government consistently provides for the team’s logistics and welfare whenever matches are held in Uyo.
Reacting to the false reports, the Secretary of the Super Eagles, Mr. Enebi Achor, described the publication alluding to players contributing to the maintenance of the stadium as “embarrassing,” noting that the players were surprised by the narrative and questioned its origin.
The Information Commissioner warned that individuals, groups, and blogs must strictly adhere to verified facts and desist from spreading false information, stressing that dissemination of fake news is punishable by law.
He further emphasized that under the leadership of Pastor Umo Eno, the Akwa Ibom State Government continues to invest heavily in sports development, including the sustained maintenance of the stadium, construction of modern facilities, provision of equipment, hosting sports festivals, and talent development programs.
The government urged the public to disregard the false publication entirely, describing it as a smear attempt that will not distract the administration from its resolve to advance sports development in Akwa Ibom State.


Oleksandr Usyk has faced an extensive list of elite opponents and has overcome every single one of them, but when it came to naming the hardest punching dance partners of his career, the Ukrainian surprisingly left out two names.
Usyk has become just the second fighter in history to become undisputed at both cruiserweight and heavyweight, picking up all four world titles in each division to match, if not better, the achievements of Evander Holyfield.
Up at heavyweight, Usyk has faced two men that can be considered as genuine knockout artists, twice beating both Anthony Joshua and Daniel Dubois, halting the latter on both occasions and outpointing ‘AJ’ in each of their matchups.
Although, in an interview with Daily Mail Boxing, the unified heavyweight ruler left both Joshua and Dubois off of a list when quizzed to name the hardest punching opponents of his career. Instead, the 39-year-old humorously gave top spot to the horse that kicked him when he was a child.
“5. Murat Gassiev, 4. Mairis Briedis, 3. Tyson Fury, 2. Derek Chisora, 1. Horses.”
Usyk met Fury twice in 2024, winning both of those battles on points, while he defeated Chisora in just his second fight at heavyweight back in 2020, in a bout that he has referred to in the past as one of his toughest in the division to date.
The Ukrainian will return to action on Saturday, May 23, when he attempts to defend his WBC world title in an unorthodox meeting against Dutch kickboxer Rico Verhoeven at the Pyramids of Giza.

NEWYou can now listen to Fox News articles!
The fiancée of Buffalo Sabres star Rasmus Dahlin received a roaring welcome home in her first appearance of the season Wednesday night, months after undergoing a lifesaving transplant after she suffered heart failure during a vacation in France.
Carolina Matovac, 25, was shown on the jumbotron during Wednesday’s game against the Boston Bruins. Fans cheered as she waved, and Dahlin, who was also shown on the screen in a split, cracked a smile at the crowd’s reaction.

Carolina Matovac and Rasmus Dahlin of the Buffalo Sabres pose on the red carpet at the Metro Toronto Convention Centre in Toronto, Ontario, Canada, Feb. 1, 2024. (Nicole Osborne/NHLI via Getty Images)
“Welcome home to Carolina Matovac, the fiancée of our captain Rasmus Dahlin,” the arena announcer said. “She is back with us, attending her first game of the season. The Sabrehood loves you, Carolina.”
CLICK HERE FOR MORE SPORTS COVERAGE ON FOXNEWS.COM
In an open letter to fans in September, Dahlin shared that Matovac had been feeling ill for several days during their trip, which led to her experiencing “major heart failure.”
“Fortunately, she received CPR on multiple occasions, and up to a couple of hours at a time to keep her alive, which ultimately saved her life. Without her receiving lifesaving CPR, the result would have been unimaginable. It is hard to even think about the worst-case scenario,” he wrote at the time.

Rasmus Dahlin (of the Buffalo Sabres prepares for a faceoff during a game against the New York Rangers at KeyBank Center in Buffalo, N.Y., Oct. 9, 2025. (Bill Wippert/NHLI via Getty Images)
Matovac remained on life support for weeks before receiving the transplant in France.
In January, Matovac revealed she was pregnant when her heart failed, adding that her unborn child was the reason she went to the hospital initially.
“You will always hold a special place in our hearts as our first baby, even though we never had the chance to meet. Our love for you is endless,” she wrote in a post on Instagram on what was supposed to be her due date.
“Though you didn’t get to experience this world, you played a vital role in ensuring that I could continue to be a part of it.”

