
Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.



Spain has temporarily blocked Polymarket and Kalshi while it investigates whether the prediction-market platforms are violating gambling laws by operating without a license. Engadget reports: The country’s ministry in charge of consumer affairs said it blocked the websites as a precautionary measure pending an official investigation. This investigation will determine if the platforms violate Spain’s gambling laws. It’s set to complete within the next four months and could mandate that these companies require specific administrative licenses to operate.
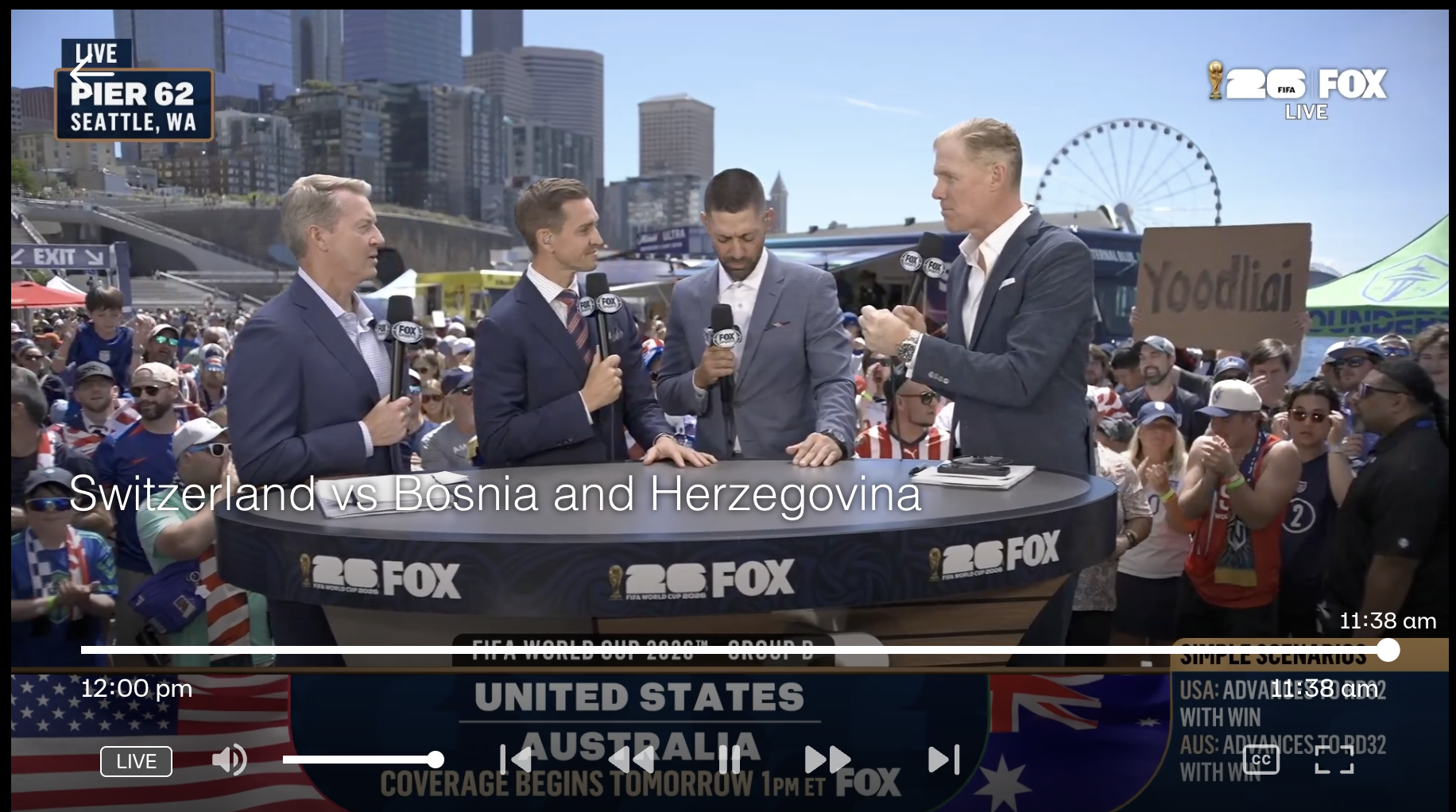

When a startup town turns into a soccer town attracting worldwide attention, it’s a great opportunity to test your guerrilla marketing skills.
Seattle’s Yoodli leaned into that theory on Thursday by getting its name and web address on Fox Sports’ live broadcast of FIFA World Cup festivities from Pier 62 on the waterfront.
The company, which launched out of the former AI2 Incubator in 2021, develops AI-powered software that allows users to simulate and practice real-world conversations. Yoodli has been at AI House all week on nearby Pier 70, and the team said grabbing free TV ad time was a “Hail Mary move” — especially in an era when AI company billboards are such a thing.
In a description of events relayed to GeekWire via email, the effort started with Yoodli’s new growth marketing manager Connor Wright scrolling Instagram earlier that morning to catch up on World Cup updates. He saw that Fox was live-streaming from Pier 62.
A scrappy startup lightbulb went off.
Communications and content leader Sage Ke’alohilani Quiamno said she quickly ripped up a monitor box — because the startup is getting a new office soon — and wrote “Yoodli.ai” on the front and “USA” on the back.

