‘Bringing the cost of replicating strong coding agents down to a few hundred dollars will unlock research that simply wasn’t possible before’, AI2 said.
The non-profit Allen Institute for AI (AI2) has launched a family of open-source coding models targeting independent developers and SMEs.
The idea behind the launch is to simplify building coding agents for any code base, with the added benefit of cost effectiveness, the company explained.
The first release from the Open Coding Agents suite is called SERA (Soft-verified Efficient Repository Agents), which is available in two versions.
Advertisement
SERA-32B is a 32bn-parameter model that can solve 54.2pc of problems classed as ‘SWE-bench verified’, part of a benchmark used for evaluating large language models (LLMs) on real-world software engineering tasks. This success rate beats previous open-source models of comparable sizes such as Qwen3-Coder, and closed models such as Mistral3’s Devstral Small 2.
SERA-8B is an 8bn-parameter model that solves 29.4pc SWE-bench verified problems.
AI2 collaborated with Nvidia to optimise SERA’s interface in order to help researchers and developers get the most out of the new models in production environments, the company said in a launch blog post.
Every component of the family is open, including the models, training recipes and integration with Anthropic’s Claude Code, the company said.
Advertisement
SERA can be launched with a single line of code, making it easy to use even for those without LLM experience, it added. The company has also released training data for researchers to inspect before recommending tweaks.
According to AI2, the total cost to use SERA to reproduce the performance levels of the best existing open-source result is around $400, which is around 25 times cheaper than many existing approaches, while the total cost to reproduce top open-weight models in industry is around $12,000.
“We believe bringing the cost of replicating strong coding agents down to a few hundred dollars will unlock research that simply wasn’t possible before. Instead of being limited to a handful of well-funded labs, agentic coding can become a widely accessible practice,” the company said in the post.
AI2 was established in 2014 by the late co-founder of Microsoft, Paul Allen. The institute aims to deliver “real-world impact” via large-scale open models, data and robotics.
Advertisement
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
Amgen’s Luke Sheppard discusses Ireland’s biopharma space and how his career trajectory was powered by graduate opportunities.
“I was always interested in science at school, especially biology and physics. The turning point came when I spent two summers working with a mechanical engineer on the construction of a biopharmaceutical facility,” said Luke Sheppard, a senior associate for syringe manufacturing at Amgen.
“Seeing the facility take shape helped me to connect what I was learning in the classroom with the industry in real life. That experience ignited my passion and led me to study biotechnology at DCU.”
As part of his degree he completed an internship with Amgen during his undergraduate studies and moved on to Amgen’s FUEL graduate programme. He said, “Alongside this, I completed a master’s in pharma and biopharma engineering at UCC, which ties in closely with the work I do now.”
Advertisement
Can you describe Ireland’s biopharmaceutical space?
Ireland’s biopharmaceutical sector is dynamic and well-established. It is recognised as a centre of excellence for manufacturing. The sector is also highly connected, with a healthy sense of competition and a strong shared awareness of best practice. For anyone with a STEM background, it is an attractive industry because it offers real depth in the work as well as a wide range of potential career paths.
What is your day-to-day like if there is such a thing?
My role is quite diverse. My time is split between supporting and driving operations, contributing to projects and seeking solutions. Part of the day can involve reviewing data or meeting leadership to discuss strategy. Equally, I could be troubleshooting an issue on the production floor. The variety keeps things interesting. Collaboration is a big part of the job. You are constantly working with specialists and moving things forward together to achieve the same goal.
What skills do you utilise in your role and are any unexpected?
Technical knowledge is extremely important, but the skill that matters most is the ability to work as part of a team and to support colleagues. Clear, concise communication, relationship‑building and dedication take centre stage. There will always be new systems to learn, processes to improve and tools to adopt, but real progress ultimately depends on how well you work with others and how quickly you can build trust. The stronger your working relationships, the easier it is to ask questions, gain input and work efficiently when challenges arise. In a manufacturing environment, strong relationships truly make the difference.
You moved through the ranks via the FUEL programme, how was the experience?
The Amgen FUEL programme was an incredible experience as it gave me exposure to the highest levels of the business early on in my career. I completed three rotations across process development, quality assurance and utilities engineering. Each rotation lasted eight to nine months. In a relatively short time, I had to integrate into new teams, build relationships fast and learn new processes to contribute to meaningful work. Rotations teach resilience and determination, as well as creating visibility for participants. I had the opportunity to present my work to senior sites and European leaders, which accelerated my learning and professional development. The programme has allowed me to gain a strong understanding of operations and an insight into decisive leadership on the issues that matter most to our industry.
Advertisement
How can mentorship and internship opportunities positively impact a young person’s career in the long-term?
Mentorships and internships can have a long-lasting, positive impact. An internship allows graduates to experience the pace, teamwork and problem-solving involved in a working environment, which is difficult to replicate in a classroom. It can also help you understand what type of work suits you best. Mentorship adds another dimension, providing early-stage professionals with a broader perspective of industry and career development. Mentors can offer guidance, challenge thinking, and help you to spot career development opportunities that you may otherwise overlook. Over time, this support can make a meaningful difference in shaping long‑term career direction.
What do you enjoy most about your role?
I thrive on continued commitment, resilience and integrity on the issues that matter most to my team. I enjoy the variety of problem-solving, teamwork and planning to ensure multiple priorities are being achieved. I have grown personally and professionally by advancing my technical and analytical capabilities. I have also significantly broadened my range of soft skills.
Have you any predictions for how the biopharma space might evolve in 2026?
