







ADP is one of the largest providers of payroll, HR, and tax services in the business world, but its products are more often associated with larger enterprises – so RUN powered by ADP is a refreshing change of pace.
It’s a payroll and HR platform specifically designed for smaller businesses with fewer than 50 employees. We’ve reviewed all the best HR software, with this particular service built to make potentially complex functions faster, easier, and more reliable, so the people in charge of small businesses can concentrate on the work they really want to be doing.
Over 900,000 small businesses already rely on ADP, so there’s plenty to suggest that this solution will work for your small enterprise – and with a healthy array of features and a solid selection of product tiers available, your organization will have plenty of choice when it comes to picking its next payroll and HR solution.
RUN Powered by ADP: Plans and pricing
As with many HR and payroll tools, pricing for RUN Powered by ADP is available on a case-by-case basis, and you’ve got to talk to the company to get concrete figures.
RUN powered by ADP is available in four different packages. All are designed around smaller businesses, but there’s a broad array of features available.
The Essential Payroll option is ideal for small organizations that just need a product to handle payroll, taxes, and compliance in all fifty US states, and the Enhanced Payroll adds background checks, State Unemployment Insurance and ZipRecruiter compatibility. The Complete Payroll & HR Plus product provides basic HR support, while HR Pro offers in-depth HR support and employee perks.

RUN Powered by ADP: Features
Even the entry-level Essential Payroll package is packed with capabilities, including online, phone, and mobile payroll functionality, direct deposits, reporting, tax filing, multi-company and multi-jurisdiction payroll support, and more.
That entry-level product also includes employee self-service payroll and document portals, new-hire onboarding, background checks and employee discounts.
Upgrade to Enhanced Payroll and you get State Unemployment Insurance management, Job Costing and more. Opt for the basic HR support of the Complete Payroll & HR Plus tier and you get phone and email support, an employee handbook wizard, salary benchmarking, HR tracking, training, and documentation. And by upgrading to the top product, HR Pro, you add ATS capability, learning management and legal assistance to the product.
This impressive list of features is bolstered by solid functionality.
Many of those key payroll tasks can be automated, and mobile access and an effective system of reminders ensure that your HR staff can keep things running smoothly. The system now also includes AI-powered error flagging so you can spot issues before they have an impact.
The payroll system keeps things moving with logical, sensible workflows and comprehensive reporting capabilities, and there’s a document vault for cataloguing employee information.
That’s great, but this product does have some limitations, especially when compared to solutions that are designed for larger organizations. You won’t find the depth of reporting and analytics here that you’ll see elsewhere, for instance, and customized workflow functionality is limited.
Several add-ons can enable extra functionality, albeit at extra cost. The Time and Attendance module helps you manage schedules and tackle time away from work, and the Retirement utility allows you to build and choose competitive retirement plan options through ADP Retirement Services.
The Workers’ Compensation module adds pay-as-you-go solutions for your employees, and a Health Insurance add-on lets staff choose from a wide variety of group coverage options.

