
Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.




Every generation has its iconic cars. From the hot rods of the 1930s to the sleek sports cars of the 1980s, each era can be defined by its unique take on the age-old idea of how to make cars that are fast, cool, and expressive.
Across all of automotive history, the 1960s stand out as a special time for cars. High-performance vehicles were incredibly affordable, and gas wasn’t the premium product it is now. Many houses had one- or two-car garages, and most had a car that served as an extension of their own personality. The cars of this era had not yet settled into the homogenized style of the 1970s, retaining much of the hot-rod flair of earlier decades without becoming luxury status symbols reserved for only the wealthiest elites.
Let’s travel back in time to the golden age of automobiles and look at some of the most legendary vehicles of that one-of-a-kind decade. If you grew up in the ’60s, you definitely remember these cars. And if you didn’t, you surely still find yourself looking at them with an envious wistfulness of vicarious nostalgia. Simply put, they don’t make ’em like that anymore.
Over the years, Jay Leno’s Garage featured tons of iconic and expensive cars, but few are as downright legendary as this one. When the 1965 Pontiac GTO Royal Bobcat was featured on an episode of Jay Leno’s Garage, the former Tonight Show host described the vehicle as the first true supercar, an early example of the burgeoning American muscle car scene. He even went so far as to say, “This was the dream car when I was 14 or 15 years old.”
The Pontiac GTO was special because it broke, or at least sidestepped, the rules. Back in the day, General Motors limited the size of a midsize car’s engine to 330 cubic inches. Big cars get big engines, small cars get small engines. But the engineers at Pontiac managed to stuff a 389-cubic-inch V8 engine into a midsize car, and the rest was history. Initially pitched as an optional engine upgrade for the Pontiac Tempest, its popularity led to the invention of the 1966 GTO as its own bespoke vehicle, and the birth of the American muscle car.
There’s nothing like the rev of an oversized V8 engine that’s just a little (or a lot) too big for the car it’s powering. Every child of the ’60s who sat in a car and felt the entire frame vibrate as the driver revved the engine had the exact same thought: “When I grow up, I want one of these.” Chances are, that car was a Pontiac GTO.
For many automotive enthusiasts, love for cars comes from exposure to TV and movies. In that regard, the 1960s had some of the most legendary vehicles ever to grace the screen. There’s the 1966 Batmobile driven by Adam West in “Batman” and the Mach 5 from “Speed Racer,” as well as the Black Beauty from “The Green Hornet” and the Elva Mk VI, driven by none other than Elvis Presley in “Viva Las Vegas.”
However, if there’s a single scene that represents the blending of cars and cinema, it’s the 1968 Ford Mustang driven by Steve McQueen in “Bullitt.” For the most part, “Bullitt” is a by-the-numbers detective movie bolstered by McQueen’s cool charisma in the title role. However, it kicks into overdrive during the show-stopping ten-minute car chase sequence, which was a turning point in action cinema. The entire car chase genre, including the “Fast & Furious” series, would not exist without “Bullitt.” McQueen does much (but not all) of his own driving in the scene, which sees Frank Bullitt outmaneuver hitmen in a pulse-pounding pursuit through the streets of San Francisco.
The movie and its car chase inspired a whole generation of car fanatics. Everyone who saw “Bullitt” wanted a Ford Mustang. More than five decades later, Ford is still releasing modern Mustangs inspired by the one used in the film, such as the 2020 Ford Mustang Bullitt, named after the movie. As for the original 1968 Mustang used in the movie, it was sold for $3.74 million at a 2020 auction, making it the single most valuable Mustang of all time.
In 1966, Car and Driver magazine went hands-on with the 1967 Chevrolet Camaro SS 350 and came away impressed, though with more than a hint of melancholy. The Camaro, they surmised, was aimed at the youth market, which had been sideswiped by the escalation of the Vietnam War. The Camaro was hip and relatively inexpensive but hindered by the fact that its target audience of young men had been drafted into military service.
Nevertheless, the Camaro was priced reasonably, with both the hardtop and convertible versions retailing for less than $3,000 each, competitive with its main rival, the Ford Mustang. One of the more popular versions of the Camaro was the RS, or Rally Sport, variant, which featured concealed headlights, mag wheels, options for vinyl roof customization, and rally stripes. They don’t make the car any faster, but they sure look neat!
The car was marketed toward young people, though it earned the respect of auto enthusiasts due to its use as the Pace Car in the 51st Indy 500 in 1967, with none other than three-time Indy 500 champion Mauri Rose behind the wheel, thus giving the vehicle credibility among the gearhead community. As a result, the Camaro ingratiated itself with Indy 500 fans of all ages. There would be many Camaro variants over the decades, but the 1967 version is among the best-looking Chevy Camaros of all time. Not bad for a car approaching 60 years old.
Even if you’re not a “car person,” you know what a Volkswagen van is. It’s the iconic “hippie bus,” and it’s instantly recognizable as an iconic car of the era. Design-wise, it had a ton of room in the back, which was perfect for road trips and the nomadic lifestyle of counterculture kids. Remember, back in, say, 1967, gasoline was only 33 cents per gallon on average, so going on even a cross-country trek wasn’t as difficult as it is now. If you wanted to drive for days at a time, you could just go without selling off all of your possessions first.
The original run of the Volkswagen Transporter was actually introduced way back in 1950, and it became popular in the beach scene. Teenagers of the era would pack into a VW and head to the beach for fun in the sun. Later on in the 1960s, however, the bus would become the de facto automobile mascot of the hippie scene. It was perfect for packing in many riders to go to protests, and there was plenty of room in the back for a little “free love,” if you will.
In 1967, the second-generation iteration of the vehicle was introduced, though it lost some of its bus-like novelty with the removal of the iconic split windshield design in favor of a more traditional single-pane windshield, among other changes that sacrificed the classic identity of the original Transporter. The VW Bus would evolve considerably over the years, but the original is still a fan favorite.
There were sports cars before Porsche, but the 1963 Porsche 911 changed the game. It wasn’t the first classic Porsche, but it was sleek and small with an instantly recognizable silhouette. Under the hood, the 911 boasted an air-cooled engine that delivered 130 HP. Despite making sports cars, Porsche also had a reputation for being (relatively) affordable and would go on to develop the Porsche 912 in 1965 as a less expensive alternative to the regular 911.
The Porsche 911 is an iconic car for bringing luxury sensibilities to everyday suburbia in the 1960s. Its engine may not have been able to compete with the muscle cars of Pontiac or Ford, but Porsche would upgrade the engine over the years. In 1966, the Porsche 911S boosted the engine to a more palatable 160 HP, and by 1971, the Porsche Carrera RS would boast a stellar 210 HP engine.
For many young people in the 1960s, Porsche was their introduction to the very concept of a sports car. For those who didn’t see the appeal of a bulky, muscular hot rod but still wanted to go fast, Porsche was the origin point for a lifetime of aspirational thinking.
Apple will report its third-quarter financial results on July 30. Here’s what happened in the quarter, and what analysts believe will be the highlights of Tim Cook’s last earnings report as CEO.
Apple’s Q3 2026 financial results will be issued by Apple in a press release on July 30. As is tradition, it will be followed by the analyst and investor conference call at 5 p.m. EDT.
The call will see current CEO Tim Cook and CFO Kevan Parekh talking about the quarter and providing guidance for future quarters. Analysts will also ask questions about Q3 and what to expect from upcoming trade periods.
The discussions will almost certainly also cover Cook’s last financials call as CEO.
As usual, AppleInsider will be reviewing the data and reporting on the subjects raised in the conference call.
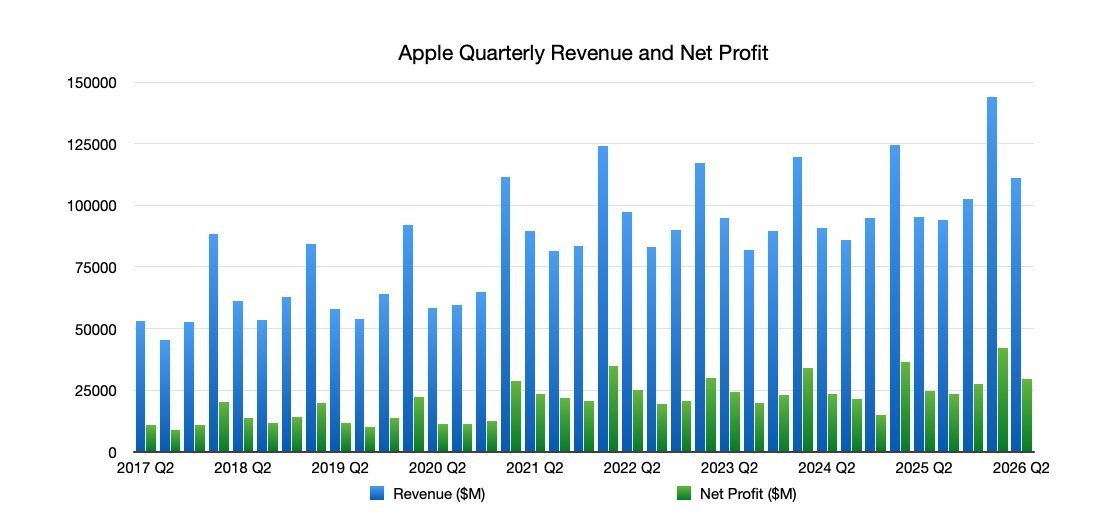
Released on April 30, the Q2 earnings were a second-quarter record, with $111.2 billion in revenue reported. There were also gains across almost all areas, exceeding the expectations of Wall Street analysts.
The revenue included $56.99 billion from iPhone, with Mac revenue also up at $8.4 billion, iPad rose to $6.9 billion, and Wearables, Home, and Accessories shifted to $7.9 billion.

