






-SOURCE-Scott-Gilbertson.jpg)








It sounds absurd: an airline trying to channel Apple. Can an airline fly as high and smoothly as the tech icon?
After a few days with United Airlines — testing Starlink in the sky and previewing its next-gen ‘Elevate’ cabins — the comparison stopped feeling like an impossible stretch and more like a strategy.
United Airlines will turn 100 next month on April 6, 2026, and while it has plenty of competition domestically in the United States and on the global stage, it’s seen something of a renaissance in recent years.
Article continues below
It’s been swapping smaller jets for larger ones, upping the in-seat experience with redesigned interiors, going all-in on a next-gen Wi-Fi product, and doubling down on infrastructure in ways that passengers actually see — and that employees feel behind the scenes.
Now, much of my focus is on technology and consumer electronics, but after attending United Elevated, the idea that United wants to be the Apple of airlines, not just a better airline, started to make sense.
It all really began to sink in when I sat inside one of its hangars at Los Angeles International Airport this week, where United debuted its latest aircraft with the elevated interior – a massive Boeing 787-9 – and several other eye-opening announcements, including more aircraft.
Reaching Apple-like heights might sound a little lofty, but the more time I spent with what United is building, the more it clicked.
To be fair, Scott Kirby — CEO of United Airlines — essentially said it first: “We’re trying to copy Apple’s approach to their supply chain” for what the airline does with engines, adding, “we’ll do it for other stuff as well.”
Yes, the comment came in response to a question about supply chain strategy and tariffs, but it’s a telling one. Even in that narrower context, it offers a window into how United is thinking more broadly.
And honestly, you can see it.
United has long been a partner with Apple and is quick to adopt its ecosystem. It rolled out Bluetooth connectivity for seatback screens and spotlighted it with AirPods, integrated with the Find My network so you can share an AirTag if your bag goes missing, and its app has been early to support things like Live Activities and the Dynamic Island.
None of that is revolutionary on its own. But together, it starts to feel familiar — like an airline trying to build a more connected, cohesive experience instead of just layering on features.
That shows up most clearly in the app.
The app is becoming central to the experience

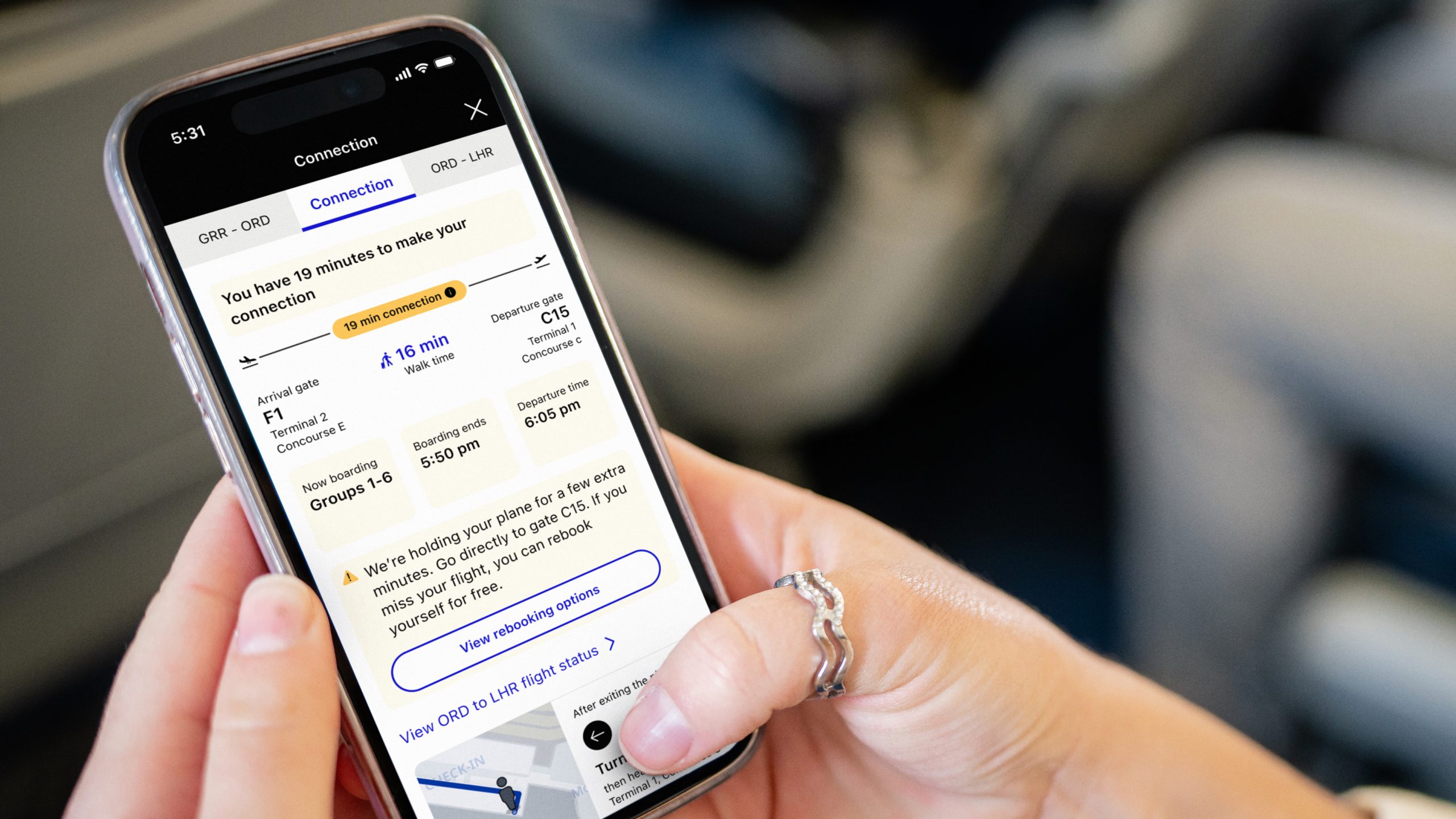
Over time, United has turned it into something closer to a travel control center than a simple boarding pass. Boarding groups are easier to see, ConnectionSaver proactively helps with tight transfers (so long as it doesn’t delay an on-time departure), airport maps make navigating less of a guessing game with turn-by-turn directions, and bag tracking removes some of the usual anxiety. More recently, the “Trips” experience has been redesigned to put everything front and center in the days leading up to as well as on departure day.
Again, none of these are huge swings individually. But that’s kind of the point, and United was the first for many of these, and with a keen ability to squash bugs. Other airlines, including Delta, JetBlue, and American, have added these similar features, but none were first.
It’s the same playbook Apple has used for years — iterate, refine, and stack improvements until the whole thing just feels better to use. The innovation isn’t always obvious, but you notice it when everything works the way you expect it to. Similar to the Cupertino-based tech giant, it’s clear that United isn’t necessarily rushing to swing for the fences with major updates or even smaller ones.
Of course, not every bet has landed.

