Google is lowering the cost of its cheapest AI subscription to make Gemini models even easier to access. The Google AI Plus plan will now cost $5 per month, according to a post from Vikas Kansal, the company’s Product Lead focused on Gemini AI subscriptions, down from its original $8 per month price. It now also comes with double the storage, 400GB instead of 200GB.
The subscription plan became available in January 2026 as a cheaper way to access Google’s Gemini 3 Pro model, Nano Banana Pro and Deep Research. Google previously offered those features as part of its more expensive AI Pro plan, but Plus lowered the price in exchange for more severe usage limits. Sweetening the deal further now that Google I/O 2026 has come and gone, the AI Plus plan also includes new benefits, like AI-powered email tools, a new Daily Brief agent that can summarize your upcoming day in the Gemini app and access to Gemini Omni, Google’s newest AI model for generating video “from any input.”
📣We’re updating the price of our Google AI Plus plan to $4.99/mo💰or local equivalent (down from $7.99), and doubling the included storage, from 200GB to 400GB ☁️. Now you can unlock tools to boost your productivity and creativity – and get more space to store your photos,…
Your mileage may vary with Google’s AI features, but getting double the storage for half the price is obviously meant to be a deal that’s hard to say no to. You can sign up for the AI Plus plan now on Google’s website. According to Kansal, existing subscribers should see their extra storage space in the next few days, and the updated subscription price on their next bill.
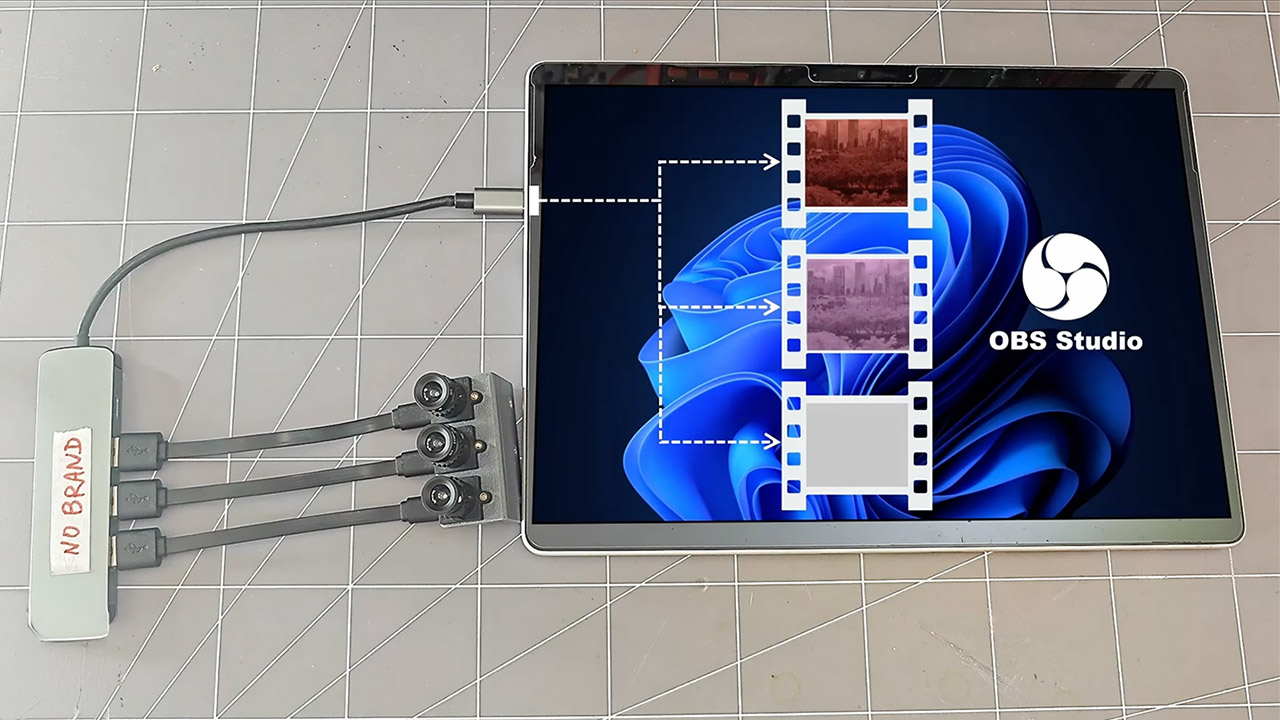
Most cameras ignore a wide stretch of near-infrared light that plants reflect and certain materials absorb in unexpected ways. One maker spent three months turning three ordinary USB webcams into a single system that records that invisible band as full color video. Project 326 started with the same $15 modules many people already own. Each sensor already responds to near-infrared once the factory IR-cut filter is gone.
That filter is placed between the lens and the sensor to prevent typical photographs from becoming foggy. Taking it out is a simple process: open the camera housing, remove the tiny red or green glass or plastic piece, and your sensor will become far more sensitive to anything above 700 nanometers. The catch is that even with a full-spectrum camera, while that infrared-pass filter is in place, you’ll still receive monochrome images since colour requires three different cameras, each locked to a narrow slice of the infrared spectrum.