Apple quarterly revenue and net profit as of Q2 2026
The ever-reliable Services category reached $30.9 billion, up from $26.6 billion in Q2 2025.
During the period, Apple enjoyed post-holiday launches including the M4 iPad Air, the iPhone 17e, M5 upgrade to MacBook Air, and the M5 Pro and M5 Max MacBook Pro. There was also the updated Apple Studio Display, the Studio Display XDR, and the MacBook Neo.
The Q3 2025 figures were an improvement to $94.04 billion in revenue, again soundly beating Wall Street expectations.
The iPhone revenue was up to $44.58 billion, with Mac also growing to $8.05 billion, and Services marching upward to $27.4 billion.

Apple quarterly revenue by unit as of Q2 2026
However, iPad revenue dipped from $7.16 billion in Q3 2024 to $6.58 billion in Q3 2025. Similarly, Wearables, Home, and Accessories went from $8.09 billion to $7.4 billion.
The quarter had a backdrop of a global trade war, with Apple getting a minimal hit from grossly increased tariffs. Apple also managed to get a new all-time high for its install base across all product categories and geographic segments.
The quarter is the first to fully benefit from the Q2 releases, since they were available for the entire period instead of part of it. Aside from the launch of the AirPod Max 2, there aren’t really any major in-quarter launches to be concerned about.
However, the ongoing memory crisis has made an impact. Warned in June by Cook, he admitted that price rises were “unavoidable,” and the situation unsustainable.
A few days later, Apple raised the prices of its products across the range significantly.
This included the MacBook Air starting from $1,299 instead of $1,099 and the MacBook Neo jumping from $599 to $699. The Mac Studio was badly hit, with the M4 Max starting from $2,499 instead of $1,999, and the M3 Ultra going up from $3,999 to $5,299.
While products like the HomePod and Apple Vision Pro also saw hikes, Apple didn’t adjust the prices of the iPhone 17 generation. It may simply be waiting for the iPhone 18 to do that.
During the Q2 results, Parekh provided some forward-looking statements. This included expectations of revenue growth at between 14% and 17% year-over-year, and a gross margin between 47.5% and 48.5%.
Operational Expenditure should reach between $18.8 billion and $19.1 billion.
The Wall Street consensus refers to a survey of analysts. The results are averaged out to give a general opinion of where investors and analysts are leaning in their quarterly forecasts.
Yahoo Finance
Yahoo Finance’s revenue estimate for Apple in Q3 stems from 27 analysts. As of July 22, the average estimate is $108.9 billion, with a low of $107.5 billion and a high of $112.17 billion.
For the earnings per share estimate, 31 analysts put it at an average of $1.89. The low is $1.83 and the high is $1.99.
TipRanks
TipRanks also does its own analyst polling on Apple’s quarter. In its forecast as of July 22, its consensus is for revenue at $108.85 billion, with a high of $112.20 billion and a low of $105.20 billion.
On the earnings per share, the consensus is $1.89, with a low of $1.80 and a high of $1.99.
Ahead of the results and call, analysts offer their own forecasts of what they think Apple will be declaring in its financials. Depending on the firm and the analyst, these hot takes include both positive and negative opinions about Apple.
AppleInsider will add to the analyst speculation here as the predictions roll in.
Bank of America
In a forecast that rolled in on July 20, Bank of America is a little positive about Apple’s potential results. In its July 20 forecast, it believes Apple will get $109 billion in revenue with an earnings per share of $1.89.
iPhone build plans for a Pro-centric production are robust, but the analysts are being more conservative due to the new hardware cycle staggering. For Services, BoA thinks there will be 14% year-over-year growth.
As expected, BoA believes that investor focus will be on things like component cost rises, as well as the Cook-Ternus changeover.
BoA has a Buy rating for Apple, with a price target of $380.
Morgan Stanley
On July 24, Morgan Stanley provided its own guidance on the quarterly results, with expectations it will slightly beat market expectations.
Working on guidance of potential increases in revenue and EPS, Morgan Stanley thinks that Apple’s gross margin may go slightly below the market’s forecast. It blames potential changes to iPhone shipment volumes, price hikes, and cost inflation.
Under this forecast, Morgan Stanley reiterated its “Overweight” rating for Apple, but raised the price target from $360 to $364.
UBS
On July 16, UBS issued a report giving Apple a “Neutral” rating and maintained a price target of $296.
For the quarter, UBS expects revenue to reach $107.8 billion, just below a $108.1 billion consensus. The diluted earnings per share is anticipated to be $1.84, slightly down from the $1.87 of the consensus.
On a per-unit basis, iPhone market share increased in the quarter, with Mac revenue up thanks to new models, albeit with a small shift to a lower average selling price. Services is projected to get a 13% year-over-year growth, though with headwinds in App Store growth and Google search-related revenue.
Over the weekend, Reddit user -void1 posted an alarming discovery on the r/ClaudeAI subreddit: some conversations that users of Anthropic’s Claude AI chatbot had made “shareable” via a link were being indexed by Google Search, and could be clicked on and accessed by seemingly anyone.
The conversation took off on the social networks X and Reddit, the latter with thousands of upvotes and comments, many expressing concern about user privacy and information security, and the additional finding by users that shared Claude Artifacts — including interactive applications, dashboards, documents and other AI-generated work products — were also appearing in Google Search results.
VentureBeat independently verified that some Claude Artifacts not shared directly with us were indeed searchable and accessible via Google. We could not access any shared conversations.
By Sunday morning, many of the original Google search results for shared Claude conversations appeared to have disappeared or become significantly harder to find, suggesting either Google, Anthropic or both had begun taking action.
The exposure could carry broader implications for enterprise users. Anthropic has increasingly positioned the feature as a collaborative workspace for building and sharing software, dashboards, documents and other business assets rather than simply chatbot responses.
I have reached out to Anthropic for comment and will update this article when the company responds.
Reddit user -void1 posted to r/ClaudeAI on July 25, 2026, demonstrating that the Google query site:claude.ai/share surfaced numerous publicly accessible Claude conversations.
Screenshots shared across Reddit and X showed Google returning pages from Claude’s /share URLs, while other users reported finding conversations containing cryptocurrency wallet creation, legal questions, résumés and internal business discussions.
While many users expressed concern that conversations they believed were effectively “unlisted” could become discoverable through public search engines, others argued the behavior reflected the expected consequences of creating publicly accessible share links rather than a software vulnerability.
Indeed, Anthropic requires the user themselves to go into Claude’s options and select to make a conversation or Artifact shareable to others with the link, warning them it will be accessible to anyone with it, over multiple dialog boxes. It is similar to sharing a Google Doc link, where the user must also select the option — it is not enabled by default.