For a while, United moved away from seatback screens on some aircraft, leaning into personal device streaming instead. It was a tech-forward idea, but it didn’t quite line up with the goal of delivering a consistent, premium experience across the board. Now, the airline is course-correcting, bringing screens back as part of its next-generation cabins. That’s a process, though, and some aircraft still fly without seatback screens.
That push for consistency extends beyond software.
United has generally taken a more unified approach to its premium cabins —especially Polaris — compared to competitors like Delta Air Lines, which has introduced multiple versions of its Delta One seat across different aircraft. With its “United Elevated” strategy, that consistency is becoming more deliberate, stretching from widebody jets to narrowbody planes and even regional aircraft. It’s also ensuring large OLED screens at every seat — these looked especially punchy and vibrant — plus power and USB-C ports, even in economy.
And then there’s Wi-Fi.
Cabins, seatback screens, and Starlink Wi-Fi show the push for consistency

By rolling out fast, free Starlink connectivity — and tying it to loyalty — United is making internet access a core part of the experience, not just an add-on. It’s not just about having Wi-Fi; it’s about having Wi-Fi that works well enough, consistently enough, that you start to expect it every time you fly. It’s a process, though, and while 344 aircraft currently boast the improved connectivity, it’ll take until the end of 2027 for Starlink to be on every aircraft in United’s fleet. Other airlines have offered free Wi-Fi, such as Delta and JetBlue, but United Airlines is the first to work toward equipping the entire fleet with a much faster standard. It’s likely that other airlines will end up going this route, with American Airlines rumored to be in talks with Starlink, and JetBlue opting for Amazon’s Leo, formerly Project Kuiper.
Even so, that’s a very Apple-like move: set the baseline high, and don’t go backwards. Doubly so with United doing it first or setting the pace, and then having other airlines seemingly copy it.
But here’s the reality check — airlines aren’t iPhones, iPads, MacBooks, or even any type of consumer electronics analogy.

Apple controls the hardware, the software, and the services. It can be designed for consistency because it owns the entire stack, and we’ve seen that flourish across the line, especially with the advent of Apple Silicon. Airlines don’t get that same level of control.
Weather, air traffic control, airport congestion, maintenance — so much of the flying experience sits outside of any airline’s hands. Even within their control, fleets are mixed, configurations vary, and not every plane can be brought up to the same standard overnight.
So the thing United is chasing — consistency — is also the hardest thing to actually deliver. And that’s what makes this strategy interesting, and one to keep watching.
The goal might not be to eliminate every variable. Maybe it’s just to smooth out the parts passengers actually feel. If the app is clear, the Wi-Fi works, the seat feels familiar, and when something goes wrong, it’s handled quickly, the overall experience can still feel… reliable — even if the system behind it isn’t perfect.
If Apple’s whole thing is “it just works,” then United Airlines is trying to bring that idea to 35,000 feet — turbulence and all. And it might have started to show its cards with the day-long event where it showed off its new Elevated Boeing 787-9, a reimagined CRJ450, countless demos, fireside chats, and speeches from leaders. It all felt very Apple event-esque — albeit at a location that might even rival Apple Park for views. I mean, you can’t beat a sound system for music and speakers that can be heard over an active taxiway and runway, right?
I connected with Zach Griff, a travel expert and author of From the Tray Table, on this idea, and he shared: “Just look at how United took inspiration from Apple at Tuesday’s event. It referenced the company numerous times — both overtly in how it wants to mimic Apple’s supply chain strategy and the more subtle, in how it came prepared with a ‘one more thing’ style reveal. United wants to be to airlines what Apple is to tech.”
That one more thing was an upgrade to Economy, dubbed the Relax Row — essentially the ability to book out three Economy Plus seats with leg rests that raise to create a bed that takes up a whole row, paired with bedding, pillows, and stuffed plushies. It’ll likely be a hit for long-haul routes, as it’s set to debut on the 777 and 787 in 2027, and be far cheaper than Polaris.
In short, United has a bold goal ahead. Maybe even an impossible one. But for an airline about to turn 100, it’s a pretty compelling direction to take.
Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button!
And of course, you can also follow TechRadar on YouTube and TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.


































































You must be logged in to post a comment Login