The Meadow slips into a pocket without a second thought. Measuring just 1.3 by 2 by 0.4 inches and weighing four ounces, it feels closer to a good luck charm than a conventional smartphone. The recycled polycarbonate shell has a smooth, understated feel that should hold up well to everyday use, and the three inch square display sits centered in that compact body, clear enough for a quick glance but small enough that lingering on it for too long simply isn’t that appealing. That last part is rather the point.
Setup takes under five minutes and works with your existing phone number, no new SIM required. Calls go to your main phone first, and if that is unavailable Meadow picks up automatically. Messaging works on a similar principle, with one deliberate restriction: only 12 contacts you have approved can reach you by text. Anything from outside that list simply does not come through, which cuts spam and unwanted pings entirely. Leave your main phone behind and an auto-reply lets people know you are unreachable for the time being.
Google Pixel 10 is the everyday phone unlike anything else; it has Google Tensor G5, Pixel’s most powerful chip, an incredible camera, and advanced…
Unlocked Android phone gives you the flexibility to change carriers and choose your own data plan[2]; it works – Google Fi, Verizon, T-Mobile, AT&T…
The upgraded triple rear camera system has a new 5x telephoto lens – up to 20x Super Res Zoom for stunning detail from far away; Night Sight takes…
The app selection is deliberately minimal but covers what most people actually need day to day. You get calls, messaging, a camera, a clock, maps, notes, and weather. Spotify and Apple Music handle music streaming, with local playback and a dedicated app available for podcasts and audiobooks. Strava covers fitness tracking and Uber handles rides. That is the full list, and there is no app store to tempt you into adding more. For anyone who has grown tired of their attention being pulled in a dozen directions at once, that simplicity feels less like a limitation and more like a breath of fresh air.
The hardware is more than capable of handling the lean app selection without any lag, with 6GB of memory and 128GB of storage on board. A single 13 megapixel rear camera is there when you need it, and the absence of a front facing lens is a deliberate trade-off rather than an oversight. Battery life stretches to a day or two of mixed use depending on how you are using it, and USB-C fast charging keeps top-ups quick. Bluetooth handles headphones and speakers without issue, though there is no headphone jack. Wi-Fi, Bluetooth, NFC, and 4G are all supported, with connectivity managed through a monthly service that costs $10 after the first nine months of free service included with purchase.
Pre-orders are open now at $399, with the price rising to $449 once stock arrives. US customers can expect delivery around June 2026, with each unit coming bundled with a beach pouch, an activity case, and a charging cable. [Source]
Seattle-based data management firm Qumulo is looking across the Atlantic for its next phase of growth.
The company announced Friday the launch of a new European software research and development and customer success hub in Cork, Ireland, a move expected to create 50 jobs over the next three years.
Qumulo Chief Technology Officer Kiran Bhageshpur said Cork was “the obvious choice for us to build a team focused on leveraging AI to help businesses manage global-scale data infrastructure.”
Other Seattle-area tech companies also operate in Cork, including Amazon and F5. Apple recently announced a new office in Cork, with capacity for up to 1,300 employees.
For Qumulo, the move comes as it works to maintain its edge in an increasingly crowded field of AI-driven data management. Founded in 2012 by the engineering team behind Isilon Systems — acquired by EMC for $2.25 billion in 2010 — the company has long been a notable part of the Seattle region’s storage and cloud sector. It raised a $125 million series E funding round in 2020, at the time giving the company a $1.25 billion valuation.
Advertisement
Since then, Qumulo has navigated a shifting landscape, including significant layoffs in 2022 as it prioritized a path toward profitability.
Now, under the leadership of CEO Douglas Gourlay, the company is betting that the global hunger for “AI-ready” data will fuel its next chapter.
In a landmark case, a jury found this week that Meta and YouTube negligently designed their platforms and harmed the plaintiff, a 20-year-old woman referred to as Kaley G.M. The jury agreed with the plaintiff that social media is addictive and harmful and was deliberately designed to be that way. This finding aligns with my view as a clinical psychologist: that social mediaaddiction is not a failure of users, but a feature of the platforms themselves. I believe that accountability must extend beyond individuals to the systems and incentives that shape their behavior.
