We got asked a great question in the mailbag segment on the Podcast this week: are there hacks that we have read about on Hackaday that we use in our everyday life? The answer was absolutely yes, and I loved Tom’s take it often goes the other way – he sees a hack, tests it out, and then writes it up.
But I started looking around the office and I found more examples of projects that were absolutely inspired by projects I had seen on Hackaday, yet weren’t the same. I made a DIY mechanical keyboard because I saw someone else do it. There are a few home-made battery packs that I probably wouldn’t have attempted without having read about someone doing the same thing. I riffed on [Ted Yapo]’s Tritiled project, making a slightly inferior, but workable knockoff, and they’ve been glowing for many years now.
That got me to thinking about reproducing a project versus taking inspiration from it, and though I enjoy both, I’m find myself most often in the “inspiration” mode. I just can’t leave well enough alone, even when I’m fundamentally copying someone. NIH syndrome? Expediency? Probably both, and sometimes with a dose of hubris or feature creep.
Looking back at [Ted]’s TritiLED, though, I found some great examples in both the rebuild and redesign modes on Hackaday.io. [schlion]’s Making Ted Yapo’s TritiLED couldn’t be a clearer example of the former, and it’s great to look over his shoulder and appreciate all the lessons he learned along the way. [Stephan Walter]’s Yet another ultra low power LED is inspired by [Christoph Tack]’s Ultra low power LED, which is in turn inspired by [Ted]’s project, like a conceptual grandchild.
In a way, I look at this like with music: sometimes you play the notes the way they were written down, and sometimes you riff on someone else’s theme. Both are equally valid, and both owe a debt to the upstream source. Is Hackaday the hackers’ jazz club? And which of these modes do you find yourself working in most?
For the last 24 months, one narrative justified every over-provisioned data center and bloated IT budget: the GPU scramble. Silicon was the new oil, and H100s traded like contraband. Reserve capacity now or your enterprise would be left behind.
The bill is now due, and the CFO is paying attention. Gartner estimates AI infrastructure is adding $401 billion in new spending this year. Real-world audits tell a darker story: average GPU utilization in the enterprise is stuck at 5%.
That utilization floor is driven by a self-reinforcing procurement loop that makes idle GPUs nearly impossible to release. What makes this shift more urgent is the CapEx reality now hitting enterprise balance sheets. Many organizations locked in GPU capacity under traditional three- to five-year depreciation cycles, with the hyperscalers being at five years. That means the infrastructure purchased during the peak of the “GPU scramble” is now a fixed cost, regardless of how much it is actually used.
As those assets age, the question is no longer whether the investment was justified. It’s whether it can be made productive. Underutilized GPUs are not just idle resources, they are depreciating assets that must now generate measurable return. This is forcing a shift in mindset: from acquiring capacity to maximizing the economic output of what is already deployed.
Advertisement
The scramble was a sideshow
For the “Tier 1” enterprise — the Intuits, Mastercards, and Pfizers of the world — access was rarely the true bottleneck. Leveraging deep-pocketed relationships with AWS, Azure, and GCP, these organizations secured capacity reservations that sat idle while internal teams struggled with data gravity, governance, and architectural immaturity.
The industry narrative of “scarcity” served as a convenient smokescreen for this inefficiency. While the headlines focused on supply chain delays, the internal reality was a massive productivity gap. Organizations were activity-rich (buying chips) but output-poor (generating near-zero useful tokens).
At 5% utilization, the math simply doesn’t work. For every dollar spent on silicon, 95 cents is essentially a donation to a cloud provider’s bottom line. In any other department, a 95% waste metric would be a firing offense; in AI infrastructure, it was just called “preparedness.”
The Q1 tracker: A market in pivot
VentureBeat’s Q1 2026 AI Infrastructure & Compute Market Tracker confirms that the panic phase has officially broken. The tracker is directional rather than statistically definitive — January surveyed 53 qualified respondents, and in February there were 39 — but the pattern across both waves is consistent. When we asked IT decision-makers what actually drives their provider choices today, the results show a market in rapid pivot:
Advertisement
The access collapse: “Access to GPUs/availability” factor dropped from 20.8% to 15.4% in a single quarter — from primary concern to secondary in 90 days.
The pragmatic pivot: “Integration with existing cloud and data stacks” held steady as the top priority at roughly 43% across both waves, while security and compliance requirements surged from 41.5% to 48.7% — nearly closing the gap with integration.
The TCO mandate: “Cost per inference/TCO (total cost of ownership)” as a top priority jumped from 34% to 41% in a single quarter, overtaking performance as the dominant procurement lens.
The era of the blank check is dead. Inference is where AI becomes a line item.
Training and even fine-tuning were a tactical project; inference is a strategic business model. For most enterprises, the unit economics of that model are currently unsustainable. During the initial pilot phase, flat-fee licenses and bundled token deals allowed for architectural waste. Teams built long-context agents and complex retrieval pipelines because tokens were effectively a sunk cost.
As the industry moves toward usage-based pricing in 2026, those same architectures have become liabilities. When metered billing is applied to an infrastructure stack that sits idle 95% of the time, the cost per useful token becomes a line-item emergency the moment a project moves into production.
From activity to productivity
The shift highlighted in our Q1 data represents more than just a budget correction; it is a fundamental change in how the success of an AI leader is measured.
For the last two years, success was about “securing” the stack. In the efficiency era, success is “squeezing” the stack. This is why cost optimization platforms saw the largest planned budget increase in our survey, becoming a top-tier priority as organizations realize that buying more GPUs is often the wrong answer.
Advertisement
Increasingly IT users are asking how to stop paying for GPUs they aren’t using. They are moving away from measuring GPU activity (how many chips are powered on) and toward GPU productivity (how many useful tokens are generated per dollar spent).
The luxury of underutilization is now a liability. The next act of the enterprise AI play is more about finding a way to make the silicon you already have pay for itself.
Owning the mint: The choice between token consumer and producer
As organizations move from proof-of-concept to production, the focus is shifting away from the latest GPU and toward the architecture of token generation. In this new economic reality, every enterprise must decide its role in the token economy: will you be a token consumer, paying a permanent tax to a model provider, or a token producer, owning the infrastructure and the unit economics that come with it?
This choice is not just about cost; it is about how an organization decides to handle complexity. Owning inference infrastructure means overcoming KV cache persistence, understanding the storage architecture, knowing what are tolerable latency guarantees, and addressing power constraints. It also introduces real-world enterprise limitations, power availability, data center footprint, and operational complexity, that directly impact how far and how fast AI can scale.
Advertisement
At the core of this challenge is KV cache economics. Storing context in GPU memory delivers performance but comes at a premium, limiting concurrency and driving up cost per token. Offloading KV cache to shared NVMe-based storage can improve reuse and reduce prefill overhead, but introduces tradeoffs in latency and system design. As NVMe costs rise and GPU memory remains scarce, organizations are forced to balance performance against efficiency.
For a token producer, managing these tradeoffs, across memory, storage, power, and operations, is simply the cost of doing business at scale. For others, the overhead remains too high, requiring a different path.
The specialized cloud pivot
VentureBeat’s Q1 tracker shows that the market is already voting on this strategy. The top strategic direction for enterprises is now to move more workloads to specialized AI clouds, a category that grew from 30.2% to 35.9% in our latest survey.
These providers — including Coreweave, Lambda, and Crusoe — are evolving. While they initially gained ground by serving model builders and training-heavy workloads, their revenue mix is changing rapidly. Today, training represents roughly 70% of their business volume, but inference customers now make up 30%. We expect that ratio to flip by the end of 2026 as the long tail of enterprise inference begins to scale.
