‘AI companies shouldn’t leave American ratepayers to pick up the tab’: Anthropic says it will cover electricity price increases caused by its data centers
President Trump has urged Big Tech to absorb rising energy bills, not consumers
Anthropic says it will pay upgrade costs and procure net-new power generation where possible
CEO Dario Amodei promises to be a “responsible neighbor” and work with communities and governments
Anthropic has boldly offered to cover electricity price increased caused by its own data centers, with CEO Dario Amodei stating the power of powering its AI models should fall on the company, not consumers.
This, of course, follows a recent request by President Trump for Big Tech companies to “pay their own way”, and not let US citizens face higher electricity bills as a result of their operations.
Back in January 2026, when Trump posted this request to Truth Social, he confirmed Microsoft had already shown willingness to comply with this, promising “major changes.”
Anthropic to help US citizens lower their energy bills
Though it may be near-impossible to quantify the exact effects that Anthropic has on local and national grids, Amodei did offer some suggestions: it would pay 100% of grid upgrade costs needed to connect its data centers and it would procure net-new power generation where possible to match its consumption.
Where that’s not possible, Anthropic is offering to cover the estimated demand-driven price increases.
Besides covering those extra bills, the company also covered its commitment to improving energy efficiency in the first place, including deploying liquid cooling.
Advertisement
Anthropic also stressed that it’s been a “responsible neighbor,” and that it’s set to create “hundreds of permanent jobs and thousands of construction jobs” per its existing project pipelines.
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
“These commitments are the beginning of our efforts to address data centers’ impact on energy costs,” the post reads.
“We look forward to working with communities, local governments, and the Administration to get this right,” Amodei added (via The Register).
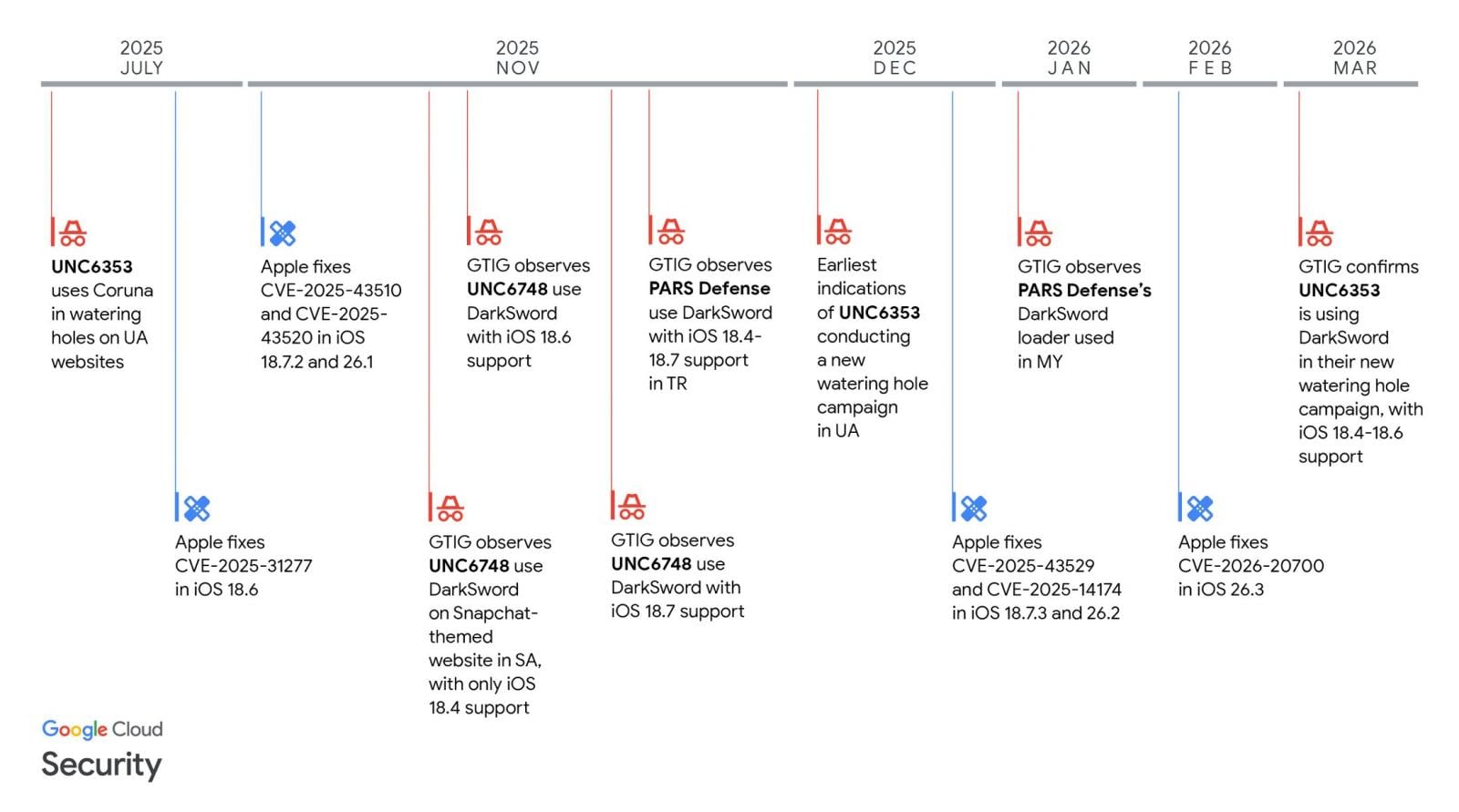
Apple has now made it possible for more iPhones still running iOS 18 to receive security updates that protect against the actively exploited DarkSword exploit kit.
