
Crypto World
Lessons Learned After a Year of Building with Large Language Models (LLMs)


Over the past year, Large Language Models (LLMs) have reached impressive competence for real-world applications. Their performance continues to improve, and costs are decreasing, with a projected $200 billion investment in artificial intelligence by 2025. Accessibility through provider APIs has democratised access to these technologies, enabling ML engineers, scientists, and anyone to integrate intelligence into their products. However, despite the lowered entry barriers, creating effective products with LLMs remains a significant challenge. This is summary of the original paper of the same name by https://applied-llms.org/. Please refer to that documento for detailed information.
Fundamental Aspects of Working with LLMs
· Prompting Techniques
Prompting is one of the most critical techniques when working with LLMs, and it is essential for prototyping new applications. Although often underestimated, correct prompt engineering can be highly effective.
– Fundamental Techniques: Use methods like n-shot prompts, in-context learning, and chain-of-thought to enhance response quality. N-shot prompts should be representative and varied, and chain-of-thought should be clear to reduce hallucinations and improve user confidence.
Structuring Inputs and Outputs: Structured inputs and outputs facilitate integration with subsequent systems and enhance clarity. Serialisation formats and structured schemas help the model better understand the information.
– Simplicity in Prompts: Prompts should be clear and concise. Breaking down complex prompts into more straightforward steps can aid in iteration and evaluation.
– Token Context: It’s crucial to optimise the amount of context sent to the model, removing redundant information and improving structure for clearer understanding.
· Retrieval-Augmented Generation (RAG)
RAG is a technique that enhances LLM performance by providing additional context by retrieving relevant documents.
– Quality of Retrieved Documents: The relevance and detail of the retrieved documents impact output quality. Use metrics such as Mean Reciprocal Rank (MRR) and Normalised Discounted Cumulative Gain (NDCG) to assess quality.
– Use of Keyword Search: Although vector embeddings are useful, keyword search remains relevant for specific queries and is more interpretable.
– Advantages of RAG over Fine-Tuning: RAG is more cost-effective and easier to maintain than fine-tuning, offering more precise control over retrieved documents and avoiding information overload.
Optimising and Tuning Workflows
Optimising workflows with LLMs involves refining and adapting strategies to ensure efficiency and effectiveness. Here are some key strategies:
· Step-by-Step, Multi-Turn Flows
Decomposing complex tasks into manageable steps often yields better results, allowing for more controlled and iterative refinement.
– Best Practices: Ensure each step has a defined goal, use structured outputs to facilitate integration, incorporate a planning phase with predefined options, and validate plans. Experimenting with task architectures, such as linear chains or Directed Acyclic Graphs (DAGs), can optimise performance.
· Prioritising Deterministic Workflows
Ensuring predictable outcomes is crucial for reliability. Use deterministic plans to achieve more consistent results.
Benefits: It facilitates controlled and reproducible results, makes tracing and fixing specific failures easier, and DAGs adapt better to new situations than static prompts.
– Approach: Start with general objectives and develop a plan. Execute the plan in a structured manner and use the generated plans for few-shot learning or fine-tuning.
· Enhancing Output Diversity Beyond Temperature
Increasing temperature can introduce diversity but only sometimes guarantees a good distribution of outputs. Use additional strategies to improve variety.
– Strategies: Modify prompt elements such as item order, maintain a list of recent outputs to avoid repetitions, and use different phrasings to influence output diversity.
· The Underappreciated Value of Caching
Caching is a powerful technique for reducing costs and latency by storing and reusing responses.
– Approach: Use unique identifiers for cacheable items and employ caching techniques similar to search engines.
– Benefits: Reduces costs by avoiding recalculation of responses and serves vetted responses to reduce risks.
· When to Fine-Tune
Fine-tuning may be necessary when prompts alone do not achieve the desired performance. Evaluate the costs and benefits of this technique.
– Examples: Honeycomb improved performance in specific language queries through fine-tuning. Rechat achieved consistent formatting by fine-tuning the model for structured data.
– Considerations: Assess if the cost of fine-tuning justifies the improvement and use synthetic or open-source data to reduce annotation costs.
Evaluation and Monitoring
Effective evaluation and monitoring are crucial to ensuring LLM performance and reliability.
· Assertion-Based Unit Tests
Create unit tests with real input/output examples to verify the model’s accuracy according to specific criteria.
– Approach: Define assertions to validate outputs and verify that the generated code performs as expected.
· LLM-as-Judge
Use an LLM to evaluate the outputs of another LLM. Although imperfect, it can provide valuable insights, especially in pairwise comparisons.
– Best Practices: Compare two outputs to determine which is better, mitigate biases by alternating the order of options and allowing ties, and have the LLM explain its decision to improve evaluation reliability.
· The “Intern Test”
Evaluate whether an average university student could complete the task given the input and context provided to the LLM.
– Approach: If the LLM lacks the necessary knowledge, enrich the context or simplify the task. Decompose complex tasks into simpler components and investigate failure patterns to understand model shortcomings.
· Avoiding Overemphasis on Certain Evaluations
Do not focus excessively on specific evaluations that might distort overall performance metrics.
Example: A needle-in-a-haystack evaluation can help measure recall but does not fully capture real-world performance. Consider practical assessments that reflect real use cases.
Key Takeaways
The lessons learned from building with LLMs underscore the importance of proper prompting techniques, information retrieval strategies, workflow optimisation, and practical evaluation and monitoring methodologies. Applying these principles can significantly enhance your LLM-based applications’ effectiveness, reliability, and efficiency. Stay updated with advancements in LLM technology, continuously refine your approach, and foster a culture of ongoing learning to ensure successful integration and an optimised user experience.



