Earlier this year, FIFA named YouTube a preferred partner for experiencing the World Cup 2026. On Wednesday, the next step in this partnership was announced, with the inaugural YouTube FIFA Creator Cup. It’s an exhibition match that’ll feature popular content creators from the platform, as well as athletes and celebrities. It’ll take place in New York City on July 12, ahead of the FIFA World Cup Final.
The Creator Cup is the latest step in FIFA’s moves to broaden soccer’s appeal through creator-involved content, potentially reaching the platform’s digital audience. The creators, athletes and celebrities competing in the match will be announced closer to the date.
Being a FIFA preferred partner means YouTube will, for the first time ever, broadcast unique World Cup-themed coverage — including the ability for viewers to stream the first 10 minutes of each game live on approved creators’ channels.
According to the platform, these creators have collectively amassed more than 350 million subscribers, all specializing in different content niches from sports analysis to food features, social challenges and travel videos. This means you’ll have an array of options to choose from for unique programming featuring your favorite YouTube personalities, all while still getting your World Cup fix.
A YouTube spokesperson didn’t immediately respond to our request for further comment.
Photo credit: Kelsonik Nikita Chuicko works under the name kelsonik and spends his time turning existing cars into the versions manufacturers never quite got around to building. His latest set of renderings takes the Tesla Model S and stretches it into a shooting brake while adding a full widebody kit. Everything is finished in solid black, the stance is dropped, and the proportions feel deliberate rather than forced.
Tesla has finally closed the book on the Model S and Model X, but it has left a tiny window open to make one last shot at a limited Signature Series of the two cars, complete with Gold badges and a price tag to match, before moving on to the next thing. Chuicko, on the other hand, saw and appreciated a chance. As far as he could tell, the shape of that iconic vehicle still had life in it. So he preserved the Model S design but went a little further with the roof, elevating it well over the back axle and squaring off the back end to give it a functional hatch, ultimately changing it into a car that sits somewhere between a grand tourer and a high-speed hauler.
2.4 GHz Remote Control Car – 1:18 scale cool design, waterproof RC truck toys made of premium material and sturdy, with LED lights, waterproof remote…
High Quality & DIY Removable Toys RC Cars – This remote control monster truck structure design quality, flexibility and strength in one. The rc truck…
All Terrain Amphibious Monster Truck – 4-wheel drive off-road design rc trucks for kids, with high-quality tires (shock absorption, strong grip…
Out front, the design is reminiscent of the newer Model Y, with two independent headlights flanking a continuous LED light strip that spans the entire front of the vehicle. The bumper is nice and low and clean, with just enough going on to keep the face from looking plain, and then there are those enormous front wheel flares that push the front wheels out and give it a planted aspect even when it’s just sitting in the driveway. The Black concave Y-spoke wheels, which run way down into the flares, help to secure those wheels.
Along the sides, the extra width stands out. The size of the flares suggests that they are structural rather than purely aesthetic. There is still a high beltline that protects the glass area from looking stretched out, as well as a modest small roof spoiler that sits right above the back window. That spoiler works in tandem with the second one positioned on the hatch. At the back, there’s a translucent full-width LED light bar that runs down the tailgate, lit in a mellow crimson that really shows out against the matte black paint. Then, beneath that, there is this quite aggressive diffuser that caps off the edge of the lower paneling and connects the entire rear track.
The entire car is finished in a single deep black color that absorbs light rather than reflecting it back out. There are no bright particles to be found breaking up the surface. The end effect is a car that is both silent and hefty, with a finish that makes the extra width appear to be there by design. Looking at it from the back three quarters, you can see that the elevated roof, two spoilers, and flared arches give the car a low, purposeful appearance while still allowing for a load behind the rear seats. [Source]
Gamers looking to start off the week by relaxing with their Xbox might need to find something else to do. On Monday, Microsoft reported that several issues were preventing gamers from using the platform. According to the Xbox Live Status page, the problems range from sign-in issues to difficulty viewing games in the Xbox store. And as of 2 p.m. PT, the problems were continuing.
The latest post from the official Xbox Support account on X, posted around 1:40 pm PT on Monday, said, “Thanks for your continued patience. Our engineers are still working to identify a fix, and we’ll share more as soon as we can.”
An earlier post Monday on the status page warned that players might not be able to sign in to their Xbox profiles, might be disconnected while signed in, or face other related problems. It also said that “features that require sign-in, like most games, apps and social activity, won’t be available.”
A Microsoft representative didn’t immediately respond to a request for comment.
The Xbox Live Status page says a resolution for all issues is “pending,” but no further detail or timing is listed.
Advertisement
“We are aware that some users are encountering errors when attempting to sign in, see your game library, or launch games,” the official Xbox Support account on X posted early Monday. “Our engineers are actively working to mitigate the issue.”
Microsoft later posted two updates, neither of which offers any real news on progress.
“Another update on the game library, sign-in, and game launch issue: Our teams are focused on multiple investigation angles and remain hard at work,” one update reads. “Thanks for your patience while teams keep working — we’ll share more details as they become available here or at http://support.xbox.com.”
