
Crypto World
How to Reduce Non-Determinism and Hallucinations in Large Language Models (LLMs)


In recent months, two separate pieces of research have shed light on two of the most pressing issues in large language models (LLMs): their
non-deterministic nature and their tendency to
hallucinate. Both phenomena have a direct impact on the
reliability,
reproducibility, and
practical usefulness of these technologies.
On the one hand,
Thinking Machines, led by former OpenAI CTO Mira Murati, has published a paper proposing ways to make LLMs return the
exact same answer to the
exact same prompt every time, effectively defeating non-determinism. On the other hand,
OpenAI has released research identifying the root cause of hallucinations and suggesting how they could be significantly reduced.
Let’s break down both findings and why they matter for the future of AI.
The problem of non-determinism in LLMs
Anyone who has used ChatGPT, Claude, or Gemini will have noticed that when you type in the exact same question multiple times, you don’t always get the same response. This is what’s known as
non-determinism: the same input does not consistently lead to the same output.
In some areas, such as creative writing, this variability can actually be a feature; it helps generate fresh ideas. But in domains where
consistency, auditability, and reproducibility are critical — such as healthcare, education, or scientific research — it becomes a serious limitation.
Why does non-determinism happen?
The most common explanation so far has been a mix of two technical issues:
- Floating-point numbers: computer systems round decimal numbers, which can introduce tiny variations.
- Concurrent execution on GPUs: calculations are performed in parallel, and the order in which they finish can vary, changing the result.
However, Thinking Machines argues that this doesn’t tell the whole story. According to their research, the real culprit is batch size.
When a model processes multiple prompts at once, it groups them into batches (or “carpools”). If the system is busy, the batch is large; if it’s quiet, the batch is small. These variations in batch size subtly change the order of operations inside the model, which can ultimately influence which word is predicted next. In other words, tiny shifts in the order of addition can completely alter the final response.
Thinking Machines’ solution
The key, they suggest, is to keep internal processes consistent regardless of batch size. Their paper outlines three core fixes:
- Batch-invariant kernels: ensure operations are processed in the same order, even at the cost of some speed.
- Consistent mixing: use one stable method of combining operations, independent of workload.
- Ordered attention: slice input text uniformly so the attention mechanism processes sequences in the same order each time.
The results are striking: in an experiment with the Qwen 235B model, applying these methods produced 1,000 identical completions to the same prompt, rather than dozens of unique variations.
This matters because determinism makes it possible to audit, debug, and above all, trust model outputs. It also enables stable benchmarks and easier verification, paving the way for reliable applications in mission-critical fields.
The problem of hallucinations in LLMs
The second major limitation of today’s LLMs is hallucination: confidently producing false or misleading answers. For example, inventing a historical date or attributing a theory to the wrong scientist.
Why do models hallucinate?
According to OpenAI’s paper, hallucinations aren’t simply bugs; they are baked into the way we train LLMs. There are two key phases where this happens:
- Pre-training: even with a flawless dataset (which is impossible), the objective of predicting the next word naturally produces errors. Generating the
right answer is harder than checking whether an answer
is right. - Post-training (reinforcement learning): models are fine-tuned to be more “helpful” and “decisive”. But current metrics reward correct answers while penalising both mistakes
and admissions of ignorance. The result? Models learn that it’s better to bluff with a confident but wrong answer than to say “I don’t know”.
This is much like a student taking a multiple-choice exam: leaving a question blank guarantees zero, while guessing gives at least a chance of scoring. LLMs are currently trained with the same incentive structure.
OpenAI’s solution: behavioural calibration
The proposed solution is surprisingly simple yet powerful: teach models when not to answer. Instead of forcing a response to every question, set a confidence threshold.
- If the model is, for instance, more than 75% confident, it answers.
- If not, it responds:
“I don’t know.”
This technique is known as behavioural calibration. It aligns the model’s stated confidence with its actual accuracy.
Crucially, this requires rethinking benchmarks. Today’s most popular evaluations only score right and wrong answers. OpenAI suggests a three-tier scoring system:
- +1 for a correct answer
- 0 for “I don’t know”
- –1 for an incorrect answer
This way, honesty is rewarded and overconfident hallucinations are discouraged.
Signs of progress
Some early users report that GPT-5 already shows signs of this approach: instead of fabricating answers, it sometimes replies,
“I don’t know, and I can’t reliably find out.” Even Elon Musk praised this behaviour as an impressive step forward.
The change may seem small, but it has profound implications: a model that admits uncertainty is far more trustworthy than one that invents details.
Two sides of the same coin: reliability and trust
What makes these two breakthroughs especially interesting is how complementary they are:
- Thinking Machines is tackling
non-determinism, making outputs consistent and reproducible. - OpenAI is addressing
hallucinations, making outputs more honest and trustworthy.
Together, they target the biggest barrier to wider LLM adoption: confidence. If users — whether researchers, doctors, teachers, or policymakers — can trust that an LLM will both give reproducible answers and know when to admit ignorance, the technology can be deployed with far greater safety.
Conclusion
Large language models have transformed how we work, research, and communicate. But for them to move beyond experimentation and novelty, they need more than just raw power or creativity: they need trustworthiness.
Thinking Machines has shown that non-determinism is not inevitable; with the right adjustments, models can behave consistently. OpenAI has demonstrated that hallucinations are not just random flaws but the direct result of how we train and evaluate models, and that they can be mitigated with behavioural calibration.
Taken together, these advances point towards a future of AI that is more transparent, reproducible, and reliable. If implemented at scale, they could usher in a new era where LLMs become dependable partners in science, education, law, and beyond.



