Even as the geopolitical conversation around AI continues to grow more fraught following the U.S. government’s actions to limit the new models from Anthropic and OpenAI, Chinese open source darling DeepSeek is back with yet another open release that could once again change AI development around the globe.
Over the weekend, the firm released DSpark, a new, MIT-Licensed system designed to make large language models answer faster without changing what the underlying model is trying to say.
The easiest way to think about it is this: most AI chatbots write like someone crossing a river one stepping stone at a time. They choose one small chunk of text, then the next, then the next.
DSpark gives the system a scout that runs a few steps ahead, guesses the likely path, and lets the larger model quickly check which steps are safe. When the guesses are good, the model moves faster. When the guesses are weak, DSpark tries not to waste time checking them.
Advertisement
DeepSeek published the work with a technical paper, model checkpoints and DeepSpec, a codebase for training and evaluating speculative decoding systems. The release is available through DeepSeek’s public GitHub and Hugging Face pages, both under the permissive, friendly, commonplace MIT license, making the new technique broadly usable by developers, researchers and commercial enterprise operations that want to study or adapt the approach.
The system is aimed at one of the most expensive problems in AI deployment: serving large models quickly enough for real users, while using hardware efficiently enough to make the economics work. That matters for consumer chatbots, coding assistants, agentic workflows and enterprise AI systems where users expect long answers to stream quickly rather than crawl out word by word.
DeepSeek is applying DSpark to its own latest frontier open model, DeepSeek-V4.
Specifically, DeepSeek used its new DSpark framework on DeepSeek-V4-Flash, its already speed-optimized 284-billion-parameter mixture-of-experts model with 13 billion active parameters, and DeepSeek-V4-Pro, its more thoughtful and powerful 1.6-trillion-parameter model with 49 billion active parameters (Both support context windows up to one million tokens).
Advertisement
But the broader significance is that DSpark is not conceptually limited to DeepSeek-V4. DeepSeek’s own tests and released checkpoints cover other open model families, including Alibaba’s open weights Qwen and Google’s open weights Gemma.
That means enterprise teams running open-weight models could, in principle, train or fine-tune DSpark-style draft modules for their own target models. It is not a switch that any API customer can flip from the outside, but it is a method that can travel to other models when the operator controls the weights and serving stack.
Staggering speed increases for generating tokens during inference
In DeepSeek’s live production tests, DSpark improved aggregate throughput by 51% for DeepSeek-V4-Flash at an 80-token-per-second-per-user service target, and by 52% for DeepSeek-V4-Pro at a 35-token-per-second-per-user target. At matched system capacity, DeepSeek reports per-user generation speedups of 60% to 85% for V4-Flash and 57% to 78% for V4-Pro over its prior MTP-1 production baseline.
The different speed claims measure different things. The 60% to 85% figure for V4-Flash, and the 57% to 78% figure for V4-Pro, describe how much faster individual users receive generated tokens when DeepSeek compares DSpark with MTP-1 at matched practical system capacity.
Advertisement
Credit: DeepSeek, ‘DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation’
Those are the cleaner “generation speed” numbers. DeepSeek also reports much larger 661% and 406% increases, but these measure aggregate throughput under very strict speed targets: 120 tokens per second per user for V4-Flash and 50 tokens per second per user for V4-Pro.
At those targets, DeepSeek says its older MTP-1 baseline approaches an operational cliff, meaning it can keep only a small number of concurrent requests running while preserving that level of responsiveness.
DSpark avoids more of that collapse, so the percentage difference in total system output becomes much larger. Put simply: the 85% number is closer to “how much faster the ride feels for a user” under comparable conditions, while the 661% and 406% figures are closer to “how much more traffic the road can still carry” when the old system is already bottlenecking.
Advertisement
Why speculative decoding matters
LLMs usually generate text one token at a time. A token can be a word, part of a word, punctuation mark or other small piece of text. Every new token depends on the text already produced, so the model has to keep pausing, checking the full context and choosing the next piece.
That is accurate, but slow. It is like having a senior editor approve every word before a writer can move to the next one. The editor may be excellent, but the process creates a bottleneck.
Speculative decoding, developed in the early Transfomer era, tries to fix that bottleneck. Instead of asking the large model to produce every token one by one, the system uses a smaller or lighter draft component to suggest several likely next tokens. The large model then checks that batch of guesses in parallel. If the draft guessed correctly, the system moves ahead several tokens at once. If the draft made a bad guess, the system rejects the bad token and anything after it, adds a corrected token, and tries again.
The point is speed without changing the larger model’s intended output. In the standard speculative decoding setup, the draft model is not replacing the target model. It is acting more like an assistant who prepares a rough next sentence for the senior editor to approve or reject.
Advertisement
The idea did not appear out of nowhere with today’s large language models. A key precursor came in 2018, when Mitchell Stern, Noam Shazeer and Jakob Uszkoreit proposed blockwise parallel decoding for deep autoregressive models. Their method predicted multiple future steps in parallel, then kept the longest prefix validated by the main model. That paper established much of the draft-and-check intuition behind later speculative decoding work.
Those 2022 and 2023 papers are the clearest ancestors of how speculative decoding is discussed in current LLM inference work: a faster draft process proposes tokens, and the larger target model verifies them in a way designed to preserve the target model’s output distribution.
Since then, the field has moved quickly through several variants, including separate draft models, multi-token prediction heads, tree-based verification, feature-level methods such as EAGLE, self-speculation, Medusa-style extra heads and parallel/blockwise drafters such as DFlash.
Advertisement
The key metric is not how many tokens a draft model can guess. It is how many of those guesses the larger model actually accepts. Long speculative blocks help only if enough of the proposed tokens survive verification. Otherwise, the system spends compute checking guesses that it throws away.
That is the context for DSpark. Speculative decoding is already an established inference technique before DeepSeek’s release, with support in major serving stacks and multiple competing research approaches. But it is still not a solved problem. Speedups depend heavily on the draft model, the workload, the serving setup and the current traffic level. DSpark’s contribution is to improve both sides of the trade-off: it tries to draft more coherent token blocks and then verify only the parts of those blocks that are likely to pay off under real serving conditions.
What DSpark changes
DSpark tackles two related problems: bad guesses and wasted checking.
First, the system uses what DeepSeek calls semi-autoregressive generation. In plain English, that means DSpark tries to combine speed with a bit more awareness of sequence.
Advertisement
A fully parallel drafter can guess several tokens at once, which is fast, but its later guesses can become less coherent because each position is predicted too independently. A purely step-by-step drafter can keep better track of how one token leads to the next, but it loses much of the speed advantage.
DSpark tries to keep the best of both. It uses a parallel backbone for most of the drafting work, then adds a lightweight sequential head that lets the draft take nearby token relationships into account. In the paper’s example, a parallel drafter might confuse likely phrase endings such as “of course” and “no problem,” producing awkward combinations because it is guessing positions too separately. DSpark’s sequential component helps the system make the later tokens fit the earlier ones.
Second, DSpark adds confidence-scheduled verification. Rather than always asking the target model to check the same number of draft tokens, DSpark estimates which prefix of the draft is likely to survive. A hardware-aware scheduler then adjusts how much of each draft should be verified based on both model confidence and current serving load.