Marketing intern Luis Quiroz ran down Alaskan Way with Wright to get inside Fox’s Pier 62 makeshift studio space and hold up the sign just over the shoulder of soccer commentator Alexi Lalas.
“When you’re standing outside with a piece of cardboard and a Fox broadcast camera sweeps by, you seize the moment,” Quiamno said. “Connor held the sign without hesitation while I directed him via phone from the office.”
Yoodli has been watching World Cup action daily from the lunchroom at AI House, and Quiamno said the energy downtown has been something else, especially in anticipation of Friday’s noon match between the U.S. and Australia at Seattle Stadium (Lumen Field).
“It’s the kind of vibe Seattle rarely gets: the waterfront is packed, everyone’s in a good mood, and there’s this collective feeling that the city is on the global stage,” she said.
Yoodli was co-founded by Esha Joshi and Varun Puri and is ranked No. 22 on the GeekWire 200 index of the Pacific Northwest’s top startups. The company currently has about 80 employees.
“We’re growing but still small enough to pull off a guerrilla PR stunt,” Quiamno said.
And apparently it worked. Yoodli says it saw an increase in website traffic and demo inquiries following the broadcast.
“Proof that a handmade sign and a little World Cup energy go a long way,” Quiamno added.
A visit to a hardware store can be quite intimidating for newcomers. Familiarity with specific types and sizes of tools comes with experience, so it’s hard to know exactly what you’re looking for when starting your own tool set.
While the staff members in your local store would be glad to help, you could end up purchasing more than you’d actually intended to or may ultimately need. A tool kit is a collection that you can easily add to or customize at any time, so it doesn’t necessarily have to take up a lot of space or be particularly expensive. You’ll want to make practical choices that can grow with your confidence and won’t be left gathering dust, though.
Developing your own tool set and keeping it stocked and cared for is exciting for any budding garage-tinkerer, and we’ll take a look at how to do just that. From deciding on the particular type of tools you’d like to buy to to organizing their storage, and alongside some of the toolbox essentials, here are some simple tips that’ll help you get started.
As with anything you start from scratch, the key is to consider the basics first. These are the items like slide rules, spirit levels, screwdrivers, and hammers, and there can be more to them than you think. Screwdrivers are divided into categories based on the type of screw they’re designed to work with, and attempting to use the wrong type could damage the screw and make it difficult to extract.
Different varieties, such as the Phillips head, have their own advantages. This particular type is easy to grip and work with because of the cross-shaped head of the screws designed for it, which makes it difficult to accidentally overtighten. There are also less familiar models like ratcheting screwdrivers, which boast a motion that takes some of the force required out of their use.
With more specialised models on the market too, there will be tools with unique applications that you may never have to use at all. Researching different types of tools and the jobs they’re used for is invaluable, but you don’t have to own every different type. General purpose, individual, quality items will be an excellent start. Consider this over simply buying an all-in-one tool kit, which might have a lot of smaller attachments and tools that you don’t really need.
A large set of quality tools can be expensive. To help get your money’s worth from everything, remember that you don’t need to buy everything you ultimately want to have in your collection all at once.
Plan each home improvement project as it comes. Do you have every tool in your set that you’ll need for it? If not, it’s time to make that purchase. As simple as this piece of advice is, it’s vital to bear in mind, in case your enthusiasm about creating your first tool set sends you way over budget. This way, you know that you’ve only ever bought tools that you’ve actually used.
As your skill and confidence with DIY tasks develops, you may find yourself tackling more of them. It’s likely, then, that your toolkit will grow accordingly, and you’ll also begin to find that you already have everything you need for later jobs. Just as importantly, you’ll be experienced with how to use the items in your collection, thanks to taking it steadily and being selective.
The previous advice will help to curb excessive spending as you get more comfortable in the world of DIY. It doesn’t mean you need to buy every tool you use, though, and certainly not brand-new. If you don’t know someone who can lend you any tools you lack, you have other options.
Your town’s community library may have the facility to rent out power tools, at a tiny fraction of the cost of buying them outright. For more of a long term bargain, though, try scouting social media to see if anybody in your local area is selling the tool you need second-hand. Somebody else, after all, might have fallen into the very trap you’ve just avoided — buying a brand-new tool and using it just once or twice.
The usual warning applies with this, however: Be sure that the tool is exactly as advertised before completing a transaction. If you’re not familiar with the specific item, researching new prices will show you exactly how much of a bargain you might be getting. On the other hand, buying new from local hardware stores isn’t necessarily to be avoided, especially when the next big sale is advertised; you might be surprised at what you’re able to pick up.
You’re well on your way to planning out your tool kit and stocking it with a variety of essentials. Before long, then, you’re going to come up against the question of where to store all of your tools.
There are several elements to this. Firstly, a quality toolbox can be a must. SlashGear has rated the best and worst garage toolboxes, as well as the major portable toolboxes, so it’ll be a big help to take a look and choose the options that best suit your needs.
You’ve also got to consider where on your property you’ll keep all your new items. Fortunately, new tools are provided with manuals that detail not only the essentials of operation, but safe storage too. Avoiding certain temperatures, keeping them away from water, keeping those items that require it separate from each other, and so on are all vital considerations.
Then there’s the way you use your tools. Are you expecting to travel a lot with them? If that’s the case, a sturdy yet portable toolbox or other system will be vital. If you aren’t, and will largely be working in your garage, it’s not as much of a concern to have everything travel-ready. An organized storage system may take up a lot of space, but it’ll pay dividends when it comes to knowing that everything is locked away safe and, crucially, where to find it when you need it.
There are a lot of resources available for DIY newcomers. Be sure to double-check SlashGear’s list of home tool kit essentials, for instance, for anything you might be missing. Another great place to start would be the websites of some of the biggest names in home improvement. Lowe’s has created a very convenient guide to the best sorts of items to include in a toolkit, from saw horses to safety equipment.
The outlet recommends a square, which will prove important for accurate measurements and making the types of cuts that can make or break a whole project. In tandem with this, Lowe’s DIY Basics is a series of super brief YouTube tutorials that will show you how to use these new items. For instance, if you’re unsure about your new combination square, the below Lowe’s guide will be invaluable.
Technique develops with experience, but you need to understand not only which items to include, but why they’re there. Fortunately, if there’s one thing that the home improvement community can relied on for, it’s producing tutorials and advice for newcomers into the fold. Make use of it all. Remember, though, that you don’t have to tackle a job that feels like more than you can handle. You can get quotes for a given task, and then determine whether it’s something you can feasibly tackle yourself.


