

AI is coming for the laptop class. While you clack away at your keyboard — writing code or drafting memos or making spreadsheets or scrolling X or perusing DoorDash or reading Vox or dreading death — machines are teaching themselves how to do your job.
Tech
Will AI replace your job? 4 reasons it might not.
Over the past four years, chatbots have gone from neat parlor tricks to hyperproductive polymaths. AI models can now generate new software out of a single English sentence, summarize case law in seconds, read CT scans with superhuman accuracy, and coordinate complex office workflows with scant human oversight.
Large language models (LLMs) — today’s premier form of artificial intelligence — still have their limitations. They can’t reliably fulfill most white-collar workers’ every function. But AI progress is compounding on itself. As LLMs automate the process of building better LLMs, they will kick off a feedback loop of exponential self-improvement.
- Despite AI’s rapid advances, it still hasn’t substantially increased unemployment.
- You don’t necessarily have to outperform AI at your job in order to keep it.
- The go-to evidence for exponential AI progress has serious methodological flaws.
Thus, by the end of next year — if not this one — AI will render much of America’s professional class obsolete and push unemployment to 20 percent. Within a decade, the technology could wipe out virtually all forms of knowledge work.
Or so many of AI’s champions and detractors believe.
In recent weeks, the drumbeat of catastrophic labor-market forecasts has grown louder, with tech CEOs, financial analysts, and journalists penning viral predictions of an impending unemployment crisis.
In my view, the threat of AI-induced unemployment is worth taking seriously. And I’ve sketched out the case for alarm in past essays.
If the AI doomers’ concerns are warranted, however, their certainty is misplaced. Artificial intelligence could trigger mass white-collar layoffs in the near future. But there are plausible arguments against that scenario.
To inject some balance into the AI discourse — and/or, reassure myself that my hard-won verbal skills aren’t about to be less economically valuable than my flimsy biceps — I’ve sought out reasons for optimism about the white-collar labor market. Here are the four that I found most compelling:
1) You can see the AI age everywhere except in the jobs data
The first reason to doubt the doomer scenario for AI and unemployment is that it keeps not happening.
Or, more precisely: Despite the astounding capacities of today’s LLMs, there still aren’t many signs of large-scale, AI-induced job loss.
It takes time for firms to adopt new technologies, of course. But generative AI has been remarkably powerful for a while now. As of late 2024, it could already automate many coding tasks, generate research reports, write ad copy, review legal documents, and make terrible music at a near-human level.
Yet America’s unemployment rate has barely budged over the past two years, hovering near 4 percent.
Even in the industries most suited to AI-driven automation, employment shifts have been modest. Job postings for software developers have actually increased over the past year. Employment in market research, meanwhile, went up after ChatGPT hit the market. Even customer service representatives — arguably, the workers most threatened by chatbots — have not suffered massive job losses: Although employment in the field fell 10 percent from 2023 to 2024, it has held steady since then and remains close to its pre-pandemic level.
What’s more, there are few indications that mass, white-collar layoffs are on the horizon. In a December survey by the accounting firm KPMG, 92 percent of CEOs said they were planning to grow their head counts, even as 69 percent were dedicating a large share of their budgets to AI deployment.
Similarly, a January survey from EY-Parthenon found that 69 percent of CEOs expected that AI would lead them to either maintain or expand their payrolls.
One could dismiss this as sunny bluster. But there is evidence that these executives’ ostensible intuition — that AI adoption and downsizing don’t necessarily go together — holds true in practice. In a study of 12,000 European businesses published in February, firms that adopted AI saw a 4 percent increase in labor productivity — yet did not reduce their staffing in response.
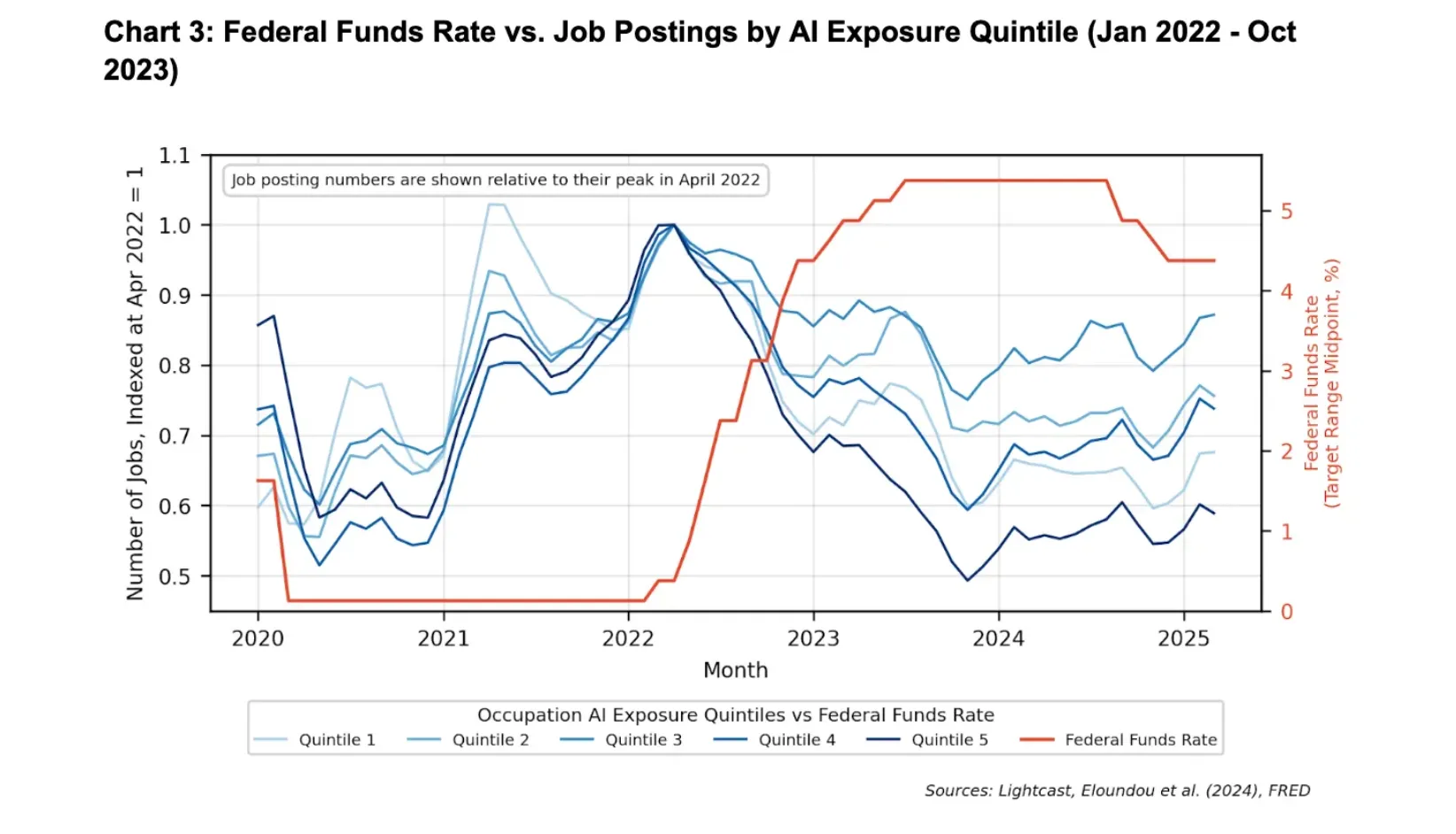
Granted, if you scour the jobs data for portents of an AI-driven unemployment crisis, you can come up with a few. For one, between November 2022 and January 2026, America’s core white-collar industries — finance, insurance, information, and professional and business services — cut their staffing by 1.9 percent. This is unusual; outside of recessions, these sectors have historically added jobs at a steady rate.
For another, a Stanford Digital Economy Lab study suggests that young workers in heavily AI-exposed fields have seen declining job prospects, relative to those in other sectors, since ChatGPT debuted.
Forecasts of an impending white-collar “bloodbath” tend to put a lot of weight on these data points. And yet, both developments likely have less to do with AI adoption than with monetary policy.
As two economists at Google recently observed, America’s most AI-exposed industries began to slash hiring six months before ChatGPT hit the market in November 2022. And white-collar job postings fell most precipitously in 2023, when corporate deployment of LLMs had barely begun; in the fourth quarter of that year, fewer than 10 percent of large businesses said they were even planning to use AI in the next six months.
This timeline is hard to square with the theory that AI drove the slowdown in white-collar hiring. By contrast, the timing neatly aligns with the Federal Reserve’s tightening cycle.
In March 2022, the central bank began hiking interest rates at a historically aggressive pace. A little over one month later, job postings began to fall in white-collar fields. When the Fed paused its hikes in 2024, that decline bottomed out; when the central bank began cutting rates in 2025, job openings started rebounding.

