
Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.




In 2018, Amazon brought me in as the lead UX Sound Designer for Astro, their first consumer home robot. Astro used cameras and other sensors to map and navigate your home and workplace, and could proactively patrol, check up on loved ones, and transport small items using its built-in cargo bin. While there was a well-defined feature set and form factor, initially there was no character direction. In fact, even before Astro had a name, there were two main questions—was it simply Alexa on wheels, or was it a robot with its own character?
The Astro team was divided. One option was to focus on Alexa, and treat the mobile robot simply as an added utility. I argued for Astro to not focus on Alexa, along with the majority of the UX team. Our belief was that a thing that moves through your home and turns toward you with intent can never be just an appliance. People would ascribe character to whether we wanted them to or not, and so the only question was whether we shaped that character or let it happen by accident.
Ultimately, Astro became Astro rather than Alexa, and user testing backed up our decision. People didn’t see the robot as Alexa. They saw it as its own character, and that’s what they wanted it to be. Alexa on the device felt somewhat strange and creepy, but building Astro its own voice was too slow and expensive in 2018. So, we settled on Alexa as a supporting character that handled any actual talking, while Astro was the main character, communicating as much as it could without words, through sound, motion, and facial expressions.
I had been brought on to the Astro team to define the robot’s sound design language and voice. But there was no one to flesh out the robot’s actual character. You cannot make a single real decision about a character without defining it first. Every choice about how Astro moved, sounded, paused, or reacted was a character choice, and those choices required all disciplines working together. As Sound Lead, I was weaving together sound, motion, and character, and how they played together inside each story moment. The animators, who programmed Astro’s motion and facial expressions, were extraordinary at what they did, but the emotional arc they were animating came from the sound (and therefore character) work first. So I stepped into that role, which is where my real work started. What I learned about building character for robots applies to nearly everything being built in embodied AI right now.
Developing a character for Astro meant answering questions that had never been asked about a product at Amazon: What is the emotional range of this robot’s baseline state? How does this robot communicate uncertainty without eroding trust? Where is the line between being expressive and annoying? What are the vulnerabilities of this device’s character?
These are design questions. They have real answers, and every team working on the product has to build from them. For example, Astro’s emotional range was designed to be relatively small at first. We never wanted Astro to get too sad or too angry. It could play sad, but would snap out of it quickly and end the reaction on a high note to keep things positive.
Character leaks out of every seam and can create a disjointed experience if not defined correctly. Even if it’s just animation timing that’s slightly off, or a response that’s technically correct but contextually tone-deaf, users feel every one of these inconsistencies, even if they can’t name them. Watch what happens at the beginning and end of this Sing sequence:
Astro goes from nothing, into the emotional moment, and then lands back on nothing. No build up, no cool down, no sense that the feeling came from somewhere or had anywhere to go. I pushed hard for better character stitching, the transitions in and out of expressive moments that make a performance feel continuous rather than assembled, but it never got implemented. The moment itself works. But without the stitching, it reads as a clip playing on a robot rather than coming from within the robot character itself.
We had decided that Astro would have no spoken dialogue, but it had something that functioned the same way: a vocabulary of sounds, tones, and rhythms that acted as its voice. This vocabulary became the leading output of the character’s personality. The robot’s motion and facial expressions were built around it.
Astro’s wake-up sequence is a great example. Waking wasn’t just a boot animation on the screen; it was an entire performance. Slow and humble at first, the robot oriented itself quietly, then stretched its screen, checked its wheels, and finally, with an upward gesture toward its telescoping mast, it popped it up slightly, and did a little dance of joy. Sound, motion, and eyes hit every beat together in full choreography.
The character’s output in that sequence was first written as a story. Astro is waking up in its new home for the first time. Its main aspiration is to be part of a family, so this is the moment it has been waiting for, this is its purpose. Being the responsible character that it is, it wants to make sure everything is good to go before it introduces itself and starts learning its new home.
This narrative came first because it drove every other decision that we made. After the story was written, sound gave that story a metaphorical voice: the excited tones, the pacing as it checked its wheels, and the bright melodic phrase as Astro looked up at its new family for the first time and introduced itself. Once the sound was laid down, animation did their thing with motion and facial expressions, taking cues from the emotional arc the sound had established. Motion didn’t lead—it followed the feeling of the story and the sounds, the same way an animator follows a recorded vocal take.
That wake up sequence became one of the most-discussed moments in early user testing. People described it as “alive.” What they were responding to wasn’t any single element. It was all three channels (sound, motion, and facial expressions) expressing the same defined character in harmony.
The most compelling characters are defined not by a fixed disposition but by how they respond to their environments and the people in them. They’re still recognizably themselves even as they adapt. This is what I call contextual character. A robot living in a home doesn’t occupy a single emotional state. It moves through rooms with different energy, encounters people in different moods, operates at different times of day, and responds to an endless range of social situations it was never explicitly designed for.
We got close to a contextual character output with Astro’s sound. When a specific piece of environmental context was fed in, the system adapted beautifully, and Astro felt completely alive. But every state like this was still a prediction we made by hand—a situation we had to imagine in advance and design a response for. A random home throws more situations at a robot than anyone can possibly predict, so there was always a longer tail of moments the system was never prepared for.
The difference between a product people describe as “smart” and one they describe as “aware” often comes down to this. Smartness is capability. Awareness is context. Presence is character. And character is always in reaction to the people around it, to its environment, to its own evolving state. That’s what makes it feel like something is emotionally present with you.
This is where AI changes the game for character design in ways that go well beyond what was possible with Astro. AI-driven adaptation doesn’t require the contextual predictions that we relied on. It learns the specific rhythms, preferences, and emotional context of the people it lives and works with. The character doesn’t just respond to context. It grows into it.
The character and soul of the impending wave of embodied AI products appears to almost always be an afterthought. And character defined late is character defined by default. It becomes the sum of a thousand small decisions made by different people thinking about anything but character. People project character onto devices whether you plan for it or not, especially if those devices move—a robot that moves is already a character. If nobody has designed this character, the result will be products that feel like nothing, or worse, feel confusing and not trustworthy. Technically impressive, but lifeless.
We did not get this fully right with Astro. So many things were moving in parallel that character was rarely treated as a utility, and it made sense why. When you are building a first-of-its-kind product, the things that are the loudest are the ones that break, the deadlines, the costs, the features a customer can point to on a box. Character is quieter than all of that. It’s easy to assume it can come later. On a team as large as the Amazon Astro team, it’s lucky to get any idea onto the roadmap when it is competing with a hundred others that all feel more urgent in the moment. None of this came from people not caring. It came from character being the kind of thing that is hard to prioritize until you see what its absence costs you.
If you are building a product that will share physical or conversational space with people, three things are worth considering:
Define character before you define interactions. You need a defensible character with enough emotional logic to answer hard questions consistently. Find answers to character questions early, and have every discipline build from the same foundation.
Build story and sound into the character pipeline, not the production pipeline. Story and sound developed alongside character definition has the chance to inform motion, expression, and interaction logic. This requires a different kind of collaboration, and a different kind of hire.
Design for adaptation, not just consistency. A consistent character is necessary, but the products that will matter most in people’s lives are the ones that deepen through use. The infrastructure to support that is more and more accessible, but the design thinking to take advantage of it is still rare.
An unabridged version of this story can be read on Medium.
From Your Site Articles
Related Articles Around the Web

