TL;DR
Qualcomm unveiled Snapdragon Reality Elite for MR headsets and START, a turnkey smart glasses toolkit. CEO says 40+ AI wearable designs are underway.



Qualcomm unveiled Snapdragon Reality Elite for MR headsets and START, a turnkey smart glasses toolkit. CEO says 40+ AI wearable designs are underway.
Qualcomm announced two products on Tuesday aimed at positioning the company as the silicon supplier for whatever computing device eventually displaces the smartphone. The first is Snapdragon Reality Elite, a mixed reality chip platform with substantially improved AI processing for headsets and tethered glasses. The second is START, a white-label toolkit that gives eyewear manufacturers a near-complete smart glasses design they can brand, customise, and ship without building the technology stack themselves.
The announcements came alongside comments from CEO Cristiano Amon, who told CNBC that Qualcomm is working on more than 40 different AI wearable devices spanning jewelry, camera-equipped earbuds, pins, and watches. “I think there’s going to be a lot of experimentation with different form factors,” Amon said. He described the unifying principle as “something that you wear, something that is with you all the time, something that can see the world around you.”
Snapdragon Reality Elite delivers up to 60% higher GPU performance, 30% higher CPU performance, and 160% higher NPU performance compared to the previous XR2+ Gen 2 platform. The chip’s neural processing unit is rated at 48 TOPS, enough to run a 3-billion-parameter language model at 45 tokens per second on-device, according to Qualcomm. The platform also runs up to 20% longer on battery and up to 12 degrees Celsius cooler under the same workloads.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
The display capability supports 4.4K per-eye resolution at 90 frames per second, a modest increase from the XR2+ Gen 2’s 4.3K per-eye figure. Qualcomm says the chip enables improved head and hand tracking alongside better see-through performance. Those improvements matter for reducing the motion sickness and eye strain that have historically limited how long users can wear mixed reality headsets.
Reality Elite is designed to power two categories of device. The first is standalone video-see-through headsets that overlay digital content on a camera feed of the real world, the approach used by devices like the Meta Quest. The second is lightweight, tethered optical-see-through glasses that blend digital imagery directly into the wearer’s field of view.
Among the first products using the platform are XREAL’s Project Aura, the Android XR glasses shown at Google I/O with a 70-degree field of view and binocular displays, and an upcoming device from Play for Dream. Qualcomm has not disclosed pricing for the platform or a timeline for when consumer devices will reach retail.
START, which stands for Scalable Turnkey AI-Ready Toolkit, takes a different approach to market entry. It bundles a hardware module built on Qualcomm’s AR1+ chip with a software platform, companion iOS and Android apps, an AI cloud solution, and three white-label reference designs. The designs cover an audio-and-camera configuration similar to Meta’s Ray-Ban smart glasses, a monocular display variant, and a binocular display variant.
The programme’s first partners are eyewear manufacturer Inspecs and O’Neill, the latter owned by TitanFlex. Qualcomm has also made a $10 million strategic equity investment in Inspecs, subscribing for 7.5 million new shares at £1 each. The investment signals that Qualcomm is not merely licensing silicon but taking a financial stake in the supply chain that will manufacture and distribute the devices.
The strategic logic is that traditional eyewear companies have the design expertise, retail distribution, and consumer trust to sell smart glasses as fashion accessories, but lack the chip architecture, AI software, and sensor integration to build the technology themselves. START is Qualcomm’s attempt to bridge that gap, mirroring the reference design programme it used in the early 2010s to help manufacturers build smartphones on its Snapdragon platform. Qualcomm says START will expand beyond smart glasses to other form factors in the future, though it has not specified which.
The competitive landscape is crowded and moving fast. Meta has sold more than seven million pairs of Ray-Ban smart glasses and commands roughly 82% of the market, with annual production capacity being expanded to 10 million units by the end of 2026. Snap launched its $2,195 Specs AR glasses this week.
Apple is reportedly testing multiple frame designs for a possible 2027 launch. Google is shipping Android XR audio glasses this autumn with Samsung, Warby Parker, and Gentle Monster. Qualcomm silicon already powers many of these devices, but the company is now building the full stack rather than waiting for partners to assemble it themselves.
What Qualcomm is betting on is that none of those companies will dominate the category alone. If the smart glasses market fragments the way the smartphone market did, with dozens of manufacturers building on a shared platform, the company supplying the foundational silicon layer captures value regardless of which brand wins. That is the same bet Qualcomm made with mobile phones, and Amon’s 40-device pipeline suggests the company sees the transition accelerating faster than the public market does.
The claims remain largely forward-looking, however. The 48 TOPS figure and performance percentages are Qualcomm’s own, measured against its own previous generation, and no independent benchmarks have been published. The 40 AI wearable designs Amon referenced are in various stages of development, not shipping products.
Whether the smart glasses category actually becomes large enough to justify Qualcomm’s investment depends on consumer adoption that has so far been limited to Meta’s ecosystem and a handful of developer-focused devices. The company is placing a structural bet that the transition away from smartphones is inevitable, but the timeline remains anyone’s guess.