The U.S. Securities and Exchange Commission and Commodity Futures Trading Commission published interpretive guidance explaining how they might define what is or isn’t a security in crypto; the CFTC also issued a no-action letter for a non-custodial wallet provider to facilitate derivatives and prediction markets transactions; Arizona is filing criminal charges against a prediction market provider; and by the way we kind-of-sort-of have hints of movement on market structure legislation.
What a week, huh?
You’re reading State of Crypto, a CoinDesk newsletter looking at the intersection of cryptocurrency and government. Click here to sign up for future editions.
The narrative
The U.S. Securities and Exchange Commission published interpretive guidance this week — joined by the Commodity Futures Trading Commission — laying out how it approached the question of what in crypto it will deem a security.
Why it matters
What is, and isn’t, a security has long bedeviled the industry. We had efforts at somewhat defining this from the SEC in the past — Bill Hinman’s “When Howey met Gary (plastics)” speech, for example — but this week’s interpretative guidance is one of the most specific efforts to define this for the industry.
Breaking it down
The SEC laid out several categories it saw in the crypto space, with one of these categories being digital securities. These are cryptocurrencies that meet the definition of a security under any other context, but happen to be tokenized, the guidance said. For example, if a crypto asset meets the prongs of the Howey Test, it’s a security.
This is the category of tokens the SEC will oversee.
Other categories include payment stablecoins, digital tools, digital collectibles and digital commodities, which are generally not securities unless the issuers or operators take actions that might meet securities regulations, such as fractionalizing the tokens in question.
“We establish a straightforward taxonomy of crypto assets — most of which are not securities — and clarify how the Supreme Court’s Howey test applies when a crypto asset is part of an investment contract,” SEC Chair Paul Atkins and Commissioners Hester Peirce and Mark Uyeda wrote in an oped for CoinDesk.
The CFTC said it would sign on to the guidance and administer it under the Commodities Exchange Act.
“Market participants — from innovators and issuers to individual investors — should review this interpretation to better understand the regulatory jurisdiction between the SEC and CFTC,” the CFTC said in a press release. “The interpretation will be published on CFTC.gov and in the Federal Register.”
Congressman Troy Downing (R-Mont.) called the guidance “very positive,” but said Congress still needed to pass market structure legislation as a future administration could undo the interpretative guidance.
“Just having another two or three years of this and then having ambiguity out there doesn’t make most people comfortable on doing any kind of big investment,” he told CoinDesk. “But it’s a great start because this is exactly what the industry wants, and it allows some people to move forward.”
Chris LaVigne, a partner at the law firm Withers, said the guidance “predictably concludes that most crypto assets and many common crypto activities are not securities,” though the agency kept some discretion to being an enforcement action in this area.
“The guidance moves the securities inquiry away from the asset or activity itself (which are mostly deemed digital commodities not within the purview of the SEC) and re-centers the analysis on the transactions and representations in which these assets or activities arise or are marketed,” he said. “By doing so, the SEC did not completely eliminate uncertainty or its enforcement role, because it concludes that a crypto asset that is not a security can nonetheless be sold as part of an investment contract if it is marketed with promises of profit derived from the issuer’s essential managerial efforts.”
A crypto that was marketed as a security may eventually be deemed something else “once those promises are fulfilled or no longer operative,” he said. This might affect securities more broadly than just crypto assets.
It’s less clear what may constitute a commodity under the guidance.
Jason Gottlieb, a partner at Morrison Cohen, said the Commodity Exchange Act defines commodities as a list of products (excluding onions and motion picture box office receipts), services and other issues “in which contracts for future delivery are presently or in the future dealt in.”
This legal definition diverges from the definition seemingly being used in the guidance. The CFTC’s approach to crypto over the past decade has evolved since some early lawsuits, where it claimed jurisdiction over bitcoin , leading it to seemingly have jurisdiction over non-security cryptocurrencies. But this definition needs to be codified by market structure legislation, he told CoinDesk.
“People need to understand that jurisdiction is still uncertain. The SEC is clearly saying ‘we don’t have jurisdiction if the token does not meet these criteria,’” he said. “Just because the SEC does not have jurisdiction does not mean the CFTC does.”
Gottlieb said he was part of a case before the Seventh Circuit Court of Appeals seeking to gain clarity on this question, but market structure legislation would be needed to cleanly grant the CFTC jurisdiction over all non-security cryptocurrencies.
The status of that legislation also remains up in the air. Senator Cynthia Lummis (R-Wyo.), speaking at the DC Blockchain summit earlier this week, said she anticipated a markup may happen in the final weeks of April. The issue of stablecoin yield may be resolved with an agreement that stablecoin issuers and their partner firms would not describe their products using bank terminology, though she cautioned that she hadn’t seen any specific language yet.
The flip side, several individuals told me, is that the Clarity Act might require the SEC to go back to the drawing board on how it’s defining securities in crypto. But this falls under the category of bridges that can be crossed when they’re reached.
Senator Tim Scott (R-S.C.), the chair of the Senate Banking Committee, said lawmakers are also close to agreements on issues like ethics and quorums on the regulatory agencies — some of the outstanding areas of disagreement on the bill.
Downing said he saw an April time frame as doable for advancing market structure legislation. The closer lawmakers get to the end of the year, however, the less likely it would be that anything could be passed, he said, pointing to the midterm election. “But I don’t think it’s impossible.”
Senator Kirsten Gillibrand (D-N.Y.) said on stage at the DC summit that she was “optimistic” there would be a markup soon, which would then lead to the Banking and Agriculture Committee’s bills combining.
The combined bill would need to incorporate areas of bipartisan agreement, she said.
“One of the issues that I think is very important that people should be aware of is the Senate wants an ethics provision,” she said. “I think the House would have had even more support on the Democratic side if they had retained their ethics provisions in their bill. It’s very important that members of Congress do not get rich off of this industry, because they have access to non-public information, because they have positions of power and authority.”
Downing said the market structure bill needed to address consumer protections and money laundering, without being so restrictive that companies would be scared to do anything.
“Nobody wants bad actors in their space and nobody wants that reputation of bad actors using this as a tool to do bad things,” he said. “… If you bring those [provisions] in too narrow, nobody’s going to do anything innovative.”
He said he understood why banks might be concerned about the yield issues.
“Community lenders, community banks are worried about depositors all exiting the market, in which case you’re not doing mortgages on small farms in Montana, right?” he said.
Late Friday, Senators Angela Alsobrooks and Thom Tillis told Politico they had reached an agreement on the yield issue, though the details had not been shared with the banking or crypto industries as of press time.
Kalshi was just ordered to cease offering most of its prediction markets in the state of Nevada for at least two weeks, pending a hearing on April 3.
The order came after an appeals court refused to grant an administrative motion that could have blocked the state court’s action. Earlier in the week, the state of Arizona filed criminal charges against Kalshi, alleging some of its election and other contracts violate state law.
In Nevada, a judge ruled that Kalshi can’t offer sports, election or entertainment-related event contracts at least temporarily.
According to the order by Judge Jason Woodbury, the record in Nevada’s case against Kalshi so far suggests that it offers products defined by state law, making its conduct subject to Nevada’s gaming regulators.
“The question of federal preemption in this regard is nuanced and rapidly evolving,” the judge wrote. “At the moment, the balance of convincing legal authority weighs against federal preemption in this context.”
The Arizona action goes further, alleging misdemeanor violations on small bets placed on professional football and college basketball games, upcoming elections and on whether bills become law and whether public figures will show up to sporting events.
“Arizona law prohibits operating an unlicensed wagering business, and separately bans betting on elections outright,” Arizona Attorney General Kris Mayes’ office said in a press release.
Kalshi co-founder Tarek Mansour called the charges a “total overstep” that “have nothing to do with gambling or the merits.”
There’s a broader growing backlash to prediction markets. Senator Catherine Cortez-Masto, who represents Nevada, wrote an opinion piece saying prediction markets “blatantly violate state and tribal laws and regulations.”
“To ensure responsible gaming, casinos, sportsbooks and online gaming sites have to follow minimum age requirements, participate in integrity monitoring and support critical consumer protections, like programs that help people with gambling addictions,” she said. “Yet, this past year, emboldened by limp and overly permissive federal regulators like the Commodity Futures Trading Commission (CFTC), so-called ‘prediction markets’ have transformed themselves into illegal sportsbooks, offering their users illicit sports wagers.”
This week
- There are no hearings or public meetings scheduled (at least pertaining to crypto).
If you’ve got thoughts or questions on what I should discuss next week or any other feedback you’d like to share, feel free to email me at [email protected] or find me on Bluesky @nikhileshde.bsky.social.
You can also join the group conversation on Telegram.
See ya’ll next week!
Crypto World
Blackstone’s BCRED Posts First Monthly Loss in Over Three Years as Investor Withdrawals Hit $3.7B