Advertisement
These specialized providers are gaining strategic attention because they are not just selling GPU access. They are selling the removal of infrastructure friction. They optimize the full stack — storage, networking, and scheduling — around inference-first economics rather than general-purpose cloud operations. For an organization aiming to be a token producer, these environments offer a more efficient factory floor than traditional hyperscalers.
The rise of managed inference
For organizations that realize they cannot efficiently build or manage their own inference factories, a different trend is emerging. Our survey found that the intention to evaluate inference outsourcing and managed LLM providers jumped from 13.2% to 23.1% in a single quarter.
This nearly 10-percentage-point increase represents a realization that building inference infrastructure internally often creates hidden costs. Providers like Baseten, Anyscale, FireworksAI, and Together AI offer predictable pricing and service-level agreements without requiring the customer to become experts in vLLM tuning or distributed GPU scheduling.
In this model, the enterprise remains a token consumer, but one that is actively looking to price away the complexity of the stack. They are learning that managing inference internally is only viable if they have the volume to justify the operational burden.
Advertisement
Simplifying the hybrid stack
The choice to be a producer is also being made easier by a new layer of hybrid-cloud AI platforms. Solutions from Red Hat, Nutanix, and Broadcom are designed to operationalize open-source inference infrastructure without forcing every company to become a systems integrator.
The challenge is that modern inference depends on complex open-source components like vLLM, Triton, and Kubernetes. These systems rely on a rapidly evolving stack, with vLLM for high-throughput serving, Triton for model orchestration, and Ray for distributed execution, each powerful on its own, but complex to integrate, tune, and operate at scale. For most enterprises, the challenge isn’t access to these tools, it’s stitching them together into a reliable, production-grade inference pipeline. The promise of these newer platforms is portability: the ability to build an inference stack once and deploy it anywhere, whether in a hyperscaler, a specialized cloud, or an on-premises data center.
Our Q1 2026 AI Infrastructure & Compute Market Tracker confirms that interest in these DIY-but-managed stacks is growing, jumping from 11.3% in January to 17.9% in February, alongside provider adoption, with a steady rise in organizations leaning into open source. This flexibility matters because enterprise AI will not be centralized in one place. Inference workloads will be distributed based on where data lives, how sensitive it is, and where the cost of running it is lowest.
The winner in the next phase of the token economy will not be the platform that forces standardization through restriction. It will be the one that delivers standardization through portability, allowing enterprises to switch between being consumers and producers as their needs evolve.
Advertisement
The architecture of efficiency: The technical levers of productivity
Fixing the 5% utilization wall requires more than just better software; it requires a structural overhaul of the efficiency stack. Many organizations are discovering that high activity is not the same as high productivity. A cluster can run at full tilt but remain economically inefficient if time-to-first-token is too high or if inference requests spend too much time in prefill.
Inference economics are determined by how much useful output a cluster generates per unit of cost. This requires a shift from measuring GPU activity — simply having the chips powered on — to measuring GPU productivity. Achieving that productivity depends on three technical levers: the network, the memory, and the storage stack.
Networking: The cost of waiting
The network is the often-ignored backbone of inference economics. In a distributed environment, the speed at which data moves between compute nodes and storage determines whether a GPU is actually working or merely waiting.
RDMA (Remote Direct Memory Access) has become the non-negotiable standard for this move. By allowing data to bypass the CPU and move directly between memory and the GPU, RDMA eliminates the latency spikes that traditional network architectures introduce. In practical terms, an RDMA-enabled architecture can increase the output per GPU by a factor of ten for concurrent workloads.
Without this level of networking, an enterprise is effectively paying a “waiting tax” on every chip in the rack. As model context windows expand and multi-node orchestration becomes the norm, the network determines whether a cluster is a high-speed factory or a bottlenecked warehouse.
Advertisement
Solving the memory tax: Shared KV cache
As models become larger and context windows expand toward the millions of tokens, the cost of repeatedly rebuilding the prompt state has become unsustainable. Large language models rely on key-value (KV) caches to maintain context during a session. Traditionally, these are stored in local GPU memory, which is both expensive and limited.
This creates a “memory tax” that crushes unit economics as concurrency rises. To solve this, the industry is moving toward persistent shared KV cache architectures. By storing the cache centrally on high-performance storage rather than redundantly across multiple GPU nodes, organizations can reduce prefill overhead and improve context reuse.
Newer architectures are already proving this out. The VAST Data AI Operating System, running on VAST C-nodes using Nvidia BlueField-4 DPUs, allows for pod-scale shared KV cache that collapses legacy storage tiers. Similarly, the HPE Alletra Storage MP X10000 — the first object-based platform to achieve Nvidia-Certified Storage validation — is designed specifically to feed data to inference resources without the coordination tax that causes bottlenecks at scale. WEKA is another provider in this space.
The compression edge
Beyond the physical hardware, new algorithmic contributions are redefining what is possible in inference memory. Google’s recent presentation of TurboQuant at ICLR 2026 demonstrates the scale of this shift. TurboQuant provides up to a 6x compression level for the KV cache with zero accuracy loss.
Advertisement
Techniques like these allow for building large vector indices with minimal memory footprints and near-zero preprocessing time. For the enterprise, this means more concurrent users on the same hardware estate without the “rebuild storms” that typically cause latency spikes. The caveat: compression standards remain contested — no open-source consensus has emerged, and the space is shaping up as a proprietary stack war between Google and Nvidia.
Storage as a financial decision
Storage is no longer just a backend decision; it is a financial one. Platforms like Dell PowerScale are now delivering up to 19x faster time-to-first-token compared to traditional approaches, according to Dell. By separating high-performance shared storage and memory-intensive data access from scarce GPU resources, these platforms allow inference to scale more efficiently.
When a storage layer can keep GPU-intensive workloads continuously fed with data, it prevents expensive resources from sitting idle. In the efficiency era, the goal is to drive the 5% utilization wall upward by ensuring that every cycle is spent on token generation, not on data movement.
But as the stack becomes more efficient, the perimeter becomes more porous. High-productivity tokens are worthless if the data powering them cannot be trusted.
Advertisement
Sovereignty and the agentic future: Building the trust foundation
The final barrier to achieving return on AI is not a technical bottleneck, but a trust bottleneck. As enterprise AI shifts from simple chatbots to autonomous agents, the risk profile changes. Agents require deep access to internal systems and intellectual property to be useful. Without a sovereign architecture, that access creates a liability that most organizations are not equipped to manage.
VentureBeat research into the state of AI governance reveals a stark disconnect. While many organizations believe they have secured their AI environments, 72% of enterprises admit they do not have the level of control and security they think they do. This governance mirage is particularly dangerous as agentic systems move into production. In the last 12 months, 88% of executives reported security incidents related to AI agents.
Sovereignty as an architecture principle
Data sovereignty is often treated as a geographic or regulatory checkbox. For the strategic enterprise, it must be treated as a core architecture principle. It is about maintaining control, lineage, and explainability over the data that powers an agentic workflow.
This requires a new approach to data maturity, modeled on the traditional medallion architecture. In this framework, data moves through layers of usability and trust — from raw ingestion at the bronze level to refined gold and, eventually, platinum-quality operational data. AI inference must follow this same discipline.
Advertisement
Agentic systems do not just need available context; they need trusted context. Providing the wrong data to an agent, or exposing sensitive intellectual property to a non-sovereign endpoint, creates both business and regulatory risk. Compartmentalization must be designed into the stack from the start. Organizations need to know which models and agents can access specific data layers, under what conditions, and with what lineage attached.
