You’ve seen this comic before: An anthropomorphic dog sits smiling, surrounded by flames, and says, “This is fine.”
It’s become one of the most durable memes of the past decade, and now AI startup Artisan seems to have incorporated it into an ad campaign — an ad for which KC Green, the artist who created the comic, said his art was stolen.
A Bluesky post seems to show an ad in a subway station featuring Green’s art, except the dog says, “[M]y pipeline is on fire,” and an overlaid message urges passersby to “Hire Ava the AI BDR.”
Quoting that post, Green said he’s “been getting more folks telling me about this” and that “it’s not anything [I] agreed to.” Instead, he said the ad has “been stolen like AI steals,” and he told followers to “please vandalize it if and when you see it.”
Advertisement
When TechCrunch sent Artisan an email asking about the ad, the company said, “We have a lot of respect for KC Green and his work, and we’re reaching out to him directly.” In a follow-up email, the company said it had scheduled time to speak with him.
Artisan has courted controversy with its ads before, specifically with billboards urging businesses to “Stop hiring humans” — although founder and CEO Jaspar Carmichael-Jack insisted that the message was about “a category of work,” not “humans at large.”
“This is fine” first appeared in Green’s webcomic “Gunshow” in 2013, and while he hasn’t disavowed the smiling-melting dog entirely (he recently turned the comic into a game), it’s clearly escaped from his control. And of course, Green is far from the only artist to see his meme-able art used in ways he finds objectionable.
Techcrunch event
Advertisement
San Francisco, CA | October 13-15, 2026
But some artists have still taken action when their art is monetized or used in commercial ways without their permission, for example when cartoonist Matt Furie sued right-wing conspiracy theory site Infowars for using his character Pepe the Frog in a poster. (Furie and Infowars eventually settled.)
Advertisement
Green told TechCrunch via email that he will be “looking into [legal] representation, as I feel I have to.” Still, he said it “takes the wind out of my sails” that he has to take “time out of my life to try my hand at the American court system instead of putting that back into what I am passionate about, which is drawing comics and stories.”
Green added, “These no-thought A.I. losers aren’t untouchable and memes just don’t come out of thin air.”
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
As a Star Wars fan and someone who grew up with Lego as my favourite toy, Lego Star Wars sets have become some of my aspirational purchases as an adult — partly because the larger sets are expensive on their own, and I also don’t have the room to display all the sets in my wish list in my small apartment.
So it’s a good thing that Amazon has slashed prices on several Lego Star Wars sets in celebration of May the Fourth, including the ones on my wish list, but there are offers on the flashy new Smart Play sets that were unveiled at CES earlier this year. With Star Wars Day here, even those are now quite affordable.
There are also a lot of other sets across a variety of price ranges that have discounts too. So go on, indulge yourself and May the Fourth be with you.
For years, the smartphone chip conversation has been pretty straightforward. A phone with Snapdragon inside was almost always assumed to be the better option. If it had Exynos or MediaTek, the reaction was usually more doubtful. Qualcomm earned its reputation over time, but by 2026, that hierarchy no longer feels as solid.
MediaTek’s last couple of Dimensity 9000-series chips have been going neck and neck with Snapdragon 8-series SoCs, while Exynos has typically trailed behind both. Now, though, the race has become a lot more interesting.
My recent time with the Galaxy S26, powered by Exynos 2600, has already surprised me in terms of performance. And once you widen the lens to include the Snapdragon 8 Elite Gen 5 in the S26 Ultra and the Dimensity 9500 in devices like the Oppo Find X9, the whole “Snapdragon automatically equals better” idea starts showing some cracks.
Benchmark
Galaxy S26 (Exynos 2600)
Galaxy S26 Ultra (Snapdragon 8 Elite Gen 5)
Oppo Find X9 (Dimensity 9500)
AnTuTu Total
3,101,654
3,638,265
3,512,048
Geekbench 6 Single-Core
3,036
3,524
3,207
Geekbench 6 Multi-Core
10,534
10,823
9,345
3DMark Wild Life Extreme
6,366
6,519
7,142
3DMark Wild Life Extreme Stress Test Stability (%)
53.5
63.2
54.9
Temperature After Stress Test (°C)
40.2
38.7
39.2
Galaxy S26 was a pleasant surprise
The easiest surprise here is that the Exynos 2600 does not show up as some obvious weak link. In my testing, the base Galaxy S26 put up 3,036 single-core and 10,534 multi-core in Geekbench 6, plus an AnTuTu score of 2,859,177. Historically, Samsung released its flagship devices in two variants. Historically, Samsung released its flagship devices in two variants. North America, China, and Japan got Snapdragon versions, while the rest of the world got Exynos processors. The company faced a lot of criticism for that split because older flagship models on Exynos chips often fell behind their Snapdragon-powered counterparts.
Advertisement
Nadeem Sarwar / Digital Trends
That, along with chip production yield issues, pushed Samsung to make a few generations of Galaxy S phones exclusively with Snapdragon processors. But it looks like Exynos is back. On 3DMark Wild Life Extreme, the Galaxy S26 scored 6366. The stress-test results are a little more mixed, delivering 53.5% stability in the stress test. These are healthy numbers for a smaller flagship, especially one many people were probably ready to dismiss the moment they saw “Exynos” on the spec sheet.
The S26 Ultra is faster, but not by much
The Galaxy S26 Ultra still has advantages, and that’s not really surprising. Its Wild Life Extreme Stress Test posted a best loop score of 6,519 and 63.2% stability, helped by its larger vapor chamber cooling setup. So yes, the overall thermal performance was better, but not by the kind of margin that completely changes the conversation when you compare it with the standard S26. In both AnTuTu and Geekbench, the Galaxy S26 Ultra led the pack. Exynos still lags a bit, but the gap is no longer the kind you would notice in ordinary day-to-day performance.