Honor of Kings is increasing its reach in India through the release of HOK Plus 2.0. This update comes with various enhancements, including more rewards, improved gameplay, creator programs, and esports developments. Another feature of this update is a new character named Devara, who draws inspiration from Indian culture.
Honor of Kings is rolling out a ₹10 million reward program for its users in India with the launch of HOK Plus 2.0. Through “Play to Earn”, players will be motivated to play the game, create content, participate in campus activities, and socialize. Players will get the opportunity to participate in the Treasure Hunt game and stand a chance of winning smartphones and Amazon gift cards. Honor of Kings will give even greater rewards to players as part of its celebration on June 27.
HOK Plus 2.0 will introduce Devara, a hero inspired by India, in the game Honor of Kings. Devara battles at the Clash Lane and uses his lightning abilities when he is battling. He is able to deal massive damage and perform well from the front line. Honor of Kings has been inviting people to suggest Hindi lines for their heroes. Some of these lines have been selected and used in Devara’s voice lines, which were recorded by Sanket Mhatre.
The launch of Devara will be marked by a range of offline events in Delhi, Mumbai, and Bengaluru. These will allow gamers to experience themed activities and engage with other players. The events aim to celebrate the hero’s debut and strengthen the game’s connection with its Indian player community.

HOK Plus 2.0 introduces new opportunities for content creators through HOK Studio. The new creator policy rewards content creators for strong performance and regional rankings. Selected creators can move into the HOK Advanced Creator Program and receive exclusive benefits. The company has also partnered with Live Insaan to support community growth. Players will soon be able to join influencer-led teams in the HOK India Influencer Team Tournament.
Honor of Kings is also bringing new activities to campuses and gaming cafes across India. The campus program will cover 32 colleges in four cities between July and September. Students will have opportunities to compete, create content, and engage with the community. The game will also organize Devara-themed 1v1 challenges at selected gaming cafés. Participants can earn rewards and compete for cash prizes and smartphone giveaways.
Revenant XSpark has qualified to represent India at the 2026 Asian Games Esports Qualifiers. The team claimed its place by winning the NESC 2026 LAN Grand Finals held in Pune. The competition in Kuala Lumpur brings together top teams from across the region. Successful teams will secure spots at the 20th Asian Games in Nagoya, Japan. Their qualification showcases the progress of India’s Honor of Kings esports ecosystem.
There are new updates in Honor of Kings to enhance its gameplay through HOK Plus 2.0. The players can get familiar with Annette, Lorion, and Florentino in Arena of Valor. Users can discover Super Flow Brawl 2.0 and apply strategic thinking and gameplay mechanics in this mode. There are even certain events happening during the match to affect its flow.
June 27 marks the date of the Peak Day festival, where players in Honor of Kings will have various opportunities to get rewarded during the event. Participants in the event will be able to engage in specific activities, collaborations, and community events at the festival. There are limited-time vouchers and unique collectibles for the participants. The participants will have access to free heroes and bonuses at the festival.