Courtesy of the Economic Innovation Group
Critically, interest rate hikes disproportionately impact AI-exposed industries. The sectors most susceptible to artificial intelligence — tech, finance, and professional services — are also among the most sensitive to tightening financial conditions. And when companies come under strain, they often pause entry-level hiring.
A pullback in employment caused by the Fed could therefore look a lot like one triggered by LLMs.
None of this is to deny that artificial intelligence has reduced employment in some occupations (for example, AI is almost certainly implicated in the recent decline of computer programming jobs). The point is just that the overall labor market impacts have been remarkably modest, given the scale of AI’s current capacities.
2) White-collar workers don’t need to outperform AI to remain economically valuable
The absence of a one-to-one correlation between increases in AI’s capabilities — and declines in white-collar employment — isn’t entirely surprising.
To remain economically valuable, a human worker does not need to outperform a machine at their job’s core tasks; they merely need to usefully complement that machine’s operations.
Consider translators. LLMs can convert text from one language to another at a speed and cost that no human could ever match. For many tasks, if corporations, authors, and publishers were forced to choose between having access to AI — or the world’s most gifted linguist — they would choose the bot.
And yet, a human translator working with an LLM still produces better text than the machine does by itself. While the latter blitzes through a first draft, the former can correct excessively literal translations of idiomatic expressions, tailor tone to the intended audience, and catch subtle errors that invite confusion or legal risk.
So long as human translators retain this utility, AI progress won’t necessarily reduce demand for their services. In fact, the technology could conceivably increase such demand.
That claim might seem unintuitive. After all, it surely takes fewer people to translate any given quantity of text in the age of generative AI than it did in years prior.
Yet humanity’s appetite for translated text is not fixed. If you drastically increase the efficiency of translation — and thus, reduce its cost — then people will purchase more of it.
And indeed, since the introduction of ChatGPT in 2022, demand for translation has surged. Perhaps for this reason, even as machines have come to match or exceed the skills of human translators across several dimensions, employment in the industry has grown in the European Union and stayed roughly level in the US.
And you can tell a similar story about myriad other fields.
AI can read medical images faster — and, for some types of cancer, more accurately — than any human. Still, a radiologist working with an AI yields better diagnoses than the machine working alone. And as LLMs have made radiology more efficient, demand for imaging has spiked — and with it, radiology employment.
3) People want some things done by people
In some domains, white-collar workers may retain an advantage over AI simply because they are human.
As the economist Adam Ozimek notes, many contemporary occupations could have been automated out of existence long ago, were technology the only concern. We’ve had player pianos and recorded music since the late 19th century. Yet many hotels and bars still pay human beings to tickle the keys for their customers.
“People are often willing to pay a premium for the ‘human touch.’”
For decades, it’s been easy to book your own travel online, relying on aggregators like Expedia and reviews on Yelp. Yet 67,500 Americans still make a living as travel agents. Workout videos make it possible for anyone to perform yoga at home, yet many hire personal instructors. Mechanical reproductions of famous paintings can be had at a low cost, yet people shell out millions for visibly indistinguishable versions that were produced by a specific human hand.
You could have asked ChatGPT to give you four reasons why AI won’t cause mass unemployment, and it would have instantly spit out a listicle. Instead, you’re reading an artisanally crafted explainer that Vox Media Inc. paid me to produce.
In other words, people are often willing to pay a premium for the “human touch.”
This won’t preempt an AI-induced employment crisis, all by itself. Consumers don’t typically care how their smartphone apps were coded or insurance claims were processed or tax returns were prepared. But a market for explicitly human-produced goods and services is likely to persist in many realms — including sales, medicine, legal services, and entertainment.
Heck, there might even be durable demand for journalism that’s conspicuously free of AI’s bizarre syntactical tics. That’s not just cope — it’s a serious possibility.
4) AI progress won’t necessarily be exponential
All these arguments may count for little, if AI’s capacities are truly growing at an exponential rate.
After all, exponential processes tend to creep up on you. When 32 cases of a supervirus become 64, almost no one notices. If that bug keeps doubling every couple days, however, the world will wake up a month later to 2.1 million infections. In that scenario, a glance at the pathogen’s impact on day three would have told you little about its consequences four weeks later.
In a world where AI progress is exponential, similar principles apply. Look around three years after ChatGPT’s debut and you might see little job loss. But if artificial intelligence is recursively self-improving — such that every advance accelerates the next — then today’s AI is only a pale imitation of 2030’s. The former may be to the latter as a hot-air balloon is to a space shuttle.
If so, then examining AI’s impact on jobs over the past four years wouldn’t shed much light on its effects over the next four. Likewise, the fact that white-collar workers can usefully complement AI today would scarcely guarantee their utility in the future.
But it’s not clear that AI has actually been improving at an exponential rate, much less that it will keep doing so, for years on end.
Without question, LLMs’ capabilities have been growing rapidly. But claims that this progress has been exponential tend to rest on a single, widely cited benchmark.
The AI research institute METR has long been the authority on the speed of AI progress. To gauge that pace, it tracks the duration of tasks that LLMs can complete with at least 50 percent accuracy. In this context, duration is measured by how long it would take a skilled human worker to complete the same assignment.
METR’s charts of how this has changed over time are ubiquitous in discussions of AI. And the trends are eye-popping.


Faced with these vertiginous slopes, many jump straight to wondering whether they will enjoy life as a “machine God’s” pet — forgetting to first ask themselves, “Wait, how does METR know that?”
Which is unfortunate, since the short answer is it doesn’t.
METR isn’t spying on every white-collar laborer in America, implanting bugs and honeypots in their break rooms, so as to determine how long it takes each worker to perform their jobs’ tasks.
Rather, to generate its estimates, the institute presents human software engineers with a bucket of coding assignments, measures how long they take to complete their tasks, and then sees whether AI models can perform the same feats. Through this process, METR estimates that the latest version of Claude can autonomously perform tasks that would take a skilled worker up to 14.5 hours to execute.
And yet, as NYU’s Nathan Witkin argues, there are massive problems with METR’s methodology, defects that severely limit what its findings can actually tell us about AI’s capabilities. To name just a few:
METR’s tasks are unrealistically basic. In METR’s own analysis, the bulk of their sample tasks differ from real-world engineering problems in systematic ways. Specifically, the former occur in static environments, require no coordination with other people (or agents), and include few resource constraints. METR also largely excluded tasks in which a single mistake could derail the entire project, so as to “reduce the expected cost of collecting human baselines.”
When the institute charted AI’s progress on its “messiest” tasks — which is to say, its most realistic ones — this was the result:

Viewed like this, AI progress does not look terribly exponential.
METR’s human baselines are unreliable. The sample of engineers who established METR’s baseline for human performance was neither large nor representative. Rather, as of 2025, its testing included only 140 people, recruited primarily from METR staffers’ professional networks.
More critically, on the more complex tasks, these recruits were often operating outside of their areas of expertise. In real life, these assignments would typically be handled by specialists, who would surely complete them more rapidly than random engineers with little domain knowledge.
Making matters worse, METR paid its baseliners on a per-hour basis, giving them an incentive to drag out their tasks.
AI could have simply memorized the answers to many of its assigned tasks. About one-third of the tested tasks had publicly available solutions. For these assignments, the models may have just been recalling answers they had encountered on the internet, in which case their success wouldn’t necessarily reflect growth in their general capabilities. (If a high-school student gains access to a calculus test in advance, and memorizes the answer, their performance on that problem wouldn’t tell us much about their general math skills.)
None of this is meant to disparage METR’s intentions, or to suggest that its data has zero utility. The pace of AI progress is not an easy thing to measure. And the organization is making an admirable effort.
Still, the fact that its charts are AI boosters’ (and doomers’) go-to evidence for exponential progress — despite the extreme limitations of its figures — calls the existence of that progress into question.
Moreover, even if we knew that AI has been improving exponentially over the past three years, we still couldn’t take a continuation of that trend for granted. Technologies routinely improve at an exponential rate for a period, only to stall out at a certain level of capability.
Machines might still replace us
These arguments don’t prove that the laptop class is going to be fine. They merely offer a basis for believing that it might be.
Indeed, everything I just wrote could be true — and AI could still drastically erode knowledge workers’ economic prospects.
Even if most white-collar laborers still usefully complement AI, a large minority may not. Meanwhile, those who remain employable might command drastically lower wages than they once did: When building software merely requires the ability to write instructions in plain English — rather than mastering complicated coding languages — programmers’ bargaining power may plummet.
And while AI-driven productivity gains might increase demand for certain goods and services, Americans’ latent appetite for tax advice, HR compliance audits, and contract review is not infinite. In these areas, AI’s boosts to efficiency are liable to yield job losses.
Finally, AI might not be improving at an exponential rate. But over time, linear gains may be sufficient to drastically reduce knowledge workers’ economic utility.
All this said, as the world’s most influential business leaders and intellectuals discuss the impending elimination of white-collar work as though it were no more hypothetical than tomorrow’s sunrise, it’s worth keeping their narrative’s liabilities in mind: This doomsday scenario has scant support in existing employment trends, sits in tension with multiple economic principles, and relies on dubious assumptions about the pace of AI progress.
In other words, while it’s past time for policymakers to prepare for AI-induced unemployment spikes, knowledge workers don’t yet need to toss our keyboards and learn to plumb.

