Tech
Apple AI research examines spatial reasoning, ASL annotation

Apple hasn’t abandoned spatial computing, judging by its research studies.
Apple’s interest in AI models and their applications in spatial computing shows no signs of slowing down, even as some claim the Apple Vision Pro is dead.
In April 2026, it was argued that the Apple Vision Pro was an outright failure and that, as a result, we’d never see a successor product. That rumor, though it always seemed unreasonable, has since come into question.
Even though the company’s Vision Products Group may have seen some changes, there’s ultimately still hope for a new generation of the Apple Vision Pro. Apple’s AI research suggests the company hasn’t abandoned its spatial-related projects.
On the contrary, new studies posted on the Apple Machine Learning blog explore the use of LLMs in sign language annotation, 3D head modeling, and more. Apple’s researchers also developed a new benchmarking system to evaluate the spatial-functional intelligence of LLMs.
Benchmarking spatial-functional intelligence for multimodal LLMs
The paper titled “From Where Things Are to What They’re For: Benchmarking Spatial-Functional Intelligence for Multimodal LLMs” outlines a new testing and grading system for MLLMs.

Apple’s researchers developed a benchmarking framework that tests the spatial reasoning capabilities of MLLMs. Image Credit: Apple
As the study explains, to mimic human understanding of a space and its objects, AI models rely on two distinct structures. This includes “a spatial
representation that captures object layouts and relational structure, and a functional representation that encodes affordances, purposes, and context-dependent usage.”
In other words, a multi-modal LLM needs to understand the geometry of a particular space, along with the purpose and location of the objects inside it. Apple’s researchers say that existing benchmarking methods, such as VSI-Bench, only test the first aspect, largely ignoring the latter.
To combat this, they developed the Spatial-Functional Intelligence Benchmark, abbreviated as SFI-Bench. It’s described as a video-based benchmark with 1,555 expert-annotated questions derived from 134 indoor video scans.
As for what SFI-Bench tests specifically, the study explains this in a fairly straightforward manner:
“Beyond spatial cognition, SFI-Bench incorporates functional and knowledge-grounded reasoning, probing whether models understand what objects in the scene are for, how they are operated, and how failures can be diagnosed.”
In other words, the benchmark tests if AI models comprehend what an object is, where it’s located, how it’s used, what it’s used for, and how it can be fixed.

Apple’s AI researchers tested how well LLMs understand the world around them. Image Credit: Apple.
If this sounds familiar, it’s because Google has had tools with this type of spatial awareness since at least 2024. At its i/o conference that same year, Google’s AI model correctly identified an object in front of it as a record player and even suggested how to repair the device.
In practice, SFI-Bench would serve to test similar and more advanced AI models. Some of the tests mentioned include asking an LLM to identify the largest subset of the same brand bottles on a cabinet, asking it to cancel the current program on a washing machine, what a TV remote is used for, and more.
Apple’s researchers tested several open-source and proprietary AI models with their SFI-Bench framework. Unsurprisingly, Google Gemini 3.1 Pro achieved the best overall result, while Gemini-3.1-Flash-Lite placed third. OpenAI’s GPT-5.4-High scored second.
However, the study notes that “Across all models, global conditional counting emerges as a key bottleneck, revealing persistent limitations in compositional and logical reasoning.”
In other words, most current MLLMs “struggle with spatial memory, functional knowledge integration, and linking perception to external knowledge.” Still, the study noted that models with internet access performed better, relative to offline-only models.
As for potential applications within iOS, we could see Apple unveil a version of Siri with both spatial and contextual awareness. This would make sense, given that the company has partnered with Google for Apple Intelligence features.
It remains to be seen if and when that would debut, though, or how well the AI might perform.
Using AI models for sign language annotation
In a separate study, dubbed “Bootstrapping Sign Language Annotations with Sign Language Models,” Apple’s researchers explored how AI could be used to annotate sign language videos.
