In short: Nvidia CEO Jensen Huang warned on the Dwarkesh Podcast that DeepSeek optimising its AI models for Huawei’s Ascend chips instead of American hardware would be “a horrible outcome” for the United States, as the Chinese AI lab prepares to launch its V4 foundation model on Huawei’s Ascend 950PR processor. The migration from Nvidia’s CUDA to Huawei’s CANN framework threatens to break the software-hardware dependency underpinning American AI dominance, even as US lawmakers push to place DeepSeek on the entity list for export control.
Nvidia CEO Jensen Huang said on the Dwarkesh Podcast on Wednesday that if DeepSeek optimised its new AI models to run on Huawei chips rather than American hardware, it would be “a horrible outcome” for the United States. The warning frames the emerging partnership between China’s most capable AI lab and its most advanced chipmaker as a direct threat to the technological leverage that has underpinned American AI dominance for the past decade.
“If future AI models are optimised in a very different way than the American tech stack,” Huang said, and as “AI diffuses out into the rest of the world” with Chinese standards and technology, China “will become superior to” the US. The statement is notable because it comes from the CEO of the company that has benefited most from the current arrangement, in which virtually every frontier AI model in the world is trained on Nvidia GPUs using Nvidia’s CUDA software framework.
What DeepSeek is building
DeepSeek is preparing to launch V4, a multimodal foundation model expected later this month. The Information reported earlier in April that V4 would run on Huawei’s latest Ascend 950PR processor, while a separate Reuters report suggested the model had been trained on Nvidia’s Blackwell chips, which would constitute a violation of US export controls. The two claims are not necessarily contradictory: a model can be trained on one set of hardware and deployed for inference on another.
Advertisement
What makes the Huawei integration significant is the software migration behind it. DeepSeek has spent months rewriting its core code to work with Huawei’s CANN framework, moving away from the CUDA ecosystem that Nvidia has spent two decades building into the foundation of AI development. CUDA’s dominance has functioned as a second layer of American control over AI, beyond the chips themselves. Export restrictions can limit which Nvidia hardware reaches China, but as long as Chinese labs wrote their software for CUDA, they remained dependent on the Nvidia ecosystem even when using alternative processors. DeepSeek’s move to CANN breaks that dependency.
DeepSeek’s V3 model, launched in late 2024, was trained on 2,048 Nvidia H800 GPUs, a chip tailor-made for the Chinese market that was itself banned from sale to China in 2023. The company has already demonstrated that it can producefrontier-competitive modelswith fewer resources than its American rivals. Its R1 reasoning model matched or exceeded the performance of models that cost orders of magnitude more to train. V4 would extend that approach by proving the company can do it without American hardware at all.
The hardware gap and why it may not matter
On raw performance, Huawei’s chips are not competitive with Nvidia’s best. The Ascend 910C, the predecessor to the 950PR, delivers roughly 60% of the inference performance of Nvidia’s H100, a chip that is itself two generations behind Nvidia’s current best. American chips are approximately five times more powerful than their Chinese equivalents today, and that gap is projected to widen to 17 times by 2027. Huawei is targeting 750,000 AI chip shipments in 2026, but its total production represents only 3 to 5% of Nvidia’s aggregate computing power.
But Huang’s concern is not about the current performance gap. He said on the podcast that even if China had inferior chips, it could still catch up with the US in AI development given its “abundant energy” and “large pool of AI researchers.” The implication is that raw hardware performance is only one variable, and that software optimisation, researcher talent, and energy availability can compensate for silicon disadvantages. If V4 performs well on Ascend chips, it validates an alternative path for AI development that does not depend on Nvidia at any point in the supply chain.
The export control paradox
The situation exposes a tension at the centre of American chip export policy. Nvidia restarted production of the H200, a more powerful chip, for sale in China, as Huang confirmed in March. But China has been blocking H200 imports to protect Huawei’s domestic chip business, and Nvidia’s CFO has said the company has recorded no revenue from China H200 sales. The controls designed to limit China’s AI capabilities are instead accelerating the development of a Chinese alternative.
Advertisement
DeepSeek’s experience with its R2 model illustrates both the promise and the limits of the Huawei path. R2 was repeatedly delayed because of training failures on Huawei hardware. Chinese authorities had urged DeepSeek to train on domestic chips, but the company encountered stability issues that forced it to revert to Nvidia GPUs for training while using Huawei chips only for inference. The distinction matters: training is the most compute-intensive phase of AI development, and the fact that Huawei chips could not handle it reliably suggests the hardware gap is real. But inference, the phase where models serve users, is where commercial value is generated, and Huawei’s chips appear adequate for that purpose.
