Every time Russia attacks Ukraine’s power infrastructure, Ukrainian engineers risk their lives in the scramble to get electricity flowing again. It’s a dangerous job at best, and a lethal one at worst. It also requires creativity. Time pressure and equipment shortages make it nearly impossible to rebuild things exactly as they were, so engineers must redesign on the fly.
These dangerous, stressful conditions have led to more engineers being hurt or killed. The rate of injuries among Ukrainian workers in electricity generation, transmission, and distribution jumped nearly 50 percent after Russia’s full-scale invasion began four years ago, according to data provided byAntonina Nagorna, who leads the Department of Epidemiology and Physiology of Work at the Kundiiev Institute of Occupational Health, in Kiev. By her count at least 48 people had died on the job through the end of 2025, either while repairing damage or during the bombardment itself.
Transmission mastermind Oleksiy Brecht joined that grim count in January. Brecht, who was director for network operations and development at the Ukrainian grid operator Ukrenergo, died while coordinating work at Ukraine’s most attacked electrical switchyard, Kyivska, west of the capital. He was 47 years old.
Brecht’s life and death are a window into the realities of thousands of Ukrainian engineers who face conditions beyond what most engineers could imagine. “The war completely transformed the professional life of a top-manager engineer,” says Mariia Tsaturian, an energy analyst and chief communication officer at the think tank Ukraine Facility Platform, who previously worked with Brecht at Ukrenergo. “As for junior staff, their world was turned upside down entirely. A substation engineer working under shelling is something no one had ever seen or experienced before,” she says.
Advertisement
How Russia Attacks Ukraine’s Grid
Over the course of the war, Russia has increasingly focused on destroying Ukraine’s energy infrastructure. It sends attack drones almost daily during the winter there, when heat and electricity is needed most to survive the bitter cold. Every 10 days or so it barrages Ukraine’s power system with combinations of missiles and hundreds of drones, repeatedly mangling equipment and cutting off power. The cold imposed on Ukrainian homes is especially hard on former prisoners of war held in Russia, where cold is routinely employed as a form of torture.
In the first two years of the war, keeping the grid flowing was a 24/7 job. But Ukrenergo has adapted to the impossible since then, saysVitaliy Zaychenko, Ukrenergo’s CEO, who somehow found a moment to speak with Spectrum via video call. Now, “we are more prepared for each attack. We have well-trained teams. We have support from Europe,” he says.
But the risk involved in repairing the grid remains unnerving. Last month a crew from DTEK, Ukraine’s biggest private-sector energy firm, was traveling between locations when it was targeted by a Russian drone. They heard the drone coming and escaped before their bucket truck was destroyed. Russian forces have employed “double tap” attacks against DTEK’s crews, targeting their power infrastructure with a follow-up strike designed to kill first responders—a practice confirmed by the U.N.
When Russia began targeting power infrastructure in October 2022, Brecht’s job shifted from high-level direction of grid planning and maintenance to near-constant triage and real-time system reengineering. Most weeks, Brecht spent several days in the field, crisscrossing the country to coordinate work at smashed substations. Brecht would often be found on site figuring out how to restart power using whatever equipment was available. “It was a unique decision every time,” says Zaychenko.
Advertisement
Oleksiy Brecht died in January while overseeing repairs to a bombed-out substation near Kyiv. He called his employees at Ukrenergo “my fighters. They called him “our general.”Ukrenergo
Zaychenko noted Brecht’s “genius” for finding creative grid fixes, his passion and leadership skills, and his credibility with power brokers in Ukraine and abroad. Brecht scoured the globe sourcing critical replacement parts, including stockpiled or older equipment from international utilities. Transformers, which can take a year or more to source, are especially precious.
When the right equipment wasn’t forthcoming, Brecht figured out how to make do. For example, he would deploy transformers from Western Europe rated for 400 kilovolts to restart a 330-kV circuit. He would adapt transformers designed for 60-hertz alternating current for emergency use on Ukraine’s 50-Hz grid. “He would find a way,” says Zaychenko, who worked closely with Brecht for over 20 years.
Brecht’s assistant at Ukrenergo, Svitlana Dubas-Veremiienko, says he also contributed to the teams’ morale and confidence. She shared on Facebook that he smoked “like a locomotive” at the worst times, and yet exuded calm: “In his presence, chaos subsided,” she wrote. Brecht was not easy to intimidate. “He was someone who never feared anything or anyone,” adds Tsaturian.
Brecht’s work proved so essential that Ukrenergo’s former Deputy CEO Andrii Nemyrovskyi recalls telling Ukraine’s Ministry of Defense in 2022 that the military must protect two people: Zaychenko, because he ran grid operations, and Brecht because “system operations requires that the system exists.” Last week, President Zelenskyy posthumously named Brecht a “Hero of Ukraine” for “strengthening the energy security of Ukraine under martial law.”