I expect regulation, automation and AI to shape the industry’s trajectory over the coming years. There is greater regulatory focus on reducing human interaction in manufacturing processes and tightening controls around unit operations. AI will play an increasingly central role, supporting research and process optimisation. By analysing real time data effectively, AI capabilities will identify anomalies and patterns, helping production line teams to work more efficiently.
Don’t miss out on the knowledge you need to succeed. Sign up for the Daily Brief, Silicon Republic’s digest of need-to-know sci-tech news.
We spend hours testing every product or service we review, so you can be sure you’re buying the best. Find out more about how we test.
Asus ROG Kithara: one-minute review
There are a number of gaming headsets available that support high-res audio, such as the SteelSeries Arctis Nova Elite, but the new Asus ROG Kithara is one of the first we’ve seen that really takes the plunge into the challenging waters of the specialist hi-fi market.
Named after a stringed instrument in ancient Greece, the Kithara takes its old-school approach seriously, with a wired-only design that turns its back on modern digital features such as Bluetooth, noise-cancellation, and spatial audio. The focus on wired audio may well be a deal-breaker for some people, but in return, the Kithara provides outstanding sound quality that works a treat both for gaming and listening to lossless and high-res music on modern streaming services.
Advertisement
Although it carries the Asus name, and is part of the company’s popular Republic Of Gamers (ROG) brand, the Kithara was developed in conjunction with HiFiMan, a New York-based manufacturer of seriously expensive hi-fi equipment (founded by the fabulously-named Dr Fang, who really sounds like he should be the villain in a Bond movie).
HiFiMan is known in the audiophile market for its focus on ‘planar-magnetic’ headphones, which provide a more precise and detailed sound than the less expensive ‘dynamic driver’ designs used by most mass-market headphones. And, like many audiophile headphones, the Kithara also employs an ‘open-back’ design, which allows sound to pass freely through the earpieces.
Again, this could be a problem for some people, as background noise can leak right through the earpieces while you’re wearing them, while people nearby can also hear every note of your music, and every zap, ker-pow, ka-boom of your gaming action. However, the advantage of open-back headphones is that they provide a spacious, atmospheric soundstage that really immerses you in sound, whether it’s a concert performance or an alien planet crawling with zombies.
Advertisement
(Image credit: Future/Cliff Joseph)
Asus ROG Kithara: Price and Availability
List price: $299.99 / £284.99 / AU$569
Less expensive than many high-end gaming headsets
Focus is on sound quality, with few additional features
The planar-magnetic drivers used by the Kithara represent the high end of the hi-fi market and are normally more expensive than conventional headphones and headsets. Even so, the Kithara’s price of $299.99 / £284.99 / AU$569 isn’t wildly high when compared to high-end rivals such as the Razer BlackShark V3 Pro, SteelSeries Arctis Nova Pro, or Audeze Maxwell 2 headsets.
Remember, though, that most gaming headsets also provide additional features, such as Bluetooth for wireless connectivity, noise-cancellation, or spatial audio. In contrast, the Kithara is a wired-only headset that spends its entire budget on producing the best possible sound quality, with little in the way of added extras.
Sign up for breaking news, reviews, opinion, top tech deals, and more.
Advertisement
Asus ROG Kithara: Specs
Swipe to scroll horizontally
Row 0 – Cell 0
Asus ROG Kithara
Price
$299.99 / £284.99 / AU$569
Weight
Advertisement
14.8oz / 420g
Drivers
100mm Planar Magnetic
Compatibility
Advertisement
PS5*, PS4* Nintendo Switch*, Nintendo Switch 2*, PC, Mac, Xbox Series X|S, Xbox One (audio only via audio jack on Xbox)
Frequency response of 8Hz – 55KHz; 1.8m gaming cable with boom mic; 1.8m hi-fi cable with 3.5mm, balanced 4mm, 6.3mm, USB-C adaptors (USB-C supports 24-bit/96KHz)
Advertisement
Software
N/A
Asus ROG Kithara: Design
Bulky 100mm drivers
Separate cables and adaptor for a gaming rig and hi-fi system
Limited console compatibility
This is one instance where form and function go completely hand-in-hand. The outstanding feature of the Kithara is its use of HiFiMan’s 100mm planar-magnetic drivers, which puts them in an entirely different league to conventional headsets, such as the 40mm drivers used in the SteelSeries Arctis Nova Elite. The precision of the planar-magnetic technology also provides an impressive frequency range of 8Hz – 55KHz, which goes beyond any gaming headset I’ve used, including my trusty Master & Dynamic MG20, and only rivalled by hi-fi headphones such as Sennheiser’s HDB 630.
The downside of those humungous drivers is that the Kithara is also one of the biggest and heaviest headsets that I’ve ever used. Wearing the Kithara for the first time, I was taken aback at the sheer size of the earpieces, which cover my ears with so much room to spare that the Kithara initially slid right down over my ears and almost ended up dangling around my neck. It’s heavy too, weighing in at 14.8oz / 420g, which is considerably heavier even than Apple’s metal-clad AirPods Max at 13.6oz / 386g.
Advertisement
Fortunately, HiFiMan’s experience comes to the rescue, managing to make the Kithara more comfortable than I might have expected. The headband provides plenty of room for adjustment, so I was quickly able to find a comfortable position for the earpieces, and the well-balanced design ensures that the Kithara doesn’t feel oppressively heavy when you’re wearing it. One nice touch is that there are two sets of removable earpieces included in the box – one set with thick memory foam padding and a leatherette finish, or a slightly smaller set of earpieces covered with a lighter mesh material. The open-back design of the earpieces also provides good ventilation, so your head shouldn’t get too swampy during long gaming sessions. You will, however, end up looking like a Cyberman from Dr Who, due to the sheer size of the headset.