The last thing you want to happen after dropping hundreds of dollars on a wearable is to discover that it doesn’t work with your body. But, that’s a fairly common problem people with wrist tattoos have been running into since the advent of smartwatches and fitness trackers. As countless posts on device support pages and Reddit have chronicled over the years, tattooed skin and the sensors used by wearables often don’t mix well.
One of the main issues people experience is with heart rate sensing. Wearables use a light-based technique called photoplethysmography (PPG) to measure heart rate. That’s the green light you see when you flip your device over. But, tattoos can get in the way of that light, messing with the readings. The other problem is wrist detection, which also uses lights to determine if the tracker is on a person’s wrist (along with an accelerometer and electrical sensors). Slap a fitness tracker on a wrist that’s covered by a tattoo, and the device may not register that it’s being worn at all, consequently requiring the wearer to repeatedly unlock the device whenever they want to interact with it.
It might seem a bit silly that technology advanced enough to respond to gesture controls and provide personalized sleep coaching would be stumped by a bit of pigment, but the tattoo issue isn’t just a baseless gripe that consumers have latched onto. Device makers have acknowledged it and advised buyers to avoid putting their trackers on top of tattoos.
“Tattoos (ink, pattern, saturation) can block the heart rate sensor’s light, causing inaccurate or missing readings,” Garmin notes on a support page. “For best performance, wear the watch on skin that is free of tattoos if possible.” Apple has issued similar notices going back to the release of the first Apple Watch.
People with tattoos have devised sorts of workarounds to get the most out of their smart watches and fitness trackers, though none are exactly ideal. The simplest? If the inside of your wrist isn’t tattooed (or at least has larger areas of clear skin), you can position the device there instead of on top of the wrist. Similarly, if your other wrist is tattoo-free, wear the device on that one. But if you’ve grown used to wearing a watch on a certain wrist for years, it’s going to feel pretty weird to change it up.
As a quick fix, some people swear by epoxy bottle cap stickers or layering pieces of clear tape, either of which are placed over the sensors and inexplicably correct the problem for a lot of wearers. Reusable accessories designed to work the same way have seen some success too. There’s also the option of using a chest strap if accurate heart rate tracking is all you’re after — and if you don’t have chest tattoos. Again, though, this isn’t the most comfortable or convenient way to use a wearable in most situations day-to-day.
Ultimately, it’ll continue to be an issue until the sensors these watches and fitness trackers rely on are improved to account for skin variations like tattoo ink. Likewise, light-based sensors have been found to be less reliable for people with dark skin, highlighting a need for more diversity in the research and development of this type of technology.
Anecdotally, it seems like Google’s Pixel Watch 4 might be much better at handling tattooed skin than its predecessors. There were rumors of Samsung introducing an update a few years back to improve things in this area too, but the complaints of tattooed Galaxy Watch users would suggest otherwise.
Identifying the problem is theoretically the first step to solving it, but unhelpfully, the reality is that how much tattoos interfere with sensor readings isn’t consistent from case to case. A study published in 2025 attempted to quantify the difference in readings taken from devices worn over tattooed skin versus non-tattooed skin, and while it did find the former suffered inaccuracies, the results were mixed.
The researchers used the Polar Verity Sense and armband, outfitting participants with one device over a tattoo plus one on the same arm in an area without a tattoo. Participants also wore a Polar H10 chest strap heart rate monitor to establish a baseline, as this style of wearable is considered to be more accurate. Over the course of a day, they were monitored when at rest, walking at their own pace and jogging.
This revealed that the presence of the tattoos did have an impact on heart rate readings, but it was dependent on the wearer’s activity level, “with the greatest effect observed at rest and variation decreasing as exercise intensity increases.” And in some cases, the researchers note, “the presence of an arm tattoo did not affect the heart rate validity measurement at all.” There are a number of variables that must be taken into account — like ink color, saturation and depth — and as it stands today, there just hasn’t yet been enough research down to the nitty-gritty of the problem to bring about a solution.

Looking for the most recent Connections answers? Click here for today’s Connections hints, as well as our daily answers and hints for The New York Times Mini Crossword, Wordle, Connections: Sports Edition and Strands puzzles.
Today’s NYT Connections puzzle changed at the last minute. The Times had another puzzle scheduled for today, but moved it to June 30 at the last minute. And if you’re a fan of a certain New York team that just won a basketball championship, you can see why. They substituted today’s puzzle, which features some words relating to that winning team. Read on for clues and today’s Connections answers.
The Times has a Connections Bot, like the one for Wordle. Go there after you play to receive a numeric score and to have the program analyze your answers. Players who are registered with the Times Games section can now nerd out by following their progress, including the number of puzzles completed, win rate, number of times they nabbed a perfect score and their win streak.
Read more: Hints, Tips and Strategies to Help You Win at NYT Connections Every Time
Here are four hints for the groupings in today’s Connections puzzle, ranked from the easiest yellow group to the tough (and sometimes bizarre) purple group.
Yellow group hint: The 11th letter.
Green group hint: I’m behind you!
Blue group hint: Sit down.
Purple group hint: Rock on.
Yellow group: Featuring silent and pronounced “K”s.
Green group: Endorse.
Blue group: Kinds of chairs.
Purple group: Words repeated in hit song titles.
Read more: Wordle Cheat Sheet: Here Are the Most Popular Letters Used in English Words
The completed NYT Connections puzzle for June 20, 2026.
The theme is featuring silent and pronounced “K”s. The four answers are jackknife, knapsack, Knicks and knock-knock.
The theme is endorse. The four answers are back, bolster, champion and support.
The theme is kinds of chairs. The four answers are beanbag, recliner, rocker and stool.
The theme is words repeated in hit song titles. The four answers are Jumpin’, Louis, New York and Rebel.


