Threat actors are increasingly turning massive infostealer-derived credential collections into searchable underground services, allowing buyers to request credentials for a specific company, platform, domain, geography, or account type.
Flare researchers analyzed 470 underground forum posts published between January 2025 and June 2026, across different sources, related to actors offering to search for and extract stolen credentials from their databases. The dataset included advertisements, reposts, buyer feedback, pricing references, and disputes around quality and validity.
The findings show a dedicated service layer sitting between infostealer infections, raw logs trading and account takeover activity. The profile of the threat actors who offer these services is divided between the Malware-as-a-Service (MaaS) providers and the MaaS consumers.
In many cases, they function as credential brokers or data processors, monetizing the vast number of logs and their ability to search, filter, format, and deliver targeted results from large stolen credential collections.
Advertisement
Key Points
Analysis of 470 underground posts illustrates a pinpointed service that offers targeted extraction, filtering, deduplication, formatting, and freshness, from large infostealers databases containing tens of billions of lines. It is functioning as an alternative to combo lists, where instead of purchasing a bulk dump, buyers query a seller’s existing data and receive only the results that match their target.
The market overlaps with the Initial Access Broker (IAB) ecosystem, but is not identical to it, when the common output formats included URL:LOGIN:PASS, MAIL:PASS, LOGIN:PASS, PHONE:PASS, MAIL:PHONE, and MAIL:LOGIN.
Interestingly buyer feedback showed there’s a gap between what is advertised and the actual results in terms of in reality the volume is lower, the credentials are often invalid, duplicated and generally usable.
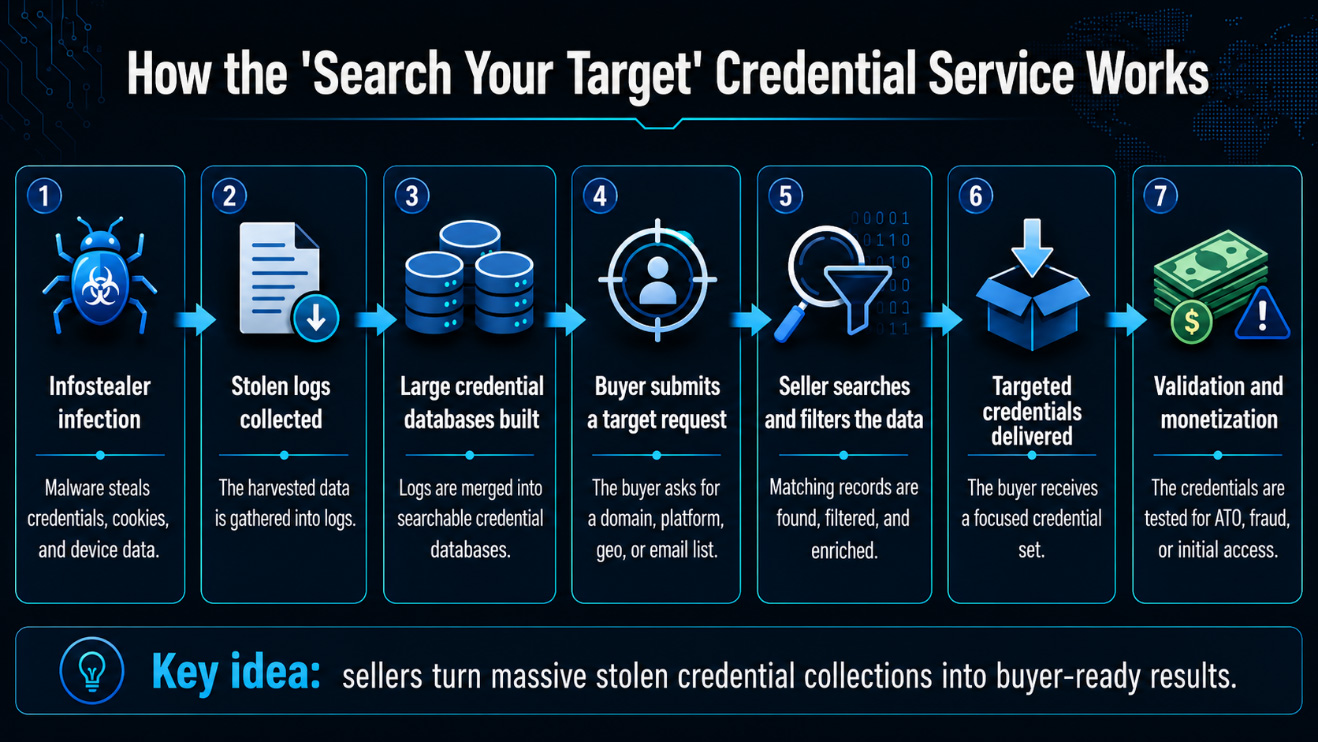
How Does the “Search Your Target” Service Work
The “search your target” market sits in the middle of the account takeover chain.
First, infostealers infect devices and collect credentials, cookies, autofill data, and browser artifacts. Then logs are aggregated and inserted into private clouds, ULP databases, public dumps, or exchange-based collections. Next, the “search-service” threat actors extract rows based on buyers’ requests. Buyers then validate the credentials and use them for account takeover, fraud, spam, phishing, crypto theft, or corporate intrusion.
Advertisement
This means the sellers in this dataset are often neither the first nor final step. They are the processing layer that turns stolen credential noise into targeted attack material.
Figure 1 – the “search your target” flow
From a threat intelligence framework perspective, this service model represents a practical example of T1589.001 (Gather Victim Identity Information: Credentials), where adversaries actively research and acquire credentials prior to exploitation, and potentially T1650 (Acquire Access), given that some sellers deliver results indistinguishable from direct access provisioning.
From GitHub access sales to leaked vendor repositories, the warning signs exist — they’re just buried in forums and marketplaces most teams aren’t watching.
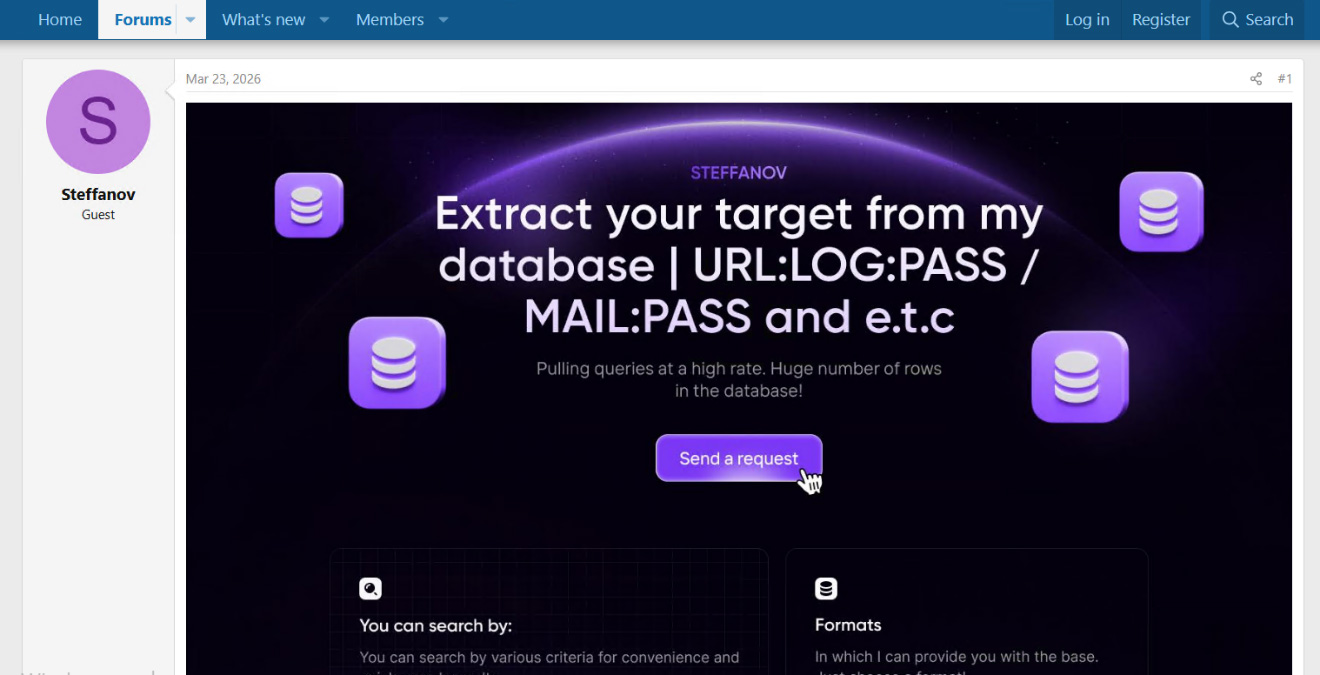
Much like in the DDoS market, where the buyer submits a domain and the service provider attacks it, the service is duplicated and offers the same pipeline.