The connectivity options are a little complicated, though. Wired headphones are normally relatively straightforward – you just plug them into your PC, console or mobile devices, and off you go. However, the Kithara is attempting to satisfy both gamers and audiophiles, so it provides an extensive set of cables and connectors for use with different types of devices.
There are two separate cables in the box – one cable that includes a flexible microphone boom for gaming, and a second cable designed for listening to music with hi-fi equipment, such as an external DAC or amplifier. Each earpiece on the Kithara has its own 3.5mm audio socket, so both cables have a double-ended connector that plugs into the 3.5mm connectors on the Kithara earpieces (having removable cables like this also allows audiophiles to use their own specialist cables if they prefer).
(Image credit: Future/Cliff Joseph)
As mentioned, the gaming cable includes a microphone, and there’s an inline control for adjusting volume or muting the microphone as well. This cable has two 3.5mm audio jacks on each end, and the two jacks attached to the inline control plug into the 3.5mm connectors on the Kithara’s earpieces.
Advertisement
The other end of the cable plugs into your PC or gaming console, with one 3.5mm jack handling microphone input while the other handles the audio from your gaming rig. Some PCs do combine the microphone and audio into a single 3.5mm connector, but the Kithara also includes a USB-C-to-dual-3.5mm adaptor, which you can use with any device that has an available USB-C port. Asus states that a USB-C interface can provide a little more power and volume for the headphones, so it recommends using the USB-C adaptor whenever possible. The USB-C adaptor also supports high-res audio formats up to 24-bit/96KHz, so it can handle most of the high-res audio available on Spotify, Apple Music, and other services.
Unfortunately, this does raise some compatibility issues for console users. Asus states that when using a PlayStation 4 or PS5, the microphone on the Kithara only works via the USB-C adaptor included in the box. However, the microphone doesn’t work with the Xbox at all, and audio input requires the 3.5mm audio connector on an Xbox controller, so console owners should pay close attention to the compatibility info on the Asus website to make sure the Kithara will work with the console you own.
The second cable is designed for use with a variety of hi-fi and audio devices and has a slightly different design. It does have two 3.5mm jacks on one end for connecting to the Kithara’s earpieces. However, the other end has a special ‘3-in-1’ connector that can be used to connect any of the 3.5mm, balanced 4.4mm, or 6.3mm audio adaptors that are included in the box. Most computers, consoles, and mobile devices will work fine with the standard 3.5mm adaptor, but audiophiles may prefer to use the 4.4mm and 6.3mm adaptors with a DAC, amplifier, or other hi-fi equipment.
(Image credit: Future/Cliff Joseph)
Advertisement
Asus ROG Kithara: Performance
Planar-magnetic drivers provide superb sound quality
Open-back design creates a relaxed, open soundstage
The Kithara arrived just in time for the new season of Diablo 4, and the first thing I notice as I zone into the capital town of Kyovashad is the sheer clarity and detail of its sound. The Kithara creates a real sense of a lively, bustling town around me, clearly picking out the sound of clanking metal from the blacksmith, and the bubbling cauldron of the alchemist when I stop by to stock up on some potions – details that I never really notice when I’m using my normal set of external speakers with my gaming laptop.
I’m not sure I’d call Diablo 4 a true open-world game, but the soundscape really opens up as I head out through the town gates. A crow squawks as I pass by, and I hear the sound of flapping wings panning over my head as it takes to the air. I also notice – for the very first time – the rattling armour and shield of my trusty companion, Raheir, as he jogs along behind me. The Kithara doesn’t have the spatial audio features of more expensive rivals such as the SteelSeries Arctis Nova Pro Wireless, but the open-back earpieces are highly effective at creating a sense of space as I run along the road, including the crashing sound of a waterfall over to the left of me.
I get my first taste of combat as a band of Rogues pops up out of nowhere, and the first thing I notice is the power of those chunky 100mm drivers as I fire off a couple of lightning bolts. I only have the game volume set to 50%, but that’s more than enough as the chaos of combat erupts all around me. And there’s clarity as well as power, capturing the satisfying fizz of energy as my bolts swirl around, bouncing from enemy to enemy. My sorcerer is a typical glass canon, so I trigger my Earthen Bulwark magical shield, and it sounds like a slab of concrete being dragged along the ground as it swirls around me.
I’ve got to hand it to the sound design team on Diablo 4, as they’ve done a great job of keeping all the clashing sounds clear and balanced, and the Kithara is a great fit for the game as it has the precision needed to pick out all the sonic details of swords and shields, and the mystical energy of my spells as they all clash in combat.
Editor’s note – PS5 performance
Advertisement
Alongside Cliff’s extremely thorough and deep testing of the Asus ROG Kithara on a host of platforms, I have also been able to put the headset through its paces on PS5. Performance on Sony’s current-gen console looks to be a big deal to Asus, with a dedicated badge adorning the Kithara’s box – and largely it performs brilliantly. The audio quality is excellent and gives excellent, crisp, and detailed audio that’s a joy to experience. However, the connectivity, cable setup, and the fact that you can only use the headset’s microphone when plugged into the PS5’s USB-C port hold it back and make the logistics of using the headset a bit of a challenge, especially in ‘traditional’ under-the-TV setups.
Rob Dwiar, Managing Editor, TechRadar Gaming
The sound design on Doom: The Dark Ages is, admittedly, a little less subtle, but the Kithara digs deep for the opening music, landing the grinding sound of fuzz-drenched guitars with real weight, while the martial beat of drums sets the mood for the mayhem to come.
