When it comes to AI models, size matters.
Even though some artificial-intelligence experts warn that scaling up large language models (LLMs) is hitting diminishing performance returns, companies are still coming out with ever larger AI tools. Meta’s latest Llama release had a staggering 2 trillion parameters that define the model.
As models grow in size, their capabilities increase. But so do the energy demands and the time it takes to run the models, which increases their carbon footprint. To mitigate these issues, people have turned to smaller, less capable models and using lower-precision numbers whenever possible for the model parameters.
But there is another path that may retain a staggeringly large model’s high performance while reducing the time it takes to run an energy footprint. This approach involves befriending the zeros inside large AI models.
For many models, most of the parameters—the weights and activations—are actually zero, or so close to zero that they could be treated as such without losing accuracy. This quality is known as sparsity. Sparsity offers a significant opportunity for computational savings: Instead of wasting time and energy adding or multiplying zeros, these calculations could simply be skipped; rather than storing lots of zeros in memory, one need only store the nonzero parameters.
Unfortunately, today’s popular hardware, like multicore CPUs and GPUs, do not naturally take full advantage of sparsity. To fully leverage sparsity, researchers and engineers need to rethink and re-architect each piece of the design stack, including the hardware, low-level firmware, and application software.
In our research group at Stanford University, we have developed the first (to our knowledge) piece of hardware that’s capable of calculating all kinds of sparse and traditional workloads efficiently. The energy savings varied widely over the workloads, but on average our chip consumed one-seventieth the energy of a CPU, and performed the computation on average eight times as fast. To do this, we had to engineer the hardware, low-level firmware, and software from the ground up to take advantage of sparsity. We hope this is just the beginning of hardware and model development that will allow for more energy-efficient AI.
What is sparsity?
Neural networks, and the data that feeds into them, are represented as arrays of numbers. These arrays can be one-dimensional (vectors), two-dimensional (matrices), or more (tensors). A sparse vector, matrix, or tensor has mostly zero elements. The level of sparsity varies, but when zeroes make up more than 50 percent of any type of array, it can stand to benefit from sparsity-specific computational methods. In contrast, an object that is not sparse—that is, it has few zeros compared with the total number of elements—is called dense.
Sparsity can be naturally present, or it can be induced. For example, a social-network graph will be naturally sparse. Imagine a graph where each node (point) represents a person, and each edge (a line segment connecting the points) represents a friendship. Since most people are not friends with one another, a matrix representing all possible edges will be mostly zeros. Other popular applications of AI, such as other forms of graph learning and recommendation models, contain naturally occurring sparsity as well.

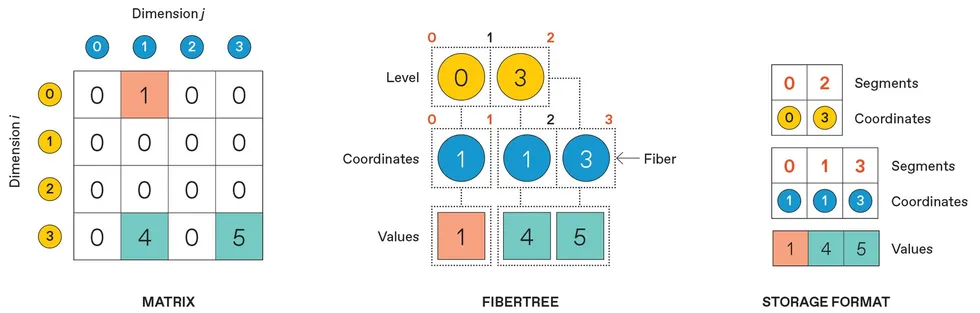
Normally, a four-by-four matrix takes up 16 spaces in memory, regardless of how many zero values there are. If the matrix is sparse, meaning a large fraction of the values are zero, the matrix is more effectively represented as a fibertree: a “fiber” of i coordinates representing rows that contain nonzero elements, connected to fibers of j coordinates representing columns with nonzero elements, finally connecting to the nonzero values themselves. To store a fibertree in computer memory, the “segments,” or endpoints, of each fiber are saved alongside the coordinates and the values.
Beyond naturally occurring sparsity, sparsity can also be induced within an AI model in several ways. Two years ago, a team at Cerebras showed that one can set up to 70 to 80 percent of parameters in an LLM to zero without losing any accuracy. Cerebras demonstrated these results specifically on Meta’s open-source Llama 7B model, but the ideas extend to other LLM models like ChatGPT and Claude.
The case for sparsity
Sparse computation’s efficiency stems from two fundamental properties: the ability to compress away zeros and the convenient mathematical properties of zeros. Both the algorithms used in sparse computation and the hardware dedicated to them leverage these two basic ideas.