CNET editor Gael Fashingbauer Cooper, a journalist and pop-culture junkie, is co-author of “Whatever Happened to Pudding Pops? The Lost Toys, Tastes and Trends of the ’70s and ’80s,” as well as “The Totally Sweet ’90s.” She’s been a journalist since 1989, working at Mpls.St.Paul Magazine, Twin Cities Sidewalk, the Minneapolis Star Tribune, and NBC News Digital. She’s Gen X in birthdate, word and deed. If Marathon candy bars ever come back, she’ll be first in line.
See full bio
Tekever AR5 drone regarded as more up-to-date answer to provide battlefield surveillance for soldiers
The UK Ministry of Defence (MoD) is investing up to £400 million in new surveillance drones to replace the British Army’s troublesome Watchkeeper fleet.
The MoD has selected the Tekever AR5 uncrewed aerial vehicle (UAV) for a fleet of “spy-in-the-sky” aircraft intended to provide real-time intelligence, protect troops, and inform battlefield decisions.
Advertisement
Tekever AR5 surveillance droneTekever UK
The initial order will be for six AR5 drones, with up to 24 expected by 2029. The aircraft will be built at a soon-to-open manufacturing facility in Swindon and, subject to contract signature and final approval, will begin entering service later this year. Support is expected to continue for at least five years, with options to extend it.
Tekever is a small aerospace and defense biz based in Portugal, but with a number of manufacturing and test facilities in the UK. One of its other products has already been adopted by the Royal Air Force as the basis for the StormShroud electronic warfare drone.
The AR5 is a medium-endurance UAV that resembles a small conventional light aircraft. It is 4 m (13 ft) long with a 7.3 m (24 ft) wingspan and is powered by a pair of 170 cc two-stroke boxer piston engines, so it isn’t going to break any speed records. It is capable of carrying a 50 kg (110 pounds) payload, with an endurance of up to 20 hours, and can take off and land on rough ground.
The newcomer is expected to replace the Watchkeeper in British Army service, a drone system perhaps best known to Reg readers for its tendency to not remain in the air.
Advertisement
According to Janes, Watchkeeper only saw brief operational service at the end of the conflict in Afghanistan, and was also used to track refugee boats in the English Channel in 2020. Other than that, it has largely been used for training, which may explain why at least seven are known to have been lost in incidents.
Former defence secretary John Healey announced in 2024 that Watchkeeper was set to be retired, despite the system having entered service only in 2014 and being expected to serve the Army until 2042.
The reasons for this should be obvious: the war in Ukraine has seen airborne drone technology advance significantly over the past several years, and Watchkeeper was already seen as not up to snuff.
The British Army began the procurement process for Watchkeeper’s successor last year under the codename Project Corvus.
Advertisement
Newly appointed defence secretary Wes Streeting said the chosen replacement has already been put to good use by Ukraine’s military.
“Proven in Ukraine and designed to protect British soldiers globally, we’ve chosen the UK-based Tekever AR5 drone to supply our personnel with kit that will keep them ahead of emerging threats,” he said.
It offers significantly improved endurance, sensor capability, and reliability, according to the MoD.
Payload options include electro-optical and infrared sensors, maritime radar, signals intelligence equipment, and search-and-rescue capability.
Advertisement
Tekever UK managing director Karl Brew insisted that this wouldn’t be about supplying a point solution, but helping the Army to stay one step ahead of its adversaries.
“Tekever aims to create a new type of partnership between government and industry where we will ensure a constant cycle of capability evolution that delivers decisive advantage to our end users,” he claimed. ®
Microsoft opened a new front in the AI security wars on Monday, unveiling its first custom-built cybersecurity model and a sweeping agentic defense platform — and making an argument that could reshape how enterprises buy AI: the future belongs not to the biggest model, but to the cheapest one that’s good enough, routed intelligently.
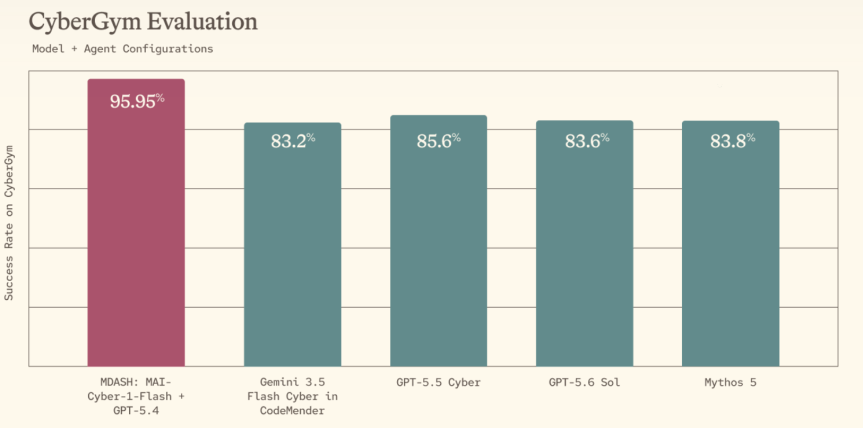
The company announced MAI-Cyber-1-Flash, a compact security model developed in-house by its Microsoft AI (MAI) division, embedded inside MDASH, Microsoft’s multi-agent harness for finding and fixing software vulnerabilities. Together, the company says, the system scores 96% on CyberGym — a benchmark measuring how well AI systems reason over large codebases to find real vulnerabilities — beating frontier models including Mythos, Gemini, and GPT, while cutting costs roughly in half compared to Microsoft’s own current production configuration.