“We enabled the availability of iOS 18.7.7 for more devices on April 1, 2026, so users with Automatic Updates turned on can automatically receive important security protections from web attacks called DarkSword,” reads a note in today’s iOS 18.7.7 security update changelog.
“The fixes associated with the DarkSword exploit first shipped in 2025.”
In March, researchers at Lookout, iVerify, and Google Threat Intelligence revealed a new “DarkSword” exploit kit that targeted iPhones running iOS 18.4 through 18.7.
Advertisement
The six vulnerabilities used by the DarkSword exploit kit are tracked as CVE-2025-31277, CVE-2025-43529, CVE-2026-20700, CVE-2025-14174, CVE-2025-43510, and CVE-2025-43520.
While iOS exploits have typically been used in highly targeted spyware campaigns, this iOS exploit kit was used much more widely, including by Turkish commercial surveillance vendor PARS Defense, a threat actor tracked as UNC6748, and a suspected Russian espionage group tracked as UNC6353.
In these attacks, GTIG observed three separate information-stealing malware families deployed on victims’ devices: a highly aggressive JavaScript infostealer named GhostBlade, the GhostKnife backdoor, and the GhostSaber JavaScript malware, which can execute code and steal data.
Since July 2025, with the release of iOS 18.6, Apple has been steadily fixing the flaws as they are disclosed in security updates pushed out to compatible devices.
Advertisement
Threat actors using the DarkSword exploit kit Source: GTIG
However, by late 2025, Apple stopped offering iOS 18 updates to newer devices capable of running the newer iOS 26.
For those who decided not to upgrade and stay on iOS 18, availability to the security updates became limited, with newer devices no longer receiving patches for DarkSword vulnerabilities released in 2026.
Since then, only a small number of devices remained able to receive iOS 18 updates, and the last 18.7.6 update was offered only to iPhone XS, iPhone XS Max, and iPhone XR devices.
To make matters worse, a researcher released the DarkSword exploit kit on GitHub last month, making it accessible to other threat actors who wanted to target older iPhones.
Today, Apple has released iOS 18.7.7 to make it available to more devices that want to stay on the older operating system while remaining protected from the latest threats.