First, sparse data can be compressed, making it more memory efficient to store “sparsely”—that is, in something called a sparse data type. Compression also makes it more energy efficient to move data when dealing with large amounts of it. This is best understood by an example. Take a four-by-four matrix with three nonzero elements. Traditionally, this matrix would be stored in memory as is, taking up 16 spaces. This matrix can also be compressed into a sparse data type, getting rid of the zeros and saving only the nonzero elements. In our example, this results in 13 memory spaces as opposed to 16 for the dense, uncompressed version. These savings in memory increase with increased sparsity and matrix size.

Multiplying a vector by a matrix traditionally takes 16 multiplication steps and 16 addition steps. With a sparse number format, the computational cost depends on the number of overlapping nonzero values in the problem. Here, the whole computation is accomplished in three lookup steps and two multiplication steps.
In addition to the actual data values, compressed data also requires metadata. The row and column locations of the nonzero elements also must be stored. This is usually thought of as a “fibertree”: The row labels containing nonzero elements are listed and linked to the column labels of the nonzero elements, which are then linked to the values stored in those elements.
In memory, things get a bit more complicated still: The row and column labels for each nonzero value must be stored as well as the “segments” that indicate how many such labels to expect, so the metadata and data can be clearly delineated from one another.
In a dense, noncompressed matrix data type, values can be accessed either one at a time or in parallel, and their locations can be calculated directly with a simple equation. However, accessing values in sparse, compressed data requires looking up the coordinates of the row index and using that information to “indirectly” look up the coordinates of the column index before finally reaching the value. Depending on the actual locations of the sparse data values, these indirect lookups can be extremely random, making the computation data-dependent and requiring the allocation of memory lookups on the fly.
Second, two mathematical properties of zero let software and hardware skip a lot of computation. Multiplying any number by zero will result in a zero, so there’s no need to actually do the multiplication. Adding zero to any number will always return that number, so there’s no need to do the addition either.
In matrix-vector multiplication, one of the most common operations in AI workloads, all computations except those involving two nonzero elements can simply be skipped. Take, for example, the four-by-four matrix from the previous example and a vector of four numbers. In dense computation, each element of the vector must be multiplied by the corresponding element in each row and then added together to compute the final vector. In this case, that would take 16 multiplication operations and 16 additions (or four accumulations).
In sparse computation, only the nonzero elements of the vector need be considered. For each nonzero vector element, indirect lookup can be used to find any corresponding nonzero matrix element, and only those need to be multiplied and added. In the example shown here, only two multiplication steps will be performed, instead of 16.
The trouble with GPUs and CPUs
Unfortunately, modern hardware is not well suited to accelerating sparse computation. For example, say we want to perform a matrix-vector multiplication. In the simplest case, in a single CPU core, each element in the vector would be multiplied sequentially and then written to memory. This is slow, because we can do only one multiplication at a time. So instead people use CPUs with vector support or GPUs. With this hardware, all elements would be multiplied in parallel, greatly speeding up the application. Now, imagine that both the matrix and vector contain extremely sparse data. The vectorized CPU and GPU would spend most of their efforts multiplying by zero, performing completely ineffectual computations.
Newer generations of GPUs are capable of taking some advantage of sparsity in their hardware, but only a particular kind, called structured sparsity. Structured sparsity assumes that two out of every four adjacent parameters are zero. However, some models benefit more from unstructured sparsity—the ability for any parameter (weight or activation) to be zero and compressed away, regardless of where it is and what it is adjacent to. GPUs can run unstructured sparse computation in software, for example, through the use of the cuSparse GPU library. However, the support for sparse computations is often limited, and the GPU hardware gets underutilized, wasting energy-intensive computations on overhead.
 Petra Péterffy
Petra Péterffy
When doing sparse computations in software, modern CPUs may be a better alternative to GPU computation, because they are designed to be more flexible. Yet, sparse computations on the CPU are often bottlenecked by the indirect lookups used to find nonzero data. CPUs are designed to “prefetch” data based on what they expect they’ll need from memory, but for randomly sparse data, that process often fails to pull in the right stuff from memory. When that happens, the CPU must waste cycles calling for the right data.
Apple was the first to speed up these indirect lookups by supporting a method called an array-of-pointers access pattern in the prefetcher of their A14 and M1 chips. Although innovations in prefetching make Apple CPUs more competitive for sparse computation, CPU architectures still have fundamental overheads that a dedicated sparse computing architecture would not, because they need to handle general-purpose computation.
Other companies have been developing hardware that accelerates sparse machine learning as well. These include Cerebras’s Wafer Scale Engine and Meta’s Training and Inference Accelerator (MTIA). The Wafer Scale Engine, and its corresponding sparse programming framework, have shown incredibly sparse results of up to 70 percent sparsity on LLMs. However, the company’s hardware and software solutions support only weight sparsity, not activation sparsity, which is important for many applications. The second version of the MTIA claims a sevenfold sparse compute performance boost over the MTIA v1. However, the only publicly available information regarding sparsity support in the MTIA v2 is for matrix multiplication, not for vectors or tensors.