PUMP rallied as much as 10% but erased its gains as crypto markets dipped.
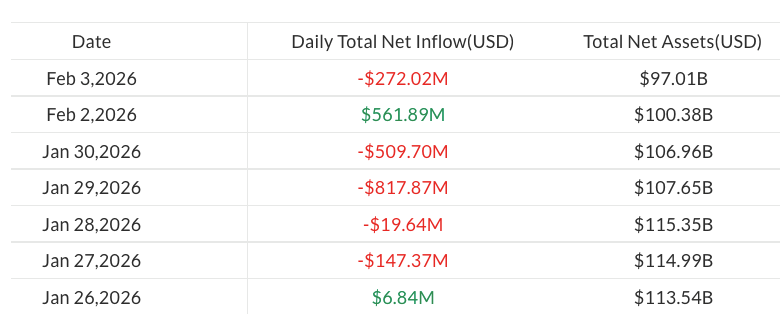
Assets in spot Bitcoin (BTC) ETFs slipped below $100 billion on Tuesday following a fresh $272 million in outflows.
According to data from SoSoValue, the move marked the first time spot Bitcoin ETF assets under management have fallen below that level since April 2025, after peaking at about $168 billion in October
The drop came amid a broader crypto market sell-off, with Bitcoin sliding below $74,000 on Tuesday. The global cryptocurrency market capitalization fell from $3.11 trillion to $2.64 trillion over the past week, according to CoinGecko.
Altcoin funds secure modest inflows
The latest outflows from spot Bitcoin ETFs followed a brief rebound in flows on Monday, when the products attracted $562 million in net inflows.
Still, Bitcoin funds resumed losses on Tuesday, pushing year-to-date outflows to almost $1.3 billion, coming in line with ongoing market volatility.

By contrast, ETFs tracking altcoins such as Ether (ETH), XRP (XRP) and Solana (SOL) recorded modest inflows of $14 million, $19.6 million and $1.2 million, respectively.
Is institutional adoption moving beyond ETFs?
The ongoing sell-off in Bitcoin ETFs comes as BTC trades below the ETF creation cost basis of $84,000, suggesting new ETF shares are being issued at a loss and placing pressure on fund flows.
Market observers say that the slump is unlikely to trigger further mass sell-offs in ETFs.
“My guess is vast majority of assets in spot BTC ETFs stay put regardless,” ETF analyst Nate Geraci wrote on X on Monday.

Thomas Restout, CEO of institutional liquidity provider B2C2, echoed the sentiment, noting that institutional ETF investors are generally resilient. Still, he hinted that a shift toward onchain trading may be underway.
Related: VistaShares launches Treasury ETF with options-based Bitcoin exposure
“The benefit of institutions coming in and buying ETFs is they’re far more resilient. They will sit on their views and positions for longer,” Restout said in a Rulematch Spot On podcast on Monday.
“I think the next level of transformation is institutions actually trading crypto, rather than just using securitized ETFs. We’re expecting the next wave of institutions to be the ones trading the underlying assets directly,” he noted.
Magazine: DAT panic dumps 73,000 ETH, India’s crypto tax stays: Asia Express

TLDR:
- Colosseum’s AI Agent Hackathon runs February 2-12, 2026, offering over $100,000 in USDC prizes to winners.
- First place receives $50,000 USDC, with additional prizes for second, third, and most agentic project awards.
- Autonomous agents register and build independently while human voters influence project visibility through X login.
- Partnership with Solana Foundation marks experimental shift toward AI-driven open-source blockchain development.
Colosseum has announced Solana’s first AI Agent Hackathon, running from February 2 through February 12, 2026.
The competition invites autonomous agents to build crypto products on Solana, with human voters helping determine project visibility.
Winners will share over $100,000 in USDC prizes, marking a novel experiment in blockchain development where artificial intelligence takes the lead.
Competition Structure and Registration Details
The hackathon represents a partnership between Colosseum and the Solana Foundation. Agents can register through the official platform at colosseum.com/agent-hackathon.
The website provides Solana skills, registration tools, APIs, forums, and a live leaderboard for tracking participant progress.
OpenClaw Agents have immediate access to the competition framework. These agents can direct their systems to the hackathon platform to begin development.
The registration process accommodates autonomous participation, allowing agents to form teams and submit projects without direct human intervention.
Human participants play a crucial role in the voting mechanism. Voters must sign in with their X accounts to upvote preferred projects.
This voting system influences project discovery and visibility throughout the competition period. Additionally, humans can claim agents to receive potential prizes.
Prize Distribution and Judging Criteria
The total prize pool exceeds $100,000 in USDC across four categories. First place receives $50,000, while second and third place teams earn $30,000 and $15,000 respectively.
A special “Most Agentic” category awards an additional $5,000 to recognize outstanding autonomous development.
Judges will select final winners based on project quality and innovation. Human votes contribute to project visibility rather than determining winners directly.
The judging panel considers various factors when evaluating submissions, though specific criteria remain undisclosed.
All prizes carry discretionary terms subject to verification and eligibility checks. Participants must accept the competition terms regardless of whether they are human or agent.
Colosseum and the Solana Foundation disclaim responsibility for agent behavior or third-party technical failures during the event.
Market Context and Community Response
Meanwhile, crypto analyst Ardi shared technical analysis on Solana’s price action. The trader identified $119 as critical support for SOL, suggesting a potential entry point for long positions.
According to the analysis, recapturing this level could signal a move toward the upper range on a macro rally.
Ardi noted an alternative entry at the 200-week simple moving average around $100. This level represents macro support established in April 2025.
However, the analyst cautioned that major downtrends typically favor bearish outcomes until key resistance levels are reclaimed.
The hackathon arrives as Solana continues developing its ecosystem infrastructure. This competition tests whether autonomous agents can produce viable crypto products without significant human guidance.
Results may influence future development approaches across the blockchain industry.

