



















Mobile gaming is the future. At least, that’s what we’ve heard for the last decade. But it’s fair to say that plenty of us are still pretty skeptical about that notion.
It seemed that, for a while, the available technology was not making the leaps forward needed to deliver a satisfying gameplay experience in this alternative format. Console gaming excelled while mobile gaming fell behind.
Article continues below
Choosing the game

Selecting the right game to test out the Galaxy S26 Ultra’s performance credentials was critical. The title in question needed to not only push the best Samsung phone to its limits, but also be well-known among the mobile gaming community. That’s why I settled on Genshin Impact.
Developed and published by miHoYo, with HoYoverse taking on distribution duties globally, Genshin Impact was released back in 2020 on Windows, PlayStation 4, and, critically, iOS and Android. The action RPG has proven extremely popular and has since been released on both the PlayStation 5 and Xbox Series X|S. It’s a title with critical acclaim, a firm player base, and crucially, the ability to perform cross-platform.
Genshin Impact received over 23 million downloads in its first week of release and has since become a staple of mobile gaming. Its stunning world, vibrant graphics, and fast-paced combat provide a perfect variety of tests to push the S26 Ultra to its limits.
Of course, I played the game with high SFX quality, the highest render resolution, high shadow quality, the highest environmental detailing, high motion blur, and bloom all activated.
The initial performance

Logging in to Genshin Impact was a breeze, with the game taking around 30 seconds to get through its various loading screens. Sure, a dedicated console goes through the same motions slightly quicker, but 30 seconds is significantly quicker than the minute-long wait times demanded by previous smartphone generations.
Running smoothly with a target of 60fps, I was instantly struck by the ease of traversing the game’s settings and menus. The Galaxy S26 Ultra showed no signs of early stress, and jumping into the game itself, I thought it appropriate to take a minute to explore the lush landscape of Teyvat, one of the game’s seven nations.
It’s a landscape full of rich greenery and ethereal man-made constructs, the complex lighting putting the phone’s custom Snapdragon chipset to work. Whether it was a desert-like landscape with dry, barren vistas or a more fruitful, forest backdrop, I couldn’t help but marvel at the level of detail the Galaxy S26 Ultra captured. The Snapdragon 8 Elite Gen 5 chipset showed initial promise as it powered through some difficult moments, avoiding lag where needed.

