Right-clicking could go the way of the 3.5-inch floppy at the Chocolate Factory
Google doesn’t design mouse traps, so it’s trying to design a better mouse.
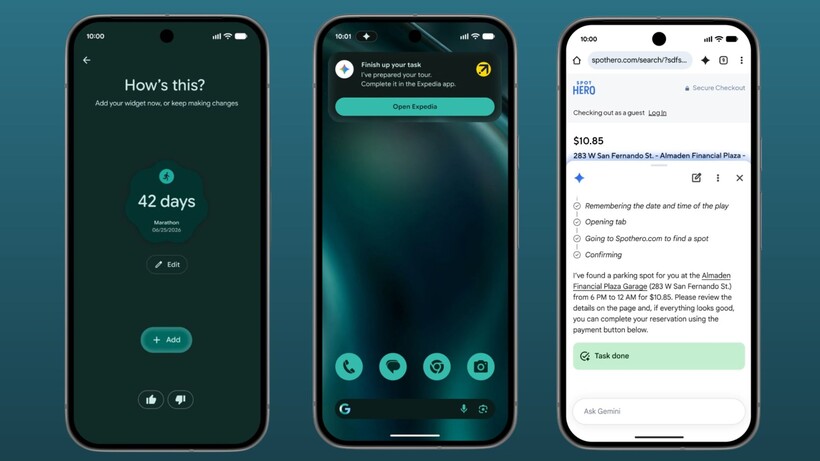
Google DeepMind announced a research effort to transform the standard computer mouse cursor into a context-aware, AI-powered tool, marking what the company described as the first major rethinking of the cursor in more than 50 years.
Advertisement
The project by researchers Adrien Baranes and Rob Marchant integrated Google’s Gemini AI model with an experimental context-aware mouse pointer. In this way, the company said, the system can understand where a user clicks, what they are clicking on, and the likely intent behind the interaction.
Researchers said there is a persistent friction in how people currently interact with AI tools. Most AI assistants today live in a separate window, requiring users to copy, paste, or drag content into a chat interface before receiving help. The new approach aims to reverse that dynamic.
“We want the opposite: intuitive AI that meets users across all the tools they use, without interrupting their flow,” the researchers stated in the blog post.
The mouse pointer works alongside the computer’s microphone, allowing Gemini to listen as the user points. This lets users refer to features on the screen with object pronouns like “this” and “that.”
Advertisement
In a demonstration website, a user can hover a cursor over a crab and say “move this here,” and the system understands enough context to grab the crab and move it to where the cursor indicates.
The first computer mouse, a one-button prototype with metal wheels for the x- and y-axis, was built out of wood in 1964 and was patented in 1970 by its inventors Doug Engelbart and Bill English, who worked at the Stanford Research Institute.
Engelbart foresaw a day when humans and computers would interact more easily and naturally, which he talked about during his 1997 acceptance speech for the Lemelson-MIT Prize.
“The computer technology, the digital capabilities, it’s affecting communications, displays, storage, computer processing. It’s affecting the way you can interface to things a lot more flexibly,” he said. “That’s going to be so pervasively high-impact in our society and our organizations that it’s more than anything we’ve had to cope with evolutionary wise.”
Advertisement
Maintain the flow
At Google, the team said it laid out four design principles guiding the project. The first, which the researchers called “Maintain the flow,” stated that AI capabilities should work across all applications rather than forcing users into separate AI-specific environments. Under this principle, a user could point at a PDF and request a summary, or hover over a statistics table and ask for a chart, all without leaving the current application.
The next, “Show and tell,” addressed the burden of prompt writing. The researchers stated that an AI-enabled pointer could capture visual and semantic context from the screen, reducing the need for users to write detailed text instructions to the model.
They also developed the AI cursor based on how humans naturally communicate using short phrases and gestures like “this” and “that.” The researchers stated that the system would allow users to issue commands like “Fix this” or “Move that here” while the AI fills in the contextual gaps.
The fourth principle, “Turn pixels into actionable entities,” lets the pointer recognize structured objects within on-screen content. The researchers stated that this capability could turn a photo of a handwritten note into an interactive to-do list, or convert a paused video frame showing a restaurant into a booking link.
Advertisement
In the blog, the researchers said that Google DeepMind has already begun integrating the lessons learned into products. A feature called Magic Pointer will soon roll out on the forthcoming Googlebook laptop platform, which The Chocolate Factory introduced earlier this week. The company said the technology will also allow users of Gemini in Chrome to point at specific parts of a webpage and ask questions, rather than composing a full text prompt.
Experimental demos of the AI-enabled pointer are currently available through Google AI Studio, where users can test image-editing and map-based interactions using the point-and-speak approach.
The company said it plans to continue testing the concept across additional platforms, including Google Labs’ Disco. ®
Microsoft’s professional network becomes the latest name on a list that now includes Meta, Amazon, Oracle, and IBM, even as the same companies are guiding $725 billion of AI capital spending this year.