Premium Image Quality: Upgrade to Link 2 4K webcam with a 1/2″ sensor. Captures true-to-life webcam 4K visuals with HDR and low-light performance for…
Professional Audio: Experience best-in-class audio with advanced AI noise-canceling algorithms. Filter out unwanted background noise for clear…
True Focus: Insta360 Link 2 streaming camera with Phase Detection Auto Focus (PDAF). No more blurry shots—this web cam ensures instant focusing and…
Dichroic bandpass filters effectively resolved the isolation issue. You only need to put a filter on each camera that is centered around 750 nanometers, another around 850 nanometers, and a third around 940 nanometers; they will pass only a little window of wavelengths while rejecting everything else, including normal visible light. After a few tests with handheld infrared flashlights, you can observe that each one only hits one camera: a 745-nanometer lamp would light up the first camera, an 850-nanometer lamp the second, and a 940-nanometer lamp the third, with no overlap.
Getting the mechanical alignment correct was far more difficult than the optical filters. He tried utilizing a beam-splitting prism and a single shared lens to ensure that all three sensors saw the same scene, but 3D-printed mounts couldn’t keep the optics stable enough, so the idea was abandoned. In the end, he decided on three different lenses side by side. He removed the sensors from their original boards and remounted them on new printed circuit boards, ensuring that each chip sits squarely and at the same distance from the lens. The new housings maintain everything nice and rigid, as we’re talking a baseline of roughly 17 millimeters between cameras, which is small enough that parallax only interferes with the image at close range.
He had to switch the footage to a Raspberry Pi because Windows wouldn’t let him utilize three identical USB cameras at the same time. Python programs are currently pulling simultaneous monochromatic streams and writing them out as independent MKV files; but, because these webcams use free-running RC oscillators, their frame rates are drifting by one or two frames per minute.
To address this, he set up a post-processing system that also handles the minor geometric offsets. He uses DaVinci Resolve to manually align the first frames of each stream, including translation, scale, and rotation, and then a script applies those fixes to the rest of the sequence. Once he had three grayscale videos layered on top of one another, he simply assigned each to a red, green, or blue channel. There are six different mappings, and selecting the appropriate one can significantly alter the final appearance of elements such as flora, sky, and skin.
Its first usable color footage resulted from testing conducted outside under the scorching tropical sun. Leaves that appear to be one solid green to our eyes begin to break apart into distinct tones as you use the near-infrared light that reflects off them to add depth to the footage. Atmospheric haze behaves differently when picked up in the three various color bands, giving distant objects a layered appearance that draws the observer in. Now, the system still needs some fine-tuning to get the focus right, and a steady hand is required, since one of the early recording sessions was ruined because the silly lens cap remained on throughout. The Python scripts used to capture the footage, as well as the 3D printed objects, are available on GitHub for anyone interested in following in his footsteps. [Source]
The build relies on a unique motion system, wherein two NEMA 17 stepper motors drive either side of the linkage to control the position of the end effector—in this case, a pen carriage. By controlling the position of each side of the mechanism, it’s possible to move the pen through XY space. Running the show is an Arduino Nano, fitted with a GRBL shield and appropriate stepper motor drivers.
The magnetic tool changer is particularly nifty, too. It allows the plotter to grab a different ink at will to add more color to the drawing. It’s well-designed, with the plotter able to change inks without losing accuracy or otherwise fumbling the switchover. The plotter uses Muji ball point pens, which are available in a range of colors and draw with slick, clean lines. It’s also quite a fast plotter, thanks in part to [András]’s efforts to keep the pen carriage light by using a smart mechanism to offload the pen lifting actuator to the main body.
Advertisement
[András] has plans available, but you’re going to have to pay for them. Still, it’s always nice to see a new machine in the wild. Video after the break.
TCL Q-Series Air Conditioner (10,000 BTU) for $369: Chinese electronics company TCL has been making air conditioners for only five years, but it is tackling the category the way it did for TVs—that is, by quickly conquering turf with excellent value. I tested the 10,000-BTU version of the Q Series window AC in an 120-square-foot upstairs bedroom that gets very little flow from my home’s central AC. It took three hours to drop the temperature by 10 degrees from a sweltering 78, but as it operated at a fairly quiet 60 decibels, I didn’t mind it. Installation was a breeze thanks to the included frame. The TCL has Matter connectivity, but I was not able to get it to connect to my Apple Home app, apparently a common issue. There is a remote that has all the controls from the unit itself. The thermostat is accurate within one degree, and the unit reliably turns itself on and off to keep the room temperature on its mark. The CEER rating ranks an impressive 15.0, equaling WIRED’s top-pick Midea, and the TCL costs $100 less at the same power output. But while quiet compared well with many other models, this TCL is still louder than the Midea and doesn’t offer the U-shaped device’s superior insulation. Easy install may be a selling point over the U-Shaped model. —Martin Cizmar
Dreo Portable Air Conditioner 740S (10,000 BTU) for $700: Look, I’m loving the new generation of portable air conditioners but not because they’re portable. Fact is, wheels aside, they’re pretty big and heavy, and the thick hoses make them bulky in a room. But they’re easy to install without lifting into a window frame, a real boon for solo residents. And because the only thing that needs mounting in a window is a bracket for the hoses, these ACs can be used on pretty much any window shape—a boon especially for those in older buildings. The Dreo has all these virtues, plus a respectable 12 CEER rating, courtesy of dual hoses and a smart inverter. (In general, avoid portable units without dual hoses, as this can cause a depressurization effect that lowers efficiency.) I’ve been using this portable in the difficult-to-access window in my 150-square-foot office, and its effects are basically instant. The evaporative cooling tech also means I don’t have to drain water. But our top-pick Zafro offers a lower price, and a slightly better CEER efficiency rating at a similar operating noise level of around 60 to 65 decibels on high fan speeds. Still, this is an excellent portable AC unit. If you see a deal, snap it up.