In my clinical practice, I regularly see patients struggling with compulsive social media use. Many describe a pattern of “doomscrolling,” often using social media to numb themselves after a long day. Afterwards, they feel guilty and stressed about the time lost yet have had limited success changing this pattern on their own.
It’s easy to understand why scrolling can be so addictive. Social media interfaces are built around a powerful behavioral mechanism known as intermittent reinforcement, says Judson Brewer, an addiction researcher at Brown University, which is the strongest and most effective type of reinforcement learning. This is the same mechanism that slot machines rely on: Users never know when the next reward—a shower of quarters, or a slew of likes and comments—will appear. Not all the videos in our feeds captivate us, but if we scroll long enough, we are bound to arrive at one that does. The ongoing search for rewards ensnares us and reinforces itself.
Why Social Media Feels Addictive
Individuals typically struggle on their own to address compulsive social media use. This should be no surprise, as habits are not typically broken through sheer discipline but rather by altering the reinforcement loops that sustain them. Brewer argues that “there’s actually no neuroscientific evidence for the presence of willpower.” Placing the burden to self-regulate solely on users misses the deeper issue: These platforms are engineered to override individual control.
Advertisement
A growing body of research identifies social media use and constant digital connectivity as important influences on the growing incidence of adolescent mental health problems. Brewer notes that adolescents are particularly vulnerable, as they are in a “developmental phase” in which reinforcement learning processes are especially strong. This vulnerability can be exploited by the design features of large social media platforms.
How Platforms Are Designed to Maximize Engagement
NPR uncovered records from a recent lawsuit filed by Kentucky’s attorney general against TikTok. According to these documents, TikTok implemented interface mechanisms such as autoplay, infinite scrolling, and a highly personalized recommendation algorithm that were systematically optimized to maximize user engagement.
TikTok’s algorithmically tailored “For You” content continuously tracks user behaviors, such as how long a video is watched, whether it is replayed, or quickly skipped. The feed then curates short videos, or reels, for the user based on past scrolling behavior and what is most likely to hold attention.
These documents show one example of a tech company knowingly designing products to maximize attention. I believe social media companies also have the capacity to reduce addictiveness through intentional design choices.
Advertisement
How Governments Are Regulating Social Media
The good news is we are not helpless. There are multiple levers for change: how we collectively talk about social media, how our governments regulate its design and access, and how we hold companies accountable for practices that shape user behavior.
Some countries are moving quickly to set policy around social media use. Australia has imposed a minimum age of 16 for social media accounts, with similar bans pending in Denmark, France, and Malaysia.
These bans typically rely on age verification. Users without verified accounts can still passively watch videos on platforms like YouTube, but this approach removes many of the most addictive features, including infinite scroll, personalized feeds, notifications, and systems for followers and likes. At the same time, age verification may cause different problems in the online ecosystem.
Other countries are targeting social media use in specific contexts. South Korea, for example, banned smartphone use in classrooms. And the United Kingdom is taking a different approach; its Age Appropriate Design Code instructs platforms to prioritize children’s safety while designing products. The code includes strong privacy defaults, limits on data collection, and constraints on features that nudge users toward greater engagement.
Advertisement
How Social Media Platforms Could Be Redesigned
A report called Breaking the Algorithm, from Mental Health America, argues that social media platforms should shift from maximizing engagement to supporting well-being. It calls for revamping recommendation systems to spot patterns of unhealthy use and adjusting feeds accordingly—for example, by limiting extreme or distressing content.
The report also argues that users should not have to intentionally opt out of harmful design features. Instead, the safest settings should be the default. The report supports regulatory measures aimed at limiting features such as autoplay and infinite scroll while enforcing privacy and safety settings.
Platforms could also give users more control by adding natural speed bumps, such as stopping points or break reminders during scrolling. Research shows that interrupting infinite scroll with prompts such as “Do you want to keep going?” substantially reduces mindless scrolling and improves memory of content.
