Enterprise AI applications that handle large documents or long-horizon tasks face a severe memory bottleneck. As the context grows longer, so does the KV cache, the area where the model’s working memory is stored.
A new technique developed by researchers at MIT addresses this challenge with a fast compression method for the KV cache. The technique, called Attention Matching, manages to compact the context by up to 50x with very little loss in quality.
While it is not the only memory compaction technique available, Attention Matching stands out for its execution speed and impressive information-preserving capabilities.
The memory bottleneck of the KV cache
Large language models generate their responses sequentially, one token at a time. To avoid recalculating the entire conversation history from scratch for every predicted word, the model stores a mathematical representation of every previous token it has processed, also known as the key and value pairs. This critical working memory is known as the KV cache.
Advertisement
The KV cache scales with conversation length because the model is forced to retain these keys and values for all previous tokens in a given interaction. This consumes expensive hardware resources. “In practice, KV cache memory is the biggest bottleneck to serving models at ultra-long context,” Adam Zweiger, co-author of the paper, told VentureBeat. “It caps concurrency, forces smaller batches, and/or requires more aggressive offloading.”
In modern enterprise use cases, such as analyzing massive legal contracts, maintaining multi-session customer dialogues, or running autonomous coding agents, the KV cache can balloon to many gigabytes of memory for a single user request.
To solve this massive bottleneck, the AI industry has tried several strategies, but these methods fall short when deployed in enterprise environments where extreme compression is necessary. A class of technical fixes includes optimizing the KV cache by either evicting tokens the model deems less important or merging similar tokens into a single representation. These techniques work for mild compression but “degrade rapidly at high reduction ratios,” according to the authors.
Real-world applications often rely on simpler techniques, with the most common approach being to simply drop the older context once the memory limit is reached. But this approach causes the model to lose older information as the context grows long. Another alternative is context summarization, where the system pauses, writes a short text summary of the older context, and replaces the original memory with that summary. While this is an industry standard, summarization is highly lossy and heavily damages downstream performance because it might remove pertinent information from the context.
Advertisement
Recent research has proven that it is technically possible to highly compress this memory using a method called Cartridges. However, this approach requires training latent KV cache models through slow, end-to-end mathematical optimization. This gradient-based training can take several hours on expensive GPUs just to compress a single context, making it completely unviable for real-time enterprise applications.
How attention matching compresses without the cost
Attention Matching achieves high-level compaction ratios and quality while being orders of magnitude faster than gradient-based optimization. It bypasses the slow training process through clever mathematical tricks.
The researchers realized that to perfectly mimic how an AI interacts with its memory, they need to preserve two mathematical properties when compressing the original key and value vectors into a smaller footprint. The first is the “attention output,” which is the actual information the AI extracts when it queries its memory. The second is the “attention mass,” which acts as the mathematical weight that a token has relative to everything else in the model’s working memory. If the compressed memory can match these two properties, it will behave exactly like the massive, original memory, even when new, unpredictable user prompts are added later.
“Attention Matching is, in some ways, the ‘correct’ objective for doing latent context compaction in that it directly targets preserving the behavior of each attention head after compaction,” Zweiger said. While token-dropping and related heuristics can work, explicitly matching attention behavior simply leads to better results.
Advertisement
Before compressing the memory, the system generates a small set of “reference queries” that act as a proxy for the types of internal searches the model is likely to perform when reasoning about the specific context. If the compressed memory can accurately answer these reference queries, it will very likely succeed at answering the user’s actual questions later. The authors suggest various methods for generating these reference queries, including appending a hidden prompt to the document telling the model to repeat the previous context, known as the “repeat-prefill” technique. They also suggest a “self-study” approach where the model is prompted to perform a few quick synthetic tasks on the document, such as aggregating all key facts or structuring dates and numbers into a JSON format.
With these queries in hand, the system picks a set of keys to preserve in the compacted KV cache based on signals like the highest attention value. It then uses the keys and reference queries to calculate the matching values along with a scalar bias term. This bias ensures that pertinent information is preserved, allowing each retained key to represent the mass of many removed keys.