Bringing the AI to the data
The fundamental question for the agentic future is whether to bring the data to the AI or the AI to the data. For highly sensitive workloads, moving data to a centralized model endpoint is often the wrong answer.
The move toward private AI — where inference happens closer to where trusted data resides — is gaining momentum. This architecture uses sovereign clouds, private environments, or governed enterprise platforms to keep the data perimeter intact.
This is where the choice to be a token producer becomes a security advantage. By owning the inference stack, an enterprise can enforce governance and lineage at the infrastructure layer. It ensures that the intellectual property used to ground an agent never leaves the organization’s control.
Advertisement
The next platform war
The battle for AI dominance will not be decided by who owns the largest GPU clusters. It will be won by the companies with the best inference economics and the most trusted data foundation.
The organizations that win the efficiency era will be those that deliver the lowest cost per useful token and the fastest path to production. They will be the ones that have moved past the hoarding hangover to focus on productive output.
Achieving return on AI requires a shift in mindset. It means moving from a culture of securing the stack to a culture of squeezing the stack. It requires architectural rigor, a focus on token-level ROI and a commitment to sovereignty. When an organization can generate its own tokens efficiently and securely, AI moves from a science project to an economically repeatable business advantage.
That is how ROI becomes real. That is where the next generation of enterprise advantage will be built.
Advertisement
Rob Strechay is a Contributing VentureBeat analyst and principal at Smuget Consulting, a research and advisory firm focused on data infrastructure and AI systems.
Disclosure: Smuget Consulting engages or has engaged in research, consulting, and advisory services with many technology companies, which can include those mentioned in this article. Analysis and opinions expressed herein are specific to the analyst individually, and data and other information that might have been provided for validation, not those of VentureBeat as a whole.
All 20 of America’s state-run healthcare marketplace sites “include advertising trackers that share information with Big Tech companies,” reports Gizmodo, citing a report from Bloomberg:
Per the report, seven million Americans bought their health insurance through state exchanges in 2026, and many of them may have had personal information shared with companies, including Meta, TikTok, Snap, Google, Nextdoor, and LinkedIn, among others. Some of the data collected and shared with those companies included ZIP codes, a person’s sex and citizenship status, and race.
In addition to potentially sensitive biographical details about a person, the trackers also may reveal additional details about their life based on the sites they visit. For instance, Bloomberg found trackers on Medicaid-related web pages in Rhode Island, which could reveal information about a person’s financial status and need for assistance. In Maryland, a Spanish-language page titled “Good News for Noncitizen Pregnant Marylanders” and a page designed to help DACA recipients navigate their healthcare options were found to be transmitting data to Big Tech firms…
Per Bloomberg, several states have already removed some trackers from their exchange websites following the report.
Thanks to Slashdot reader JoeyRox for sharing the news.
Honeywell-backed Quantinuum filed for a US IPO targeting a valuation above 20 billion dollars. The quantum computing company reported 30.9 million dollars in annual revenue and 192.6 million in losses, pricing itself on a fault-tolerant machine planned for 2029.
Advertisement
Quantinuum filed for a US initial public offering on Thursday that could value the company at more than 20 billion dollars. In the year ended 31 December 2025, Quantinuum reported revenue of 30.9 million dollars and a net loss of 192.6 million dollars. The company is asking public market investors to pay a premium of more than 600 times revenue for a quantum computer that does not yet exist in its final form. The computer it is building, a universal fault-tolerant machine called Apollo, is scheduled for 2029.
The filing is significant not because of Quantinuum’s current financials, which are modest by any standard, but because of what the IPO market’s appetite for it will reveal about how investors price a technology that has been five to ten years away from commercial utility for the past twenty years. Quantinuum is backed by Honeywell, which owns 54 per cent of the company. JPMorgan and Morgan Stanley are leading the offering. The ticker will be QNT on the Nasdaq Global Select Market.
The company
Quantinuum was formed in 2021 from the merger of Honeywell Quantum Solutions and Cambridge Quantum Computing. It builds quantum computers based on trapped-ion architecture, a technology in which individual atoms are suspended in electromagnetic fields and manipulated with lasers to perform calculations. The company claims the highest average two-qubit gate fidelity in the industry as of December 2025, a measure of how accurately the machine performs the basic operations of quantum computation.
Its customers include BMW, Airbus, JPMorgan Chase, HSBC, Mitsui, and Thales. BMW expanded its multi-year partnership with Quantinuum in May 2026 to apply quantum computing to catalyst chemistry research for fuel cells. Airbus is exploring quantum simulation for hydrogen-powered aircraft. JPMorgan has been working with Quantinuum since 2020 and is one of the most active corporate users of its software development kit.
These are research partnerships, not production deployments. No company is running quantum computing in production at a scale that affects its bottom line. The partnerships exist because the companies believe quantum computing will eventually transform their industries and want to be ready when it does. The word “eventually” carries all the risk.
Advertisement
The numbers
Quantinuum’s 2025 revenue of 30.9 million dollars represented 34 per cent growth over the prior year’s 23 million dollars. The net loss of 192.6 million dollars represented 34 per cent growth over the prior year’s 144.1 million dollars. Revenue and losses grew at exactly the same rate.
The first quarter of 2026 was worse. Revenue fell to 5.2 million dollars from 19.1 million dollars in the same quarter a year earlier. The net loss expanded to 136.6 million dollars from 30.5 million dollars. The quarterly numbers suggest that revenue is lumpy and dependent on the timing of contract milestones, a pattern common in pre-commercial deep technology companies.
The target valuation of more than 20 billion dollars would represent a doubling from the 10 billion dollar pre-money valuation at which Quantinuum raised 600 million dollars in September 2025. Before that, it raised 300 million dollars in January 2024 at a 5 billion dollar valuation. The valuation has quadrupled in two years while the company’s revenue has grown from 23 million to 31 million dollars.
The roadmap
Quantinuum’s hardware roadmap has four generations. The current system, Helios, is commercially available. Sol is planned for 2027. Apollo, the system that the company describes as universal and fully fault-tolerant, is planned for 2029. A fault-tolerant quantum computer is one that can perform complex calculations with enough error correction to produce reliable results, the threshold at which quantum computing transitions from a research tool to a commercial platform.
Advertisement
Riverlane raised 75 million dollars to build chips that solve quantum error correction, targeting one million error-free operations by 2026. Error correction is the central engineering challenge of the field. Without it, quantum computers produce results that are too noisy to be useful for the complex simulations that justify the technology’s theoretical advantages. Quantinuum’s Apollo is designed to solve this problem at the system level. Whether it will, and whether 2029 is achievable, are the questions on which the IPO valuation rests.
Quantinuum would join a small cohort of publicly traded quantum computing companies. IonQ, which uses the same trapped-ion technology, went public via SPAC in 2021 and is the only pure-play quantum stock with positive returns in 2026, up 16 per cent year to date after posting more than 100 million dollars in annual revenue. Rigetti Computing, which uses superconducting qubits, is down 10 per cent. D-Wave Quantum is down 9 per cent.
IQM has built 30 full-stack quantum computers from its facility in Finland and announced a 1.8 billion dollar SPAC merger to list on the NYSE. The quantum computing sector is pre-profit and largely sentiment-driven, with stock prices moving on milestone announcements, government contracts, and capital raises rather than fundamentals. Quantinuum’s IPO would be the largest quantum computing listing to date and would set a valuation benchmark for the entire sector.