Some social media platforms are already experimenting with more ethical engagement. Mastodon, an open-source, decentralized platform, displays posts chronologically rather than ranking them for engagement, and does not offer algorithmically generated feeds like “For You.” Bluesky gives users control by letting them customize their own algorithms and toggle between different feed types, such as chronological or topic-based filters.
Advertisement
In light of the recent verdict, it is time for a national conversation about accountability for social media companies. Individual responsibility will always be important, but so are the mechanisms employed by big tech to shape user behavior. If social media platforms are currently designed to capture attention, they can also be designed to give some of it back.
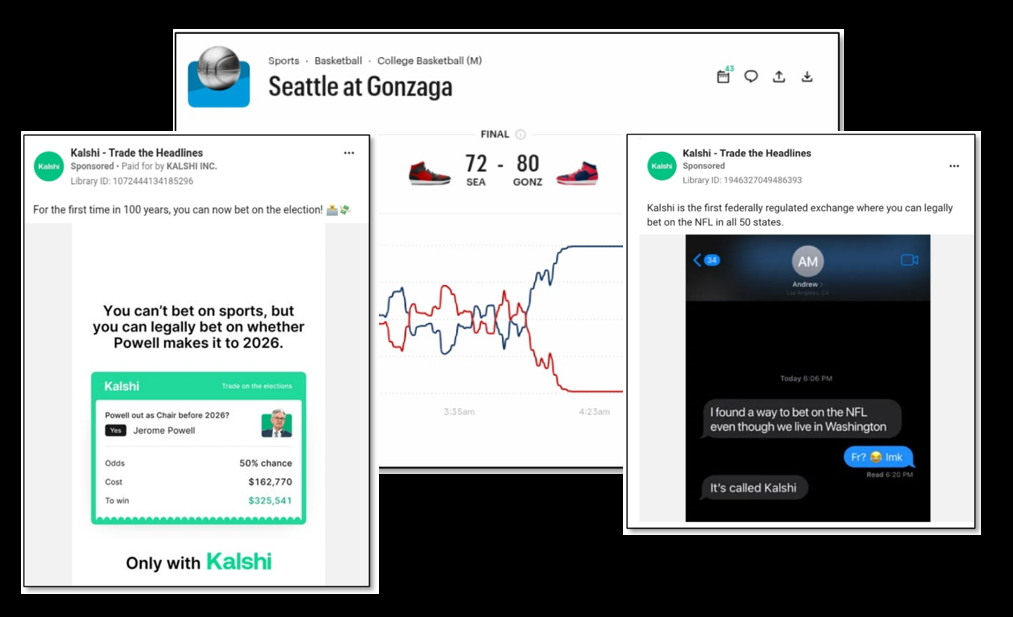
Screenshots of Kalshi ads and betting markets included in Washington state’s complaint. At right, an ad cited by the state shows a text conversation in which one person tells another they “found a way to bet on the NFL even though we live in Washington.”
Washington Attorney General Nick Brown is suing prediction market platform Kalshi, alleging the company violates state gambling and consumer protection laws by operating an online betting service where users can wager on sports, elections, wars and other events.
The civil suit, filed Friday in King County Superior Court, seeks to shut down Kalshi’s operations in Washington, recover money lost by state residents and assess civil penalties.
It’s the latest in a growing wave of state actions against the New York-based company, which is facing more than 20 civil lawsuits. Earlier this month, Arizona’s attorney general filed criminal charges against Kalshi, believed to be the first such case against a prediction market.
The Washington state complaint highlights a Kalshi advertisement in which one person texts another that they “found a way to bet on the NFL even though we live in Washington,” which the state says shows the company knowingly circumvented state law.
Advertisement
GeekWire has contacted Kalshi for comment. The company has called similar legal actions in other states “meritless.”
Kalshi entered the sports betting market in early 2025 and now offers spread bets, over/under wagers and proposition bets on college and professional sports — all standard sportsbook products that are illegal in Washington outside of tribal lands, the complaint says.
But the complaint notes that Kalshi’s offerings go far beyond sports. The platform lets users bet on the total number of measles cases in a given year, what witnesses will say during a child trafficking hearing, and whether Iran’s supreme leader will be removed from power.