“The rise of TikTok, Instagram Reels and Amazon storefronts has created a new kind of white-collar exit strategy,” reports Bloomberg. Workers ditch office jobs not to become celebrities, necessarily, “but to piece together an income online through brand deals, affiliate links and highly personal videos documenting everyday life.”
In many cases, the followers necessary to sustain a living are smaller (and more attainable) than people might assume. A small but loyal audience can now generate enough income to rival a midlevel salary. Welcome to the middle-class creator economy. Last year, 25-year-old Abi Platock balanced a corporate marketing job in New York while posting online in her spare time. She built her audience by posting one or two videos a day, offering career advice, beauty tips and daily vlogs. “I signed my first brand deal in the four-figure range, and for me that was just such a big eye-opening moment,” Platock says of her partnership with deodorant brand Secret. She had 8,000 followers on TikTok at the time. “You can totally make it work without having hundreds of thousands of followers.” Platock, who now has roughly 25,000 followers across platforms, has signed about $25,000 in brand deals so far this year and expects her annual creator income to reach around $50,000 by yearend.
Her experience reflects a broader shift in advertising. Brands are increasingly moving money toward so-called microinfluencers — smaller online personalities who have less than 100,000 followers. “They are hiring a bunch of microcreators at scale instead of hiring a handful of macrocreators for what could potentially be the same cost,” says Ali Grant, co-chief executive officer of the Digital Department, a creator management company. And they perform where it matters most: engagement. An engagement rate of 3% is considered strong, and some microinfluencers exceed 10%, Grant says of the closely watched metric that tracks how often followers interact with content through likes, comments, shares and saves. Microinfluencers average a 3.2% engagement rate, almost triple the 1.1% rate for macroinfluencers (more than 1 million followers), according to growth marketing agency ATTN… A TikTok partnership with a creator who has around 50,000 followers can run a brand more than $3,500 for a single post, Grant says; with 10 times the followers, that fee might just triple, to around $10,000….
The influencer marketing economy ballooned to a projected $33 billion in 2025 up from $1.7 billion in 2015. The segment gained momentum after the COVID-19 pandemic, as dissatisfaction with traditional work pushed many to reconsider conventional career paths, says Brooke Duffy, a professor of communications at Cornell University. “They realized the trade-offs in terms of the investments of time, energy and human capital were not necessarily worth sacrificing so much of one’s personal self for,” she says. Success online can bring greater freedom — and even higher pay than many traditional office jobs, which have a median US salary of $69,000, according to Glassdoor. But the middle-class hustle still requires constant effort to maintain. The career has no promise of lifetime longevity. And unlike traditional workers, creators have no predictable paycheck or job protections, making career stability elusive. Roughly 57% of 3,000 surveyed full-time creators earn below a living wage from content creation, according to a report last year from Influencer Marketing Hub. Income from social media can fluctuate wildly from month to month, driven by shifts in algorithms, sponsorship cycles and platform trends.
“You could have a month where you make zero dollars, or you could have a month where you make $10,000,” Platock says.
The article cites Gallup Poll data released last year that found employee engagement in the U.S. had fallen to its lowest level in a decade [with engagement defined as “the psychological attachment workers have to their work/team/employer]. “Among the hardest-hit groups were Generation Z and workers in finance and technology. Broader workplace challenges, including rapid organizational change, hybrid and remote work transitions, and rising employee expectations are considered drivers of the overall trend.”
“For many workers, influencing can seem like a better deal; flexible schedules and independence wrapped in a veneer of creativity and fun. Almost 60% of Gen Zers say they’d become an influencer if given the opportunity, according to a 2023 survey from Morning Consult.”

Previously exclusively in the US, AppleCare One is now launching in the UK, France, Germany, and Australia, with Apple’s best insurance deal for users with multiple devices — as long as you’re careful in selecting what’s covered.
A year after it launched in the US, AppleCare One is expanding outside of the US. It’s only going to four more countries, and they’re countries you’d expect it to launch in, but that’s a start.
“At Apple, we’re focused on creating and delivering exceptional experiences,” Bob Borchers, Apple’s vice president of Worldwide Product Marketing, said in a statement to AppleInsider. “With AppleCare One, customers in the UK can now enjoy the trusted protection of AppleCare+ in a way that’s simpler and more flexible than ever before — one plan, one price, and the peace of mind that comes with knowing all their eligible products can be covered.”
Full details of the terms, conditions and all pricing have yet to be published, but based on the details provided by Apple UK, the program will cost around the same as it does in the US. It will also offer the same befits, which are:
There are limits in that, for instance, AppleCare One users may only make up to three claims of theft or loss per year. But then there are also extra benefits in that iPad accidental damage from handling (ADH) coverage can include an associated Apple Pencil or Apple-branded iPad keyboard.
Users who have any single device, such as one iPhone or one iPad, should not take up the new AppleCare One option. They should use AppleCare+, which Apple has also improved.
That AppleCare+ plan used to only feature theft and loss coverage for the iPhone, but it now extends this to the iPad and Apple Watch. AppleCare+ prices vary depending on the model of device, but for example the monthly cost in the US at time of writing is:
Each of these comes with an annual version which is roughly equivalent to 10 months at the monthly rate. Note that AppleCare+ only allows annual payment for insuring displays, Apple TV, HomePod, or AirPods.
Those items can, though, be paid for monthly via the new AppleCare One. Again, non-US details will not be fully available until AppleCare One launches on August 4, but the US version does allow adding headphones, for example.
Nonetheless, users who want to insure single devices get no financial benefit from the new AppleCare One. Users who have two devices will definitely benefit if those devices include the Apple Vision Pro.
Covering the Apple Vision Pro by itself with AppleCare+ is exactly the same price as covering it via AppleCare One. So that would be like getting coverage for a second and even third device for free.
There are ways in which AppleCare One’s coverage of three devices is more than the price of insuring them each with a separate AppleCare+ plan. It depends on if the devices include a Mac, which on its own ranges from $3.99 per month for a Mac mini, to $17.99 per month for a Mac Pro.
Or with the iPhone, the separate monthly cost is $9.99 for an iPhone 17e, rising to $13.99 for an iPhone Air, iPhone 17 Pro, or iPhone 17 Pro Max.
It naturally gets more complicated if you have both an iPhone and a Mac in the equation. For example, if the three devices to be insured consist of an iPhone 17e, Mac mini, and an Apple Watch SE, the total individual cost is $16.97 where AppleCare One is $19.99 and you shouldn’t go near it.
But then if the devices are, say, an iPhone 17 Pro Max, an M5 13-inch iPad Pro, and a Mac Studio, you’d save a startling $12.48 per month by going to AppleCare One. In that case, that’s a hell of a deal.
That’s if you stick to just the basic AppleCare One and its coverage of three devices. It’s possible to add a fourth or any number of more devices, for $5.99 per month each.
Do that by adding, say, an Apple Vision Pro to the example with the iPhone 17 Pro max, 13-inch iPad Pro, Mac Studio and your monthly cost goes up to $25.99. The cost of doing these separately is more than double at $57.46.
Not long ago, all of this comparison of coverage costs would be moot because you were limited to which devices could get any AppleCare. It was typically a new device, or a device bought in the last 60 days.
Now with AppleCare One, the coverage is not only cheaper for most people in most circumstances, it is broader. Instead of solely being for new devices, AppleCare One can potentially be used for Apple devices that are up to four years old.
Those devices have to be in good condition, and during online registration users are prompted through questions regarding potential damage. It’s also possible that Apple will require the device to be brought to a store for a visual inspection.
If a user is starting with a new device, then instructions for signing up to AppleCare One will be displayed in Settings. Otherwise it can be done via the Apple website using the user’s Apple Account.
Those users who already have AppleCare plans will be able to switch to AppleCare One. Apple says that their existing plans will be cancelled and a new AppleCare One plan put in place.
As long as you check out the pricing differences between AppleCare+ and AppleCare One, this new program can represent a very significant saving. So it’s unquestionably worth examining the details once Apple has published them for the UK, France, Germany, and Australia, on August 4, 2026.
Note, though, that the US service had some teething problems with eligible devices not always being displayed. If that happens again with the new countries, there are steps you can take to get the correct coverage.