Advertisement
The risk is that the benchmark reflects the market’s enthusiasm for a technology whose commercial timeline remains uncertain. Industry experts surveyed in 2025 said quantum utility is at most ten years away, a timeline that has not changed meaningfully in a decade. Google’s chief executive said five to ten years. NVIDIA’s chief executive said at least fifteen.
The bet
Honeywell’s decision to take Quantinuum public is part of a broader restructuring that includes the spin-off of its aerospace division and the separation of its advanced materials business. The IPO gives Quantinuum access to public capital markets and gives Honeywell a path to gradually reduce its 54 per cent stake. The 600 million dollar raise in September 2025 was led by investors including JPMorgan, which is now also leading the IPO underwriting, a dual role that reflects the degree to which the investment banking community’s interests are aligned with the offering’s success.
Quantinuum’s filing is a bet that public market investors will value a quantum computing company the way private markets have: on the promise of a technology that does not yet work at scale, priced against a future in which it does. The 30.9 million dollars in revenue is not the product. The product is Apollo, a machine that is three years and several fundamental engineering breakthroughs away. The IPO is a wager that the market will pay 20 billion dollars for the right to wait.
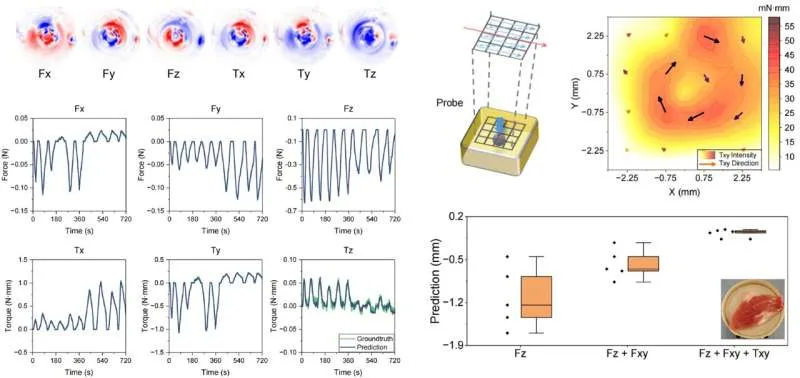
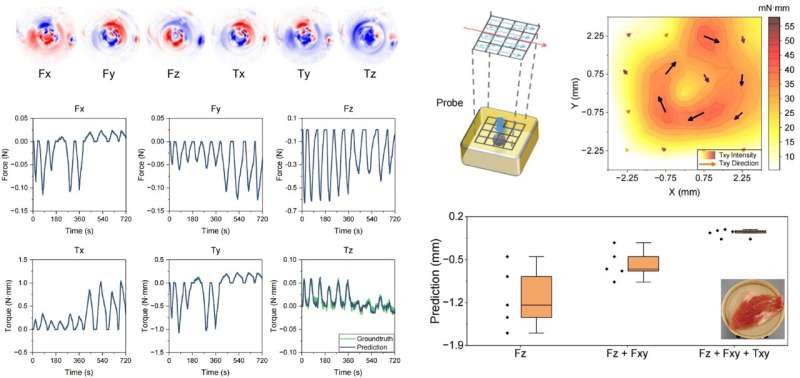
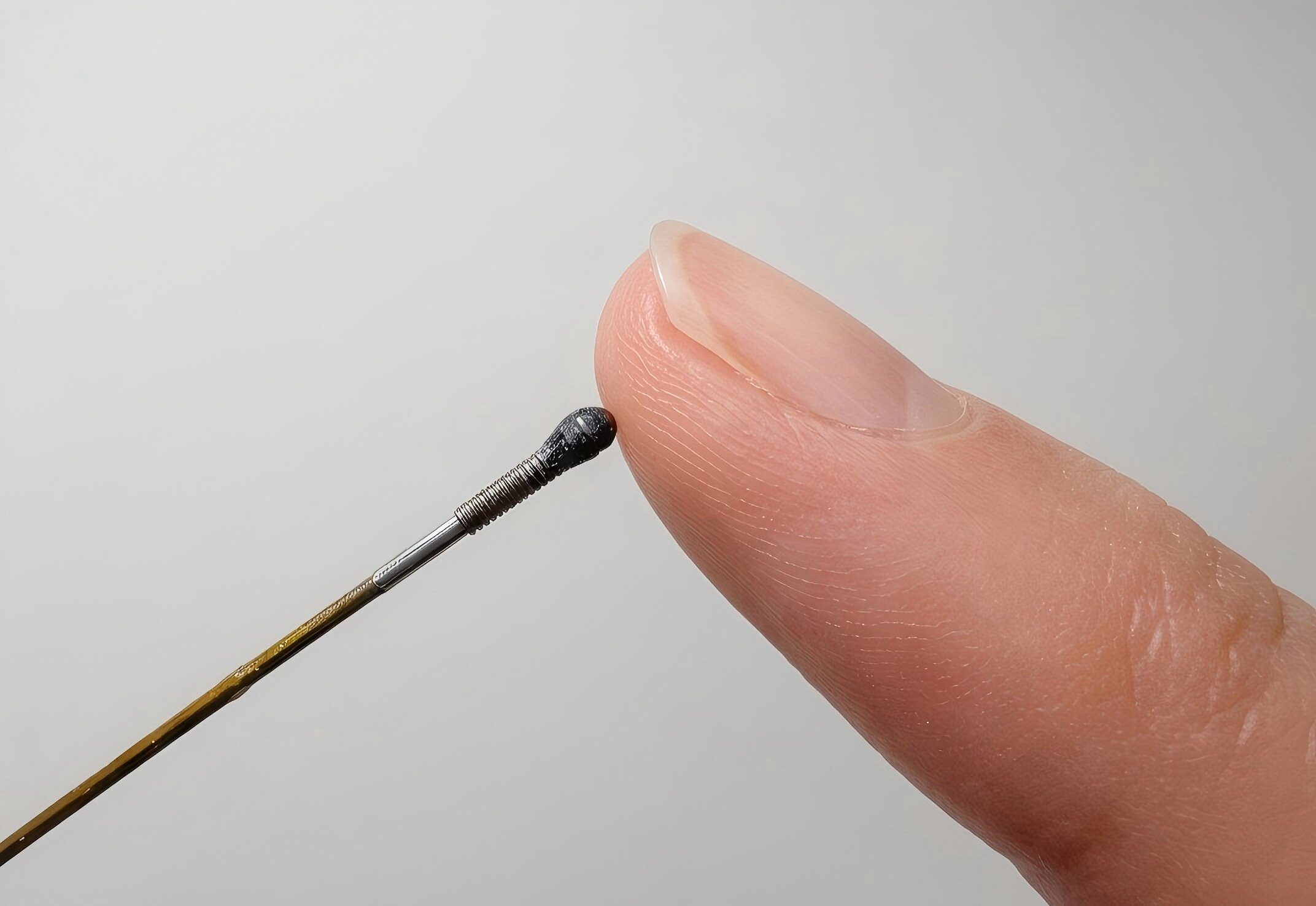
Robots are incredibly precise, but being gentle is not always their strong suit. A machine that can build a car with near-perfect accuracy can still apply too much pressure when working in places where even the smallest mistake matters, like inside a human eye or during delicate surgery. That is why researchers at Shanghai Jiao Tong University are developing a new type of force sensor that could help robots “feel” what they are touching more accurately.
