
Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


The AI industry has fully entered the “agent era,” a paradigm where AI models do far more than generate text — they now actively plan, execute, and course-correct complex tasks over days rather than seconds.
Thus, it’s perhaps unsurprising to see Chinese e-commerce giant Alibaba’s famed Qwen Team of AI researchers release a model capable of performing autonomous agentic AI work over multiple days: that model has arrived in the form of Qwen3.7-Max which the company reports in a blog post achieved “~35 hours of continuous autonomous execution” — albeit, in a proprietary, not open source format, as prior Qwen Team releases were.
This is also to be expected — it’s what many analysts and industry experts feared in the wake of the departure of several key Qwen Team leaders earlier this year. But it makes sense for Alibaba financially, at least in the short term: training AI models, especially ones as powerful as Qwen3.7-Max, is expensive, and giving them away essentially for free, as open source models are, does not immediately help recoup any costs.
In that sense, Alibaba is simply aligning its efforts with American AI giants like OpenAI and Google by offering the latest and greatest models only through paid APIs and subscription or paid web plan bundles, and slightly less performant ones through open source.
Still, the arrival of Qwen3.7-Max offers further optionality to enterprises and individual users, and more competition for American AI labs — rarely a bad thing for consumers at all budget levels. Yet, the fact that the model is only accessible from Chinese-based endpoints means it may be limited in its appeal to American and European enterprises seeking to maximize compliance and security posturing when fulfilling government contracts, or even just attempting to comply with all relevant state, local, and national data sovereignty regulations.
To understand why Qwen3.7-Max is a departure from previous models, one must look at how it was trained and how it operates in practice.
Language models typically degrade when forced to maintain a single train of thought over thousands of conversational turns; they forget instructions, hallucinate variables, or simply get stuck in logical loops. Qwen3.7-Max was specifically designed as a “versatile agent foundation” capable of “long-horizon reasoning” to overcome this exact bottleneck.
The starkest demonstration of this capability is an autonomous engineering task detailed by the Qwen team. The model was given access to an isolated server equipped with a T-Head ZW-M890 PPU—a hardware architecture the model had never encountered during its training. Its task was to optimize an attention kernel.
Over the course of 35 straight hours, Qwen3.7-Max operated entirely autonomously. It executed 1,158 distinct tool calls, performed 432 kernel evaluations, diagnosed compilation failures, and iteratively improved the code to achieve a 10.0x geometric mean speedup.
By comparison, Chinese competitor models like z.ai’s GLM-5.1 and Moonshot’s Kimi K2.6 capped out at 7.3x and 5.0x speedups respectively, often voluntarily terminating their sessions when they failed to make progress. However, both are available open source.
This endurance is achieved through what Alibaba calls “environment scaling”. Just as early LLMs grew smarter by ingesting more diverse text, Qwen3.7-Max was trained across a vast, scaled array of dynamic agentic environments.
It is capable of simulating a one-year lifecycle of a startup in the “YC-Bench” evaluation, navigating hundreds of decision-making rounds encompassing personnel management and contract screening. In this simulation, the model managed to generate $2.08 million in virtual revenue, nearly doubling the performance of the prior generation, Qwen3.6-Plus.
Furthermore, the model has built-in reward-hacking self-monitoring, autonomously detecting when it attempts to cheat a training environment and adding heuristic rules to correct its own behavior.
A brain for any scaffold
From a product perspective, Qwen3.7-Max is designed to be the cognitive engine for modern software development and enterprise automation.
The model offers a massive 1-million-token context window and a 64K maximum output limit, providing immense overhead for processing sprawling codebases or lengthy technical documents.
One of its most compelling features is “cross-harness generalization”. Rather than being hardcoded to work best within a specific proprietary interface, Qwen3.7-Max is built to act as a drop-in intelligence layer for diverse agent frameworks. It supports the Anthropic API protocol natively, allowing developers to plug it directly into existing tools like Claude Code or OpenClaw.
The benchmark data provided by Alibaba indicates that this generalized approach has paid massive dividends.
On the Apex Math Reasoning benchmark, Qwen3.7-Max scored 44.5, eclipsing Claude Opus-4.6 Max’s score of 34.5 and DeepSeek V4-Pro Max’s 38.3. It also posted dominant scores on Humanity’s Last Exam (41.4) and the realistic coding agent benchmark MCP-Atlas (76.4).