Alongside the model, Microsoft introduced Project Perception, an agentic security system that coordinates “red team” agents that hunt for paths to compromise, “blue team” agents that investigate and triage risk, and “green team” agents that remediate and harden defenses. Project Perception enters public preview on August 3.
In a wide-ranging interview with VentureBeat, Microsoft AI CEO Mustafa Suleyman made clear the company sees Monday’s announcement as the opening move in a much longer campaign.
Advertisement
“We really do have a pretty significant data and harness and expertise moat, and that is enabling us to train models which are faster, better, cheaper, and I think this is genuinely the tip of the iceberg,” Suleyman said. “We haven’t been working on this for long. The next model is going to be pretty phenomenal.”
Microsoft’s MDASH system, which pairs its new MAI-Cyber-1-Flash model with OpenAI’s GPT-5.4, scored 95.95 percent on the CyberGym benchmark, outperforming rival configurations from Google, OpenAI and others by more than 10 percentage points. (Source: Microsoft)
Inside the 90/10 architecture that still depends on OpenAI’s GPT-5.4
The most technically revealing detail in the announcement is not the model itself but how Microsoft deploys it. MAI-Cyber-1-Flash was designed to handle up to 90% of security tasks efficiently, while MDASH escalates the remaining 10% of exceptionally difficult problems to a larger frontier model — which, notably, is OpenAI’s GPT-5.4. In other words, Microsoft’s flagship security AI still leans on its longtime partner-turned-rival for the hardest work.
Asked to explain that relationship, Suleyman pointed to the harness, the orchestration layer that routes each incoming problem to the right model. “The harness is like a router,” he told VentureBeat. “It’s kind of like guardrails and a rule set of an organizing logic, which matches queries to… incoming problems to a model that suits the problem.” The system has three components, he explained: the harness, the small and fast MAI-Cyber-1-Flash handling the bulk of queries, and GPT-5.4 sitting alongside as “just a generalist coding model.”
Advertisement
Pressed on how a system reliant on OpenAI’s model can outperform frontier competitors, Suleyman argued the performance comes from the whole system, not any single model. “These are very complicated, long, agentic loops which require storing state, drawing on another database, consulting best practice… handing back to a small model, writing a bunch of code, validating that that was correct,” he said. “There’s like hundreds of steps to solve that, and that’s why it’s really the system together that delivers the better performance.”
And why GPT-5.4 specifically for the escalation tier? Cost, again. “GPT-5.6 is expensive. GPT-5.4 is incredibly good relative to its cost,” Suleyman said. “The whole game here is to reduce the costs. Mythos and so on are extremely expensive models… we want to be able to deliver better performance for cheaper. That’s what customers want.” The arrangement captures Microsoft’s evolving posture toward OpenAI: still a customer of the partnership that drew regulatory scrutiny in Brussels and Washington in 2024, but increasingly determined to own the layers of the stack where it believes it holds durable advantages.
Why token costs — not model quality — are becoming the real barrier to enterprise AI adoption
The economics may matter more than the benchmark. Microsoft says the new configuration delivers roughly 50% cost savings against the current MDASH setup, which runs a blend of GPT-5.4, 5.4 mini, and 5.3 codex. In security — an always-on workload processing enormous volumes of signals — token costs compound relentlessly, and Microsoft argues they have become the binding constraint for defenders.
Suleyman frames the cost issue as downstream of a harder physical limit. “The key barrier to adoption is access to chips, and cost is a function of chips,” he said. “No matter how much money you’ve got, there’s actually a limited supply of chips. Then trying to squeeze more model output on fewer chips is clearly super valuable.”
Advertisement
He also described a broader enterprise backlash against frontier-model pricing. Companies initially maxed out on the best available models, he said, but “then they realize they’re sort of paying… a phenomenal amount of money, and people are absolutely token maxing everywhere across their business. So there’s a massive pushback to reduce cost everywhere.”
That positions Microsoft to ride a market trend rather than fight it. Cost-efficient, near-frontier models have proliferated over the past year — from xAI’s recent Grok release to a wave of Chinese models built on the same premise — and Microsoft is betting that as a platform company it can align itself with enterprise cost pressure. “The top model providers want you to use the most expensive model continuously, whereas because we are a platform, we’re on the side of the enterprise,” Suleyman said. “There’s no point asking… Mythos what the capital of France is.”
The 100-trillion-signal data moat Microsoft says no competitor can replicate
Every AI lab claims differentiation. Microsoft’s claim in security rests on something genuinely hard to copy: telemetry. The company processes more than 100 trillion security signals daily — a figure consistent with its 2025 Digital Defense Report, which also cited 4.5 million new malware files blocked and 5 billion emails screened per day — and draws operational insight from 1.6 million customers.
“We have trillions and trillions of data points going back decades,” Suleyman said. “It is, I think, the largest longitudinal cybersecurity dataset around,” in part because Microsoft’s customer base includes governments “who have been consistently attacked for years, and we have been consistently attacked.” Asked directly whether this constitutes an advantage no competitor can match, Suleyman didn’t hedge: “That is definitely a moat for us. Both the data and the expertise, and just the experience in the institution of going through that process.”