LinkedIn is cutting roughly 5% of its staff, the latest reduction at a Microsoft-owned business and the most recent entry in a year-long Big Tech contraction that has now displaced more than 100,000 workers across the sector.
Chief executive Dan Shapero, who took over from Ryan Roslansky in late April when Roslansky moved into a new AI role inside Microsoft, set out the cuts in a memo to employees, citing the need to operate “more profitably” and to reinvent how the company works with smaller, more agile teams. Bloomberg reported the memo on Wednesday.
LinkedIn employed roughly 17,500 staff at the start of 2026, implying a cut in the region of 900 to 1,000 roles.
Advertisement
The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
The company has not confirmed an absolute number, but multiple outlets briefed by sources put the figure at about 875 jobs, with engineering, product, marketing, and the Global Business Organization carrying most of the impact.
The bigger number is the one that frames everything else. By 13 May, the global technology sector had announced more than 100,000 layoffs across some 250 separate events, an average of roughly 880 a day, according to industry trackers.
Advertisement
The TrueUp layoffs tracker had logged 286 events affecting 128,270 workers, the highest reading since the 2023 contraction.
The defining feature is the divergence between payroll and capital expenditure. Amazon, Microsoft, Alphabet, and Meta are collectively guiding to roughly $725 billion of capital spending in 2026, almost all of it directed at AI infrastructure, GPUs, and data centres.
That figure is up from $410 billion in 2025, and rising faster than at any point since the cloud build-out of the late 2010s. Headcount, meanwhile, is going the other direction at the same firms.
The biggest single tranche still ahead this week is Meta’s. The company will begin companywide layoffs on 20 May, cutting approximately 8,000 employees, or about 10% of its 78,865-person workforce, with further reductions planned for the second half of 2026.
Advertisement
Microsoft has taken a different shape. Rather than involuntary cuts, the company in April opened a voluntary-separation programme to around 8,750 US employees, roughly 7% of its domestic headcount, structured under a “Rule of 70” formula in which years of service plus age must total at least 70.
It is the first such programme in the company’s 51-year history. Final notifications went out on 7 May, with a 30-day decision window. LinkedIn’s cuts now layer on top of those Microsoft moves.
Amazon has been quieter but is on a larger absolute trajectory. The company confirmed in January that it was cutting 16,000 corporate roles, bringing total reductions since October 2025 to roughly 30,000, the largest workforce contraction in its history.
Chief executive Andy Jassy framed the cuts as a flattening of layers built up during the 2020-2022 hyper-growth phase, not a direct AI substitution.
Advertisement
The smaller players are following the same pattern at a different scale. Oracle has cut roughly 30,000 positions, around 18% of its global workforce. IBM, Salesforce, Cisco, and SAP have all confirmed cuts over the year, and defence-adjacent contractors tied to federal technology procurement have shed several thousand roles since the start of the year.
For LinkedIn, the framing is narrower. Shapero’s memo pointed to slower revenue growth and an organisational flattening rather than an AI substitution, and the cuts are part of a wider Microsoft-group rebalance that began with the April Rule-of-70 programme.
LinkedIn’s revenue still grew 12% year on year in the most recent quarter, which makes the cut a profitability call, not a top-line one.
Whether the AI-substitution reading holds across the rest of the sector will probably be settled by the second-half 2026 round of disclosures, particularly Meta’s.
Advertisement
Until then, the running 2026 total is the only honest summary of the labour story: more than 100,000 jobs out, $725 billion of capex going in, and a widening gap between where the money sits and where the people do.
You’ve no doubt heard the short version of this story time and again: AI startups are gobbling up all of the memory that manufacturers can produce, leaving traditional electronics firms to fight for the remaining scraps. In all situations, that means heavily inflated prices and for some near the bottom… Read Entire Article Source link
If you’ve watched a Saturn V launch, you’ve probably seen how a large rocket will often jettison a stage on the way up. There are several reasons for this — there is no reason to haul an empty fuel container, for example. However, you can probably imagine how the separation works. You release something — probably explosive bolts — and gravity pulls the old stage away from you as you climb on the next stage’s engines. But what about on the way back? The command module drops the service module before reentry. [Apollo11Space] has a video explaining just how complicated that was to pull off. You can watch it below.
The main problem? The service module has almost everything you need: oxygen, a big engine, fuel, and electrical generation capability. If you’ve ever seen a real command module, they are tiny. Somehow, you need to get the command module prepared to be on its own for the amount of time it takes to land, and get the service module safely away.
In orbit, gravity isn’t a big help in pulling the two pieces apart. For that reason, the mission design called for a very specific orientation for the separation. There are a number of other details you might not have known about.
Advertisement
Landing Apollo 11 successfully depended on some spy tech. We imagine the separation of the LEM had some similar issues, although even the moon’s weak gravity would have helped.