On July 26, X user Om Patel, founder of research firm BigIdeasDB, posted allegingthat searches such as site:claude.ai/public/artifacts surfaced publicly shared applications, dashboards, reports and documents.
Screenshots circulating online appeared to show search results referencing internal-looking proposal documents and other business materials. Another widely circulated post warned that users often interpret “Anyone with the link” as equivalent to an unlisted YouTube video—accessible only if someone possesses the URL—not necessarily as content eligible for indexing by public search engines.
VentureBeat independently verified that multiple third-party Claude Artifacts appeared in Google Search results for the query site:claude.ai/public/artifactslaunch and were accessible without authentication, despite the URLs not being previously known to the reporter.
However, VentureBeat has not independently verified the full volume or representativeness of the examples circulating on social media.
The reports are particularly significant because Artifacts has become one of Anthropic’s flagship product initiatives.
First introduced alongside Claude 3.5 Sonnet in June 2024, Artifacts transformed Claude from a conventional chatbot into a collaborative workspace capable of generating interactive web applications, dashboards, visualizations, documents, games and other live software alongside a conversation.
VentureBeat previously described the launch as potentially marking the beginning of an “interface war” among AI companies, shifting competition from raw model performance toward collaborative AI workspaces.
Anthropic subsequently rolled Artifacts out to all Claude users, saying tens of millions had already been created, before expanding the concept again this year into Claude Code.
That update allows engineering teams to publish live HTML dashboards and interactive project workspaces directly from coding sessions, making Artifacts an increasingly important part of Anthropic’s enterprise strategy.
That broader functionality raises the potential stakes if publicly shared Artifacts were also being indexed. Unlike ordinary chat transcripts, Artifacts can contain interactive software prototypes, engineering dashboards, planning documents, product mockups, data visualizations and other work products organizations increasingly rely on to collaborate across technical and business teams. If those pages become searchable through public search engines, the exposure could extend well beyond conversational text.
Importantly, nothing so far suggests attackers gained access to private Claude accounts or conversations.
Rather, the controversy centers on conversations and Artifacts that users explicitly chose to share publicly via Claude’s sharing tools.
The dispute instead is whether users reasonably understood those shared pages could become discoverable through public search engines rather than only by recipients possessing the link.
Technically, pages that are publicly accessible without authentication can generally be indexed by search engines unless publishers explicitly prevent crawling through mechanisms such as noindex directives or other indexing controls.
Several Reddit commenters noted that Claude’s long, randomly generated share URLs are effectively impossible to guess. Instead, search engines typically discover them only after links appear somewhere they are permitted to crawl, such as public websites, forums or social media posts. Others questioned exactly how Google initially discovered so many Claude share URLs.
The issue also illustrates a growing challenge for AI companies as chatbots evolve into collaborative workspaces for creating software, documents, dashboards and business applications.
Features originally designed to make sharing AI-generated work easier now increasingly expose assets that may carry significantly more business value than a simple conversation.
As enterprises adopt AI as a platform for building internal tools and workflows, the distinction between “shared by link” and “publicly discoverable through search” becomes far more consequential.
Anthropic is far from the first AI company to confront the distinction between “shared” and “searchable.”
Reddit users quickly pointed out that OpenAI previously faced criticism after publicly shared ChatGPT conversations became discoverable through Google, prompting similar debates over whether “share by link” should imply a publicly indexed webpage or something closer to an unlisted document.
Anthropic’s situation also echoes an incident involving Google’s pre-Gemini AI assistant, Bard, in September 2023. SEO consultant Gagan Ghotra discovered that Google Search had begun indexing shared Bard conversation links, warning that users could mistakenly assume they were sharing conversations only with intended recipients rather than making them discoverable through search.
Google later responded publicly that it did not intend for shared Bard chats to be indexed and said it was working to block them from Google Search while emphasizing that only conversations users explicitly chose to share were affected.
Together, the Bard, ChatGPT and now Claude episodes suggest AI companies continue to wrestle with the boundary between content that is technically public on the web and users’ expectations that “share with a link” behaves more like an unlisted Google Doc or YouTube video than a webpage eligible for indexing by search engines.
For organizations deploying generative AI broadly across employees, the distinction between “shared with a link” and “publicly discoverable through search” is not merely semantic. It can determine whether an internal engineering dashboard, financial model, product roadmap, customer-facing prototype or AI-generated application remains effectively private—or becomes visible to anyone using a search engine.
Whether this ultimately proves to be a technical indexing oversight, a mismatch between product design and user expectations, or some combination of both, the episode serves as another reminder that AI products are increasingly functioning less like chatbots and more like collaborative operating systems for knowledge work.
As those platforms begin hosting internal dashboards, software prototypes, financial analyses, business planning documents and increasingly sophisticated enterprise applications, seemingly small decisions about how shared links behave can have outsized consequences for enterprise security, product design and user trust.
Enterprise leaders should consider taking several practical steps:
Audit existing shared AI content: Review shared conversations, Artifacts and other publicly accessible AI-generated assets to determine whether they should remain available or be unpublished.
Clarify what “Share” actually means to your ENTIRE organization: Don’t assume employees understand the difference between “accessible by link” and “discoverable through search.” Update internal guidance to explain how each AI platform handles shared content.
Treat AI platforms like collaboration software: Apply the same governance you use for Google Docs, Microsoft 365, Slack, GitHub, Notion or SharePoint—including policies around sharing sensitive intellectual property, customer information and regulated data.
Prefer authenticated enterprise workspaces for sensitive information: When possible, keep confidential projects, code, financial models and customer data inside enterprise accounts with identity-based access controls instead of publicly accessible links.
Review vendor defaults and sharing controls: As AI platforms evolve rapidly, administrators should periodically revisit default sharing settings, retention policies and indexing behavior rather than assuming they remain unchanged after new feature releases.
For now, it appears Anthropic has begun limiting the visibility of at least some shared pages in Google Search, though reports suggest cached copies, archived pages and indexing by other search engines may persist for some content. Enterprises that have relied on Claude’s sharing features may wish to review existing shared conversations and Artifacts while Anthropic’s investigation continues.

