MCP’s STDIO transport, the default for connecting an AI agent to a local tool, executes any operating system command it receives. No sanitization. No execution boundary between configuration and command. A malicious command returns an error after the command has already run. The developer toolchain raises no flag.
OX Security researchers Moshe Siman Tov Bustan, Mustafa Naamnih, Nir Zadok and Roni Bar scanned the ecosystem and found 7,000 servers on public IPs with STDIO transport active — and estimate 200,000 total vulnerable instances extrapolated from that ratio. They confirmed arbitrary command execution on six live production platforms with paying customers. The research produced more than 10 CVEs rated high or critical across LiteLLM, LangFlow, Flowise, Windsurf, Langchain-Chatchat, Bisheng, DocsGPT, GPT Researcher, Agent Zero, LettaAI and others.
Kevin Curran, IEEE senior member and professor of cybersecurity at Ulster University, independently told Infosecurity Magazine the research exposed “a shocking gap in the security of foundational AI infrastructure.”
Advertisement
Anthropic confirmed the behavior is by design and declined to modify the protocol — characterizing STDIO’s execution model as a secure default and input sanitization as the developer’s responsibility. That characterization comes from OX; the only word Anthropic explicitly stated on the record is “expected.” Anthropic has not issued a standalone public statement and did not respond to VentureBeat’s request for comment.
OX says expecting 200,000 developers to sanitize inputs correctly is the problem. Anthropic’s strongest technical counter: sanitizing STDIO would either break the transport or move the payload one layer down. Both positions are technically coherent. The question is what to do while that debate plays out.
Every major outlet covered the disclosure. None built the prescriptive product-by-product audit a security director needs to triage her own MCP deployments. This piece does.
Five questions determine whether your MCP deployments are exposed, whether your patches hold, and what to do Monday morning.
Advertisement
Am I exposed?
If your teams deployed any MCP-connected AI agent using the default STDIO transport, yes. The insecurity is not a coding bug in any single product. It is a design default in Anthropic’s MCP specification that propagated into every official language SDK: Python, TypeScript, Java, and Rust. Every downstream project that trusted the protocol inherited it.
OX identified four exploitation families. Unauthenticated command injection through AI framework web interfaces, demonstrated against LangFlow and LiteLLM. Hardening bypasses in tools that implemented command allowlists, demonstrated against Flowise and Upsonic, where OX bypassed the allowlist through argument injection (npx -c). Zero-click prompt injection in AI coding IDEs, where malicious HTML modifies local MCP configuration files. Windsurf (CVE-2026-30615) was the only IDE where exploitation required zero user interaction, though Cursor, Claude Code, and Gemini-CLI are all vulnerable to the broader family. And malicious package distribution through MCP registries, where OX submitted a benign proof-of-concept to 11 registries, and nine accepted it without security review.
Carter Rees, VP of AI and Machine Learning at Reputation and member of the Utah AI Commission, told VentureBeat the framing needs to change entirely. “MCP stdio is a privileged execution surface, not a connector. Enterprise teams should treat it like production shell access. Deny by default, allowlist, sandbox and stop assuming downstream input validation will hold at scale,” Rees said.
The IDE family deserves particular attention because it hits developer workstations, not servers. A developer who visits an attacker-controlled website can trigger a modification to their local MCP configuration file — and in Windsurf’s case, the change executes immediately with no approval prompt. Cursor, Claude Code and Gemini-CLI require some form of user interaction, but if the UI presents a configuration change without surfacing the execution consequence, clicking ‘approve’ does not constitute informed consent.
Advertisement
Did my vendor patch?
Some did. Some partially. Some have not confirmed. The matrix below maps each affected product against the exploitation family, patch state, and the gap that remains. The critical column is “Protocol fix?” Every row says no.
Product
Exploit type
Patched?
Advertisement
Protocol fix?
The gap
Action
LiteLLM
Advertisement
Command injection via adapter UI
YES
NO
LiteLLM is fixed. New STDIO configs outside LiteLLM inherit the same insecure default.
Advertisement
Pin to v1.83.7-stable or later (CVE-2026-30623). Verify against GitHub advisory. Audit all other STDIO definitions.
LangFlow
RCE via public auto_login + STDIO
Partial
Advertisement
NO
Auth token freely available via public endpoint. STDIO executes whatever follows.
Block public auto_login. Sandbox all MCP services from the host OS.
Flowise / Upsonic
Advertisement
Allowlist bypass (npx -c argument injection)
Hardened, bypass confirmed
NO
Allowlist gives false confidence. OX bypassed it. Trivial.
Advertisement
Do not rely on command allowlists. Enforce process-level sandbox isolation.
Windsurf (CVE-2026-30615)
Zero-click prompt injection to local RCE
REPORTED, unconfirmed
Advertisement
NO
Only an IDE with a true zero-interaction exploit. Hits developer workstations, not servers.
Disable automatic MCP server registration. Review all active configs manually.
Cursor / Claude Code / Gemini-CLI
Advertisement
Prompt injection to local MCP config modification
Cursor patched (CVE-2025-54136); others vary
NO
User interaction required, but config-change UI does not surface execution consequence. Approval does not equal informed consent.
Advertisement
Audit MCP config files (~/.cursor/mcp.json, equivalent paths). Disable auto-registration. Review all pending config changes before approval.