The sensor is tiny, about the size of a grain of rice at just 1.7 millimeters wide, making it small enough to fit inside advanced surgical tools. What makes it especially interesting is that it does not rely on traditional electronics. Instead, it uses light to measure force from every direction, including pressure, sliding movements, and twisting. Here is how it works. At the tip of an optical fiber sits a soft material that slightly changes shape when it comes into contact with something. That tiny deformation alters how light travels through the sensor. The altered light pattern is then sent through optical fibers to a camera, which captures it like an image. Researchers then use a machine learning model to study those light patterns and translate them into precise force readings. In simple terms, the system learns how to “read” touch through light alone, without needing a bunch of wires or multiple separate sensors packed into such a tiny space.
Why robots need to feel, not just see
Modern surgical imaging is already incredibly advanced. Surgeons today can see inside the human body with impressive clarity. But one thing they still struggle with, especially during minimally invasive procedures, is actually feeling what their tools are touching. A surgeon may be able to see the area clearly on a screen, but distinguishing between healthy tissue and something problematic often comes down to experience and instinct rather than feedback from the instrument itself.
OPG
That is exactly the problem this new sensor is trying to solve. During testing, researchers used it on a soft gelatin block with a small hard sphere hidden underneath, meant to mimic a tumor inside human tissue. The sensor detected the hidden object by sensing differences in stiffness as it moved across the surface. In robotic surgeries, where doctors operate in extremely tight spaces and cannot always rely on direct touch, this kind of tactile feedback could make procedures safer, more precise, and far less dependent on guesswork.
There’s still work to do before this reaches an operating room
Right now, these results are still more of a proof that the idea works rather than a finished medical breakthrough. The researchers themselves admit there is still a lot left to figure out. Building sensors this tiny with consistent quality at scale is much harder than making a single working version in a lab. The setup process also still needs to become simpler and more reliable before it can realistically be used in hospitals. On top of that, the sensor has not yet undergone the long-term stress testing that medical devices need before doctors would trust them during real procedures.
Advertisement
OPG
Even so, the core idea behind the technology feels genuinely promising. Instead of relying on multiple complicated sensing parts, the system uses a much simpler setup built around a single optical channel and a camera. That kind of simpler design often makes technologies easier to improve and scale over time once the engineering matures. The team is now working on fitting the sensor into actual robotic surgical tools and testing it in environments closer to real operating rooms. And while a sensor the size of a grain of rice that can “feel” may sound like a tiny innovation on paper, it could become incredibly important for surgeons guiding robotic instruments through spaces smaller than a fingernail.
Tracy Drinkwater, founder of the Seattle Universal Math Museum, accepts the 2026 GeekWire Award for STEM Educator of the Year, presented by First Tech Federal Credit Union, at the Showbox SoDo in Seattle. (GeekWire Photo / Kevin Lisota)
This week on the GeekWire Podcast: Conversations with finalists and special guests at the annual GeekWire Awards about AI, innovation, startups, and the forces reshaping their industries. Guests on this episode include:
Luis Poggi, CEO of HouseWhisper AI, winner of CEO of the Year
Ross Finman, CEO of Augmodo, finalist for Hardware/Robotics/Physical AI of the Year
Mohammad Rastegari, CEO of ElastixAI, finalist for Startup of the Year
Plus, a special trivia challenge marking GeekWire’s 15th year hosting the event, featuring a serendipitous and fun connection to Andrew Putnam of Microsoft, a pioneer in FPGAs (field programmable gate arrays) and a winner of the 2017 GeekWire Award for Innovation of the Year (pictured above).
Unlike the other glasses I tested, Even doesn’t sell a subscription plan; everything’s included out of the box.
The only downside I could find with the G2 is that it is largely devoid of offline features, so the glasses have to be connected to the internet to do much of anything. Considering the G2’s capabilities, it’s a trade-off I am more than happy to make.
Other Captioning Glasses I Tested
There are plenty of capable captioning eyeglasses on the market, but they are surprisingly similar in both looks and features. While many are quite capable, none had the combination of power and affordability that I got with Even’s G2. Here’s a rundown of everything else I tested.
Advertisement
Photograph: Christopher Null
Photograph: Christopher Null
Photograph: Christopher Null
Leion’s Hey 2 is the price leader in this market, and even its prescription lenses ($90 to $299) are pretty affordable. The hardware, however, is heavy: 50 grams without lenses, 60 grams with them. A full charge gets you six to eight hours of operation; the case adds juice for up to 12 recharges.
I like the Leion interface, which lays out caption, translation, “free talk” (two-way translation), and a teleprompter feature on its clean app. You get access to nine languages; using Pro minutes expands that to 143. Leion sells its premium plan by the minute, not the month, so you need to remember to toggle this mode off when you don’t need it. Pricing is $10 for 120 minutes, $50 for 1,200 minutes, and $200 for 6,000 minutes. There’s no offline use supported, and I often struggled to get AI summaries to show up in English instead of Chinese (regardless of the recorded language).
Photograph: Christopher Null
Photograph: Christopher Null
You’re not seeing double: XRAI and Leion use the same manufacturer for their hardware, and the glasses weigh the same. The battery spec is also similar, with up to eight hours on the frames and another 96 hours when recharging with the case. XRAI claims its display is significantly brighter than competitors’, but I didn’t see much of a difference in day-to-day use.
The features and user experience are roughly the same, though Leion’s teleprompter feature isn’t implemented in XRAI’s app, and it doesn’t offer AI summaries of conversations. I also didn’t find XRAI’s app as user-friendly as Leion’s version, particularly when trying to switch among the admittedly exhaustive 300 language options. Only 20 of these are included without ponying up for a Pro subscription, which is sold both by the month and minute: $20/month gets you a max of 600 upgraded transcription minutes and 300 translation minutes; $40/month gets you 1,800 and 1,200 minutes, respectively. On the plus side, XRAI does have a rudimentary offline mode that works better than most. For prescription lenses, add $140 to $170.
Advertisement
Photograph: Christopher Null
Photograph: Christopher Null
AirCaps
AirCaps Smart Glasses
AirCaps does not make its own prescription lenses. Instead, you must purchase a pair of $39 “lens holders” and take them to an optician if you want prescription inserts. I was unable to test these with prescription lenses and ultimately had to try them out over my regular glasses, which worked well enough for short-term testing. Frames weigh a hefty 53 grams without add-on lenses; the company couldn’t tell me how much extra weight prescription lenses would add to that, but it’s safe to say these are the bulkiest and heaviest captioning glasses on the market. Despite the weight, they only carry two to four hours of battery life, with 10 or so recharges packed into the comically large case. Another option is to clip one of AirCaps’ rechargeable 13-gram Power Capsules ($79 for two) to one of the arms, which can provide 12 to 18 extra hours of juice.
The AirCaps feature list and interface make it perhaps the simplest of all these devices, with just a single button to start and stop recording. Transcriptions and translations are available for free in nine languages. For $20/month, you can add the Pro package, which offers better accuracy, access to more than 60 languages, and the option to generate AI summaries on demand (though only if recordings are long enough). As a bonus: Five hours of Pro features are free each month. Offline mode works pretty well, too. The only bad news is that these bulky frames just aren’t comfortable enough for long-term wear.
Advertisement
Photograph: Christopher Null
Photograph: Christopher Null
The most expensive option on the market (up to $1,399 with prescription lenses!) weighs a relatively svelte 40 grams (52 grams with lenses) and offers about four hours of battery life. There’s no charging case; the glasses must be charged directly using the included USB-connected dongle.