 Jeffrey Hazelwood/CNET
Jeffrey Hazelwood/CNETYour phone is essentially a miniature computer. They help us stay connected with friends online, organize our schedules and even stream our favorite shows. And you probably have a strong opinion on how your phone performs, its battery life and which features are actually useful — and which aren’t.
This month, we’re asking which phone you rely on. You can take our two-minute survey to share your experience with your device’s camera quality, battery life, durability and value. The top picks will make it to our roundup, so be sure to check back in a few weeks to see if yours made the list.
Spec tables on retailer sites don’t capture the full story about a phone. How your phone performs every day, your experience with the camera in dim lighting and whether the hardware holds up over time are invaluable insights for others.
“I’ve been reviewing phones at CNET for a decade and my absolute favorite part of my job is meeting readers and hearing about what they love about their handsets and what annoys them. I’m incredibly excited to hear from you and encourage you to share your experiences with us,” says Patrick Holland, director of content at CNET.
Whether you go for budget phones or prefer devices with all the bells and whistles, you can help other CNET readers find a phone that’s actually worth their money by sharing your thoughts.
This survey is open through mid-August and takes only a few minutes to complete. After we gather enough information, we’ll tally up the numbers and publish the winners.
Need a refresher? Check out our list of the best phones to see which ones CNET editors recommend.

This messaging is cause for concern, according to ADHD specialists who spoke with WIRED.
“Stimulant medications have been in existence for nearly 100 years, and approved for use in children since the 1960s,” says Kristen Leinung, a mental health nurse practitioner and director of psychiatric services at the Northwest ADHD Treatment Center in Portland, Oregon. The drugs are well-studied for efficacy and have predictable side effects, she adds, but because they can be misused, they’re often stigmatized online. “This style of advertising does further that stigma.”
Leinung believes that with their pessimistic framing of Adderall and similar pharmaceuticals, these supplement ads could lead people to go off their medication, which can be dangerous. “We know untreated or under-treated ADHD carries a high mortality and morbidity risk,” Leinung says, decreasing life expectancy and doubling the risk of premature death; it’s associated with factors that range from less exercise and worse sleep to riskier driving and a higher likelihood of smoking.
US pharmacies have seen shortages of the stimulants Adderall, Vyvanse, Ritalin, and Concerta since 2022. Though the Drug Enforcement Administration increased production quotas last fall, various production bottlenecks have continued to create supply problems, according to the nonprofit Understood, which supports Americans with learning and thinking differences including dyslexia and ADHD.
The difficulty of accessing these medications may factor into someone’s decision to try unproven alternative treatments instead, says Cindy Goldrich, a mental health counselor, educator, and ADHD coach in Boulder, Colorado. That’s what makes the supplement ads feel “exploitative” to her.
“When someone can’t get their prescription filled and doesn’t know when they will, a product promising to fill that gap—or claiming you didn’t need the ‘harsh’ medication anyway—becomes very appealing, very fast,” she says. “It’s not just selling to people who are curious about alternatives. It’s selling to people in crisis, who are scared and out of options through a system failure that has nothing to do with whether their medication works.”
Andrew Kahn, a psychologist and associate director of expertise and behavioral health at Understood, says these supplements also lack robust regulation while suggesting, without evidence, “benefits equal to or similar to medication.” But unlike prescription and over-the-counter drugs, he explains, “supplements don’t have to prove they’re safe or effective to the FDA before they’re sold.”
That very fact can become a selling point. “People are wary of big pharma, wary of side effects, and a ‘natural’ option feels safer even when it isn’t better tested,” Goldrich says. Some of the more common ingredients in the supplements, like omega-3s, L-theanine with caffeine, and certain adaptogens “have modest supporting research as general cognitive or mood support, and there’s nothing wrong with someone using them alongside medication if their doctor is aware.” But an underlying problem, she adds, is that whether a person takes medication or supplements or both, they still need to learn skills like planning and emotional regulation.
In the MAHA era, of course, medically suspect claims often circulate unchallenged. Kennedy, who swears by dubious supplements like the synthetic dye methylene blue, has in many ways normalized these fringe products as the top authority of the vast US health care apparatus. In a statement to WIRED, HHS press secretary Emily G. Hilliard reiterated the department’s position that the nation is facing a challenge of “overmedicalization in behavioral health care,” with patients and parents not always informed about the potential hazards of psychiatric drugs. “Under Secretary Kennedy’s leadership, HHS is embedding informed consent, transparency, and evidence-based alternatives into federal policy and practice,” Hilliard said.
Leinung, however, feels people should think twice before making that decision based on a video they saw on social media. “I do worry that encouraging people to stop or avoid starting prescribed medication to treat their ADHD can negatively impact their quality of life,” she says. “I would caution any person considering stopping their prescribed stimulants to have a thorough discussion with their health care provider.”


The ShinyHunters extortion gang has claimed responsibility for a recently disclosed Ernst & Young data breach, saying it obtained credentials for some of the company’s systems via a supply-chain attack.
Ernst & Young disclosed the breach earlier this month, saying a third-party support ticket system used by its IT personnel was compromised and support tickets that may contain client tax information were stolen.
EY says it detected unusual activity on April 23 and determined that the attacker accessed the platform between March 28 and April 12, downloading multiple documents.

“EY uses a third-party information technology service management platform to help EY information technology personnel provide support to EY teams performing tax-related work for clients,” reads the EY data breach notification.
“Support tickets submitted through the platform may include documents containing client tax information”
Th notification goes on to say that the stolen documents contained personal and financial information included in or used to prepare tax filings.
However, the company has not disclosed the name of the compromised support system, the specific types of information exposed, or how many people were affected.
At the time the breach was disclosed, no ransomware or data extortion group had claimed responsibility for the attack.
Today, the ShinyHunters extortion gang added Ernst & Young to its data leak site, claiming it conducted the attack and threatened to release the allegedly stolen data if the company does not contact the group by July 31, 2026.
The threat actors claimed to BleepingComputer that EY credentials were obtained through a supply-chain attack and used to breach the company. These stolen credentials allegedly allowed them to breach Ernst & Young’s Jira, GitHub, and Azure environments.
The threat actor would not identify the allegedly compromised third party or disclose what data was stolen. However, it claimed that the information EY acknowledged as compromised was exposed, along with more data.
BleepingComputer has no way to verify the threat actor’s claims independently, and Ernst & Young has not confirmed that ShinyHunters was behind the attack.
BleepingComputer contacted Ernst & Young again Monday morning to ask whether ShinyHunters was behind the attack and whether the company had received an extortion demand from the group.
We also asked EY to identify the compromised support system and disclose how many people were affected by the breach.
Ernst & Young previously said it secured its systems, removed the unauthorized access, and notified federal law enforcement.
Affected clients are being offered 24 months of identity monitoring and restoration services through Experian.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.


