For the last 24 months, one narrative justified every over-provisioned data center and bloated IT budget: the GPU scramble. Silicon was the new oil, and H100s traded like contraband. Reserve capacity now or your enterprise would be left behind.
The bill is now due, and the CFO is paying attention. Gartner estimates AI infrastructure is adding $401 billion in new spending this year. Real-world audits tell a darker story: average GPU utilization in the enterprise is stuck at 5%.
That utilization floor is driven by a self-reinforcing procurement loop that makes idle GPUs nearly impossible to release. What makes this shift more urgent is the CapEx reality now hitting enterprise balance sheets. Many organizations locked in GPU capacity under traditional three- to five-year depreciation cycles, with the hyperscalers being at five years. That means the infrastructure purchased during the peak of the “GPU scramble” is now a fixed cost, regardless of how much it is actually used.
As those assets age, the question is no longer whether the investment was justified. It’s whether it can be made productive. Underutilized GPUs are not just idle resources, they are depreciating assets that must now generate measurable return. This is forcing a shift in mindset: from acquiring capacity to maximizing the economic output of what is already deployed.
Advertisement
The scramble was a sideshow
For the “Tier 1” enterprise — the Intuits, Mastercards, and Pfizers of the world — access was rarely the true bottleneck. Leveraging deep-pocketed relationships with AWS, Azure, and GCP, these organizations secured capacity reservations that sat idle while internal teams struggled with data gravity, governance, and architectural immaturity.
The industry narrative of “scarcity” served as a convenient smokescreen for this inefficiency. While the headlines focused on supply chain delays, the internal reality was a massive productivity gap. Organizations were activity-rich (buying chips) but output-poor (generating near-zero useful tokens).
At 5% utilization, the math simply doesn’t work. For every dollar spent on silicon, 95 cents is essentially a donation to a cloud provider’s bottom line. In any other department, a 95% waste metric would be a firing offense; in AI infrastructure, it was just called “preparedness.”
The Q1 tracker: A market in pivot
VentureBeat’s Q1 2026 AI Infrastructure & Compute Market Tracker confirms that the panic phase has officially broken. The tracker is directional rather than statistically definitive — January surveyed 53 qualified respondents, and in February there were 39 — but the pattern across both waves is consistent. When we asked IT decision-makers what actually drives their provider choices today, the results show a market in rapid pivot:
Advertisement
The access collapse: “Access to GPUs/availability” factor dropped from 20.8% to 15.4% in a single quarter — from primary concern to secondary in 90 days.
The pragmatic pivot: “Integration with existing cloud and data stacks” held steady as the top priority at roughly 43% across both waves, while security and compliance requirements surged from 41.5% to 48.7% — nearly closing the gap with integration.
The TCO mandate: “Cost per inference/TCO (total cost of ownership)” as a top priority jumped from 34% to 41% in a single quarter, overtaking performance as the dominant procurement lens.
The era of the blank check is dead. Inference is where AI becomes a line item.
Training and even fine-tuning were a tactical project; inference is a strategic business model. For most enterprises, the unit economics of that model are currently unsustainable. During the initial pilot phase, flat-fee licenses and bundled token deals allowed for architectural waste. Teams built long-context agents and complex retrieval pipelines because tokens were effectively a sunk cost.
As the industry moves toward usage-based pricing in 2026, those same architectures have become liabilities. When metered billing is applied to an infrastructure stack that sits idle 95% of the time, the cost per useful token becomes a line-item emergency the moment a project moves into production.
From activity to productivity
The shift highlighted in our Q1 data represents more than just a budget correction; it is a fundamental change in how the success of an AI leader is measured.
For the last two years, success was about “securing” the stack. In the efficiency era, success is “squeezing” the stack. This is why cost optimization platforms saw the largest planned budget increase in our survey, becoming a top-tier priority as organizations realize that buying more GPUs is often the wrong answer.
Advertisement
Increasingly IT users are asking how to stop paying for GPUs they aren’t using. They are moving away from measuring GPU activity (how many chips are powered on) and toward GPU productivity (how many useful tokens are generated per dollar spent).
The luxury of underutilization is now a liability. The next act of the enterprise AI play is more about finding a way to make the silicon you already have pay for itself.
Owning the mint: The choice between token consumer and producer
As organizations move from proof-of-concept to production, the focus is shifting away from the latest GPU and toward the architecture of token generation. In this new economic reality, every enterprise must decide its role in the token economy: will you be a token consumer, paying a permanent tax to a model provider, or a token producer, owning the infrastructure and the unit economics that come with it?
This choice is not just about cost; it is about how an organization decides to handle complexity. Owning inference infrastructure means overcoming KV cache persistence, understanding the storage architecture, knowing what are tolerable latency guarantees, and addressing power constraints. It also introduces real-world enterprise limitations, power availability, data center footprint, and operational complexity, that directly impact how far and how fast AI can scale.
Advertisement
At the core of this challenge is KV cache economics. Storing context in GPU memory delivers performance but comes at a premium, limiting concurrency and driving up cost per token. Offloading KV cache to shared NVMe-based storage can improve reuse and reduce prefill overhead, but introduces tradeoffs in latency and system design. As NVMe costs rise and GPU memory remains scarce, organizations are forced to balance performance against efficiency.
For a token producer, managing these tradeoffs, across memory, storage, power, and operations, is simply the cost of doing business at scale. For others, the overhead remains too high, requiring a different path.