Buffalo Sabres defenseman Rasmus Dahlin follows the puck in the first period against the Ottawa Senators at the Canadian Tire Centre in Ottawa, Ontario, Canada, on April 1, 2025. (Marc DesRosiers/Imagn Images)
CLICK HERE TO DOWNLOAD THE FOX NEWS APP
Despite taking some time to be with Matovac as she recovered in their native Sweden, Dahlin is second on the team with 65 points, and the Sabres are on the cusp of ending an NHL-record 14-season playoff drought.
The Associated Press contributed to this report.
Follow Fox News Digital’s sports coverage on X, and subscribe to the Fox News Sports Huddle newsletter.
As Arizona prepares to play in its 12th all-time Elite 8 on Saturday, we’ve compiled a list of all such appearances by schools in the West.
The region boasts 29 Elite 8 teams, 19 of which have made two or more appearances, led by UCLA with 22, Arizona with 12, and Oregon, Oregon State, and San Francisco all with seven.
But before we get to the list, for those who may be interested, a little history.
The NCAA recognizes Elite 8 appearances since the first tournament in 1939, even though only eight teams participated in the tournament from 1939 to 1950.
Between 1939 and 1950, there were only 8 teams in the tournament, so all teams can claim an Elite 8 appearance.
However, from 1975 to 1984, all teams were required to play at least one game before the Sweet 16, and since 1985, all have been required to play at least three games to make the Elite 8.
Here is the list of participating schools from the region.
All-Time Elite 8 Appearances by Schools in the West
| Appearances | School | Most Recent |
|---|---|---|
| 22 | UCLA | 2021 |
| 12 | Arizona | 2026 |
| 7 | Oregon | 2017 |
| 7 | Oregon State | 2021 |
| 7 | San Francisco | 1974 |
| 6 | Colorado | 1963 |
| 6 | Gonzaga | 2023 |
| 6 | Utah | 1998 |
| 5 | UNLV | 1991 |
| 5 | Santa Clara | 1969 |
| 5 | Wyoming | 1952 |
| 4 | USC | 2021 |
| 3 | Stanford | 2001 |
| 3 | BYU | 1981 |
| 3 | Arizona State | 1975 |
| 3 | California | 1960 |
| 3 | Washington | 1953 |
| 2 | Utah State | 1970 |
| 1 | San Diego State | 2023 |
| 1 | Cal State Fullerton | 1978 |
| 1 | Idaho State | 1977 |
| 1 | New Mexico State | 1970 |
| 1 | Colorado State | 1969 |
| 1 | Pacific | 1967 |
| 1 | Saint Mary’s | 1959 |
| 1 | Seattle | 1958 |
| 1 | Washington State | 1941 |
| 1 | Pepperdine | 1944 |
| 1 | Loyola Marymount | 1990 |

NEWYou can now listen to Fox News articles!
It was a day of Olympic history.
After the International Olympic Committee updated its policies to prevent biological males from competing in women’s sports, multiple Olympians gave their reactions.
Several Olympians, including gold medalists, shared their thoughts on the new policy with Fox News Digital.
CLICK HERE FOR MORE SPORTS COVERAGE ON FOXNEWS.COM
Kaillie Humphries, three-time Olympic gold medalist bobsled athlete for US and Canada

Kaillie Humphries, a U.S. Olympic bronze medalist bobsled athlete, presents the Order of Ikkos to President Donald Trump during a Women’s History Month event in the East Room of the White House in Washington, D.C., March 12, 2026. (Al Drago/Bloomberg)
“Today is a great day for women’s sports and a big win in the Olympic world. By implementing the sex testing, it will allow for fair competition. It used to happen years ago, and by bringing it back it will protect the women’s category. I think it’s very fitting that LA28 will be the games to protect women’s sports as it’s something that our president has advocated for,” Humphries told Fox News Digital.
Donna de Varona, three-time Olympic gold medalist swimmer for the US