This formulation makes it possible to fit the values with simple algebraic techniques, such as ordinary least squares and nonnegative least squares, entirely avoiding compute-heavy gradient-based optimization. This is what makes Attention Matching super fast in comparison to optimization-heavy compaction methods. The researchers also apply chunked compaction, processing contiguous chunks of the input independently and concatenating them, to further improve performance on long contexts.
Attention matching in action
To understand how this method performs in the real world, the researchers ran a series of stress tests using popular open-source models like Llama 3.1 and Qwen-3 on two distinct types of enterprise datasets. The first was QuALITY, a standard reading comprehension benchmark using 5,000 to 8,000-word documents. The second, representing a true enterprise challenge, was LongHealth, a highly dense, 60,000-token dataset containing the complex medical records of multiple patients.
The key finding was the ability of Attention Matching to compact the model’s KV cache by 50x without reducing the accuracy, while taking only seconds to process the documents. To achieve that same level of quality previously, Cartridges required hours of intensive GPU computation per context.
Advertisement
Attention Matching with Qwen-3 (source: arXiv)
When dealing with the dense medical records, standard industry workarounds completely collapsed. The researchers noted that when they tried to use standard text summarization on these patient records, the model’s accuracy dropped so low that it matched the “no-context” baseline, meaning the AI performed as if it had not read the document at all.
Attention Matching drastically outperforms summarization, but enterprise architects will need to dial down the compression ratio for dense tasks compared to simpler reading comprehension tests. As Zweiger explains, “The main practical tradeoff is that if you are trying to preserve nearly everything in-context on highly information-dense tasks, you generally need a milder compaction ratio to retain strong accuracy.”
The researchers also explored what happens in cases where absolute precision isn’t necessary but extreme memory savings are. They ran Attention Matching on top of a standard text summary. This combined approach achieved 200x compression. It successfully matched the accuracy of standard summarization alone, but with a very small memory footprint.
Advertisement
One of the interesting experiments for enterprise workflows was testing online compaction, though they note that this is a proof of concept and has not been tested rigorously in production environments. The researchers tested the model on the advanced AIME math reasoning test. They forced the AI to solve a problem with a strictly capped physical memory limit. Whenever the model’s memory filled up, the system paused, instantly compressed its working memory by 50 percent using Attention Matching, and let it continue thinking. Even after hitting the memory wall and having its KV cache shrunk up to six consecutive times mid-thought, the model successfully solved the math problems. Its performance matched a model that had been given massive, unlimited memory.
There are caveats to consider. At a 50x compression ratio, Attention Matching is the clear winner in balancing speed and quality. However, if an enterprise attempts to push compression to extreme 100x limits on highly complex data, the slower, gradient-based Cartridges method actually outperforms it.
The researchers have released the code for Attention Matching. However, they note that this is not currently a simple plug-and-play software update. “I think latent compaction is best considered a model-layer technique,” Zweiger notes. “While it can be applied on top of any existing model, it requires access to model weights.” This means enterprises relying entirely on closed APIs cannot implement this themselves; they need open-weight models.
The authors note that integrating this latent-space KV compaction into existing, highly optimized commercial inference engines still requires significant effort. Modern AI infrastructure uses complex tricks like prefix caching and variable-length memory packing to keep servers running efficiently, and seamlessly weaving this new compaction technique into those existing systems will take dedicated engineering work. However, there are immediate enterprise applications. “We believe compaction after ingestion is a promising use case, where large tool call outputs or long documents are compacted right after being processed,” Zweiger said.
Advertisement
Ultimately, the shift toward mechanical, latent-space compaction aligns with the future product roadmaps of major AI players, Zweiger argues. “We are seeing compaction to shift from something enterprises implement themselves into something model providers ship,” Zweiger said. “This is even more true for latent compaction, where access to model weights is needed. For example, OpenAI now exposes a black-box compaction endpoint that returns an opaque object rather than a plain-text summary.”