Langchain-Chatchat (CVE-2026-30617)
RCE via MCP STDIO transport
REPORTED, unconfirmed
Advertisement
NO
Downstream chatbot framework inherits the same STDIO default. Patch status unconfirmed.
Inventory all Langchain-Chatchat deployments. Sandbox from host OS. Monitor vendor advisory for patch.
MCP registries (9 of 11)
Advertisement
Accepted malicious PoC without review
N/A
NO
Registries lack submission security review. Install and risk a backdoor.
Advertisement
Use registries with documented submission review. Audit installs against known-good hashes.
Does the flaw survive the patch?
Yes. Every product-level patch in the matrix addresses the specific entry point in that product. None of them changes the MCP protocol’s STDIO behavior. A security director who patches LiteLLM today and configures a new MCP STDIO server tomorrow will inherit the same insecure default on the new server. The patches are necessary. They are not sufficient.
This was predictable. When VentureBeat first reported on MCP’s security flaws in January, Merritt Baer, chief security officer at Enkrypt AI and former deputy CISO at AWS, warned: “MCP is shipping with the same mistake we’ve seen in every major protocol rollout: insecure defaults. If we don’t build authentication and least privilege in from day one, we’ll be cleaning up breaches for the next decade.” The Cloud Security Alliance independently confirmed OX’s findings in a separate research note and recommended organizations treat MCP-connected infrastructure as an active, unpatched threat. The defaults did not change. The attack surface grew.
Rees argued that Anthropic’s position, while internally consistent, does not survive contact with enterprise reality. “It stops being a developer mistake and starts being a distributed failure mode when the same class of failure reproduces across that many independent implementations,” he told VentureBeat. “Guidance is not an architectural control. Relying on thousands of downstream implementers to consistently interpret a trust boundary is a known anti-pattern in enterprise security.”
Advertisement
Anthropic updated its SECURITY.md file nine days after OX’s initial contact in January 2026 to note that STDIO adapters should be used with caution, but made no architectural changes. The researchers’ assessment of that update: “This change didn’t fix anything.”
Rees took a more measured view. “It’s worth giving Anthropic credit where it’s due,” he told VentureBeat. “After the disclosure, they updated their security guidance to recommend caution with stdio adapters. That’s a meaningful step even if researchers argue it falls short of a protocol-level fix.”
What changed at the protocol level?
Nothing architectural. Anthropic has not implemented manifest-only execution, a command allowlist in the official SDKs, or any other protocol-level mitigation. OX recommended all three. The SECURITY.md guidance update was the only change. OX’s research began in November 2025 and included more than 30 responsible disclosure processes across the ecosystem before the April 15 publication.
The disagreement is substantive. Anthropic’s architectural argument deserves its full weight. STDIO is a local subprocess transport designed to launch processes on the machine that configured it. The trust boundary, in Anthropic’s model, sits with whoever controls the configuration file. If you can write to the MCP config, you are by definition someone authorized to execute commands on that machine. Under that logic, what looks like command injection is a feature working as intended. Restricting what STDIO can launch at the protocol level would either break the transport’s core function, since its purpose is to launch arbitrary local processes, or displace the attack surface into the launched process itself. The unopinionated-standard argument is also defensible: a universal protocol that hard-codes execution constraints stops being universal. OX’s counter, from their advisory: “Shifting responsibility to implementers does not transfer the risk. It just obscures who created it.”
Advertisement
Do not wait for a protocol-level fix. Treat every MCP STDIO configuration as an untrusted input surface, regardless of which product it sits inside.
Monday morning remediation sequence
Enumerate. Identify every MCP server deployment across dev, staging, and production. Search for MCP configuration files (mcp.json, mcp_config.json) in developer home directories and IDE config paths (~/.cursor/, ~/.codeium/windsurf/, ~/.config/claude-code/). List running processes that match MCP server binaries. Flag any using STDIO transport with public IP accessibility. OX found 7,000 on public IPs. Your environment may have instances you do not know about.
Patch. Pin every affected product to its patched release. LiteLLM v1.83.7-stable includes the fix for CVE-2026-30623. DocsGPT, Flowise, and Bisheng have also shipped fixes. Windsurf and Langchain-Chatchat remain in reported state as of May 1, 2026. Cursor was patched against an earlier related disclosure (CVE-2025-54136) but inherits the same protocol default. Check each vendor’s advisory in the morning you execute this step.
Sandbox. Isolate every MCP-enabled service from the host operating system. Never give a server full disk access or shell execution privileges. The Flowise/Upsonic allowlist bypass proves that restricting commands alone is not enough.
Advertisement
Audit registries. Review every MCP server installed from a third-party registry. Nine of 11 registries accepted OX’s proof-of-concept without a security review. Use registries with documented submission review processes. Remove any MCP server whose origin you cannot verify.
Treat STDIO config as untrusted. This step survives every future patch and every future product. The protocol-level default has not changed. Every STDIO server definition is a command execution surface. Treat it the same way you treat user input to a database query: assume it is hostile until validated.
Your exposure cannot wait for a protocol fix
Anthropic and OX Security disagree on where the responsibility for securing MCP’s STDIO transport belongs. That disagreement will not be resolved this week. What can be resolved this week is whether your MCP deployments are enumerated, patched, sandboxed, and treated as the untrusted execution surfaces they are.
As Rees put it: “The core question here is architectural policy, not exploit payloads.” Baer warned in January that insecure defaults would produce exactly this outcome. OX documented 200,000 servers running with a configuration field that doubles as an execution surface. The protocol’s designer says it is working as intended. Your Monday morning question is not who is right. It is which of your servers are exposed.