Meanwhile, US lawmakers are pushing to tighten restrictions further. On Thursday, lawmakers and experts accused China of buying “what they can” and stealing “what they cannot” in the AI industry, and called for the government to evaluate placing DeepSeek, Moonshot AI, and MiniMax on the entity list for export control.
What Huang is really warning about
Huang’s warning is ultimately about software-hardware co-design. Nvidia’s dominance rests not just on making the fastest chips but on CUDA’s position as the default development environment for AI. When researchers write code, they write it for CUDA. When startups build products, they build them on CUDA. When governments invest in AI infrastructure, they buy Nvidia GPUs because that is what the software requires. DeepSeek’s migration to CANN threatens to create a parallel ecosystem in which none of that applies.
Thescale of Nvidia’s businessmakes the stakes concrete. The company’s market capitalisation exceeds $3 trillion. Its data centre revenue grew 93% year over year in its most recent quarter. Its chips power the training runs for virtually every major AI model outside China. If the most capable Chinese AI lab demonstrates that competitive models can be built without Nvidia, the argument for maintaining export controls weakens, the argument for buying Nvidia weakens, and thegeopolitical assumptionsthat have shaped AI policy for the past three years come under pressure.
Advertisement
None of this means Huawei is about to overtake Nvidia. The performance gap is large and growing. The R2 training failures demonstrate that Chinese hardware is not yet ready for the most demanding AI workloads. But Huang is not warning about today. He is warning about a trajectory in which DeepSeek proves the concept, other labs follow, and the CUDA moat that has made Nvidia the mostvaluable companyin the AI supply chain begins to erode.
The fact that the CEO of Nvidia is the one making this argument publicly suggests he believes the risk is no longer theoretical. DeepSeek’s V4 will be the first major test. If a multimodal foundation model runs competitively on Huawei silicon, the warning Huang issued on Wednesday will look less like corporate lobbying and more likethe most consequential forecastin the AI chip war so far.
The journey from a laboratory hypothesis to a pharmacy shelf is one of the most grueling marathons in modern industry, typically spanning 10 to 15 years and billions of dollars in investment.
Progress is often stymied not just by the inherent mysteries of biology, but by the “fragmented and difficult to scale” workflows that force researchers to manually pivot between the actual experimental design equipment, software, and databases.
But OpenAI is releasing a new specialized model GPT-Rosalind specifically to speed up this process and make it more efficient, easier, and ideally, more productive. Named after the pioneering chemist Rosalind Franklin, whose work was vital to the discovery of DNA’s structure (and was often overlooked for her male colleagues James Watson and Francis Crick), this new frontier reasoning model is purpose-built to act as a specialized intelligence layer for life sciences research.
By shifting AI’s role from a general-purpose assistant to a domain-specific “reasoning” partner, OpenAI is signaling a long-term commitment to biological and chemical discovery.
Advertisement
What GPT-Rosalind offers
GPT-Rosalind isn’t just about faster text generation; it is designed to synthesize evidence, generate biological hypotheses, and plan experiments—tasks that have traditionally required years of expert human synthesis.
At its core, GPT-Rosalind is the first in a new series of models optimized for scientific workflows. While previous iterations of GPT excelled at general language tasks, this model is fine-tuned for deeper understanding across genomics, protein engineering, and chemistry.
To validate its capabilities, OpenAI tested the model against several industry benchmarks. On BixBench, a metric for real-world bioinformatics and data analysis, GPT-Rosalind achieved leading performance among models with published scores.
In more granular testing via LABBench2, the model outperformed GPT-5.4 on six out of eleven tasks, with the most significant gains appearing in CloningQA—a task requiring the end-to-end design of reagents for molecular cloning protocols.
Advertisement
The model’s most striking performance signal came from a partnership with Dyno Therapeutics. In an evaluation using unpublished, “uncontaminated” RNA sequences, GPT-Rosalind was tasked with sequence-to-function prediction and generation.
When evaluated directly in the Codex environment, the model’s submissions ranked above the 95th percentile of human experts on prediction tasks and reached the 84th percentile for sequence generation.
This level of expertise suggests the model can serve as a high-level collaborator capable of identifying “expert-relevant patterns” that generalist models often overlook.
The new lab workflow
OpenAI is not just releasing a model; it is launching an ecosystem designed to integrate with the tools scientists already use. Central to this is a new Life Sciences research plugin for Codex, available on GitHub.