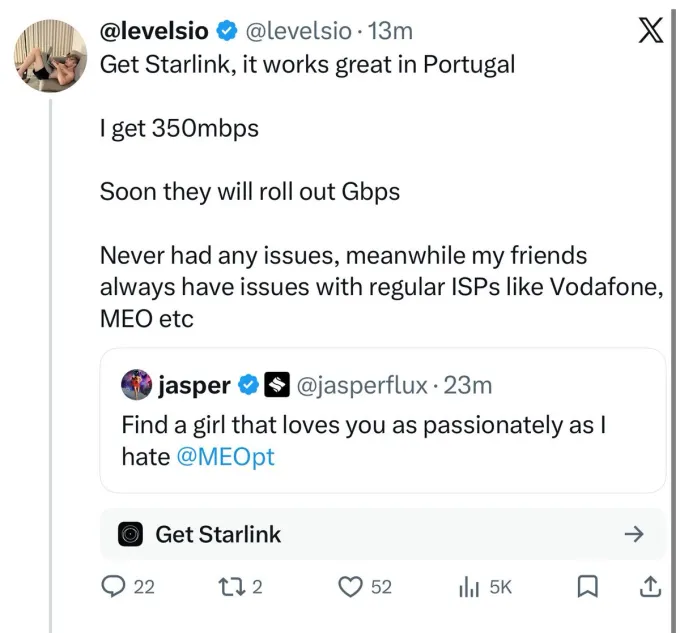
X is testing a new ad format that inserts a recommendation directly underneath a post that references the company or its products. The initial test, spotted by an X user in Europe, displayed a suggestion to “Get Starlink” beneath a post from a user that said Starlink’s satellite service works great in Portugal. The link, when clicked, directed users to Starlink’s website.
X head of product Nikita Bier confirmed the test, responding, “Trying to make an ad product that isn’t an ad.”
The Starlink ad is not visible to all users at this time, but the placeholder where the ad sits is.
If you visit X user @levelsio’s post from March 6 (screenshotted below in case of deletion), you’ll see an outlined box beneath the text of his post. This box currently showcases a random X post, unless you’re in the market where the ad test is live.
In the thread, Bier also responded to a suggestion that X should allow affiliate links in this ad slot by saying, “No, then people will lie. I want to trust recommendations on here.”
Image Credits:Screenshot from X
X could not be immediately reached for comment. TechCrunch will update the article if the company responds.
The test follows news earlier this week that the company is rolling out “Paid Partnership” labels for creators. The labels can be applied to posts to comply with regulations around social media advertising, instead of requiring creators to use a hashtag like “ad” or “paid partnership.”
If creators’ sponsored posts were to be combined with an embedded link to an advertiser like the one being tested, X could potentially attract more marketers to the platform. That could boost creators’ use of the app, allowing it to better compete against larger social networks favored by creators, like Instagram, YouTube, and TikTok.
X has been chasing creator content for some time — even before it was called “X” and before it was owned by Elon Musk. Yet the app has never quite found its footing in this space. So far, the company has rolled out a number of creator products, including payouts for viral content, ad-revenue sharing, creator subscriptions, and more.
Advertisement
The company this week also revamped its Creator Subscriptions offering with a number of new features, including the ability to monetize individual threads.
In addition, X announced Friday that the integrated chatbot Grok is now capable of reading X’s long-form content, known as Articles. This feature, too, is underutilized, as creators who publish lengthy written text tend to prefer doing so through their own websites or newsletters.
Haier has introduced the Couture Care Collection, a two-product premium fabric care range comprising a stacked Laundry Centre and a wardrobe-style Clothes Drying Closet.
It’s a little boujee, but the collection is focused on offering complete fabric care for your clothes, rather than just traditional wash and dry functionality.
That’s because the Couture Care Collection 11 Laundry Centre combines washing and drying in a space-saving stacked format, with AI-powered Smart Link technology automatically syncing wash and dry cycles based on load type and fabric composition. The I-Refresh Pro steam function handles lightly worn garments without running a full wash cycle, while an Ultra Fresh Air system keeps laundry fresh for up to 12 hours after the cycle ends.