Continue Reading
Looking for the most recent Strands answer? Click here for our daily Strands hints, as well as our daily answers and hints for The New York Times Mini Crossword, Wordle, Connections and Connections: Sports Edition puzzles.
Today’s NYT Strands puzzle has an unusual topic. Some of the answers are difficult to unscramble, so if you need hints and answers, read on.
I go into depth about the rules for Strands in this story.
If you’re looking for today’s Wordle, Connections and Mini Crossword answers, you can visit CNET’s NYT puzzle hints page.
Read more: NYT Connections Turns 1: These Are the 5 Toughest Puzzles So Far
Hint for today’s Strands puzzle
Today’s Strands theme is: That’s dedication.
If that doesn’t help you, here’s a clue: I’m cheering you on.
Clue words to unlock in-game hints
Your goal is to find hidden words that fit the puzzle’s theme. If you’re stuck, find any words you can. Every time you find three words of four letters or more, Strands will reveal one of the theme words. These are the words I used to get those hints but any words of four or more letters that you find will work:
- LORE, REST, RESTS, ROTE, ROTS, STORE, TENT, DOVE, DEVOTE, STEW, LONE
Answers for today’s Strands puzzle
These are the answers that tie into the theme. The goal of the puzzle is to find them all, including the spangram, a theme word that reaches from one side of the puzzle to the other. When you have all of them (I originally thought there were always eight but learned that the number can vary), every letter on the board will be used. Here are the nonspangram answers:
- STAN, LOVER, DEVOTEE, FOLLOWER, ENTHUSIAST
Today’s Strands spangram
The completed NYT Strands puzzle for March 6, 2026.
Today’s Strands spangram is YOURBIGGESTFAN. To find it, start with the Y that’s three letters down on the far-left vertical row, and wind down, up and over.

It’s one thing to create your own relay-based computer; that’s already impressive enough, but what really makes [DiPDoT]’s design special– at least after this latest video— is swapping the SRAM he had been using for historically-plausible capacitor-based memory.
A relay-based computer is really a 1940s type of design. There are various memory types that would have been available in those days, but suitable CRTs for Williams Tues are hard to come by these days, mercury delay lines have the obvious toxicity issue, and core rope memory requires granny-level threading skills. That leaves mechanical or electromechanical memory like [Konrad Zeus] used in the 30s, or capacitors. he chose to make his memory with capacitors.
It’s pretty obvious when you think about it that you can use a capacitor as memory: charged/discharged lets each capacitor store one bit. Charge is 1, discharged is 0. Of course to read the capacitor it must be discharged (if charged) but most early memory has that same read-means-erase pattern. More annoying is that you can’t overwrite a 1 with a 0– a separate ‘clear’ circuit is needed to empty the capacitor. Since his relay computer was using SRAM, it wasn’t set up to do this clear operation.
He demonstrates an auto-clearing memory circuit on breadboard, using 3 relays and a capacitor, so the existing relay computer architecture doesn’t need to change. Addressing is a bit of a cheat, in terms of 1940s tech, as he’s using modern diodes– though of course, tube diodes or point-contact diodes could conceivably pressed into service if one was playing purist. He’s also using LEDs to avoid the voltage draw and power requirements of incandescent indicator lamps. Call it a hack.
He demonstrates his circuit on breadboard– first with a 4-bit word, and then scaled up to 16-bit, before going all way to a massive 8-bytes hooked into the backplane of his Altair-esque relay computer. If you watch nothing else, jump fifteen minutes in to have the rare pleasure of watching a program being input via front panel with a complete explanation. If you have a few extra seconds, stay for the satisfyingly clicky run of the loop. The bonus 8-byte program [DiPDoT] runs at the end of the video is pure AMSR, too.
Yeah, it’s not going to solve the rampocalypse, any more than the initial build of this computer helped with GPU prices. That’s not the point. The point is clack clack clack clack clack, and if that doesn’t appeal, we don’t know what to tell you.
from the lawless-administration dept
This story was originally published by ProPublica. Republished under a CC BY-NC-ND 3.0 license.
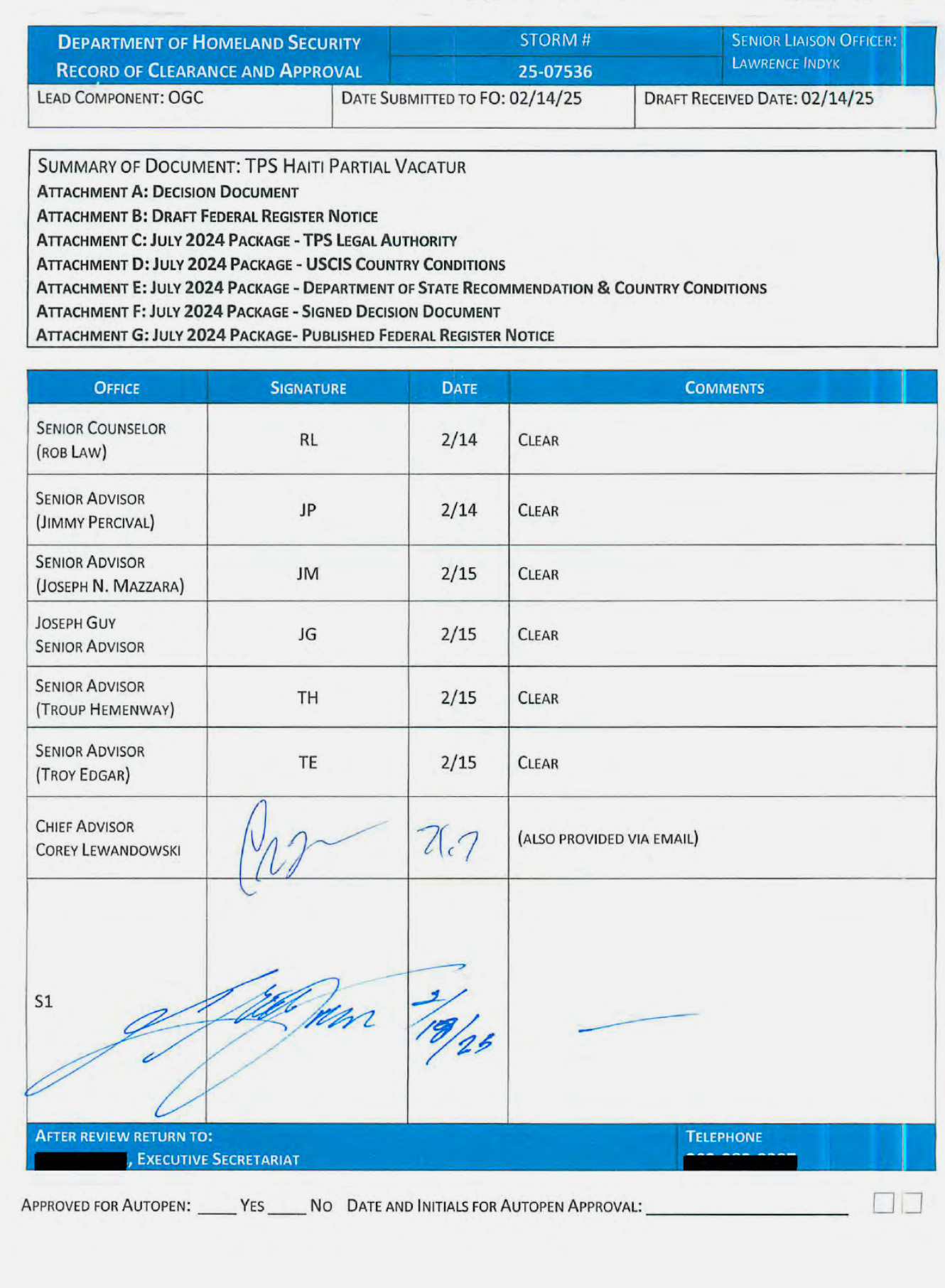
Homeland Security Secretary Kristi Noem misled Congress on Tuesday about the powers of her controversial top aide Corey Lewandowski, according to records reviewed by ProPublica and four current and former DHS officials.
Lewandowski has an unusual role at DHS, where he is not a paid government employee but is nonetheless acting as a top official, helping Noem run the sprawling agency. For months, members of Congress have asked the agency to detail the scope of his work and authority.
At a Senate Judiciary Committee hearing on Tuesday, Sen. Richard Blumenthal, D-Conn., asked Noem whether Lewandowski has “a role in approving contracts” at DHS. Noem responded with a flat denial: “No.”
But internal DHS records reviewed by ProPublica contradict Noem’s Senate testimony. The records show Lewandowski personally approved a multimillion-dollar equipment contract at the agency last summer.
That was not a one-off. Lewandowski has approved numerous contracts at DHS and often needs to sign off on large ones before any money goes out the door, the current and former department employees said.
Last year, Noem imposed a new policy that consolidated her and her top aides’ power over all spending at DHS, requiring that she personally review and approve all contracts above $100,000. Before the contracts reach Noem, they must be approved by a series of political appointees, who each sign or initial a checklist sometimes referred to internally as a routing sheet. Typically, the last name on the checklist before Noem’s is Lewandowski’s, the DHS officials said.
Under federal law, it is a crime to “knowingly and willfully” make a false statement to Congress. But in practice, it is rarely prosecuted.
In a statement, a DHS spokesperson reiterated Noem’s claim. “Mr. Lewandowski does NOT play a role in approving contracts,” the spokesperson said. “Mr. Lewandowski does not receive a salary or any federal government benefits. He volunteers his time to serve the American people.” Lewandowski did not respond to a request for comment.
Several news outlets, including Politico, have previously reported on aspects of Lewandowski’s involvement in contracting at DHS.
There have been widespread reports of delays caused by the new contract approval process at the agency, which has responsibilities spanning from immigration enforcement to disaster relief to airport security. DHS has asserted that the review process saved taxpayers billions of dollars.
A similar sign-off process exists for other policy decisions at DHS. One of the checklists, about rolling back protections for Haitians in the U.S., emerged in litigation last year. It featured the signatures of several top DHS advisers. Under them was Lewandowski’s signature, and then Noem’s.