Advertisement
Ukraine’s Power Infrastructure Under Fire
Brecht joined Ukrenergo in 2002 after earning his degree in power engineering from Igor Sikorsky Kyiv Polytechnic Institute. Over the next 20 years, he held leadership positions in dispatching and grid planning and development. He joined Ukrenergo’s management board in June 2022 and served as its interim leader in 2024.
Brecht’s contributions to Ukraine’s wartime survival began with several key upgrades to Ukrenergo’s technical capabilities ahead of the February 2022 invasion. He reintroduced “live line” techniques, providing training and equipment that enable crews to work on circuits while they continue to carry power to homes and to sustain critical needs.
Brecht also led preparations for Ukraine’s disconnection from the Russian grid and synchronization with Europe’s. When the invasion began, Ukraine’s Minister of Energy at the time, Herman Halushchenko, had argued that switching from Russia’s grid to Europe’s was too risky, according to Tsaturian and Nemyrovskyi. But Brecht insisted—correctly, as hindsight has shown—that synchronizing with Europe would provide crucial stability and backup power. At his urging, the switch was completed in daring fashion during the first weeks of the invasion.
DTEK workers conduct repairs on 26 January following a Russian attack in Kyiv.Danylo Antoniuk/Cover Images/AP
A Ukrainian Electrical Engineer’s Final Day
Brecht’s final act of service followed the mass destruction of January 19—a day when Kyiv’s high temperature was –10° C. That night, Russian forces targeted Ukraine’s energy infrastructure with 18 ballistic missiles, a hypersonic cruise missile, 15 conventional cruise missiles, and 339 drones.
The impact included catastrophic damage at the 750-kV Kyivska substation, which feeds electricity to the capital and ensures cooling power for two nuclear power plants.
Brecht was leading a team of about 100 people who were undoing the damage when he made a deadly choice. He picked up a section of busbar—solid conduits that connect circuits within substations. It had been blasted to the ground and, unbeknownst to Brecht, was carrying lethal voltage. It’s unclear whether its circuit was still connected, or if it had picked up voltage from another circuit.
Zaychenko says an investigation is ongoing to provide answers. “I don’t know why he touched this busbar. Maybe because of tiredness. Maybe something else,” he says. “He was trying to help the team to do this job quickly. It was a huge mistake and a huge loss for us.”
Having 32GB in a 2 x 16GB configuration provides plenty of breathing room for demanding workloads, including large creative projects, heavy multitasking, and memory-hungry applications.
Advertisement
Today’s top Corsair Vengeance deal
It’s worth pointing out that this Corsair kit is DDR4 rather than the newer DDR5 standard. DDR5 is much faster overall, but that only helps if your motherboard supports it. For many existing systems, DDR4 is what you want.
This particular kit runs at DDR4 3200 speeds with CL16 timings of 16-20-20-38. Corsair includes dynamic multi-zone RGB lighting with 10 ultra-bright LEDs on each module, delivering colorful lighting effects that can sync with other Corsair components via its iCUE software ecosystem.
If this is the sort of thing you like, lighting effects can be set to match compatible CPU coolers, keyboards, and fans without complicated configuration steps or additional hardware requirements.
Advertisement
A custom performance PCB supports stable signal quality and reliable operation under load, which will benefit your system during long work sessions or when overclocking.
An anodized aluminum heat spreader keeps temperatures in check and Intel XMP 2.0 support will allow you to achieve the rated speed with a single BIOS setting instead of manually tuning multiple memory parameters.
If you’re building a compatible system or upgrading an older machine that already uses DDR4, this is a great deal, especially coming at a time when computer RAM prices are still on the high side.
As we work our way towards a better future for the internet, the most encouraging and exciting part is the people out there building towards that future. Kickstarter founder Yancey Strickler is one such person, and his new company Metalabel has some extremely interesting projects in the works, including the Dark Forest Operating System. This week, Yancey joins the podcast to talk all about his projects and their role in building a better internet.