Advertisement
Scientific research is famously siloed. A single project might require a researcher to consult a protein structure database, search through 20 years of clinical literature, and then use a separate tool for sequence manipulation. The new plugin acts as an “orchestration layer,” providing a unified starting point for these multi-step questions.
Skill Set: The package includes modular skills for biochemistry, human genetics, functional genomics, and clinical evidence.
Connectivity: It connects models to over 50 public multi-omics databases and literature sources.
Efficiency: This approach targets “long-horizon, tool-heavy scientific workflows,” allowing researchers to automate repeatable tasks like protein structure lookups and sequence searches.
Limited and gated access
Given the potential power of a model capable of redesigning biological structures, OpenAI is eschewing a broad “open-source” or general public release in favor of a Trusted Access program.
The model is launching as a research preview specifically for qualified Enterprise customers in the United States. This restricted deployment is built on three core principles: beneficial use, strong governance, and controlled access.
Organizations requesting access must undergo a qualification and safety review to ensure they are conducting legitimate research with a clear public benefit.
Advertisement
Unlike general-use models, GPT-Rosalind was developed with heightened enterprise-grade security controls. For the end-user, this means:
Restricted Access: Usage is limited to approved users within secure, well-managed environments.
Governance: Participating organizations must maintain strict misuse-prevention controls and agree to specific life sciences research preview terms.
Cost: During the preview phase, the model will not consume existing credits or tokens, allowing researchers to experiment without immediate budgetary constraints (subject to abuse guardrails).
Warm reception from initial industry partners
The announcement garnered significant buy-in from OpenAI parnters across the pharmaceutical and technology sectors.
Sean Bruich, SVP of AI and Data at Amgen, noted that the collaboration allows the company to apply advanced tools in ways that could “accelerate how we deliver medicines to patients”.The impact is also being felt in the specialized tech infrastructure that supports labs:
NVIDIA: Kimberly Powell, VP of Healthcare and Life Sciences, described the convergence of domain reasoning and accelerated computing as a way to “compress years of traditional R&D into immediate, actionable scientific insights”.
Moderna: CEO Stéphane Bancel highlighted the model’s ability to “reason across complex biological evidence” to help teams translate insights into experimental workflows.
The Allen Institute: CTO Andy Hickl emphasized that GPT-Rosalind stands out for making manual steps—like finding and aligning data—more “consistent and repeatable in an agentic workflow”.
This builds on tangible results OpenAI has already seen in the field, such as its collaboration with Ginkgo Bioworks, where AI models helped achieve a 40% reduction in protein production costs.
Advertisement
What’s next for Rosalind and OpenAI in life sciences?
OpenAI’s mission with GPT-Rosalind is to narrow the gap between a “promising scientific idea” and the actual “evidence, experiments, and decisions” required for medical progress.
By partnering with institutions like Los Alamos National Laboratory to explore AI-guided catalyst design and biological structure modification, the company is positioning GPT-Rosalind as more than a tool—it is meant to be a “capable partner in discovery”.
As the life sciences field becomes increasingly data-dense, the move toward specialized “reasoning” models like Rosalind may become the standard for navigating the “vast search spaces” of biology and chemistry.
University of Washington physicist David Hertzog checks out the 50-foot-wide superconducting magnetic ring for the Muon g-2 experiment at the time of its startup at Fermilab in 2018. (Photo Courtesy of David Hertzog)
University of Washington physicist David Hertzog can’t wait to find out how hundreds of researchers who worked on a geeky project known as the Muon g-2 Collaboration will react when they hear they’ve each won thousands of dollars for that work.
The money is coming from this year’s $3 million Breakthrough Prize for fundamental physics, which was awarded tonight during a gala ceremony in Los Angeles. Hertzog and his colleagues decided that the prize should be divided equally among everyone who was an author on research papers relating to the decades-long series of muon experiments.
“There are students who were in and out of this thing — two years or less,” Hertzog said. “They’re going to be shocked out of their lives about something they did a long time ago that they don’t remember doing. They’re going to get a phone call or email from the Breakthrough people, and they’re going to go, ‘What!?’ That’s kind of fun.”
Hertzog said the money will be shared by about 400 researchers who were involved in the Muon g-2 experiments at Fermilab in Illinois and at the Brookhaven National Laboratory in New York. The prize also honors the role played by Europe’s CERN research center, going as far back as 1959. “There was one very, very old man who was still alive from the 1970s experiment, but I think he has died,” Hertzog said.
Although the precise math hasn’t yet been worked out, dividing $3 million among 400 people would give each recipient $7,500. “That’s nothing to throw around if you’re a student or a young postdoc,” Hertzog said.