Security
So much for Microsoft and CrowdStrike’s plans for consistent names across the industry
Google has created a new taxonomy to describe cybercrime outfits, seemingly abandoning a Microsoft-led effort to create consistent names.
The Big G announced its new schema on Saturday in a post that notes its 2022 acquisition of Mandiant and its subsequent incorporation into a new team called the Google Threat Intelligence Group (CTIG).
Now that two have become one, Google reckons they need consistent naming conventions to describe cybercrime crews.
The result is a two-word schema in which the first word “is a unique and memorable term chosen to represent the specific actor.” If security folk have already applied a particular moniker Google will use it, otherwise it will randomly generate a word “to remove bias.”
Google says the second word “categorizes threat clusters by motivation, attribution, or activity type based on which category we consider to be most important for defense and response strategies.”
More on that later.
Google has decided on the following names:
CASTLE to describe crews from the People’s Republic of China
ION for threats from Iran
NEPTUNE for North Korean attackers
RELIC for Russians
COMET for cybercrims who aren’t backed by a state
Google’s post notes that other infosec industry players have developed their own schemas for describing threat actors and says the web giant is therefore “intentionally seeking to keep this system as simple as possible to streamline operations and facilitate mapping to other naming taxonomies.”
That’s an odd position, given that in 2025 Microsoft and CrowdStrike tried to spark an industry-wide effort to apply consistent names to threat actors. As we noted at the time, the existence of multiple naming schemas means that researchers often refer to the same group by ten different names. Researchers use the names Seashell Blizzard, IRIDIUM, VOODOO BEAR, BE2, UAC-0113, Blue Echidna, PHANTOM, BlackEnergy Lite, and APT44 to refer to the same entity – Russia’s Military Intelligence Unit 74455.
With most orgs using multiple security tools and therefore receiving threat intelligence security info from many vendors, users must try to understand which crews they’re trying to defend against.
At the time, sources told us Google and Mandiant were keen to adopt the Microsoft-led scheme.
Google’s new announcement suggest the relationship either wasn’t consummated or didn’t last.
Back to the issue of possible bias, as in 2024 China’s National Computer Virus Emergency Response Center (CVERC) complained that western companies choose names like “Typhoon,” “Panda,” or “Dragon” to describe Chinese cybercrime groups.
CVERC suggested names that reflect English language idioms, such as “Hurricane” or “Koala” are more appropriate.
For what it’s worth, “Koala” is a word from the language spoken by the Darug people, the indigenous tribe who lived around Sydney, Australia, prior to British colonization. Koalas are utterly supine creatures that sleep 18 to 22 hours a day, and a mention of the marsupials may therefore not spur defenders to action, even if the creatures’ habits do perhaps describe the behavior of some sleeper malware. ®


When you hear the word TV, you probably think of a big LED screen, maybe even the old CRT TVs, but in either case it’s something large and fairly complicated. However, thanks to the persistence of vision, it doesn’t have to be. In this handheld-sized project from [Ancient], the Scanwheel is born, a miniature mechanical TV that uses a spinning disk and some LEDs to produce an image.
The electronics of the Scanwheel are pretty straightforward. The smarts come from a Raspberry Pi Pico, an A4988 motor driver, a couple of LEDs, and a small 21-02485 stepper motor. The Raspberry Pi Pico is used to command the motor speed as well as coordinate the LEDs to turn on at the right time. The case is 3D printed; the base includes space for the various support electronics as well as some small light baffles to ensure the LEDs don’t bleed over outside their intended area. The top of the case is a disk that includes 20 small holes spaced evenly around the perimeter at varying heights, allowing light to only leave the disk when one of these holes is in front of the LEDs.
When you put all these pieces together, spin the motor up to roughly 900 RPM, and turn the LEDs on in a precise order, you end up with a really cool result: a miniature TV. And due to the five different LEDs in this build, you actually have a color 20×20 pixel display in the center and, on either side of that, two more 20×20 black-and-white displays capable of showing different images. Thanks [Ancient] for sharing this awesome build that takes advantage of the persistence of vision effect to create a unique display. Be sure to check out the video below as well as the instructions on how to build your own. And if you enjoy this sort of thing, check out some of our other persistence-of-vision projects as well.


Yeast spends its days chewing through sugar and splitting the leftovers into alcohol and carbon dioxide. Most people chasing homemade ethanol treat the second half of that reaction as pure waste and let the gas drift away. One maker decided the gas was too useful to ignore and set out to trap every molecule, dry it, chill it, and pack it into the same kind of high-pressure bottles that drive paintball markers and soda siphons.
The numbers appear almost too clean, since 4 kilograms of ordinary sugar dissolved in 14 liters of water already gives a solution that is nearly 22% sugar. If the yeast performs its job and converts everything, the process should result in little more than 2 kg of CO2. That’s enough liquid to fill nearly four 20-ounce paintball cylinders. The problem is that the gas comes out of the fermenter wet and diluted, making the first job (gathering it) difficult, as does maintaining the pressure up and preventing air from entering the system.
Sale

A 5-gallon water jug serves as a fermentation tank. The carbon dioxide is routed out via an airlock tube and into a recycled water-filter canister. The works is stuffed with silica-gel beads, which reduces moisture slightly, but we later discovered that the dew point remains too high, causing ice to form inside the valves. The next step is to transfer the gas to a beach ball. It takes a few days, but the ball eventually fills up with hundreds of gallons of CO2. It serves the purpose of providing some extra room to keep the pressure near the proper level while the yeast is still active.