Nadeem Sarwar / Digital Trends
The S26 Ultra is clearly faster, but the difference is nowhere near as dramatic as older Snapdragon-versus-Exynos comparisons used to be. Especially when you compare the GeekBench scores, the performance is almost identical. Even without the upgraded cooling setup, the Galaxy S26 managed to stay surprisingly close to the S26 Ultra in the stress test. Where the Ultra does pull ahead more clearly is stability, which matters more once you start talking about sustained performance under load.
MediaTek is the part that makes the race fun
The Dimensity 9500 in the Oppo Find X9 Pro is what really makes this conversation interesting. Its Geekbench 6 single-core score of 3,203 beats the base Galaxy S26, while its AnTuTu score of 3,512,048 edges ahead as well. On 3DMark Wild Life Extreme, it posted 7,142, which puts it above both the S26 and the S26 Ultra.
Oppo
MediaTek is no longer showing up as the “other” flagship chip brand. It is putting up top-tier numbers and staying in the same conversation as Qualcomm and Samsung’s in-house silicon. For a long time, Dimensity chips were seen as the more budget-friendly alternative powering cheaper mid-range and entry-level phones. Results like these show how much ground MediaTek has made up at the high end. There is still a weak point here, which is the 54.9% stress-test stability, which trails the S26 Ultra.
Snapdragon still makes excellent chips, and the S26 Ultra proves that easily. But reputation alone is no longer a substitute for looking at the actual results. The Exynos 2600 has enough performance to not fall behind anymore, and the Dimensity 9500 is close enough in raw horsepower to make the flagship chip race feel properly competitive again.
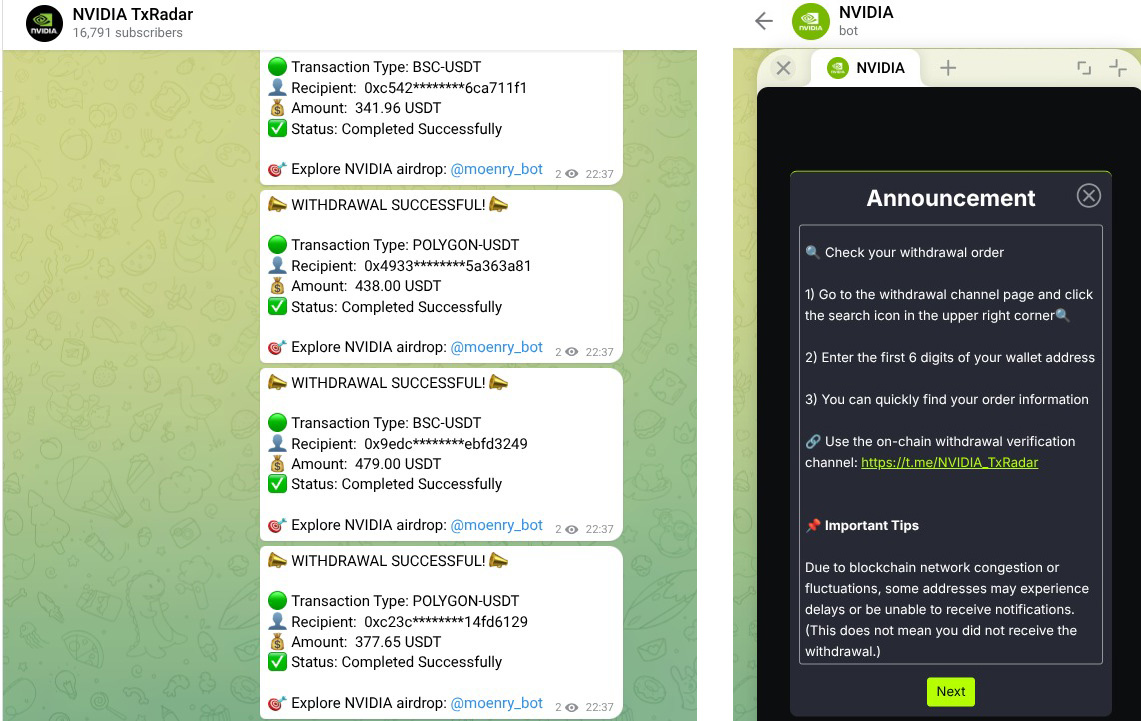
Cybersecurity researchers have uncovered a large-scale fraud operation that uses Telegram’s Mini App feature to run crypto scams, impersonate well-known brands, and distribute Android malware.
A new report by CTM360 says the platform, dubbed FEMITBOT, is based on a string found in API responses and uses Telegram bots and embedded Mini Apps to create convincing, app-like experiences directly within the messaging platform.
Telegram Mini Apps are lightweight web applications that run inside Telegram’s built-in browser, enabling services such as payments, account access, and interactive tools without requiring users to leave the app.
Abusing Telegram mini apps
According to a CTM360 report shared with BleepingComputer, the FEMITBOT platform is used to conduct multiple types of scams, including fake cryptocurrency platforms, financial services, AI tools, and streaming sites.
Advertisement
In various campaigns, threat actors impersonated widely recognized brands to increase credibility and engagement, while using the same backend infrastructure with different domains and Telegram bots.
Some of the brands impersonated in this campaign include Apple, Coca-Cola, Disney, eBay, IBM, Moon Pay, NVIDIA, YouKu,
Telegram Mini App impersonating NVIDIA Source: CTM360
Researchers say the activity uses a shared backend, where multiple phishing domains use the same API response, “Welcome to join the FEMITBOT platform,” indicating they are all using the same infrastructure.
API response found in FEMITBOT campaigns Source: CTM360
The operation uses Telegram bots to display phishing sites directly within the social media platform. When a user interacts with a bot and clicks “Start,” the bot launches a Mini App that displays a phishing page in Telegram’s built-in WebView, making it appear as part of the app itself.
Once inside, victims are shown dashboards with fake balances or “earnings,” often paired with countdown timers or limited-time offers to create a sense of urgency.
When users attempt to withdraw funds, they are prompted to make a deposit or complete referral tasks, a common tactic in investment and advance-fee scams.