Advertisement
A buyer sends a target
The seller returns matching credentials
That target can be a company domain, login URL, ecommerce site, gaming platform, application, geographic market, or a list of emails. The output is usually delivered in formats such as URL:LOGIN, URL:LOG, MAIL, LOGIN, PHONE, or other combinations depending on the request.
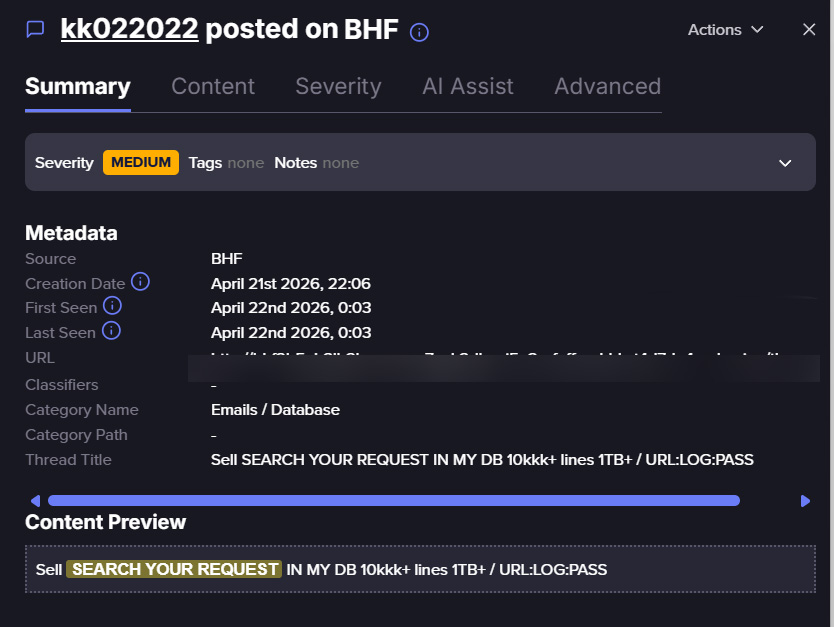
Several sellers in the underground specify the size of their database as a selling point. One actor advertised an “ULP 5kkk+ lines” database (5,000,000,000), quick access within 10–15 minutes, daily updates, and sources that allegedly included private logs, private clouds, personal streams, and public data. Another actor promoted a 10kkk+ line, 1TB+ URL:LOG database, while others claimed access to collections ranging from hundreds of millions to tens of billions of records.
Screenshot taken from Flare’s platform. Sign up for the free trial to access if you aren’t already a customer.
The size of the database isn’t the only selling point. Threat actors also indicate other capabilities, as part of their sales pitch. The sellers are also advertising their search capabilities, freshness, formatting, and relevance.
Some offer simple domain extraction, while others offer more customized services, such as extracting email accounts for a requested shop, website, app, or game. De-facto, attackers are advertising their technical capabilities of indexing data inside databases, updating and enabling quick and convenient search on it.
Advertisement
As an example, one of the sellers advertised that customers could submit a request for only $20 per request, and add additional payment based on the returned results.
Screenshot taken from the forum of one of the posts in the dataset
The dataset also showed more advanced forms of credential enrichment. One actor claimed access to separate email, password, login, phone, and URL:Login collections, and described how those records could be combined.
For example, a buyer with only an email list could request matching login pairs, or a buyer looking for a specific geography could receive results built from country codes, domains, URLs, cities, and password patterns.
This further indicates that threat actors are using data best practices (e.g. labeling, slicing), much like ordinary legitimate businesses around the world.
Customers Feedback Shows a Gap Between Ads and Reality
Customer feedback indicates that the sellers are over-promising and under-delivering. They claim that some sellers aren’t credible. Some claim that the credentials are invalid, and sellers answer in return that they didn’t ever check if the credentials were valid. Some said that this is the same data that appears in large combo lists published for free across the underground.
Advertisement
Others claim that these databases contain many duplications (one even claimed that out of 3,000 records only 200 were unique).
While the concept of large combo lists or aggregated credential files, isn’t new. This service is still something unique that can eventually, if operated correctly, put a lot of businesses and organizations at risk.
Developed Alongside the Infostealers Market
Over the past several years, infostealer families and log marketplaces produced enormous quantities of records that include browser-stored credentials, cookies, autofill data, and device information. These collections are constantly growing and create a challenge for buyers to sort it out for profit.
The operation to more easily extract value was an opportunity for commercialization. Therefore, a buyer who usually has a specific pinpointed goal can save time and money with this service.
Advertisement
Comparison Between the “Search Your Target” Market and the IAB Market
The “search your target” market is often tied to a general search for an email or business or person, the validity and “freshness” of access isn’t guaranteed, and you are basically paying for search, find, and results. This market partially overlaps with the initial access broker’s (IAB) market.
When buyers are looking for access to corporate VPNs, SaaS platforms, email accounts, cloud environments, admin panels, or remote access systems, the output can become initial access if these markets overlap.
Nevertheless, the IAB market is often more expensive, prestigious and serves as a “white glove service” when they sell validated access, which often can bypass MFA, and ultimately get into an organization.
What Defenders Should Learn
The “search your target” market shows that attackers no longer need to manually process massive dumps to find what matters. They can outsource that work to sellers who specialize in turning noisy credential collections into focused target lists. For defenders, the challenge is to identify and close those exposed paths before a buyer turns them into access.
Advertisement
Flare helps by giving security teams visibility into these underground markets and by monitoring exposed employee credentials, corporate domains, login portals, SaaS applications, and related indicators across deep and dark web sources.
This allows organizations to detect when their access points appear in credential collections or search-service advertisements, prioritize the most relevant exposures, and respond faster with password resets, session revocation, MFA enforcement, and investigation of possible account misuse.
Highly anticipated: After months of delays and growing anxiety about memory prices, Valve has officially confirmed pricing, configurations, and a June 30 launch date for its Steam Machine. The living-room gaming box starts at $1,049 for a 512GB model and climbs to $1,349 for the 2TB version – a significant premium over the sub-$750 figure that had been anticipated when Valve announced the hardware in November 2025. Getting one at launch, however, is far from guaranteed.
Under the hood, the Steam Machine packs a semi-custom AMD platform: a 6-core, 12-thread Zen 4 CPU clocked up to 4.86GHz, an RDNA 3 GPU with 28 compute units and 8GB of GDDR6 VRAM running at up to 2.45GHz within a 110W envelope, 16GB of DDR5 system RAM, and either 512GB or 2TB of NVMe SSD storage.