The major issue is turning the squishy substance into liquid. At room temperature, the CO2 must be compressed to roughly 64bar before it can condensate. The problem is that standard shop compressors can only reach a fraction of that capacity. The solution is to simply leave it in the air box. To cool a copper coil, a DIY system makes use of propylene as a refrigerant. This lowers the temperature to roughly -33 degrees Celsius and reduces the condensation pressure to about 13 bar absolute, which is well within the capabilities of a severely modified oil-less air compressor with its over-pressure cut-out switch disabled.

That copper coil is a 2-inch pipe, approximately 2 feet long, with a thinner copper coil within to convey the propylene. The CO2 from the beach ball enters at the top, meets the chilly surface, and condenses into a liquid that gathers at the bottom. A second coil (the same as the first) is housed in a 96% ethanol-lined thermos. A paintball tank sits in that bath, keeping the metal cool. Once some liquid has accumulated in the coil, a valve opens and the liquid flows into the chilled tank.
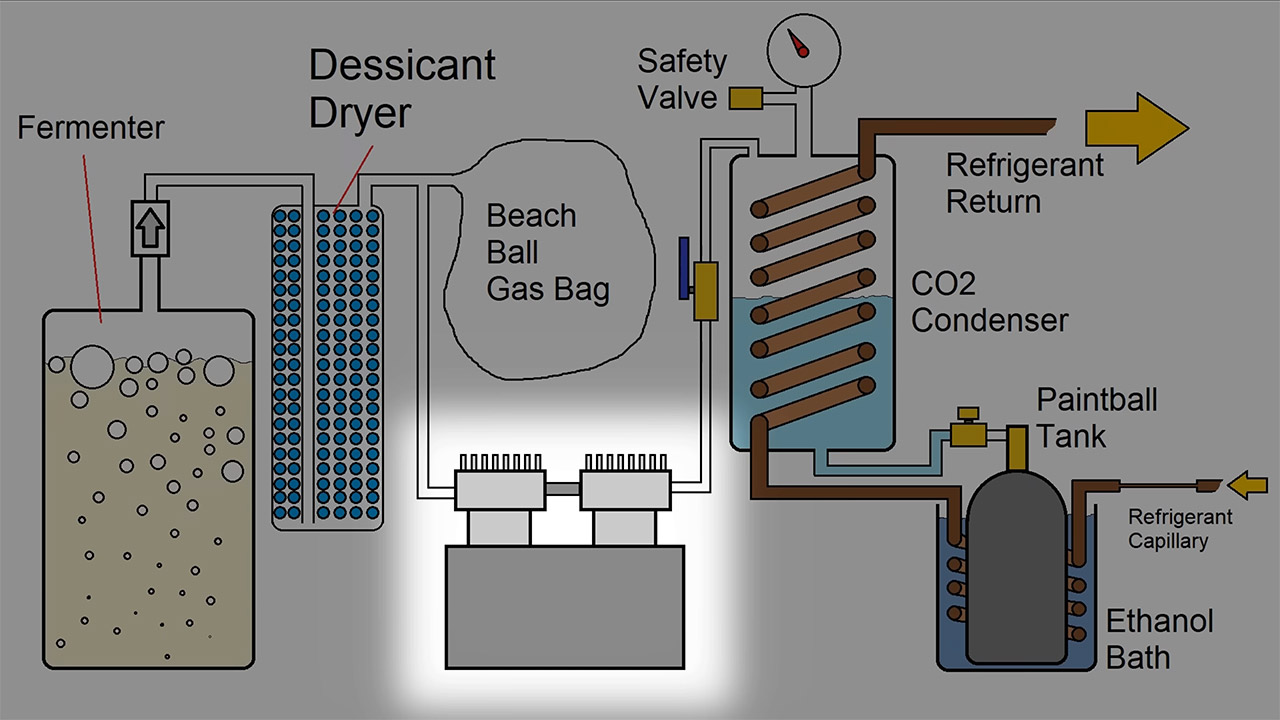
An typical oil-free compressor can move the gas, but only at a very sluggish rate; at 17 bar, it moves like a snail. Switching to a refrigerated compressor provides the necessary pressure, 400 psi or greater, and reduces fill time to 10 or 15 minutes. But now we have a new problem: oil separation. Any lubricant that gets into the tank degrades the purity. Then there’s water, which still freezes inside the tank valve while we pump it out, and this can jam the nozzle until the metal heats up again.

After filling the bottle to capacity, the scales read 1312 grams with the valve still connected. When the contents were drained, 974 grams remained, indicating that 338 grams of liquid carbon dioxide had been trapped inside. The container wasn’t even full to the brim, but that liquid was unmistakable, and when that valve was opened quickly, the temperature of the tank dropped to the point where it iced over. If you discharge it completely and quickly, you could bring it down to the temperature of dry ice.