Owners of original PlayStation consoles have watched their disc drives age for decades. Lasers fade. Games start to skip or fail to load altogether. Replacement drives grow scarce and expensive. A new device called ArcStation steps in with a direct solution. It replaces the entire optical drive assembly inside the console with a compact circuit board that loads games from an SD card instead. No discs stay necessary after setup. The change keeps the original hardware intact and authentic while removing the most common point of failure.
Installation is mercifully simple: simply unplug and open the case with a single Phillips screwdriver, and you’re done. Owners then carefully remove the old drive, flip over to the shiny new board, and adjust two little DIP switches to match the region settings on their console. Once that’s done, simply plug in the short cables provided, which go into the exact same locations as the originals. You will not need to apply any solder or make any lasting modifications to the motherboard. Instead, the new board sits well on the existing posts inside the casing thanks to a 3D manufactured mount that also accommodates both the larger “fat” PlayStation models and the handy tiny PSOne. A simple test boot with the lid remaining open will ensure that the old Sony logo and boot animation are back in action. Put the case back on, and you’re finished.


Once inserted, the board appears as soon as you turn on the console and displays a very clean small menu on a tiny built-in LED screen. Users just copy their game files to a normal SD card formatted in either FAT32 or exFAT. It is not an issue to have CUE/BIN pairs, BIN files on their own, or ISO pictures on there; the board can handle them all. You can keep the games in folders or subfolders if you like, as this is all about organization. Simply hit the refresh button in the menu, and the board will scan your card and generate a list for you. Then simply press the title button with your controller, and the game will launch immediately on the original hardware. In terms of load timings, they’re not far off from what you’d get from an actual CD, and there’s even a special option for early motherboard revisions that can shave even more off.

The reason this works so well is that it accurately mimics the behavior of the original CD-ROM drive, down to the radio frequencies that the console expects. Games that generally look for modchips or copy protection will not even blink an eye. You get region-free access on all PS console generations, including the legendary PSOne. If you’re playing a game with multiple discs, the board will usually handle the queue for you. You can even build a manual queue of up to six discs and move between them as needed; simply press the button next to the SD slot while keeping an eye on the LED display.

Save games are moved to virtual memory cards that are kept directly on the SD card; each game has its own dedicated file, so storage never runs out like it did on the old physical cards. You can attach the virtual card to either slot 1 or 2 on the fat models, but be careful because some older systems cannot handle it. Owners can access the menu without having to turn off the console by specifying a button combination on the controller, which is far more convenient than fiddling around in the settings. The tiny PSOne differs from the others in that it cannot use virtual memory cards or the game reset combo due to its completely different internal layout, but it can still use all other functionalities. Some additional options on the main menu allow you to adjust video settings, switch to a light or dark theme, receive sound cues, have the console auto-start the previous game you played with a slight delay, and even display the game title from either a database or what is actually on the folder name.

Pre-orders began at the end of May at a reduced price of roughly 140 euros. Shipping is expected in September, but fingers crossed it will arrive sooner. The kit contains all of the wires required for both the fat and slender models, as well as the board, which is pre-mounted for ease of installation. There has been thorough testing on over a hundred titles, and the results on the fat models have been remarkably consistent, even after extended gaming sessions.


Market intelligence platform Klue has publicly confirmed a recent security incident that allowed threat actors to steal OAuth tokens used to connect to customers’ Salesforce environments, as the new “Icarus” extortion group publicly claims the attack.
The disclosure comes after cybersecurity firms Huntress and ReliaQuest detailed how attackers abused compromised Klue Battlecards integrations to steal Salesforce CRM data from multiple organizations.
In a statement published this week, Klue CEO Jason Smith confirmed that the company discovered unauthorized activity on June 12 affecting part of Klue’s integration infrastructure.