Advertisement
Devices eligible to receive the new update now include iPhone XR, iPhone XS, iPhone XS Max, iPhone 11 (all models), iPhone SE (2nd generation), iPhone 12 (all models), iPhone 13 (all models), iPhone SE (3rd generation), iPhone 14 (all models), iPhone 15 (all models), iPhone 16 (all models), iPhone 16e, iPad mini (5th generation – A17 Pro), iPad (7th generation – A16), iPad Air (3rd – 5th generation), iPad Air 11-inch (M2 – M3), iPad Air 13-inch (M2 – M3), iPad Pro 11-inch (1st generation – M4), iPad Pro 12.9-inch (3rd – 6th generation), and iPad Pro 13-inch (M4).
iPhone users still running iOS 18 with Automatic Updates enabled will now receive the latest version and protections against the DarkSword exploit kit.
Automated pentesting proves the path exists. BAS proves whether your controls stop it. Most teams run one without the other.
This whitepaper maps six validation surfaces, shows where coverage ends, and provides practitioners with three diagnostic questions for any tool evaluation.
It will consolidate production in its Johor and Selangor plants
Yeo Hiap Seng (Yeo’s) announced today (Mar 31) that it will retrench 25 employees at its Senoko facility in Singapore as it shifts its can manufacturing operations to Malaysia.
The company explained that consolidating production in its Johor and Selangor plants will help “optimise capacity utilisation and strengthen overall manufacturing efficiency” across its network.
Despite the move, Yeo’s Senoko site will remain its headquarters, as well as a hub for cross-border logistics and limited-scale production.
Yeo’s added that it will support affected staff through job placement services, career guidance, and counselling, and may offer them opportunities in Malaysia where suitable roles are available.
Advertisement
The company said it worked closely with the Food, Drinks and Allied Workers Union to ensure that the retrenchment package and transition support “reflect appreciation for the contributions of affected staff”.
The compensation packages will follow guidelines from Singapore’s Ministry of Manpower and will be based on each worker’s salary and length of service.
“These benefits will be commensurate with each employee’s salary and years of service.”
This is not the first round of layoffs for Yeo’s.
Advertisement
In Dec 2024, it cut 25 jobs after Oatly shut its Singapore plant—roles that had been created specifically for that production. Earlier, in 2022, the company retrenched 32 employees, citing shifts in consumer behaviour, retail challenges, and rising costs.
Financially, the SGX-listed firm reported a net profit of S$21.1 million for the year ending Dec 31, 2025, a significant increase from S$6.9 million the year before.
However, both overall revenue and core food and beverage revenue declined, which the company attributed to softer consumer spending and stronger competition in key markets.
Read other articles we’ve written on Singaporean businesses here.
Featured Image Credit: Google Street View/ Yeo’s via Facebook
Longtime Slashdot reader Elektroschock writes: When Ubisoft pulled the plug on The Crew’s servers without warning, players were left with a worthless game they’d already paid for. Now, consumer watchdog UFC-Que Choisir is fighting back, demanding gamers’ right to play regardless of publisher whims. Supported by the “Stop Killing Games” movement, this landmark case challenges unfair terms before the Creteil Judicial Court (Val-de-Marne near Paris), and aims to protect players from disappearing games. The lawsuit that UFC-Que Choisir filed against Ubisoft on Tuesday alleges that the video game publisher “misled consumers about the permanence of their purchase and imposed abusive contractual clauses stripping players of ownership rights,” reports Reuters.
When Intuit shipped AI agents to 3 million customers, 85% came back. The reason, according to the company’s EVP and GM: combining AI with human expertise turned out to matter more than anyone expected — not less.
Marianna Tessel, the financial software company’s EVP and GM, calls this AI-HI combination a “massive ask” from its customers, noting that it provides another level of confidence and trust.
“One of the things we learned that has been fascinating is really the combination of human intelligence and artificial intelligence,” Tessel said in a new VB Beyond the Pilot podcast. “Sometimes it’s the combination of AI and HI that gives you better results.”