Advertisement
The researchers say the infrastructure is designed to be used across different campaigns, allowing attackers to easily switch branding, languages, and themes.
The campaigns also use tracking scripts, such as Meta and TikTok tracking pixels, to track users’ activity, measure conversions, and likely to optimize performance.
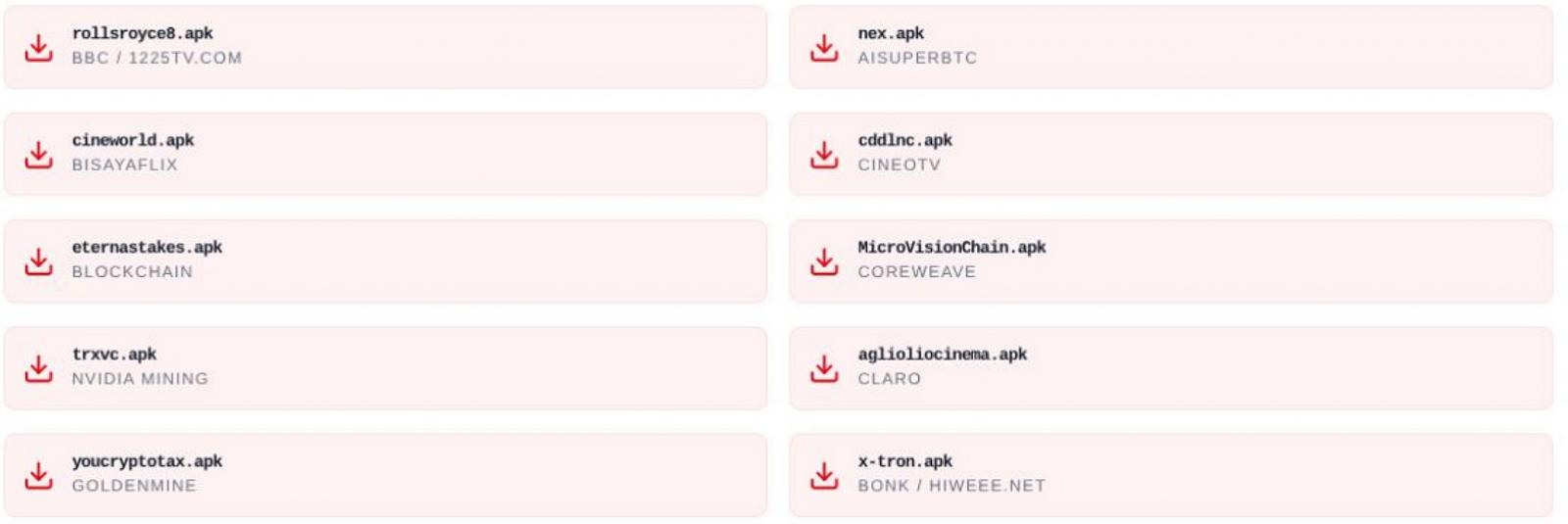
Some Mini Apps also attempted to distribute malware in the form of Android APKs that impersonated brands like the BBC, NVIDIA, CineTV, Coreweave, and Claro.
Some of the Android APKs pushed by FEMITBOT Source: CTM360
Users are prompted to download Android APK files, open links within the in-app browser, or install progressive web apps that mimic legitimate software.
“The APK filenames are carefully chosen to resemble legitimate applications or use random-looking names that don’t immediately trigger suspicion,” explains CTM360.
Advertisement
“The APKs are hosted on the same domain as the API, ensuring TLS certificate validity and avoiding mixed-content warnings in the browser.”
Users should be cautious when interacting with Telegram bots that promote crypto investments or prompt them to launch Mini Apps, especially if they are asked to deposit funds or download apps.
As a general rule, Android users should avoid sideloading APK files, which are commonly used to distribute malware outside the Google Play Store.
AI chained four zero-days into one exploit that bypassed both renderer and OS sandboxes. A wave of new exploits is coming.
At the Autonomous Validation Summit (May 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls hold, and closes the remediation loop.
A new Quordle puzzle appears at midnight each day for your time zone – which means that some people are always playing ‘today’s game’ while others are playing ‘yesterday’s’. If you’re looking for Sunday’s puzzle instead then click here: Quordle hints and answers for Sunday, May 3 (game #1560).
Quordle was one of the original Wordle alternatives and is still going strong now more than 1,400 games later. It offers a genuine challenge, though, so read on if you need some Quordle hints today – or scroll down further for the answers.
Enjoy playing word games? You can also check out my NYT Connections today and NYT Strands today pages for hints and answers for those puzzles, while Marc’s Wordle today column covers the original viral word game.
Advertisement
SPOILER WARNING: Information about Quordle today is below, so don’t read on if you don’t want to know the answers.
Article continues below
Quordle today (game #1561) – hint #1 – Vowels
How many different vowels are in Quordle today?
• The number of different vowels in Quordle today is 4*.
* Note that by vowel we mean the five standard vowels (A, E, I, O, U), not Y (which is sometimes counted as a vowel too).
Advertisement
Quordle today (game #1561) – hint #2 – repeated letters
Do any of today’s Quordle answers contain repeated letters?
• The number of Quordle answers containing a repeated letter today is 2.
Quordle today (game #1561) – hint #3 – uncommon letters
Do the letters Q, Z, X or J appear in Quordle today?
• No. None of Q, Z, X or J appear among today’s Quordle answers.
A friend asked ChatGPT for input on a professional matter and received a banal, lackluster response. I suggested she try a different approach: ask for 15 different ideas, scan them, pick the two that felt most promising, and then ask ChatGPT to refine. She came back overjoyed. ChatGPT had not gotten smarter, but she became better at prompting.
This is my favorite gambit: ask AI for many options, delve deeper into the promising ones, and most importantly, if at first you don’t succeed, prompt, prompt again!