Your workforce is building agents in Salesforce Agentforce, Microsoft Copilot Studio, Cursor, Zapier, Retool, and a dozen other tools, often without visibility or approval from IT or security.
For IT and security teams, the decision of whether or not agents should be used has already been made by the business, one shadow agent at a time. The challenge now is keeping up. New agents can be created in minutes, connected to sensitive systems in a click, and changed daily.
The job is to maintain visibility and control (who built it, what it can access, what it can do) while enabling the workforce to keep experimenting, automating, and moving fast.
That’s exactly what Nudge Security does.
AI chatbots are a known problem by now. Shadow AI agents are a different, and arguably bigger, one. An agent holds persistent permissions. It connects to your corporate apps and data. It takes action on its own, without waiting for someone to hit send.
When an unmanaged agent goes wrong, the result isn’t a bad response in a chat window. It’s a system that got touched.
The numbers back this up:
That gap between exposure and readiness is exactly where shadow AI agents live.
Learn how each approach works, what it actually detects, and where the blind spots are, so you can build a discovery strategy that matches your real agent risk surface.
As AI agents multiply across your stack, the gaps between methods are where risk hides.
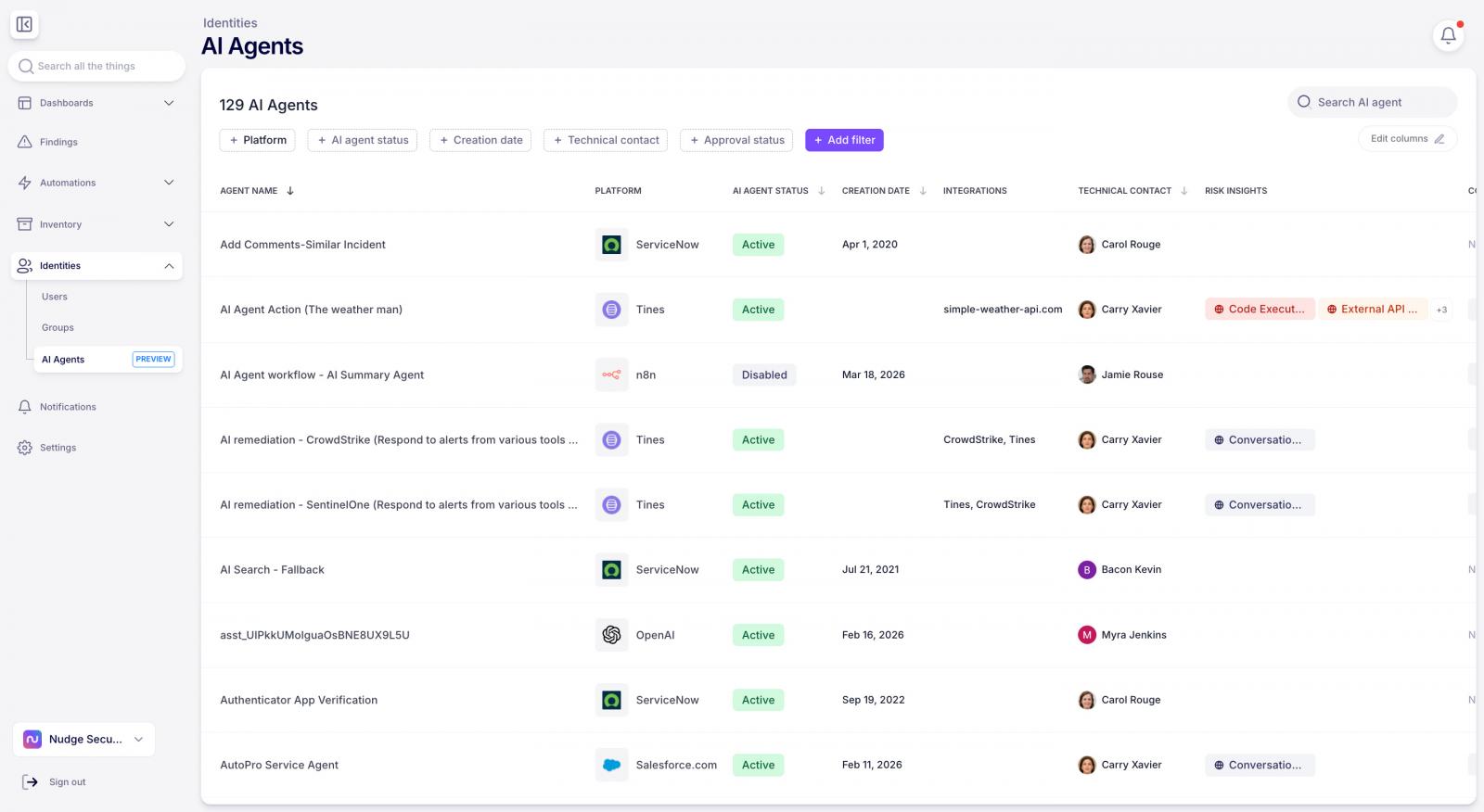
You can’t govern an agent you don’t know exists. Nudge Security gives you an immediate inventory of AI agents, across the most popular agentic platforms including Microsoft Copilot, Google Gemini, ChatGPT, Claude Managed Agents, Tines, ServiceNow, Salesforce Agentforce, Cursor Automations, and many more.
No spreadsheets. No self-reporting. No waiting for an incident to find out what’s already running in your environment.
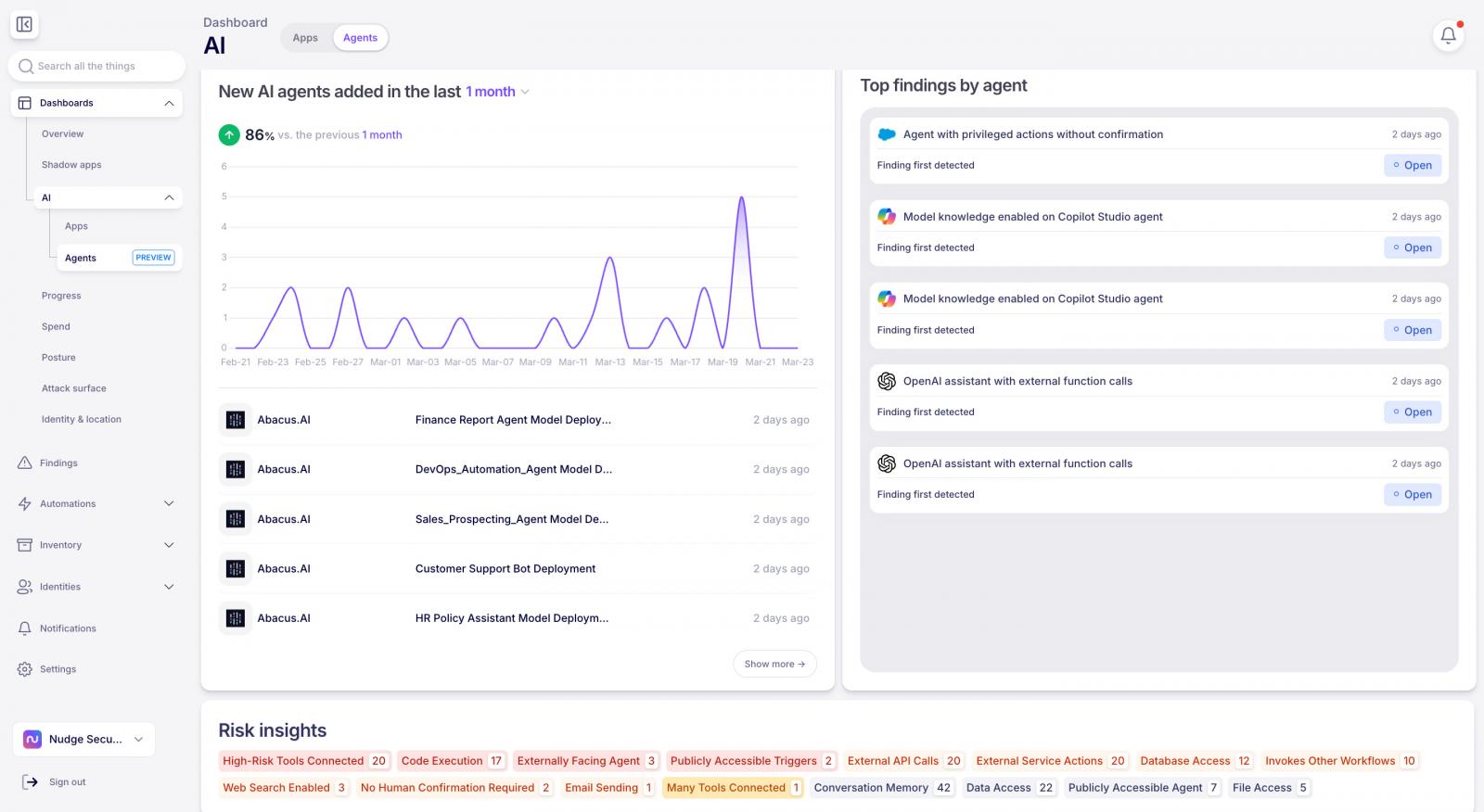
Most AI agent discovery methods have the same blind spot: they only see what agentic platform vendors choose to expose through a public API. That leaves out an enormous amount of shadow AI activity, because a lot of the platforms where employees build agents don’t offer an API, or don’t expose agent details through it.
Nudge Security closes that gap with two complementary discovery methods:
API-based discovery connects to the platforms that do expose agent data: Salesforce Agentforce, Microsoft Copilot Studio, Google Gemini, ServiceNow, n8n, Tines, ChatGPT, Abacus.AI, and Workato. It continuously pulls agent name, creator, creation date, status, configuration, and risk insights.
Browser-based discovery, through the Nudge Security browser extension, covers the platforms that don’t expose an API at all: Cursor automations, OpenAI Agent Workflows, ChatGPT workspace agents, Zoom AI Workflows, Atlassian Rovo, Retool, Zapier Agents, and HyperAgent. The extension passively observes the moment an employee views, lists, or creates an agent, then adds it to your inventory automatically, with the creator, connected apps, permissions, and risk signals already attached.
Between the two channels, Nudge Security covers 17+ agentic platforms today, and the list keeps growing based on where customers are actually seeing agent activity.
The agents built on platforms without APIs aren’t a minor edge case. They’re often where the real shadow AI lives. These are the fast, low-friction tools your engineers, ops teams, and product managers already love, precisely because nobody has to ask IT for permission to use them.
That’s also why they tend to carry the broadest access and the least oversight. An agent built in an afternoon to save someone twenty minutes can end up with standing access to a CRM, a code repository, or a shared drive, and no one outside the person who built it knows it’s there.
Finding an agent is only useful if you know what it’s capable of. For every agent it discovers, Nudge Security automatically surfaces these agentic AI risks:
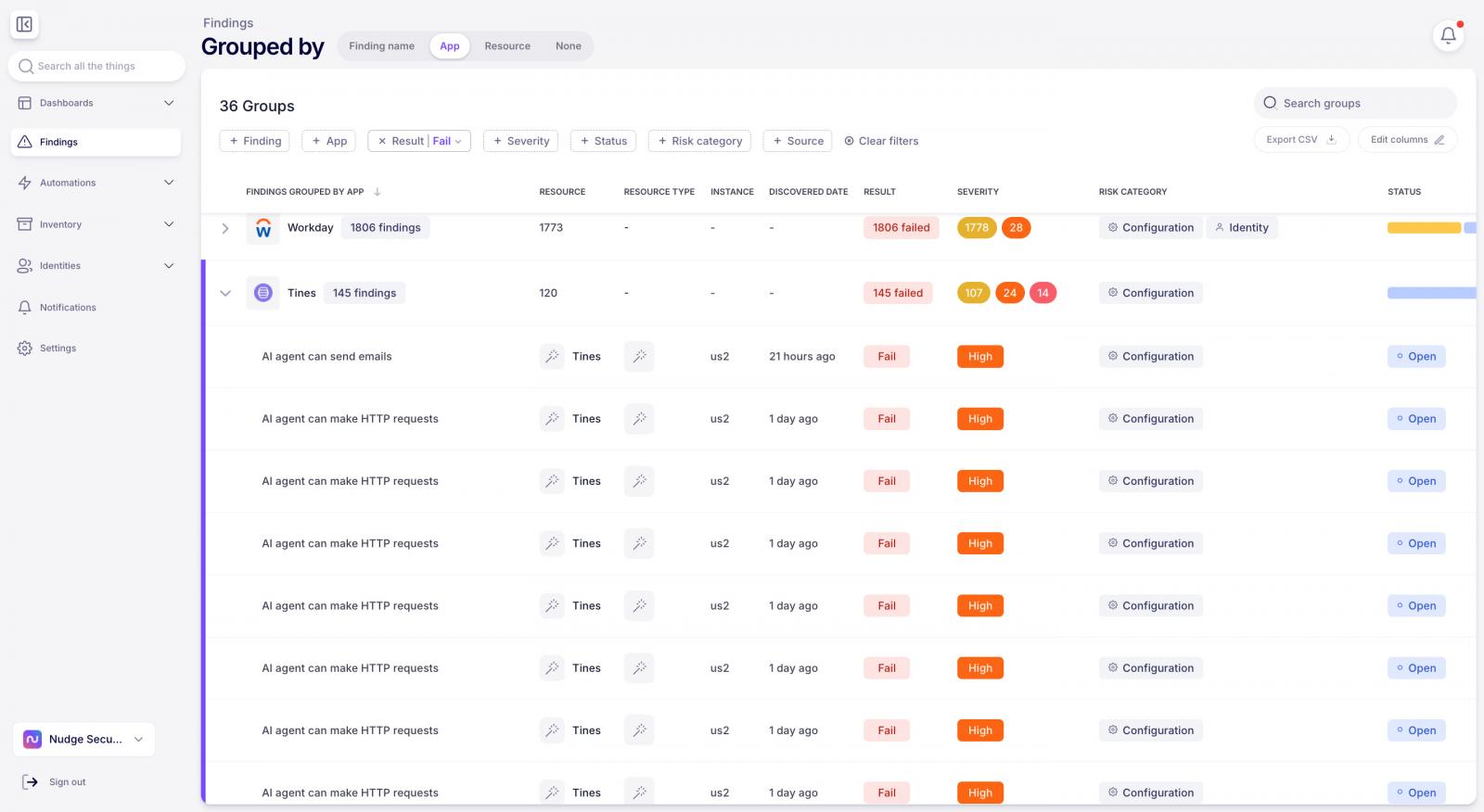
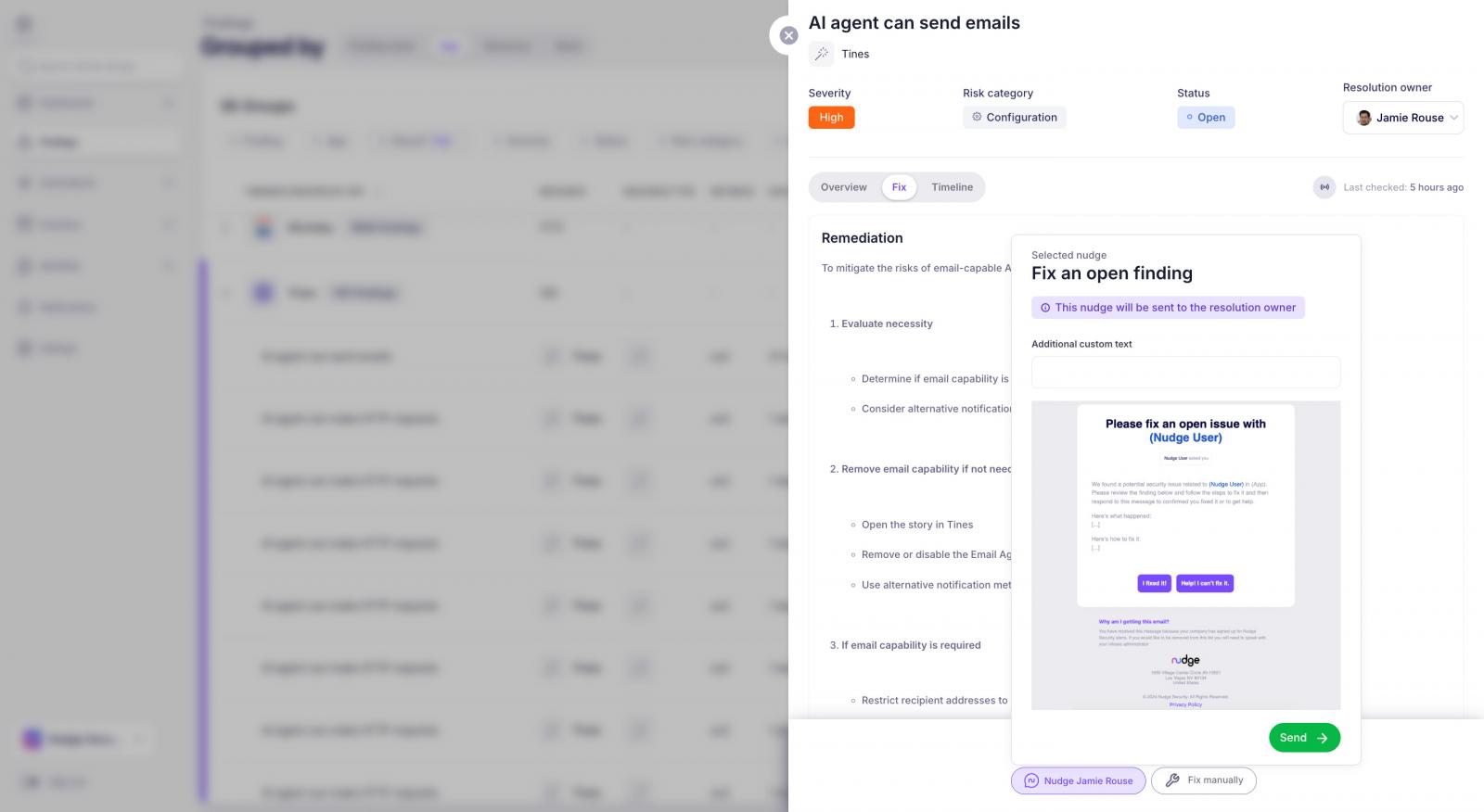
Discovery tells you what’s out there. Governance is what you do about it, and Nudge Security is built so that step doesn’t require your team to chase down every agent creator one by one.
Once an agent is in your inventory, you can:
It’s proactive AI governance that doesn’t ask you to play whack-a-mole with every new agent that pops up, and it doesn’t ask your workforce to slow down to get security’s blessing before they build something useful.
Your job isn’t to stop people from building agents. It’s to make sure that when they do, someone knows it happened, knows what the agent can touch, and can act fast if something looks wrong.
Nudge Security gives you Day One AI agent discovery with risk context and governance workflows across the agentic platforms your employees are actually using.
Sponsored and written by Nudge Security.
Earlier this year the Trump administration decided to illegally dismantle the 2021 Digital Equity Act, which was intended to help push internet access into long-neglected parts of the U.S. The Act took very vague aim at digital redlining, or the longstanding practice by telecom giants of refusing to upgrade (or at times even timely repair) broadband service in minority and low-income neighborhoods.
Big ISPs like AT&T have long been caught not only refusing to upgrade or repair broadband access in minority areas of cities like Detroit and Cleveland, but charging minority neighborhoods more money for slower service than their less diverse, more affluent counterparts.
Here’s the thing: the Digital Equity Act barely mentions race; it simply included some vague language stating that deployments and broadband grants must be even and non-discriminatory. The law identified minority status as one of eight nonexclusive indicators of barriers to digital access, while separately prohibiting discrimination in programs receiving funds.
As it has done with numerous other programs of this kind aimed at lowering broadband bills, the Trump administration clumsily — and quite illegally — tried to dismantle the whole law last year, insisting it was somehow racist against white people.
Last week, the DC District Court issued a ruling that allowed the Act to survive, but stripped out the already modest race-based components of the law, declaring them unconstitutional.
Groups like the National Digital Inclusion Alliance, which had done a lot of good studies on broadband redlining, celebrated the decidedly mixed bag:
“We are proud to have pushed to keep the Digital Equity Competitive Grant Program alive. This crucial program provides communities across the country not just with access or technology, but the skills, confidence, and pathways necessary to fully participate and thrive in our digital age. We fundamentally object to the government’s position that empowering Black and Brown communities is unconstitutional.“
So the competitive grant program at the heart of the law will continue, but there’s no real consensus on what that will look like or how helpful it will be under a federal government too racist and corrupt to function in the public interest. And there’s not much left to address the very real issue of broadband digital discrimination, which runs parallel with racial discrimination in other U.S. infrastructure sectors like energy.
The Infrastructure Act not only featured $42.5 billion to expand broadband access, it featured a lot of included (and adjacent) legislation intending to address racism in broadband and broadband affordability more generally. Most of that’s been brutally stripped away by the Trump administration, which is instead funneling billions of dollars to Elon Musk for costly Starlink service, then declaring the problem solved.
It’s a lovely bundle of corruption, racism, and regulatory/court capture all thrown into a stew by a bunch of zealots keen to pretend they’re engaging in policy reform and serious legal analysis.
Filed Under: broadband, digital discrimination, digital equite act, fiber, illegal, racism, redlining, ruling, telecom