Advertisement
A big moment for the muon
Russian-born tech investor Yuri Milner and his wife, Julia Milner, established the Breakthrough Prize in 2012 to recognize achievements in fundamental physics, mathematics and the life sciences. They also wanted to add some Hollywood-style pizazz to the public perception of scientists, going so far as to spread out a red carpet for celebrities at the “Oscars of Science.” The host for this year’s ceremony was James Corden, and the guest list included Robert Downey Jr., Eileen Gu, Anne Hathaway, Paris Hilton, Salma Hayek Pinault and Michelle Yeoh.
The $3 million Breakthrough Prize is the world’s richest scientific award, outdoing the roughly $1.2 million prize given to Nobel laureates. More than $344 million has been handed out since the creation of the prize program. Past winners from the University of Washington include physicists Eric Adelberger, Lukasz Fidkowski, Jens Gundlach and Blayne Heckel, plus biochemist David Baker.
This year’s prize in fundamental physics touches on a long-running effort to reconcile experimental findings with one of history’s most successful scientific theories: the Standard Model of particle physics. The theory lays out a framework for classifying and understanding a menagerie of subatomic particles — including the muon, which is similar to the electron but 207 times heavier.
The Standard Model predicts the various properties of the muon. One such property is the strength and orientation of the muon’s magnetic field, known as its magnetic moment. The theory’s simplest formulation calls for the value of the muon’s magnetic moment, represented in equations by the letter g, to be equal to 2.
Advertisement
Few things in particle physics are that simple, however. Experimental tests measured the g-factor to be slightly more than 2, and that discrepancy became the focus of the Muon g-2 (pronounced “mew-on gee-minus-two”) experiments.
If there was a confirmed mismatch between the Standard Model and experimental results, that could open the door to new physics. For example, perhaps whole new sets of subatomic particles not predicted by theory had somehow eluded direct observation. So, physicists across the globe marshaled their forces to determine the value of g, either to fill in the gap between experiment and theory or to zero in on a new frontier in physics.
Over the years, physicists have been conducting increasingly fine-tuned experimental runs using powerful magnets at CERN, Brookhaven and Fermilab. Hertzog has been in on the quest since Brookhaven joined in, about 30 years ago, and he was part of the team in 2013 when the experiment’s massive main magnet was moved from Brookhaven to Fermilab.
“We set the goal at 140 parts per billion, and we got 127 parts per billion,” Hertzog said. “When we wrote the proposal, we were ambitious as we could get in our minds, because we wanted to get people to take us on. Then we just blew away all the systematic errors, better than we expected. And then new ones came along, which caused us to have a little bit of a struggle.”
Researchers install the storage ring and magnets for the first Muon g-2 experiment at CERN in 1960. (CERN PhotoLab)
At the same time, other physicists were wrestling with theoretical models. They factored in the ever-so-subtle effects of particles popping in and out of the quantum foam that’s thought to make up the fabric of spacetime at its smallest scale. Last year, one of the models came up with a range of theoretical values for g that overlapped with the Muon g-2 Collaboration’s range of experimental values.
That led some to claim that there was no discrepancy after all. “A famous particle physics experiment has ended not with a bang, but a whimper,” Science magazine reported. But once again, few things in particle physics are that simple. Hertzog insisted that reports of the muon mystery’s death have been greatly exaggerated.
“I just throw up my hands, because after 30-some years of working on this, it’s a little disappointing that it’s not clear,” he said. “Not only has the number that they recommended shifted, but the certainty of their number got way wider. The uncertainty on the theory recommendation is actually pretty big. It’s shifted, but it’s also pretty large.”
Hertzog said the Breakthrough Prize recognizes a scientific quest that’s still in progress. “This story is not finished,” he said. “The story is really about the extraordinary achievement of the precision of this delicate measurement which probes nature to such a deep, deep level.”
Advertisement
Will there ever be a definitive answer to the muon mystery?
“We don’t know it yet, but it’s knowable, as opposed to walking out into a vast cloud of ambiguity,” Hertzog said. “So, I think we will find out in a couple of years where that finally lands. … Who knows whether that’ll lead us to another chapter in this business. But I’m confident that we’ll know it.”
A big night for breakthroughs
The Muon g-2 Collaboration’s Breakthrough Prize was awarded to hundreds of researchers from 31 institutions in seven countries, but just four team members were selected to take the stage for tonight’s award ceremony. Hertzog was joined by Chris Polly from Fermilab, William Morse from Brookhaven, and Lee Roberts from Brookhaven and Boston University.