A simple analogy: when a restaurant is quiet, the head chef can inspect more of the prep cook’s work. When the kitchen is slammed, the chef spends attention only on the dishes most likely to be ready. DSpark applies a similar idea to AI serving. Under lighter traffic, the system can afford to check longer draft prefixes. Under heavier traffic, it trims low-confidence trailing guesses before they consume batch capacity that could be used for other users.
Advertisement
DeepSeek frames this as an answer to a common production trade-off. Static multi-token drafting can look attractive in isolation, but can hurt throughput under high concurrency because the system keeps checking tokens that are likely to be rejected. DSpark’s scheduler makes the verification budget flexible instead of fixed.
Offline results: better draft acceptance across Qwen and Gemma
DeepSeek tested DSpark offline on Qwen3-4B, Qwen3-8B, Qwen3-14B and Gemma4-12B target models across math, coding and chat benchmarks.
In those tests, the team compared DSpark with DFlash, a parallel drafter, and Eagle3, an autoregressive drafter. The paper reports accepted length per decoding round, a measure of how many tokens survive verification on average.
DSpark model speed improvement over Eagle3 and DFlash on Qwen3-4B, Qwen3-8B, Qwen3-14B, and Gemma4-12B. Credit: DeepSeek, ‘DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation’
Advertisement
Across the three Qwen3 model sizes, DSpark improved macro-average accepted length over Eagle3 by 30.9%, 26.7% and 30.0%, respectively. Compared with DFlash, it improved accepted length by 16.3%, 18.4% and 18.3%. The paper also says the gains generalized to Gemma4-12B.
That supports a point raised by developer Daniel Han, who highlighted on X that DeepSeek showed DSpark working beyond DeepSeek’s own V4 models, including Gemma and Qwen. I would include Han as community reaction, not as the sole evidence for the claim. The stronger support comes from DeepSeek’s own benchmarks and released checkpoints.
The offline results also show why workload matters. Structured tasks such as math and code tend to have higher accepted lengths than open-ended chat. That makes intuitive sense: a code completion or math step often has fewer reasonable next moves than a free-form conversation.
For enterprises, this means DSpark-style methods may be especially attractive for coding assistants, data analysis agents, structured workflow automation and other settings where outputs follow more predictable patterns.
Advertisement
How enterprises could use DSpark without DeepSeek-V4
One of the most important questions is whether DSpark is a DeepSeek-only optimization or a broader method that can be applied to other models. The answer is: broader method, but not automatic plug-in.
For open-weight models, the path is relatively clear. An enterprise running Qwen, Gemma, Llama, Mistral, Granite, Command-style open weights or another model it hosts itself could train or fine-tune a DSpark-style draft module against that target model.
The team would then measure acceptance on its own workloads and integrate the verification scheduler into its inference stack.
That is different from simply downloading DeepSeek’s DSpark module and attaching it to any model. Speculative decoding depends on alignment between the draft module and the target model. The draft has to learn what the target model is likely to accept. A drafter trained for DeepSeek-V4 will not automatically be the right drafter for a different model, especially one fine-tuned on a company’s internal data or configured for different reasoning behavior.
Advertisement
DeepSpec’s workflow reflects this. The process involves preparing data, regenerating target-model answers, building a target cache, training the draft model and evaluating speculative-decoding acceptance. For domain-specific use, the draft model may need additional fine-tuning, especially if the target model runs in a thinking or reasoning mode.
For proprietary models, the answer depends on what the enterprise controls. If a company owns or fully hosts the model weights and serving stack, it could theoretically train and deploy a DSpark-style drafter. If the model is available only through a hosted API from a vendor, the customer cannot directly add DSpark from the outside. The API provider could implement a similar optimization internally, but the customer generally cannot access the token verification loop, logits, batching behavior or serving scheduler needed to make DSpark work.
That distinction matters for enterprise buyers. DSpark strengthens the case for open or self-hosted AI infrastructure because it gives advanced teams another lever to improve speed and cost. But it also shows why model serving is becoming a specialized discipline. The value is not just in picking a model, but in how intelligently that model is run.
What developers get from DeepSpec
For developers, DeepSpec gives a concrete implementation path for training and evaluating speculative decoding draft models. It includes data preparation, training and benchmark evaluation steps, along with released checkpoints for several open model families. That makes the release useful not only for running DeepSeek-V4 with DSpark, but also for researchers and infrastructure teams studying how to add faster decoding to other open models.
Advertisement
There are real deployment caveats. DeepSpec’s own README says the default Qwen3-4B data preparation setup can require roughly 38 TB of target cache storage, and the default scripts assume a single node with eight GPUs. That makes the release more immediately relevant to AI labs, cloud teams and sophisticated enterprise AI infrastructure groups than to ordinary application developers.
Still, releasing the training pipeline matters. Many inference optimizations appear only as papers, vague benchmarks or closed production claims. DeepSpec gives developers something closer to a set of blueprints: not a finished enterprise product, but a way to reproduce, adapt and evaluate the method.
Early community testing
The release has already drawn fast developer attention. Developer Rafael Caricio published a GitHub pull request documenting single-stream DeepSeek-V4-Flash DSpark work, reporting warmed benchmark anchors of 26.33 tokens per second without speculative decoding, 39.88 tokens per second with MTP-1, and roughly 60 tokens per second with DSpark — about 1.5x over MTP-1 and 2.3x over no-spec decoding.
A later commit in the same thread recorded a five-run mean of 60.31 tokens per second, with a 1.51x gain over MTP-1 and 2.29x over non-speculative decoding.
Advertisement
The same work also points to an important practical limit: in realistic multi-turn coding sessions, performance can degrade as draft acceptance falls with growing context. In other words, DSpark can make decoding faster, but acceptance quality still determines how much speed the system actually realizes.
That is a useful reality check. DSpark is not magic. It still depends on how predictable the next tokens are and how well the drafter stays aligned with the target model. But the early implementation work suggests DeepSeek’s claims are not purely academic. Developers are already testing the method in practical serving environments and reporting gains close to the paper’s single-stream expectations.
The bottom line
DSpark shows how much performance remains available in the inference layer, even when the underlying model architecture stays the same. As AI companies compete on model quality, context length and pricing, decoding efficiency is becoming another major battleground.
Faster generation means lower latency for users, higher throughput for providers and better economics for teams serving open models at scale.
Advertisement
DeepSeek’s release is notable because it combines a production-tested method, open code, public checkpoints and a detailed paper. The main innovation is not just drafting more tokens. It is making the system more selective about which speculative work is worth verifying.
For enterprise teams, the broader lesson is that the next wave of AI performance gains will not come only from larger models. It will also come from smarter ways to run the models companies already have — especially when those companies control enough of the stack to tune the model, train a compatible draft module and optimize the serving engine around real workloads.
The EY Ireland CEO Outlook survey found that Irish CEOs remain confident about growth over the next 12 months despite global volatility and geopolitical risk.
EY Ireland has released its CEO Outlook survey, which explores how those in leadership are responding to global issues, challenges and opportunities. To gather data, EY partnered with FT Longitude and collected information from 1,200 globally dispersed CEOs throughout March and April of this year.