The Ultra Reverse Drum and Flexy Air technology apparently reduce tangling and creasing during the drying phase, which honestly sounds like a lifesaver given how crinkled my clothes look when I remove them from dryer at home – although that serves me right for not looking at the best tumble dryers before buying.
Advertisement
Most interestingly of all though, is the Clothes Drying Closet, which looks like a wardrobe, but can dry delicate fabrics shoes, and accessories. If you’re used to running back and forth to the dry cleaners every week, this might be the home gadget you’ve been looking for.
Advertisement
Quick refresh cycles run from around ten minutes for lightly worn clothing, while a combination of steam, UV, and plasma technology sanitises up to 99.99% of bacteria.
Both products connect to Haier’s hOn app for remote control, cycle customisation, and notifications, with pricing and availability for the Couture Care Collection expected to be confirmed closer to the product’s retail launch.
Apple’s industrial design chief says the MacBook Neo was created to bring the Mac into a much lower price tier without sacrificing the materials and design language associated with Apple laptops.
MacBook Neo
Apple vice president of industrial design Molly Anderson said in a rare March 6 solo interview that the MacBook Neo retains its MacBook identity despite its $599 starting price. Apple introduced the MacBook Neo on March 4 as its most affordable Mac laptop. The MacBook Neo uses the A18 Pro processor instead of the Apple Silicon M-series chips found in other Macs. Apple is targeting students and first-time Mac buyers who might otherwise choose inexpensive Windows laptops or Chromebooks. Continue Reading on AppleInsider | Discuss on our Forums
Usage of an automatic stoker. (Source: Claymills Pumping Station, YouTube)
Hacks are of all ages, with the Victorian-era Claymills Pumping Station being no exception. When its old Lancashire boilers from the 19th century were finally replaced with modern 1930s boilers, the 1920s-era automatic stokers were bodged onto the new boilers with a rather ill-fitting adapter plate, as there was no standard Lancashire boiler design. Nearly a hundred years later it was up to the volunteers at this Victorian-era pumping station to inspect and refurbish this solution, before fitting it back onto the boiler.
Lancashire boilers have two flue channels in which the coal is burned, which used to be done purely by hand. The automatic stokers are belt-driven devices that continuously add fresh fuel and massively lighten the workload. The 1920s stokers are still in place at this pumping station and a feature that they would love to retain.
Thus, after previously pressure-testing this #1 boiler to well beyond its operating pressure, the refurbished adapter plate was mounted back on with some percussive persuasion of the ‘very large beam’ variety.
Before the stokers could be mounted again, however, the boiler inspector had to give his OK to put the brickwork around the boiler back in place which helps to insulate it, among other functions. Once this is completed the boiler can finally see a fire again since it was last used in the 1970s. Whether these vintage stokers will work flawlessly will remain a surprise until then, but it’ll be a treat to see them operate.
Retail investors are famously locked out of the startup world. Robinhood is attempting to change that by allowing the general public to invest in a portfolio of what it calls “some of the most exciting private companies operating today.”
To do this, the company that pioneered the commission-free brokerage model has secured access to eight startups—including Databricks, Stripe, Mercor, and Oura—grouping them into a vehicle called Robinhood Ventures Fund I. The fund, which also includes Ramp, Airwallex, Revolut, and Boom, set out last month with an ambitious $1 billion target, but demand for this novel way of investing in private companies was lower than expected.
On Thursday, Robinhood announced the fund had raised $658.4 million — which could reach $705.7 million if underwriters exercise their full allotment. The shares, priced at $25 in the offering, began trading on Friday and closed the day at $21, a 16% decline.