TLDR:
- BCRED reported a 0.4% loss in February 2025, its first monthly decline since September 2022’s 1.3% drop.
- Investors withdrew $3.7 billion from BCRED in Q1 2025, surpassing the fund’s typical quarterly redemption volume.
- Blackstone wrote down loans for select borrowers, including software firm Medallia, per a letter to financial advisers.
- Blackstone shares have dropped over 28% this year as banks tighten lending and rivals cap investor withdrawals.
Blackstone’s private credit fund, BCRED, recorded its first monthly loss in over three years in February 2025. The $82 billion fund reported a total loss of 0.4%, drawing attention to growing pressures across the private credit sector.
Investor concerns around liquidity, credit quality, and withdrawal surges have grown steadily this year. This development marks a turning point for one of the largest private credit vehicles in the world.
BCRED Reports February Loss as Withdrawals Surge
BCRED’s last recorded monthly loss before February was in September 2022, when it posted a decline of 1.3%. The February 2025 loss of 0.4% comes as investor sentiment around private credit has noticeably shifted.
For context, the Morningstar LSTA index of publicly traded leveraged loans fell 0.8% in February, per Morningstar’s website.
During the first quarter of this year, Blackstone’s fund faced a larger-than-usual wave of redemption requests. Investors pulled $3.7 billion from BCRED, a figure that exceeded typical quarterly withdrawal volumes.
The fund allows investors to withdraw a portion of their holdings every quarter, which adds a layer of liquidity pressure.
Financial news reporter Kristen Shaughnessy shared the development on social media, drawing wider public attention. The post referenced a Financial Times report citing a letter sent to financial advisers by Blackstone. According to that report, customer service software firm Medallia was among the companies whose loans were written down.
BCRED wrote down the value of a “select” number of loans during February, per the Financial Times report. Despite this, Blackstone maintained that the fund has delivered a 9.5% annualized total return since inception for Class I shares. The firm also noted that BCRED has outperformed the leveraged loan market by 100 basis points so far this year.
Private Credit Sector Faces Growing Scrutiny From Banks and Investors
Private credit funds have come under growing scrutiny due to weakening credit quality across the sector. Their high exposure to vulnerable sectors such as software has raised concerns among analysts and investors. Additionally, a lack of transparency has made it harder for market participants to assess underlying risks.
These concerns have spilled over onto Wall Street, where some major U.S. banks have tightened lending to the private credit industry.
JPMorgan Chase marked down the value of certain loans to private credit players earlier this month. That move is expected to reduce available lending to funds operating in the space.
Morgan Stanley and BlackRock were among the firms that moved to limit withdrawals from their own funds. Both firms acted following a surge in redemption requests from investors. This pattern across multiple funds points to a broader trend of tightening liquidity across private credit markets.
Shares of Blackstone, the world’s largest alternative asset manager, have lost more than 28% of their value so far this year.
That decline mirrors the broader unease investors have expressed toward the alternative asset space. As the sector navigates these pressures, fund managers are being watched more closely than at any point in recent years.

TLDR:
- XRP open interest is falling across major exchanges, with Binance still holding the largest derivatives market share.
- Liquidation spikes and soft taker volume confirm that leveraged XRP positions are actively being unwound market-wide.
- XRP has gained dual commodity classification from the SEC and CFTC, marking a turning point in regulatory clarity.
- ETF inflows of $1.44B and Ripple’s $2.7B in acquisitions reflect rising institutional confidence heading into 2026.
XRP open interest continues to contract across major derivatives exchanges, reflecting an ongoing deleveraging trend in the market.
Despite this broad decline, Binance maintains the largest share of XRP open interest among top platforms. At the same time, a growing set of regulatory and institutional developments is taking shape in 2026.
Analysts are watching closely to see whether these catalysts can reverse the current market structure.
Binance Dominates as Leveraged Positioning Unwinds
Binance remains the primary venue for XRP leveraged trading, holding the most open interest across major exchanges.
However, the exchange’s own 24-hour data shows continued weakness in positioning, with no strong recovery in sight.
Net taker volume on Binance also remains soft, which points to limited aggressive demand from new buyers. This combination suggests the market is still in a reset phase rather than entering a fresh expansion.
Liquidation data adds further weight to this view. Recent liquidation spikes show that forced leverage cleanup has played a role in driving open interest lower.
Rather than reflecting fresh long conviction, the current structure points to position unwinding. Speculative appetite across XRP derivatives continues to fade as a result.
The overall trend across exchanges mirrors what Binance is showing internally. Open interest is falling in a broad and sustained manner, not in isolated bursts.
This pattern typically follows periods of elevated speculation and leverage buildup. For open interest to recover, the market would need stronger directional participation from both retail and institutional traders.
Until that recovery arrives, the market structure for XRP derivatives remains under pressure. Binance will likely continue to lead the space by volume and open interest.
However, the gap between Binance and other exchanges may shift if conditions improve on other platforms. Traders are watching these metrics carefully as a leading signal for XRP’s next move.
Regulatory and Institutional Catalysts Are Aligning in 2026
On the fundamental side, a series of developments are converging that some analysts say could drive a major move.
XRP has been officially classified as a digital commodity by both the SEC and the CFTC, bringing long-awaited regulatory clarity.
The CLARITY Act markup is targeting April, and Ripple CEO Brad Garlinghouse has placed the odds of passage at 80 to 90 percent. Additionally, a stablecoin yield compromise is reportedly near completion.
Institutional interest is also building at a fast pace. XRP-related ETFs have pulled in $1.44 billion in inflows, while Evernorth has filed its S-4 for a Nasdaq listing.
Ripple has also made over $2.7 billion in acquisitions and is expanding its global footprint. A Ripple National Trust Bank application is currently under review as well.
Crypto analyst X Finance Bull noted on X that in 2024, XRP ran from $0.49 to $3.60 on news alone. The analyst argued that the 2026 setup carries heavier weight, with regulation, infrastructure, and institutional capital aligning together. That framing has drawn attention from traders reassessing their positions.
Whether the derivatives market responds to these catalysts remains to be seen. Open interest recovery alongside stronger volume would signal a shift in market sentiment. For now, XRP sits at a crossroads between fading speculative leverage and growing structural support.