President Ronald Reagan with Donna De Varona as they address the Women’s Sports Foundation. (Getty Images)
“With the election of Kirsty Coventry, an Olympic champion, and her decision to appoint another woman to lead the medical commission, it was informative that the IOC decided to go outside to reach researchers to base this opinion on science and fairness. And it’s the right decision,” de Varona told Fox News Digital.
“Really, science and research is how this decision was based. I mean, I basically think everyone should have an opportunity in sport, but, in the Olympic arena, it’s a zero-sum game.”
Gary Hall Jr., five-time Olympic gold medalist swimmer for the US

U.S. swimmers Anthony Ervin, left, and Gary Hall Jr., center, who tied for the gold medal in the men’s 50m freestyle, stand with Dutch swimmer Pieter van den Hoogenband, right, who won the bronze medal, Sept. 22, 2000 at the Sydney International Aquatic Center during the Summer Olympics in Sydney. (AP Photo/David Longstreath, file)
“The IOC made the right decision, supporting women’s rights. Transgender athletes are not being banned from the Olympic Games. The ruling very specifically bans born males from competing in women’s events. Which is the right thing to do, by every account of science and common sense. A born male after transition can still compete in men’s events, and I wish they luck,” Hall told Fox News Digital.
MyKayla Skinner, US silver medalist gymnast at Tokyo 2020

MyKayla Skinner of the United States poses with the silver medal after the women’s vault final at Ariake Gymnastics Centre during the Tokyo 2020 Olympic Games Aug. 1, 2021, in Tokyo, Japan. (Jamie Squire/Getty Images)
“The best news! About time!” Skinner told Fox News Digital.
Leah Amico, three-time gold medalist softball player for the US

Leah Amico of the USA competes during the preliminary softball game between the USA and Italy on Aug. 14, 2004 during the Athens 2004 Summer Olympic Games at the Softball Stadium in the Helliniko Olympic Complex in Athens, Greece. The USA defeated Italy 7-0. (Chris McGrath/Getty Images)
“I fully support the IOC’s decision to protect the women’s category in Olympic competition. As a three-time Olympic gold medalist in softball, I believe women deserve to compete on a level playing field, against other biological females. Girls and women fought a long time to compete on the world’s greatest athletic stage and this is their chance to shine. I am so thankful the IOC had the courage to take this stand,” Amico told Fox News Digital.
Katie Uhlaender, US skeleton athlete, five-time Olympian

Katie Uhlaender of the U.S. competes during the women’s skeleton race during the 2025 IBSF World Championships at Mt. Van Hoevenberg March 7, 2025, in Lake Placid, N.Y. (Al Bello/Getty Images)
“This is huge for women’s sport. For years, female athletes have asked for clarity, consistency and fairness in competition. Not politics. Not ambiguity. Just clear standards that protect the integrity of the category we train our entire lives to compete in. Sport only works when rules are applied consistently and athletes can trust them,” Uhlaender told Fox News Digital.
“Progress doesn’t come from avoiding hard conversations. It comes from addressing them with courage. Thank you to everyone who helped to make this happen, who protected women’s sport.”
Tyler Clary, US gold medalist swimmer at London 2012

U.S. swimmer Tyler Clary celebrates winning gold in the men’s 200-meter backstroke final at the London 2012 Olympic Games Aug. 2, 2012, in London. (Christophe Simon/AFP)
“This is a long-overdue return to common sense, and the IOC deserves credit for taking a clear stand. At the elite level, fairness matters, and protecting the women’s category based on biological reality is essential to preserving it,” Clary told Fox News Digital.
Maciej Czyżowicz, Polish Olympic gold medalist pentathlete at Barcelona 1992

Polish pentathalon gold medalist Maciej Czyżowicz (Courtesy of Maciej Czyzowicz)
“Better late than never. This decision by the IOC is a big step in the right direction. After all, it has long been known that one cannot change one’s sex. And if someone was born a man, then even if they start wearing women’s clothing, they will still remain a man. Besides, there are significant differences between the two sexes in terms of strength and speed, which puts female athletes at a disadvantage right from the start,” Czyzowicz told Fox News Digital.
“So, it is absolutely clear that it would not be fair for biological males to compete in the female category. In addition, in some sports, it would simply not be safe. I believe this decision protects women’s sports, specifically by preventing transgender athletes from competing against biological women.”
Nancy Hogshead, three-time Olympic gold medalist swimmer for the US