AI AND ML
History’s biggest infrastructure build-out is pushing up hardware and software prices, analyst says
Spending on AI infrastructure is pushing tech sector expenditure to historic levels, and enterprise customers are already footing the bill through higher software and hardware prices.
John-David Lovelock, Distinguished VP Analyst at Gartner, told The Register that tech companies’ own technology spending already amounted to around $1 trillion and was set to grow by 34.7 percent in 2026.
The colossal splurge is driving global sales, leading Gartner to raise its 2026 estimates to $6.37 trillion, a surge of 14.2 percent year-on-year. That’s up from April‘s forecast of $6.31 trillion and February’s $6.15 trillion.
Lovelock said overall growth was accelerating, although tech spending was moving at three different speeds. Devices, which include consumer purchases as well as business laptops, are set to grow by 9.8 percent. However, a significant chunk of that increase comes from higher prices as memory and chips become more expensive. Services and telecoms had lower growth, at 5.3 percent and 4.4 percent respectively.
Infrastructure as a service – one segment of cloud computing – is on pace to grow by 29.3 percent this year to reach $287 billion. In 2025, the market grew by 25.3 percent, Gartner said.
Much of the acceleration is being driven by technology companies equipping datacenters to provide capacity for the expected AI boom. Gartner’s spending figures exclude the buildings themselves and their cooling systems.
Lovelock told us: “The AI infrastructure build-out is the largest infrastructure project humanity has ever undertaken. Bigger than the US highways, bigger than European rail, bigger than the Great Wall of China, and the International Space Station combined.
“That’s how big this sucker is. It is transformational in that sense. We are shifting from a world where we spend on information technology to a world where we’re going to spend on intelligence technology. And right now, you can have your head in the sand and try and avoid that reality, but it’s coming.”
As enterprise software companies embed AI into their products and partner with foundation model builders such as OpenAI and Anthropic, organizations buying IT are concerned about price increases.
“CIOs are extremely concerned about price increases coming at them from all of their vendors, and they are pushing back hard in every area where they can. But the only place that they’re being successful is in the IT services area, where when a service provider adds AI to their product offering, the service provider is rewarded with a lower price point from their customers,” Lovelock said.
There were also unanswered questions about whether the market can sustain the increases, or whether higher prices are a defensive move by vendors trying to protect their market share. For example, by adding AI model Gemini to a search engine, it could be argued Google is defending its dominant position in the market from the threat of AI, as opposed to gaining new revenue.
There is also the problem of users trying to manage AI costs in response to price increases from model builders, several of whom have switched from capped subscription to usage-based billing.
Lower-cost models are coming onto the market from China, while developers are looking to use open source models where appropriate to curb their use of proprietary foundation models.
Whether the price crunch will leave the tech industry able to continue paying for its AI infrastructure building program is “the big open question,” Lovelock said. “But it’s not being investigated well or answered incredibly well.” ®