Lewandowski is what’s known as a “special government employee,” a designation historically used to let experts serve in government for limited periods without having to give up their outside jobs. (At the beginning of the Trump administration, Elon Musk was one, too.) Special government employees have to abide by only some of the same ethics rules as normal officials and are permitted to have sources of outside income.
Lewandowski has declined to disclose whether he is being paid by any outside companies and, if so, who.
Filed Under: contracts, corey lewandowski, corruption, kristi noem, perjury, richard blumenthal
Tech
Lenovo’s modular ThinkBook gambit blends enterprise grit with AI ambition and quietly distances itself from Project Ara’s collapse


- Lenovo reframes modular computing through enterprise durability requirements
- The ThinkBook concept is more for fleets than consumers
- System-level AI integration anchors the broader hardware strategy
At MWC 2026, Lenovo showed off a move toward modular hardware and system-level artificial intelligence, combining adaptive concepts with a broad commercial refresh.
The most conspicuous example of this is the ThinkBook Modular AI PC concept, which borrows a Lego-like philosophy of interchangeable parts and configurable layouts.
The approach revives long-running industry ambitions around modular computing, inviting comparisons with Project Ara, the abandoned modular smartphone initiative developed under Motorola ownership before Google discontinued it.
Modular ambition meets enterprise pragmatism
At the center of this showcase is a 14-inch ultra-thin base system built to accept detachable displays, input modules, and modular I/O elements.
A secondary screen can attach in different orientations or replace the keyboard entirely, expanding the workspace to roughly 19 inches while retaining portability.
“The AI era will not be defined by a single device or application, but by intelligent systems that work seamlessly across everything we use,” said Luca Rossi, President, Intelligent Devices Group, Lenovo.
“We are demonstrating how Lenovo and Motorola are bringing that vision to life, combining adaptive hardware innovation with a single, unified system-level AI integration that works naturally across PCs, smartphones, tablets, wearables, and beyond.”
That ecosystem relies heavily on Lenovo Qira, which it describes as Personal Ambient Intelligence embedded at the system level rather than layered on top as an app.
Although the modular ThinkBook may draw attention for its flexibility, the surrounding portfolio signals a clear commercial emphasis, as the updated ThinkPad T Series focuses on serviceability and lifecycle value, with select models earning high iFixit repairability scores.
Lenovo connects those improvements to reduced downtime and sustainable fleet management, a message that resonates more with procurement teams than casual buyers.
The ThinkPad X13 Detachable extends this approach with field-replaceable components in a lightweight format suited to frontline professionals.
The ThinkTab X11, a rugged Android tablet built for industrial settings, further reinforces that direction.
These devices prioritize durability, manageability, and integration with corporate security frameworks such as firewall controls and endpoint security policies.
Lenovo’s approach’s does not follow the same trajectory as Motorola Ara, given its clearer business-to-business strategy where versatility sits at the center.
It embeds the system within a broader commercial ecosystem that includes lifecycle services and AI deployment tools.
Even so, the viability of detachable displays and modular I/O components will depend on durability, pricing, and real-world adoption across enterprise fleets.
The failure of Project Ara stemmed from both the appeal and the practical constraints of modular hardware at scale, and increased complexity, cost pressures, and limited developer support at the time also contributed to its demise.
At present, modular systems appear to face stronger enterprise demand and fewer structural barriers, which explains why brands such as Getac and HP continue to develop devices like the Getac S510AD and HP EliteBook 8 G1 for organizations that require configurable, durable hardware environments.
Lenovo’s modular ThinkBook concept appears to sit closer to that tradition than to consumer experimentation.
Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button!
And of course you can also follow TechRadar on TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.

Nothing has officially unveiled its latest audio offering in the Headphone A, an over-ear model strategically aimed at a younger, style-conscious demographic.
Maintaining the brand’s signature transparent design aesthetic, the new headphones introduce vibrant Pink and Yellow colorways alongside the classic Black and White, positioning style as a key differentiator in the crowded audio market.
Positioned below the company’s flagship Headphone 1, the Headphone A serves as a more accessible entry point without significantly compromising on premium audio features. Key specifications include Hi-Res Audio certification and support for the high-fidelity LDAC wireless codec.
The headphones also offer flexible listening options through both USB-C and traditional 3.5 mm wired connections. The battery life is alonger than most headphones, boasting up to 135 hours of playback (with the caveat of ANC being off).
Furthermore, a rapid charge feature delivers eight hours of listening time from just five minutes plugged in, addressing a crucial need for on-the-go users.
The core acoustic performance is driven by a 40 mm titanium-coated diaphragm driver, engineered to deliver robust deep bass and crisp, clear high notes.

This hardware is complemented by AI-powered Dynamic Bass Enhancement technology. For noise management, the Headphone A incorporates ANC utilizing a dual feedforward and feedback microphone system with three distinct adjustable levels.
A dedicated Transparency Mode is also included, allowing users to safely engage with their external environment when necessary.
Call quality is a strong focus, with Nothing equipping the Headphone A with three microphones paired with AI-boosted Clear Voice Technology. This system has been extensively trained on millions of conversational scenarios to guarantee crystal-clear, echo-free voice transmission.
For entertainment, the headphones also feature Static Spatial Audio, offering immersive soundscapes through dedicated Cinema and Concert listening modes.
The design emphasizes both durability and user comfort. The unit features reinforced sliding arms and plush memory-foam ear cups for extended wear. An IP52 rating provides resistance against dust and light water exposure. Control features mechanical buttons, a Roller for precise volume and ANC adjustments, and a Paddle for seamless track navigation.
All controls are fully customizable via the Nothing X companion app.
This release signals Nothing’s commitment to broadening its market appeal through value-driven innovation.


Many associate the NAND crisis with higher priced memory sticks for desktops or laptops, more expensive consumer electronics like Raspberry Pi hobby boards, and smartphones with less RAM than we are accustomed to. Companies like Nintendo also have to be cognizant of how the shortage will affect software sales.
Read Entire Article
Source link

Verdict
Like the Phone 3a before it, the Nothing Phone 4a offers a very appealing option for those in the market for a more affordable device. The design and software are unique, and offer an experience that won’t leave you feeling you’ve got a budget device. While performance hasn’t improved all that much over last year, the solid battery life and reliable camera systems and better zoom lens all add up to a slightly more mature device.
-
Attractive, unique design -
Lightweight but delightful software experience -
Reliable battery and camera performance -
Affordable price – There’s a pink one!
-
Not the most powerful phone around -
Display is a little dark at times -
Glyph Light bars are gone -
Not a big jump on the Phone 3a
Key Features
-

Review Price: £349 -
Design
Distinctive Nothing design with transparency -
Unique software approach
Software matches the style of the phone -
Big battery and fast charging
50w charging and sizable battery
Introduction
Nothing is taking a slightly different approach in 2026 than it did last year.
The company has said we’re not getting a ‘proper’ flagship model to replace the Nothing Phone 3. Still, because it’s been so popular – and because the 3a was such a good phone – the brand opted to upgrade that series and give us a new model.
Enter the Nothing Phone 4a. Still very much a Nothing phone, but with a few changes and upgrades under the hood. But is it closer to being a flagship like Nothing says it is?
Design
- Four colour choices, including pink
- Classic Nothing looks
- Glass back, plastic frame
Since its inception, Nothing has been a company with a very clear design philosophy. And unlike most other tech companies, it is one that clearly cares quite deeply about the aesthetic of its products. They all tend to have that same retro futuristic look, that wouldn’t look out of place anthropomorphised as a character in Portal 2.
The phones have long had character to them, and while the transparent back doesn’t technically allow you to see the internals of the phone, the layers of texture, patterns and exposed screws all help create a very distinctive look.