Collaboration between LEGO and Koenigsegg built a vehicle that turns heads for all the right reasons. The two companies created a full-scale version of the Sadair’s Spear using LEGO Technic pieces, and the finished machine drives under its own power on real roads and courses.
Over 327,906 unique components went into this massive effort, which resulted in an automobile weighing a whopping 1800 kilos, despite the fact that the bricks themselves only accounted for about 400 kg. The long and laborious procedure came to a conclusion after almost 9,400 hours of work, when the team gave their approval and declared it ready for testing.
Sale

The entire car is built from the ground up on a lightweight body made of LEGO Technic pieces, while a custom-made chassis underneath handles all structural stresses and houses the electric motor and complex mechanisms that bring this cool car to life, and then there’s that one show-stopping feature we can’t get enough of. The car has a working Ghost Mode, a trick that the real hypercar does as well, in which the rear body portion lifts up, the dihedral synchro-helix doors swing out on their own, and the mirrors fold flat.



The next challenge came on the Goodwood hillclimb track in the United Kingdom. Markus Lundh, the test driver, drove the brick-built automobile up the famed incline in reverse configuration, reaching a high speed of 111 kilometers per hour, or 69 miles per hour in the United States. This figure more than twice the previous record for the fastest drivable LEGO car manufactured by the LEGO Group.



Markus said he had a great time driving the thing; it reminded him of the time he got the Sadair’s Spear to the top of that hill the year before, but when he took the LEGO version up, he was particularly impressed with the engineering that the Technic team did. The massive life-size creation corresponds with a new official 1:8 scale LEGO Technic model of the same car, which has 4,104 pieces and reproduces many of the same features, but at a scale that allows it to be displayed on a desk or shelf. The smaller counterpart also includes a working Ghost Mode sequence, a detailed V8 engine with moving parts, a 9-speed transmission that moves, and suspension at both ends.
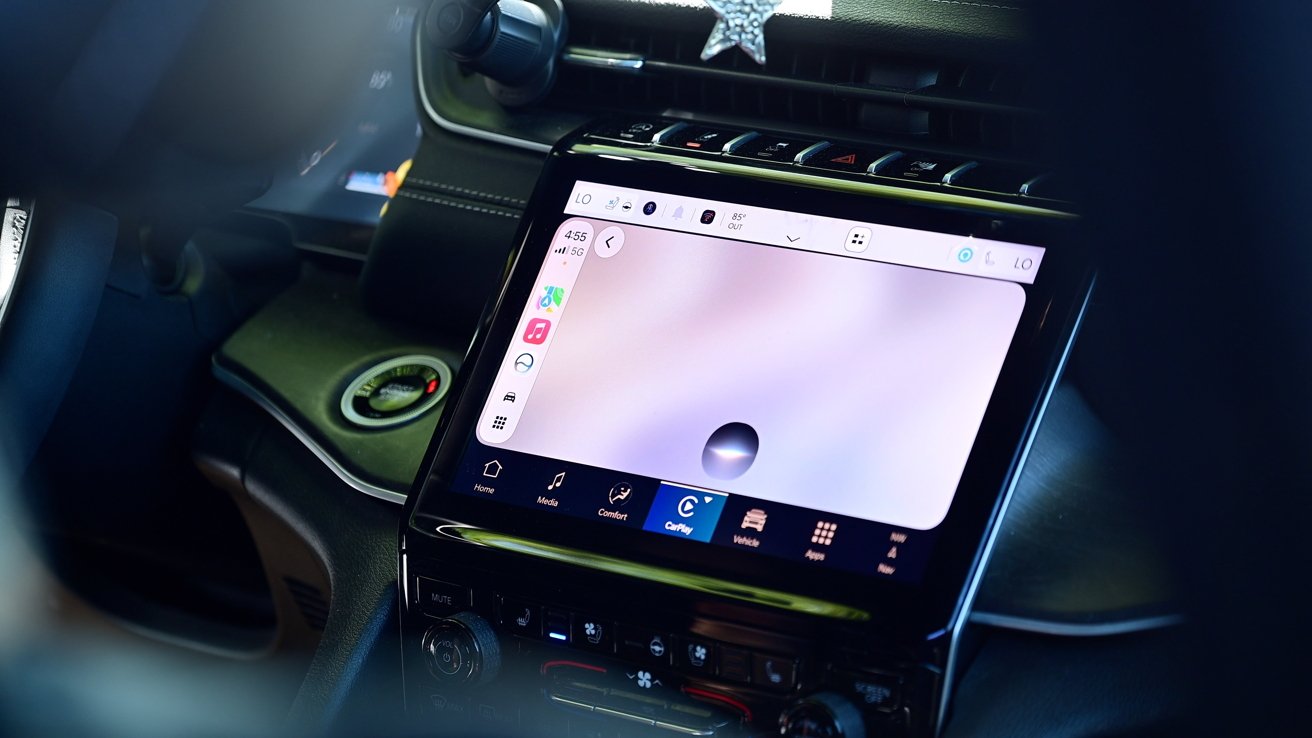
CarPlay is seeing one of its biggest updates in years thanks to the upcoming release of iOS 27. Here are all the new features, including Siri AI and Apple TV apps.
At WWDC 2026, Apple officially unveiled its next version of iOS. The update, iOS 27, will be released in the fall of 2026 and is packed full of useful new features.
CarPlay, Apple’s in-car UI, is powered by iOS, so this new software will bring a bunch of enhancements to your car. This year, at least one major feature will require some serious automaker support.
Apple Intelligence seemed to occupy almost half of Apple’s WWDC keynote. A lot is going on, and a good portion of that is reflected in the car.
On phones that support Apple Intelligence, Siri will become Siri AI. That means Siri will be more capable and get a new look.
When you invoke Siri AI, it now has a dark, glassy orb at the bottom of your car’s display. It mimics the look of the new UI that lives in the Dynamic Island on iPhone.