Advertisement
The strategic logic is that cybersecurity functions as a live reinforcement-learning loop: defenders act, outcomes are observed, models improve. Microsoft argues that connecting actions to outcomes — what was exploited, what was contained, what was blocked — yields training signal that pure model labs simply cannot buy or manufacture.
There is real substance here, but the usual caveats apply. The CyberGym results come from Microsoft’s own evaluation, the fine print shows the headline “96%” is actually 95.95%, and vendor-run benchmarks that pit an entire tuned agentic system against competitors’ base models are not apples-to-apples comparisons. What Microsoft has measured is a full harness-plus-models configuration against what customers might otherwise assemble — arguably the commercially relevant comparison, but not a controlled model-versus-model test.
The dual-use dilemma: how Microsoft plans to keep a vulnerability-hunting AI out of the wrong hands
A model built to find challenging vulnerabilities in complex codebases is, by definition, a model that could find vulnerabilities for attackers. This is not a theoretical concern. Microsoft’s own threat intelligence team, in joint research with OpenAI published in February 2024, documented nation-state actors from Russia, North Korea, Iran, and China probing large language models for reconnaissance, scripting, and vulnerability research. Its 2025 Digital Defense Report went further, warning that AI agents could eventually automate the entire attack lifecycle.
Suleyman said Microsoft is gating access accordingly. “We’re very strict about who gets access to the model, and we’re very careful about that,” he said. “We constantly monitor the API and usage.” An approved user, he added, “has to be seen to be having good intent, but also have technical competence.” The rollout will be deliberately staged: “It’s not going to be thousands next week. There will be tens, and then hundreds, and then thousands.”
Advertisement
Microsoft says the model was evaluated by its AI Red Team, subjected to automated and expert-led adversarial exercises, and independently assessed by a third party, with deployment wrapped in tenant isolation, auditing, and sandboxed execution environments with no internet access.
Suleyman also offered a candid acknowledgment of Microsoft’s positioning relative to the bleeding edge — one that doubles as a pitch to risk-averse buyers. “Even though we might be a few months behind the absolute cutting edge at any given moment… it matters that we’re doing it very carefully and thoughtfully, and we have a track record of doing that,” he said. For a company that spent 2024 absorbing hard security lessons — from delaying its Recall feature over privacy concerns to convening an industry summit after the CrowdStrike outage disabled some 8.5 million Windows devices — that trust-first framing is both strategy and necessity.
What Microsoft’s superintelligence roadmap signals about the future of enterprise AI
Suleyman described a rapidly accelerating MAI roadmap, roughly nine months after Microsoft stood up its superintelligence team. “We have the compute that we need. We certainly have the data we need. We have the talent,” he said. “Our momentum is accelerating rapidly.” The top enterprise demand he’s hearing is for “agents that can produce arbitrary code to solve whatever problem they direct them at,” as vibe-coded internal tools graduate from experiments into production. The next phase, he said, pulls voice, transcription, image, and coding models “all integrated into the same harness.”
Notably, Suleyman expressed skepticism about the industry’s default assumption that everything eventually converges into one giant unified model. “It remains to be seen whether one giant model that is fully multimodal is actually able to deliver additional transfer learning benefit because of the integration,” he said, “or whether it’s just a big lumbering expensive giant.”
Advertisement
That skepticism is the through line of the entire announcement. Microsoft is wagering that the unit of competition in enterprise AI is no longer the model at all — it’s the system: the router, the specialized small models, the frontier fallback, and the proprietary data feeding the loop. In security, where Microsoft controls both the telemetry flowing in and the products that act on it, that wager is at its strongest. Whether it holds in domains where the company’s data advantage is thinner remains the open question hanging over the MAI roadmap.
For now, though, Microsoft has offered the industry a preview of how it intends to fight the next phase of the AI race: not by building the biggest brain, but by building the best machine around it. As Suleyman put it, this is the tip of the iceberg — and Microsoft is betting everything on what sits below the waterline.
Microsoft has a new AI cybersecurity model called MAI-Cyber-1-Flash, and when it’s combined with agentic security system MDASH and OpenAI’s GPT-5.4 model, it outscores Anthropic’s Claude Mythos 5 by 12 points on a key benchmark. The security product is designed for “using AI to defend against AI,” Microsoft says.
The combination of MAI-Cyber-1-Flash with MDASH — which launched in May — is called Project Perception, and it enters public preview on Aug. 3, built directly into Microsoft Defender. It will slowly roll out to all Microsoft Security products.
According to benchmarks posted by Microsoft on Monday, the combination scored 96% on CyberGym, compared with Mythos 5 at 84%.
Microsoft
Pricing is consumption-based, measured by the number of security compute units you use. As AI agents run scenarios, they consume SCUs, so the more work performed, the more you pay — but Microsoft says cost savings are almost 50% of the current MDASH configuration on the market now.
Speaking at a Microsoft briefing on Monday morning, Mustafa Suleyman, CEO of Microsoft AI, explained the handover process between MAI-Cyber-1-Flash and GPT-5.4.