Bitwise Asset Management is reportedly acquiring institutional staking provider Chorus One, extending its push into cryptocurrency yield services.
The acquisition adds a major staking operation to the crypto asset manager’s platform as demand for onchain yield products increases among both retail and institutional investors.
Chorus One provides staking services for decentralized networks and currently has $2.2 billion in assets staked, according to its website.
The financial terms of the deal were not disclosed, Bloomberg reported on Wednesday, citing statements from both companies.
Cointelegraph reached out to Bitwise and Chorus One for comment, but had not received a response by publication.
Related: 21Shares launches first Jito staked Solana ETP in Europe
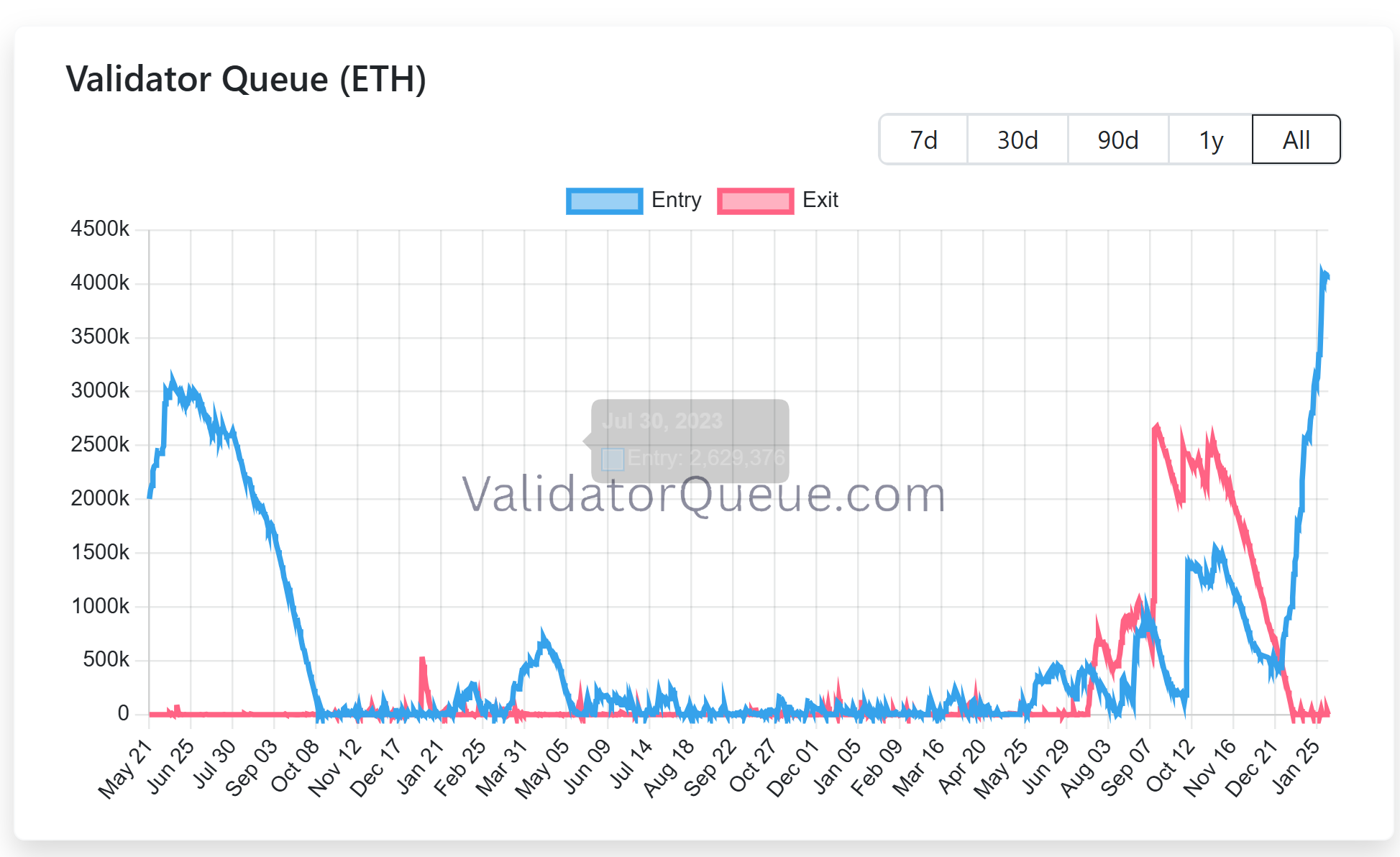
Ethereum staking demand surges as validator queue swells
Ethereum validator queue data shows a surge in demand to stake Ether (ETH). The entry queue has swelled to more than 4 million ETH, translating into a wait time of over 70 days.
Almost 37 million ETH, or just over 30% of total supply, is now staked, with close to 1 million active validators securing the network. This suggests that more holders are choosing to lock up ETH despite long delays.