Fidelity Investments told the US Securities and Exchange Commission (SEC) on Friday that it should continue to develop the regulatory framework for broker-dealers to offer, custody and trade crypto assets on alternative trading systems (ATS).
The letter from the US’ third-largest asset manager was in reply to a call for comments earlier this month by the regulator’s Crypto Task Force.
Fidelity said it is “critical” for the SEC to develop a comprehensive regulatory framework and clear rules of the road for tokenized securities trading, including rules for trading tokenized securities issued by third parties.

Tokenized instruments have different issuance structures, legalities, and valuation models, the letter said. For example, tokenized real-world assets (RWAs) span entirely different asset classes like equities, real estate, bonds, or private credit.
“Tokenization models vary significantly in structure and in the rights afforded to holders,” the letter said. The company explained:
“In some models, the crypto asset represents a holder’s indirect interest in the underlying security through a securities entitlement, while in others, the crypto asset may constitute a securities‑based swap, which may be offered only to eligible contract participants.”
Fidelity also urged the SEC to bridge the regulatory gap between centralized and decentralized trading systems to “consider how intermediated and disintermediated trading venues can evolve and coexist,” the company’s general counsel, Roberto Braceras, wrote.

This includes overhauling existing reporting rules to reflect that decentralized finance (DeFi) trading platforms and other “disintermediated” systems cannot produce the detailed financial reporting required by the SEC because there is no central authority.
Additionally, Fidelity recommended that the SEC issue guidance permitting broker‑dealers to use distributed ledger technology for ATS and other recordkeeping purposes.
Overhauling reporting requirements to reflect this technological reality removes “undue burden” from decentralized systems, the letter said.
The Securities and Exchange Commission, under the leadership of Chairman Paul Atkins, has repeatedly signaled support for 24/7 capital markets and has given the regulatory approval for financial companies to experiment with tokenized trading.
Related: SEC interpretation on crypto laws ‘a beginning, not an end,’ says Atkins
US regulators say tokenized securities are subject to the same capital rules as underlying assets
Tokenized securities, which include equities, debt instruments, real estate investment trusts (REITs) and other securitized assets, are subject to the same banking capital requirements as the underlying assets they hold.
This view was shared in a joint policy statement published in March from the Federal Reserve, the Federal Deposit Insurance Corporation (FDIC) and the Office of the Comptroller of the Currency (OCC).
“The technologies used to issue and transact in a security do not generally impact its capital treatment,” according to the agencies.
Magazine: When privacy and AML laws conflict: Crypto projects’ impossible choice
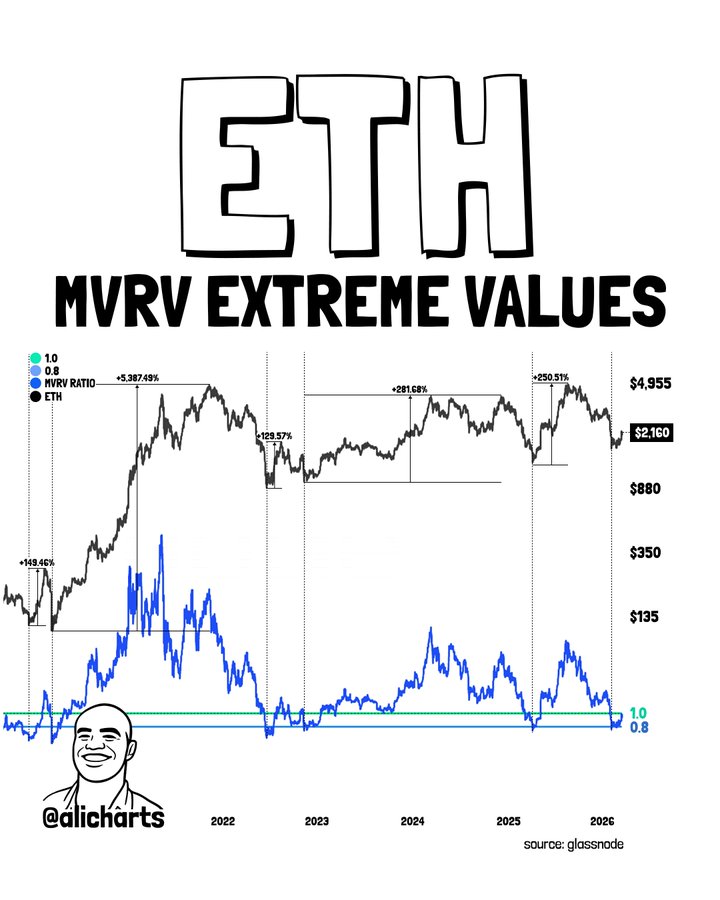
TLDR:
- Ethereum’s MVRV ratio dropped below 0.8, historically flagging a rare and powerful generational buy zone for ETH.
- ETH price tested the ascending triangle’s rising trendline near $1,800, defending a critical multi-year structural support level.
- The daily Supertrend flipped green for the first time since May, signaling a potential end to ETH’s prolonged sideways trend.
- Reclaiming $2,356 is the first confirmation needed before Ethereum can advance toward the long-term $10,000 price target.
Has Ethereum bottomed? That question is gaining traction across the crypto market as key signals begin to align. Ethereum recently tested the $1,800 price level, a zone that has drawn attention from both technical analysts and on-chain researchers.
A combination of chart structure and blockchain data now points to a potential trend reversal. The roadmap to $10,000 is becoming clearer with each passing week.
Price Action and On-Chain Data Point to a Potential Floor
Ethereum continues to trade within a well-defined ascending triangle on the weekly chart. The recent move toward $1,800 aligned precisely with the triangle’s rising trendline support.
This type of reaction at a major structural level carries significant weight for analysts. It suggests the market is defending a critical price floor rather than breaking below it.
On-chain data adds further backing to the bottoming thesis. The MVRV ratio recently dropped below 0.8, a historically rare reading for Ethereum.