Advertisement
GE AWAS05BBA Window Air Conditioner Unit (5,000 BTU) for $231: This 5,000 BTU unit is less powerful than our favorite budget window air conditioner pick from GE. There’s no app and no remote, and airflow options are limited: You can’t direct air up and down, only left and right. But it’s the cheapest model we recommend, relatively easy to install, and much quieter than you’d expect for the price. It’ll cool a small 150-square-foot space quickly and mostly frictionlessly. But we haven’t tested it as long as for our top budget pick.
LG Window Air Conditioner Unit (12,000 BTU) for $379: The LG 12,000 BTU Smart Window Air Conditioner offers efficient large-room cooling at a surprisingly low price. It weighs 90 pounds and requires professional installation with a bracket. Its 60-decibel operation places it squarely in the middle of the pack on noise. This said, WIRED reviewer Lisa Wood Shapiro found it blends into a room well with its white-on-white design, and that the filter replacement indicator light is useful. The app was laggy and difficult to use during Wood Shapiro’s testing, but there is a remote.
Advertisement
Friedrich Kuhl Air Conditioner for $1,228: This unit from Friedrich is among the most expensive we’ve tested, and one of the heaviest—in part because of a metal chassis designed to provide easy maintenance access and deter first-floor break-ins. This model allows adding a custom Friedrich FreshAire MERV 13 filter to clean the air as it cools. The screen is easy to read, and the device comes with a remote. An app lets you schedule the unit’s use over the course of the week, but note that connection with the smart app was a little janky, and it paired only with 2.4 GHz signals.
EcoFlow Wave 2 for $1,299 (but usually on sale for much less): Wood Shapiro tested the newest model, but previous models of the EcoFlow are often available at steep discounts. After happily testing the EcoFlow Wave 1 for more than a year in his wife’s office, WIRED senior editor Julian Chokkattu far preferred the EcoFlow Wave 2 (8/10, WIRED Recommends) because it’s both lighter and more cost-friendly, with a higher 5,100 BTU rating (up from 4,000). A heating mode rated at 6,100 BTU means you can keep using it in the winter to warm up. The company says it’s best for rooms up to 107 square feet. You do need to place it near a window to have one of the included ducts connected to the vent to take hot exhaust from the back of the unit out of the room. What makes this unit versatile is its alternate power sources. You can use a standard AC outlet, but you can also buy an add-on battery to keep it working when you don’t have access to electricity, or hook it up to solar panels.
Zero Breeze Mark II for $999: With its 2,300 BTU, the Zero Breeze (7/10, WIRED Review) won’t have the same cooling power as the EcoFlow Wave, but it’s much lighter at 17 pounds. This bundle includes a battery that makes the whole thing weigh about 30 pounds, but you’ll get four hours of use without needing to be near a wall outlet. Like the EcoFlow, you get a few vent pipes to direct exhaust away and direct cool air to a specific area, but unlike the EcoFlow, you can’t charge the battery and use the AC at the same time.
Advertisement
Zero Breeze Mark III for $1,399: As WIRED reviewer Chris Null notes, the Mark III (7/10, WIRED Review) is both larger than the Mark II and quite a bit heavier, now at 22 pounds. Add on the 1,022-Wh battery pack and you’ll pack on another 14 pounds, though that frees you from having to be near a power outlet. New for the Mark III is the fact that batteries can now be stacked and charged in sequence, each daisy-chained to the next (though at $600+ per battery, this can get pricey fast). Each Mark III battery also has extra outputs that can be used for other devices—one USB-C port, one USB-A port, and a 12-volt DC socket. However, the Mark II battery had all of the above plus a second USB-A port. No word on why this was removed. However, the new version is a bigger, punchier unit by most standards and a worthwhile buy for outdoors enthusiasts
Frequently Asked Questions
What Size Air Conditioner Do I Need?
Advertisement
Look for the BTU, or British thermal unit. In the case of air conditioners, the number of BTUs per hour measures how much heat the compressor can remove from a room. It’s a quick and easy way to figure out whether an AC unit is powerful enough to cool your space.
The BTU rating also helps you avoid using a too-powerful unit, which will cool too quickly without dehumidifying, and possibly lead to mold formation in the room and within the device.
To find the right power air conditioner for your room, you’ll want to find the square footage of your room by multiplying its length and its width. The US Department of Energy’s guidelines call for a minimum of 20 BTUs for every square foot of space. But this figure also assumes optimal conditions and good efficiency. For a 150-square-foot room, more typical recommendations are to opt for a 5,000 BTU AC unit. If the room is especially sunny, high-ceilinged, or has poor insulation, you may even want a 6,000 to 7,000 BTU unit for that space.
When in doubt, your best bet is to use a BTU calculator. For a truly precise estimate, here’s a complex whole-house BTU calculator that takes into account building layout and construction, plus your location and climate. For a fast and dirty rule-of-thumb BTU calculator, try here.