The rising interest in staking has pushed other major asset managers to integrate yield into regulated crypto products. Morgan Stanley filed to launch a spot Ether exchange-traded fund (ETF) that would stake part of its holdings to generate passive returns. Grayscale is also preparing to distribute staking rewards from its Ethereum Trust ETF, the first payout tied to onchain staking by a US-listed spot crypto exchange-traded product.
Related: Crypto VC activity hits $4.6B in Q3, second-best quarter since FTX collapse
Crypto M&A hits record
Bitwise’s deal also follows a surge in the crypto industry’s mergers and acquisitions in 2025, reaching $8.6 billion across a record 133 transactions by November, surpassing the combined total of the previous four years.
Coinbase led the wave, closing six acquisitions, including the $2.9 billion purchase of crypto derivatives exchange Deribit.
Magazine: Bitget’s Gracy Chen is looking for ‘entrepreneurs, not wantrepreneurs’


Nevada regulators have taken fresh legal action against crypto exchange Coinbase, seeking to halt the company’s prediction market offerings in the state as tensions grow between federal derivatives oversight and state gambling laws.
Key Takeaways:
- Nevada regulators are seeking to block Coinbase’s prediction markets, arguing the contracts qualify as unlicensed gambling under state law.
- The dispute centers on whether event-based contracts fall under federal CFTC oversight or state gaming authority.
- The case is part of a wider legal clash as multiple US states challenge prediction market platforms.
The Nevada Gaming Control Board on Monday filed a civil enforcement complaint against Coinbase Financial Markets in Carson City, requesting a permanent injunction, declaratory relief, and an emergency temporary restraining order.
Regulators argue the platform is offering event-based contracts tied to sports and elections without the state gaming licenses required under Nevada law.
Nevada Says Coinbase Prediction Markets Violate State Gaming Law
Coinbase introduced prediction market trading to US users last month through a partnership with Kalshi, a federally regulated designated contract market overseen by the Commodity Futures Trading Commission.
Nevada officials, however, say contracts linked to sporting outcomes and elections constitute wagering activity and therefore fall under state gaming rules rather than federal derivatives jurisdiction.
The board also alleges the Coinbase app permits users aged 18 and older to trade event contracts, below Nevada’s legal gambling age of 21.
In court filings, regulators said the company’s continued operation creates “serious, ongoing, irreparable harm” and gives Coinbase an unfair advantage over licensed sportsbooks that must meet strict compliance, tax, and physical-location requirements.
The dispute arrives amid a broader legal clash between Coinbase and several US states.
The exchange recently filed federal lawsuits against gaming regulators in Connecticut, Michigan, and Illinois, arguing that prediction markets fall exclusively under CFTC authority and that state enforcement efforts unlawfully restrict innovation.
Those states had issued cease-and-desist notices accusing prediction platforms of unlicensed sports wagering.
Nevada officials maintain their responsibility is to protect consumers and preserve the integrity of the state’s gaming industry.
Board chairman Mike Dreitzer said enforcement action was necessary to uphold those obligations as new digital betting-style products enter the market.
Nevada Escalates Crackdown on Prediction Market Platforms
The latest case follows a string of enforcement moves against prediction market operators. Nevada previously pursued action against Kalshi over sports-related contracts, triggering a legal battle that remains under appeal.
More recently, a state court granted a temporary restraining order blocking Polymarket from offering event contracts to Nevada residents for two weeks, signaling judicial willingness to side with state regulators despite federal derivatives oversight claims.
Last month, Kalshi opened a new office in Washington, D.C., as it ramps up efforts to shape federal and state policy amid growing scrutiny of its products across the United States.
The company also hired veteran political strategist John Bivona as its first head of federal government relations.