Uber has a long-term ambition that goes well beyond shuttling passengers: the company eventually wants to outfit its human drivers’ cars with sensors to soak up real-world data for autonomous vehicle (AV) companies — and potentially other companies training AI models on physical-world scenarios.
Praveen Neppalli Naga, Uber’s chief technology officer, revealed the plan in an interview at TechCrunch’s StrictlyVC event in San Francisco on Thursday night, describing it as a natural extension of a nascent program the company announced in late January called AV Labs.
“That is the direction we want to go eventually,” Naga said of equipping human drivers’ vehicles. “But first we need to get the understanding of the sensor kits and how they all work. There are some regulations — we have to make sure every state has [clarity on] what sensors mean, and what sharing it means.”
For now, AV Labs relies on a small, dedicated fleet of sensor-equipped cars that Uber operates itself, separate from its driver network. But the ambition is clearly much larger. Uber has millions of drivers globally, and if even a fraction of those cars could be transformed into rolling data-collection platforms, the scale of what Uber could offer the AV industry would dwarf what any individual AV company could assemble on its own.
Advertisement
The insight driving the program, Naga said, is that the limiting factor for AV development is no longer the underlying technology. “The bottleneck is data,” he said. “[Companies like Waymo] need to go around and collect the data, collect different scenarios. You may be able to say: in San Francisco, ‘At this school intersection, I want some data at this time of day so I can train my models.’ The problem for all these companies is access to that data, because they don’t have the capital to deploy the cars and go collect all this information.”
Becoming the data layer for the entire AV ecosystem is a pretty smart play, particularly considering Uber years ago abandoned its own ambitions to build self-driving cars (a move that co-founder Travis Kalanick has publicly lamented as a big mistake). Indeed, many industry observers have wondered if, without its own self-driving cars, Uber might one day be rendered irrelevant as AVs increasingly spring up around the globe.
The company currently has partnerships with 25 AV companies — including Wayve, which operates in London — and is building what Naga described as an “AV cloud”: a library of labeled sensor data that partner companies can query and use to train their models. Partners, which Uber plans to more aggressively invest in directly, can also use the system to run their trained models in “shadow mode” against real Uber trips, simulating how an AV would have performed without actually putting one on the road.
Techcrunch event
Advertisement
San Francisco, CA | October 13-15, 2026
“Our goal is not to make money out of this data,” Naga said. “We want to democratize it.”
Advertisement
Given the obvious commercial value of what Uber is building, that positioning may not last long. The company has already made equity investments in numerous AV players, and its ability to offer proprietary training data at scale could give it significant leverage over a sector that right now depends on Uber’s ride marketplace to reach customers.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
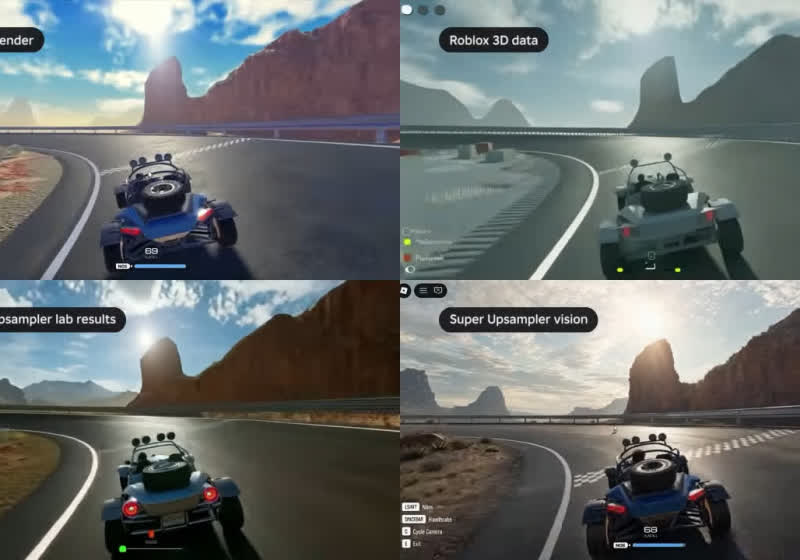
Roblox Reality combines the popular game creation platform’s real-time graphics engine with an AI-powered video generator to dramatically increase the visual quality of user creations. The hybrid architecture does not yet run in real time, but Roblox aims to launch the first iteration in late 2026 or early 2027. Read Entire Article Source link
While Elon Musk faces off against his former colleague and OpenAI co-founder Sam Altman in court, Musk’s rival firm xAI, founded to take on OpenAI, isn’t slowing down on launching competitive new products and services.
The new products arrive after months of tumult from xAI that saw all of Musk’s 10 original co-founders of the lab and dozens more researchers exit the firm and Grok was eclipsed on performance by many new competing LLMs from the likes of OpenAI, Anthropic, Google, and Chinese firms DeepSeek, Moonshot (Kimi), Alibaba (Qwen), z.ai, and others.
While Grok 4.3 does mark a significant leap in performance on third-party benchmarks over its direct predecessor Grok 4.2, according to the independent AI model evaluation firm Artificial Analysis, it still remains below the state-of-the-art set by OpenAI and Anthropic’s latest models.