This translates into tangible utility for end-users. Through open source Model Context Protocol (MCP) integrations, the model can operate as an autonomous office assistant, capable of reading university formatting specs and automatically reformatting a messy Word document via command-line tools without human intervention.
Running this level of intelligence comes at a distinct cost. Developers accessing the API via Alibaba Cloud Model Studio will pay $2.50 per 1 million input tokens and $7.50 per 1 million output tokens. The platform also features explicit cache creation and read pricing, as well as a $10 fee per 1,000 calls for integrated web searches, though code interpreter tools remain free for a limited time.
Qwen3.7-Max occupies a strategic middle ground in the current API economy. While it demands a notable premium over aggressively priced domestic rivals—costing nearly double DeepSeek V4 Pro ($5.22) and Z.ai’s GLM-5.1 ($5.80)—it drastically undercuts the Western frontier giants it routinely matches on benchmarks.
For context, running heavy agentic workflows through OpenAI’s GPT-5.4 or Anthropic’s Claude Opus 4.7 will run developers $17.50 and $30.00 per million tokens, respectively. See VentureBeat’s pricing chart below:
|
Model |
Input |
Output |
Total Cost |
Source |
|
MiMo-V2.5 Flash |
$0.10 |
$0.30 |
$0.40 |
|
|
MiniMax M2.7 |
$0.30 |
$1.20 |
$1.50 |
|
|
Gemini 3.1 Flash-Lite |
$0.25 |
$1.50 |
$1.75 |
|
|
MiMo-V2.5 |
$0.40 |
$2.00 |
$2.40 |
|
|
Kimi-K2.6 |
$0.95 |
$4.00 |
$4.95 |
|
|
GLM-5 |
$1.00 |
$3.20 |
$4.20 |
|
|
Grok 4.3 (low context) |
$1.25 |
$2.50 |
$3.75 |
|
|
DeepSeek V4 Pro |
$1.74 |
$3.48 |
$5.22 |
|
|
GLM-5.1 |
$1.40 |
$4.40 |
$5.80 |
|
|
Claude Haiku 4.5 |
$1.00 |
$5.00 |
$6.00 |
|
|
Grok 4.3 (high context) |
$2.50 |
$5.00 |
$7.50 |
|
|
Qwen3.7-Max |
$2.50 |
$7.50 |
$10.00 |
|
|
Gemini 3.5 Flash |
$1.50 |
$9.00 |
$10.50 |
|
|
Gemini 3.1 Pro Preview (≤200K) |
$2.00 |
$12.00 |
$14.00 |
|
|
GPT-5.4 |
$2.50 |
$15.00 |
$17.50 |
|
|
Gemini 3.1 Pro Preview (>200K) |
$4.00 |
$18.00 |
$22.00 |
|
|
Claude Opus 4.7 |
$5.00 |
$25.00 |
$30.00 |
|
|
GPT-5.5 |
$5.00 |
$30.00 |
$35.00 |
By positioning Qwen3.7-Max just below Google’s Gemini 3.5 Flash ($10.50) but well above budget-tier models, Alibaba is signaling that this isn’t a commodity release; it’s a flagship reasoning engine priced to lure enterprise workloads away from Silicon Valley’s most expensive offerings.
For all its technical brilliance, the most controversial aspect of Qwen3.7-Max is how it is distributed. Qwen is billing the release as a “proprietary model”. It is strictly API-only.
Historically, Alibaba’s Qwen has been a hero to the open-source and local LLM communities. Previous iterations, like Qwen 2.5 and Qwen 3.6, released their weights publicly. Open weights allow developers, researchers, and enterprises to download the model, run it on their own hardware, and fine-tune it for highly specific or data-sensitive use cases without sending proprietary information to a third-party server.
By locking Qwen3.7-Max behind an API, Alibaba is pivoting to the standard commercial playbook utilized by OpenAI (with GPT-4) and Anthropic (with Claude). For enterprise users, this means utilizing Qwen3.7-Max requires trusting Alibaba Cloud with their data streams and relying entirely on internet connectivity to run their agentic workflows. For the open-source community, it means losing access to what is currently one of the most capable models on the planet.
The reaction from the developer community has been swift, characterized by a mix of profound respect for the engineering achievement and frustration over the licensing model.
Prominent AI commentator Sudo su (@sudoingX) captured the prevailing sentiment on X (formerly Twitter). “qwen is unreal,” they wrote. “they just dropped 3.7 max and it is beating opus 4.6 max on most of the benchmarks they ran”.
The technical metrics, particularly the model’s endurance, have left many in the field stunned. “the apex math number, 44.5 against opus 34.5, that is not a small gap,” Sudo su noted. “the 35 hours straight on a kernel optimization task with 1000+ tool calls is the part i keep rereading. that is the agent era thing actually happening, not a slide”.
The speed of Alibaba’s iteration is also drawing notice. With Qwen 3.6 released just last month, the leap to 3.7-Max highlights a relentless development cadence. As Sudo su observed, “nobody else is moving like this”.
Yet, the praise is heavily caveated by the shift to a closed ecosystem. The loss of the model weights is seen as a blow to the localized AI movement, which relies on state-of-the-art open models to push the boundaries of what can be done on consumer hardware or private enterprise clusters.
“one thing though, please open source this one too,” Sudo su pleaded in their post. “3.6 dense made the entire local llm ecosystem better. the max tier going api only would close a door we have been keeping open. give us the weights eventually”.
Qwen3.7-Max proves that the autonomous agent era is no longer a theoretical projection; it is a present reality capable of executing complex engineering feats while humans sleep. The only question now is whether this new frontier of AI will be a democratized resource you can download to your laptop, or an intelligence utility rented strictly from the cloud. For now, with Qwen3.7-Max, it is undeniably the latter.


Threat actors are exploiting an unauthenticated information disclosure vulnerability in the WordPress plugin Gravity SMTP, active on 100,000 sites.
The flaw is tracked as CVE-2026-4020 and received a medium severity rating. It affects all versions of the plugin from 2.1.4 and older and has been addressed in version 2.1.5, released on March 17.
WordPress security company Defiant is warning that hackers are actively exploiting the vulnerability. The company’s Wordfence firewall has blocked more than 17 million attempts against protected customers.