Olympic gold medalist Nancy Hogshead (Courtesy of XX-XY Athletics)
“Playing sport is a human right. Today’s IOC announcement affirms that principle of inclusion and diversity. All athletes are to compete in their category; their weight, age, ability category and, now, their sex category. On behalf of women in sport, thank you for your leadership, IOC,” Hogshead said in a statement.
Martina Navratilova, women’s tennis legend and US Olympian at Athens 2004

Former Czech tennis player Martina Navratilova receives the golden racket during the Italian tennis internationals at the Foro Italico in Rome, Italy, May 21, 2023. (Massimo Insabato/Archivio Massimo Insabato/Mondadori Portfolio via Getty Images)
Brian Goodell, two-time gold medalist swimmer for the US

The 1976 Summer Olympic Games aired on the ABC Television Network from July 17 to August 1, 1976. Shoot Date: July 20, 1976. (ABC Photo Archives/ABC via Getty Images)
“The Olympic Games are predicated on the best athletes in the world competing in fair competition. Today, the IOC took a stand for fairness. Women deserve their own category so that they can showcase their incredible athletic accomplishments at the Olympics. Preserving the women’s category is both fair for women, and it is also good for the Olympic Movement,” Goodell told Fox News Digital.
Inga Thompson, US women’s cyclist, three-time Olympian
“If men are allowed to compete in women’s sports, in time, women will be erased from ever having opportunities to even compete at the Olympic level. You will have two categories in the Olympics. DSD/trans and the men’s category. Sex testing worked very well and was non-intrusive. A simple buccal cheek swab once in your lifetime,” Thompson told Fox News Digital.
“Welcome news today from the IOC. People who adopt different gender identities, such as transgender, gender non-conforming or others should be afforded the same human rights as other citizens and protected from discrimination, so long as no sex-based rights are compromised,” Navratilova said in a statement.
“It’s what the gay, lesbian and bisexual community fought for over decades. Today’s IOC decision recognizes that, in Olympic sports, sex matters, and women’s sex-based rights must take precedence over gender-based identities.”
Giddeon Massie, US men’s cyclist, two-time Olympian
“There really is little to be lauded over the IOC’s woefully slow decision. It should have always been a most simple and basic logical conclusion that is unequivocally founded in God’s design of male and female,” Massie told Fox News Digital.
“Our female Olympic and Paralympic athletes work too hard to have their dreams of achievement undermined by a man’s self-deception of reality. Sadly, the battlegrounds remain extensive amongst the grassroots and recreational sporting arenas, and those must continue to be contested for the sake of young ladies everywhere, now and into the future.”
CLICK HERE TO DOWNLOAD THE FOX NEWS APP
Carrie Englert Zimmerman, US women’s gymnast at Montreal 1976
“Finally, the International Olympic Committee showed some balls and chose fairness over fear. As an Olympian, I didn’t dedicate my life to competing on a manipulated playing field — one tilted and disguised as inclusion,” Zimmerman told Fox News Digital.
“As an Olympian, I didn’t dedicate my life to competing on a manipulated playing field —one tilted and disguised as inclusion. Women’s sport exists because biological differences matter — strength, power and muscle developed through male puberty aren’t erased, and pretending otherwise erases us. Fairness isn’t controversial. Let little girls dream of gold — not allow those dreams to be lost or tarnished.”
Follow Fox News Digital’s sports coverage on X, and subscribe to the Fox News Sports Huddle newsletter.