RVI’s reception on Wall Street stands in stark contrast to another attempt to give individual investors exposure to buzzy startups. When Destiny Tech100 — a publicly traded, closed-end fund holding stakes in 100 venture-backed companies including SpaceX, OpenAI, and Discord — direct-listed on the NYSE in March 2024, its shares surged from a reference price of $4.84 to an opening trade of $8.25, eventually closing its first day at $9.00.
Advertisement
Destiny Tech100 has kept climbing since its public debut. The fund closed trading on Friday at $26.61, a 33% premium to its net asset value of $19.97, meaning its shares trade well above the actual value of its underlying holdings.
So what explains why retail investors aren’t nearly as excited about Robinhood’s fund as they are about Destiny Tech 100? The most likely explanation is RVI’s lack of exposure to the companies widely expected to go public at enormous valuations: OpenAI, Anthropic, and SpaceX.
Robinhood is looking to address this. RVI intends to add more startups to the fund, eventually aiming to hold what Robinhood Ventures President Sarah Pinto described to TechCrunch as “15 to 20 of the best late-stage growth companies out there.” The company’s CFO, Shiv Verma, told Axios Pro on Friday that Robinhood is eyeing exposure to OpenAI.
Techcrunch event
Advertisement
San Francisco, CA | October 13-15, 2026
But securing access to these high-profile companies is far from straightforward. Robinhood is aiming to get directly onto their cap tables directly through primary capital raises or secondary share sales — and that’s difficult even for a firm with deep roots in Silicon Valley.
Advertisement
A cap table — the official record of who owns equity in a company — is closely guarded at most high-profile startups, and winning a spot on one requires either being invited by the company or purchasing shares from existing investors with the company’s blessing.
“It’s very difficult to get into any of these companies, and the investment rounds are very expensive,” acknowledged Pinto.
That is just one of the reasons democratizing private markets is easier said than done, and why the companies most retail investors actually want to own remain, for now, out of reach.
Outlander season 8 is here! It marks the closing chapter of Claire (Caitriona Balfe) and Jamie’s (Sam Heughan) torrid love story – at least on the small screen. You can watch Outlander free in the UK and US but fans abroad needn’t miss out…
Here’s the secret: You can access your usual streaming service (and free trial) from anywhere with NordVPN – it let’s you select your location. Best of all, it’s cheaper than ever and our exclusive deal throws in a freeAmazon gift card
Yep. You could effectively get paid up to $50 to watch Outlander season 8! No messy sign-ups, no plot holes.
Advertisement
Season 8 sees The Revolutionary War follow the lovers home to Fraser’s Ridge, along with some threats. Uh-oh. Prepare for a moving Outlander 2026 finale.
This quick and easy guide shows you how to watch Outlander season 8 for free…
How to watch Outlander 2026 for free
Advertisement
Use a VPN to access Outlander from anywhere
NordVPN is the best VPN we’ve tested. Our in-house expert Mike rates it above all others thanks to its streaming capabilities, security and price.
Nothing works as well as Nord when it comes to unblocking streaming platforms, so it’s well worth buying for the longterm. Plus it boosts your privacy.
The sign-up process only takes a minute – and costs less than $3/£2.50 a month with our special deal below:
Advertisement
If you’re determined to watch Outlander without paying a penny but you’re away from the UK when it’s on, combine the MGM+/Prime Video free trials with the Surfshark free trial below! Don’t forget to cancel before the free trials end.
You should also consider Surfshark VPN – it’s very good. Doesn’t have the same features as Nord and there’s no free gift card, but they do offer a 7-day free trial when you click through below….
2. Connect to a server based in the UK (e.g. London).
3. Fire up MGM+ on Prime Video. Pro tip: try it in Chrome’s Incognito mode and it should be plain-sailing.
4. Sign up to to MGM+ on Prime Video to catch Outlander for free. Use an Amazon gift card if you don’t have a credit card.
Advertisement
5. Watch Outlander season 8 at no cost – and potentially grab a $50 Amazon card. Sweet deal, eh?
What to know about Outlander season 8
“I’ve been reading Frank’s book. He says war is coming to the backcountry. And that James Fraser dies in it,” a tearful Jamie tells Claire in the Outlander season 8 teaser. The book in question? Frank Randall’s The Soul of a Rebel: The Scottish Roots of the American Revolution.