Advertisement
Chatbots alone aren’t the answer
Intuit — the parent company of QuickBooks, TurboTax, MailChimp and other widely-used financial products — was one of the first major enterprises to go all in on generative AI with its GenOS platform last June (long before fears of the “SaaSpocalypse” had SaaS companies scrambling to rethink their strategies).
Quickly, though, the company recognized that chatbots alone weren’t the answer in enterprise environments, and pivoted to what it now calls Intuit Intelligence. The dashboard-like platform features specialized AI agents for sales, tax, payroll, accounting and project management that users can interact with using natural language to gain insights on their data, automate tasks, and generate reports.
Customers report invoices are being paid 90% in full and five days faster, and that manual work has been reduced by 30%. AI agents help close books, categorize transactions, run payroll, automate invoice reminders and surface discrepancies.
For instance, one Intuit customer uncovered fraud after interacting with AI agents and asking questions about amounts that didn’t add up. “In the beginning it was like, ‘Is that an error? And as he dug in, he discovered very significant fraud,” Tessel said.
Advertisement
Why humans are still in the loop
Still, Intuit operates on the principle that humans are “always accessible,” Tessel said. Platforms are built in a way that users can ask questions of a human expert when they’re not getting what they need from the AI agent, or want a human to bounce ideas off of.
“I’m not talking about product experts,” Tessel said. “I’m talking about an actual accounting expert or tax expert or payroll expert.”
The platform has also been built to suggest human involvement in “high stakes” decision-making scenarios. AI goes to a certain level, then human experts review and categorize the rest. This provides a level of confidence, according to Tessel.
“We actually believe it becomes more needed and more powerful at the right moments,” she said. “The expert still provides things that are unique.”
Advertisement
The next step is giving customers the tools to perform next-gen tasks like vibe coding — but with simple architectures to reduce the burden for customers. “What we’re testing is this idea of, you can actually do coding without realizing that that’s what you are doing,” Tessel said.
For example, a merchant running a flower shop wants to ensure that they have the right amount of inventory in stock for Mother’s Day. They can vibe code an agent that analyzes previous years’ sales and creates purchase orders where stock is low. That agent could then be instructed to automatically perform that task for future Mother’s Days and other big holidays.
Some users will be more sophisticated and want the ability to dive deeper into the technology. “But some just want to express what they want to have happen,” Tessel said. “Because all they want to do is run their business.”
Listen to the full podcast to hear about:
Advertisement
Why first-party data can create a “moat” for SaaS companies.
Why showing AI’s logic matters more than a polished interface.
Why 600,000 data points per customer changes what AI can tell you about your business.
My life has changed so much since my time as a Voices of Change fellow during the 2023 school year. As I wrote in my final essay of the fellowship, the beautiful, imperfect school I loved and helped build had closed. With the support of my fellowship editor, Cobretti Williams, I applied and was admitted to the Creative Writing Workshop at the University of New Orleans, where I am taking graduate classes and teaching a freshman English composition course.
In deciding what to write as a reflection on my time since the fellowship, I started three different essays and hated all of them. I did a lot of cursing, went on a couple of brooding walks and wondered why I agreed to write this in the first place. During the similarly maddening process of designing the syllabus for the first college course I taught, I took a break to write my students a letter. Here is an excerpt:
Before we start this course together, it’s important for me to name something foundational to how I approach teaching it: Writing is hard for everyone. I love writing and I believe that, if I keep practicing, I can become great at it… and I still hate doing it a lot of the time. This is why writing is so important. Almost everything we want is on the other side of making ourselves do things we don’t want to do. When we sit down to write, whether we want to or not, and we keep writing when we hit that initial point where we want to stop, and continue when those moments arise again and again like waves, we are getting vital practice. This skill, ignoring the complacent you, the you that would rather do the thing tomorrow, or tomorrow’s tomorrow, and doing the thing now instead is an act of becoming the you that has the things you want. Like anything else, this becomes easier the more you do it.