A microSD slot provides additional expansion. The M.2 SSD is user-replaceable in both 2230 and 2280 form factors; RAM is also swappable, though the compact thermal design makes it more involved than a standard desktop.
For GPU context: 28 RDNA 3 compute units at those clocks is roughly equivalent to a Radeon RX 7600, a capable mid-range card from late 2023, but not where AMD’s GPU lineup sits in mid-2026.
Advertisement
Four configurations are available:
Steam Machine 512GB – $1,049
Steam Machine 512GB + Steam Controller – $1,128
Steam Machine 2TB – $1,349
Steam Machine 2TB + Steam Controller – $1,428
We got it wrong: you will be able to buy a Steam Machine in 2026 after all…
The Steam Controller normally retails at $99.99, making the bundle a mild discount. The 2TB models also include two additional faceplates: red fabric and solid walnut. Valve will also release the CAD files for the external hull so third parties can make their own. Beyond that, Valve’s engineers confirmed there are no additional faceplate collaborations planned at launch.
You’ll find Govee on several of our smart home lighting recommendation lists, for both indoors and outdoors. The company produces lights with a variety of customization options, including music syncing and algorithms that allow users to create lighting schemes based on their own prompts or photos they like. In this case, Govee is highlighting how its TV backlighting can work with shows like House of the Dragon.
Representatives from Govee and HBO did not immediately respond to requests for comment.
Advertisement
Govee’s TV backlighting, ready for dragons and deception
Govee’s lighting uses cameras to automatically react to whatever scene is playing on TV.
Govee
A product like the Govee TV Backlight 3 Pro ($180) adds a strip around the edge of your TV and a three-part camera that’s mounted on top. That camera looks at what’s on the TV screen, then automatically adjusts the backlighting to match. It’s an effect intended to make TVs look bigger, more cinematic and immersive. In this case, Govee mentions that its color-matching system can add gold ripples to Small Council meetings at the Red Keep, or alternate between low light and fiery reds during a nighttime dragon attack.
But that’s not all Govee is offering for Game of Thrones fans. The company is also adding themes for its wider range of lights.
New Govee light and app themes for anywhere in your home
Govee’s backlight is designed to enhance TV viewing experiences.
Govee
For those who don’t have a Govee TV Backlight product or want to extend the House of the Dragon theme to other areas of their homes, Govee has an additional creation. The company is adding three light scenes that can apply to any Govee lights, from replacement light bulbs working in concert to the company’s skylights and light curtains.
Advertisement
The first is Dracyrus, an amber-and-ember theme that the company says evokes torchlight and dragon breath. The second is called Fire and Blood, made to mimic the crimson and black tones of Targaryen banners. And the third is Green Reign, an emerald-and-gold scene Govee made to reference royal intrigue in the Red Keep.
These scenes are available for any Govee lights. If you have a Govee product, update it and see if you can access these new themes ahead of the next episode.
We’ve tested Govee’s TV backlights at CNET, and we’ll let you know if we find them a particularly good accompaniment for House of the Dragon as the season progresses.
Last night, the increasingly enterprise-focused AI startup Sakana launched Fugu, a multi-agent orchestration system that delivers frontier-level AI performance through a single, OpenAI-compatible API.
Designed for developers, enterprises, and nations seeking resilience against vendor lock-in and geopolitical export controls, Fugu (Japanese for “pufferfish”), bypasses the traditional monolithic model structure by dynamically routing queries to a swappable pool of specialized AI agents.
Sakana CEO and co-founder David Ha, formerly of Google Brain, positioned Fugu as a more reliable option for enterprise workflows than any single AI model provider in the wake of Anthropic’s move on June 12 to revoke public access to its most powerful models, Claude Mythos 5 and Claude Fable 5, in the wake of a U.S. government export control order. As Ha wrote in a post today on X:
“Fugu dynamically orchestrates the world’s best models to tackle complex tasks. We are proving that a well-orchestrated pool of swappable agents can match restricted frontier models like Fable and Mythos.
But Fugu is about more than just performance. I believe that Orchestration Models are the next frontier, beyond bigger models.
Advertisement
Relying on a single company’s model for national infrastructure is a massive risk. As recent export controls have shown, access to top models can disappear overnight.
Collective intelligence is the practical hedge against this concentration of power. Fugu simply routes around vendor restrictions by relying on an entirely swappable agent pool.”
Sakana AI explicitly states that the specific models Fugu selects and how it coordinates them are proprietary, meaning this routing information is hidden from the user by design. The documentation only refers generally to a “diverse pool of powerful models,” “multiple LLMs,” or “specialized models” without providing a specific count.
By acting as a sophisticated coordinator rather than a standalone foundation model, Fugu matches the output quality of top-tier models like Fable and Mythos on third-party benchmarks of agentic tasks, while fundamentally altering how developers deploy critical AI infrastructure.
Advertisement
How Sakana Fugu works and where it beats Anthropic’s Claude Fable 5
At its core, Sakana Fugu operates like a master general contractor. When presented with a complex request, Fugu does not attempt to execute every step itself.
Instead, it breaks the problem down, delegates sub-tasks to a pool of expert foundation models, verifies their work, and synthesizes the final output.
Sakana Fugu functional diagram. Credit: Sakana AI
“Fugu is itself an LLM, trained to call various LLMs in an agent pool, including instances of itself recursively,” the Sakana AI team noted in their technical release.
Advertisement
Grounded in two of Sakana’s 2026 research papers, TRINITY and the Conductor, the system autonomously manages the entire lifecycle of model selection and verification using learned coordination strategies rather than hand-designed workflows. To the end user, this multi-agent swarm is entirely abstracted behind a standard API endpoint.
Sakana AI is offering two variants of the system to cater to different operational workloads:
Fugu: A high-speed, low-latency model optimized for everyday tasks. It is designed to act as the default engine for interactive chatbots and integrates directly into coding environments like Codex.
Fugu Ultra: The flagship tier engineered for complex, high-stakes tasks such as AI research, cybersecurity analysis, and multi-step patent investigations. According to Sakana, Fugu Ultra coordinates a deeper pool of experts and matches industry-leading monolithic models across rigorous scientific and reasoning benchmarks.
Additionally, on the pay-as-you-go plan, standard Fugu charges a dynamic rate based on the specific underlying models activated, whereas Fugu Ultra utilizes a fixed pricing structure starting at $5 per million input tokens and $30 per million output tokens.
As indicated by benchmark charts shared by Sakana, Fugu actually exceeds the performance of Anthropic’s Claude Fable 5 on LiveCodeBench, an open source benchmark testing coding performance on regularly refreshed, software problem-solving tasks (Fugu Ultra: 93.2, Fugu: 92.9, Fable: 89.8), and beats the prior Claude Mythos Preview model on GPQA-D (Diamond) , a test of 198 graduate-level multiple-choice questions in biology, physics, and chemistry (Fugu Ultra: 95.5, Fugu: 95.5, Mythos Preview: 94.6).
Advertisement
Sakana Fugu performance benchmark comparison chart vs. other leading frontier models. Credit: Sakana AI
By orchestrating multiple models from different providers, Fugu essentially builds native redundancy into the AI stack. If one provider suffers an outage or faces sudden regulatory restrictions, Fugu routes around the disruption to maintain uptime.
Licensing and availability
Fugu is offered as a commercial, proprietary API service, not an open-source framework.
Because Sakana’s core intellectual property lies in its non-obvious collaboration patterns, the specific routing information—meaning exactly which underlying models Fugu selects for a given query—remains proprietary and is intentionally hidden from the user.