Android and ChromeOS are merging into a single operating system that will debut in Google’s new laptop lineup, Googlebooks, announced during this week’s Android Show. With no official name yet, the merged operating system has been going by Aluminum OS, but that will likely change by the time it arrives on machines.
We’ve known for some time that Google’s mobile and cloud-based operating systems would be merging, but several questions still remain. Through a handful of leaks, we have a pretty good idea of what to expect. Here’s what we know.
What do we know about Aluminum OS?
Though it won’t be called Aluminum OS when it officially arrives, Google has remained tight-lipped about the name. And beyond what Google has shown us, we haven’t seen much of the operating system in action.
Advertisement
Previously, a now-private issue ticket gave us our first glimpse of the full Android desktop view. This short video shows two side-by-side windows replicating an issue. Hours before this week’s Android Show, the full setup experience of the OS was leaked in detail.
The interface looks similar to Android’s existing desktop view, but the video also showed an extensions icon — something entirely new to the Android operating system outside of third-party web browsers.
We can also expect a lot from Aluminum OS in the way of artificial intelligence. Gemini is already at the heart of Google’s Pixel phones, and that’s exactly what we should see with its laptop lineup.
How is this different from ChromeOS’s Android features?
Given that Chromebooks ship with the Google Play Store out of the box, you might wonder what the big deal is with Aluminum OS, which is fair. Unlike the Play Store on ChromeOS, the base layer of Aluminum is Android, offering native app support combined with a full desktop browsing experience from Chrome.
Advertisement
In essence, Aluminum OS seems poised to be a more powerful and flexible version of Android. Given the billions of Android devices worldwide, the appeal of this new OS could be substantial. Having both your laptop and phone running the same operating system should create a far more integrated software experience across devices, with Gemini at the center.
The unified Alexa for Shopping assistant absorbs Rufus and arrives in the main search flow as Amazon sues to keep external AI agents like Perplexity’s Comet off its marketplace.
Amazon is moving its AI shopping assistant into the main search bar. Starting this week, US customers typing into the search field on Amazon.com or in the Amazon app will be routed through Alexa for Shopping, a unified version of the company’s Rufus chatbot and its Alexa+ assistant that returns conversational answers, product comparisons, up to a year of price history, and personalised shopping guides alongside the standard product listings.
The Rufus brand is being retired from the shopping interface. The chatbot, launched in 2024 and used by more than 300 million customers in 2025, is being folded into the Alexa for Shopping name across Amazon’s app, website, and Echo devices.
Amazon says the new assistant can also automate reordering of household staples, track prices, alert customers to new products in tracked categories, and build out shopping carts based on stated preferences.
It is available without a Prime membership, an Echo device, or the standalone Alexa app, and is free for any signed-in US account.
Advertisement
The structural change is that the AI now sits inside the default search flow rather than behind a separate icon. Rufus, in its original form, was accessible but optional.
Alexa for Shopping reframes the search box itself as a conversational interface, in the same way Google’s AI Overviews changed what happens after a query on Google.com.
Amazon’s own framing is that the move makes the assistant “agentic,” meaning able to complete multi-step tasks like comparison, cart construction, and reorder, on the customer’s behalf.
The competitive backdrop is what makes the placement significant. OpenAI launched Instant Checkout in September 2025 with Stripe and an open-source Agentic Commerce Protocol that lets ChatGPT complete purchases inside its own interface.
Advertisement
Google is building Buy for Me into Gemini and runs its A2A agent-to-agent protocol with 150-plus supporting organisations. Perplexity’s Comet browser has had a Buy with Pro feature since late 2024, with checkout via PayPal across 5,000-plus merchants.
In China, Alibaba integrated its Qwen AI directly into Taobao for end-to-end agentic shopping last quarter. Each of those routes the buy flow through someone other than Amazon.
The Perplexity case sharpens the picture. Amazon sued the AI search company in November, alleging its Comet shopping agent was accessing Amazon.com in violation of the site’s terms and creating problems for ad-impression measurement.
A federal judge granted Amazon a preliminary injunction in March; Perplexity took the case to the Ninth Circuit, which has temporarily paused parts of the order while the appeal is heard.
Advertisement
The legal argument is over agent access, but the commercial argument is over who captures the high-intent search query at the top of the funnel.
That is what Alexa for Shopping is designed to defend. Amazon’s $56 billion advertising business, all of it built around sponsored placements inside search and product pages, depends on Amazon being the first and last surface a buyer touches.
If a third-party AI agent does the comparison and the click on a customer’s behalf, the sponsored slot loses its target.
The internal answer is to make Amazon’s own AI assistant the most fluent shopper on Amazon.com, with access to the price history, recommendation graph, and account-level purchase data that an external agent does not have.
Advertisement
Whether it works as a product is a separate question. Amazon has tried to make Alexa the front door to its shopping business for the better part of a decade, with mixed results.
Voice shopping never reached the share the company once projected, and the original Rufus chatbot, while widely used, has been described in trade reporting as more useful for product research than for closing transactions.