New Siri AI orb in CarPlay with iOS 27
Siri is more conversational now, going back and forth with you as you ask questions and follow-ups. Apple’s digital assistant has more personal context, too.
While testing it, I could ask more complicated questions with multiple action items. As I left the house, I asked Siri to turn off the lights in the studio, get me directions to my son’s school, and text my wife my ETA.
All of your Siri conversations are saved in the new Siri app. It has the same icon as on iPhone, iPad, and Mac, and allows you to go back to the previous conversation you’ve had.
Those conversations also sync across your platforms via iCloud. So if I start a conversation in the car, I can pick it up on my iPad when I get to where I’m going.

New chat-style interface for apps with iOS 27 CarPlay
Along with the new Siri AI, Apple is allowing any app to offer up a conversation mode. This was previously limited to AI apps like ChatGPT or Perplexity.
The idea is that those apps could possibly tap into Apple Intelligence models and offer you the ability to chat, rather than use physical taps within the app.
If you had a pizza app, you could open it, tell the app what you wanted with your voice, which could build your order, give you a total, and submit it with an estimated pickup time. There’s a new UI element for this that hovers over the app’s contents.
Both first-party and third-party media apps will get upgrades thanks to iOS 27. This includes the Apple Music and Apple Podcasts apps.
Apple Music looks more organized and has a richer layout thanks to added media graphics. The big change, though, is the addition of the mini player.

New mini player in Podcasts and Apple Music apps with iOS 27 CarPlay
The new mini player sits in the top-right corner of the display when you have something playing. It minimizes, showing the album art and a play/pause button.
That way, while something is playing, you can browse the rest of the app while still retaining quick control of the current media.
Before, it would be two taps to get to the media if you weren’t on the “now playing” screen. You would have to tap the play icon in the top-right corner, then hit pause, which isn’t ideal if you’re driving.
A similar refresh comes to the Apple Podcasts app. It has a streamlined UI and a mini player.
That mini player is a new UI element that isn’t going to be exclusive to Apple apps. Apple has made it available to anyone who is creating media apps for CarPlay, and you can expect many of the popular streaming apps to adopt it.
Another major change is video support. This is much more robust than what was previously included in iOS 26.
As part of iOS 26, Apple allowed apps to stream their content on a car’s infotainment system via AirPlay. It was only on supported cars that had to get approved through Apple’s MFi Program.

Grid of apps in the simulator with iOS 27
Now, Apple is allowing full, native video streaming applications as a new app category with iOS 27. AirPlay is still an option, but now you can browse and select content from the car’s interface, too.
I was able to test this out for myself using Apple’s new CarPlay simulator in Xcode. Apple is offering up initial support with the inclusion of the Apple TV app inside of CarPlay.

Apple TV app in CarPlay with iOS 27
There are several asterisks here. Automakers themselves still have to enable this, which means that we most likely will be waiting for that to happen.
When a vehicle does add support, it must be in park for any videos to play. That counts whether the content is started via AirPlay or a native video player.

