TL;DR
As AI search engines cite the same media outlets that drive SEO, paid media placement platforms have become dual-purpose tools for both Google rankings and AI visibility. This roundup evaluates 10 platforms by their unique capabilities, from MCP-powered automation and AI Visibility Seeding to group buying and price-comparison aggregation.
Millions now choose products through ChatGPT, Gemini, and Perplexity, and Google AI Overviews appear in nearly half of all search queries. According to Muck Rack, 84% of AI citations come from media outlets, the same outlets where SEO specialists have been placing links for years.
That means media distribution remains one of the key levers for influencing both AI and Google results. Manual outreach to media outlets doesn’t scale well: pitching, checking metrics, and negotiations are too time-consuming.
Best Platforms for AI visibility and Link Building
We’ve evaluated multiple platforms that let companies boost their AI visibility and link building performance with paid placements in media outlets. Instead of focusing on standard features like price on publishing conditions, we highlight their unique features that allow companies to achieve their goals in the way aligned with their overall strategy and approach.
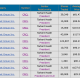
Here are the top 10 platforms that we handpicked.
| Platform |
Best for |
|
1. Medialister
|
PR and digital agencies that need a publication pipeline for a client portfolio, AI-driven management, and post-payment without cash flow gaps
|
|
2. PRNEWS
|
International agencies building customized media plans with multi-format placements
|
|
3. PRposting
|
Link builders who need a clean backlink profile through closed, exclusive outlets
|
|
4. INSERT.LINK
|
SEO specialists buying link insertions by the hundreds per day
|
|
5. PressWhizz
|
SEO teams that need a turnkey managed service or a year-long link replacement guarantee
|
|
6. Linksman
|
Marketers of SaaS and tech products
|
|
7. Respona
|
In-house teams building direct Tier-1 relationships with newsrooms, bypassing marketplaces
|
|
8. Ereferer
|
Teams with a fixed budget for multilingual link building
|
|
9. NO-BS Marketplace
|
Those who want to choose between a ready-made outlet selection by the team or a self-service catalog
|
|
10. LinkBuilder
|
Buyers comparing vendor prices at the final stage of media planning
|
1. Medialister
Medialister was built for running large-scale PR and AI visibility campaigns, with a catalog of 106,000+ vetted outlets worldwide. Scalability is built into the platform itself: add team members and assign roles to run dozens of campaigns with multiple placements in parallel.
Notably, the platform helps match outlets to a specific business goal. You can connect your Google Search Console to get recommendations, set your goal directly in the catalog, or use Medialister’s MCP. Through MCP, AI assistants find outlets, draft tailored guest posts and press releases, submit them, and track indexing in Google.
To avoid a cash flow gap, agencies can use the post-payment option: they’ll receive a consolidated invoice at the end of the month instead of paying per placement.
2. PRNEWS
PRNEWS is an international platform for paid media placements with one of the largest catalogs: 107,000+ media outlets across 175 countries, from global-scale publications to hyperlocal media outlets targeting specific cities. Forbes alone is represented here with 20 different country editions. You can use a dozen filters to navigate that volume. If you don’t want to filter anything yourself, you can use goal-based presets: for example, for AI visibility or fintech PR. Advanced filters immediately show which outlets accept sensitive topics like gambling and crypto or allow tracking pixels.
For teams that need more, PRNEWS offers a PRO account. Its Bulk Site Checker lets you upload domains a competitor has published on and secure placements there. The entire catalog with prices and metrics can be exported to CSV so that agencies can calculate budgets for several clients at once.
3. PRposting
PRposting is a platform with a catalog of 23,000+ outlets. Its distinguishing feature is that around 20% of its media are exclusive: these sites are added to the database manually after direct negotiations with owners, bypassing intermediaries and exchanges.
It provides a free audience breakdown for each outlet across its 5 key source countries. If a publication writes in Spanish but most of its traffic comes from the US rather than Latin America, that becomes immediately clear. If a placement doesn’t go live on time, you receive a full refund within 7 days.