The specialized cloud pivot
VentureBeat’s Q1 tracker shows that the market is already voting on this strategy. The top strategic direction for enterprises is now to move more workloads to specialized AI clouds, a category that grew from 30.2% to 35.9% in our latest survey.
These providers — including Coreweave, Lambda, and Crusoe — are evolving. While they initially gained ground by serving model builders and training-heavy workloads, their revenue mix is changing rapidly. Today, training represents roughly 70% of their business volume, but inference customers now make up 30%. We expect that ratio to flip by the end of 2026 as the long tail of enterprise inference begins to scale.
Advertisement
These specialized providers are gaining strategic attention because they are not just selling GPU access. They are selling the removal of infrastructure friction. They optimize the full stack — storage, networking, and scheduling — around inference-first economics rather than general-purpose cloud operations. For an organization aiming to be a token producer, these environments offer a more efficient factory floor than traditional hyperscalers.
The rise of managed inference
For organizations that realize they cannot efficiently build or manage their own inference factories, a different trend is emerging. Our survey found that the intention to evaluate inference outsourcing and managed LLM providers jumped from 13.2% to 23.1% in a single quarter.
This nearly 10-percentage-point increase represents a realization that building inference infrastructure internally often creates hidden costs. Providers like Baseten, Anyscale, FireworksAI, and Together AI offer predictable pricing and service-level agreements without requiring the customer to become experts in vLLM tuning or distributed GPU scheduling.
In this model, the enterprise remains a token consumer, but one that is actively looking to price away the complexity of the stack. They are learning that managing inference internally is only viable if they have the volume to justify the operational burden.
Advertisement
Simplifying the hybrid stack
The choice to be a producer is also being made easier by a new layer of hybrid-cloud AI platforms. Solutions from Red Hat, Nutanix, and Broadcom are designed to operationalize open-source inference infrastructure without forcing every company to become a systems integrator.
The challenge is that modern inference depends on complex open-source components like vLLM, Triton, and Kubernetes. These systems rely on a rapidly evolving stack, with vLLM for high-throughput serving, Triton for model orchestration, and Ray for distributed execution, each powerful on its own, but complex to integrate, tune, and operate at scale. For most enterprises, the challenge isn’t access to these tools, it’s stitching them together into a reliable, production-grade inference pipeline. The promise of these newer platforms is portability: the ability to build an inference stack once and deploy it anywhere, whether in a hyperscaler, a specialized cloud, or an on-premises data center.
Our Q1 2026 AI Infrastructure & Compute Market Tracker confirms that interest in these DIY-but-managed stacks is growing, jumping from 11.3% in January to 17.9% in February, alongside provider adoption, with a steady rise in organizations leaning into open source. This flexibility matters because enterprise AI will not be centralized in one place. Inference workloads will be distributed based on where data lives, how sensitive it is, and where the cost of running it is lowest.
The winner in the next phase of the token economy will not be the platform that forces standardization through restriction. It will be the one that delivers standardization through portability, allowing enterprises to switch between being consumers and producers as their needs evolve.
Advertisement
The architecture of efficiency: The technical levers of productivity
Fixing the 5% utilization wall requires more than just better software; it requires a structural overhaul of the efficiency stack. Many organizations are discovering that high activity is not the same as high productivity. A cluster can run at full tilt but remain economically inefficient if time-to-first-token is too high or if inference requests spend too much time in prefill.
Inference economics are determined by how much useful output a cluster generates per unit of cost. This requires a shift from measuring GPU activity — simply having the chips powered on — to measuring GPU productivity. Achieving that productivity depends on three technical levers: the network, the memory, and the storage stack.
Networking: The cost of waiting
The network is the often-ignored backbone of inference economics. In a distributed environment, the speed at which data moves between compute nodes and storage determines whether a GPU is actually working or merely waiting.
RDMA (Remote Direct Memory Access) has become the non-negotiable standard for this move. By allowing data to bypass the CPU and move directly between memory and the GPU, RDMA eliminates the latency spikes that traditional network architectures introduce. In practical terms, an RDMA-enabled architecture can increase the output per GPU by a factor of ten for concurrent workloads.
Without this level of networking, an enterprise is effectively paying a “waiting tax” on every chip in the rack. As model context windows expand and multi-node orchestration becomes the norm, the network determines whether a cluster is a high-speed factory or a bottlenecked warehouse.
Advertisement
Solving the memory tax: Shared KV cache
As models become larger and context windows expand toward the millions of tokens, the cost of repeatedly rebuilding the prompt state has become unsustainable. Large language models rely on key-value (KV) caches to maintain context during a session. Traditionally, these are stored in local GPU memory, which is both expensive and limited.
This creates a “memory tax” that crushes unit economics as concurrency rises. To solve this, the industry is moving toward persistent shared KV cache architectures. By storing the cache centrally on high-performance storage rather than redundantly across multiple GPU nodes, organizations can reduce prefill overhead and improve context reuse.
Newer architectures are already proving this out. The VAST Data AI Operating System, running on VAST C-nodes using Nvidia BlueField-4 DPUs, allows for pod-scale shared KV cache that collapses legacy storage tiers. Similarly, the HPE Alletra Storage MP X10000 — the first object-based platform to achieve Nvidia-Certified Storage validation — is designed specifically to feed data to inference resources without the coordination tax that causes bottlenecks at scale. WEKA is another provider in this space.
The compression edge
Beyond the physical hardware, new algorithmic contributions are redefining what is possible in inference memory. Google’s recent presentation of TurboQuant at ICLR 2026 demonstrates the scale of this shift. TurboQuant provides up to a 6x compression level for the KV cache with zero accuracy loss.