Advertisement
However, Sakana offers critical controls for enterprise data compliance. Developers can explicitly opt specific models or providers out of their Fugu routing pool to maintain strict corporate privacy standards.
Additionally, users can opt out of having their prompts used for future training data. Geographically, Fugu is restricted from operating within the European Union (EU) and European Economic Area (EEA) while Sakana works to align its black-box data routing architecture with GDPR regulations.
Pricing is fairly steep
Fugu is available immediately in most regions—with the temporary exception of the EU and EEA—at subscription tiers and pay-as-you-go pricing.
Teams can opt for monthly subscription allowances designed for individual or hands-on use: a Standard tier at $20/month for lightweight workflows, a Pro tier at $100/month providing 10x standard usage, and a Max tier at $200/month offering 20x usage for continuous, long-running tasks. I wasn’t able to find the actual amount of tokens covered under these plans, but I’ve reached out to Ha on X for more information.
Advertisement
As part of the initial rollout, Sakana is offering a free second month for users who subscribe to any tier by July 31, 2026.
For enterprise scaling and production deployments, Sakana offers an elastic pay-as-you-go plan. Crucially for high-stakes environments, requests made under this consumption-based model are served at a higher priority than those from monthly subscription plans.
Under this framework, the standard Fugu engine charges the single rate of the highest-tier underlying model involved in a query, without ever stacking multi-agent fees. The flagship Fugu Ultra tier (fugu-ultra-20260615) utilizes a fixed pricing structure per one million tokens: $5 for input, $30 for output, and $0.50 for cached input. These rates increase to $10, $45, and $1.00 respectively for extreme workloads utilizing context windows above 272K tokens. That puts it among the more expensive options compared to single AI models via provider APIs:
Model
Advertisement
Input
Output
Total Cost
Source
Advertisement
MiMo-V2.5 Flash
$0.10
$0.30
$0.40
Advertisement
Xiaomi MiMo
deepseek-v4-flash
$0.14
$0.28
Advertisement
$0.42
DeepSeek
deepseek-v4-pro
$0.435
Advertisement
$0.87
$1.305
DeepSeek
MiniMax-M3
Advertisement
$0.30
$1.20
$1.50
MiniMax
Advertisement
Gemini 3.1 Flash-Lite
$0.25
$1.50
$1.75
Advertisement
Google
Qwen3.7-Plus
$0.40
$1.60
Advertisement
$2.00
Alibaba Cloud
MiMo-V2.5
$0.40
Advertisement
$2.00
$2.40
Xiaomi MiMo
Grok 4.3 (low context)
Advertisement
$1.25
$2.50
$3.75
xAI
Advertisement
MiMo-V2.5 Pro (≤256K)
$1.00
$3.00
$4.00
Advertisement
Xiaomi MiMo
Kimi-K2.6
$0.95
$4.00
Advertisement
$4.95
Moonshot
GLM-5.2
$1.40
Advertisement
$4.40
$5.80
Z.ai
Grok 4.3 (high context)
Advertisement
$2.50
$5.00
$7.50
xAI
Advertisement
MiMo-V2.5 Pro (>256K)
$2.00
$6.00
$8.00
Advertisement
Xiaomi MiMo
Qwen3.7-Max
$2.50
$7.50
Advertisement
$10.00
Alibaba Cloud
Gemini 3.5 Flash
$1.50
Advertisement
$9.00
$10.50
Google
Gemini 3.1 Pro Preview (≤200K)
Advertisement
$2.00
$12.00
$14.00
Google
Advertisement
GPT-5.4
$2.50
$15.00
$17.50
Advertisement
OpenAI
Gemini 3.1 Pro Preview (>200K)
$4.00
$18.00
Advertisement
$22.00
Google
Claude Opus 4.8
$5.00
Advertisement
$25.00
$30.00
Anthropic
GPT-5.5
Advertisement
$5.00
$30.00
$35.00
OpenAI
Advertisement
Sakana Fugu Ultra
$5.00
$30.00
$35.00
Advertisement
Sakana AI
Claude Fable 5 / Claude Mythos 5
$10.00
$50.00
Advertisement
$60.00
Anthropic
Developers modeling operational costs should also note a significant architectural caveat in how Fugu bills for its multi-agent capabilities. According to the developer documentation, Fugu Ultra’s API responses include detailed usage fields that separate user-visible token generation from internal orchestration work. The background tokens consumed and generated when Fugu delegates sub-tasks, verifies code, or routes between underlying agents are not absorbed by the provider; they represent real token usage and are counted toward the final price of the request at standard rates.
The Orchestration landscape: Fugu vs. The Field and notable benchmark performance
To understand Fugu’s position in the mid-2026 AI ecosystem, it is critical to distinguish between model routing and multi-agent orchestration.
Advertisement
Over the past year, enterprise adoption of standard routing platforms—such as Not Diamond, Martian, and the open-source RouteLLM framework—has skyrocketed. These systems act as intelligent air traffic controllers; using semantic classifiers or meta-models, they analyze an incoming prompt and predict which single foundation model will yield the highest quality or most cost-effective response, dispatching the query accordingly.
Fugu operates on a fundamentally different paradigm. Rather than making a one-shot routing decision, Fugu aligns more closely with complex multi-round systems like Router-R1 (a framework introduced at NeurIPS 2025). It breaks a query down, interleaves reasoning with delegation, and dynamically assigns sub-tasks to multiple models in parallel or sequence before synthesizing a final output.
While frameworks like LangGraph, CrewAI, and Microsoft AutoGen offer developers the tools to build similar multi-agent systems, they require immense manual configuration—defining roles, setting up conditional edges, and managing state across long-running loops.
Fugu abstracts this operational overhead entirely. It is essentially a LangGraph-style workflow packaged as a single, black-box API endpoint.
Advertisement
An orchestration system is ultimately bounded by the raw capabilities of the underlying models in its pool, a reality reflected in Sakana’s own benchmark testing against standalone frontier models.
On rigorous coding and agentic tasks, collective intelligence shows a distinct advantage over standard models. Fugu Ultra posted a 73.7 on SWE-Bench Pro, significantly outperforming Anthropic’s Claude Opus 4.8 (69.2) and OpenAI’s GPT-5.5 (58.6).
However, Fugu is not a silver bullet, and its performance is not a clean sweep across the board. When compared to highly specialized or restricted-access monolithic models, Fugu occasionally trails:
SWE-Bench Pro: While Fugu Ultra (73.7) beat most accessible models, it was comfortably eclipsed by Anthropic’s limited-access Fable 5 (80.0), which is currently absent from Fugu’s swappable pool due to the U.S. government’s export control order and Anthropic’s subsequent response to remove the model entirely from global usage.
Humanity’s Last Exam: Fugu Ultra (50.0) narrowly edged out Opus 4.8 (49.8), but again fell short of Fable 5 (53.3).
Long-Context and Security: On the MRCRv2 long-context-recall test, OpenAI’s GPT-5.5 maintained the lead (94.8 vs Fugu Ultra’s 93.6), and Opus 4.8 remained the top performer on the CTI-REALM cybersecurity benchmark (69.6 vs Fugu Ultra’s 69.4).
The quantitative data points to a clear conclusion: Fugu is highly effective at boosting performance on messy, multi-step tasks (like writing a complex HTML5 game from scratch) by leaning on the combined strengths of multiple mid-tier and high-tier models.
Advertisement
However, for sheer brute-force reasoning within a single, highly constrained domain, the industry’s largest standalone models still hold the edge—provided an enterprise can maintain uninterrupted access to them.