This excerpt reminds me that writing is much more difficult than most of the things we do in a world that commodifies ease and comfort, upholds them as desirable and makes us feel we are entitled to them while simultaneously less and less able to tolerate their lack.
There is a common misconception that my students come to me with that manifests most often in the statement “I don’t know what to write.” They think this means they are not ready to begin, because they believe that writing is putting what you already know onto paper. I understand why this misconception exists. So often in life, we only see finished products. The published novel, the final cut, the social media post depicting the outcome and not the process and the struggle. It’s easy to think that everyone else has things figured out, that what you see is how something was from the beginning. This can trick us into believing that if something isn’t good right away, we should abandon it. Drafting insists that we try before we feel sure, finish something even if it is not yet “good.” Revision insists that what we have can be something different, something better, and teaches us to hold multiple things in our heads at the same time. Throughout this process, we gain clarity.
Advertisement
Each time we give or receive feedback and assess whether it moves us closer to or further from our vision, we get better at articulating what we want and closer to achieving it. When teachers and students do this work together and commit to improvement, even when we both have moments of uncertainty about what to do next, we are practicing true collaboration. We both grow. What a way to become more skillful at building the world we want.
It is a strange time to be devoting so much of my life to writing, to be telling students that they should care about writing too. Just this week, an article came out detailing pervasive, undisclosed AI use to grade and give feedback to student writing in some New Orleans schools. A study conducted in May of 2025 showed that 84 percent of high school students used generative AI to complete their school work. I understand intimately the overwhelm of educators and students, and the temporary relief that cognitive offloading with AI can provide.
However, what we lose in the long term by not engaging deeply in the writing process, the practice of giving and receiving feedback, of watching revision unfold, is so much greater than the gains we feel in accepting AI’s “help” in our moments of overwhelm. What world are we building when we delegate the human work of communication through writing to machines? We would do better to engage in a process of re-evaluating our priorities, taking on fewer assignments for longer and working collaboratively as educators and administrators to redesign curricula and systems so that teachers have the capacity to get to know their students through repeated contact with their written work.
Sometimes, it feels like we are already living in a completely different world from the one in which I grew up and was educated. Luckily, these times, despite how often folks like to say they are not, are precedented. In these times, I have been turning to Black women writers like Toni Morrison, Toni Cade Bambara, Audre Lorde and June Jordan for guidance, and they all insist writing only becomes more urgent the more dire the times. In facing what Toni Morrison described in 2004 as “a burgeoning ménage a trois of political interests, corporate interests and military interests” working to “literally annihilate an inhabitable, humane future,” I have been especially steeled by Audre Lorde’s words, “In this way alone we can survive, by taking part in a process of life that is creative and continuing, that is growth.”
Advertisement
In the face of a world that would automate us right out of existence, I intend for us to survive, and so I insist we write.
Let’s be honest, the modern web is… a mess. Pop-ups, autoplay videos, cookie banners, ads everywhere. In fact, sometimes it feels like actually reading something online is the hardest part. And that’s exactly where Textise comes in.
Textise
Think of it as a “strip everything away” button for the internet. Textise is a simple web tool that converts any webpage into a clean, text-only version, removing ads, images, scripts, and all the extra clutter. What you’re left with is just the content: no distractions, no loading bloat, no nonsense. It’s fast, lightweight, and honestly feels like going back to a simpler version of the web.
Why does it feel so refreshing?
Modern websites are built for engagement, not readability. That means heavy layouts, tracking scripts, and design choices that often get in the way of just consuming information. Tools like Textise flip that on its head by streamlining content into plain text, making it easier to read and more accessible. In fact, for long articles or research-heavy pieces, it can genuinely feel like a productivity boost: less scrolling, fewer distractions, and quicker load times.
Textise
You can even tweak how Textise looks and behaves, from fonts and text size to background colors and link styles. It’s a surprisingly flexible tool, letting you tailor the reading experience exactly the way you like it. Of course, you lose things along the way. Images, videos, interactive elements — all gone. But that’s also what makes it work. Textise isn’t trying to enhance the web; it’s trying to simplify it to the bare minimum. And weirdly enough, that’s exactly why it feels so useful in 2026.