With the Nothing Phone 4a in particular, it’s not that far off the look and feel of the Nothing Phone 3a that came out last year. There are some different colours, though. Or, at least one new colour. Alongside the black, white and blue models this year is a pink one, which is the best looking of the bunch. It almost reminds me of the transparent-backed iMacs from the turn of the century.

It’s glass on the front and back this year too, with the only plastic being the frame around the edges.
As for the elephant in the room, or at least the obvious change to any Nothing phone, or anyone familiar with Nothing’s first few phones: yes, the Glyph Light bars are gone. And with that, it appears those LED strips have been consigned to history.

That doesn’t mean there are no lights at all, but the makeup of them is very different. Instead of several curved strips, there’s one vertical stacked line of square LEDs that make up one pulsing, flashing light system to the right of the camera.
Just like before, you can have it pulse and animate when notifications come in, or use it as a visual countdown timer, and the bottom, red LED will light up when recording video or audio. It even has integration with third-party apps like Uber and Google Calendar, to act as a live visual for updates and events.
Display
- 6.78-inch OLED display
- Gorilla Glass 7i
- 30-120Hz adaptive
For the most part, the display on the 4a offers a solid experience. There are ways in which it’s beaten by the much more expensive devices, but for a screen in this price category, it’s solid.
It doesn’t have the super-bright display you’d find on something like the Pixel 10 Pro XL, or the superb anti-reflective qualities of the Galaxy S26 Ultra. But for a device that’s half the price, you wouldn’t expect it to.
What that means is that at times it feels as though the display is a little dark, especially when not viewed directly head-on and watching HDR shows and movies.

Still, it’s generally quite a vibrant and colour-rich display with deep contrast that offers a solid media experience with the brightness cranked up and viewed directly.
On that note, there were a few times during travel and phone testing where the bright sun was glaring and reflecting off the screen, and the Nothing Phone’s auto brightness kicked in to ramp it right up, making it clear, vivid and easily visible in harsh daylight. There was no awkward jumping or a delayed response. It was quick and smooth.

Software
- Software follows the look of the hardware
- Deep integration with Nothing’s audio products
- AI features don’t get in the way
Nothing’s software and the way it’s integrated into the phone, the themes, the widgets, haptic feedback and smart features are some of the biggest reasons to buy the Phone 4a. Just like it was the phones that came before it.
It’s rare to find a company with such a clear, distinct and laser-focused software approach. All the layers, widgets, icons and elements are not only consistently applied through every part of the interface, but also look like it belongs with the hardware. The font styles, stylised widgets and graphics all match the hardware aesthetics perfectly.
The fact that it feels both light and feature-rich is great. It’s not cluttered or bloated with additional apps and features. Nothing, unlike other companies, hasn’t gone down the route of copying Apple’s ‘Liquid Glass’ transparencies and effects random parts of the software like Oppo, Honor and Vivo have.

Because it’s light, it gives it the feeling that it’s responsive and effortless to use, but does it in a way that’s not plain or boring.
I enjoy the little things, like when you tap on the virtual keyboard to type. There’s a subtle tap from the haptic engine, not a cheap buzzy vibration that you often get on the more affordable devices. That just helps elevate the experience somewhat and means I actively keep that feedback on instead of switching it off.
You get deep integration with Nothing’s audio products with custom widgets for headphone battery levels, and a fun music player window widget which shows album art and play/pause/skip controls on your Home Screen. This effectively is just mirroring the music player notification widget.
There are a few AI features loaded, but they don’t feel like they’ve been overloaded or shoehorned in just because it’s 2026 and it must have lots of AI features. And, you can largely ignore them if you want. But there is a custom ChatGPT widget designed to match Nothing’s OS design and make it easier to interact with OpenAI’s popular agent.

Essential space is there again this year, with its dedicated button that allows you to quickly capture voice notes or screenshots and save them directly to what is effectively a digital corkboard to help you remember things that have inspired you. I quite like it, but I never found myself using it all that often.
Cameras
- 50MP main camera
- 50MP periscope zoom
- 8MP ultrawide
Being a mid-range phone means it’s always best to temper expectations somewhat for how good the cameras are going to be. And while it’s true that Nothing’s triple camera system won’t match up to the best camera phones, it’s an all-round solid system that is more than good enough for daily use and is pretty good at night time too.

What I like most about the camera is actually the experience of shooting with it. You can just point, tap to focus and shoot, and your image will be captured quickly with the appropriate exposure and the right area in focus.
In the daytime, if this phone cost more, I would criticise the overall texture and treatment of colours, highlights and shadows. But it’s hard to find too much fault with it. Sure, sometimes the HDR treatment of bright colourful spots leaves it looking a little artificial, but for the most part, I’m pleased with how well it contains those super bright points in the photos.
I sometimes found the blues were a little unrealistic, not quite matching what I saw with my eye, especially when looking at blue skies. But again, it wasn’t horrendous, and the treatment and saturation of colour meant most pictures had a pleasing vibrancy that I’d be happy to post on social media without any filters.
There’s a new zoom lens this year, the same one that’s in the Nothing Phone 3, which means better light capture and stabilisation when you kick into 3.5x zoom, adding a bit more zoom range but at the same time adding to that consistent, solid camera performance across multiple focal lengths.
Nothing also has a bunch of its own preset filters loaded, which can be fun to play with if you want to get creative with looks. You can shoot black and white, or add a cool, grainy texture, add soft focus for portraits, and all manner of other presets.
At night, shooting urban scenes in the lit streets of Barcelona, I was pretty happy with the results from all three cameras for the most part. Clearly, the primary lens is the one that captures cleaner, crisper images with better detail and colour, but the others aren’t awful.
That main sensor is also more sensitive to light than the other two and more capable of drawing it in quickly, and so when using the night mode setting, it usually takes less than a second to capture the scene, whereas the ultrawide might take a second and a half, or two seconds.
The perk of that delay though, is that if you just happen to catch a moving vehicle at just the right moment, you can get a pretty effective motion blur that adds a bit of movement to the picture, without needing to dive into any manual controls or needing a tripod.
Being critical, the zoom lens often produced results where you can tell that machine learning or image processing is doing a lot of work to smooth it out. To the point where, at times, surfaces lose natural texture and detail, and so don’t quite look like a faithful reproduction of the real thing.
So clearly, the main camera is still the best one – particularly in low light, with the second and third lenses not quite matching it in terms of ability to capture light, or reproducing detail quite as cleanly.
Performance
- Qualcomm Snapdragon 7s Gen 4 chip
- 8 and 12GB memory
- LPDDR4X RAM, UFS3.1 storage
Whether or not you’d be happy with the performance of the Phone 4a very much depends on how you use your phone. But if you’re after the best phone in this section of the market, it’s safe to say the 4a is not it.
For the most part, doing casual tasks and swiping around, moving between different layers of the interface is pretty responsive and smooth. But if you were to try to load demanding games with high visual fidelity and fast frame rates, it would soon start to struggle if you put those games into their highest settings.
It’s just not the super-powerful type of phone. But I suspect those people who buy the phone aren’t buying it to crunch through hours of Call of Duty or Genshin Impact in ultra visual settings. You can get more powerful devices in and around this price range, but it typically means compromising on things like good software, camera performance and getting a good-looking device.
Test Data
| Nothing Phone 4a | Nothing Phone 3 | Nothing Phone 3a | |
|---|---|---|---|
| Geekbench 6 single core | 1236 | 2073 | 1164 |
| Geekbench 6 multi core | 3312 | 6531 | 3273 |
Still, cranking through more casual games like Mario Kart Tour is a breeze thanks to the Qualcomm Snapdragon 7s Gen 4 chip and up to 12GB RAM. It’s responsive and quick enough to cope with the less demanding, but still fast-paced games. And if there’s any resolution dropping to keep frame rates smooth, that’s kept to a minimum.

It doesn’t seem to struggle with poor download speeds too much either, which is often a telltale sign of a cheaper device. I was never left waiting ages for news pages and images to download and game/app downloads were about the same as usual.
In short, I think the performance is fast and efficient enough that virtually anyone but the most demanding of users is well catered for.
Battery Life
- 5080 mAh battery, although in India it is 5400mAh
- 50w fast charging
The battery capacity might not completely blow you away when read on a spec sheet. Especially not with brands like Oppo and Vivo pushing towards the 7000mAh mark.
Still, there was never a concern for me that I wouldn’t make it through the day. In fact, it was virtually a two-day phone for me in most of my testing. And this was including a day when I did some of the stress testing benchmarks and camera tests we perform for all of our reviews.