Advertisement
But the marquee feature of the Grok brand has — other than Musk’s stated opposition to “wokeness” and its more freewheeling personality and image generation policy — increasingly been its low price point when accessed by developers and users via the xAI application programming interface (API), a trend only furthered by Grok 4.3, which costs $1.25 per million input tokens and $2.50 per million output tokens (up to 200,000 input tokens, at which point costs double, a common pricing strategy of leading AI labs) compared to its direct predecessor Grok 4.2’s initial API pricing of $2/$6 per million input/output tokens.
Grok 4.3 API pricing screenshot. Credit: VentureBeat
According to xAI’s release notes, Grok 4.3 began beta testing in April for subscribers to xAI’s SuperGrok ($30 monthly) plan, and those of its sibling social network, X, through its Premium+ plan ($40 monthly with 50% for first two months). Now it’s available to all through the xAI API and through partner OpenRouter.
Reasoning baked-in and agentic tool-use capabilities
At the core of Grok 4.3 is a fundamental shift in how the model processes information. Unlike previous iterations where “chain-of-thought” or reasoning could often be toggled or configured by effort levels, Grok 4.3 is built with reasoning as an active, permanent state.
Advertisement
This means the model is designed to “think” before it speaks for every query, a strategy intended to maximize factual accuracy and the handling of complex, multi-step instructions.
The model’s memory is equally expansive, featuring a 1 million-token context window. To put this in perspective, a million tokens is roughly equivalent to several thick novels or the entire codebase of a mid-sized application.
This allows Grok 4.3 to maintain coherence over massive datasets, though xAI has implemented a “Higher context pricing” structure for requests that exceed the 200,000-token threshold.
This tiering suggests that while the “long-term memory” is available, the computational cost of managing that much information remains a significant overhead.Technically, the model accepts both text and image inputs, outputting text.
Advertisement
It is specifically optimized for agentic workflows—scenarios where an AI is not just answering a question but acting as an autonomous agent to complete a task.
For the first time, Grok has access to the same tools and environments a human professional would use. Evidence of this shift is visible in early user interactions:
Spreadsheet Engineering: In one instance, the model spent 6 minutes and 22 seconds in a “thought” phase to build a comprehensive OSRS Sailing Combat DPS analyzer. The resulting .xlsx file wasn’t a simple table but a multi-sheet dashboard including a “Reference_Data” set and a complex “DPS_Calculator” with formulaic auto-calculations.
Professional Documentation: Grok now generates formatted PDFs, such as 12-page reports on SpaceX products. These documents incorporate branding, logos, hero images, and structured tables, moving well beyond the markdown blocks of previous iterations.
Visual Presentations: The model can design 9-slide PowerPoint decks, utilizing a “Sandwich Structure” (dark titles/conclusions with light content) and integrating data-driven decision matrices and humor.
However, its knowledge of the world is not infinite; the release notes list a knowledge cut-off date of December 2025. Yet, thanks to built-in web search, Grok can reference and use up-to-date information.
In fact, Grok 4.3 arrives with an enhanced ecosystem of tools designed to make it a functional digital employee. The xAI platform now offers a robust set of server-side tools that the model can invoke autonomously based on the complexity of the query.
Advertisement
Web and X Search: These tools allow Grok to bypass its knowledge cutoff by browsing the live internet or searching X (formerly Twitter) posts, user profiles, and threads.
Code Execution: The model can run Python code in a sandboxed environment to solve mathematical problems or process data.
File and Collections Search: A built-in Retrieval-Augmented Generation (RAG) system allows users to query uploaded document collections or search through specific file attachments.
xAI’s Custom Voices let you clone your voice at high quality in a minute or two
Beyond text, xAI has introduced Custom Voices, a sophisticated voice-cloning API and web-based voice cloning creation suite.
This product allows developers to clone a voice from a reference audio clip as short as 120 seconds. Once cloned, the “voice ID” can be used across xAI’s Text-to-Speech (TTS) and Voice Agent APIs.
xAI’s documentation emphasizes that this is not merely about timbre; the model is designed to pick up delivery patterns.
If a user records a reference clip in a “customer support” style, the resulting AI voice will mimic that helpful, professional inflection.
Advertisement
Despite the creative potential, xAI has placed strict geographic limits on this feature, making it available only in the United States, with a notable exception for Illinois due to regional biometric and privacy regulations.
While the console playground is open for general use, programmatic access via the POST /v1/custom-voices endpoint is currently gated to teams on an Enterprise plan.
I tried it myself and after moving through the requisite voice sampling screens on the web — the tool asks you to read aloud several passages of unrelated dialog — I indeed had a copy of my voice that sounded eerily identical to mine and accurately pronounced new words the same way I would when reading allowed from a new script it was given.
You can delete your custom voices in one click on xAI’s Custom Voices web application and create up to 30 new ones at a time.
Advertisement
In terms of licensing, the Custom Voices feature is strictly “scoped to your team” and is never made available to other users, ensuring a private, commercial license for corporate assets.
Access to the new Voice Agent API (grok-voice-think-fast-1.0) is billed at a flat rate of $3.00 per hour ($0.05 per minute) for speech-to-speech interactions. This is on the low-medium end of costs for other competing voice agents, according to my research:
Service
Price per 1k Characters
Advertisement
Estimated Cost per Minute
Estimated Cost per Hour
OpenAI TTS (Standard)
$0.015
Advertisement
~$0.015
~$0.90
OpenAI TTS (HD)
$0.030
Advertisement
~$0.030
~$1.80
Grok Voice Agent
$0.05
Advertisement
$3.00
ElevenLabs (Starter)
~$0.30
~$0.30
Advertisement
~$18.00
ElevenLabs (Pro)
~$0.18
~$0.18
Advertisement
~$10.80
Play.ht
~$0.20
~$0.20
Advertisement
~$12.00
Azure/Google Cloud
$0.016 – $0.024
~$0.02
Advertisement
~$1.00 – $1.50
Complementing this is the standalone Text-to-Speech (TTS) service, which offers five distinct voices (Eve, Ara, Rex, Sal, and Leo) and is priced at $4.20 per 1 million characters.
