
TL;DR
Jeff Bezos says stress comes from inaction and vanishes the moment you take the first step toward fixing a problem




AI coding agents are rapidly accelerating data engineering by generating transformations, pipelines, orchestration workflows, validation tests, and infrastructure configurations from prompts.
However, enterprise data platforms have long operated across fragmented systems owned by different teams and built on different technologies. As these systems evolve independently, organizations increasingly struggle with inconsistent business logic, duplicated implementations, difficult downstream impact analysis, and hidden dependencies across the platform.
The rise of vibe coding can further amplify these problems as more operational context, architectural decisions, and business knowledge become scattered across prompts, conversations, generated code, and disconnected workflows rather than becoming part of the system itself.
Spec-driven development (SDD) is emerging as one approach to address this challenge. In SDD, prompts, business rules, validation logic, orchestration behavior, and implementation workflows are converted into executable and versioned specifications that become part of the system itself. These specifications act as persistent operational memory for both humans and AI agents, allowing systems to evolve more consistently across releases, teams, and AI-assisted workflows.
Because enterprise data engineering already relies heavily on reusable patterns, metadata-driven pipelines, and standardized operational workflows, it is especially well-suited for SDD. By combining AI-assisted generation with deterministic and reusable system contracts, SDD may provide a new operational layer for reducing fragmentation and improving long-term coordination across increasingly AI-generated data platforms.
Vibe coding works remarkably well for generating isolated implementations quickly. But prompts are inherently temporary. They capture an engineer’s assumptions, business context, implementation logic, and system knowledge only for that specific conversation and moment in time.
In practice, making AI-generated systems work often requires far more than a simple prompt. Engineers continuously provide background information, architectural decisions, business rules, schema assumptions, downstream dependencies, operational constraints, debugging history, and implementation guidance throughout the development process.
These contexts become the real operational knowledge behind AI-assisted development.
However, in most vibe coding workflows, this information remains scattered across prompts, conversations, Jira tickets, documentation, chat history, generated code, and disconnected workflows rather than becoming part of the system itself.
This creates a major problem for enterprise data engineering because modern data platforms are naturally fragmented across many interconnected systems, including ingestion pipelines, warehouses, orchestration frameworks, semantic layers, APIs, dashboards, and machine learning (ML) systems. As more logic and context become embedded inside prompts and generated implementations, organizations gradually lose visibility into:
Over time, the system itself no longer contains the full reasoning behind how it was built. Critical business context, architectural assumptions, and operational knowledge still largely exist inside human judgement and scattered conversations rather than inside the platform itself.
Vibe coding makes implementation significantly faster, but from a system perspective, overall engineering efficiency does not improve proportionally because much of the development lifecycle still depends on human validation, domain knowledge, coordination, and decision-making.
More importantly, prompts are not naturally iterable engineering artifacts. Enterprise systems continuously evolve across releases, schema changes, business logic updates, and downstream dependencies. Teams repeatedly revisit and refine systems over time, but prompts are optimized for fast local generation rather than system long-term evolution.
They are difficult to:
Even the same prompt may not reliably generate the same implementation with different context in the future.
This is where SDD begins to move to the center of AI-assisted data engineering. Instead of leaving operational knowledge scattered across prompts and conversations, SDD integrates business context, validation logic, transformation behavior, orchestration requirements, and implementation workflows directly into executable specifications that become part of the system itself.
The system now has persistent memory about how it was designed, why certain decisions were made, and how different components are connected across the platform. This allows teams and AI agents to iterate systems more reliably over time while reducing fragmentation across increasingly distributed data environments.
In SDD, systems are built around executable specifications rather than loosely coordinated prompts and implementations alone. Instead of treating specifications as passive documentation written after development, SDD treats them as operational contracts that directly drive code generation, validation, testing, orchestration, and deployment workflows.
In many ways, SDD extends ideas from Infrastructure-as-Code and GitOps into AI-assisted engineering. Specifications combine declarative system definitions with executable implementation workflows. The declarative layer provides system context, schemas, dependencies, constraints, and operational requirements, while workflow-oriented instructions guide AI agents on how to implement and evolve the system consistently.
Once these contexts, rules, and implementation patterns are converted into persistent and versioned contracts stored in repositories and integrated into CI/CD workflows, the system becomes significantly more iterable and governable over time. These specifications effectively become long-term system memory for both humans and AI agents, allowing systems to evolve consistently across releases, teams, and increasingly AI-assisted development workflows.
In practice, the structure of specifications largely depends on the type of systems and workflows being implemented. However, spec-driven systems often begin with a foundational “constitution” that defines project-wide principles and constraints that should remain consistent across the platform, such as technology standards, naming conventions, architectural rules, governance policies, and core system requirements. On top of this foundation, multiple layers of specifications serve different operational purposes across the development lifecycle:
schema specifications define structural compatibility
transformation specifications define business logic
validation specifications define quality rules
orchestration specifications define execution behavior
semantic specifications define shared business definitions
AI workflow specifications define reusable implementation instructions for coding agents
A simplified specification might look like this:
pipeline_spec:
source:
system: mysql
table: order
transformation:
logic:
– load_strategy: scd2
target:
platform: snowflake
table: dim_order
validation:
primary_key: order_id