What follows is practical advice on how to use AI as a power tool rather than a slot machine. For a simple request, it’s overkill, but if you’re serious about prompting, read on.
Anthropic’s own guidance for prompting Claude contains a helpful hint: treat the model as a brilliant but literal-minded new employee on their first day. They are capable. They are also new. They will do exactly what you ask, so you have to ask exactly what you want.
Advertisement
The Anthropic team’s golden rule is to show your prompt to a colleague with no context and ask whether they could follow it. If the answer is no, the model can’t either. This principle generates a handful of habits that lift output quality immediately, before any of the more advanced techniques come into play.
One caveat from me, though: don’t think of the model as a person. It’s not. The “brilliant new employee” framing is a useful starting point, but it’s a metaphor, not reality. A new hire asks follow-up questions, remembers what you said yesterday, and notices when an instruction is dumb. Claude does none of that by default. Lean on the metaphor to remember to be specific and provide context, but drop it the moment you start to expect human judgment that just isn’t there.
Here’s the playbook, organized as a list for easy reference and periodic review.
Be specific about format, length, audience, and constraints.
Advertisement
Vague prompts produce vague output. The fix is to say what you actually want.
Before: Write about marketing trends.
After: Analyze the three most significant B2B SaaS marketing trends from the past six months. For each, give one company example and a one-sentence assessment of whether the trend will accelerate or plateau. Write it as a 400-word brief for a non-technical board.
Improving prompt quality is often simply stating constraints. Vague prompts produce safe, hedged, encyclopedic answers because the model has no signal about what to optimize for and defaults to coverage. Specific prompts produce opinionated, useful answers because the constraints eliminate the safe-but-useless options. Asking for “three” instead of “some” forces ranking. Asking for “accelerate or plateau” forces a call. Asking for “a board brief” determines what gets cut. Each constraint you add is a decision the model no longer gets to dodge.
Provide a few examples.
This is the highest-leverage move in everyday prompting. Models pick up patterns from examples faster than from descriptions.
Before: Turn these meeting notes into action items.
After: Turn these meeting notes into action items. Match this format: Example 1: Note: “Sarah will look into the pricing question and get back to us next week.” Action item: Sarah → research pricing options → due next Friday. Example 2: Note: “We agreed to push the launch.” Action item: Team → revise launch timeline → due before Monday’s standup. Now do the same for these notes: [paste]
Tell the model what to do, not what not to do.
Negative instructions are easier to violate than positive ones. Reframing in the affirmative gets you cleaner results.
Advertisement
Before: Don’t be too formal. Don’t use jargon. Don’t make it boring.
After: Write in a warm, conversational tone, the way a smart colleague would explain this over coffee. Use plain English and short sentences.
Match the style of your prompt to the style of the output you want.
This one surprises some people. If your prompt is full of bullets and bold text, the model will return bullets and bold text. If you want flowing prose, write in flowing prose.
These habits sound modest. But applied together, they take prompts from the level my friend was operating at, where ChatGPT seemed unhelpful, to a level where AI yields dividends left and right. The advanced techniques in the rest of this piece build on this foundation, but they won’t rescue a prompt that fails the basics.
Beyond the basics, here is a set of effective habits that show up in guidance from OpenAI, Google, working developers, and the people who build production AI systems for a living. These are not techniques so much as workflow disciplines.
Iterate; treat prompting as test-driven.
Advertisement
Your first prompt is a draft. The most experienced practitioners build small sets of test cases (the inputs they care about), run their prompt across them, and refine until the output is consistently good. Several open-source toolkits exist to formalize this loop.
Before: Write the prompt. Try it on one example. Looks good. Ship it.
After: Write the prompt. Pick five inputs, including the awkward edge cases. Run the prompt on all five. Where it fails, change one thing in the prompt and retest. Keep the version that works on the most cases.
Specify a definition of done.
OpenAI’s own guidance for GPT-5 stresses telling the model what counts as a finished answer. Without that, the model decides for itself, often by stopping at the first plausible-looking response.
Before: Help me debug this Python error.
After: Help me debug this Python error. You are done when: (1) you have identified the root cause, (2) you have proposed a specific fix with the corrected code, and (3) you have explained why the original failed. If you are not confident on any of those three, say so explicitly rather than guessing.
Calibrate effort to the task.
Modern reasoning models have effort or thinking dials. Low effort for extraction and triage; high for synthesis and strategy. Most users leave them on default and pay for it on hard problems.
Before: Summarize this 80-page report.
After: Set thinking effort to high. Read the entire report. Identify the three most important findings, the two weakest claims, and the one question I should ask the authors. Cite page numbers.
Inject current or proprietary context directly.
Be careful to avoid jargon and abbreviations unknown to the model (instead of the acronym PMO, say “Project Management Office”). Models don’t have access to your internal documents. Paste in the relevant material.
Advertisement
Before: How should I structure a related work section comparing my framework to prior agent governance proposals?
After: Below is my current draft related work section, plus PDFs of the three papers I am positioning against (pasted). Based only on these sources, identify points of overlap I have not yet acknowledged and any claims in my draft that the cited papers would not actually support.
Build a personal prompt library.
This is a power move for a pro. The patterns that worked yesterday are likely to work tomorrow. Stop rewriting them from scratch. Save the prompts that consistently produce good results, organized by task type. Treat them as living documents, not one-off attempts.
Before: Open a new chat. Type out the framing, the constraints, the examples, and the question from memory. Watch yourself forget two of them.
After: Open your prompt library. Copy the “draft a memo for my manager” template. Paste in today’s specific topic and source material. Run.
Here are some key don’ts:
Don’t tell reasoning models to “think step by step.”
Models like OpenAI’s o-series and GPT-5 thinking already do that internally. Adding the instruction can hurt rather than help. Save it for the everyday models.
Don’t lean on “do not” or “never” instructions for everything.
Advertisement
Models, especially Gemini, can over-index on broad negative constraints and degrade on basic reasoning. Prefer positive framing: tell the model what to do.