That small charge of ours already has some substantial practical power behind it. By connecting it to a short-stroke pneumatic actuator, he was able to elevate the back end of a full-size pickup approximately 200 millimeters off the ground. The same gas, linked to a vane motor, was able to power a small generator for a few minutes, but you can probably predict where this is going: the intense chill that comes in as the liquid boils away causes the pressure to drop and the motor to turn off.
[Source]
Every accelerator makes a version of the same offer: capital, mentorship, a network, three months of support, and materially better odds of survival. Evidence suggests that little of it actually works.
In April, Youn Baek and Deepak Hegde of NYU Stern published a working paper through the National Bureau of Economic Research examining nearly 750,000 American startups across 329 programs. Between 60 and 80 percent of accelerators, they found, leave the companies that join them worse off than if they had never applied. A smaller group does the opposite, raising funding, growth and exit rates by a wide margin. Among them, Y Combinator, Techstars and Endless Frontier Labs.
The study establishes which programs work, but it does not explain why. For that, we asked founder and product-market fit expert Yann Goarin.
Goarin spent a decade at Google and YouTube, where he launched more than twenty products in Europe and the United States, and has since led product and marketing at several venture-backed startups. He founded Zag Labs in 2023, an advisory firm that has helped more than a hundred early-stage companies go to market and accelerate their path to product-market fit. He developed the “PMF System”, a method that treats product-market fit as a problem-solving process rather than an event or a vibe. He is currently Founder in Residence at AAXIS, where he leads the enterprise technology firm’s venture-building work. He also mentors and judges at five accelerator programs across the US (Techstars, gener8tor, FoundersBoost, Expert Dojo, and USC’s Iovine and Young Academy), which gives him a unique perspective on how different programs support their founders.
The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol’ founder Boris, and some questionable AI art. It’s free, every week, in your inbox. Sign up now!
Most accelerators take equity in exchange for a check and three months of support, and their return depends on whether a few companies in each cohort raise at scale or exit. What they offer founders is leverage in several forms: capital, introductions to investors and customers, brand recognition, and knowledge.
Like top universities, the best accelerators attract and select the best founders. Even so, the odds of success are very low. Building a category-defining, venture-backed company is incredibly difficult, and luck and timing decide a great deal of it. But it is not magic. There is a method to the madness, and that method, Goarin claims, is either not taught or not taught well.
Research shows that knowledge is the form of leverage that appears to matter most. Susan Cohen, Benjamin Hallen and Christopher Bingham, who spent years studying the original American accelerator programs, found that where accelerators do improve their companies, the primary driver is what those companies learned inside them. But it is also the hardest to scale.
Goarin remembers one client engagement, a seed-stage AI startup that had built a video production platform. Its founders had come through one of the world’s most selective accelerators. It raised $4 million and within twelve months passed $1.2 million in annual recurring revenue. However, churn was running above 30 percent. The response was to sell harder and build faster, adding features as customers asked for them, and investors supported that on the view that revenue was the number that mattered most.
What the founders failed to realize was that the three segments they were selling to (small marketing agencies, independent video creators, and boutique production companies) were not a cohesive market. While they appeared to need faster and cheaper video production, they differed in how much video they produced, how polished it had to be, how it fit in their workflow, and where it was distributed. The product tried to stretch across all three, and served none of them well. Customers left faster than sales could replace them. After cutting half the team and pivoting, they failed to secure a bridge round and ran out of runway.
Goarin came in near the end, too late to change the outcome. “I assumed that founders coming out of a program like that would be better at testing their assumptions and diagnosing their issues. I was wrong. They were just as clueless as most of the others I advise.”
Around that time he started mentoring at Techstars. That’s where he saw an opportunity to address the problem at scale. From inside a program, it becomes clear how knowledge actually reaches founders, and what never does.
The programs that do teach tend to teach in fragments: a product expert teaches product, a sales executive covers sales, someone who has raised four rounds helps with fundraising. Founders are expected to assemble them into a working company. Most fail. There is something odd in that, viewed from outside. Accelerators and venture funds spend enormous effort on selection, screening thousands of applicants to find the few worth backing, and then just hope they figure it out.
What goes untaught is product-market fit itself, i.e., the correct assembly of these fragmented pieces that ultimately leads to widespread demand for something people badly need, delivered profitably every time. There are two reasons it does not appear on syllabuses. Product-market fit is not understood as a discipline in its own right, so there is no settled body of practice to teach from. And the mentorship model recruits subject matter experts by function, so PMF, which sits between and over the functions, isn’t owned by anybody. Until now.
What Goarin teaches in these programs runs end-to-end, and his objective is straightforward: avoid building something nobody wants.
“Accelerators give founders access and funding, and of course that matters,” says Goarin. “But where they can have an even bigger impact is teaching first-time founders to operate like second-time founders. That means going beyond the surface-level material and breaking down the mechanics of startups.”
User experience went through the same thing. Usability testing, information architecture and interaction design were practiced separately for years before the field recognized them as one discipline and created roles for people who worked across all of them. Naming it is what made it possible to teach.
The case for teaching product-market fit as its own subject is getting stronger. As technology levels the playing field on building and execution, what separates companies is judgment: Is this problem worth solving? Is this the right customer segment? Can I deliver my solution repeatably and profitably? Is it time to pivot? None of those questions can be answered well without knowing what to look at, and that is what Goarin focuses on.
“In the early days only three things matter,” Goarin claims. “Speed of learning, speed of decision-making, speed of execution. A startup is a learning machine before it is anything else, and learning is the part founders struggle with the most. Building is fast and cheap now, so the temptation is to ship something and see if it sticks. But that’s how you end up with a product in search of a problem. That’s how you end up in pivot hell.”
His work has been expanding. He was a Lead Mentor at Techstars for the Spring 2025 and Spring 2026 cohorts and a judge in Mentor Magic, the program’s week of back-to-back mentoring and evaluation sessions. He has advised two gener8tor cohorts and judged USC’s Venture Showcase. He is in discussions with other top programs in the United States and Europe.
Top accelerator entry requirements have been rising. Joshua Lu, who runs Speedrun, told TechCrunch this year that because AI has made building and testing so much faster, the program now expects market validation or early traction before it will admit a company. That created a new market of programs beneath the accelerators. The best of them are focusing on education, and have invested accordingly. FoundersBoost, one of the world’s best pre-accelerators, brought Goarin in to strengthen its programming and asked him to teach its last two cohorts.
The gap is about to matter more. AI is accelerating a trend already underway, in which smaller and smaller teams, working alongside swarms of agents, can perform like much larger companies. That does not reduce the value of knowing what to build. Rather, it concentrates it. Judgment, pattern recognition, knowing what to focus on and when, the confidence to make a decision and move: these have always been the unfair advantage, but are ever more critical in the AI age.
“Fundraising used to be something most founders didn’t understand,” says Goarin. “Now every program teaches it. Product-market fit is more complex, but it is a subject, and I expect it will be taught the same way before long.”
Baek and Hegde could not say what separates the accelerators that work from the ones that do not. If the answer is what they teach, the programs that work it out first will be the ones worth applying to.

Why you can trust TechRadar
We spend hours testing every product or service we review, so you can be sure you’re buying the best. Find out more about how we test.
The TP-Link Tapo C660 Kit is a feature-packed 4K outdoor security camera that delivers many of the perks usually reserved for pricier models, including solar charging, pan-and-tilt coverage, color night vision and local microSD storage.
That last feature means you won’t need to pay for a subscription for video playback and download, but there are still some great (but non-essential) features in the paid Tapocare subscription, especially if you plan to expand your home’s security with more than a single camera.
The Tapo app is also easy to use, and the C660 Kit will slot in alongside other Tapo smart home gear like lights, plugs and more to form its own smart home ecosystem. On the other hand, if you have other smart devices in the mix and would prefer a hub to control them all, Alexa has the strongest support, while Google Home only works with voice commands and video streaming to smart displays and TVs. There’s no native support for Apple HomeKit.
Latest Videos FromTechRadar
While it doesn’t necessarily stand out in a crowded market with its design, the white casing looks sleek and stylish, and the IP65 waterproof rating means the C660 Kit is dust-tight and can withstand low-pressure water jets from any direction (aka rain, splashes or hose spray).