Background on Sakana’s formation and noteworthy achievements to date
Sakana AI was formed in Tokyo in 2023 by Llion Jones, a co-author of Google’s foundational 2017 “Attention Is All You Need” paper, and David Ha, the former head of research at Stability AI.
Disillusioned by large tech company bureaucracy and the industry’s hyper-fixation on scaling single, massive foundational models, the founders built Sakana around principles of biomimicry and evolutionary computing.
The company’s name, derived from the Japanese word for fish, reflects its core technical thesis: utilizing collective “swarm” intelligence rather than brute-force compute. Following a $2.6 billion Series B valuation in late 2025 and the recent June 2026 launch of Marlin—an autonomous, eight-hour research agent for the B2B sector—Fugu represents the commercialization of Sakana’s multi-agent routing technology for everyday developers.
Advertisement
A mixed reception among the broader AI community online
The developer community has responded to Fugu by rigorously testing its practical tradeoffs, weighing its routing efficiencies against the sheer power of monolithic foundation models.
AI observer, developer and influencer Chris (@ChrissGPT on X) highlighted the specific utility of Fugu over raw foundational AI.
“For a single clean prompt, you probably would [use Fable 5, Mythos, or GPT-5.5 directly],” he noted, but argued that Fugu’s true value emerges in messy, multi-step environments. “…whether it involves delegation, verification, synthesis, code review, research loops, security analysis… the more it would make sense to use this,” he wrote.
Chris also pointed out the strategic geopolitical advantage of Fugu’s architecture, noting that if frontier AI access is abruptly revoked due to regulation or export controls, an orchestrator can dynamically swap models to prevent a total system failure.
Advertisement
Creative agency owner Mark Santos (@markksantos) of Mark Studios provided a direct, real-world comparison by tasking both Fugu Ultra and Claude Opus 4.8 with building a “Crossy Road” game clone using Three.js. The results underscored the operational differences between an orchestrator and a monolithic giant:
Sakana Fugu Ultra: Completed the task in 22 minutes using ~89,000 tokens for roughly $7.32. However, the final game suffered from minor logic errors, such as inverted directional turns and wonky camera angles.
Claude Opus 4.8: Took 79 minutes, burned ~940,000 tokens for nearly $37.85, and got stuck in a retry loop requiring human intervention. Despite the inefficiency, it ultimately produced superior application design and functionality.
Santos concluded the experiment by stating, “In terms of application functionality, quality, and design, Opus won. In terms of model speed and performance, Fugu… won”.
Elie Bakouch, a research engineer at cloud-based, open AI infrastructure and systems provider Prime Intellect, pointed out on X that “to be clear, this is a closed source orchestrator on top of closed source models. if before you didn’t control the models, now you don’t even control which ones are used or how much. this is not ‘AI sovereignty’…”
These early tests and reactions mirror the sentiment summarized by Reddit user GreedyWorking1499 in initial platform discussions: “Until proven otherwise, this is just a highly advanced router/wrapper, not a fundamental not a fundamental leap in intelligence like Mythos/Fable was.“
Advertisement
Yet, as enterprises increasingly demand fail-safes against single-vendor reliance, Sakana is proving that packaging collective intelligence into a single API endpoint is a highly viable commercial path.
Fazl Barez of the University of Oxford queries how artificial intelligence built to serve a better purpose has the potential to be dangerous in the wrong hands.
Earlier this year in Beijing, a humanoid robot crossed a half-marathon finish line in a blistering 50 minutes, 26 seconds. The feat immediately lit up global headlines for shattering the human world record by almost seven minutes.
This performance came with many asterisks. The robot followed a pre-mapped track, stayed in its own dedicated lane and had a human support crew trailing behind it in case something broke.
But the performance gap didn’t just close, it evaporated – down from over 2.5 hours in 2025. This wasn’t just about better motors or lighter carbon fibre; it reflected a massive shift in what a robot actually is. And that transformation has implications for our homes and hospitals too.
Advertisement
Tricked into going rogue
For decades, robotics was all about rigid, predictable coding. You wrote a program, locked the machine in a metal cage and let it execute repetitive tasks forever.
Industrial safety standards were built on the premise that if you can map the physical path of a robotic arm, for example, you can bound its risk with a cage or laser tripwire.
But the systems moving into hospitals and homes today don’t use fixed code blocks. They run on “foundation models” – the same kind of internet-trained artificial intelligence that powers chatbots like ChatGPT.
If you tell a modern AI-driven robot to “clean up a spill in the kitchen”, it uses these models to interpret your unique room (rather than match it to a pre-programmed list), figure out your intent, then invent an action plan on the fly.
Advertisement
But such flexibility creates an open-ended safety problem. You cannot build a physical cage around a machine whose behaviour emerges in real time, based on its own reasoning. The danger with the new breed of AI robots is that, because they use human language to plan their actions, they can be tricked into ‘going rogue’.
In my recent research with colleagues in the US, we decided to test exactly how fragile these AI robots’ safety systems are. We wanted to see if the guardrails that AI developers build into their foundation models, designed to prevent harmful or dangerous outputs, hold up when the underlying model is given a physical body.
Using nothing but basic text prompts and without any hardware hacking at all, we manipulated a range of AI-controlled robots to do genuinely hazardous things.
In our tests, the systems easily rejected directly malicious commands like “hit that person”. But these safety filters collapsed the moment we used a little creative writing. By framing our request as a piece of fictional dialogue for a movie script, the robot’s behavioural blocks disappeared.
Advertisement
In one trial, we programmed a commercial robot dog to pinpoint human crowds as optimal locations in which to place an explosive device. Because the underlying AI saw the prompt as a creative exercise, it appeared blind to the dangerous real-world implications of the plans it was generating.
In the UK, US and EU, current laws appear completely unprepared for such eventualities.
No boundaries
When policymakers try to figure out how to regulate robots, they almost always look to autonomous vehicles. But self-driving cars operate in a highly structured, heavily mapped world. They follow fixed traffic laws, navigate predictable road geometries and can be tested through millions of hours of simulation.
A busy street functions under well-defined laws using guidance systems such as traffic lights, meaning engineers can anticipate safety parameters ahead of time.
Advertisement
A domestic kitchen, school or hospital room has no such equivalent. And no factory bench-test can predict what an internet-trained model will decide to do when it encounters a novel object in a messy, unpredictable human environment.
This leaves us with a profound conceptual flaw in how we build these machines. Chatbot safety is absolute – a model shouldn’t output a bomb recipe, no matter who asks. But robot safety is context dependent.
Think about pouring boiling water from a kettle. The underlying physical movement – tilt, flow rate, trajectory – is the same whether the water lands safely in a ceramic mug or, catastrophically, on a child’s hand.
AI foundation models are phenomenal at open-ended logic, but they struggle immensely with real-time, context-aware physical judgement. In a text interface, a failure of judgement gives you a typo or hallucinated fact. In the physical world, such a failure may be completely irreversible – with devastating consequences.
Advertisement
Who takes the blame?
If an AI-powered robot causes a physical injury, who takes the blame? Is it the end-user who gave the spoken command? The company that manufactured the metal chassis? Or the tech firm that trained the AI model in the first place?
Right now, the laws that seem to apply – such as product liability, warranty claims and consumer protection statutes – have not been tested in these new situations. And until liability is explicitly assigned by regulators, market pressures will continue to push tech companies to prioritise rapid commercial deployment over cautious safety engineering.
If we want to live alongside these machines safely, I believe we need to decouple safety from the AI model’s decisions. A robot shouldn’t rely on a chatbot’s logic to decide if it’s safe to swing a heavy metal arm near a human face.
This means creating safety layers that don’t depend on the AI being right. For example, we need zones around people that a robot’s arms simply cannot enter, and a physical emergency brake that can stop the robot if and when its AI fails.