Don’t trust polished prose as evidence of correctness.
Hallucinations are most dangerous when they are well-written. As I pointed out in How to Read with AI, you have to carefully verify AI output.
Don’t use aggressive language (“CRITICAL: You MUST…”).
Advertisement
Modern models are highly responsive to ordinary instructions. Aggressive phrasing can produce overcautious output and triggers refusals. Use normal language.
Don’t include undefined acronyms in your prompt.
They measurably degrade output. For research on the impact of prompt changes see this recent paper on Brittlebench.
Don’t change three things at once when iterating.
Advertisement
When a prompt isn’t working, change one variable, test, then change the next. Otherwise you don’t know what helped.
Don’t assume that the same prompt works across models.
Different model families need different prompting. The same instruction can help one and hurt another. The temperature and effort settings that work for GPT are not the ones that work for Claude or Gemini.
Don’t treat the first answer as the final one.
Advertisement
Failing to iterate is a common failure mode in everyday AI use. Here’s a trick for making AI better at multi-step tasks: after each attempt, have the AI write a short critique of what went wrong and tuck that note into its memory for the next try. No fancy mechanics, just the model “talking to itself” in plain English. On the next attempt, it reads its own past reflections and adjusts. This loop can produce meaningful gains over one-shot prompts.
The people who get the most out of AI aren’t the ones with the best prompt templates. They’re the ones who treat the model as a powerful tool for advancing their work. You don’t need to show up with perfect clarity about what you want. A good dialog can get you there, surfacing options and questions you’d have missed on your own. What it can’t do is recognize the right answer when it appears. That part is still on you.
Editor’s note: GeekWire publishes guest opinions to foster informed discussion and highlight a diversity of perspectives on issues shaping the tech and startup community. If you’re interested in submitting a guest column, email us at tips@geekwire.com. Submissions are reviewed by our editorial team for relevance and editorial standards.
Welcome back to TechCrunch Mobility — your central hub for news and insights on the future of transportation. To get this in your inbox, sign up here for free — just click TechCrunch Mobility!
We’re going to do a bit of a deep dive today, which may make this newsletter look a little different than normal. There is a reason!
This newsletter is not region-specific, but sometimes there are policies at the state level that have widespread implications for tech companies and startups alike. Which brings me to California and the new autonomous vehicle testing and deployment rules issued this week by the state’s Department of Motor Vehicles.
There are two new sets of rules — collectively 100 pages long — that cover requirements for the testing and deployment of AVs. I spent the past few days speaking to engineers and policy folks working at AV companies and discovered that they have strong opinions and few want to speak publicly about it. But thanks to the public commentary period on these regulations, we have some insight into what the industry supported and what it did not.
Advertisement
The regulations include new, more robust requirements for data collection and sharing, training, and operations. Here are a few items that stuck out and what insiders told me.
How do you ticket a robotaxi? Under these new rules, law enforcement can cite AV companies for traffic violations committed by their vehicles. The rule, called “Notice of Autonomous Vehicle Noncompliance,” requires the manufacturer (meaning the robotaxi company) to report the violation to the DMV within 72 hours of receiving it from law enforcement.
I’ve heard a number of interpretations of this rule and how it will be implemented, but it appears there is not a monetary fine attached to these violations. Instead, these violations are another piece of data that the DMV can use to identify problems and take action if needed.
Techcrunch event
Advertisement
San Francisco, CA | October 13-15, 2026
Insiders told me that the data is actionable and more important than a monetary fine. My question: Why not both?
Advertisement
The good news for industry: The DMV will now allow heavy-duty vehicles equipped with autonomous vehicle tech to test and eventually deploy on public roads. Self-driving truck companies are happy with this outcome. Daniel Goff, VP of external affairs at Kodiak, told me the company is already working on the required documentation to apply for a permit.
The burden for the industry: The word that came up in every conversation I had with someone in the AV industry was “burdensome.” And it was always used in reaction to the new data collection and sharing regulations.
Goodbye, disengagement reports; hello, malfunctions: Others were happy to see annual disengagement reporting disappear. Disengagement reports, which detailed instances when human drivers had to take over control due to technology failures or safety concerns, have been controversial because companies use varying standards. This has made it impossible to compare the results or rate the proficiency of autonomous vehicle technology.
That entire section has been removed and replaced with a requirement to report “dynamic driving task performance relevant system failure.” This may seem like semantics — trading one jargony phrase for another. Insiders tell me that while it is not a perfect metric, it is clearer than its predecessor. That doesn’t mean it is beloved either.
Advertisement
There is a lot more in these documents, including a requirement to provide annual updates to first responder interaction plans, access to manual vehicle override systems, two-way communication links with 30-second response times, and updated training requirements to ensure safe and timely interactions with first responders.
My question for you, reader, is whether these rules go too far or if they are appropriate and provide the kind of reporting and data collection needed to keep these companies accountable? Sign up for the Mobility newsletter to vote in our polls!
A little bird
Image Credits:Bryce Durbin
We had a lot of little birds talk to us about the new California AV rules, so nothing new to add here. But remember, you can always send us tips. Here’s how.
BMW i Ventures launched a new $300 million fund with a timely thesis: AI will reshape how the automotive industry operates. The fund will invest in early-stage through Series B startups in North America and Europe that are working on agentic AI and physical AI as well as industrial software, advanced materials, and manufacturing and supply-chain technologies. This third fund brings the firm’s total capital under management to $1.1 billion.
Other deals that got my attention …
Advertisement
Sereact, a German robotics startup, raised $110 million in a Series B funding round led by VC Headline. Other investors include Bullhound Capital, Felix Capital, Daphni, Air Street Capital, Creandum, and Point Nine.
Spirit Airlines is preparing to shut down after failing to secure a $500 million lifeline from the government, the WSJ reports. The company is expected to cease operations around 3 a.m. ET Saturday.