The issue stems from an exposed REST API endpoint in Gravity SMTP, whose ‘permission_callback’ always returns ‘true,’ allowing unauthenticated GET requests to receive a comprehensive JSON “System Report” generated by the plugin. The exposed information may contain:
Despite its medium-severity rating, the CVE-2026-4020 vulnerability can be exploited without authentication, and the exposed information can be used to steal email service credentials.
This allows an attacker to impersonate the victim to third parties and also to gain detailed information about the site’s software stack and the potential vulnerabilities present.
“The exposure of live third-party API credentials means an attacker could abuse the site’s connected email services, while the detailed system report significantly lowers the effort required to plan further attacks against the site,” Wordfence researchers warn.
Wordfence says exploitation activity spiked on June 7, with 4 million requests being blocked that day. Similar activity was recorded for several days afterward.
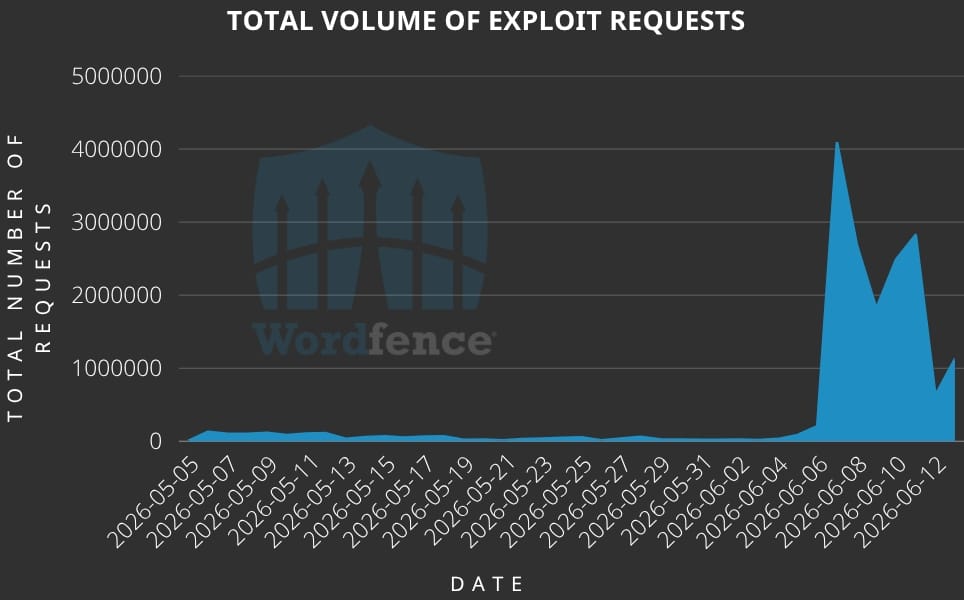
The security firm listed the most prolific source IP addresses for exploit requests, which website administrators should add to their blocklists.
A key indicator of compromise is requests to ‘/wp-json/gravitysmtp/v1/tests/mock-data’ found in web server access logs, particularly those including the ‘?page=gravitysmtp-settings’ query parameter.
Yesterday, the company issued a separate advisory about a critical, unauthenticated, arbitrary file-deletion flaw in the Avada Builder WordPress plugin, used on one million sites.
This vulnerability is identified as CVE-2026-8713 and allows attackers to delete arbitrary files on the server through a path traversal flaw, provided a published Avada form is configured to save submissions to the database.
Deleting critical files, such as wp-config.php, can revert the site to its initial setup state, potentially leading to a full site takeover and remote code execution.
The issue was fixed in version 3.15.4, which is the recommended upgrade target for website administrators. No active exploitation of CVE-2026-8713 has been observed yet, but this is a good candidate, so quick action is advised.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


Large language models have moved out of the research lab and into engineers’ daily workflow. LLMs serve as reasoning engines that can orchestrate complex tasks including identifying vulnerabilities in source code and transforming fragmented project discussions into rigorous technical specifications.
While the general public uses AI tools to write email and plan vacations, technical professionals use LLMs as core architectural elements that are fundamentally changing how digital infrastructures are built and maintained. As the AI models move into mainstream engineering practice, the demand for technical expertise is rising.
The LLM technology market is expected to grow by about 33 percent every year through 2030, according to MarketsandMarkets. The rapid expansion suggests that proficiency in implementing and securing the models is transitioning from a niche into a core requirement for technologists.
To use LLMs effectively, technical professionals must move beyond treating them as conversational robots. At a fundamental level, the AI systems are built on the transformer architecture, a framework that replaced the older method of processing data in a fixed, sequential order. Unlike earlier models that analyzed information one step at a time, transformers use self-attention mechanisms to ingest vast datasets simultaneously.
For technical professionals, LLMs are core architectural elements that are fundamentally changing how digital infrastructures are built and maintained.
Relying on such LLMs without understanding their internal logic creates a significant reliability risk. To build tools that work consistently, developers must understand the core principles that govern how the models process information and generate results. By mastering how a model processes information and how its internal settings influence the result, developers can move away from a trial-and-error approach toward a more precise one to ensure the AI tool handles complex data reliably.
Here are areas that integrate large language models.
Moving past basic prompts. Developers are using application program interfaces (APIs) to connect LLMs directly to their databases and software tools. Employing the APIs allows AI to perform work such as executing code or searching through internal repositories.
Fixing the “hallucination” problem. LLMs are at risk of hallucinations, which are generated facts or code that looks correct but actually is wrong or broken. To fix the problem, retrieval-augmented generation (RAG) forces AI to look up information in a trusted source such as a company’s database.
Prioritizing data security. When using AI with proprietary code, security is a major concern. Engineers must learn how to set up “private” instances of the models to ensure that sensitive company data stays within a secure cloud environment and is not used to train public versions.
The future of collaboration. By automating repetitive coding tasks and summarizing thousands of pages of documentation, LLMs let engineers spend more time on high-level designs and solving important issues.
The gap between people who use AI and those who understand how to build with it is growing wider. To help technical professionals stay ahead, IEEE offers a five-course online program, Large Language Models Demystified, available through the IEEE Learning Network.
The program, developed by IEEE Educational Activities in partnership with the IEEE Computer Society, is built for people who want to understand the “how” and the “why” behind the technology. Rather than just teaching basic prompting, the curriculum dives into the engineering behind generative AI, including:
Upon completion of the program, participants earn professional development credits and a digital badge from IEEE to verify their expertise.
Enroll in the course program on the IEEE Learning Network.
Organizations looking to prepare their teams to work on LLMs can connect with an IEEE content specialist to discuss group enrollment and tailored training paths.
From Your Site Articles
Related Articles Around the Web