4. INSERT.LINK
INSERT.LINK is a highly specialized service for fast link integration into already-published articles. There are two ways to find a spot for your link: choose an outlet by topic, as in a regular marketplace, or enter a keyword to find a specific, already-published page on that topic among 50 million indexed pages. The catalog includes 30,734 sites across 152 countries and 15+ niches, with formats spanning link insertions, guest posts, listicles, press releases, and PR publications.
Agencies get MCP and API access. You can connect this platform to your internal tools to run searches and place orders programmatically. There’s also a separate list of outlets with guaranteed publication within 3 days, for time-sensitive campaigns.
5. PressWhizz
PressWhizz is a marketplace for guest posts and link insertions with a catalog of 41,000+ sites across 90 countries. The platform has a proprietary AI Visibility Seeding™ method: the team studies hundreds of real user prompts on a given topic and places the brand in sources already trusted by ChatGPT, Perplexity, and Google AI Overviews. In addition, they offer traditional link building services.
If necessary, you could buy a managed service, so that the platform’s team will handle outlet selection and negotiations with editorial teams.
6. Linksman
Linksman is a marketplace for guest posts, niche edits, and link building with a catalog of 9,000+ sites across 25+ niches. After signup, you can see DR, traffic, and price for each media outlet. You can also choose a ready-made package that includes several guest posts at a fixed price, split by DR tier. The higher the authority, the higher the price.
It’s worth mentioning the platform’s free SEO tools. You can check whether a purchased link is still live and providing value.
7. Respona
Respona isn’t a marketplace with a ready-made catalog of outlets. It’s a SaaS tool for self-service outreach. This means you still have to negotiate with each newsroom or journalist yourself, but the service automates everything else, from finding publications and authors to personalizing pitches with AI-generated snippets from the recipient’s content.
This platform is used for link building, digital PR, affiliate partner sourcing, and blogger outreach, offering a different set of outlets and templates for each use case. Unlike others on this list, the service runs on a subscription, with pricing based on campaign volume and team size.
8. Ereferer
Ereferer is a catalog of 45,000 sites across five languages. The service’s standout feature is the ability to save several media outlets into a single project, say, three blogs and one directory site, and have the platform automatically distribute their publication over time so they don’t go live all at once.
Group buying is another distinct feature. The cost of a single placement is split between two clients, and the article itself carries two separate links, one for each.
9. NO-BS Marketplace
NO-BS Marketplace is a catalog of sites for guest posts and link insertions with 110,000+ publishers. Its database can be flexibly filtered by niche, domain authority, traffic, and price. The platform supports a wide range of goals, from classic link building to digital PR and promotion in AI-generated answers, helping brands land in the sources that generative AI cites.
If you already know what you’re looking for, you can select outlets from the catalog yourself. For agencies and larger projects, there’s a NO-BS Pro plan, which adds a dedicated account manager, volume discounts, and white-label reports.
10. LinkBuilder
LinkBuilder is a price-comparison aggregator for guest posts and link insertions, comparing offers from 50 vendors across 300,000 sites in a single interface. Domains can be uploaded in bulk via CSV for comparison. The service is useful once you’ve already chosen an outlet but want to find the best possible price.
They also have a Check Link Price extension for Chrome that overlays placement pricing for a specific domain right on top of Google, Ahrefs, Semrush, Moz, Majestic, and Serpstat results. You can check prices without ever leaving the tools you’re currently using.
The choice of platform depends on your goal
None of these platforms will replace a proper strategy that starts with the goal. For Google rankings, the number and authority of links matter most. For AI visibility, it’s the outlet’s reputation and consistent mentions in expert content that count.
First, set the goal, then choose the platform. Their value lies in speed because they save time you could waste on manually outreach and negotiations.

































































You must be logged in to post a comment Login