The unification with Alexa+ is also a tacit acknowledgement that running two AI assistants, one for the home and one for the cart, was confusing to customers and expensive to maintain.
The rollout this week is US-only, with international expansion timed to Alexa+’s broader availability, which Amazon has been pushing through 2026.
Google has announced plenty of new features and upcoming products, but one of the most intriguing is undoubtedly Gemini Intelligence.
Gemini Intelligence is promised to bring the “best of Gemini” to compatible devices, by integrating premium hardware and software to help users in everyday life. For an overview of what the new system specifically includes, visit our Gemini Intelligence explainer.
Google has revealed that Gemini Intelligence features will roll out in waves from the summer, but which phones are expected to see the upgrade?
We’ve rounded up the Android phones that should see Gemini Intelligence and, where possible, we detail when handsets are likely to receive the upgrade.
Advertisement
For more on Google’s recent Android 17 announcements, make sure you visit our guides on the new Pause Point feature and the Emoji revamp. Finally, the best Android phones list reveals our current favourite handsets on the market.
Advertisement
Which Android phones are expected to see Gemini Intelligence?
At the time of writing, Google hasn’t revealed the exact dates for when we can expect the Android 17 update to launch. Instead, the company has just stated it will begin the roll out this summer.
Gemini Intelligence. Image Credit (Google)
We should also disclaim that, at the time of writing, Google hasn’t officially announced the specific phones that will support Gemini Intelligence. Instead, Google states that the first Android devices to see Gemini Intelligence will be the latest Samsung Galaxy and Google Pixel phones. With this in mind, we can assume the entire Pixel 10 series, including the Pixel 10 Pro Fold and potentially even the affordable Pixel 10a, will see the feature.
Pixel 10a in hand. Image Credit (Trusted Reviews)
We don’t currently know if the Pixel 9 series will benefit from Gemini Intelligence, so we’ll have to wait and see.
Similarly, we can reasonably expect that the Galaxy S26 series, including the Galaxy S26 Ultra, will sport Gemini Intelligence. Plus, considering the upcoming Z Fold 8 and Z Flip 8 are rumoured to launch sometime in the summer, it’s likely that the foldable may also use Gemini Intelligence – though that’s speculation on our part.
Advertisement
Advertisement
Which other Android devices will see Gemini Intelligence?
Google has teased that other Android devices will include Gemini Intelligence features. Such devices will include “your watch, car, glasses and laptops.” WearOS will see features like Create my Widget, while Android Auto will soon be able to pair and integrate with Gemini Intelligence-compatible Androids.
Finally, we also know that Google’s new Googlebook line-up will also benefit from Gemini Intelligence features, including the Magic Pointer and Create my Widgets.
Most users put up with AWS the way you put up with the DMV. I say this with love, but it’s hard to disagree that the UI is awful. The console is a UX time capsule if time capsules weren’t allowed to ever look like other time capsules. The pricing pages were designed by someone who hates you personally, and you accept all of it because the one thing AWS has historically gotten right is the boring, important stuff. The security model. The IAM language no one likes, but everyone trusts. The boundary between your account and someone else’s. Get that wrong, and the whole bargain collapses.
So when Fog Security disclosed an authorization bypass in Amazon Quick on May 12 (that’s the BI service formerly known as QuickSight, briefly known as Quick Suite, and now apparently just Quick, but check back next week) and AWS responded with a statement claiming “no customer data was at risk,” it’s fair to ask which definition of customer data they’re using. Because it isn’t an obvious one, and it certainly isn’t mine.
What Fog found
Fog reports that when an Amazon Quick administrator (which is an absolutely devastating personal insult) uses “custom permissions” to explicitly deny access to AI Chat Agents, the UI correctly hides the feature. Great! Awesome! I sure wish to hell I could do that with S3 buckets to which I do not have access! Notably, there’s no other way for an admin to do this – it’s custom permissions or naught.
The API, however, was perfectly willing to keep answering chat requests for any user in the account who knew how to send them. Fog’s proof-of-concept was a non-admin asking the agent “Tell me about mangoes” from a session that was, on paper, locked out of the agent entirely. The agent told them about mangoes.
Advertisement
AWS deployed the fix between March 11 and March 12, eight days after Fog reported it via HackerOne. So far, so coordinated. Seriously, for a company of this scale, that’s underpants-outside-the-pants superhero speed. Good for you; gold star.
What came next
Where this gets uncomfortable is the response. AWS classified the severity as “none.” It issued no customer notification. It published no advisory.
After Fog disclosed the HackerOne report and published a blog post, AWS provided a statement to Fog Security reading, in full: “We appreciate Fog Security’s coordinated disclosure. This issue was addressed in March 2026. No customer data was at risk and there is no customer action required. As always, customers can contact AWS Support with any questions or concerns about the security of their account.”
Take that sentence apart and see how much work “no customer data was at risk” is doing.