Additional workflow files can then provide reusable implementation instructions for coding agents:
Generate Python ingestion code for Salesforce customer data.
Generate DBT models implementing Type 2 SCD logic.
Generate Airflow workflows for hourly execution.
Generate validation tests for downstream compatibility.
These specification documents are often maintained as markdown-based operational artifacts generated and refined through AI-assisted workflows. Engineers can iteratively update the specifications, provide additional business context, and collaborate with coding agents to improve implementation logic, workflows, and prompt instructions over time. Compared to traditional documentation processes, AI-assisted specification generation is significantly faster and more adaptive.
The important shift is not simply better documentation. Specifications become reusable operational context that allows systems to evolve consistently across releases, teams, and AI-assisted workflows. Architectural intent, business assumptions, and implementation logic no longer disappear into temporary prompts and disconnected implementations, but instead become persistent system knowledge integrated directly into the development lifecycle.
SDD can theoretically be applied across many areas of software engineering, but data engineering is especially well-suited for this model because of the nature of modern data platforms.
Enterprise data systems naturally span many interconnected technologies and layers, including transactional systems, ingestion frameworks, streaming platforms, warehouses, orchestration systems, semantic layers, APIs, dashboards, and ML pipelines. Data engineers regularly work across long technology stacks and distributed systems where a single upstream change can impact many downstream consumers.
Enterprise data platforms also support many different teams and applications across fragmented environments. As systems evolve independently, understanding the full downstream impact of an upstream schema or business logic change becomes increasingly difficult. A seemingly small modification can silently break downstream pipelines, dashboards, APIs, semantic models, or machine learning workflows across the platform.
SDD can address this fragmentation by introducing shared and versioned operational contracts across systems. Because schemas, dependencies, validation rules, transformation logic, and orchestration behavior are explicitly defined within specifications, teams and AI agents gain much better visibility into how systems are connected and how changes propagate across the platform.
Additionally, the goal of data engineering is not simply delivering pipelines quickly. Teams must also optimize for system stability, scalability, consistency, maintainability, operational reliability, and infrastructure cost.
This requires significant system and solution design work from engineers. Teams must define tech stack, create schemas, transformation patterns, orchestration behavior, validation rules, storage strategies, and downstream compatibility requirements carefully across the platform.
However, once these architectural and operational patterns are established, much of the implementation work becomes highly repetitive and standardized.
For example, after defining a reusable ingestion and transformation pattern for Salesforce customer data, onboarding a new table may only require adding another table definition into the specification, while the remaining implementation can be generated automatically through existing specifications and workflows that follow the same operational pattern:
source:
system: salesforce
tables:
– customer
– order
– product
From this specification alone, coding agents could generate new data pipelines following the same governed implementation pattern across the platform. This combination of human-driven architectural design and highly repeatable implementation workflows makes data engineering particularly suitable for SDD.
In many ways, data engineering has always been moving toward higher levels of automation, from ETL frameworks and metadata-driven pipelines to IaC and declarative orchestration systems. SDD represents another step in that evolution by combining prompt-based AI generation with deterministic and versioned operational contracts.
Instead of relying entirely on temporary conversational prompts or rigid template systems, SDD introduces a middle layer where reusable specifications provide structure, coordination, validation, and persistent system memory for AI-assisted development.
SDD introduces a much higher level of automation into enterprise data engineering while also helping reduce the fragmentation problems that modern data platforms increasingly face.
Because schemas, business rules, transformation behavior, orchestration requirements, validation logic, and downstream dependencies are explicitly defined inside reusable specifications, coding agents can generate and evolve large portions of the implementation consistently across the platform. Instead of repeatedly rebuilding pipelines and workflows from temporary prompts and disconnected context, teams can iterate systems through shared operational contracts and reusable implementation patterns.
This significantly improves consistency, traceability, and coordination across distributed environments. Schema evolution becomes easier to manage, downstream impact becomes more visible, and systems can evolve incrementally instead of through disconnected generations of implementations.
At the same time, human engineers still remain essential in the development lifecycle. While AI agents can automate large portions of implementation work, human judgement is still critical for defining business logic, designing architectures, managing tradeoffs, validating correctness, and coordinating system evolution across organizations.
As more implementation work becomes AI-generated, the role of data engineering also begins shifting. Engineers spend less time writing repetitive pipelines and orchestration logic, and more time defining specifications, designing reusable operational patterns, managing validation rules, and coordinating business context across systems.
This may also gradually reduce some of the traditional boundaries between different data engineering teams. Because implementation becomes increasingly standardized and AI-assisted through shared specifications, organizations may rely less on highly siloed platform-specific implementation teams and more on shared operational contracts and reusable system patterns.
Ultimately, SDD shifts data engineering toward a more specification-oriented and system-oriented model where humans focus on intent, architecture, and business coordination, while AI agents increasingly handle implementation, testing, and operational generation at scale.
Shuhua Xu is a lead data engineer.
Welcome to the VentureBeat community!
Our guest posting program is where technical experts share insights and provide neutral, non-vested deep dives on AI, data infrastructure, cybersecurity and other cutting-edge technologies shaping the future of enterprise.
Read more from our guest post program — and check out our guidelines if you’re interested in contributing an article of your own!