Advertisement
“MAI-Cyber-1-Flash handles about 90% of the queries. It detects the vulnerabilities, it patches them, ships them and then proves that it was actually a valid and correct solve. And then it basically defers about 10% of the queries to GPT-5.4, which is obviously a larger model, about 10x larger, and it solves those,” Suleyman said. “In conjunction, as the models hand off between each other, they’re actually not just able to deliver better performance than all of the other models combined — they do so at 50% of the cost.”
Suleyman called the CyberGym benchmark result “quite a remarkable result.”
It follows the launch of Anthropic’s Claude Fable 5 last month, the first publicly available model from the Mythos family. At the time, Anthropic said Mythos was so good at finding cybersecurity flaws that it could break the internet if used unchecked — and Anthropic was forced to walk back the Fable 5 and Mythos 5 launches within days because the US government said it was aware of a way to “jailbreak” the model and bypass limits. When Mythos was first announced, it was released only to select government agencies and tech professionals.
“Microsoft has long been the trusted steward of some of the most valuable, important government and enterprise data in the world over many decades. We’ve accrued a phenomenal amount of data in that time,” Suleyman said Monday. “It’s that data combined with the expertise that we have from the world-class cybersecurity experts in the company that we’ve been able to really drive this combined model.”
Advertisement
Corinne Reichert
Senior Editor
Corinne Reichert (she/her) grew up in Sydney, Australia and moved to California in 2019. She holds degrees in law and communications, and currently writes news, analysis and features for CNET across the topics of electric vehicles, broadband networks, mobile devices, big tech, artificial intelligence, home technology and entertainment. In her spare time, she watches soccer games and F1 races, and goes to Disneyland as often as possible.
See full bio
AMD’s MI400 press release publishes exactly one performance figure
288 TFLOPS of hardware FP64 on the MI430X, a GPU it positions as its go-to for sovereign AI and HPC
Unlike the MI455X, which it launched alongside, the MI430X will have researchers and sovereign AI clients waiting longer, with AMD targeting early 2027 for its first shipments
AMD has launched its latest Instinct MI400 series, unveiling two new chips which bring performance gains, larger, faster HBM4 memory, and a continued promise to support its open-source ROCm stack.
While both chips come with 432GB of HBM4 memory, they both have very different use cases: the MI455X is AMD’s attempt to dominate AI data centers and run training and inference for frontier models, while the MI430 is positioned as a high-performance compute (HPC) alternative that offers superior precision thanks to it being tuned for superior FP64 performance at a hardware level.
Both GPUs are based on AMD’s CNDA 5 architecture, but the MI430X offers FP64 performance that dwarfs both the MI455X and Nvidia‘s Rubin-based offerings.
Latest Videos FromTechRadar
Advertisement
Frontier AI demand comes first
The launch, which was effectively on paper, still showcased where AMD’s focus lies: the Instinct MI455X. There is a simple reason for that: AI data centers prioritize faster FP4 and FP8 performance for most tasks, such as inference, and the MI455X delivers on that front.
AMD is simply responding to market demand by aiming to ship the MI455X first, even as it has sovereign AI buyers lining up, both directly and indirectly, including the U.S. Department of Energy, Oracle, and even the UK government, to name a few.
AMD stated that the MI455X delivers up to 34 times the token throughput of the MI355X at 18 times lower cost, showcasing a significant performance and efficiency upgrade. It is also arguably AMD’s most heavily drummed-up release to date, even as it continues to play catch-up to Nvidia’s market dominance in the AI data center space.
The MI455X ships with the recently announced Helios, AMD’s first rack-scale AI system that launched alongside the new Instinct chips. One of these has 72 MI455X GPUs and 18 sixth-gen EPYC server CPUs, configured in a 1:6 ratio per compute node.
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
The MI430X, on the other hand, seems to be competing specifically to score buyers who require higher precision, such as science researchers or even government departments where correctness is required at the edges, and memory limitations apply even with the MI series accelerator’s 432GB of HMB4 in play.
Advertisement
“The next generation of AI will span frontier AI, sovereign AI and scientific computing, and each requires infrastructure optimized for its unique demands,” said Vamsi Boppana, SVP AI at AMD.
“The AMD Instinct MI400 Series extends our AI portfolio with purpose-built solutions optimized for the full spectrum of AI and HPC deployments, built on an open software foundation that gives customers the flexibility to innovate at every scale.”
AMD also has an important buyer for the MI455X in its Helios rack-scale form that will also grant it further exposure to it pre-IPO: Anthropic. The company has agreed to invest $5 billion in the AI giant, with the latter agreeing to deploy 2 GW of AMD’s MI450 accelerators, even though its AI head wasn’t exactly enthused recently by a perceived drop in performance on Claude Code in early 2026.
Portable CD players are suddenly everywhere again, which is what happens when streaming fatigue collides with a physical format that costs less than vinyl and does not arrive warped. US CD sales jumped 16% to 16.3 million units during the first half of 2026, but many of the new portable players still force buyers to choose between mobility and enough power to drive demanding headphones.
The $629 Shanling EC Zero T Max addresses that problem with a revised battery-powered amplifier delivering up to 1,300mW into 32 ohms, while retaining the original model’s 24-bit R2R DAC, dual JAN6418 tubes, USB DAC, Bluetooth transmission and CD-ripping capabilities.