Advertisement
Amazon Quick is described on its own product page as an AI assistant that “connects Slack, Microsoft Teams and Outlook, CRMs, databases, and documents in one place” and “grounds every answer in your real business data.” The default chat agent, which is automatically and annoyingly provisioned the instant Quick is enabled whether the customer wants those AI features or not, is the front end for that data. It is the whole point of the front end for that data.
Now consider the actual scenario AWS just patched. An administrator at, say, a regulated bank (an unregulated bank is called “a criminal enterprise that hasn’t been caught yet”) configures custom permissions denying chat agent access to a large group of users. Maybe those users are contractors. Maybe they’re in a business unit that isn’t cleared for AI tools. Maybe the bank’s compliance posture flat-out prohibits shadow AI usage on top of internal data. Until two months ago, every one of those users could send an HTTP request directly to the agent endpoint and get a response.
Fog asked about mangoes because they’re a security firm doing a clean disclosure, not a malicious insider. A malicious insider would not have asked about mangoes.
The question to AWS, with no rhetoric attached: In what sense was customer data not at risk? Either the chat agent doesn’t actually have access to the data the product page says it does (in which case the marketing department has some serious splainin’ to do) or unauthorized users could query an agent wired into customer data, in which case “customer data was at risk” is the correct English-language description of the situation.
Advertisement
AWS clarifies, and says the quiet part out loud
After this story started circulating, AWS offered a follow-up comment that I sincerely appreciate, because it’s so much more honest than the first one. Per a hounded-looking AWS spokesperson: “The researcher was using the Admin Control capability that no customers were actively using when the server side validation was not present.”
Reading that twice doesn’t help. Let me translate.
AWS is saying: Yes, the server-side authorization check was missing. Yes, an authenticated user in your Quick account could bypass the only access control mechanism the service offers. The reason this is fine, apparently, is that no real customer had bothered to configure that access control during the window when it didn’t work.
Um … what?
Advertisement
The defense isn’t “the bug wasn’t real,” which you could be forgiven for hearing in AWS’s first statement. The defense also isn’t “the bug couldn’t have done what Fog says it could have done,” which is the even stronger implication of their first statement. The defense is “the access control didn’t enforce what we said it did, but luckily nobody was relying on it.” This is the corporate-comms equivalent of “the lock on the front door didn’t work, but nobody had locked it anyway, so why are you upset?”
It’s also a surprisingly specific telemetry claim. AWS is asserting that they know zero customers had configured custom permissions to deny chat agent access during the exposure window. That’s a confident thing to say, and an even more interesting thing to volunteer as a defense, because it doubles as a withering review of Quick’s access management model: the only knob the service provides for this purpose, the one AWS’s own documentation explicitly tells administrators to use, has zero recorded uptake.
The same follow-up also pointed back to the HackerOne thread to demonstrate that AWS told Fog throughout the disclosure window that “user-based authorization remained enforced.” Translation: you needed authenticated credentials in the same Quick account to exploit this. Yes. That’s intra-account scope, which Fog documented in their writeup, and which is precisely the scope in which custom permissions are supposed to function as a security boundary. AWS saying “user-based authorization was fine” is saying “you couldn’t exploit this anonymously from the internet,” which was never the threat model in question. The threat model is the contractor with valid SSO credentials whose admin tried to lock them out of some datasets.
Why this matters more than it sounds
Amazon Quick’s access model is already an outlier: IAM policies don’t govern Quick’s AI Chat Agent, SCPs don’t apply, and RCPs don’t apply. Custom permissions are the only knob the service provides. If those don’t enforce, nothing else does. And per AWS’s own follow-up, literally nobody was using them anyway. Both halves of that sentence should be alarming, and AWS is offering them as reassurance.
Advertisement
AWS’s competitive moat for the last decade hasn’t been pricing. It sure as poop hasn’t been developer experience, documentation, console design, or the inscrutable poetry of service names. It’s been the well-earned belief that AWS gets the foundational things right: boundaries, identity, durability, reliability, and the parts customers can’t easily verify themselves. Customers have paid the AWS premium because they trusted the boring stuff.
This year that trust is being tested in a way it hasn’t been before. The 2025–2026 cadence of AWS security advisories has noticeably increased, for reasons that are as yet unclear. Coordinated disclosures from independent researchers keep surfacing missing authorization checks in newer, AI-adjacent services.
The fixes are landing fast, which is good. The customer communication isn’t landing at all, which is, charitably, a choice. A “severity: none” rating on a bypass of the only access control a service offers is not an objective security finding so much as it is a communication decision. And the communication decision now reads, with the benefit of AWS’s follow-up: “We’ll fix the bug, we won’t tell you it existed, and if you ask we’ll explain that you weren’t using the feature anyway.”
AWS gets a lot of forgiveness on the small stuff because they own the big stuff. They might want to reconsider how much of the big stuff they keep classifying as “none.” ®
A critical vulnerability affecting certain configurations of the Exim open-source mail transfer agent could be exploited by an unauthenticated remote attacker to execute arbitrary code.