Even on that day, having taken it off charge at around 7 am, I started the next morning with 54% left. Included in those tests was an hour-long session watching Sweet Tooth on Netflix at 50% brightness, which only drained 5% of the battery.
Just guessing based on my experience and what I know about the device – I suspect the battery efficiency has a lot to do with the fact that the Snapdragon chipset inside isn’t the most power hungry on the market. That helps the phone easily get through days. And I suspect that even power users should at least make a full day on a full battery quite comfortably.
Should you buy it?
You want a fun, unique Android phone
The design here is great, and in a sea of fairly dull phones the Phone 3a looks great. Nothing has also done a great job of keeping the software and hardware uniform.
This is an affordable phone, and as such it doesn’t with a chipset that can rival even the better mid-range phone.
Final Thoughts
I think in the end, the feeling I’m left with about the Nothing Phone 4a is that it’s a very usable phone. And I don’t mean that in a negative way. At all.
It’s one of those phones I love to have in my daily life, that I can pick up and use, and its software doesn’t get in the way, it looks good, works well and has solid battery life.
There’s not much more you can ask from a phone that costs less than half what the very best phones on the market would set you back.
How We Test
We test every mobile phone we review thoroughly. We use industry-standard tests to compare features properly and we use the phone as our main device over the review period. We’ll always tell you what we find and we never, ever, accept money to review a product.
- Used as a main phone for a week
- Thorough camera testing in a variety of conditions
- Tested and benchmarked using respected industry tests and real-world data
Test Data
Full Specs
| Nothing Phone 4a Review | |
|---|---|
| UK RRP | £349 |
| Manufacturer | Nothing |
| Screen Size | 6.78 inches |
| Storage Capacity | 256GB |
| Rear Camera | 50MP + 50MP +8MP |
| Front Camera | 32MP |
| Video Recording | Yes |
| IP rating | IP65 |
| Battery | 5080 mAh |
| Fast Charging | Yes |
| Size (Dimensions) | 77.57 x 8.55 x 163.95 INCHES |
| Weight | 204.5 G |
| Operating System | Nothing OS 4.1 powered by Android 16 |
| Release Date | 2026 |
| First Reviewed Date | 05/03/2026 |
| Resolution | 2720 x 1224 |
| HDR | Yes |
| Refresh Rate | 120 Hz |
| Ports | USB-C |
| Chipset | Qualcomm Snapdragon 7s Gen 4 |
| RAM | 12GB, 8GB |
| Colours | Silver, Black, Blue, Pink |
Tech
BYD says its next-gen EV battery can delivers 625 miles on a single charge and be topped up in minutes

- The Yangwang U7 will be first model to use new Blade Battery tech
- Company says Blade 2.0 can deliver more than 625 miles on a single charge
- BYD is working on high-performance EVs that also boast massive range
Not content with being a global leader in EV sales, Chinese car-making giant BYD is set to reveal all about the next generation of its battery and charging systems at a “Disruptive Technology” even due to be held in China this week.
Tidbits are already being released by the company on social media, including the fact that the Yangwang U7 will be the first high-performance EV from the BYD stable to receive the second generation of its advanced Blade Battery technology.
The company says the quad-motor, high-powered EV will be capable of returning a maximum range of 1,006 km (625 miles) on a single charge, according China’s CTLC testing standard (via Car News China).
When adjusted for the more stringent WLTP cycle in Europe and North America’s EPA rating, those numbers still hover around 559 miles and 450 miles respectively — easily making it the longest range EV on sale.
In addition to the Yangwang U7, BYD plans to introduce the Blade Battery 2.0 into a number of Denza models, as well as the BYD Seal 07, the Sealion 06 and a recently-announced Great Tang seven-seat SUV (see image below), which has the likes of Kia, Hyundai and Volvo clearly in its sights.

Even in that enormous luxury crossover, the Chinese automaker claims its upcoming battery technology will be capable of delivering 590 miles on the CTLC testing standard, which is over 200 miles more than the Kia EV9, for example.
Not content with simply producing extremely energy-dense EV batteries, BYD has also been working on its megawatt ‘Flash Charging’ network, which is capable of delivering up to 1,500kW of electricity to compatible EV batteries.
It released a number of 10-70% charging times for models due to receive its Blade Battery 2.0 technology, with the Yangwang U7 reportedly taking just four minutes and 54 seconds to reach the aforementioned State of Charge.
Finding a charging outlet in Europe and the US that provides just 350kW is tough enough, but BYD says it will roll out 20,000 of its innovative gas station-style Flash Charging stalls in China this year.
Analysis: It’s all in the chemistry

The most pertinent point here is not the fact that BYD, alongside Chinese battery-making giant CATL, have managed to improve the energy density, charging rates and longevity of their EV battery packs. It’s that they’ve done so using a Lithium Iron Phosphate battery chemistry.
Where rivals have been exploring more costly Nickel Manganese Cobalt (NMC) cathodes or awaiting the arrival of mass produced all-solid-state batteries, BYD has been gradually improving its relatively cheap LFP technology to match the statistics of more costly alternatives.
Judging from the progress, there is likely even more room for improvement here, which could open the door to Blade Battery 2.0 technology eventually filtering down into the more affordable, mass market BYD models, both in China and further afield.
Right now, the BYD Seal can manage up to 345 miles on a single charge in the UK, according to WLTP tests. But the second generation battery could see those figures rise to over 400 miles, if not more.
On top of this, future owners will also be able to make use of ultra-rapid charging, which brings EV charging sessions more in line with fuel stops.
If the infrastructure can be put in place, we will start to see customer attitudes towards electrification shift dramatically.
Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button!
And of course, you can also follow TechRadar on YouTube and TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.

Following a strong showing at CES 2026, LG has announced pricing and availability for its new OLED evo G6 and C6 televisions, the successors to last year’s G5 and C5 models. The 2026 lineup builds on LG’s established OLED platform with refinements to brightness, processing, and smart features, but it arrives at a moment when the premium TV market is facing real pressure.
Chinese brands like TCL and Hisense have rapidly gained ground with aggressive pricing and increasingly competitive MiniLED and large screen offerings, while traditional rivals Samsung and Sony continue to push their own premium display technologies.
Against that backdrop, LG’s latest OLED evo models represent both an evolution of its flagship TV strategy and a reminder that the fight for the living room is getting more crowded every year.
LG OLED evo G6 Series

The LG OLED evo G6 Series serves as LG’s flagship TV lineup. It introduces Hyper Radiant Color technology built around the new Primary RGB Tandem 2.0 OLED panel, which LG says delivers up to 20% higher brightness than the 2025 G5 series. The G6 also incorporates enhanced color processing and a Reflection Free Premium screen coating designed to improve visibility in brighter rooms while maintaining the deep contrast OLED is known for.
While the G6 is currently available in 55, 65, 77, 83, and 97-inch screen sizes, LG has confirmed that the 97-inch version does not include the Primary RGB Tandem 2.0 OLED panel or the Reflection Free Premium screen coating.
Processing duties are handled by LG’s Alpha 11 Gen. 3 processor, which supports 12-bit signal processing. However, the panel itself remains limited to 10-bit color depth, which is still the high end industry standard for consumer displays. As a result, incoming 12-bit signals are downsampled to 10-bit before being displayed.
That being said, the G6 panels support a 4K/165 Hz refresh rate when supported by the source and include NVIDIA G SYNC and AMD FreeSync Premium compatibility for tear free, ultra smooth gameplay.
A 0.1 ms pixel response time and Auto Low Latency Mode (ALLM) should also appeal to dedicated gamers. The G6 further supports sub millisecond response times using ULL (Ultra Low Latency) Bluetooth, allowing compatible Bluetooth gaming controllers to connect directly to the TV for responsive cloud based gaming.
The G6 Series can be placed on a stand or wall mounted, and also supports a recessed mounting option for flush to wall installation for a cleaner, more integrated look.
Price & Availability (G6)
- OLED97G6WUA (97-inches): $24,999.99 (April 20, 2026)
- OLED83G6WUA (83-inches): $6,499.99 (May 11, 2026)
- OLED77G6WUA (77-inches): $4,499.99 (March 30, 2026)
- OLED65G6WUA (65-inches): $3,399.99 (March 30, 2026)
- OLED55G6WUA (55-inches): $2,499.99 (March 30, 2026)
All LG G6 Series TVs are available now for preorder at LG.
LG OLED evo C6 Series