“On June 12, we identified unauthorized activity affecting a portion of Klue’s integration infrastructure. Since then, we’ve been working alongside trusted cybersecurity experts to understand what happened, support our customers, and restore the connections you rely on,” wrote Smith.
“Our investigation determined that an attacker gained access through a compromised legacy credential associated with an integration service. The attacker used that access to obtain OAuth tokens used to connect Klue with certain third-party platforms, including Salesforce, and subsequently accessed data within a number of connected customer environments.”
The company says there is currently no evidence that customer content stored directly within the Klue platform was impacted and that the incident was limited to third-party integrations.
Klue says it immediately revoked affected credentials and tokens, removed unauthorized code, disabled impacted integrations, launched an investigation, and notified law enforcement. The company also confirmed it engaged CrowdStrike to assist with the response.
ReliaQuest and Huntress found that the attackers used stolen OAuth credentials associated with Klue integrations to access customer Salesforce environments and conduct large-scale data theft.
ReliaQuest observed attackers generating OAuth tokens and using Python scripts to query Salesforce’s API for extended periods, as data was stolen.
Huntress later disclosed that its own Salesforce environment was affected by the Klue breach and that the stolen data included business contacts, sales communications, pricing information, and other records.
While BleepingComputer and Huntress previously linked the incident to the Icarus extortion operation, the threat actors have now publicly claimed responsibility on their data leak site.
“As you’ve probably already heard, Klue.com has been impacted by us recently. A number of other companies’ Salesforce instances, which were partners to Klue, were exfiltrated,” reads the Icarus post.
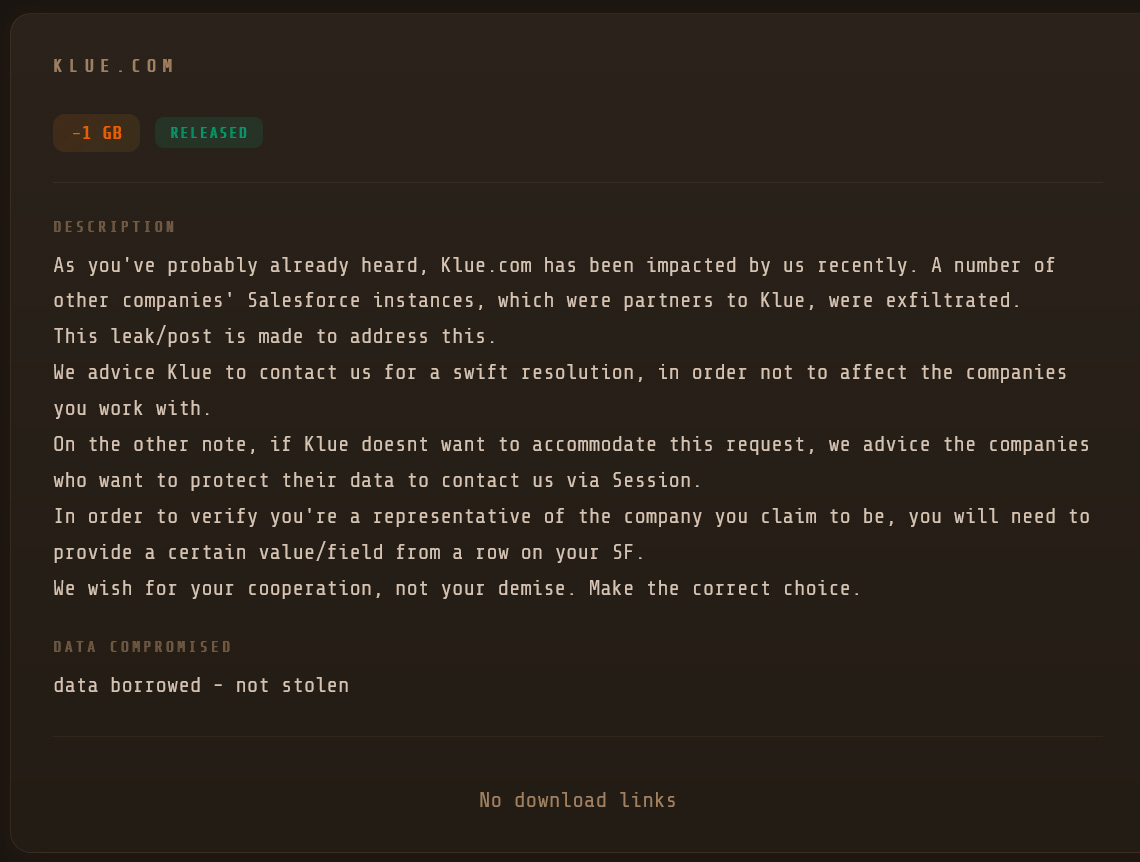
The threat actors went on to pressure Klue and affected organizations to contact them through the Session messaging platform to prevent the leaking of stolen data.
The post comes after BleepingComputer previously reported that the attacks were linked to Icarus, after sources shared extortion emails sent to affected organizations. Huntress also independently connected the operation to Icarus through Session Messenger IDs used in the extortion emails and the group’s data leak site.
Since then, additional victims have disclosed that they were affected by the attacks, including Recorded Future, Tanium, Jamf, Sprout Social, Gong, and Insurity.
Almost all say the incident led to the theft of data from their Salesforce instances and did not affect their platforms, infrastructure, payment information, or internal systems.
Several organizations warned that the stolen business contact information could be used in follow-on phishing, social engineering, and extortion campaigns and urged customers to be vigilant.