England won all eight of their qualifying games, scoring 22 goals and conceding none to finish comfortably clear at the top of Group K.
However, their group opponents were Albania, Andorra, Latvia and Serbia – four sides ranked outside the top 20 in the world.
Indeed their toughest test in terms of ranking last year was a friendly against Senegal, who were 19th in the world at the time. England lost 3-1.
It may have been a non-competitive match, but the Three Lions’ performance in that game was concerning.
“No discernible plan. No identity. No improvement – arguably even a regression – since Sir Gareth Southgate stepped down after defeat by Spain in the Euro 2024 final in Berlin,” wrote BBC Sport’s chief football writer Phil McNulty after the game.
“[Tuchel] may offer up mitigating circumstances as he made 10 changes from the World Cup qualifying win against Andorra, plus this was a friendly at the end of a long season. But it was still a sobering, alarming evening as Senegal outclassed England.”
While that result and performance may have been a blip, England needed to face higher-ranked opponents to test them before heading to the World Cup – and they should get that against Uruguay and then Japan, who are 19th in the world.


NEWYou can now listen to Fox News articles!
President Donald Trump on Thursday addressed the Iranian regime’s execution of 19-year-old wrestler Saleh Mohammadi.
“About two weeks ago, they put out a notice that if you protest, we will shoot you. They kill them. Look what they did to the wrestler. They killed him for, for speaking up. They killed him. He was a star wrestler, a great wrestler, actually,” Trump said during an interview on Fox News’ “The Five.”
“Iran has great wrestlers, and he was a star, one of the best. And they killed him because he spoke up. He spoke against the regime, which is largely decimated.”
Mohammadi was reportedly killed in a public hanging earlier this month, according to Iranian American human rights activists and dissidents.
CLICK HERE FOR MORE SPORTS COVERAGE ON FOXNEWS.COM
Iran International reported that Iran’s regime hanged Mohammadi and two other Iranian men, Mehdi Ghasemi and Saeed Davoudi “after being accused of killing two police officers during nationwide protests earlier this year,” the judiciary-linked Mizan news agency reported.
Mohammadi previously told Islamic Republic of Iran Broadcasting that his dream was to be an Olympic champion.
Mohammadi won a bronze medal in September 2024 for Iran’s national freestyle wrestling at the Saytiyev International Cup in Krasnoyarsk, Russia.
The execution prompted comments of mourning and outrage from multiple Olympians, including U.S. gold medalists Brandon Slay, a wrestler; Tyler Clary, a swimmer; and Kaillie Humphries, a women’s bobsledder.
The International Olympic Committee prompted criticism for its statement addressing the execution because it did not condemn Iran.
“Sadly, today’s world is divided and full of conflicts and tragedies. The IOC cares deeply about the situation of athletes all around the globe and is concerned every time it learns of individual cases of mistreatment,” the IOC said in a statement to Fox News Digital.
“However, it is very difficult to comment on situations of individuals during a conflict or unrest in a country without the IOC being able to verify the often contradicting information.
“At this moment in time, we are particularly concerned about the situation of Iranian athletes impacted by the events unfolding in their country, as we are with all athletes who face conflict and tragedies elsewhere in the world. Unfortunately, these situations are more regularly brought to our attention due to the increasingly divided world in which we live.”
The IOC noted it does not have the power to dictate the decisions of a sovereign nation.
“The IOC, as a civil, non-governmental organization, has neither the remit nor the ability to change the laws or political system of a sovereign country. This is the legitimate role of governments and the respective intergovernmental organizations.
CLICK HERE TO DOWNLOAD THE FOX NEWS APP
“The IOC is a sports organization whose remit and success is based on bringing the world together in peaceful competition. We have to be realistic about the IOC’s ability to directly influence global and national affairs,” the statement continued.
“At the same time, we will continue to work with our Olympic stakeholders to help where we can, often through quiet sports diplomacy. The IOC remains in touch with the Olympic community from Iran.”
Follow Fox News Digital’s sports coverage on X, and subscribe to the Fox News Sports Huddle newsletter.
A new licence has been granted for the Peterborough BMX Club as part of its aspirations to attract national-level competitions.
On Tuesday, Peterborough City Council’s cabinet members voted to replace its previous agreement, where the authority was liable for the track’s maintenance, and issued a community licence that would enable the club to apply for funding from groups such as Sport England.
Advertisement
The council owns the track based in Orton Malborne, which is a community sports facility that has been used by the club for more than 40 years.
The track was an important local facility that had unrestricted access for community use, the council said.
Any external funding secured by the club would be used to upgrade the facility to a national competition standard.
Following the decision, the club will be liable for all the track’s repairs, maintenance and improvements.
Mohammed Jamil, the authority’s Labour cabinet member for finance and corporate services, said: “Granting this licence is a win-win for Peterborough City Council because it is reducing the financial burden on the authority of maintaining the site.
Advertisement
“It also preserves the unrestricted public access and gives Peterborough the opportunity of becoming a location for national BMX events, putting the city on the map as a place to visit for BMX enthusiasts.”
Follow Peterborough news on BBC Sounds, Facebook, Instagram and X.
More stories like this