Past instances of this level preceded some of the largest bull rallies in the asset’s history. Analysts widely refer to this threshold as a “Generational Buy” zone.
The timing of this on-chain reset is particularly notable. It occurred exactly as price tested the triangle’s trendline support on the chart.
The convergence of both signals at the same price point strengthens the case considerably. Such alignment across different analytical frameworks rarely happens by coincidence.
Ali Charts noted in a recent post that this combination is the strongest seen in a while. The analyst pointed to the $1,800–$2,000 range as a prime area for accumulation.
Dips into this zone should be treated as buying opportunities by market participants. This view holds as long as the $1,800 floor remains structurally intact.
The Roadmap to $10,000 Runs Through These Key Levels
The roadmap to $10,000 begins with reclaiming the $2,356 resistance level. This is the first confirmation that Ethereum is exiting the accumulation phase.
A sustained move above it would mark the transition into a true bull market expansion. Without clearing this level, the recovery remains in an early and unconfirmed stage.
The next targets on the roadmap sit at $2,647 and $3,639. These mid-term levels correspond to MVRV pricing bands that previously acted as notable resistance.
Breaking through them would validate the broader uptrend in a meaningful way. Each successful level cleared adds further confidence to the $10,000 target.
Beyond the mid-term range, long-term expansion zones are mapped at $4,632 and $5,624. These areas are expected to attract increased selling activity from market participants.
A clean breakout above them, however, would keep the bullish structure fully intact. Momentum through these zones would accelerate the broader move higher.
The all-time high region near $4,900 remains the most critical threshold on the roadmap. A decisive weekly close above it would complete the ascending triangle structure.
That breakout would open the path directly toward $10,000 for Ethereum. The entire bull market case rests on this level eventually being cleared.
The first couple of months of 2026 have forced the Ethereum community into a kind of introspection—one that goes beyond price, beyond technical upgrades, and into the question of what the network is actually trying to be.
Even before this year, there has been a sense among builders and executives that Ethereum was on the verge of another growth phase—this time driven not by crypto-native users but by institutions and technology. Neobanks, as some argued, would quietly onboard millions by abstracting away the complexity of wallets and gas fees. Ethereum, in this framing, wouldn’t need to win users directly. It would sit beneath the interface, powering a new financial stack that, on the surface, looked nothing like crypto.
It was a continuation of a long-running thesis: that Ethereum’s success would come from invisibility.
That vision has been shaped in part by years of previous upgrades aimed at improving user experience and reducing costs. Changes like “proto-danksharding”, introduced in the Dencun upgrade, significantly lowered fees for layer 2 networks by increasing data downloads for transactions, while ongoing improvements to the base layer have made transactions more efficient.
While the price of the network’s ether (ETH) token has been determined by market forces, these upgrades have, together, helped move Ethereum closer to a model where users interact with applications without needing to understand the underlying infrastructure.
But that narrative began to change a few weeks into the year, refocusing on the core roadmap.
The L2 debate
Earlier this year, the co-founder of the network, Vitalik Buterin, delivered a sharp reality check to the broader ecosystem: “You are not scaling Ethereum.”
The comment cut through what had, until then, been a largely celebratory conversation around rollups. These types of networks, also known as layer-2 (L2) networks, process transactions off Ethereum and then bundle them back onto the main chain to make it faster and cheaper. Layer-2 networks have exploded over the last few years, transaction fees have come down, and activity has spread—but the deeper question was whether any of this amounted to coherent scaling.
Buterin’s argument went further than a general critique of progress. In his view, many of today’s layer 2 designs are drifting away from Ethereum’s core model: relying on centralized components and siloed environments that don’t fully inherit the guarantees of the base chain. The concern wasn’t that L2s exist, but that in their current form, they may not be delivering the kind of scaling Ethereum was meant to achieve.
His critique highlighted a growing unease.
Fragmentation across L2s, inconsistent security assumptions, and reliance on centralized components were beginning to look less like temporary trade-offs and more like structural risks. Ethereum, in trying to scale outward, risked losing the very properties that made it valuable in the first place—its strong security, decentralization, and role as a shared, neutral settlement layer where applications and liquidity can seamlessly interoperate.
L2 teams, for their part, didn’t push back so much as recalibrate. Some acknowledged the critique and leaned into a future where rollups differentiate through specialization: privacy, consumer apps, or unique execution environments, rather than simply acting as cheaper Ethereum. Others defended their role more forcefully, arguing that high-throughput environments are still essential.
Ethereum’s base layer, meanwhile, has made incremental progress on its own. Recent upgrades, such as December’s Fusaka hard fork, increased data capacity and efficiency on the main network, allowing more transactions to be processed while lowering costs. Although that spike in transactions came under scrutiny recently, with some calling them ‘address poisoning’ scams.