The CD revival has officially reached the stage where a Discman now requires resistor ladders, vacuum tubes and more output than some desktop amplifiers.
What Changed From the EC Zero T?
Shanling EC Zero T Portable CD Player
The Max is not a different finish wrapped around last year’s electronics.
Shanling replaced the original TPA6120-based headphone section with a revised amplifier built around the Analog Devices AD8397. The balanced 4.4mm output now produces as much as 1,300mW into 32 ohms in transistor mode and 1,162mW in tube mode while operating from the internal battery. The 3.5mm output reaches 361mW into the same load.
Advertisement
The original EC Zero T delivered 551mW into 32 ohms from its balanced output on battery power and required external DC power to reach its maximum 1,220mW specification. Its single-ended output was limited to 158mW on battery. The Max therefore supplies more power away from the wall than the previous model could produce even when plugged into one.
That matters because a supposedly portable player that requires an external power supply to unlock its best amplifier performance is portable in much the same way that a countertop microwave is technically movable.
Shanling has also reduced output impedance from 4.7 ohms on the original 3.5mm output and 6.6 ohms on the balanced output to approximately 0.4 and 0.7 ohms, respectively. That change may be even more useful than the additional power for owners of sensitive multi-driver IEMs, which can react unpredictably when connected to a source with high output impedance.
Shanling EC Zero T Max
The R2R DAC Gets Revised Power and Signal Circuits
The EC Zero T Max retains Shanling’s in-house 24-bit R2R DAC module, built around 192 precision resistors with 0.1% tolerance. Users can choose between oversampling and non-oversampling modes, depending on whether they prefer conventional digital filtering or a more direct NOS presentation.
Shanling says it revised the DAC’s power supply and portions of the analog signal path using experience gained during the development of its newer PRO R2R platform. The company claims the changes produce a wider and deeper soundstage with greater midrange and treble transparency. Those claims will require listening rather than obediently copying the brochure, but this appears to be circuit-level work rather than a new firmware filter wearing a party hat.
Advertisement
The dual JAN6418 miniature vacuum tubes also return, with selectable tube and transistor output modes. Shanling isolates the tubes inside a damped mounting structure to reduce microphonic noise, which becomes especially important when two vacuum tubes are sharing a chassis with a spinning optical mechanism.
Advertisement. Scroll to continue reading.
Still a CD Player and Quite a Bit More
The EC Zero T Max uses a custom CD mechanism with an active magnetic clamp and anti-skip system. It supports gapless CD playback and can rip discs in real time to an attached USB storage device as uncompressed WAV files.
It can also operate as a USB DAC, supporting PCM up to 32-bit/768kHz and DSD512. Analog connectivity includes separate 3.5mm and balanced 4.4mm headphone and line outputs, while coaxial and optical connections allow the Shanling to feed an external DAC or full-size audio system.
Advertisement
Bluetooth 5.3 transmission supports aptX Adaptive, aptX and SBC. The important word is transmission: the Shanling can send CD audio to compatible wireless headphones or speakers, but it is not advertised as a Bluetooth receiver for streaming music from a phone. LDAC is also absent.
The internal 5,500mAh battery is rated for up to eight hours through the single-ended output, approximately 7.5 hours through the balanced output and as much as 20 hours when the player is used as a Bluetooth transmitter.
Shanling EC Zero T Max
Shanling EC Zero T Max Specifications
Type: Portable CD player, USB DAC and headphone amplifier
DAC: Shanling 24-bit R2R module
Resistor network: 192 resistors with 0.1% tolerance
Digital modes: Oversampling and non-oversampling
Tube stage: Two JAN6418 miniature vacuum tubes
Amplifier: AD8397-based revised headphone stage
Output modes: Tube or transistor
Balanced output: Up to 1,300mW into 32 ohms in transistor mode
Balanced tube output: Up to 1,162mW into 32 ohms
Single-ended output: Up to 361mW into 32 ohms
Headphone outputs: 3.5mm and 4.4mm balanced
Line outputs: 3.5mm and 4.4mm balanced
Digital outputs: Coaxial and optical
USB DAC support: PCM up to 32-bit/768kHz and DSD512
Bluetooth: Version 5.3 transmitter
Bluetooth codecs: aptX Adaptive, aptX and SBC
CD ripping: Real-time WAV ripping to USB storage
Battery: 5,500mAh
Battery life: Up to 8 hours wired or 20 hours over Bluetooth
Display: 1.68-inch color LCD
Construction: Aluminum chassis with tempered-glass panels
Dimensions: 6.2 x 5.9 x 1.1 inches
Weight: 1.47 pounds
Finish: Titanium gray
What Makes the EC Zero T Max Unique?
Portable CD players with balanced headphone outputs are no longer especially unusual. The Max separates itself by combining a custom R2R DAC, selectable physical tube stage, CD ripping, high-resolution USB DAC support and a genuinely powerful battery-operated amplifier in one component.
The critical improvement is not that it reaches 1.3 watts. The original model could approach that figure when connected to external power. The difference is that the Max provides its full amplifier output from the internal battery while also lowering output impedance enough to work more predictably with sensitive IEMs.