The prophecy forces them to ponder choice and fate. Claire urges Jamie not to fight, but maintains that she won’t retreat either because it was destiny that brought her to this place at this moment in time. Jamie believes, just as firmly, that he has no choice in the matter – that he must fight.
Advertisement
The previous season was inspired by books six and seven in Gabaldon’s series (available on Amazon), A Breath of Snow and Ashes and An Echo in My Bones, which ordinarily would indicate that season 8 would be adapted from books eight and nine, Written in My Own Heart’s Blood and Go Tell the Bees That I Am Gone.
However, the 10th and final novel in the series, A Blessing for a Warrior Going Out, is yet to be published.
You may also be interested in…
We test and review VPN services in the context of legal recreational uses. For example: 1. Accessing a service from another country (subject to the terms and conditions of that service). 2. Protecting your online security and strengthening your online privacy when abroad. We do not support or condone the illegal or malicious use of VPN services. Consuming pirated content that is paid-for is neither endorsed nor approved by Future Publishing.
Today, the company announced Claude Marketplace, a new offering that lets enterprises with an existing Anthropic spend commitment apply part of it toward tools and applications powered by Anthropic’s Claude models but made and offered by external partners including GitLab, Harvey, Lovable, Replit, Rogo and Snowflake.
According to Anthropic’s Claude Marketplace FAQ, the program is designed to simplify procurement and consolidate AI spend. Anthropic says the Marketplace is now in limited preview and that enterprises interested in using it should reach out to their Anthropic account team to get started.
For customers interested in the Marketplace, Anthropic says purchases made through it “count against a portion of your existing Anthropic commitment,” and that the company will manage invoicing for partner spend — meaning enterprises can use part of their existing Anthropic commitment to buy Claude-powered partner solutions without separately handling partner invoicing.
Advertisement
In effect, Anthropic is positioning Claude Marketplace as a more centralized way for enterprises to procure certain Claude-powered partner tools.
Yet, the whole point of Anthropic’s Claude Code and Claude Cowork applications for many users was that they could shift enterprise spend and time away from current third-party software-as-a-service (Saas) apps and instead, they could “vibe code” new solutions or bespoke, AI-powered workflows. This idea is so pervasive that prior Claude integrations have on several recent occasions caused a major selloff in SaaS stocks after investors thought Claude could threaten the underlying companies and applications.
Claude Marketplace seems to be pushing against that idea, suggesting current SaaS apps are still valuable and perhaps even more useful and appealing to enterprises with Claude integrated into them.
The launch raises a broader question about how enterprises will choose to use Claude: directly through Anthropic’s own products and APIs, or through third-party applications that embed Claude for more specialized workflows.
Advertisement
Tool integration
Model and chat platforms have always sought to offer integrations, aiming to cut the time users spend building their app versions.
OpenAI added third-party apps into ChatGPT and launched a new App Directory in December 2025. This brought in offerings from companies such as Canva, Expedia and Figma that users can invoke by using “@” mentions while prompting on the chatbot.
However, three months in, it’s unclear exactly how many people use ChatGPT Apps, particularly in enterprises — will Claude’s Marketplace be able achieve more success here, given rising enterprise adoption of Claude and Anthropic products?
Other AI tool marketplaces have also cropped up. Lightning AI launched an AI Hub last year following similar moves from AWS and Hugging Face. Many AI marketplaces, such as Salesforce’s, focus on surfacing AI agents that may already have the capabilities customers need.
How does Anthropic’s solution stand out from these? Asked for comment a spokesperson responded:
“Claude is a model — it reasons, writes, analyzes, and codes. But Harvey isn’t just Claude with a legal prompt. It’s a purpose-built platform built for how legal teams actually work — with the domain expertise, workflow integrations, compliance infrastructure, and institutional knowledge that enterprises require. Same with Rogo for finance, Snowflake for enterprise data, or GitLab for software development. These partners have spent years building the product layer on top of Claude that makes it useful for specific industries and workflows.