Notable reads and other tidbits
Image Credits:Bryce Durbin
China suspended issuing new licenses for autonomous vehicles after dozens of Baidu’s Apollo Go robotaxis suddenly stopped last month, Bloomberg reported.
Faraday Future paid around $7.5 million to a company controlled by its founder, Jia Yueting, in 2025, senior reporter Sean O’Kane discovered in a recent SEC filing.
Advertisement
Rivian reported earnings this week and one item that stood out to us — and to many others — was the downsizing of its DOE loan from $6.6 billion to $4.5 billion. That loan restructuring comes with changes to its Georgia factory. Instead of two 200,000-vehicle capacity structures on the Georgia site, Rivian will now build a 300,000-vehicle capacity factory and leave the adjacent “pad” untouched and ready for future development. Analysts didn’t necessarily view this as negative but did position this as rightsizing. Barclays, for instance, views the modification as Rivian adjusting to the current EV environment, according to a research note published Friday. Barclays also stated it didn’t believe Rivian currently plans to build the second plant at Georgia, “at least not until early/mid next decade.”
Tesla launched a Semi-Charging for Business program, which includes a new product called the Basecharger that is designed for depot and overnight use.
Uber has tapped Hertz to clean, charge, and fix its Lucid Motors robotaxis. This announcement left us with a cheeky question: How many companies does it take to launch a robotaxi service?
Uber customers in the United States can now book hotels directly through the app, one of several new features announced this week that pushes far beyond the company’s original ride-hailing purpose and even deeper into its users’ lives. At launch, Uber customers will have access to more than 700,000 hotels worldwide through a partnership with Expedia Group, the travel company that Uber CEO Dara Khosrowshahi led for 12 years.
Advertisement
Vay, a remote driving tech startup, says it has grown its fleet to 175 vehicles on the road and has surpassed 60,000 rides.
When you purchase through links in our articles, we may earn a small commission. This doesn’t affect our editorial independence.
Saveitforparts picked up a heavy Sigma 400mm XQ lens and its matching 2x teleconverter at a local thrift store for $14.99. He carried the whole assembly home, attached a simple adapter, and mounted it on a decade-old Sony NEX-3 digital camera. The goal looked simple on paper: point the bargain rig skyward when the International Space Station passed overhead and record whatever showed up in the frame.
He began by checking the pass predictions on n2yo.com and the NASA Spot the Station app to determine when and where the ISS would cross the sky above his position. Timing was critical since the ISS moves so quickly that one second too late leaves you with nothing but an empty blue sky. He placed the lens on its built-in tripod foot, approximately oriented it along the projected route, and simply waited for the bright little dot formed by sunlight reflecting off the station’s solar panels.
Superior Optics: 400mm(f/5.7) focal length and 70mm aperture, fully coated optics glass lens with high transmission coatings creates stunning images…
Magnification: Come with two replaceable eyepieces and one 3x Barlow lens.3x Barlow lens trebles the magnifying power of each eyepiece. 5×24 finder…
Wireless Remote: This refractor telescope includes one smart phone adapter and one Wireless camera remote to explore the nature of the world easily…
Getting a clear focus was difficult from the start, as dirt had gathered inside the old lens over time, dispersing light and destroying the details. So he began by practicing on the moon, adjusting the focus until the craters appeared sharp enough to see through the viewfinder. Getting the shutter speed and exposure exactly right required a delicate balance; too slow and the station blurred into a streak, too quick and the small dot vanished against the sky.
The first few passes produced exactly what he expected: a small white speck dead center in each frame. He switched to a Canon HF G70 camcorder with a 2.2x telephoto converter, which produced video rather than stills, but the results were still unimpressive. He was able to re-capture the station as a moving blob, occasionally catching a glimpse of its center body and extending solar arrays when the alignment and illumination conditions were exactly right.
He was fired up and undeterred, so he focused on solar transits. These events last less than 4 seconds and occur low on the horizon, 12,000 kilometers away from the station. He put a pair of solar viewing glasses over the camcorder lens to block out some of the sun’s brightness, programmed the camera to capture a series of photos in quick succession at 1/250th of a second, and waited for the projected moment to arrive. But the atmospheric haze from the morning added another layer of distortion, making it a little difficult, but he still managed to capture a few frames that showed the station as a clear black speck traveling across the sun’s disk. Taking those frames and putting them together in software proved that the timing was exactly what the transit calculation predicted.
Every attempt revealed the same limitations, with the total focal length reaching a whopping 800mm on the still camera and even more on the camcorder, but the station remained too far away to capture any full-on structural details. Hand-tracked motions were a pain; there was no fancy motorized mount to speak of, so any tiny movement during the limited window could put the target straight out of view. A full moon transit was cut short by a bank of clouds and a lot of bad luck. [Source]
A new NYT Connections puzzle appears at midnight each day for your time zone – which means that some people are always playing ‘today’s game’ while others are playing ‘yesterday’s’. If you’re looking for Sunday’s puzzle instead then click here: NYT Connections hints and answers for Sunday, May 3 (game #1057).
Good morning! Let’s play Connections, the NYT’s clever word game that challenges you to group answers in various categories. It can be tough, so read on if you need Connections hints.
What should you do once you’ve finished? Why, play some more word games of course. I’ve also got daily Strands hints and answers and Quordle hints and answers articles if you need help for those too, while Marc’s Wordle today page covers the original viral word game.
Advertisement
SPOILER WARNING: Information about NYT Connections today is below, so don’t read on if you don’t want to know the answers.
Article continues below
NYT Connections today (game #1058) – today’s words
(Image credit: New York Times)
Today’s NYT Connections words are…
MARSHMALLOW
LABUBU
RADIO
CHOWDER
BEANIE BABY
STOVE
PITTER-PATTER
ETCH A SKETCH
TEDDY BEAR
DESICCANT PACKET
DOODLEBUG
SWEETHEART
HACKY SACK
CONTROL PANEL
SOFTIE
EYE PILLOW
NYT Connections today (game #1058) – hint #1 – group hints
What are some clues for today’s NYT Connections groups?