What this tense episode established for Ethereum is that the path forward needs a delicate balance between the base layer’s structural upgrades and a new breed of specialized rollups that can grow the ecosystem without breaking its foundational security.
This could also lead to consolidation among the layer 2 networks, according to 21shares. “The year ahead is likely to mark Ethereum’s L2 consolidation: a leaner, more resilient layer anchored by ETH-aligned, exchange-backed, and high-performance networks,” the firm said in a research report.
The quantum threat
At the same time, another issue—long discussed but rarely urgent—suddenly moved up the priority list: Quantum Computing.
The Ethereum Foundation signaled a shift in posture, elevating efforts like ‘LeanVM’ and post-quantum signature schemes. What had once been treated as a distant, almost academic concern was now being folded into near-term planning.
The implication was hard to ignore: the network is no longer just building for the next cycle, but for threats that could fundamentally break its cryptographic assumptions. The foundation has signaled it is taking that risk seriously, establishing dedicated research efforts focused specifically on post-quantum security.
Vitalik Buterin also outlined a roadmap to protect the blockchain from the long-term risks posed by quantum computers
The internal shuffle
If scaling exposed cracks in Ethereum’s present, quantum risk cast a shadow over its future, and it seemed that the network was taking the threat seriously.
Then came changes from within.
The departure of Tomasz Stańczak as co-executive director of the Ethereum Foundation marked more than a leadership reshuffle. At a moment when the network is facing technical, strategic, and philosophical reevaluations all at once, even subtle shifts at the top can signal a broader recalibration.
The move also came as something of a surprise.
The foundation is not known for abrupt shifts, and Stańczak had only stepped into the role about a year earlier, following the long-standing tenure of Aya Miyaguchi. In an ecosystem that tends to favor continuity, the rapid turnover hinted at a deeper internal recalibration underway, as the foundation reassesses its priorities amid growing demands for scaling, security, and Ethereum’s potential role in new frontiers such as artificial intelligence (AI).
‘Trust layer’
And AI, a topic that has become impossible to ignore, not just for crypto but for every industry, began to shape a separate line of thinking for the network.
Buterin outlined how Ethereum could play a foundational role in the future of artificial intelligence. The vision extends beyond payments or DeFi—into a world where Ethereum acts as a coordination layer for decentralized AI systems, enabling verifiable outputs, trust-minimized data sharing, and machine-to-machine economic activity.
That push didn’t emerge overnight.
Early last year, the foundation spun up a dedicated decentralized AI research unit (dAI) exploring how the network could support autonomous agents and machine-to-machine economies. What felt experimental at the time has since accelerated into something more deliberate in 2026, with the foundation increasingly framing Ethereum as a potential “trust layer” for AI: a system for verifying outputs, coordinating agents, and anchoring a rapidly evolving ecosystem that, until now, has been largely controlled by centralized players.
All of this is an ambitious expansion of scope, placing Ethereum at the intersection of two of the most consequential technologies today.
But overall, the first three months of the year suggest that Ethereum no longer has the luxury of tackling these questions in isolation; rather, they are converging.
What emerges is a network being pulled in multiple directions, each one with its own sense of urgency, and a balancing act is becoming harder to ignore. And unlike previous cycles, where narratives could shift as quickly as prices, the issues now feel deeper, less about momentum, and more about structure.
These tensions are unlikely to be resolved anytime soon and will continue to shape Ethereum’s trajectory in the months ahead.
In the immediate term, however, the focus remains on scaling the base layer, with the upcoming Glamsterdam upgrade, slated for this year, expected to accelerate that effort. The upgrade will likely become a litmus test for the network’s ability to solve issues that can successfully shift Ethereum into a robust, quantum-secure “trust layer” capable of anchoring the global AI economy.
Read more: Ethereum’s ‘Glamsterdam’ upgrade aims to fix MEV fairness
Crypto World
Polkadot (DOT) Drops to $1.43 After 97.80% Macro Correction: Can It Repeat a 4,529% Rally?
TLDR:
- Polkadot has declined approximately 97.80% from its all-time high of over $55 reached in 2021.
- Analysts identify a high-risk HTF accumulation zone for DOT between the $1.10 and $1.30 price range.
- A weekly close below $1.20 serves as the formal invalidation level for any current accumulation thesis.
- DOT must reclaim and hold above $4.50 to confirm a descending channel breakout and bullish structure shift.
Polkadot (DOT) is currently trading at $1.43, recording a 4.68% price decline in the last 24 hours. The asset posted a 0.81% gain over the past seven days. Trading volume over the same 24-hour period stood at $123,467,162.
The token sits near a critical demand zone, drawing attention from technical analysts. Market observers are now assessing whether a major recovery is forming.
Polkadot Enters Deep Corrective Phase After 2021 Cycle Top
Polkadot reached an all-time high of over $55 during the 2020–2021 bull run. Since that peak, the asset has declined approximately 97.80% to its current price.
This places DOT firmly within what analysts describe as a macro corrective accumulation phase. The correction has extended from 2022 through the present period in 2026.
Crypto analyst CryptoPatel shared a detailed breakdown of the asset on X. The post noted that Polkadot may be forming the same structure that preceded a 4,529% rally.
According to the analysis, DOT is trading below a confirmed bearish breakdown level. This positions the token at a key accumulation versus invalidation zone.
The chart reflects a multi-year descending channel marked by consistent lower highs and lower lows. Dynamic trendline resistance has rejected price on every retest since the 2021 cycle top.
Additionally, a breakdown below the $3.20 horizontal support level confirmed a bearish structural shift. Weak consolidation near current lows further adds to the cautious near-term picture.
The higher time frame demand zone sits between $1.10 and $1.30, which analysts flag as a high-risk accumulation range. However, it also represents a historically notable area for long-term positioning.
A weekly close below $1.20 would serve as the formal invalidation level. Until that occurs, the structure remains technically watchable for patient market participants.
Key Price Levels Outline the Road Ahead for Polkadot Recovery
For a bullish scenario to materialize, Polkadot must reclaim and hold above the $4.50 level. This marks the descending channel breakout confirmation on the higher time frame.
Without that reclaim, any upside move carries the risk of being a short-term relief bounce. Traders are treating this threshold as the primary structural trigger.
CryptoPatel’s analysis also outlined specific bull cycle targets for Polkadot. These targets are set at $4.47, $9.33, $22.27, and $51.75, moving progressively higher.
Each level represents a distinct recovery zone tied to prior market structure. The final target closely mirrors DOT’s previous all-time high territory.
The risk invalidation level remains a weekly close below $1.20. Such a close would negate the accumulation thesis and point to further downside.
At the time of writing, Polkadot trades at $1.43, sitting just marginally above that threshold. The gap between current price and invalidation is notably slim.
The seven-day gain of 0.81% points to some buying activity near the lows. Yet the 24-hour decline of 4.68% reflects ongoing selling pressure in the short term.
As a result, investors tracking DOT will need to see a sustained move above $4.50. Only then can a confirmed directional shift be considered valid.
TLDR:
- CoinDCX co-founders Sumit Gupta and Neeraj Khandelwal were arrested by Thane Police over an alleged Rs 71.6 lakh fraud.
- The complainant was promised high returns and franchise opportunities linked to CoinDCX between August 2025 and February 2026.
- CoinDCX says fraudsters impersonated its founders and diverted funds to accounts unrelated to the exchange.
- Between April 2024 and January 2026, CoinDCX reported over 1,212 fake websites impersonating its official domain.
CoinDCX co-founders Sumit Gupta and Neeraj Khandelwal were arrested by Thane Police in a financial fraud case. Both were detained in Bengaluru and produced before a court.
The court remanded them to police custody until March 23. The case involves an alleged fraud of Rs 71.6 lakh tied to fake promises of high returns and franchise opportunities related to CoinDCX.
Fraud Allegations and Police Action
An FIR was filed against six individuals, including the two co-founders. The complainant, an insurance advisor, said he was approached between August 2025 and February 2026.
He was promised high returns and franchise opportunities linked to CoinDCX. Neither the promised returns nor the franchise were ever delivered to him.
Police confirmed that the accused collected money through cash and bank transfers. Authorities have invoked provisions of the Bharatiya Nyaya Sanhita in the case.
The investigation is currently active and ongoing. Both co-founders remain in police custody pending further proceedings.
CoinDCX denied any wrongdoing on the part of the company or its leadership. The firm stated the FIR is tied to fraudsters who impersonated its founders.
These impersonators allegedly diverted collected funds to unrelated third-party accounts. The accounts cited in the complaint bear no connection to CoinDCX.
In response, CoinDCX took to its official social media account to address the public directly. The company stated that “the FIR filed against our co-founders is false and appears to be part of a conspiracy involving impersonators posing as CoinDCX founders and cheating the public.”
It added that it had “issued a public notice on our website highlighting that CoinDCX is being targeted by fraudsters.” The firm further confirmed that the accounts mentioned in the complaint are not linked to the company in any way.
CoinDCX Raises Industry-Wide Concerns Over Impersonation
Following its public statement, CoinDCX published a notice on its website alerting users about the ongoing fraud. The firm stressed that individuals posing as its founders had misled members of the public.
These fraudsters reportedly directed collected funds into unrelated third-party accounts. The exchange has been proactively communicating these threats to its community.
Between April 1, 2024 and January 5, 2026, CoinDCX reported over 1,212 fake websites. These sites were impersonating the official CoinDCX domain, coindcx.com.
The volume reflects the scale of brand abuse the exchange has faced over that period. CoinDCX has been actively working to flag and remove such fraudulent platforms.
Brand impersonation and cyber fraud are growing concerns in India’s digital finance space. More people investing online has provided greater opportunity for fraudsters to operate. CoinDCX noted that such cases are rising across the broader industry.
The firm stated that it “strongly condemns such actions” and remains “fully committed to supporting authorities in addressing such misconduct.”
CoinDCX remains focused on user education and community awareness as protective measures. The exchange continues to fully cooperate with relevant law enforcement authorities throughout the investigation.
Users are urged to verify all communications and transactions through the official CoinDCX platform only.
Crypto World
Strategy calls its new bitcoin funding tool an ‘iPhone’ moment but analysts warn of hidden risks
Strategy (MSTR), the leading corporate holder of bitcoin, has described the launch of its Perpetual Stretch Preferred Stock (STRC) as the firm’s “iPhone moment,” and despite its support in BTC accumulation, risks remain.
Before digging into these risks, it’s worth noting that while the focus is on STRC, specifically over its larger liquidity and adoption, they also apply to similar preferred offerings, including another bitcoin treasury company, Strive’s preferred offering, SATA.
These instruments are “not well understood through the lens of traditional credit or equity,” and instead require a different analytical framework, said NYDIG’s Global Head of Research Greg Cipolaro in a note.
By design, STRC targets a steady $100 share price, using a variable monthly dividend to keep trading near that level. The approach has already supported multi-billion dollar issuance and the acquisition of more than 50,000 bitcoin, according to STRC.live data.
At its core, STRC works by adjusting yield to steer price. If shares trade above $100, the company can trim the dividend to cool demand. If shares fall below that level, it can raise dividends to attract buyers. Keeping the price anchored lets the firm issue new shares near par, bringing in capital that is then deployed to buy bitcoin.
The novel financial instrument has been a success so far. Not only has it allowed Strategy to buy more than $3.5 billion worth of bitcoin, but it has also attracted institutions that have added STRC to their balance sheets.
In practice, the product resembles a money market fund with a floating yield of 11.5%, far above U.S. Treasuries. The appeal hinges on the steady $100 price tag coupled with high yields.
When conditions are favorable, NYDIG’s Cipolaro wrote, the mechanism creates a powerful feedback loop. The loop, in which STRC trades near par, enables the firm to raise capital, deploy proceeds to buy more bitcoin, expand the asset base, and sustain investor confidence. That confidence sustains additional issuance.
“As long as preferreds remain anchored near par, equity trades above the NAV, and capital markets stay open, the flywheel drives ongoing bitcoin demand,” Cipolaro wrote in the note.
Still, not everything’s rosy.
BitMEX Research has written in a note titled “A bit of Stretch” that it sees the risks related to the product as “substantially greater than those related to short duration U.S. treasuries.”
Where the risks actually sit
Bullish investors often point out that STRC is well-capitalized and could easily cover dividend payments, given Strategy’s massive 761,068 BTC war chest and more than $2.2 billion in cash reserves. That’s around 50 years of covered dividend payments, while the company can still lower STRC’s dividend over time to further the coverage. On top of that, there are monetization options for the company’s massive bitcoin stash, which could further dividend payments.
The risks, however, aren’t based on dividend coverage at all, according to NYDIG’s Cipolaro.
“The appropriate way to assess risk in STRC and SATA is through the lens of governance and subordination rather than focusing solely on payment risk,” he wrote.
The mechanism STRC uses also creates a stress path. If bitcoin drops and confidence in Strategy’s balance sheet weakens, STRC could slip below par.
To defend the price, the company would need to raise the dividend. Higher payouts increase cash obligations, which can, in turn, worry investors and push the price lower. That feedback loop is a familiar one in credit markets.
In a standard corporate setting, that cycle can end in forced asset sales. Companies may have to sell core holdings to meet rising obligations, locking in losses at the worst time. For Strategy, that would mean selling BTC into a falling market. However, Strategy’s Michael Saylor has repeatedly said he won’t sell the company’s bitcoin stack.
The STRC terms, however, give the company another option. The target price is not a binding promise. If conditions turn, Strategy can reduce the dividend rather than increase it.
According to BitMEX Research’s reading of the SEC filings related to STRC, Strategy can “at its absolute discretion, lower the dividend rate by up to 25 bps a month, no matter what else is happening.”
Unpaid dividends can, in addition, accrue without triggering default or forcing asset sales. As BitMEX Research put it, instruments like these were “written by the company for the company.”
Read more: Strategy’s latest massive bitcoin purchase offers insight into its evolving funding model
Built to bend, not break
That flexibility shifts what would happen to STRC in cases of a crisis.
Instead of a company caught in a squeeze, the pressure moves to the security holders. If the dividend is reduced, the yield becomes less attractive, and the market price can fall to reflect the new reality.
NYDIG’s Cipolaro made it clear in his note that the structure “can remain solvent while still delivering suboptimal outcomes for preferred holders due to the loss of confidence and funding access.” The risk isn’t a default on its dividend, but rather the loss of its attractiveness.
Strategy’s legacy software business does not cover those payments on its own. The model depends on continued issuance or balance sheet management tied to its bitcoin holdings.
The binding constraint is not income generation, but the combination of continued access to capital markets and sufficient asset coverage,” NYDIG’s Cipolaro wrote. The setup invites comparisons to structures that rely on new inflows to support payouts.
The difference here is that payouts are not fixed. If demand slows, the company can lower the dividend instead of maintaining a rate it cannot sustain. That feature helps protect the issuer but weakens the claim for investors seeking stability and income.
“When the music stops, if things become challenging for MSTR, instead of selling bitcoin, MSTR could just abandon the narrative that STRC is targeting stability,” BitMEX Research wrote. “This feels very favourable for MSTR and the dividend payments are therefore quite sustainable and affordable, in our view.”
Breaking the mechanism
Market impact will depend on how long the $100 anchor holds.
As long as demand for yield products remains strong and bitcoin sentiment is supportive, STRC can keep channeling funds into the company’s treasury strategy.
That, in turn, reinforces Strategy’s position as a major public holder of bitcoin. NYDIG has shown that bitcoin’s price stability is what enables the economic viability of at-the-market issuance of these products.
STRC and Striv’es SATA have seen their prices drop below par during periods of sharp bitcoin price declines, the firm’s research found. When that happens, “issuance becomes uneconomic, limiting the ability to raise capital and slowing the flywheel.”