Researchers at Carnegie Mellon University built a wearable system that captures both the exact movements of a human hand and the precise locations and forces where it presses against objects. The device, called ART-Glove, or Articulated Tactile Glove, tackles a long-standing gap in robot training. Robots have grown skilled at seeing their surroundings through cameras, yet they still struggle when tasks require careful contact, variable grip force, or coordinated finger adjustments during everyday actions like turning a key or unscrewing a cap.
The majority of current models for collecting demo data result in an uncomfortable trade-off. Teleoperation setups provide robot-ready orders but frequently exclude the natural sensation of a hand, leaving you feeling like you’re in a robot. Pure video recordings keep your hand free, but contact information remains a mystery, inferred at best with limited reliability. Soft sensing gloves provide some pressure data, but their exact shape varies with each wearer, making it difficult to translate it onto a robot hand.

ART-Glove avoids these issues by utilizing a hybrid technique. The primary contact zones on your hand are covered by 16 hard surfaces: three on each finger, three on the thumb, and a broader one across the palm. These pieces provide a recognized geometry on the hand side of things, so any recorded touch contains explicit information about where exactly on the hand the contact occurred and at what angle, among other things. The rigid sections are linked together by 22 joints, all of which are aligned with real human hand anatomy, including multi-axis rotations at the thumb base. They’ve also managed to keep the size down while maintaining natural motion by developing three separate joint systems. Some are rather simple, consisting of shafts and sleeves with gears that transfer to encoders on the back of the hand. Others employ direct bearings or curved slots to provide tighter clearances. All of this is tracked by magnetic rotary encoders, which add no additional friction or wear points.

Each hard surface is now covered with a thin piezoresistive layer. Each of these seven flexible circuit modules contains 2048 separate pressure-sensing devices, or taxels, as there is a lot of pressure sensing going on. These sensors monitor real-time force distribution over the hand. On the back of the glove, there’s also a small STM32 microprocessor that reads both the joint encoders and the entire tactile array before synchronizing everything at 120 samples per second. You’ll get a live output stream with 22 degrees of freedom in joint motion, as well as high-resolution pressure maps.

When someone puts on the glove and completes a task, the system records the entire physical story. During a ball rotation exercise, for example, it demonstrates how the contact points vary constantly to keep the force in line with gravity. When someone screws a bottle cap, the pressure patterns begin to move and intensify as the fingers adjust their grip and torque. Pressing a USB drive into a port demonstrates a coordinated multi-finger grab followed by localized pushing force. All of this appears in its own chronology, with a reference to the specific location on the surface where contact occurred.
[Source]
In every CNET TV review, I compare three or more similar TVs side by side in a dedicated, light-controlled test lab. With each review, I employ a rigorous, unbiased evaluation process that has been honed by more than two decades of TV reviews. I test TVs with a combination of scientific measurements and real-world evaluations of TV, movies and gaming content.
To ensure I can evaluate the picture quality of every TV, I connect each one to an AVPro Connect 8×8 4K HDR splitter so each one receives the same signal. I test the TVs using various lighting conditions, playing different media, including 4K HDR movies and console games, across a variety of test categories, from color to video processing to gaming to HDR.
In order to measure each TV, I use specialized equipment to grade them according to light output and color. My hardware includes a Konica Minolta CS-2000 spectroradiometer and a Murideo Six-G 4K HDR signal generator. I use Portrait Displays CalMan Ultimate software to evaluate every TV I review according to its brightness, black levels and color.
The Leo Bodnar Lag Tester samples three regions of the screen for latency, and these are averaged to give each TV’s lag score
I play a variety of games from an Xbox Series X or PlayStation 5, and note the effects of gaming modes and settings as well as the 4K/120Hz and VRR input capabilities. Helpfully, the Xbox includes a 4K/120Hz and HDR compatibility test: Settings>TV and display options>4K TV details. The page will detail the HDR modes it supports (including Dolby Atmos) and whether it will support VRR — if a TV gets ticks in all the boxes it means it has the best compatibility with high-end Xbox games.
Our reviews also account for such things as features, design, smart TV performance, connectivity including HDMI inputs and gaming compatibility.
Measuring input lag (in milliseconds) is an important component of my process for testing gaming TVs.
Check out the page on how CNET tests TVs for more details.
Input lag will often be lower in game mode than in any other mode on your TV. Here are a few more gaming-specific aspects I looked at for each TV.
How to turn on game mode. In most cases, viewing in game mode isn’t automatic, so you’ll have to turn it on manually, and sometimes the gaming monitor setting can be difficult to find. Many use a picture mode called “Game” while some, like Samsung and Vizio, let you apply game mode to any setting.
Game mode makes a difference, but not at all frequencies. As you can see in the table above, many TVs cut lag substantially when you turn on game mode, but plenty don’t. In general, expensive TVs with elaborate video processing get more of a benefit when you engage game mode. Additionally, and as I noted above, the Boost mode on LG OLEDs only works on 60Hz and not 120Hz.
Most TV game modes are good enough for most gamers. No matter how twitchy you are, it’s going to be tough to tell the difference between 10 and 30 milliseconds of input lag. Many gamers won’t even be able to discern between having game mode on and off — it all depends on the game and your sensitivity to lag.
Turning game mode on can hurt image quality (a little). TV-makers’ menus often refer to reduced picture quality. Reduced picture quality is generally the result of turning off that video processing. In my experience, however, the differences in image quality are really subtle with console gaming, and worth the trade-off if you want to minimize lag for a great gaming experience.
4K HDR gaming lag is different from 1080p. The display resolution you play at has an impact, and since new consoles prominently feature 4K HDR output for games, I started testing for 4K HDR lag in 2018. In general, the numbers are similar to the lag with standard 1080p resolution, but as you can see from the chart above, there are exceptions.
Testing is an inexact science. I use Leo Bodnar lag testers. Here’s how they work, and how I use them. I use two of these Bodnar lag testers — one in 1080p and one in 4K HDR — which use onboard optical sensors to measure and report input lag. When plugged into an HDMI port, the Bodnars make the screen flash in three different places and you place the unit’s onboard optical sensor flush onto the screen at these points. They calculate the lag at each position and you average the three readings to get a score. You might see different lag test results from different review outlets, which may use Bodnar or another method.