I’m more of a role-playing games (RPG) guy these days, but the gonzo adrenaline rush of the Doom games is hard to resist, and I enjoy the metallic thud of the shield charge that softens up my enemies as I return to the game’s opening section in Khalim. I decide to get some target practice in the Ripatorium mode, picking Unchained Predator by Finishing Move from the Jukebox. It’s not my favourite musical genre, but the track’s chugging guitar riffs cleverly sync with the bullets spewing from my pulse rifle, and the sheer gritty power of the guitar and drums will satisfy even the most die-hard metal-heads. And, as mentioned, the Kithara’s oversized drivers have enough power to really make your ears bleed.
But, of course, the Kithara is designed for audiophiles who will enjoy a range of different musical genres, so I grab my iPad with Apple Music and switch to the hi-fi cable that is also included in the box. I start with the bouncing bass of Billie Eilish on Bad Guy, powered by an iFi Go Link Max DAC with a balanced 4mm connector.
Advertisement
The deep electronic bass that opens the track is firm and precise, but the rhythm is relaxed enough to bounce along like a playful puppy, and it immediately gets my feet tapping. The bass isn’t overwhelming, though, and there’s a really crisp sound to the finger-snaps that lead through the chorus, and a smooth, whispery quality on Billie’s vocals. Planar-magnetic headphones are sometimes criticized for weak bass, but the Kithara can hold its head up with planar-magnetic rivals such as the Audeze Maxwell 2, as it lands the final section of the song with a slow, juddering bass pulse that hits like a pile-driver.
A new high-res mix of Queen’s Seven Seas Of Rhye recently turned up on Apple Music, and the Kithara proves that it can match the power and precision of traditional hi-fi headphones such as the Sennheiser HDB 630 as it really lets rip on Brian May’s swooping power chords. It can handle Queen’s multi-tracked harmonies too, catching all the different layers of sound, and making room for Roger Taylor’s shrieking falsetto as it leads into the guitar break.
The old-school approach of the Kithara won’t suit everyone, and the lack of Bluetooth and noise-cancellation features means that it will mainly appeal to wired-only purists. But, if you’re an audiophile who really prefers the quality of traditional wired headphones, then the clarity, precision and spacious sound of the Kithara are hard to beat at this price.
(Image credit: Future/Cliff Joseph)
Advertisement
Should you buy the Asus ROG Kithara?
Buy it if…
Don’t buy it if…
Also consider…
If the Asus ROG Kithara might not be quite for you, then check out these fine alternatives as excellent audiophile options.
Advertisement
Swipe to scroll horizontally
Row 0 – Cell 0
Asus ROG Kithara
SteelSeries Arctis Nova Elite
Audeze Maxwell 2
Price
Advertisement
$299.99 / £284.99 / AU$569
$599.99 / £599.99 / AU$1,349
$329 / £319 / about AU$450
Weight
Advertisement
14.8oz / 420g
13.4oz / 380g
17.3oz / 490g
Drivers
Advertisement
100mm Planar Magnetic
40mm carbon fiber with brass surround
90mm Planar Magnetic
Compatibility
Advertisement
PS5*, PS4* Nintendo Switch*, Nintendo Switch 2*, PC, Mac, Xbox Series X|S, Xbox One (audio only via audio jack on Xbox)
(*Microphone requires USB-C adaptor)
PS5, PS4, Xbox Series X|S, Nintendo Switch 2, Nintendo Switch, PC, Mac, Mobile
Playstation or Xbox, Nintendo Switch, Nintendo Switch 2, PC, Mac, Mobile
Hi-Res wireless (2.4Ghz via dongle), Wired (audio jack), Bluetooth 5.3 (LE Audio, LC3, LC3+)
Wireless (2.4Ghz via dongle), Wired (USB-C & audio jack), Bluetooth 5.3 (LC3plus /
Advertisement
LC3 / LDAC / AAC)
Battery life
N/A
Up to 60 hours (2 x fully-charged batteries), Infinite Power System
Advertisement
80+ hours
Features
Frequency response of 8Hz – 55KHz; 1.8m gaming cable with boom mic; 1.8m hi-fi cable with 3.5mm, balanced 4mm, 6.3mm, USB-C adaptors (USB-C supports 24-bit/96KHz)
Certified Hi-Res audio (96kHz/24-bit), 40mm carbon fiber, brass ring surround drivers, ClearCast Gen 2.X – Retractable Boom Mic and Smart-Switching On-Ear Beamforming Microphone with AI noise rejecting, ANC, Omniplay GameHub (connect four devices simultaneously)
Advertisement
Detachable hypercardiod mic, beamforming mic with physical and AI reduction, FILTER™ Noise Reduction Technology, embedded Dolby Atmos license (Xbox),
Used on PC, Mac and mobile devices, on a variety of games and listening to high-res music on Apple Music
Compared directly with the Master & Dynamic MG20 and Sennheiser HDB 630, as well as other gaming headsets and headphones
I’m lucky enough to test hi-fi quality headphones on a fairly regular basis, so I was able to compare the Asus Kithara with gaming headsets such as the Master & Dynamic MG20, as well as more conventional headphones from Sennheiser and Bowers & Wilkins.
As mentioned, I was eager to test the Kithara by jumping into the new season of Diablo 4 on my Alienware gaming laptop. Diablo has taken up most of my gaming time in recent weeks, but I also paid a return visit to Doom: The Dark Ages. And, believe it or not, I also spend a fair amount of time reviewing games on the Mac, allowing me to revisit Baldur’s Gate 3 and the zombie hordes of Resident Evil 3. And I was able to cover both bases with Death Stranding, which has a wonderfully eerie and atmospheric ambient soundtrack, alongside the beautiful, melancholy song-writing of Low Roar.