What was discovered is that Irish CEOs are confident about the potential for growth over the course of the next 12 months, despite growing pressures from global volatility and geopolitical risk. Of those who were surveyed, 92pc of CEOs in Ireland said they were optimistic about revenue growth and their competitive position.
However, despite the optimism, Irish CEOs harbour significant concerns about the landscape. Instability and conflict stand out as the most pressing issues for 70pc of Irish CEOs and other concerns include macroeconomic volatility (42pc), trade and supply chain disruption (22pc) and talent and capability gaps (16pc).
Advertisement
There is a similar pattern among the global respondents, albeit at lower levels compared to the Irish figures. 56pc of global CEOs ranked geopolitical risk among their top two concerns, followed by macroeconomic volatility (31pc), technology disruption including AI-related risks (23pc) and trade and supply chain disruption (22pc).
Commenting on the results of the report, Helena O’Dwyer, a partner and the head of strategy at EY-Parthenon Ireland, said: “Irish CEOs are navigating a complex, unpredictable and rapidly evolving landscape. The confidence in their own growth prospects is real and there is a track record over the past decade of successfully navigating global uncertainty with confidence.
“Even still, the pace and scale of the geopolitical upheaval is extraordinary, and geopolitical risk is no longer a background concern, it is a day‑to‑day operating reality – shaping decisions on costs, supply chains, capital and growth. From conversations with clients we know, however, that for mid-sized businesses in particular, the challenge is somewhat different.
“They may lack the scale of management capacity to find the time to actively manage these issues, or struggle with the level of working capital or technology to be able to address issues or take advantage of opportunities. These leaders are more focused on keeping income steady, reducing costs, looking after staff and staying connected to customers.”
Advertisement
Past the testing phase
The report also noted that for many organisations and CEOs, artificial intelligence investment has moved on from the experimental stage to accountability – particularly for those sitting in Irish boardrooms.
84pc of Irish CEOs who contributed their insights explained that they have increased AI investment since 2025, with the focus increasingly shifting from experimentation to the expectation of measurable results.
Data also suggests that leaders based in Ireland are expecting AI to deliver measurable results, with 68pc using standard metrics to measure and report on AI impact across major projects.
60pc expect the large-scale AI reskilling and upskilling of existing employees to be among the two most significant workforce impacts over the next three years, while only one in 10 fear that it will reduce hiring in certain roles.
Advertisement
‘Cultural resistance to change’, however, emerged as a major concern for four out of every 10 contributing Irish CEOs, who found it to be a barrier to deriving real value from AI. Globally, CEOs were less concerned, with just 16pc reporting a similar worry.
The report explained that this is reflective of the broader maturation in how businesses are approaching AI. The question is no longer whether or not to invest, but rather, how to demonstrate that investment is generating returns and whether you are building the internal structures needed to sustain and scale it.
Carol Murphy, a partner and the head of markets at EY Ireland, said: “CEOs increasingly are not asking whether to invest in AI, they’re asking what it’s delivering and what comes next. The focus has shifted firmly to results and that’s starting to change how work is organised across businesses.
“We’re seeing companies move beyond pilots and build AI into core operations, but that shift also brings a workforce challenge. Many organisations know they need to reskill and redesign roles to make the most of AI, but progress isn’t always straightforward. There can be resistance to change at all levels and for smaller and mid-sized businesses in particular, training and transformation have to happen in step with day-to-day delivery.”
Advertisement
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
Sony may have just dropped its biggest hint yet that a true PlayStation handheld is on the way. In a recently published Q&A with investors, Sony Interactive Entertainment CEO Hideaki Nishino said the company’s next-generation PlayStation strategy will deliver a seamless gaming experience that extends “beyond the living room.” While he never explicitly mentioned a handheld, the comments have once again fueled speculation that Sony is preparing to return to the portable gaming space with the PS6 generation.
Sony finally said what everyone was thinking
The statement wasn’t made out of nowhere. Nishino acknowledged that gaming habits have changed over the years, with more players choosing personal monitors and flexible gaming setups instead of gathering around a TV in the living room. Sony says it’s already trying to adapt to those changing habits by expanding its ecosystem with accessories like monitors and speakers, while also pointing to the positive reception of the PlayStation Portal as proof that gamers want more ways to access the PlayStation experience. The executive also emphasized that future PlayStation hardware will leverage technologies that can work “in various forms and locations,” suggesting Sony is thinking beyond the traditional home console.
Sony
That said, Sony also poured a little cold water on the excitement. Nishino reiterated that the company doesn’t intend to sell future hardware at significant losses. That’s a notable statement at a time when component costs continue to rise, and gaming hardware is becoming increasingly expensive.
“As a principle, we do not intend to sell hardware at significant losses.” – PlayStation
Naturally, that has led many to question whether now is really the right time for Sony to launch a premium handheld, or whether the economics simply don’t add up. Honestly, I think that’s a fair concern. But I’m not convinced it’s enough to stop Sony.
The numbers might actually work in Sony’s favor
The biggest mistake people make when imagining a PlayStation handheld is expecting it to be a PS5 squeezed into a smaller shell. But honestly, it doesn’t need to be that.
A portable with an 8-inch display isn’t trying to push native 4K graphics onto a 65-inch television. A clean 1080p target changes the equation completely. Modern AMD APUs have already shown just how much performance can be packed into handheld hardware, and by the time Sony is ready with its next device, that technology will only become more efficient. Throw in dynamic resolution scaling, modern upscaling techniques, and a platform where developers know exactly what hardware they’re building for, and suddenly running current-generation PlayStation games on a handheld doesn’t sound nearly as far-fetched.
Then comes pricing. Could Sony really launch something like this for around $550 to $600? Maybe.
Yes, $600 is still a lot of money. There’s no pretending otherwise. But gaming hardware has become expensive across the board. Microsoft’s latest Xbox refresh now starts at around $800, while the Steam Deck, despite being several years old, has seen its price hiked to a little under $800 now. Suddenly, a $600 PlayStation handheld starts looking a lot less outrageous.
Sony
More importantly, Sony isn’t just selling a handheld. It’s selling an ecosystem. Every player who buys a PlayStation handheld is also likely buying first-party games, third-party titles, PlayStation Plus subscriptions, accessories, and digital content. That’s a luxury companies like Valve simply don’t enjoy to the same extent. Sony doesn’t need to make huge profits on the hardware itself if the ecosystem keeps players spending for years afterward.
There’s an even bigger reason why this makes sense
Now what about the launch timeline? See, on paper, launching a PlayStation handheld alongside Grand Theft Auto VI sounds like the ultimate power move, right? Pair the biggest game of the generation with brand-new hardware, and you’ve got a marketing campaign that practically writes itself.
Rockstar Games
But if Sony were really gearing up for a 2026 launch, the rumor mill would probably be working overtime by now. Hardware has a habit of leaking months before it’s announced, and so far, things have been surprisingly quiet. Besides, Sony is already using GTA 6 as one of the biggest reasons to buy a PS5 Pro. Launching another premium device at the same time could end up stealing its own thunder.
I feel that’s why a 2027 launch actually makes more sense.