PATCHES
One bug disabled the security service on restart, another blocked installation on hardened RHEL systems
Not content with broken Windows updates, Microsoft has disclosed two problems with Defender for Endpoint on Linux – one that could disable the security service after a reboot, and another that prevents updates on FIPS-enabled Red Hat Enterprise Linux 8 and 9.
The more serious problem affected versions 101.26042.0000 through 101.26042.0009 across all supported Linux operating systems. After an upgrade or reinstall followed by a reboot, “the Defender service might be disabled on some devices,” according to Microsoft.
“If you use Defender for Servers (Plan 1 or 2) with Defender for Cloud and have the MDE [Microsoft Defender Endpoint] integration enabled, automatic updates for the MDE.Linux extension are enabled by default, which means your machines could have received an affected version automatically,” it explained.
“If an affected version was installed, the issue might impact active protection on rebooted devices until remediation steps are taken.”
Microsoft did not specify what caused Defender to become disabled, but anything that could knock out endpoint protection will give administrators sweaty palms.
A separate problem affected RHEL 8 and 9 systems running in FIPS mode: the 101.26042.x update could fail to install, leaving devices on their previous version. FIPS refers to US Federal Information Processing Standards, which in this context impose requirements on the cryptography used by government and other regulated systems.
Although Microsoft’s alert did not mention an available update, its release notes direct users affected by the disabled-service bug to build 101.26042.0011. The separate FIPS installation problem is fixed in version 101.26052.0011 and later.
Microsoft Defender for Endpoint on Linux protects server workloads on-premises and in the cloud. According to Microsoft, “it helps you prevent, detect, investigate, and respond to advanced threats with unified visibility through the Microsoft Defender portal.”
Other endpoint security platforms are available, but where an organization has gone all-in with Microsoft, the unified management offered by Defender for Endpoint on Linux can be difficult to resist.
Microsoft has an unfortunate habit of shipping broken updates for its flagship operating system, Windows. An update that breaks software specifically designed to protect a device takes things to another level, particularly given the relentless rise in attacks and the need to both fend them off and monitor activity. Hence the appeal of unified visibility through the Microsoft Defender portal.
However, an update that could leave Defender disabled after a reboot – while also refusing to install on some security-hardened systems – is less than ideal. ®