So… who is this for? Well, pretty much anyone who reads a lot online. Whether it’s articles, blogs, or even cluttered news pages, Textise makes everything feel cleaner and easier to digest. It’s especially handy for people who just want to focus on content without distractions.
Same idea, very different vibe
If this all sounds familiar, that’s because most modern browsers already have a built-in Reader Mode, like the one in Safari or Chrome. These features clean up a webpage by removing ads, menus, and distractions, and reformat the article into a more readable layout with better fonts and spacing.
Advertisement
Textise (left) vs Chrome Reader Mode (right)Varun Mirchandani / Digital Trends
But here’s where Textise feels different. Reader modes are still design-aware, meaning they keep images and basic formatting and rely on the browser to figure out what the “main article” is. Textise, on the other hand, goes full savage mode. It strips everything down to raw text, no images, no styling, no fluff. In a way, Reader Mode is like switching to a clean reading theme… while Textise is like opening the internet in Notepad. And honestly, depending on the day (or how chaotic the webpage is), both have their moment.
And maybe that’s the best part about it. In a web that’s constantly trying to grab attention, Textise just quietly steps back and lets you focus. Sometimes, all it takes to make the internet better… is less internet.
Batteries are notoriously difficult pieces of technology to deal with reliably. They often need specific temperatures, charge rates, can’t tolerate physical shocks or damage, and can fail catastrophically if all of their finicky needs aren’t met. And, adding insult to injury, for many chemistries, the voltage does not correlate to state of charge in meaningful ways. Battery testers take many efforts to mitigate these challenges, but often miss the mark for those who need high fidelity in their measurements. For that reason, [LiamTronix] built their own.
The main problem with the cheaper battery testers, at least for [LiamTronix]’s use cases, is that he has plenty of batteries that are too large to practically test on the low-current devices, or which have internal battery management systems (BMS) which can’t connect to these testers. The first circuit he built to help solve these issues is based on a shunt resistor, which lets a smaller IC chip monitor a much larger current by looking at voltage drop across a resistor with a small resistance value. The Pi uses a Python script which monitors the current draw over the course of the test and outputs the result on a handy graph.
This circuit worked well enough for smaller batteries, but for his larger batteries like the 72V one he built for his electric tractor, these methods could draw far too much power to be safe. So from there he built a much more robust circuit which uses four MOSFETs as part of four constant current sources to sink and measure the current from the battery. A Pi Zero monitors the voltage and current from the battery, and also turns on some fans pointed at the MOSFETs’ heat sink to keep them from overheating. The system can be configured to work for different batteries and different current draw rates, making it much more capable than anything off the shelf.
AI bias is usually talked about in terms of algorithms: skewed datasets, flawed outputs, and stereotypes baked into models. But new research suggests there’s another, more subtle problem about who gets to use AI in the first place. According to a recent report by Lean In, women are less likely than men to use AI tools at work, and even when they do, they’re less likely to get recognition or support for it.
Elina Fairytale / Pexels
The numbers paint a clear picture. Men are more likely to use AI regularly (33% vs 27%), more likely to have ever used it at work, and significantly more likely to be encouraged by managers to adopt it. And it’s not just about access, but also about perception. Women are more likely to worry about the risks of AI, question its accuracy, and even fear being judged for using it, including concerns that it might be seen as “cheating.”
Why this matters more than it seems
Chances are, this gap could compound fast. AI is quickly becoming a core workplace skill, and early adoption often translates into better opportunities. If one group is consistently using it less, or getting less credit for it, that gap can grow into real career disadvantages over time. And this isn’t happening in isolation. Broader research already shows women are underrepresented in tech and AI roles, meaning they’re not just using these tools less, but they’re also less involved in building them.