A special lifetime prize for fundamental physics went to David Gross, a theorist at the Kavli Institute of Theoretical Physics at the University of California at Santa Barbara. Gross won a share of the 2004 Nobel Prize in Physics for filling gaps in the Standard Model relating to the strong nuclear force. More recently, he helped write a landmark 40-year national plan for particle physics.
Another prize went to Stuart Orkin, a physician at Harvard Medical School and Boston Children’s Hospital; and to Swee Lay Thein at the National Heart, Lung and Blood Institute for elucidating the mechanism driving the switch from fetal to adult hemoglobin and validating it as a therapeutic target for sickle-cell disease and beta-thalassemia.
Frank Merle of the Institut des Hautes Études Scientifiques in Paris was awarded this year’s prize in mathematics for achieving breakthroughs in nonlinear evolution equations. His work could have implications from aeronautical engineering and safety to astrophysics.
For his part, Hertzog doesn’t intend to rest on his laurels. Even as the Muon g-2 Collaboration is winding down, he has joined the team for another particle physics experiment called PIONEER. That experiment will probe inconsistencies between the Standard Model and observations of pion decay. As was the case with the Muon g-2 experiments, there’s a chance that PIONEER could point the way to physics beyond the Standard Model.
“This is a stock market golden opportunity,” Hertzog said. “That’s how I look at it.”
The Breakthrough Prize website has the full list of this year’s honorees, including the winners of New Horizons Prizes for early-career physicists and mathematicians, Maryam Mirzakhani New Frontiers Prizes for women mathematicians and the inaugural Vera Rubin New Frontiers Prize for women physicists. The recorded awards show is due to air at noon PT on April 26 via YouTube.
The new funding will be used to expand the Copenhagen-based company’s AI platform for banks and fintech companies, and accelerate adoption across financial institutions globally.
Danish financial compliance AI start-up Spektr has raised $20m in a Series A funding round led by New Enterprise Associates (NEA) with participation from existing investors including Northzone, Seedcamp and PSV Tech.
The new funding will be used to expand the Copenhagen-based company’s AI platform for banks and fintech companies, and accelerate adoption across financial institutions globally, according to the company.
According to Spektr, its specialised AI agents are designed to perform the work financial analysts typically do during compliance reviews – such as researching companies, interpreting information, verifying business activity and generating structured risk assessments – and instead of analysts spending hours gathering and interpreting data, the agents complete the work in minutes so compliance teams can review and approve the results.
Advertisement
“Compliance technology has mostly focused on workflow and data collection,” said Mikkel Skarnager, CEO and co-founder of Spektr.
“But the real bottleneck has always been the work itself – analysts researching companies, interpreting information and documenting decisions. Spektr automates those tasks with AI agents designed specifically for KYC and KYB compliance.”
Spektr was co-founded by Skarnager, CTO Ciprian Florescu, CRO Jan-Erik Wagner and CPO Jeremy Joly. Its live customers include Santander Leasing, Pleo, Mercuryo, Monta and Phantom.
“Financial institutions are under constant pressure to do more compliance work with fewer resources,” said Luke Pappas, partner at NEA.
Advertisement
“Spektr is tackling the most manual part of compliance operations in financial services. Their approach has the potential to redefine how compliance operations are run.”
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
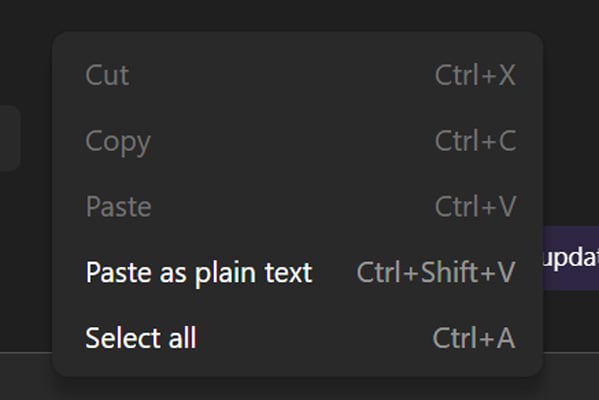
Microsoft is warning that a recent Microsoft Edge browser update introduced a bug that breaks right-click paste in chats in the Microsoft Teams desktop client.
In an advisory published on April 14, Microsoft says users are reporting that they are unable to paste URLs, text, or images into Teams chats when using right-click context menus, with the “Paste” option greyed out.
To work around the bug, Microsoft says users can still copy and paste content using keyboard shortcuts: Ctrl + C and Ctrl + V on Windows, or Cmd + C and Cmd + V on macOS.
“Impacted users report that they are unable to copy and paste URLs, text, and images in Microsoft Teams desktop client chats, as the paste option appears greyed out when using the right-click dropdown menu method,” explains Microsoft.