Advertisement
Check the combined energy-efficiency ratio (CEER) rating. The specs on any air conditioner you buy should list a CEER rating, which is one of the best ways of checking the energy efficiency of a unit. You’ll usually see a number between 9 and 15. The higher the number, the less you’ll pay when the electricity bill comes around. A cheap window AC unit will save you money at first, but you may end up shelling out more in the long run. The US Energy Star program has a website that lets you browse AC units based on their CEER ratings.
Check local laws. Some cities, like New York, require installing brackets to support your window AC. A simple one like this model should do the trick, though we haven’t tried it out. You may also need to head to a hardware store for some plywood to make sure your windowsill sits flat, but this depends on the type of windows you have and the AC model you buy. Get a friend to help you out with installation. These units can be heavy and difficult to hold, and the last thing you want is to drop one out the window.
Measure your window. Before you buy, read up on the supported window types and sizes for the AC unit you’re looking at, and measure your window to be safe. Make sure to seal any gaps as best you can with the included foam. (You can always buy more if you need it.)
A company spokesperson said that it’s “still exploring all our options for the best approach.”
If you’re an owner of any of Meta’s AI glasses, you should take advantage of the Conversation Focus feature while you can. As first reported by The Verge, Meta is pausing its rate limits for the accessibility feature that uses the glasses’ speakers to amplify the voice of who you’re talking to. Meta spokesperson Tyler Yee told The Verge, “we heard the feedback so we’re pausing its subscription tests for now,” adding that “Conversation Focus will remain available for free through our Early Access Program for early testers while we work on a better approach.”
Last month, Meta discreetly added rate limits to its Conversation Focus feature for its smart glasses. The feature would be free to use until you surpassed three hours a month, after which you would have to pay for a $20-a-month Meta One Premium Plan, which still had a cap of 15 hours of use per month. It’s still unclear why Meta added rate limits to the Conversation Focus feature, since it was proven by The Verge to run on device and without an Internet connection.
Advertisement
While Meta made the choice to keep the Conversation Focus feature free for now, there’s no clarity on its future yet. According to Yee, Meta wants “to make sure we get it right” when talking about the feature, and that the company is “still exploring all our options for the best approach.” Even more vague, the Meta spokesperson told The Verge that “some premium features will be subscription-based over time,” attributing this to how charging for certain features helps Meta sustain its strategy of subsidizing hardware prices.
DreamScapes A/V didn’t arrive at Southwest Audio Fest 2026 with a soundbar, a folding table and a bowl of mints. They showcased a 32,000-watt, 11.8.6 home theater featuring Alcons Audio CRMSQ Series with eight infrasonic subwoofers, Trinnov audio processing, Kaleidescape movie playback, Lumagen video processing, Christie 4MK15 projector and 150-inch Stewart Filmscreen G3 2:05:1 screen. The system is one of two immersive theaters and five two channel hi-fi systems being demonstrated by DreamScapes during the three day show.
That 32,000-watt figure comes from DreamScapes and has not been independently measured by eCoustics. Even so, eight infrasonic subwoofers should provide sufficient evidence that someone checked the hotel’s insurance policy.
Related Reviews:
Alcons Audio Goes Big in Dallas
The main DreamScapes theater took over the Press Club, adjacent to event registration. DreamScapes says the installation improved upon the theater it created with Keith Yates Design at Capital Audiofest 2025, adding a larger room, more loudspeaker channels and further software updates.
A Separate Alcons System for Music
DreamScapes also demonstrated Alcons MR12 monitors with MB12 bass units for two channel listening to reveal how proprietary Pro Ribbon transducers from the company’s cinema and professional monitoring products could sound in your home. The complete system only included two more components. The Grimm Audio MU2 for streaming, digital conversion, and preamplifier duties, which fed the external Alcons ALC amplified loudspeaker controller that power and actively crossover the MR12 monitors and MB12 bass modules.
Theory Audio Design Gets Its Own Theater
The second DreamScapes theater featured a less expensive Theory Audio Design9.2.4 system in Room 1043. It combined Theory loudspeakers, subwoofers and controllers with Kaleidescape Strato V playback, Trinnov AltitudeCI processing, Lumagen video processing, Epson QL7000 projector and a 135-inch Stewart Filmscreen Harmony G3 acoustically transparent screen.
Advertisement
Having installed and reviewed a Theory Audio Design system, I know the company’s loudspeakers can deliver considerable output, dialogue intelligibility and dynamic impact without becoming aggressive. Theory’s new DLC and PLC loudspeaker controllers also add Dante and AES67 networking, DSP and substantially greater channel capacity.
More Hardware Upstairs
The 10th Floor Presidential Suite featured five additional two channel systems, including Aretai loudspeakers, Benchmark Electronics, A-Definition tube electronics, Kronos analog components, the Mola Mola Lupe phono stage and active loudspeakers from Norway’s Sigberg Audio.
The Sigberg Audio Manta, Saranna and 10D are covered separately because their active architecture and controlled directivity deserve more than a brief mention beneath 32,000 watts of home theater mayhem.
The Bottom Line
Southwest Audio Fest is primarily associated with two channel audio, but the DreamScapes rooms demonstrate why properly designed home theater belongs at events like this.