That gives it a broader range than most portable disc players. It can drive efficient earphones, more demanding over-ear headphones, powered speakers or an external DAC without requiring the owner to construct a small equipment shrine beside the CD case.
Advertisement
Three Alternatives
FiiO DM15 R2R
FiiO DM15 R2R
The $269.99 FiiO DM15 R2R is substantially less expensive and uses FiiO’s own 24-bit resistor-ladder DAC. It provides 3.5mm and balanced 4.4mm outputs, Bluetooth 5.4 transmission, USB DAC operation and digital outputs. Output reaches 812mW into 32 ohms on battery or 1,150mW in desktop mode.
The DM15 is lighter, cheaper and offers newer Bluetooth connectivity. The Shanling counters with substantially more battery-driven power, selectable tube and transistor stages, lower output impedance and a more elaborate analog section.
Cayin CP6
The $699 Cayin CP6 is the closest conceptual rival. It uses two JAN6418 tubes, offers classic tube, modern tube and solid-state sound modes, supports bidirectional Bluetooth 5.4 and includes USB DAC and CD-ripping functions. Its amplifier can produce as much as 1,300mW into 32 ohms when operating in DC power mode.
The Cayin offers more Bluetooth flexibility and three distinct output modes, but uses dual Cirrus Logic DACs rather than an R2R network. The Shanling also reaches its maximum balanced output on battery power rather than requiring external DC power.
Moondrop DiscDream 2 Ultra
The $349 Moondrop DiscDream 2 Ultra provides balanced and single-ended headphone outputs, an optical output, USB DAC operation and approximately eight hours of battery life. It is a simpler and much less expensive route into transportable CD playback.
Advertisement
Advertisement. Scroll to continue reading.
It does not offer Bluetooth, CD ripping, an R2R DAC or a tube stage. The Moondrop makes sense for listeners who primarily want a well-built portable CD transport and headphone source rather than an entire personal-audio laboratory.
Who Is It For?
The EC Zero T Max makes the most sense for CD collectors who use a mixture of sensitive IEMs and full-size headphones and want one component that can travel between portable and desktop systems.
It also suits listeners who prefer R2R conversion or want the option of switching between a tube and solid-state presentation without purchasing two separate headphone amplifiers.
Advertisement
Who Should Avoid It?
Anyone who only wants to play CDs through efficient earbuds can spend substantially less on the FiiO DM15 R2R, Shanling EC Play or Moondrop DiscDream 2 Ultra.
The Max also lacks LDAC and Bluetooth reception, while its 1.47-pound weight stretches the meaning of “portable.” You can carry it, but nobody is clipping it to a tracksuit and running the Jersey Shore boardwalk unless their chiropractor has fallen behind on the boat payments.
The Bottom Line
The Shanling EC Zero T Max is the version the original EC Zero T probably should have been from the beginning.
It preserves the unusual combination of physical CD playback, R2R conversion and real vacuum tubes while addressing the original model’s most obvious weaknesses: limited battery-powered output and relatively high output impedance.
The result is not merely a louder EC Zero T. It is better suited to both demanding over-ear headphones and sensitive IEMs, while still functioning as a USB DAC, CD ripper, Bluetooth transmitter and digital transport.
Advertisement
Portable CD playback in 2026 has become remarkably sophisticated. It has also become remarkably expensive, but at least Shanling remembered to improve the parts that matter.
Price & Availability
The Shanling EC Zero T Max is priced at $629 and is now shipping to distributors. Shanling lists European pricing at €689 and says the player will be offered in titanium gray. Final US dealer pricing and local availability may vary as inventory reaches regional distributors.
A second gremlin is rolling through Spotify this evening.
Spotify
It’s not just you. Spotify has been inoperable or bugged out for many users today, and while the original batch of issues appears to have been fixed, there’s currently another outage affecting the company’s web page and apps. At just past 3PM ET on Monday, July 27, the Spotify Status account shared on X, “We’re aware of some issues right now with our web page and are checking them out!”
The website problems followed an outage in the early morning of July 27. The Spotify Status account said that glitch was cleared up about an hour after reports started rolling in. Spotify hasn’t yet given the all-clear for the second round of problems today, and users are still reporting issues with the service on Downdetector. I can confirm that I am currently unable to listen to “Pookie’s Requiem” on Spotify, and this is a tragedy.
The initial outage was resolved quickly, so for the sake of your commute home, cooking tunes or evening chill time, let’s hope this one is, too.
The Department of Homeland Security’s top numbers-cruncher has resigned, citing the Trump administration’s “war on immigrants” on his way out.
DHS has been a hub of controversy during the second Trump term: the ICE raids in American cities, the wild spending, the growing archipelago of detention centers, the attempts to hide data about it all. But vanishingly few officials have left the department and been openly critical of the direction it has taken. Marc Rosenblum, who served as executive director of the Office of Homeland Security Statistics and a deputy assistant secretary at the department, is one of the first.
“I’m thrilled to end my relationship with the current administration,” Rosenblum said in a LinkedIn post over the weekend. “Between the war on immigrants, the war on feds, and the war on facts (not to mention the crazy war in Iran and the brazen corruption), I just need a change.”