The Tapo C660 Kit costs $169.99 / £179.99 / AU$299 for a single camera unit, although multipacks of 2-, 3- and 4-camera kits are available either as set bundles or as part of a build-your-own package option directly from Tapo as well as through third-party retailers like Amazon.
While you may not need a subscription package, especially if you use a single camera unit, Tapocare might well be worthwhile for some users. It offers cloud storage, extended video clip history for up to 30 days and enhanced notifications, with plans starting at $3.49 / £2.99 / AU$3.99 per month for one camera on the Basic Tapocare tier. Prices increase as you add more cameras.
You can also buy the camera on its own without the solar panel under the TP-Link Tapo C560WS name for $99.99 / £109.99 / AU$199.
|
Price |
$169.99 / £179.99 / AU$299 |
|
Megapixels |
8MP |
|
Resolution |
4K / 3840 x 2160 pixels |
|
Field of view |
105º |
|
Pan/tilt |
360º horizontal rotation, 90º vertical |
|
Storage |
microSD up to 512GB (not included) |
|
Smart home |
Alexa, Google Home, Siri Shortcuts; no HomeKit |
|
Battery |
10,000mAh |
|
Connectivity |
2.4GHz / 5GHz Wi-Fi 4 |
|
IP Rating |
IP65 |
The Tapo C660 Kit has a sleek white plastic body with black accents around the lens, with IP65 rating for dust ingress protection and resistance to low-pressure water jets from any direction. This means water from rain, splashes or hose spray will be fine, but it won’t withstand immersion and pressure washing.
The solar panel is just the right size relative to the camera — it isn’t small and subtle by any means and it’s definitely noticeable once installed, but it isn’t too imposing either. As mentioned above, there is a rubber flap underneath the camera lens concealing the power button, a reset button and a microSD card slot.
Installing the Tapo C660 Kit is straightforward thanks to the easy-to-follow instructions included in the box. You start by drilling holes where you want to mount the base plate, then slot the camera in. The solar panel is screwed on top, then plugged into the camera’s USB-C port located on the bottom.

It’s worth taking some time to think about where you want the camera placed before you install it, though. While the Tapo C660 Kit can pan and tilt the camera, getting the full view of an entire space isn’t guaranteed if it’s mounted too low since it doesn’t tilt upward. TP-Link recommends mounting it between 2.5m and 3m (8-10 feet) and in a location where the solar panel gets the most sunlight throughout the year.
TP-Link also recommends that the camera shouldn’t point at swaying trees and other moving objects like vehicles and pedestrians to prevent an avalanche of notifications, but if it’s unavoidable, the C660 lets you set motion detection zones via the app to reduce or minimize notifications of movement within those zones.

One thing to note about the installation is that the camera has a manual power button tucked away beneath a flap under the lens. Unlike other security cameras that power up automatically when plugged into a power source (like the solar panel or a USB-C cable), this button needs to be switched on before mounting (especially when it’s in a hard-to-reach height) and pairing with the Tapo app.
Pairing the camera to the app is quick and straightforward, with only a few setup options at the beginning, like Wi-Fi connection type (2.4GHz for longer range or 5GHz for better video streaming quality, both using the Wi-Fi 4 standard), assigning the camera’s location and even the icon you want displayed in the Tapo app home screen.
TP-Link’s Tapo C660 Kit natively integrates with the Tapo smart home app, allowing the camera to slot into any existing Tapo smart home ecosystem that might include lights, plugs, switches, robot vacuums, door locks and more.
If you have devices from other brands and use a smart assistant to consolidate them into one interface, the camera supports Amazon Alexa and Google Home. Alexa supports both live footage playback and voice commands, while Google Home only supports voice controls and video streaming on select devices. Apple HomeKit isn’t supported, but alerts and automations can still be done through Siri via iOS shortcuts enabled through the Tapo app.

The app works well, with an intuitive interface using tiles to show all your Tapo devices, with dedicated tabs for the different gadget categories (like cameras, vacuums and ‘Smart’ for automations). You can play the live feed and adjust settings by tapping on the tile for the camera (or cameras if you have more).
Camera settings include two-way audio, a toggle for the built-in spotlight and adjustments for panning and tilting the camera. There’s also an option to ‘save’ a set camera position via ‘Viewpoints’ and easily access those positions without manually adjusting each time. Those views can be used for automations, too.
To try out the feature, I set the camera to monitor the rear of the house instead of the driveway and front stairs for just a few hours during the day, and it would activate as scheduled each time. Patrol Mode also lets you move the camera between those set positions, but the Tapo app warns that this mode may impact the camera motor’s longevity.

One annoyance I found with the Viewpoints feature was that the motion detection zone that I set also moved with the camera and there’s no option to lock it to a specific spot. Thankfully, I didn’t have to move my camera too often for that to personally impact me, but I can see it being inconvenient for some users.
Adding to the motion tracking is a setting subject detection like person, pet or vehicle, and it can also be set for different motion detection zones as well.
The Tapo C660 Kit captures videos through its 8MP lens with 4K (3840 x 2160 pixels) resolution, with a frame rate of 15 or 20 frames per second. The recorded video clips were crisp and detailed when viewing live or when playing back previously recorded footage. It was clear enough for me to see details like faces, vehicle license plates and larger text from further away, while the 18x digital zoom provided more detail than lower-resolution cameras.
It managed to retain detail in brighter areas and the video wasn’t washed out, like when direct sunlight was hitting the driveway. There’s built-in wide dynamic range to prevent overexposure in bright sunlight or underexposure in dark shadows.
Motion tracking was responsive, and the C660 Kit could track me moving when I was walking quickly, running or cycling (although I wouldn’t necessarily call myself a fast runner or cyclist to try and avoid the tracking). I also liked that the camera automatically reverts to the original position after detecting movement, so I didn’t have to adjust it manually as some security cameras require you to do.
At night, the f/1.6 aperture takes in enough light to provide a clear image, and the built-in spotlight adds more low-light visibility. There’s also an infrared sensor as an alternative to color night vision. While I found both modes were able to detect movement almost instantly, the image quality isn’t as crisp as daytime mode, but it was still decent enough to be clear and fully visible.
The built-in microphone produced clear audio and was loud enough for a conversation even when I wasn’t at home.