Advertisement
Techniques like these allow for building large vector indices with minimal memory footprints and near-zero preprocessing time. For the enterprise, this means more concurrent users on the same hardware estate without the “rebuild storms” that typically cause latency spikes. The caveat: compression standards remain contested — no open-source consensus has emerged, and the space is shaping up as a proprietary stack war between Google and Nvidia.
Storage as a financial decision
Storage is no longer just a backend decision; it is a financial one. Platforms like Dell PowerScale are now delivering up to 19x faster time-to-first-token compared to traditional approaches, according to Dell. By separating high-performance shared storage and memory-intensive data access from scarce GPU resources, these platforms allow inference to scale more efficiently.
When a storage layer can keep GPU-intensive workloads continuously fed with data, it prevents expensive resources from sitting idle. In the efficiency era, the goal is to drive the 5% utilization wall upward by ensuring that every cycle is spent on token generation, not on data movement.
But as the stack becomes more efficient, the perimeter becomes more porous. High-productivity tokens are worthless if the data powering them cannot be trusted.
Advertisement
Sovereignty and the agentic future: Building the trust foundation
The final barrier to achieving return on AI is not a technical bottleneck, but a trust bottleneck. As enterprise AI shifts from simple chatbots to autonomous agents, the risk profile changes. Agents require deep access to internal systems and intellectual property to be useful. Without a sovereign architecture, that access creates a liability that most organizations are not equipped to manage.
VentureBeat research into the state of AI governance reveals a stark disconnect. While many organizations believe they have secured their AI environments, 72% of enterprises admit they do not have the level of control and security they think they do. This governance mirage is particularly dangerous as agentic systems move into production. In the last 12 months, 88% of executives reported security incidents related to AI agents.
Sovereignty as an architecture principle
Data sovereignty is often treated as a geographic or regulatory checkbox. For the strategic enterprise, it must be treated as a core architecture principle. It is about maintaining control, lineage, and explainability over the data that powers an agentic workflow.
This requires a new approach to data maturity, modeled on the traditional medallion architecture. In this framework, data moves through layers of usability and trust — from raw ingestion at the bronze level to refined gold and, eventually, platinum-quality operational data. AI inference must follow this same discipline.
Advertisement
Agentic systems do not just need available context; they need trusted context. Providing the wrong data to an agent, or exposing sensitive intellectual property to a non-sovereign endpoint, creates both business and regulatory risk. Compartmentalization must be designed into the stack from the start. Organizations need to know which models and agents can access specific data layers, under what conditions, and with what lineage attached.
Bringing the AI to the data
The fundamental question for the agentic future is whether to bring the data to the AI or the AI to the data. For highly sensitive workloads, moving data to a centralized model endpoint is often the wrong answer.
The move toward private AI — where inference happens closer to where trusted data resides — is gaining momentum. This architecture uses sovereign clouds, private environments, or governed enterprise platforms to keep the data perimeter intact.
This is where the choice to be a token producer becomes a security advantage. By owning the inference stack, an enterprise can enforce governance and lineage at the infrastructure layer. It ensures that the intellectual property used to ground an agent never leaves the organization’s control.
Advertisement
The next platform war
The battle for AI dominance will not be decided by who owns the largest GPU clusters. It will be won by the companies with the best inference economics and the most trusted data foundation.
The organizations that win the efficiency era will be those that deliver the lowest cost per useful token and the fastest path to production. They will be the ones that have moved past the hoarding hangover to focus on productive output.
Achieving return on AI requires a shift in mindset. It means moving from a culture of securing the stack to a culture of squeezing the stack. It requires architectural rigor, a focus on token-level ROI and a commitment to sovereignty. When an organization can generate its own tokens efficiently and securely, AI moves from a science project to an economically repeatable business advantage.
That is how ROI becomes real. That is where the next generation of enterprise advantage will be built.
Advertisement
Rob Strechay is a Contributing VentureBeat analyst and principal at Smuget Consulting, a research and advisory firm focused on data infrastructure and AI systems.
Disclosure: Smuget Consulting engages or has engaged in research, consulting, and advisory services with many technology companies, which can include those mentioned in this article. Analysis and opinions expressed herein are specific to the analyst individually, and data and other information that might have been provided for validation, not those of VentureBeat as a whole.
UFC 328 live streams feature two titles up for grabs in the Octagon, with middleweights Khamzat Chimaev vs Sean Strickland headlining proceedings after a flyweight title tussle between Joshua Van vs Tatsuro Taira in the co-main event at the Prudential Center in Newark, New Jersey on Saturday night.
The impressive Chimaev remains unbeaten throughout his professional MMA career and makes the first defense of the UFC gold he won last August thanks to a unanimous points victory over Dricus du Plessis. With the often controversial ‘Tarzan’ Strickland having made his debut Octagon appearance more than 12 years ago, however, Chimaev comes up against a Californian fighter who has a wealth of know-how, tradecraft and experience of winning this championship before.
‘The Fearless’ Van is another star making his first title defense. There was an element of good fortune that saw him injure Alexandre Pantoja’s arm at UFC 323 in just 26 seconds and take the Brazilian’s flyweight strap. That won’t bother Van, who became the second-youngest champion in UFC history in the process. Many fancy that Taira has a good shot to take the title following his devastating TKO of Brandon Moreno at the same event. In doing so he would create his own slice of history – Japan’s first ever UFC champ.
Advertisement
Here’s where to watch UFC 328 live streams online and from anywhere with a VPN – including a clever way to watch UFC 328 for just $1.