The Alcons installation combines a large channel count, eight infrasonic subwoofers, sophisticated audio and video processing and professional cinema technology inside a hotel demonstration room. The separate Theory Audio Design theater provides a second look at what an integrated immersive system can achieve without requiring a commercial auditorium.
Advertisement
Will either system fit inside the average living room? Probably not.
Advertisement. Scroll to continue reading.
That is hardly the point. The best audio show systems should demonstrate what is possible when engineering, installation expertise and budget are permitted to operate without much adult supervision.
Pricing & Availability
All components are currently available from DreamScapes A/V, but we haven’t been able to verify all pricing. Once provided, this article will be updated.
“Coyote vs. ACME” debuted its long-awaited final trailer. CNET calls it “an animation-meets-live-action story,” with the Coyote catapulting into theaters this August 28. (The film began development back in 2018, but was shelved for a tax write-off in 2023 by Warner Bros. until a backlash led to its sale to Ketchup Entertainment.) “Fed up with Acme’s unreliable products, Wile E. Coyote decides to hire a lawyer and sue the company…” writes CNET. “The movie also features Lana Condor along with a host of Looney Tunes characters like Porky Pig, Tweety, Foghorn Leghorn and Granny (who gets dinged by an anvil).”
In other movie news, CNET says Johnny Depp also “made a surprise appearance at Comic-Con, donning a costume as Ebenezer Scrooge” to promote his November 13 movie about the miser from Charles Dickens’ famous Christmas novella. (Ian McKellen and Daisy Ridley are also in the movie.)
But several geek favorites are being filmed as TV series…
There’s big news for William Gibson fans, reports Entertainment Weekly. “Two years after Apple TV announced production on the first-ever series adaptation of William Gibson’s seminal 1984 novel Neuromancer, the lucky few hundred who attended the studio’s Hall H panel at Comic-Con 2026 got to watch the first teaser.
For Amazon’s Prime Video, the Tolkien-derived “Rings of Power” series released a season 3 trailer that CNET said “successfully hides the best parts with fire… The trailer suggests that Sauron is building an army, and all of Middle-earth is trying to find ways to stop him… Rings of Power season 3 will start dropping weekly episodes on Nov. 11, meaning this show will be airing at the same time the Peter Jackson films will be celebrating their 25th anniversary.”
Later in November Amazon’s Prime Video will also debut Blade Runner 2099, an eight-episode series that’s a sequel to 2017’s film Blade Runner 2049, reports CNET. “Set in an alternate version of LA where replicants run things and the humans play second fiddle, the series sees Yeoh’s replicant Olwen chasing down outlaw replicants who’ve gone missing. With her own shelf life on a ticking clock, the stakes are high for her and for her human fugitive partner, Cora…”
Paramount Plus will debut Avatar: Seven Havens in October, a new animated series from the creators of Avatar: The Last Airbender which CNET says “follows a pair of twin avatars, one of whom is Korra’s successor.”
Kevin Feige said Marvel’s television slate will include more seasons of “X-Men ’97” and the upcoming “VisionQuest” TV series.
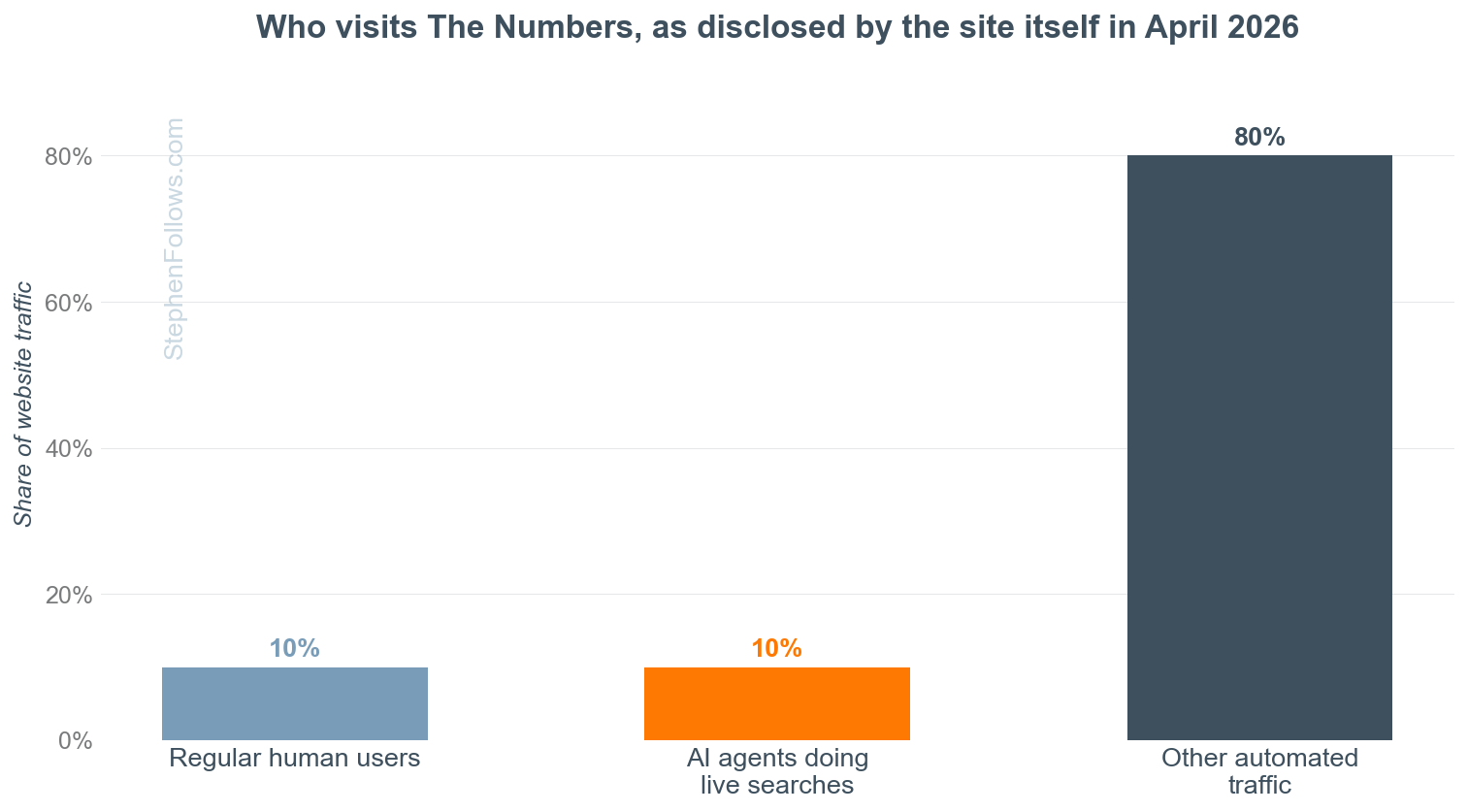
A lot has been made about the increase of automated traffic on the Internet, with the past years LLM-related crawlers having quite literally swarmed the picture here. Not only does this drive up traffic, it also increases load on web servers, whose owners find themselves faced with increased hosting costs. This recently led to The-Numbers.com going offline for a while as automated traffic was quite literally destroying their bottom line.