The company also offers “mention markets” where bettors wager on specific words a TV host or politician will say during a broadcast, as noted in the complaint.
Advertisement
“Kalshi wants people betting on almost everything possible in life — the outcome of elections, Supreme Court cases, even wars,” Washington AG Brown said in a statement. “As they advance this bleak vision of the future, they line their pockets and pat themselves on the back for sneaking around Washington’s gambling laws. No more.”
The complaint also takes aim at Kalshi’s marketing to young people, saying the company has targeted users between the ages of 18 and 21 and leveraged college student influencers to promote the platform. The state says Kalshi briefly attempted to recruit a 15-year-old influencer.
On its own Instagram account, Kalshi once described its platform as “kind of addicting,” according to the complaint.
The industry has also drawn scrutiny after bettors on rival platform Polymarket made six-figure profits wagering on the capture of Nicolás Maduro and the killing of Iran’s supreme leader.
Advertisement
Kalshi, founded in 2018, is a designated contract market regulated by the Commodity Futures Trading Commission. The company has argued in other cases that its federal status preempts state gambling laws, a position that has been supported by the Trump administration and senior CFTC leadership.
That argument has produced mixed results in court. Federal judges in New Jersey and Tennessee have at least temporarily blocked state enforcement against Kalshi, while state‑court decisions in Massachusetts and Ohio have sided with state regulators by insisting that Kalshi obtain traditional sports‑betting licenses.
A bipartisan bill introduced this week by Sens. Adam Schiff (D-Calif.) and John Curtis (R-Utah) would ban sports betting on prediction market platforms.
Washington has some of the most restrictive gambling laws in the country. The state constitution prohibited gambling when Washington became a state in 1889, and the legislature banned internet gambling in 2006. The exception is sports wagers placed in person at tribal casinos.
The cybersecurity industry needs to ‘fight fire with fire’ when it comes to AI, according to Integrity360’s Brian Martin.
Earlier this month, cybersecurity company Integrity360 held the Dublin edition of its global cyber conference, Security First.
Held on 10 March, the conference saw cybersecurity experts and companies from across the country flock to the Aviva Stadium to sit in on a number of keynotes and panels, all exploring a wide variety of pressing cyber topics and trends.
Richard Ford, CTO at Integrity360, told SiliconRepublic.com at the Aviva that the Security First series of events provides an opportunity to bring some thought leaders from across the cyber industry together.
Advertisement
“From inside Integrity as well, but also from across industry because I think it’s important to get multiple voices,” he said.
But what does ‘security first’ mean?
Ford told us that the term refers to Integrity360’s model and view of cybersecurity, which is “to enable organisations to look at the full life cycle of cybersecurity, and look at it holistically, rather than just looking at one single segment”.
Advertisement
He explained that cybersecurity needs to be a whole-of-organisation priority, rather than just an IT concern.
“You know, it can’t just be a technology, it can’t be the technologists, the analysts, the engineers. It has to come from the very top of the organisation to think, actually, cybersecurity is important, it’s one of our key risks to our business,” he said.
“So we need to take that seriously and put the right effort, the right spend and the right focus on it to make sure that we are not the next organisation to be in the headlines and get breached.”
Human-AI era
This year, the conference theme was ‘Resilience Redefined: Securing the Human-AI Era’, with the event examining “how AI, machine identities and changing regulations are reshaping organisational defence”, according to the company.
Advertisement
While AI has certainly become a top opportunity for today’s cybersecurity teams, it has also introduced considerable cyberthreats as well.
“It’s not so much that AI is actually finding new things to exploit, but rather that it can automate a lot of the activities that normally would be performed by human attackers,” explained Brian Martin, Integrity360’s director of product management.
“So therefore, they can find exposures a lot faster, they can adapt more quickly to blockers that they find, and then they can execute more and more stages of the attack autonomously and at scale.”
Chris Hosking, AI and cloud security evangelist at SentinelOne, said AI has impacted cybersecurity by “empowering the threat landscape”.
Advertisement
“It’s made [threat actors] faster, it’s given them more sophistication than they’ve had before and it’s also lowered the barrier to entry,” he said.