Although matrix multiplications take up the majority of computation time in most modern ML models, it’s important to have sparsity support for other parts of the process. To avoid switching back and forth between sparse and dense data types, all of the operations should be sparse.
Onyx
Instead of these halfway solutions, our team at Stanford has developed a hardware accelerator, Onyx, that can take advantage of sparsity from the ground up, whether it’s structured or unstructured. Onyx is the first programmable accelerator to support both sparse and dense computation; it’s capable of accelerating key operations in both domains.
To understand Onyx, it is useful to know what a coarse-grained reconfigurable array (CGRA) is and how it compares with more familiar hardware, like CPUs and field-programmable gate arrays (FPGAs).
CPUs, CGRAs, and FPGAs represent a trade-off between efficiency and flexibility. Each individual logic unit of a CPU is designed for a specific function that it performs efficiently. On the other hand, since each individual bit of an FPGA is configurable, these arrays are extremely flexible, but very inefficient. The goal of CGRAs is to achieve the flexibility of FPGAs with the efficiency of CPUs.
CGRAs are composed of efficient and configurable units, typically memory and compute, that are specialized for a particular application domain. This is the key benefit of this type of array: Programmers can reconfigure the internals of a CGRA at a high level, making it more efficient than an FPGA but more flexible than a CPU.
 The Onyx chip, built on a coarse-grained reconfigurable array (CGRA), is the first (to our knowledge) to support both sparse and dense computations. Olivia Hsu
The Onyx chip, built on a coarse-grained reconfigurable array (CGRA), is the first (to our knowledge) to support both sparse and dense computations. Olivia Hsu
Onyx is composed of flexible, programmable processing element (PE) tiles and memory (MEM) tiles. The memory tiles store compressed matrices and other data formats. The processing element tiles operate on compressed matrices, eliminating all unnecessary and ineffectual computation.
The Onyx compiler handles conversion from software instructions to CGRA configuration. First, the input expression—for instance, a sparse vector multiplication—is translated into a graph of abstract memory and compute nodes. In this example, there are memories for the input vectors and output vectors, a compute node for finding the intersection between nonzero elements, and a compute node for the multiplication. The compiler figures out how to map the abstract memory and compute nodes onto MEMs and PEs on the CGRA, and then how to route them together so that they can transfer data between them. Finally, the compiler produces the instruction set needed to configure the CGRA for the desired purpose.
Since Onyx is programmable, engineers can map many different operations, such as vector-vector element multiplication, or the key tasks in AI, like matrix-vector or matrix-matrix multiplication, onto the accelerator.
We evaluated the efficiency gains of our hardware by looking at the product of energy used and the time it took to compute, called the energy-delay product (EDP). This metric captures the trade-off of speed and energy. Minimizing just energy would lead to very slow devices, and minimizing speed would lead to high-area, high-power devices.
Onyx achieves up to 565 times as much energy-delay product over CPUs (we used a 12-core Intel Xeon CPU) that utilize dedicated sparse libraries. Onyx can also be configured to accelerate regular, dense applications, similar to the way a GPU or TPU would. If the computation is sparse, Onyx is configured to use sparse primitives, and if the computation is dense, Onyx is reconfigured to take advantage of parallelism, similar to how GPUs function. This architecture is a step toward a single system that can accelerate both sparse and dense computations on the same silicon.
Just as important, Onyx enables new algorithmic thinking. Sparse acceleration hardware will not only make AI more performance- and energy efficient but also enable researchers and engineers to explore new algorithms that have the potential to dramatically improve AI.
The future with sparsity
Our team is already working on next-generation chips built off of Onyx. Beyond matrix multiplication operations, machine learning models perform other types of math, like nonlinear layers, normalization, the softmax function, and more. We are adding support for the full range of computations on our next-gen accelerator and within the compiler. Since sparse machine learning models may have both sparse and dense layers, we are also working on integrating the dense and sparse accelerator architecture more efficiently on the chip, allowing for fast transformation between the different data types. We’re also looking at ways to manage memory constraints by breaking up the sparse data more effectively so we can run computations on several sparse accelerator chips.
We are also working on systems that can predict the performance of accelerators such as ours, which will help in designing better hardware for sparse AI. Longer term, we’re interested in seeing whether high degrees of sparsity throughout AI computation will catch on with more model types, and whether sparse accelerators become adopted at a larger scale.
Building the hardware to unstructured sparsity and optimally take advantage of zeros is just the beginning. With this hardware in hand, AI researchers and engineers will have the opportunity to explore new models and algorithms that leverage sparsity in novel and creative ways. We see this as a crucial research area for managing the ever-increasing runtime, costs, and environmental impact of AI.
From Your Site Articles
Related Articles Around the Web
































































You must be logged in to post a comment Login