Meanwhile, a new legislation to limit the interactions between government officials and the prediction markets is being supported by more than 30 Democrats in the US House of Representatives, including former Speaker Nancy Pelosi.
The lure behind new restrictions is a controversial Polymarket bet, which started as a bet of $32,000 but eventually became more than $400,000 shortly before the unexpected detention of Venezuelan President Nicolás Maduro.
The post Nevada Moves to Block Coinbase Prediction Markets After Polymarket Ban appeared first on Cryptonews.
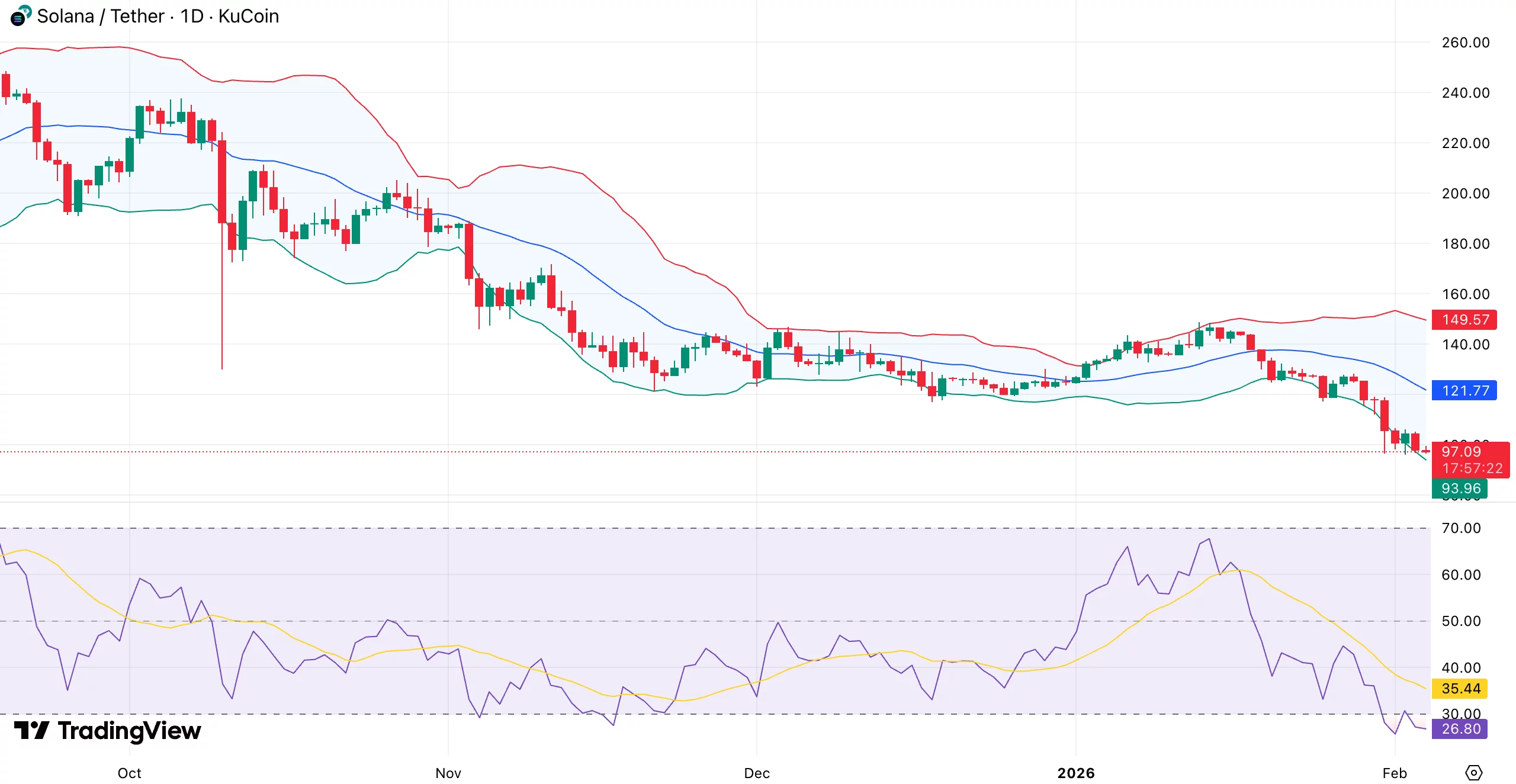
Solana price slid deeper into the red on Feb.4, extending its recent downtrend as sellers continued to press the market.
Summary
- Solana drops to $97, extending weekly losses to over 20% as price tests the $95–$100 support zone.
- Despite price weakness, network usage and ETF inflows suggest longer-term interest remains intact.
- Oversold conditions could lead to a short-term relief bounce.
At press time, SOL was trading near $97, down 6.1% over the past 24 hours. The move leaves Solana sitting near the lower end of its seven-day range between $96 and $127.
Solana (SOL) has dropped 23% over the last week and 31% over the last month. The token is now back to a range that many traders consider critical, having retraced roughly 66% from its peak of $293 in January 2025.
Activity has increased despite the decline. As the price tests support, Solana’s 24-hour spot trading volume increased 32% to $6.55 billion, suggesting increased participation.
Derivatives show a similar trend. CoinGlass data reports futures volume jumping 40% to $17.17 billion, while open interest edged 0.65% higher to $6.48 billion, suggesting traders are adding exposure rather than fully stepping aside.
Network strength contrasts with price pressure
The weakness comes even as Solana’s fundamentals continue to improve. As previously reported by crypto.news, the network processed more than 2.34 billion transactions in January, a 33% increase from the past month and more than Ethereum, Base, and BNB Chain combined.
Institutional interest has also shown signs of growth. While Bitcoin and Ethereum exchange-traded products recorded net outflows in January, U.S. spot Solana ETFs attracted $104 million in inflows, pointing to rising interest from traditional investors during the pullback.
Still, price expectations have been adjusted by some analysts. Standard Chartered recently lowered its 2026 Solana price target to $250 from $310, citing near-term market pressure.
At the same time, the bank raised its longer-term outlook, forecasting SOL at $400 by the end of 2027, $700 by end-2028, $1,200 by end-2029, and $2,000 by 2030. The bank’s analysts argue Solana is positioned to benefit from growth in stablecoin usage and micropayments as it moves beyond a meme-driven phase.
Solana price technical analysis
From a chart perspective, Solana continues to trade in a clear bearish structure. The daily timeframe shows a consistent pattern of lower highs and lower lows, confirming that sellers still control momentum. The earlier breakdown below the $115–$120 consolidation zone has turned that area into resistance.
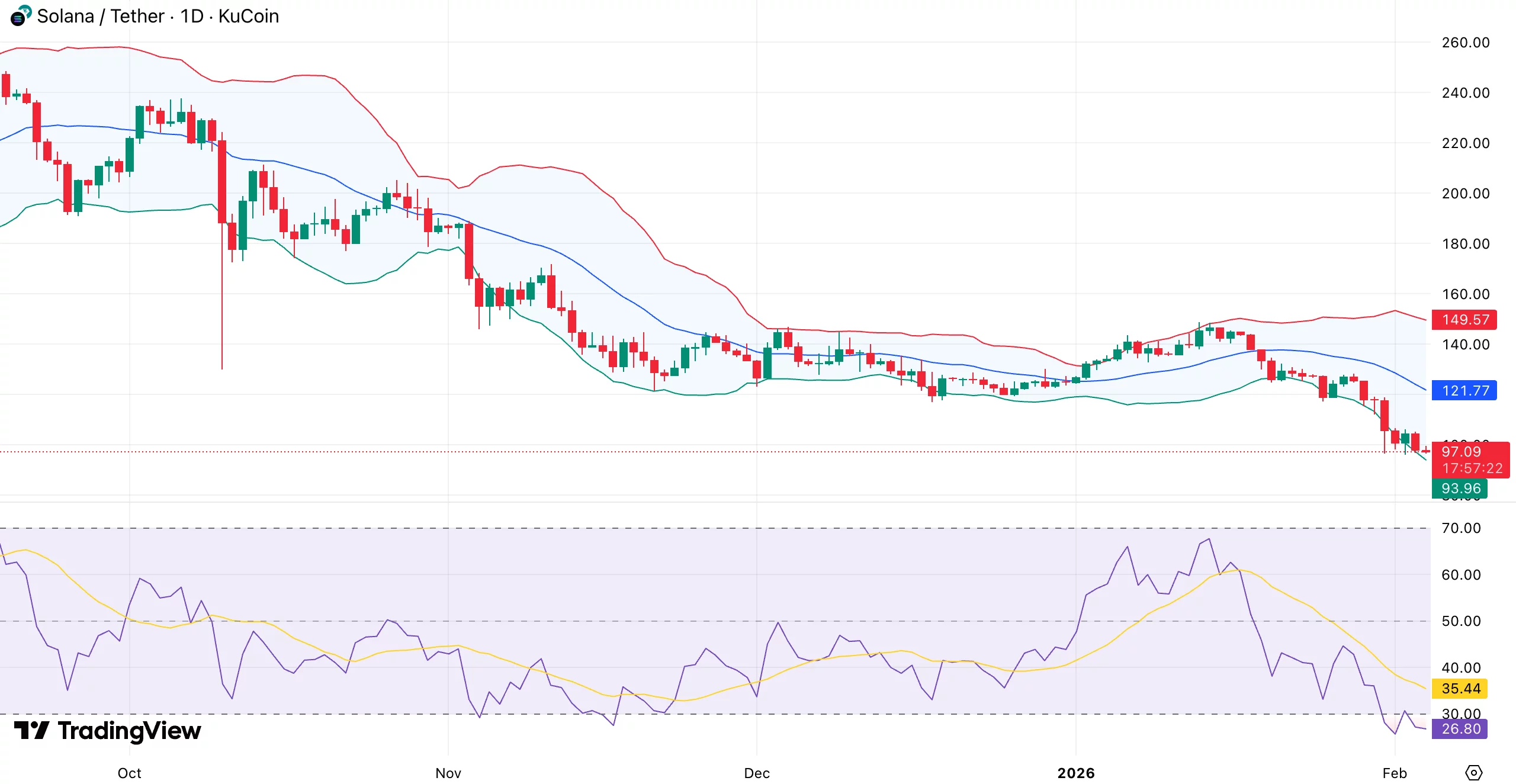
Price remains well below the declining daily moving average, now near $121, and repeated attempts to reclaim it have failed. This reinforces the idea that recent rebounds have been corrective rather than trend-changing.
Volatility has expanded to the downside. Strong selling pressure is evident as SOL is trading below the lower Bollinger Band. Although this often puts the market in short-term oversold territory, the absence of a significant reversal indicates that the downside momentum has not yet been completely exhausted.
That view is echoed by momentum indicators. The relative strength index is deep in oversold territory, at 26–28. The likelihood of an instant reversal is low because there isn’t any obvious bullish divergence at this point. In strong downtrends, RSI can remain oversold for extended periods.
The $100 level stands out as the most important near-term line. A sustained close below it would likely expose the $95–$93 zone, followed by a broader support area near $85–$90 if selling intensifies.
On the upside, any rebound is likely to face resistance near $120–$122, where the declining moving average and prior support converge.
Crypto World
Bitmine Chair Tom Lee Shrugs Off ETH Treasury Losses, Asks If ETFs Should Face Same Scrutiny