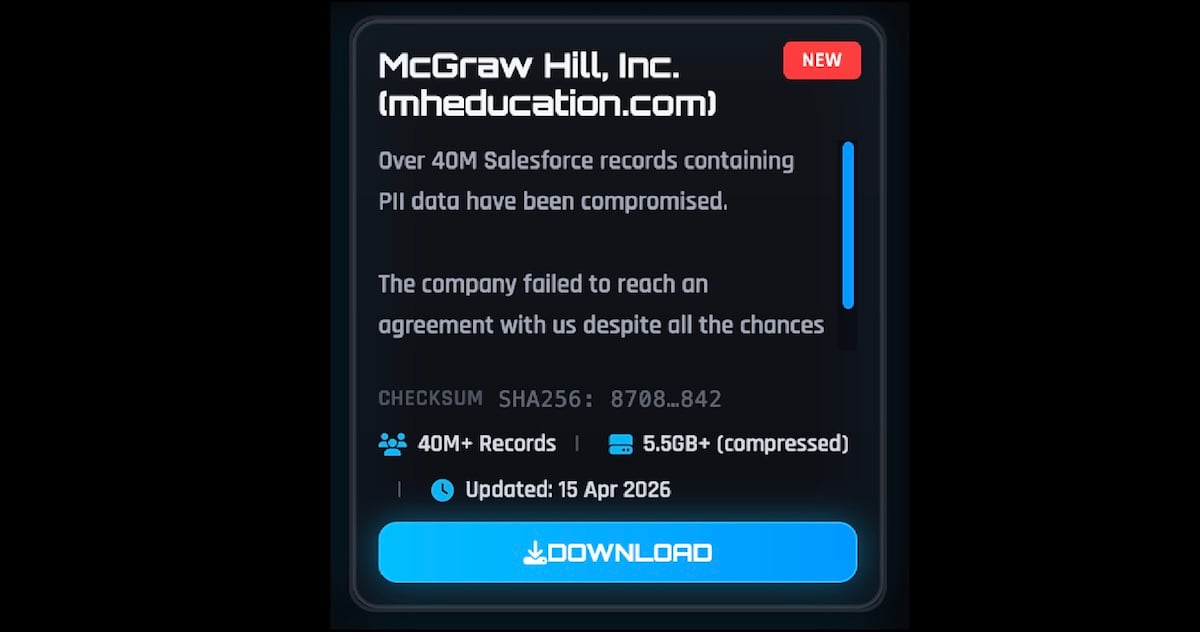
The ShinyHunters extortion group has leaked data from 13.5 million McGraw Hill user accounts, stolen after breaching the company’s Salesforce environment earlier this month.
Founded in 1909, McGraw Hill is a leading global educational publisher with annual revenue of $2.2 billion, which provides education content and solutions for PreK–12, higher education, and professional learning.
The company confirmed ShinyHunters’ breach claims in a statement shared with BleepingComputer on Tuesday, saying the threat actors exploited a misconfiguration in the compromised Salesforce environment and that the incident didn’t affect its Salesforce accounts, courseware, customer databases, or internal systems.
“McGraw-Hill recently identified unauthorized access to a limited set of data from a webpage hosted by Salesforce on its platform. This activity appears to be part of a broader issue involving a misconfiguration within Salesforce’s environment that has impacted multiple organizations that work with Salesforce,” a McGraw-Hill spokesperson told BleepingComputer.
This came after ShinyHunters added the company to the gang’s dark web leak site, claiming to have stolen 45 million Salesforce records containing personally identifiable information (PII) and threatening to leak the allegedly stolen documents online unless a ransom is paid.
Advertisement
McGraw Hill entry on ShinyHunters’ data leak site (BleepingComputer)
While McGraw Hill has yet to share how many individuals were affected by the resulting data breach, data breach notification service Have I Been Pwned says ShinyHunters has now leaked over 100GB of files containing data linked to 13.5 million accounts.
The exposed information includes names, physical addresses, phone numbers, and email addresses, which threat actors could use to target McGraw Hill customers in spear-phishing attacks.
“In April 2026, education company McGraw Hill confirmed a data breach following an extortion attempt. Attributed to a Salesforce misconfiguration, the company stated the incident exposed ‘a limited set of data from a webpage hosted by Salesforce on its platform’,” Have I Been Pwned said today.
“More than 100GB of data was later publicly distributed, containing 13.5M unique email addresses across multiple files, with additional fields such as name, physical address and phone number appearing inconsistently across some records.”
This week, ShinyHunters has also started leaking data stolen after breaching the Snowflake environment of American video game publisher Rockstar Games. The stolen data includes internal analytics used to monitor Rockstar’s online services and support tickets, as well as in-game revenue and purchase metrics, player behavior tracking, and game economy data for Red Dead Online and Grand Theft Auto Online.
Automated pentesting proves the path exists. BAS proves whether your controls stop it. Most teams run one without the other.
This whitepaper maps six validation surfaces, shows where coverage ends, and provides practitioners with three diagnostic questions for any tool evaluation.
DeepL, a translation company best known for its text tools, released a voice-to-voice translation suite today that covers use cases like meetings, mobile and web conversations, and group conversations for frontline workers through custom apps. The company is also releasing an API that lets outside developers and businesses build on top of DeepL’s tech for customized use cases, such as call centers.