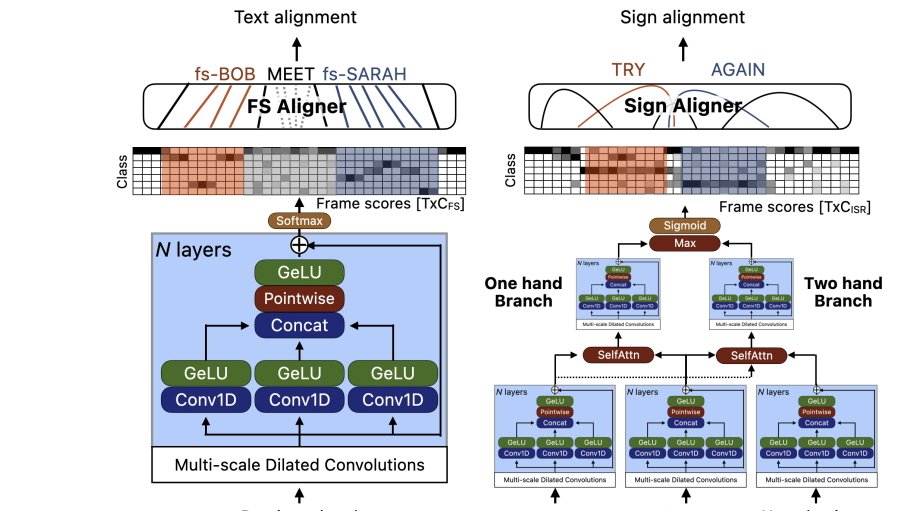
Apple’s researchers explored using AI for ASL annotation. Image Credit: Apple
The company’s research team says it developed a “pseudo-annotation pipeline that takes signed video and English as input and outputs a ranked set of likely annotations, including time intervals, for glosses, fingerspelled words, and sign classifiers.”
In doing so, they seek to reduce the time and cost of annotating hundreds of hours of sign language manually. This approach involved creating “simple yet effective baseline fingerspelling and ISR models, achieving state-of-the-art on FSBoard (6.7% CER) and on ASL Citizen datasets (74% top-1 accuracy).”
Apple’s researchers developed nearly 500 manual English-to-glossary annotations. They validated them through back translation, manual annotations, and pseudo-annotations for over 300 hours of ASL STEM Wiki and 7.5 hours of FLEURS-ASL.
For testing, Claude Sonnet 4.5 was given a gloss-to-English variation of a prompt and had to translate it from manual ASL STEM Wiki annotations to the reference English text that signers interpreted.
The study notes that “Errors were predominantly in cases where a sentence does not have any fingerspelling.” While additional work remains to be done, the researchers say their “approach for fingerspelling recognition and isolated sign recognition can be trained with modest GPU resources and could also be used for further iteration on pseudo annotation pipelines.”
As for why Apple is researching this, it could have something to do with the long-rumored camera-equipped AirPods. Perhaps the company plans to expand its Live Translation feature to include sign language.
3D gaussian head Reconstruction from multi-View captures
Another study called “Large-Scale High-Quality 3D Gaussian Head Reconstruction from Multi-View Captures” explores how head models can be made from images with the help of AI.