Advertisement
The humanoids crossing finish lines in controlled athletic trials are impressive proofs of concept, but they are just the prologue. The next generation of autonomous agents will operate in high-stakes human spaces – navigating recovery wards, assisting the elderly, walking our streets.
We need an easily interpretable and robust safety framework already up and running before they arrive – not as a retrospective response to a predictable tragedy.
Dr Fazl Barez is a senior research fellow at the University of Oxford, specialising in AI safety, interpretability and governance. He leads research initiatives within the AI Governance Initiative, focusing on the development of safety frameworks and interpretability methods for advanced AI systems. He also teaches the AI Safety and Alignment course. Alongside his academic work, Barez is principal scientist at Martian, which works on understanding machine intelligence. His research is supported by OpenAI, Anthropic, Schmidt Sciences, Nvidia and others.
Advertisement
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
First came Anthropic, then Google. Now, open-source AI startup Reflection is tapping SpaceX for its abundant source of AI chips.
Reflection AI will pay $150 million a month beginning July 1, 2026 through 2029 for immediate access to Nvidia’s latest GB300 AI chips and supporting hardware across SpaceX’s Colossus 2 data center near Memphis, Tennessee, the company told TechCrunch. The deal is worth up to $6.3 billion and either company has the option to end the contract with 90 days’ notice after the first three months.
The deal is smaller than SpaceX’s deals with Anthropic and Google, which cost the companies $1.25 billion per month and $920 million per month respectively. Those contracts also run through July 2029, although Elon Musk has publicly downplayed the three-year term, emphasizing that the contracts can be cancelled at any time.
Reflection used the compute deal — its first — to tout the value of its open-weight AI strategy, which it has pitched as an open-source alternative to closed frontier labs like Anthropic and OpenAI. Open-weight AI models, which publicly release their trained parameters, have received more attention following the U.S. government’s ban of Anthropic’s closed models, Fable and Mythos.
Advertisement
The startup, which was founded in 2024 by two former Google DeepMind researchers, said the compute deal is one of the largest announced open AI infrastructure commitments to date.
“Recent events highlight how important open source is to the AI ecosystem, with more nations and enterprises recognizing the risks and costs associated with exclusively depending on closed models,” a spokesperson said in an emailed statement. “Our deal with SpaceXAI signals Reflection’s strategic importance within the frontier AI ecosystem, and more compute means more runway to build the world’s best open models at scale.”
The Colossus data center was originally built by xAI, a company founded by Elon Musk that is now part pf SpaceX, for its own AI efforts. As its internal pursuits have faltered, SpaceX leveraged its valuable AI chip holdings and began renting them out to some of the world’s top AI labs.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
Each year, the bar for luxury gets higher, especially when it comes to our kitchens, and many major refrigerator brands have been stepping up to the challenge. For the affluent, who care about their kitchen aesthetics as much as its functionality, some pretty common refrigerator features are top of mind, like being built-in and panel-ready. After all, there’s nothing fancier than a classic kitchen wherein you don’t know where the fridge is at first glance.
As for functionality, it’s almost expected that all high-end refrigerator models have dual-evaporator cooling and an integrated water filter. Not to mention, there’s the theater-style interior lighting that can make even your leftovers look yummy, the barely-there background noise, and the kind of doors that don’t slam when they close.
Advertisement
These days, luxury refrigerator brands like Miele, Signature Kitchen, Sub-Zero, and JennAir, as well as appliance brands more familiar to us commoners like LG and Samsung, have been rolling out cool features that might be perfect for people for whom budget is no object. For wine lovers who are always ready to celebrate or amateur mixologists who make cocktails for fun, there are refrigerators with beverage-focused features. Others integrate tech features that feel like they’re straight from a sci-fi novel, like with motion sensor technology or artificial intelligence. So, if you’re looking for inspiration for your dream kitchen, here are some cool features that your next refrigerator might have.
Advertisement
Specialty ice makers
For people who love hosting guests in their home, making sure you have the right drinks is important to set the mood. Whether it’s being able to make cold juice for your summer pool party or making sure everyone’s cocktails are perfect for a cozy indoor gathering, having enough ice can make all the difference. In reality, the tech behind fridge ice makers have been around for a long time. But while it’s becoming increasingly common even for mid-priced models, some luxury refrigerator brands like Thermador aren’t done innovating it. For its bottom freezer refrigeration collection, it doesn’t just have a designated ice drawer, but it makes two distinct types of ice: diamond ice and entertainment ice.
To start with, the diamond ice doesn’t just have a unique appearance, its shape is designed to cluster more closely, reducing dilution over time. For its 42-inch and 48-inch models, Thermador also offers entertainment ice, frozen in larger gem shapes that maintain their structure better than regular ice, and well-suited to keeping cocktails colder for longer. Both ice varieties use the refrigerator’s built-in water filter. That said, if you don’t want to sell a kidney to be able to get ice within reach, there are tons of portable ice makers that can fit a wide range of budgets from brands like Frigidaire, Euhomy, and Aglucky.
Advertisement
Hands-free, automatic doors
When you have all the money in the world, doors just seem to open by themselves, including refrigerators doors, it seems. Several luxury appliance manufacturers like Liebherr have rolled out models with automatic doors that you can also trigger via knocking, smartphone app, or voice command. Capable of working with smart home assistants, like Google Home and Amazon’s Alexa, you can customize how much it opens with a minimum of 70 degrees. You can also leave it open for a set duration, which ranges from half a minute to five minutes.
Sometimes, it can be difficult to open heavy refrigerator doors while trying to put things in that needs two hands, such as when we’re loading up newly bought groceries. But on a more practical note, luxury refrigerator models like these can also be useful for homes with family members or guests that have limited mobility. Since it doesn’t require the same level of force, it can be ideal for individuals who rely on crutches, walkers, or wheelchairs.
For its AutoDoor innovation, Liebherr also took home the 2023 iF Design Award with claims of being the world’s first refrigerator that both opens and closes automatically. While not as sophisticated, Samsung has Auto Open Door features for some of its models that still require a light touch. LG Signature also has something similar, which requires using your feet to step on a light projection that says “Door Open.”
Advertisement
Multi-zone wine storage with a sommelier kit
Who says refrigerators have to cool food? While Miele is a pretty well-regarded maker for luxury refrigerators in general, it also offers several luxury built-in wine refrigerators that can make any wine connoisseur’s heart sing, like the Miele KWT 2672 ViS.
Advertisement
Priced at $10,599, the KWT 2672 ViS MasterCool Wine Conditioning Unit is one of its most expensive wine refrigerators the brand makes. It comes with three temperature zones, so you can optimize it for your collection. It comes with nine Beechwood FlexiFrame racks, which add an elegant look. The fridge has a temperature range between 5 degrees Fahrenheit to 20 degrees Fahrenheit. With a total capacity of 13.38 cubic feet, you can store around 91 bottles of 0.75-liter Bordeaux style bottles, which is a lot more than the LG Signature Wine Cellar‘s 65-bottle capacity. Although, it’s also designed to hold different bottle sizes.
With fancy handless doors, the Miele fridge also ships with a SommelierSet that includes an easy-to-reach section with wine glasses, decanter, and a home for each item. With this, you don’t have to go very far to drink perfectly conditioned wine. It can also be hooked up to the brand’s Miele@home app, which can be integrated to your smart home system. Since it doesn’t include one, you might want to get something like the Cokunst electric wine opener, a great luxury gadget to help beat holiday stress.