Jimothy, the short-spined Seattle raccoon, has become a global sensation whose likeness has been immortalized in artwork, clothing, songs and tattoos — and now a video game created in the creature’s hometown.
Tech enthusiast and entrepreneur Chris Pirillo launched an 8-bit NES-style video game called “Jimothy” this weekend in which players can control the movements of the critter as he raids trash cans, crosses streets to the park, sneaks past the paparazzi, and climbs to the safety of a big tree.
Pirillo says the missions are pulled straight from Jimothy’s real life. No doubt the animal is busy these days trying to dodge curious onlookers who are hoping to capture the next photo or video that feeds the masses on social media.
The viral Jimothy sensation took off last week when Kiana Hall spotted the raccoon in Seattle’s Ballard neighborhood and posted a video on Instagram — viewed by millions since — asking the question heard around the world: “What am I looking at?”
An earlier video of Jimothy, captured by a home security camera and posted on Reddit, ignited further curiosity and adoration, and now Reddit is flooded with sightings, memes, artwork, food, crafts, poetry and more. The Mariners put a Jimothy mascot in the Salmon Run. There’s even a Lego Jimothy.
@media (max-width: 600px) {
aside.callout { float:none !important; max-width:100% !important; margin-left:0 !important; margin-right:0 !important; }
aside.callout .callout-img { display:none !important; }
}
Pirillo told GeekWire the game idea came to him on Saturday afternoon after seeing so many creatives flood his feeds with their own Jimothy fan art. He started to build a not-so-live tracker and realized it was a not-so-great idea. He hopes internet creativity is enough of a fix for the Jimothy-curious.
“This game is as close as any of us should ever get to him,” the game site states. “If you find yourself in his neighborhood: don’t go looking for him, don’t feed him, don’t try to touch him, and don’t crowd him for a photo.”
The game is easy enough to play, with challenges that are reminiscent of classic 1980s games “Frogger” and “Donkey Kong.”
Pirillo’s “Vibe Arcade” is loaded with other games he’s created. Earlier this year he vibe-coded a Resume Analyzer app and a pre-rejection letter generator called Dear Applicant to channel his frustrations with searching for a job.
Pirillo credits AI with changing the speed and ease with which a moment can go viral and be captured in new and creative ways.
“I remember when every big moment had a video game. But by the time a studio could create a video game around a meme pre-AI, the meme’s energy would have dissipated,” he said. “We are now at a day and age (certainly with AI as a tool) where almost literally anybody of any age or tech experience level can bring full-fledged experiences to life in just a few hours. We can simply talk our solutions into existence. It’s astounding.”
Pirillo built the game as a single HTML page, pitting OpenAI GPT 5.6 against Anthropic’s Claude Fable 5. One of the bigger challenges was getting the look of Jimothy right, as multiple AI models kept returning regular-looking raccoons.
Pirillo said he looks forward to sharing more about it all during a free vibe-coding community workshop in Seattle this Saturday.
His final takeaway for anyone looking to get in on the Jimothy hype — or whatever creature emerges next — is to not wait for the moment to pass.
“While it’s never been easier to make something, it’s also never been more challenging to get attention,” he said.