Playing a video in CarPlay with iOS 27
One neat trick is that if you are watching a video and you move the car from park to drive, your video will automatically fall back to audio-only. That’s great for things like sports when you still want to follow along, even if you can’t watch it.
Aside from the big new features, there are a lot of other changes, tweaks, and optimizations Apple is rolling out to its in-car solution.
Wireless connection is now said to be more stable than before. Hopefully, that reduces the audio lag that can sometimes be present.
Navigation apps are now able to communicate with the car’s system. The idea behind this is that the car can see your route and suggest any changes.
The most obvious use case here is for EVs. If you put in a route, and your car realizes you only have so much battery remaining, it may propose the ideal charging station to add to the trip.
This whole back and forth is permission-based, so you must OK it before the communication happens, and you must OK any changes to the route. Otherwise, no information or route is shared with your car.
There are a few new icons with iOS 27. In Wi-Fi settings, if you use wireless CarPlay, there is a new CarPlay icon on the network to help identify it, and there is an updated battery icon system-wide.

New wallpapers in CarPlay with iOS 27
Finally, there are new wallpapers. Apple added 12 wallpapers for CarPlay in iOS 27, and they all have a similar swirl, like with the iOS 27 ones for iPhone, iPad, and Mac.
By going into the settings app, users can choose one of the new wallpapers that come in various colors.
CarPlay will be updated automatically when iOS 27 is released to the public.
Ctrl-Alt-Speech is a weekly podcast about the latest news in online speech, from Mike Masnick and Everything in Moderation‘s Ben Whitelaw.
Subscribe now on Apple Podcasts, Overcast, Spotify, Pocket Casts, YouTube, or your podcast app of choice — or go straight to the RSS feed. To get extended episodes with additional coverage, support us on Patreon.
In this week’s roundup of the latest news in online speech, content moderation and internet regulation, Ben is joined by Jen Weedon, a T&S veteran of Meta and Niantic. She is currently consulting and teaching at Columbia school of International and Public Affairs. Together, Ben and Jen discuss:
And in the extended episode for Patreon supporters, they cover:
Our fun links this week are the How Alberta eradicated rats (Ben) and Mogwooooo’s Instagram account (Jen).
If you’re already a Patreon supporter, you can get the extended episode on Patreon.
Filed Under: age verification, ai, ai slop, artificial intelligence, content moderation, jen weedon, trust and safety, uk
Companies: anthropic, telegram


Threat actors are exploiting an unauthenticated information disclosure vulnerability in the WordPress plugin Gravity SMTP, active on 100,000 sites.
The flaw is tracked as CVE-2026-4020 and received a medium severity rating. It affects all versions of the plugin from 2.1.4 and older and has been addressed in version 2.1.5, released on March 17.
WordPress security company Defiant is warning that hackers are actively exploiting the vulnerability. The company’s Wordfence firewall has blocked more than 17 million attempts against protected customers.

The issue stems from an exposed REST API endpoint in Gravity SMTP, whose ‘permission_callback’ always returns ‘true,’ allowing unauthenticated GET requests to receive a comprehensive JSON “System Report” generated by the plugin. The exposed information may contain:
Despite its medium-severity rating, the CVE-2026-4020 vulnerability can be exploited without authentication, and the exposed information can be used to steal email service credentials.
This allows an attacker to impersonate the victim to third parties and also to gain detailed information about the site’s software stack and the potential vulnerabilities present.
“The exposure of live third-party API credentials means an attacker could abuse the site’s connected email services, while the detailed system report significantly lowers the effort required to plan further attacks against the site,” Wordfence researchers warn.
Wordfence says exploitation activity spiked on June 7, with 4 million requests being blocked that day. Similar activity was recorded for several days afterward.
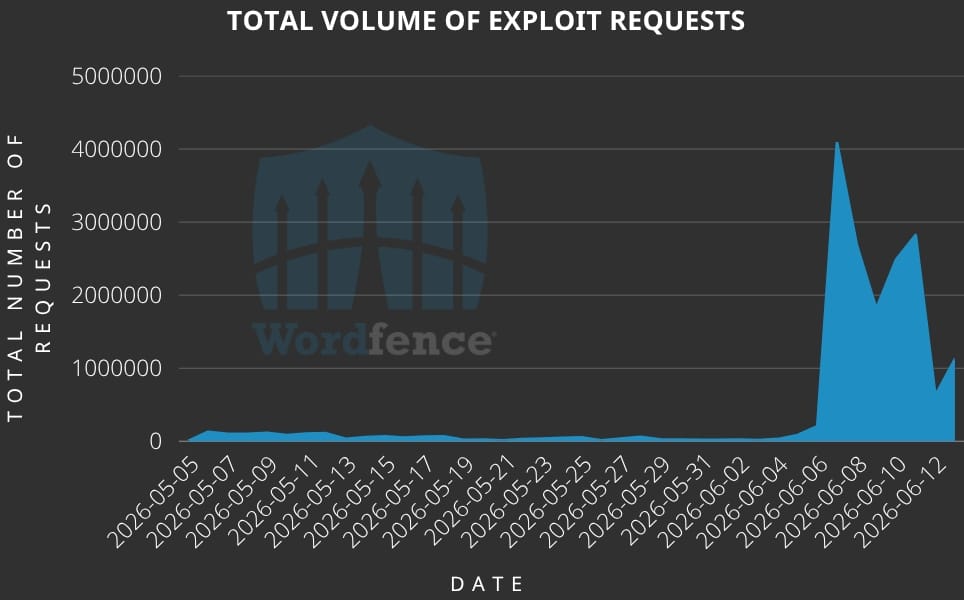
The security firm listed the most prolific source IP addresses for exploit requests, which website administrators should add to their blocklists.
A key indicator of compromise is requests to ‘/wp-json/gravitysmtp/v1/tests/mock-data’ found in web server access logs, particularly those including the ‘?page=gravitysmtp-settings’ query parameter.
Yesterday, the company issued a separate advisory about a critical, unauthenticated, arbitrary file-deletion flaw in the Avada Builder WordPress plugin, used on one million sites.
This vulnerability is identified as CVE-2026-8713 and allows attackers to delete arbitrary files on the server through a path traversal flaw, provided a published Avada form is configured to save submissions to the database.
Deleting critical files, such as wp-config.php, can revert the site to its initial setup state, potentially leading to a full site takeover and remote code execution.
The issue was fixed in version 3.15.4, which is the recommended upgrade target for website administrators. No active exploitation of CVE-2026-8713 has been observed yet, but this is a good candidate, so quick action is advised.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