This saga is covered by [Stephen Follows], who had a chance to talk with the founder and CEO of the site, [Bruce Nash], after the site went basically offline for a few months. Since the website both licenses data for commercial purposes as well as offering the free access on its website, there were accusations of this being a ‘rug pull’.
The site was started in 1997, as a static HTML site on Geocities where [Bruce] provided box office analyses for investment purposes. Since that beginning traffic was generally polite, with human visitors and usually well-behaved search engine crawlers. Then around 2024 the first wave of scraper bots arrived, followed by a larger wave around December of 2025.
Despite implementing a few mitigations, such as LLM-targeted text, the increased traffic and the resulting load on a site architecture that was never designed for this ultimately led to a collapse. One of the major sources of traffic turned out to be from so-called ‘prediction markets’, like Polymarket, whose bots absolutely hammered the site.
Advertisement
Fortunately for [Bruce] and his team they do not rely on the free website for income, but they have had to massively rework the site’s architecture to bring back a semblance of the original features. As noted in the article, the amount of crawling traffic by these LLMs and ‘agentic AI’ tools is logarithmically more than that for search engines, which makes this a major challenge.
Issues like these is why services such as Cloudflare are offering blocking features for such automated traffic. After all, unless such traffic is of use to you, you may as well treat it like a DDoS attack and cut it off at the root.
When an appliance like a refrigerator breaks, the first thing to decide is whether it’s more cost effective to repair or replace it. Decide to get a new one and you’ll need to navigate the crowded domestic appliance market, which currently hosts a bevy of different manufacturers both familiar and new. One brand you might come across is Fisher & Paykel, which is one of the more historic names in the market.
The company was founded back in 1934 in New Zealand, when Maurice Paykel and Woolf Fisher first decided to import appliances like refrigerators to their homeland. They later began manufacturing their own appliances after the country’s government banned imports, first building them under license before eventually creating their own designs.
Advertisement
After decades as an independent company, Fisher & Paykel was acquired by Haier Group in 2012. Haier was founded in Qingdao, China, in 1984, and remains headquartered there today. It also owns the GE Appliance brand in the U.S., alongside a portfolio of other brands including Candy, Casarte, and Leader. As well as being owned by a Chinese company, some of Fisher & Paykel’s appliances are also made in China. It has additional manufacturing facilities in Italy, Mexico, and Thailand.
Advertisement
What kind of refrigerators does Fisher & Paykel offer?
In the U.S., Fisher & Paykel offers a range of different refrigerators catered towards the upper end of the market. As well as the typical selection of column refrigerators, French door refrigerators, and bottom freezer fridges, the company also sells wine refrigerators and other specialist undercounter appliances.
Within its lineup are a selection of smart refrigerators, although the features offered generally aren’t anything that makes its products stand out from those sold by other major smart fridge brands. Instead, where Fisher & Paykel shines is in the durability of its high-end refrigerators — in fact, some studies have crowned it the most reliable refrigerator brand on the market.
None of its products are cheap, with its basic refrigerators starting from just over $2,000 and larger, smarter models quickly increasing in price from there. For its Red Dot award-winning 36-inch Series 11 fridge-freezer, buyers can expect to pay at least $11,499. For their money, they’ll receive features like a variable temperature drawer which can be adjusted to better suit a wide variety of fresh foods, a steel-lined interior compartment, and a slimline water dispenser.