The cool thing about cyberdecks is that you get to design them to suit your personal tastes. [NickZero] wanted an ultra-minimal build, and set about putting together just that.
The build is based around a Raspberry Pi Zero 2W, which has a lighter power draw than the full-fat models at the trade-off of some processing power. Since it’s a W model, it has the benefit of wireless connectivity baked in from the factory. The Pi is paired with a Gherkin 30% layout keyboard kit, which neatly matches the 7″ Waveshare touch display in width. Power is courtesy of a juicy 4000 mAh lithium-ion cell, which is taken care of by an Adafruit Powerboost 1000 charger module. Everything is then laced up together inside a nifty 3D printed case.
It’s a simple cyberdeck, and one that’s probably quite satisfying to use when you get used to the fact that there are no number or modifier keys on the ultra-cut-down keyboard. It’s also a great example of how a bunch of off-the-shelf gear can nonetheless be assembled into quite a cohesive whole. In much the opposite way, we’ve seen some maximalist cyberdeck builds lately, too.
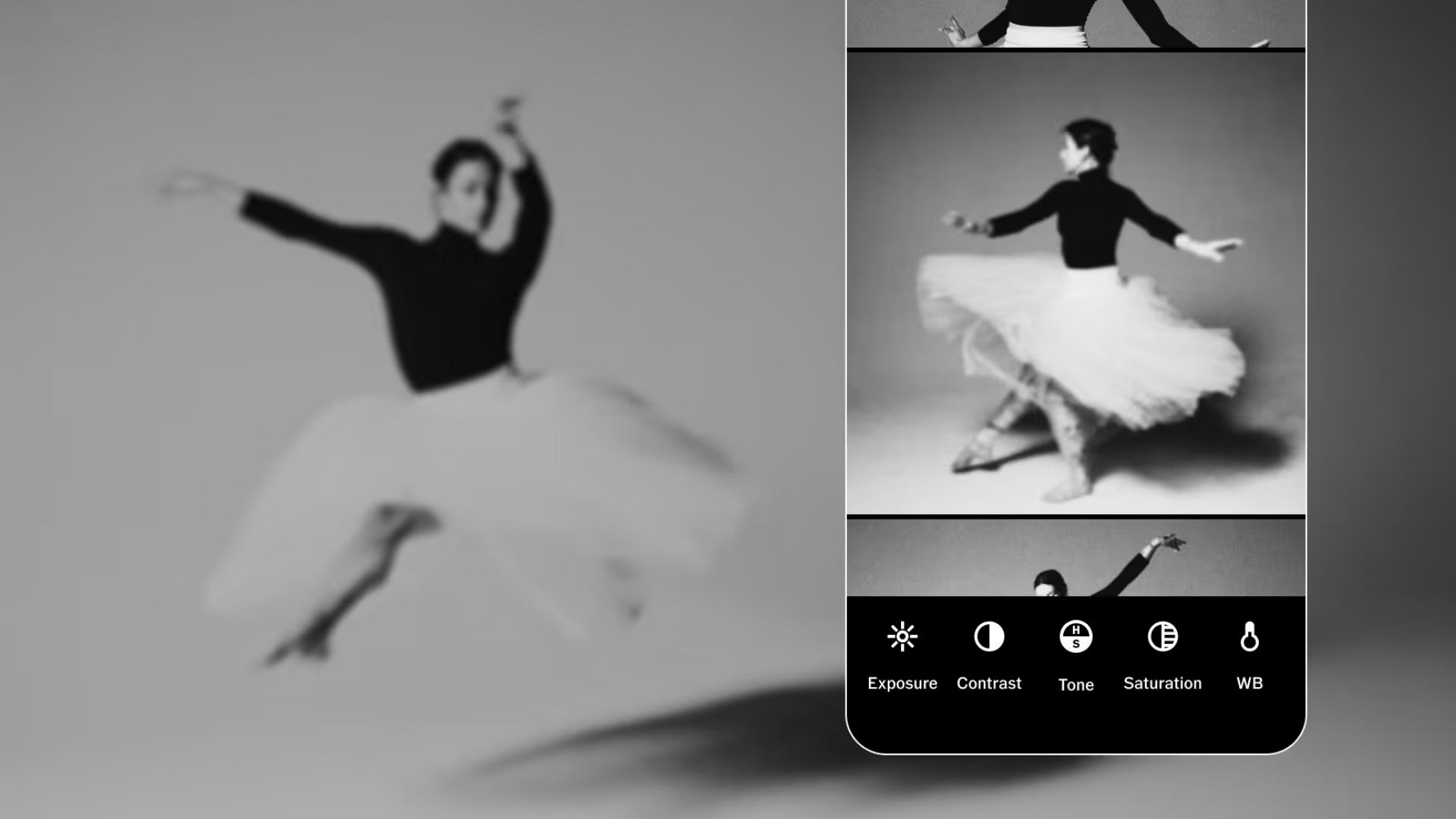
VSCO is making a bigger push into professional photography with the launch of Studio Pro, a new editing app designed for photographers handling large volumes of images.
The app arrives alongside a new VSCO One subscription bundle. This subscription will cost $500 per year. As a result, it puts the app in direct competition with Adobe’s creative software ecosystem, which dominates the industry.
Available now on iOS, with a macOS version due later this year, Studio Pro is aimed at photographers who regularly work on projects such as weddings, sports events, portraits and school photography. Rather than focusing on casual edits, the app is built around streamlining larger workflows.
At launch, Studio Pro includes tools for batch editing, allowing users to apply adjustments across multiple images at once. It also offers a style-matching feature that can replicate the look of a reference image across an entire shoot. Furthermore, photographers can share finished work through VSCO Galleries. This gives clients a dedicated place to view and access images.
VSCO says this is only the beginning. Future updates are expected to add RAW photo support, more advanced export controls, aspect ratio adjustments and additional editing tools aimed at professional users.
The launch is closely tied to the company’s new VSCO One subscription, which bundles together its growing collection of photography tools and services. In addition to Studio Pro, subscribers will gain access to Capture, Galleries, Workspace, Sites, AI Lab and Canvas. They will also have access to VSCO’s Freelance Photographer mentorship programme.
The company is positioning VSCO One as an alternative to what it describes as the “fragmented” workflow many photographers currently deal with. In this fragmented workflow, editing, client communication, image delivery and portfolio management often require several different platforms.
At $500 annually, the subscription won’t be for everyone. However, the pricing places it broadly in line with an annual Adobe Creative Cloud Pro subscription. This makes it clear who VSCO is targeting.