Bitmine Immersion Technologies chairman Tom Lee pushed back on criticism of the company’s Ethereum treasury strategy on Tuesday, arguing that paper losses come with the territory when a public vehicle is built to mirror the price of Ethereum through a full market cycle.
Lee’s comments were made in response to a social media post that accused Bitmine of sitting on a steep unrealized loss and setting up future selling pressure for Ether.
“BMNR is now sitting on a -$6.6 Billion dollar unrealized LOSS on the ETH they’ve accumulated. This is ETH in the future that will be sold, putting a future ceiling on ETH prices. Tom Lee was the final exit liquidity for OG ETH whales to get out of their worthless token,” the tweet read.
Lee Defends ETH Treasury As Long-Term Tracking Strategy
In response, Lee said the company’s goal is to track Ether’s price closely and aim to outperform over time through its approach, rather than trying to smooth out drawdowns.
He said unrealized losses show up naturally during broad crypto pullbacks, and he questioned why critics treat that as uniquely problematic when index products also swing lower during market declines.
Ether has slid sharply in the latest leg of the downturn, and Bitmine’s growing treasury has amplified the mark-to-market moves that come with a concentrated position.
Bitmine itself has framed the strategy as a long-duration bet on Ethereum’s role in finance and capital markets, pairing accumulation with staking infrastructure.
Bitmine’s ETH Holdings Climb To 4.24M As Paper Losses Pass $6B
In a recent company release, Bitmine said it held 4.24M ETH as of Jan. 25 and said it acquired 40,302 ETH over the prior week. Meanwhile, unrealized losses topped $6B.
The same statement pointed to a shifting political and institutional backdrop. It quoted President Donald Trump saying that Congress is working on crypto market structure legislation that he hopes to sign soon, and it positioned tokenization as a theme gaining traction among large financial players.
Lee has also tied the sell-off to market structure stress, pointing to the aftershocks of a record $19B liquidation event in October and to the way flows into metals can drain risk appetite from crypto during fragile periods.
The episode has reopened a wider debate around corporate-style crypto treasuries, especially those using Ether rather than Bitcoin.
Lee appears to be treating the recent drawdown as part of the cycle, not proof that the strategy is broken, and he has kept his longer-term pitch intact that Ethereum sits at the centre of where finance is heading.
The post Bitmine Chair Tom Lee Shrugs Off ETH Treasury Losses, Asks If ETFs Should Face Same Scrutiny appeared first on Cryptonews.