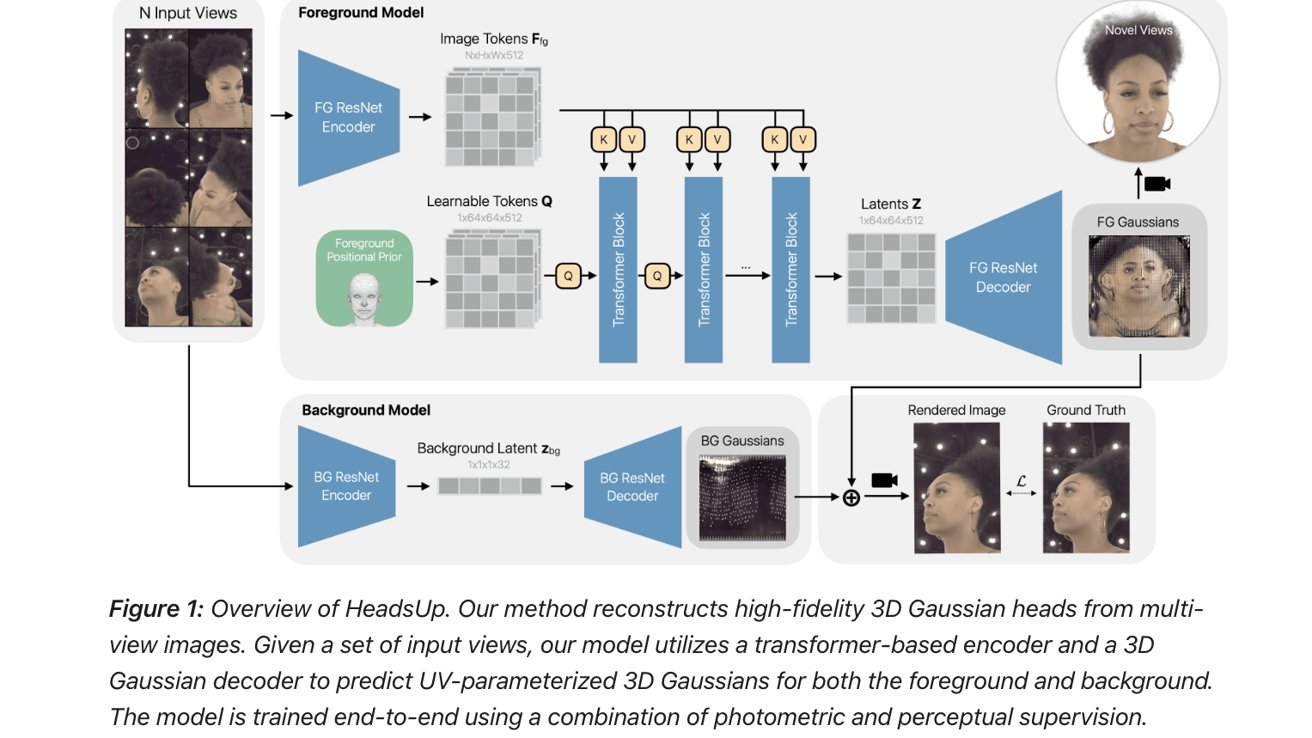
Apple’s AI researchers explored how LLMs can be used to create 3D head models from multi-view captures. Image Credit: Apple.
Apple’s researchers developed “HeadsUp, a scalable feed-forward method for reconstructing high-quality 3D Gaussian heads from large-scale multi-camera setups.”
In essence, the study explores how different head views can be converted into Gaussian blobs and then into 3D models through a series of encoders and decoders.
To test their image-to-3D-model method, those behind the study used “an internal dataset with more than 10,000 subjects, which is an order of magnitude larger than existing multi-view human head datasets.” The 3D head models were also animated using expression blendshapes.
Overall, the study explains that “HeadsUp achieves state-of-the-art reconstruction quality and generalizes to novel identities without test-time optimization.”
In terms of practical applications, the study could be related to the Apple Vision Pro and its Persona feature. Apple may be looking for ways to improve how expressions are rendered, or how faces themselves are captured and rendered within visionOS.
There may also be hardware or comfort-related applications. During the development of the headset, AppleInsider was told that the company included various 3D head types alongside Apple Vision Pro models.
Time will tell what Apple does with the information its researchers create. While we have to wait and see what its next product will be, one thing is for sure: the company isn’t backing down when it comes to AI and spatial computing.
Apple is set to announce iOS 27 and its corresponding OS updates at WWDC 2026, which will begin on June 8.
You must be logged in to post a comment Login