For transcription needs, the Speech-to-Text (STT) API provides real-time streaming at $0.20 per hour, while batch processing is available at a discounted rate of $0.10 per hour.
To ensure security for client-side applications, xAI utilizes Ephemeral Tokens, allowing for secure WebSocket connections without exposing primary API keys.
Advertisement
Once created, these voices are private to the user’s team and can be used across all voice APIs by referencing a unique 8-character alphanumeric voice_id.
For highly regulated sectors, xAI maintains production-ready standards, including SOC 2 Type II auditing, HIPAA eligibility for healthcare workloads, and GDPR compliance.
Aggressively low API pricing as a differentiator
The most aggressive aspect of the Grok 4.3 announcement is its pricing structure. Bindu Reddy, CEO of enterprise assistant startup Abacus AI noted on X that the model is “as smart as Sonnet 4.6 and 5x cheaper and faster”.
The standard API rates are set at $1.25 per million input tokens and $2.50 per million output tokens. This reflects a significant reduction in cost compared to its predecessor, Grok 4.20, with Artificial Analysis reporting an approximately 40% lower input price and 60% lower output price.
Advertisement
According to our calculations at VentureBeat, that places Grok-4.3 firmly in the lowest cost half of all major foundation models, far closer to Chinese open source offerings than its U.S. proprietary rivals:
However, the “reasoning” nature of the model introduces a new billing category: Reasoning tokens.
Advertisement
These are tokens generated during the model’s internal thinking process and are billed at the same rate as standard completion tokens. Effectively, users pay for the AI to “think” before it provides the final answer. xAI has also introduced several unique fee structures:
Prompt Caching: Repeated prompts are significantly cheaper, at $0.20 per million tokens, incentivizing developers to reuse context.
Tool Invocations: While token usage for tools is billed at standard rates, the act of invoking a tool carries a flat fee—$5.00 per 1,000 calls for Web Search or Code Execution, and $10.00 for File Attachments.
Usage Guideline Violation Fee: In a move that may set a new industry precedent, xAI charges a $0.05 fee for requests that are blocked by their safety filters before generation even begins.
The model itself remains accessible via a standard commercial API, with xAI recommending that all developers migrate to grok-4.3 as their “most intelligent and fastest model”.
Third-party benchmark evaluations and analysis
The reception of Grok 4.3 has been polarized, depending largely on the specific use case. Professional benchmarkers and developers have highlighted a “stark gap” between the model’s domain-specific strengths and its general reasoning consistency.
According to independent AI evaluation firm Vals AI, Grok 4.3 has taken the top spot on several specialized indices. It currently ranks #1 on CaseLaw v2 (79.3% accuracy) and #1 on CorpFin.
Advertisement
This 25-point jump in legal reasoning over Grok 4.20 suggests that the “always-on reasoning” architecture is particularly well-suited for the dense, logical structures of law and finance.
Artificial Analysis corroborated this performance, noting a massive improvement in agentic tasks, scoring an Elo of 1500 on the GDPval-AA benchmark, surpassing competitors like Gemini 3.1 Pro and GPT-5.4 mini.
Conversely, users focused on general-purpose agents and coding have highlighted deficiencies.
They colorfully described the model as having “narcolepsy problems,” preferring to remain inactive for multiple simulation days rather than taking the required actions.
The sentiment was echoed by Vals AI, which noted that while the model improved in some coding areas, it remains weak on general coding tasks and “struggles with difficult math problems,” scoring only 11% on ProofBench.
Should your enterprise use Grok 4.3?
The launch of Grok 4.3 represents a calculated bet by xAI that the market wants specialized brilliance and extreme cost efficiency over a perfectly balanced generalist.
By achieving a score of 53 on the Artificial Analysis Intelligence Index while remaining on the “Pareto frontier” of cost-per-intelligence, xAI is positioning itself as the “value” leader for enterprise applications in legal and financial tech.
Advertisement
The “always-on reasoning” is a double-edged sword. While it provides the depth needed to navigate complex case law, the community reports of “narcolepsy” suggest that a model that is always “thinking” may occasionally think itself into a state of paralysis, or at least a state of excessive caution that inhibits agentic action.
For developers, the decision to adopt Grok 4.3 will likely come down to the nature of their data. For those needing to process a million tokens of legal documents at a fraction of the cost of Claude 4.6 or GPT-5.5, Grok 4.3 is a clear front-runner.
For those building high-frequency autonomous agents or complex math solvers, the “narcolepsy” and coding regressions suggest that xAI’s latest model may still need a few more “tuning passes”.
Advertisement
As OpenRouter noted on X upon making the model live, the “large jump in agentic performance” at a lower price point is an undeniable milestone. Whether that performance can be sustained across all domains remains the primary question for the summer of 2026.