However, he emphasised that AI also provides considerable opportunities for cyber defence teams. “We can have a phenomenal edge if we move to things like agentic auto triage, auto investigation. But we’re really sort of only dipping our toes right now into what AI can do for us, but a lot of opportunity ahead.”
Martin agreed, stating that cybersecurity teams need to “fight fire with fire” by utilising AI technology.
“We need to be able to move away from some of the manual and sort of fragmented visibility that we’ve had in order to be able to respond to that increasing scale and rapidity of attack.”
Advertisement
With the scale and complexity of cybersecurity and cyberthreats greater than it’s ever been, plenty in attendance at the conference had advice for companies that might be wondering how to adapt.
Niall Errity, director of professional services at Vectra, said that companies need to “understand their own gaps in their own network”.
“I think a lot of organisations tend to be very one or two tool-focused,” he said. “They think, ‘oh, I have an EDR [endpoint detection and response] installed on my endpoints and I’m perfectly fine now, I don’t need to worry about anything else beyond that’.
“Unless they’re doing the proper analysis in their own environments, doing proper testing to really make sure they’re resilient, they won’t really know their own gaps. So my recommendation would be to constantly look at what’s happening in the news, what’s happening with organisations. Take those learnings and test your own environments to make sure that you have those gaps closed.”
Advertisement
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
The European Commission is investigating a breach after a threat actor allegedly accessed at least one of its AWS cloud accounts and claimed to have stolen more than 350 GB of data, including databases and employee-related information. AWS says its own services were not breached. BleepingComputer reports: Sources familiar with the incident have told BleepingComputer that the attack was quickly detected and that the Commission’s cybersecurity incident response team is now investigating. While the Commission has yet to share any details about this breach, the threat actor who claimed responsibility for the attack reached out to BleepingComputer earlier this week, stating that they had stolen over 350 GB of data (including multiple databases).
They didn’t disclose how they breached the affected accounts, but they provided BleepingComputer with several screenshots as proof that they had access to information belonging to European Commission employees and to an email server used by Commission employees. The threat actor also told BleepingComputer that they will not attempt to extort the Commission using the allegedly stolen data as leverage, but intend to leak the data online at a later date.
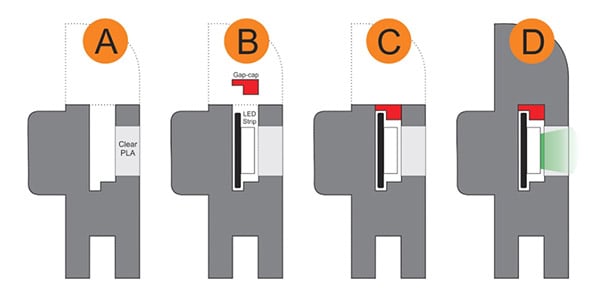
Embedding fasteners or other hardware into 3D prints is a useful technique, but it can bring challenges when applied to large or non-flat objects. The solution? Use a gap-cap.
The gap-cap technique is essentially a 3D printed lid. One pauses a print, inserts hardware, then covers it with a lid before resuming the print. The lid — or gap-cap — does three things. It seals in the part, it fills in empty space left above the component, and it provides a nice flat surface for subsequent layers which makes the whole process much cleaner and more reliable.
This whole technique is a bit reminiscent of the idea of manual supports, except that the inserted piece is intended to be sealed into the print along with the embedded hardware under it.
If you have never inserted anything larger than a nut or small magnet into a 3D print, you may wonder why one needs to bother with a gap-cap at all. The short version is that what works for printing over small bits doesn’t reliably carry over to big, odd-shaped bits.
For one thing, filament generally doesn’t like to stick to embedded hardware. As the size of the inserted object increases, especially if it isn’t flat, it increasingly complicates the printer’s ability to seal it in cleanly. Because most nuts are small, even if the printer gets a little messy it probably doesn’t matter much. But what works for small nuts won’t work for something like an LED strip mounted on its side, as shown here.
Advertisement
Cross-section of a print with an embedded LED strip. The print pauses (A), LED strip is inserted and capped with a gap-cap (B, C), then printing resumes and completes (D).