A quick word on the Galaxy S26 Ultra’s size. We’ve seen a drive towards larger phone displays in recent years, and sitting at 6.9 inches, Samsung‘s latest flagship mobile display offers plenty in the way of cinematic spectacle. With a high-fidelity stereo speaker system providing a promising audio balance, I felt as though there was real depth to everything I was seeing and hearing in Genshin Impact.
For a moment, it seemed that perhaps this smartphone was genuinely giving the console world a run for its money….
Long-term play became slightly more taxing
However, after extended play, things started to look a little different. The longer I played, the more framerate imperfections I noticed. Momentary lag started to creep in, and with the phone’s gradual but managed warming, it became clear that mobile gaming is built to be a sprint, not a marathon.
Image 1 of 3
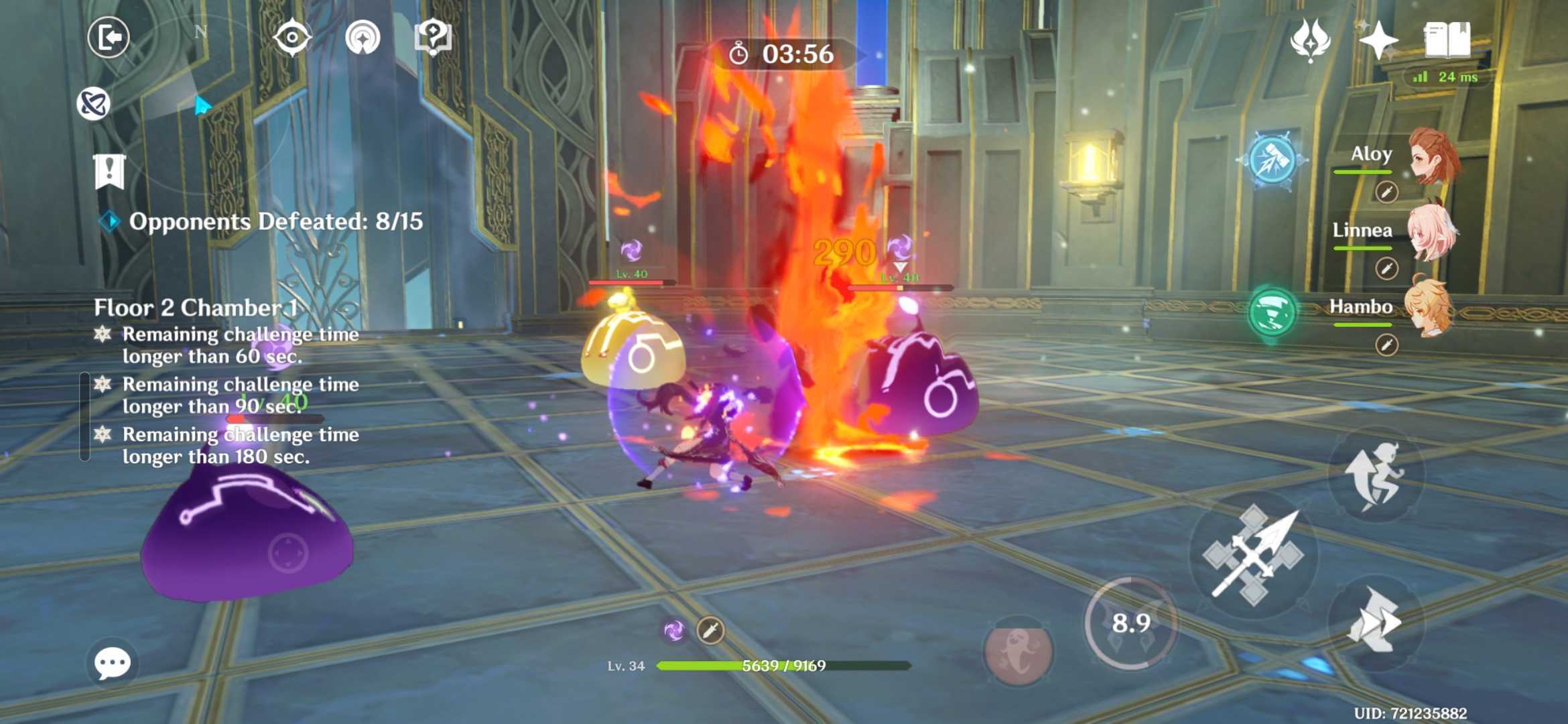
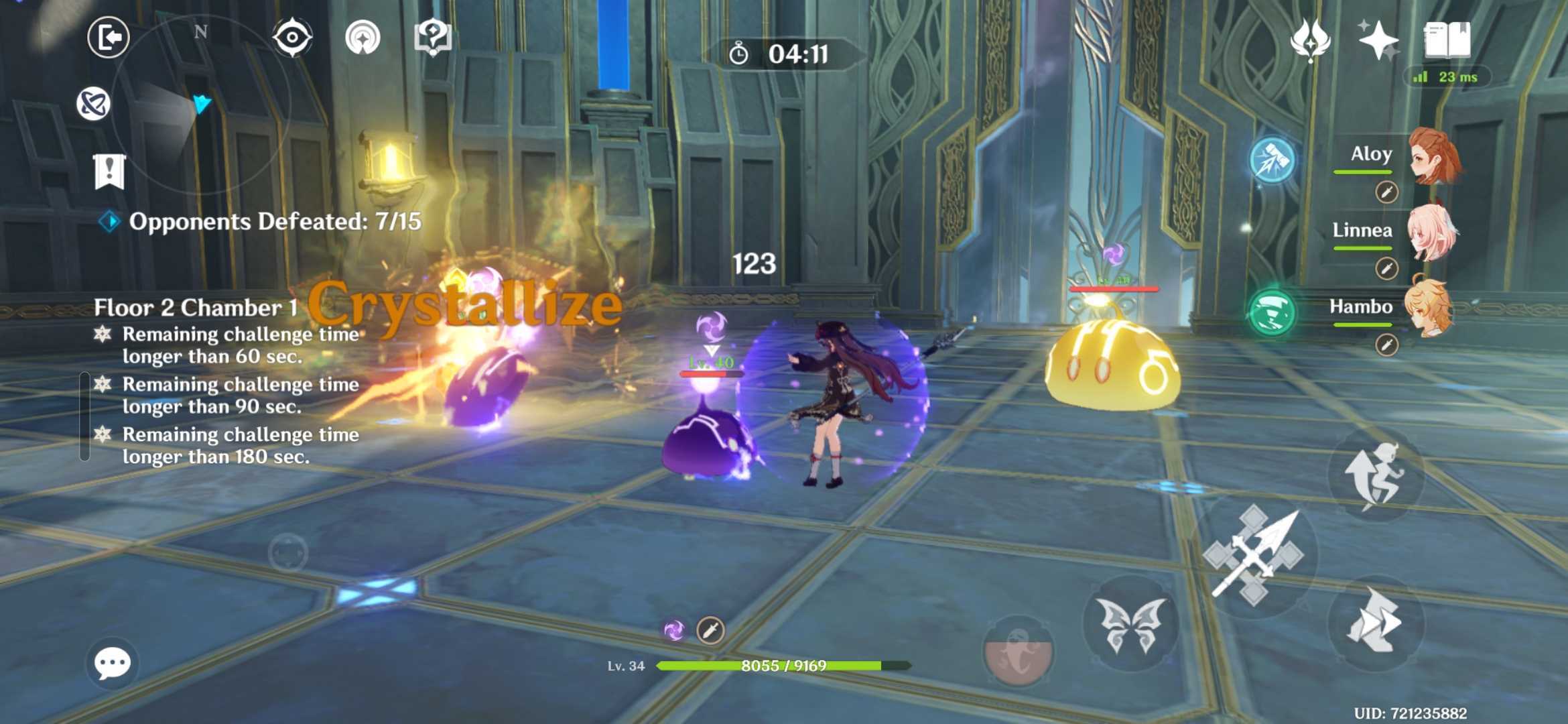
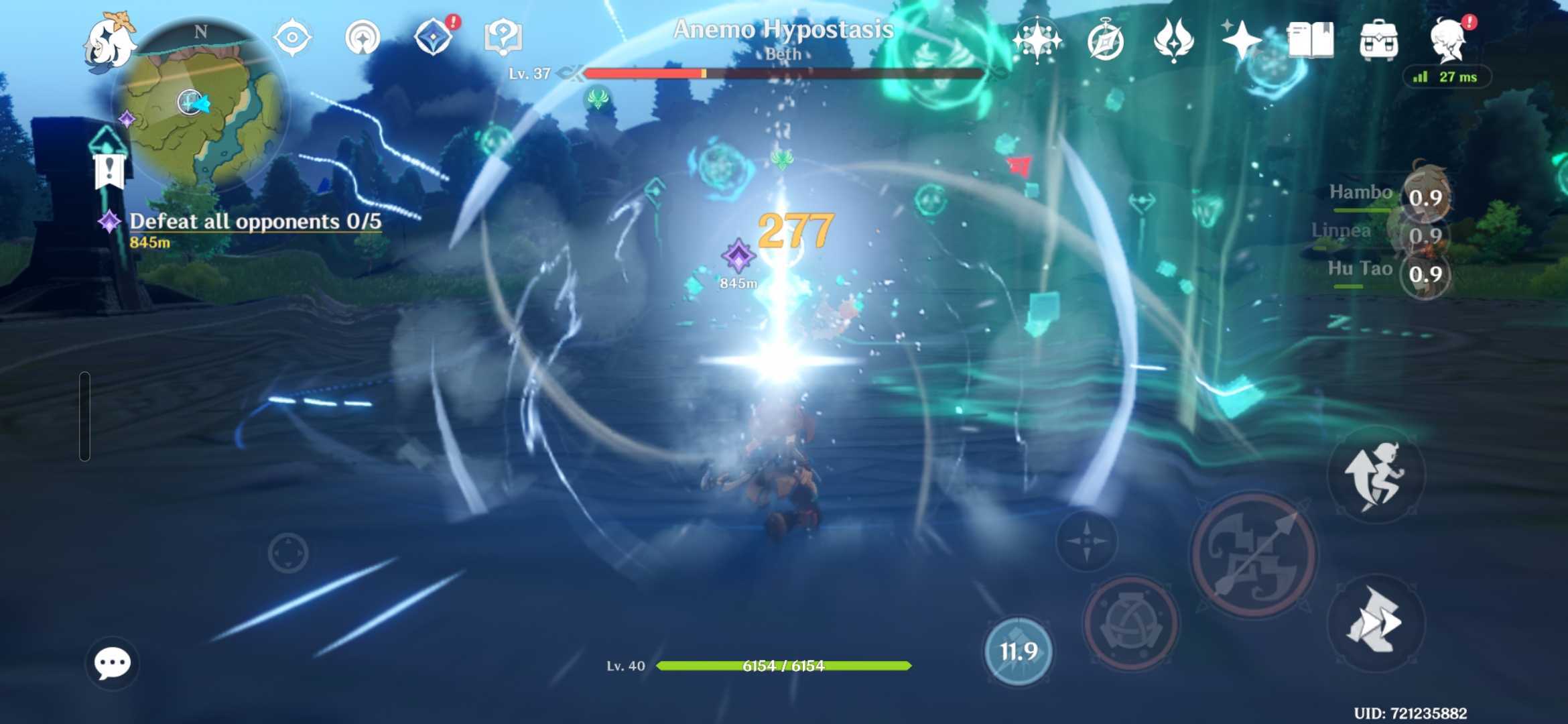
Prolonged, busy set pieces began to have a visible impact on the Galaxy S26 Ultra’s performance. With combat sequences came screen cramming, as multiple enemies and detailed SFX fought for visual dominance. Inconsistencies were rare, but they were still present.
So, while the Galaxy S26 Ultra is far better for gaming than many other mobile devices I’ve tried, Genshin Impact still played as if it were not the phone’s primary focus.
And in fairness, why should it be? This is a smartphone after all. But there’s still a noticeable gap between the performance of phones and consoles.
Still, considering that the Galaxy S26 Ultra is not a stationary block of mains-powered circuitry à la the PS5, it handled the intense demands of Genshin Impact remarkably well. Mobile gaming isn’t yet a threat to major PC and console platforms, but it is a genuine alternative that can provide quick, easy, and satisfying access to the AAA titles you love.
For an even more complete experience, the best gaming phones offer extras like shoulder triggers and improved cooling mechanisms, but the Galaxy S26 Ultra gets the seal of approval for accessible, short-term play.
Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button!
And of course you can also follow TechRadar on TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.


![Young Thug - Money On Money (feat. Future) [Official Video]](https://wordupnews.com/wp-content/uploads/2026/04/1776012320_maxresdefault-80x80.jpg)












































You must be logged in to post a comment Login