Security teams log 54% of successful attacks and alert on just 14%. The rest move through your environment unseen.
The Picus whitepaper shows how breach and attack simulation tests your SIEM and EDR rules so threats stop slipping by detection.
If there’s an avid DIYer who doesn’t love a good tool sale, they are few and far between. Many of us are always on the lookout for a chance to score new tools or replace those that are getting old. Getting them at a discount feels like a win-win regardless of whether you’re buying tools for yourself or someone else.
At Lowe’s, you can choose from one of the tool brands it owns, brands with which it has exclusive relationships, or some well-known options that can also be found at other retailers. You can take advantage of the deep discounts Lowe’s is offering on its line of professional-grade tools in June of 2026 by shopping in-store or online.
There are discounts across much of Lowe’s product lineup, but we’ll look at examples ranging from standard mechanic’s hand tools, battery-powered cordless tools, carpentry and woodworking tools, and tools to make time spent working in your shop or garage more productive.
Tools are an investment in our future DIY projects. As such, the term “buy once, cry once” is as accurate here as it is in any situation. That’s why a quality tool storage solution is so important. It makes no sense to buy good tools only to throw them into a greasy pile in the corner of a musty garage.
There are a lot of pros and cons to consider when deciding if you need a $500 tool chest. However, what if you could get a $600 tool chest on sale at Lowe’s for just $400? Quality tool storage and deep discount pricing are obviously items to add to the pros column.
The tool chest we’re looking at is the $399 Craftsman 2000 Series. It’s a 52-inch wide, by 38.05-inch tall, 10-drawer red rolling steel tool cabinet (model CMST98273RB), and it also comes in black (CMST98273BK) for the same price while they’re on sale, ending July 8, 2026.
While there is likely some overlap in the reviews, Lowe’s credits the red version with 2,916 and the black with 3,004 reviews, with each model averaging 4.3 stars. The 10 drawers support up to 100 pounds of tools each, and the chest rolls on four 5-inch diameter by 2-inch wide casters, providing a final load rating of 1,500 pounds. A 10-year limited warranty provides protection for your investment.
It’s no surprise that DeWalt produces a popular cordless drill. It’s frequently at or near the top of the list anytime we see major cordless drill brands ranked worst to best. The surprise is that one of DeWalt’s top-rated cordless drills is currently hugely discounted at Lowe’s. The DeWalt 20V Max 1/2-in keyless brushless cordless drill kit (model DCD793D1) includes the drill, a 20V Max battery, and a battery charger that also charges 12V DeWalt batteries if you have them.
This drill provides up to 1,650 revolutions per minute (RPM) without a load, has a ratcheting ½-inch keyless chuck to hold bits securely without the need for tools, and lights up the workspace in front of it with an integrated LED work light. While Lowe’s claims it provides up to 16% more power using the included DCB203 battery than its DCD771 drill using the same battery, the DCD793’s biggest perk may be its 2-inch shorter head length compared to the DCD771. The DeWalt 20V Max drill is priced at $99 (down from $179) until July 15.
Whether you’re interested in creating cabinetry, installing trim inside your home, or building a pole barn, a good saw is a must-have. While you could make do with a number of different saw types, it’s important to pick the right saw for the job at hand. With these June 2026 deep discounts at Lowe’s, you might as well have a saw capable of creating compound miter cuts on your workbench.
Through July 31, 2026, Lowe’s has the Bosch Glide 12-inch 15-amp dual bevel sliding compound corded miter saw (model GCM12SD) priced at $449, a savings of $280 from its standard list price. The Bosch Glide miter saw is listed as one of Lowe’s best sellers and carries a 4.4-star customer approval rating.
The Bosch miter saw’s 15-amp corded electric motor delivers up to 4,000 RPM to power a 12-inch saw blade on a 1-inch diameter arbor. Compared to typical 10-inch-bladed saws, the 12-inch blade cleanly cuts through material up to 1 inch thicker. The upfront miter and bevel controls, along with easy-to-read scales and detents at common angles, make setting the precision saw a simple task.
The Bosch GCM12SD specifications show it can swing 52 degrees left and 60 degrees right, while allowing left and right bevel cuts of up to 47 degrees. It provides a 6.5-inch depth of cut measured at 90 degrees and a 4-inch maximum at 45 degrees.
Having a robust selection of tools, and just as importantly, a place for each tool, is one of life’s greatest blessings. That might sound a little dramatic, but the time saved by easily finding the right size tool, or having a visual reminder that something is out of place before calling the project finished, isn’t something to be taken lightly.
Lowe’s owns Kobalt, so the prices of these tools don’t fluctuate a lot, and deep discounts can be rare. However, the Kobalt 302-piece metric and standard (SAE) mechanics tool set with a hard case is on sale for $119 until July 29, 2026. While its discount of $30 from the standard Lowe’s price isn’t extremely deep, at this price point, it’s rare to find a comparable set of tools.
The comprehensive Kobalt tool set includes ¼, ⅜, and ½-inch drive socket wrench sets, each with 90-tooth ratchets, 100+ sockets including 6- and 12-point styles, combination wrenches, nut drivers, and other small tools. While the sockets, ratchets, and wrenches are made of heat-treated chrome vanadium steel polished to a grime-resistant finish, the two-drawer molded tool chest they come in might be the deciding factor if tool control is a high priority.

AI infrastructure startup Tensordyne has taped out its first commercial accelerator, with fabrication on TSMC’s 3nm process already underway.
Developed in collaboration with Juniper Networks and Broadcom, Tensordyne’s systems promise higher throughput and lower power consumption than GPUs. It claims to achieve this using an unorthodox approach to mathematics that uses logarithms – which you might recall from high school arithmetic – to make matrix multiplication heavy AI workloads less computationally intensive to run.
In conventional computing, addition is cheap, and multiplication is expensive. Logarithms flip this on its head. Using logs, multiplication essentially becomes an addition problem. a*b becomes log(a) + log(b).
The trick is converting those values to logs and back again efficiently. There are a couple of ways of dealing with this. One of the easier options would have been to use a lookup table (LUT). However, Tensordyne cofounder Gilles Backhus tells El Reg that relying on LUTs would have been too large to be practical.
Instead, the company uses a heuristic, specifically the Mitchell approximation, to estimate log and antilog for each value. This is still an approximation and on its own introduces too much error to be tenable. To overcome this, Backhus tells us Tensordyne has implemented a section-wise correction mechanism in hardware that delivers accuracy equivalent to that of FP16. However, it’s worth noting that Napier will also support FP8 and 4-bit block floating data types.
In effect, Tensordyne claims to have built a chip in which the multiply accumulate (MAC) unit works without actually doing multiplication in the conventional sense. The result is a chip that delivers power efficiency significantly greater than what you’d see on modern GPUs. Or at least that’s the claim.
Tensordyne says its rack systems will spit out up to 17x more tokens per watt and achieve 13x higher throughput than Nvidia’s Blackwell systems.
Tensordyne’s first commercial chip, Napier, boasts many of the same specs you’d have seen from a high-end GPU just a couple of years ago.
The accelerator boasts a 300-watt nominal TDP, 144 GB of HBM3e spread across four stacks, 4.7 TB/s of memory bandwidth, and up to 2.1 petaFLOPS of dense FP8 performance. This makes it roughly comparable to Nvidia’s H200 accelerators announced in 2023, while using nearly 60 percent less power.
Having said that, max achieved FLOPS often fall far short of peak FLOPS, so take that comparison with a grain of salt. We won’t know how Napier actually compares to Nvidia or AMD’s latest generation of GPUs until it arrives next year.