I also use a Mac for work all day long, so the Kithara was often plugged into my Mac mini in order to stream music from Apple Music, ranging from the high-res bombast of Queen to the classical elegance of Max Richter.
Hackers started exploiting a critical vulnerability in the Marimo open-source reactive Python notebook platform just 10 hours after its public disclosure.
The flaw allows remote code execution without authentication in Marimo versions 0.20.4 and earlier. It tracked as CVE-2026-39987 and GitHub assessed it with a critical score of 9.3 out of 10.
According to researchers at cloud-security company Sysdig, attackers created an exploit from the information in the developer’s advisory and immediately started using it in attacks that exfiltrated sensitive information.
Marimo is an open-source Python notebook environment, typically used by data scientists, ML/AI practitioners, researchers, and developers building data apps or dashboards. It is a fairly popular project, with 20,000 GitHub stars and 1,000 forks.
CVE-2026-39987 is caused by the WebSocket endpoint ‘/terminal/ws’ exposing an interactive terminal without proper authentication checks, allowing connections from any unauthenticated client.
Advertisement
This gives direct access to a full interactive shell, running with the same privileges as the Marimo process.
Marimo disclosed the flaw on April 8 and yesterday released version 0.23.0 to address it. The developers noted that the flaw affects users who deployed Marimo as an editable notebook, and those who expose Marimo to a shared network using –host 0.0.0.0 while in edit mode.
Exploitation in the wild
Within the first 12 hours after the vulnerability details were disclosed, 125 IP addresses began reconnaissance activity, according to Sysdig.
Less than 10 hours after the disclosure, the researchers observed the first exploitation attempt in a credential theft operation.
Advertisement
The attacker first validated the vulnerability by connecting to the /terminal/ws endpoint and executing a short scripted sequence to confirm remote command execution, disconnecting within seconds.
Shortly after, they reconnected and began manual reconnaissance, issuing basic commands such as pwd, whoami, and ls to understand the environment, followed by directory navigation attempts and checks for SSH-related locations.
Next, the attacker focused on credential harvesting, immediately targeting the .env file and extracting environment variables, including cloud credentials and application secrets. They then attempted to read additional files in the working directory and continued probing for SSH keys.
Stealing credentials Source: Sysdig
The entire credential access phase was completed in less than three minutes, notes a Sysdig report this week.
Roughly an hour later, the attacker returned for a second exploitation session using the same exploit sequence.
Advertisement
The researchers say that behind the attack appears to be a “methodical operator” with a hands-on approach, rather than automated scripts, focusing on high-value objectives such as stealing .env credentials and SSH keys.
The attackers did not attempt to install persistence, deploy cryptominers, or backdoors, suggesting a quick, stealthy operation.
Marimo users are recommended to upgrade to version 0.23.0 immediately, monitor WebSocket connections to ‘/terminal/ws,’ restrict external access via a firewall, and rotate all exposed secrets.
If upgrading is not possible, an effective mitigation is to block or disable access to the ‘/terminal/ws’ endpoint entirely.
Advertisement
Automated pentesting proves the path exists. BAS proves whether your controls stop it. Most teams run one without the other.
This whitepaper maps six validation surfaces, shows where coverage ends, and provides practitioners with three diagnostic questions for any tool evaluation.
Get caught up on the latest technology and startup news from the past week. Here are the most popular stories on GeekWire for the week of April 5, 2026.
A new state law wipes out nearly all non-compete agreements in Washington, sparking debate across the tech ecosystem about innovation, talent mobility and employer rights. … Read More
Bryson DeChambeau, the two-time U.S. Open champion, is leading a group of investors in the acquisition of Bellevue-based Sportsbox AI, the startup that uses AI and 3D motion capture to analyze golf swings from smartphone video. … Read More
Microsoft’s decision to have GPT and Claude check each other’s work inside Microsoft 365 Copilot’s Researcher agent signals a broader shift: the single-model era in enterprise AI may be over. … Read More
Francois Ajenstat, who spent 13 years at Tableau including more than seven as chief product officer, is launching Golden Analytics with $7M in seed funding to build an AI-native business intelligence platform. … Read More
On today’s episode of You Asked: Sony’s new Bravia partnership with TCL raises big questions about pricing, quality, and data privacy. We break down what it means, whether a new QD-OLED is coming this year, and how anti-glare screens really perform in a dark room.
Sony and the new Bravia Inc
Sony Bravia 8Digital Trends
@charltonium4083 asks: Here’s one concern that isn’t discussed in the video or any of the comments: Which country will have primary jurisdiction over the new Bravia inc? Will it be China (TCL), or Japan (Sony)? Back in 2020, Homeland Security discovered that TCL may be directly sponsored by the CCP and that the TVs have backdoors to allow data to be breached by the government (thus allowing it to spy on customers). This has also been a more problem with other companies like TikTok and DJI, although a bit more publicized with them to the point where the USA has repeatedly threatened to ban all DJI products. If TCL owns 51% of the new Bravia inc, particularly in the manufacturing and business side, does that mean that it also has all of the customers’ data, and that the CCP could have more ability to spy on customers through the new Bravia TVs going forward? I’d be far less concerned if the customer data was actually handled by Sony (under Japan’s jurisdiction).
OK, quite a loaded question there with some implicit bias, to say the least. But we’re going to get into all of it.