In cases like these a gap-cap is ideal. By pre-printing a form-fitting cap that covers the inserted hardware, one provides a smooth and flat surface that both seals the component in snugly while providing an ideal surface upon which to resume printing.
If needed, a bit of glue can help ensure a gap-cap doesn’t shift and cause trouble when printing resumes, but we can’t help but recall the pause-and-attach technique of embedding printed elements with the help of a LEGO-like connection. Perhaps a gap-cap designed in such a way would avoid needing any kind of adhesive at all.
Bellevue, Wash.-based wireless carrier T-Mobile confirmed it made an unspecified number of layoffs this week. A tipster told GeekWire the number was in the hundreds, which the company did not verify.
“To move even faster in a dynamic market while continuing to deliver best-in-class digital experiences for our customers, we’re further aligning our IT organization to support future growth and innovation,” T-Mobile said in a statement to GeekWire on Friday. “This includes the difficult decision of eliminating some roles while continuing to invest and hire in areas.”
Posts on LinkedIn referenced the layoffs, with some alluding to a “major corporate restructuring.”
The new round of cuts comes less than two months after T-Mobile shed 393 workers in Washington state. Those cuts impacted analysts, engineers and technicians, as well as directors, managers and VP-level executives.
T-Mobile employed about 75,000 people as of Dec. 31, 2025. The company has nearly 8,000 workers in the Seattle region, according to LinkedIn.
Advertisement
The Seattle area has been hit by thousands of tech-related layoffs, including job losses at Amazon, Expedia, Meta, Zillow and other companies.
T-Mobile, the largest U.S. telecom company by market capitalization, laid off 121 workers in August 2025. Last November, former Chief Operating Officer Srini Gopalan replaced longtime leader Mike Sievert as CEO.
T‑Mobile grew service revenue to $71.3 billion in 2025, up 8% from the prior year, while posting $11 billion in net income and adding a record 7.6 million postpaid customers, underscoring how it continues to expand even as it trims IT and corporate roles.
The company said Friday it is “providing robust support to impacted employees as they transition.”
Processing 200,000 tokens through a large language model is expensive and slow: the longer the context, the faster the costs spiral. Researchers at Tsinghua University and Z.ai have built a technique called IndexCache that cuts up to 75% of the redundant computation in sparse attention models, delivering up to 1.82x faster time-to-first-token and 1.48x faster generation throughput at that context length.
The technique applies to models using the DeepSeek Sparse Attention architecture, including the latest DeepSeek and GLM families. It can help enterprises provide faster user experiences for production-scale, long-context models, a capability already proven in preliminary tests on the 744-billion-parameter GLM-5 model.
The DSA bottleneck
Large language models rely on the self-attention mechanism, a process where the model computes the relationship between every token in its context and all the preceding ones to predict the next token.
However, self-attention has a severe limitation. Its computational complexity scales quadratically with sequence length. For applications requiring extended context windows (e.g., large document processing, multi-step agentic workflows, or long chain-of-thought reasoning), this quadratic scaling leads to sluggish inference speeds and significant compute and memory costs.
Advertisement
Sparse attention offers a principled solution to this scaling problem. Instead of calculating the relationship between every token and all preceding ones, sparse attention optimizes the process by having each query select and attend to only the most relevant subset of tokens.
DeepSeek Sparse Attention (DSA) is a highly efficient implementation of this concept, first introduced in DeepSeek-V3.2. To determine which tokens matter most, DSA introduces a lightweight “lightning indexer module” at every layer of the model. This indexer scores all preceding tokens and selects a small batch for the main core attention mechanism to process. By doing this, DSA slashes the heavy core attention computation from quadratic to linear, dramatically speeding up the model while preserving output quality.
But the researchers identified a lingering flaw: the DSA indexer itself still operates at a quadratic complexity at every single layer. Even though the indexer is computationally cheaper than the main attention process, as context lengths grow, the time the model spends running these indexers skyrockets. This severely slows down the model, especially during the initial “prefill” stage where the prompt is first processed.