A VPN, or virtual private network, is an important tool for privacy and security. It works by hiding your IP address from public view, helping you access content that might be region-restricted or censored. Many VPNs, like Windscribe, also offer additional features, such as ad blocking.
But it may never have occurred to you to give your AI agent VPN access, too.
If you use OpenClaw, ChatGPT or one of the many other LLMs with access to the internet, your autonomous AI agent can now take advantage of the same privacy and security features.
“Using a VPN with an LLM can provide several advantages, such as keeping your identity private. Your internet provider won’t be able to see your AI agent’s activity, or that you’re using an AI agent,” said Moe Long, CNET senior editor.
“You can also unblock regional content in an LLM. Running your VPN through an AI agent may let you avoid traffic throttling or blocked access. Gen’s VPN for AI Agents works with multiple AI agents, doesn’t require any downloads or client setup, and has multiple tunnel tech that lets you run several agents simultaneously through a VPN.”
Advertisement
A VPN offers improved security and privacy for your internet activities, preventing an ISP and other actors from tracking you.
Panchanut Chobjit/Getty Images
Long said more people are turning to AI agents, but those agents often access the internet without additional protection, meaning your IP address is associated with all their activities. That means not only does your ISP see your activities via the AI agent, but the agent also can’t access regional content or bypass throttling or restricted access.
Windscribe recently debuted OpenClaw agent support, and Gen Digital now has a VPN that supports multiple LLMs, including OpenClaw and ChatGPT.
Atila Tomaschek, CNET senior writer, said that Windscribe expresses it in its blog post, where the company notes: “If your agent gets a little too enthusiastic and triggers a security challenge or lands on a blocklist, it’s your digital reputation on the line, and potentially your entire home network that takes the hit.”
Advertisement
OpenClaw is one of the major AI agents that will be able to take advantage of VPN services.
OpenClaw
“Perhaps most importantly, your ISP can’t distinguish between your own internet traffic and that of your autonomous AI agent,” said Tomaschek. “But with this integration, as well as with Windscribe’s, the VPN encrypts the agent’s traffic as well, so basically you’re protected from whatever your agent might autonomously get up to on the internet.”
A representative for Gen Digital did not immediately respond to a request for comment.
Panelists during a session at the Women in Tech Regatta in Seattle on Wednesday. From left, moderator Sarah Studer of the University of Washington, Maria Martin of Nordstrom, Nandita Krishnan of Adobe, and Anya Edelstein of Highspot. (WiT Regatta Photo)
Women have long been left out of the datasets and decisions shaping everything from car safety to medical diagnoses. Industry leaders warn a rushed approach to artificial intelligence risks repeating those patterns.
That was a central message at this week’s Women in Tech Regatta in Seattle, where speakers urged earlier and broader participation in AI development as adoption accelerates.
“Exclusion compounds over time and becomes much harder to detect,” Anya Edelstein, learning experiences manager at Seattle-based Highspot, said during an AI leadership panel on Wednesday. “If your perspective isn’t taken into account in the room when those decisions are initially made, it’s harder to make a change later down the road.”
Over the past few years, researchers have sought to mitigate the failures of machine-learning models trained on biased or skewed datasets, including misdiagnosis of kidney failure in women. In the meantime, women worldwide are about 20% less likely than men to engage with AI tools, furthering the training disparity.
In the tech field, at least, the AI gender gap seems to be closing. It’s a noteworthy shift as companies race toward automation at scale, and concerns about misinformation and data security swirl around Anthropic and OpenAI going public.
Advertisement
Women are leading AI strategy – with caution
Most women in senior roles (80%) are driving AI strategy in the workplace, where they prioritize responsible adoption over speed, according to a poll of more than 1,700 industry leaders published earlier this month by Chief, a women-focused leadership network.
This is often in contrast to company pressures to deploy AI tools and strategies at an increasingly rapid pace, said Maria Martin, product management director at Nordstrom.
“There’s less runway between a decision getting made, and a decision scaling,” Martin said at the panel Wednesday. “It’s important to get ahead and get involved early.”
In the group of women Chief surveyed, 71% were first at their companies to flag AI risks.
The problem with bringing qualified women into AI leadership and decision-making spaces may start with hiring. At least two-thirds of recruiters use AI to screen candidates, a process shown to reproduce race and gender bias, often intersectionally.
Attendees connect at the Women in Tech Regatta in Seattle on Wednesday. (Courtesy of WiT Regatta)
Women and people of color face pressures to assimilate and code-switch – like using a race-and gender-neutral name on a resume – before they even enter the office. Once they’re hired, it’s about finding the right people for support, said Cynthia Tee, a longtime engineering leader and computer scientist.
Tee suggests more industry leaders can implement a sponsorship model, which requires greater intention, tangible risk and cost compared to typical allyship in the workplace.
Advertisement
“Keep insisting on promoting people who deserve it,” Tee said during a panel about navigating workplace dynamics. “Keep bringing more diverse people through your hiring pipelines. Keep bringing up people whose voices are not heard.”
The AI conversation is for everyone
There can be a confidence barrier to understanding or using AI, partially due to the industry’s “black box” design. Nandita Krishnan, a data scientist at Adobe who builds apps on the side, suggests setting time aside every week to read up on the latest news and experiment with automating daily tasks.
“If you’re vibe coding, do it in a manner that makes the software still secure,” she said at the panel with Edelstein and Martin. “When you’re building out AI systems, it’s very prone to hallucinate. Add something to ground the LLMs, and give your agent this fact or database of knowledge to make sure it does not derail.”