The solar panel kept the battery topped up, with the camera almost always running at 100% apart from some overcast days. It was only when I switched on 24/7 Capture (which frankly most people won’t need) that the solar panel struggled to keep the camera charged, and I eventually had to bring it indoors (it can be removed from its base plate easily) for a top-up via a USB-C cable.
In a different test, I tried running the camera without the solar panel plugged in, and the camera ran uninterrupted for just over 2 weeks before it needed charging.

The Tapo C660 Kit isn’t necessarily the cheapest 4K security camera, but having local storage via a microSD card makes it a great value option compared to others that require a subscription to access cloud storage for recorded footage. It supports up to 512GB, though you’ll need to purchase the microSD card separately as it doesn’t come with one in the box.
TP-Link says that’s enough for around 16 complete days of recording, which is plenty for most people. Local storage means you can also back up those recordings to your home computer or another drive for redundancy. The Tapo app also lets you password-protect the microSD card for an extra layer of security.
Accessing footage from the card is easy through the app, and notifications reliably link to recordings with almost no delay after the camera detects motion. Video playback is also very smooth in the app. If you prefer cloud storage, you can opt for the aforementioned Tapocare subscription and choose a plan based on the number of connected cameras you plan to have.
Other features in Tapocare include 30 days of encrypted video storage for events, rich notifications and video summaries.
|
Attribute |
Notes |
Score |
|
Value |
You get some premium features like 4K resolution and 360º views for an affordable price, while on-device storage means you don’t have to pay for a subscription. |
5/5 |
|
Design |
It features a clean, sleek white design that’s relatively sturdy, and the solar panel that helps to extend its battery life is a proportionate fit. |
5/5 |
|
Software |
The Tapo app is clean and intuitive, with plenty of adjustments to fine-tune the settings. Alexa has the strongest support for smart home integrations, with Google Home at a distant second. |
4/5 |
|
Performance |
It captures crisp 4K footage well, and also performs reasonably well in low-light situations thanks to a built-in spotlight. |
4/5 |
I installed the Tapo C660 Kit to a porch post on my property for a few months to get a sense of both its recording capabilities and whether its solar panel would keep the camera’s battery charged.
I tested all the settings, but had the alarm and spotlight mostly turned off to avoid disturbing neighbors, only doing one-off tests to see if they perform as advertized. I would also check captured footage whenever I got a push notification.
The smart home integrations were tested with smart displays (a 2nd-gen Google Nest Hub and an Amazon Echo Show 5) in addition to the Alexa and Google Home mobile apps.
First reviewed July 2026


An Illinois man was sentenced on Tuesday to 76 months in prison and three years of supervised release for hacking the Snapchat accounts of over 750 women to steal nude photos, which he later traded or sold online.
After being charged in December, 26-year-old defendant Kyle Svara admitted in February to having used various social engineering tactics to phish Snapchat access codes from over 750 women.
Between May 2020 and February 2021, he targeted more than 4,500 victims while posing as a representative of Snap Inc and using anonymized phone numbers.

After stealing the victims’ credentials, Svara accessed approximately 517 women’s Snapchat accounts without permission to download nude or semi-nude photos and activated two-factor authentication to lock them out of the compromised accounts.
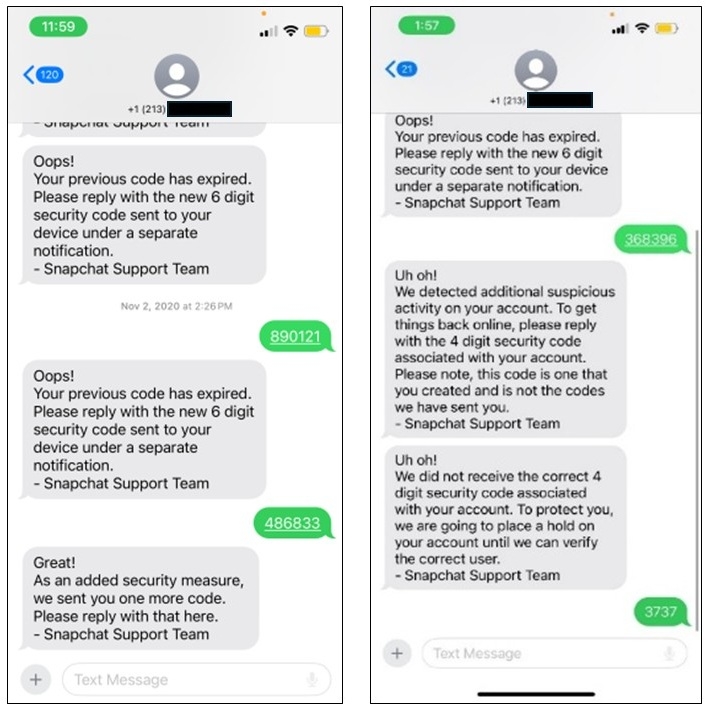
The investigators also found that Svara distributed child sexual abuse material (CSAM), finding approximately 530 images and 600 videos depicting CSAM in his Mega account.
“When Svara was interviewed by investigators, he falsely stated that he did not know anything about hacking Snapchat,” the Justice Department said in February.
“Additionally, he falsely stated that had no interest in child pornography and had never actively sought out or accessed child sexual abuse material (CSAM). Contrary to these statements, the defendant collected, distributed and solicited CSAM.”
According to court documents, he also advertised his “services” online, trading the stolen images, offering to “get into girls snap accounts,” and asking potential clients to reach out through the Kik encrypted messaging app.