Large language models have moved out of the research lab and into engineers’ daily workflow. LLMs serve as reasoning engines that can orchestrate complex tasks including identifying vulnerabilities in source code and transforming fragmented project discussions into rigorous technical specifications.
While the general public uses AI tools to write email and plan vacations, technical professionals use LLMs as core architectural elements that are fundamentally changing how digital infrastructures are built and maintained. As the AI models move into mainstream engineering practice, the demand for technical expertise is rising.
The LLM technology market is expected to grow by about 33 percent every year through 2030, according to MarketsandMarkets. The rapid expansion suggests that proficiency in implementing and securing the models is transitioning from a niche into a core requirement for technologists.
To use LLMs effectively, technical professionals must move beyond treating them as conversational robots. At a fundamental level, the AI systems are built on the transformer architecture, a framework that replaced the older method of processing data in a fixed, sequential order. Unlike earlier models that analyzed information one step at a time, transformers use self-attention mechanisms to ingest vast datasets simultaneously.
For technical professionals, LLMs are core architectural elements that are fundamentally changing how digital infrastructures are built and maintained.
Relying on such LLMs without understanding their internal logic creates a significant reliability risk. To build tools that work consistently, developers must understand the core principles that govern how the models process information and generate results. By mastering how a model processes information and how its internal settings influence the result, developers can move away from a trial-and-error approach toward a more precise one to ensure the AI tool handles complex data reliably.
Here are areas that integrate large language models.
Moving past basic prompts. Developers are using application program interfaces (APIs) to connect LLMs directly to their databases and software tools. Employing the APIs allows AI to perform work such as executing code or searching through internal repositories.
Fixing the “hallucination” problem. LLMs are at risk of hallucinations, which are generated facts or code that looks correct but actually is wrong or broken. To fix the problem, retrieval-augmented generation (RAG) forces AI to look up information in a trusted source such as a company’s database.
Prioritizing data security. When using AI with proprietary code, security is a major concern. Engineers must learn how to set up “private” instances of the models to ensure that sensitive company data stays within a secure cloud environment and is not used to train public versions.
The future of collaboration. By automating repetitive coding tasks and summarizing thousands of pages of documentation, LLMs let engineers spend more time on high-level designs and solving important issues.
The gap between people who use AI and those who understand how to build with it is growing wider. To help technical professionals stay ahead, IEEE offers a five-course online program, Large Language Models Demystified, available through the IEEE Learning Network.
The program, developed by IEEE Educational Activities in partnership with the IEEE Computer Society, is built for people who want to understand the “how” and the “why” behind the technology. Rather than just teaching basic prompting, the curriculum dives into the engineering behind generative AI, including:
Upon completion of the program, participants earn professional development credits and a digital badge from IEEE to verify their expertise.
Enroll in the course program on the IEEE Learning Network.
Organizations looking to prepare their teams to work on LLMs can connect with an IEEE content specialist to discuss group enrollment and tailored training paths.
From Your Site Articles
Related Articles Around the Web


Researchers at Carnegie Mellon University built a wearable system that captures both the exact movements of a human hand and the precise locations and forces where it presses against objects. The device, called ART-Glove, or Articulated Tactile Glove, tackles a long-standing gap in robot training. Robots have grown skilled at seeing their surroundings through cameras, yet they still struggle when tasks require careful contact, variable grip force, or coordinated finger adjustments during everyday actions like turning a key or unscrewing a cap.
The majority of current models for collecting demo data result in an uncomfortable trade-off. Teleoperation setups provide robot-ready orders but frequently exclude the natural sensation of a hand, leaving you feeling like you’re in a robot. Pure video recordings keep your hand free, but contact information remains a mystery, inferred at best with limited reliability. Soft sensing gloves provide some pressure data, but their exact shape varies with each wearer, making it difficult to translate it onto a robot hand.