Participation in AI decision-making isn’t limited to technical expertise. Edelstein suggests establishing values around AI – including education, healthcare and the environment – and finding industry leaders or companies who align to engage with.
Advertisement
Many workers are learning AI out of fear of being left behind, she added, but curiosity leads to better outcomes.
“If we can shift a lot of the perceptions around AI,” she said, “that is the first step to bringing more people into the conversation.”
These days, even an old Game Boy will set you back $100 or more, and a new handheld console will be many multiples of that. However, you can build a really cheap handheld gaming toy if you follow [Chris Dell’s] example.
In [Chris]’s own words, he used Rust to build a $1 handheld gaming console. How is that possible? Well, it all comes down to the CH32V003—a microcontroller cheaper than just about anything else out there. It sells for just 9 cents in bulk, and it’s no slouch either. The RISC-V device is a fully-fledged 32-bit chip running at 48 MHz, though with only 2 KB of RAM and 16 KB of flash. Still, that’s more than enough to make some little games. To this end, [Chris] paired the CH32V003 with an SSD1306 OLED display, and three tactile pushbuttons. He then whipped up some code in Rust with the aid of the ch32-hal project, implementing a neat platform game that ran at a healthy 25 fps.
The CH32V003 probably won’t be starring in a new handheld gaming revolution anytime soon. Still, it’s always interesting to see just what can be achieved with one of the cheapest microcontrollers on the market.
A quick reminder: America has not had a confirmed Surgeon General at the federal level since January of 2025. Yes, that’s over a year ago. How we got here is a microcosm of the Trump administration generally: chaos, misfires, and the wrong people at the very top. Janette Nesheiwat was Trump’s first nominee. MAGA gremlin Laura Loomer complained about her very loudly, leading Trump to obediently pull back the nomination.
In her place, he then nominated Casey Means in May of 2025. Means has been described as RFK Jr.’s “favorite wellness influencer”, which is a more subtle way of saying that she’s not a licensed doctor. That fact generated a lot of pushback in Congress, not only from Democrats, but Republicans too. Then, during her confirmation hearing in March of this year, Means dodged questions about vaccines as much as she possibly could, leading Senators like Bill Cassidy and others to question what her actual belief structure on vaccines is, and how much it aligns with RFK Jr.’s. Ultimately, few people thought her nomination was in a good place when it comes to confirmation.
Trump finally woke up to that fact, angrily of course, and has now pulled the Means nomination as well. In her place, he has now nominated radiologist Nicole Saphier, who also moonlights as a health commentator for Fox News. In many ways, Saphier is merely Casey Means wearing sunglasses and a false mustache.
In some ways she’s different. For instance, she’s an actual practicing doctor. On the other hand, she’s caked in the same wellness industry nonsense as Casey Means.
Advertisement
Saphier got her medical degree from Ross University School of Medicine in Barbados, according to her LinkedIn profile. She then completed a radiology residency through Creighton University School of Medicine. She joined Memorial Sloan Kettering Cancer Center in 2016 and has been a Fox News contributor since 2018. She is also the founder of Drop Rx, a herbal supplement business that develops “clean, thoughtfully crafted tinctures that support focus, calm, balance, and overall wellness.”
As for the topic of vaccines, her commentary rings as though she has a similar belief structure to Means, but knows how to hide it better.
On this front, she appears to walk a fine line—being skeptical of vaccines and critical of vaccination recommendations, while avoiding overt opposition to them. In 2022, she falsely claimed on social media that the Centers for Disease Control and Prevention was set to mandate COVID-19 vaccines for schoolchildren—something the CDC does not have the power to do; school vaccination requirements are set by the states. Despite being wrong, her claim sparked outrage among right-wing media.
In August, she posted a video criticizing the American Academy of Pediatrics for continuing to recommend COVID-19 vaccines for children—after Kennedy had unilaterally dropped the recommendation in line with his anti-vaccine views.
Oh, and she was more than a little careless when it came to COVID.
Advertisement
In Dec 2021, Nicole Saphier — a Fox contributor now tapped as Trump’s surgeon general nominee — argued that “it is time to move forward and allow this mild infection to circulate so we can continue to build that hybrid immunity.”250,000 Americans died of covid in 2022.
This administration keeps making the same mistakes over and over again. The dual facts that we’ve been without a confirmed AG for over a year into this administration and that we can’t get a vanilla nominee that can pass through to confirmation without generating headlines is both crazy and a complete failure of this administration.
Trump has been on a tirade blaming Cassidy for all of this. But Cassidy isn’t the problem here. Trump and Kennedy keep stepping on rake after rake by nominating the wrong people for important jobs. I doubt that anyone that was skeptical of Means won’t have the same concerns about Saphier, so we may be back at this all over again months from now.
Global data on math achievement is revealing a dismaying trend: Girls are doing worse than boys — and the margins are huge.
In 2023, fourth-grade boys outperformed their female peers in a vast majority of schools, growing the gender gap that existed prior to the pandemic, according to an international study released last week.
Among eighth-graders, the rate of boys scoring higher than girls increased exponentially since 2019, rolling back gains in math equity that had been shaping up for more than a decade. Matthias Eck, a program specialist for UNESCO’s Section of Education for Inclusion and Gender Equality, tells EdSurge that prior data showed girls were catching up with boys in math achievement.
“But in the latest data, we see that the gap is widening again between girls and boys, and that’s at the detriment of girls, which is quite concerning,” he says.