Steve Waithe, a former Northeastern University track and field coach and one of his clients, hired Svara to hack the Snapchat accounts of students at Northeastern and members of the women’s track and field and soccer teams.
After being found guilty of targeting at least 128 women and stealing thousands of explicit photos from more than 100 women, Waithe was sentenced in March 2024 to five years in prison for cyber fraud, cyberstalking, and sextortion.
Between paid hacking jobs, Svara also independently hacked into the accounts of many women in Plainfield, Illinois (including neighbors, family friends, classmates, his own personal friends), as well as students at Colby College in Waterville, Maine.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.

Forget cheating on homework and chatbot friends. Some kids are getting in on a new AI trend: thinking it sucks.
In the four years since chatbots went mainstream, and their marketing campaigns went into overdrive, young people have grown increasingly skeptical of the hype around LLMs. Yes, many of them still use the tech for school assignments and companionship, but according to market research firm YPulse, 37 percent of teens aged 13 to 17 cringe when they see AI content like music and videos, and more than half worry about misinformation and deepfakes.
The polling on youthful AI attitudes shows a great deal of contradiction. Adoption rates are high, with a majority of America’s teens reporting they use chatbots, but enthusiasm is mixed. A recent Pew Research report found that while many teens think AI will be good for them personally, over a fourth of their cohort believe AI will have a negative impact on society in the next 20 years, citing job loss, the decline of critical thinking skills, and environmental impacts as concerns.
Young people typically adopt new consumer technology eagerly, but Melanie Green, a communications professor at the University at Buffalo, says AI is different. This time, the moral panic isn’t coming from older generations—in fact, kids are turned off by the way AI is being pushed on them by adults and tech corporations. They’re also, Green says, “acutely aware that whatever disruption happens, their generation is going to be bearing the brunt of it.”
Ergo, the eye-rolls. On Bluesky, parents bond over their kids’ distrust of AI, with many claiming that their children come home saying “that’s AI” to mean “that’s BS.” On Reddit, educators share that students—even those who use AI—worry about its consequences and can’t stand the art it produces. WIRED spoke to young people, their parents, and their teachers to find out why some kids don’t want to be on the AI bandwagon.


science
Super Heavy booster had a super heavy landing, but other reusability tech did the trick
The 13th flight of SpaceX’s Starship made it off the launchpad on Friday and ticked off just about everything on the company’s to-do list.
After delays and engine replacements, Elon Musk’s colosso-launcher took to the skies at beer-o’clock on Friday evening – 5:51PM Texas time.
One hour, five minutes and 21 seconds later, Starship made a controlled splashdown in the Indian Ocean, where it floated after landing.
SpaceX says it was able to gather critical data on the performance of Starship’s heatshield, and that the craft made “a dynamic banking move to mimic the trajectory that future missions returning to Starbase will fly.”
Gathering data on Starship’s heatshield performance will help SpaceX ensure the craft is re-usable. Simulating missions that land at Starbase, SpaceX’s Texas home, builds toward future missions that launch and land at the same facility, speeding turnarounds for re-usable hardware.
The test flight also saw SpaceX test a new routine for de-orbiting the Super Heavy booster used to hoist Starship into space. “The booster successfully completed the high thrust portion of the boostback burn with all 33 engines, the first time with a Super Heavy V3, before ending the burn early,” SpaceX said. “It attempted to relight its engines for the landing burn, with a subset successfully igniting before experiencing a hard splashdown in the Gulf.”
That part of the mission didn’t go perfectly, as SpaceX hoped for a softer landing and more engines lighting to make it possible.
Once Super Heavy and Starship separated, the latter vehicle used its six Raptor engines to reach desired speed and orbit. It then deployed 20 Starlink V3 satellites. SpaceX crew verified the sats worked and half a dozen of them got a look at Starship’s heatshield. While the satellites were functional, SpaceX did not intend them to form part of the Starlink constellation and allowed them to re-enter Earth’s atmosphere. Or as the company’s mission report put it, the satellites “demised upon reentry approximately 20 minutes after deployment.”
Starship performed one more trick on its way back to Earth, by starting one of its Raptor engines while coasting through space. The success of that test again demonstrated tech that will be needed for future missions, in this case flights that push Starship into sustainable orbit – or allow it to reach a trajectory capable of reaching the Moon, as NASA envisages will be the case for future Artemis missions that land humans on Earth’s permanent natural satellite.
SpaceX boss Elon Musk said he hopes the next Starship test flight will see the Super Heavy booster caught by robot arms at Starbase, another step towards improved reusability and turnaround times between flights. ®





Weekend Open Thread: Brooks Brothers


Grayscale Files For Worldcoin ETF, WLD Registers Sharp Rise


How a former Blue Peter presenter stunned America’s Got Talent judges
Sail Virtually Aboard The “Itanic” With IA-64 Emulator
Turtle Beach Command Series KB7 review: a nifty screen-equipped gaming keyboard


Unregistered fitter used Gas Safe logo on business flyers


Intel is reversing course and bringing hyper-threading back to its server chips

New Jersey voter registration controversy explained: How 6,600 noncitizens got on the rolls, and what happens next

Johnny Depp’s R-Rated Gothic Cult Classic Gets New Release Ahead of Sydney Sweeney Remake


Watch Flock Safety CEO Garrett Langley discuss the future of surveillance at TechCrunch Disrupt 2026


Ethics, other provisions in crypto Clarity Act to be further discussed

Shanghai science forum photos show China’s AI and robotics advances in rivalry with US
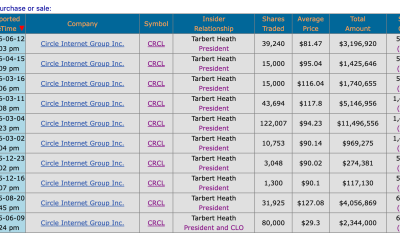
Circle’s President Sold Over 360,000 Shares, The Filings Explain Why

Commonwealth Games boxing: Jadumani Singh seals dominant 5-0 win over Pakistan’s Sumama Rehman to enter quarter-finals | Commonwealth Games News


The Peugeot Family: How 200 Years of an “Old Money” Dynasty Died in A Boardroom


2026 3M Open leaderboard: Scottie Scheffler finds putter in Round 1, sits three back


Spain sweeps the board at 2026 World Cup with individual awards


16 Dresses for the High Summer Event


Andrew Cuomo joins OKX board as crypto exchange expands in U.S.


The 35 Best Board Games for Family Game Night






You must be logged in to post a comment Login