First, Bravia Inc will be located in Tokyo, Japan within Sony’s headquarters. So that’s where the business will be. Manufacturing is likely to take place where TCL has its larger facilities, like China, Mexico, and Vietnam. One of their biggest advantages is large-scale production facilities that keep efficiency high and prices low.
As for your spying concerns, you might be surprised to know that just last month, March 2026, a Texas judge dismissed a lawsuit from the Texas Attorney General accusing TCL of tracking user habits without consent and selling that data to advertisers. So while our internet privacy remains an ongoing concern, TCL and Sony probably shouldn’t be a major concern. Personally, I’m more concerned about Meta, Google, Amazon, and hundreds of phone apps that have more access than a smart TV.
Advertisement
Either way, be sure to practice safe internet use. Read the user agreements when you register. Understand where your data is going, who it can be sold to, and how to limit what is tracking you with VPNs, ad blockers, and other tools.
Manufacturing and pricing strategy
Sony A95LZeke Jones / Digital Trends
@theGovnr1 asks: To me, it seems the new products will have the Sony technology and design but be manufactured by TCL.
And that’s my take as well. I think the goal is for manufacturing to become less expensive. There are several outstanding Bravia-branded TVs on the market, and most would tell you their picture quality is best in class. But if I’m not mistaken, they fall behind Samsung, LG, TCL, and Hisense in overall sales, likely due to price. So if having TCL handle manufacturing lowers the price while maintaining the image processing technology that makes Sony what it is, that’s a win.
Time will tell, and until the day comes when we have a TCL-manufactured Bravia TV to test, there’s really not much anyone can do to change minds. Based on comments, many of you have clearly decided that this is not for the better and the Bravia brand is doomed. Hopefully, you’re wrong, because then we can all get Sony-level TVs for less.
Sony OLED lineup outlook
Bravia 9 and Bravia 8 Mk IIDigital Trends
@1.doubleyou asks: Will there be a new QD-OLED TV from Sony this year?
I’m leaning toward no, for a couple of reasons. One, they’re pouring a ton of resources and marketing into the release of their True RGB Mini LED TV. And two, they’ve been staggering their big TV updates every other year.
Advertisement
In 2023, we got the A95L QD-OLED. In 2024, we got the Bravia 9, their flagship Mini LED TV. Then in 2025, the Bravia 8 Mark II became the successor to the A95L in the QD-OLED department. And this year, probably sooner than later, we’ll have more details on this True RGB TV that will take over the flagship Mini LED role from the Bravia 9.
Not to mention, with the TCL merger, there may need to be some adjustments in how Sony’s OLEDs are manufactured before we get a new one.
@CoolVibe-w5f has a Samsung question in reference to their anti-glare screens, asking: How do the blacks look in a dark room compared to a glossy screen? From what I’ve read, the blacks are not quite 100 percent, especially next to a glossy screen.
A wise person once said: You can’t believe everything you read on the internet. What I’ve seen, take it or leave it, is very little to no difference in a dark room. If the only light being emitted in the room is coming from the TV, you will see pure black. I’m confident in that, and clearly Samsung is as well as they continue to expand that anti-glare panel into more TVs.
This year, it’s in the S95H as well as the S90H. Previous S90 models still had the glossy screen. The anti-glare panel is featured in several Mini LED TVs as well.
Advertisement
I don’t think they’d keep going all in on the technology if they weren’t sure it was delivering a viewing experience on par with the best from Sony and LG. We did a video a while ago putting the Samsung S95D next to LG’s flagship OLED in a dark room to show the difference. And I’ve seen others put their 2025 models, the S95F and S90F, side by side, and it’s very difficult to see a difference, if you can see one at all.
For a brief moment, it looked like Apple’s long-awaited foldable iPhone had hit a classic case of “almost, but not quite.” Reports of manufacturing hurdles and testing issues had people bracing for a delay — some even pushing the deadline to 2027. Naturally, the internet did what it does best: panic and speculate. But it turns out, the situation may not be nearly as dramatic as it first seemed.
Not quite the crisis it was made out to be
Despite the noise, Apple doesn’t appear to be scrambling behind the scenes trying to fix a broken product. From what’s being heard, development is still very much on track, and the foldable iPhone is progressing without any catastrophic roadblocks. In fact, the company is still eyeing its usual September launch window — the same stage where the next wave of flagship iPhones is expected to debut. That’s a strong sign that things are moving along more smoothly than the rumors suggested. This is confirmed by Bloomberg’s Mark Gurman, so we shouldn’t expect any emergency brakes on this.
The stakes are high, so is the price
This isn’t just another iPhone refresh. The foldable model represents one of Apple’s biggest design shifts in years. Expectations are sky-high, and for good reason. A foldable iPhone is expected to sit comfortably in ultra-premium territory, with a price tag that could exceed $2,000. That alone makes it less of a mass-market device and more of a statement piece. But even as a niche product, it has the potential to push Apple’s average selling price higher, which, let’s be honest, is something the company wouldn’t mind at all.
Foldable iPhoneMajinBuofficia
However, availability might be the real catch. Even if Apple sticks to its launch timeline, getting your hands on one might not be immediate. Initial supply is expected to be limited, which isn’t unusual for a first-generation product with a complex design. Foldables are notoriously tricky to manufacture at scale, and Apple is unlikely to rush that process just to flood the market on day one. That said, the plan is still to make the device available alongside, or shortly after, the Pro iPhones. So while it may not be easy to buy, it shouldn’t be stuck in limbo either.
A moment Apple can’t afford to miss
This upcoming iPhone cycle is shaping up to be a big one. A foldable device, paired with the next generation of Pro models, could mark a significant shift in Apple’s smartphone lineup. Which is precisely why the delay rumors hit a nerve. But if current indications hold true, Apple seems ready to deliver on time. Just a very expensive, very anticipated new form factor making its debut right on schedule.