The risk shows up when conditions change. A prolonged drop in BTC’s price or a shift in rates could test the price mechanism. If the dividend is cut to preserve cash, STRC could trade well below par. Losses would be borne by investors who treated the shares as a near-cash substitute.
“It resembles being short a put on bitcoin asset coverage, earning yield in exchange for bearing downside risk if bitcoin declines and erodes the asset cushion,” NYDIG offered as a frame for institutional investors. “Unlike a standard option, however, there is no fixed strike or maturity, and outcomes are path-dependent and shaped by management discretion.”
The broader significance is the template itself.
STRC blends equity features with bond-like behavior and a built-in adjustment lever. It offers a new path for companies to raise capital tied to volatile assets without locking in fixed obligations.
For now, these instruments have done their job: attract capital and support further bitcoin accumulation. The open question is how it behaves under stress and who absorbs the cost when the trade no longer looks stable.
The interpretation of that scenario isn’t great, but not for MSTR, “it’s the investors who may feel somewhat aggrieved when the music stops,” BitMEX concluded.
Read more: Strategy’s credit risk falls as preferred equity value surpasses convertible debt
TLDR:
- Hackers are using fake Google Play Store pages in Brazil to distribute malware disguised as legitimate apps.
- The malware runs XMRig on infected Android devices, silently mining crypto while avoiding battery detection.
- A banking Trojan targets Binance and Trust Wallet, replacing wallet addresses during live USDT transactions.
- BTMOB RAT, a malware-as-a-service tool, gives attackers camera, GPS, and credential access on infected phones.
Android malware is spreading across Brazil through counterfeit Google Play Store pages, according to a new report by SecureList.
Hackers are using phishing websites to distribute apps that appear legitimate. Once installed, these apps silently convert infected phones into crypto mining devices.
Some variants also deploy a banking Trojan. The campaign currently targets Brazilian users exclusively, with newer versions spreading through WhatsApp and additional phishing channels.
Fake App Turns Phones Into Crypto Mining Machines
The campaign starts with a phishing website that closely mimics the Google Play Store. One of the fake apps is called INSS Reembolso, which claims to be tied to Brazil’s social security service.
The design copies trusted government branding and the Play Store layout, making the download appear safe to unsuspecting users.
After a user installs the fake app, the malware begins unpacking hidden code through multiple stages. It uses encrypted components and loads the main malicious code directly into the phone’s memory.
SecureList noted that “there are no visible files on the device, making it hard for users to detect any suspicious activity.”
The malware also takes steps to evade detection by security researchers. It checks whether the phone is running in an emulated environment and stops all activity if it detects one.
This evasion technique makes it harder to analyze in a lab setting. Android normally kills background apps to save battery, but the malware loops a silent audio file to fake active use.
Once the malware is fully active, it fetches a crypto mining payload from attacker-controlled infrastructure. This payload is a version of XMRig compiled for ARM devices, which are common in Android smartphones.
The infected device connects to mining servers and mines cryptocurrency silently in the background. According to SecureList, “the malware monitors the battery charge percentage, temperature, installation age, and whether the phone is being actively used,” with mining starting or stopping based on that data.
Banking Trojan Targets Binance and Trust Wallet Users
Beyond crypto mining, some versions of the malware install a banking Trojan that targets Binance and Trust Wallet.
During USDT transfers, the Trojan overlays fake screens on top of the real apps. It then quietly replaces the recipient wallet address with one controlled by the attacker.
The banking module also monitors popular browsers, including Chrome and Brave. SecureList confirmed the module “supports a wide range of remote commands,” including screen recording, audio capture, SMS sending, keystroke logging, device locking, and data wiping.
It additionally uses Firebase Cloud Messaging to receive instructions from attackers. All of these actions are carried out remotely without the user’s knowledge.
Other recent samples use the same fake app delivery method but switch the payload to BTMOB RAT. This remote access tool is sold in underground markets as part of a malware-as-a-service ecosystem. It provides deeper access, including camera control, GPS tracking, and credential theft.
SecureList confirmed that “all known victims are in Brazil,” though newer variants are also spreading through WhatsApp and other phishing pages.
BTMOB is actively promoted across online platforms, including YouTube and Telegram. Sales and support are handled through a dedicated Telegram account, which lowers the barrier for less-skilled attackers.