YELLOW: Kind people
GREEN: Filled with beads etc
BLUE: Turn the dials
PURPLE: Begin with types of canine
Need more clues?
We’re firmly in spoiler territory now, but read on if you want to know what the four theme answers are for today’s NYT Connections puzzles…
Advertisement
Sign up for breaking news, reviews, opinion, top tech deals, and more.
NYT Connections today (game #1058) – hint #2 – group answers
What are the answers for today’s NYT Connections groups?
YELLOW: TENDER-HEARTED PERSON
GREEN: PELLET-FILLED THINGS
BLUE: THINGS WITH KNOBS
PURPLE: STARTING WITH FAMILIAR NAMES FOR KINDS OF DOGS
Right, the answers are below, so DO NOT SCROLL ANY FURTHER IF YOU DON’T WANT TO SEE THEM.
Advertisement
NYT Connections today (game #1058) – the answers
(Image credit: New York Times)
The answers to today’s Connections, game #1058, are…
YELLOW: TENDER-HEARTED PERSON MARSHMALLOW, SOFTIE, SWEETHEART, TEDDY BEAR
BLUE: THINGS WITH KNOBS CONTROL PANEL, ETCH A SKETCH, RADIO, STOVE
PURPLE: STARTING WITH FAMILIAR NAMES FOR KINDS OF DOGS CHOWDER, DOODLEBUG, LABUBU, PITTER-PATTER
My rating: Hard
My score: 2 mistakes
My first mistake was thinking that LABUBU, BEANIE BABY, ETCH A SKETCH and HACKY SACK were all something to do with childhood trends — I was less confident about HACKY SACK, obviously.
Next, I connected the soft and squishy things and after getting one away realized we were looking for soft and squishy people types of people or indeed a TENDER-HEARTED PERSON, so swapped EYE PILLOW for SWEETHEART.
CONTROL PANEL seemed an odd tile but after a shuffle I managed to cotton on that we were looking for THINGS WITH KNOBS.
With eight tiles left I got four of the dog-related tiles and gambled on PITTER-PATTER. All in all not my finest day of deduction.
Advertisement
Yesterday’s NYT Connections answers (Sunday, May 3, game #1057)
YELLOW: HOME STRUCTURES GARAGE, HOUSE, PORCH, SHED
GREEN: ASSOCIATED WITH 1960S COUNTERCULTURE ACID, COMMUNE, FREE LOVE, HIPPIE
BLUE: FAMOUS REVOLUTIONS IN HISTORY FRENCH, GREEN, INDUSTRIAL, SEXUAL
PURPLE: GESTURES MADE WITH THE INDEX AND MIDDLE FINGERS AIR QUOTES, BUNNY EARS, FINGERS CROSSED, PEACE
What is NYT Connections?
NYT Connections is one of several increasingly popular word games made by the New York Times. It challenges you to find groups of four items that share something in common, and each group has a different difficulty level: green is easy, yellow a little harder, blue often quite tough and purple usually very difficult.
On the plus side, you don’t technically need to solve the final one, as you’ll be able to answer that one by a process of elimination. What’s more, you can make up to four mistakes, which gives you a little bit of breathing room.
It’s a little more involved than something like Wordle, however, and there are plenty of opportunities for the game to trip you up with tricks. For instance, watch out for homophones and other word games that could disguise the answers.
It’s playable for free via the NYT Games site on desktop or mobile.
OpenAI has opened ChatGPT subscriptions to OpenClaw, the open-source AI agent framework with 346,000 GitHub stars and 3.2 million users, allowing subscribers to run autonomous agents via GPT-5.4 for $23 per month. The move is the opposite of Anthropic’s decision to block Claude subscriptions from OpenClaw in April, creating a competitive split where OpenAI bets on distribution and Anthropic protects margins.
Advertisement
Sam Altman posted on X at 2:33 a.m. on 2 May: “you can sign in to openclaw with your chatgpt account now and use your subscription there! happy lobstering.” The announcement, delivered with the casual register of a founder pushing a minor product update, is anything but minor. OpenAI has made its ChatGPT subscription the authentication and billing layer for OpenClaw, the open-source AI agent framework that became the fastest-growing project in GitHub history, accumulated 346,000 stars in under five months, and is now used by more than three million people. ChatGPT Plus subscribers can log in via OAuth, access GPT-5.4 through the Codex endpoint, and run autonomous AI agents on their own hardware for $23 per month total. OpenAI did not build the most popular AI agent in the world. It hired the developer, backed the foundation, and opened the login.
The lobster
OpenClaw was created in November 2025 by Peter Steinberger, an Austrian developer who had previously sold a software company for $100 million and was experimenting with AI coding tools in a Madrid cafe. The first version was called Clawdbot, a play on Anthropic’s Claude with a lobster mascot. Anthropic filed a trademark complaint. Steinberger renamed it Moltbot, then, because that “never quite rolled off the tongue,” renamed it again to OpenClaw. The lobster stayed.
The product is a locally hosted AI agent that connects to large language models, Claude, GPT, DeepSeek, and others, and operates through the messaging apps people already use: WhatsApp, Telegram, Signal, Discord, Slack, iMessage, Microsoft Teams. It manages calendars, sends emails, organises files, writes code, browses the web, and executes multi-step workflows autonomously. The data stays on the user’s machine. The agent runs continuously in the background. Jensen Huang called it “the most popular open-source project in the history of humanity” at Nvidia’s GTC conference in March. It surpassed React’s ten-year GitHub record in 60 days.
On 4 April, Anthropic blocked Claude Pro and Max subscribers from using their flat-rate subscription plans with OpenClaw and other third-party AI agent frameworks. The reason was cost: OpenClaw agents running autonomously can generate thousands of API calls per day, consuming far more compute than a human typing queries into a chat window. Anthropic decided that unlimited subscription access through an agent framework was economically unsustainable and shut it down.