Backhus tells us that Tensordyne is leaning heavily on the scalability of its accelerators rather than individual performance. Each chip features roughly a terabyte of interconnect bandwidth, allowing for rack-scale deployments of up to 72 accelerators per pod.
Tensordyne’s system, codenamed the TDN72, consists of eight air-cooled compute blades, each with a single 10-core Intel Xeon-D host CPU and nine Napier accelerators.
These chips are interconnected by a high-speed interconnect fabric topology reminiscent of the one used by Nvidia’s GB200 NVL72 rack systems.
Each chip connects to six proprietary fabric switch blades developed by Tensordyne’s networking partner Juniper, located at the back of the system, in an all-to-all fabric.

Despite some similarities to Nvidia’s NVL72 racks, Tensordyne’s TDN72 will be much smaller and won’t require liquid cooling, which should make it easier to deploy in older brownfield datacenters.
According to Backhus, up to four 30 kW TDN72 systems can be packed into an – admittedly large – 52U rack. That works out to 608 petaFLOPS in a 120 kW footprint, or about 1.68x more dense FP8 compute per rack than Nvidia’s GB200 NVL72. That doesn’t take into consideration the fact that Nvidia’s kit supports NVFP4 acceleration while Napier is limited to FP4 weights. But again, don’t read too much into that comparison. Peak FLOPS are not representative of real-world performance.
Tensordyne’s TDN72 launches next year, and it’ll be competing against Nvidia’s next-gen Vera Rubin and Vera Rubin Ultra systems, which will no doubt be a stiffer fight, especially when software compatibility is taken into consideration.
Since building its first prototype silicon a few years ago, the company has gone to great lengths to keep its software platform as simple and easy for customers to deploy, as possible.
For example, the prototype lacked the error correction found in its Napier chips, and would have required users to use quantization-aware training to adapt their models to run accurately on the hardware – not exactly feasible for those looking to run trillion-parameter models.
The software has also matured such that the hardware’s compiler can convert existing models to run directly on its latest hardware, an approach we’ve seen from other chip startups like Tenstorrent.
For inference, Tensordyne has developed its own proprietary serving platform, as well as a runtime environment that Backhus says will allow customers to use their preferred inference servers, such as vLLM. PyTorch support is under development.
Before the chip has even shipped, the company is making some bold performance claims. Backhus expects the chips to deliver upwards of 1,000 tokens a second, and that’s without relying on multi-token prediction or other forms of speculative decoding to boost token generation.
Tensordyne’s platform has certainly attracted the attention of neocloud providers like Cirrascale and BlueSky Compute, both of which have expressed interest in deploying the company’s hardware when available.
But, as we’ve seen with AMD and others, software can make or break a chipmaker. With Napier slated for release in Q2 or Q3 of 2027, Tensordyne won’t have long to get things right. ®


Shibu Kaithalamattathil, a senior engineer at MSD, explores the day to day as an engineer in the biopharma space and having the opportunity to watch his son enter the industry.
Shibu Kaithalamattathil is a senior engineer at MSD Biotech in Dublin.
In this role, he oversees the day-to-day engineering activities that support manufacturing, “ensuring that equipment, processes and systems operate safely, reliably and in full compliance with site standards”, he tells SiliconRepublic.com.
Kaithalamattathil says that no two days feel alike in her job, which he puts down to the team and the culture on-site.
“You’re genuinely excited to go to work every morning,” he says.
Never was this truer, Kaithalamattathil says, than last year, when he had a “unique opportunity”.
“My son Alan joined MSD Biotech, Dublin as an intern and worked on-site alongside me,” he explains. “Alan is studying chemical engineering in college and to be able to work alongside him for that period of time was amazing, not just because of the feeling of pride I got knowing my son was following in my footsteps, but also the sense that he’s taking his first professional steps in what will be a hugely exciting and rewarding career.
“With the way science is advancing, I think it’s safe to say his day to day will eventually look very different to my own, but there’s so much excitement in that.”
One of the things I enjoy most about my role is that every day I have to use both technical and non-technical skills alike. My role is as much about dealing with machinery, systems and equipment as it is about dealing with people, so it’s a mix of very technical troubleshooting skills as well as communications, teamwork and project management.
And at the heart of it, the biggest skill I think is problem-solving, whether looking at equipment or looking at our ways of working, it’s about being able to adapt and solve any issues or challenges as they arise.
That is something I think Alan experienced first-hand during his internship as well. While at university, you’re so focused on the technical side of things with the science, the engineering and chemistry. Across STEM, softer skills can sometimes be an afterthought. But on a day-to-day basis, whatever area you end up specialising in, the skills that will come in handy are usually communication and problem-solving.
The most challenging part of the day is dealing with the unexpected. It creates a sense of excitement and learning, but at the same time it is always a challenge to manage unexpected breakdowns or issues, all while ensuring that planned work is completed on time no matter what is going on.
That requires quick decisions and effective prioritisation, as well as a real passion for problem-solving. Whatever issue is in front of you, it’s really about just stepping back, looking at it holistically and then figuring out what the best way to fix or address it is. It’s about not just finding a solution, but making sure you’re finding the best solution.
I start my day by taking a few minutes to prioritise my workload, focusing on key tasks and then I get working on the to-do list. Engineering roles can be fast-paced and unpredictable, so having a clear structure helps me stay focused and calm, even when challenges arise.
I tend to break tasks into smaller, manageable steps, which keeps me organised and makes it easier to maintain momentum throughout the day. I also make a point of taking short breaks to reset, especially during busy periods. Staying refreshed helps me think more clearly and safely, both are essential in a biotech environment. And finally, I’ve learned the value of leaning on the team.
I was struck by the importance of adaptability. Even with years of experience, I quickly learned that continuous learning is part of daily life here.
The facility is equipped with modern, cutting‑edge technology and the systems evolve regularly as the industry advances. Being open to new tools, new processes and new ideas has been just as important as any technical skill I brought with me. Having my son on-site with me, I tried to encourage those same habits and behaviours for him too as I really do think they make a difference. And it’s been brilliant to see him taking them on, both in his academic and professional development.
The biopharmaceutical sector is expanding rapidly and with that growth has come significant technological advancement. My role has evolved from focusing mainly on hands-on engineering tasks to now also incorporating more data-driven decision-making and working with highly sophisticated equipment, which has been very exciting.
Automation, digital systems and advanced monitoring tools have become part of our daily operations, allowing us to work more efficiently while maintaining the highest standards of safety and quality. I’m also sure that by the time Alan finishes university and moves fully into the workforce, the role will have evolved even further, given the pace at which technology, automation and digital systems continue to develop across the sector.
However, although the tools and processes have evolved, what hasn’t changed is the purpose behind the work. We’re producing medicines that make a real difference to people’s health and you can really feel how much that sense of responsibility guides everything our team does.
What I enjoy most is the atmosphere on-site. There’s a real sense of community at MSD Biotech, Dublin. People are friendly, supportive and proud of the work they do. It genuinely feels like a home away from home in a way and that makes a huge difference in an industry where teamwork and trust are so important.
Every day, I also get to work with colleagues who share the same commitment to quality and the same passion for improving patients’ lives. That always feels very powerful too.
Seeing Alan walk into the same site where I work and watching him experience the same warm, welcoming environment was such a proud moment. It just reinforced everything I love about this job, the strong culture, the sense of belonging and the meaningful work we do every day.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.