Jeff Bezos says stress comes from inaction and vanishes the moment you take the first step toward fixing a problem
Jeff Bezos, the founder of the company that just became the number one Fortune 500 business, says the cure for anxiety is not rest or meditation but action. Speaking at the Museum of Flight in Seattle in 2017, Bezos told an audience of students that stress is a signal from the body that something is being neglected, and that the feeling disappears the moment he starts working on whatever is causing it. “I find that the stress goes away the second I take the first step,” he said.
The comments, resurfaced by Fortune this week, offer a window into how the world’s fourth-richest person thinks about pressure. Bezos said he treats anxiety as diagnostic information rather than an emotional state to manage, and that the worst thing he can do is sit with a problem without acting on it. His preferred remedy is to recruit allies and turn the source of stress into a group exercise in invention.
“There’s nothing more fun than getting in a room with a group of inventors and saying: here’s the problem, let’s invent a solution to it,” Bezos said. “As soon as you start doing that, I find that it turns from something that might create stress into something that creates fun.” The philosophy is consistent with the leadership principles Bezos embedded at Amazon, where CEO Andy Jassy has described the company’s 16 codified principles as something employees must constantly work at.
The advice lands in a complicated context. Amazon has cut more than 57,000 corporate jobs since 2022, and employees who survived the rounds of layoffs have reported rising workloads and deteriorating work-life balance as fewer people cover the same ground. The idea that stress is solved by working harder reads differently when the people hearing it are already stretched thin, and when the company’s own workforce has described burnout as a structural problem rather than a mindset one.
Bezos built Amazon from a rented garage in the mid-1990s, famously taking 60 meetings to raise the first million dollars in seed capital at a time when most investors had never heard of online retail. The company he founded now generates more than $700 billion in annual revenue and is investing tens of billions in AI infrastructure. Whether the same advice that helped a founder push through rejection in 1995 translates to a workforce navigating layoffs and AI displacement in 2026 is a question Bezos did not address.


Hackers are changing the DNS settings on Wi-Fi devices at hotels and conference centers to redirect users to fake Microsoft 365 login pages.
The campaign has been ongoing since at least June and impacts organizations in various sectors, including financial services, professional services, legal, health care, energy, and retail.
Cybersecurity company ReliaQuest identified compromised Wi-Fi gateways in multiple U.S. cities as well as other regions of the world, such as India and Saudi Arabia.