The SEC explains how it’s viewing a crypto security: State of Crypto

Hastings sees viral Jewish protest over Israel death penalty plans

St. John's vs. Kansas odds, time, March Madness predictions: 2026 NCAA Tournament picks from proven model






-

 Tech7 days ago
Tech7 days agoYour Legally Registered ‘Motorcycle’ Might Not Count Under Proposed US Law
-

 Fashion2 days ago
Fashion2 days agoWeekend Open Thread: Adidas – Corporette.com
-

 Politics2 days ago
Politics2 days agoJenni Murray, Long-Serving Woman’s Hour Presenter, Dies Aged 75
-
 Tech5 days ago
Tech5 days agoAre Split Spacebars the Next Big Gaming Keyboard Trend?
-

 Crypto World19 hours ago
Crypto World19 hours agoBest Crypto to Buy Now: Strategy Just Spent $1.57 Billion on Bitcoin During Fear While Early Investors Quietly Enter Pepeto for 150x Potential
-

 News Videos4 days ago
News Videos4 days agoRBA board divided on rate cut, unusually buoyant share market | Finance Report | ABC NEWS
-

 Crypto World20 hours ago
Crypto World20 hours agoBitcoin Price News: Bhutan Sells $72 Million in BTC Under Fiscal Pressure, but the Smart Money Entering Pepeto Sees What the Market Does Not
-

 Business7 days ago
Business7 days agoSearch for Savannah Guthrie’s Mother Enters Seventh Week with No Arrests
-
 Crypto World2 days ago
Crypto World2 days agoNIO (NIO) Stock Plunges 6.5% as Shelf Registration Sparks Dilution Worries
-

 Business6 days ago
Business6 days agoAustralian shares drop as Iran war enters third week
-

 Crypto World6 days ago
Crypto World6 days agoCrypto Lender BlockFills Enters Chapter 11 with Up to $500M in Liabilities
-

 Politics4 days ago
Politics4 days agoThe House | The new register to protect children from their abusers shows Parliament at its best
-

 Fashion6 days ago
Fashion6 days ago25 Celebrities with Curly Hair That Are Naturally Beautiful
-

 Tech3 days ago
Tech3 days agoinKONBINI Lets You Spend Summer Days Behind the Register
-
 Politics5 days ago
Politics5 days agoReal-time pollution monitoring calls after boy nearly dies
-

 Crypto World4 days ago
Crypto World4 days agoCanada’s FINTRAC revokes registrations of 23 crypto MSBs in AML crackdown
-
 NewsBeat4 days ago
NewsBeat4 days agoResidents in North Lanarkshire reminded to register to vote in Scottish Parliament Election
-

 Business6 days ago
Business6 days agoMeta planning major layoffs as AI spending and automation reshape workforce
-

 News Videos4 days ago
News Videos4 days agoPARLIAMENT OF MALAWI – PAC MEETING WITH REGISTRAR OF FINANCIAL ON AMARYLLIS HOTEL – INQUIRY LIVE
-
Crypto World7 days ago
U.S. Oil Companies Post Record Profits as Oil Prices Break $100
You must be logged in to post a comment Login