“To bypass impact, we recommended that users attempt to copy the intended URLs, text, and images using Ctrl + C and paste using Ctrl + V for Windows, and corresponding Cmd + C and Cmd + V for Mac.”
Advertisement
Microsoft says the bug is caused by a recent browser update that introduced a code regression in Microsoft Edge, which Microsoft Teams uses for certain functionality.
Admins on Reddit and the Microsoft forums report that the problem is affecting users in corporate environments as well as individual users.
“I have multiple users on version 26072.519.4556.7438 experiencing this issue, including myself. Cannot right-click Paste, but CTRL+V and paste as text are allowed,” an admin posted to the Microsoft Forums.
Paste option in Microsoft Teams is greyed out
Other users said that reinstalling Teams or clearing the cache did not fix the problem.
Microsoft says it identified the cause and is rolling out a fix in stages while monitoring telemetry to confirm that systems are recovering.
Advertisement
As of the latest update on April 16, Microsoft has not provided an exact timeline for when the fix will be fully rolled out.
AI chained four zero-days into one exploit that bypassed both renderer and OS sandboxes. A wave of new exploits is coming.
At the Autonomous Validation Summit (May 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls hold, and closes the remediation loop.
Seattle Mayor Katie Wilson addressed concerns about a potential wave of new data centers in the city and raised the possibility of a moratorium, citing economic and environmental issues.
Wilson’s public statement Saturday followed a Seattle Times report April 10 that four companies have approached Seattle City Light about building five large-scale data centers with a combined peak demand of 369 megawatts, equal to roughly a third of Seattle’s average daily power consumption.
“I share community concerns about environmental justice, economic resilience, and impacts of increased costs for Seattle rate payers,” Wilson wrote on Facebook. “That’s why my team is working closely with Seattle City Light, City Council and stakeholders to identify a range of long-term policy approaches, including exploring a moratorium on siting new centers.”
Seattle already has about 30 data centers, but they’re relatively small. The proposed facilities would be the first at this scale in the city and could consume nearly 10 times more power than the existing ones at full capacity, according to the Seattle Times report.
The world’s biggest tech companies, including hometown tech giants Microsoft and Amazon, have been spending hundreds of billions of dollars building data centers to scale up artificial intelligence.
Advertisement
Those facilities have historically gone up in rural areas, but power availability has grown scarce in many markets, driving developers to look at cities with their own utility resources.
It’s not clear who the proposed data centers would be built for. Seattle City Light hasn’t disclosed the companies involved or proposed locations due to nondisclosure agreements.
Seattle City Light is rewriting its contract terms for large-load customers and plans to require data center operators to secure their own power generation and pay for infrastructure upgrades rather than passing costs to ratepayers. The companies are expected to decide in the next two to three months whether to formally apply for service.
Sometimes the best finds at AXPONA 2026 aren’t planned. I walked into Chesky Audio’s room chasing Schiit Audio gear in Room 709; there was plenty of it, including the Yggdrasil Singular DAC, Loki Max, Kara, and a pair of Tyr monoblocks driving the new Chesky LC2 loudspeakers, but no one from Schiit to talk shop. So I stayed put, listened, and let the room tell its own story.
That story changed fast when the pricing banner came into focus: $1,995. Not each. Per pair. In a show full of six-figure loudspeakers, the Chesky LC2 doesn’t just feel affordable; it feels like a direct challenge to how high-end audio defines itself.
And that’s where this gets more interesting. If high-end audio wants a future, it needs more designers like Lucca Chesky. He comes from a family name that carries real weight in the music world, but he’s not coasting on it. He’s studying engineering at Carnegie Mellon University, and it shows in how he approaches both design and people.
There’s no gatekeeping here, no “you don’t belong in this room” energy. The LC1 and now the LC2 are priced where actual listeners can engage, and he speaks about them in a way that makes you feel like you’re part of the conversation and not being lectured from behind a stack of gear you can’t afford.
Advertisement
The kid gets it. And judging by what I heard in that room, he’s not just talking a good game.
Admittedly, a $1,995 price tag only matters if the speakers can actually deliver. The original Chesky LC1 set a high bar, earning multiple “Best of Show” nods from the eCoustics team at previous events; something Chesky made no effort to hide with the awards laid out on the table. So yes, I was a bit late to the party.
Better late than never.
I stayed for several tracks to get a clearer sense of what the team had already heard in the Chesky LC1, and what that might mean for the new Chesky LC2. It didn’t take long to recognize a familiar foundation, but with more scale and a bit more weight behind it, suggesting this isn’t a departure so much as a more developed version of the same idea.