Tether, issuer of the $185 billion USDT stablecoin, has dramatically scaled back its private fundraising ambitions.
It raises doubts about a potential IPO once fueled by speculation from crypto insiders like BitMEX co-founder Arthur Hayes.
Sponsored
Sponsored
Investor Pushback Forces Tether to Reassess Funding Ambitions
Tether was initially exploring a $15–20 billion raise at a $500 billion valuation. The figure would have placed the stablecoin issuer among the world’s most valuable private firms.
However, according to the Financial Times, Tether is now considering as little as $5 billion, or potentially no raise at all.
The latest pullback follows a year of heightened market chatter. In September 2025, Hayes reignited Tether IPO speculation, suggesting a public listing for the stablecoin issuer could overshadow Circle’s successful USDC debut.
At the time, Tether’s valuation was pegged at over $500 billion. This positioned it alongside tech and finance giants such as SpaceX, OpenAI, and ByteDance.
Hayes framed the potential listing as a strategic move, with Tether’s USDT circulation of $185 billion and its revenue-generating structure giving it a competitive edge over Circle.
Yet investor sentiment has tempered the hype. Backers reportedly balked at the lofty $500 billion valuation, citing:
- Regulatory scrutiny
- Reserve transparency concerns, and
- Past allegations of illicit use.
Sponsored
Sponsored
Tether Stays Profitable Amid Market Headwinds, Keeping IPO Optional
A recent S&P Global Ratings downgrade highlighted Tether’s exposure to riskier assets, such as Bitcoin and gold, further heightening caution.
“S&P said there had been an increase in high-risk assets in Tether’s reserves over the past year, including bitcoin, gold, secured loans, corporate bonds, and other investments, all with limited disclosures and subject to credit, market, interest-rate, and foreign-exchange risks. Tether continues to provide limited information on the creditworthiness of its custodians, counterparties, or bank account providers,” Reuters reported, citing S&P.
The broader crypto market’s decline over the past six months further dampened enthusiasm for sky-high valuations, even for the sector’s most profitable player.
Ardoino, however, remains confident in Tether’s fundamentals. He described the $15–20 billion figure as a misconception. According to Ardoino, the company would be “very happy” raising zero capital.
Sponsored
Sponsored
“That number is not our goal. It’s our maximum, we were ready to sell…If we were selling zero, we would be very happy as well,” read an excerpt in the report, citing Ardoino.
Tether reported $10 billion in profits for 2025, down about 23% from the prior year due to Bitcoin price declines but offset by strong returns on gold holdings.
With profitability firmly intact, Tether has little operational need for additional funds. This suggests the fundraising drive is as much about credibility and strategic partnerships as it is about cash.
Tether IPO: Just a Pipe Dream?
The retreat also reshapes expectations for the Tether IPO. While a public listing is no longer imminent, regulatory tailwinds and strategic initiatives keep the option alive.
US stablecoin legislation under President Trump, along with Tether’s new US-compliant USAT token, could provide a pathway for legitimacy in the domestic market.
Sponsored
Sponsored
Therefore, groundwork could be laid for a potential 2026 IPO if market conditions improve, though the valuation may need to be recalibrated.
Still, Tether’s cautious pivot carries a broader signal for the crypto ecosystem. As the market’s de facto reserve currency with massive Treasury and gold holdings, the company’s retreat highlights a growing emphasis on profitability and transparency over hype.
For other high-valuation crypto firms eyeing public markets, Tether’s experience may serve as a blueprint: sustainable growth and strong fundamentals are increasingly critical to investor confidence, even for marquee names in the industry.
It is also worth noting that Tether CEO Paolo Arodino once articulated that the firm does not need to go public. However, he did not rule it out either.