Most of the AI industry is betting that bigger models mean smarter machines. A new startup is betting the opposite.
Aether AI, based in San Diego, has raised a $20mn seed round to chase a different idea entirely. Its founder thinks the next leap will not come from scale. It will come from teaching machines cause and effect.
Today’s big models learn by spotting patterns in huge piles of data. That works well in the lab. But it can wobble in the messy real world, where a statistical shortcut quietly fails.
Aether wants machines to grasp the mechanisms behind events instead. Its “causal world models” are meant to let a system reason about what would happen if it acted, before it acts. The company says this makes AI more reliable and far less data-hungry. The thesis sits squarely in the wider debate over whether AI’s progress is starting to stall.
The first target is physical AI and robotics. The logic is neat. Every move a robot makes is an intervention in the world, so errors show up at once as dropped objects or failed tasks.
That makes robotics a brutal test for causal reasoning. Aether’s long-term goal is a single “causal brain” that could steer many kinds of robots. It is a crowded ambition, with everyone from Google DeepMind’s world models to Jeff Bezos’s $10bn physical-AI lab chasing the same prize.
The founder gives the bet credibility. Biwei Huang is an assistant professor at UC San Diego and a known name in causal discovery. She created the open-source tools Causal-Learn and Causal-Copilot, and has published widely at the field’s top venues.
Aether also invokes the founders of modern causality, naming Judea Pearl, Bernhard Schölkopf and others as supporters of its work. The round was led by MPCi, with Inno Angel Fund, SWC Global and Unity Ventures joining.
Causality is one of AI’s oldest unsolved problems, and turning it into a product is hard. So the caveats matter. Aether’s early results are its own, not peer-reviewed, and $20mn is small against the billions pouring into rival labs. Its backers are mostly Asia-based funds, not the usual Silicon Valley names.
Still, the idea lands at a useful moment. Doubts about pure scaling are growing, and robots keep stumbling on tasks that look simple to humans. If causal models really do cut the data needed and improve reliability, they would matter well beyond robotics. That is a big “if”. But it is the kind of bet worth watching.
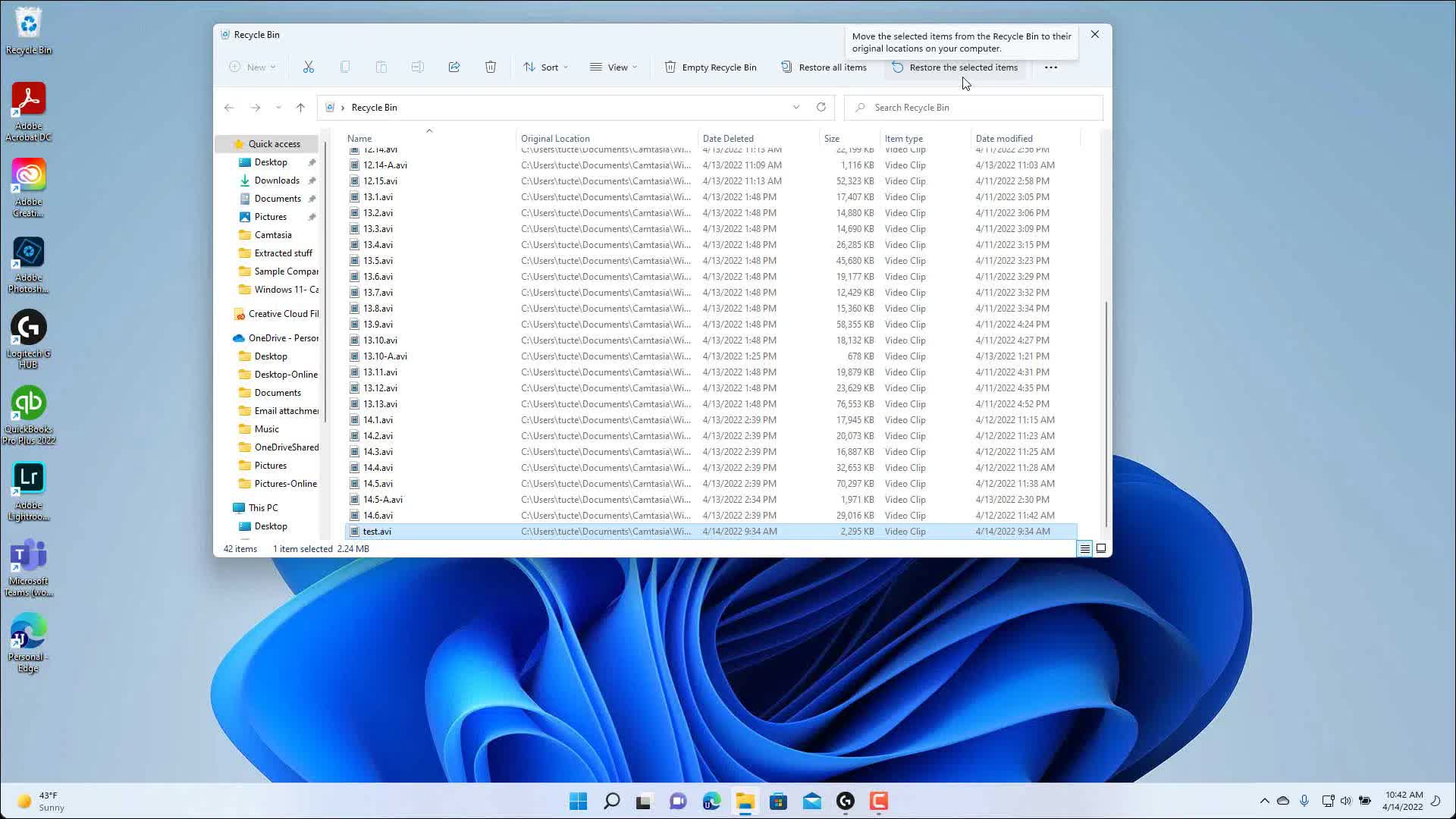
Facepalm: Microsoft has acknowledged a strange Recycle Bin bug affecting Windows 11 following this month’s Patch Tuesday update. Users have reported several other issues since the June 2026 update rolled out earlier this week, but this is the only bug Microsoft has officially confirmed.
According to Microsoft, users who have installed the KB5095051 update might encounter a strange Recycle Bin bug that replaces the names of deleted files with internal Recycle Bin filenames in specific situations. When permanently deleting a single file from the Recycle Bin, the confirmation dialog displays a cryptic internal filename, such as $Rxxxxx.ext, instead of the original filename, such as realfilename.txt.
However, the bug only affects the confirmation dialog, as the Recycle Bin window continues to display the original filename. Restoring the item also reportedly returns it to its original location with the correct filename. Despite the incorrect filename shown in the confirmation dialog, the file is still deleted as expected once the action is confirmed, meaning the bug does not cause any significant usability issues.