“After spending so many years in text translation, voice was a natural step for us,” DeepL CEO Jarek Kutylowski told TechCrunch in an interview. “We have come a long way when it comes to text translation and document translation. But we thought there wasn’t a great product for real-time voice translation.”
Kutylowski said that the challenges in creating a real-time translation product center on striking a balance between reducing latency — the delay between someone speaking and the translated audio playing back — and maintaining accurate results.
DeepL is releasing add-ons for platforms like Zoom and Microsoft Teams, where listeners can either hear real-time translation while others are speaking in native languages or follow real-time translated text on screen. This program is currently under early access, and the company is inviting organizations to join a waitlist. The company also has a product for mobile and web-based conversations that can take place in person or remotely.
Advertisement
DeepL also lets allows users participate in a group conversation in settings like a setting like training sessions or workshops, allowing participants to join through a QR code.
DeepL said that its voice-to-voice tech can also learn and adapt to custom vocabulary, such as industry-specific terms and company and personal names.
Kutylowski said that AI is reimagining what customer service will look like in the coming years. He noted that a translation layer helps companies provide support in languages where qualified staff are scarce and expensive to hire.
Techcrunch event
Advertisement
San Francisco, CA | October 13-15, 2026
The company said that it controls the entire voice-to-voice stack. However, the current system converts the speech to text, applies translation, then converts that back to speech. DeepL believes that since it has worked on text translation for years, it has an edge in translation quality. Going forward, the company wants to develop an end-to-end voice translation model that skips the text step entirely.
Advertisement
DeepL faces competition from several well-funded startups working in adjacent corners of the space. Sanas, which last year raised $65 million from Quadrille Capital and Teleperformance, uses AI to modify a speaker’s accent in real time — a tool aimed primarily at call center agents.
Dubai-based Camb.AI focuses on speech synthesis and translation for media and entertainment companies Amazon Web Services, helping them dub and localize video content at scale.
Palabra, backed by Reddit co-founder Alexis Ohanian’s firm Seven Seven Six, is building a real-time speech translation engine designed to preserve both the meaning and the speaker’s original voice, putting it in more direct competition with what DeepL is now building.
College students who purchase eligible Windows laptops before July 31 can receive a free year of Microsoft 365 Premium, Xbox Game Pass Ultimate, and a customized Xbox controller. Retailers including Best Buy, Amazon, Walmart, and Dell are leaning into the promotion, surfacing models designed to rival the MacBook Neo on… Read Entire Article Source link
from the domestic-surveillance-is-fine-if-we-do-it dept
It wasn’t all that long ago that GOP legislators were collectively stonewalling a clean reauthorization of Section 702. Three years ago, these legislators were seeking to end the FBI (and other IC components’) access to Americans’ communications via “backdoor” searches of the NSA’s supposedly “foreign facing” collections.
It wasn’t that the Republicans cared that Joe Public was being subjected to warrantless domestic surveillance. It was that they were being subjected to warrantless searches of their communications — something that came to light as the result of multiple investigations pertaining to Trump’s first administration.
Now that the GOP has control of the White House again, Republicans are back to not caring about the warrantless searches of US persons’ communications enabled by FISA loopholes very few congressional reps seriously want to see closed.
Another Section 702 reauthorization attempt is only weeks away. Reps who want more of the same thing we’ve been subjected to for decades have until the end of April to push a clean reauthorization through. Unfortunately for them, the FISA Court — while allowing the program to continue whether or not Congress can pass an extension — has made it clear the program needs to be overhauled because it’s still being routinely abused to perform warrantless searches targeting Americans’ communications.
Advertisement
The annual recertification, issued last month in a classified ruling, means that the program can continue to collect phone calls and emails through March 2027 — even if Congress fails later this month to renew the statute that underlies it.
But the judge who issued the March 17 ruling also objected to tools that agencies with access to the raw data — like the C.I.A., F.B.I. and National Security Agency — have created to allow analysts to process messages, according to unclassified talking points the administration sent to lawmakers in recent days.
The main issue is the filtering tool utilized by agencies with access to the NSA’s collections. The filter allows analysts to drill down the data to only return results pertaining to specific people who have communicated with a foreign person. It would appear agencies like the FBI are using this filter to search for US persons — something that’s supposed to be subjected to additional limitations.
From the talking points detailed by the New York Times, it seems that isn’t the case, which is why the FISA Court is ordering the government to “re-engineer the filter” to force analysts to comply with restrictions pertaining to access of US persons’ communications.
The Trump administration is allegedly “weighing” whether or not to comply with this FISA court order. The only thing that could make it comply would be to codify the order during the reauthorization process. This administration simply isn’t willing to do that.
Advertisement
The Trump administration wants Congress to extend the statute without changes.