Rockstar has a history of bringing GTA games to PC much later, and GTA 6 is widely expected to follow the same pattern. That gives Sony a golden opportunity to pitch its handheld as the easiest, and potentially only, way to play GTA 6 and PlayStation exclusives on the go. Suddenly, waiting a little longer doesn’t sound like a delay; it sounds like smart timing.
By then, Sony would have more mature hardware, better manufacturing yields, and a stronger lineup of games to support a new platform. It would also arrive at a time when handheld gaming has become more competitive than ever. Nintendo has the Switch. Valve proved the Steam Deck wasn’t just a one-hit wonder. ASUS, Lenovo, MSI, and Acer are all pushing Windows gaming handhelds further every year. Even Microsoft has finally embraced the category. Sony is now the only major gaming company without a true native handheld.
There’s another piece of the puzzle that makes this even more interesting. Sony has reportedly shifted away from bringing its flagship single-player games to PC, choosing instead to keep those experiences exclusive to PlayStation hardware. If that strategy continues, a native handheld becomes far more valuable than just another gadget. Instead of waiting years for a PC release, the only way to experience PlayStation’s biggest exclusives on the move would be through Sony’s own hardware. Honestly, that’s a pretty compelling reason to buy one.
Am I reading too much into this?
Will any of this actually happen? We don’t know yet. Sony hasn’t confirmed a handheld, revealed any hardware, or shared a launch window. Right now, it’s all speculation based on a few carefully chosen words. But sometimes, those carefully chosen words tell a bigger story. And if Sony really is preparing to take PlayStation beyond the living room, I think a premium handheld is exactly the kind of gamble worth taking.
Ahmad Mohammadnejad / Unsplash
So here’s my question to you: if Sony launched a “premium” handheld with a gorgeous 1080p display that let you play your entire PlayStation library anywhere, even if it cost around $600, would you buy one?
Amazon is looking at OpenAI and other alternatives after a renegotiated contract will shift Anthropic billing to per-token pricing next year.
Amazon is looking for cheaper alternatives to Anthropic’s Claude models after a renegotiated contract will shift to token-based pricing that could substantially increase the company’s AI costs, according to The Information. The new pricing structure does not take effect until next year, but Amazon is already exploring options including OpenAI. The report highlights a deepening rift between two companies that were once inseparable partners in the AI race.
Amazon’s dependence on Claude runs deep. Its coding agent Kiro, workplace assistant Quick, and consumer-facing Alexa for Shopping all rely on Anthropic’s models, according to The Information. A shift to token-based billing would make that dependence far more expensive, particularly after Amazon recently scrapped an internal leaderboard that encouraged employees to burn through as many AI tokens as possible.
The search for cheaper models has sent Amazon toward OpenAI, a company it has already been growing closer to. Earlier this year Amazon committed $50 billion to OpenAI, giving the AI lab access to its cloud infrastructure in exchange for access to its models. That deal followed Amazon’s initial $4 billion investment in Anthropic, which has since grown to a potential $33 billion.
Advertisement
Anthropic, meanwhile, has been expanding its own relationships beyond Amazon. The company committed to spending $200 billion on Google Cloud and chips over five years, according to The Information, a deal that effectively makes Google a major infrastructure partner alongside AWS. Amazon’s latest $25 billion investment in Anthropic included a reciprocal commitment of more than $100 billion in AWS spending, but the Google arrangement signals Anthropic no longer depends on a single cloud provider.
The tension boiled over last month when the US government ordered Anthropic to shut down its Fable 5 and Mythos 5 models after a security report that originated from Amazon. Andy Jassy reportedly told government officials that Amazon researchers had used Fable 5 to obtain information useful for cyberattacks. The timing raised questions, coming as Amazon was preparing to launch its own cybersecurity-focused AI agent designed to spot vulnerabilities.
The contract dispute, the move toward OpenAI, and the Fable 5 incident together suggest the Amazon-Anthropic relationship has entered a new and more adversarial phase. Amazon remains one of Anthropic’s largest investors and cloud customers, but both companies now have reasons to reduce their dependence on each other. For the broader AI industry, the fracturing of its most prominent investor-model-provider partnership would redraw the competitive map.
At least two vulnerabilities are already under attack
Not everyone is willing to follow responsible disclosure of vulns. An anonymous researcher has dumped what they say is working exploit code for zero-day vulnerabilities across 15 software products and open source projects without notifying any vendors or maintainers prior to publishing – and attackers are already exploiting at least two of these.
The first is CVE-2026-55200, a critical, pre-authentication remote code execution (RCE) vulnerability in libssh2, a popular client-side C library that implements the SSH2 protocol. Remote attackers can send crafted SSH packets with excessively large packet_length values to corrupt heap memory and achieve remote code execution.
The second is CVE-2026-20896, a critical authentication bypass vulnerability affecting self-hosted Gitea Docker deployments that allows unauthenticated remote attackers to impersonate any user and fully take over the Git server. It’s fixed in Gitea 1.26.3.
The researcher, who goes by bikini, dropped the exploit code and vulnerability write-ups in a now-removed GitHub repository called exploitarium. They remind us of Nightmare Eclipse – the zero-day bug hunter who has been publishing Microsoft exploits over the past couple of months.
Unlike Nightmare Eclipse, however, bikini doesn’t appear to hold a grudge against any one vendor, publishing purported vulnerabilities across multiple products and projects including libssh2, Splunk, RustDesk, 7-Zip, VLC, AnyDesk, OpenVPN, c-ares, Gitea, and Floci.
Advertisement
Bikini claimed – and, to be clear, The Register has not verified these claims or that the code works – that none of the exploits in the repo have been reported.
“Feel free to report them yourself and take credit for the CVE if handed out lulz,” the anonymous researcher wrote, as shown in this screenshot posted on X by Ledger CTO Charles Guillemet. “Please do not abuse these. I do this so to allure people into the field.”
Other researchers, including Federal Signal analyst Ethan Andrews, suggested that bikini used advanced AI models – specifically GPT-5.5 Codex – to automate fuzzing and vulnerability discovery, in yet another indication that the AI-inducedvulnpocalypse is nigh.
In response to bikini’s data dump, Andrews built 44 KQL detection rules covering the full exploitarium repo with language translation available for non-KQL stacks.
Advertisement
“The most technically significant findings – libssh2 pre-auth heap write and Gitea default Docker auth bypass – have been independently verified as high-risk with active exploitation observed,” Andrews wrote, noting that some of the exploitarium disclosures “have been dismissed by the community as low-impact AI-fuzzing noise.”
While the repository has since been removed by GitHub, nothing ever truly dies on the internet, and it’s safe to assume that attackers are now also using AI to scan for vulnerable instances. In many cases, bikini’s PoCs mean they don’t even have to spend time developing an exploit. ®
If you’ve ever been on vacation and chose to record video instead of taking photos only to avoid missing the fun moments, thinking you’d pause and take screenshots later, you might have ended up questioning your decision later.
You see, the process involves multiple steps, starting from hunting for the right frame, pausing, and taking a screenshot. If it doesn’t look good, you go back to the video, pause somewhere else, and try taking another screenshot. You see where I’m going with this?
It’s a specific little misery that iOS 27 has now quietly fixed, and I genuinely can’t believe it took this long.