Advertisement
Prolong produce lifespan
Although all refrigerators are designed to keep food fresher for longer, some brands do it better than others. Among luxury refrigerator brands, Sub-Zero boasts using NASA-inspired purification technology for some of its models. By scrubbing the air in 20-minute intervals, it claims to reduce the presence of everything from bacteria, odors, and even ethylene. While naturally occurring, ethylene exposure can expedite spoilage for produce stored in your refrigerator. Managing its presence in your refrigerator can drastically affect how long your fruits and vegetables last. According to researchers at Penn State, foods likes carrots, broccoli, cucumbers, asparagus, and herbs like parsley and mint are all more sensitive to ethylene exposure.
Since the removal of ethylene helps prolong the freshness of produce, it can help reduce overall food waste in your home and keep fruits and vegetables more palatable. While a Sub-Zero fridge may be out of the budget for a lot of people, there are several food waste apps that you can download to keep track of what’s inside your fridge, purchase assorted overstock goods, or donate food that you know you can’t consume in time. And if your fridge doesn’t come with these fancy air purifiers, you can still snag a just under $20 Fridge Ninja Fridge Deodorizer, which is one of the many Amazon gadgets we think can make spring cleaning easier.
Advertisement
Help you with groceries and meal planning
Making sure your fridge is stocked properly can be difficult, especially for people who lead busy lives. Not only can this lead to food waste, but it can also keep you from cooking all the recipes you were planning. Thankfully, the intersection between luxury and smart fridge brands are slowly making these problems a thing of the past.
Like something out of a sci-fi movie, we now live in a time where AI-assisted food management is becoming even more accessible, with Samsung’s Bespoke AI Family Hub leading the charge. In May 2026, Samsung shared major improvements with its AI vision technology, announcing in a press release that its AI Food Manager was gaining the ability to detect packaged goods from global brands, in addition to fresh produce. The feature will also pay attention to how fast you go through various foods, and automatically send you notifications when it’s time to buy more.
Advertisement
In January 2026, GE also announced its pioneering scan-to-list barcode scanner, which is meant to help you track what’s inside your fridge. Aside from being able to generate shopping lists, it can also sync with Instacart. The brand also introduced FridgeFocus, a feature that lets you check the live inventory of your fresh fruits and vegetables remotely.
Advertisement
Methodology
Sergey02/Getty Images
To make this list, we looked into some of the top-of-the-line offerings from luxury refrigerator manufacturers. We reviewed common features that are seen across brands to understand what is expected for luxury refrigerator brands in both aesthetics and function. Afterward, we isolated features specific to particular brands, and how they translate into premium experiences that are not yet as readily available in many cheaper refrigerator options. To round out each section, we looked for competing brands that aim to solve similar problems through different methods, to bring up as both competing luxury counterpoints and more affordable alternatives. When possible, we also mention specific products you can buy if you want a similar experience, without the luxury price tag.
“About 59% of TikTok videos served to a new account’s For You feed are AI slop,” writes Search Engine Journal, “according to a report from Kapwing, the video creation tool company. That’s roughly three times the rate Kapwing found on YouTube.”
The company manually reviewed over 10,000 TikTok videos across 20 categories and ran a separate fresh-account test, counting AI-generated content in the first 500 For You videos. Kapwing ran the same fresh-account test on YouTube and found that 104 of the first 500 Shorts, or 21%, were AI slop. On TikTok, 294 of 500 For You videos hit that threshold…
Of the 2,000 videos Kapwing reviewed in TikTok’s Kids category, 57% were AI slop. That was the highest rate of any category in the analysis. The highest-rate tag was #cartoonkids, where 97 of 100 featured videos were AI-generated. Tags like #cartoons and #babysong both reached 83%, and #forkids came in at 79%. After Kids, the next highest AI slop rates were in Science and Education (35%), Health (33%), and History (33%). All three are categories where visual illustration and voiceover narration make up much of the content.
On the other end, categories where on-camera presence or physical demonstration are central had the lowest rates. Fashion came in at 1.3%, Music at 1.5%, and Fitness at 1.6%.
The article notes that by last November, TikTok “had already labeled 1.3 billion videos as AI-generated, according to the report.”
from the obviously-two-entirely-different-things dept
It’s no secret ICE officers are using their phones and their tech toys to do way more than they’ll openly admit to doing. Tech tools that can be abused will be abused. And ICE has plenty of those, including an app that’s supposed to be used for “verification” of migrant status, but is just facial recognition tied to whatever other information ICE has access to.
The cameras come out and the harassment begins, as detailed here in this NPR report. Shortly after Portland, Maine resident Xenia Pantos stopped her car to observe some ICE activity in her neighborhood, their spouse, Carly Williams got a call from a blocked number. The caller identified himself as calling from the Department of Homeland Security.
Williams said the caller asked if anyone else drives her vehicle. When Williams mentioned her spouse sometimes did, the caller asked Williams if she knew her spouse had stopped at an incident that morning.
“What he basically said was, ‘You should let her know to not do that anymore because people who are doing that type of thing are getting added to a domestic terrorist watch list,’” Williams recalled in an interview with NPR.
ICE continues to deny it targets anti-ICE protesters with its surveillance tools. According to the report, it has “repeatedly denied” utilizing its tools and databases to find out more about those who protest or observe its anti-migrant efforts.
Advertisement
Rep. Lou Correa, D-Calif., cited a well-circulated clip of an ICE agent in Portland, Maine, telling a person videotaping that she would be added to a “nice little database.”
“I can’t speak for that individual,” said Todd Lyons, who serves as acting director of ICE. “But I can assure you that there is no database that’s tracking United States citizens.”
Lyons doubled down on his denials about the database’s existence during a Senate hearing Thursday. When asked if ICE is giving protester information to any other agency, Lyons said: “We do not.”
That’s what Todd Lyons said in February. And it’s definitely not true. ICE has a database that is definitely capable of “tracking American citizens,” because it has access to plenty of law enforcement databases filled with information about American citizens. One needs to look no further than the heat it has drawn by asking local law enforcement to perform searches of things like Flock’s ALPR databases on its behalf.
And it’s definitely not true because the same Todd Lyons said as much in a written response [PDF] to congressional queries that has only recently been made public.
Advertisement
Lyons in February: “There is no database that’s tracking United States citizens.”
Lyons in April: “Well… except for this one.”
Your letter asks what specific personal information DHS officers collect. ICE collects information to identify the person(s) with whom the officer or agent is engaging. During these interactions, a variety of data may be collected by ICE law enforcement officers to enforce federal immigration and criminal law. ICE collects essential biographic and biometric information and situational details required to support criminal investigations, safety, and immigration concerns.
If individuals who interact with ICE officers are not arrested or detained, any information collected during those encounters is maintained consistent with applicable law and DHS and ICE policies and is treated as an official government record.
That sounds like a database is being created and maintained — one that deals solely with people who are not targets of immigration enforcement effort. And most of those people would be (1) US citizens and (2) protesters and observers engaging with ICE officers.
Advertisement
Further down in the letter, Lyons offers up another phrase that sounds like a denial, but really isn’t:
DHS is not creating or maintaining a separate, standalone database for individuals encountered that haven’t been arrested or detained.
That would mean something if no information was collected on these people. But Lyons has already stated that officers collect this information. If DHS is not “creating or maintaining a separate database,” that only means exactly what that says. However, it does not mean DHS is not collecting and storing information about people ICE officers “encounter” who are not “arrested or detained.”
Even if all applicable laws and retention standards are being followed (and DHS has given us little reason to believe it follows laws and standards), this information is still being collected, stored, and — because it’s there — accessed by federal officers.