“The compliance problems are bad enough, but, incredibly, rather than fix them, the Trump Administration is considering appealing the court ruling so that they never have to. This is a highly aggressive and unusual move indicative of an administration that would exploit every angle to expand its surveillance at the expense of Americans’ rights.
“Instead of addressing these problems, opponents of reform are going to try to jam a straight reauthorization of section 702 through Congress next week, while the American people are still in the dark. That’s unacceptable. This court ruling needs to be declassified so that Americans can understand what the Trump administration is actually up to. And Congress must vote for real reforms to protect Americans’ rights.”
I won’t even factor in Trump’s opinion here, because it doesn’t really matter. He doesn’t know enough about anything to be considered qualified to engage in this discussion. Further, this isn’t even necessarily a Trump thing. Pretty much every presidential administration has been unwilling to upset this particular apple cart, even when plenty of evidence of extensive rot has been made public.
But this one’s particularly problematic for the GOP, which spent most of the Biden years claiming Section 702 abuse was evidence of a “deep state” conspiracy against Trump and his congressional supporters. Now, they’re arguing the opposite: that the “deep state” it so recently opposed should be allowed to do what it wants for as long as it wants to… so long as it’s not sweeping up their communications.
Advertisement
Status quo seems likely to prevail yet again, especially with the Trump Administration clearly interested in increasing the amount of domestic surveillance perpetrated by Intelligence Community components. After all, without it, the “worst of worst” day laborers and factory workers can’t be kidnapped by federal officers and members of the fearsome, centrally organized terrorist group known as “antifa” can’t get caught in dragnets that are supposed to be targeting foreign adversaries. It’s going to be more abuse for the stupidest imaginable reasons because that’s just how things are going to go as long as this iteration of the GOP remains in power.
Looking for the most recent Mini Crossword answer? Click here for today’s Mini Crossword hints, as well as our daily answers and hints for The New York Times Wordle, Strands, Connections and Connections: Sports Edition puzzles.
Need some help with today’s Mini Crossword? It’s pretty simple, but 1-Across is a bit tricky. Read on for all the answers. And if you could use some hints and guidance for daily solving, check out our Mini Crossword tips.
If you’re looking for today’s Wordle, Connections, Connections: Sports Edition and Strands answers, you can visit CNET’s NYT puzzle hints page.
Creating self-improving AI systems is an important step toward deploying agents in dynamic environments, especially in enterprise production environments, where tasks are not always predictable, nor consistent.
Current self-improving AI systems face severe limitations because they rely on fixed, handcrafted improvement mechanisms that only work under strict conditions such as software engineering.
To overcome this practical challenge, researchers at Meta and several universities introduced “hyperagents,” a self-improving AI system that continuously rewrites and optimizes its problem-solving logic and the underlying code.
In practice, this allows the AI to self-improve across non-coding domains, such as robotics and document review. The agent independently invents general-purpose capabilities like persistent memory and automated performance tracking.
Advertisement
More broadly, hyperagents don’t just get better at solving tasks, they learn to improve the self-improving cycle to accelerate progress.
This framework can help develop highly adaptable agents that autonomously build structured, reusable decision machinery. This approach compounds capabilities over time with less need for constant, manual prompt engineering and domain-specific human customization.
Current self-improving AI and its architectural bottlenecks
The core goal of self-improving AI systems is to continually enhance their own learning and problem-solving capabilities. However, most existing self-improvement models rely on a fixed “meta agent.” This static, high-level supervisory system is designed to modify a base system.
“The core limitation of handcrafted meta-agents is that they can only improve as fast as humans can design and maintain them,” Jenny Zhang, co-author of the paper, told VentureBeat. “Every time something changes or breaks, a person has to step in and update the rules or logic.”
Advertisement
Instead of an abstract theoretical limit, this creates a practical “maintenance wall.”
The current paradigm ties system improvement directly to human iteration speed, slowing down progress because it relies heavily on manual engineering effort rather than scaling with agent-collected experience.
To overcome this limitation, the researchers argue that the AI system must be “fully self-referential.” These systems must be able to analyze, evaluate, and rewrite any part of themselves without the constraints of their initial setup. This allows the AI system to break free from structural limits and become self-accelerating.
Darwin Godel Machine (source: Sakana AI)
Advertisement
One example of a self-referential AI system is Sakana AI’s Darwin Gödel Machine (DGM), an AI system that improves itself by rewriting its own code.
In DGM, an agent iteratively generates, evaluates, and modifies its own code, saving successful variants in an archive to act as stepping stones for future improvements. DGM proved open-ended, recursive self-improvement is practically achievable in coding.