TIRED
I still remember the moment I realized Samsung’s The Frame Pro 2026 is the best art television around. I loaded Van Gogh’s The Starry Night painting with its various shades of blue. The masterpiece came alive with texture and realism thanks to the contrast ratio and clear picture quality. I marched friends and family members down to my office to gaze in wonder.
Installing The Frame Pro is a bit of a process, though. I ended up watching a YouTube video for help. About an inch thin, this model sits mostly flush to the wall. Rather than connecting your streaming boxes directly to the TV, Samsung’s Wireless One Connect breakout box acts as a bridge. I connected my Xbox Series X and PC to the HDMI ports (there are four total) on the breakout box, which then connects to The Frame Pro using Wi-Fi 7 from across the room. Navigating The Frame Pro was also easy, thanks to the intuitive UI and the lightweight, long-lasting remote.
Free users have access to Samsung’s rotating catalog of 30 free images, but subscribers willing to pay $4.99 monthly will have access to 5,000 pieces of art. The Frame Pro 2026 has the widest variety of artwork, including hundreds of masterpieces, but I preferred Amazon’s Ember Artline “moving artwork” feature better.
At $2,000, The Frame Pro is the most expensive option on our list, and it’s worth its price. Even though most manufacturers, Samsung included, don’t list specs for their art TVs, The Frame Pro 2026 displayed artwork and photos with the best contrast and picture quality.
I was blown away by the picture quality for movies. When viewing Netflix’s Awake, which displays a lot of night scenes, I was able to still see all of the action. In comparison, the same scenes looked muddy and dull on the TCL NXTVISION and Amazon Ember Artline.
The 2026 model now supports high-fidelity gaming with a 240 Hz refresh rate when connected to a gaming computer (though it does lower the resolution). I played Crimson Desert and the main character—wearing a black suit of armor—moved realistically and responded quickly to my controller nudges.
For AI features, you have a few options. Samsung lets you pick from Alexa+ or Samsung’s Bixby to control the volume by voice or ask about which thrillers came out this month. You can also use Microsoft Copilot or Perplexity. However, the Amazon Ember Artline was the only art television that let me generate AI artwork by voice.
The Frame Pro 2026 is my top pick for art TVs because paintings looked the most realistic. If you want the best quality and are willing to pay a higher price, it’s a phenomenal choice.
WIRED







No Jackpot Winner as $257 Million Prize Rolls Over to $269 Million Monday Draw

Zimbabwe Requires Crypto Businesses to Register Annually Under New FIU Regulations


Bitget enters Argentina’s regulated crypto market through PSAV registration

Matt Damon’s Viral Sci-Fi Thriller Has Taken Over HBO Max


Anthropic staff to meet White House officials next week, Axios reports


As AI companies race to go public, who else is along for the ride?


Weekend Open Thread: Miami – Corporette.com

Bitcoin could crash to $48,000, if this historical pattern is triggered

Warning of disruption as Cardiff Crossrail works to start


“Israel’s” ban on ICRC visits ruled illegal, but Knesset moves to stop them permanently


Financial Accounting | Last Day Revision Strategy and Booster | CMA Inter – June 2026

Tributes to former deputy head teacher at Cambridge school among death and funeral notices
Deion Sanders Shares Powerful Post After Viral Advice To Deiondra
what doctors are seeing in ebike crashes

Kate Middleton Glare Goes Viral After Kids Booed At Royal Event

XRP ETFs Outperform As Bitcoin And Ethereum Funds Extend Outflow Trend
Market Preview: SpaceX (SPCX) IPO Record, Federal Reserve Meeting, and Iran Nuclear Agreement


Over 400 Arch Linux packages compromised to push rootkit, infostealer


Invesco Quality Income Fund Q1 2026 Commentary

44 Years Later, This Is the Greatest Star Trek Quote in Sci-Fi History
You must be logged in to post a comment Login