The glasses are extremely simple, offering transcription and translation features—with support for about 80 languages, which is impressive. I unfortunately found the prescription lenses Captify sent to be the blurriest of the bunch, making the captions comparatively hard to read. And while the device supports offline transcription, performance suffered badly when disconnected from the internet. I couldn’t get translations to work at all when offline. For $15/month, you get better accuracy and speaker differentiation, and access to AI summaries of conversations. Prescription lenses cost between $99 and $600.
The iFi GO Link 2 is designed to do one thing, and it does it very well: it upgrades your laptop or smartphone’s audio output to deliver impressive hi-res audio with no fuss and no unnecessary features.
It’s a very good way to add wired headphone support to devices that have long since dropped the headphone jack, although if you want to connect 4.4mm headphones you’ll need to look at one of iFi’s larger DACs: the tiny GO Link 2 has just enough space for one 3.5mm headphone output.
Advertisement
This model delivers lower harmonic distortion and a wider dynamic range, and it does so in a device that’s even smaller than the already tiny original. With an unchanged price tag the second-generation GO Link is one of the most affordable ways to improve your audio experience, especially for music on the move.
Latest Videos From
iFi GO Link 2 review: price and release date
Released February 2026
$59 / £59 (about AU$111)
The GO Link 2 was announced in February 2026 with a recommended retail prices of $59 / £59 (about AU$111). That’s the same price as the original model and slightly less than the larger GO Link Max, which has a balanced 4.4mm output as well as the standard 3.5mm socket.
Pricing is competitive with the likes of the FiiOKA11 and KA1 headphone DAC/amps.
Advertisement
iFi GO Link 2 review: features
The cable feels a little flimsy but it helps keep the GO Link 2 from being bulky. (Image credit: Future)
ESS SABRE DAC with up to 6dB extra range
Low noise floor and low distortion
S-Balanced 3.5mm output
The GO Link 2 is based on the same ESS SABRE DAC as before, but this time around it comes with what iFi calls Dynamic Range Enhancement, which adds up to 6dB between the loudest and quietest moments. It also features lower harmonic distortion — up to 62% lower than the first-gen model, iFi says.
Although there’s only a 3.5mm output, the GO Link 2 features iFi’s S-Balanced system which iFi claims significantly reduces crosstalk between channels by “applying balanced circuitry principles to a single-ended headphone output”.
Sign up for breaking news, reviews, opinion, top tech deals, and more.
This is the first GO Link model that’s fully compatible with iFi’s Nexis app, which you can use to customize the filters and apply firmware updates — but only on Android so far. As an iPhone/iPad user I wasn’t able to take advantage of those features, as the iPhone app wouldn’t communicate with the DAC. Hopefully an update is incoming.
Features score: 4 / 5
Advertisement
iFi GO Link 2 review: sound quality
iFi keeps it simple: there’s one output and a single color changing status light. (Image credit: Future)
Impressively loud with great bass
Excellent clarity and positioning
Best suited to lower impedance headphones
The GO Link 2 will make you smile. It delivers excellent clarity, a spacious soundstage and a really inviting audio experience, especially on nice headphones. It’s pretty great on budget ones, too.
I already have an iFi desktop DAC/amp, and I was pleased by how close this comparatively microscopic model sounded to its much more expensive sibling at sensible listening levels. It’s particularly impressive at the low end, which it handles with power and precision, and if you’re upgrading your phone or laptop you’ll be really pleased that you did.
One of my favourite songs for testing audio is the live version of Peter Gabriel’s Digging in the Dirt. It’s beautifully performed and recorded, but there’s a lot going on from the very low end to the very high, with a subterranean percussive bass, all kinds of instruments, and powerful vocals from Gabriel and Paula Cole. The GO Link 2 took it all in its stride, delivering a deeply involving sound from an Apple Lossless stream. I had a lot of fun with FLACs too, for instance U2’s remastered Achtung Baby and Talk Talk’s various masterpieces.
The GO Link 2 is surprisingly loud, and louder still when you connect it to a computer: there was a noticeable increase in volume when I played the same Apple Lossless audio on my Mac compared to on my iPhone.
Advertisement
However, I did find that being able to push the headphones harder on my Mac was counter-productive: towards full volume, snare drums and distorted guitars became harsh, while deliberately loud-mastered pop music such as Kygo and Selina Gomez’s It Ain’t Me became too bright and noticeably distorted by the deep bass notes. The same thing didn’t happen on iPhone.
If you like to listen loud on a computer then a desktop DAC or one of iFi’s more powerful DACs will have more headroom for your headphones.
Sound quality: 5 / 5
Advertisement
iFi GO Link 2 review: design
Tiny and minimalist
137mm x 12mm x 7.6mm
7.8g
Dongles don’t get much dinkier than this. The GO Link 2 is absolutely tiny, with the main section smaller than half of a Biro pen. It’s 8% smaller than the first generation model, and it’s 29% lighter.
There are no buttons, no switches, nothing to turn or poke or press, and because it’s too small to have a screen it has a colour-changing status LED instead. That LED is green for PCM audio from 44.1 to 96kHz; yellow for PCM from 176.4 to 384kHz; and blue for DSD256.
The USB-C connector is attached with a short braided cable to the main unit, which has a 3.5mm headphone socket. Although the GO Link 2 is USB-C it comes with adapters for USB-A and Lightning ports, covering all the bases.
The cable feels very thin and I’d worry about it fraying long term; it’s a known issue with some of the first-generation models, so it’s probably wise to treat the GO Link 2 with care.
Design score: 4 / 5
Advertisement
iFi GO Link 2 review: ease of use and setup
Plug…
…and play
No buttons, screens or switches
It doesn’t get much easier than this: plug it in and you’re good to go, although as ever with USB audio devices if you’re connecting to a Mac you’ll need to tweak Audio and MIDI setup on your computer to enable higher quality than 16-bit/44.1KHz.
It’s a shame that the app that enables you to adjust filters and other settings is currently Android-only, although I was quite happy with the out-of-box settings.
Usability and setup score: 4 / 5
Advertisement
iFi GO Link 2 review: value
Superb value for money
No unnecessary features or gimmicks
Even better than the original
The original GO Link is much-loved, and iFi has very sensibly decided not to mess with its winning formula. Instead it’s refined it with more dynamic range, even smaller dimensions and the same plug-and-go ease of use. The GO Link 2 is cheap and it’ll make you cheerful.
Value score: 5 / 5
Should I buy the iFi GO Link 2?
Swipe to scroll horizontally
Attributes
Notes
Advertisement
Rating
Features
S-balanced 3.5mm output and good hi-res audio support. App compatibility is currently Android-only.
4/5
Advertisement
Design
Function over form: tiny size means little room for design flair or fancy features.
4/5
Sound quality
Advertisement
Even better than before with wider range.
5/5
Value
An instant, enjoyable audio upgrade that’s perfect for phones.
Advertisement
5/5
Buy it if…
Don’t buy it if…
Advertisement
iFi GO Link 2 review: Also consider
FiiO’s KA1 is similarly small and equally affordable, but unlike the GO Link 2 it also supports MQA rendering. It’s available in both USB-C and Lightning options.
For an extra 20% over the GO Link 2 or KA1’s price you could buy iFi’s larger but still eminently portable GO Link Max, which has higher power output and both 3.5mm and 4.4mm balanced outputs.
How I tested the iFi GO Link 2
Open-back, closed-back and IEM headphones
Lossy streaming, lossless FLAC and multitrack Logic Pro projects
I tested the iFi GO Link 2 for 10 days using my usual headphones and IEMs: BeyerDynamic DT990 Pro open-back headphones, DT770 closed-back headphones, and the affordable and punchy SoundMagic E11C IEMs.