When looking at motorcycle engines, one of the first things to note is the engine’s displacement, as this usually has a strong correlation with the bike’s overall weight and power output. But that isn’t the only factor worth considering. It’s also worth taking a look at the number and orientation of the engine’s pistons.
Most of the motorcycles being made these days use either a parallel-twin or an inline triple-cylinder engine. These are affordable to manufacture and offer a unique blend of power and efficiency. Then there are the inline-four motorcycle engines, which are also sometimes called ‘screamers.’ These became very popular starting in the late ’60s, with that popularity seeming to peak in the mid-2010s. It’s only recently that these have started to slow down in production, and we have begun seeing fewer and fewer of them coming out each year. Many riders still consider these bikes highly desirable for their high-RPM power, smooth balance, and racetrack competence, but there’s no denying they’re slowly slipping out of vogue.
Advertisement
There are a few reasons why you’re seeing fewer inline-four engines coming out than before, and it isn’t just because they’re more expensive to make. There are several other disadvantages that might make them less appealing to the rider. You can still find a fair few affordable inline-4 motorcycles being made even now, but you might want to stop and consider the drawbacks before seeking one out.
Advertisement
1. Inline-fours typically have less low-to-mid-range torque
Most of the arguments in favor of the inline-four engine model primarily cite performance. The bikes that use them are known for delivering a large amount of power smoothly during acceleration, pushing the bike harder at higher speeds. That said, performance isn’t exactly a zero-sum game. While it’s true that inline-four engines are well known for their ability to output incredible amounts of horsepower at high RPMs (which is one of the reasons they are still so popular at the racetrack), this comes at a slight cost.
Inline-fours produce slightly less low-to-mid-range torque than some other engine types. This means riders often discover that they have a little less get-up-and-go when accelerating from a stop than if they were riding a bike with something like a parallel twin in its chassis. This makes them less than ideal for a daily driver, especially for those living in cities with plenty of traffic lights.
So, what qualifies as performance can vary depending on the type of bike and how it’s being ridden. An ultra-lightweight sport bike might have no trouble getting up to speed using an inline-four, while a heavy cruiser might struggle. Likewise, those who primarily ride in urban areas might prefer a bit more low-end torque, while those who prefer to push the red line at the track might prefer something with more power at higher speeds. This makes the inline-four a less practical choice for those seeking a commuter who aren’t looking to get any speeding tickets on the highway.
Advertisement
2. Inline-fours can be wider and heavier
Motorcycles that use inline-four engines are exceptionally well balanced. This is because the pistons move in pairs along a single plane, so there’s always one in the up position and one in the down position on each side, creating a smooth counterbalance. That said, they aren’t exactly petite.
It’s true that the pistons themselves are generally smaller in an inline-four than they are in a two- or three-cylinder motorcycle, but there are more of them, which means that they still end up having more parts and taking up more space overall. That means the casing has to be bigger, which means more metal, which means more weight. That alone can cause a ripple of other issues, such as lowering fuel efficiency and making the bikes feel a little more intimidating to smaller or less confident riders who want something light.
Advertisement
What’s more, the vast majority of modern inline-four engines are mounted transversely. As a result, the straight row of four cylinders is mounted perpendicular to the bike’s frame, not parallel. This effectively makes the engine wider, with each side protruding farther from the centerline than you might get in a two- or three-cylinder engine. That, in turn, means the bike needs a wider frame to accommodate it. This is another factor that might be detrimental to smaller riders, as it can be difficult for them to comfortably place their feet flat on the ground when stopped if they need to straddle a significantly wider seat.
Advertisement
3. Inline-fours drive up price tags
DAMRONG RATTANAPONG/Shutterstock
Inline-four engines are complex machines that are meticulously engineered for smooth acceleration and raw horsepower. Four smaller pistons being attached to the crankshaft in a row create a constant state of balance within each revolution as the bike is consistently receiving power. This is how these engines can accelerate with minimal thumping, and it’s also why they produce that signature screaming exhaust sound. Getting this to work properly requires that all four cylinders be perfectly balanced to prevent them from ever falling out of sync, but that complexity comes at a cost.
We’ve already mentioned that inline-four engines are being used less because they are more expensive to manufacture than parallel twins and some other design styles, but it isn’t actually the manufacturers who swallow that cost. The 2026 Kawasaki Ninja 650, for instance, has a 649cc parallel-twin engine and retails for $7,599. Compare that to the 2026 Honda CBR650R, which runs on a 649cc inline-four. Both are Japanese sport bikes with the same displacement as well as comparable designs and features, but the Honda starts at $9,199. Then take a look at the supersports. The 2026 Kawasaki Ninja ZX6R has a 636cc inline-four engine and retails for $11,599. But despite having a lower displacement, it costs more than the $9,399 2026 Yamaha YZF-R7, which runs on a 689cc parallel-twin. Perhaps one of the most extreme examples might be within Kawasaki’s own line. The 2026 Ninja 500 has a 451cc parallel-twin and starts at $5,799 for the ABS model. The 2026 Ninja ZX-4RR has a 399cc inline-four cylinder engine and costs $9,999.
Advertisement
4. Inline-fours have higher maintenance costs
While we’ve discussed the fact that manufacturing costs drive up the prices of the bikes that run on inline-fours, you also might find that you’re spending a lot more at the mechanic than you were on your last motorcycle. The very intricacy of the inline-four’s design that makes it such a powerhouse can also drive up maintenance costs.