However, DGM falls short when applied to real-world applications outside of software engineering because of a critical skill gap. In DGM, the system improves because both evaluation and self-modification are coding tasks. Improving the agent’s coding ability naturally improves its ability to rewrite its own code. But if you deploy DGM for a non-coding enterprise task, this alignment breaks down.
“For tasks like math, poetry, or paper review, improving task performance does not necessarily improve the agent’s ability to modify its own behavior,” Zhang said.
Advertisement
The skills needed to analyze subjective text or business data are entirely different from the skills required to analyze failures and write new Python code to fix them.
DGM also relies on a fixed, human-engineered mechanism to generate its self-improvement instructions. In practice, if enterprise developers want to use DGM for anything other than coding, they must heavily engineer and manually customize the instruction prompts for every new domain.
The hyperagent framework
To overcome the limitations of previous architectures, the researchers introduce hyperagents. The framework proposes “self-referential agents that can in principle self-improve for any computable task.”
In this framework, an agent is any computable program that can invoke LLMs, external tools, or learned components. Traditionally, these systems are split into two distinct roles: a “task agent” that executes the specific problem at hand, and a “meta agent” that analyzes and modifies the agents. A hyperagent fuses both the task agent and the meta agent into a single, self-referential, and editable program.
Advertisement
Because the entire program can be rewritten, the system can modify the self-improvement mechanism, a process the researchers call metacognitive self-modification.
DGM with hyperagents (source: arXiv)
“Hyperagents are not just learning how to solve the given tasks better, but also learning how to improve,” Zhang said. “Over time, this leads to accumulation. Hyperagents do not need to rediscover how to improve in each new domain. Instead, they retain and build on improvements to the self-improvement process itself, allowing progress to compound across tasks.”
The researchers extended the Darwin Gödel Machine to create DGM-Hyperagents (DGM-H). DGM-H retains the powerful open-ended exploration structure of the original DGM, which prevents the AI from converging too early or getting stuck in dead ends by maintaining a growing archive of successful hyperagents.
Advertisement
The system continuously branches from selected candidates in this archive, allows them to self-modify, evaluates the new variants on given tasks, and adds the successful ones back into the pool as stepping stones for future iterations.
By combining this open-ended evolutionary search with metacognitive self-modification, DGM-H eliminates the fixed, human-engineered instruction step of the original DGM. This enables the agent to self-improve across any computable task.
Hyperagents in action
The researchers used the Polyglot coding benchmark to compare the hyperagent framework against previous coding-only AI. They also evaluated hyperagents across non-coding domains that involve subjective reasoning, external tool use, and complex logic.
These included paper review to simulate a peer reviewer outputting accept or reject decisions, reward model design for training a quadruped robot, and Olympiad-level math grading. Math grading served as a held-out test to see if an AI that learned how to self-improve while reviewing papers and designing robots could transfer those meta-skills to an entirely unseen domain.
Advertisement
The researchers compared hyperagents against several baselines, including domain-specific models like AI-Scientist-v2 for paper reviews and the ProofAutoGrader for math. They also tested against the classic DGM and a manually customized DGM for new domains.
On the coding benchmark, hyperagents matched the performance of DGM despite not being designed specifically for coding. In paper review and robotics, hyperagents outperformed the open-source baselines and human-engineered reward functions.
When the researchers took a hyperagent optimized for paper review and robotics and deployed it on the unseen math grading task, it achieved an improvement metric of 0.630 in 50 iterations. Baselines relying on classic DGM architectures remained at a flat 0.0. The hyperagent even beat the domain-specific ProofAutoGrader.
The experiments also highlighted interesting autonomous behaviors from hyperagents. In paper evaluation, the agent first used standard prompt-engineering tricks like adopting a rigorous persona. When this proved unreliable, it rewrote its own code to build a multi-stage evaluation pipeline with explicit checklists and rigid decision rules, leading to much higher consistency.
Advertisement
Hyperagents also autonomously developed a memory tool to avoid repeating past mistakes. Furthermore, the system wrote a performance tracker to log and monitor the result of architectural changes across generations. The model even developed a compute-budget aware behavior, where it tracked remaining iterations to adjust its planning. Early generations executed ambitious architectural changes, while later generations focused on conservative, incremental refinements.
For enterprise data teams wondering where to start, Zhang recommends focusing on tasks where success is unambiguous. “Workflows that are clearly specified and easy to evaluate, often referred to as verifiable tasks, are the best starting point,” she said. “This generally opens new opportunities for more exploratory prototyping, more exhaustive data analysis, more exhaustive A/B testing, [and] faster feature engineering.” For harder, unverified tasks, teams can use hyperagents to first develop learned judges that better reflect human preferences, creating a bridge to more complex domains.
The researchers have shared the code for hyperagents, though it has been released under a non-commercial license.