The International Olympic Committee (IOC) said on Thursday only “biological females” will be allowed to compete in women‘s events, preventing transgender women from competing.
The IOC is reintroducing testing for gender to determine eligibility to take part in women’s events from the 2028 Los Angeles Olympics onwards.
The move will also rule out many athletes with differences in sexual development (DSD).
In a major shift of policy, the IOC is abandoning rules it brought in in 2021 which allowed individual federations to decide their own policy and is instead implementing a policy across all Olympic sports.
“Eligibility for any female category event at the Olympic Games or any other IOC event, including individual and team sports, is now limited to biological females, determined on the basis of a one-time SRY gene screening,” the IOC said in a statement.
One of your browser extensions seems to be blocking the video player from loading. To watch this content, you may need to disable it on this site.

They will be carried out through a saliva sample, cheek swab or blood sample. It will be done once in an athlete’s lifetime.
IOC president Kirsty Coventry said: “The policy we have announced is based on science and has been led by medical experts.
“At the Olympic Games even the smallest margins can be the difference between victory and defeat.
“So it is absolutely clear that it would not be fair for biological males to compete in the female category. In addition, in some sports it would simply not be safe.”
In a press conference later, Coventry added: “I do feel that this policy is a policy that is supporting equality and fairness and the protection of the safety on the field of play.”
Removes potential Trump clash
The new policy removes a potential source of conflict between the IOC and US President Donald Trump as the Los Angeles Olympics comes onto the horizon.
Trump issued an executive order banning transgender athletes from women’s sport soon after he came to office.
While sports such as swimming, athletics, cycling and rowing have brought in bans, many others have permitted transgender women to compete in the female category if they lowered their testosterone levels, normally through taking a course of drugs.
World Athletics welcomed the change of tack.
Read moreBars, Pride and dating apps: How China is closing down its LGBT+ spaces
“We have led the way in protecting women’s sport over the last decade,” said a spokesperson for track and field’s international body.
“Attracting and retaining more girls and women into sport requires a fair and level playing field where there is no biological glass ceiling.
“This means that gender cannot trump biology. A consistent approach across all sport has to be a good thing.”
Gender testing was first introduced at the 1968 Olympics and last used at the 1996 Atlanta Games but then scrapped after criticism from the scientific community.
The new policy is set to face some opposition too, especially in relation to athletes with DSD, the rare condition in which a person’s hormones, genes and reproductive organs may have a combination of male and female characteristics.
The British Journal of Sports Medicine said in an article this month there was “no scientific data of acceptable quality regarding sport performance advantage of people with DSDs possessing an SRY gene.”
It added: “Evidence regarding their athletic performance is extremely limited and problematic.”
Read moreSenegal passes law doubling penalty for same-sex relations to 10 years in prison
The best-known DSD athlete of recent years is South African runner Caster Semenya, the two-time Olympic women’s 800m champion who has male XY chromosomes.
The IOC is bringing in the new policy after the women’s boxing competition at the 2024 Paris Olympics was rocked by a gender row involving Algerian fighter Imane Khelif and Lin Yu-ting of Taiwan.
Khelif and Lin were excluded from the International Boxing Association’s 2023 world championships after the IBA said they had failed eligibility tests.
However, the IOC allowed them both to compete at the Paris Games, saying they had been victims of “a sudden and arbitrary decision by the IBA”.
Both boxers went on to win gold medals.
Lin has since been cleared to compete in the female category at events run by World Boxing, the body that will oversee the sport at the 2028 Los Angeles Olympics.
(FRANCE 24 with AFP)