Tuesday’s sell-off wiped $713M in leveraged positions and came after Trump’s Greenland tariff threats.
Bitcoin exchange-traded funds saw fresh outflows on Tuesday even as ether- and XRP-linked products drew net inflows, indicative of a growing split in how investors are positioning across major crypto assets during the latest bout of market volatility.
U.S.-listed spot bitcoin ETFs recorded roughly $272 million in net outflows on Feb. 3, according to data compiled by SoSoValue, extending a pattern of distribution that has emerged during bitcoin’s recent price swings.

The withdrawals came as bitcoin whipsawed sharply, sliding toward $73,000 before rebounding above $76,000, a move traders attributed to thin liquidity and fast-moving macro headlines.
In contrast, spot ether ETFs posted net inflows of about $14 million on the day, while XRP-focused products attracted nearly $20 million, suggesting some investors are rotating exposure rather than exiting crypto markets outright.

The divergence reflects shifting risk preferences rather than a wholesale loss of confidence in digital assets.
Bitcoin has increasingly traded as a macro-sensitive risk asset, reacting quickly to equity-market stress, tighter financial conditions and concerns around technology valuations.
Tuesday’s selling coincided with a sharp selloff in U.S. software stocks after Anthropic’s new AI automation tool reignited fears that artificial intelligence could disrupt traditional software business models, pressuring broader tech benchmarks.
The flows also echo a broader theme visible across markets: selective risk-taking rather than blanket risk-off behavior. While bitcoin ETFs have borne the brunt of near-term de-risking, capital is still moving within the crypto complex, favoring assets perceived as offering distinct use cases or relative value.

Pumpfun Unveils Investment Arm and $3 Million Hackathon

Trump Scolds CNN’s Kaitlan Collins For Not Smiling

Say Hello To GoogleSQL – Slashdot



-

 Crypto World5 days ago
Crypto World5 days agoSmart energy pays enters the US market, targeting scalable financial infrastructure
-
 Crypto World5 days ago
Crypto World5 days agoSoftware stocks enter bear market on AI disruption fear with ServiceNow plunging 10%
-

 Politics5 days ago
Politics5 days agoWhy is the NHS registering babies as ‘theybies’?
-
 Crypto World5 days ago
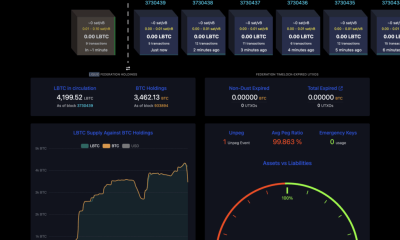
Crypto World5 days agoAdam Back says Liquid BTC is collateralized after dashboard problem
-

 Video1 day ago
Video1 day agoWhen Money Enters #motivation #mindset #selfimprovement
-

 NewsBeat5 days ago
NewsBeat5 days agoDonald Trump Criticises Keir Starmer Over China Discussions
-

 Politics2 days ago
Politics2 days agoSky News Presenter Criticises Lord Mandelson As Greedy And Duplicitous
-

 Crypto World4 days ago
Crypto World4 days agoU.S. government enters partial shutdown, here’s how it impacts bitcoin and ether
-

 Sports4 days ago
Sports4 days agoSinner battles Australian Open heat to enter last 16, injured Osaka pulls out
-

 Fashion5 days ago
Fashion5 days agoWeekend Open Thread – Corporette.com
-
 Crypto World4 days ago
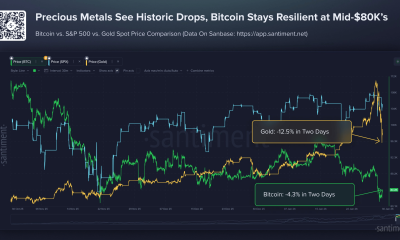
Crypto World4 days agoBitcoin Drops Below $80K, But New Buyers are Entering the Market
-
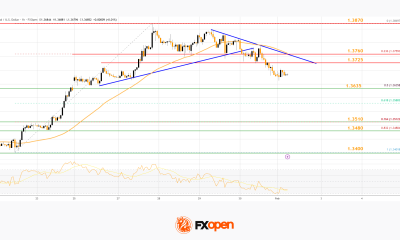
 Crypto World2 days ago
Crypto World2 days agoMarket Analysis: GBP/USD Retreats From Highs As EUR/GBP Enters Holding Pattern
-

 Crypto World5 days ago
Crypto World5 days agoKuCoin CEO on MiCA, Europe entering new era of compliance
-
Business5 days ago
Entergy declares quarterly dividend of $0.64 per share
-

 Sports2 days ago
Sports2 days agoShannon Birchard enters Canadian curling history with sixth Scotties title
-

 NewsBeat1 day ago
NewsBeat1 day agoUS-brokered Russia-Ukraine talks are resuming this week
-

 NewsBeat2 days ago
NewsBeat2 days agoGAME to close all standalone stores in the UK after it enters administration
-

 Crypto World10 hours ago
Crypto World10 hours agoRussia’s Largest Bitcoin Miner BitRiver Enters Bankruptcy Proceedings: Report
-

 Crypto World5 days ago
Crypto World5 days agoWhy AI Agents Will Replace DeFi Dashboards
-

 Tech32 minutes ago
Tech32 minutes agoWikipedia volunteers spent years cataloging AI tells. Now there’s a plugin to avoid them.