Atlantic Ambience / Pexels
What makes this interesting is how familiar it feels. This isn’t a new kind of bias; it’s an old one, just showing up in a new space. The same patterns seen in workplaces for decades, with less recognition, less encouragement, and more scrutiny, are now playing out in how AI is adopted and used.
Same bias, new tech?
As AI becomes a core workplace skill, even small gaps like this can snowball into missed opportunities, slower career growth, and less representation in shaping the tech itself. Because if the people using AI aren’t equally represented… the future it builds won’t be either.
If you’re online at all in 2026, you know it can feel like April Fools’ Day every day. You’ve almost certainly come across videos and content, often created with AI, and had to stop and ask yourself if what you’re looking at is true or made up.
Some are obvious. You mean, there aren’t really beds made of kittens, cotton candy and rubies? And I wasn’t really offered a job guarding a spooky funeral home where I might hear tapping coming from the morgue freezer at 3 a.m.? (Both of these are TikTok videos, and the AI is scarily good — and also just scary.)
As brands roll out their April Fools’ Day jokes for this year, I keep thinking that in an AI-heavy world, the jokes seem less surprising, the faked-up art less novel. Here are some highlights from this year’s list of April 1 corporate and tech jokes.
Advertisement
Fortnite: Big heads and llama riding
Here’s an April Fool’s prank that’s more than a joke, it’s real — but only temporary. Fortnite players can try out a 24-hour-only April Fool’s Day game update that throws some truly wacky changes into the popular game. Players get enormous heads, can ride on other players’ shoulders, can use finger guns that go “pew, pew,” make a splat sound when landing after a fall, and, perhaps best of all, rideable llamas have appeared.
Warhammer: The Musical
Hey, if Broadway can make a musical about Alexander Hamilton, or a bunch of cats, surely they can make one about the Warhammer universe? That’s the joke behind this trailer for The Emperor Protects: A Warhammer 40,000 Musical, the April 1 joke from Games Workshop, creator of the popular game world. The 2.5-minute trailer, with impressive costumes and music, really sells it.
Traeger: AI-powered grilling glasses
A
Advertisement
Screenshot by Gael Fashingbauer Cooper/CNET
This April 1 joke seems like it could maybe be a practical, real thing. Traeger makes wood-pellet grills, and this year’s joke is their claim to offer AI-powered grilling eyeglasses. “With smart guidance, thermal imaging, night‑vision, and hands‑free photo and video capture, MEAT‑AI lets you command every cook like never before,” the site touts. Hmm, I wouldn’t actually mind a pair of glasses that could look down at my grill and tell me whether my steak is done or how much more time it needs to cook. Get on that, Traeger.
T-Mobile cologne
Can you smell me now? Wait, wrong cellphone company.
T-Mobile
Want to smell like your cellphone? What does that even mean? Wireless tech giant T-Mobile’s prank is Metro by T-Mobile CALLoGNE, combining call, as in phone call, with cologne. The company touts its April 1 joke as “the world’s first luxury fragrance inspired by the unmistakable scent of a brand-new phone.” Metro is T-Mobile’s prepaid brand, formerly known as MetroPCS.
Advertisement
Timekettle British translation
They say the US and UK are two nations separated by a common language. You may already know some British phrases, including “boot” for what Americans call a car trunk, and “bonnet” for what we call the hood of a car. Timekettle makes AI-powered translation products, and its April 1 prank is a British-to-American language translation update for its translation devices. Cheerio, old chap.
Timekettle offers translation services, but the British English to American English version is a special April 1 joke.
Timekettle
Whisker cat hair clothing
Advertisement
From couture to cat hair, Whisker’s April 1 prank involves cat-hair clothing.
Whisker
If you own a cat, cat hair is already on everything in your closet. So Cataire (like couture, I guess), a line of designer clothing made out of real cat hair, doesn’t seem that far off. Whisker, the company behind the Litter-Robot litter box, is taking this April 1 prank to the meowy max. They’ve actually used real cat hair from adoptable cats at a Michigan animal shelter to adorn three sweaters that will later be sold on eBay. Each eBay listing doubles as an adoption profile for a real shelter cat.