How to watch UFC 328 live stream in the US
Exclusive US coverage of the full UFC 328 event is on Paramount Plus. It’s being headlined by Khamzat Chimaev vs Sean Strickland, which is expected to start at around 11pm ET / 8pm PT.
Plans start from only $8.99 a month with the Paramount Plus Essential Plan, or upgrade to Premium for $13.99 a month (see below for more details). You can also get a Paramount Plus trial with Walmart+ for $1 as with this sneaky trick we found.
Advertisement
While Paramount Plus will show UFC 328 in its entirety, you can also watch the Early Prelims with the UFC Fight Pass.
A VPN is a handy piece of software that can make your device appear as if it’s back in your home country, thereby letting you unlock your usual streaming services. The best VPN right now? We recommend NordVPN – it does everything and comes with a 76% discount.
Advertisement
Using a VPN is incredibly simple:
1. Install the VPN of your choice. As we’ve said, NordVPN is our favorite.
2. Choose the location you wish to connect to in the VPN app. For instance, if you’re visiting the UK and want to view your usual US service, you’d select a United States server from the list.
Advertisement
3. Sit back and enjoy the action. Head to your usual local streaming service and watch the UFC.
How to watch UFC 328 live stream in the UK
The UFC 328 live stream is on TNT Sports 1in the UK.
You can get it by adding TNT Sports to your Sky, Virgin Media or EE TV package, or pay from £25.99 per month for a HBO Max plan that includes TNT Sports.
Advertisement
The main card action is set to begin at 2am BST on Sunday morning. UFC Fight Pass subscribers can also watch the Prelims and Early Prelims there.
If you’re abroad whilst the MMA live stream is on, a VPN like NordVPN can help you to access your home streaming services from anywhere.
How to watch UFC 328 live stream in Canada
There are a host of pay-per-view providers offering a UFC 328 live stream in Canada.
Advertisement
You can head to the likes of Sportsnet, Bell or the UFC Fight Pass to watch the whole event, where the PPV price is set at $69.99. Prelims will also be shown on Sportsnet and TVA Sports, with Early Prelims also on UFC Fight Pass.
North of the border from the US? You can use NordVPN to watch your Paramount Plus subscription like you were back at home.
That means you can live stream UFC 328 via your web browser and devices like Android, iOS, Samsung TV, Apple TV, Android TV, Telstra TV and Chromecast.
You can also catch all the Prelims (but not the Chimaev vs Strickland main event) via Paramount+ and free-to-air Network 10.
Downloading a VPN will help you access your subscriptions from anywhere if you’re abroad when the fight is on.
Can I watch UFC 328 for free?
Not quite. Other than the sneaky little Walmart+ for $1 trick described above in the US, there doesn’t seem to be any way to watch UFC 328 for free. It’s on Paramount Plus in the US, which no longer carries a free trial. And it’s on PPV in many other countries around the world.
Advertisement
TVNZ+ will also broadcast the early prelims for free in New Zealand if you are looking to catch the full card.
When does UFC 328 start?
The UFC 328 Main Card is scheduled to begin at 9pm ET / 6pm ET on Saturday, May 9. That’s 2am BST or 11am AEST in the UK and Australia on Sunday, May 10.
Before that, the Early Prelims start at 5pm ET / 2pm PT / 10pm BST / 7am AEST (Sun) and the Prelims at 7pm PT / 4pm PT / 12am BST (Sun) / 9am AEST (Sun).
Can I watch UFC 328 on my mobile?
Yes. Most broadcasters have streaming services that you can access through mobile apps or via your phone’s browser – Paramount Plus, HBO Max and Kayo Sports all have mobile apps, for example.
Advertisement
You can also stay up-to-date with the latest UFC news and plays on the official social media channels on X (@ufc), Instagram (@ufc), Facebook (UFC) TikTok (@ufc) and YouTube (@ufc).
UFC 328 full card
Main card Khamzat Chimaev vs Sean Strickland (for UFC Middleweight title) Joshua Van vs Tatsuro Taira (for UFC Flyweight title) Alexander Volkov vs Waldo Cortes Acosta (Heavyweight) Sean Brady vs Joaquin Buckley (Welterweight) King Green vs Jeremy Stephens (Lightweight)
Prelims Ateba Gautier vs Ozzy Diaz (Middleweight) Joel Álvarez vs Yaroslav Amosov (Welterweight) Grant Dawson vs Mateusz Rębecki (Lightweight) Jim Miller vs Jared Gordon (Lightweight)
Advertisement
Early prelims Roman Kopylov vs Marco Tulio (Middleweight) Pat Sabatini vs William Gomis (Featherweight) Baisangur Susurkaev vs Djorden Santos (Middleweight) Clayton Carpenter vs Jose Ochoa (Flyweight)
We test and review VPN services in the context of legal recreational uses. For example: 1. Accessing a service from another country (subject to the terms and conditions of that service). 2. Protecting your online security and strengthening your online privacy when abroad. We do not support or condone the illegal or malicious use of VPN services. Consuming pirated content that is paid-for is neither endorsed nor approved by Future Publishing.
My nerd cred, painstakingly built up over the last 30 years, is about to take a big hit. Until 2021, I’d never seen The Lord of the Rings trilogy. Until 2026, very recently, I’d never played Middle-earth: Shadow of Mordor. I’d made attempts, you understand, way back in the wilderness years of the 2010s, but it never really grabbed me. Then, just recently, I gave it another go, and, it really did.