Rosenblum also served in the first Trump and Biden administrations, initially running DHS’s office of immigration statistics, and then overseeing stats for the entire department—collating numbers on everything from cybersecurity intrusions to trafficking investigations to deportations. His office peaked at 45 people in the Biden years, and started to shrink since.
Advertisement
“He had one of the most interesting charges at DHS,” a former colleague tells WIRED of Rosenblum. “There’s 22 component agencies, and so there are 22 different ways of aggregating data that were just completely siloed.”
“So Marc’s charge was to consolidate all the data and put it in a way that internally, I at headquarters could know exactly how many Coast Guard interdictions happened off the Coast Guard station in Miami, and how many of those were Cuban, Haitian, Nicaragua, Venezuelan. And then kind of conceptualize that with the same population of people that were crossing the Southwest border,” the former colleague adds.
A domestic security agency like DHS is never going to be a model of transparency. But Rosenblum, a long-time immigration policy wonk and an immigration specialist for the Congressional Research Service, promised as much openness as possible when he took on his department-wide role in 2023. “We’ll begin releasing data more quickly, with greater granularity and covering a broader scope of DHS activities,” he told Federal News Network that November.
That data itself became controversial in Trump 2.0. The Office of Homeland Security Statistics’ website on ICE detentions, Border Patrol encounters, and DHS repatriations hasn’t been updated since February 11, 2025, just weeks into the second Trump term. What information has been pried from DHS since then, often through Freedom of Information Act lawsuits, has been at times spotty and unreliable, analysts say.
Advertisement
“There’s no accountability, no way to assess, no public understanding about what’s really going on that is not curated by a press release from the agency,” David Bier, the Cato Institute’s director of immigration studies, told NOTUS in November.
DHS didn’t immediately respond to a request to comment for this story. Neither did Rosenblum. But he did allude to the difficulty of publishing quality data under this administration in his LinkedIn post. “My OHSS co-workers are outstanding career federal civil servants. They are smart, mission-focused experts who produce high quality results in a challenging and often hostile work environment,” he wrote.
“Marc was exactly what every American should want in a career public servant,” Luis Miranda, a top DHS spokesman during the Biden years, tells WIRED. “The Trump administration has governed by silencing or ignoring facts and information they believe doesn’t line up with their extreme rhetoric, and that has damaging implications, so it’s no surprise career officials whose job is transparency are unable to do those jobs.”
Since its introduction over two decades ago, HDMI has slowly but surely replaced the old video cables such as VGA. Eventually, it became an industry standard, and basically any TV, monitor, gaming console, and media player now uses HDMI as its primary connection port. Even if you don’t know what HDMI stands for, you likely know its use — to send high-definition video signals to a screen. However, last year, a new challenger arrived that could give HDMI a run for its money.
Bearing a similar name, GPMI (General Purpose Media Interface) was introduced by Shenzhen 8K UHD Video Industry Cooperation Alliance. The group is a consortium of over 50 Chinese companies, including well-known TV manufacturers like Hisense and TCL. The most impressive thing about GPMI is probably the fact that it’s designed to handle everything at once, meaning you get video, audio, data, control signals, and power with just one cable. And, as you likely know, eliminating cable clutter and management is always a good thing.
Fewer cables isn’t the only notable feature, since GPMI has some pretty good specs. For starters, it has noticeably more bandwidth than HDMI 2.0 and can offer higher bandwidth than HDMI 2.2. GPMI comes in two different formats: one uses the familiar USB-C standard (which delivers 96 Gbps and 240 watts of power), and the other uses a special Type-B cable designed just for this system. The Type-B cable steps things up, as it provides 192 Gbps and 480 watts. For comparison, HDMI 2.2 can deliver up to a maximum of 96 Gbps of bandwidth, which only matches GPMI’s USB-C connector.
Advertisement
Can GPMI replace HDMI?
Adi Sunandar/Shutterstock
Similarly to GPMI, HDMI 2.2 was released last year as the latest and best HDMI to date. From a technical viewpoint, the GPMI obviously has better specs, with the all-in-one cable being a big quality-of-life improvement. But HDMI is a better-known technology that numerous companies use. Due to this, new TVs in the coming years, maybe even 2027, will have an HDMI 2.2 port, which is a luxury GPMI doesn’t have.
Naturally, we’re talking about GPMI use outside of China. Considering the massive number of Chinese companies behind the new standard, it’s reasonable to expect it becoming prevalent throughout the country in the near future. Elsewhere, though, it would take massive support from other companies and manufacturers to adopt it across the industry. This isn’t just for TVs either, since other items (like graphics cards and gaming consoles) would need to support GPMI inclusion. While Chinese companies might be in favor of adoption, it’s hard to say whether Western ones will follow suit.
Advertisement
Still, GPMI did put China on the map when it comes to connectivity standards, since that part of the industry has long been dominated by the West. It will be interesting to see how things will go from here, now that there’s one more contender. As it stands now, we’ll likely continue to use HDMI (despite several reasons why you might want to stop) for quite some time in our households.






































































You must be logged in to post a comment Login