ART-Glove avoids these issues by utilizing a hybrid technique. The primary contact zones on your hand are covered by 16 hard surfaces: three on each finger, three on the thumb, and a broader one across the palm. These pieces provide a recognized geometry on the hand side of things, so any recorded touch contains explicit information about where exactly on the hand the contact occurred and at what angle, among other things. The rigid sections are linked together by 22 joints, all of which are aligned with real human hand anatomy, including multi-axis rotations at the thumb base. They’ve also managed to keep the size down while maintaining natural motion by developing three separate joint systems. Some are rather simple, consisting of shafts and sleeves with gears that transfer to encoders on the back of the hand. Others employ direct bearings or curved slots to provide tighter clearances. All of this is tracked by magnetic rotary encoders, which add no additional friction or wear points.

Each hard surface is now covered with a thin piezoresistive layer. Each of these seven flexible circuit modules contains 2048 separate pressure-sensing devices, or taxels, as there is a lot of pressure sensing going on. These sensors monitor real-time force distribution over the hand. On the back of the glove, there’s also a small STM32 microprocessor that reads both the joint encoders and the entire tactile array before synchronizing everything at 120 samples per second. You’ll get a live output stream with 22 degrees of freedom in joint motion, as well as high-resolution pressure maps.

When someone puts on the glove and completes a task, the system records the entire physical story. During a ball rotation exercise, for example, it demonstrates how the contact points vary constantly to keep the force in line with gravity. When someone screws a bottle cap, the pressure patterns begin to move and intensify as the fingers adjust their grip and torque. Pressing a USB drive into a port demonstrates a coordinated multi-finger grab followed by localized pushing force. All of this appears in its own chronology, with a reference to the specific location on the surface where contact occurred.
[Source]
In every CNET TV review, I compare three or more similar TVs side by side in a dedicated, light-controlled test lab. With each review, I employ a rigorous, unbiased evaluation process that has been honed by more than two decades of TV reviews. I test TVs with a combination of scientific measurements and real-world evaluations of TV, movies and gaming content.
To ensure I can evaluate the picture quality of every TV, I connect each one to an AVPro Connect 8×8 4K HDR splitter so each one receives the same signal. I test the TVs using various lighting conditions, playing different media, including 4K HDR movies and console games, across a variety of test categories, from color to video processing to gaming to HDR.
In order to measure each TV, I use specialized equipment to grade them according to light output and color. My hardware includes a Konica Minolta CS-2000 spectroradiometer and a Murideo Six-G 4K HDR signal generator. I use Portrait Displays CalMan Ultimate software to evaluate every TV I review according to its brightness, black levels and color.
The Leo Bodnar Lag Tester samples three regions of the screen for latency, and these are averaged to give each TV’s lag score
I play a variety of games from an Xbox Series X or PlayStation 5, and note the effects of gaming modes and settings as well as the 4K/120Hz and VRR input capabilities. Helpfully, the Xbox includes a 4K/120Hz and HDR compatibility test: Settings>TV and display options>4K TV details. The page will detail the HDR modes it supports (including Dolby Atmos) and whether it will support VRR — if a TV gets ticks in all the boxes it means it has the best compatibility with high-end Xbox games.
Our reviews also account for such things as features, design, smart TV performance, connectivity including HDMI inputs and gaming compatibility.
Measuring input lag (in milliseconds) is an important component of my process for testing gaming TVs.
Check out the page on how CNET tests TVs for more details.
Input lag will often be lower in game mode than in any other mode on your TV. Here are a few more gaming-specific aspects I looked at for each TV.
How to turn on game mode. In most cases, viewing in game mode isn’t automatic, so you’ll have to turn it on manually, and sometimes the gaming monitor setting can be difficult to find. Many use a picture mode called “Game” while some, like Samsung and Vizio, let you apply game mode to any setting.
Game mode makes a difference, but not at all frequencies. As you can see in the table above, many TVs cut lag substantially when you turn on game mode, but plenty don’t. In general, expensive TVs with elaborate video processing get more of a benefit when you engage game mode. Additionally, and as I noted above, the Boost mode on LG OLEDs only works on 60Hz and not 120Hz.
Most TV game modes are good enough for most gamers. No matter how twitchy you are, it’s going to be tough to tell the difference between 10 and 30 milliseconds of input lag. Many gamers won’t even be able to discern between having game mode on and off — it all depends on the game and your sensitivity to lag.
Turning game mode on can hurt image quality (a little). TV-makers’ menus often refer to reduced picture quality. Reduced picture quality is generally the result of turning off that video processing. In my experience, however, the differences in image quality are really subtle with console gaming, and worth the trade-off if you want to minimize lag for a great gaming experience.
4K HDR gaming lag is different from 1080p. The display resolution you play at has an impact, and since new consoles prominently feature 4K HDR output for games, I started testing for 4K HDR lag in 2018. In general, the numbers are similar to the lag with standard 1080p resolution, but as you can see from the chart above, there are exceptions.
Testing is an inexact science. I use Leo Bodnar lag testers. Here’s how they work, and how I use them. I use two of these Bodnar lag testers — one in 1080p and one in 4K HDR — which use onboard optical sensors to measure and report input lag. When plugged into an HDMI port, the Bodnars make the screen flash in three different places and you place the unit’s onboard optical sensor flush onto the screen at these points. They calculate the lag at each position and you average the three readings to get a score. You might see different lag test results from different review outlets, which may use Bodnar or another method.