From the Backlog
Every gamer has a backlog — and that’s no different for us at TechRadar Gaming. From the Backlog is a series about overdue first-plays, revisiting classics, returning to online experiences, or rediscovering and appreciating established favorites in new ways. Read the full series here.
The thing is, I think what I needed more than a really strong awareness of The Lord of the Rings (LOTR) was a bit of patience. The game begins with a fairly lengthy bit of tutorial before opening up properly, but once you’re in, the world is extremely entertaining in a very similar way to the Arkham series.
Advertisement
You step into the half-dead shoes of Talion, a Ranger of Gondor who is just a little bit dead after Sauron’s servants attacked. However, death is not the end, as the wraith of an Elven smith called Celebrimbor takes possession of your body and revives you. This leads to a bit of a Tyler Durden situation, two minds living in just one body, to put a spin on the words of Phil Collins.
Latest Videos From
Keen-eyed readers will likely recognise Celebrimbor. He’s the smith who forged the Rings of Power in LOTR, and was then fully killed by Sauron. That’s just the biggest of many differences between Shadow of Mordor and the work of Tolkien, with another notable difference being that the Black Gate had been abandoned, uh, 1000 years before the game begins.
Never mind! See what I mean about the LOTR lore not really mattering?
Advertisement
Bye-bye, Uruk-Hai
(Image credit: Warner Bros.)
After being revived, you meet Smeagol (400 years before he was born), and attempt a dual-pronged mission: getting your revenge and also helping Celebrimbor remember his past. Being a wraith is bad for the memory, it seems. Getting revenge is the order of the day, though, and you’ll be getting a lot of it. The big bad may be the Black Hand of Sauron, but you’re going to get revenge in instalments along the way by taking on innumerable numbers of Uruks, which is where the game’s real masterstroke comes into play.
The Nemesis System was a particularly fantastic innovation for the time and one that has yet to be equalled, even 12 years on. Essentially, it’s a way to keep track of the Uruk Captains who command the rank-and-file footsoldiers of Sauron’s hordes. Each one has a personality, fears, and a wide range of character traits.
Sign up for breaking news, reviews, opinion, top tech deals, and more.
Advertisement
The best part of all of this is that your interactions with them will affect their personality and physicality. Attack them with fire, and if they survive, they may well develop a fear of fire, for example. Beat them badly, they’ll come back with scars and additional dialogue about how angry they are with you, MANFILTH!
It’s a hell of a tightrope to walk, and one that Shadow of Mordor pulls off near-effortlessly
It’s not just one-sided, however. If a footsoldier has the skill to take you down in battle (looking at you, archers and javelin throwers), they can be promoted into an open captain slot. By killing the captain, you’ve just allowed another enemy to go up the echelons of Uruk society. To quote Civilization 5, itself quoting Aesop, “we often give our enemies the means of our own destruction.”
This means that the game doesn’t really have meaningless fights. As soon as you start mulching your way through the ranks of Sauron’s army, you’ll start creating more captains yourself. They don’t sit still, either: the captains have their own motives, and their own power struggles. They will frequently attempt to level themselves up and become stronger, or kill one another over squabbles. You can sit back, if you like, and watch an Uruk climb the ranks, only to be felled by a young upstart.
The Nemesis System makes the enemies matter. Mooks become potential rivals, and captains become sworn enemies that you have fought several times before and that have become powerful enough that running in with a sword simply won’t do. Now, you need to carefully plan your attack, exploiting their fears and weaknesses to make up for their increased power. It’s a hell of a tightrope to walk, and one that Shadow of Mordor pulls off near-effortlessly.
Patently problematic
(Image credit: Warner Bros.)
The real problem, such as it is, with the Nemesis System is extrinsic. Patent and copyright law have made it so that only Warner Bros. Interactive Entertainment can use it until 2036, by which time it will likely have been forgotten. It’s tragic. Genuinely, heartachingly tragic, that this fantastic system, so suited to action games of all calibres, is now locked away in an IP vault.
Even Warner Bros. haven’t touched it since the 2017 sequel, Middle-earth: Shadow of War. There was talk of it being used in Monolith’s Wonder Woman game, but that’s now been canned, so it’s unlikely that we’ll see it used again, at least until after the patent expires.
Advertisement
By then, I suspect that, like Ridge Racer‘s usage of playable games in loading screens, technology will have moved past the need for the Nemesis System, with new approaches to gaming making it redundant. That’s a real shame, a backsliding of gaming’s development, and something that makes Shadow of Mordor well worth your time.
Playing this game gives you a glimpse of an alternate LOTR, sure, and it’s interesting for that. But it also gives you a glimpse of a lost future of games, and that bittersweet beauty is worth more than an entire Silmarillion of backstory could ever be.
Cisco has released an open-source tool “to trace the origins of AI models,” reports SC World, “and compare model similarities for great visibility into the AI supply chain.”
[Cisco’s Model Provenance Kit] is a Python toolkit and command-line interface (CLI) that looks at signals such as metadata and weights to create a “fingerprint” for AI models that can then be compared to other model fingerprints to determine potential shared origins. “Think of Model Provenance Kit as a DNA test for AI models,” Cisco researchers wrote. “[…] Much like a DNA test reveals biological origins, the Model Provenance Kit examines both metadata and the actual learned parameters of a model (like a unique genome that comprises a model), to assess whether models share a common origin and identify signs of modification.”