An alternator is an important part that enables you to power your car’s electrical system and maintains the batteries charge. While the battery stores enough of a charge to get the vehicle’s engine running, it’s not doing much once the vehicle is in motion.
The alternator, which gets its power from the engine, runs systems like your dashboard lights, power windows, and even electric power steering. So, you can’t operate a car without a healthy alternator (at least not for long). There are ways to tell if your car’s alternator is bad, especially if your electronic components start flickering or dimming, and this isn’t something to ignore.
An alternator typically lasts up to a decade, though there are ways to extend their lifespan, so, older vehicles will eventually need а new alternator. The cost of a new alternator depends on several factors, such as your vehicle model and your mechanic’s labor rate. According to J.D. Power, typical prices fall between $100 and $350, not including installation.
If you include the cost of the part along with installation, you’re looking at $230 on the low end and north of a $1,000 on the upper end. In addition, since the alternator is belt driven, you may need to invest in a new belt, pulley, and tensioner, which can run anywhere from around $30 up to $300. Of course, you can always save money by making the repair yourself.
If you have some familiarity around vehicle engines, replacing an alternator is a fairly straightforward job. You’ll need some basic tools like a socket set in order to remove the bolts that hold the part in place. However, depending on the engine configuration, the ease of accessing it can vary. Before getting anywhere near the alternator, you must first disconnect your car’s battery, which helps protect the electrical system and prevents you from getting shocked.
Next, take a picture of the belt going around the alternator so you’ll have an idea of how it wraps around the various pulleys. Remove the belt going around the alternator by loosening the tensioner, which holds it taut. You can find various instructional clips showing this process, such as O’Reilly Auto Parts’ YouTube video, “How To: Replace an Alternator.”
Once the belt is lifted off the pulley on the alternator, you have two different connections to remove; a plug which regulates voltage, and a positive cable, which is held in place by a nut. Finally, there are a few bolts holding the alternator in place that will need to be removed. Once you extract the old part, simply install the new alternator and follow these steps in reverse.
You can choose to have an alternator fixed rather than replace it with a new unit, but it only makes sense in certain situations. The age of the part, complexity of the repair and your skills are the determining price factors when opting whether to fix or replace it. If the alternator is only a few years old for instance, it might be worth fixing yourself, especially if you want to save some money.
Current must flow only one way in an alternator, and this is accomplished with diodes, which can sometimes develop faults. This is something you can check using a multimeter as demonstrated by the maddoxmechanic YouTube short called, “Quick Check: How to Test Alternator Diodes with a Multimeter.” The diodes themselves typically run around just under $50, but they do require you to take apart the alternator, which demands more skill. Optionally, you can also find alternator rebuild kits, which can be between $28 and $60.
However, if you’re not comfortable with more in-depth automotive tasks or are short on time, having a mechanic do the repair work might not save much money at all. This is especially true if the part is old and worn, which would be better to replace rather than salvage. Labor costs for replacing the diodes could run between $150 and $400, per Partcatalog.com.




Weekend Open Thread: Brooks Brothers


Grayscale Files For Worldcoin ETF, WLD Registers Sharp Rise


How a former Blue Peter presenter stunned America’s Got Talent judges


Intel is reversing course and bringing hyper-threading back to its server chips
Sail Virtually Aboard The “Itanic” With IA-64 Emulator
Turtle Beach Command Series KB7 review: a nifty screen-equipped gaming keyboard

New Jersey voter registration controversy explained: How 6,600 noncitizens got on the rolls, and what happens next

Johnny Depp’s R-Rated Gothic Cult Classic Gets New Release Ahead of Sydney Sweeney Remake


Ethics, other provisions in crypto Clarity Act to be further discussed


Luke Littler dismantles Gerwyn Price to retain title in Blackpool

Shanghai science forum photos show China’s AI and robotics advances in rivalry with US

Commonwealth Games boxing: Jadumani Singh seals dominant 5-0 win over Pakistan’s Sumama Rehman to enter quarter-finals | Commonwealth Games News


2026 3M Open leaderboard: Scottie Scheffler finds putter in Round 1, sits three back


The Peugeot Family: How 200 Years of an “Old Money” Dynasty Died in A Boardroom


16 Dresses for the High Summer Event


Spain sweeps the board at 2026 World Cup with individual awards


Andrew Cuomo joins OKX board as crypto exchange expands in U.S.

A New Post-Apocalyptic Gundam Anime Series Blasts Into SDCC

BITCOIN JUST ENTERED THIS CRITICAL ZONE…


XRP Ledger adds $2.6B as RWA inflows rank second





You must be logged in to post a comment Login