Advertisement
The DSA indexing tax increases with context length (source: arXiv)
Caching attention with IndexCache
To solve the indexer bottleneck, the research team discovered a crucial characteristic of how DSA models process data. The subset of important tokens an indexer selects remains remarkably stable as data moves through consecutive transformer layers. Empirical tests on DSA models revealed that adjacent layers share between 70% and 100% of their selected tokens.
To capitalize on this cross-layer redundancy, the researchers developed IndexCache. The technique partitions the model’s layers into two categories. A small number of full (F) layers retain their indexers, actively scoring the tokens and choosing the most important ones to cache. The rest of the layers become shared (S), performing no indexing and reusing the cached indices from the nearest preceding F layer.
IndexCache splits layers into full and shared layers
Advertisement
During inference, the model simply checks the layer type. If it reaches an F layer, it calculates and caches fresh indices. If it is an S layer, it skips the math and copies the cached data.
There is a wide range of optimization techniques that try to address the attention bottleneck by compressing the KV cache, where the computed attention values are stored. Instead of shrinking the memory footprint like standard KV cache compression, IndexCache attacks the compute bottleneck.
“IndexCache is not a traditional KV cache compression or sharing technique,” Yushi Bai, co-author of the paper, told VentureBeat. “It eliminates this redundancy by reusing indices across layers, thereby reducing computation rather than just memory footprint. It is complementary to existing approaches and can be combined with them.”
The researchers developed two deployment approaches for IndexCache. (It is worth noting that IndexCache only applies to models that use the DSA architecture, such as the latest DeepSeek models and the latest family of GLM models.)
Advertisement
For developers working with off-the-shelf DSA models where retraining is unfeasible or too expensive, they created a training-free method relying on a “greedy layer selection” algorithm. By running a small calibration dataset through the model, this algorithm automatically determines the optimal placement of F and S layers without any weight updates. Empirical evidence shows that the greedy algorithm can safely remove 75% of the indexers while matching the downstream performance of the original model.
For teams pre-training or heavily fine-tuning their own foundation models, the researchers propose a training-aware version that optimizes the network parameters to natively support cross-layer sharing. This approach introduces a “multi-layer distillation loss” during training. It forces each retained indexer to learn how to select a consensus subset of tokens that will be highly relevant for all the subsequent layers it serves.
Real-world speedups on production models
To test the impact of IndexCache, the researchers applied it to the 30-billion-parameter GLM-4.7 Flash model and compared it against the standard baseline.
At a 200K context length, removing 75% of the indexers slashed the prefill latency from 19.5 seconds down to just 10.7 seconds, delivering a 1.82x speedup. The researchers note these speedups are expected to be even greater in longer contexts.
Advertisement
During the decoding phase, where the model generates its response, IndexCache boosted per-request throughput from 58 tokens per second to 86 tokens per second at the 200K context mark, yielding a 1.48x speedup. When the server’s memory is fully saturated with requests, total decode throughput jumped by up to 51%.
IndexCache speeds up the prefill and decode stages significantly (source: arXiv)
For enterprise teams, these efficiency gains translate directly into cost savings. “In terms of ROI, IndexCache provides consistent benefits across scenarios, but the gains are most noticeable in long-context workloads such as RAG, document analysis, and agentic pipelines,” Bai said. “In these cases, we observe at least an approximate 20% reduction in deployment cost and similar improvements in user-perceived latency.” He added that for very short-context tasks, the benefits hover around 5%.
Remarkably, these efficiency gains did not compromise reasoning capabilities. Using the training-free approach to eliminate 75% of indexers, the 30B model matched the original baseline’s average score on long-context benchmarks, scoring 49.9 against the original 50.2. On the highly complex AIME 2025 math reasoning benchmark, the optimized model actually outperformed the original baseline, scoring 92.6 compared to 91.0.
Advertisement
The team also ran preliminary experiments on the production-scale 744-billion-parameter GLM-5 model. They found that eliminating 75% of its indexers with the training-free method yielded at least a 1.3x speedup on contexts over 100K tokens. At the same time, the model maintained a nearly identical quality average on long-context tasks.