The tool aims to address gaps in visibility into the AI model supply chain. For example, many organizations utilize open-source models from repositories like HuggingFace, where models could potentially be uploaded with incomplete or deceptive documentation. The Model Provenance Kit provides a way for organizations to verify claims about a model’s origins, such as claims that a model is trained from scratch, when in reality it may be copied from another model, Cisco said. This may put organizations at risk of using models with unknown biases, vulnerabilities or manipulations and make it more difficult to resolve any incidents that arise from these risks.
Thanks to Slashdot reader spatwei for sharing the news.
Both the Nissan Frontier and Toyota Tacoma start around $33,000 (including destination fee) for the 2026 model year, but they won’t be worth that much for long. In fact, as soon as drivers leave the dealership, their trucks will lose some of their original value; they’ll continue to do so as the months and years tick by. Yet based on the latest data, one of these two trucks is likely to lose its value notably faster than the other.
The estimated difference in depreciation between the two trucks varies between data sources, but the overall picture remains consistent. The Tacoma is predicted to lose less of its value over a 5 year period than the Frontier, although both models hold their value well compared to best-selling full-size pickups like the Ford F-150 and Chevrolet Silverado 1500.
Advertisement
According to the latest iSeeCars study, the Frontier will lose an average of 35.5% of its value after 5 years on the road, while the Tacoma will lose just 19.9% of its value across the same period of time. That makes the Tacoma the least-depreciating pickup truck on the market according to the study, just ahead of the larger Toyota Tundra. Meanwhile, CarEdge predicts that a new Frontier will lose 37% of its value after five years, while a new Tacoma will only drop 22% in value. KBB isn’t so optimistic about either truck’s depreciation rates, predicting that the Frontier and Tacoma will lose 52.2% and 44.3% of their value respectively over the same period.
Advertisement
Value retention estimates are only a rough guide, but the Tacoma remains a winner
The difference in predicted values between sources can be attributed to a variety of factors, from differences in calculation methodology to assumptions about the average new price each buyer will be paying. The latter factor is particularly important when comparing the Frontier and Tacoma, since the Tacoma has a far bigger price difference between its base and top trims.
Although both trucks start around the same MSRP for a bare-bones, base-spec model, many buyers will be looking further up the trim range to add as much extra capability and comfort as their budget allows. The costliest trim of the 2026 Frontier is the Long Bed Pro-4X, which starts from $44,115 (including a $1,745 destination fee). That price dwarfs the top end of the Tacoma’s trim range, where the TRD Pro starts from $66,195 (also including a $1,745 destination fee).
The currently available study data doesn’t confirm whether buyers who pick a top-spec Tacoma, which retails for roughly double the price of a base variant, can expect to hold onto as much of their original investment as those who buy a base-spec truck. Nonetheless, average value retention across the model as a whole remains very high, and given that the Tacoma was crowned the most dependable midsize truck on the market by JD Power in 2026, that class-leading value retention is unlikely to change anytime soon.
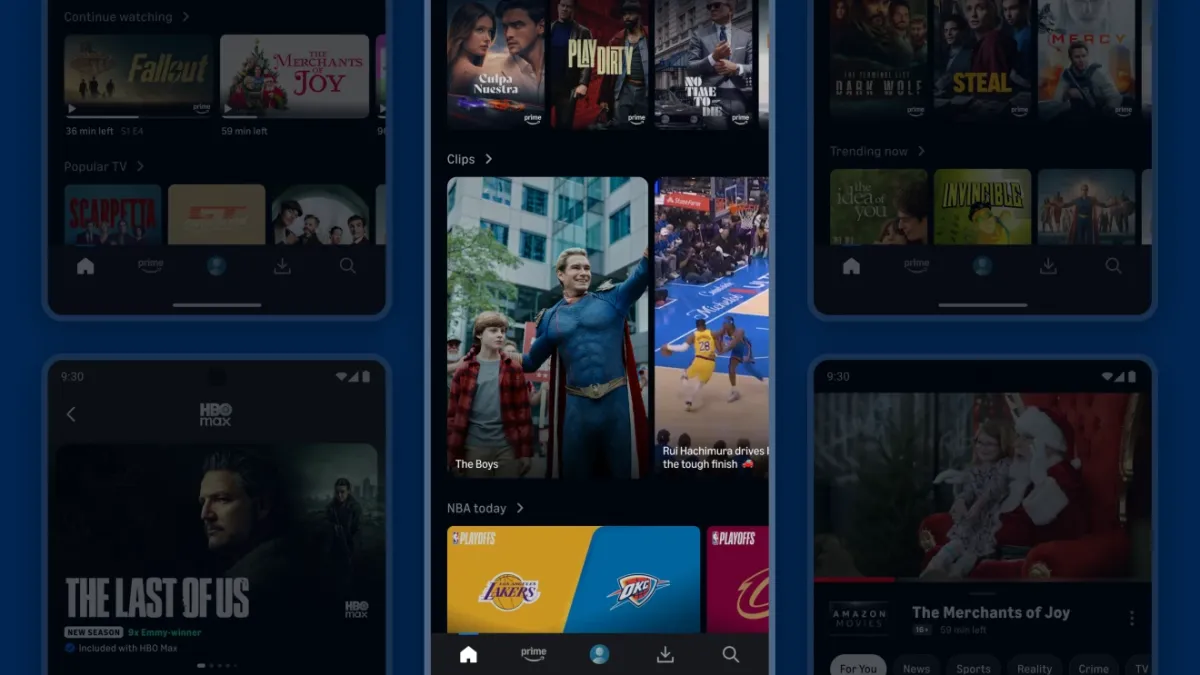
Amazon is adding a short-form video feed to the Prime Video app called “Clips,” the company announced on Friday.