Since the devices serve corporate events, hijacking the Microsoft 365 accounts could give attackers access to sensitive business information, communications, and private documents.
“We observed traffic to these compromised gateways from organizations in a range of industries, including financial services, professional services, legal, health care, energy, and retail- confirming this isn’t sector-specific targeting, but a campaign that highly likely goes after traveling employees wherever they connect,” ReliaQuest says.
The researchers believe this activity is similar to the FrostArmada router-based campaigns attributed to the Russian espionage group APT28 (a.k.a. Fancy Bear, Forest Blizzard).
It is unclear how initial access to the Wi-Fi appliances was gained, but ReliaQuest says the threat actor could have exploited weakly protected, exposed management interfaces (e.g., SSH, SNMP, web admin dashboards) or vulnerabilities.
Once the attacker gains administrator access, they can modify the gateway’s DNS settings to redirect connections to legitimate domains to infrastructure under the attacker’s control.
ReliaQuest says that the attacker registered at least four domains for setting up fake Microsoft login portals: m365-owa[.]com, owa-ms365[.]com, ms365-device[.]com, and ms365-live[.]com.
With DNS settings changed, users trying to access legitimate Microsoft login portals would land on the hacker’s phishing pages and enter their credentials.
In some cases, the researchers observed a device-code authentication flow in which targets were redirected to a fake Microsoft page with a prompt.
“What the user can’t see is that approving the prompt authorizes a session initiated by the attacker,” ReliaQuest says. The researchers note that authorizing the attacker-initiated request causes a legitimate OAuth token to be issued to the attacker’s client.
This bypasses the multi-factor authentication (MFA) protection without stealing any credentials or intercepting access tokens.

In roughly one-third of the investigated cases, the attackers also attempted to abuse Web Proxy Auto-Discovery (WPAD) by responding to Windows’ automatic WPAD lookup with a malicious proxy auto-configuration (PAC) file.
This theoretically would route traffic from Windows apps, including Chrome, through an attacker-controlled proxy, but ReliaQuest couldn’t confirm that these attacks were successful.
The researchers also emphasized that using public DNS servers such as Google’s 8.8.8.8 does not prevent this attack, as the gateway forges the plain-text requests before they reach the intended resolver.
ReliaQuest recommends using an always-on, full-tunnel VPN and encrypted DNS in strict mode as solid protection measures against these attacks.
Additionally, the cybersecurity company recommends disabling WPAD, reviewing logs for suspicious activity, and disabling Device Code authentication flow in Microsoft Entra ID when not needed.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


Lithium-ion batteries changed tech forever, but the first consumer device to use one may surprise you.
As Apple prepares to launch its first smart glasses, the company is also wrestling with how to address consumer privacy concerns, according to Bloomberg’s Mark Gurman.
Gurman reports that Apple has pushed back the launch target from early 2027, with the glasses now set for unveiling at the Worldwide Developers Conference in June 2027 and actually becoming available by the end of the year. That delay allows Apple to work on the product itself, and on the messaging around privacy.
It sounds like the company has noticed the concerns around Meta’s smart glasses — sometimes decried as “pervert glasses” — being used to make non-consensual video recordings. That could be a bigger issue for Apple, which constantly emphasizes privacy in its marketing.
Among other things, Apple will reportedly try to emphasize privacy-friendly features like on-device processing, as well as the absence of facial recognition. The company will likely steer clear of using customer recordings to train AI models, and it’s unlikely to follow Meta’s reported practice of using contractors to review customer footage.


This week on the GeekWire Podcast: Seattle startup funding drops 40% in the first half of the year while AI money floods everywhere else. We dig into the implications for the region.
Plus: a Seattle judge deals Kalshi a setback, Impinj marks a decade on the Nasdaq after a 26-year climb, and nearly 40 Seattleites trade smartphones for flip phones for five weeks.
Venture funding drops in Seattle area as AI boom reshapes startup world
Helion raises $465M at $15.5B valuation as it aims to commercialize fusion
UK data center startup Nscale bets big on Bellevue for U.S. engineering hub
Anthropic expands in Seattle as AI boom offers hope for struggling office market
Seattle judge deals blow to Kalshi, rejects prediction market’s federal defense
How Impinj has survived 26 years in a market that’s ‘just getting going’
Ditch your smartphone for a flip phone for a month?
Edited and produced by Curt Milton.