Advertisement
Foldable iPhoneMajinBuofficia
The foldable iPhone may not be facing the crisis it was briefly accused of. While challenges are inevitable with a product this ambitious, Apple appears to have things under control for now. So if you’ve been mentally preparing to wait another year, you might want to rethink that. Your wallet, however, may need a little more time.
The group responsible, ShinyHunters, says it didn’t breach Rockstar or its data-warehouse provider, Snowflake. Instead, it exploited access from Anodot, a SaaS analytics tool Rockstar uses to track cloud costs and performance. The attackers allegedly stole authentication tokens from Anodot’s systems and used them to gain unauthorized access to Rockstar’s… Read Entire Article Source link
Apple Glass will be a direct competitor to Meta’s Ray-Ban smart glasses, but it will be only a part of a larger three-pronged AI wearable strategy for the company. Here’s what’s coming.
Optimistic renders of what Apple Glass could look like – Image Credit: AppleInsider
Apple has long been working on its smart glasses, known as Apple Glass. What is anticipated to actually launch will be quite close to what the existing Meta Ray-Bans can already do. In Sunday’s “Power On” newsletter for Bloomberg, Mark Gurman writes that the Apple Glass will be easily able to handle everyday uses, including photographs and video capture, dealing with phone calls, handling notifications from an iPhone, and music playback. Rumor Score: 🤔 Possible Continue Reading on AppleInsider | Discuss on our Forums
Data quality has always been an afterthought. Teams spend months instrumenting a feature, building pipelines, and standing up dashboards, and only when a stakeholder flags a suspicious number does anyone ask whether the underlying data is actually correct. By that point, the cost of fixing it has multiplied several times over.
This is not a niche problem. It plays out across engineering organizations of every size, and the consequences range from wasted compute cycles to leadership losing trust in the data team entirely. Most of these failures are preventable if you treat data quality as a first-class concern from day one rather than a cleanup task for later.
How a typical data project unfolds
Before diagnosing the problem, it helps to walk through how most data engineering projects get started. It usually begins with a cross-functional discussion around a new feature being launched and what metrics stakeholders want to track. The data team works with data scientists and analysts to define the key metrics. Engineering figures out what can actually be instrumented and where the constraints are. A data engineer then translates all of this into a logging specification that describes exactly what events to capture, what fields to include, and why each one matters.
That logging spec becomes the contract everyone references. Downstream consumers rely on it. When it works as intended, the whole system hums along well.
Advertisement
Before data reaches production, there is typically a validation phase in dev and staging environments. Engineers walk through key interaction flows, confirm the right events are firing with the right fields, fix what is broken, and repeat the cycle until everything checks out. It is time consuming but it is supposed to be the safety net.
Once data goes live and the ETL pipelines are running, most teams operate under an implicit assumption that the data contract agreed upon during instrumentation will hold. It rarely does, not permanently.
Here is a common scenario. Your pipeline expects an event to fire when a user completes a specific action. Months later, a server side change alters the timing so the event now fires at an earlier stage in the flow with a different value in a key field. No one flags it as a data impacting change. The pipeline keeps running and the numbers keep flowing into dashboards.
Weeks or months pass before anyone notices the metrics look flat. A data scientist digs in, traces it back, and confirms the root cause. Now the team is looking at a full remediation effort: updating ETL logic, backfilling affected partitions across aggregate tables and reporting layers, and having an uncomfortable conversation with stakeholders about how long the numbers have been off.
Advertisement
The compounding cost of that single missed change includes engineering time on analysis, effort on codebase updates, compute resources for backfills, and most damagingly, eroded trust in the data team. Once stakeholders have been burned by bad numbers a couple of times, they start questioning everything. That loss of confidence is hard to rebuild.
This pattern is especially common in large systems with many independent microservices, each evolving on its own release cycle. There is no single point of failure, just a slow drift between what the pipeline expects and what the data actually contains.
Why validation cannot stop at staging
The core issue is that data validation is treated as a one-time gate rather than an ongoing process. Staging validation is important but it only verifies the state of the system at a single point in time. Production is a moving target.
What is needed is data quality enforcement at every layer of the pipeline, from the point data is produced, through transport, and all the way into the processed tables your consumers depend on. The modern data tooling ecosystem has matured enough to make this practical.
Advertisement
Enforcing quality at the source
The first line of defense is the data contract at the producer level. When a strict schema is enforced at the point of emission with typed fields and defined structure, a breaking change fails immediately rather than silently propagating downstream. Schema registries, commonly used with streaming platforms like Apache Kafka, serialize data against a schema before it is transported and validate it again on deserialization. Forward and backward compatibility checks ensure that schema evolution does not silently break consuming pipelines.
Avro formatted schemas stored in a schema registry are a widely adopted pattern for exactly this reason. They create an explicit, versioned contract between producers and consumers that is enforced at runtime and not just documented in a spec file that may or may not be read.