The LG OLED evo C6 Series sits just below the G Series in LG’s lineup with more affordable pricing, but it still delivers a comprehensive feature set capable of top notch performance.
One notable move is that LG has incorporated its Primary RGB Tandem 2.0 OLED panel, the same panel used in the G6 Series, into the 77 inch and 83 inch C6 models. C6 models 65 inches and smaller instead use LG’s latest standard W-OLED panel, which still delivers absolute black levels with precise pixel level lighting control, though with lower peak brightness.
However, the C6 models do not include Hyper Radiant Color technology or Brightness Booster Pro, meaning the C6 Series outside of the 77 inch and 83 inch sizes will not reach the same brightness levels as the G6. The C6 also uses a glossy screen coating rather than LG’s Reflection Free Premium technology, which remains exclusive to the G6 Series.
All models in the C Series will have the same Alpha 11, Gen 3 processor as the G6 series for improved video upconversion and better handling of low-bandwidth streaming content. The new processor also boosts the performance of the WebOS smart platform, so navigating through settings and content should be a more seamless and responsive experience.
Price & Availability (C6)
- OLED83C6PUA (83-inches): $5,299.99 (May 4, 2026)
- OLED77C6PUA (77-inches): $3,699.99 (March 23, 2026)
- OLED65C6PUA (65-inches): $2,699.99 (March 23, 2026)
- OLED55C6PUA (55-inches): $1,999.99 (March 23, 2026)
- OLED48C6PUA (48-inches): $1,599.99 (March 23, 2026)
- OLED42C6PUA (42-inches): $1,399.99 (May 4, 2026)
All LG C6 Series TVs are available now for preorder at LG.
LG OLED evo G6 vs C6: Key Differences Explained

- Brightness and Panel: The G6 incorporates LG’s Hyper Radiant technology and is designed to be up to 20% brighter than the previous G5 series, delivering significantly higher peak brightness than the standard C6 models.
- Reflection Handling: The G6 includes LG’s Reflection Free Premium screen coating on the 55 inch to 83 inch models, offering improved glare reduction compared with the glossy screen used on the C6 series.
- Screen Sizes: The G6 lineup ranges from 55 to 97 inches, while the C6 series covers a broader range from 42 to 83 inches.
- Mounting Options: Both the G6 and C6 can be placed on a stand or wall mounted, but the G6 is specifically designed for flush fit wall installation using LG’s dedicated recessed mounting system.
For more details on the LG OLED evo G6 and C6 Series TVs, including LG’s expanded AI features for 2026, refer to our previous hands-on coverage from CES 2026.

The Bottom Line
The TV technology race has reached a near fever pitch heading into 2026 as the major brands continue to reshape the competitive landscape. TCL made headlines with the introduction of its X11L SQD MiniLED TV, while Samsung and Hisense are aggressively pushing new MicroRGB and MiniLED RGB display platforms. Sony has effectively handed off its TV manufacturing to TCL, and Panasonic has shifted production of its televisions to Skyworth.
Against that backdrop, LG arrived at CES 2026 projecting confidence with the latest generation of its OLED evo lineup. But the pressure is very real. LCD based technologies continue to close the performance gap while often undercutting OLED on price and screen size.
Based on what we’ve seen so far, LG’s 2026 OLED lineup looks extremely compelling. If pricing holds and real world performance matches the promise shown at CES, the G6 and C6 could make a strong case that OLED still belongs at the top of the TV food chain.
For more information, visit LG’s OLED evo TV website.
Related Reading:
Tech
OpenAI launches GPT-5.4 with native computer use mode, financial plugins for Microsoft Excel, Google Sheets