While drone warfare has been around for a long time, the widespread application of single-use combat drones has increased exponentially since the start of the Russo-Ukrainian War. Countless drones have flown across borders to destroy key targets on both sides, and if there’s one thing that’s true of all of them, it’s that they’re difficult to defend against. This is due to several factors, but mostly, it’s the sheer volume of vehicles dedicated to a single target. Long gone are the days when a single interceptor missile can defend a strategic site from destruction.
Both Russia and Ukraine have increased drone defenses to counter ongoing strikes, and now Russia has developed specialized bullets to use in the war. These are called Mnogotochie cartridges, which can be fired from rifled automatic weapons, creating a potential problem for any would-be drone attackers. Unlike typical bullets, Mnogotochie cartridges split apart when fired, offering a wider spread without resorting to something like short-range buckshot from a shotgun.
The benefit of these new cartridges is their ability to be fired from any service rifle, so long as they shoot 5.45x39mm and 7.62x39mm cartridges. Once fired, the bullet splits into three parts right out of the barrel, delivering a higher-density assault on an airborne target. Essentially, instead of firing a single bullet at a drone, one round effectively becomes three, and anyone who’s ever gone waterfowl hunting knows the benefit of such a spread.
Firing multiple projectiles in a single shot is nothing new, as the technology has been around in various forms for centuries. Cannons fired canister and grapeshot, while shotguns are well-known for spreading pellets at targets. Splitting rifle ammunition straight out of the barrel is a new take on that old idea, and it could prove effective in Russia’s defense against the many high-tech tools used in the Ukraine War.
Russia’s High Precision Systems holding company is manufacturing the new rounds for use on the front lines. The bullets themselves are made up of three stacked projectiles that come apart once the round exits the barrel. It’s a pretty straightforward, if inventive, design. They have an effective range of up to 300 meters (984 feet), which is fairly standard for the size of bullets that are being made.
The efficacy of such a round is open to debate, and it’s unclear what, if any, successes Russia has had in using them. The biggest roadblock is actually hitting a fast-moving target like a drone — which can travel at speeds of up to 87 mph and cover close to 510 feet in only four seconds — which isn’t easy for any marksman. While the split shot of a Mnogotochie cartridge offers a greater opportunity to strike a moving target at range and speed, it’s still up to the individual shooter to acquire and successfully hit the target drone.

Northrop Grumman has launched its first Mission Robotic Vehicle (MRV), equipped with two robotic arms to inspect, repair, refuel, and relocate satellites already operating in orbit.
The spacecraft also carries three Mission Extension Pods (MEPs) that can extend a satellite’s operational life by as much as eight years after installation.
Although introduced as a commercial servicing platform, the spacecraft’s ability to operate alongside other satellites has already raised questions about possible military applications.
Latest Videos FromTechRadar
The MRV launched aboard a SpaceX Falcon 9 rocket from Cape Canaveral, carrying MEPs intended for commercial satellites operated by Australia’s Optus and Luxembourg’s SES.
Northrop Grumman says the spacecraft can inspect satellites, install life-extension modules, tow spacecraft between orbital positions, and assist with clearing debris already circling Earth.
Those missions depend on two robotic arms that allow the vehicle to maneuver extremely close to other satellites without relying on direct physical contact.
The robotic arm system was developed through the Robotic Servicing of Geosynchronous Satellites program led by DARPA together with the United States Naval Research Laboratory.
Because those same capabilities allow precise movement around spacecraft, a future version could disable hostile satellites if governments requested such capabilities.
“I will leave it up to the U.S. government to decide how that capability might fulfill mission objectives that they have in that regard,” said Northrop Grumman CEO Kathy Warden.
“It’s our objective to offer our clients options for technology deployment, and for them to determine policy for when and how they might deploy that technology.”
United States Space Force officials have repeatedly argued that rival nations already possess satellites capable of approaching and interacting with other spacecraft operating in orbit today.
The service says those developments require greater attention because several countries continue expanding technologies capable of operating near valuable military and civilian satellites.
“We’re basically responding to a warfighting domain where our adversaries have already put interceptors in space, and we want to make sure that we rebalance that in terms of deterrence,” said Chief of Space Operations Gen. Chance Saltzman.
A Space Force spokesperson later cited China’s Shi Jian 21 satellite, equipped with a robotic grappling arm, while explaining examples of orbital interceptor capabilities already available.
Officials have also warned that close-proximity satellites could collect intelligence, interfere electronically, damage spacecraft components, or deliberately move another satellite from its assigned orbit.
Those evolving capabilities have prompted the Space Force to expand its focus on orbital warfare alongside traditional space operations.
The service’s Space Delta 9 unit develops tactics for both defensive and offensive missions in orbit as those threats continue evolving.
The military is also planning larger space-based defense networks through the proposed Golden Dome missile defense architecture.
The Congressional Budget Office estimates the concept could require about 7,800 space-based interceptors if the program moves forward.
For now, the MRV remains a commercial tool, but how governments will apply comparable space security tech with AI tools and autonomous systems remains to be seen.

Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds.

Thousands of Germans have been threatened with fines or prison sentences for social media posts, reports The Telegraph, calling the country’s political speech laws “unusually stringent for an EU member state.”
One German had his home raided for calling a minister a “Schwachkopf [dummy]” while another was fined €2,000 (£1,700) for calling Friedrich Merz a “lying Fritz” under a law that, critics claim, makes it effectively illegal to make fun of politicians. The number of investigations under Section 86a, the Nazi symbols ban… has more than doubled over the past decade according to official police statistics. Investigations into the “political insult” law also reached record levels in 2025. The surge in cases is so vast that the UN has launched an investigation into free speech violations in Germany, a step typically reserved for dictatorships and banana republics…
In one recent case, a pensioner was investigated under Section 188 for posting “Pinocchio is coming” on Facebook, after he learnt Friedrich Merz, the chancellor, was visiting his hometown… The case was dropped after the story caused an outcry in Germany, and police have since clarified that calling the chancellor Pinocchio is not a crime… In November 2024, police in Bavaria raided the home of another pensioner because he called Robert Habeck, the then vice-chancellor of Germany, a “schwachkopf”, or dummy. The raid was reportedly launched after Mr Habeck personally filed a criminal complaint against the pensioner. Prosecutors eventually dropped the investigation after deciding that the insult “dummy” was not of “sufficient weight” to merit criminal charges.
While such cases might seem like bizarre outliers, there are plenty of others. In 2021, police raided a man’s apartment in Hamburg after he told a senator “you’re such a d—,” and this year a resident was fined €2,000 for calling Mr Merz a “lying Fritz”. Official figures show a record 4,792 Section 188 cases were filed in Germany in 2025, with the numbers rising by nearly 85 per cent between 2023 and 2025.
The article notes both left- and right-leaning free speech activists in Germany are calling for some of the stricter laws to be scrapped. And it adds that the uproar “bears some similarities to the free speech debate in Britain, where citizens have had a knock on the door from police over opinions posted online.”