Advertisement
Anthropic’s decision to ban OpenClaw from Claude subscriptions was a defensive move to protect margins. OpenAI’s decision to do the opposite, to open ChatGPT subscriptions to OpenClaw, is an offensive one. By making ChatGPT the default backend for the world’s most popular agent framework, OpenAI is betting that the volume of new subscribers will more than compensate for the increased compute cost per user. The economics only work if OpenClaw converts a significant number of its 3.2 million users into paying ChatGPT subscribers. If it does, OpenAI will have acquired a distribution channel for its subscription product that no amount of marketing could have built.
The competitive dynamics are stark. Anthropic looked at OpenClaw and saw a cost problem. OpenAI looked at the same product and saw a distribution opportunity. One company locked the door. The other opened it and handed out the keys.
The risks
OpenClaw’s rapid growth has been accompanied by equally rapid security failures. In late January, a critical remote code execution vulnerability, CVE-2026-25253, was disclosed: any website a user visited could silently connect to the agent’s local server through an unvalidated WebSocket, chaining a cross-site hijack into full code execution on the user’s machine. Security researchers audited ClawHub, OpenClaw’s skills marketplace, and found 824 confirmed malicious entries out of 10,700 available skills, with 335 traced to a single coordinated attack operation. More than 30,000 OpenClaw instances were found exposed on the public internet without authentication. Moltbook, the social layer for agents, suffered a breach that exposed 1.5 million API tokens and thousands of private conversations.
The vulnerabilities have been patched in current versions. The problem is that a significant portion of the installed base is running older, unpatched versions. Anything before version 2026.1.30 remains vulnerable to at least some of the disclosed exploits, and attackers are still targeting them. OpenAI’s decision to tie its ChatGPT subscription to OpenClaw means that OpenAI’s brand, its billing system, and its user credentials are now flowing through an open-source platform that has had more security incidents in four months than most enterprise software accumulates in a decade.
Advertisement
The ecosystem
Nvidia turned OpenClaw into an enterprise platform with NemoClaw, adding security hardening, compliance features, and integration with Nvidia’s inference infrastructure. Tencent launched ClawPro, an enterprise AI agent platform built on OpenClaw’s architecture and optimised for the Chinese market. Meta launched Manus AI as a desktop agent, a competing approach that runs as a native application rather than through messaging apps. The agent layer is now a battlefield where every major technology company is staking a position.
The ChatGPT subscription integration positions OpenAI at the centre of this ecosystem without requiring it to own or control the agent framework itself. OpenClaw remains open source, governed by an independent foundation, and compatible with multiple language model providers. But with Anthropic blocking access and OpenAI enabling it, the practical effect is that OpenClaw’s three million users are being funnelled toward ChatGPT as their default model. The foundation structure gives OpenAI deniability. The subscription integration gives it distribution.
The model
The economics are unusual. A ChatGPT Plus subscription costs $20 per month. OpenClaw Launch Lite, a hosted management layer, costs $3 per month. For $23, a user gets access to GPT-5.4 through OpenClaw’s agent framework without per-token API charges. This is substantially cheaper than using the OpenAI API directly, which would cost hundreds of dollars per month at the volume an autonomous agent generates. OpenAI is subsidising agent usage through its subscription tier, betting that the lifetime value of a subscriber who uses ChatGPT through OpenClaw is higher than the compute cost of serving their agent’s requests.
This is the same logic that drove mobile carriers to subsidise smartphones: give away the hardware economics to lock in the subscription revenue. OpenAI is giving away the agent access to lock in the ChatGPT subscription. If the bet works, ChatGPT becomes not just a chatbot but the default intelligence layer for a generation of autonomous AI agents that manage people’s digital lives. If it does not work, OpenAI will have opened its most valuable product to a compute-intensive use case that burns through inference capacity without generating proportional revenue.
Advertisement
Altman’s tweet was seven words and a lobster joke. The decision behind it is one of the most consequential distribution bets OpenAI has made since launching ChatGPT. The most popular open-source project in history now runs on your ChatGPT subscription. Whether that is a masterstroke or a margin trap depends entirely on whether three million lobster enthusiasts convert into paying customers, and whether the agent they are running on their laptops is secure enough to deserve the trust that both OpenAI and its subscribers are placing in it.
On a March afternoon, artificial intelligence detected something resembling smoke on a camera feed from Arizona’s Coconino National Forest. Human analysts verified it wasn’t a cloud or dust, then alerted the state’s forest service and largest electric utility. One of dozens of AI cameras installed for the utility Arizona Public Service had spotted early signs of what came to be known as the Diamond Fire. Firefighters raced to the scene and contained the blaze before it grew past 7 acres (2.8 hectares).
As record-breaking heat and an abysmal snowpack raise concerns about severe wildfires, states across the fire-prone West are adding AI to their wildfire detection toolbox, banking on the technology to help save lives and property. Arizona Public Service has nearly 40 active AI smoke-detection cameras and plans to have 71 by summer’s end, and the state’s fire agency has deployed seven of its own. Another utility, Xcel Energy in Colorado, has installed 126 and aims to have cameras in seven of the eight states it serves by year’s end… ALERTCalifornia is a network of some 1,240 AI-enabled cameras across the Golden State that work similar to the system in Arizona….
Pano AI, whose technology combines high-definition camera feeds, satellite data and AI monitoring, has seen a growing interest in its cameras since launching in 2020. They’ve been deployed in Australia, Canada and 17 U.S. states, including Oregon, Washington and Texas… Last year, its technology detected 725 wildfires in the U.S., the company said… Cindy Kobold, an Arizona Public Service meteorologist, said the technology notifies them about 45 minutes faster on average than the first 911 call.







































































You must be logged in to post a comment Login