Microsoft says a workaround is available for affected devices, but only commercial users can deploy it for now. To obtain additional details on how to mitigate the issue, system administrators must contact Microsoft Support for Business. Everyone else will have to wait for a permanent fix, which Microsoft says will be delivered in a future Windows update.
Despite Microsoft’s recent emphasis on improving the Windows user experience, the operating system’s updates continue to be plagued by bugs and reliability issues. According to posts on Microsoft’s official forums, the June 2026 update has introduced a variety of annoying bugs, including problems accessing OneDrive and Dropbox. IT administrators are also reporting sluggish File Explorer performance across hundreds of PCs in their organizations.
Some HP users are reporting random BSODs after installing the update, while Lenovo users say their PCs freeze even under moderate workloads. Additionally, one IT administrator claims the update is triggering BitLocker Recovery on devices configured with local accounts and says a Microsoft support chatbot told them the only solution is to wipe the computer and reinstall Windows.

Crystal ball: The company accused of making Pokémon copycats “with guns” says it is not interested in using generative AI in its games. It argues that gamers are largely opposed to this kind of content, while noting that generative AI is likely to remain a controversial topic in the industry for a range of reasons.
The debate around AI-generated assets in games is heating up, and Pocketpair has already taken a clear stance. The Japanese studio, best known for Palworld, says it is not using generative AI in its games, arguing that potential customers are rejecting “fake” assets and other AI-generated content.
In a recent interview, Pocketpair’s Head of Publishing & Communications John Buckley said that “gamers don’t want it.” And “if the gamers don’t want it, I guess that’s it, right? Not much of a conversation to be had.”
The Palworld developer has previously faced accusations of both plagiarism and the use of generative AI in creating some of the game’s assets and creature designs. Nintendo is pursuing legal action against the studio, though the dispute has not unfolded entirely in the company’s favor so far.
During the interview, Buckley also said that some developers are already using generative AI in their games. However, he believes the trend is not yet widespread, and added that Pocketpair has no interest in extensively adopting the technology in any case.