RUN Powered by ADP: Ease of use
Access RUN Powered by ADP and it’s immediately clear that the system has been designed for smaller businesses that may not have large HR departments – or much HR experience within the organization at all.
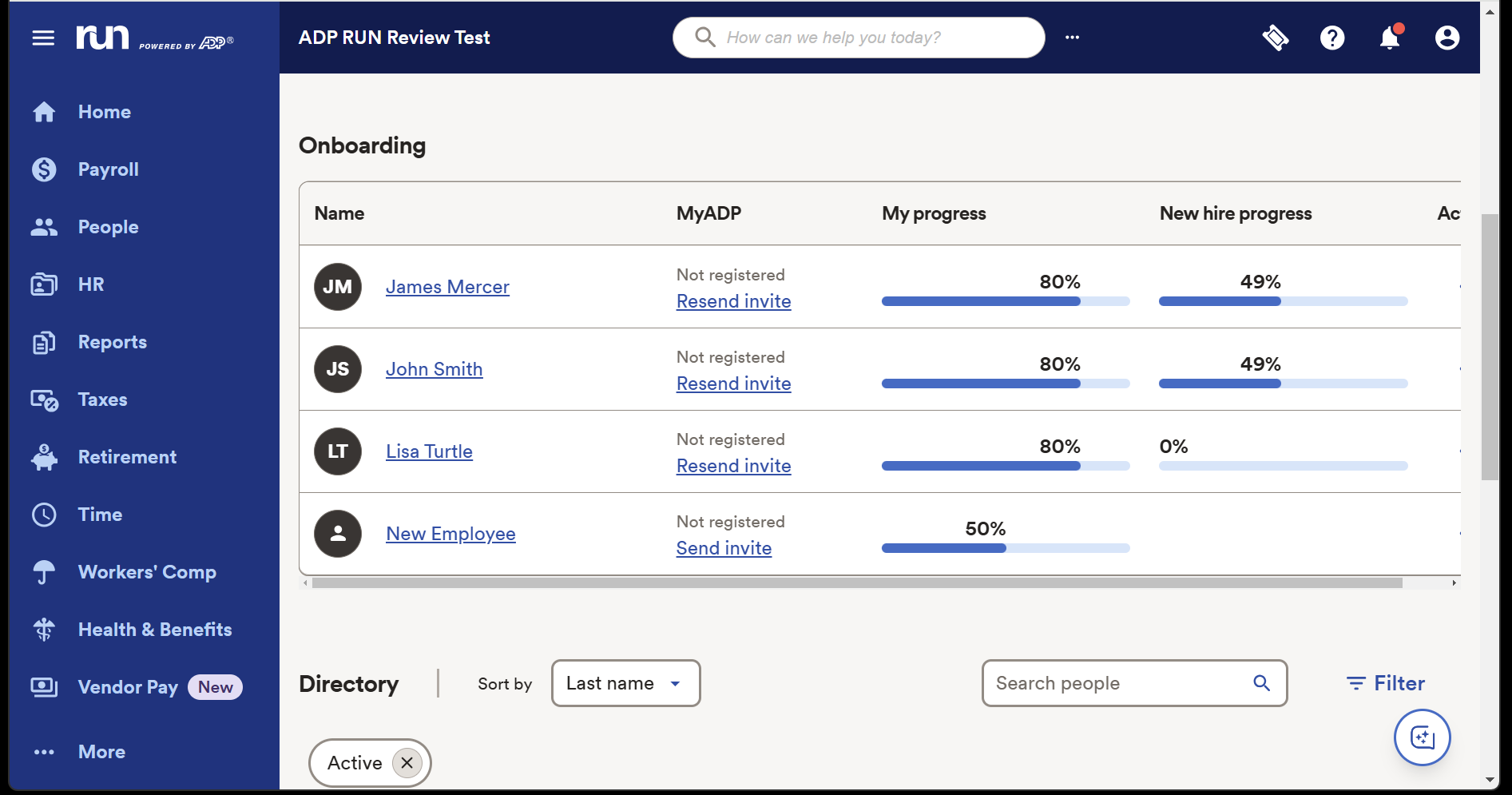
The layout is clear and intuitive. Different modules are accessible in a menu bar on the left-hand side of the product, and the Home Screen provides a slick, straightforward view of your upcoming payroll, key next steps, your latest reports and a calendar.
A button in the bottom-right corner opens up ADP Assist, a new AI helper, and you can edit quick-access links next to the search bar at the top of the home screen.
Individual sections are just as straightforward. The Payroll section puts key notifications, including W-2 and 1099 paperwork, right at the forefront. Similarly, the People section prioritizes your next steps, the Employee Directory makes it easy to find key details about your staff, and many sections around the app have Quick Action menus that make common functionality easy to tackle.
The system is easy to navigate even for people without lots of HR experience, which is key for a product like RUN Powered by ADP – and it gives this solution an instant advantage when compared to many rivals.
The downside of that? Limited customization. You can’t tweak every option on the home screen like you can in other products, you can’t integrate using API, and you can’t add any of the thousands of utilities available in ADP Marketplace – RUN supports integrations with several leading accounting, business, and POS system providers, but that’s it.
For smaller organizations none of those issues will be a deal-breaker, because RUN will provide everything they need, but it’s worth bearing this in mind – and noting that you may need to upgrade to a more flexible product if your organization grows and develops more complex HR requirements.

RUN Powered by ADP: Support
As well as the aforementioned ADP Assist module, RUN provides several different support routes for small businesses.
Every tier of the product provides 24/7 payroll phone support from ADP agents, and live chat agents are available from 7.30am to 10pm on weekdays. Users can file service tickets and leave messages for those chat agents. If you opt for the Complete or HR Pro packages you also get phone and email HR support, too, alongside training modules.
ADP’s website has a knowledge base with answers to common questions and a client community called The Bridge, where administrators can ask questions.
That’s a good slate of options, but online user reviews suggest that payroll support is sometimes not particularly fast, which may be an issue in your organization.

RUN Powered by ADP: Competition
We’re going to start this section in a slightly unusual way: by talking about another ADP product. ADP Workforce Now is built for midsized and enterprise-level businesses with more than fifty employees – in contrast to RUN Powered by ADP, which is designed for organizations with less than fifty members of staff.
ADP Workforce Now provides much of the functionality as RUN Powered by ADP, and adds more robust capabilities around benefits administration, talent acquisition, reporting, and professional services.
This broader product concentrates on streamlining, automation, and cost management, and it also supports integrations through the ADP Marketplace and via standard APIs – something you don’t get with RUN Powered by ADP.
Beyond ADP’s own products, RUN faces some tough competitors. If you’d like to explore straightforward payroll tools that work well with smaller organizations, Gusto and QuickBooks are perennially popular options.
If you’re on the hunt for a solution that offers HR capabilities alongside payroll, then Rippling is a more complex choice, and Paylocity is another contender that can grow with your business and provide a broader slate of features.
RUN Powered by ADP: Final verdict
RUN Powered by ADP makes payroll, taxes, and core HR admin tasks feel manageable for small businesses that don’t have an HR team or managers who want to deal with the extra burden – and if you find yourself in that position, this is an excellent and effective choice.
It’s got an intuitive interface, easy learning curve, and excellent payroll features that make compliance, tax, and financial reporting a breeze.
There are negatives, though, with a lack of flexibility, customization, and integration options compared to many other products. A lack of pricing transparency can hinder decision-making, and costs can escalate if you invest in a pricier tier with add-ons to deploy extra functionality.
RUN Powered by ADP does a good job with the essentials of payroll and HR, so it’s a solid choice for smaller businesses that don’t have in-house expertise, but we’d consider shopping around if you’d like to grow your business and may require a more ambitious selection of features.
























































You must be logged in to post a comment Login