I listened to a range of music on my iPhone 16 Pro, my iPad Pro and my Mac mini, with sources including lossy and lossless streaming, uncompressed multitrack projects on my Mac, and FLAC audio files.
When the iPhone was first released in 2007, it didn’t just set the bar for how people expected their mobile phones to look, but it also changed the way we used our phones entirely. Because of how it fits so perfectly into the Apple ecosystem, iPhones play a crucial role as the most mobile way to communicate among its connected products. This makes it perfect for people whose jobs require them to be on the go, such as those who travel for work.
Among the many reasons why people prefer the iPhone over Android, Apple is known to have stringent policies on its app store. Considering how it has a lot of great built-in apps that have features that rival even paid options, this isn’t that surprising. Throughout the years, Apple has thoughtfully added to its list of free apps that you probably aren’t using to its full advantage. And if you’re looking to make your days at work even more productive, some of them can even replace an arsenal of gadgets and accessories that once graced our cubicles. With these apps, you can save on subscriptions or physical tools and focus your budget on the things that truly move the needle.
Advertisement
Document scanners
While there’s still a benefit to having a physical scanner, especially if your work requires high-resolution images such as artwork, your iPhone can work just fine as a scanner for regular documents. Depending on your preference, there are actually multiple ways to scan documents on your iPhone. The most brute-force way to “scan” a document is just by using the camera app and simply cropping the image to remove the background.
However, if you want a more elegant solution, you can use your Files or Notes app. On your Files app, tap the three dots icon that is located in the upper-right corner of the screen. In the drop-down menu, select Scan Documents. Alternatively, open your Notes app and create a new note (or open an existing one). In the lower part of the screen, tap the paperclip icon and select Scan Documents. Regardless of which option you choose, the apps will open a special camera with scanning-related features.
Advertisement
Once you take a photo of the document, you’ll have the option to retake it or proceed to adjust the corners and keep the scan. Afterward, you can keep repeating the process for all the pages you need to scan and tap Save when you’re done. If you want more flexibility with the output, there are additional settings when you scan. You’ll have the option to add or remove the flash and select if you want the scan to be colored, grayscale, black & white, or a photo.
Advertisement
Notebooks and planners
Staying on top of your deliverables at work can be challenging, and it used to require you to juggle all kinds of notebooks that you would need to bring to different meetings. With your Notes app, you can sync your notes across different Apple devices, plus annotate with photos, videos, voice notes, and more. And well, if you’re the type to want to keep track of your thoughts and experiences at work, there’s also the iPhone Journal app. Since it’s integrated with all of your other iPhone apps, it fills in the gaps for what happened. If you’re being practical, it can be a great way to keep track of your progress on projects, specific feedback that you applied, or document work-related attendance to meetings or events.
Instead of a physical planner, there’s the Calendar app, which lets you keep track of your meetings, company holidays, and personal leaves. When you create an event, you can list the basic details, like the name, date, and time, plus repetitions if it’s a weekly cadence. But if you want to make sure you have all your ducks in a row, you can select whether it’s an in-person or online meeting, expected travel time, who is going to be joining, important attachments / links, and even notes. Apart from listing events, your Apple Calendar can be integrated with your Reminders app, so you have a more holistic view of both your schedule and deliverables.
Advertisement
Measurement and calculations
Released in 2018, the iPhone Measure app uses its camera, built-in sensors, and, in some cases, its LiDAR scanner, to measure surfaces and test the level with augmented reality. Using this, you don’t have to borrow measuring tape to know if the white board you’re thinking of getting will fit your office’s breakout room. That said, our team did test the accuracy of the iPhone’s measuring app, wherein it was off by up to 5%. We deduced that several factors could lead to significant discrepancies. Apart from owning an older iPhone model, things like the angle, distance, background, and lighting can impact its accuracy. However, it can still be a good solution for those one-off projects that don’t need to be super precise.
While some jobs require heavy-duty Excel sheets with pivot tables, for which you’ll need to use a proper laptop, others only require simple calculations. With your iPhone, you can go from basic functions (plus, minus, divide, multiply, and percentage) to scientific calculations. You can even use your Notes app to make some quick math calculations. You can also use the calculator to convert currencies, areas, speed, temperature, time, volume, weight, and so on. Because of this, it’s an ideal companion for any business trips abroad, where you have to stay under budget in a different currency or they follow a different measurement system.
Advertisement
Wallet and keys
Tada Images/Shutterstock
For some workplaces, there’s a revolving door of access depending on your clearance levels, whether it’s to authorized rooms or documents. Instead of having physical keys around, your iPhone’s wallet can let you store digital keys that you can use instead. Not only is it not prone to getting stolen, but it makes it possible to manage, even remotely. It will also be easier to track the history of people who have been given access if any problems arise. With compatible smart door locks, you can enjoy the benefits of the Apple Home Key. Although, you may need to download separate apps for some added features, such as managing access remotely, like adding or removing users or setting timed entries. Using the same NFC technology, you can also use your iPhone (and even Apple Watch) to lock and unlock compatible smart cabinet locks for confidential documents.
Similar to a physical wallet, you can store more than just your bank cards in your Apple Wallet, like tickets to events and boarding passes. With this, it takes away the need for printed files for any business trips as well, since they may accept digital files already. Apple has also rolled out the option to add your driver’s license to your Wallet. But it’s important to note that it does have limitations, such as not being accepted in every country or some establishments still requiring your physical ID.
Advertisement
Business cards
While the art of networking is still an absolutely useful skill in every office environment, how we follow up after has evolved. In the past, we had to spend money on printing business cards and hand them out to people, hoping that they wouldn’t simply throw them in the trash after meeting you. Thankfully, you can skip the physical business cards with all the contact management features on your iPhone. These days, sharing contacts can be as easy as putting your iPhones together to use the NameDrop feature, which was introduced in iOS 17.
On the most basic level, there’s the built-in Contacts app, wherein you can combine their details across different platforms, from numbers, emails, and instant messaging apps, to social profiles. If you’re the type to mix up people, there are plenty of ways to add more context to your relationship. You can easily change their photo, list the company they work for, add their birthday, and pronouns. And if you don’t want to miss out on when they try to reach out, it’s possible to customize ringtones and text tones. But if you do need more, we’ve mentioned before that there are a lot of great iPhone contact apps that might be worth downloading. For example, if you’re still meeting people who prefer physical business cards, the AI-powered CamCard lets you scan them and add their information to your database.
The creative minds behind Mortal Kombat II know precisely how to make an awful ’90s-style action movie. We get a glimpse of that with footage from “Uncaged Fury,” an in-film demonstration of Hollywood playboy Johnny Cage’s replete with one-liners, glacially slow choreography and ridiculous stunts, all of which would have felt right at home in a forgettable Van Damme flick. By nodding to schlocky action cinema — which definitely includes Mortal Kombat (1995)— director Simon McQuoid and screenwriter Jeremy Slater are also making a statement: They know what not to do. That self-awareness ultimately makes it the best Mortal Kombat film yet.
This sequel is practically a point-by-point refutation of everything in “Uncaged Fury.” McQuoid, Slater and crew made the action far more complex than what we’ve seen before in the franchise. Moves hit harder, characters make more inventive use of their surroundings and everything is shot to emphasize the profound level of skill involved in constructing a modern fight scene. There are quips, to be sure (including a nod to Big Trouble in Little China, which directly influenced the Mortal Kombat games), but they’re more than just throw-away lines.