Rolling out first in the U.S., Clips will include… well, clips of shows on Prime Video that are designed to hook a viewer and get them to give the full show a try. From that clip, users can add a title to their watchlist, share it with a friend, or navigate to rent, buy, or access the title through their subscription.
“Clips gives customers a whole new way to browse with short, personalized snippets tailored to their interests,” said Prime Video’s director of Global Application Experiences, Brian Griffin, in a press release. “Whether they have a few minutes to scroll or are looking for something to watch when they have more time, entertainment is just a tap away.”
Amazon first tested this short-form feed during the NBA season, showing highlights that users can scroll through as though they’re watching TikToks.
Advertisement
It’s not a surprise to see Prime Video make this change — Netflix, Peacock, Tubi, Disney, and others have recently rolled out similar experiences, which are designed to promote discovery. Netflix’s short-form feed even shares the Clips name.
Clips is first rolling out to select U.S. customers on iOS, Android, and Fire tablets, but it will be available more broadly this summer. Users can navigate to Clips by scrolling down on the Clips carousel on the Prime Video mobile home page, which will surface a full-screen vertical feed.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
“Plant seeds can sense the vibrations generated by falling raindrops,” reports ScienceAlert, “and respond by waking from their state of dormancy to welcome the water, new research shows…. to germinate in ‘anticipation’ of the coming deluge.” The finding, discovered by MIT mechanical engineers Nicholas Makris and Cadine Navarro, offers the first direct evidence that seeds and seedlings can sense and respond to sounds in nature… “The energy of the rain sound is enough to accelerate a seed’s growth,” [explains Markis].
Plants don’t have the same aural equipment we do to actually hear sounds, of course. But the study suggests that seeds respond to the same vibrations that can produce a sound experience in our human ears. Across a series of experiments, the researchers submerged nearly 8,000 rice seeds in shallow tubs of water, at a depth of around 3 centimeters (1 inch), and exposed some of them to falling water drops over periods of six days… A hydrophone recorded the acoustic vibrations produced by the drops, confirming that the experiment mimicked the vibrations produced by actual raindrops falling in nature — such as the driving downpours that can sometimes pelt Massachusetts’ puddles, ponds, and wetlands… In their study, the researchers observed that seeds exposed to the falling drops germinated up to around 37% faster, compared with seeds that did not receive the simulated rainstorm treatment but were housed in otherwise identical conditions.
Ad patterns alone reveal identity traits without accessing personal data directly
AI profiling from ads is faster, cheaper, and more scalable
Short browsing sessions provide enough data for accurate personal inference
The ads that appear on your screen are not chosen at random, and researchers have now proven AI can turn those ads into a detailed picture of your private life.
A team from UNSW Sydney and QUT examined more than 435,000 Facebook ads collected from 891 Australians through a citizen science project.
Using widely available large language models, the researchers found they could predict users’ personal alignments without ever seeing their history or personal data.
Latest Videos From
Advertisement
How your ad stream becomes a mirror of your life
Advertising platforms build profiles on you and then choose which ads to send your way – those choices create a unique pattern of ads that reveals information about you to anyone who can see that pattern.
The study showed AI tools could infer gender, age, education, employment, political preference, and economic standing from ad exposure alone.
The process was more than 200 times cheaper and 50 times faster than human analysis of the same ad patterns.
Even short browsing sessions gave the AI enough data to build an accurate profile, meaning attackers do not need to watch you for weeks on end.
Advertisement
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
The most likely attack vector is browser extensions, because most of these tools already require permission to read web page content.
Popular extensions like ad blockers, coupon finders, and page translators need that access to function normally – however, those same permissions could be repurposed to quietly collect the ads you see and send them to an attacker.
This scenario is severe due to its inherent stealth, as the extension continues to perform its normal job, so you would never suspect anything is wrong.
Advertisement
No hacking is required, and the advertising platform never knows that its delivery system is being used as a surveillance tool.
What this means for your online privacy
You can lower your risk by being careful with browser extensions and adjusting your privacy settings.
Advertisement
Unfortunately, a VPN offers no protection here, because the ads reach your device no matter how you connect to the internet.
Individuals cannot fully solve this problem on their own because they cannot easily opt out of the ad economy entirely.
The researchers argue that privacy laws must evolve to address not just what data is collected, but what can be inferred from the content you passively consume.
Your ad stream is a fingerprint that AI can now read, and it is only ethical for laws to protect that fingerprint.
Nvidia continues to be a major investor in the AI ecosystem, committing more than $40 billion to equity investments in AI companies — and that’s just in these early months of 2026, according to CNBC.
Much of that total comes from a single bet, a $30 billion investment in OpenAI. But CNBC reports that the chipmaker has also announced seven multi-billion dollar investments in publicly traded companies, most recently deals to invest up to $3.2 billion in glassmaker Corning and up to $2.1 billion in data center operator IREN.
We’ve previously rounded up Nvidia’s investments in AI startups, including 67 venture deals in 2025. And according to FactSet data, it’s already participated in around two dozen investment rounds in private startups in 2026.
The fact that Nvidia has been investing in some of its own customers has led to the recurring criticism that these are circular deals moving money back-and-forth between the same companies.
Advertisement
Wedbush Securities analyst Matthew Bryson said Nvidia’s investments fall “squarely into the circular investment theme,” but suggested that if successful, they could help the company build a “competitive moat.”