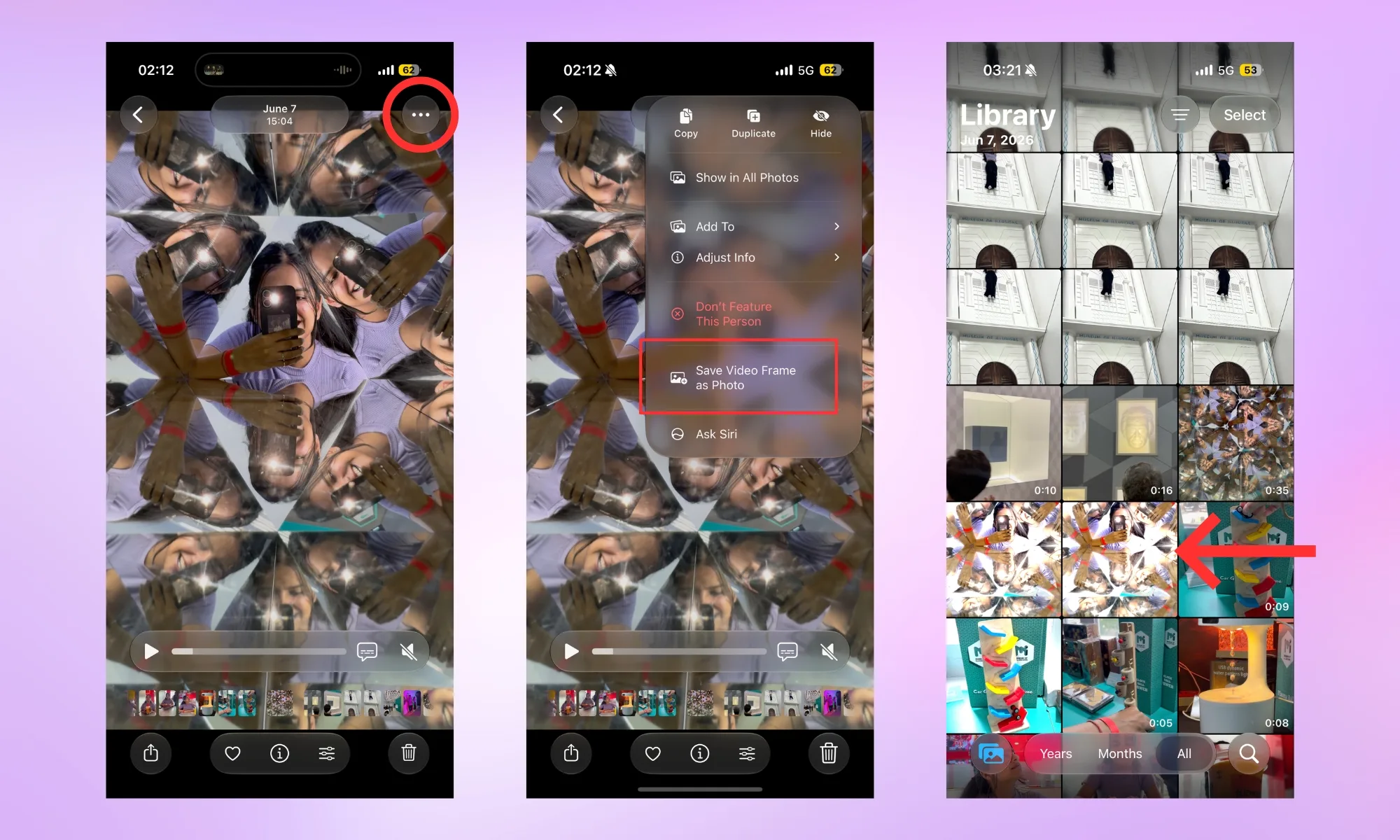
How does the new “Save video frame as photo” feature work?
The new “Save Video Frame as Photo” option in the Photos app does exactly what it sounds like. You can save a single frame from a video directly to the gallery as a photo, without the hassle of capturing screenshots. You can use it in two ways.
Advertisement
Shikhar Mehrotra / Digital Trends
The first one lets you use the feature quickly and save a video frame as a photo in as little time as possible. Open the video in the Photos app, scrub to the moment you want, pause, tap the three-dot menu at the top right of the screen, then tap the “Save Video Frame as Photo” button.
You should see a “Saved Video Frame” dialogue box pop up at the bottom of the screen. The saved frame shows up in your library, right next to the video you’ve extracted it from.
Shikhar Mehrotra / Digital Trends
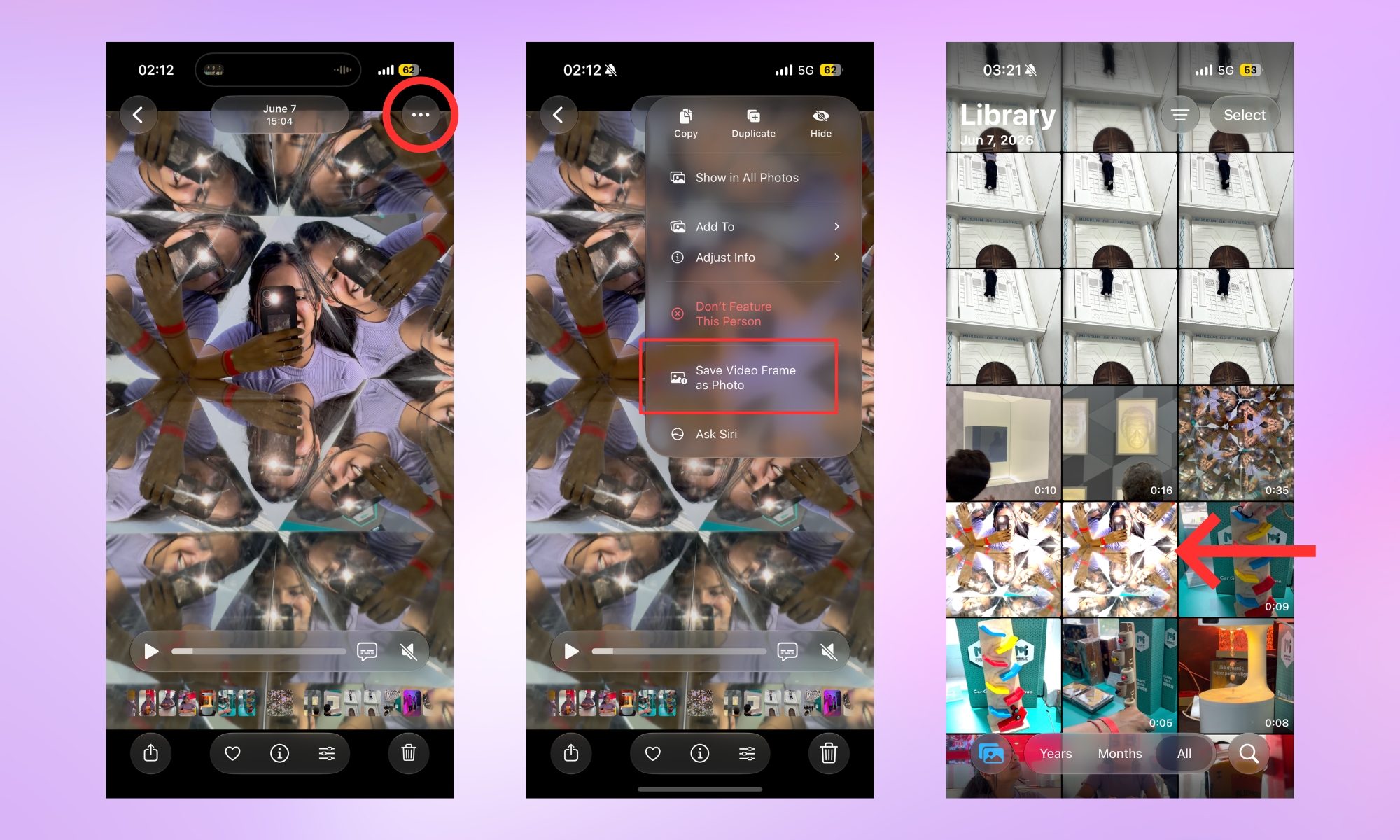
However, if you need frame-by-frame flexibility, open a video, then tap the hamburger menu at the bottom to enter the edit menu. Use the timeline at the bottom of the screen to scrub through the video one frame at a time.