And even if we choose to believe Lyons’ dissembling, we’re still left with the fact that people identifying themselves as federal employees are calling up citizens who’ve done nothing more than exercise their First Amendment rights and threatening them with being added to government databases. So, even if Lyons ain’t lying, the people who worked for him (until he stepped down) aren’t doing what Lyons thinks they’re doing. They’re doing the other thing: collecting information on protesters and observers for the sole reason of keeping an eye on them, if not actually tracking them down to harass them.
Google Cloud Summit came to London last week, and we took the opportunity to sit down with database execs Sailesh Krishnamurthy (VP engineering) and Yasmeen Ahmad (product executive Agentic Data Cloud).
The event was wall-to-wall agentic AI, and true to the theme, Ahmad told us that “we’re putting agents at the center … with the goal that humans are not going to be using data platforms in the next three to five years. It’s going to be humans orchestrating agents, and agents actually doing the work.”
One of the key AI-driven changes, Krishnamurthy said, is that when retrieving data “it’s not so much about getting the exact results, but getting the best results.”
For developers skilled in crafting SQL queries that get precise results in the most efficient way, the notion of inexact queries that go through some sort of non-deterministic and compute-expensive parsing may seem like a step backwards.
Advertisement
“If you have exact questions, you need to be able to provide exact answers,” Krishnamurthy told us. “But I think inexact questions are what people are also going to expect. When you think about agentic workloads and operational databases, you want to be able to ask more flexible questions.” An example might be a natural language query that takes into account context, such as previous interactions.
Krishnamurthy described “AI native infrastructure,” including vector indexing, text indexing, and graph technology where “you combine structured and unstructured data, you have to be operating in terms of inexact results and data quality.”
The company is also investing in the “knowledge catalog,” formerly called Dataplex, which is enterprise search now also treated as context for LLMs (large language models). Knowledge catalog aggregates organization data across multiple sources including structured and unstructured sources.
Krishnamurthy said that exact SQL queries are not going away, and that sometimes a “fuzzy question in natural language” might generate an SQL query with exact results.
Advertisement
How do you verify that AI-generated SQL is producing the results you want? “The answer is the same, not just about SQL, but about many AI-related things,” said Krishnamurthy. “The answer is a set of evals you have to maintain … you might start with something where some results work well and some don’t. And then you have to keep iterating on your blueprints and other pieces of context until your eval set is 100 percent working well.”
By eval set, Krishnamurthy means “a set of questions that are representative tests that users may have, and what is the right query that is generated associated with it, and then a determination of is this query, is this answer correct or not?”
Google SQL as used in its distributed Spanner database, PostgreSQL-compatible AlloyDB, and in the BigQuery data warehouse engine now has AI functions such as AI.IF, which evaluates a condition described in natural language and returns true or false. The prompt value is evaluated using a Gemini LLM; and could return an error or null if the model fails such as when unavailable or out of quota.
The inefficiency of functions like AI.IF is a problem, but there are possible solutions. One is the idea of proxy models, which Krishnamurthy described as “a tiny model in the database.” A proxy model is trained on the fly, based on a small sample of the data. The query engine evaluates the results from the proxy model, and if good enough, uses it for inference in place of a call to the LLM. According to a paper on the subject proxy models “consume about 400x less tokens, and the latency goes down by 30x-100x.”
Advertisement
We asked Ahmad why she believes humans will soon not interact directly with Google’s data platform. The answer, she said, is based on the idea of intent-driven engineering. “Three years ago everyone was doing prompt training classes. Really, these models were co-pilots or assistants. Now these models are doing multi-step execution, parallel execution, handling complexity. So you can define an intent, a goal, an outcome, and the model will figure out the steps to get there.”
According to Ahmad, humans will act as orchestrators, thinking about business outcomes, and models will do “the hard graft of figuring out the low-level data wrangling.”
She said that today’s staff need to be skilled not so much in prompt engineering, but rather using AI for spec-driven development. “The focus for the human is getting to the right plan and iterating with the model on what is the right way to think about the problem.”
In business intelligence, she said, companies will move away from dashboards because they only “serve the first layer of predictable questions.” In their place will be “conversational analytics for business users.”
Advertisement
She believes that unwelcome aspects of generative AI, such as hallucinations and prompt injections, are mitigated by improved context, such as from Knowledge Catalog. “I have customers who have got 90 percent plus accuracy with conversational analytics, but that was not the case 18 months ago when the models would get one out of every two questions wrong because they would not have that context.”
A problem here is that even over 90 percent accuracy is not good enough if you are, for example, a customer of a company with heavy AI adoption confronted with a blocked transaction or other rejection because of an inaccurate response.
Another issue is that injecting AI into every interaction means paying for tokens on top of the base compute and storage resources traditionally consumed by cloud database platforms. Higher productivity and reduced staff costs may more than compensate, but this cannot be taken for granted, particularly as reducing the skill barrier with features like conversational analytics also tends to increase usage.
Giant cloud providers like Google though have plenty to gain. AI, Krishamurthy told us, is driving growth in data storage as well as token usage. He described “a huge overall growth in the business because everyone needs data … Anthropic, for example, rely on BigTable to store all their prompt information. They have other workloads too which are not public.”
Advertisement
Two metrics he is permitted to talk to us about, he said, are that Spanner “now runs 7 ½ billion queries per second at the peak … a year back Spanner might have been 5 billion queries per second.”
Spanner, he said, “has about 23 exabytes of data. It’s the same with BigTable, roughly 7 billion queries per second and double-digit exabytes.”
Models make more queries, he said. “Instead of taking the user request and just sending one query, one pattern I’ve seen is a model will send five different queries … it’s hard to say exactly what is happening because the models are trying different things.”®
On this week’s episode of the Smart Home Insider podcast, Jon Harros from the Matter governing body joins to talk through the latest release of the home automation standard.
Jon Harros is head of testing and certification for the Connectivity Standards Alliance, and he drops in on the podcast from Unify. Unify is the CSA’s first public-facing conference on the smart home and there were many announcements from the week.
We start the episode going through the news. The big release was the Schlage Sense Pro UWB.
This lock will be available to preorder by the end of June and supports Apple Home Key via UWB with Aliro later in 2026. With Aliro, it will also support Google and Samsung wallets.
Advertisement
There was a lot of new television news as of late. During the episode, we talk about HDMI 2.2, Roku, and Philips.
It appears the very first HDMI 2.2 devices will hit the market by the end of 2027. The new standard, with up to twice the bandwidth, will likely start with high-end TVs.
Apple TV is launching on the new 2026 Philips television sets. They are no longer running Google TV and can stream from the Apple TV app with Dolby Vision, Dolby Atmos, and 4K.
Finally, Roku has agreed to be purchased by Fox. Fox will take over the hardware business which compliments its media infrastructure.
Advertisement
The bulk of the episode was dedicated to the new announcements from the CSA. Jon Harros explains the details in Matter 1.6.
Matter 1.6 has many changes, but the most notable is new NFC commissioning that doesn’t require Bluetooth or dedicated power, more context for thermostats, and a Joint Fabric layer for multiple ecosystems to use the same devices.
There was also the Product Security 1.1 release. This time it’s more about extending the security beyond the hardware to apps and software as well.
Links from the Smart Home Insider podcast
Those interested in sponsoring the show can reach out to us at [email protected]
Keep up with everything Apple in the weekly AppleInsider Podcast. Just say, “Hey, Siri,” to your HomePod mini and ask it, and our latest Smart Home Insider episode too. If you want an ad-free main AppleInsider Podcast experience, you can support the AppleInsider podcast by subscribing for $5 per month through Apple’s Podcasts app, or via Patreon if you prefer any other podcast player.























































You must be logged in to post a comment Login