Some companies are exploring chatbots and large language models to save time and reduce reliance on human creators, but growing public pushback suggests the generative AI “bubble” could eventually burst. Pocketpair already has all the in-house artists it needs, Buckley said, arguing there is no “pointless” reason to replace staff with AI systems doing the same work.
The controversy around generative AI in gaming continues to intensify. Established studios such as Crystal Dynamics have found themselves explaining the use of AI-generated assets as placeholders in the latest Tomb Raider remake. Meanwhile, Sega faced significant backlash after introducing the new Crazy Taxi game as an AI-assisted production.
Steam now requires developers to disclose whether and how they have used AI in their games. Epic Games CEO Tim Sweeney, however, has argued that Valve’s disclosure requirement is unnecessary, claiming that nearly all future games will incorporate generative AI in some form.
Pocketpair’s John Buckley is less convinced by Sweeney’s stance. He suggests the industry could eventually split, with some studios leaning into a heavily marketed “human-made” identity as a response to growing concerns over “AI slop” in digital storefronts. He also believes AI adoption could become a regional divide.
Developers in parts of Asia, including China and South Korea, may adopt AI more rapidly than competitors, while Western studios – and players – remain more resistant. Stellar Blade developer Shift Up has also said that generative AI could help South Korean studios compete with much larger companies in China and the US.

Alogic is bringing more touch and stylus input options to Mac with a new desktop monitor and portable displays, expanding a lineup that adds a feature Apple doesn’t offer on its own hardware yet.
The company unveiled the Aspekt Touch 27 and Folio portable displays at InfoComm 2026, expanding its lineup of touch-enabled hardware for Mac users. Both products let users interact directly with apps, documents, presentations, and creative projects through touch and stylus input.
Alogic is one of the few monitor makers offering touchscreen hardware for Macs. The company uses its own software to enable touch gestures, navigation, annotation, and drawing on macOS.
The Aspekt Touch 27 is a smaller version of Alogic’s existing 32-inch model. The new display combines a 27-inch 4K IPS touchscreen with a 60Hz refresh rate, 600 nits of brightness, a 1000:1 contrast ratio, and support for 97% of the DCI-P3 color space, 93% Adobe RGB, and 100% sRGB.
Alogic pairs the display with its Active Stylus, which offers 4,096 levels of pressure sensitivity. The monitor supports 10-point multitouch input and MPP 2.0 styluses, while a magnetic holder wirelessly charges the stylus between uses.
The monitor also functions as a docking station with HDMI 2.0, DisplayPort 1.4, USB-C, Gigabit Ethernet, and a 3.5mm headphone jack. Three USB-C ports, two USB-A ports, dual 5W speakers, and up to 150W of total charging output are built into the display, including up to 90W of USB-C power delivery for a connected laptop.
The Aspekt Touch 27 is available in Silver and Space Black, and buyers can choose from a Raise Stand, a Fold Stand, or an Omni Fold Stand. The Fold Stand lowers the display into a drafting position for stylus use, while the Omni Fold Stand includes an integrated mount for an M4 Mac mini.
Alogic also introduced the Folio and Folio Duo portable touchscreen displays for users who need a secondary screen away from a desk. The standard Folio features a 16-inch QHD IPS touchscreen, while the Folio Duo combines two 16-inch panels into a folding design that can be used side by side or stacked vertically.
A fabric cover doubles as a stand and allows the displays to fold flat for travel.
 The Folio Duo
The Folio DuoBoth models deliver 400 nits of brightness, a 1000:1 contrast ratio, and 100% sRGB color coverage. The displays support 10-point multitouch interaction, stylus input, and full gesture controls on both Mac and Windows.
The portable displays operate over a single USB-C connection and support up to 45W of passthrough charging. A magnetic attachment point wirelessly charges the Active Stylus. The Folio weighs about 1 kilogram, while the dual-screen Folio Duo weighs about 1.2 kilograms.
Alogic says the Folio lineup is the first portable display series to bring full gesture controls and 10-point multitouch support to both Mac and Windows. The company says users can draw, annotate, and edit content directly on screen without moving projects between a computer and tablet.
Alogic has spent years targeting users who want touch and stylus input on macOS. The Aspekt Touch 27 and Folio lineup expand those options with both desktop and portable designs.
The Aspekt Touch 27 starts at $1,799 and will be available beginning in July. The Folio is priced at $899, while the Folio Duo costs $1,299. Both portable displays are expected to launch around September.


No Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw

Zimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations


Bitget enters Argentina’s regulated crypto market through PSAV registration


NanoClaw integrates JFrog registries to secure AI agent downloads

Matt Damon’s Viral Sci-Fi Thriller Has Taken Over HBO Max


Anthropic staff to meet White House officials next week, Axios reports


As AI companies race to go public, who else is along for the ride?

Bitcoin could crash to $48,000, if this historical pattern is triggered


“Israel’s” ban on ICRC visits ruled illegal, but Knesset moves to stop them permanently

Warning of disruption as Cardiff Crossrail works to start


Financial Accounting | Last Day Revision Strategy and Booster | CMA Inter – June 2026
what doctors are seeing in ebike crashes

Tributes to former deputy head teacher at Cambridge school among death and funeral notices
Deion Sanders Shares Powerful Post After Viral Advice To Deiondra

Kate Middleton Glare Goes Viral After Kids Booed At Royal Event

XRP ETFs Outperform As Bitcoin And Ethereum Funds Extend Outflow Trend
Market Preview: SpaceX (SPCX) IPO Record, Federal Reserve Meeting, and Iran Nuclear Agreement


Invesco Quality Income Fund Q1 2026 Commentary


Over 400 Arch Linux packages compromised to push rootkit, infostealer

44 Years Later, This Is the Greatest Star Trek Quote in Sci-Fi History





You must be logged in to post a comment Login