That’s actually the point. Thousands of businesses use Claude to power their products — and the best ones have built something Claude alone can’t replicate. Claude Marketplace isn’t Anthropic trying to replace those products. It’s Anthropic investing in them — making it easier for enterprises to access the best Claude-powered tools without managing a separate procurement process for each one. Claude is the intelligence layer. Our partners are the product.”
Advertisement
Native vs app
Enterprise users adapted their Claude or ChatGPT platforms to recognize preferences, connect to their data sources and retain context. So much of how people use enterprise AI these days focuses on customizability, on making the system work for their needs.
Platforms like OpenClaw also allowed people to set up autonomous agents that can have full access to their computers to complete tasks and execute workflows. In other words, Claude and other platforms can already do much of the work that these new third-party Marketplace tools enable — provided they have the right context and data.
However, third-party tools and integrations allow enterprise users to avoid doing the work themselves and instead invoke an existing tool to handle it. For those whose businesses are built around specific, tool-based workflows, the Marketplace may be exactly the right AI integration for them. In addition, there’s also a good chance that enterprises already paying for Claude may now take advantage of the new Marketplace to explore third-party tools and services they wouldn’t have otherwise.
While it’s still unclear what Claude Marketplace would look like in action, it’s possible that, with these tools, enterprises could use Claude as an orchestrator, where the platform acts as a command center that taps the right tool and accesses the right context without constantly prompting.
Advertisement
Observers noted that Claude Marketplace offers enterprises a way to “pre-approve” apps, bypassing the often long and cautious approval process.
Some people noted that Anthropic’s move tracks with how many businesses will want to work directly with the platforms without requiring users to move to their separate offerings.
Anthropic’s biggest challenge with Claude Marketplace, however, is adoption. Many of the partners for its launch already have enterprise customers who deploy their tools through an API or already connect via MCP or other protocols for context.
Some users may have already vibe-coded apps that tap into these integrations. It’s now a matter of enterprise users showing they want to use these new tools within their Claude workflows.
An early print of the linoleum block that Kristina started carving during the podcast. (It’s the original Cherry MX patent drawing, re-imagined for block printing.)
This week, Hackaday’s Elliot Williams and Kristina Panos met up over assorted beverages to bring you the latest news, mystery sound results show, and of course, a big bunch of hacks from the previous seven days or so.
In the news, we’ve launched a brand-new contest! Yes, the Green-Powered Challenge is underway, and we need your entry to truly make it a contest. You have until April 24th to enter, so show us what you can do with power you scrounge up from the environment around you!
On What’s That Sound, Kristina was leaning toward some kind of distant typing sounds, but [Konrad] knew it was our own Tom Nardi’s steam heat radiator pinging away.
After that, it’s on to the hacks and such, beginning with an exploration of all the gross security vulnerabilities in a cheap WiFi extender, and we take a look inside a little black and white pay television like you’d find in a Greyhound station in the 80s and 90s.
We also discuss the idea of mixing custom spray paint colors on the fly, a pen clip that never bends out of shape, and running video through a guitar effects pedal. Finally, we discuss climate engineering with disintegrating satellites, and the curse of everything device.
Advertisement
Check out the links below if you want to follow along, and as always, tell us what you think about this episode in the comments!
Download in DRM-free MP3 and savor at your leisure.
Episode 360 Show Notes:
News:
What’s that Sound?
Congrats to [Konrad] who knew this was Tom Nardi’s radiator!
It’s been roughly half a year since Apple released the AirPods Pro 3 to the world, and I’m revisiting them to see how they’ve held up after months of near-daily use.