Identified as CVE-2026-45185, the security issue impacts some Exim versions before 4.99.3 that use the default GNU Transport Layer Security (GnuTLS) library for secure communication. It is a user-after-free (UAF) flaw triggered during the TLS shutdown while handling BDAT chunked SMTP traffic.
Exim frees a TLS transfer buffer but later continues using stale callback references that can write data into the freed memory region, which can lead to unauthenticated remote code execution (RCE).
Exim is a widely deployed open-source mail transfer agent (MTA) used to send, receive, and route email on Linux and Unix servers. It is used on Linux servers, in shared hosting environments, enterprise mail systems, and on Debian- and Ubuntu-based distributions, where it has historically been the default mail server.
Advertisement
CVE-2026-45185 was discovered and reported by XBOW researcher Federico Kirschbaum. It impacts Exim versions 4.97 through 4.99.2 on builds compiled with GnuTLS that have STARTTLS and CHUNKING advertised. OpenSSL-based builds are not affected.
Attackers exploiting the vulnerability could execute commands on the server as well as access Exim data and emails, and potentially pivot further into the environment depending on server permissions and configuration.
XBOW reported the vulnerability to the Exim maintainers on May 1st and received an acknowledgment on May 5th. Impacted Linux distributions were notified three days later.
XBOW reports that creating the proof-of-concept (PoC) exploit was a seven-day challenge between the company’s autonomous AI-driven development system, XBOW Native, and a human researcher assisted by a large language model.
While XBOW Native successfully produced a working exploit for a simplified target Exim server that had no Address Space Layout Randomization (ASLR) and non-PIE (Position Independent Executables) binary.
In a second attempt, the LLM achieved an exploit on a machine with ASLR, but still a non-PIE binary.
Advertisement
“[…] instead of continuing to attack glibc’s allocator with off-the-shelf mechanisms, XBOW Native had taken on Exim’s own allocator,” XBOW researchers say.
Despite the surprising result below, it was the human researcher who won the race, with assistance from the LLM for tasks such as assembling files and testing exploitation avenues.
While the researcher acknowledged the impressive speed of the LLM, they realized the need to shape the work environment instead of letting the model create its own space.
Advertisement
“Honestly, I don’t think LLMs alone are quite ready to write exploits against real-world software yet. After this experience, I think it can solve something CTF-shaped, but I don’t see them reaching the level of real production targets just yet.”
Still, the researcher acknowledged the crucial role of AI tools in helping humans understand unfamiliar code and dig deeper into suspicious areas much faster than without them.
To mitigate the risk, users of Ubuntu and Debian-based Linux distributions should apply the available Exim updates (v4.99.3) through their package managers.
AI chained four zero-days into one exploit that bypassed both renderer and OS sandboxes. A wave of new exploits is coming.
At the Autonomous Validation Summit (May 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls hold, and closes the remediation loop.
The updated Android Auto brings a complete Material 3 Expressive design overhaul, including expressive typography, smooth animations, and vibrant wallpapers. It is the biggest update to the platform since the 2023 “Coolwalk” redesign, which introduced a dynamic interface, split-screen multitasking, a revamped dock, and enhanced safety features. Read Entire Article Source link
For decades, the IQ test has been one of the most familiar — and most contested — yardsticks for human intelligence. Now, a startup project called AI IQ is applying the same metaphor to artificial intelligence, assigning estimated intelligence quotients to more than 50 of the world’s most powerful language models and plotting them on a standard bell curve.
The result is a set of interactive visualizations at aiiq.org that have ricocheted across social media in the past week, drawing praise from enterprise technologists who say the charts make an impossibly complex market legible — and sharp criticism from researchers and commentators who warn the entire framework is misleading.
“This is super useful,” wrote Thibaut Mélen, a technology commentator, on X. “Much easier to understand model progress when it’s mapped like this instead of another giant leaderboard table.”
Brian Vellmure, a business strategist, offered a similar endorsement: “This is helpful. Anecdotally tracks with personal experience.”
Advertisement
But the backlash arrived just as quickly. “It’s nonsense. AI is far too jagged. The map is not the territory,” posted AI Deeply, an artificial intelligence commentary account, crystallizing a worry shared by many researchers: that reducing a language model’s sprawling, uneven capabilities to a single number creates a dangerous illusion of precision.
More than 50 AI language models, plotted on a standard IQ bell curve by the site AI IQ. The most capable models crowd the right tail of the distribution. (Credit: AI IQ)
Twelve benchmarks, four dimensions, and one controversial number: how AI IQ actually works
AI IQ was created by Ryan Shea, an engineer, entrepreneur, and angel investor best known as a co-founder of the blockchain platform Stacks. Shea also co-founded Voterbase and has invested in the early stages of several unicorns, including OpenSea, Lattice, Anchorage, and Mercury. He holds a Bachelor of Science in Mechanical Engineering from Princeton University.