Advertisement
Chesky Audio LC2 Stand-mount Speakers with Schiit electronics at AXPONA 2026
An Affordable Speaker With Real Ambition
Much like the original Chesky LC1, the Chesky LC2 sticks to a compact two way monitor format. It pairs a dual chamber aperiodic 1 inch tweeter with a roughly 6.5-inch mid bass driver, both modified in house rather than pulled off a shelf. The familiar passive radiator approach is still here as well, now using larger 8-inch radiators on either side to extend low frequency output without relying on a traditional port.
Where things diverge, and where Chesky is clearly doing its own thing, is the cabinet. The front baffle is a 5/8-inch thick slab of machined aluminum, and the rest of the enclosure is 3D printed around that structure. It is an unusual approach, but the result is a cabinet that feels both rigid and relatively lightweight for its size. Each speaker measures roughly 13 x 9 x 13 inches and comes in just under 30 pounds.
It is also worth noting that these are not outsourced, mass produced boxes. Chesky Audio assembles, finishes, and tests the speakers in New Jersey before they ship. In a category where “designed here, built somewhere else” is the norm, these are actually made in the United States, and that still matters.
Advertisement. Scroll to continue reading.
Advertisement
Lucca Chesky is also quick to point out that the drivers are not an afterthought. The mid-bass unit uses a cast-basket high-definition design more commonly found in higher-priced speakers, and the tweeter follows that same philosophy. He stops short of naming suppliers, but the implication is clear this is not generic OEM hardware.
Schiit Audio stack powered the Chesky Audio LC2 Speakers at AXPONA 2026.
The crossover is designed in house, although Chesky remains somewhat tight-lipped on specifics. Instead of locking into a fixed number, the crossover point is described as falling somewhere in the 3 to 5 kHz range. On paper, the speaker is rated at 86 dB sensitivity with a 4 ohm impedance that does not dip below 3.1 ohms across a stated 40 Hz to 20 kHz frequency range.
That combination suggests an easy enough load for most modern amplifiers, whether it is a vintage Kenwood receiver, a newer NAD integrated, or even a well-sorted ST-70 style tube amp build. But if our experience with the Chesky LC1 taught us anything, it is that specs do not tell the whole story. The LC1 benefited from more power than you might expect, and giving it better amplification paid off.
Until we get the Chesky LC2 in for a full review, it is too early to say how closely it follows that pattern.
Chesky LC2 in a Real Room at AXPONA 2026
Sound wise, the Chesky LC2 delivers clean mid-bass with solid detail and impact for a speaker of this size, but sub-bass is limited. That is not a surprise given the form factor. In a nearfield setup such as a desktop or small studio, there is enough low end to get by without a subwoofer, but in a larger room, adding one would make sense.
Advertisement
The midrange is where things come into better focus. There is a clear emphasis on clarity and balance, which aligns with what you would expect from anything carrying the Chesky name. Vocals come through naturally without sounding nasal or forced, and strings have enough presence to avoid sounding thin. That is not always a given with compact speakers, where cabinet limitations can work against natural timbre. The construction here likely plays a role, but that is something that needs more controlled listening to fully evaluate.
The top end had good energy and dynamic presence, but this is where the limitations of the show environment start to creep in. Between room noise and less than ideal setup conditions, it would be premature to draw firm conclusions without spending more time with the speakers in a more controlled space.
The Bottom Line
I can see several use cases for the Chesky LC2. Those looking for unpowered monitors for nearfield use will find them easy to live with as a standalone pair, and they also make sense in smaller rooms where space is limited. For larger spaces or mixed use systems that pull double duty for music and home theater, Chesky offers two, three, and five speaker packages that can be built out as needed.
Adding a subwoofer would round things out in those scenarios. Models like the REL Tzero or SVS 3000 Micro R|Evolution come to mind as good matches, offering tight, controlled low end without taking over the room or the budget.
Advertisement
With that kind of setup, the LC2 starts to make a lot of sense for multi purpose spaces where flexibility matters just as much as performance.
Proof-of-concept exploit code has been published for a critical remote code execution flaw in protobuf.js, a widely used JavaScript implementation of Google’s Protocol Buffers.
The tool is highly popular in the Node Package Manager (npm) registry, with an average of nearly 50 million weekly downloads. It is used for inter-service communication, in real-time applications, and for efficient storage of structured data in databases and cloud environments.
In a report on Friday, application security company Endor Labs says that the remote code execution vulnerability (RCE) in protobuf.js is caused by unsafe dynamic code generation.