Once you find the exact moment, tap the three-dot menu again and tap “Save Video Frame as Photo.” You should see a “Photo saved to your library” message on the screen. Tap the “OK” button below it, and you’re good to go.
Shikhar Mehrotra / Digital Trends
The feature is genuinely better than capturing screenshots
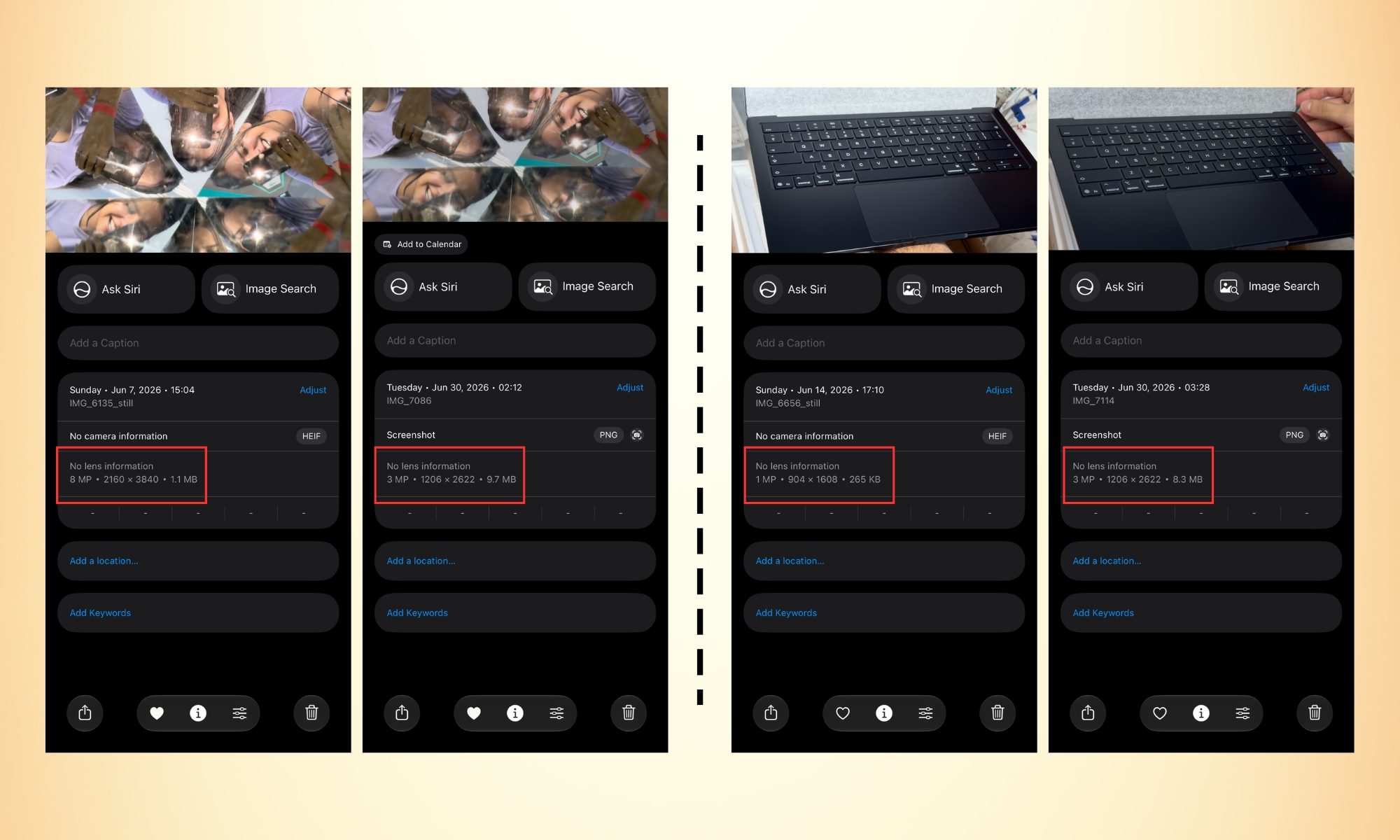
The difference in quality here is worth understanding. Saving a video frame as a picture is the same as taking a picture when you’re recording a 4K video at 60 fps; the saved frame comes out as an 8 MP photo (in Apple’s HEIF format).
Screenshots, on the other hand, save as PNG files that are lower in resolution but larger in file size. In a nutshell, the frame-extracted picture has both a smaller file size and a higher resolution than screenshots.
Furthermore, it doesn’t capture unwanted visual elements, such as the video progress bar at the bottom or a notification pop-up that shows up at the exact moment (I hate those).
It’s not surprising that Microsoft is looking to turn its Copilot platform into a “Super App,” given that its rivals are doing the same. But Microsoft is going about the task in a way that doesn’t follow its usual playbook, by putting a big bet on a consumer-savvy hire from the outside with some feather-ruffling ways.
The company’s newly minted Copilot Executive Vice President Jacob Andreou came to Microsoft from Greylock Partners and before that, Snapchat-maker Snap. Andreou currently oversees more than 11,000 Microsoft employees, according to a recent profile in Fortune.
Microsoft is bringing onboard another former Snap (and Discord) vice president, Peter Sellis, to help, GeekWire has learned. Sources say Sellis will be leading Copilot Design, Growth and Engineering, reporting to Andreou.
Andreou is part of a recently formed Copilot Leadership Team. His charter is to lead the “Copilot experience” by driving design, product, growth and engineering, as outlined in a March 2026 reorg memo from CEO Satya Nadella. He is one of a small group charged with shaping the future of Copilot, alongside others focused on the underlying Copilot platform and AI models.
Given Andreou’s Snap background, his plan to meld Microsoft’s consumer and enterprise Copilot experiences makes sense. It won’t be a snap, however. (See what I did there?)
Advertisement
Even though both share the Copilot brand, consumer Copilot and Microsoft 365 Copilot don’t work the same way or use the same data sources or architecture. To boot, Microsoft hasn’t had a lot of luck with this kind of consumer-enterprise unification, as evidenced by the low interest in and uptake of its free, consumer-focused Teams product compared to its business-focused Teams collaboration offering.