Part of this is simple math. More cylinders mean more parts that require maintenance (twice as many valves), so your mechanic will need to spend twice as long checking the cylinders simply because there are twice as many. This also means more expendable parts like spark plugs and gaskets, but this is only a small part of it. The bigger issue is the effort required to get inside the engine. The inline-four sitting horizontally across the motorcycle’s frame means that it isn’t easy to access from the outside. Mechanics will often need to remove the fairings and tank from the bike just to get to it, which can drive up labor costs quite a bit.
Then there’s the additional complexities of the design. A routine valve adjustment, for instance, might cost between $300 and $600 for an inline-four engine, which usually requires a shim-under-bucket style valve adjustment. That would only run you between $150 and $400 on a V-twin that uses a screw and locknut valve adjustment system. Some of them even use a hydraulic lift valve adjustment system that is self-adjusting and doesn’t need to be serviced at all unless it breaks.
Advertisement
5. Inline-fours are less fuel-efficient
Fuel efficiency wasn’t as big of a consideration for a lot of riders back in the inline-four’s heyday, but it’s definitely become a major factor in how people choose their motorcycles now. Unfortunately, inline-fours sacrifice a fair amount of fuel efficiency in favor of high-RPM power. This might not be that big a deal for the kinds of riders who only use their motorcycles at the track, but it’s definitely something to think about if you’re planning on riding one of these bikes for your daily commute.
Take a look at some of the most fuel-efficient motorcycles on the market, and you’ll quickly find that all of them, except of course for the electric and hybrid models, are powered by one- or two-cylinder engines. Of course, fuel efficiency can be affected by other factors, such as overall weight, gearbox type, chain drive, throttle control, tire pressure, modifications, cargo, and the rider’s weight. There are a few examples of inline-four bikes that are more fuel efficient than you might think, like the Kawasaki Z900, which can get up to 49 MPG. As a rule, however, inline-four bikes are consistently less fuel-efficient than most other engine types and often get city miles closer to those of an SUV than an economy vehicle. Even Honda, which is exceptionally well known for efficiency, can only offer about 40 MPG on its inline-four CBR600RR, while its parallel-twin CBR500R boasts over 65 MPG. Even the larger parallel-twin Kawasaki Ninja 650 is able to hit over 51 MPG.
Advertisement
How we listed these disadvantages
Inline-four engines are immensely popular, and they certainly have a lot of great things going for them. However, there are certain weaknesses that riders who are thinking about getting one should be aware of. There is a wide variety of inline-four engines that have been released over the years, and they are attached to an even wider variety of motorcycles. As such, it is difficult to make any universal claims about design or performance that won’t be disproven by at least one exception. That said, there are certain general rules of thumb that one can apply to the vast majority of them when looking at these weaknesses.
Advertisement
By taking a look at several different professional reviews, motorcycle forums, mechanic forums, and the raw stats of many of the inline-four motorcycles that are on the market today, we have rooted out five key weaknesses that appear to apply to most of them. Once we had our list of weaknesses, we sought to corroborate these claims by verifying them against specs, price comparisons, and reports from trusted sources. We then explained these weaknesses, breaking down why they are tied to the design and how they can serve as a detriment to the rider. In this way, we hope to arm prospective buyers with as much information as possible when weighing the pros and cons of a purchase.
Marvel capped off Saturday evening’s Hall H presentations at San Diego Comic-Con, giving audiences a small taste of what’s next on the menu. And we mean small. Kevin Feige and cast members teased out some movies (no TV shows, today), and we’re breaking it down for you here.
Footage from Avengers: Doomsday was shown, with Doom commanding sentinels and a history lesson on the dynamic between the Fantastic Four and the doctor. But there were only two other major announcements, and nothing for X-Men, and no chart outlining Phase 6 or Phase 7.
Ryan Gosling as Ghost Rider
Johnny Blaze is making his MCU debut with Ryan Gosling in the role, which has been rumored for some time among Marvel’s fandom. Shawn Levy will be directing the new movie for the MCU after his successful run with Deadpool & Wolverine. Could this eventually segue into Midnight Sons? Fingers crossed, my friends.
Agent Carter in Avengers: Doomsday
Hayley Atwell is now officially confirmed to be in Avengers: Doomsday as Agent Peggy Carter, who was first introduced in the MCU in Captain America: The First Avenger. She was in Hall H during Marvel’s presentation for the film.
Advertisement
Black Panther 3 coming in 2028
Feige pretended to exit the stage for the night but then walked back out with one more update: Black Panther 3 will arrive in Dec. 2028. Actor David Jonsson will play T’Challa Jr. in the film, which is directed by Ryan Coogler. Jonsson is best known for roles as Andy in Alien: Romulus, Peter in The Long Walk and as Gus Sackey in Industry.
Kourtnee Jackson
Senior Editor
Kourtnee covers streaming services and entertainment. She previously worked as an entertainment reporter at Endgame 360, where she wrote about film, television, music, celebrities and streaming platforms.
See full bio

























































You must be logged in to post a comment Login