IndexCache increases the speed of GLM-5 by 20% while maintaining the accuracy (source: arXiv)
Getting IndexCache into production
For development teams wanting to implement the training-free approach today, the process is straightforward but requires careful setup. While the greedy search algorithm automatically finds the optimal layer configuration, the quality of that configuration depends on the data it processes.
“We recommend using domain-specific data as a calibration set so that the discovered layer-sharing pattern aligns with real workloads,” Bai said.
Advertisement
Once calibrated, the optimization is highly accessible for production environments. Open-source patches are already available on GitHub for major serving engines. “Integration is relatively straightforward — developers can apply the patch to existing inference stacks, such as vLLM or SGLang, and enable IndexCache with minimal configuration changes,” Bai said.
While IndexCache provides an immediate fix for today’s compute bottlenecks, its underlying philosophy points to a broader shift in how the AI industry will approach model design.
“Future foundation models will likely be architected with downstream inference constraints in mind from the beginning,” Bai concluded. “This means designs that are not only scalable in terms of model size, but also optimized for real-world throughput and latency, rather than treating these as post-hoc concerns.”
We’ve professionally sat in a lot of office chairs, and the Branch Ergonomic Chair Pro has held the top spot in our office chair buying guide ever since we first tested it. It’s easy to spend a lot on an office chair, but this one packs in plenty of features for a relatively modest price. We like it at full price, and we’ve shared deal stories when it has gone on sale for $450 in the past.
Right now, though, it’s down to $400 thanks to the Amazon Spring Sale. That’s $50 cheaper than we’ve seen it before, and so of course, we had to tell you.
Photograph: Julian Chokkattu
Branch
Ergonomic Chair Pro
Advertisement
Many of the products and gadgets that we recommend are nice to have, but not necessary. Headphones are cool, but you might not need an upgrade. A fancy smart bird feeder is neat, but not crucial. But working from an inefficient, ergonomically poor office setup can wreak havoc on your body. It’s actually bad for you. If you’re sitting at a desk working from a computer, you genuinely, truly need a good office chair.
We recommend this chair for most people because it’s easy to adjust and offers several customizable features. Its armrests, seat, and back can be tilted and maneuvered to dial in the perfect fit for your sit, and there are several different upholstery options available, including leather, vegan leather, and mesh. (Although the Amazon sale only features the mesh option; you’ll have to go to Branch’s website for the other materials.) All of the finishes offer a nice mix of softness, durability, and breathability. You could spend a lot more money for a little more customization, some higher-end materials, or even more adjustments, but we think this mesh version does a darn good job for what you’ll pay and what most people need. Snagging it for $100 less is a no-brainer if you’re in the market.
Laser Welding is apparently the new hotness, in part because these sci-fi rayguns masquerading as tools are really cool. They cut! They weld! They Julienne Fry! Well, maybe not that last one. In any case, perhaps feeling the need to cancel out that coolness as quickly as he possibly could, YouTuber [Wesley Treat] decided to make a giant version of his own head.
[Wesely] had previously been 3D scanned as part of the maker scans project, which you can find over on Printables. Those of you who really hate YouTubers, take note: finally you have something to take your frustrations out on. [Wesely] takes that model into Blender to decimate and decapitate– fans of the band Tyr may wonder if the model questioned his sword–before feeding that head through an online papercraft tool called PaperMaker to generate cut files for his CNC. There are also a lot of welding montages interspersed there as he practices with the new tool. [Wesely] did first try out his new raygun on steel in a previous video, but even knowing that, he makes the learning curve on these lasers look quite scalable.
While we’re not likely to follow in [Wesely]’s footsteps and create our own low-poly Zardoz– Zardozes? Zardii?– using a papercraft toolchain and CNC equipment with sheet aluminum is absolutely a great idea worth stealing. It’s very similar to what another hacker did with PCBs— though that project was perhaps more reasonable in scale and ego.

































































You must be logged in to post a comment Login