Tech
The AI Robot Air Hockey Player That Skipped Every Practice Session on the Actual Table


Engineering physics students at the University of British Columbia finished a capstone project that produced something unusual in robotics. Their air hockey robot learned every move inside a computer simulation and then stepped onto real hardware ready to face human opponents with no further adjustments. The approach bypassed the usual slow and risky process of training directly on physical equipment.


Over the course of around two years, multiple student teams worked together to complete the project. Hudson Nock, Ian Hartley, and Mauro Ferraz led the last assault. They took over an early iteration of the hardware foundation, with the primary purpose of narrowing the gap between virtual training and real-world performance. The whole code and two pretty lengthy technical reports are now available on GitHub for anyone who want to read everything and understand every decision they made.
For any automated system, air hockey presents some significant issues. The table surface is never completely smooth, the puck travels at high speeds, bounces vary depending on where it hits the wooden rails, and motor efficiency degrades when the power supply voltage lowers under strain. Conventional physics models frequently fall short of adequately capturing these differences in order to transition from simulation to reality. Instead than relying just on a generic engine, the UBC team chose to meticulously measure the actual hardware and then mimic its unique characteristics within the code.
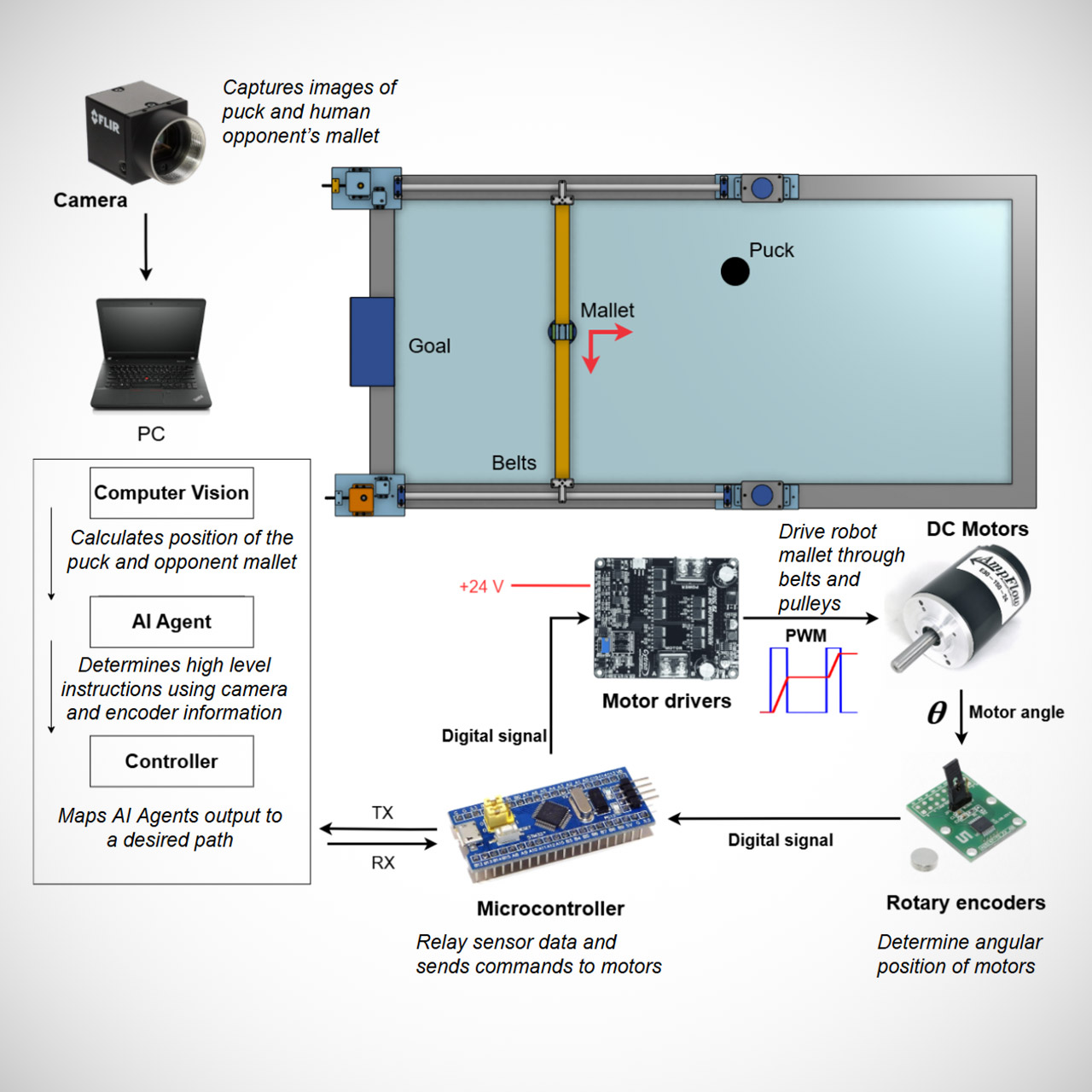
All the sensing is controlled by a single camera above. The puck is marked with retroreflective tape, while the opposing mallet is marked with a unique marker. Even when the camera uses very short exposures of only 100 microseconds to stop the movement, some bright LEDs close to the lens make both objects appear exceptionally clear and crisp. In order to keep the position error down to nearly precisely one millimeter over the entire surface, they also performed some calibration work using markers around the table edges. This is quite astounding given the little warping that would otherwise be an issue. A contour tracker can follow the puck all the way through even when the gantry obstructs the view. The human player’s mallet can be found by the same camera at a scorching 120 frames per second.

A Core XY gantry positioned high above one side of the table generates movement. The mallet is guided by two belt-driven motors and an STM32 Blue Pill microcontroller. During system testing, the team went to the trouble of determining how the mallet reacts to various voltage signals and recording it all as a third order transfer functions. They used a combination of feedforward controls and PID feedback to keep the mallet on track and virtually perfectly aimed. A sizable supercapacitor is also used to stabilize the voltage during rapid accelerations.

Custom code designed for speed and accuracy powers the simulation itself. The application employs analytical solutions to simulate both puck and mallet motion, reducing the need for time-consuming numerical integration stages. They use an adaptive collision timing technique to ensure that no impacts are missed. When the puck strikes the wooden rails, a small neural network with only 112 parameters kicks in, predicting both the departing velocity and angle, as well as a measure of uncertainty. The simulator then draws from that uncertainty distribution at random throughout each run, so the learning agent should expect slightly unfair and noisy bounces rather than flawless ones.
Vectorization allows a standard laptop to run thousands of game instances at the same time. On a normal Intel i5, the entire simulation runs approximately 230 times faster than real time, which is rather impressive. That kind of pace makes it absolutely practical to run extensive training sessions. To account for issues such as camera lag and control input latency, the agent is given a state that includes the most recent puck and mallet action over a variety of delays. It then outputs the voltage parameters for the motion profile together with the intended final mallet position.

The Soft Actor Critic reinforcement learning technique was used to train networks with about 200,000 parameters. The squad took action since self-play alone can result in one-dimensional strategies. After training, they just applied the policy to the actual controller without any further fine-tuning in the real world, resulting in some deviation. The round trip delays are all kept in sync while the entire system runs on a 60-Hz loop.
[Source]

You must be logged in to post a comment Login