The 33-year-old, Los Angeles-based Andreou seemingly is undaunted by the challenge and is pushing some employees to clock 12-hour days to keep up with younger, AI-focused companies, Fortune reports.
Microsoft was infamous for requiring employees to work long hours and weekends during crunch times leading up to delivering Windows NT and Windows 95, but not so much in recent years. Microsoft is known as a place where outsiders often struggle to thrive compared to those who climb the corporate ladder for years, making Andreou’s approach feel even riskier.
Andreou has been a big backer of the Tasks productivity layer in consumer Copilot, which is still in public preview. Tasks, which enables Copilot to handle actionable items, is similar to the recently released Copilot Cowork layer that is part of Microsoft 365 Copilot. (I asked Microsoft if the two would merge as a single Cowork-type offering at some point but was told the company had no comment.)
Advertisement
However, the holy grail remains the “Super App.” With the Copilot Super App, Microsoft is looking to give consumers and business users a reason to stay within Copilot regardless of the AI task with which they – or their agents – are engaging.
“Come summer, we will be bringing coding to all knowledge work within one Copilot Super App. That’s really exciting. So you’re going to have Chat, Cowork, and Code all in Copilot,” Nadella told Microsoft Build conference attendees in early June.
Microsoft isn’t the only AI-focused company working on extending its AI coding capability beyond just developers. Nor is it the only one betting on the Super App concept.
OpenAI is working to turn ChatGPT into a Super App that brings together ChatGPT and Codex into a single environment that operates like a personal assistant.
Anthropic is extending Claude to become a Super App (though it hasn’t used that terminology), as well, by creating a single environment that combines productivity, development and automation tools.
The Copilot Super App isn’t Andreou’s only focus. He tells Fortune that AI model choice and home-grown AI model excellence also are among his key priorities.
Microsoft is expanding model choice in the Copilot Cowork feature beyond Anthropic to include OpenAI and soon, Microsoft’s own Cowork 1 model – which may be based on Microsoft’s hosted version of the open-source DeepSeek model. Cowork 1 will be the newest addition to Microsoft’s growing pool of Microsoft-developed models, seven of which debuted at Build this year. Microsoft is seeking to position itself as the champion of lower cost, efficient models built for those who are token-maxxed out.
Advertisement
Andreou definitely has his work cut out for him as a consumer guy in a heavily enterprise-centric company.
Microsoft 365 Copilot and consumer Copilot are just two of more than two dozen different “Copilot”-branded commercial offerings available across the various Microsoft product teams, which can feel overwhelming.
Microsoft also needs to give users a clearer way to find and use the quickly expanding stable of first- and third-party agents, like the OpenClaw-based Microsoft Scout personal assistant. Will Andreou and his Super App quest bring at least some order to the Copilot and agent madness? We’ll know more sometime this summer.
EOFY is a good time to check gaming laptop deals, even if the laptop isn’t going to be used for work. Gaming laptops can be quite expensive, so a legitimate discount can make a bigger difference than it does on a basic everyday laptop.
That said, a gaming laptop can also be a powerful workstation if your work does need extra grunt. A fast CPU, dedicated GPU and plenty of RAM can help with video editing, 3D work, coding, running AI tools, creative apps or just keeping a lot of browser tabs and programs open at once.
It’s also worth checking our main EOFY laptop deals hub even after June 30, because in previous years we’ve seen some great laptop deals hang around or pop up in early July as retailers clear leftover stock.
For gaming laptops, we have deals from lower-cost RTX 5060 machines with generous RAM, through to much more expensive RTX 5090 desktop replacements.
Advertisement
The Acer Nitro V 16S is a good option for a buyer who wants current-gen gaming performance without paying big money. You still get an RTX 5060, 32GB RAM, a 1TB SSD and a 180Hz display for AU$1,777, which is a lot of hardware for the price.
The RTX 5060 is a lower-end current-gen GPU, but that’s still a good fit for 1080p or 1200p gaming, especially if you’re happy to use DLSS or turn down a few settings in the most demanding games. With RAM prices rising, 32GB of RAM is harder to take for granted at this price, so it’s good to see Acer include it rather than cutting back to 16GB.
The Lenovo Legion Pro 7i is at the other end of the scale. Our Lenovo Legion Pro 7i review described it as “perfect for a desktop replacement, just okay as a portable”, and that’s exactly how I’d frame this deal.
Advertisement
You’re not buying it because it’s cheap or easy to carry everywhere. You’re buying it because you want a very powerful 16-inch gaming laptop with an RTX 5090, 32GB RAM, a 1TB SSD and a 240Hz OLED screen.
Our review gave the Legion Pro 7i 4 stars and called out its excellent gaming performance, gorgeous OLED screen and useful port selection. That makes it a good fit if you want one machine for demanding games, an external monitor setup and heavier work like editing, rendering or development.
The big caveat is battery life, which our review said “is not great”, but that’s the trade-off with this kind of desktop-replacement gaming laptop.
If neither of these gaming laptop deals is quite right, our main EOFY laptop deals hub has more options across cheaper Windows laptops, MacBooks, 2-in-1s and higher-end gaming machines.
from the moral-panic-creeping-further-and-further dept
Several U.S. states are pushing to ban young people from social media entirely. This marks the latest wave of censorship bills masquerading as “children’s online safety” measures, with states like Massachusetts, Idaho, Minnesota, North Carolina, South Carolina, Illinois, and EFF’s home state of California leading the charge.
Just a few years ago, lawmakers supporting age-gating laws insisted their efforts were narrowly targeted at limiting young people’s access to adult content. At the time, we warned that they would not stop there: once the government established the authority and built the infrastructure to collect and “verify” massive troves of user data, it would inevitably sweep broader and broader categories of lawful speech into this mass surveillance and censorship system.
Unfortunately, our predictions came true. As legislators across the country advance proposals that would block all young people from accessing the “modern public square,” the Overton window has shifted dramatically towards mass censorship—and the speed of this shift should concern all of us.
This primer breaks down this dangerous wave of social media bans: how they work (and why they don’t), who they harm, and how we can fight back.
Advertisement
How to Spot a Social Media Ban
The details of these bills vary from state to state. Some (like California’s AB 1709) are a flat-out social media ban for all young people under a certain age, while other states (like South Carolina and Minnesota) allow access to young users who hand over even more data to show verifiable parental consent. Many bills regulate certain social media features, too, including by setting default privacy settings, time limits, or notification preferences for all accounts that fail the age-gate.
As for the age-gating mechanism itself, most proposals fall into two broad categories: age verification bills and behavioral age estimation bills.
Age VerificationBills require online services to collect highly sensitive data, including government ID and biometric information, from all users before either restricting or allowing them access.
For example, take California’s social media ban (AB 1709). Starting in January 2027, operating systems will be required to collect enough information from users to sort them into age groups, or “brackets.” Under AB 1709, social media apps would then use that age bracket information to completely block anyone under 16, while supposedly letting everyone else through. By contrast, Florida’s law (HB 3) takes a more aggressive route by forcing platforms to verify users’ identities directly, usually by contracting with private third-party companies to perform verification services.