NewsBeat2 minutes ago
Trump Reveals ‘Present’ He Received From Iran

Business3 minutes ago
Octopus Investments cuts one fifth of workforce amid AI-driven overhaul

Crypto World4 minutes ago
David Sacks ends Czar term and joins White House tech council






-
 Crypto World6 days ago
Crypto World6 days agoNIO (NIO) Stock Plunges 6.5% as Shelf Registration Sparks Dilution Worries
-
 NewsBeat2 days ago
NewsBeat2 days agoManchester United reach agreement with Casemiro over contract clause amid transfer speculation
-

 Fashion7 days ago
Fashion7 days agoWeekend Open Thread: Adidas – Corporette.com
-

 Politics7 days ago
Politics7 days agoJenni Murray, Long-Serving Woman’s Hour Presenter, Dies Aged 75
-

 Crypto World5 days ago
Crypto World5 days agoBest Crypto to Buy Now: Strategy Just Spent $1.57 Billion on Bitcoin During Fear While Early Investors Quietly Enter Pepeto for 150x Potential
-

 Crypto World5 days ago
Crypto World5 days agoBitcoin Price News: Bhutan Sells $72 Million in BTC Under Fiscal Pressure, but the Smart Money Entering Pepeto Sees What the Market Does Not
-

 News Videos1 day ago
News Videos1 day agoParliament publishes latest register of MPs’ financial interests
-

 Sports4 days ago
Sports4 days agoRemo Stars and Kano Pillars Strengthen Survival Hopes in NPFL
-

 Sports4 days ago
Sports4 days agoGary Kirsten Accuses Pakistan Cricket Board Of ‘Interference’, Mohsin Naqvi Responds
-
 Tech5 days ago
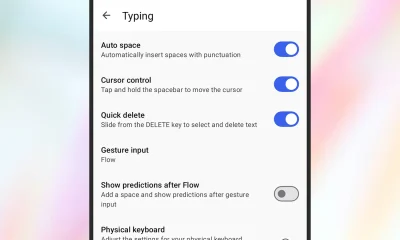
Tech5 days agoGive Your Phone a Huge (and Free) Upgrade by Switching to Another Keyboard
-

 Business5 days ago
Business5 days agoNo Winner in March 21 Drawing as Prize Rolls to $133 Million for Next
-

 Sports7 days ago
Sports7 days ago2026 Kentucky Derby horses, odds, futures, preview, date: Expert who nailed 12 Derby-Oaks Doubles enters picks
-
 Tech4 days ago
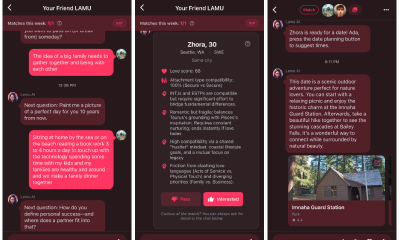
Tech4 days agoAI enters the chat: New Seattle dating app relies on tech to facilitate meaningful human connections
-
Business6 days ago
Columbia Sportswear enters $500 million credit agreement with JPMorgan Chase
-

 News Videos4 days ago
News Videos4 days agoCh 9 Financial Management Part 1 | Detailed One Shot | Class 12 Business Studies Boards 2026
-

 Tech5 days ago
Tech5 days agoToday’s NYT Connections Hints, Answers for March 22 #1015
-

 Business12 hours ago
Business12 hours agoInstagram, YouTube Found Responsible for Teen’s Mental Health Struggle in Historic Ruling
-
 Crypto World7 days ago
Crypto World7 days agoSmall-cap Russell 2000 enters correction territory
-

 Business5 days ago
Business5 days agoWill Duke Basketball Win It All? Duke Basketball Enters Second Round as Third Favorite to Claim NCAA Title
-

 Sports4 days ago
Sports4 days ago2026 Kentucky Derby horses, odds, futures, preview, date: Expert who hit 12 Derby-Oaks Doubles enters picks
You must be logged in to post a comment Login