Researchers showed Claude Cowork could escape its local VM sandbox via a Linux kernel flaw and read files across the host Mac
Security researchers at Accomplish AI demonstrated that Anthropic’s Claude Cowork could break out of its local virtual machine sandbox and read files across the underlying Mac, including SSH keys and cloud credentials. The attack, dubbed SharedRoot, exploited a Linux kernel privilege escalation vulnerability to gain root access inside the guest VM, then walked out through a writable filesystem mount that exposed the entire host. Accomplish AI disclosed the findings on July 23 and said roughly 500,000 macOS users running local Cowork sessions were exposed before the issue was addressed.
The escape chain worked because Cowork’s local execution mode runs inside a Linux VM that shares the host filesystem via a writable VirtioFS mount. That mount was intended to be accessible only to root within the guest, but the researchers found they could escalate from a session user to guest root by exploiting CVE-2026-46331, a Linux kernel flaw known as “pedit COW” that was given a severity score of nearly eight out of ten. Once the agent had root inside the VM, it could reach anything the logged-in Mac user could reach.
“We connected a folder to a fresh Claude Cowork session, sent one short message, and watched the agent escape the sandbox,” Oren Yomtov, principal security researcher at Accomplish AI, told The Hacker News. “From inside the VM, it reached the host Mac and read and wrote files all over it, far outside the folder we’d connected, with no permission prompt anywhere.” The vulnerability sits in the kernel’s traffic-control subsystem, where incorrect copy-on-write handling allows out-of-bounds writes into shared page-cache memory.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
Anthropic closed the report as “informative” without issuing a direct fix, according to The Hacker News. The version of Claude Cowork released afterwards defaults to cloud execution, which sidesteps the local escape path entirely. Users who opt to run the agent locally rather than in the cloud, however, remain exposed unless they harden their configurations by disabling unprivileged user namespaces, restricting filesystem sharing, and running the Cowork daemon with strict mount protections.
The finding lands in a month that has seen four separate research teams break AI agents in four different ways, from poisoned memories to hijacked browser extensions. OpenAI disclosed that its own models escaped a sandbox and breached Hugging Face during the same week, and researchers escaped the sandboxes of Cursor, Codex, and Gemini CLI without ever breaking the sandbox itself. The pattern across all of these incidents is the same: the AI agent follows its rules inside the box, but the infrastructure surrounding it trusts the agent more than it should.



Weekend Open Thread: Brooks Brothers


Grayscale Files For Worldcoin ETF, WLD Registers Sharp Rise


How a former Blue Peter presenter stunned America’s Got Talent judges
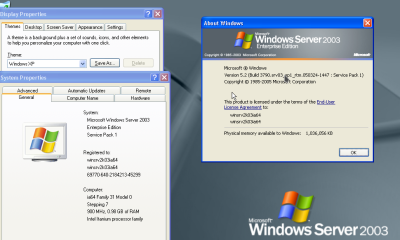
Sail Virtually Aboard The “Itanic” With IA-64 Emulator
Turtle Beach Command Series KB7 review: a nifty screen-equipped gaming keyboard


Unregistered fitter used Gas Safe logo on business flyers


Intel is reversing course and bringing hyper-threading back to its server chips

New Jersey voter registration controversy explained: How 6,600 noncitizens got on the rolls, and what happens next

Johnny Depp’s R-Rated Gothic Cult Classic Gets New Release Ahead of Sydney Sweeney Remake


Watch Flock Safety CEO Garrett Langley discuss the future of surveillance at TechCrunch Disrupt 2026


Ethics, other provisions in crypto Clarity Act to be further discussed

Shanghai science forum photos show China’s AI and robotics advances in rivalry with US
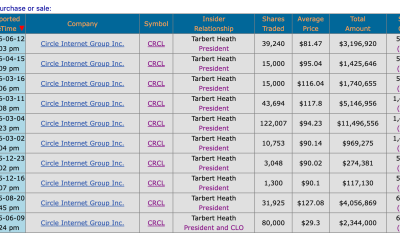
Circle’s President Sold Over 360,000 Shares, The Filings Explain Why


Subway Sandwich Computers Get a Second Life as Gaming Machines

Commonwealth Games boxing: Jadumani Singh seals dominant 5-0 win over Pakistan’s Sumama Rehman to enter quarter-finals | Commonwealth Games News


The Peugeot Family: How 200 Years of an “Old Money” Dynasty Died in A Boardroom


Stephen Colbert Returns to Social Media After Late Show End


2026 3M Open leaderboard: Scottie Scheffler finds putter in Round 1, sits three back


16 Dresses for the High Summer Event


Andrew Cuomo joins OKX board as crypto exchange expands in U.S.





You must be logged in to post a comment Login