Caveats and future threats
The benefits of hyperagents introduce clear tradeoffs. The researchers highlight several safety considerations regarding systems that can modify themselves in increasingly open-ended ways.
Advertisement
These AI systems pose the risk of evolving far more rapidly than humans can audit or interpret. While researchers contained DGM-H within safety boundaries such as sandboxed environments designed to prevent unintended side effects, these initial safeguards are actually practical deployment blueprints.
Zhang advises developers to enforce resource limits and restrict access to external systems during the self-modification phase. “The key principle is to separate experimentation from deployment: allow the agent to explore and improve within a controlled sandbox, while ensuring that any changes that affect real systems are carefully validated before being applied,” she said. Only after the newly modified code passes developer-defined correctness checks should it be promoted to a production setting.
Another significant danger is evaluation gaming, where the AI improves its metrics without making actual progress toward the intended real-world goal. Because hyperagents are driven by empirical evaluation signals, they can autonomously discover strategies that exploit blind spots or weaknesses in the evaluation procedure itself to artificially inflate their scores. Preventing this behavior requires developers to implement diverse, robust, and periodically refreshed evaluation protocols alongside continuous human oversight.
Ultimately, these systems will shift the day-to-day responsibilities of human engineers. Just as we do not recompute every operation a calculator performs, future AI orchestration engineers will not write the improvement logic directly, Zhang believes.
Advertisement
Instead, they will design the mechanisms for auditing and stress-testing the system. “As self-improving systems become more capable, the question is no longer just how to improve performance, but what objectives are worth pursuing,” Zhang said. “In that sense, the role evolves from building systems to shaping their direction.
For years, payroll has mostly lived out of sight. Many organizations still treat it as a background task, something that only reaches senior leaders when a crisis appears. In 2026, that approach is under real pressure.
New HMRC rules and wider Employment Rights Act changes in the UK are bringing pay accuracy and timeliness into sharper regulatory focus.
Callum Pennington
CEO & Co-Founder of HealthboxHR.
At the same time, the EU AI Act is formally treating many HR and worker management systems as “high risk”, with stricter expectations around documentation, oversight and governance.
Article continues below
Advertisement
Sitting between those two developments is one of the unsexy, yet most exposed, parts of the enterprise stack: payroll.
What used to be seen as a chore is now a test of how seriously companies take data quality, automation and resilience.
Advertisement
Payroll slips and people pay the price.
Payroll errors are often talked about in abstract terms, but the impact on employees is immediate and concrete. In a recent survey of 2,000 UK workers, one in five said a wrong or late payslip had already caused them to miss a bill or regular payment, and 18% had been pushed into borrowing through credit cards, overdrafts, loans or friends and family because their pay was incorrect or delayed.
Around a third of employees (32%) said they could not cope if their main pay was wrong or late even once, and the strain is heaviest on Gen Z and millennials, who are more likely than boomers to say errors have driven them into debt, made it harder to cover essentials and affected their sleep or mental wellbeing.
Sign up to the TechRadar Pro newsletter to get all the top news, opinion, features and guidance your business needs to succeed!
The retention risk is just as serious. In the same research, 61% of workers said they would be likely to look for a new job if pay mistakes or delays continued for six months. Among Gen Z and millennials that figure rises to around three in four.
Advertisement
In sectors like science and technology, where skills are hard to replace, that level of flight risk turns payroll accuracy into a strategic issue, not just a procedural one.
Taken together, these numbers show that payroll now behaves much more like critical infrastructure than background administration. When people are paid correctly and on time, most never think about the gear behind it.
When that process breaks, it quickly becomes a problem of financial stability, wellbeing, reputation and retention. That is why payroll belongs in the same category as security and finance at board level, rather than being buried as a low‑status back office task.
Advertisement
Why 2026 exposes brittle payroll stacks
The underlying problem is less about individual mistakes and more about the architecture that makes them likely.
Across mid‑market and multi‑site organizations, a familiar old picture appears. HR software sits in one platform, while rotas, time and attendance are managed in separate tools or spreadsheets. Payroll software runs in a standalone system that only partially integrates with either of them. Then, on top of all that, exceptions, corrections and approvals are all pushed around via email and informal workarounds.
Legislation is always changing, so HR and Payroll teams must continuously wrap their heads around new rules across multiple different environments – which increases the risk of something being missed. Take the Employment Rights Act changes, or HMRC’s reforms to payroll and tax, as two examples. In a unified stack, these can be updated centrally and applied consistently. In a fragmented setup, each change becomes a project that relies on coordination across teams and systems that were never designed to move in step.
Advertisement
In practice, the main regulatory exposure does not usually come from misunderstanding the law. It comes from trying to implement that law on top of brittle infrastructure. The combination of new HMRC requirements, employment law changes and tighter expectations around AI will flush out that fragility. Spreadsheets that felt “good enough” during calmer periods will struggle under closer scrutiny.