General Motors has reached a privacy-related settlement with a group of law enforcement agencies led by California Attorney General Rob Bonta.
Back in 2024, The New York Times reported that automakers including GM were sharing information about their customers’ driving behavior with insurance companies, and that some customers were concerned that their insurance rates had gone up as a result.
The settlement announcement from Bonta’s office similarly alleges that GM sold “the names, contact information, geolocation data, and driving behavior data of hundreds of thousands of Californians” to Verisk Analytics and LexisNexis Risk Solutions, which are both data brokers. Bonta’s office further alleges that this data was collected through GM’s OnStar program, and that the company made roughly $20 million from data sales.
However, Bonta’s office also said the data did not lead to increased insurance prices in California, “likely because under California’s insurance laws, insurers are prohibited from using driving data to set insurance rates.”
Advertisement
As part of the settlement, GM has agreed to pay $12.75 million in civil penalties and to stop selling driving data to any consumer reporting agencies for five years, Bonta’s office said. GM has also agreed to delete any driver data that it still retains within 180 days (unless it obtains consent from customers), and to request that Lexis and Verisk delete that data.
“General Motors sold the data of California drivers without their knowledge or consent and despite numerous statements reassuring drivers that it would not do so,” Bonta said in a statement, adding that the settlement “requires General Motors to abandon these illegal practices and underscores the importance of the data minimization in California’s privacy law — companies can’t just hold on to data and use it later for another purpose.”
GM told Reuters that the settlement “addresses Smart Driver, a product we discontinued in 2024, and reinforces steps we’ve taken to strengthen our privacy practices.”
Advertisement
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
Deletion of a longstanding privacy assurance sparks concerns
Google has changed Chrome’s disclosure language about how its on-device AI works, but that doesn’t mean the company intends to capture on-device AI interactions.
The Chrome menu modification, which isn’t universally rolled out yet even in Chrome 148, was noted this week on Reddit.
Advertisement
The “On-device AI” message in Chrome’s System settings previously read, “To power features like scam detection, Chrome can use AI models that run directly on your device without sending your data to Google servers. When this is off, these features might not work.”
But the message changed recently – it lost the phrase “without sending your data to Google servers.”
That prompted privacy advocate Alexander Hanff to question whether the edit signaled an architectural change that would see local AI interactions processed by Google servers instead of remaining on-device.
“Why was the sentence ‘without sending your data to Google servers’ removed from the on-device AI description in Chrome’s Settings UI?” Hanff asked. “Was the previous text inaccurate? Has the architecture changed? Was the wording withdrawn on legal advice because Google was unwilling to defend it as a representation?”
Advertisement
Asked about this, a Google spokesperson said, “This doesn’t reflect a change to how we handle on-device AI for Chrome. The data that is passed to the model is processed solely on device.”
It appears this situation deserves a more genteel rendering of Hanlon’s Razor – “Never attribute to malice that which is adequately explained by stupidity.”
In this case, it’s “Never attribute to malice that which is adequately explained by bad timing.”
Word of the menu modification surfaced as Chrome was rolling out the Prompt API, which is designed to provide web pages with a programmatic way to interact with a browser-resident AI model. The API’s arrival and public discussion of it drew attention to the fact that Chrome has been silently downloading Google’s 4GB Nano model onto users’ devices. The coincidence of these events made it seem that Google was preparing to capture on-device prompts and responses, which would be a significant privacy retreat.
Advertisement
In fact, Chrome has been letting Nano sleep on the couch for early adopters dating back two years when local AI was implemented in Chrome 126 as a preview program. While Google hasn’t yet made model downloading and storage opt-in, the biz did earlier this year implement a way to deactivate and remove the space-hogging model.
“We’ve offered Gemini Nano for Chrome since 2024 as a lightweight, on-device model,” a Google spokesperson explained, pointing to relevant help documentation.
“It powers important security capabilities like scam detection and developer APIs without sending your data to the cloud. While this requires some local space on the desktop to run, the model will automatically uninstall if the device is low on resources. In February, we began rolling out the ability for users to easily turn off and remove the model directly in Chrome settings. Once disabled, the model will no longer download or update.”
The edit to the “On-device AI” message occurred in early April. According to Google, Gemini Nano in Chrome processes all data on-device.
Advertisement
But when websites interact with Gemini Nano in Chrome – via the Prompt API, for example – they can see the inputs and outputs of the model. In such cases, the data handling would fall under the privacy policy of the website interacting with the user’s Nano instance.
Google decided to change its “On-device AI” message to avoid confusion – and perhaps to preclude legal claims alleging policy violations – when the user is interacting with a Google site that calls out to the Nano model on-device, in support of some service it provides.
In that scenario, the Google site would have access to the prompts it sends and responses it gets from the user’s on-device model. That interaction would happen “without sending your data to Google servers,” at least in the context of a user querying a model running in Google Cloud.
But since the user’s on-device Chrome-resident Nano model would send data to the Google site in response to that site’s API calls, that data transmission might be interpreted as a violation of the local AI commitment language. Hence the edit.
Advertisement
Google’s decision to have Gemini Nano become a Chrome squatter is a novel way of doing things, given that co-opting people’s computing resources has largely been the province of covert crypto-mining scripts. But perhaps after years of offering Gmail and Search at no monetary cost, Google feels entitled to a few gigabytes of Chrome users’ local storage and occasional bursts of their on-device compute. ®























































You must be logged in to post a comment Login