The site’s methodology rests on a deceptively simple formula. AI IQ groups 12 benchmarks into four reasoning dimensions: abstract, mathematical, programmatic, and academic. The composite IQ is a straight average of those four dimension scores: IQ = ¼ (IQ_Abstract + IQ_Math + IQ_Prog + IQ_Acad).
Each raw benchmark score gets mapped to an implied IQ through what the site describes as “hand-calibrated difficulty curves.” Crucially, the methodology compresses ceilings for benchmarks considered easier or more susceptible to data contamination, preventing them from inflating scores above 100. Harder, less gameable benchmarks retain higher ceilings. The system also handles missing data conservatively: models need scores on at least two of the four dimensions to receive a derived IQ, and when benchmarks are absent, the pipeline deliberately pulls scores down rather than up. The site states that “every derived IQ averages all four dimensions, so missing coverage cannot make a model look better by omission.”
OpenAI leads the bell curve, but the gap between the top AI models has never been smaller
As of mid-May 2026, the AI IQ charts tell a story of rapid convergence at the top of the frontier — and widening diversity in the tiers below.
According to the Frontier IQ Over Time chart, GPT-5.5 from OpenAI currently sits at the peak of the bell curve, with an estimated IQ near 136 — the highest of any model tracked. It is closely followed by GPT-5.4 (approximately 131), Opus 4.7 from Anthropic (approximately 132), and Opus 4.6 (approximately 129). Google’s Gemini 3.1 Pro lands near 131, making the top cluster extraordinarily tight.
Advertisement
That compression is not unique to AI IQ’s framework. Visual Capitalist, drawing from a separate Mensa-based ranking by TrackingAI, recently observed the same dynamic, noting that “the biggest takeaway is how compressed the top of the leaderboard has become.” On that scale, Grok-4.20 Expert Mode and GPT 5.4 Pro tied at 145, with Gemini 3.1 Pro at 141.
Below the frontier cluster, the AI IQ charts show a crowded midfield. Models from Chinese labs — Kimi K2.6, GLM-5, DeepSeek-V3.2, Qwen3.6, MiniMax-M2.7 — bunch between roughly 112 and 118, making the cost-performance tier increasingly competitive for enterprise buyers who don’t need the absolute best model for every task. One X user, ovsky, noted that the data “confirms experience with sonnet 4.6 being an absolute workhorse as opposed to opus 4.5” — pointing to the way the charts can validate practitioner intuitions that headline rankings often miss.
The trajectory of frontier AI models from October 2023 to mid-2026, as tracked by AI IQ. Provider-colored step-lines connect each lab’s flagship releases, showing roughly 60 points of estimated IQ improvement in 30 months. (Credit: AI IQ)
Why emotional intelligence scores are becoming the new battleground in AI model rankings
What distinguishes AI IQ from most other benchmarking efforts is its inclusion of an “EQ” — emotional intelligence — score. The site maps each model’s EQ-Bench 3 Elo score and Arena Elo score to an estimated EQ using calibrated piecewise-linear scales, then takes a 50/50 weighted composite of the two.
Advertisement
The EQ scores produce a meaningfully different ranking than IQ alone. On the IQ vs. EQ scatter plot, Anthropic’s Opus 4.7 leads on EQ with a score near 132, pushing it into the upper-right quadrant — the most desirable position, signaling both high cognitive and high emotional intelligence. OpenAI’s GPT-5.5 and GPT-5.4 cluster in the high-IQ zone but lag slightly on EQ. Google’s Gemini 3.1 Pro sits in a strong middle position on both axes.
One notable methodological choice has drawn attention: EQ-Bench 3 is judged by Claude, an Anthropic model, which the site acknowledges “creates potential scoring bias in favor of Anthropic models.” To correct for this, AI IQ subtracts a 200-point Elo penalty from the EQ-Bench component for all Anthropic models before mapping to implied EQ. The Arena component is unaffected since it uses human judges. That self-correction is unusual in the benchmarking world, and it suggests Shea is aware of the methodological minefield he has entered. Still, the EQ dimension captures something IQ alone cannot: the growing importance of conversational quality, collaboration, and trust in models deployed for user-facing work.
Plotting IQ against EQ reveals that the smartest models aren’t always the most emotionally intelligent. Anthropic’s Opus 4.7 dominates the upper-right quadrant. (Credit: AI IQ)
The AI cost-performance chart that enterprise buyers actually need to see
Perhaps the most practically useful chart on the site is not the bell curve but the IQ vs. Effective Cost scatter plot. It maps each model’s estimated IQ against an “effective cost” metric — defined as the token cost for a task using 2 million input tokens and 1 million output tokens, multiplied by a usage efficiency factor.