The AI updates aren’t slowing down. Literally two days after OpenAI launched a new underlying AI model for ChatGPT called GPT-5.3 Instant, the company has unveiled another, even more massive upgrade: GPT-5.4.
Actually, GPT-5.4 comes in two varieties: GPT-5.4 Thinking and GPT-5.4 Pro, the latter designed for the most complex tasks.
Both will be available in OpenAI’s paid application programming interface (API) and Codex software development application, while GPT-5.4 Thinking will be available to all paid subscribers of ChatGPT (Plus, the $20-per-month plan, and up) and Pro will be reserved for ChatGPT Pro ($200 monthly) and Enterprise plan users.
ChatGPT Free users will also get a taste of GPT-5.4, but only when their queries are auto-routed to the model, according to an OpenAI spokesperson.
The big headlines on this release are efficiency, with OpenAI reporting that GPT-5.4 uses far fewer tokens (47% fewer on some tasks) than its predecessors, and, arguably even more impressively, a new “native” Computer Use mode available through the API and its Codex that lets GPT-5.4 navigate a users’ computer like a human and work across applications.
The company is also releasing a new suite of ChatGPT integrations allowing GPT-5.4 to be plugged directly into users’ Microsoft Excel and Google Sheets spreadsheets and cells, enabling granular analysis and automated task completion that should speed up work across the enterprise, but may make fears of white collar layoffs even more pronounced on the heels of similar offerings from Anthropic’s Claude and its new Cowork application.
OpenAI says GPT-5.4 supports up to 1 million tokens of context in the API and Codex, enabling agents to plan, execute, and verify tasks across long horizons— however, it charges double the cost per 1 million tokens once the input exceeds 272,000 tokens.
Native computer use: a step toward autonomous workflows
The most consequential capability OpenAI highlights is that GPT-5.4 is its first general-purpose model released with native, state-of-the-art computer-use capabilities in Codex and the API, enabling agents to operate computers and carry out multi-step workflows across applications.
OpenAI says the model can both write code to operate computers via libraries like Playwright and issue mouse and keyboard commands in response to screenshots. OpenAI also claims a jump in agentic web browsing.
Benchmark results are presented as evidence that this is not merely a UI wrapper.
On BrowseComp, which measures how well AI agents can persistently browse the web to find hard-to-locate information, OpenAI reports GPT-5.4 improving by 17% absolute over GPT-5.2, and GPT-5.4 Pro reaching 89.3%, described as a new state of the art.
On OSWorld-Verified, which measures desktop navigation using screenshots plus keyboard and mouse actions, OpenAI reports GPT-5.4 at 75.0% success, compared to 47.3% for GPT-5.2, and notes reported human performance at 72.4%.
On WebArena-Verified, GPT-5.4 reaches 67.3% success using both DOM- and screenshot-driven interaction, compared to 65.4% for GPT-5.2. On Online-Mind2Web, OpenAI reports 92.8% success using screenshot-based observations alone.
OpenAI also links computer use to improvements in vision and document handling. On MMMU-Pro, GPT-5.4 reaches 81.2% success without tool use, compared with 79.5% for GPT-5.2, and OpenAI says it achieves that result using a fraction of the “thinking tokens.”
On OmniDocBench, GPT-5.4’s average error is reported at 0.109, improved from 0.140 for GPT-5.2. The post also describes expanded support for high-fidelity image inputs, including an “original” detail level up to 10.24M pixels.
OpenAI positions GPT-5.4 as built for longer, multi-step workflows—work that increasingly looks like an agent keeping state across many actions rather than a chatbot responding once.
Tool search and improved tool orchestration
As tool ecosystems get larger, OpenAI argues that the naive approach—dumping every tool definition into the prompt—creates a tax paid on every request: cost, latency, and context pollution.
GPT-5.4 introduces tool search in the API as a structural fix. Instead of receiving all tool definitions upfront, the model receives a lightweight list of tools plus a search capability, and it retrieves full tool definitions only when they’re actually needed.
OpenAI describes the efficiency win with a concrete comparison: on 250 tasks from Scale’s MCP Atlas benchmark, running with 36 MCP servers enabled, the tool-search configuration reduced total token usage by 47% while achieving the same accuracy as a configuration that exposed all MCP functions directly in context.
That 47% figure is specifically about the tool-search setup in that evaluation—not a blanket claim that GPT-5.4 uses 47% fewer tokens for every kind of task.
Improvements for developers and coding workflows
OpenAI’s coding pitch is that GPT-5.4 combines the coding strengths of GPT-5.3-Codex with stronger tool and computer-use capabilities that matter when tasks aren’t single-shot.
GPT-5.4 matches or outperforms GPT-5.3-Codex on SWE-Bench Pro while being lower latency across reasoning efforts.
Codex also gets workflow-level knobs. OpenAI says /fast mode delivers up to 1.5× faster performance across supported models, including GPT-5.4, describing it as the same model and intelligence “just faster.”
And it describes releasing an experimental Codex skill, “Playwright (Interactive)”, meant to demonstrate how coding and computer use can work in tandem—visually debugging web and Electron apps and testing an app as it’s being built.
OpenAI for Microsoft Excel and Google Sheets
Alongside GPT-5.4, OpenAI is announcing a suite of secure AI products in ChatGPT built for enterprises and financial institutions, powered by GPT-5.4 for advanced financial reasoning and Excel-based modeling.
The centerpiece is ChatGPT for Excel and Google Sheets (beta), which OpenAI describes as ChatGPT embedded directly in spreadsheets to build, analyze, and update complex financial models using the formulas and structures teams already rely on.
The suite also includes new ChatGPT app integrations intended to unify market, company, and internal data into a single workflow, naming FactSet, MSCI, Third Bridge, and Moody’s.
And it introduces reusable “Skills” for recurring finance work such as earnings previews, comparables analysis, DCF analysis, and investment memo drafting.
OpenAI anchors the finance push with an internal benchmark claim: model performance increased from 43.7% with GPT-5 to 88.0% with GPT-5.4 Thinking on an OpenAI internal investment banking benchmark.
Measuring AI performance against professional work
OpenAI leans on benchmarks intended to resemble real office deliverables, not just puzzle-solving. On GDPval, an evaluation spanning “well-specified knowledge work” across 44 occupations, OpenAI reports that GPT-5.4 matches or exceeds industry professionals in 83.0% of comparisons, compared to 71.0% for GPT-5.2.
The company also highlights specific improvements in the kinds of artifacts that tend to expose model weaknesses: structured tables, formulas, narrative coherence, and design quality.
In an internal benchmark of spreadsheet modeling tasks modeled after what a junior investment banking analyst might do, GPT-5.4 reaches a mean score of 87.5%, compared to 68.4% for GPT-5.2.
And on a set of presentation evaluation prompts, OpenAI says human raters preferred GPT-5.4’s presentations 68.0% of the time over GPT-5.2’s, citing stronger aesthetics, greater visual variety, and more effective use of image generation.
Improving reliability and reducing hallucinations
OpenAI describes GPT-5.4 as its most factual model yet and connects that claim to a practical dataset: de-identified prompts where users previously flagged factual errors. On that set, OpenAI reports GPT-5.4’s individual claims are 33% less likely to be false and its full responses are 18% less likely to contain any errors compared to GPT-5.2.
In statements provided to VentureBeat from OpenAI and attributed early GPT-5.4 testers, Daniel Swiecki of Walleye Capital says that on internal finance and Excel evaluations, GPT-5.4 improved accuracy by 30 percentage points, which he links to expanded automation for model updates and scenario analysis.
Brendan Foody, CEO of Mercor, calls GPT-5.4 the best model the company has tried and says it’s now top of Mercor’s APEX-Agents benchmark for professional services work, emphasizing long-horizon deliverables like slide decks, financial models, and legal analysis.
Pricing and availability
In the API, OpenAI says GPT-5.4 Thinking is available as gpt-5.4 and GPT-5.4 Pro as gpt-5.4-pro. Pricing is as follows:
-
GPT-5.4: $2.50 / 1M input tokens; $15 / 1M output tokens
-
GPT-5.4 Pro: $30 / 1M input tokens; $180 / 1M output tokens
-
Batch + Flex: half-rate; Priority processing: 2× rate
This makes GPT-5.4 among the more expensive models to run over API compared to the entire field, as seen in the table below.
|
Model |
Input |
Output |
Total Cost |
Source |
|
Qwen 3 Turbo |
$0.05 |
$0.20 |
$0.25 |
|
|
Qwen3.5-Flash |
$0.10 |
$0.40 |
$0.50 |
|
|
deepseek-chat (V3.2-Exp) |
$0.28 |
$0.42 |
$0.70 |
|
|
deepseek-reasoner (V3.2-Exp) |
$0.28 |
$0.42 |
$0.70 |
|
|
Grok 4.1 Fast (reasoning) |
$0.20 |
$0.50 |
$0.70 |
|
|
Grok 4.1 Fast (non-reasoning) |
$0.20 |
$0.50 |
$0.70 |
|
|
MiniMax M2.5 |
$0.15 |
$1.20 |
$1.35 |
|
|
Gemini 3.1 Flash-Lite |
$0.25 |
$1.50 |
$1.75 |
|
|
MiniMax M2.5-Lightning |
$0.30 |
$2.40 |
$2.70 |
|
|
Gemini 3 Flash Preview |
$0.50 |
$3.00 |
$3.50 |
|
|
Kimi-k2.5 |
$0.60 |
$3.00 |
$3.60 |
|
|
GLM-5 |
$1.00 |
$3.20 |
$4.20 |
|
|
ERNIE 5.0 |
$0.85 |
$3.40 |
$4.25 |
|
|
Claude Haiku 4.5 |
$1.00 |
$5.00 |
$6.00 |
|
|
Qwen3-Max (2026-01-23) |
$1.20 |
$6.00 |
$7.20 |
|
|
Gemini 3 Pro (≤200K) |
$2.00 |
$12.00 |
$14.00 |
|
|
GPT-5.2 |
$1.75 |
$14.00 |
$15.75 |
|
|
Claude Sonnet 4.6 |
$3.00 |
$15.00 |
$18.00 |
|
|
GPT-5.4 |
$2.50 |
$15.00 |
$17.50 |
|
|
Gemini 3 Pro (>200K) |
$4.00 |
$18.00 |
$22.00 |
|
|
Claude Opus 4.6 |
$5.00 |
$25.00 |
$30.00 |
|
|
GPT-5.2 Pro |
$21.00 |
$168.00 |
$189.00 |
|
|
GPT-5.4 Pro |
$30.00 |
$180.00 |
$210.00 |
Another important note: with GPT-5.4, requests that exceed 272,000 input tokens are billed at 2X the normal rate, reflecting the ability to send prompts larger than earlier models supported.
In Codex, compaction defaults to 272k tokens, and the higher long-context pricing applies only when the input exceeds 272k—meaning developers can keep sending prompts at or under that size without triggering the higher rate, but can opt into larger prompts by raising the compaction limit, with only those larger requests billed differently.
An OpenAI spokesperson said that in the API the maximum output is 128,000 tokens, the same as previous models.
Finally, on why GPT-5.4 is priced higher at baseline, the spokesperson attributed it to three factors: higher capability on complex tasks (including coding, computer use, deep research, advanced document generation, and tool use), major research improvements from OpenAI’s roadmap, and more efficient reasoning that uses fewer reasoning tokens for comparable tasks—adding that OpenAI believes GPT-5.4 remains below comparable frontier models on pricing even with the increase.
The broader shift
Across the release and the follow-up clarifications, GPT-5.4 is positioned as a model meant to move beyond “answer generation” and into sustained professional workflows—ones that require tool orchestration, computer interaction, long context, and outputs that look like the artifacts people actually use at work.
OpenAI’s emphasis on token efficiency, tool search, native computer use, and reduced user-flagged factual errors all point in the same direction: making agentic systems more viable in production by lowering the cost of retries—whether that retry is a human re-prompting, an agent calling another tool, or a workflow re-running because the first pass didn’t stick.

NewsBeat10 seconds ago
Scarborough’s Alpamare water park could be sold to new owner

Business1 minute ago
Grove Collaborative Holdings, Inc. 2025 Q4 – Results – Earnings Call Presentation (NYSE:GROV) 2026-03-05

Crypto World2 minutes ago
ZeroHash applies for national trust bank charter to expand regulated stablecoin services






-

 Politics7 days ago
Politics7 days agoITV enters Gaza with IDF amid ongoing genocide
-

 Politics3 days ago
Politics3 days agoAlan Cumming Brands Baftas Ceremony A ‘Triggering S**tshow’
-

 Fashion6 days ago
Fashion6 days agoWeekend Open Thread: Iris Top
-

 Tech5 days ago
Tech5 days agoUnihertz’s Titan 2 Elite Arrives Just as Physical Keyboards Refuse to Fade Away
-
Sports6 days ago
The Vikings Need a Duck
-
 NewsBeat5 days ago
NewsBeat5 days agoDubai flights cancelled as Brit told airspace closed ’10 minutes after boarding’
-

 NewsBeat5 days ago
NewsBeat5 days agoAbusive parents will now be treated like sex offenders and placed on a ‘child cruelty register’ | News UK
-
 NewsBeat5 days ago
NewsBeat5 days agoThe empty pub on busy Cambridge road that has been boarded up for years
-

 NewsBeat4 days ago
NewsBeat4 days ago‘Significant’ damage to boarded-up Horden house after fire
-

 Tech16 hours ago
Tech16 hours agoBitwarden adds support for passkey login on Windows 11
-

 Entertainment4 days ago
Entertainment4 days agoBaby Gear Guide: Strollers, Car Seats
-
 Sports4 hours ago
Sports4 hours ago499 runs and 34 sixes later, India beat England to enter T20 World Cup final | Cricket News
-
 Tech6 days ago
Tech6 days agoNASA Reveals Identity of Astronaut Who Suffered Medical Incident Aboard ISS
-
Politics5 days ago
FIFA hypocrisy after Israel murder over 400 Palestinian footballers
-
 NewsBeat5 days ago
NewsBeat5 days agoEmirates confirms when flights will resume amid Dubai airport chaos
-

 NewsBeat3 days ago
NewsBeat3 days agoIs it acceptable to comment on the appearance of strangers in public? Readers discuss
-

 Crypto World7 days ago
Crypto World7 days agoFrom Crypto Treasury to RWA: ETHZilla Retreats and Relaunches as Forum Markets on Nasdaq
-

 Tech5 days ago
Tech5 days agoViral ad shows aged Musk, Altman, and Bezos using jobless humans to power AI
-

 Video4 days ago
Video4 days agoHow to Build Finance Dashboards With AI in Minutes
-

 Business2 days ago
Business2 days agoGuthrie Disappearance Enters Fifth Week as Family Visits Memorial