Yahoo’s Scrōll Stoppr
Doomscrolling isn’t even a possibility with Yahoo’s thumb guard, ScrōllStoppr.
Advertisement
Yahoo
Those who spend too much time on their phones might appreciate the idea behind Yahoo’s prank, Scrōll Stoppr. It’s described as “a delightfully absurd finger accessory that physically blocks your thumb from touching your phone screen.” I hate to break it to Yahoo, but I discovered this myself years ago when I cut my thumb slicing onions for Thanksgiving and had to wrap it in a Band-Aid. Yahoo says you can actually buy this — it will be available for $5 on Yahoo TikTok Shop on April 1 and will be delivered in a box that sounds off with the Yahoo signature yodel. If it sells out, just put on a Band-Aid for the same results. BYO yodel.
Omaha Steaks pocket steak
Stake out a spot in your shirt for this pocket steak.
Omaha Steaks
Need a spot of protein on the go? Omaha Steaks is best known for sending giant crates of beef as gifts, but the company’s April 1 product is “the world’s first pocket-sized steak.” It gets beefier: The company jokes that the steak is cooked by motion-activated technology. A rare deal indeed, if well done.
Advertisement
Baskin-Robbins ice cream soup
Slurp up Baskin-Robbins April Fools’ Day joke, ice-cream soup.
Baskin-Robbins
Baskin-Robbins has always had creative ice cream flavors, but for April 1, the company is hyping… ice cream soup. Not real, of course, but they’re promoting the faux frozen dessert in hopes that people will be inspired to take advantage of a buy-one-get-one 50% off deal on pre-packed quarts April 1-2 for Baskin-Robbins Rewards Members. Slurp ’em if you got ’em.
Baby Bottle Pop, supplement style
Advertisement
Suck on this, say the makers of Baby Bottle Pop.
Baby Bottle Pop
Grown-ups don’t get any of the fun kid candy, but instead are stuck taking vitamins and supplements. Baby Bottle Pop Candy, which is exactly what it sounds like, candy in a baby-bottle container, is pretending for April 1 that it now comes in adult flavors. Is protein a flavor? Is fiber? Salmon is, but candy salmon is too much, even for this Seattleite. Thankfully, it’s just for April Fools’ Day.
NASA’s Artemis II Space Launch System (SLS) rocket and Orion spacecraft and the launch gantry at the Kennedy Space Center in Florida on March 31, 2026.
NASA/Keegan Barber
Fifty-four years after the last Apollo mission to the moon, NASA’s Artemis II mission is set to return. The Space Launch System rocket carrying the Orion spacecraft is scheduled to take off from the Kennedy Space Center in Florida on Wednesday afternoon. The four-person crew, made up of American and Canadian astronauts, will be 250,000 miles from Earth at its farthest point in the journey to orbit the moon. This is everything you need to know about NASA’s mission, its dreams for a future lunar base and this new age of space exploration.
How to watch Artemis II moon launch
Advertisement
Takeoff is scheduled for Wednesday at 6:24 p.m. ET / 3:24 p.m. PT from NASA’s Kennedy Space Center in Cape Canaveral, Florida. Delays are common during launches, especially due to weather, so we’ll keep this story updated if the takeoff time changes.
Here’s all the ways you can keep up with the Artemis II mission.
Advertisement
NASA
What to expect from this mission to the moon
The Artemis II mission is designed to orbit the moon on a 10-day trip. The astronauts will not be touching down on the moon’s surface this trip, but they will be testing the system’s life support systems for the first time, according to NASA. This mission also sets the stage for future Artemis missions, including Artemis IV, scheduled for 2028, which should put humans back on the moon.
We’ll be keeping up-to-date on all the latest Artemis II news, so check back here today and throughout the week for updates.


























































You must be logged in to post a comment Login