Perhaps most importantly, it balances those (slightly) loftier cinematic aspirations against the campier aspects of Mortal Kombat. It’s still about a tournament that determines the fate of the world. People have superpowers. There’s a necromancer. But there’s still room to find the humanity in these ridiculous characters.
Advertisement
Warner Bros
The best example of this is Johnny Cage himself, who is typically just presented as an annoying movie star in the games. In this film, he’s a washed up action star attending a geek convention where nobody recognizes him. As played by Karl Urban — a genre actor who’s appeared in Xena: The Warrior Princess, Lord of the Rings and currently stars in The Boys — Cage is the quintessential sad sack. He hates himself so much, he can’t even accept a modicum of praise from a former fan. Urban captures a man who is both past his prime, and whose prime was giving up a legitimate martial arts career to make schlock movies.
When he’s chosen to fight in Mortal Kombat, it’s impossible for Cage to see himself as an actual hero — after all, he’s only ever pretended to be one. Urban gets to show off his physical comedy chops as he’s thrown about in his first fight, showing us the campy side of the character. But he’s compelling enough as an actor to make us believe in Cage’s gradual heroic transformation.
Warner Bros.
While Johnny Cage steals the show, Mortal Kombat II starts off by introducing us to Kitana as a child princess who is forced to watch her father be brutally murdered by the tyrant Shao Kahn. That loss puts her realm, and all of its people, under Kahn’s rule. Inexplicably, he chooses to adopt her and take her mother on as a consort. Kitana’s focus becomes revenge, all the while putting on the face of a loyal warrior for Kahn. Given the weight of her storyline, there’s less room for Kitana to lean into camp like Johnny Cage, but at least she gets a sick combat fan made of knives.
Everyone else from the Mortal Kombat reboot returns, including Jessica McNamee as Sonya Blade, Ludi Lin as Liu Kang and Lewis Tan’s Cole Young, a new character invented for that film. They all get their time to shine with more elaborate fight scenes, which also appear more frequently, since the tournament serves as the spine of the film. In an interview for my film podcast, The Filmcast, McQuoid mentioned that his stunt team spent more time visualizing choreography and set pieces, which led to far more dynamic action sequences than the first film. It’s something I think even general audiences, who aren’t as particular about fight choreography, will notice.
Now I’m not going to pretend that Mortal Kombat II is a perfect film. It leans so much on the previous entry that it’ll be completely nonsensical to anyone jumping straight in. And people who are less enamored with the world of martial arts films may not appreciate that the characters spend more time punching and kicking than talking. But if you can appreciate the wordless ballet of a well-choreographed fight scene, where character depth is revealed through action itself, you’ll likely have a great time with Mortal Kombat II.
In an increasingly AI-driven and digital world, analog instant film and retro-style cameras remain popular, fueled by a combination of both nostalgia and charm. Instant cameras, in particular, stand out for their simplicity and an experience that has remained largely unchanged over time.
Fujifilm’s $175 Instax Wide 400 builds on the familiar instant photography experience and expands it with a wider format. As someone who appreciates simple, easy-to-use instant cameras and often shoots with an Instax Square, I was interested in trying a model that offers larger prints and support for landscape photography.
The Instax Wide 400 is built for capturing group shots, scenic landscapes, and moments where fitting more of the scene into the frame really matters. It produces 62 × 99 mm prints, about twice the size of Instax Mini photos, giving you a lot more space to work with in every shot.
Since it’s a simple point-and-shoot camera, it requires no prior photography experience and is designed to be easy and intuitive to use. Its appeal lies in fun and simplicity rather than advanced controls.
Advertisement
With its one-button design, the camera offers no manual exposure controls. It automatically manages flash, focus, and other settings, leaving you to simply frame the image and take the shot.
Image Credits:TechCrunch /
When lighting is ideal, the images print with nice color and a good amount of detail with some extra saturation. I was quite impressed by the quality because it managed to pick up accurate colors and distant details.
However, the simplicity of the camera does have some trade-offs because there isn’t much you can do to make photos brighter if you’re not in an ideal lighting situation. I did end up with some less-than-ideal shots because, in scenes with strong contrast, like dark trees against a bright sky, the details tended to blur together.
Techcrunch event
San Francisco, CA | October 13-15, 2026
Advertisement
The rest of the camera is equally straightforward. To power on the camera, you rotate the lens counterclockwise. The first click activates close-up mode for subjects about 0.9 to three meters away. Turning it once more switches to landscape mode for distant subjects beyond three meters. Rotating the lens clockwise powers the camera off.
The camera comes with a close-up lens attachment that snaps onto the front for close-up shots. I found the attachment was good at helping for avoiding focus and blur issues when taking close-ups.
Advertisement
Loading the cartridge is simple, with guide lines to help you align it correctly in the camera. The door closes securely using a twist lock that latches shut. There is also a small indicator on the back that shows how much film is left.
Image Credits:TechCrunch
Coming in at 162 mm x 98 mm x 123 mm and 1.4 pounds, the camera is quite bulky. It’s noticeably bigger than the Instax Mini cameras and the Instax Square models. However, I wasn’t too surprised by the size, since it makes sense that larger photos would require a bigger camera.
That said, it’s not something you’d want to carry around without a bag, and while the shoulder strap helps, I was still very conscious of it and careful not to bump it into people or objects in busy spaces. Although Instax does offer a camera case sold separately, I didn’t receive one alongside my review unit, so I can’t speak to it.
Since it’s a bit bulky, it’s pretty noticeable, and it ended up attracting the attention of a few people when I was testing it. A worker at a downtown gelato shop even stopped to compliment it, calling it a “cool looking camera.”
That kind of attention is part of the appeal.
Advertisement
Image Credits:TechCrunch
The camera’s self-timer is a nice feature, as it makes it possible to include everyone in a shot without needing someone to press the shutter button. It works by pushing a lever on the side and choosing one of four durations, ranging from two to 10 seconds. The camera emits a ticking sound to indicate that the timer is active, and red lights provide a visual countdown.
If you don’t have a tripod, the camera’s strap includes two angle adjustment accessories that can help prop and position the camera on a flat surface. To use one, slide it into the indented space on the camera’s underside, set the self-timer, and step back into the frame.
Film for the camera is available in standard white frame, black frame, metallic borders, and monochrome. Fujifilm sent me the standard white film alongside my review unit, which is the film I used for this review. Each box of film comes with 20 sheets and costs between $25-$28.
As for colors, the Instax Wide 400 comes in two options: green and jet black. As someone who loves a good shade of green, I liked that the color of the camera gave it a more playful, fun vibe.
Overall, I think this camera is a great option for people of all ages, as it offers high-quality images while remaining simple enough for kids and teens who are just starting out in photography.
Advertisement
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.



 That got me to thinking about reproducing a project versus taking inspiration from it, and though I enjoy both, I’m find myself most often in the “inspiration” mode. I just can’t leave well enough alone, even when I’m fundamentally copying someone. NIH syndrome? Expediency? Probably both, and sometimes with a dose of hubris or feature creep.
That got me to thinking about reproducing a project versus taking inspiration from it, and though I enjoy both, I’m find myself most often in the “inspiration” mode. I just can’t leave well enough alone, even when I’m fundamentally copying someone. NIH syndrome? Expediency? Probably both, and sometimes with a dose of hubris or feature creep.




























































You must be logged in to post a comment Login