Advertisement
Behavioral Age Estimation Bills, on the other hand, are a more recent innovation of states like Minnesota (HF 1438) and South Carolina (H 4591). These bills require platforms to estimate the ages of users based largely on data that they already collect, including self-attested age, behavioral information, and account history and activity. In practice, these bills enable tech companies to use algorithms and/or AI to analyze our online behavior and estimate age based on that.
Proponents of behavioral age estimation bills claim that their proposals avoid the massive security risks that come with mandatory age verification bills. However, much of the data that social media platforms collect from us “in the ordinary course of operation” is collected in order to serve us targeted behavioral ads. If we force platforms to use this imperfect data to make more important judgments about who can access their services, we risk entrenching those insidious data collection practices. Surely we don’t want to give social media companies more reasons to justify and sustain their reliance on this exploitative business model.
If you want to dig into the nuance here, our terminology guide sheds more light on the technical differences between age verification and age estimation bills.
Overall, it’s a lose-lose scenario: either platforms collect new forms of our most sensitive and immutable data, or they unleash their AI and algorithms on our existing behavioral data to make creepy guesses about who we are and what we deserve to see. No matter which age-gating method your state chooses to execute its social media ban, there will be lots of error at the margins—and lots of users who will be blocked or chilled from access to lawful online speech.
Advertisement
Why Social Media Bans Are So Dangerous
Social media bans are unconstitutional, discriminatory, and deeply misguided. They reinforce existing structures of oppression, and they are broadlyunsupported by young people, whose voices are conspicuously absent from this conversation. They undermine parental decision-making and replace tailored family-level solutions with a one-size-fits-all band-aid. And, in the places we have seen social media bans go into effect, early reports show that they don’t evenwork.
For example, in Australia, where a social media ban has been in effect since late 2025, a majority of young people can still access social media, those who can’t have lost their access to the news, and crisis helplines are reporting skyrocketing numbers of calls from youth left stranded without online community or resources.
We could go on and on about all of the inherent harms here, but we’ll try to keep this short as we walk through some of the major issues.
1. Security Risks and Privacy Harms
In order to ban some users, social media platforms first must confirm the ages of all users, regardless of age. Bans thus incentivize companies to force users of all ages to hand over government IDs, face scans, and other sensitive information. When parental consent is required, companies must collect even more verification data and often create explicit links between child and parent accounts—further destroying users’ anonymity.
Advertisement
Both of these databases create massive data “honeypots” that invite identity theft and permanent surveillance. We’ve already seen repeated data breaches involving age- and identity-verification services. Yet these laws would force both adults and the youth they claim to protect to feed their most sensitive data into this growing surveillance ecosystem.
If we don’t trust tech companies with our private information now, we shouldn’t pass laws that force us to give them even more of it.
2. Disproportionate Harm to Vulnerable Communities
Where these bills require parental consent, they impose disproportionate access barriers on low-income, non-traditional, and immigrant families. These sorts of families are more likely to share a single family device or have strong reasons to not want the government to track family associations and ID documents.
Advertisement
Beyond the technical failures, these bans cut off a vital lifeline. For LGBTQ+ youth, foster kids, and those stuck in unsupportive home environments, social media is often the only place to find community, explore their identity, or access life-saving resources. Forcibly removing young people isolates those who need connection the most, while creating massive new barriers for adults.
Social science indicates that moderate internet use is a net positive for teens’ development, and negative outcomes are usually due to either lack of access or excessive use. For LGBTQ+ and marginalized youth in particular, social media offers an essential space to access support they might lack offline. By forcing youth into digital isolation, these bans cut off vital access to political news, community, and health resources. They also completely ignore the calls of young people themselves who favor digital literacy and education over restrictive government control.
Advertisement
Instead of cutting off these lifelines, we should support measures that arm all youth (and the adults in their lives) with the knowledge they need to navigate online spaces safely.
4. Reckless Free Speech Violations for Users of All Ages
No matter your age, the First Amendment protects your right to speak and access information.
Blanket social media bans immensely and unconstitutionally chill all users’ exercise of this right. They cut off young people’s access to lawful speech, or ruin their privacy in the home by mandating parental consent and sometimes even parental access to their account activities and settings. They force all users (adults and young people alike) to hand private information over to tech companies before speaking or accessing information on social media platforms, imposing annoying obstacles on lawful online expression and wrongfully blocking some adults outright.
Critically, these bans destroy our right to online anonymity—a cornerstone of our right to free expression that protects whistleblowers, journalists, activists, immigrants, and everyone who has ever used a private browser or account to ask the internet an embarrassing question.
Advertisement
How to Fight Back
Social media bans weaponize parents’ concerns about children’s safety to justify unprecedented levels of surveillance and censorship. In the process, these laws deny young people their rights, threaten online anonymity for everyone, expose our sensitive personal data to breach and abuse, and replace parental decision-making with state authority. This is a battle over the future of the open, private, and free internet, and we must act now to protect it.
Here’s how you can help us fight back: Talk to your community (including young people!) about what’s at stake. If you’re a parent, lean on open conversations and platforms’ existing tools to tailor your child’s experiences instead of handing that power over to the government. And no matter where you live, contact your government representatives and tell them clearly that social media bans are not the answer to kids’ online safety.
Ethan Tan, a memory industry consultant and former Samsung China executive, told Jefferies Equity Research analysts during a recent briefing that he expects memory prices to rise by 40% to 50% in the third quarter of 2026 compared to the prior quarter, and by another 30% to 40% in Q4…. Read Entire Article Source link
Want a cheap Yeti cooler for your 4th of July celebrations? I’m a deal-hunting outdoor expert, and I’ve tracked down the only holiday offers actually worth your money
Looking for a deal on a Yeti cooler for your July 4th celebrations? I’ve got you covered. As the former editor of an outdoor adventure website, I know exactly where to look to find the best offers on Yeti gear, and I have uncovered some great deals that will arrive in time for the big day.
Amazon has some great offers, particularly on soft coolers like the Hopper Flip 8 and 12, both of which are ideal for cans or lunches. There are also big discounts on the roomier Yeti M Series, including backpack-style coolers that make carrying your food and drinks a breeze.
Want a hard cooler? Take a look at Yeti Rescues, where you can find heaps of like-new coolers approved by the company itself, and with big price cuts. It’s a smart way to get a top-quality cooler for a lot less than list price. I’ve tested outdoor gear for years, and these price cuts are rare, so grab them while you can.
Advertisement
Yeti deals at Amazon
Yeti’s online store often holds seasonal sales and special deals on selected colors and product lines. Here are today’s best offers.
Yeti Rescues deals
Can’t see the cooler you want in the Black Friday sale? Take a look at Yeti Rescues — an official Yeti program that takes coolers and other equipment that’s not brand spanking new (products that have been returned, for example, or that Yeti has used for demos or displays), inspects them, cleans them, and sells them at a bargain price.
Advertisement
More Yeti deals
Amazon and Yeti Rescues aren’t your only options when you’re shopping for a cheap Yeti cooler. Dick’s Sporting Goods has a decent selection of offers as well. I’ve rounded up a handful of the best below, but you can also check out the full sale yourself.


























































You must be logged in to post a comment Login