The security issue has not received an official CVE number and is currently being tracked as GHSA-xq3m-2v4x-88gg, the identifier assigned by GitHub.
Endor Labs explains that the library builds JavaScript functions from protobuf schemas by concatenating strings and executing them via the Function() constructor, but it fails to validate schema-derived identifiers, such as message names.
Advertisement
This lets an attacker supply a malicious schema that injects arbitrary code into the generated function, which is then executed when the application processes a message using that schema.
This opens the path to RCE on servers or applications that load attacker-influenced schemas, granting access to environment variables, credentials, databases, and internal systems, and even allowing lateral movement within the infrastructure.
The attack could also affect developer machines if those load and decode untrusted schemas locally.
The flaw impacts protobuf.js versions 8.0.0/7.5.4 and lower. Endor Labs recommends upgrading to 8.0.1 and 7.5.5, which address the issue.
Advertisement
The patch sanitizes type names by stripping non-alphanumeric characters, preventing the attacker from closing the synthetic function. However, Endor comments that a longer-term fix would be to stop round-tripping attacker-reachable identifiers through Function at all.
Endor Labs is warning that “exploitation is straightforward,” and that the minimal proof-of-concept (PoC) included in the security advisory reflects this. However, no active exploitation in the wild has been observed to date.
The vulnerability was reported by Endor Labs researcher and security bug bounty hunter Cristian Staicu on March 2, and the protobuf.js maintainers released a patch on GitHub on March 11. Fixes to the npm packages were made available on April 4 for the 8.x branch and on April 15 for the 7.x branch.
Apart from upgrading to patched versions, Endor Labs also recommends that system administrators audit transitive dependencies, treat schema-loading as untrusted input, and prefer precompiled/static schemas in production.
Advertisement
AI chained four zero-days into one exploit that bypassed both renderer and OS sandboxes. A wave of new exploits is coming.
At the Autonomous Validation Summit (May 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls hold, and closes the remediation loop.
The first mission when it comes to this machine was to dump the ROMs, which have thus far not been preserved in any major archive. With that done, [beaumotplage] worked to hack a version of MAME that could emulate the Three Monitor Version’s unique mode of operation. As it turns out, each screen is driven by its own arcade board, with the three boards linked via C139 serial links. To emulate this, the trick was simply to write some C139 linkup code and run three versions of MAME all at once, letting them communicate with each other as the original boards would have. It’s a little janky in operation right now, but it does work!
You can download the hacked version of MAME for three-monitor operation here, though note that this does not include the ROM dumps from the machine itself. We look forward to seeing if the hardware ends up getting a full restoration back to operational standard, too.
Statistics from Google show a steady rise in global IPv6 usage, climbing from near zero in early 2012 to 50.1% on March 28, briefly surpassing IPv4. Although the milestone did not hold, usage now hovers between 45% and 50%. Read Entire Article Source link
Apple has secured a major victory for its redesigned smartwatches as per the latest decision from the US International Trade Commission. The federal agency ruled against reinstating an import ban on Apple Watches, allowing the tech giant to continue selling its devices with a reworked blood-oxygen monitoring technology.
The ITC decided to terminate the case and refer to a preliminary ruling from one of its judges in March that claimed that Apple’s redesigned smartwatches don’t infringe on patents held by Masimo, the medical tech company that has long been embroiled in lawsuits surrounding the Apple Watch. Apple thanked the ITC in a statement, adding that “Masimo has waged a relentless legal campaign against Apple and nearly all of its claims have been rejected.” We reached out to Masimo for comment and will update the story when we hear back.
The latest decision could offer some closure to the longstanding legal feud between Masimo and Apple. The patent battle dates back to 2021 with Masimo’s first filing against Apple that requested an import ban on Apple Watches. The ITC ended up ruling that Apple violated Masimo’s patents, resulting in the previous import ban and the Apple Watch maker redesigning the blood-oxygen reading feature in certain models. However, Masimo wasn’t satisfied with this conclusion and sought another import ban on the updated Apple Watch models. Now that the ITC has ruled against that, Masimo is left with the option to appeal the decision with the US Court of Appeals for the Federal Circuit.
While Masimo may currently be on the losing side of this legal battle, it’s confronting Apple on multiple fronts. In November, a federal jury sided with Masimo and ruled that Apple has to pay $634 million in a separate patent infringement case.

































































You must be logged in to post a comment Login