AirPods Pro 3 long-term review: Holding the newest AirPods Pro
In my original review of Apple’s latest earbuds, I largely praised them for improving audio quality, ANC, as well as adding new features. Now that the initial excitement has subsided, let’s examine the changes that have stood out. I went from the AirPods Pro 2 to the AirPods Pro 3. This wasn’t a major jump by any means, but I felt it was worth it, especially since the battery life on my years-old pair had deteriorated, and I was able to pass them down to my partner. Continue Reading on AppleInsider | Discuss on our Forums
The device comes with a 400mm telephoto lens accessory
But the leaked Oppo Find X9 Ultra could soon be a strong rival
When people talk about the best camera phones, they usually have something like Apple’s iPhone 17 Pro Max or Samsung’s Galaxy S25 Ultra in mind — you know, a normal-looking phone with an advanced-yet-unobtrusive camera system on the back. Well, the Vivo X300 Ultra is about to blow all of those expectations away.
Revealed at MWC 2026, Vivo says this device is equipped with a 200-megapixel lens, matching that of last year’s X200 Ultra. But what really catches the eye is the optional 400mm-equivalent Telephoto Extender Gen2 Ultra. This is a clip-on lens made by Zeiss that adds serious zoom capabilities to the phone.
That should give you some pretty incredible power when it comes to long-range photography, especially for a smartphone. With a little digital cropping, it can even apparently act as 1600mm super-telephoto lens (albeit with some image quality compromises).
The obvious compromise is portability — it’s not exactly like you’ll be able to safely fit the phone in your pocket when the lens is attached. And the image processing is something we’ll be keen to see in action before passing judgement — this really is pushing the limits of smartphone photography.
Vivo has been reticent with the X300 Ultra’s specs, leaving us guessing at what else it might come with. But if you’re a smartphone photography buff and want high-end zoom power without resorting to one of the best DSLRs, Vivo is gunning for your attention.
As well as the Telephoto Extender Gen2 Ultra, Vivo also revealed a “pro-grade” Camera Cage to hold its new phone. This is designed to complement video recording and puts “an array of cold shoe mounts and quick-release ports” at your fingertips, Vivo says. There are two hand grips for added stability, physical buttons for shutter and zoom adjustment, and even an active cooling fan to keep your device performing optimally. The Camera Cage is compatible with Vivo’s lens extender, too.
These releases suggest that Vivo is aiming to appeal to the professional market — or is at least targeting ‘pro-adjacent’ users with lofty ambitions. This kind of setup is beyond what most casual consumers will need but could be just the ticket for photographers and videographers.
Advertisement
Sign up for breaking news, reviews, opinion, top tech deals, and more.
An unreleased accessory
(Image credit: Vivo)
While these MWC teasers are out in the open, a leak from Weibo suggests that Vivo might have something else up its sleeve.
According to leaker Digital Chat Station on the Chinese social media site (via Gizmochina), Vivo’s X300 Ultra will come with a 6.82-inch display equipped with a 2K resolution and a dynamic 120Hz refresh rate. This screen will feature very slim bezels and rounded corners, while the Ultra’s battery will be slightly larger than the one found in the X300 Pro.
Advertisement
As well as that, Digital Chat Station alluded to an unreleased “teleconverter” that hasn’t yet been revealed. Interestingly, they then followed that up with the phrase, “It’s more suitable for general photography enthusiasts.” That suggests that this accessory will have broader use cases than the Telephoto Extender Gen2 Ultra addon, which is very niche. We’ll have to wait for more information on that, though.
In the meantime, new rivals are popping up almost by the day, it seems. The Xiaomi 17 Ultra recently landed with an impressive camera setup, and now the Oppo Find X9 Ultra has entered the arena with a surprise global release and a 200MP periscope telephoto sensor that could combine a large 1/1.28-inch sensor size and f/2.2 aperture. That would be a quite a combo, and could give it strong safari credentials — if not quite on the level of Vivo’s 400mm-equivalent telephoto accessory.
Vivo says the X300 Ultra will launch later this year and will be its first Ultra phone available on a global scale outside of China. Given Vivo’s past releases, though, it’s unlikely to be sold in the US, while European availability is uncertain too. There’s also no word yet on the price or exact release date, so stay tuned for more information on that front.