This international trend echoes what U.S. analysts saw when data from the Nation’s Report Card was released last year.
Advertisement
The latest analysis is based on data from the Trends in International Mathematics and Science Study (TIMSS), a global study published every four years that measures math and science achievement among fourth- and eighth-grade students. The International Association for the Evaluation of Educational Achievement performed the analysis in partnership with UNESCO.
Widening Achievement Gaps
The new data is part of the first set of TIMSS results that measure student performance following the onset of the pandemic. The analysis shows that among top performers in fourth grade, 85 percent of counties’ results skewed toward boys. Slightly over half of the countries and territories from which data was collected have an advanced math achievement gap that favors eighth-grade boys, while none are lopsided toward girls in either grade.
Eck, one of the report’s authors, argues the data shows a correlation between longer school closures and higher rates of learning loss in math, with some variation among countries and territories. “One of the hypotheses is really that those disruptions during the pandemic may have exacerbated existing disparities and have reduced learning opportunities for girls, and potentially those that were at risk of low achievement have been more affected,” Eck says. “The fact that girls were out of school and were not in the learning environment, it could have impacted their confidence, but that’s just the hypothesis.”
But the numbers contain other alarming signals.
Advertisement
For example, the share of regions with a gender gap among fourth-grade students who are failing to reach basic math proficiency is on the rise, and most of them have a higher proportion of struggling girls, according to the report. And while the gender gap in underperformance among eighth-graders is shrinking, the proportion of countries and territories where girls have a higher failure rate spiked.
“Boys and girls are equally able in mathematics, but these learning outcomes can be shaped by a range of factors,” Eck explains, “and that can be persistent gender stereotypes, but also teacher expectations — and they’re based, of course, on those gender stereotypes.”
Targeted Solutions
UNESCO is pushing education systems across the globe to take a hard look at whether their gender equity strategies are working, especially efforts aimed at younger students.
Advertisement
Eck notes that the consequences of girls’ achievement in math can have far-reaching effects in their lives — and very real consequences in societies writ large. “We know that mathematics is quite foundational to learning across the school subjects, it’s also critical for pathways into science, technology, engineering, mathematics careers,” he says. “These sectors are at the center of innovation, technology advancement, inclusive growth and sustainable development, so that’s quite concerning in terms of those sectors.”
Increasing girls’ math performance will take work at the national policy level, local communities, within families and the culture of classrooms, Eck says. And changes have to include challenging gender stereotypes that limit how far girls think they can go in mathematics, he adds.
“I think what is really critical is that we see those large gaps emerging early, at the fourth grade level when students usually are around 9 or 10 years old,” he says. “That means that whatever we do, the action we take to address the issue must start quite early and must be very targeted.”
The market is saturated with red light therapy products, so even if you don’t choose one I personally recommend, keep these features in mind when shopping.
Wavelength: This is one of the most important specs for me. Red light in the 630 to 660nm and near-infrared 810 to 850nm ranges are the most clinically studied. Anything lower than this will not be as effective.
Irradiance: This spec is the power density of light delivered to your skin at a given distance. In general, look for 20 to 50 mW/cm2 for wearable masks and 50 to 100 mW/cm2 for panels used at greater distances.
FDA clearance or registration: FDA clearance requires a manufacturer to submit clinical studies demonstrating that the product is safe and effective. FDA registration, on the other hand, means the device has been presented and registered to the FDA. FDA clearance is a more rigorous process, so we prioritized products with it over those without.
Advertisement
Special features: While not necessary for red light therapy’s efficacy, look for features that make your treatment time more enjoyable. For example, some products on this list offer cryotherapy or flexible forms so you can use them on different body parts.
Apple has quietly discontinued the $599 Mac mini, making the 256GB model no longer available for purchase. Rather than raising its price to reflect rising memory and NAND costs, the company simply pulled it from the lineup, leaving buyers with a steeper entry point than before.
Did Apple just raise the Mac mini’s price without calling it a price hike?
Since Apple pulled the 256GB model from its website, the cheapest Mac mini you can buy now comes with a $799 price tag, featuring an M4 chip, 16GB of RAM, and 512GB of storage. Apple has not made an official statement on why, but the reason is not hard to guess. Profitability. Rising RAM and NAND costs have made consumer electronics more expensive to produce, and in most cases, those costs have been passed directly on to customers. Apple appears to have taken a different approach, choosing to quietly drop the less profitable model rather than raise its price. For context, the 512GB Mac mini launched at $799 back in late 2024.
Apple
Why does the Mac mini matter so much?
The M4 Mac mini has become one of Apple’s easiest computers to recommend because it gives users solid performance in a tiny form factor. It appeals to students, home users, coders, creators, office workers, and anyone who already owns a monitor, keyboard, and mouse. For many buyers, it was the cheapest way to enter the Mac ecosystem without buying a MacBook or iMac.
The bigger question now is what happens next. Rising RAM and storage prices could eventually force Apple to rethink whether the $799 512GB Mac mini can hold its ground. Samsung recently warned that the memory shortage shortage could worsen in 2027, with demand outpacing supply.As that gap widens, the missing $599 Mac mini may turn out to be an early sign of how the crunch reshapes Apple’s desktop and other product lineups.























































You must be logged in to post a comment Login