Advertisement
The chart reveals a familiar pattern in enterprise technology: the best models are not always the best value. GPT-5.5 and Opus 4.7 sit in the upper-left corner — high IQ, high cost, with effective per-task costs north of $30 and $50 respectively. Meanwhile, models like GPT-5.4-mini, DeepSeek-V3.2, and MiniMax-M2.7 occupy a sweet spot in the middle: respectable IQ scores between 112 and 120, at effective costs ranging from roughly $1 to $5 per task. At the cheapest extreme, GPT-oss-20b (an open-source OpenAI model) appears near $0.20 effective cost with an IQ around 107 — potentially the most economical option for bulk classification or extraction workloads.
The site also offers a 3D visualization mapping IQ, EQ, and effective cost simultaneously. A dashed line running through the cube points toward the ideal: higher IQ, higher EQ, and lower cost. Models near the “green end” of that axis are stronger all-around deals; those near the “red end” sacrifice capability, cost efficiency, or both. For CIOs staring at API invoices, the implication is clear: the intelligence gap between a $50 model and a $3 model has narrowed enough that routing — using expensive models for hard problems and cheap ones for everything else — is no longer optional. It is the dominant architecture for serious AI deployments.
Critics say AI’s “jagged” capabilities make a single IQ score dangerously misleading
The loudest objection to AI IQ is philosophical, and it cuts deep. Critics argue that collapsing a model’s uneven capabilities into a single score obscures more than it reveals.
“IQ as a proxy is fading — we’re seeing reasoning density spikes that don’t map to g-factor,” posted Zaya, a technology commentator, on X. “GPT-5.5 already hit saturation on MMLU-Pro, but still fails ClockBench 50% of the time.”
Advertisement
That observation touches on what AI researchers call the “jaggedness” problem: large language models often exhibit wildly uneven capabilities, excelling at graduate-level physics while failing at tasks a child could do. A composite score can paper over those gaps.
Pressureangle, another X user, posted a more granular critique, calling out “complete lack of transparency” and arguing the site never fully discloses how its calibration curves were created or validated. In fairness, AI IQ does list its 12 benchmarks and shows the shape of each calibration curve in its methodology modal. But the raw data and precise mathematical transformations are not published as open datasets — a gap that matters to researchers accustomed to fully reproducible methods.
Others questioned the premise itself. “As useless as human IQ testing,” wrote haashim on X. Shubham Sharma, an AI and technology writer, offered a constructive alternative: “Why not having the Models take an official (MENSA-Grade) test? Wouldn’t this be the most accurate and most ‘human-comparable’ way to benchmark intelligence?” That approach already exists through TrackingAI, which administers the Mensa Norway IQ test to language models. But Mensa-style tests measure only abstract pattern recognition, while AI IQ attempts a broader composite across coding, mathematics, and academic reasoning. As Visual Capitalist noted, “an IQ-style benchmark captures only one slice of capability.” Each approach has tradeoffs — and neither has won the argument yet.
The real race isn’t for the highest score — it’s for the smartest model stack
For all the debate about methodology, the most important signal in AI IQ’s data may not be any single model’s score. It is the shape of the market the charts reveal.
Advertisement
There are now more than 50 frontier-class models available through APIs, from at least 14 major providers spanning the United States, China, and Europe. Each provider publishes its own benchmarks, often cherry-picked to showcase strengths. The result is a Tower of Babel where no two companies measure the same thing in the same way. Academic research has highlighted that “most benchmarks introduce bias by focusing on a particular type of domain,” and the Frontier IQ Over Time chart on AI IQ shows just how fast the targets are moving: in October 2023, GPT-4-turbo sat near an estimated IQ of 75. By early 2026, the top models were brushing 135 — roughly 60 points of improvement in 30 months.
That pace raises a fundamental question about whether any scoring system can keep up. The site compresses ceilings for saturated benchmarks, but as models continue to max out even the hardest tests — ARC-AGI-2, FrontierMath Tier 4, Humanity’s Last Exam — the framework will face the same ceiling effects that have plagued every AI evaluation before it. Connor Forsyth pointed to this dynamic on X: “ARC AGI 3 disagrees,” he wrote, referencing a next-generation benchmark that may already be undermining current scores.
AI IQ is not perfect. Its methodology is partially opaque. Its IQ metaphor can mislead. And its creator acknowledges known biases while likely missing others. But the alternative — wading through dozens of provider-specific benchmark tables, each using different test suites and scoring conventions — is worse. The site offers enterprise buyers something genuinely scarce: a single framework for comparing models across providers, dimensions, and price points, updated regularly, with enough nuance to show that the right answer to “which model is best?” is almost always “it depends on the task.”
Maybe. But if the AI IQ data shows anything clearly, it is that orchestration — knowing which model to deploy, when, and at what price — has become its own form of intelligence. And for that, there is no benchmark yet.































































You must be logged in to post a comment Login