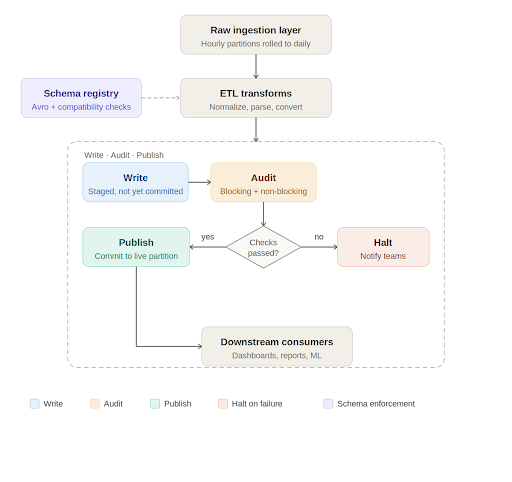
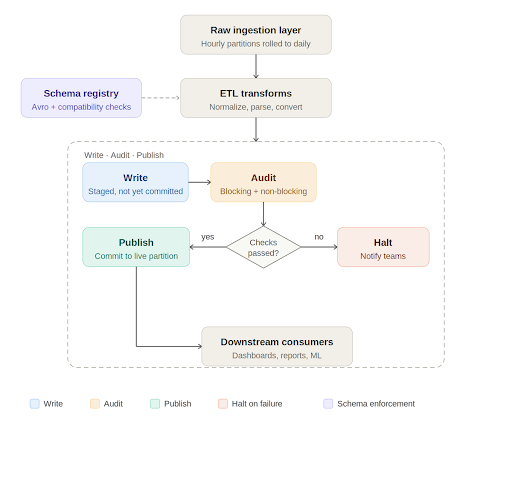
Write, audit, publish: A quality gate in the pipeline
At the processing layer, Apache Iceberg has introduced a useful pattern for data quality enforcement called Write-Audit-Publish, or WAP. Iceberg operates on a file metadata model where every write is tracked as a commit. The WAP workflow takes advantage of this to introduce an audit step before data is declared production ready.
Advertisement
In practice, the daily pipeline works like this. Raw data lands in an ingestion layer, typically rolled up from smaller time window partitions into a full daily partition. The ETL job picks up this data, runs transformations such as normalizations, timezone conversions, and default value handling, and writes to an Iceberg table. If WAP is enabled on that table, the write is staged with its own commit identifier rather than being immediately committed to the live partition.
At this point, automated data quality checks run against the staged data. These checks fall into two categories. Blocking checks are critical validations such as missing required columns, null values in non-nullable fields, and enum values outside expected ranges. If a blocking check fails, the pipeline halts, the relevant teams are notified, and downstream consumers are informed that the data for that partition is not yet available. Non-blocking checks catch issues that are meaningful but not severe enough to stop the pipeline. They generate alerts for the engineering team to investigate and may trigger targeted backfills for a small number of recent partitions.
Only when all checks pass does the pipeline commit the data to the live table and mark the job as successful. Consumers get data that has been explicitly validated, not just processed.
Data quality as engineering practice, not a cleanup project
There is a broader point embedded in all of this. Data quality cannot be something the team circles back to after the pipeline is built. It needs to be designed into the system from the start and treated with the same discipline as any other part of the engineering stack.
Advertisement
With modern code generation tools making it cheaper than ever to stand up a new pipeline, it is tempting to move fast and validate later. But the maintenance burden of an untested pipeline, especially one feeding dashboards used by product, business, and leadership teams, is significant. A pipeline that runs every day and silently produces wrong numbers is worse than one that fails loudly.
The goal is for data engineers to be producers of trustworthy, well documented data artifacts. That means enforcing contracts at the source, validating at every stage of transport and transformation, and treating quality checks as a permanent part of the pipeline rather than a one time gate at launch.
When stakeholders ask whether the numbers are right, the answer should not be that we think so. It should be backed by an auditable, automated process that catches problems before anyone outside the data team ever sees them.
The word clanker — a disparaging term for AI and robots — “has made its way into the Linux kernel,” reports the blog It’s FOSS “thanks to Greg Kroah-Hartman, the Linux stable kernel maintainer and the closest thing the project has to a second-in-command.”
He’s been quietly running what looks like an AI-assisted fuzzing tool on the kernel that lives in a branch called “clanker” on his working kernel tree. It began with the ksmbd and SMB code. Kroah-Hartman filed a three-patch series after running his new tooling against it, describing the motivation quite simply. [“They pass my very limited testing here,” he wrote, “but please don’t trust them at all and verify that I’m not just making this all up before accepting them.”] Kroah-Hartman picked that code because it was easy to set up and test locally with virtual machines.
“Beyond those initial SMB/KSMBD patches, there have been a flow of other Linux kernel patches touching USB, HID, F2FS, LoongArch, WiFi, LEDs, and more,” Phoronix wrote Tuesday, “that were done by Greg Kroah-Hartman in the past 48 hours…. Those patches in the “Clanker” branch all note as part of the Git tag: “Assisted-by: gregkh_clanker_t1000”
The T1000 presumably in reference to the Terminator T-1000. It’s FOSS emphasizes that “What Kroah-Hartman appears to be doing here is not having AI write kernel code. The fuzzer surfaces potential bugs; a human with decades of kernel experience reviews them, writes the actual fixes, and takes responsibility for what gets submitted.” Linus has been thinking about this too. Speaking at Open Source Summit Japan last year, Linus Torvalds said the upcoming Linux Kernel Maintainer Summit will address “expanding our tooling and our policies when it comes to using AI for tooling.”
Advertisement
He also mentioned running an internal AI experiment where the tool reviewed a merge he had objected to. The AI not only agreed with his objections but found additional issues to fix. Linus called that a good sign, while asserting that he is “much less interested in AI for writing code” and more interested in AI as a tool for maintenance, patch checking, and code review.






















































































You must be logged in to post a comment Login