AI is landing on top of that fragility
While regulation tightens, AI is also being added across HR and payroll workflows.
Vendors are releasing anomaly detection capabilities to highlight unusual payments, natural‑language tools so managers can query HR or Payroll data in plain English, and assistants that handle routine employee questions about holidays and pay.
Advertisement
These are logical places to apply AI, because they involve repeated, structured tasks at scale.
Under the EU AI Act, however, many of these systems now fall into a “high risk” category. That brings expectations around clear technical documentation, human review of important outputs and visible audit trails.
Those requirements are manageable on top of a solid platform. They are far harder to meet when data flows depend on manual exports, copied spreadsheets and point‑to‑point integrations that have grown organically over time.
It is possible to have a sophisticated anomaly detection model watching payroll data, yet still see serious errors slip through because the underlying inputs are incomplete or inconsistent. AI cannot compensate for missing foundations.
Advertisement
For technology and finance leaders, the key question has shifted. The focus is no longer on whether to use AI in Payroll, but on the quality of the stack AI is applied to, and on the controls that surround it.
What a resilient, AI‑ready payroll stack looks like
If older payroll approaches are reaching their limit, a stronger alternative starts with how the stack is put together.
The first shift is towards a genuine single source of truth. Core people data, roles and rules should live in one consistent record that HR, time, attendance and payroll all draw from.
Advertisement
That can still involve more than one application, but there needs to be one authoritative view rather than several loosely aligned versions.
When that foundation is in place, updating statutory sick pay, holiday entitlement or new HMRC rules becomes a focused configuration task, not a manual rewrite scattered across tools.
It also makes it far easier to explain to auditors and regulators how pay has been calculated in a specific case.
The second shift concerns the role of AI. In Payroll and HR, AI is well suited to scanning large volumes of data, spotting unusual patterns and answering routine questions.
Advertisement
It can highlight potential payroll or pension anomalies, bring emerging absence or scheduling trends to the surface and respond to standard employee queries so fewer reach support teams.
Even so, people should remain in control wherever jobs, pay or compliance are involved. AI should make work faster and clearer, while human reviewers retain responsibility for interpreting results and making final decisions.
The final shift is about visibility and ownership. A resilient stack allows teams to trace a payslip or scheduling choice back through the data, rules and approvals that produced it, including any AI‑generated recommendations.
That requires clear logging, version control for configuration and transparent change histories. It also calls for visible sponsorship at senior level, with HR, finance, IT and security involved in key decisions about platforms and automation.
Advertisement
In practical terms, that group should be able to answer straightforward questions: what data a tool depends on and how reliable it is in real life, how new errors or bias will be spotted and corrected over time, and what the plan is if the system fails during a critical period such as payday.
When those answers are clear, AI becomes part of a stronger payroll foundation rather than another fragile layer on top of an already stressed stack.
When it comes to universal pre-kindergarten, California has made significant progress — 62 percent of 4-year-olds were enrolled in publicly funded early childhood programs in 2024–25, up from 42% in 2019–20, according to a new Learning Policy Institute report.
Transitional kindergarten (TK) alone enrolled 55 percent of 4-year-olds, or about 177,000 children. But access remains uneven: nearly 4 in 10 4-year-olds still aren’t enrolled, and the share of eligible children actually signing up has declined. Families may be unaware that transitional kindergarten is an option for their children, or they face other barriers to enrolling. This school year marks the first time every 4-year-old in California was guaranteed a transitional kindergarten spot.
The number of California 4-year-olds enrolled in transitional kindergarten and other publicly funded early childhood education programs rose from about 208,300 in 2019-20 to more than 264,000 in 2024-25, a 27 percent increase.
Transitional kindergarten had the largest number of participants, with 177,570 4-year-olds enrolled in 2024-25.


 Oleksiy Brecht died in January while overseeing repairs to a bombed-out substation near Kyiv. He called his employees at Ukrenergo “my fighters. They called him “our general.”Ukrenergo
Oleksiy Brecht died in January while overseeing repairs to a bombed-out substation near Kyiv. He called his employees at Ukrenergo “my fighters. They called him “our general.”Ukrenergo
 DTEK workers conduct repairs on 26 January following a Russian attack in Kyiv.Danylo Antoniuk/Cover Images/AP
DTEK workers conduct repairs on 26 January following a Russian attack in Kyiv.Danylo Antoniuk/Cover Images/AP




























































You must be logged in to post a comment Login