The cool thing about cyberdecks is that you get to design them to suit your personal tastes. [NickZero] wanted an ultra-minimal build, and set about putting together just that.
The build is based around a Raspberry Pi Zero 2W, which has a lighter power draw than the full-fat models at the trade-off of some processing power. Since it’s a W model, it has the benefit of wireless connectivity baked in from the factory. The Pi is paired with a Gherkin 30% layout keyboard kit, which neatly matches the 7″ Waveshare touch display in width. Power is courtesy of a juicy 4000 mAh lithium-ion cell, which is taken care of by an Adafruit Powerboost 1000 charger module. Everything is then laced up together inside a nifty 3D printed case.
It’s a simple cyberdeck, and one that’s probably quite satisfying to use when you get used to the fact that there are no number or modifier keys on the ultra-cut-down keyboard. It’s also a great example of how a bunch of off-the-shelf gear can nonetheless be assembled into quite a cohesive whole. In much the opposite way, we’ve seen some maximalist cyberdeck builds lately, too.
VSCO is making a bigger push into professional photography with the launch of Studio Pro, a new editing app designed for photographers handling large volumes of images.
The app arrives alongside a new VSCO One subscription bundle. This subscription will cost $500 per year. As a result, it puts the app in direct competition with Adobe’s creative software ecosystem, which dominates the industry.
Available now on iOS, with a macOS version due later this year, Studio Pro is aimed at photographers who regularly work on projects such as weddings, sports events, portraits and school photography. Rather than focusing on casual edits, the app is built around streamlining larger workflows.
At launch, Studio Pro includes tools for batch editing, allowing users to apply adjustments across multiple images at once. It also offers a style-matching feature that can replicate the look of a reference image across an entire shoot. Furthermore, photographers can share finished work through VSCO Galleries. This gives clients a dedicated place to view and access images.
VSCO says this is only the beginning. Future updates are expected to add RAW photo support, more advanced export controls, aspect ratio adjustments and additional editing tools aimed at professional users.
The launch is closely tied to the company’s new VSCO One subscription, which bundles together its growing collection of photography tools and services. In addition to Studio Pro, subscribers will gain access to Capture, Galleries, Workspace, Sites, AI Lab and Canvas. They will also have access to VSCO’s Freelance Photographer mentorship programme.
The company is positioning VSCO One as an alternative to what it describes as the “fragmented” workflow many photographers currently deal with. In this fragmented workflow, editing, client communication, image delivery and portfolio management often require several different platforms.
At $500 annually, the subscription won’t be for everyone. However, the pricing places it broadly in line with an annual Adobe Creative Cloud Pro subscription. This makes it clear who VSCO is targeting.






![J MONEY - NA NHA NOME [VIDEO OFICIAL]](https://wordupnews.com/wp-content/uploads/2026/05/1777799968_maxresdefault-80x80.jpg)


No Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw

Zimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations


Bitget enters Argentina’s regulated crypto market through PSAV registration


NanoClaw integrates JFrog registries to secure AI agent downloads

Matt Damon’s Viral Sci-Fi Thriller Has Taken Over HBO Max


Anthropic staff to meet White House officials next week, Axios reports


As AI companies race to go public, who else is along for the ride?

Bitcoin could crash to $48,000, if this historical pattern is triggered


“Israel’s” ban on ICRC visits ruled illegal, but Knesset moves to stop them permanently

Warning of disruption as Cardiff Crossrail works to start


Financial Accounting | Last Day Revision Strategy and Booster | CMA Inter – June 2026
what doctors are seeing in ebike crashes

Tributes to former deputy head teacher at Cambridge school among death and funeral notices
Deion Sanders Shares Powerful Post After Viral Advice To Deiondra

Kate Middleton Glare Goes Viral After Kids Booed At Royal Event

XRP ETFs Outperform As Bitcoin And Ethereum Funds Extend Outflow Trend
Market Preview: SpaceX (SPCX) IPO Record, Federal Reserve Meeting, and Iran Nuclear Agreement


Over 400 Arch Linux packages compromised to push rootkit, infostealer


Invesco Quality Income Fund Q1 2026 Commentary

44 Years Later, This Is the Greatest Star Trek Quote in Sci-Fi History
You must be logged in to post a comment Login